1. Introduction
In the current state of technology, not only the data and its services but also their users are increasing day by day. A user is required to visit multiple webs/apps using some credentials to access the personal/private information. In order to access public information, a user searches the appropriate webs/apps and explores them to reach to the information as per their need. It is obvious that instead of searching and visiting the multiple webs/apps, the users would like to view all their needed information at one digital place, which could be his personal web page, email account, social media page, desktop application or their mobile screen, etc. The data mashup is a set of techniques and user-friendly approaches to allow ordinary users to fetch the required data from multiple data sources and facilitates them to mashup the data and view them together in a single digital place. The industries and researchers are continuously working on the development of user-friendly approach for performing the data mashup after fetching the hybrid kind of data from the disparate data sources even by ordinary users. Mashup users can be divided into two types of groups namely End User Developer (EUD)/End User Programmer (EUP) [
1,
2] and Ordinary User (OU) [
3]/naive End User (EU) who are supposed to use mashup applications according to their skills. The end user developer possesses some technical skills and can use mashup tools and techniques to develop mashup application for himself but the ordinary user does not have any technical skill and can use only those mashup tools and techniques which expect simple skills like internet browsing, mouse click, key press or filling the web forms, etc.
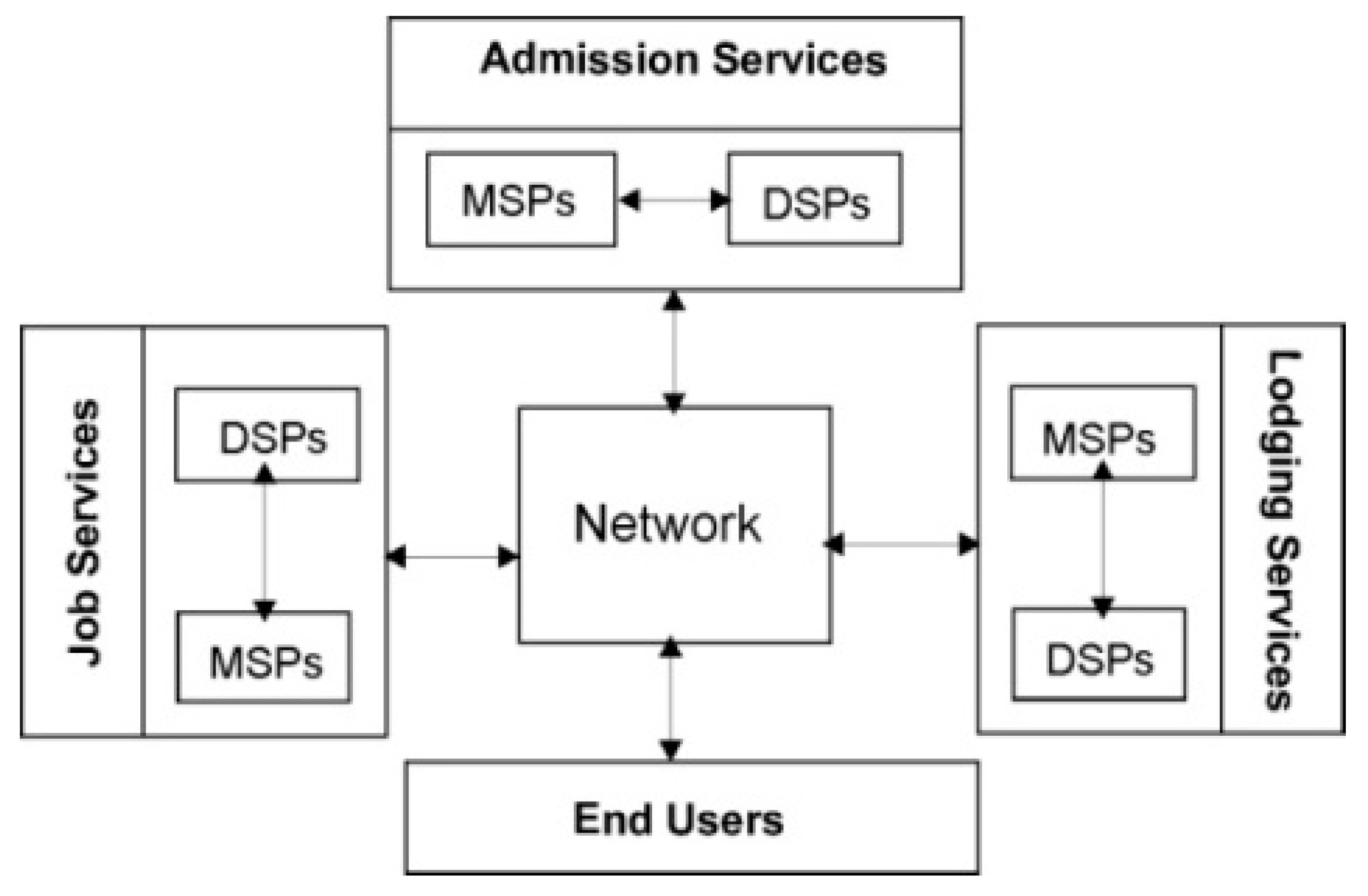
Most of the mashup tools expect some technical skills from users and are suitable for end user developers only. Initially, the mashup development was started to fulfill the need of ordinary users but later on, the development of mashup was diverted to make the mashup tools targeted for end user developer. The proposed work targets to ordinary user and we will use the term ‘End User (EU)’ or ‘user’ for ordinary user who does not have any technical skill. Other than end user, there are two other major stakeholders called Mashup Service Provider (MSP) and Data Service Provider (DSP) involved in mashup development [
4]. The details about MSP and DSP and their roles have been explained later in this paper. Generally, data mashup performed by end user includes seven basic steps—(1) determining its own digital place; (2) defining requirement of the data to be mashed up in a data mashup box; (3) searching appropriate MSPs/DSPs for mashup services and/or data services; (4) configuring each mashup box for mashing up data from relevant services; (5) fetching required data from multiple MSPs/DSPs; (6) mashing up the data, received from MSPs/DSPs into mashup box and injecting them into pre-determined/customized view; (7) showing the integrated view of mashed up data to the end user. Unlike other research works on data mashup, this paper covers all the steps required in the data mashup development as mentioned above.
The proposed work is based on the standard REpresentational State Transfer (REST) protocol [
5] to perform end to end data mashup which includes all stakeholders (EU, MSP, DSP) for performing data mashup using mashup communication between any two stakeholders (EU and MSP, EU and DSP, MSP and MSP or MSP and DSP). Data mashup techniques and approaches have not become as popular as email till now because of the less utilization of the standard communication protocols for mashup communication and the lack of generalized user-friendly approaches. Any mashup tool and technique cannot become popular among ordinary users until it provides user-friendly approach, which does not expect any technical skills from users and uses the general but secured communication protocol for performing the data mashup.
This paper focuses on SDRest protocol to develop user-friendly mashup approach, which allows ordinary users to define requirement of the data to be mashed up, fetch and integrate the needed Structured Data (SD) from multiple data sources at their own defined digital place without any programming and facilitate them to view the integrated UI in a single screen.
The rest of the paper is organized as follows. The
Section 2 covers the related literature review and the major challenges. The
Section 3 clearly mentions the motivation behind the proposed work and sets the goal. The
Section 4 describes our contributions in brief.
Section 5 explains the model and architecture of the proposed Structured Data Rest Protocol (SDRest) and various algorithms required in different stages of the data mashup development. The
Section 6 explains the algorithms used by end user and mashup service provider for performing data mashup. The
Section 7 shows the implementation of the proposed work by developing the data mashup service network for three services which explores the user-friendly approach for performing the pre-mashup configuration and end user data mashup by an ordinary user. The
Section 8 evaluates the proposed work by comparing it with some other related works based on some important parameters needed to evaluate each step of the mashup development and at last the conclusion and the future work.
2. Related Work and Challenges
The data mashup is useful in terms of the direct involvement of ordinary users for developing the information system. It will not only increase the user’s satisfaction but also will reduce the network traffic and overcome so many challenges of IT system developers. Many researchers and market players developed many mashup tools and techniques based on various approaches and also got success up to certain level but the actual aim for developing mashup by ordinary user without any programming/scripting in user friendly manner is still ahead. According to [
6,
7] widget approaches generally become popular among ordinary users because these include drag and drop like feature to mashup the desired data. In this approach, EU selects a widget, drops it onto a canvas, customizes the widget, and species how to connect a widget to other widgets by creating a connected graph [
8]. Reference [
9] proposed a mashup model that enables the integration at the presentation layer of “actionable UI components” which are equipped with both data visualization templates and a proper logic consisting of functions to manipulate the visualized data. References [
1,
8,
10] discussed mashup technologies of the market players which include Google Mashup Editor, IBM Mashup Center, Intel MashMaker, Microsoft Popfly, Yahoo Pipes etc. Google Mashup editor [
8] was the simple graphical editor to create AJAX based application with no plug-ins required and used to pull data from RSS feeds and Atoms. IBM Mashup Center [
8] allows users to create widgets and to wire them to assemble pages to create mashup. Intel
® Mash Maker [
11] uses browser plug-ins which allows the user to see information from other websites in a single page. It learns new mashups by simply copy and paste method which can further be used to suggest other users. Yahoo! Pipes [
10,
12] allows to mix popular data feeds using a visual editor to create data mashup. Yahoo pipe consists of various data sources like RSS, Atom, XML etc. and defines the set of operations to perform some task. It was providing visual tools to connect one widget to other widget in such a way that output of one widget was input to other and so on. Three problems as identified in widget approaches include locating the appropriate widget, customization of some widgets expects knowledge of programming and most of the mashup tools are not complete in all respect to perform independent mashup. FlexMash [
13] is an approach and tool implemented for flexible data mashups based on pattern-based model transformation and subdivided the data mashup into modeling, transformation, execution and presentation level.
Another approach is the End User Programming (EUP) [
14,
15] approach which allows end users to write and/or edit various script codes. Some tools provide the visual editor to copy and paste the script to integrate the data from various data resources but simply copy and paste of the script is inadequate because it requires re-scripting, modification and debugging as per situational need. Looking to the need of the ordinary user, programming by example/demonstration approach [
16] was designed which allows them to just perform simple drag and drop operations with instant output as an example so as to teach the mashup framework to do the remaining task automatically. According to this, five steps are required to perform mashup i.e., data retrieving (data extraction from web sites), source modeling (mapping between source data and destination data model), data cleaning (dealing with data formats, spelling etc.), data integration (combining the data from multiple sources) and data visualization (integrated UI). They used the “drag and drop” approach from a web page to extract web data based on Document Object Model (DOM) by allowing ordinary user to try with an example. It was really simple approach for normal user but it has limitations like extracting data from website, time consuming process of data cleaning and its limitation on data sources (suitable for a well-structured web page only).
Web data extraction [
17] has been the focus of researchers, but still remains challenging because a web page may contain the data in structured, semi-structured or unstructured format. Reference [
18] explained extracting Web API Specifications from HTML documentation but due to uncertainty on structure of the web page, the approach of data extraction from web page can never be reliable. Another problem with web data extraction is to extract data of deep web pages because a deep page is generated when some inputs are given through some web form. Reference [
19] present discovery algorithms which can generate optimal plans by applying strategies and can play a critical role in conducting further API composition which follows a graph-based approach. Reference [
20] presented the Linked Web APIs dataset which supports API consumers and API Provider in the process of discovery, selection and use of Web APIs. Spread sheet approach [
21,
22] is another UI approach which aims to provide a spreadsheet-like view to mash up the data and is becoming popular because most of the ordinary users are familiar with spread sheet. The RESTful architectural model is helpful for widget development for mashup purpose because of its nature of portability, scalability and multi-platform support [
5]. Reference [
23] presented process data widget approach to assist designers by configuring RESTful services but this is also not suitable for ordinary user because ordinary user can not define his requirement in terms of web services. Service oriented approaches [
24,
25] involve selection and composition of various services made available by MSP/DSP to the end user. Because of increasing popularity and demands of cloud computing, cloud mashup service approaches [
24] are also being experimented to promote Mashup as a Service (MaaS)/Data as a Service (DaaS). In database driven approach, reference [
26] proposed the service data model for adaptation of heterogeneous web services, the service relation model for representation and refinement of data interaction between services, and the service process graph for describing business logics of mashup applications. Another approach is the linked data mashup approach [
27,
28] which uses semantic web technology based on linked data for combining, aggregating, and transforming data from heterogeneous data resources to build linked data mashups.
The followings are the major challenges found during study on the data mashup.
2.1. Involvement of Stakeholders
Ordinary users are the actual targeted users of the mashup hence their involvement cannot be avoided. In mashup applications, users are given freedom to fetch data from multiple data sources and to perform the data mashup at one digital place, most preferably their personal page/desktop or mobile application. In order to provide the data to its users, data sources should have service interfaces and user-friendly access mechanism so that even an ordinary user can use it. Generally, MSP does not own the user’s data but provides mashup services or tools to its users to mashup the data at their end. Based on various skills, reference [
21] divided mashup users into three categories namely developer, power user and casual user. The developer should be familiar with web technologies and programming, power user has no programming skills but has functional knowledge of specific tools but casual user or ordinary user should have the skills to use the web browser only. Our work is completely concerned with casual user or ordinary user. Reference [
29] discussed the mashup ecosystems consisting of mashup authors, service providers and mashup users. Thus, mashup has three major stakeholders called Mashup Service Provider (MSP), Data Service Provider (DSP) and Ordinary User (OU). While performing the mashup, the ordinary users generally face problems like high learning curve of the tools, expectation of some technical skills from end user, dependency on mashup developers for processing of mashup and approaches, the reliability of services and lack of user-friendly mechanism of searching the correct data sources, etc. Involvement of MSPs as intermediate between actual end users and DSPs always raise issues such as disclosure of private data and their security, which have been mentioned in
Section 2.3. Involvement of end users and DSPs are compulsory in data mashup but the involvement of MSP is optional.
2.2. Searching the Right MSP/DSP
Data services as well as mashup services, are increasing day by day and their users too. Due to an exponential growth of the services, searching the right MSP/DSP is becoming the challenging task for users. Each MSP/DSP publishes one or more services and thus searching the appropriate service of that MSP/DSP again is tedious and time consuming. Reference [
3] designed and implemented lightweight services mashup platform for service creations by ordinary user without expecting specific computing knowledge. Reference [
30] recommended the framework for data service mashup, based on several mashup patterns and the corresponding recommendation method. Reference [
31] proposed a novel framework for service discovery which exploits social media information and different methods to measure social factors with weight learning algorithm to learn an optimal combination of the measured social factors. Reference [
32] proposed a novel category-aware service clustering and distributed recommending method for automatic mashup creation and developed a category-aware distributed service recommendation model, which is based on a distributed machine learning framework.
Reference [
33] explored API recommendation for mashups in the reusable composition context with the goal of helping developers to identify the most appropriate APIs for their composition tasks and proposed a probabilistic matrix factorization approach to solve the recommendation problem and enhance the recommendation diversity. Reference [
24] suggested the MapReduce in skyline query processing for optimizing composite web services in large scale cloud mashup applications and proposed a block-elimination-based partitioning approach to shorten the process. Reference [
34] proposed a service-oriented approach to generate and manage mashups and also developed the mashup services system to support users to create, use, and manage mashups with little or no programming effort. All these approaches were developed for service discovery for creating the mashup but cover only one aspect of the whole life cycle of the mashup development and suitable for MSP/EUD but not for ordinary users because of some learning expectation and the complexity. Searching the mashup or data services can be automatic, manual or semi-automatic. The method for searching of the MSP/DSP and then selecting appropriate service is assumed to be manual in the current work. There is no need of searching the DSP when a user would like to mashup his own private data because its source is already known to him but it still requires selection of the right data service among all the services available at DSP. In case of public data mashup, users are required to search the right MSP/DSP and select the appropriate service thereafter.
2.3. Data Privacy and Security
The data mashup involves ordinary user as well as mashup service providers hence data privacy and security has become the major concern of the researchers and the industries. Fung et al. [
35] proposed service-oriented architecture to resolve privacy problem in real life mashup applications. According to it, there is always chance of revealing sensitive data of a user when third party MSP is involved in data mashup. According to [
36], REST is an abstract model for designing large-scale distributed systems and can be adopted with suitable technologies of any kind, such as HTTP, CoAP, or RACS, to build highly scalable service systems such as the web, IoT, SOA, or cloud applications.
Reference [
37] developed an ID-based authentication algorithm to achieve a secure RESTful web service using Boneh–Franklin ID-based encryption and REST URI which enables server to handle client’s request by acknowledging client’s URI rather than storing client’s entire status for stateless REST. Reference [
38] proposed an extended UsernameToken-based approach for REST-style web service by adding UsernameToken and secondary password into the HTTP header which makes current security aspect of REST-style web services more secured. According to [
39], instead of choosing SOAP, the service providers nowadays are shifting to REST-based services but the same time it is vulnerable to security. In our work, we have used the concept of transactions of mashup keys and uniquely identified private Mashup Configuration Service Identifier (MCSI) and private Mashup Data Service Identifier (MDSI) for private data mashup to make the mashup communication secured (See
Section 5.10).
2.4. Data Refreshing
Data mashup not only fetches the data from multiple data sources but also facilitate the end user to integrate and view mashed up data in a single screen. Data to be mashed up are fetched instantly by end users from MSP and DSP to get refreshed data, every time they visit their own mashed up page/screen. According to [
40], the refresh rate of the data made available to the user, depends on pull or push strategies used for data mashup. Based on the pull/push strategies of request-response pattern [
41,
42], the data mashup can be divided into two types, i.e., Pull Data Mashup and Push Data Mashup. In pull data mashup, the data are fetched by end user on each and every request sent to MSP/DSP hence refresh rate of mashed up data is high and it may also be called live data mashup. However, in push data mashup, data are sent by MSP/DSP to end user, whenever there are some updates on it. The refresh rate of push data mashup is not as high as pull data mashup but it consumes fewer bytes of the network traffic as compared to pull data mashup. The data mashup approach used in the proposed work is based on pull data mashup which is highly recommended for public data mashup but it can also be implemented for push data mashup. The public data mashup and private data mashup are two different types of data mashup which can be discriminated by their nature of data accessibility.
2.5. Data Mapping
Data mapping is the process needed to identify the correspondences between the elements of the source data model and the internal data model [
43]. Reference [
44] discussed general data mapping problem, which addresses two related data exchange scenarios. Like other steps of mashup development, the data mapping can also be manual, semi-automatic or automatic. Reference [
45] presented the schema, data and query mapping algorithms for storing xml into relational database. Reference [
46] proposed method to solve schema mapping and data mapping both using mutual enhancement mechanism and also described how prior knowledge of the schema mapping reduce the complexity for the comparison between two data attributes. In data mashup, every stakeholder (OU/MSP/DSP) should be independent to develop its own internal data schema and hence data mapping has become the most important task while developing the data mashup. There is a need of strategies to specify the correspondences between their internal data model and the desired data sources [
40]. Each stakeholder defines not only the different attributes but also different data types and their formats independently which makes it more challenging while data mapping. In our proposed work, SDXMapping algorithm (See
Section 5.9) has been successfully developed for performing data mapping between the data models of any two stakeholders of data mashup. SDXMapping works as a bridge between them and allows to create data mapping based on the semantical meaning of the attributes.
2.6. Standard Communication Protocol
Mashup communication is an important process to complete the life cycle of the data mashup development. Data mashup techniques cannot be generalized and secured until the standard communication protocol is commonly used. The proposed work uses the standard REST protocol for communication purpose but other standard protocols like SMTP, HTTP etc. can also be used for data mashup. References [
47,
48,
49] discussed the use of REST/web services for data fetching, integration and composition of data mashup and services. According to [
47], REST has features of light weight, scalability, multiple data format support, superior performance and popularity which have made it a better approach for web service composition and communication. Reference [
48] focused on the need of service composition using REST and discussed six composition issues like coordination, transaction, context, conversation modeling, execution monitoring and infrastructure. Reference [
49] presented overview of the life cycle of web services composition and also discussed standards, research prototypes, and platforms with several research opportunities and challenges for web services composition.
2.7. Data Accessibility
Data accessibility has been the major concern for all its stakeholders. MSPs/DSPs publish their services for accessibility of public data and private data separately. Data resides in multiple and heterogeneous data sources are accessed using web APIs, REST, SOAP, HTTP and XML RPC techniques, RSS Feeds, Atom Feeds, SOAP Services, Restful Web Services, JSON, CSV, Web Page and Annotated Web Pages etc. [
1,
8]. In our proposed work, the Mashup Configuration Service Identifier (MCSI) and Mashup Data Service Identifier (MDSI) (See
Section 5.1,
Section 5.2 and
Section 5.10) have to be accessed for pre-mashup configuration before performing the actual data mashup. In private data mashup, MCSI and MDSI are accessible to only authorized users, which make it more secured.
5. Structured Data Rest Protocol
This section describes model and architecture of the proposed protocol along with algorithms required to develop end to end data mashup.
5.1. The Model of Proposed SDRest Protocol
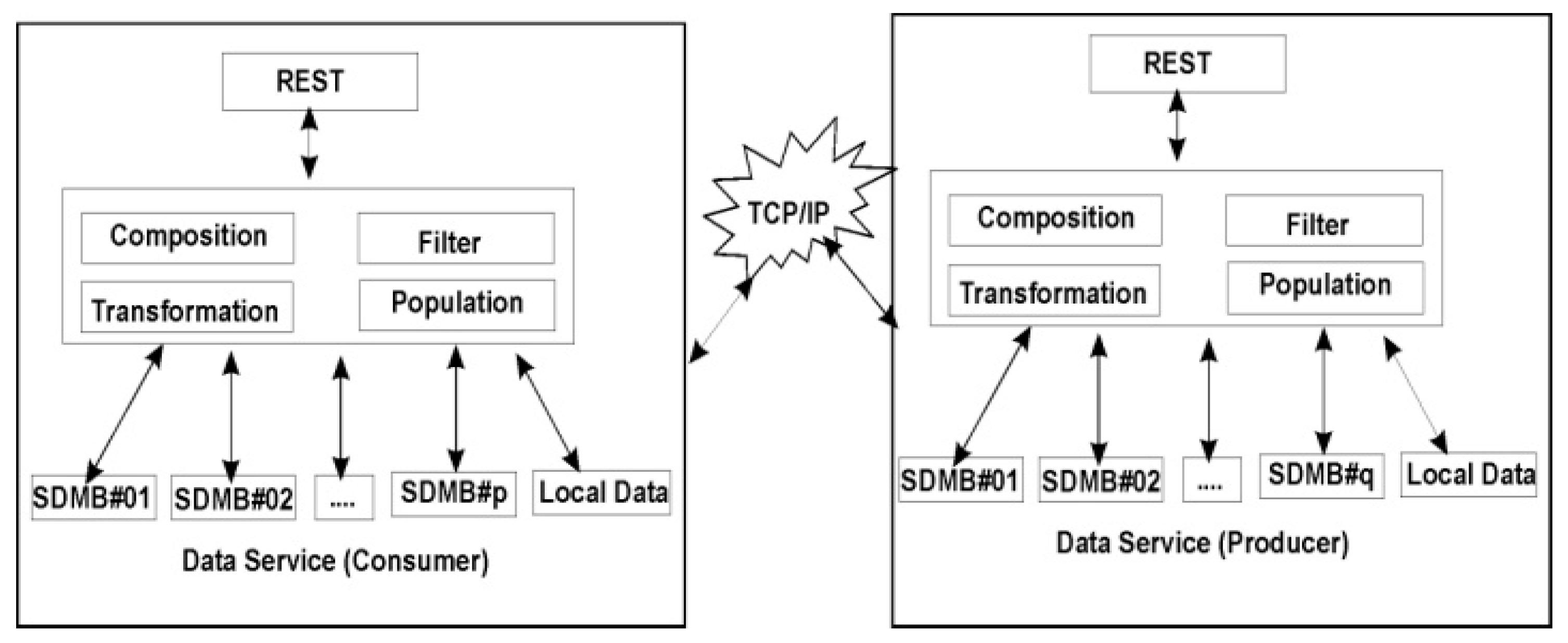
The model of the proposed protocol called Structured Data REST Protocol (SDRest) has been shown in
Figure 2 which is the extension of existing REpresentational State Transfer [
5] (REST) protocol for end to end data mashup. Here, the term “end to end data mashup” implies performing the data mashup directly between any two stakeholders (EU, MSP and DSP).
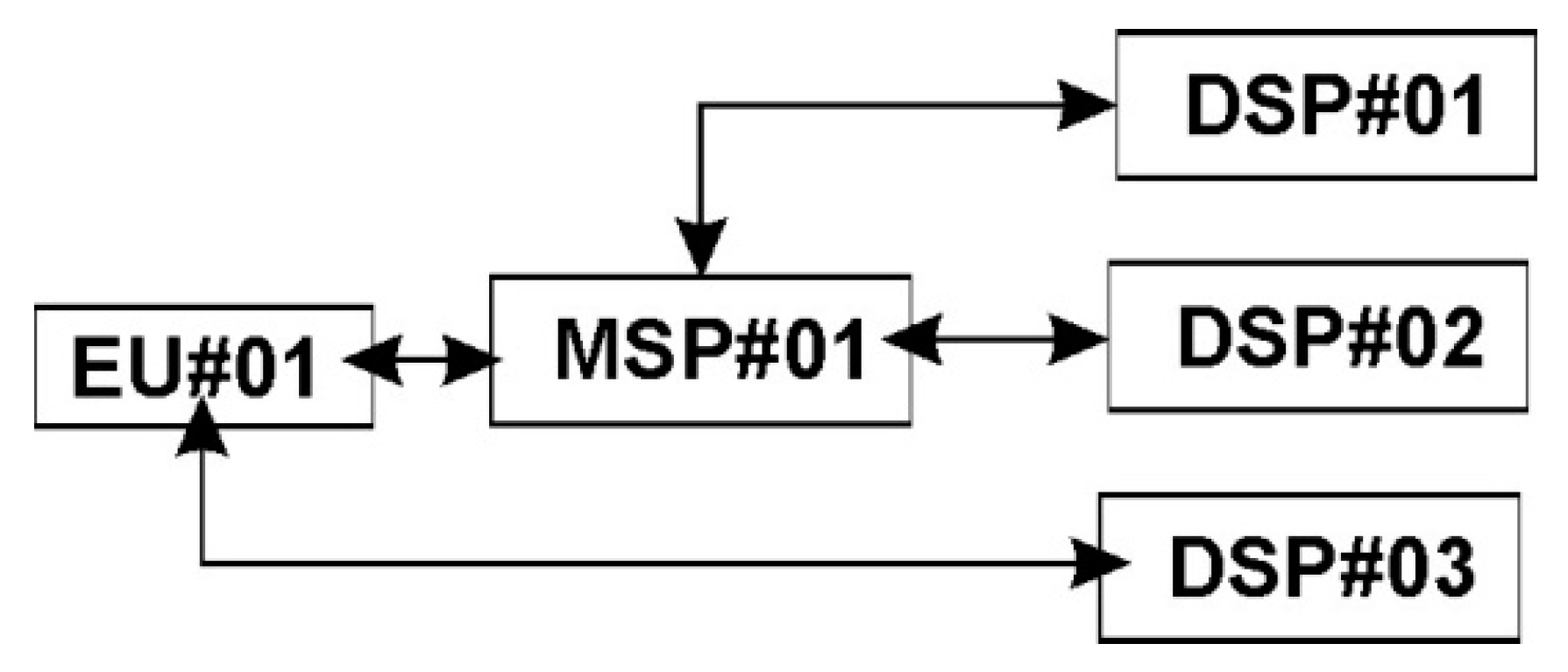
The SDRest protocol has two entities called Data Service Producer/Provider (DSP) and Data Service Consumer (DSC). DSP will produce structured data which would be consumed by DSC using the proposed SDRest protocol. In our proposed work, the entity which takes services of MSP or DSP would be called DSC and entity which provides data services to DSC would be called DSP. Thus, end user or MSP may play the role of DSC and MSP/DSP may play the role of DSP. In
Figure 1, EU#01 is DSC for MSP#01 and DSP#03 both and MSP#01 is further DSC for DSP#01 and DSP#02. The DSP is required to publish the data services through Mashup Data Service Identifier (MDSI) so that DSC can access the data in the structured format using standard REST protocol. Mashup Data Service Identifier (MDSI) is the unique REST URI used by DSC to fetch the required data from DSP. The major contribution in this model is introducing the concept of one or more Structured Data Mashup Box (SDMB) which would be used by Data Service Consumer (DSC) to view, store or forward required mashed up data.
The data service consumer as end user will use Structured Data Mashup Box (SDMB) to store and view the required mashed up data whereas data service consumer as MSP will perform mashup on the data received from various DSPs/MSPs and forward it to respective data service consumer. Further, the group of SDMBs called End User Data Mashup (EUDM) would be explored by end user to see the integrated UI view of mashed up data (fetched from multiple MSPs/DSPs) in a single screen which is the main objective of the proposed work. According to our proposed model, DSC (the REST client) will read all the Structured Data Records (SDRs) made available by DSP through Mashup Data Service Identifier (MDSI) and filter component will parse each SDR to check whether it is a valid SDR or not. Transformation component will transform each valid SDR into proper format so that it can be populated into Structured Data Mashup Box. The structured data records, which are successfully populated into SDMB would be called Mashed up Data Records (MDRs).
Valid SDR would be transformed and populated into appropriate SDMB at DSC’s end using proposed algorithm (See
Section 5.15) whereas invalid SDRs would be ignored. Cloud computing paradigm called Structured Data as Service (SDaaS) or Mashup Data Service (MDS) at MSP’s/DSP’s end will generate (compose) one or more structured data records and publish them so that they can be accessed by DSCs for data mashup. Each publication of MSP/DSP would be identified by mashup data service identifier. It can be seen from
Figure 2 that there are p SDMBs at DSC’s end and q SDMBs at DSP’s end. Here, p and q may or may not be equal to each other and SDMB at DSP’s end is optional but SDMB at DSC’s end is compulsory to implement this protocol. Following section describes the system architecture and the working of this model in detail.
5.2. SDRest System Architecture
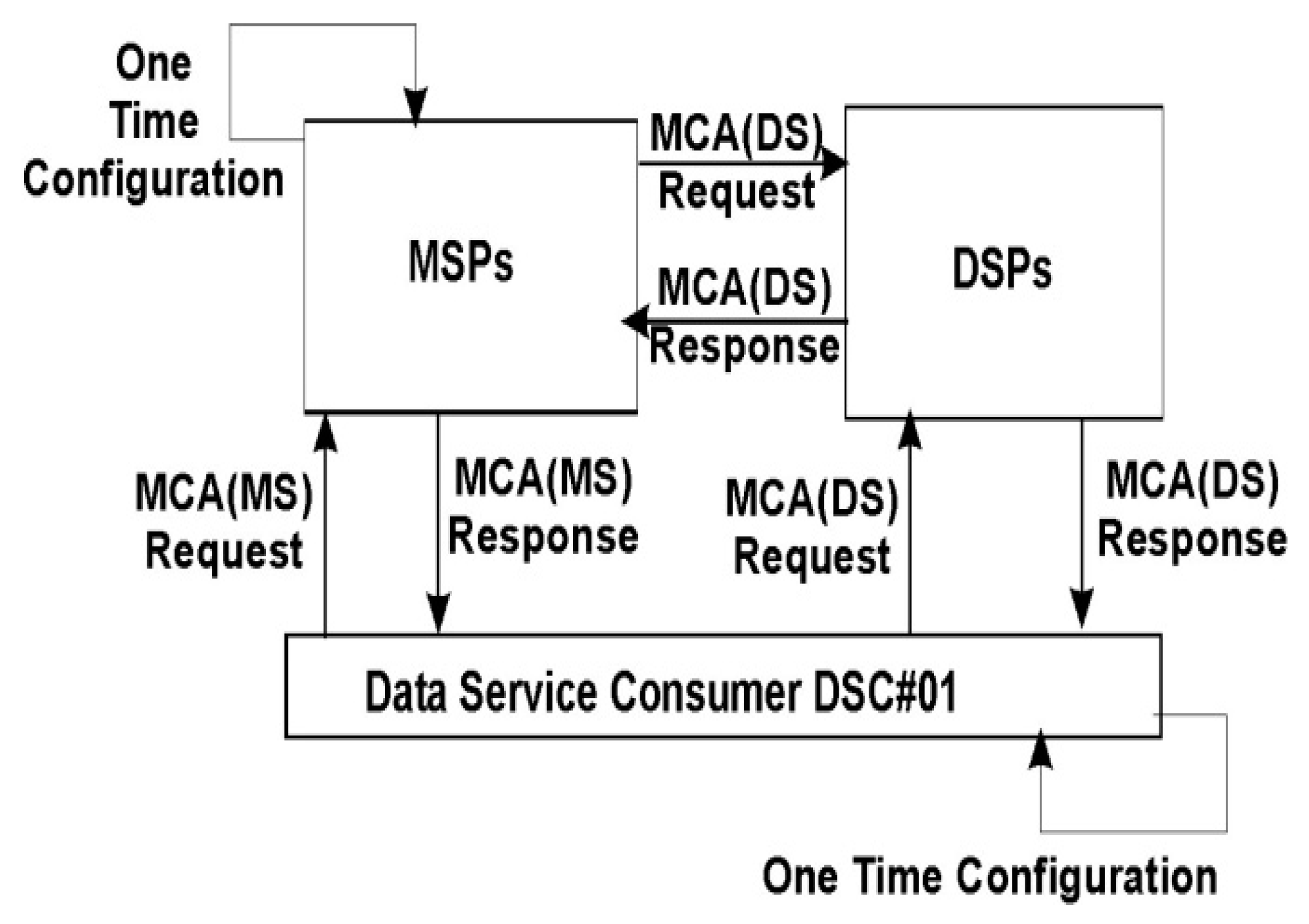
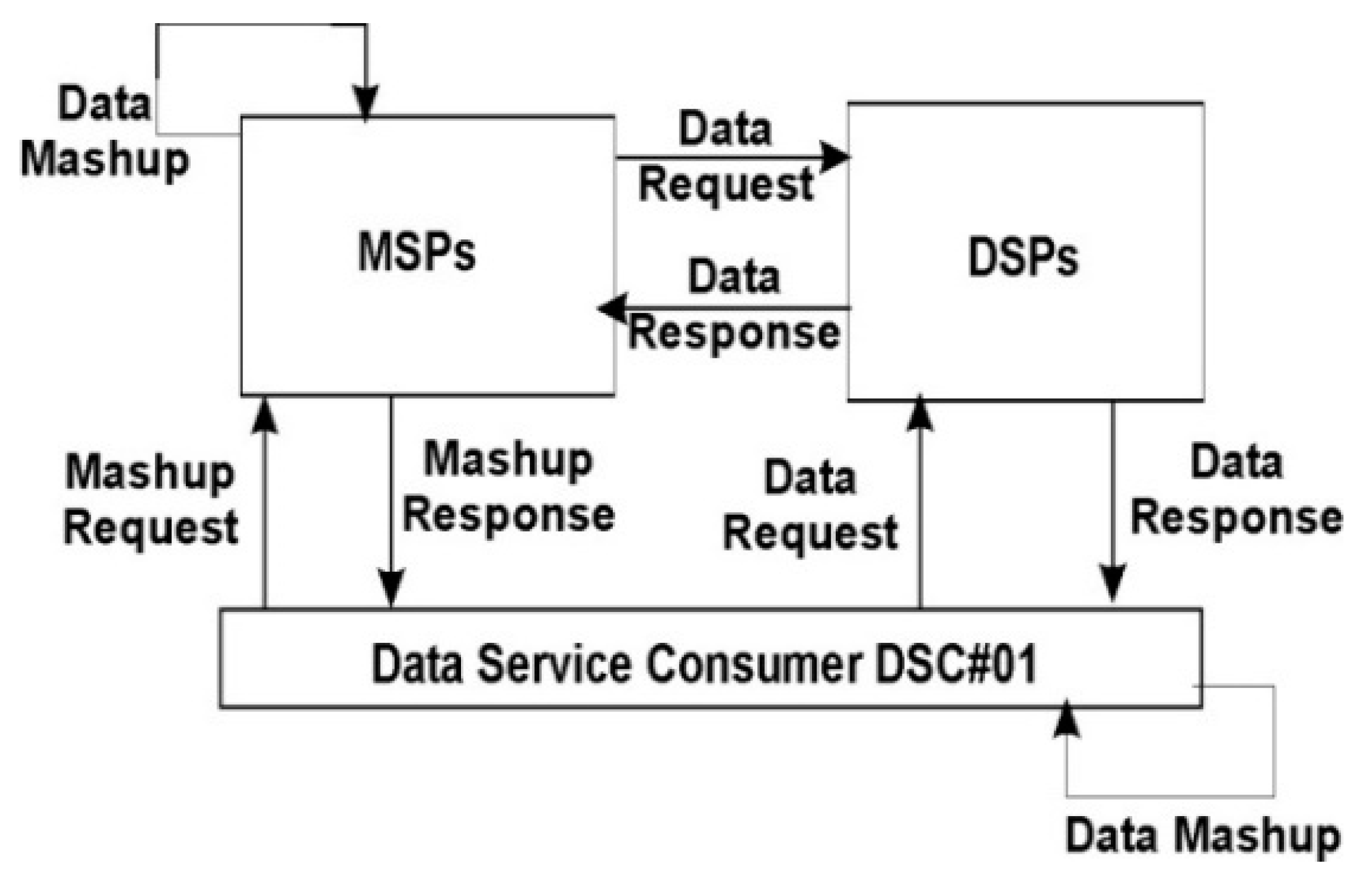
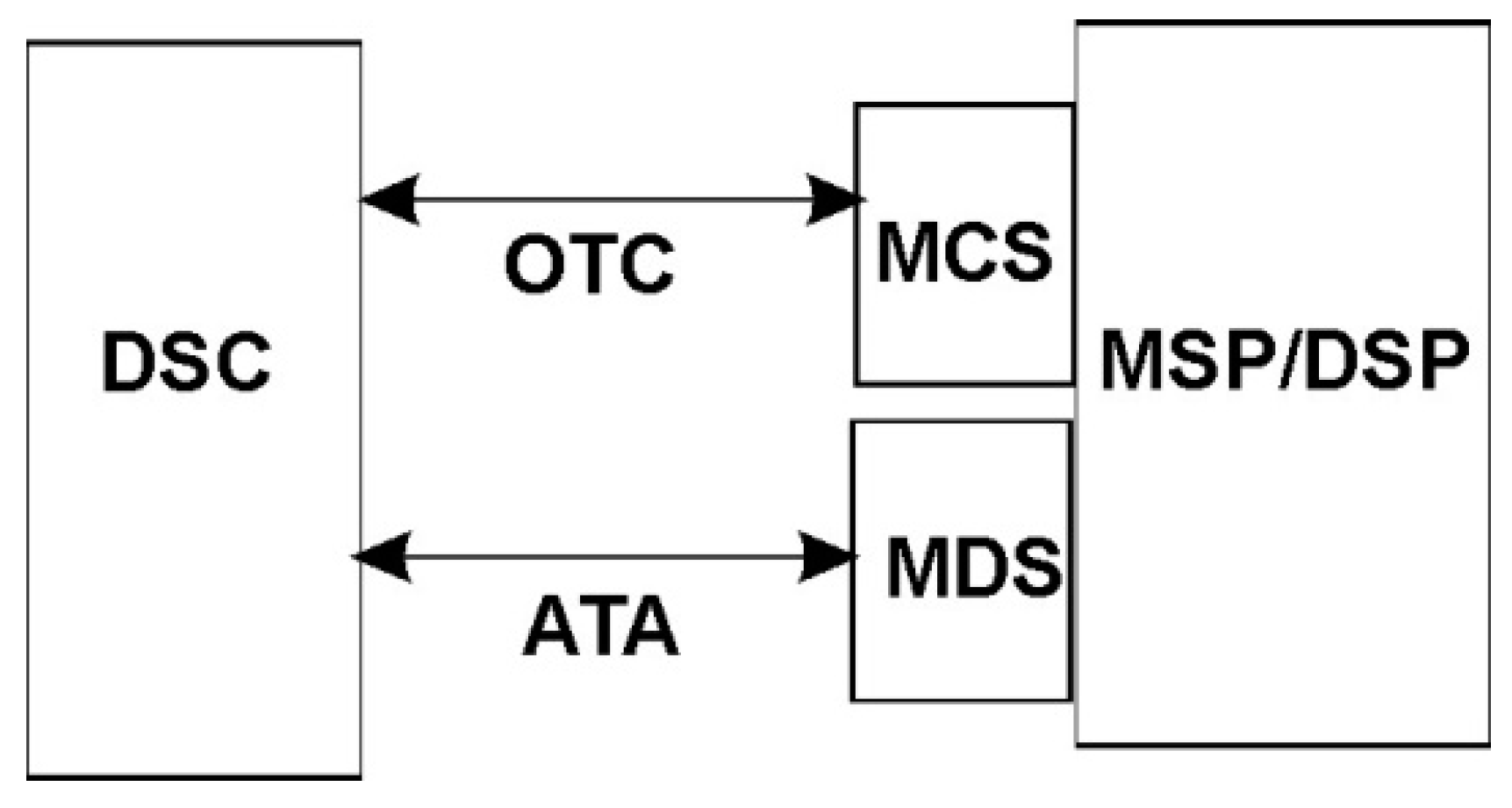
The system architecture of the proposed SDRest protocol is based on One Time Configuration-Any Time Access (OTC-ATA) model. The SDRest system architectures based on OTC and ATA models are shown in
Figure 3 and
Figure 4 respectively.
In OTC model, every user who needs mashed up data at his defined digital address (web page/desktop client etc.) searches for appropriate MSP/DSP to collect Mashup Configuration Attributes (MCA) made available through Mashup Configuration Service Identifier (MCSI). MCSI is the unique identification of REST URI available at MSP/DSP which provides mashup configuration attributes on DSC’s request. Mashup Configuration Attributes (MCA) is the set of attributes required to perform one-time configuration of DSC at its end so that later on, data can be fetched from MSP/DSP for the purpose of data mashup. DSC collects mashup configuration attributes of Mashup Services (MS) from MSP and collects mashup configuration attributes of Data Services (DS) from DSP. Accessing the mashup configuration service identifier by DSC can be manual or automatic. In manual approach, the user needs to visit each and every mashup service configuration identifier as per his requirement and use the MCA (Mashup Configuration Attributes) once only to create Structured Data eXchange (SDX) mapping (See
Section 5.7,
Section 5.8 and
Section 5.9).
In automatic approach, DSC calls mashup configuration service identifier i.e., REST URI, which returns MCA as a response. This mashup configuration attributes should be in well-structured data format i.e., JSON, XML, CSV etc. The SDXMapping algorithm developed for DSC helps the user to create Structured Data eXchange (SDX). The processing of the mashup configuration attributes to create Structured Data eXchange (SDX) is performed by DSC once only and later on, used to access MSP’s/DSP’s data for performing data mashup. It is clear from
Figure 3 that DSC#01 requests for MCA(MS) from MSP and MCA(DS) from DSP which return mashup configuration attributes as a response for performing one time configuration which resulted into creation of SDX Mapping so that mashup can be performed any time by DSC#01. All MSPs are also required to perform one time configuration for each and every DSP as per their service needs before providing mashup services to its users. After performing OTC for each and every MSP/DSP, data service consumer is ready to perform data mashup by sending data request any time to MSPs/DSPs through mashup data service identifier.
It can be seen from
Figure 4 that DSC#01 sends mashup request to MSPs and data request to DSPs and performs data mashup after getting mashup response and data response from them. All MSPs also send the data request to DSPs and perform data mashup on receiving data response from them. When a DSC sends mashup request to MSP then MSP further sends the data request to respective DSPs and resultant data response received by MSP are mashed up and are sent back to DSC as a mashup response. Let us understand how major stakeholders (EU, MSP and DSP) of data mashup, communicate with each other.
The diagram as shown in
Figure 5 has three types of stakeholders i.e., end users, MSPs and DSPs. Each user will define his requirement of data mashup by creating one or more SDMBs as per his data need. Similarly, each MSP will also create one or more SDMBs as per the service need. DSPs need not have SDMBs but should have Mashup Data Service Identifier (MDSI) to provide structured data to its clients. It is clear from
Figure 5 that the user can access mashed up data from MSPs and MSPs can further communicate with other MSPs/DSPs to access required data. The user can also directly communicate with DSPs to fetch the required data and then perform mashup at his end.
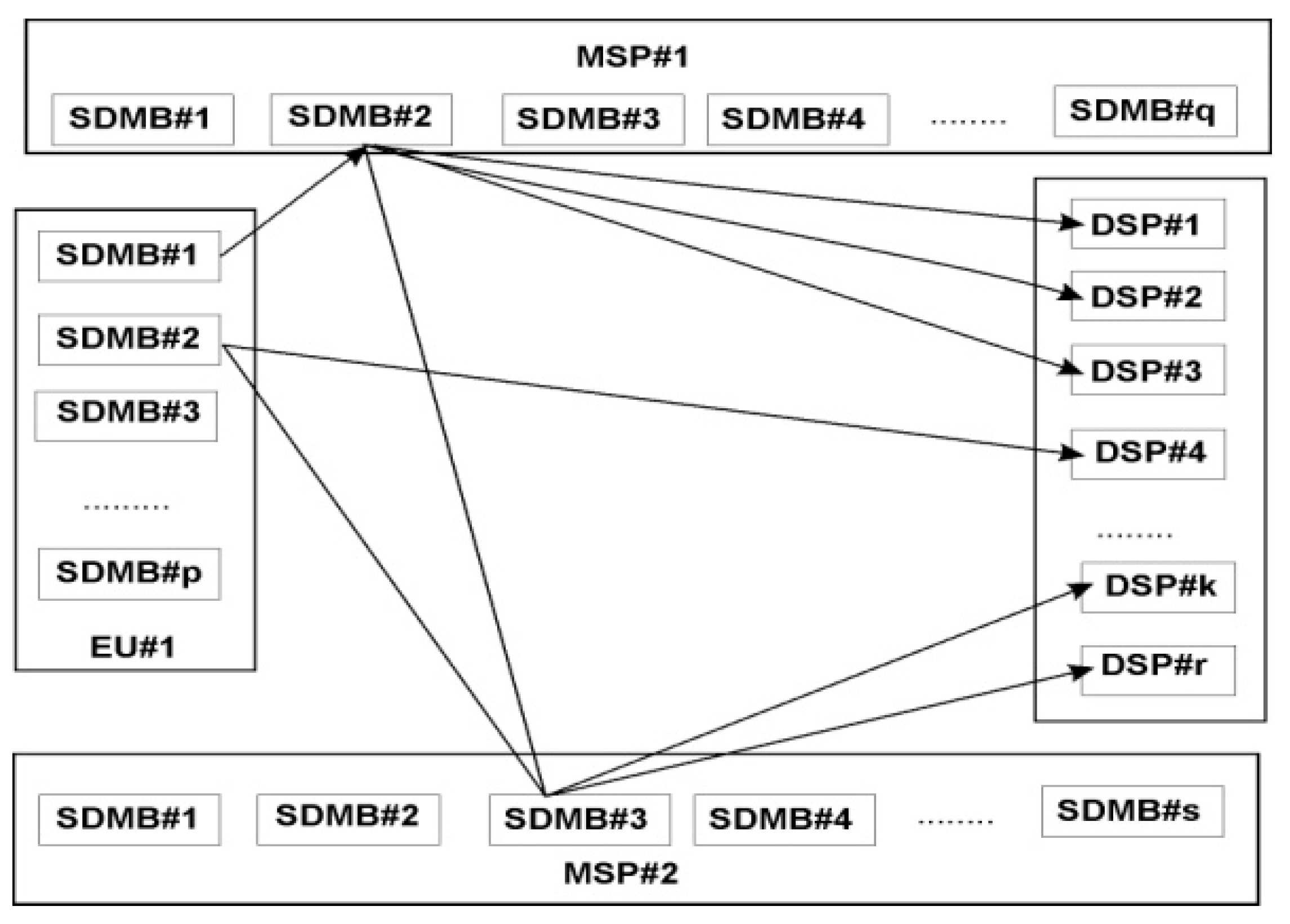
Table 1 depicts the role of DSC, MSP and DSP for various mashup communications as shown in
Figure 5. SDMB#1 of EU#1 is taking mashup services of MSP#1(SDMB#2). MSP#1(SDMB#2) is further taking mashup services of MSP#2(SDMB#3) and also taking the data services of DSP#1, DSP#2 and DSP#3. MSP#2(SDMB#3) is not connected with any mashup service but taking data services of DSP#k and DSP#r. SDMB#2 of EU#1 is connected with MSP#2(SDMB#3) and directly to DSP#4. All the stakeholders are free to connect to any MSP or DSP but there could be the problem of multi-path data mashup resulting into redundant data mashup if services are not carefully chosen. The minimum requirement of this architecture is that each user should have SDMB, OTC and REST enabled machine to communicate with the REST services of DSPs/MSPs.
One Time Configuration-Any Time Access Model
OTC-ATA model as shown in
Figure 6 follows OTC-ATA communication between Data Service Consumer (DSC) and MSP/DSP. In order to perform complete life cycle of data mashup, DSC first sends One Time Configuration (OTC) request to Mashup Configuration Service (MCS) available at MSP/DSP to get mashup configuration attributes before fetching required data for the mashup. After the completion of OTC, DSC can access mashed up data at any time by calling Mashup Data Service (MDS) available at respective MSP/DSP.
Let us understand how OTC-ATA model works in the proposed system architecture. The steps required to perform data mashup in OTC-ATA model are described below. Each step is either manual or automatic which needs to be performed either once or at any time.
Step-1(Manual-Once): DSC(EU/MSP) defines its data requirement using the schema called Data Mashup Definition (DMD) for mashing up structured data (See
Section 5.3).
Step-2(Manual-Once): DSC creates a logical entity called Structured Data Mashup Box (SDMB) to store Mashed up Data Records (MDRs) based on the schema called data mashup definition as defined in step-1 (See
Section 5.4 and
Section 5.5).
Step-3(Manual-Once): DSC defines the association between structured data mashup box and data mashup definition (See
Section 5.6).
Creating DMD, SDMB and association between them as mentioned in Step-1, 2 and 3 include simple manual GUI operations like filling data in the table of a web form, word processor, worksheet or database client tools etc.
Step-4(Manual-Once): DSC searches for right MSP/DSP as per its need and thereafter selects the appropriate mashup configuration service identifier available at MSP/DSP. This step is manual and needs to be performed once only.
Step-5(Manual-Once): DSC performs one time configuration after fetching Mashup Configuration Attributes (MCA) from MSP/DSP through mashup configuration service identifier. Upon receiving MCA, EU/MSP configures the mapping between SDMB attributes and MCAttributes, which results in the creation of Structured Data eXchange (SDX) and the association between structured data mashup box and mashup data service (See
Section 5.7,
Section 5.8,
Section 5.9,
Section 5.10 and
Section 5.11).
Step-6(Manual-Any Time): After completion of one time configuration by DSC for various mashup configuration service identifiers provided by MSPs/DSPs, data mashup can be performed any time by accessing data through mashup data service identifier. When a user clicks on any of the SDMB to view mashed up data then DSC automatically calls mashup data service identifier of MSPs/DSPs which were configured at the time of OTC (See
Section 5.12).
Step-7(Automatic-Any Time): MSPs return mashed up data as a response and DSPs return normal structured data (without mashup) as a response whenever their services (MDSIs) are called by DSC. The data received from MSP/DSP would be validated and transformed into the proper format before populating into SDMBs at DSC’s end (See
Section 5.13,
Section 5.14 and
Section 5.15).
One time configuration mentioned in Step-5 is manual but is as simple as solving the “Match Column Problems”. Step 6 is manual but is as simple as clicking the mouse.
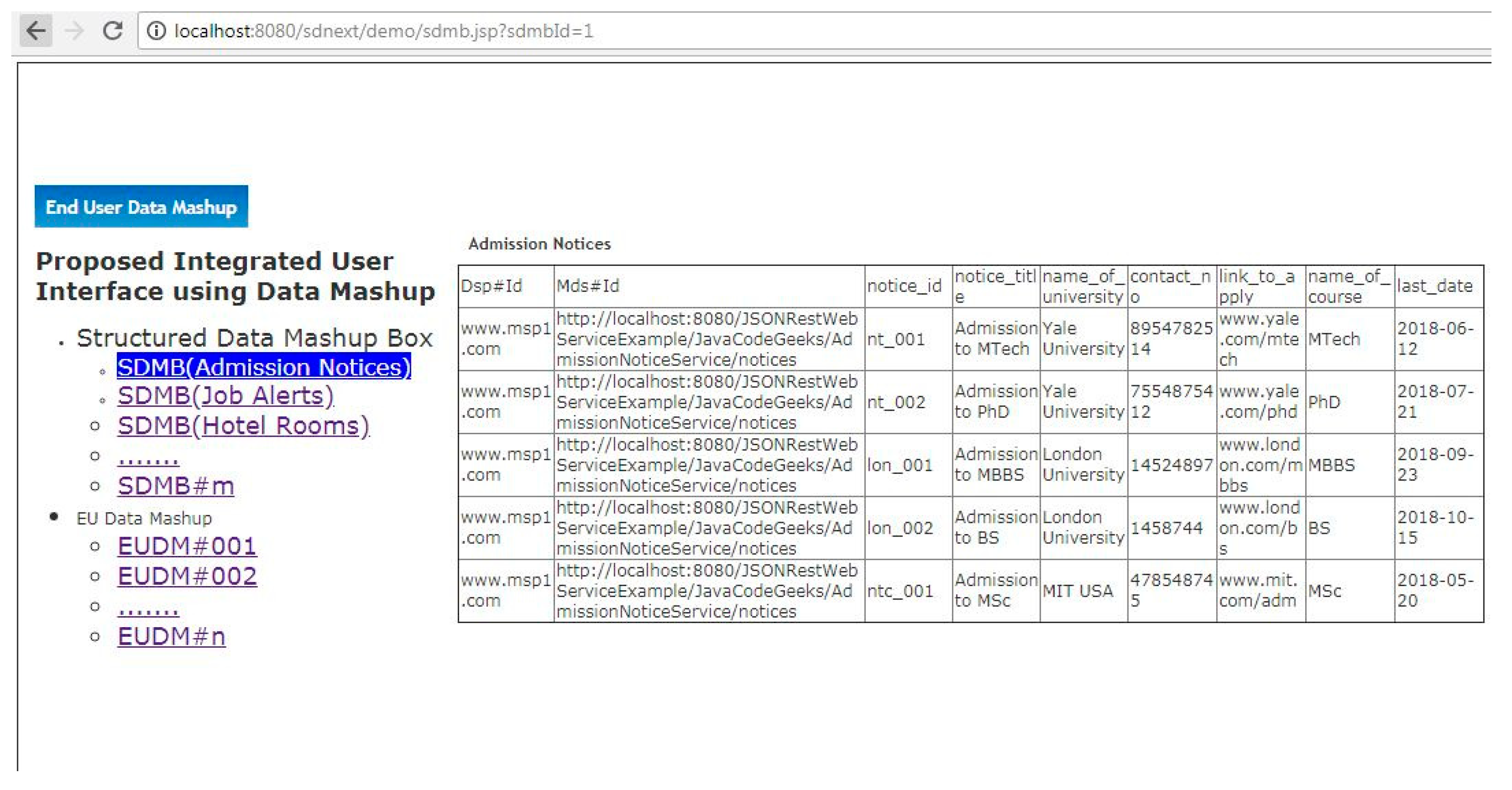
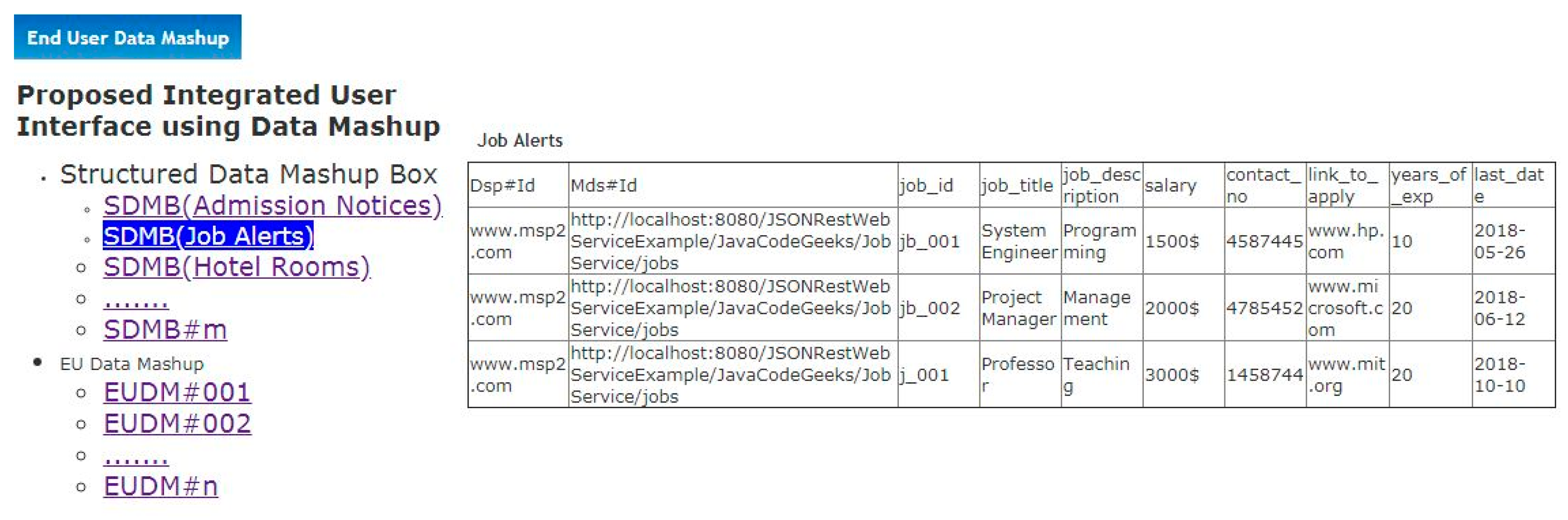
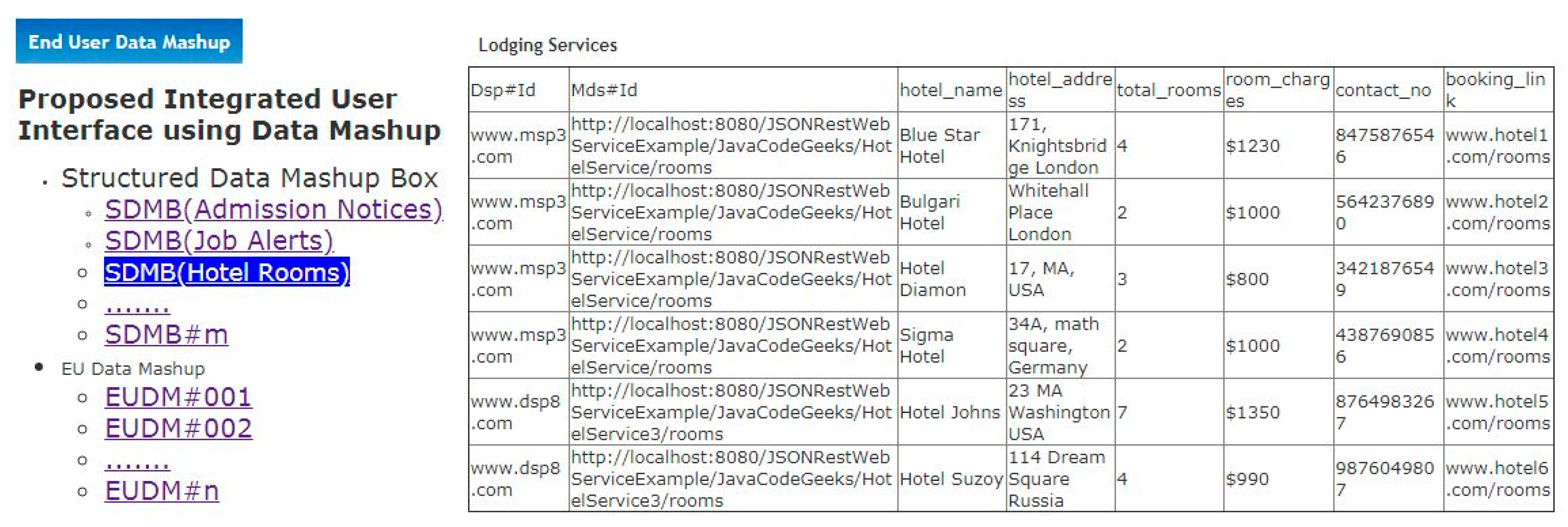
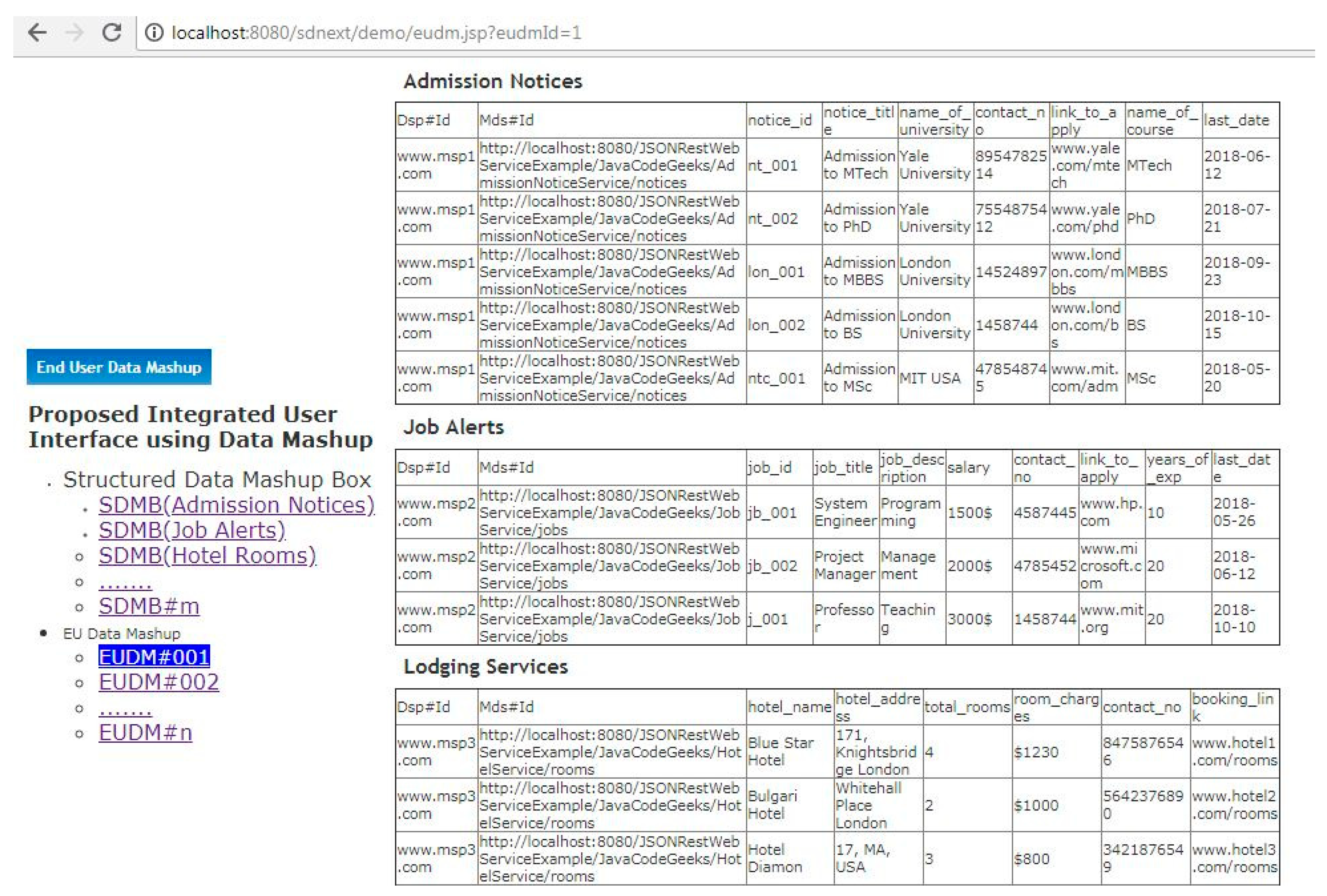
Step-8(Manual-Any Time): A user can view mashed up data of each SDMB by just clicking on it and can also make the group of two or more SDMBs to create End User Data Mashup (EUDM). EUDM can be explored by a user by clicking on it to open single mashed up screen which contains the integrated UI views of multiple SMDBs. This step is the final output of the proposed work (See
Section 6.1 and
Section 6.2).
Let us understand details of above Steps 1 to 8 in the following sections.
5.3. Data Mashup Definition (DMD)
Defining the requirement of the data by an ordinary user is really challenging because it cannot be fixed in advance. The requirement of users has been defined in various ways such as service composition [
40], document specification [
23], scripts [
8], plans [
13] etc. in the past. In this proposed work, we are introducing simple approach of defining data requirement which are called Data Mashup Definition (DMD) and Structured Data Mashup Box (SDMB). DSCs are required to define the configuration of each SDMB before mashing up the desired structured data in it. This definition is called Data Mashup Definition (DMD) and is the way of defining requirement of data by DSC. Thus, DMD is defined as the collection of metadata and the relation of attributes defined by DSC for filtering, transforming and populating the Structured Data Module (SDM) received from MSP/DSP into various Structured Data Mashup Boxes (SDMBs).
Following
Table 2 describes attributes of the Data Mashup Definition (DMD) created by DSC. Here, x
ij represents jth attribute of ith DMD. DSC can define any number of DMDs as per its need. Thus, Data Mashup Definition (DMD) can be defined as
Here,
Table 2 shows n DMDs, each with the different number of attributes. It should be noted that k, l, j, s etc. show the total number of attributes defined in the DMDs #1, #2, #i…#n respectively. The value of k, l, j, s etc. may or may not be equal to each other. The scope of this paper is limited to the number and name of attributes of the DMD. The data schema (data types and formats) of these attributes has not been covered in this paper. By default, all the data items are considered as text/string for implementation purpose. After defining DMD, DSC will create SDMB as explained in the next section.
5.4. Structured Data Mashup Box (SDMB)
Structured Data Mashup Box (SDMB) is the logical entity which contains the mashed-up data, defined by DSCs at their end under the schema called Data Mashup Definition (DMD) and has been introduced to store and/or to forward the mashed up data. According to
Figure 2, DSC contains one or more SDMBs along with local data. DSC has the filter, transformation and population components so that structured data module received from MSP/DSP can be filtered, transformed into the proper format and populated into appropriate SDMB. Generally, the user will use SDMB for storing and viewing mashed up data but MSP will use the SDMB to perform data mashup and forward them to respective DSCs to support the live (instant) data mashup. There could be any number of SDMBs as per requirement of DSC. Let us understand the composition of SDMB in the next section.
5.5. Composition of SDMB and MDRs
5.5.1. SDMB Composition
Each DSC receives Structured Data Module (SDM) through mashup data service identifier from MSP/DSP and uses SDMB to store and/or forward mashed up data. Structured Data Module (SDM) is the collection of Structured Data Records (SDRs) in the standard format like XML, JSON or CSV etc. Each SDR is filtered and transformed into DSC’s defined Mashup Data Record (MDR) and is stored in SDMB using the proposed algorithms (See
Section 5.15). Thus, SDMB is the collection of unique Sdmb#Id, Sdm#Id, Msp#Id/Dsp#Id, Mds#Id and one or more MDRs.
Sdmb#Id is generated when DSC creates new SDMB. Mds#Id is contained in MCAttributes received via mashup configuration service identifier. Msp#Id and Dsp#Id are nothing but URLs of MSP and DSP respectively. Mds#Id is the unique id of mashup data service identifier through which structured data module would be made available at MSP’s/DSP’s end.
5.5.2. Mashup Data Records (MDRs)
MDRs are the collection of one or more mashup data record stored in SDMB. Structured data (unmashed) is provided by DSP whereas structured data (mashed up) is provided by MSP. The record provided by MSP/DSP is called Structured Data Record (SDR) but when it is populated into SDMB then it is called Mashup Data Record (MDR). SDR of each structured data module is transformed into DSC’s MDR by applying the SDXMapping algorithm. Each MDR consists of unique Mdr#Id and MDR values. Thus, it can be defined as follows:
5.5.3. MDRAttributes and MDRValues
MDRAttributes are the collection of attributes of mashup data record. MDRValues are the collection of one or more Name-Value (N-V) pairs. Thus,
where x
1, x
2, x
3…x
n are the name of attributes defined by DSC using Dmd#Id which is further associated with Sdmb#Id. The symbol “?” shows the value of the attribute which has to be extracted from structured data module by applying filter and transformation algorithm at DSC’s end. The next step is to establish the association between structured data mashup box and data mashup definition.
5.6. SDMB-DMD Association
After defining Data Mashup Definition (DMD) and creation of SDMB, an association should be established between them. Each SDMB is associated with one DMD but the reverse is not true (i.e., one DMD may be associated with more than one SDMB).
Thus, association between SDMB and DMD would be defined as:
For example, association
show that attributes of Sdmb#01 are defined by Dmd#i and attributes of Sdmb#02 are defined by Dmd#k. It can be observed here that DSC defines its requirement in terms of DMD, SDMB and association between them. After defining data requirement for mashup, DSC is required to fetch mashup configuration attributes from MSP/DSP for one time configuration which has been explained in the next section.
5.7. One Time Configuration (OTC) Algorithm
After determining the right MSP/DSP, DSC is required to get Mashup Configuration Attributes (MCA) by calling mashup configuration service identifier of those MSPs/DSPs. The MCA is the set of attributes required to configure DSC so as to perform the data mashup later on, as and when needed. This is the one time process and can be performed manually or through the pre-defined algorithm. MSP/DSP provides structured data through cloud computing feature like Structured Data as a Service (SDaaS). Thus, MCA is nothing but the container of data and service attributes and can be identified by Mashup Configuration Service Id i.e., MCS#Id. In order to get mashup configuration attributes, DSC should know MCS#Id of the service provided by MSP/DSP. The mashup configuration service of MSP/DSP will return MCA as a response to DSC. It should also be noted that SDMB should be created and associated with DMD before configuring DSC client.
Table 3 shows mashup configuration service and their attributes published by various MSPs/DSPs.
Thus, Mashup Configuration Service (MCS) can be defined as:
For example, MCS = (www.p.com, Mcs#1, (p1, p2, p3, p4, …, pa)) where Mcs#1 = www.p.com/mcs1.
The Algorithm 1 is based on one time mashup configuration which would be performed by DSC to send the request to MSP/DSP to get mashup configuration attributes to configure its SDMB so that data can be fetched, transformed and populated into it.
| Algorithm 1. One Time Mashup Configuration Algorithm |
Let say p be the DSC which wants to configure its own
SDMBs for data mashup
q = getSDMBs(p)
For each SDMB r ∈ q
begin1
x = createSDX()
x.Sdx#Id = getUniqueID()
x.Dmd#Id = SDMB-DMD.getDmdId(r)
s = selectDSP_MSP(r)
For each DSP_MSP t ∈ s
begin2
u = selectMCSI(t)
w = getMCAttributes(u)
y = DMD.getDMDAttributes(x.Dmd#Id)
For each DMDAttribute z ∈ y
begin3
h = selectMCAttibute(z, w)
x.SDXMapping.add(z = h)
end3
end2
end1 |
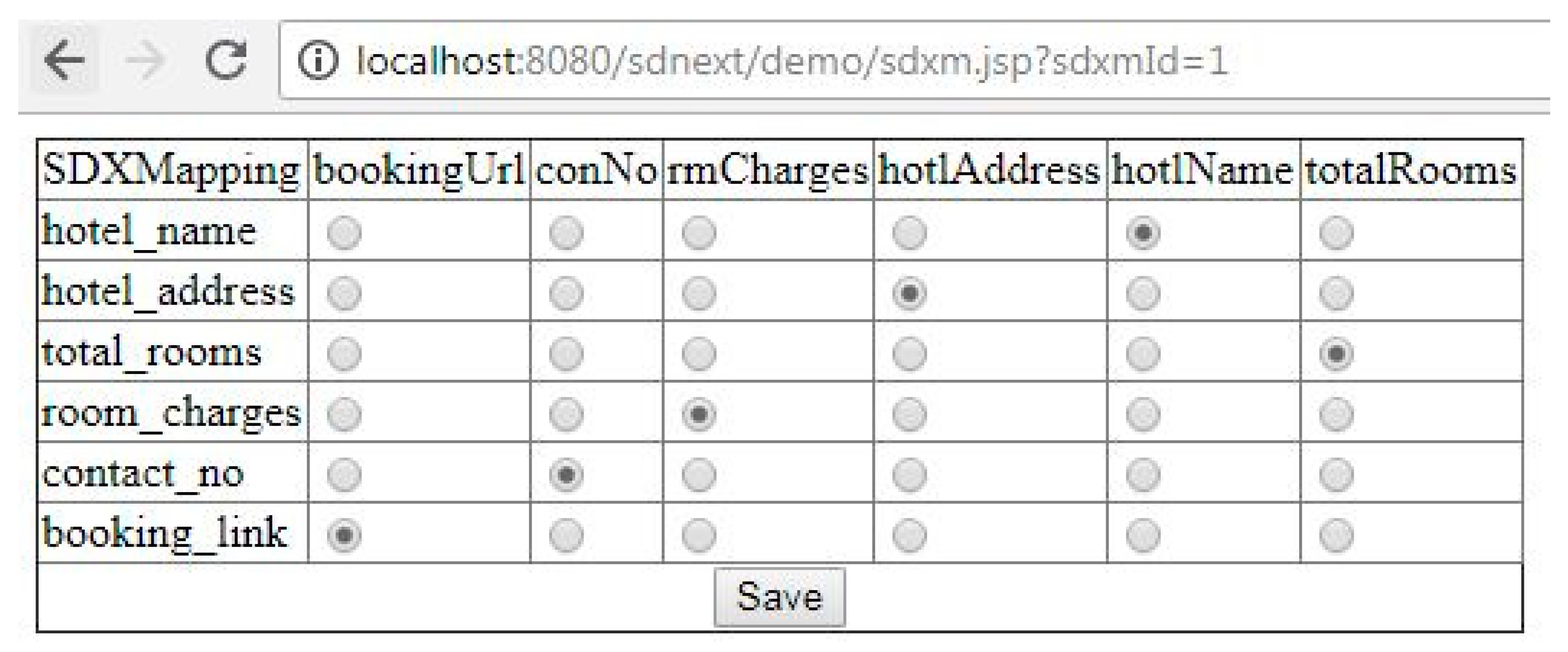
It is clear from the Algorithm 1 that data service consumer selects one or more MSPs/DSPs as per its need and configures SDMB using Mashup Configuration Attributes (MCAttributes) after receiving it from Mashup Configuration Service Identifier (MCSI) calls. The method selectMCAttibute (z, w) will return one of MCAttribute h which will be semantically matched with DMDAttribute z from the list of MCAttributes w. Structured Data eXchange (SDX) would be created at DSC’s end as a result of the mashup configuration and identified by SDX#Id. Thus, SDXMapping is the pair of DMDAttribute and MCAttribute which is semantically equal to each other.
Table 4 describes DSC’s mashup configuration done after receiving MCAttributes and is the one time process performed by data service consumer at its end. In order to perform one time configuration for private data mashup, mashup key is also provided through mashup configuration attributes by private mashup configuration service identifier. It can be noticed here that private mashup configuration service identifier is accessible to authorized data service consumer after proper authentication. In
Table 4, Mds#1 and Mds#2 are providing public data mashup and Mds#3 is providing private data mashup through MKey#3 mashup key. The data service consumer can access private mashup data service identifier only after sending this mashup key to MSP/DSP while requesting through the Any Time Access (ATA) model.
Let us understand the attributes, which are required to configure DSC in the following section.
5.8. Mashup Configuration Attributes (MCA)
MCAttributes is the collection of name of the attributes of the data to be mashed up and is associated with unique mashup data service identifier of MSP/DSP. Hence,
Mds#Id is the unique REST URI of mashup data services available at MSP/DSP and would be used by DSC, later on, to send the request to get data from MSP/DSP. Similar to DMDAttributes, MCAttributes mentioned in this paper is limited to name of the attributes only and does not cover its data type and format etc. By default, all the attributes of mashup configuration are of type text/string for implementation purpose. Let us explore the Algorithm 1 to understand the processing of MCAttributes to create Structured Data eXchange (SDX) as per requirement of the DSC.
5.9. SDX Mapping
The data exchange is the process where the data structured under one schema (the source schema) must be restructured and translated into an instance of a different schema (the target schema) [
50]. According to them [
50], a data exchange setting consists of a source schema S, a target schema T, a set of source-to-target dependencies, and a set t of target dependencies. They also explained that the input to a data exchange problem is a source instance only; the data exchange setting itself (source schema, target schema, and dependencies) is considered fixed. In our proposed work, we have developed SDXMapping in such a way that source to target and target to source mapping is fixed and unique. This process is performed at DSC’s end upon receiving MCAttributes which creates Structured Data eXchange (SDX). The SDX is the logical entity which contains the mapping between attributes of DMD and that of MCA. It is used to validate and transform the structured data records received from MSP/DSP and populate them into appropriate SDMB.
Thus, SDX can be defined as follows:
where Sdx#Id is the unique id of SDX, Dmd#Id is the id of DMDAttributes and SDXMapping is the collection of a pair of DMDAttribute and MCAttribute semantically equal to each other. For example,
where x
1, x
2,… x
n are the name of DMD attributes defined by data service consumer and p
1, p
2,… p
n are the name of attributes of MCAttributes received from MSP/DSP for one time configuration. Here, pair x
1 = p
3 shows that DMDAttribute x
1 is semantically equal to MCAttribute p
3. There should be one to one mapping between these attributes. The Algorithm 1 explains how MCAttribute is processed to create SDX.
Let us understand the output of Algorithm 1 (i.e. SDXMapping) using sample data in tabular format.
Table 5 shows the mapping between DMD attributes and MCAttributes which looks like ‘Column Matching Problem’. It is clear that the attribute “x
1” defined in DMD is mapped with the attribute “p
3” in MCA.
SDX table shown on
Table 6 contains unique Sdx#Id, Dmd#Id and SDXMapping.
After the creation of SDX by data service consumer, the association between structured data mashup box and mashup data service should be updated. Let us understand Mashup Data Service (MDS) first and then its association with SDMB in the next section.
5.10. Mashup Data Service (MDS)
Mashup Data Service (MDS) is the essential feature of MSP/DSP which is nothing but cloud computing paradigm called Structured Data a Service (SDaaS) to provide structured data in the standard format like XML, JSON, CSV etc. on DSC’s request. Data as a Service (DaaS) enables multiple users to access data simultaneously on demand but reliability to store and manage data securely is always required to gain customer trust to use data service [
51]. The mashup data service of any MSP/DSP is identified by REST URI called Mashup Data Service Identifier (MDSI). Every MSP/DSP is required to publish its mashup services/data services to make the MDSI available to its users. The information about MDSI is made available to DSC through mashup configuration service identifier while performing one time configuration. The MSP/DSP may have one or more mashup data service identifiers as per data available with them. Based on accessibility features of services, mashup data service could be of two types namely private mashup data service and public mashup data service. Private mashup data service provides the data to DSC after proper authentication and authorization of mashup keys whereas public mashup data service provides the data without any verification. Thus, private mashup data service results in private data mashup and public mashup data service results in public data mashup.
5.11. SDMB-MDS Association
Each Structured Data Mashup Box (SDMB) of DSC should be associated with Mashup Data Services (MDS) of MSP/DSP and structured data exchange so that structured data records of structured data module received at DSC’s end would be validated and transformed into proper mashup data record format before populating into structured data mashup box. Association between structured data mashup box and mashup data services would be as follows
Table 7 shows one of the snapshots of sample SDMB-MDS association.
It is clear from
Table 7 that Sdmb#2 is associated with www.p.com for Mds#1 using Sdx#1 and it is also associated with www.q.com using Sdx#4 but for Mds#2. Once SDMB-MDS association is determined by DSC, One Time Configuration (OTC) is over for an SDMB. The second phase of the proposed work is based on the ATA model, which includes the Any Time Access (ATA) algorithm, which has been described below.
5.12. Any Time Access (ATA) Algorithm
After defining the association between SDMB and mashup data service, DSC is ready to access data any time by sending service/data request to respective MSP/DSP. Following Algorithm 2 is used by any DSC at any time by just calling Mashup Data Service Identifier (MDSI) to access Structured Data Module (SDM) which is generated by mashup data service.
Here, DSC will select one SDMB and will receive SDM by calling each Mashup Data Service Identifier (MDSI) associated with SDMB. The SDM t received from MDSI would be validated thereafter transformed and populated into SDMB q using the algorithm (See
Section 5.15). Let us understand Structured Data Module and its components in the next section.
| Algorithm 2. Any Time Access (ATA) Algorithm |
Let p be the DSC which sends request to MSPs/DSPs through one SDMB q for data mashup
q = selectSDMB(p)
r = getMDSIs(q)
For each MDSI s ∈ r
begin1
t = getSDM(s)
if (validate(t))
transform&populate(t, q)
end1 |
5.13. Structured Data Module (SDM)
The data made available to data service consumer through mashup data service identifier would be called Structured Data Module (SDM). This paper proposes novel structured data processing system in which structured data module consisting of one or more structured data records would be further filtered, transformed and populated by algorithms mentioned in the
Section 5.15 and resultant mashed up data would be placed in Structured Data Mashup Box (SDMB). Let us understand a few terms used in this section.
5.13.1. SDM
The SDM is the well-structured content provided by MSP/DSP through mashup data service identifier calls. It is a module because it may contain multiple structures of data as per the specification mentioned in mashup configuration service identifier. It provides not only structured data but may also contain other information like mashup keys, SDMB details and many other information. Currently, SDM used in this paper is limited to provide structured data record in the standard format like JSON. Every MSP/DSP has one or more mashup data services which generate Structured Data Records (SDRs) to be made available to its users. Thus, each SDM contains Sdm#Id, Mds#Id and one or more SDRs generated by mashup data service. Thus,
5.13.2. Structured Data Records (SDRs)
The SDRs can be defined as the collection of one or more structured data record generated by mashup data service and each SDR contains Sdr#Id and one or more SDR values. Thus,
5.13.3. SDRAttributes and SDRValues
SDRAttributes can be defined as the collection of attributes of structured data record.
SDRValues can be defined as the collection of one or more Name-Value (N-V) pairs.
For example,
where p
1, p
2,… p
n are name of attributes of SDR and v
1, v
2,… v
n are values of those attributes. Next section explains how Structured Data Module would be composed using JSON.
5.14. JSON Composition of Structured Data Module
In our proposed system, various mashup data services of MSP/DSP generate many SDRs and put them together in an SDM. The mashup data service generates SDM on each data request made by DSC. Thus, the refresh rate of SDM provided to DSC is high. The mashup data service composes JSON-SDM as given in Algorithm 3.
| Algorithm 3. JSON Composition of SDM |
p = newSDM()
q = getSDRs(p)
r = newJSONArray()
For each SDR s ∈ q
begin1
t = getJSONObject(s)
r.add(t)
end1 |
Thus, each SDR generated by mashup data service would be converted into JSONObject and JSONObject would be added to JSONArray to make it available to DSC through mashup data service identifier.
For example, SDR = (Sdr#01, (p
1 = v
1, p
2 = v
2,…, p
n = v
n)) would be converted into JSON Object as follows
Next section explains how SDR would be validated, transformed and populating into SDMB.
5.15. SDR Validation, Transformation and Population Algorithm
Data Mashup Definition (DMD) is defined by DSC at its end whereas SDR is generated at MSP’s/DSP’s end and provided to DSC through mashup data service identifier. Numbers of attributes in DMD and that of mashup data service may differ or may be equal. The SDR, which is supposed to be populated, may be ignored, if it is not matched with the specification of SDX defined for the SDMB. SDR would be valid if all of its attributes are matched with DMDAttributes of targeted SDMB. Valid SDR is transformed into mashup data record and populated into relevant SDMB. The Algorithm 4 depicts how each SDR is validated and transformed into Mashup Data Record (MDR) before populating into proper SDMB.
| Algorithm 4. Validation, Transformation and Population of SDR |
Let p be the DSC receives SDM t through MDSI s from DSP r in SDMB q
t = getSDM(s)
v = getSDRs(t)
For each SDR w ∈ v
begin1
y = getSDRAttributes(w)
if (valid(y))
begin2
[fetch Sdx#Id from Table 7]
Sdx#Id = getSDXId(r, s, q)
[fetch SDX Mapping from Table 6]
x = getSDXMapping(Sdx#Id)
For each SDRAttribute z ∈ y
begin3
[fetch DMDAttribute from SDXMapping]
h = getDMDAttribute(z, x)
[populate SDMB q]
SDMB.Dsp#Id = r
SDMB.Mds#Id = s
SDMB.Sdmb#Id = q
SDMB.MDRValues.add(h=z.value)
end3
end2
end1 |
The transformation of structured data record into mashup data record requires fetching DMDAttribute of the corresponding SDRAttribute from SDXMapping and value of SDRAttribute is assigned to DMDAttribute. Created MDRValues (name-value pair) is added to MDRs of SDMB as mentioned in line SDMB.MDRValues.add(h=z.value).
8. Work Evaluation
Now, the turn has come to evaluate the proposed work, which includes the complete life cycle of the data mashup development by ordinary user using SDRest protocol for end to end data mashup. As already mentioned, the data mashup is the set of techniques and approaches developed in such a way that an ordinary user can use it to fetch their required data from multiple data sources and mash them up in single place without any programming or technical skills. The data mashup always intends to involve the ordinary user throughout the mashup development process and provides a user-friendly approach so that whole process can be adopted by everyone without any technical assistance. The main motivation behind the proposed work is to develop user-friendly approach using the existing technologies and the communication protocol for developing the data mashup between any two stakeholders (Ordinary User/Mashup Service Provider/Data Service Provider) and hence called end to end data mashup.
In order to evaluate the proposed work, there is need of selecting some of the related tools, techniques and approaches developed previously and the parameters to be fixed to compare the proposed work with them. We selected some tools, which were developed by few IT giants and other related works to compare with our proposed work. The comparison of the output of the data mashup only, is not enough to evaluate the work because output covers only one aspect of the whole mashup development process. The techniques and approaches used in each step of the mashup development needs to be evaluated using various parameters. Let us discuss the parameters, which should be selected for the evaluation of the work then the observations based on these parameters would be summarized.
The ordinary user has been the focus of the industries and the researchers for the mashup development since last two decades but a killer mashup application like email is still waiting for structured data communication for data mashup. Other than ordinary users, there are end user developers, mashup service providers and data service providers who use the data mashup. We have chosen “the targeted users” as a first primary parameter for evolution of the proposed work because it is really a challenging task to make the ordinary user as a major stakeholder of the IT system development. If any of the tools or technique targets the ordinary user then the development of user-friendly UI approach becomes a compulsory feature.
After the popularity of service-oriented architecture, many organizations started providing the data services and mashup services to their users but due to the availability of large numbers of services, it became cumbersome for the user to select the appropriate services from reliable service provider. Hence, selection of mashup service provider or data service provider is another important parameter for evaluating the data mashup approach and technique. The selection of data/service providers could be manual, semi-automatic or automatic. The mashup data or services made available by MSP/DSP could be private, public or hybrid, which have already been discussed previously, is the third parameter for comparison. The method of pulling or pushing the data in request-response pattern is also an important parameter because the bandwidth consumption by data mashup is an important factor to study. Data source, which is another important parameter of this comparative study, plays important role because data source and its interface decides the success of the mashup tools and approaches.
The users are given some GUI based tools like visual editors, web browser etc. and drag and drop like user-friendly approach to allow them to define their own data mashup before fetching the actual data from various disparate data sources. Hence, the mashup development tool and approach has been included as a major parameter to evaluate the proposed work. Pre-mashup configuration is compulsory steps of any mashup development tools or techniques because its output defines the requirement of the user which would be used by mashup algorithm/tools to complete the remaining task of data mashup in automatic mode. Although, the output of mashup can be made available in any desirable form but it is important to know whether this output can be shared, forwarded and reused by same/other user or not. The End User Data Mashup (EUDM) which we discussed in
Section 7.3 is also included as one of the parameters which tells whether output of various mashups itself can be combined further to create integrated UI view or not.
Based on above discussions, we have chosen the following nine parameters to evaluate the proposed work
- (A)
Targeted End Users
- (B)
End User Data Mashup (EUDM)
- (C)
Selection of MSPs/DSPs
- (D)
Types of Mashups
- (E)
Mashup Strategies
- (F)
Data Sources
- (G)
Mashup Development Tools/Approaches
- (H)
Output of the Pre-Mashup Configuration
- (I)
Output of the Mashup
We have chosen few reference works and tools developed previously and compared their features with the proposed work using the above parameters as shown in
Table 10.
The following points may be summarized after analyzing the above table data.
(A) We can analyze by observing this parameter that the most of the previous works could target to end user developers (type-1 and type-2) and but only few of them got success in developing the data mashup platform for ordinary user. Here, the EUD(type-1) is the technical person who knows some programming skills with script editing and capable to use the mashup tools. The EUD(type-2) is not fully technical person but he/she is more computer savvy than the ordinary user and have some knowledge of browser configuration, plug-ins etc. The ordinary user is completely a not technical person and knows browsing, web form entry, selecting the radio buttons and clicking the submit button only and even one cannot expect operations like drag and drop of some widgets on canvas and connecting them together. The proposed work supports end to end data mashup which facilitates the mashup communication between any two stakeholders, thus it can be used by any of the stakeholder i.e., ordinary user, mashup service provider, data service provider and end user developer. It is obvious that anything, which is developed for ordinary user, can also be used by other technical persons. There are five values taken for the parameter called ‘targeted user’ i.e., EUD(type-1), EUD(type-2), ordinary user (OU), MSP or DSP. We have explained the reasons about the values assigned to this parameter in the point ‘F’ i.e., Mashup Development Tool/Approach.
(B) The integrated UI is an important parameter, which integrates the various mashup outputs together to create a single screen of hybrid data mashup. It indicates that output of different data mashups can also be integrated so that user can view them together in single place. This feature has been easily implemented in the proposed work as compared to previous works.
(C) The method of selection of the MSPs/DSPs is the next parameter to evaluate the mashup development works. There are three ways to select MSP/DSP for data mashup i.e., manual, semi-manual and automatic. It can be seen from value of this parameter that the most of the works for selecting the MSP/DSP are manual. Refs. [
30,
34] could achieve the semi-automatic mode of selection of mashup/data services but are limited to be used by MSP only. The proposed work is also limited to the manual selection of MSP/DSP. It is one of the most challenging steps of mashup development because it involves methods and techniques to transform user’s requirement in terms of services or in some other forms. In case of private data mashup, the user already knows the source of the data and hence searching the MSP/DSP is not needed, but it still requires selection of the right services available within that MSP/DSP. In manual approach of selecting MSPs/DSPs in the proposed work, the user will choose one of the MSP/DSP just as he/she selects one email service among all the email service providers.
(D) The fourth parameter is the type of mashup, which has three possible values i.e., private, public, and hybrid. Actually, this parameter describes the accessing modes of the data available with MSP/DSP. It can be seen that most of the previous works focused their work on public data mashup. But, the mashup is generally more towards personal data mashup hence private and hybrid data mashup need to be developed to make this technology more popular among end users. Our proposed work and [
35] focused to perform mashup for private data. Study [
35] is used to preserve the privacy aspect of user’s data before providing it to third party and targets to MSP but our work can be used to perform the data mashup directly by ordinary user without any involvement of third party mashup service provider hence there is no question of preserving privacy of the user’s data.
(E) The mashup strategies based on pull and push pattern are important to study because these decide the consumption of the bandwidth of the network and should be carefully chosen. It can be observed here that almost all mashup techniques and approaches focused on pull data mashup but our proposed work recommends both patterns (pull/push) while performing the data mashup as per the nature of the data.
(F) The source of data that is chosen by mashup service provider or the end user is an important aspect of the whole data mashup process. The web pages were the target data source for most of the mashup developers at the initial stage of mashup development and thereafter developers targeted to data in well-structured format. The proposed work supports data in well-structured format provided by standard REST protocol only. It can easily be observed that the data sources mentioned here, can be categorized into four categories. The first category is the well-structured data source, which contains data in ATOM, JSON, XML, CSV, RSS, RDF etc. format. The second category is the customized data source like nested relational model, business objects etc. Some works directly used HTML, Web Page, Annotated Web, Web Page APIs to fetch the required data and can be placed in third type category and in fourth category, cloud computing paradigm and web service as DaaS, SOAP Web Services, REST calls, REST API etc. were used as data source. The proposed work has been currently implemented to support JSON data format but it can also be easily implemented to support data in well-structured format which would be provided by REST protocol.
(G) The mashup tool, technique and approach is the core thought of the whole mashup development process because it decides not only the UI approach adopted for development of data mashup by ordinary user but also decides the values of all other parameters as mentioned above. The Google Mashup Editor [
8] is an ajax based framework and runs in Mozilla Firefox and Microsoft Internet Explorer without any plug-ins and the source code is generated as a result of pre-mashup configuration in XML, Javascript API etc. The script generated by this editor can be used by EUD(type-1) only. Yahoo Pipes [
40] is a web-based tool, which allows the end user to drag, and drop pipes (some kind of UI components) and connect them with other pipes to create sequence of pipes as pre-mashup configuration which would be accessed by unique URL to get RSS or JSON etc. Yahoo pipes is suitable for EUD(type-2) user. Intel mash maker [
11,
40] is also web-based tool, which works directly with web page and suggests the end user whether there is some mashups/widgets in the visited page or not. The Microsoft popfly [
40] is very much similar to Yahoo Pipes which uses the term ‘block’ instead of pipes and used to integrated different services as a pre-mashup configuration by making chain of blocks. Reference [
52] developed a graphical Interface to use MashQL with some assumption to generate SPARQL. The approach and technologies used in MashQL editor is limited to be used by EUD(type-1) only.
Damia [
53] provides a browser-based client interface with powerful collection of set-oriented feed manipulation operators for importing, filtering, merging, grouping, and otherwise manipulating feeds to accommodate various feed formats such as RSS and ATOM, as well as other XML formats. Again, this tool is limited to be used by EUD(type-1) because the involvement of various operators cannot be easily understood by ordinary user. As far as ordinary user is concerned, the building mashup by demonstration [
16] is really a simple approach, which can be used by ordinary user, but major challenge in this work is the extraction of required data from web page whose DOM is not in the proper shape. Reference [
23] uses the PAW mashup engine which generates Service Description Document (SDD), Mashup Document (SD) which can be used by the mashup service provider and EUD(type-1) level users only because specification of documents generated here cannot be easily understood by either the ordinary user or the EUD(type-2). Reference [
30] targets to mashup service provider which allows to analyze the relationship among data services for discovering mashup patterns based on the history records of data mashup plans. This approach recommends data mashup patterns by analyzing the input and output parameters of the data services if pattern is not found but it is also suitable for MSP.
Reference [
13] proposed a flexible execution of data processing and integration scenarios to solve the Extract-Transform-Load processes related issues for end users. They presented an approach for modeling and pattern-based execution of data mashups based on mashup plans, a domain-specific mashup model which can be suitable for EUD(type-1) because the mapping from non-executable model onto different executable ones depending on the use case scenario cannot be performed by ordinary user. Reference [
54] uses the graphical interface for visual mapping between data attributes and UI templates which is not easily be used by ordinary user and suitable for EUD(type-1) because it also includes implicit control flow.
Marmite [
55] is an end-user programming tool for creating web-based mashups. It uses a set of operators to extract and process data from web pages and uses data flow to create spreadsheet view that shows the current values of the data. Reference [
56] used the cloud computing paradigm Data as a Service (DaaS) to develop mashup framework using SOAP API and limited to be used by MSP. Mashroom+ [
57] was developed to support users to easily process and combine data with visualized tables. This work focuses on an interactive matching algorithm which is designed to synthesize the automatic matching results from multiple matchers as well as user feedbacks. It can be studied in detail that it can be found suitable for EUD(type-2) because of complexity of defining the user’s requirement, data mapping and the output supported.
There is always need of pre-mashup configuration before performing actual data mashup. Pre-mashup configuration is used to define data requirement of the user. Most of the previous works tried to develop user-friendly graphical interface because of the involvement of ordinary users. The proposed work recommends to use the existing web browser without any extension or plug-ins installation or configuration. Alternatively, mobile app screen or desktop application can also be used for pre-mashup configuration. It can be seen from
Figure 9 that it simply requires skill of web form entry, selection of radio buttons etc. to complete the pre-mashup requirement, which is easier than any other tools/approaches developed previously. It can be observed here that every mashup developer has generated pre-mashup configuration before performing the actual data mashup but approaches used by them were not much suitable for ordinary user.
(H) Output of pre-mashup configuration is the one of evaluation parameter which would be used to perform data extraction, filtering, data mapping and population etc. The success of the data mashup depends on the algorithm and output of pre-mashup configuration. The outputs of pre-mashup configuration of the proposed work are DMD, SDMB, SDXMapping and data validation, transformation and population algorithm which would automate the task of fetching required data from multiple data sources and populate them into SDMB which can be viewed by ordinary user in any desired format.
(I) Output of the mashup can be a web widget, purely structured data or in some other formats which depends upon the tools and technologies used to perform the data mashup. Till now, there is no standard format of output of data mashup but it would be better if one can provide data in well-structured format so that it can be consumed and viewed in user’s preferable format.
In brief, the following points may be considered as improvements in the proposed work over the previous works.
The proposed work supports all stakeholders of mashup development i.e., Ordinary User, End User Developer, Mashup Service Provider, Data Service Providers by providing user-friendly end user configurable approach at every stage of the mashup development.
The integration of structured data mashup box helps the ordinary user to produce integrated view of his mashed-up data in single screen.
The proposed work includes all kinds of data mashups i.e., public, private and hybrid data mashup with both mashup strategies i.e., push and pull.
It supports mashup of data in any structured format which would be made available by REST protocol.
It uses simple web browser without any extensions or plug-ins and involves the user interface events like selecting the radio buttons, fill the web form and submit the button which is most suitable for an ordinary user.
Outputs of pre-mashup configuration (i.e., structured data mashup box and structured data exchange mapping) are used to populate the data in auto mode.
Currently, followings are few limitations of the proposed work which need to be investigated further.
The manual intervention on structured data exchange mapping
The manual searching of mashup and data services
The schema mapping is not covered in the current work while performing structured data exchange mapping















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
