Ranking by Relevance and Citation Counts, a Comparative Study: Google Scholar, Microsoft Academic, WoS and Scopus





Abstract
1. Introduction
2. Related Studies
- -
- -
- -
- -
- -
- Documents with many citations received have more readers and more citations and, in this way, consolidate their top position [61].
3. Methodology
“Google Scholar aims to rank documents the way researchers do, weighing the full text of each document, where it was published, who it was written by as well as how often and how recently it has been cited in other scholarly literature.”[71].
“In a nutshell, we use the dynamic eigencentrality measure of the heterogeneous MAG to determine the ranking of publications. The framework ensures that a publication will be ranked high if it impacts highly ranked publications, is authored by highly ranked scholars from prestigious institutions, or is published in a highly regarded venue in highly competitive fields. Mathematically speaking, the eigencentrality measure can be viewed as the likelihood that a publication will be mentioned as highly impactful when a survey is posed to the entire scholarly community”[76]
4. Analysis of Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. List of Terms Used in The Searches

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Search Words | Rho Google Scholar Title | Rho Google Scholar Not Title | Rho Microsoft Academic Title |
|---|---|---|---|
| Median | 0.990 ** | 0.968 ** | 0.907 ** |
| approach | 0.742 ** | 0.700 ** | 0.548 ** |
| assessment | 0.632 ** | 0.563 ** | 0.545 ** |
| authority | 0.868 ** | 0.815 ** | 0.465 ** |
| consistent | 0.956 ** | 0.783 ** | 0.596 ** |
| context | 0.851 ** | 0.681 ** | 0.483 ** |
| data | 0.645 ** | 0.662 ** | 0.601 ** |
| definition | 0.907 ** | 0.783 ** | 0.636 ** |
| derived | 0.905 ** | 0.682 ** | 0.568 ** |
| distribution | 0.781 ** | 0.649 ** | 0.458 ** |
| estimate | 0.939 ** | 0.813 ** | 0.527 ** |
| evidence | 0.761 ** | 0.616 ** | 0.488 ** |
| fact | 0.899 ** | 0.229 ** | 0.517 ** |
| factor | 0.490 ** | 0.591 ** | 0.490 ** |
| formula | 0.872 ** | 0.773 ** | 0.352 ** |
| function | 0.789 ** | 0.650 ** | 0.529 ** |
| interpretation | 0.852 ** | 0.723 ** | 0.570 ** |
| method | 0.762 ** | 0.665 ** | 0.613 ** |
| percent | 0.932 ** | 0.861 ** | 0.478 ** |
| principle | 0.879 ** | 0.812 ** | 0.530 ** |
| research | 0.500 ** | 0.642 ** | 0.521 ** |
| response | 0.741 ** | 0.603 ** | 0.500 ** |
| significant | 0.929 ** | 0.709 ** | 0.557 ** |
| source | 0.848 ** | 0.735 ** | 0.546 ** |
| theory | 0.488 ** | 0.544 ** | 0.483 ** |
| variable | 0.888 ** | 0.727 ** | 0.569 ** |
| Search Words | Rho GS Title | Rho GS Not Title | Rho MA Title | Rho Scopus | Rho WoS Version 1 | Rho WoS Version 2 |
|---|---|---|---|---|---|---|
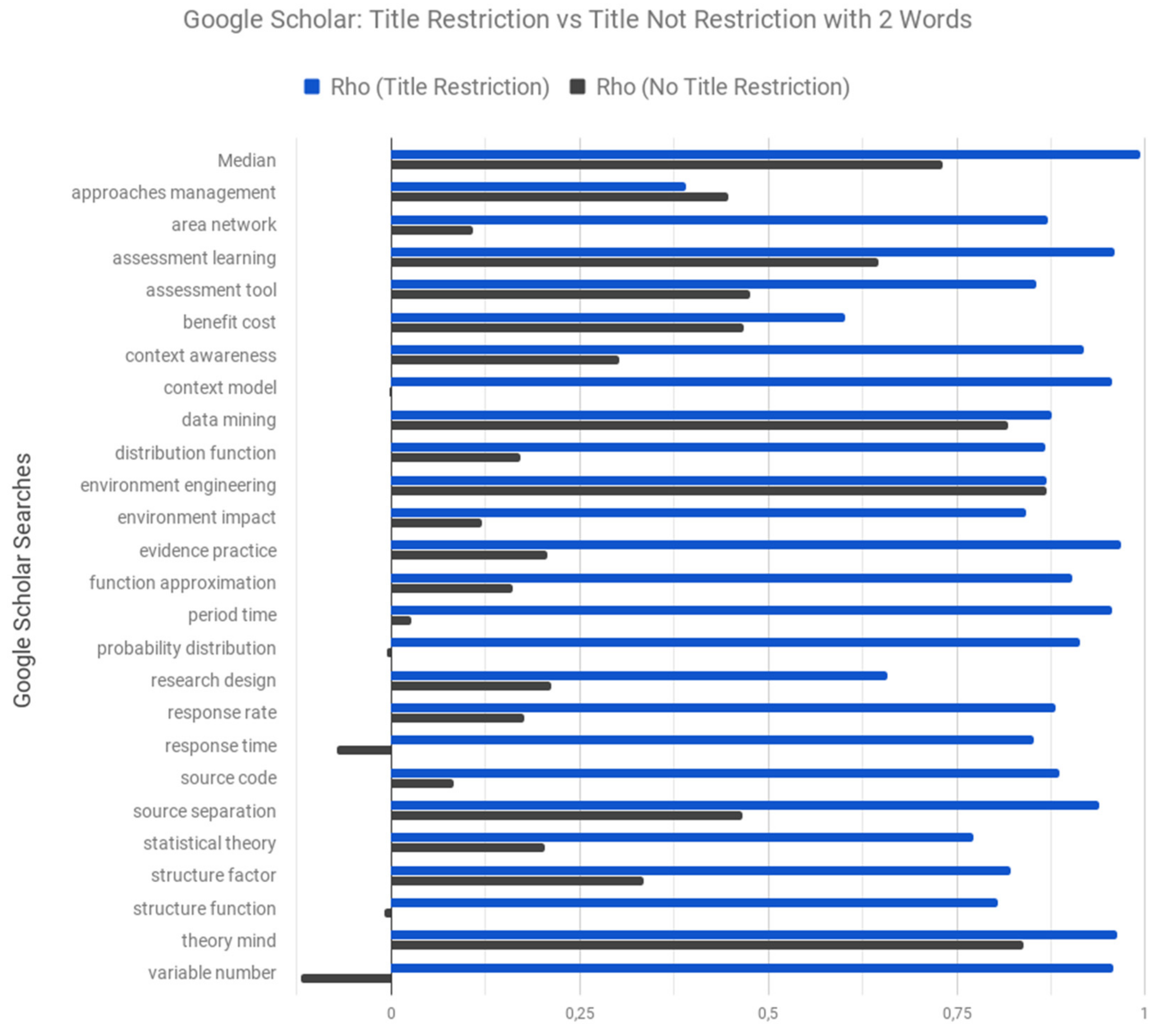
| Median | 0.994 ** | 0.721 ** | 0.937 ** | −0.107 ** | −0.075* | 0.907 ** |
| approaches management | 0.391 ** | 0.447 ** | 0.587 ** | −0.004 | −0.102 ** | 0.581 ** |
| area network | 0.871 ** | 0.108 ** | 0.462 ** | 0.025 | −0.054 | 0.610 ** |
| assessment learning | 0.960 ** | 0.646 ** | 0.683 ** | 0.009 | −0.038 | 0.605 ** |
| assessment tool | 0.855 ** | 0.476 ** | 0.619 ** | −0.006 | 0.058 | 0.556 ** |
| benefit cost | 0.602 ** | 0.467 ** | 0.490 ** | −0.048 | −0.008 | 0.522 ** |
| context awareness | 0.918 ** | 0.302 ** | 0.752 ** | −0.066* | −0.056 | 0.580 ** |
| context model | 0.956 ** | −0.003 | 0.616 ** | −0.042 | 0.023 | 0.624 ** |
| data mining | 0.875 ** | 0.818 ** | 0.747 ** | 0.072* | 0.009 | 0.654 ** |
| distribution function | 0.868 ** | 0.171 ** | 0.415 ** | −0.051 | −0.069* | 0.520 ** |
| environment engineering | 0.869 ** | 0.869 ** | 0.539 ** | −0.037 | −0.032 | 0.647 ** |
| environment impact | 0.842 ** | 0.120 ** | 0.559 ** | −0.026 | −0.065* | 0.605 ** |
| evidence practice | 0.968 ** | 0.206 ** | 0.712 ** | 0.021 | 0.005 | 0.517 ** |
| function approximation | 0.903 ** | 0.162 ** | 0.619 ** | 0.053 | −0.036 | 0.646 ** |
| period time | 0.956 ** | 0.027 | 0.525 ** | −0.102 ** | 0.036 | 0.554 ** |
| probability distribution | 0.913 ** | −0.006 | 0.522 ** | −0.077* | −0.055 | 0.683 ** |
| research design | 0.658 ** | 0.213 ** | 0.648 ** | 0.099 ** | 0.063* | 0.572 ** |
| response rate | 0.881 ** | 0.176 ** | 0.522 ** | −0.035 | 0.114 ** | 0.606 ** |
| response time | 0.851 ** | −0.072* | 0.469 ** | −0.016 | −0.043 | 0.543 ** |
| source code | 0.887 ** | 0.082 ** | 0.631 ** | −0.119 ** | 0.043 | 0.621 ** |
| source separation | 0.939 ** | 0.466 ** | 0.734 ** | 0.053 | −0.062 | 0.588 ** |
| statistical theory | 0.772 ** | 0.203 ** | 0.573 ** | −0.085 ** | −0.081* | 0.657 ** |
| structure factor | 0.821 ** | 0.334 ** | 0.575 ** | −0.209 ** | −0.026 | 0.607 ** |
| structure function | 0.804 ** | −0.01 | 0.582 ** | −0.208 ** | −0.104 ** | 0.613 ** |
| theory mind | 0.962 ** | 0.838 ** | 0.680 ** | −0.048 | 0.181 ** | 0.672 ** |
| variable number | 0.958 ** | −0.120 ** | 0.656 ** | 0.072* | −0.001 | 0.081* |
Appendix B. Data Files
References
- Baeza-Yates, R.; Ribeiro-Neto, B. Modern Information Retrieval; Addison-Wesley Professional: New York, NY, USA, 2010; pp. 3–339. [Google Scholar]
- Salton, G.; McGill, M.J. Introduction to Modern Information Retrieval; McGraw Hill: New York, NY, USA, 1987; pp. 1–400. [Google Scholar]
- Blair, D.C. Language and Representation in Information Retrieval; Elsevier: Amsterdam, The Netherlands, 1990; pp. 1–350. [Google Scholar]
- Maciá-Domene, F. SEO: Técnicas Avanzadas; Anaya: Barcelona, Spain, 2015; pp. 1–408. [Google Scholar]
- Chang, Y.; Aung, Z. AuthorRank: A New Scheme for Identifying Field-Specific Key Researchers. In Proceedings of the CONF-IRM 2015, New York, NY, USA, 16 January 2015; pp. 1–13. Available online: http://aisel.aisnet.org/confirm2015/46 (accessed on 1 July 2019).
- Brin, S.; Page, L. The anatomy of a large-scale hypertextual Web search engine. Comput. Netw. ISDN Syst. 1998, 30, 107–117. [Google Scholar] [CrossRef]
- Kleinberg, J.M. Authoritative sources in a hyperlinked environment. JACM 1999, 46, 604–632. [Google Scholar] [CrossRef]
- Romero, D.M.; Galuba, W.; Asur, S.; Huberman, B.A. Influence and passivity in social media. Mach. Learn. Knowl. Discov. Databases 2011, 6913, 18–33. [Google Scholar]
- Tunkelang, D. A Twitter Analog to PageRank. The Noisy Channel Blog. 2009. Available online: http://thenoisychannel.com/ (accessed on 1 July 2019).
- Weng, J.; Lim, E.-P.; Jiang, J.; He, Q. TwitterRank: Finding topic-sensitive influential Twitterers. In Proceedings of the 3rd ACM International Conference on Web Search and Data Mining (WSDM), New York, NY, USA, 3–6 February 2010; pp. 261–270. [Google Scholar]
- Yamaguchi, Y.; Takahashi, T.; Amagasa, T.; Kitagawa, H. TURank: Twitter user ranking based on user-tweet graph analysis. In Web Information Systems Engineering—WISE 2010; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6488, pp. 240–253. [Google Scholar]
- Hristidis, V.; Hwang, H.; Papakonstantinou, Y. Authority-based keyword search in databases. ACM Trans. Auton. Adapt. Syst. 2008, 33, 11–14. [Google Scholar] [CrossRef]
- Nie, Z.; Zhang, Y.; Wen, J.R.; Ma, W.Y. Object-level ranking: Bringing order to web objects. In Proceedings of the 14th International Conference on World Wide Web (ACM), Chiba, Japan, 10–14 May 2005; pp. 567–574. [Google Scholar] [CrossRef]
- Chen, L.; Nayak, R. Expertise analysis in a question answer portal for author ranking 2008. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT), Washington, DC, USA, 31 August–3 September 2010; pp. 134–140. [Google Scholar]
- Walker, D.; Xie, H.; Yan, K.-K.; Maslov, S. Ranking scientific publications using a model of network traffic. J. Stat. Mech. Theory Exp. 2007, 06, 6–10. [Google Scholar] [CrossRef]
- Google. How Google Search Works. Learn How Google Discovers, Crawls, and Serves Web Pages, Search Console Help. Available online: https://support.google.com/webmasters/answer/70897?hl=en (accessed on 1 July 2019).
- Ziakis, C.; Vlachopoulou, M.; Kyrkoudis, T.; Karagkiozidou, M. Important Factors for Improving Google Search Rank. Future Internet 2019, 11, 32. [Google Scholar] [CrossRef]
- Ratcliff, C. WebPromo’s Q & A with Google’s Andrey Lipattsev, Search Engine Watch. Available online: https://searchenginewatch.com/2016/04/06/webpromos-qa-with-googles-andrey-lipattsev-transcript (accessed on 1 July 2019).
- Schwartz, B. Now We Know: Here Are Google’s Top 3 Search Ranking Factors, Search Engine Land. Available online: http://searchengineland.com/now-know-googles-top-three-search-ranking-factors-245882 (accessed on 1 July 2019).
- Beel, J.; Gipp, B. Academic search engine spam and Google Scholar’s resilience against it. J. Electron. Publ. 2010, 13, 1–28. [Google Scholar] [CrossRef]
- Enge, E.; Spencer, S.; Stricchiola, J. The Art of SEO: Mastering Search Engine Optimization; O’Reilly Media: Sebastopol, CA, USA; Boston, MA, USA, 2015; pp. 1–670. Available online: https://books.google.co.in/books?id=hg5iCgAAQBAJ (accessed on 1 July 2019).
- Beel, J.; Gipp, B. Google Scholar’s ranking algorithm: The impact of articles’ age (an empirical study). In Proceedings of the Sixth International Conference on Information Technology: New Generations, ITNG’09, Las Vegas, NA, USA, 27–29 April 2009; pp. 160–164. [Google Scholar]
- Beel, J.; Gipp, B.; Wilde, E. Academic search engine optimization (ASEO) optimizing scholarly literature for google scholar & co. J. Sch. Publ. 2010, 41, 176–190. [Google Scholar] [CrossRef]
- Codina, L. SEO Académico: Definición, Componentes y Guía de Herramientas, Codina, Lluís. Available online: https://www.lluiscodina.com/seo-academico-guia/ (accessed on 1 July 2019).
- Martín-Martín, A.; Ayllón, J.M.; Orduña-Malea, E.; López-Cózar, E.D. Google Scholar Metrics Released: A Matter of Languages and Something Else; EC3 Working Papers; EC3: Granada, Spain, 2016; pp. 1–14. Available online: https://arxiv.org/abs/1607.06260v1 (accessed on 1 July 2019).
- Muñoz-Martín, B. Incrementa el impacto de tus artículos y blogs: De la invisibilidad a la visibilidad. Rev. Soc. Otorrinolaringol. Castilla Leon Cantab. La Rioja 2015, 6, 6–32. Available online: http://hdl.handle.net/10366/126907 (accessed on 1 July 2019).
- Gielen, M.; Rosen, J. Reverse Engineering the YouTube, Tubefilter.com. Available online: http://www.tubefilter.com/2016/06/23/reverse-engineering-youtube-algorithm/ (accessed on 1 July 2019).
- Localseoguide. Local SEO Ranking Factors Study 2016, Localseoguide. Available online: http://www.localseoguide.com/guides/2016-local-seo-ranking-factors/ (accessed on 1 July 2019).
- Searchmetrics. Rebooting Ranking Factors. Available online: http://www.searchmetrics.com/knowledge-base/ranking-factors/ (accessed on 1 July 2019).
- MOZ. Google Algorithm Update History. Available online: https://moz.com/google-algorithm-change (accessed on 1 July 2019).
- Beel, J.; Gipp, B. Google scholar’s ranking algorithm: An introductory overview. In Proceedings of the 12th International Conference on Scientometrics and Informetrics, ISSI’09, Istanbul, Turkey, 14–17 July 2009; pp. 230–241. [Google Scholar]
- Beel, J.; Gipp, B. Google scholar’s ranking algorithm: The impact of citation counts (an empirical study). In Proceedings of the Third International Conference on Research Challenges in Information Science, RCIS 2009c, Nice, France, 22–24 April 2009; pp. 439–446. [Google Scholar]
- Martín-Martín, A.; Orduña-Malea, E.; Ayllón, J.M.; López-Cózar, E.D. Does Google Scholar Contain all Highly Cited Documents (1950–2013); EC3 Working Papers; EC3: Granada, Spain, 2014; pp. 1–96. Available online: https://arxiv.org/abs/1410.8464 (accessed on 1 July 2019).
- Rovira, C.; Guerrero-Solé, F.; Codina, L. Received citations as a main SEO factor of Google Scholar results ranking. El Profesional de la Información 2018, 27, 559–569. [Google Scholar] [CrossRef]
- Thelwall, M. Does Microsoft Academic Find Early Citations? Scientometrics 2018, 114, 325–334. Available online: https://wlv.openrepository.com/bitstream/handle/2436/620806/?sequence=1 (accessed on 1 July 2019). [CrossRef]
- Hug, S.E.; Ochsner, M.; Brändle, M.P. Citation analysis with microsoft academic. Scientometrics 2017, 110, 371–378. Available online: https://arxiv.org/pdf/1609.05354.pdf (accessed on 1 July 2019). [CrossRef]
- Harzing, A.W.; Alakangas, S. Microsoft Academic: Is the phoenix getting wings? Scientometrics 2017, 110, 371–383. Available online: http://eprints.mdx.ac.uk/20937/1/mas2.pdf (accessed on 1 July 2019). [CrossRef]
- Orduña-Malea, E.; Martín-Martín, A.; Ayllon, J.M.; Delgado-Lopez-Cozar, E. The silent fading of an academic search engine: The case of Microsoft Academic Search. Online Inf. Rev. 2014, 38, 936–953. Available online: https://riunet.upv.es/bitstream/handle/10251/82266/silent-fading-microsoft-academic-search.pdf?sequence=2 (accessed on 1 July 2019). [CrossRef]
- Clarivate. Colección Principal de Web of Science Ayuda. Available online: https://images-webofknowledge-com.sare.upf.edu/WOKRS532MR24/help/es_LA/WOS/hs_sort_options.html (accessed on 1 July 2019).
- Elsevier. Scopus: Access and Use Support Center. What Does “Relevance” Mean in Scopus? Available online: https://service.elsevier.com/app/answers/detail/a_id/14182/supporthub/scopus/ (accessed on 1 July 2019).
- AlRyalat, S.A.; Malkawi, L.W.; Momani, S.M. Comparing Bibliometric Analysis Using PubMed, Scopus, and Web of Science Databases. J. Vis. Exp. 2018. Available online: https://www.jove.com/video/58494/comparing-bibliometric-analysis-using-pubmed-scopus-web-science (accessed on 1 July 2019).
- Giustini, D.; Boulos, M.N.K. Google Scholar is not enough to be used alone for systematic reviews. Online J. Public Health Inform. 2013, 5, 1–9. [Google Scholar] [CrossRef]
- Walters, W.H. Google Scholar search performance: Comparative recall and precision. Portal Libr. Acad. 2008, 9, 5–24. [Google Scholar] [CrossRef]
- De-Winter, J.C.F.; Zadpoor, A.A.; Dodou, D. The expansion of Google Scholar versus Web of Science: A longitudinal study. Scientometrics 2014, 98, 1547–1565. [Google Scholar] [CrossRef]
- Harzing,, A.-W. A preliminary test of Google Scholar as a source for citation data: A longitudinal study of Nobel prize winners. Scientometrics 2013, 94, 1057–1075. [Google Scholar] [CrossRef]
- Harzing,, A.-W. A longitudinal study of Google Scholar coverage between 2012 and 2013. Scientometrics 2014, 98, 565–575. [Google Scholar] [CrossRef]
- De-Groote, S.L.; Raszewski, R. Coverage of Google Scholar, Scopus, and Web of Science: A casestudy of the h-index in nursing. Nurs. Outlook 2012, 60, 391–400. [Google Scholar] [CrossRef]
- Orduña-Malea, E.; Ayllón, J.-M.; Martín-Martín, A.; Delgado-López-Cózar, E. About the Size of Google Scholar: Playing the Numbers; EC3 Working Papers; EC3: Granada, Spain, 2014; Available online: https://arxiv.org/abs/1407.6239 (accessed on 1 July 2019).
- Orduña-Malea, E.; Ayllón, J.-M.; Martín-Martín, A.; Delgado-López-Cózar, E. Methods for estimating the size of Google Scholar. Scientometrics 2015, 104, 931–949. [Google Scholar] [CrossRef]
- Pedersen, L.A.; Arendt, J. Decrease in free computer science papers found through Google Scholar. Online Inf. Rev. 2014, 38, 348–361. [Google Scholar] [CrossRef]
- Jamali, H.R.; Nabavi, M. Open access and sources of full-text articles in Google Scholar in different subject fields. Scientometrics 2015, 105, 1635–1651. [Google Scholar] [CrossRef]
- Van-Aalst, J. Using Google Scholar to estimate the impact of journal articles in education. Educ. Res. 2010, 39, 387–400. Available online: https://goo.gl/p1mDBi (accessed on 1 July 2019). [CrossRef]
- Jacsó, P. Testing the calculation of a realistic h-index in Google Scholar, Scopus, and Web of Science for FW Lancaster. Libr. Trends 2008, 56, 784–815. [Google Scholar] [CrossRef]
- Jacsó, P. The pros and cons of computing the h-index using Google Scholar. Online Inf. Rev. 2008, 32, 437–452. [Google Scholar] [CrossRef]
- Jacsó, P. Calculating the h-index and other bibliometric and scientometric indicators from Google Scholar with the Publish or Perish software. Online Inf. Rev. 2009, 33, 1189–1200. [Google Scholar] [CrossRef]
- Jacsó, P. Using Google Scholar for journal impact factors and the h-index in nationwide publishing assessments in academia—Siren songs and air-raid sirens. Online Inf. Rev. 2012, 36, 462–478. [Google Scholar] [CrossRef]
- Martín-Martín, A.; Orduña-Malea, E.; Harzing, A.-W.; Delgado-López-Cózar, E. Can we use Google Scholar to identify highly-cited documents? J. Informetr. 2017, 11, 152–163. [Google Scholar] [CrossRef]
- Aguillo, I.F. Is Google Scholar useful for bibliometrics? A webometric analysis. Scientometrics 2012, 91, 343–351. Available online: https://goo.gl/nYBmZb (accessed on 1 July 2019). [CrossRef]
- Delgado-López-Cózar, E.; Robinson-García, N.; Torres-Salinas, D. Manipular Google Scholar Citations y Google Scholar Metrics: Simple, Sencillo y Tentador; EC3 working papers; Universidad De Granada: Granada, Spain, 2012; Available online: http://hdl.handle.net/10481/20469 (accessed on 1 July 2019).
- Delgado-López-Cózar, E.; Robinson-García, N.; Torres-Salinas, D. The Google Scholar experiment: How to index false papers and manipulate bibliometric indicators. J. Assoc. Inf. Sci. Technol. 2014, 65, 446–454. [Google Scholar] [CrossRef]
- Martín-Martín, A.; Orduña-Malea, E.; Ayllón, J.-M.; Delgado-López-Cózar, E. Back to the past: On the shoulders of an academic search engine giant. Scientometrics 2016, 107, 1477–1487. [Google Scholar] [CrossRef]
- Jamali, H.R.; Asadi, S. Google and the scholar: The role of Google in scientists’ information-seeking behaviour. Online Inf. Rev. 2010, 34, 282–294. [Google Scholar] [CrossRef]
- Marcos, M.-C.; González-Caro, C. Comportamiento de los usuarios en la página de resultados de los buscadores. Un estudio basado en eye tracking. El Profesional de la Información 2010, 19, 348–358. [Google Scholar] [CrossRef][Green Version]
- Torres-Salinas, D.; Ruiz-Pérez, R.; Delgado-López-Cózar, E. Google scholar como herramienta para la evaluación científica. El Profesional de la Información 2009, 18, 501–510. [Google Scholar] [CrossRef]
- Ortega, J.L. Academic Search Engines: A Quantitative Outlook; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Hug, S.E.; Brändle, M.P. The coverage of Microsoft Academic: Analyzing the publication output of a university. Scientometrics 2017, 113, 1551–1571. [Google Scholar] [CrossRef]
- MOZ. Search Engine Ranking Factors 2015. Available online: https://moz.com/search-ranking-factors/correlations (accessed on 1 July 2019).
- Van der Graaf, P. Reverse Engineering Search Engine Algorithms is Getting Harder, Searchenginewatch. Available online: https://searchenginewatch.com/sew/how-to/2182553/reverse-engineering-search-engine-algorithms-getting-harder (accessed on 1 July 2019).
- Dave, D. 11 Things You Must Know About Google’s 200 Ranking Factors. Search Engine Journal. Available online: https://www.searchenginejournal.com/google-200-ranking-factors-facts/265085/ (accessed on 10 September 2019).
- Chariton, R. Google Algorithm—What Are the 200 Variables? Available online: https://www.webmasterworld.com/google/4030020.htm (accessed on 10 September 2019).
- Google. About Google Scholar. Available online: http://scholar.google.com/intl/en/scholar/about.html (accessed on 1 July 2019).
- Mayr, P.; Walter, A.-K. An exploratory study of google scholar. Online Inf. Rev. 2007, 31, 814–830. [Google Scholar] [CrossRef]
- Sinha, A.; Shen, Z.; Song, Y.; Ma, H.; Eide, D.; Hsu, B.; Wang, K. An Overview of Microsoft Academic Service (MAS) and Applications. In Proceedings of the 24th International Conference on World Wide Web (WWW 2015 Companion), ACM, New York, NY, USA, 18–22 May 2015; pp. 243–246. [Google Scholar] [CrossRef]
- Herrmannova, H.; Knoth., P. An Analysis of the Microsoft Academic Graph. D Lib Mag. 2016, 22, 9–10. [Google Scholar] [CrossRef]
- Ortega, J.L. Microsoft Academic Search: The multi-object engine. Academic Search Engines: A Quantitative Outlook; Ortega, J.L., Ed.; Elsevier: Oxford, UK, 2014; pp. 71–108. [Google Scholar]
- Microsoft Academic. How Is MA Different from other Academic Search Engines? 2019. Available online: https://academic.microsoft.com/faq (accessed on 1 July 2019).
- Eli, P. Academic Word List words (Coxhead, 2000). Available online: https://www.vocabulary.com/lists/218701 (accessed on 1 July 2019).
- Wiktionary: Academic word list. Available online: https://simple.wiktionary.org/wiki/Wiktionary:Academic_word_list (accessed on 18 September 2019).
- Coxhead, A. A new academic word list. TESOL Q. 2012, 34, 213–238. [Google Scholar] [CrossRef]
- Harzing, A.-W. Publish or Perish. Available online: https://harzing.com/resources/publish-or-perish (accessed on 1 July 2019).
- Harzing, A.W. The Publish or Perish Book: Your Guide to Effective and Responsible Citation Analysis; Tarma Software Research Pty Ltd: Melbourne, Australia, 2011; pp. 339–342. Available online: https://EconPapers.repec.org/RePEc:spr:scient:v:88:y:2011:i:1:d:10.1007_s11192−011−0388-8 (accessed on 1 July 2019).
- R Core Team. R: A Language and Environment for Statistical Computing, R Foundation for Statistical Computing. Available online: https://www.R-project.org (accessed on 1 July 2019).
- Revelle, W. Psych: Procedures for Personality and Psychological Research, Northwestern University. Available online: https://CRAN.R-project.org/pahttps://cran.r-project.org/package=psychckage=psych (accessed on 1 July 2019).
- Lemon, J. Plotrix: A package in the red light district of R. R News 2006, 6, 8–12. [Google Scholar]
- Farhadi, H.; Salehi, H.; Yunus, M.M.; Aghaei Chadegani, A.; Farhadi, M.; Fooladi, M.; Ale Ebrahim, N. Does it matter which citation tool is used to compare the h-index of a group of highly cited researchers? Aust. J. Basic Appl. Sci. 2013, 7, 198–202. Available online: https://ssrn.com/abstract=2259614 (accessed on 1 July 2019).












| Type | SEO/ASEO factor | Google Search | Google Scholar | Microsoft Academic | WoS | Scopus |
|---|---|---|---|---|---|---|
| On-page factors | Keywords in title | Yes [16,17,18,19,28,29,30] | Yes [31,32] | ? | Yes [40] | Yes [41] |
| Keywords in URL, h1 or first words | Yes [16,17,18,19,28,29,30] | ? | ? | No [40] | No [41] | |
| Keyword frequency | No [16,17,18,19] | ? | ? | Yes [40] | Yes [41] | |
| Technical factors: design, speed, etc. | Yes [16,17,18,19,28,29,30] | ? | ? | No [40] | No [41] | |
| Off-page factors | Backlinks | Yes [16,17,18,19,28,29,30] | ? | ? | No [40] | No [41] |
| Received citations | ? | Yes [16,31,32,33,34] | Yes [35,36,37,38,64] | No [40] | No [41] | |
| Author reputation | Yes [16,17,18,19,28,29,30] | Yes [16] | Yes [35,36,37,38,64] | No [40] | No [41] | |
| Reputation of the publication or domain | Yes [16,17,18,19,28,29,30] | Yes [16] | Yes [35,36,37,38,64] | No [40] | No [41] | |
| Signals from social networks | Yes (Indirect) [16,17,18,19] | ? | ? | No [40] | No [41] | |
| Traffic, Click Through Rate | Yes [16,17,18,19,28,29,30] | ? | ? | No [40] | No [41] | |
| Artificial intelligence | RankBrain | Yes [17,18,19,28,29,30] | ? | ? | No [40] | No [41] |
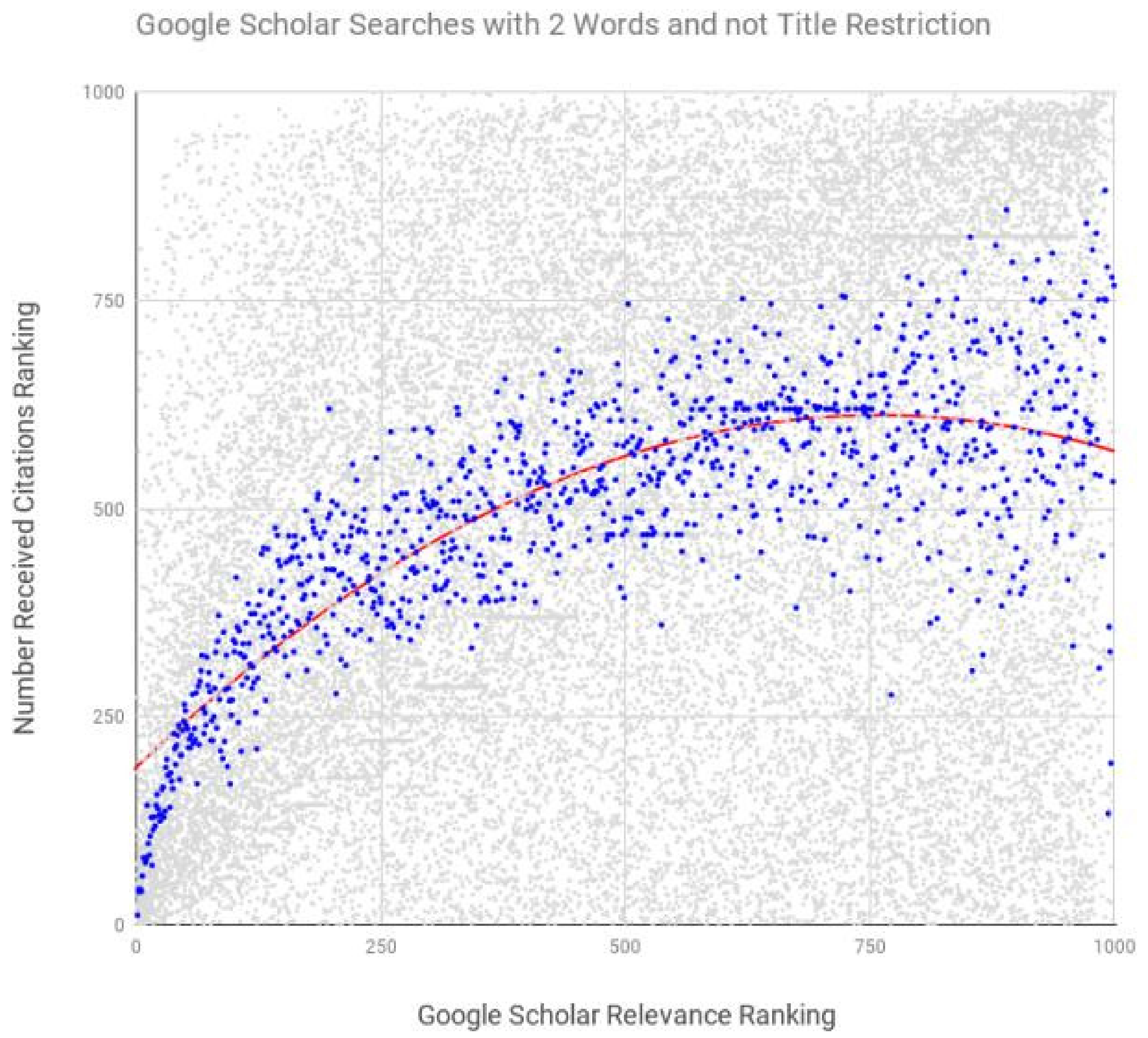
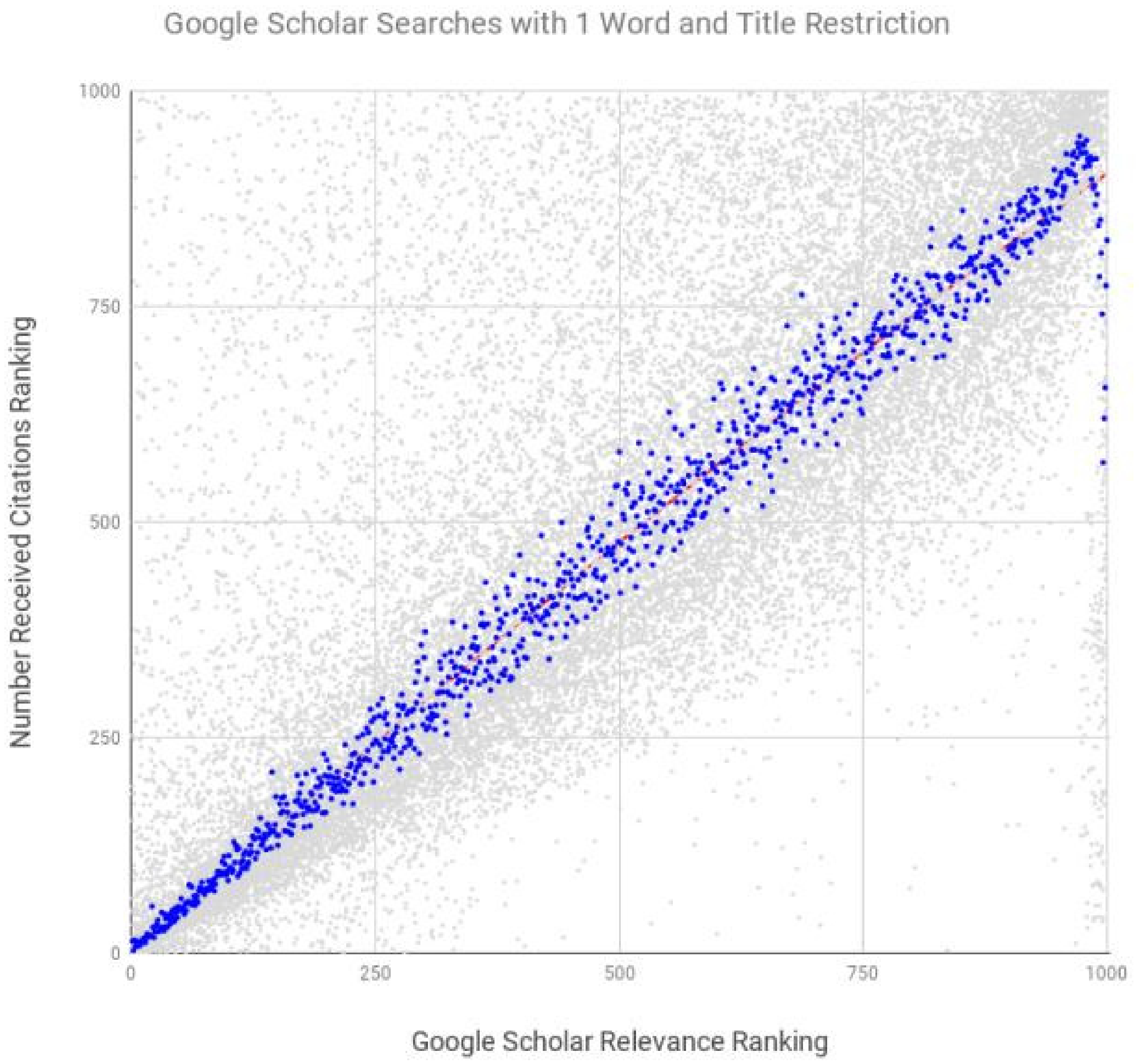
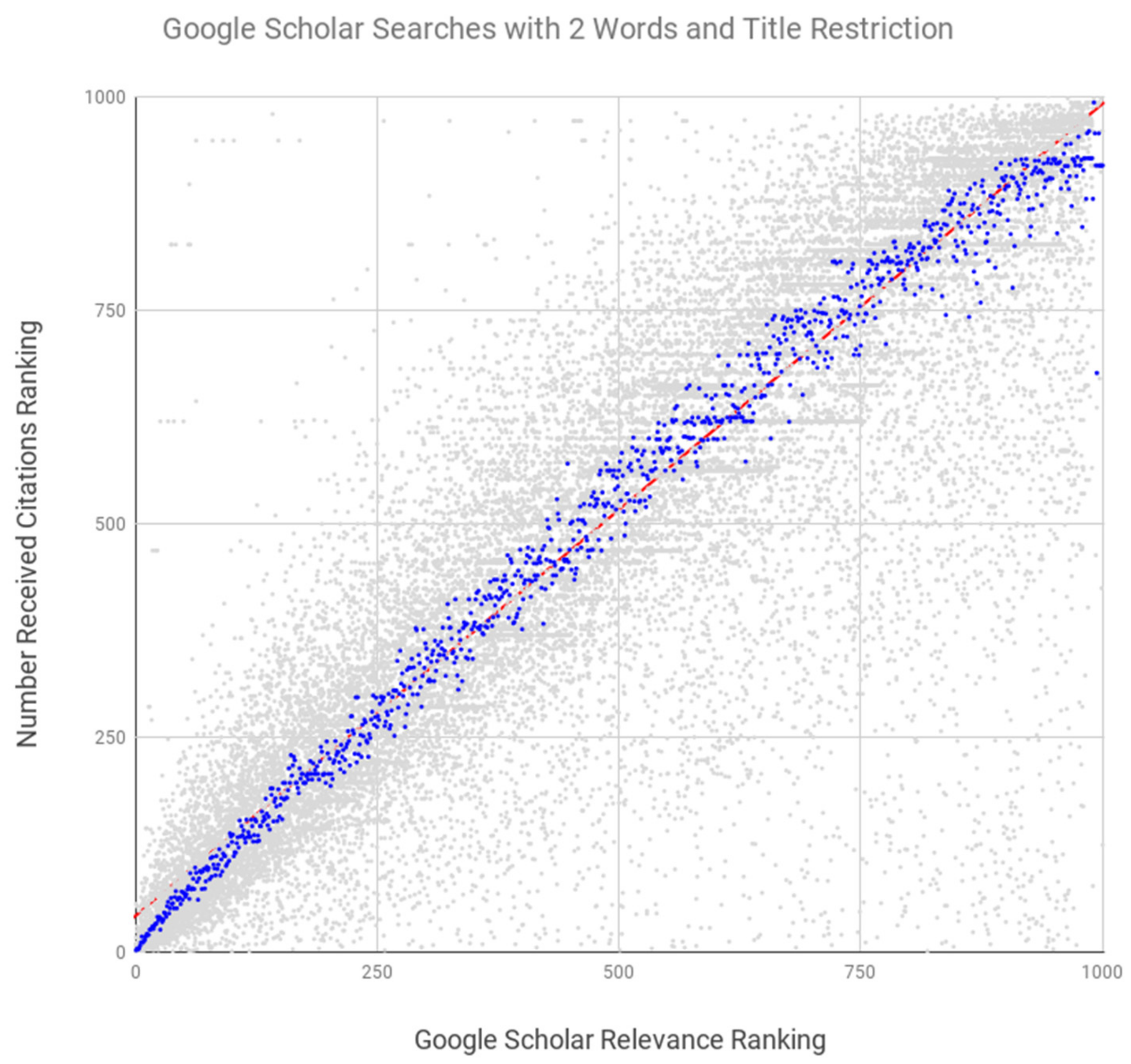
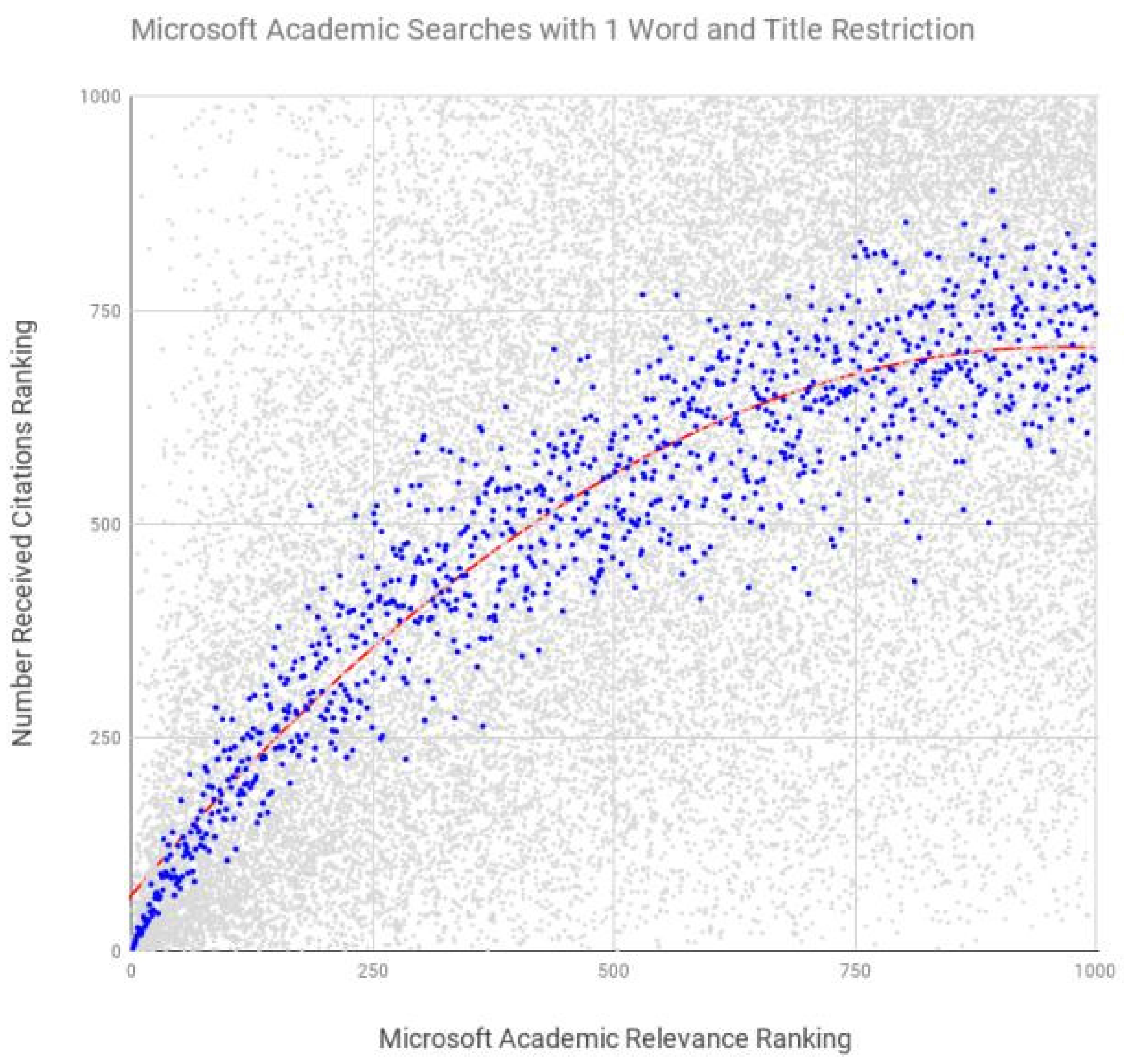
| System | Number of Search Terms | Search Restrictions Included | Spearman’s Coefficient | p |
|---|---|---|---|---|
| Google Scholar | 1 | unrestricted | 0.968 | <0.0001 |
| Google Scholar | 2 | unrestricted | 0.721 | <0.0001 |
| Google Scholar | 1 | title | 0.990 | <0.0001 |
| Google Scholar | 2 | title | 0.994 | <0.0001 |
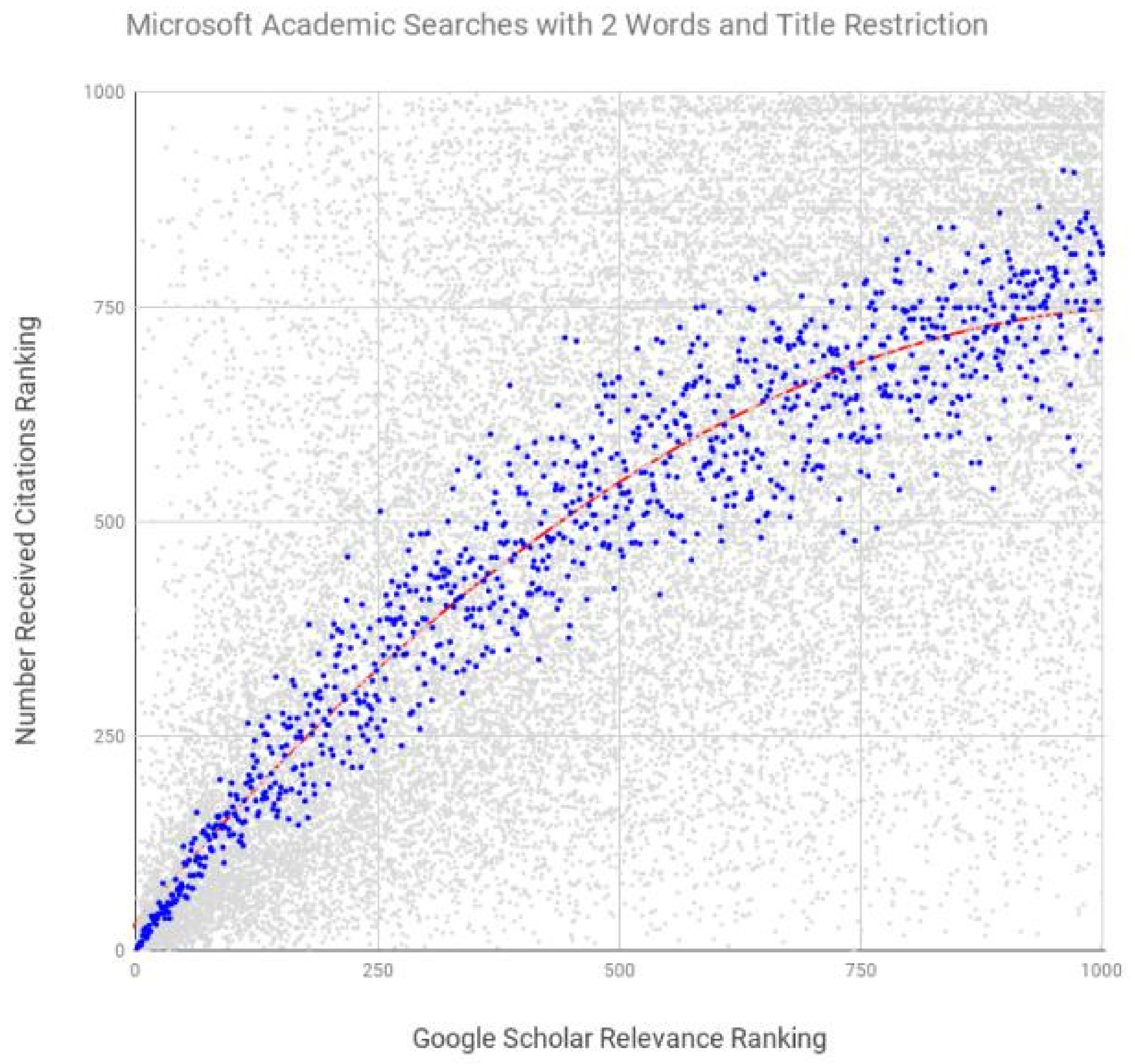
| Microsoft Academic | 1 | title, abstract, keywords | 0.907 | <0.0001 |
| Microsoft Academic | 2 | title, abstract, keywords | 0.937 | <0.0001 |
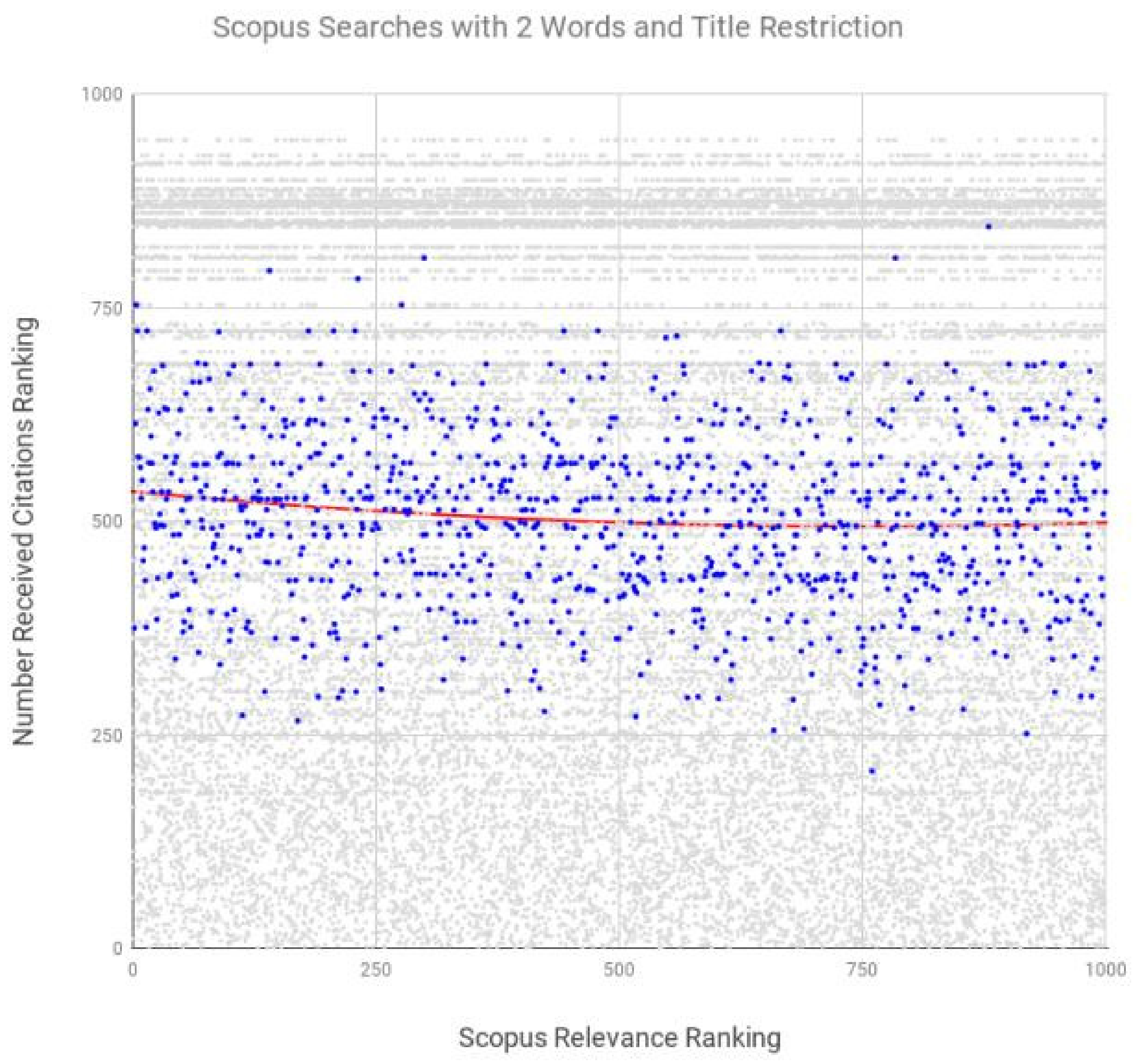
| Scopus | 2 | title, abstract, keywords | −0.107 | <0.001 |
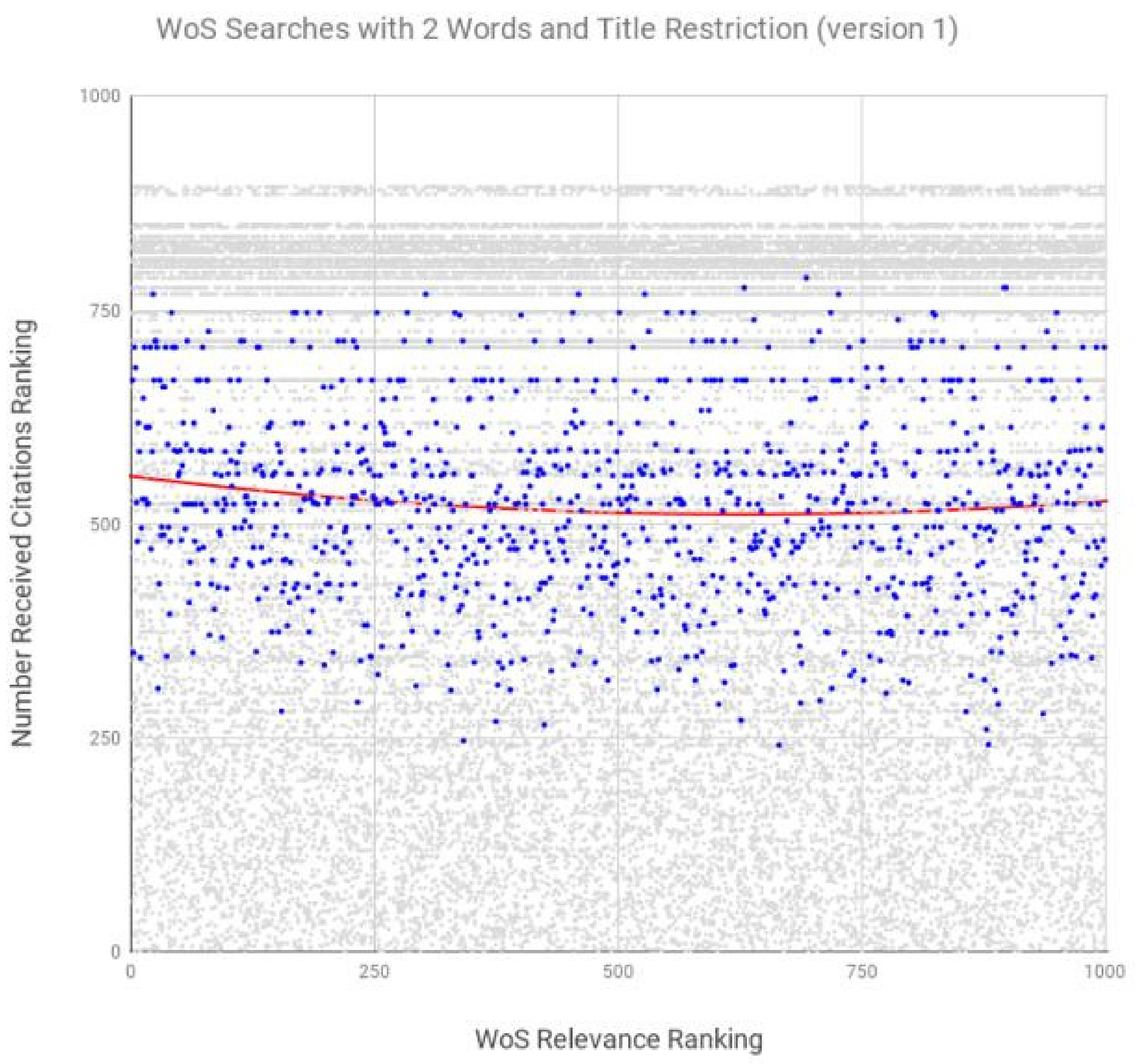
| WoS-version 1 | 2 | title, abstract, keywords | −0.075 | <0.05 |
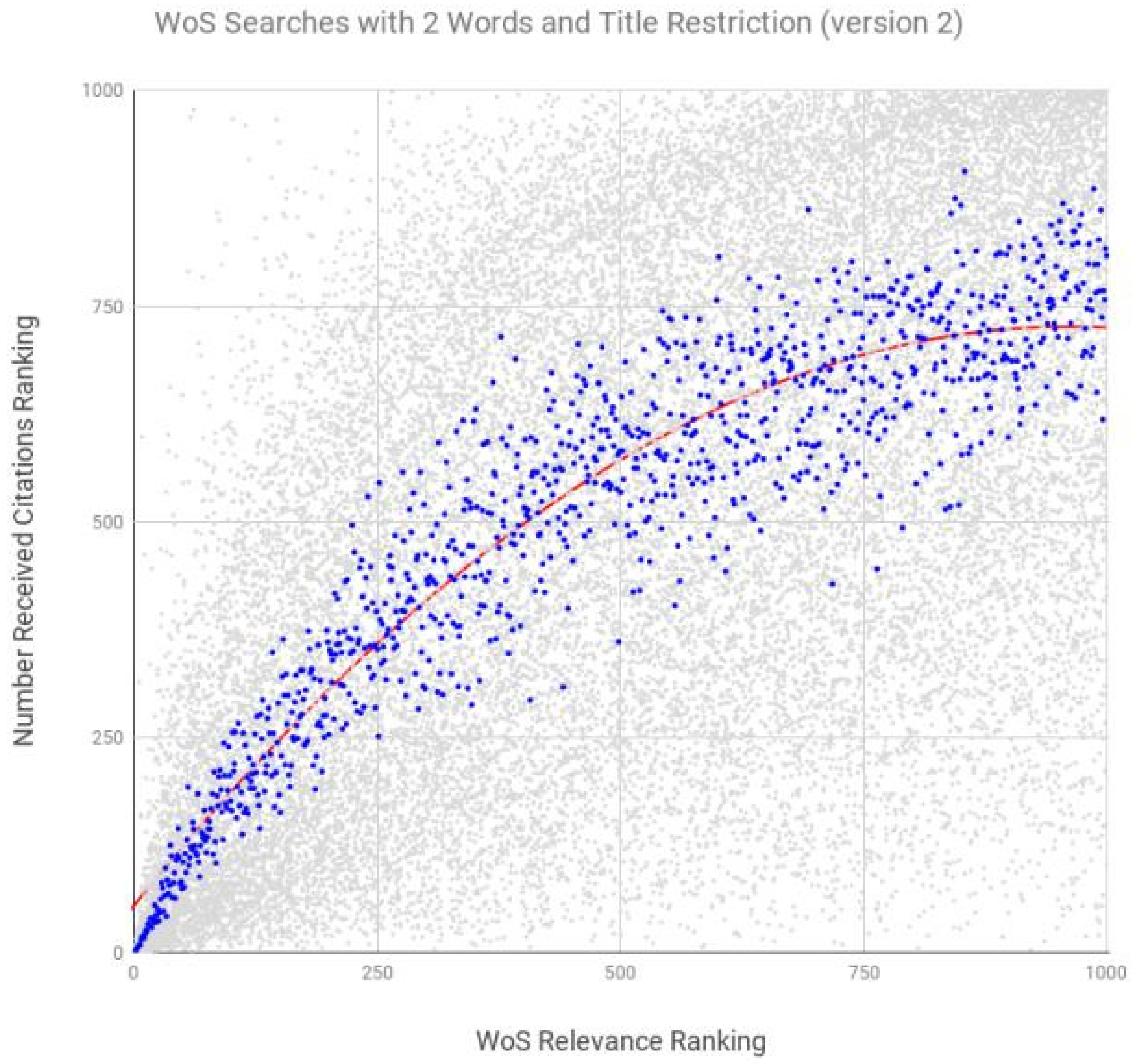
| Wos-version 2 | 2 | title, abstract, keywords | 0.907 | <0.0001 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rovira, C.; Codina, L.; Guerrero-Solé, F.; Lopezosa, C. Ranking by Relevance and Citation Counts, a Comparative Study: Google Scholar, Microsoft Academic, WoS and Scopus. Future Internet 2019, 11, 202. https://doi.org/10.3390/fi11090202
Rovira C, Codina L, Guerrero-Solé F, Lopezosa C. Ranking by Relevance and Citation Counts, a Comparative Study: Google Scholar, Microsoft Academic, WoS and Scopus. Future Internet. 2019; 11(9):202. https://doi.org/10.3390/fi11090202
Chicago/Turabian StyleRovira, Cristòfol, Lluís Codina, Frederic Guerrero-Solé, and Carlos Lopezosa. 2019. "Ranking by Relevance and Citation Counts, a Comparative Study: Google Scholar, Microsoft Academic, WoS and Scopus" Future Internet 11, no. 9: 202. https://doi.org/10.3390/fi11090202
APA StyleRovira, C., Codina, L., Guerrero-Solé, F., & Lopezosa, C. (2019). Ranking by Relevance and Citation Counts, a Comparative Study: Google Scholar, Microsoft Academic, WoS and Scopus. Future Internet, 11(9), 202. https://doi.org/10.3390/fi11090202