A questionnaire was developed to test the research model empirically. Here, we take a Wi-Fi rental service provided when traveling outside of China as the research subject, because this product only provides online recovery based on their enterprise’s WeChat subscription, and a market survey of 12 travel agencies in Chongqing from September 2017 to December 2017 shows that although this product is preferred by tourists because of its high quality and competitive price, tourists’ complaints about the product’s online recovery quality have been numerous, corresponding to a severe impact on the overall perceived service quality and repurchase intention. Therefore, solving the problem of online recovery failure has become the management focus of this product market, and we try to explain this problem through this study.
4.1. Instrument Development
First, we designed the measurement items for different expressions of apology based on the three basic elements of a complete apology, that is, the expression of apology, the acceptance of responsibility, and the repair [
51]. The description and example of these three elements are shown in
Table 2. Thus, based on the examples, we constructed two different expressions of apology, both of which meet the requirements of a complete apology (see
Table 2).
The question “To which do the actual statements used by the staff belong?” is taken to measure which form of expression the staff used in the most recent online recovery. The measurement questions for the remaining variables are adapted from the literature to ensure the validity of the scale.
Following the approach suggested by Douglas and Craig [
60], the questionnaire was evaluated by back translation to ensure the equivalence of scales and to avoid misunderstanding and misinterpretation. The questionnaire was first translated into Chinese by two Chinese/English bilingual experts. Then, the Chinese questionnaire was translated into English by two different Chinese/English bilingual experts. The original and back-translated versions were given to a bilingual judge to determine the validity of the scales. At last, the Chinese questionnaire was used to collect data in the pre-test and formal test.
Approval from the Chongqing University Ethics Committee was obtained prior to initiating the survey. Chongqing University Ethics Committee was formed by the graduate school of Chongqing University and consisted of 9 members, and this study was supported by a full vote. Furthermore, all the participants have been informed about the purpose of this survey is to better understand the quality of online services and prior consent for the survey was obtained by emphasizing the investigation as voluntary before them answered the questionnaire.
A pre-test was conducted to validate the instrument, and different expressions of apology were manipulated through three more questions: “The speaker expresses an apology indirectly by using network language”, “The speaker expresses the apology directly by saying sorry”, and “This statement shows that the speaker is aware that he/she should take responsibility for the problems that happened”.
We invited 40 participants whose mother tongue is Chinese to answer the pretest questionnaire on a website, and the results showed that the two statements can correctly describe the different expressions of apology. The “Indirect Expression” thought the service staff expressed an apology indirectly (MIDE = 4.350, MDE = 2.450, F(1,38) = 58.374, p < 0.001), and the “Direct Expression” thought the service staff expressed an apology directly (MDE = 4.200, MIDE = 1.700, F(1,38) = 110.981, p < 0.001). Both s thought the service staff admitted responsibility for the failure (MDE = 4.250, MIDE = 4.250, F(1,38) = 0.482, p > 0.5). Regarding the other measurement questions, we made a few minor modifications to the wording and the question sequence according to the comments from the participants.
As to the formal test, according to the customer database provided by the Chongqing Branch of Uroaming Company and Chongqing New Century International Travel Agency, a total of 1083 Chinese tourists who have purchased Wi-Fi rental service in the past year were contacted through sent the questionnaire to these tourists’ email from 1–12 June 2018, and 478 answered the questionnaire. Through the initial filter question “During the latest consumer experience, have you ever seeking the online customer service to resolve the service problem you have met”, 149 participants did not pass the check, while 329 stated having experienced online recovery service.
Then, because 26 questionnaires were not completely answered, and to avoid demographic errors, we deleted 6 questioners which were answered by 4 young respondents (<20 years) and 2 old respondents (>50 years), this resulted in a total of 297 valid responses that have been used in the data analysis.
Table 3 describes the demographics of the sample.
Moreover, the results also shown, 80.14% of participants last purchased the service product 6 months ago, which effectively reduced the retrospective self report bias due to memory loss [
45]. And 50.84% of participants (N = 151) thought that the service staff used direct expression mode, while the others (N = 146) thought the service staff used indirect expression mode.
4.4. Measurement Model Assessment
The adequacy of the measurement model was evaluated based on the criteria of internal consistency reliability, convergent validity, and discriminant validity.
Table 4 shows that the Dijkstra–Henseler’s rho ρ
A, Dillon–Goldstein’s ρ
C and Cronbach’s α of all individual scale items exceed the minimum value of 0.7, indicating adequate reliability [
61,
63]. The convergent validity of the constructs was also shown to be satisfactory, with an average variance explained (AVE) exceeding 0.5 (see
Table 4) in all cases and all loadings exceeding 0.7 [
64] (see
Table 5).
Discriminant validity was confirmed using the following three tests. First, the pattern of the cross-factor loadings shows that the loading of each measurement item on its assigned latent variable is larger than its loading on any other construct [
63] (see
Table 5). Second, the square root of the AVE value of a construct is larger than all correlations between the construct and other constructs in the model [
64] (see
Table 5). Third, the heterotrait-monotrait (HTMT) ratio of correlations values between perceived justice and satisfaction are 0.539 (all), 0.191 (1), and 0.767 (2); all of these values are significantly less than 0.8, providing sufficient evidence of the discriminant validity of a pair of constructs [
63]. Consequently, the results of all tests were satisfactory, and discriminant validity was verified [
61].
Furthermore, a post hoc Harman’s single factor test was used to access common method bias. The result shown a single factor did not emerge from the unrotated solution, which means the common bias was low. The total variance of the single factor model accounted for 27.65% of total variance. Accordingly, we concluded all the constructs in this study have acceptable reliability and validity.
4.5. Structural Model and Hypotheses
A PLS-SEM bootstrapping approach was used to test the hypotheses with 10,000 bootstrap samples. The results are given in
Table 6. First, the perceived justice-satisfaction model accounted for 66% of the explained variance of satisfaction in online recovery (R
2 = 63%). The levels of explained variance for perceived justice (R
2 = 47.5%) accounted for by the customer participation components are acceptable as well. Thus, the fit of the overall model is acceptable.
Second, the path coefficients and confidence intervals (CIs) show that emotional participation has no positive effect on informational justice; thus, H1a is supported. Mental participation positively influences perceived justice; thus, H1b is supported. Physical participation positively influences perceived justice; thus, H1c is supported. Perceived justice positively influences customers’ post-recovery satisfaction; thus, H3 is supported.
4.6. Mediation Effects
Following Nitzl, Roldan, and Cepeda [
65], we used a two-step method to verify the mediating role of perceived justice. First, a bootstrap analysis with 10,000 samples was performed for the model; the analysis also set lines connecting physical participation and satisfaction, and mental participation and satisfaction. Then, the results of total effect and direct effect were calculated using SmartPLS 3.2.6 software. For the direct effect of PP→SAT is significant (
t = 4.281,
p = 0.000 < 0.001), and the indirect effect of PP → SAT though PJ is significant (
t = 2.002,
p = 0.045 < 0.05), the 95% percentile CI of PP → SAT through PJ ([0.004, 0.091]) does not include 0, thus PJ partially mediates PP → SAT. The direct effect of MP → SAT is significant (
t = 5.200,
p = 0.000 < 0.001), and the indirect effect of MP → SAT though PJ is significant (
t = 2.840,
p = 0.005 < 0.01), the 95% percentile CI of MP → SAT through PJ ([0.022, 0.109]) does not include 0, thus PJ partially mediates MP → SAT.
4.7. Partial Least Squares Multi Analysis (PLS-MGA): The Moderation Role of the Expressions of the Apology
Our method of PLS-MGA followed that of Matthews [
66]. First, the SRMR, d
ULS and d
G of group 1 are 0.025, 0.032, 0.057, and group 2 are 0.045, 0.056, and 0.045 which means the overall goodness of fit of two groups’ model was verified. And the results of
Table 4 also provide clear support for the measures’ reliability and validity [
66].
Second, we use the measurement invariance of composite models (MICOM) procedure to test the measurement invariance for all groups. Configural invariance was fulfilled since the measurement models for the two groups meet the three requirements of “identical indicators per measurement model, identical data treatment, and identical algorithm settings criteria” [
66]. Then, a permutation test was executed to verify compositional invariance. A permutation test was set at 5000 samples, and the test type was set as two-tailed with a significance level of 0.05. As shown in
Table 7, the original correlations are equal to or greater than the 5.00% quantile correlations (shown in the 5% column), indicating that compositional invariance has been demonstrated for all the constructs [
66]. The data in the mean original difference column fall within the 95% CI, and the permutation
p-values are greater than 0.05, indicating that the construct passes the variance test. The data in the variance original difference column fall within the 95% CI, and the permutation
p-values are greater than 0.05, further indicating that the entire construct passes the measurement variance test [
66].
Third, since invariance is verified, we first analyze the groups separately to determine whether there is a difference between the two groups.
Table 8 shows the bootstrap results of each of the two groups with 5000 sub-samples. As the last column of
Table 7 shows, the permutation
p-values of the three types of customer participation and perceived justice are all less than 0.10, indicating that these three relationships have significant differences between the two groups [
66].
To further verify the analysis results according to the permutation test, we use the MGA algorithm to check the differences between the two groups.
Table 8 shows the results of the test of CIs, which is a non-parametric test. The criteria establish that if the parameter coefficient for a path relationship of one group (see
Table 8) does not fall within the corresponding CI of another group (
Table 8) and vice versa, then there exists no overlap, and we can assume that there is a significant difference between the two groups [
66]. Thus, according to
Table 8, H2b and H2c are verified; however, emotional participation does not influence perceived justice in either direct or indirect situations; thus, H2a is not verified.

 ” is a conceptual metaphor that represents that the speaker is expressing sadness. Thus, in this study, we take the “
” is a conceptual metaphor that represents that the speaker is expressing sadness. Thus, in this study, we take the “ 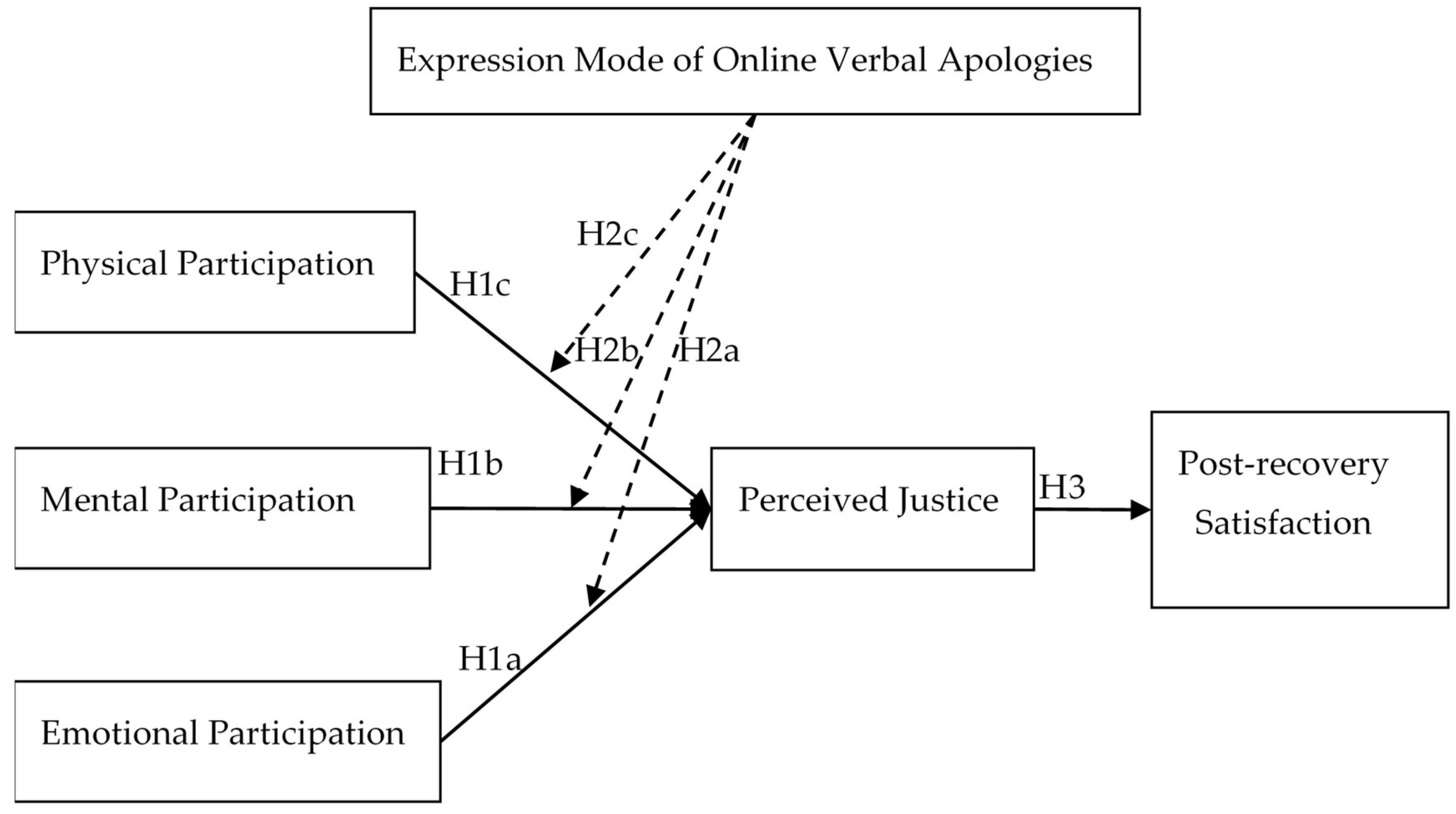

{kind=link}