Surveying Human Habit Modeling and Mining Techniques in Smart Spaces




Abstract
:1. Introduction
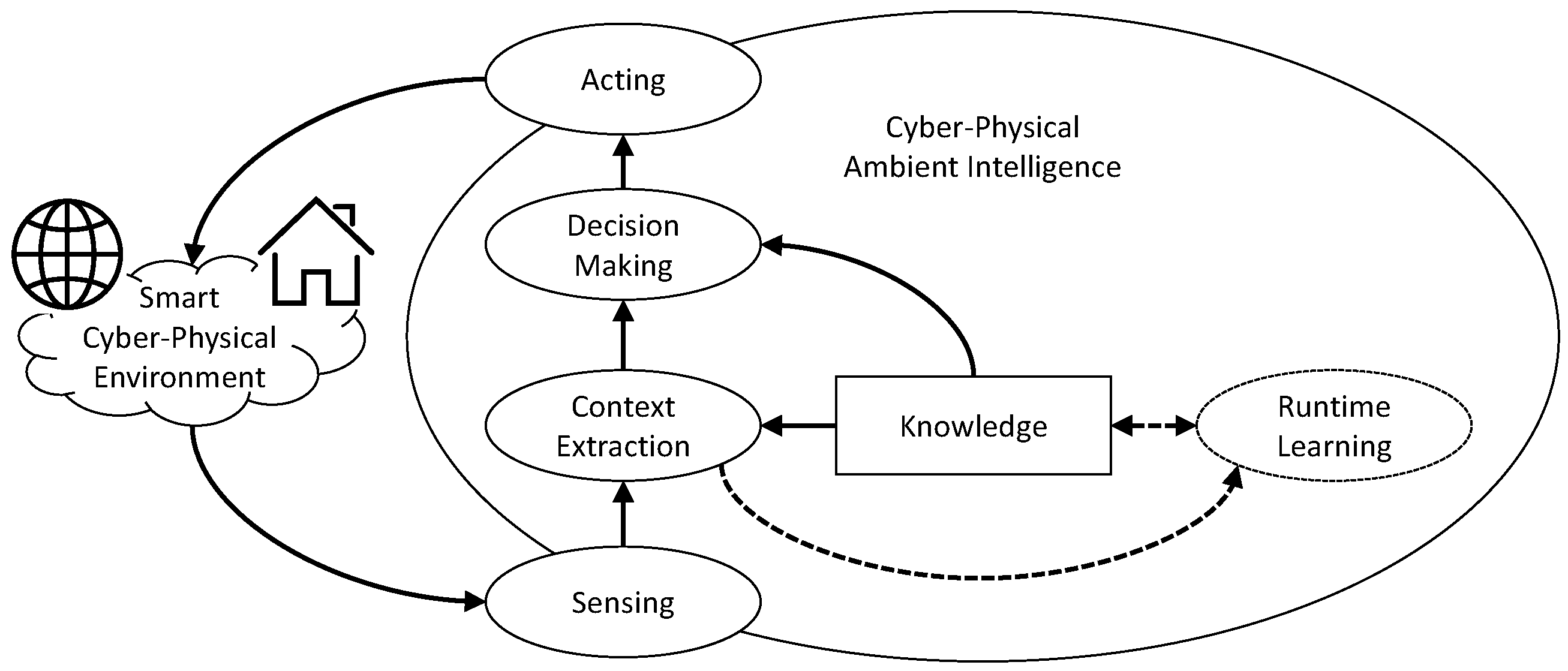
2. Background
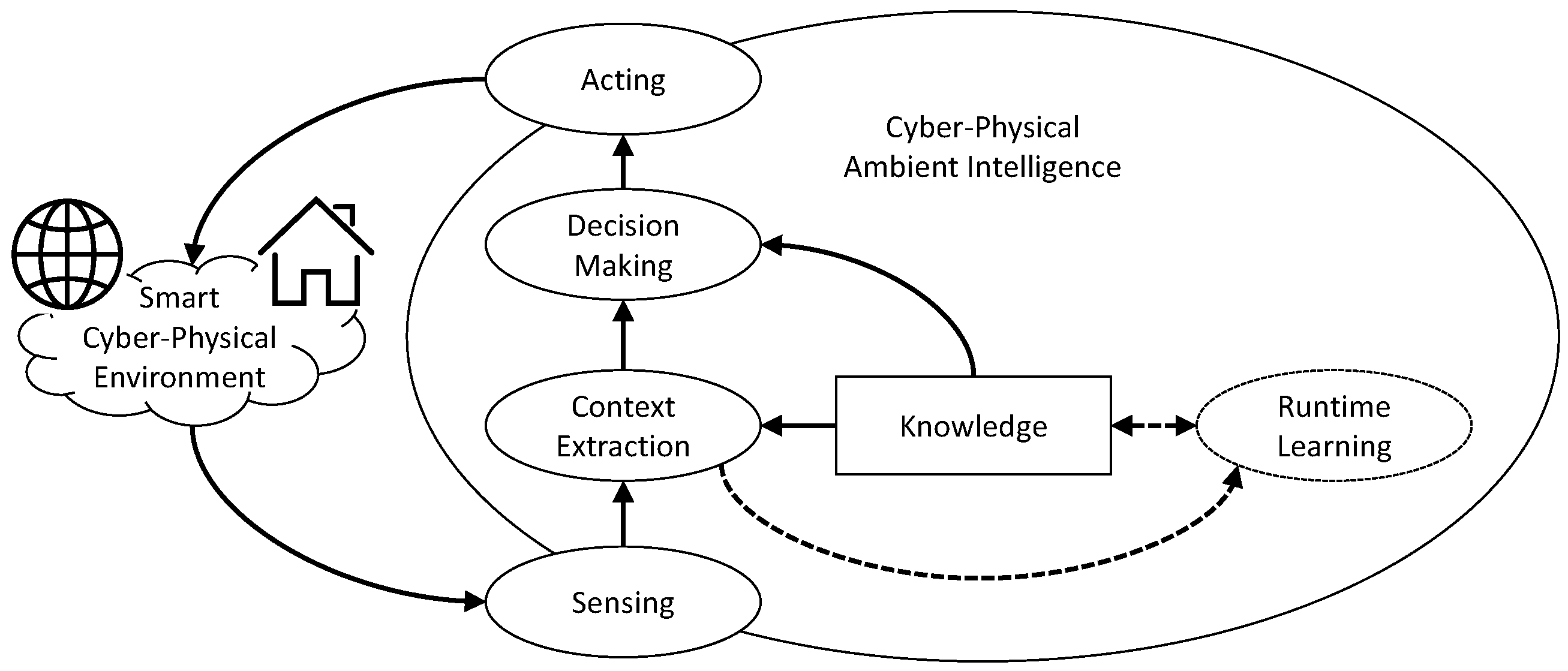
- Context: The state of the environment including the human inhabitants. This includes the output of sensors and actuators, but also the state of human inhabitants including the action/activities/habits he/she is performing. In this very comprehensive meaning, the term situation is sometimes used.
- Action: Atomic interaction with the environment or a part of it (e.g., a device). Recognizing actions can be easy or difficult depending on the sensors installed. Certain methods only focuses on actions and they will not be part of our survey. In some cases methods to recognize activities and habits completely skip the action recognition phase, only relying on the raw measurements in the sensor log.
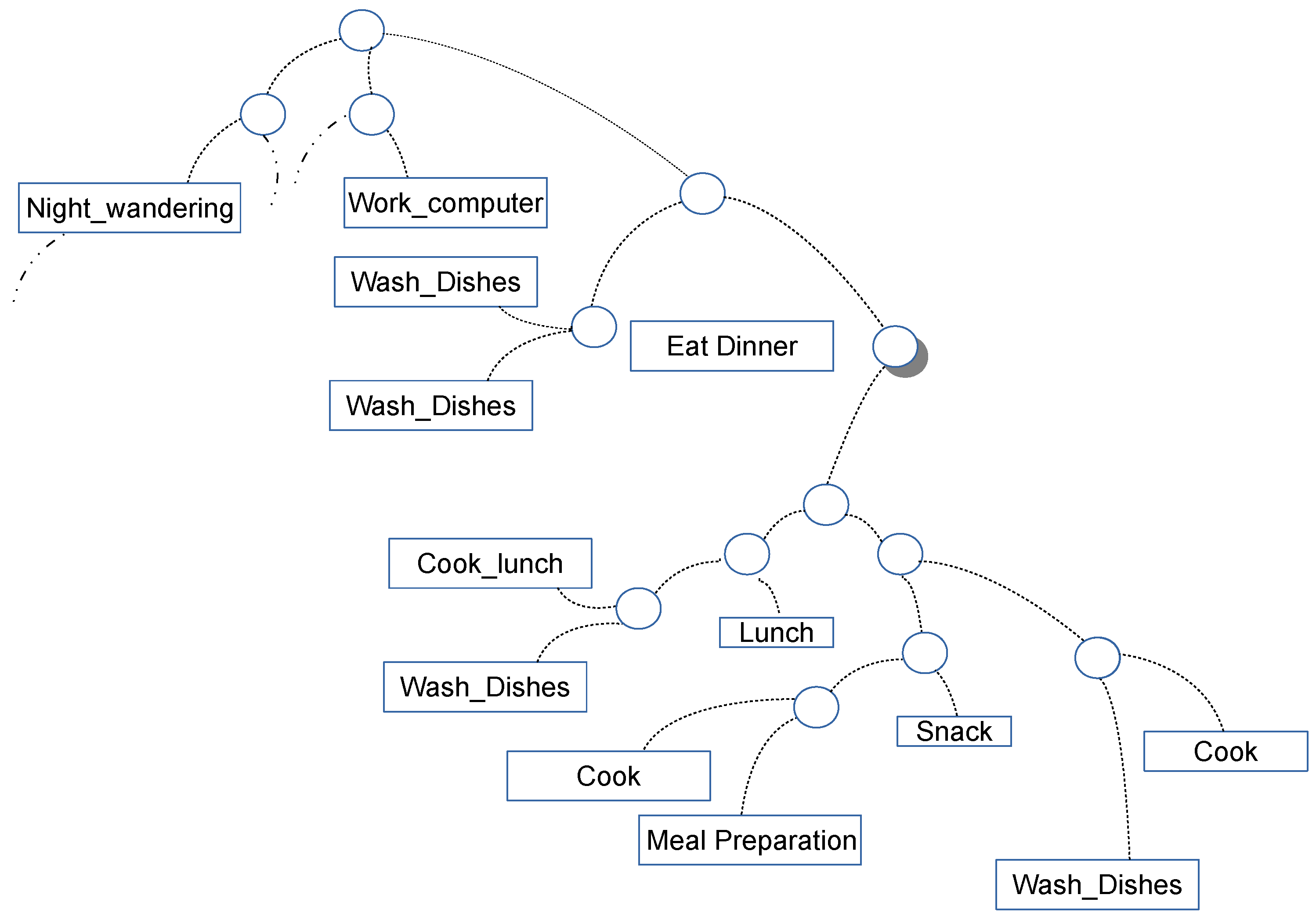
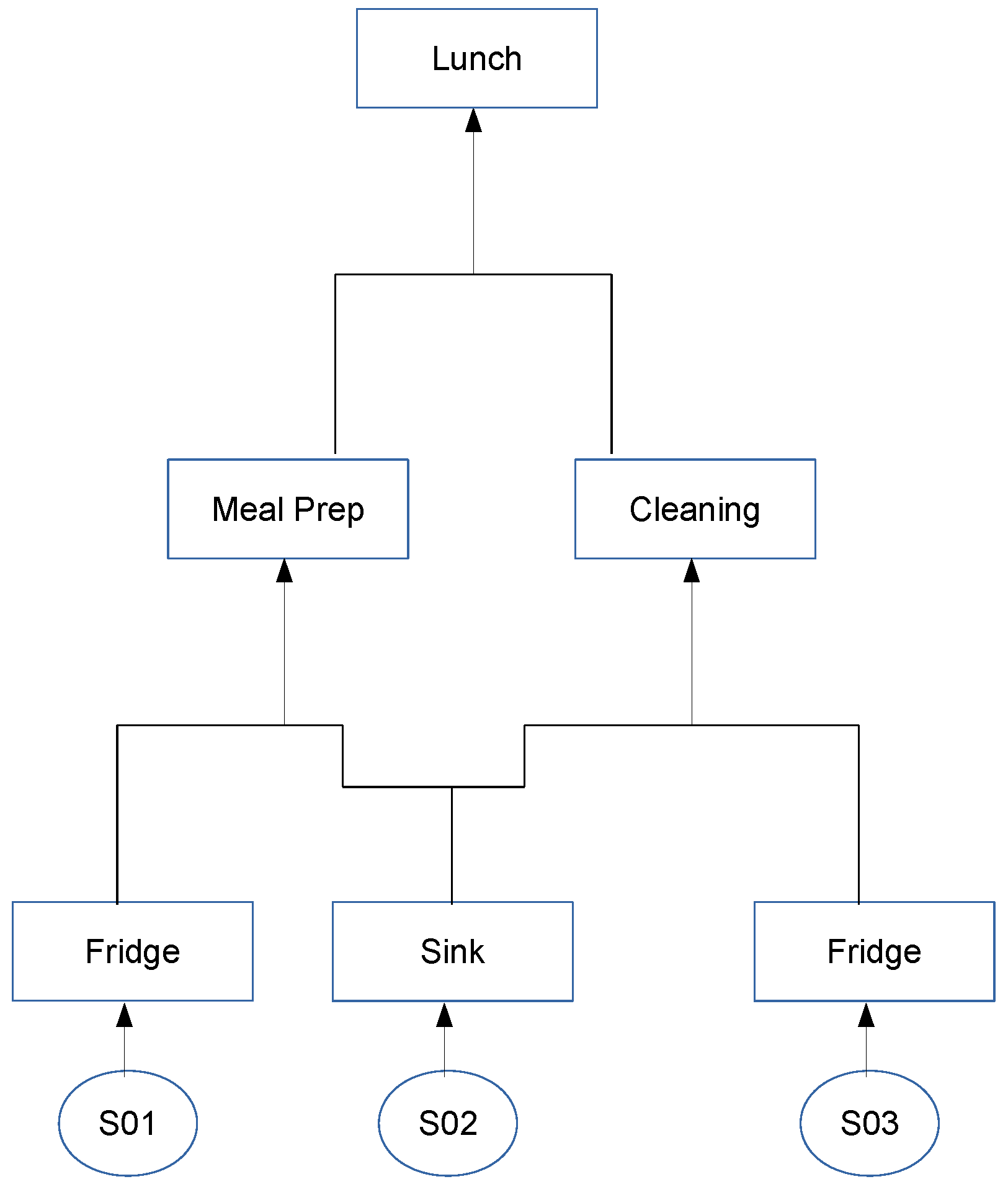
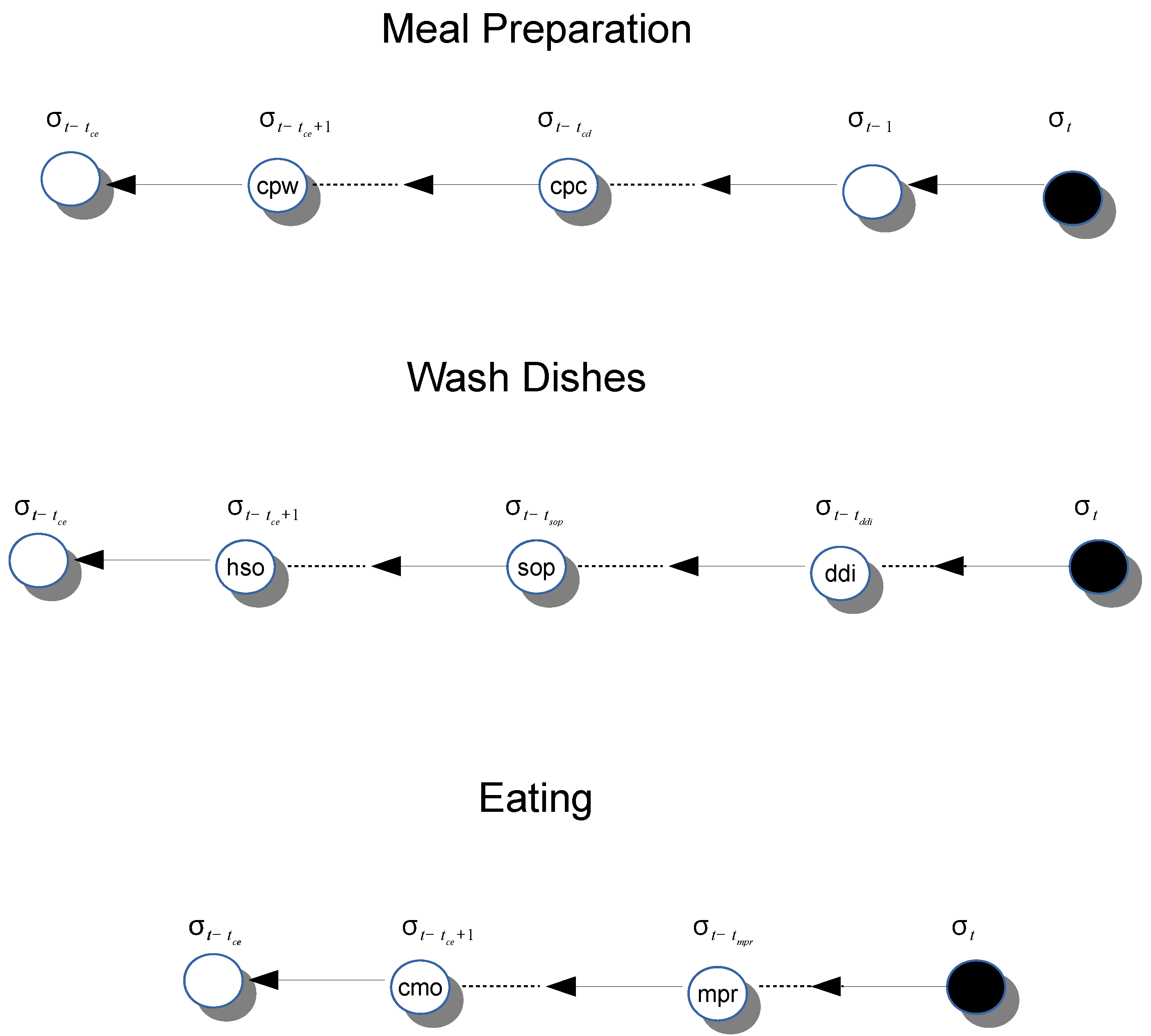
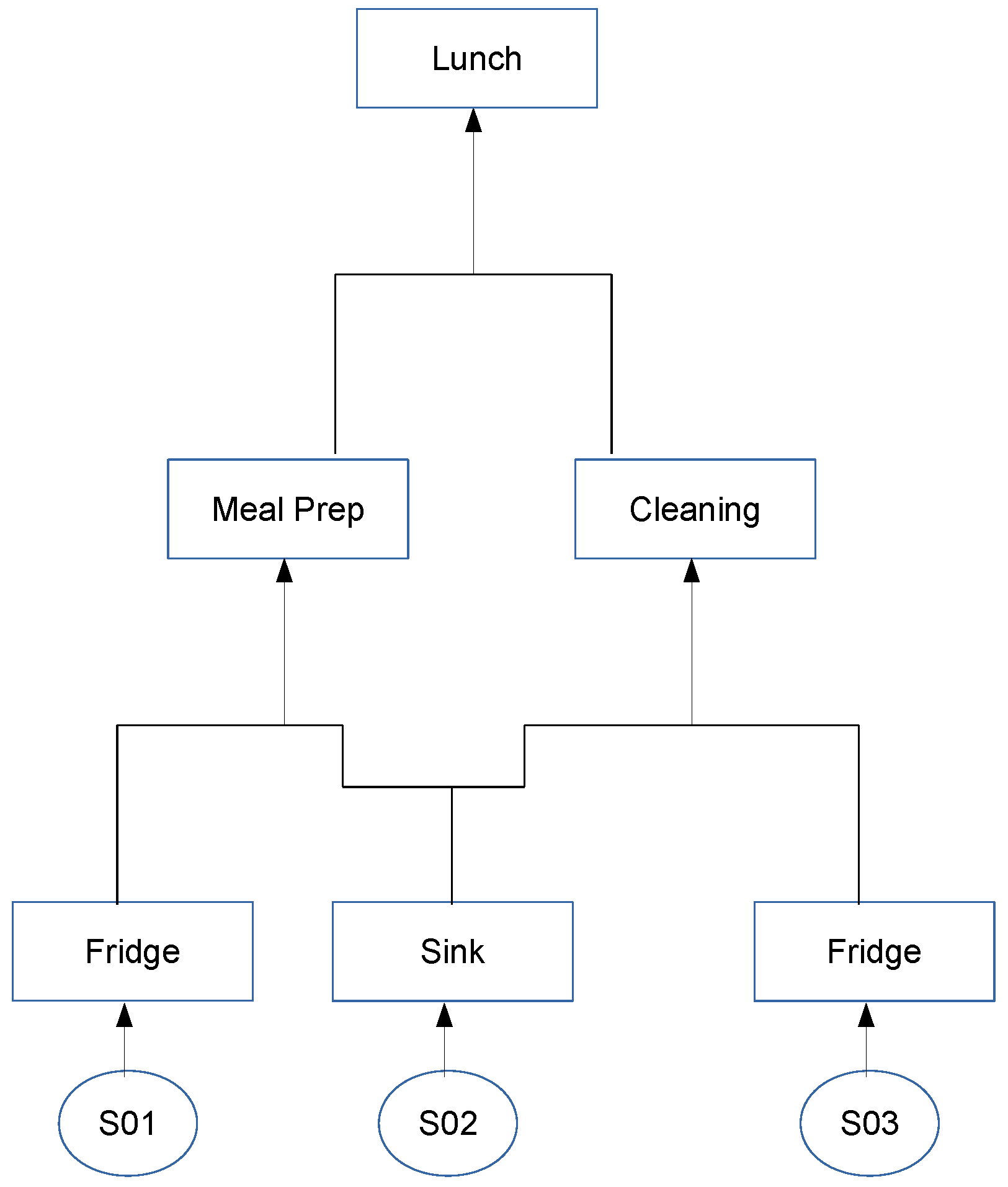
- Activity: A sequence of actions (one in the extreme case) or sensor measurements/events with a final goal. In some cases an action can be an activity itself (e.g., ironing). Activities can be collaborative, including actions by multiple users and can interleave one each other. The granularity (i.e., the temporal extension and complexity) of considered activities cannot be precisely specified. According to the approach, tidying up a room can be an activity whereas others approaches may generically consider tidying up the entire house as an activity. In any case, some approaches may hierarchically define activities, where an activity is a combination of sub-activities.
- Habit: A sequence or interleaving of activities that happen in specific contextual conditions (e.g., what the user does every morning between 08:00 and 10:00).
3. Inclusion Criteria and Comparison Framework
- RQ-A: Sensor measurements represent the traces of user behavior in the environment. This information is needed at runtime to understand the current context, but the specific available information must be known when the model is defined (through specification or learning). The current review will only take into account the sensors for which the method has been validated. Section 4 will present for each of the included papers the following information:
- -
- RQ-A1: which sensors are taken into account?
- -
- RQ-A2: are the sensors only categorical or numerical? And in the latter case,
- -
- RQ-A3: which discretization strategy is employed?
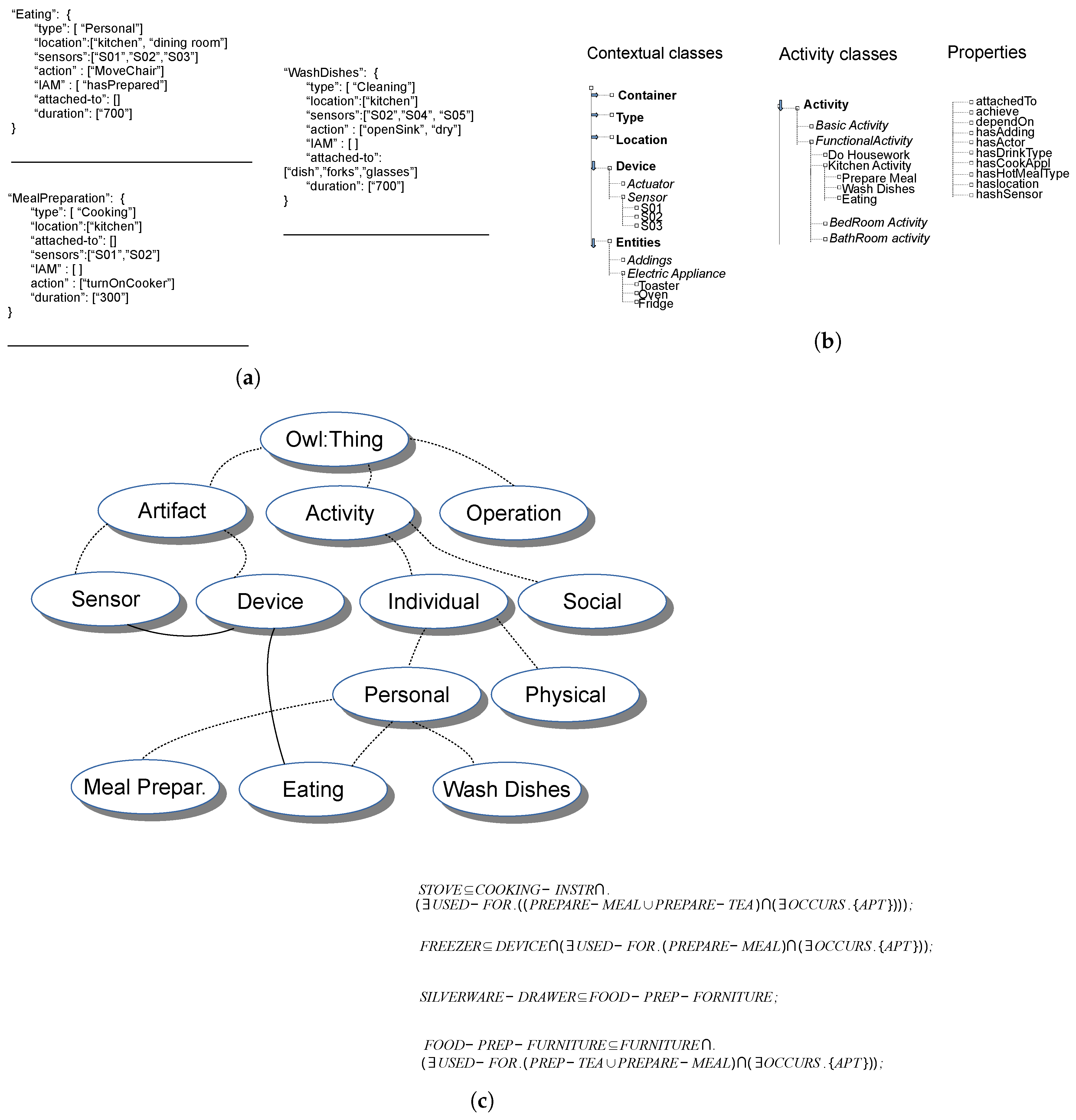
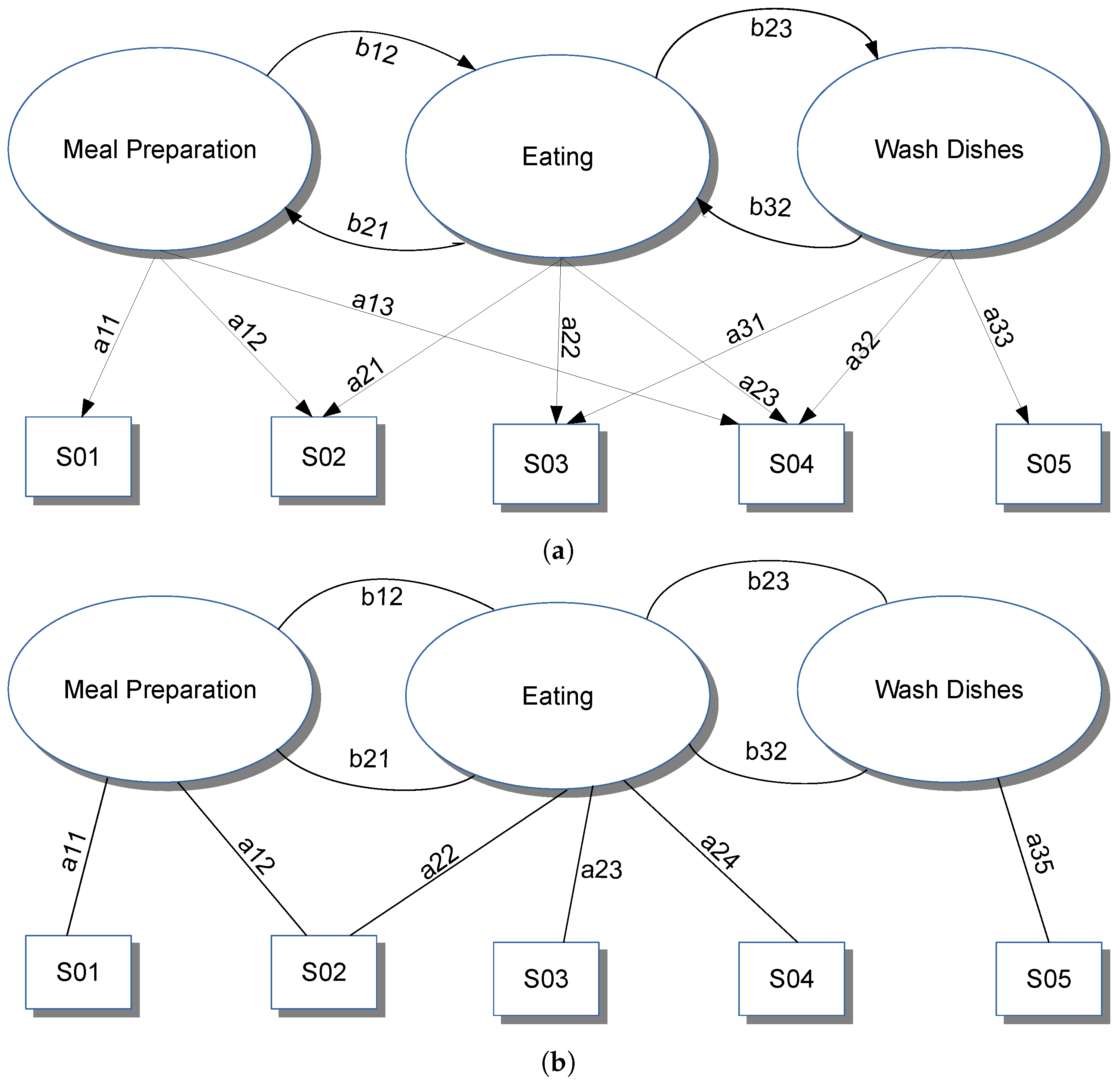
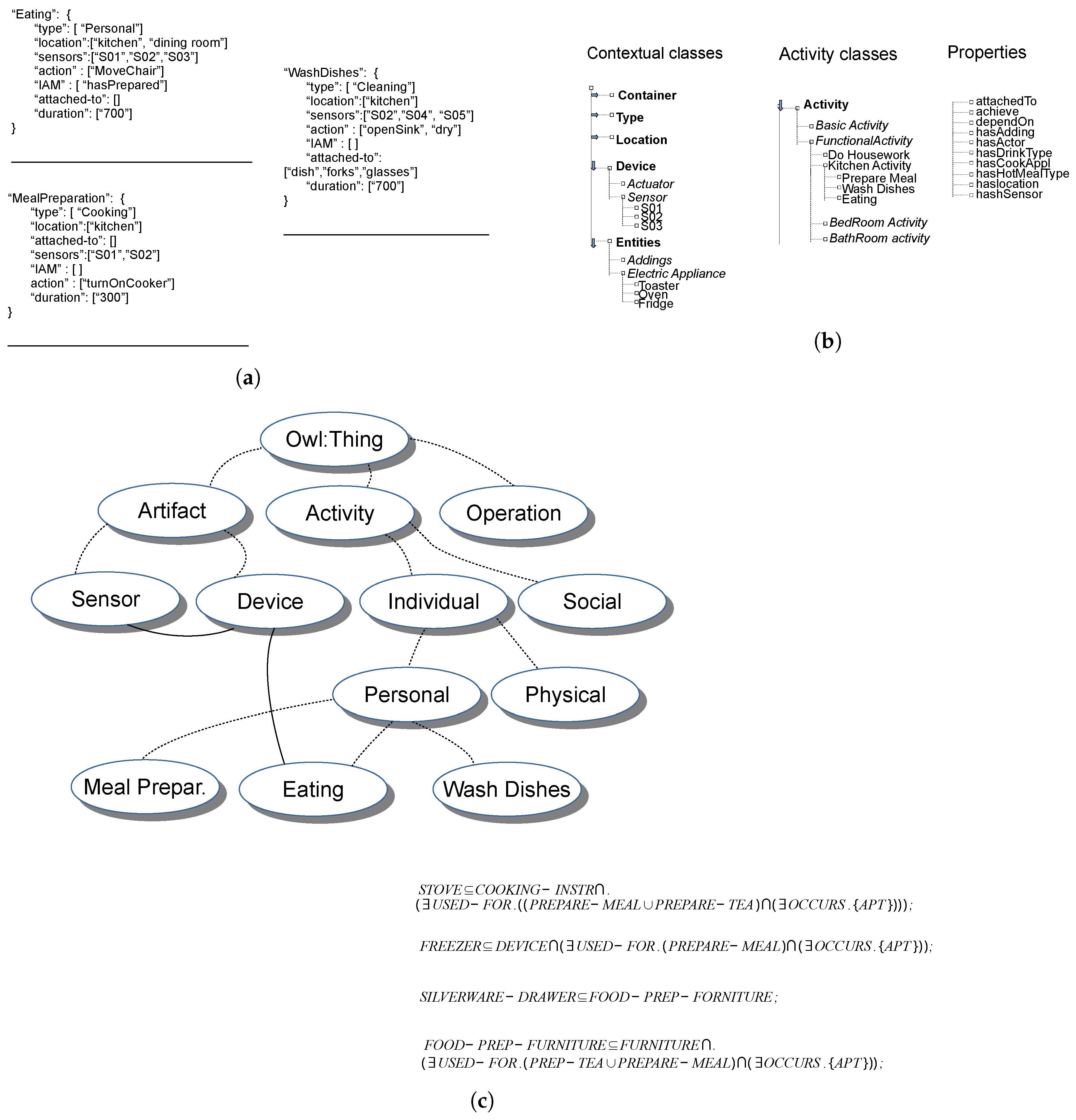
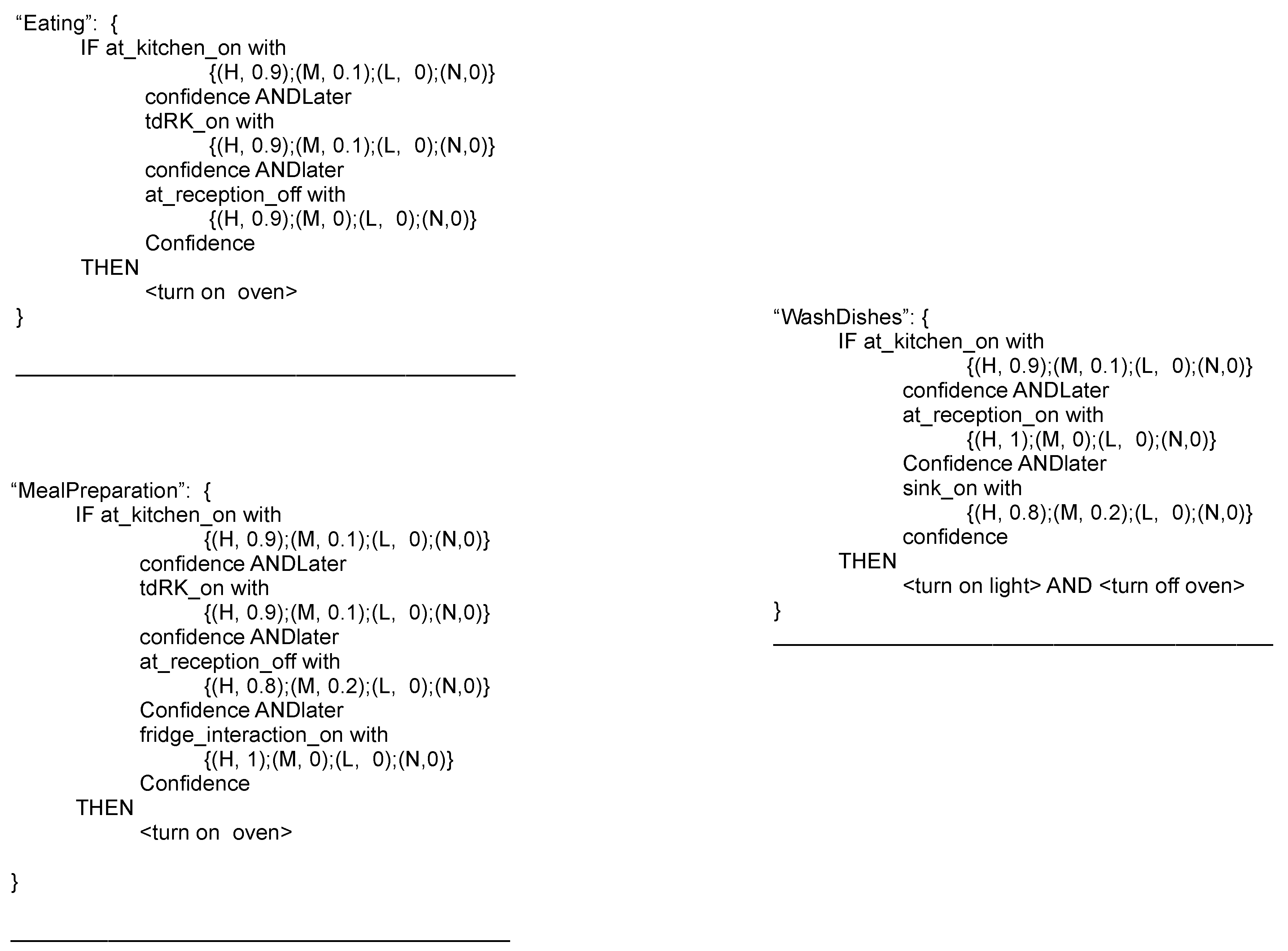
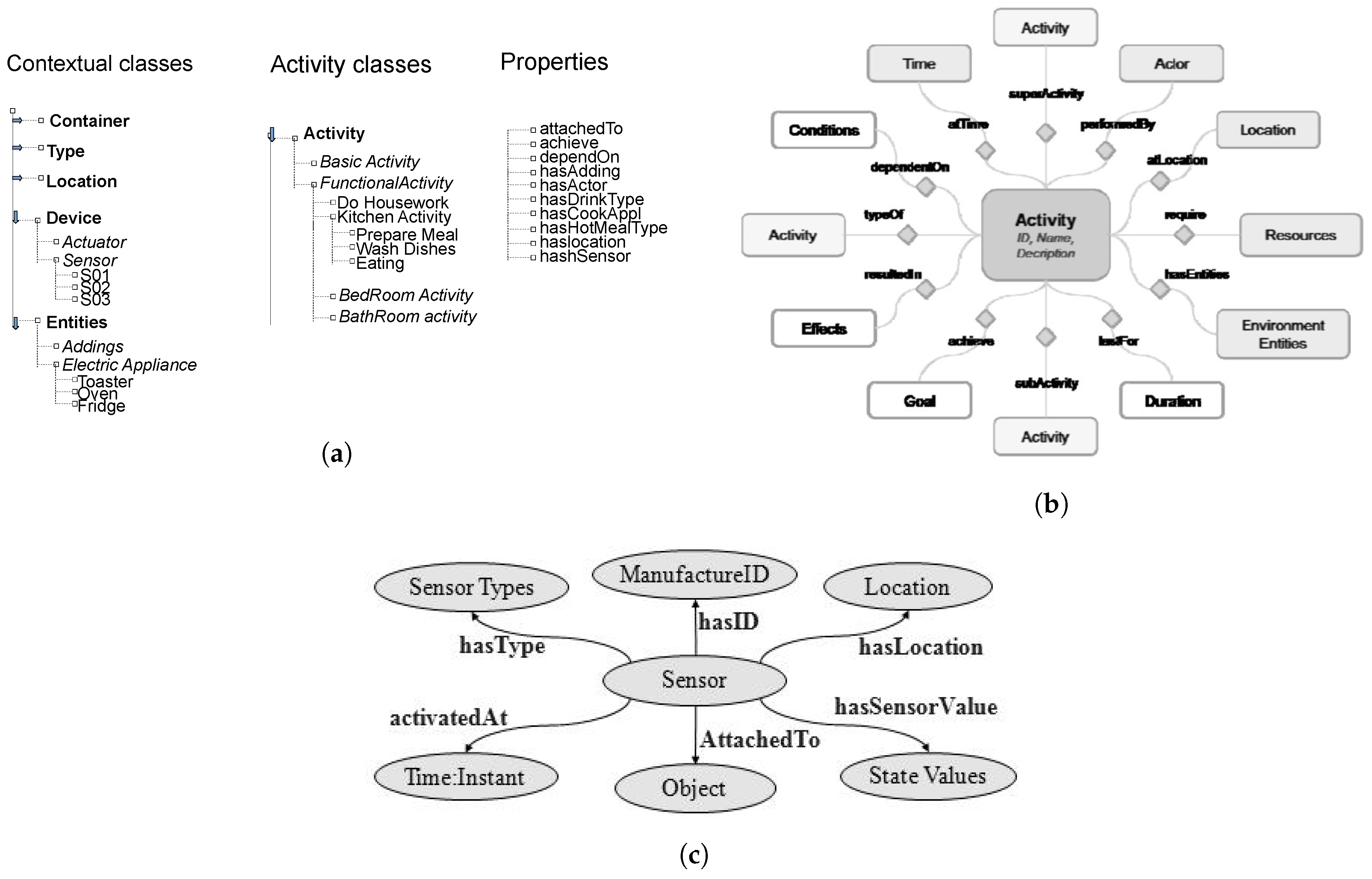
- RQ-B1: Any proposed method has a way to represent models. Models can be represented using graphical or mathematical/logic formalisms. Some methods propose formalisms that are specifically designed for the particular approach. Other methods conversely employ standard formalisms from machine learning and data mining. Section 5 analyzes the following aspects about employed models:
- -
- RQ-B1.1: the type of adopted model;
- -
- RQ-B1.2: how does an instance of the model can be represented? Is it human readable?
- -
- RQ-B1.3: which is the granularity at which the model works?
- RQ-B2: Whichever model type is adopted by a specific method, each method introduces a different way to construct the model. Section 6 expands the following analysis:
- -
- RQ-B2.1: for methods involving an, optionally partial, automatic construction of models (i.e., through learning), a training set consisting of a sensor log must be fed as input. At first, learning methods in the field of ambient intelligence can be classified according to the effort devoted to label the training set;
- -
- RQ-B2.2: does the system consider the possibility of having multiple users? How many?
- -
- RQ-B2.3: in the latter case, is some type of additional labeling needed?
4. Supported Sensors
- Supervised vs. Unsupervised. Unsupervised methods do not make use of class information in order to select cut-points. Classic unsupervised methods are equal-width and equal-frequency binning, and clustering. Supervised methods employ instead class labels in order to improve discretization results.
- Static vs. Dynamic. Static discretization methods perform discretization, as a preprocessing step, prior to the execution of the learning/mining task. Dynamic methods instead carry out discretization on the fly.
- Global vs. Local. Global methods, such as binning, are applied to the entire n-dimensional space. Local methods, as the C4.5 classifier, produce partitions that are applied to localized regions of the instance space. A local method is usually associated with a dynamic discretization method.
- Top-down vs. Bottom-up. Top-down methods start with an empty list of cut-points (or split-points) and keep on adding new ones to the list by splitting intervals as the discretization progresses. Bottom-up methods start with the complete list of all the continuous values of the feature as cut-points and remove some of them by merging intervals as the discretization progresses.
- Direct vs. Incremental. Direct methods directly divide the range of a quantitative attribute in k intervals, where the parameter k is provided as input by the user. Conversely, incremental methods start from a simple discretization and improve it step by step in order to find the best value of k.
5. Model Types
6. Model Construction
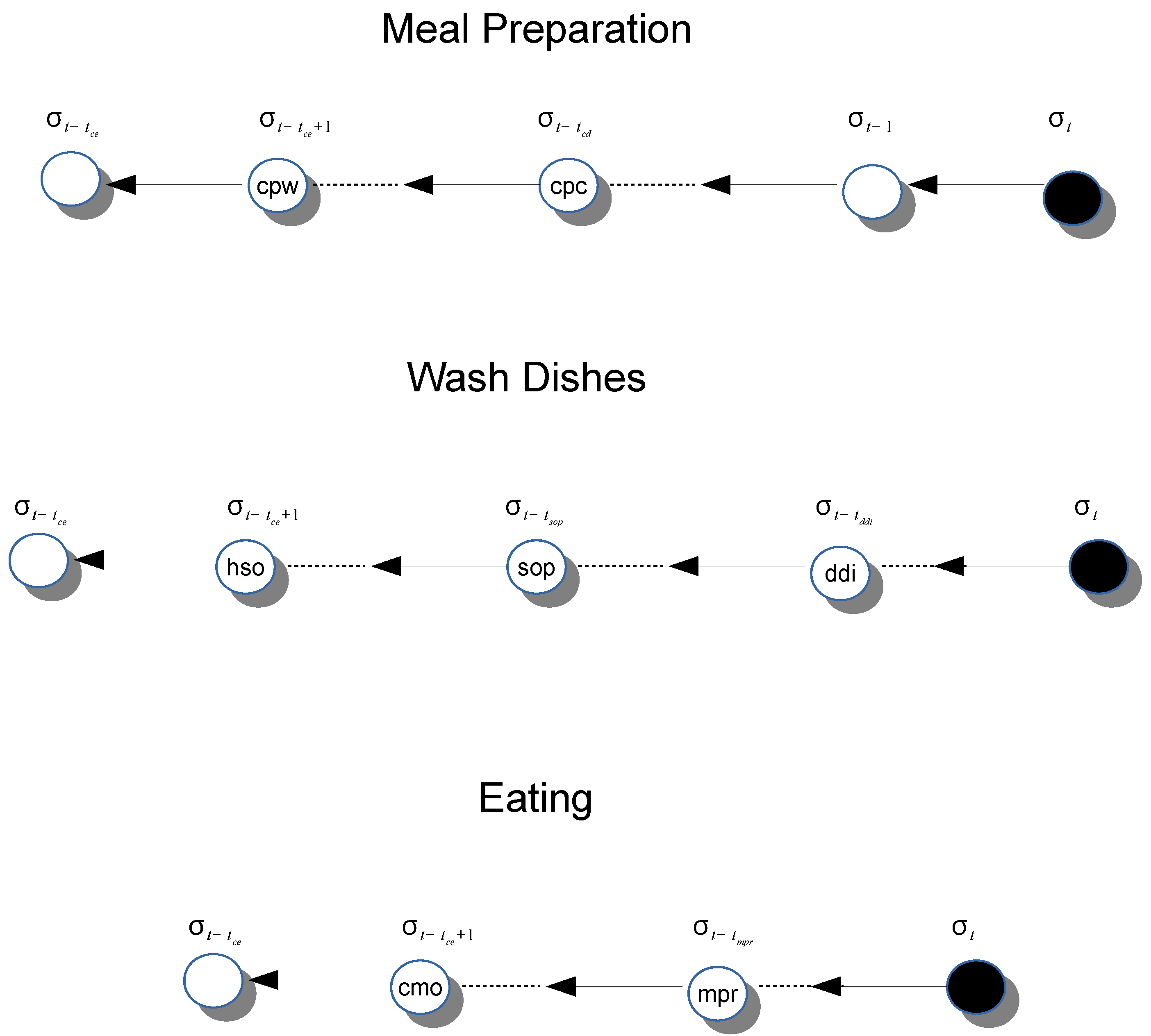
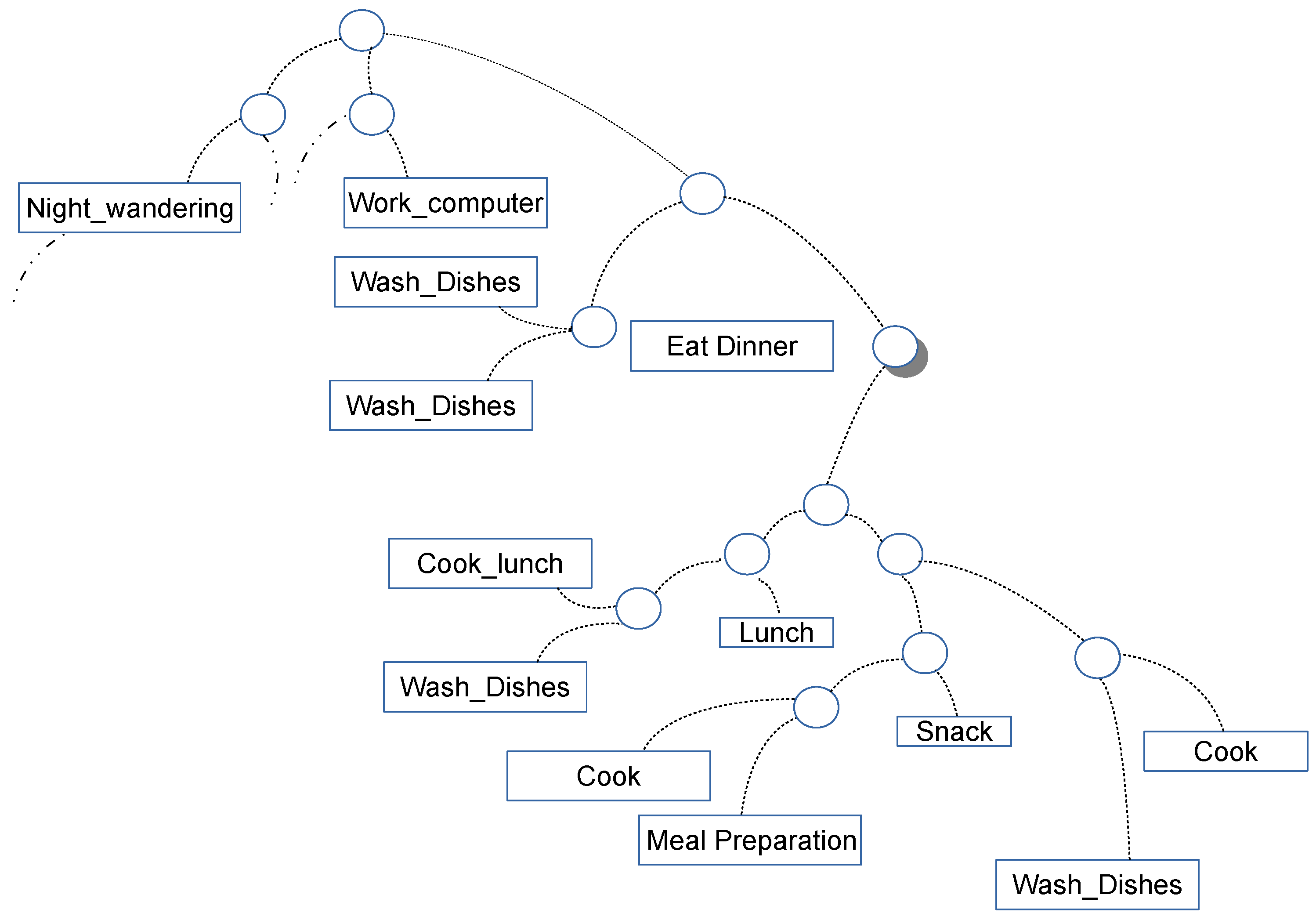
- Explicit segmentation. In this case, the stream is divided into chunks usually following some kind of classifier previously instructed over a training data set. Unfortunately, as the training data set simply cannot cover all the possible combinations of sensor events, the performance of such a kind of approach usually results in single activities divided into multiple chunks and multiple activities merged.
- Time-based windowing. This approach divides the entire sequence into equal size time intervals. This is a good approach when dealing with data obtained from sources (e.g., sensors like accelerometers and gyroscopes) that operate continuously in time. As can be easily argued, the choice of the window size is fundamental especially in the case of sporadic sensors as a small window size could not contain enough information to be useful whereas a large window size could merge multiple activities when burst of sensors occur.
- Sensor Event-based windowing. This last approach splits the entire sequence into bins containing an equal number of sensor events. Usually, bins are in this case overlapping with each window containing the last event arrived together with the previous events. Whereas this method usually performs better than the other, it shows drawbacks similar to those introduced for time based windowing.
- Type O sensors installed in objects, thus, providing direct information about the actions of the users.
- Type C sensors providing information about the environment (e.g., temperature, day of the week).
- Type M sensors providing information about the position of the user inside the house (e.g., in the bedroom).
7. Related Work
8. Discussion
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AAL | Ambient Assisted Living |
| ADB | Active DataBase |
| AI | Artificial Intelligence |
| AmI | Ambient Intelligence |
| (A)NN | (Artificial) Neural Network |
| BPM | Business Process Management |
| CRF | Conditional Random Field |
| DST | Dampster-Shafer Theory |
| ECA | Event-Condition-Action |
| EP | Emerging Pattern |
| HCI | Human-Computer Interaction |
| HMM | Hidden Markov Model |
| IMU | Inertial Measurements Unit |
| IoT | Internet-of-Things |
| MC | Markov Chain |
| NB | Naive Bayes |
| RFID | Radio-Frequency IDentification |
| RQ | Research Question |
| SLR | Systematic Literature Review |
| SVM | Support Vector Machine |
| UHF | Ultra-High Frequency |
| WSN | Wireless Sensor Network |
References
- Ye, J.; Dobson, S.; McKeever, S. Situation identification techniques in pervasive computing: A review. Pervasive Mob. Comput. 2012, 8, 36–66. [Google Scholar] [CrossRef]
- Uckelmann, D.; Harrison, M.; Michahelles, F. An architectural approach towards the future Internet-of- Things. In Architecting the Internet-of-Things; Springer: Berlin/Heidelberg, Germany, 2011; pp. 1–24. [Google Scholar]
- Augusto, J.; Nugent, C. (Eds.) Smart Homes Can Be Smarter. In Designing Smart Homes; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4008, pp. 1–15. [Google Scholar]
- Mennicken, S.; Huang, E. Hacking the Natural Habitat: An In-the-Wild Study of Smart Homes, Their Development, and the People Who Live in Them. In Pervasive Computing; Lecture Notes in Computer Science; Kay, J., Lukowicz, P., Tokuda, H., Olivier, P., Krüger, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7319, pp. 143–160. [Google Scholar]
- Tazari, M.R.; Furfari, F.; Fides-Valero, Á.; Hanke, S.; Höftberger, O.; Kehagias, D.; Mosmondor, M.; Wichert, R.; Wolf, P. The universAAL Reference Model for AAL. In Handbook of Ambient Assisted Living; IOS Press Ebooks: Amsterdam, The Netherlands, 2012; Volume 11, pp. 610–625. [Google Scholar]
- Cook, D.; Augusto, J.; Jakkula, V. Ambient intelligence: Technologies, applications, and opportunities. Pervasive Mob. Comput. 2009, 5, 277–298. [Google Scholar] [CrossRef] [Green Version]
- Aztiria, A.; Izaguirre, A.; Augusto, J.C. Learning patterns in ambient intelligence environments: A survey. Artif. Intell. Rev. 2010, 34, 35–51. [Google Scholar] [CrossRef]
- Kitchenham, B. Procedures for Performing Systematic Reviews; Keele University: Keele, UK, 2004; Volume 33, pp. 1–26. [Google Scholar]
- Augusto, J.C.; Liu, J.; McCullagh, P.; Wang, H.; Yang, J.B. Management of uncertainty and spatio-temporal aspects for monitoring and diagnosis in a smart home. Int. J. Comput. Intell. Syst. 2008, 1, 361–378. [Google Scholar] [CrossRef]
- Aztiria, A.; Augusto, J.C.; Basagoiti, R.; Izaguirre, A.; Cook, D.J. Discovering frequent user–environment interactions in intelligent environments. Pers. Ubiquitous Comput. 2012, 16, 91–103. [Google Scholar] [CrossRef]
- Cook, D.J.; Krishnan, N.C.; Rashidi, P. Activity discovery and activity recognition: A new partnership. IEEE Trans. Cybern. 2013, 43, 820–828. [Google Scholar] [CrossRef] [PubMed]
- Rashidi, P.; Cook, D.J.; Holder, L.B.; Schmitter-Edgecombe, M. Discovering activities to recognize and track in a smart environment. IEEE Trans. Knowl. Data Eng. 2011, 23, 527–539. [Google Scholar] [CrossRef]
- Rashidi, P.; Cook, D.J. COM: A method for mining and monitoring human activity patterns in home-based health monitoring systems. ACM Trans. Intell. Syst. Technol. 2013, 4, 64. [Google Scholar] [CrossRef]
- Singla, G.; Cook, D.J.; Schmitter-Edgecombe, M. Recognizing independent and joint activities among multiple residents in smart environments. J. Ambient Intell. Human. Comput. 2010, 1, 57–63. [Google Scholar] [CrossRef]
- Rashidi, P.; Cook, D.J. Keeping the resident in the loop: Adapting the smart home to the user. IEEE Trans. Syst. Man Cybern.-Part A Syst. Hum. 2009, 39, 949–959. [Google Scholar] [CrossRef]
- Cook, D.J. Learning setting-generalized activity models for smart spaces. IEEE Intell. Syst. 2012, 27, 32–38. [Google Scholar] [CrossRef] [PubMed]
- Krishnan, N.C.; Cook, D.J. Activity recognition on streaming sensor data. Pervasive Mob. Comput. 2014, 10, 138–154. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Nugent, C.D.; Wang, H. A knowledge-driven approach to activity recognition in smart homes. IEEE Trans. Knowl. Data Eng. 2012, 24, 961–974. [Google Scholar] [CrossRef]
- Gu, T.; Wang, L.; Wu, Z.; Tao, X.; Lu, J. A pattern mining approach to sensor-based human activity recognition. IEEE Trans. Knowl. Data Eng. 2011, 23, 1359–1372. [Google Scholar] [CrossRef]
- Helaoui, R.; Riboni, D.; Stuckenschmidt, H. A probabilistic ontological framework for the recognition of multilevel human activities. In Proceedings of the 2013 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Zurich, Switzerland, 8–12 September 2013; ACM: New York, NY, USA, 2013; pp. 345–354. [Google Scholar]
- Riboni, D.; Sztyler, T.; Civitarese, G.; Stuckenschmidt, H. Unsupervised recognition of interleaved activities of daily living through ontological and probabilistic reasoning. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; ACM: New York, NY, USA, 2016; pp. 1–12. [Google Scholar]
- Hong, X.; Nugent, C.; Mulvenna, M.; McClean, S.; Scotney, B.; Devlin, S. Evidential fusion of sensor data for activity recognition in smart homes. Pervasive Mob. Comput. 2009, 5, 236–252. [Google Scholar] [CrossRef]
- Wang, L.; Gu, T.; Tao, X.; Lu, J. A hierarchical approach to real-time activity recognition in body sensor networks. Pervasive Mob. Comput. 2012, 8, 115–130. [Google Scholar] [CrossRef]
- Van Kasteren, T.; Noulas, A.; Englebienne, G.; Kröse, B. Accurate activity recognition in a home setting. In Proceedings of the 10th International Conference on Ubiquitous computing, Seoul, Korea, 21–24 September 2008; ACM: New York, NY, USA, 2008; pp. 1–9. [Google Scholar]
- Brdiczka, O.; Crowley, J.L.; Reignier, P. Learning situation models in a smart home. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2009, 39, 56–63. [Google Scholar] [CrossRef]
- Yang, J.Y.; Wang, J.S.; Chen, Y.P. Using acceleration measurements for activity recognition: An effective learning algorithm for constructing neural classifiers. Pattern Recognit. Lett. 2008, 29, 2213–2220. [Google Scholar] [CrossRef]
- Stikic, M.; Larlus, D.; Ebert, S.; Schiele, B. Weakly supervised recognition of daily life activities with wearable sensors. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2521–2537. [Google Scholar] [CrossRef]
- Fleury, A.; Vacher, M.; Noury, N. SVM-based multimodal classification of activities of daily living in health smart homes: Sensors, algorithms, and first experimental results. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 274–283. [Google Scholar] [CrossRef]
- Palmes, P.; Pung, H.K.; Gu, T.; Xue, W.; Chen, S. Object relevance weight pattern mining for activity recognition and segmentation. Pervasive Mob. Comput. 2010, 6, 43–57. [Google Scholar] [CrossRef]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity recognition using cell phone accelerometers. ACM SigKDD Explor. Newsl. 2011, 12, 74–82. [Google Scholar] [CrossRef]
- Lester, J.; Choudhury, T.; Borriello, G. A practical approach to recognizing physical activities. In Proceedings of the International Conference on Pervasive Computing, Dublin, Ireland, 7–10 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1–16. [Google Scholar]
- Buettner, M.; Prasad, R.; Philipose, M.; Wetherall, D. Recognizing daily activities with RFID-based sensors. In Proceedings of the 11th International Conference on Ubiquitous Computing, Orlando, FL, USA, 30 September–3 October 2009; ACM: New York, NY, USA, 2009; pp. 51–60. [Google Scholar]
- Aggarwal, C.C. Managing and Mining Sensor Data; Springer Publishing Company, Incorporated: New York, NY, USA, 2013. [Google Scholar]
- Liu, H.; Hussain, F.; Tan, C.L.; Dash, M. Discretization: An enabling technique. Data Min. Knowl. Discov. 2002, 6, 393–423. [Google Scholar] [CrossRef]
- Krishnan, N.; Cook, D.J.; Wemlinger, Z. Learning a taxonomy of predefined and discovered activity patterns. J. Ambient Intell. Smart Environ. 2013, 5, 621–637. [Google Scholar] [PubMed]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference on Very Large Data Bases, VLDB, Santiago de Chile, Chile, 12–15 September 1994; Volume 1215, pp. 487–499. [Google Scholar]
- Loke, S.W. Logic programming for context-aware pervasive computing: Language support, characterizing situations, and integration with the web. In Proceedings of the 2004 IEEE/WIC/ACM International Conference on Web Intelligence, Beijing, China, 20–24 September 2004; pp. 44–50. [Google Scholar]
- Magherini, T.; Fantechi, A.; Nugent, C.D.; Vicario, E. Using temporal logic and model checking in automated recognition of human activities for ambient-assisted living. IEEE Trans. Hum. Mach. Syst. 2013, 43, 509–521. [Google Scholar] [CrossRef]
- Ye, J.; Coyle, L.; Dobson, S.; Nixon, P. Ontology-based models in pervasive computing systems. Knowl. Eng. Rev. 2007, 22, 315–347. [Google Scholar] [CrossRef]
- Riboni, D.; Bettini, C. Context-aware activity recognition through a combination of ontological and statistical reasoning. In Proceedings of the Ubiquitous Intelligence Computing, Brisbane, Australia, 7–9 July 2009; pp. 39–53. [Google Scholar]
- Azkune, G.; Almeida, A.; López-de Ipiña, D.; Chen, L. Extending knowledge-driven activity models through data-driven learning techniques. Expert Syst. Appl. 2015, 42, 3115–3128. [Google Scholar] [CrossRef] [Green Version]
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach, 3rd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2010. [Google Scholar]
- Augusto, J.C.; Nugent, C.D. The use of temporal reasoning and management of complex events in smart homes. In Proceedings of the 16th European Conference on Artificial Intelligence, Valencia, Spain, 22–27 August 2004; Volume 16, p. 778. [Google Scholar]
- Dumas, M.; La Rosa, M.; Mendling, J.; Reijers, H.A. Fundamentals of Business Process Management; Springer: Berlin/Heidelberg, Germany, 2013; Volume 1. [Google Scholar]
- Gottfried, B.; Guesgen, H.; Hübner, S. Spatiotemporal Reasoning for Smart Homes. In Designing Smart Homes; Lecture Notes in Computer Science; Augusto, J., Nugent, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4008, pp. 16–34. [Google Scholar]
- Aztiria, A.; Izaguirre, A.; Basagoiti, R.; Augusto, J.C.; Cook, D.J. Discovering Frequent Sets of Actions in Intelligent Environments. In Intelligent Environments; IOS Press: Barcelona, Spain, 2009; pp. 153–160. [Google Scholar]
- Aztiria, A.; Izaguirre, A.; Basagoiti, R.; Augusto, J.C.; Cook, D. Automatic modeling of frequent user behaviours in intelligent environments. In Proceedings of the 2010 Sixth International Conference on Intelligent Environments (IE), Kuala Lumpur, Malaysia, 19–21 July 2010; IEEE: Washington, DC, USA, 2010; pp. 7–12. [Google Scholar]
- William, C. Fast effective rule induction. In Proceedings of the Twelfth International Conference on Machine Learning, Tahoe City, CA, USA, 9–12 July 1995; pp. 115–123. [Google Scholar]
- Bettini, C.; Brdiczka, O.; Henricksen, K.; Indulska, J.; Nicklas, D.; Ranganathan, A.; Riboni, D. A survey of context modelling and reasoning techniques. Pervasive Mob. Comput. 2010, 6, 161–180. [Google Scholar] [CrossRef] [Green Version]
- Sadri, F. Ambient Intelligence: A Survey. ACM Comput. Surv. 2011, 43, 36. [Google Scholar] [CrossRef]
- Chen, L.; Hoey, J.; Nugent, C.D.; Cook, D.J.; Yu, Z. Sensor-based activity recognition. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2012, 42, 790–808. [Google Scholar] [CrossRef]
- Acampora, G.; Cook, D.J.; Rashidi, P.; Vasilakos, A.V. A Survey on Ambient Intelligence in Healthcare. Proc. IEEE 2013, 101, 2470–2494. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Augusto, J.C.; Callaghan, V.; Cook, D.; Kameas, A.; Satoh, I. Intelligent environments: A manifesto. Hum. Cent. Comput. Inf. Sci. 2013, 3, 12. [Google Scholar] [CrossRef]
- Amiribesheli, M.; Benmansour, A.; Bouchachia, A. A review of smart homes in healthcare. J. Ambient Intell. Hum. Comput. 2015, 6, 495–517. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acronym | Study Title |
|---|---|
| aug-eca [9] | Augusto, J. C., Liu, J., McCullagh, P., Wang, H., and Yang, J.-B. Management of uncertainty and spatio-temporal aspects for monitoring and diagnosis in a smart home. |
| aug-apubs [10] | Aztiria, A., Augusto, J. C., Basagoiti, R., Izaguirre, A., and Cook, D. J. Discovering frequent user–environment interactions in intelligent environments. |
| casas-discorec [11,12,13] | Cook, D. J., Krishnan, N. C., and Rashidi, P. Activity discovery and activity recognition: A new partnership. |
| Rashidi, P., Cook, D. J., Holder, L. B., and Schmitter-Edgecombe, M. Discovering activities to recognize and track in a smart environment. | |
| Rashidi, P. and Cook, D. J. Com: A method for mining and monitoring human activity patterns in home-based health monitoring systems. | |
| casas-hmm [14] | Singla, G., Cook, D. J., and Schmitter-Edgecombe, M. Recognizing independent and joint activities among multiple residents in smart environments. |
| casas-ham [15] | Rashidi, P. and Cook, D. J. Keeping the resident in the loop: Adapting the smart home to the user. |
| casas-hmmnbcrf [16] | Cook, D. J. Learning setting-generalized activity models for smart spaces. |
| casas-svm [17] | Krishnan, N. C. and Cook, D. J. Activity recognition on streaming sensor data. |
| chen-ont [18] | Chen, L., Nugent, C. D., and Wang, H. A knowledge-driven approach to activity recognition in smart homes. |
| wang-ep [19] | Gu, T., Wang, L., Wu, Z., Tao, X., and Lu, J. A pattern mining approach to sensor-based human activity recognition. |
| rib-prob [20,21] | Helaoui, R., Riboni, D., and Stuckenschmidt, H. A probabilistic ontological framework for the recognition of multilevel human activities. |
| Riboni, D., Sztyler, T., Civitarese, G., and Stuckenschmidt, H. Unsupervised recognition of interleaved activities of daily living through ontological and probabilistic reasoning. | |
| nug-evfus [22] | Hong, X., Nugent, C., Mulvenna, M., McClean, S., Scotney, B., and Devlin, S. Evidential fusion of sensor data for activity recognition in smart homes. |
| wang-hier [23] | William, C. et al. Fast effective rule induction. |
| kros-crf [24] | Van Kasteren, T., Noulas, A., Englebienne, G., and Kröse, B. Accurate activity recognition in a home setting. |
| reig-situation [25] | Brdiczka, O., Crowley, J. L., and Reignier, P. Learning situation models in a smart home. |
| yang-nn [26] | Yang, J.-Y., Wang, J.-S., and Chen, Y.-P. Using acceleration measurements for activity recognition: An effective learning algorithm for constructing neural classifiers. |
| stik-misvm [27] | Stikic, M., Larlus, D., Ebert, S., and Schiele, B. Weakly supervised recognition of daily life activities with wearable sensors. |
| fleury-mcsvm [28] | Fleury, A., Vacher, M., and Noury, N. Svm-based multimodal classification of activities of daily living in health smart homes: sensors, algorithms, and first experimental results. |
| palmes-objrel [29] | Palmes, P., Pung, H. K., Gu, T., Xue, W., and Chen, S. Object relevance weight pattern mining for activity recognition and segmentation. |
| moore-strawman [30] | Kwapisz, J. R., Weiss, G. M., and Moore, S. A. Activity recognition using cell phone accelerometers. |
| les-phi [31] | Lester, J., Choudhury, T., and Borriello, G. A practical approach to recognizing physical activities. |
| bue-wisps [32] | Buettner, M., Prasad, R., Philipose, M., and Wetherall, D. Recognizing daily activities with rfid-based sensors. |
| Approach | RQ-A1 | RQ-A2 | RQ-A3 |
|---|---|---|---|
| aug-eca [9] | Position | Discrete | - |
| aug-apubs [10] | Object sensor, motion sensor, and context sensor | Mixed | - |
| casas-discorec [11,12,13] | motion + interaction (RFID) | Discrete | - |
| casas-hmm [14] | motion + interaction (RFID) | Discrete | - |
| casas-hmmnbcrf [16] | motion + interaction (RFID) | Discrete | - |
| casas-ham [15] | motion + interaction( RFID) | Discrete | - |
| casas-svm [17] | Passive InfraRed | Discrete | - |
| chen-ont [18] | Dense sensed environment: RFID, PIR, context sensors (tilt, pressure) | Mixed | Sensor measurements continuously fed into the system. |
| rib-prob [20,21] | RFID + body sensor | Discrete | - |
| wang-ep [19] | RFID + user’s movement, environmental information, user location, human-object interaction | Mixed | From analogical measurements, like acceleration data and temperature, statistical values are computed (e.g., mean, variance) |
| nug-evfus [22] | PIR, contact, pressure mats | Discrete | - |
| wang-hier [23] | RFID + body sensors (IMOTE2) | Discrete | - |
| kros-crf [24] | large variety of sensors, from contact to humidity/temperature | Mixed | Temporal probabilistic model: sampling measurements creating sequences of observations |
| reig-situation [25] | Video and audio records | Analogical | Extraction of user position and speed () |
| yang-nn [26] | triaxial accelerometer on a wearable board | Discrete | - |
| stik-misvm [27] | Audio-video, object interaction, environmental conditions, appliances’ use, 3D accelerometers | Mixed | Statistical features computed over 30 s sliding window shifted in increments of 15 s. |
| fleury-mcsvm [28] | Many: position, microphones, contact, wearable | Mixed | Extraction of statistical features (e.g., number of events per microphone) |
| palmes-objrel [29] | RFID | Discrete | - |
| les-phi [31] | Accelerometers + audio + barometric pressure | Mixed | |
| bue-wisps [32] | WISPS: UHF RFID + accelerometers | Discrete | - |
| References | RQ-B1.1 | RQ-B1.2 | RQ-B1.3 |
|---|---|---|---|
| aug-eca [9] | ECA | H | Action |
| aug-apubs [10] | Action | ||
| casas-hmmnbcrf [16] | NB | L | Activity |
| casas-discorec [11,12,13] | HMM | M | Activity |
| casas-hmm [14] | Activity | ||
| casas-hmmnbcrf [16] | Activity | ||
| kros-crf [24] | Activity | ||
| reig-situation [25] | Situation | ||
| les-phi [31] | Activity | ||
| bue-wisps [32] | Activity | ||
| casas-ham [15] | MC | M | Event |
| casas-hmmnbcrf [16] | CRF | L | Activity |
| kros-crf [24] | Activity | ||
| reig-situation [25] | SVM | L | Situation |
| stik-misvm [27] | Activity | ||
| fleury-mcsvm [28] | Activity | ||
| chen-ont [18] | ONTO | H | Activity |
| rib-prob [20,21] | Action/Activity | ||
| nug-evfus [22] | Action | ||
| wang-ep [19] | EP | L | Action/Activity |
| yang-nn [26] | ANN | L | Activity |
| palmes-objrel [29] | Other | H | Activity |
| Technique | RQ-B2.1 | RQ-B2.2 | RQ-B2.3 |
|---|---|---|---|
| aug-eca [9] | Specification | S | N |
| chen-ont [18] | Specification | S | N |
| rib-prob [20,21] | Specification | S | N |
| nug-evfus [22] | Specification | S | N |
| casas-hmm [14] | Supervised | S | N |
| casas-svm [17] | Supervised | S | N |
| casas-hmmnbcrf [16] | Supervised | S | N |
| wang-ep [19] | Supervised | S | N |
| kros-crf [24] | Supervised | S | N |
| reig-situation [25] | Supervised | M | N |
| yang-nn [26] | Supervised | S | N |
| les-phi [31] | Supervised | S | N |
| bue-wisps [32] | Supervised | S | N |
| fleury-mcsvm [28] | Supervised | M | Y |
| casas-discorec [11,12,13] | Weakly Sup. | S | N |
| stik-misvm [27] | Weakly Sup. | M | Y |
| aug-apubs [10] | Unsupervised | S | N |
| casas-ham [15] | Unsupervised | S | N |
| wang-hier [23] | Unsupervised | S | N |
| palmes-objrel [29] | Unsupervised | S | N |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leotta, F.; Mecella, M.; Sora, D.; Catarci, T. Surveying Human Habit Modeling and Mining Techniques in Smart Spaces. Future Internet 2019, 11, 23. https://doi.org/10.3390/fi11010023
Leotta F, Mecella M, Sora D, Catarci T. Surveying Human Habit Modeling and Mining Techniques in Smart Spaces. Future Internet. 2019; 11(1):23. https://doi.org/10.3390/fi11010023
Chicago/Turabian StyleLeotta, Francesco, Massimo Mecella, Daniele Sora, and Tiziana Catarci. 2019. "Surveying Human Habit Modeling and Mining Techniques in Smart Spaces" Future Internet 11, no. 1: 23. https://doi.org/10.3390/fi11010023
APA StyleLeotta, F., Mecella, M., Sora, D., & Catarci, T. (2019). Surveying Human Habit Modeling and Mining Techniques in Smart Spaces. Future Internet, 11(1), 23. https://doi.org/10.3390/fi11010023