The data used in this research are comprised of 1,007,727 rows of audit logs of every user and their EPR activity at a specialist UK hospital based in the north of England over a period of 18 months (28-02-16–21-08-17). A large teaching hospital may have up to four times the number of staff and would, therefore, have a proportional increase in data quantity.
3.1. EPR Data
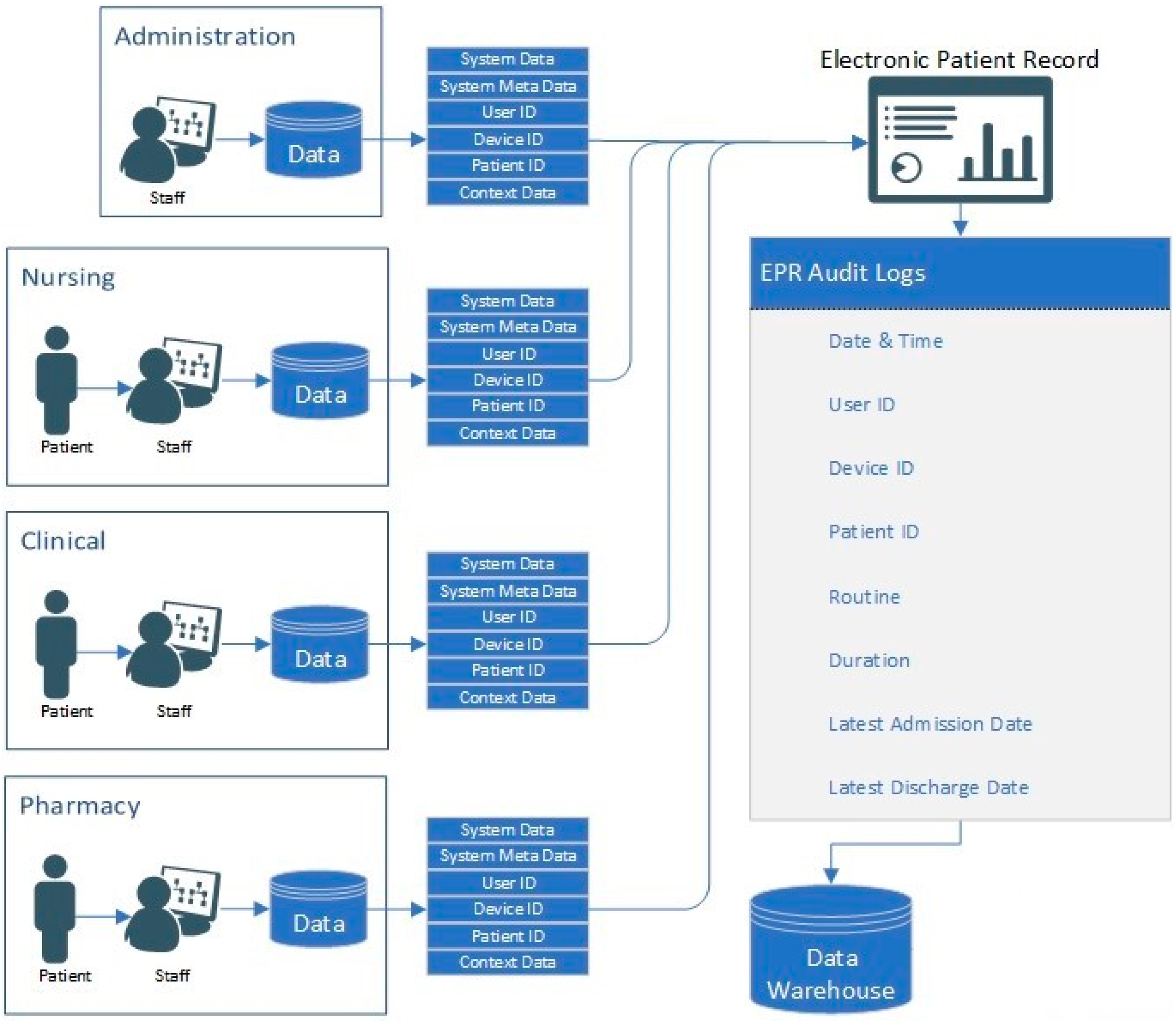
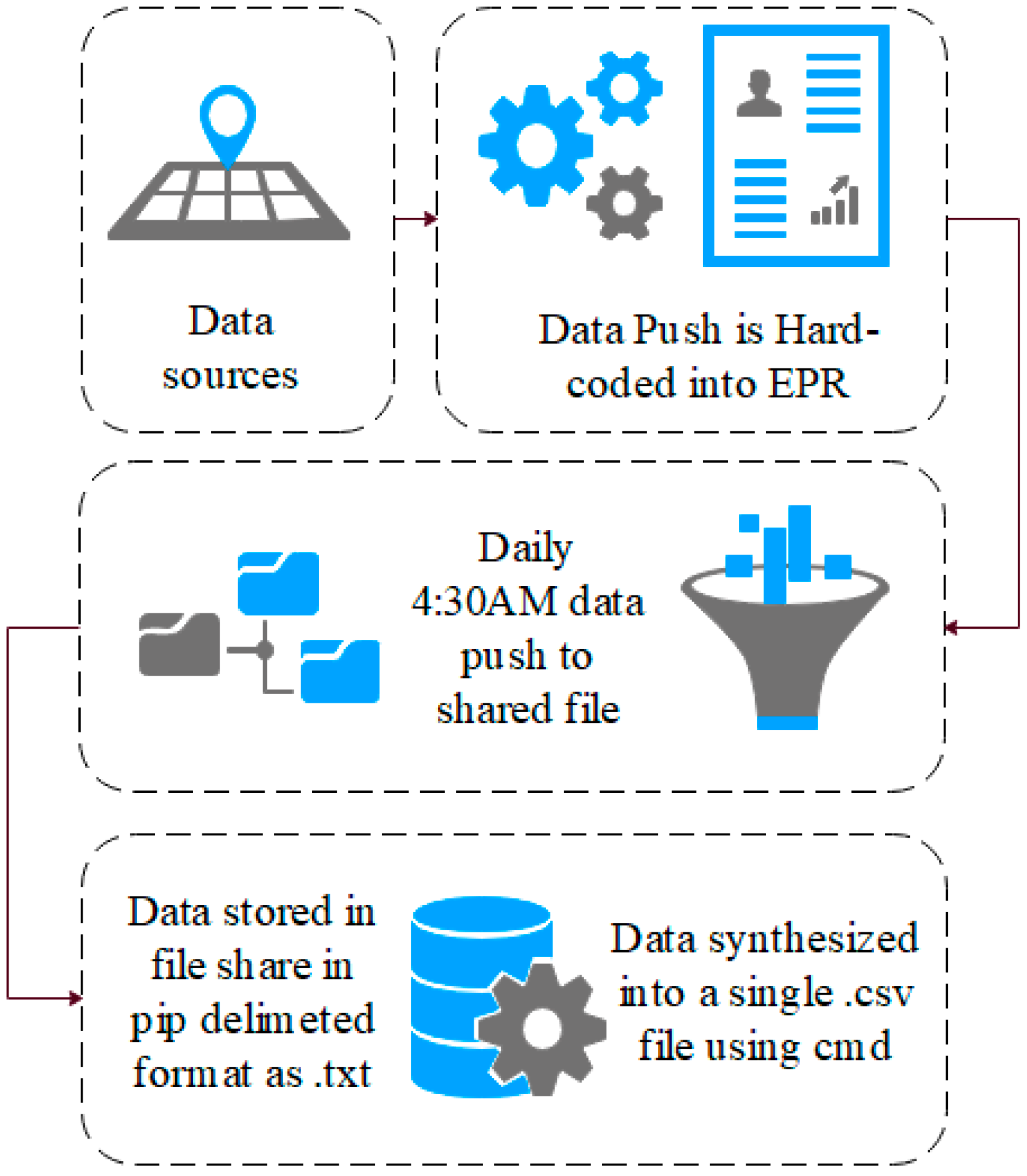
The EPR data in this study use a unique hierarchal relationship data structure (for this reason, the data cannot be queried directly and extracted). Instead, they are hard-coded into the EPR to push these data to storage on a daily basis at 04:30AM. Specifically, these data are combined into to a shared data file in pipe-delimited format (comma-delimited may cause issues with certain fields such as name, or routine). EPRs integrate many aspects of care into a single system, which are audited. Each encounter with patient data results in an audit footprint, which is stored in the data warehouse. This process is detailed in
Figure 1.
These data remain in .txt format until they are synthesised into a single .csv data file using the command prompt, as presented in
Figure 2. This, however, is unusual. Many EPRs (and other medical systems) use a relationship data structure; therefore, these data can instead be extracted using an SQL query and the .csv file will be created. A sample of the EPR data used in this research is presented in
Table 2. Each User ID, Patient ID and Device ID reading is tokenised to anonymise the data, as outlined in Algorithm 1.
| Algorithm 1. Tokenisation algorithm |
| 1. Function: Sort (values into alphabetical order) |
| 2. Set: x1 a tokenised value of 1 |
| 3. IF next value is same as previous value |
| 4. Assign same tokenised value |
| 5. ELSEIF |
| 6. Assign a value +1 to the previous tokenisation value |
| 7. ELSEIF |
| 8. Check: All values have been tokenised |
| 9. Return END |
| 10. END |
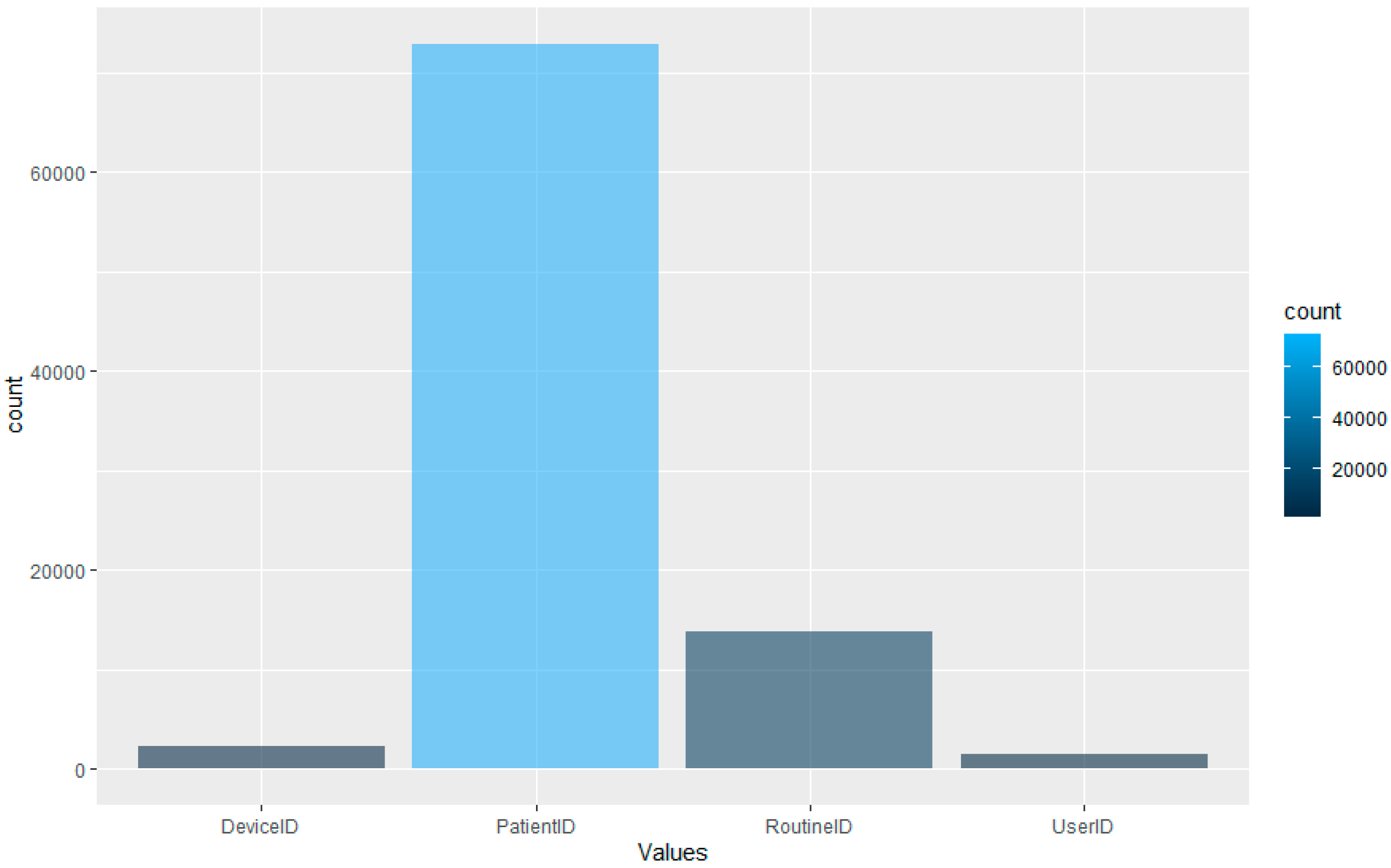
The algorithm isolates unique entries and assigns each value an incrementing number. In the dataset used in this research, there are 1515 unique User IDs, 72,878 unique Patient IDs, 2270 Device IDs and 13,722 Routine IDs. Therefore, there are 90,385 unique IDs in the dataset in total (user, patient, device and routine combined). The Routine ID is not tokenised as it denotes the tasks performed by the user on the EPR for the interaction.
The data snapshot presented in
Table 1 shows, for example, that User 865 accesses the
Pharmacy Orders function of the EPR on Patient 58,991 whilst using Device 362. As such, the premise of this research is to leverage the granularity of data within EPR for the development of internal-focused security application.
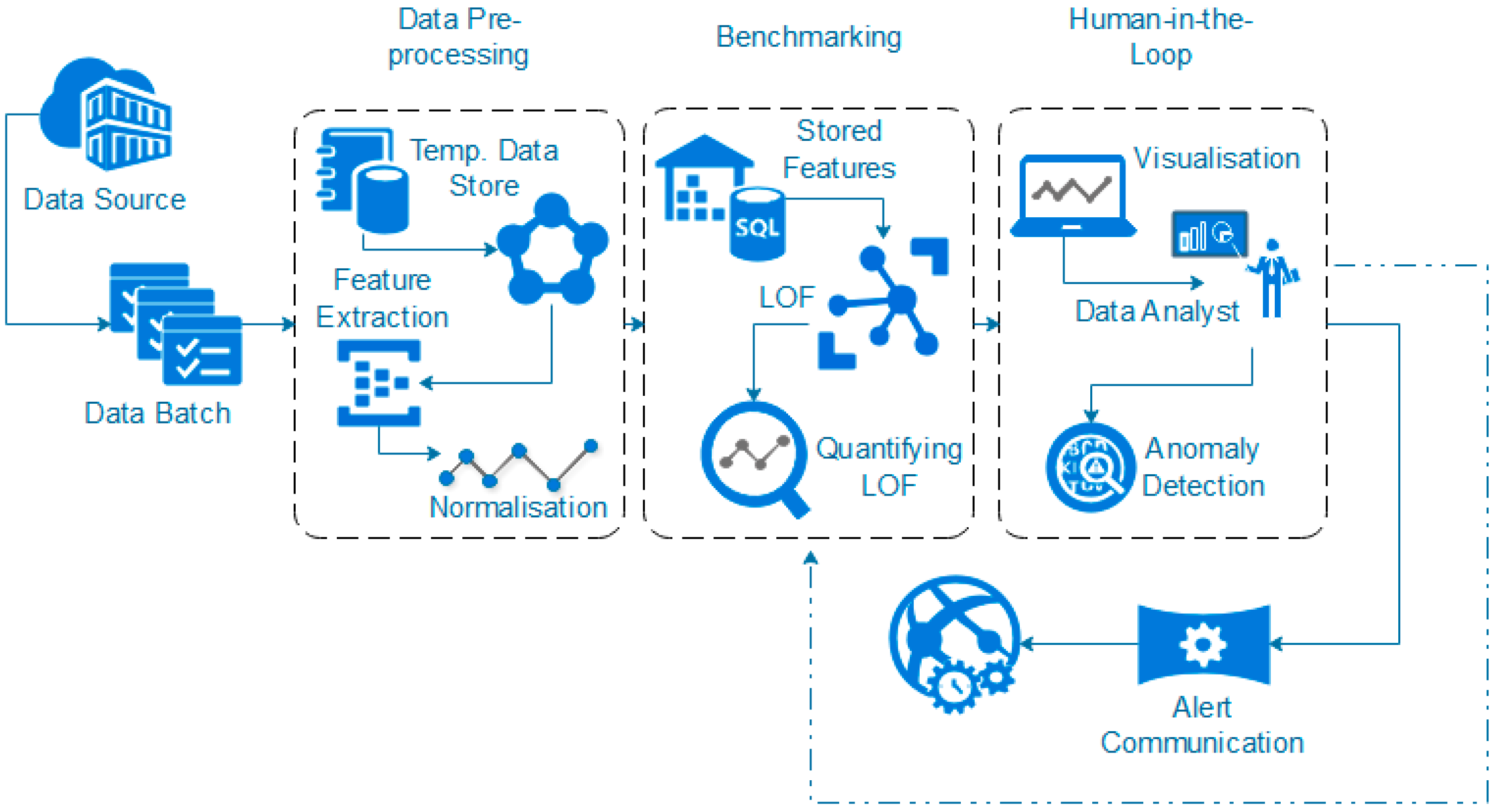
3.3. Data Pre-Processing
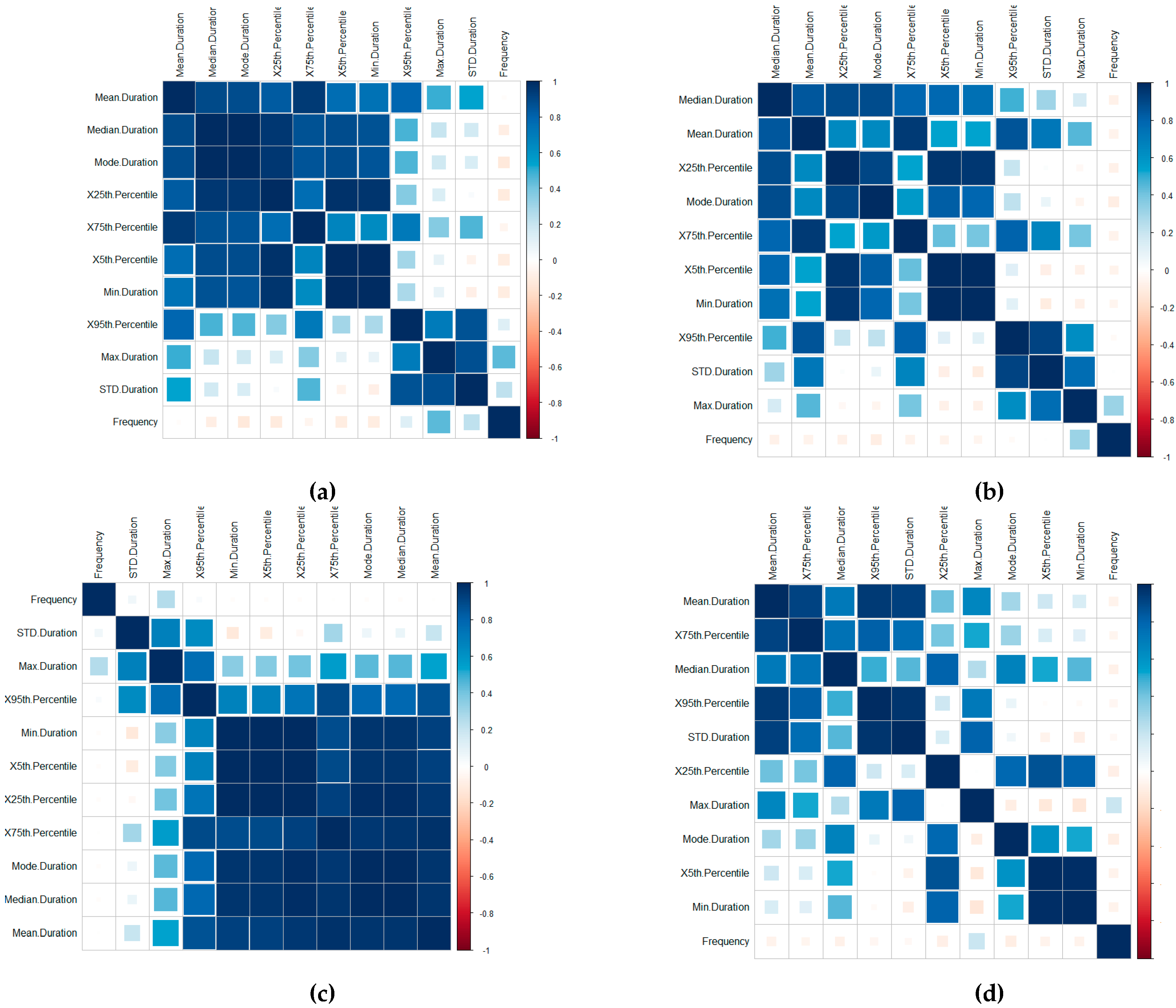
A time-series-focused statistical features extraction process is implemented in three groupings including (1) central tendency, (2) variability and (3) measures of position, calculated through the Frequency, Mean, Median, Mode, Standard Deviation, Minimum, Maximum, 1st Quartile and 3rd Quartile, the 5th Percentile and 95th Percentile features (this is further outlined in [
46]). A correlation of the features for the Device ID (a), Patient ID (b), User ID (c) and Routine ID (d) is displayed in
Figure 4. The correlation is implemented using the
corrplot (
https://cran.r-project.org/web/packages/corrplot/vignettes/corrplot-intro.html) R library package.
The visualisations display the positive and negative correlation between the features, where blue refers to positive correlation and red negative. The plots are organised using the correlation coefficient, which displays hidden structures in the matrix by means of the angular order of the eigenvectors (AOE). The ordering of the visualisation is calculated in (1) from the order of the angles (
ai), with
ei1 and
ei2 referring to the two largest eigenvalues in the correlation matrix [
47].
On visual inspection, there are clear positive correlation patterns in each of the plots. Based on the negative correlation patterns, an omission of the frequency for the User ID, Routine and Device Interaction would be beneficial to the detection process.
In terms of the Routine and Device Interaction, the frequency patterns would relate predominately to unique routine combinations. Logically, this feature is, therefore, less significant. However, it should be retained in the Patient ID classification process.
3.4. Benchmark Profiling Using LOF
The defining of benchmark behaviours is required in order to distinguish between what is classed a normal behavioural pattern and those which should be classed as abnormal/unauthorised access. Once initial benchmarking values are set, this would tailor the system to the hospital’s unique behavioural trends. This process could, theoretically, be provided by the hospital through consultation. However, to provide a more distributable/accessible approach, it can be calculated as detailed in this section, where the initial benchmark values for each of the ID types are defined by the actual LOF approach with a HIL for confirmation.
The advantage of using LOF over other techniques is that LOF is concerned with exposing the anomalous data points. It achieves this by measuring the local deviation. In this way, data points that are a deviation from the norm are revealed [
46].
In terms of EPR data, density-based outlier techniques recognise points that are deviations from related others in a single data range. This means that techniques such as LOF are beneficial for use in datasets where there might be many different professions or roles present. LOF, in particular, is advantageous over proximity-based clustering, as it considers the degree of deviance from the norm through analysing the density of one coefficient against its neighbours, whereas, if a global outlier technique is employed, a further correlation of the different hospital roles with each other would be required in order to detect irregular behaviours. The local outlier factor (LOF) calculation process involves five stages (as outlined further in [
46]). Stage one concerns the
k-distance computation. This is the calculation of the Euclidian distance of the
k-th nearest object from
p (an object). Next, the
k-nearest neighbour set construction for
p (Set
kNN(
p)) is constructed by objects within
k-distance from
p. Thirdly, a reachability distance computation for
p is required; where the reachability distance of
p to an object
o in
kNN(
p) is defined in (2) and d(
p,
o) is the Euclidian distance of
p to
o.
The
lrd computation for
p is the local reachability density (
lrd) of
p, defined in (3).
The final stage is the LOF computation for
p, where the local outlier factor of
p is computed as displayed in (4).
However, other solutions could be adopted, for example, DBSCAN. DBSCAN is a cluster analysis method that divides a dataset into
n dimensions and forms an
n-dimensional shape around each datapoint creating data clusters.
| Algorithm 2. DBSCAN |
| 1. Function: DBSCAN () |
| 2. Parameters include (Data, EPS, MinPts) |
| 3. IF SetOfPoints is Unclassifed |
| 4. ClusterID = nextID(NOISE); |
| 5. Function: SetOfPoints.size() |
| 6. FOR i from 1 to, Point = SetOfPoints(i); |
| 7. IF Point is Unclassifed THEN |
| 8 IF ExpandCluster(SetOfPoints, Point, ClusterID, Eps, MinPts) THEN |
| 9. ClusterID = nextID(ClusterID) |
| 10. END FOR |
| 11. Return DBSCAN classification |
The clusters are then expanded by including other datapoints within the cluster and adding their n dimensions in the cluster. It requires two parameters: (1) ε—the minimum distance between two points to be considered neighbours and (2) MinPoints—the minimum number of points which form a dense region. Any datapoints that do not fall within a cluster can be handled as an outlier. This process is outlined in Algorithm 2, which shows a high-level DBSCAN pseudocode.
DBSCAN is often compared with LOF as an outlier model, even with large scale analysis [
46]. However, DBSCAN is more applicable to cluster analysis data applications rather than anomaly detection. Clusters with varying densities cannot be easily identified, only high and low densities. Due to the lack of a weighted score, DBSCAN does not allow a patient privacy officer to prioritise their investigation into potentially inappropriate behaviour. Once the officer has investigated the noise points, there is the ‘needle-in-a-haystack’ problem of investigating border points. This is insufficient, and a weighted anomaly score is required to enable more nuanced investigation. However, a comparison of LOF with the DBSCAN approach is presented in the implementation as justification of the use of LOF for the detection methodology. As an example of active profiles within the dataset (as defined by highest frequency value) is displayed in
Table 4. Here, standard time frequency considerations are employed to show that User 1016 accessed data 32,557 times for a mean average of 49.50 s during the time period in which the data were collected. Further clarification on EPR data can be found in [
46].
However, for clarity, User ID refers to the unique ID number assigned to the user of the EPR data. Frequency refers to the number of occurrences or actions performed by the user when accessing the EPR records. The Mean, Standard Deviation (STD), Max and 5th Percentile are time-series-based measures of central tendency and measures of dispersion used to construct the features for the LOF and DBSCAN investigation (as discussed in
Section 3.3).
However, as the aim is to perform this type of detection using LOF. The dataset, whilst comprehensive, is unbalanced in terms of the distribution of the data across the four data types.
Figure 5 displays the distribution of the data after the feature extraction and normalisation process. The graph displays that the majority of the dataset is comprised of patient ID access. This would make sense as, logically, the most likely data accessed would be related to patients within a hospital setting. The lowest portion of the dataset is comprised of the User ID information; again, this is logical, as the hospital will have fewer staff than patients.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}