
Machine Learning for Network Intrusion Detection—A Comparative Study


Abstract
1. Introduction
- We use the CICIDS-2017 dataset, which contains frequent attacks that resemble real-world network traffic.
- We then implement four ML algorithms (random forest (RF), linear support vector machine (LSVM), Gaussian Naive Bayes (GNB), and logistic regression (LG)) to classify and predict abnormal activities.
- We perform a comparative study to evaluate the performance of these ML algorithms and evaluate their models using state-of-the-art methods based on different evaluation criteria.
2. The CICIDS-2017 Dataset
3. Related Work
4. Background
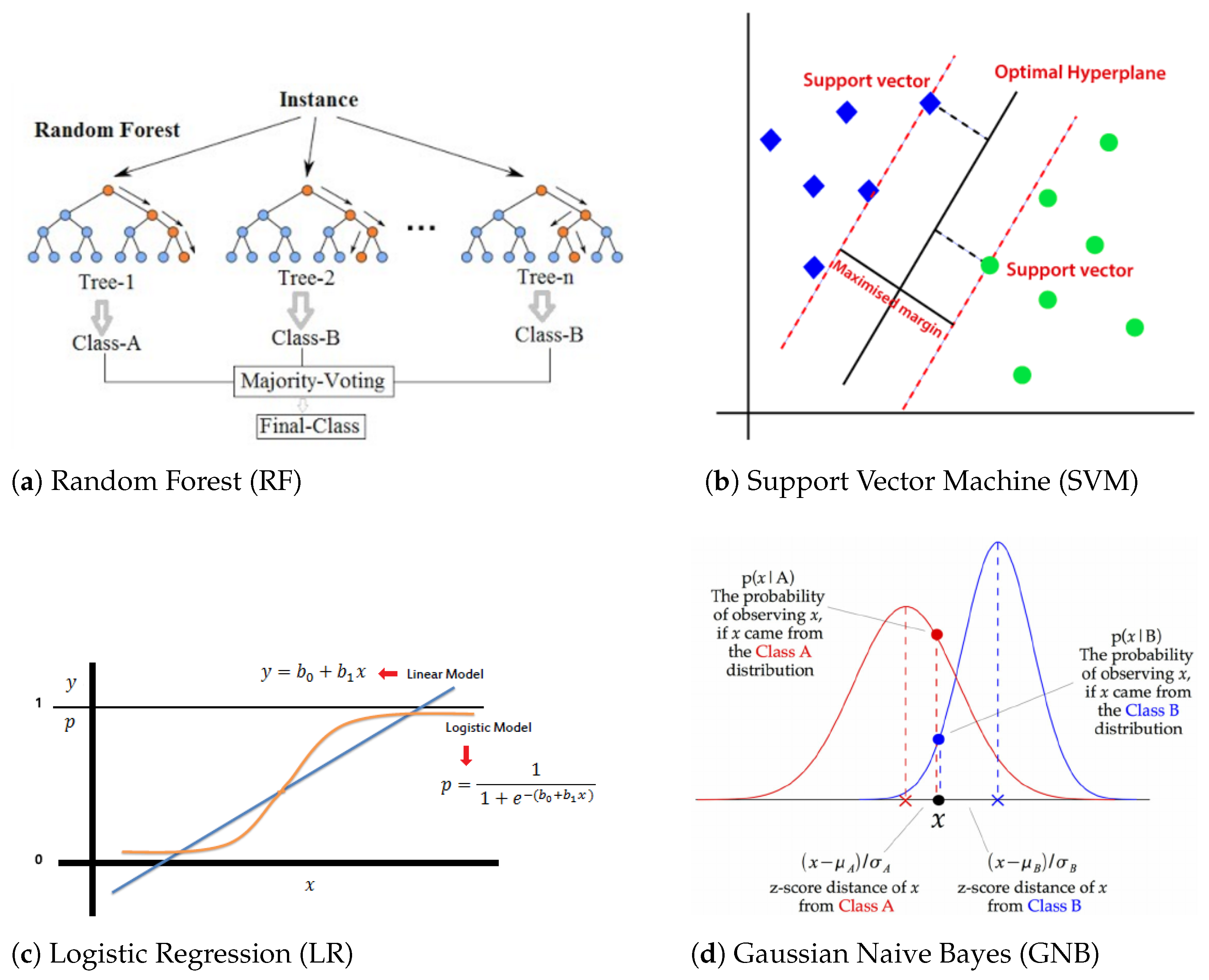
4.1. Machine Learning
4.2. Algorithms and Techniques
4.2.1. Random Forest
4.2.2. Linear Support Vector Machine
4.2.3. Gaussian Naive Bayes
4.2.4. Logistic Regression
4.2.5. Synthetic Minority Oversampling
4.2.6. Bayesian Optimization
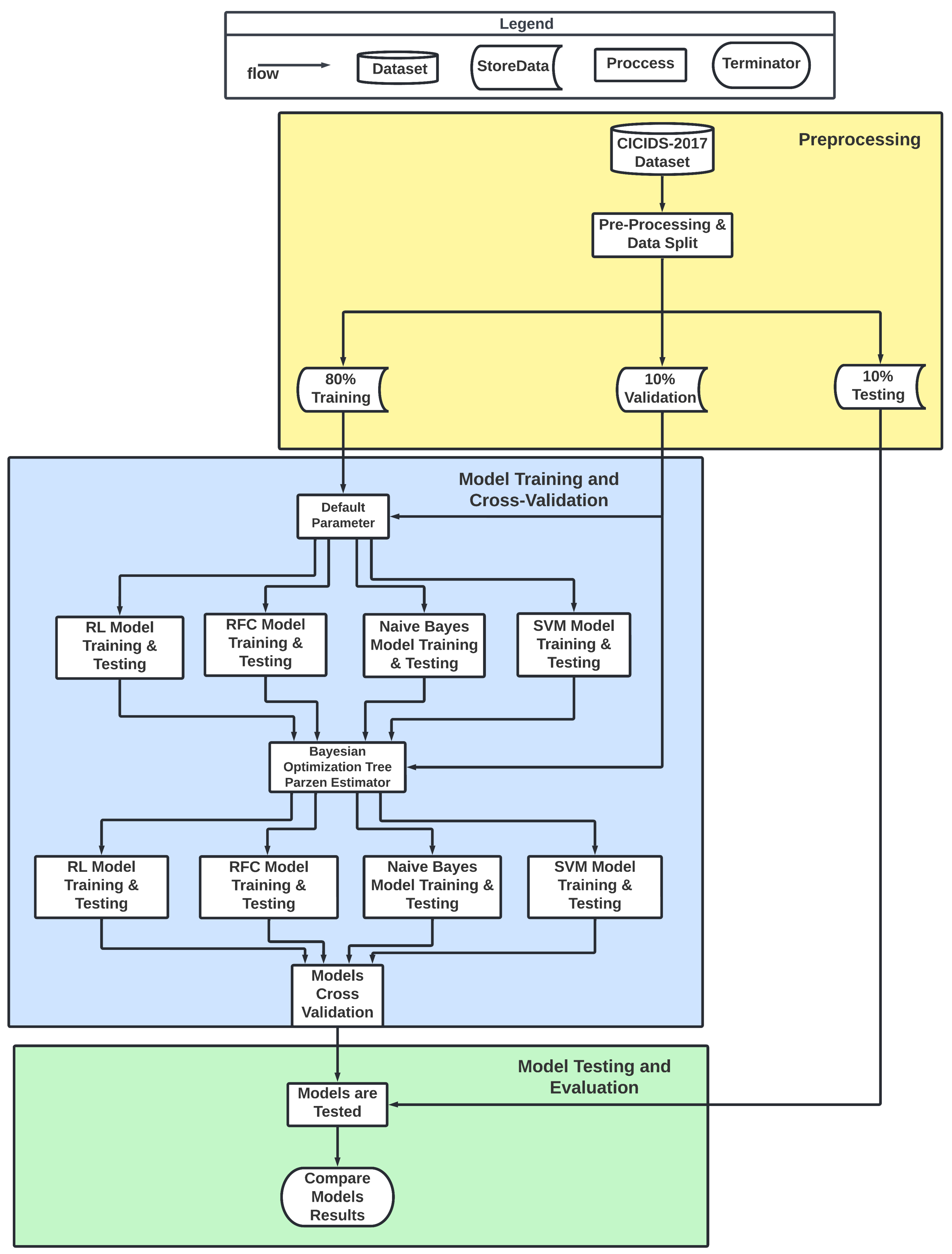
5. Methodology
5.1. Preprocessing
5.2. Model Training and Cross-Validation
5.3. Model Testing and Evaluation
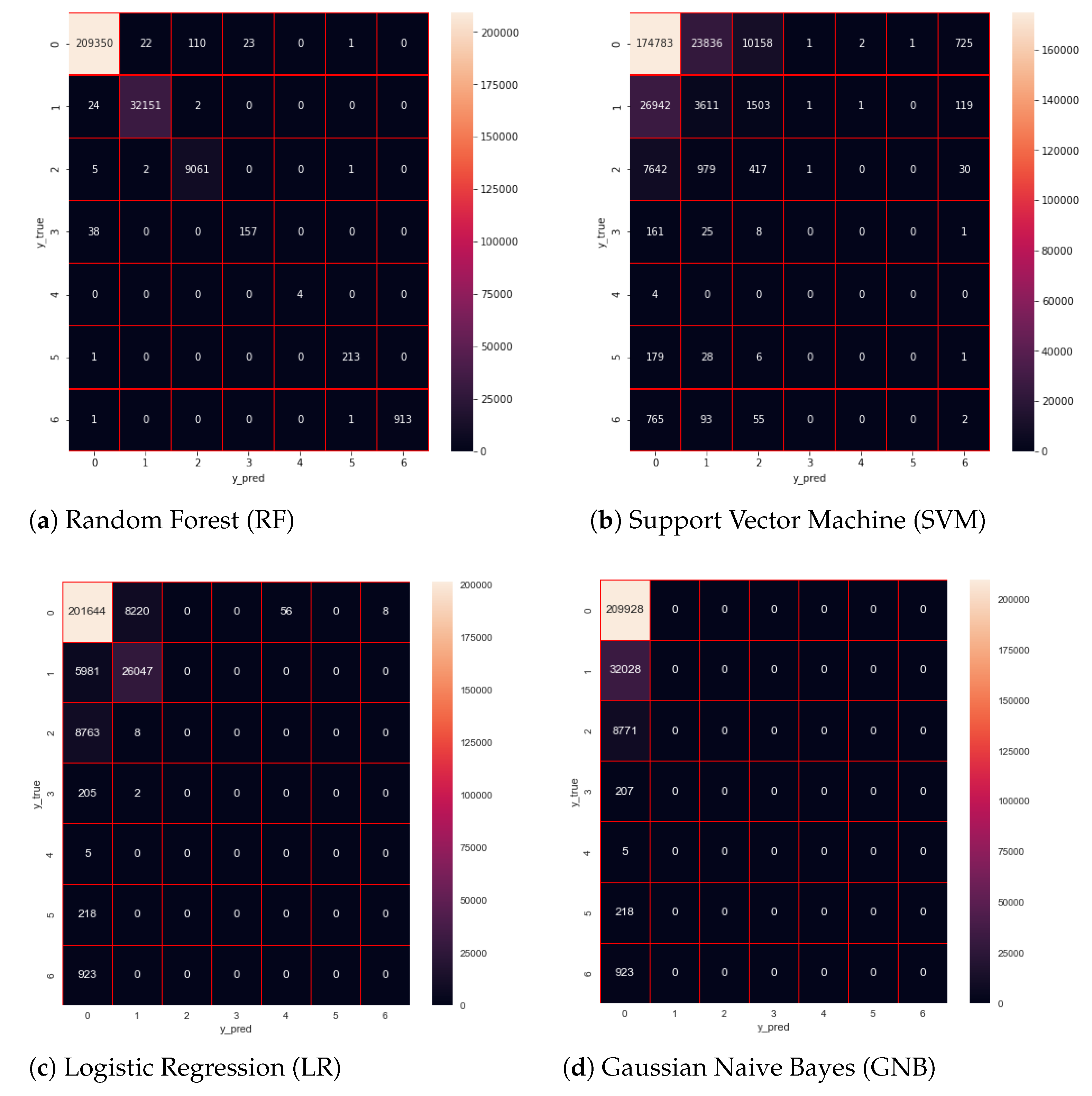
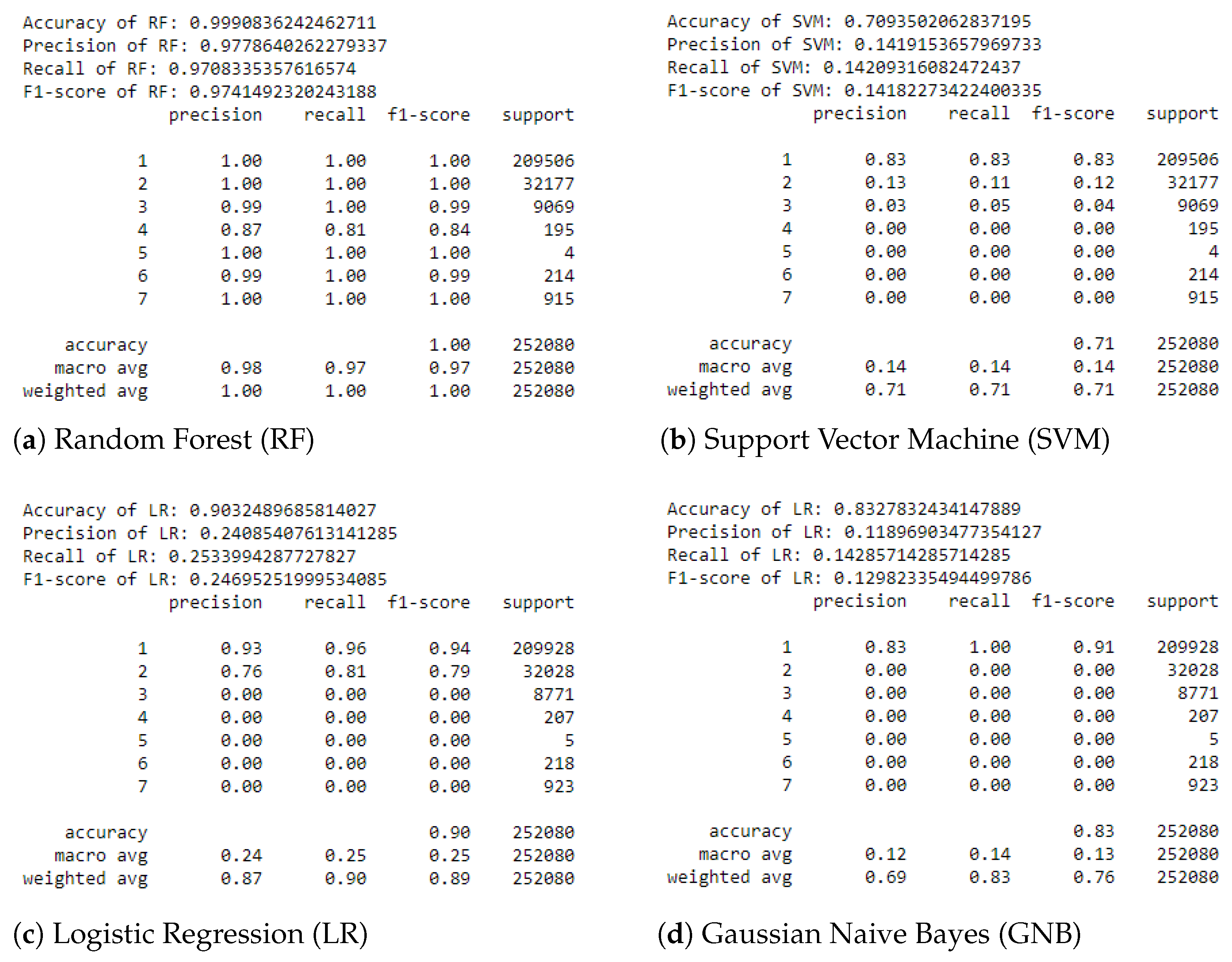
6. Results and Discussion
6.1. Confusion Matrix
6.2. Classification Report
- Accuracy = , the percentage of the total number of correct classifications.
- Precision = , the proportion of positives that are correctly identified.
- Recall (sensitivity) = , the percentage of actual positives that are classified as attacks.
- F1-score= , the harmonic mean of the precision and recall.
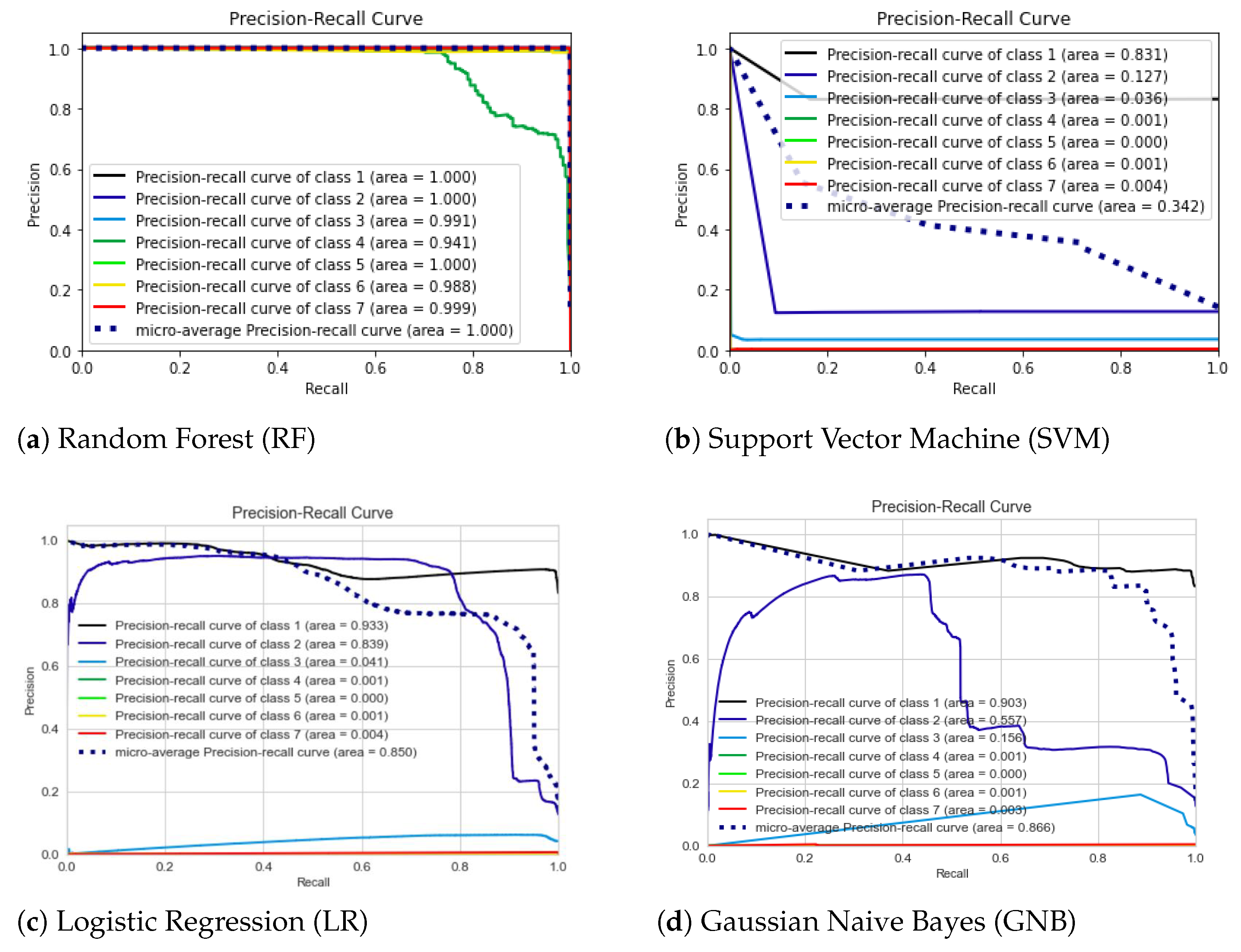
6.3. Precision–Recall Curve (PRC)
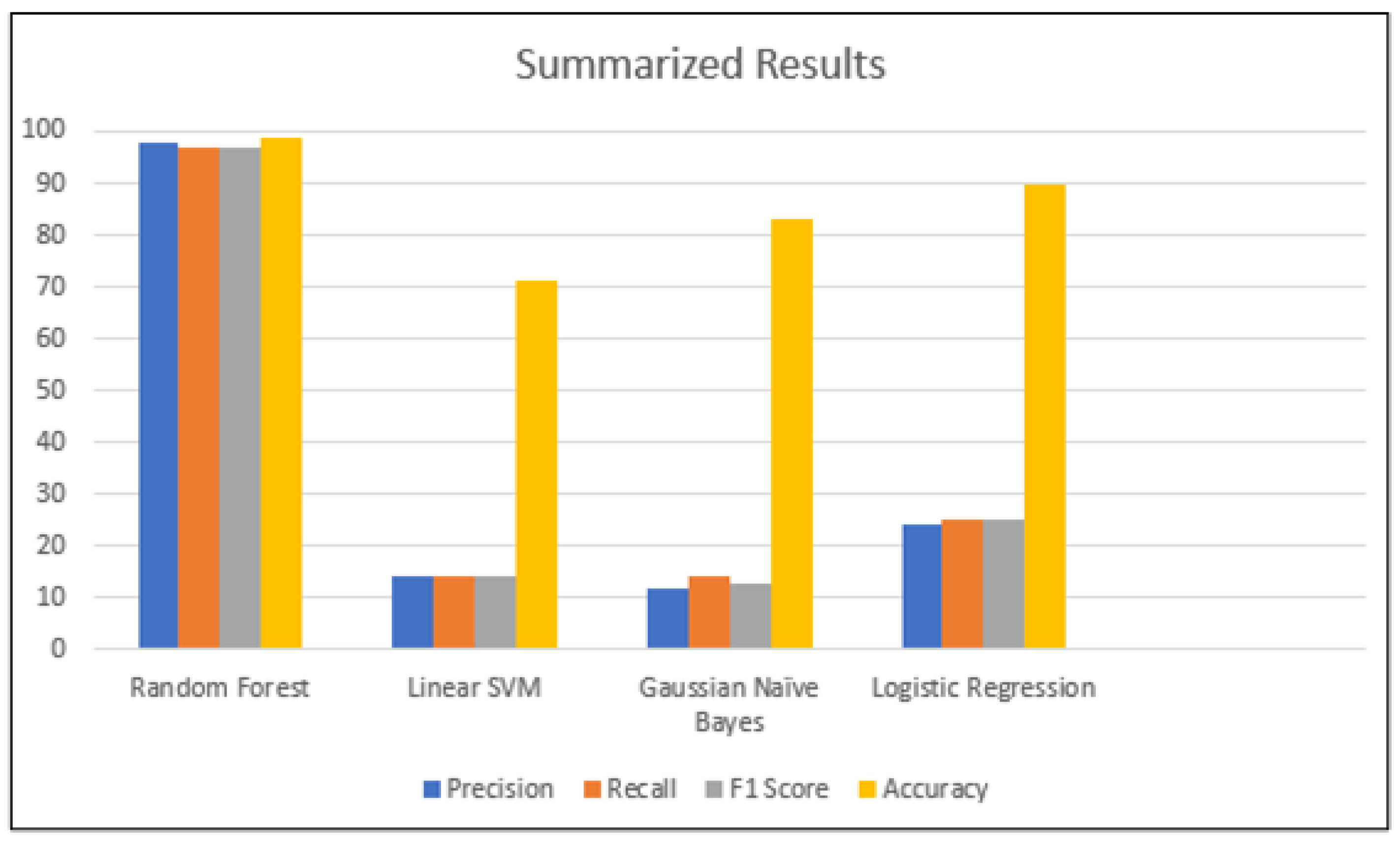
6.4. Results Summary
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Scarfone, K.; Mell, P. Guide to intrusion detection and prevention systems (IDPS). NIST Spec. Publ. 2007, 800, 94. [Google Scholar]
- Kemmerer, R.A.; Vigna, G. Intrusion detection: A brief history and overview. Computer 2002, 35, 1012428. [Google Scholar] [CrossRef]
- Cardoso, L.S. Intrusion detection versus intrusion protection. In Network Security: Current Status and Future Directions; IEEE Press: Hoboken, NJ, USA, 2007; pp. 99–115. [Google Scholar]
- Khraisat, A.; Gondal, I.; Vamplew, P.; Kamruzzaman, J. Survey of intrusion detection systems: Techniques, datasets and challenges. Cybersecurity 2019, 2, 1–22. [Google Scholar] [CrossRef]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]
- Belavagi, M.C.; Muniyal, B. Performance evaluation of supervised machine learning algorithms for intrusion detection. Procedia Comput. Sci. 2016, 89, 117–123. [Google Scholar] [CrossRef]
- Yin, C.; Zhu, Y.; Fei, J.; He, X. A deep learning approach for intrusion detection using recurrent neural networks. IEEE Access 2017, 5, 21954–21961. [Google Scholar] [CrossRef]
- Javaid, A.; Niyaz, Q.; Sun, W.; Alam, M. A deep learning approach for network intrusion detection system. In Proceedings of the 9th EAI International Conference on Bio-Inspired Information and Communications Technologies (formerly BIONETICS), New York, NY, USA, 3–5 December 2016; pp. 21–26. [Google Scholar]
- Saranya, T.; Sridevi, S.; Deisy, C.; Chung, T.D.; Khan, M.A. Performance analysis of machine learning algorithms in intrusion detection system: A review. Procedia Comput. Sci. 2020, 171, 1251–1260. [Google Scholar] [CrossRef]
- Yang, L.; Moubayed, A.; Hamieh, I.; Shami, A. Tree-based intelligent intrusion detection system in internet of vehicles. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Bertoli, G.D.C.; Júnior, L.A.P.; Saotome, O.; Dos Santos, A.L.; Verri, F.A.N.; Marcondes, C.A.C.; Barbieri, S.; Rodrigues, M.S.; De Oliveira, J.M.P. An end-to-end framework for machine learning-based network intrusion detection system. IEEE Access 2021, 9, 106790–106805. [Google Scholar] [CrossRef]
- Elmrabit, N.; Zhou, F.; Li, F.; Zhou, H. Evaluation of machine learning algorithms for anomaly detection. In Proceedings of the 2020 International Conference on Cyber Security and Protection of Digital Services (Cyber Security), Dublin, Ireland, 15–19 June 2020; pp. 1–8. [Google Scholar]
- Guo, X.; Yin, Y.; Dong, C.; Yang, G.; Zhou, G. On the class imbalance problem. In Proceedings of the 2008 Fourth international conference on natural computation, Jinan, China, 18–20 October 2008; Volume 4, pp. 192–201. [Google Scholar]
- Panigrahi, R.; Borah, S. A detailed analysis of CICIDS2017 dataset for designing Intrusion Detection Systems. Int. J. Eng. Technol. 2018, 7, 479–482. [Google Scholar]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. ICISSp 2018, 1, 108–116. [Google Scholar]
- Sharafaldin, I.; Habibi Lashkari, A.; Ghorbani, A.A. A detailed analysis of the cicids2017 data set. In Proceedings of the Information Systems Security and Privacy: 4th International Conference, ICISSP 2018, Funchal-Madeira, Portugal, 22–24 January 2018; Revised Selected Papers 4. Springer: Berlin, Germany, 2019; pp. 172–188. [Google Scholar]
- Gharib, A.; Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. An evaluation framework for intrusion detection dataset. In Proceedings of the 2016 International Conference on Information Science and Security (ICISS), Pattaya, Thailand, 19–22 December 2016; pp. 1–6. [Google Scholar]
- Gogoi, P.; Bhattacharyya, D.; Borah, B.; Kalita, J.K. MLH-IDS: A multi-level hybrid intrusion detection method. Comput. J. 2014, 57, 602–623. [Google Scholar] [CrossRef]
- Panwar, S.S.; Raiwani, Y. Data reduction techniques to analyze NSL-KDD Dataset. Int. J. Comput. Eng. Technol. 2014, 5, 21–31. [Google Scholar]
- Ambusaidi, M.A.; He, X.; Nanda, P.; Tan, Z. Building an intrusion detection system using a filter-based feature selection algorithm. IEEE Trans. Comput. 2016, 65, 2986–2998. [Google Scholar] [CrossRef]
- Zhao, G.; Zhang, C.; Zheng, L. Intrusion detection using deep belief network and probabilistic neural network. In Proceedings of the 2017 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC), Guangzhou, China, 21–24 July 2017; Volume 1, pp. 639–642. [Google Scholar]
- Roy, S.S.; Mallik, A.; Gulati, R.; Obaidat, M.S.; Krishna, P.V. A deep learning based artificial neural network approach for intrusion detection. In Proceedings of the Mathematics and Computing: Third International Conference, ICMC 2017, Haldia, India, 17–21 January 2017; Proceedings 3. Springer: Berlin, Germany, 2017; pp. 44–53. [Google Scholar]
- Kamarudin, M.H.; Maple, C.; Watson, T.; Safa, N.S. A logitboost-based algorithm for detecting known and unknown web attacks. IEEE Access 2017, 5, 26190–26200. [Google Scholar] [CrossRef]
- Al-Zewairi, M.; Almajali, S.; Awajan, A. Experimental evaluation of a multi-layer feed-forward artificial neural network classifier for network intrusion detection system. In Proceedings of the 2017 International Conference on New Trends in Computing Sciences (ICTCS), Amman, Jordan, 11–13 October 2017; pp. 167–172. [Google Scholar]
- Xu, C.; Shen, J.; Du, X.; Zhang, F. An Intrusion Detection System Using a Deep Neural Network With Gated Recurrent Units. IEEE Access 2018, 6, 48697–48707. [Google Scholar] [CrossRef]
- Belouch, M.; El Hadaj, S.; Idhammad, M. Performance evaluation of intrusion detection based on machine learning using Apache Spark. Procedia Comput. Sci. 2018, 127, 1–6. [Google Scholar] [CrossRef]
- Jia, Y.; Wang, M.; Wang, Y. Network intrusion detection algorithm based on deep neural network. IET Inf. Secur. 2019, 13, 48–53. [Google Scholar] [CrossRef]
- Halimaa, A.; Sundarakantham, K. Machine learning based intrusion detection system. In Proceedings of the 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019; pp. 916–920. [Google Scholar]
- Faker, O.; Dogdu, E. Intrusion detection using big data and deep learning techniques. In Proceedings of the 2019 ACM Southeast Conference, Kennesaw, GA, USA, 18–20 April 2019; pp. 86–93. [Google Scholar]
- Vinayakumar, R.; Alazab, M.; Soman, K.; Poornachandran, P.; Al-Nemrat, A.; Venkatraman, S. Deep learning approach for intelligent intrusion detection system. IEEE Access 2019, 7, 41525–41550. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, J.; Zhou, Y.; Han, L.; Lin, J. A multiple-layer representation learning model for network-based attack detection. IEEE Access 2019, 7, 91992–92008. [Google Scholar] [CrossRef]
- Stiawan, D.; Idris, M.Y.B.; Bamhdi, A.M.; Budiarto, R. CICIDS-2017 dataset feature analysis with information gain for anomaly detection. IEEE Access 2020, 8, 132911–132921. [Google Scholar]
- Panwar, S.S.; Negi, P.S.; Panwar, L.S.; Raiwani, Y. Implementation of machine learning algorithms on CICIDS-2017 dataset for intrusion detection using WEKA. Int. J. Recent Technol. Eng. Regul. Issue 2019, 8, 2195–2207. [Google Scholar] [CrossRef]
- Maseer, Z.K.; Yusof, R.; Bahaman, N.; Mostafa, S.A.; Foozy, C.F.M. Benchmarking of machine learning for anomaly based intrusion detection systems in the CICIDS2017 dataset. IEEE Access 2021, 9, 22351–22370. [Google Scholar] [CrossRef]
- Singh Panwar, S.; Raiwani, Y.; Panwar, L.S. Evaluation of Network Intrusion Detection with Features Selection and Machine Learning Algorithms on CICIDS-2017 Dataset. In Proceedings of the International Conference on Advances in Engineering Science Management & Technology (ICAESMT)-2019, Uttaranchal University, Dehradun, India, 14–15 March 2019. [Google Scholar]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for hyper-parameter optimization. Adv. Neural Inf. Process. Syst. 2011, 24, 2546–2554. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | File Name | Traffic Types |
|---|---|---|
| 1 | Monday-WorkingHours.pcap_ISCX.csv | Benign |
| 2 | Tuesday-WorkingHours.pcap_ISCX.csv | Benign, FTP-Patator, SSH-Patator |
| 3 | Wednesday-WorkingHours.pcap _ISCX.csv | Benign, DoS GoldenEye, DoS Hulk, DoS Slowhttptest, DoS slowloris, Heartbleed |
| 4 | Thursday-WorkingHours-Morning-WebAttacks.pcap_ISCX.csv | Benign, Web Attack—Brute Force, Web Attack—Sql Injection, Web Attack—XSS |
| 5 | Thursday-WorkingHours-Afternoon-Infilteration.pcap_ISCX.csv | Benign, Infiltration |
| 6 | Friday-WorkingHours-Morning.pcap _ISCX.csv | Benign, Bot |
| 7 | Friday-WorkingHours-Afternoon-PortScan.pcap_ISCX.csv | Benign, PortScan |
| 8 | Friday-WorkingHours-Afternoon-DDos.pcap_ISCX.csv | Benign, DDoS |
| No. | Class | Number of Samples |
|---|---|---|
| 1 | Benign | 2,359,087 |
| 2 | DoS Hulk | 231,072 |
| 3 | PortScan | 158,930 |
| 4 | DDoS | 41,835 |
| 5 | DoS GoldenEye | 10,293 |
| 6 | FTP-Patator | 7938 |
| 7 | SSH-Patator | 5897 |
| 8 | DoS slowloris | 5796 |
| 9 | DoS Slowhttptest | 5499 |
| 10 | Botnet | 1966 |
| 11 | Web Attack—Brute Force | 1507 |
| 12 | Web Attack—XSS | 652 |
| 13 | Infiltration | 36 |
| 14 | Web Attack—Sql Injection | 21 |
| 15 | Heartbleed | 11 |
| No. | Feature Name | No. | Feature Name | No. | Feature Name |
|---|---|---|---|---|---|
| 1 | Destination Port | 28 | Bwd IAT Std | 54 | AvgFwd Segment Size |
| 2 | Flow Duration | 29 | Bwd IAT Max | 55 | AvgBwd Segment Size |
| 3 | Total Fwd Packets | 30 | Bwd IAT Min | 56 | Fwd Header Length |
| 4 | Total Backward Packets | 31 | Fwd PSH Flags | 57 | FwdAvg Bytes/Bulk |
| 5 | Total Length of Fwd Packets | 32 | Bwd PSH Flags | 58 | FwdAvg Packets/Bulk |
| 6 | Total Length of Bwd Packets | 33 | Fwd URG Flags | 59 | FwdAvg Bulk Rate |
| 7 | Fwd Packet Length Max | 34 | Bwd URG Flags | 60 | BwdAvg Bytes/Bulk |
| 8 | Fwd Packet Length Min | 35 | Fwd Header Len | 61 | BwdAvg Packets/Bulk |
| 9 | Fwd Packet Length Mean | 36 | Bwd Header Length | 62 | BwdAvg Bulk Rate |
| 10 | Fwd Packet Length Std | 37 | Fwd Packets/s | 63 | SubflowFwd Packets |
| 11 | Bwd Packet Length Max | 38 | Bwd Packets/s | 64 | SubflowFwd Bytes |
| 12 | Bwd Packet Length Min | 39 | Min Packet Length | 65 | SubflowBwd Packets |
| 13 | Bwd Packet Length Mean | 40 | Max Packet Length | 66 | SubflowBwd Bytes |
| 14 | Bwd Packet Length Std | 41 | Packet Length Mean | 67 | Init_Win_bytes_forward |
| 15 | Flow Bytes/s | 42 | Packet Length Std | 68 | Init_Win_bytes_backward |
| 16 | Flow Packets/s | 43 | Packet Length Variance | 69 | act_datapktfwd |
| 17 | Flow IAT Mean | 44 | FIN Flag Count | 70 | min_seg_size_forward |
| 18 | Flow IAT Std | 45 | SYN Flag Count | 71 | Active Mean |
| 19 | Flow IAT Max | 46 | RST Flag Count | 72 | Active Std |
| 20 | Flow IAT Min | 47 | PSH Flag Count | 73 | Active Max |
| 21 | Fwd IAT Total | 48 | ACK Flag Count | 74 | Active Min |
| 22 | Fwd IAT Mean | 49 | URG Flag Count | 75 | Idle Mean |
| 23 | Fwd IAT Std | 50 | CWE Flag Count | 76 | Idle Std |
| 24 | Fwd IAT Max | 51 | ECE Flag Count | 77 | Idle Max |
| 25 | Fwd IAT Min | 52 | Down/Up Ratio | 78 | Idle Min |
| 26 | Bwd IAT Total | 53 | Average Packet Size | 79 | Label |
| 27 | Bwd IAT Mean |
| 5cNon-CICIDS-2017-Based Studies | ||||
| No. | Study | Dataset Used | ML Techniques | Key Results |
| 1 | Gogoi et al., 2013 [18] | KDD CUP ’99, DDoS dataset, NSL-KDD, TUIDS | Multi-level hybrid intrusion detection | 99.99% detection rate |
| 2 | Panwar et al., 2014 [19] | NSL-KDD | Naive Bayes, J48 | 99.88% accuracy, 99.83% specificity, 99.97% sensitivity |
| 3 | Ambusaidi et al., 2016 [20] | KDD CUP ’99, NSL-KDD and Kyoto 2006+ | Least Square Support Vector Machine (LSSVM) | Accuracy of 99.79%, 99.91%, and 99.77% for KDD CUP ’99, NSL-KDD, and Kyoto 2006+, respectively |
| 4 | Zhao et al., 2017 [21] | KDD CUP ’99 | Deep Belief Network, Probabilistic Neural Network | Accuracy of 99.14% and detection rate of 93.25% |
| 5 | Yin et al., 2017 [7] | NSL-KDD | J48, ANN, RF, SVM, RNN | Accuracy of 81.29, detection rate of 97.09% |
| 6 | Roy et al., 2017 [22] | KDD CUP ’99 | DNN, SVM | Accuracy of 99.99% |
| 7 | Kamarudin et al., 2017 [23] | NSL-KDD | NB, SVM, MLP, DT | 90% accuracy, 89.75% detection rate |
| 8 | Al-Zewairi et al., 2017 [24] | UNSW-NB15D | ANN | 98.99% accuracy |
| 9 | Xu et al., 2018 [25] | KDD CUP ’99, NSL-KDD | GRU and LSTM | Detection rate of 99.42% using KDD CUP ’99 and 99.31% using NSL-KDD |
| 10 | Beluch et al., 2018 [26] | UNSW-NB15 | DT, SVM, RF, NB | 97.49% accuracy |
| 11 | Jia et al., 2019 [27] | KDD CUP ’99, NSL-KDD | NDNN | Accuracy of 99.9% |
| 12 | Halimaa et al., 2019 [28] | NSL-KDD | SVM, NB | Accuracy of 97.29% and misclassification of 2.7% |
| 13 | Saranya et al., 2020 [9] | KDD CUP ’99 | RF, SVM, GNB | 99.81% accuracy |
| CICIDS-2017-Based Studies | ||||
| No. | Study | Dataset Used | ML Techniques | Key Results |
| 14 | Faker et al., 2019 [29] | UNSW-NB15, CICIDS-2017 | DNN, RF, GBT | 99.19 accuracy using UNSW-NB15, 99.99% accuracy using CICIDS-2017 |
| 15 | Yang et al., 2019 [10] | CICIDS-2017 | Tree-based algorithms | 98.37% accuracy |
| 16 | Vinayakumar et al., 2019 [30] | KDD CUP ’99, NSL-KDD, UNSW-NB15, WSNDS, CICIDS-2017 | Hybrid DNNs | Binary classification accuracy of 93.1% using CICIDS-2017 |
| 17 | Zhang et al., 2019 [31] | CICIDS-2017, CTU | CNN, LSTM | 99.8% accuracy for CICIDS-2017 |
| 18 | Stiawan et al., 2020 [32] | CICIDS-2017 | Random Forest (RF), Bayes Net (BN), Random Tree (RT), Naive Bayes (NB), J48, and Feature Selection | Accuracy of 99.87% |
| 19 | Elmrabit et al., 2020 [12] | CICIDS-2017, UNSW-NB15, ICS | LR, GNB, KNN, DT, AdaB, RF, CNN, CNN-LSTM, LSTM, GRU, RNN, DNN | 0.99% accuracy, precision, recall, and F-score using RF and CICIDS-2017 |
| 20 | Panwar et al., 2019 [33] | CICIDS-2017 | OneR, REPTree | Accuracy, 99.83% specificity, 99.97% sensitivity |
| 21 | Maseer et al., 2021 [34] | CICIDS-2017 | ANN, DT, KNN, NB, RF, SVM, EM, K-means, and SOM | Over 99% accuracy, precision, recall, and F1-score |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al Lail, M.; Garcia, A.; Olivo, S. Machine Learning for Network Intrusion Detection—A Comparative Study. Future Internet 2023, 15, 243. https://doi.org/10.3390/fi15070243
Al Lail M, Garcia A, Olivo S. Machine Learning for Network Intrusion Detection—A Comparative Study. Future Internet. 2023; 15(7):243. https://doi.org/10.3390/fi15070243
Chicago/Turabian StyleAl Lail, Mustafa, Alejandro Garcia, and Saul Olivo. 2023. "Machine Learning for Network Intrusion Detection—A Comparative Study" Future Internet 15, no. 7: 243. https://doi.org/10.3390/fi15070243
APA StyleAl Lail, M., Garcia, A., & Olivo, S. (2023). Machine Learning for Network Intrusion Detection—A Comparative Study. Future Internet, 15(7), 243. https://doi.org/10.3390/fi15070243