
Natural Language Processing and Cognitive Networks Identify UK Insurers’ Trends in Investor Day Transcripts



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- Uni-grams enhanced by Term Frequency - Inverse Document Frequency (TF-IDF) scores [26], and complemented with semantic network analysis, are used to identify emerging market issues;
- A lexicon-based sentiment analysis, analogous to VADER [18], is used to identify the market analysts’ perception of the insurance industry;
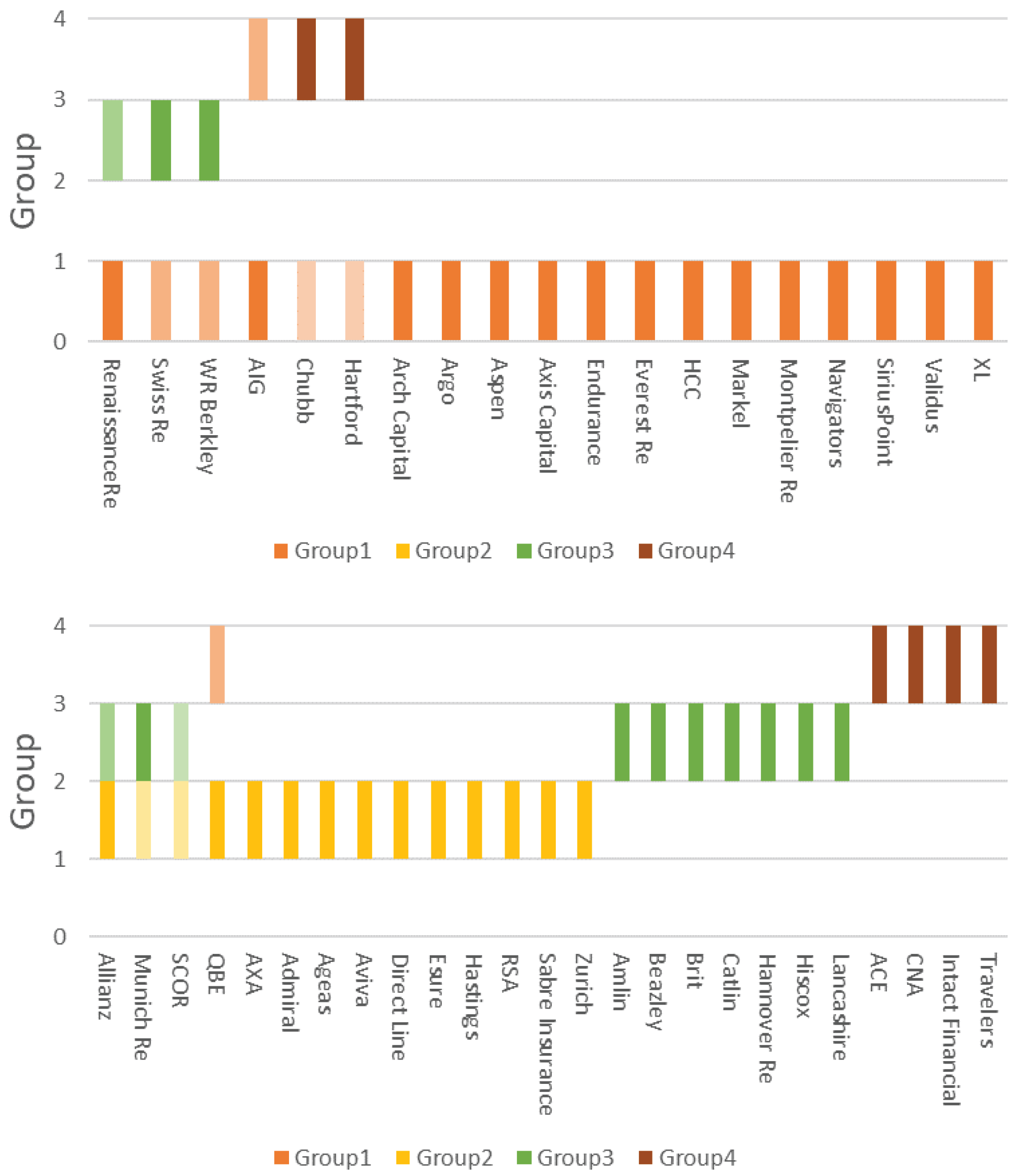
- Topic modelling, via a Latent Dirichlet Allocation (LDA) approach [4], explores whether the allocation of each insurer to a specific group aligns with or challenges existing perspectives on peer groups.
- The purpose of word/phrase automated extraction is to identify important topics in a given document [4]. According to Cavusoglu [27] there are three major methods for keyword extraction: (i) rule-based linguistic approaches, which usually rely on syntactic relationships and human coding [14]; (ii) statistical approaches, e.g., counting word frequency; and (iii) machine learning approaches, which usually require some prior knowledge for unsupervised learning or training data [4]. This paper explores statistical techniques using n-gram statistics, word frequency, and the TF-IDF measure because these techniques require no domain knowledge. The paper also explores a rule-based approach adopted from cognitive network science [19], which represents domain knowledge as a network of conceptual associations and enables greater contextual information.
- The purpose of sentiment analysis is to determine the degree of positivity, negativity, or neutrality of transcripts that provide insight on analyst opinions towards insurers. This work uses the financial lexicon provided by Loughran and McDonald [28] (referred to as the “Loughran lexicon”) to identify sentiment. This lexicon was based on VADER’s approach [18], i.e., attribute a sentiment score to each word in a text and then compute an overall sentiment score for the whole text based on single scores and simple grammatical rules. The Loughran lexicon was specifically developed for data mining financial articles to address the fact that almost 3 out of 4 negative words in common language are typically not rated negative in a financial context (see [28]). Jairo and colleagues [29] have shown that the Loughran lexicon outmatched VADER and other approaches in predicting the sentiment of financial texts. Importantly, the Loughran lexicon provides predictions of the polarity of the content (i.e., whether it contains mainly positive or negative sentiments) and a subjectivity score that assesses the extent to which the text data is based on facts or opinions.
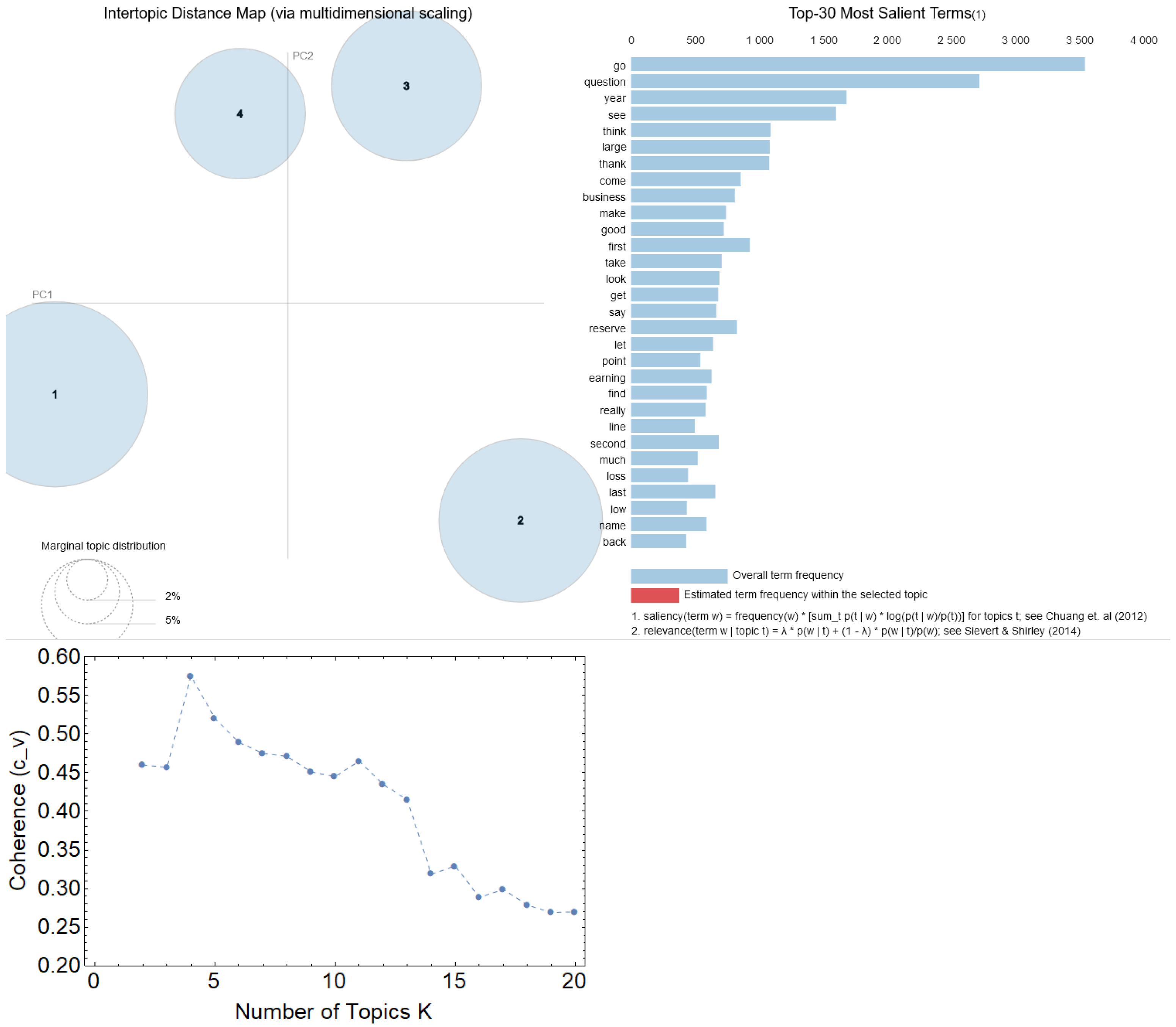
- LDA is a family of unsupervised learning algorithms that identify hidden relationships between words used across several documents. No prior knowledge of topics or themes is usually required and LDA can infer collections of words consistently co-appearing together across documents, i.e., topics [4]. This paper examines whether LDA can identify similar firms based on the identified topics.
Relevant Literature
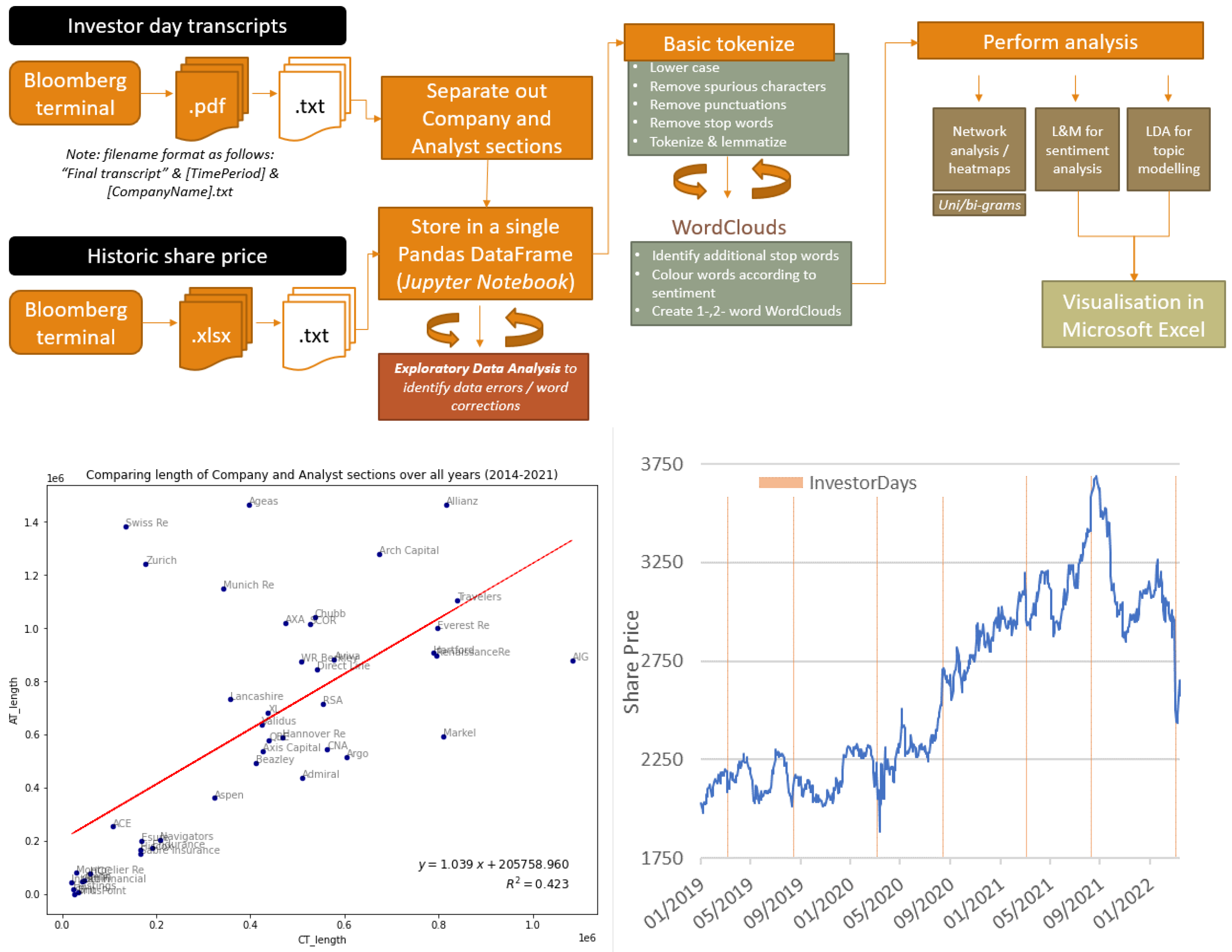
2. Materials and Methods
2.1. Investor Daily Transcripts
2.2. Share Price Information
2.3. Text Cleaning and Normalisation
- Company name: taken from the filename;
- Time period: taken from the filename, and stored as a 6-digit number. The first four digits represent the year, and the subsequent two the calendar quarter;
- Company section: all words within the text file up to a pre-defined identifier (for example, “questions and answers”) were allocated to the company section. In practice, this involved some trial and error, as the identifiers changed over the years;
- Analyst section: contained all words within the text file not allocated to the company section.
- Remove special characters (e.g., non-alphanumeric characters) and text within curly brackets. In the latter case, curly brackets are used within certain IDTs to denote who is speaking.
- Tokenise text: This process breaks up each IDT into chunks of information, known as tokens, that are treated as discrete elements for analysis. This analysis also explored the use of sub-word tokenisation—i.e., in addition to analysing individual words, the analysis also considered 2- and 3-word tokens.
- Remove stop-words: It is essential to remove stop words as these do not contain useful sentiment information (for example, words like “well, thank you”). In practice, identifying stopwords was an iterative and subjective process, using word clouds and word counts to establish those to remove. In this analysis, we started with the general stop words available from nltk, and then added firm and individual names to avoid larger insurers and analysts (who typically cover several insurers) dominating the themes.
- Lemmatise the tokens: Lemmatisation refers to the process of removing inflectional endings, to ensure only the base form of a word is retained.
2.4. Text Analysis
3. Results
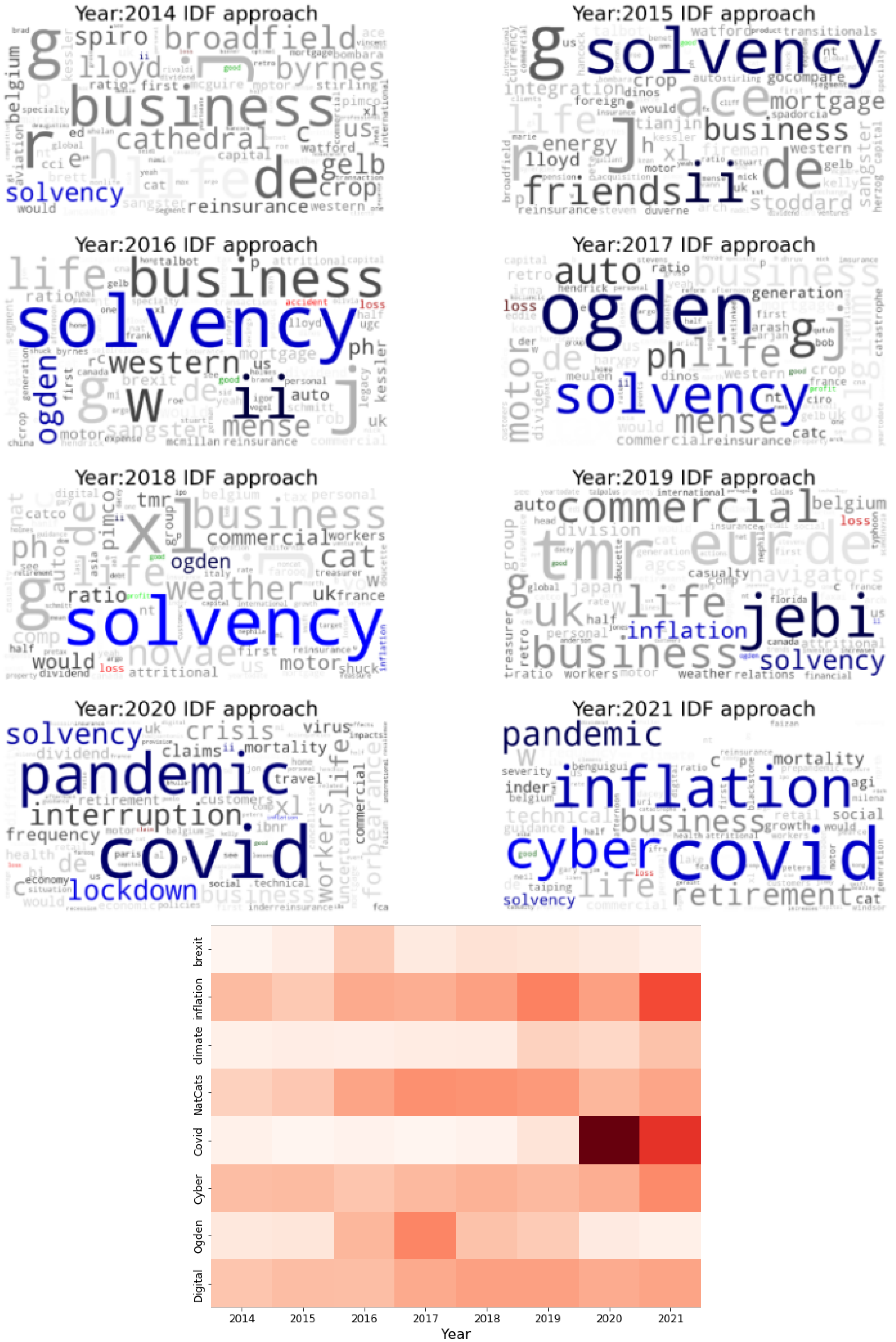
3.1. Keyword Extraction
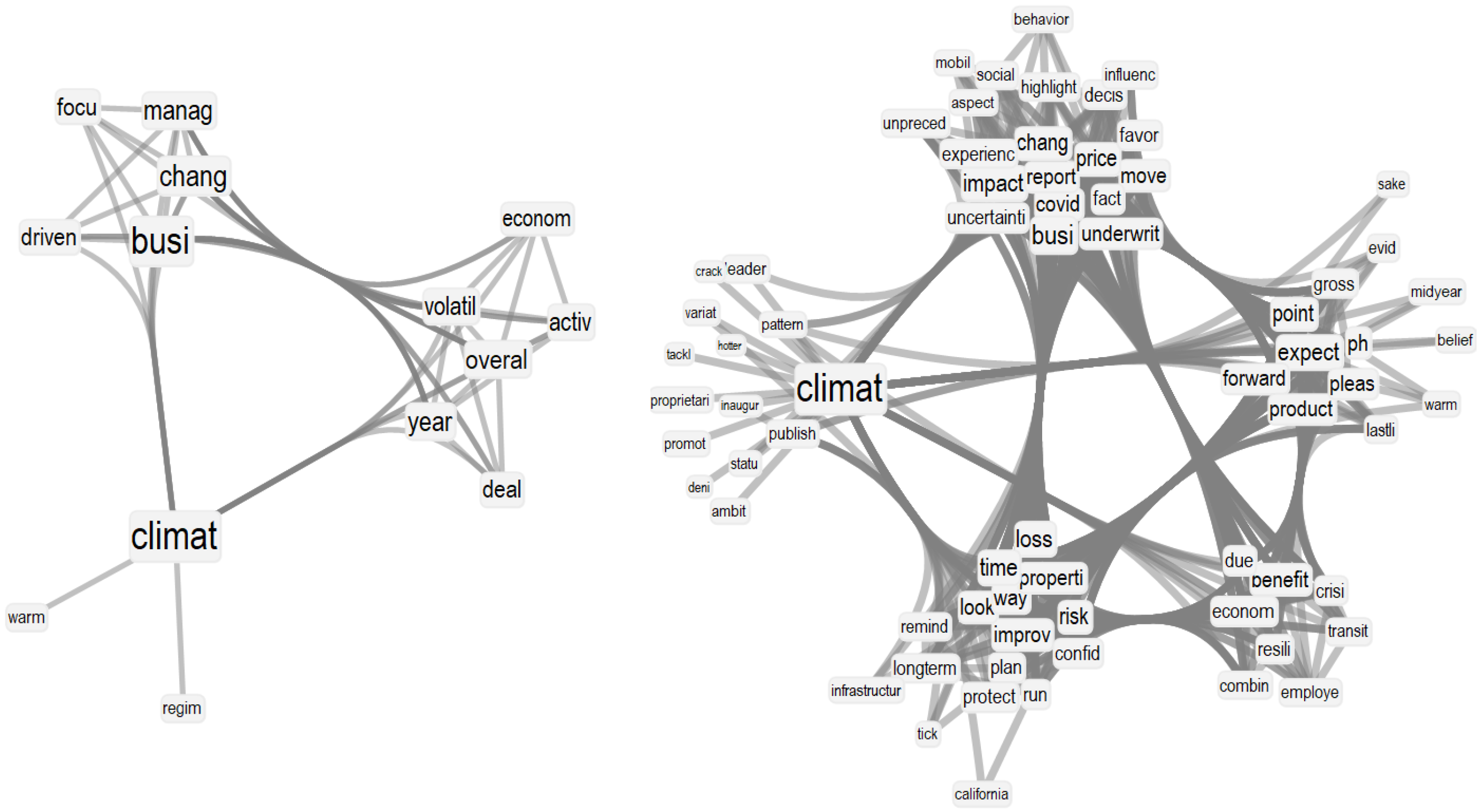
3.2. Semantic Frame Analysis
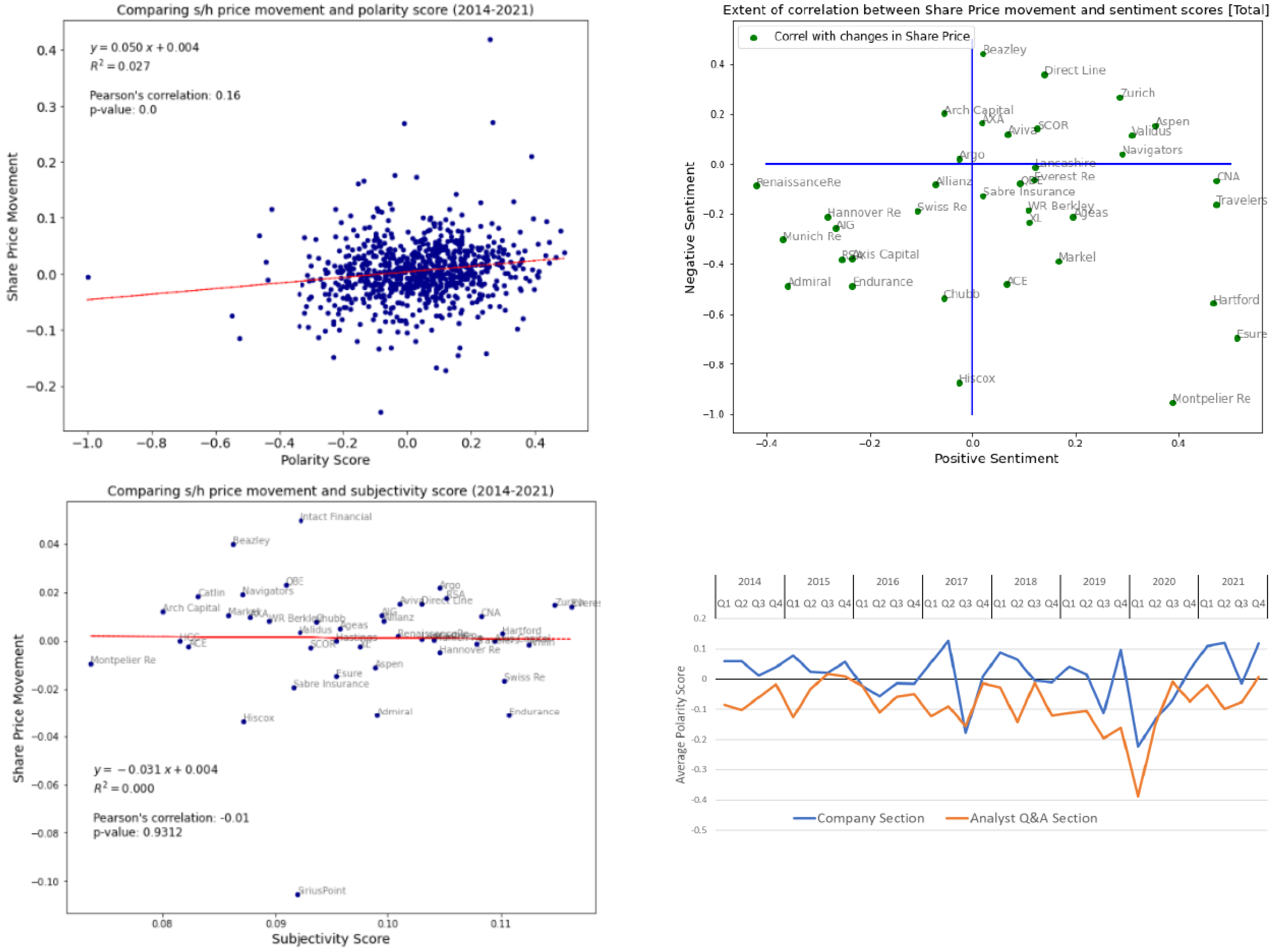
3.3. Valence/Sentiment Analysis
3.4. Topic Modelling
4. Discussion
4.1. Contributions of This Study to Improving Event Analysis in Insurance Firms
4.2. Relevance of This Study for Prudential Insurance Supervisors
4.3. Conclusions: Limitations, Future Research and Closing Remarks
4.4. Limitations and Future Research Directions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
- 1.
- Create bag-of-words representations of documents where punctuation is fully discarded, i.e., each document becomes a list of words;
- 2.
- Lemmatise all words in documents, get rid of stopwords and of additional words that do not convey meaning by themselves (e.g., names of people);
- 3.
- Creating an ID-to-word dictionary, mapping words into numerical pointers (see [42]) and running topic detection over all documents, with different values for K (number of topics);
- 4.
- Use gensim and the coherence metric denoted as [52] (for which lemmatised bag-of-words lists are required) to identify topic coherence for different numbers of topics. For each value of K select a random start of 150 and let the hyperparameter be left to get tuned internally;
- 5.
- Select the value of K relative to the highest coherence.

References
- Sharma, T.; French, D.; McKillop, D. The UK equity release market: Views from the regulatory authorities, product providers and advisors. Int. Rev. Financ. Anal. 2022, 79, 101994. [Google Scholar] [CrossRef]
- Bailey, A.J.; Breeden, S.; Stevens, G. The Prudential Regulation Authority; Bank of England Quarterly Bulletin: London, UK, 2012; p. Q4. [Google Scholar]
- Klumpes, P.J. Performance benchmarking in financial services: Evidence from the UK life insurance industry. J. Bus. 2004, 77, 257–273. [Google Scholar] [CrossRef]
- Chowdhary, K.R. Natural language processing. In Fundamentals of Artificial Intelligence; Springer: New Delhi, India, 2020; pp. 603–649. [Google Scholar]
- Semeraro, A.; Vilella, S.; Ruffo, G.; Stella, M. Emotional profiling and cognitive networks unravel how mainstream and alternative press framed AstraZeneca, Pfizer and COVID-19 vaccination campaigns. Sci. Rep. 2022, 12, 14445. [Google Scholar] [CrossRef] [PubMed]
- Elshendy, M.; Colladon, A.F.; Battistoni, E.; Gloor, P.A. Using four different online media sources to forecast the crude oil price. J. Inf. Sci. 2018, 44, 408–421. [Google Scholar] [CrossRef]
- Pagolu, V.S.; Challa, K.; Panda, G.; Majhi, B. Sentiment analysis of Twitter data for predicting stock market movements. In Proceedings of the 2016 International Conference on Signal Processing, Communication, Power and Embedded System (SCOPES), Paralakhemundi, India, 3–5 October 2016; pp. 1345–1350. [Google Scholar]
- Ranco, G.; Aleksovski, D.; Caldarelli, G.; Grcar, M.; Mozetic, I. The Effects of Twitter Sentiment on Stock Price Returns. PLoS ONE 2015, 10, e0138441. [Google Scholar] [CrossRef]
- Montefinese, M.; Ambrosini, E.; Angrilli, A. Online search trends and word-related emotional response during COVID-19 lockdown in Italy: A cross-sectional online study. PeerJ 2021, 9, e11858. [Google Scholar] [CrossRef]
- Vilella, S.; Semeraro, A.; Paolotti, D.; Ruffo, G. Measuring user engagement with low credibility media sources in a controversial online debate. Epj Data Sci. 2022, 11, 29. [Google Scholar] [CrossRef]
- Stella, M. Cognitive network science for understanding online social cognitions: A brief review. Top. Cogn. Sci. 2022, 14, 143–162. [Google Scholar] [CrossRef]
- Kadilli, A. Predictability of stock returns of financial companies and the role of investor sentiment: A multi-country analysis. J. Financ. Stab. 2015, 21, 26–45. [Google Scholar] [CrossRef]
- Fillmore, C.J. Frame semantics. Cogn. Linguist. Basic Readings 2006, 34, 373–400. [Google Scholar]
- Carley, K. Extracting culture through textual analysis. Poetics 1994, 22, 291–312. [Google Scholar] [CrossRef]
- Stella, M.; Zaytseva, A. Forma mentis networks map how nursing and engineering students enhance their mindsets about innovation and health during professional growth. PeerJ Comput. Sci. 2020, 6, e255. [Google Scholar] [CrossRef] [PubMed]
- Wecker, A.J.; Lanir, J.; Mokryn, O.; Minkov, E.; Kuflik, T. Semantize: Visualizing the sentiment of individual document. In Proceedings of the 2014 International Working Conference on Advanced Visual Interfaces, Como, Italy, 27–30 May 2014; pp. 385–386. [Google Scholar]
- Kiritchenko, S.; Zhu, X.; Mohammad, S.M. Sentiment analysis of short informal texts. J. Artif. Intell. Res. 2014, 50, 723–762. [Google Scholar] [CrossRef]
- Hutto, C.; Gilbert, E. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; Volume 8, pp. 216–225. [Google Scholar]
- Stella, M.; Restocchi, V.; De Deyne, S. #lockdown: Network-enhanced emotional profiling in the time of COVID-19. Big Data Cogn. Comput. 2020, 4, 14. [Google Scholar]
- Cropanzano, R.S.; Massaro, S.; Becker, W.J. Deontic justice and organizational neuroscience. J. Bus. Ethics 2017, 144, 733–754. [Google Scholar] [CrossRef]
- Gandhi, P.; Loughran, T.; McDonald, B. Using annual report sentiment as a proxy for financial distress in US banks. J. Behav. Financ. 2019, 20, 424–436. [Google Scholar] [CrossRef]
- Zappa, D.; Clemente, G.P.; Borrelli, M.; Savelli, N. Text mining in insurance: From unstructured data to meaning. Variance 2019, 14, 1–15. [Google Scholar]
- Siew, C.S.; Wulff, D.U.; Beckage, N.M.; Kenett, Y.N. Cognitive network science: A review of research on cognition through the lens of network representations, processes, and dynamics. Complexity 2019, 2019, 2108423. [Google Scholar] [CrossRef]
- Citraro, S.; Rossetti, G. Identifying and exploiting homogeneous communities in labeled networks. Appl. Netw. Sci. 2020, 5, 55. [Google Scholar] [CrossRef]
- Corrêa, E.A., Jr.; Marinho, V.Q.; Amancio, D.R. Semantic flow in language networks discriminates texts by genre and publication date. Phys. A Stat. Mech. Its Appl. 2020, 557, 124895. [Google Scholar] [CrossRef]
- Aizawa, A. An information-theoretic perspective of tf-idf measures. Inf. Process. Manag. 2003, 39, 45–65. [Google Scholar] [CrossRef]
- Çavusoğlu, D.; Dayibasi, O.; Sağlam, R.B. Key Extraction in Table Form Documents: Insurance Policy as an Example. In Proceedings of the 2018 3rd International Conference on Computer Science and Engineering (UBMK), Sarajevo, Bosnia and Herzegovina, 20–23 September 2018; pp. 195–200. [Google Scholar]
- Loughran, T.; McDonald, B. When is a liability not a liability? Textual analysis, dictionaries, and 10-Ks. J. Financ. 2011, 66, 35–65. [Google Scholar] [CrossRef]
- Jairo, P.B.Y.; Aló, R.A.; Olson, D. Comparison of Lexicon Performances on Unstructured Behavioral Data. In Proceedings of the 2019 Sixth International Conference on Social Networks Analysis, Management and Security (SNAMS), Granada, Spain, 22–25 October 2019; pp. 28–35. [Google Scholar]
- Boudoukh, J.; Feldman, R.; Kogan, S.; Richardson, M. Which News Moves Stock Prices? A Textual Analysis; Technical Report; National Bureau of Economic Research: Cambridge, MA, USA, 2013. [Google Scholar]
- Tetlock, P.C. Giving content to investor sentiment: The role of media in the stock market. J. Financ. 2007, 62, 1139–1168. [Google Scholar] [CrossRef]
- Heston, S.L.; Sinha, N.R. News vs. sentiment: Predicting stock returns from news stories. Financ. Anal. J. 2017, 73, 67–83. [Google Scholar] [CrossRef]
- Sinha, N.R. Underreaction to news in the US stock market. Q. J. Financ. 2016, 6, 1650005. [Google Scholar] [CrossRef]
- Tetlock, P.C.; Saar-Tsechansky, M.; Macskassy, S. More than words: Quantifying language to measure firms’ fundamentals. J. Financ. 2008, 63, 1437–1467. [Google Scholar] [CrossRef]
- Petropoulos, A.; Siakoulis, V. Can central bank speeches predict financial market turbulence? Evidence from an adaptive NLP sentiment index analysis using XGBoost machine learning technique. Cent. Bank Rev. 2021, 21, 141–153. [Google Scholar] [CrossRef]
- Rastelli, C.; Greco, A.; Kenett, Y.N.; Finocchiaro, C.; De Pisapia, N. Simulated visual hallucinations in virtual reality enhance cognitive flexibility. Sci. Rep. 2022, 12, 4027. [Google Scholar] [CrossRef]
- Kumar, A.M.; Goh, J.Y.; Tan, T.H.; Siew, C.S. Gender Stereotypes in Hollywood Movies and Their Evolution over Time: Insights from Network Analysis. Big Data Cogn. Comput. 2022, 6, 50. [Google Scholar] [CrossRef]
- de Arruda, H.F.; Marinho, V.Q.; Costa, L.d.F.; Amancio, D.R. Paragraph-based representation of texts: A complex networks approach. Inf. Process. Manag. 2019, 56, 479–494. [Google Scholar] [CrossRef]
- Quispe, L.V.; Tohalino, J.A.; Amancio, D.R. Using virtual edges to improve the discriminability of co-occurrence text networks. Phys. A Stat. Mech. Its Appl. 2021, 562, 125344. [Google Scholar] [CrossRef]
- Stella, M.; Vitevitch, M.S.; Botta, F. Cognitive Networks Extract Insights on COVID-19 Vaccines from English and Italian Popular Tweets: Anticipation, Logistics, Conspiracy and Loss of Trust. Big Data Cogn. Comput. 2022, 6, 52. [Google Scholar] [CrossRef]
- Golino, H.; Christensen, A.P.; Moulder, R.; Kim, S.; Boker, S.M. Modeling latent topics in social media using Dynamic Exploratory Graph Analysis: The case of the right-wing and left-wing trolls in the 2016 US elections. Psychometrika 2022, 87, 156–187. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Wang, Y.; Xu, W. Leveraging deep learning with LDA-based text analytics to detect automobile insurance fraud. Decis. Support Syst. 2018, 105, 87–95. [Google Scholar] [CrossRef]
- Patuelli, A.; Caldarelli, G.; Lattanzi, N.; Saracco, F. Firms’ challenges and social responsibilities during COVID-19: A Twitter analysis. PLoS ONE 2021, 16, e0254748. [Google Scholar] [CrossRef]
- Chen, W.; Pacheco, D.; Yang, K.C.; Menczer, F. Neutral bots probe political bias on social media. Nat. Commun. 2021, 12, 5580. [Google Scholar] [CrossRef]
- Simon, F.M.; Camargo, C.Q. Autopsy of a metaphor: The origins, use and blind spots of the ‘infodemic’. New Media Soc. 2021. [Google Scholar] [CrossRef]
- Li, Y.; Hills, T.; Hertwig, R. A brief history of risk. Cognition 2020, 203, 104344. [Google Scholar] [CrossRef]
- Picault, M.; Pinter, J.; Renault, T. Media sentiment on monetary policy: Determinants and relevance for inflation expectations. J. Int. Money Financ. 2022, 124, 102626. [Google Scholar] [CrossRef]
- Miller, G.A. WordNet: An Electronic Lexical Database; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Bento, F.; Tagliabue, M.; Lorenzo, F. Organizational silos: A scoping review informed by a behavioral perspective on systems and networks. Societies 2020, 10, 56. [Google Scholar] [CrossRef]
- Skinner, D.J. Why firms voluntarily disclose bad news. J. Account. Res. 1994, 32, 38–60. [Google Scholar] [CrossRef]
- Syed, S.; Spruit, M. Full-text or abstract? Examining topic coherence scores using latent dirichlet allocation. In Proceedings of the 2017 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Tokyo, Japan, 19–21 October 2017; pp. 165–174. [Google Scholar]
- Sievert, C.; Shirley, K. LDAvis: A method for visualizing and interpreting topics. In Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces, Baltimore, MD, USA, 27 June 2014; pp. 63–70. [Google Scholar]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Claus, S.; Stella, M. Natural Language Processing and Cognitive Networks Identify UK Insurers’ Trends in Investor Day Transcripts. Future Internet 2022, 14, 291. https://doi.org/10.3390/fi14100291
Claus S, Stella M. Natural Language Processing and Cognitive Networks Identify UK Insurers’ Trends in Investor Day Transcripts. Future Internet. 2022; 14(10):291. https://doi.org/10.3390/fi14100291
Chicago/Turabian StyleClaus, Stefan, and Massimo Stella. 2022. "Natural Language Processing and Cognitive Networks Identify UK Insurers’ Trends in Investor Day Transcripts" Future Internet 14, no. 10: 291. https://doi.org/10.3390/fi14100291
APA StyleClaus, S., & Stella, M. (2022). Natural Language Processing and Cognitive Networks Identify UK Insurers’ Trends in Investor Day Transcripts. Future Internet, 14(10), 291. https://doi.org/10.3390/fi14100291