1. Introduction
Surveys of forest resources are crucial for maintaining ecological balance, mitigating climate change, and ensuring the sustainable management of forest ecosystems [
1]. In order to assess the structural characteristics of a forest or a single tree, LiDAR is currently a mainstream tool for acquiring 3D point cloud models of forests [
2]. However, the equipment is costly and not very portable, and the required postprocessing process for the acquired point cloud data is cumbersome and time-consuming [
3]. With the improvement in the accuracy of 3D reconstruction technology, image-based 3D reconstruction technology provides a low-cost way to acquire data [
4]. Therefore, 3D reconstruction data will become another data source for sample plot investigation. The single-tree segmentation algorithm can separate a point cloud into single trees, which makes it easier to obtain the spatial coordinates, canopy structure model, and health of the trees [
5]. Meanwhile, as the challenges and costs associated with data acquisition decline, the availability of relevant open-source datasets is expected to rise, thereby facilitating advancements in single-tree segmentation accuracy.
Presently, single-tree segmentation techniques utilizing point cloud data are primarily categorized into two distinct classes: algorithms based on manual feature extraction and those based on automatic feature extraction [
6]. Among these, algorithms reliant on manual feature extraction necessitate the laborious extraction and input of numerous structural parameters of trees, thereby increasing the time and complexity associated with data preprocessing [
7]. Currently, two primary algorithms employing manual feature extraction exist: The first involves determining the position of the apex of a tree crown using the Canopy Height Model (CHM), followed by the application of a segmentation algorithm (e.g., a watershed algorithm [
8]) to isolate individual trees. Chen et al. [
9] employed a marker-controlled watershed algorithm to detect and extract single-tree information from fruit trees, demonstrating that the watershed algorithm applied to the Canopy Height Model exhibits high feasibility in addressing issues related to overlap and occlusion within tree canopies. Additionally, Chen et al. [
10] proposed a similar marker-controlled watershed algorithm to segment individual trees by identifying the apex of a tree through a variable-sized dynamic window. The other algorithm is single-tree segmentation directly based on the original point cloud data, which can directly utilize the original point cloud data without constructing additional 3D models, thus reducing the complexity of data processing [
11]. This category primarily encompasses point cloud distance clustering discriminant algorithms [
6], k-means clustering algorithms [
12], and others. Jiang et al. [
13] performed a sensitivity analysis on the point cloud distance discriminative clustering algorithm, revealing that setting the distance threshold to the average crown radius of the sample site yields optimal single-tree segmentation. In addition, Vega et al. [
14] introduced a multi-scale dynamic point cloud segmentation method which utilizes diverse evaluation criteria to ascertain the optimal tree-top location as the initial clustering center for crown clustering, achieving a correct segmentation rate of 82%.
Automatic feature extraction methods typically leverage deep learning techniques, which autonomously extract features via neural networks, significantly diminishing the reliance on manual feature extraction [
15]. Moreover, this method can autonomously complete segmentation upon the conclusion of model training, eliminating the necessity for further personnel involvement, thereby minimizing redundant operations and optimizing the overall workflow [
15]. Currently, this category comprises two primary methodological approaches: The first involves employing deep learning techniques (e.g., PointNet [
16] and PointNet++ [
17]) to conduct semantic segmentation, effectively isolating the desired tree species from the dataset, followed by manual feature extraction for single-tree segmentation. While this approach does enhance the accuracy of single-tree segmentation, it merely employs deep learning as a data-cleaning tool, failing to capitalize on deep learning’s potential for feature extraction and neglecting to fully demonstrate its advantages, including automatic feature extraction and end-to-end processing capabilities. For instance, Chen [
18] employed the PointNet network model for tree identification on voxelized data. Following the acquisition of classification results for each voxel point cloud, the segmentation of the tree-crown boundary was subsequently refined based on highly correlated gradient information. Another category of methodologies accomplishes single-tree segmentation by advancing instance segmentation models within the deep learning paradigm. Typically, this approach utilizes neural networks to extract salient data features, which are subsequently employed to perform clustering or generate predictive frames, thereby facilitating the precise segmentation of individual instances.
For example, Henrich et al. [
19] introduced a deep learning-based single-tree segmentation approach, incorporating enhancements to the PointGroup model. This technique utilizes an end-to-end training strategy to extract multi-scale geometric features from point cloud data and performs clustering based on these features. Consequently, this results in a substantial enhancement of the accuracy in single-tree segmentation.
Nonetheless, deep learning models typically demand extensive labeled datasets for training and entail prolonged training durations, thereby presenting notable challenges for real-world applications [
20].
The applicability of these methodologies to three-dimensional reconstructed datasets warrants further exploration and rigorous validation. This is attributed to the fact that point cloud data generated via 3D reconstruction display a higher density and more heterogeneous spatial distributions relative to the original LiDAR-acquired point clouds.
The Sparse 3D U-Net architecture represents a novel variant of the U-Net framework originally introduced by Ronneberger et al. [
21]. The original U-Net architecture features a symmetric encoder–decoder structure that effectively captures the contextual information of an image while simultaneously preserving intricate details. Consequently, this architecture demonstrates superior performance in medical image segmentation tasks, particularly when the available dataset is limited. Nonetheless, it possesses the potential to lose critical information during the processing of 3D data, thereby failing to fully exploit the spatial dimensions. Çiçek et al. [
22] introduced the 3D U-Net by extending the convolution operation into three dimensions, employing both 3D convolution and 3D pooling operations, thereby enabling the network to capture more intricate spatial features. Furthermore, the Sparse 3D U-Net is a framework introduced by Sun et al. [
23] which builds upon the principles of the 3D U-Net integrated with sparse convolution techniques proposed by Graham et al. [
24]. This framework significantly enhances computational efficiency and memory utilization while preserving the spatial structural features of 3D data, thereby improving segmentation performance. However, due to its high network complexity and dependence on the sparsity of the data, it may lead to slow convergence of the network.
In the realm of deep learning, attention mechanisms have been extensively employed across a variety of tasks [
25]. The fundamental attention mechanism allows the model to concentrate on the most pertinent information pertaining to the current task through the computation of the weighted sum of various segments of the input sequence [
26]. Nevertheless, despite its ability to capture contextual information, the conventional single-head attention mechanism is limited to aggregating information within a subspace and may fail to encapsulate multiple distinct semantic features. In contrast, multi-head attention seeks to address this limitation by concurrently computing several attention heads in parallel [
26]. By partitioning the input representation into multiple linearly transformed subspaces, this approach enables each attention head to independently compute the attention weights; subsequently, the outputs of each head are concatenated and linearly transformed to yield the final output [
26]. While the attention mechanism has the capacity to enhance model performance, relying solely on this mechanism may not fully leverage the structural information inherent within the data.
To address the above key challenges in practical applications, this study proposes a deep learning model based on the attention mechanism. This model effectively integrates single-tree segmentation with deep learning techniques and incorporates an attention mechanism for algorithmic optimization grounded in the U-Net network architecture, thereby enhancing the feature extraction capabilities and training speed of the model. Notably, this approach is end-to-end, requiring no professional intervention to operate the model once training is complete. The segmented data can be automatically outputted by simply inputting the forest data intended for segmentation into the model. In the experiments, not only the performance of our method and several existing methods on LiDAR point cloud datasets, but also the applicability of these methods to 3D reconstruction datasets is verified. The results show that our method not only has good performance on the LiDAR point cloud dataset, but also performs well on the 3D reconstruction dataset and is still able to output high-quality single-tree segmentation results. The specific contributions are as follows:
The Sparse 3D U-Net and multi-head attention mechanism techniques are introduced into the domain of single-tree segmentation for the first time, thereby broadening the application prospects of deep learning in this area.
A novel model architecture is proposed to extract both the spatial and offset information of points within point cloud data using the Sparse 3D U-Net. The offset information refers to the difference between the projected plane and the original coordinates. Subsequently, the multi-head attention mechanism is employed to separately aggregate this information, culminating in the use of an iterative approach to expedite the convergence of the model. These innovative designs effectively address the challenges posed by the excessive density and uneven distribution of point clouds in data acquired through image-based 3D reconstruction methods, thereby significantly enhancing both the efficiency and accuracy of single-tree segmentation.
We investigated the feasibility of an efficient and cost-effective forest inventory methodology, circumventing the reliance on expensive equipment. Furthermore, we executed single-tree segmentation in two representative forest scenarios—a nature reserve in North China and an urban ecological green space—utilizing solely image-generated point cloud data. A comprehensive series of experiments, including ablation and comparative studies, was conducted, thereby thoroughly validating the efficacy and superiority of our model with respect to single-tree segmentation.
3. Methods
This study proposes a deep learning-based model for single-tree segmentation, comprising three distinct modules: a Sparse 3D U-Net, an attention layer, and a prediction head, utilizing forest point cloud data as input [
28]. Each of the three modules performs a unique function and collaboratively operates to achieve single-tree segmentation. Initially, the Sparse 3D U-Net is employed to extract bottom-up, point-by-point features from the point cloud data. Subsequently, the attention layer incorporates a multi-head attention mechanism, a self-attention mechanism, a feedforward neural network, and a learnable query vector to augment the model’s global perceptual and semantic parsing capabilities. Ultimately, two independent Multi-Layer Perceptron (MLP) networks are utilized within the prediction head section to forecast both semantic information and offset information, respectively.
Specifically, the first phase is the preparation phase, wherein the input forest point cloud data are divided into smaller overlapping rectangular slices based on the x and y coordinates to mitigate memory constraints; the second phase is the feature extraction phase, during which point-by-point features are extracted using the Sparse 3D U-Net network and subsequently fed into the next layer; following this, the feature enhancement phase involves the attention layer performing relational modeling based on the features extracted in the previous layer. The extracted features facilitate relationship modeling and feature enhancement; this is followed by the semantic prediction and offset prediction phases, wherein the prediction head outputs the semantic prediction results and offset prediction results based on the outputs from the preceding layer. Subsequently, leveraging the semantic predictions and offset predictions, points sharing identical semantics are projected onto the same plane for clustering, and the slices are merged; finally, unallocated points from the previous step are assigned to their nearest instances. The flow of the specific session is illustrated in
Figure 2. It should be noted that the core of this study lies in the design of the proposed network’s model architecture. Unlike the model adopted by TreeLearn, we introduced an attention mechanism into the model to achieve dynamic and flexible feature selection and reweighting, which effectively improves the performance of the model. In addition, without any modification to the original framework, we directly applied the network model proposed in this study to the segmentation pipeline proposed by TreeLearn to accomplish the corresponding segmentation tasks.
3.1. Data Preprocessing
The TreeLearn dataset encompasses a point cloud representing the entire forest, comprising approximately 20 million points. Owing to memory constraints, directly processing point cloud data of this magnitude with neural networks is not feasible. Drawing inspiration from the work of Ronneberger et al. [
21], this study employed a slicing approach to address this challenge. The degree of overlap between neighboring slices can be regulated by adjusting the hyperparameters. This treatment was also used for custom datasets.
In the customized dataset, this study employed 3D reconstruction techniques to generate the corresponding point cloud data from the acquired image data, followed by point cloud filtering to mitigate the interference of isolated noise during feature extraction [
29]. Subsequently, the data underwent normalization relative to its coordinates, and the point cloud was aligned with the origin through translation and rotation. This process mitigates the interference of absolute coordinates on the deep learning model and enhances the algorithm’s robustness against scale variations. Finally, the data were manually segmented utilizing CloudCompare(version 2.13), with seven of the samples designated as the training set and the remaining sample allocated as the test set.
3.2. Sparse 3D U-Net
To address the significant computational burden associated with traversing all spatial locations when processing sparse data (such as point cloud data) using traditional convolution methods, this study adopted the approach delineated by Graham et al. [
24], who developed a U-Net architecture incorporating sub-stream form sparse convolution (SSC) and sparse convolution (SC). This module serves as the cornerstone of the model, tasked with extracting point-wise and offset features from the point cloud data. Let us assume that the input point cloud comprises N points, denoted as P∈RN×3, where each point possesses three coordinate attributes: x, y, and z. Subsequently, the input point cloud undergoes voxelization, after which the voxelized point cloud is input into the Sparse 3D U-Net network. The encoder component of this network primarily comprises four 3D sparse convolutions, which are chiefly responsible for downsampling the data, whereas the decoder component predominantly consists of four 3D sparse transpose convolutions tasked with upsampling the data. Additionally, batch normalization and ReLU activation functions are applied following all convolution operations, thereby enhancing the stability of model training. Furthermore, following each ReLU activation, a ResidualBlock is integrated, providing a direct pathway for the gradient to propagate through the network. Concurrently, the residual connections enable the encoder to capture features at varying scales, while the decoder fuses low- and high-level features owing to the skip connections. The extraction of pointwise features, denoted as P∗∈RN×C, is ultimately achieved. The specific structure of this framework is illustrated in
Figure 2.
3.3. Attention Layer
The attention module predominantly comprises multi-head attention, self-attention, a feedforward neural network (FFN), and a learnable query vector, which constitutes a pivotal component of the model [
30]. Its primary objective is to iteratively refine the query features while enhancing the multimodal information fusion capabilities through the attention mechanism. Among these components, the multi-head attention layer and the self-attention layer serve as the core modules facilitating the internal interaction of query vectors, employed to uncover long-range dependencies within the query sequence.
where
,
, and
are derived from query vectors through linear mapping and
represents the deflation factor. By employing multi-head parallel computation, the model effectively captures features from diverse subspaces. Upon completion of the attentional interaction, the features undergo nonlinear augmentation via a feedforward neural network (FFN). The FFN comprises two tiers of fully connected layers, each equipped with ReLU activation functions:
where
and
represent the learnable weights, while
and
denote the learnable bias vectors. The feedforward neural network (FFN) further amplifies the expressive capacity of the model and integrates residual connections along with normalization operations subsequent to each layer. The module takes as input point-by-point features and learnable query vectors such that each query vector corresponds to a potential instance prediction based on point-by-point features. Moreover, the query vectors progressively learn the feature templates and distributions of diverse instances within the space via the multi-layer attention mechanism. The specific architecture is illustrated in
Figure 3.
Furthermore, during the training phase, it was observed that incorporating certain true values into the outputs of the attention layer can enhance the model’s performance. Let us denote the presence of M query vectors, defining the query vector as
, where
represents the embedding dimension and
denotes the index. Here, Z0 signifies the query vector initialized at the outset, while
corresponds to the feature query vectors that are learned to represent various instance types following the training process. Subsequently, Z1 is reintroduced into the attention layer, and after numerous iterations, only the output from the final attention layer is utilized in the prediction head for generating predictions. The formula is presented as follows:
where
denotes the output of the attention layer and
represents a linear projection of
, while
and
correspond to linear projections capturing distinct features. Empirical evidence confirms that this approach facilitates an enhancement in the rate of model convergence when addressing a variable number of instance projections.
3.4. Prediction Head
The prediction head primarily functions to generate the final predictions based on the query features produced by the preceding layer, encompassing both semantic labeling and offset prediction. In the specific implementation, the input query features undergo layer normalization as an initial step to enhance training stability. Subsequently, the normalized features are mapped onto the semantic category space via a fully connected layer, which produces the target category prediction labels. Concurrently, an additional fully connected layer is employed to derive bias values. Furthermore, instance features are obtained by analyzing the relationships between query features and point-by-point features. Ultimately, the output of the prediction header amalgamates semantic information, bias information, and instance features to furnish dependable support for subsequent tasks.
3.5. Merge Tiles and Single-Tree Segmentation
Upon completion of the predictions for all slices, the slices are amalgamated according to a tailored overlap region. For multiple predictions generated in overlapping sections, the average is computed, thereby minimizing artifacts introduced by the tiling process. Should the offset predictions prove accurate, the coordinates projected from the offset values will yield x and y coordinates that correspond to the trunk. These coordinates will subsequently serve as inputs to a density-based clustering algorithm, which executes the final single-tree segmentation [
31].
3.6. Postprocessing
In the preceding step, the tree instances are identified; however, a subset of points situated at the peripheries of the clusters remains unassigned. To effectively assign these points, a straightforward strategy is employed: calculating their distances from neighboring points based on the projected coordinates, followed by assigning them to the instances corresponding to the nearest point according to the nearest neighbor principle.
3.7. Assessment Criteria
To assess the performance of the proposed methodology, the matching strategy delineated by Zhao et al. [
32] was employed, which correlates the true values with the predicted values, as illustrated in the following equation:
where
represents the distance between the true and predicted values, while (
,
,
) and (
,
,
) denote the trunk coordinates corresponding to the true and predicted values, respectively. Estimated trees
and
are deemed successfully matched when the two three-dimensional spatial points that represent the trees’ location information are in close proximity.
signifies the weight attributed to the height difference, with a default value set at 0.5.
In evaluating the results of semantic segmentation, this study adopted accuracy, defined as the ratio of correctly predicted points to the total number of points. To mitigate potential bias in the results arising from the over-weighting of regions characterized by high point densities, this study employed point cloud data that had been secondarily sampled using voxels of size 10 cm3 for evaluation.
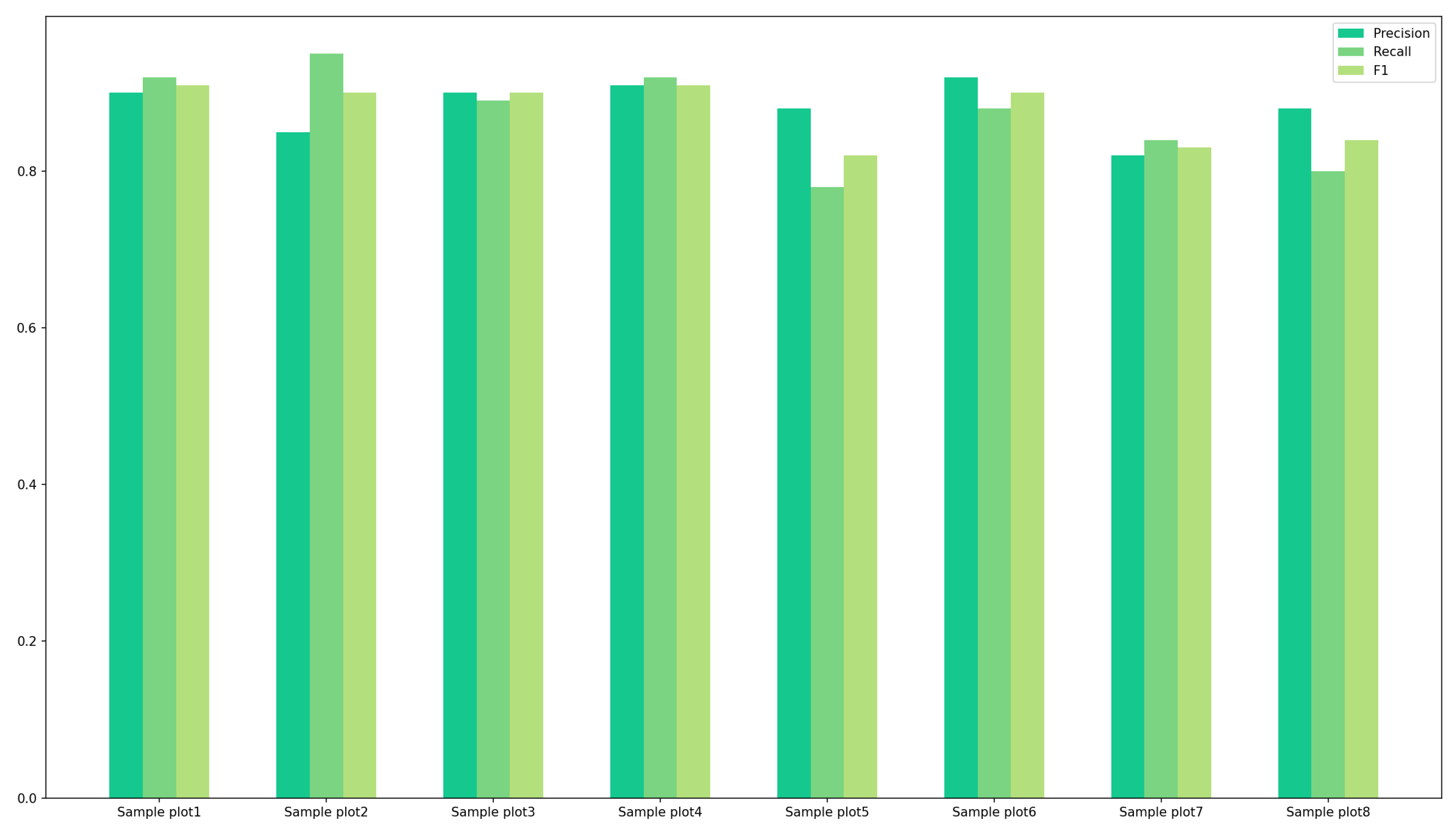
In assessing the results of instance segmentation, this study utilized recall, precision, and F1 scores to evaluate the performance of the proposed methodology, as demonstrated in the following equation:
where
denotes that the true value and the predicted value align accurately, indicating that the instance was successfully detected;
signifies that the true value and the predicted value do not correspond, such that the instance was undetected or erroneously partitioned into other instances; and
indicates that the true value and the predicted value exhibit a one-to-many relationship, whereby a single instance is fragmented into multiple instances.
is defined as the proportion of true-positive samples correctly identified by the model out of all actual positive samples, thereby highlighting the model’s sensitivity in capturing positive instances.
refers to the proportion of samples predicted as positive by the model that are truly positive, reflecting the model’s accuracy in covering positive samples and its reliability in positive predictions.
5. Discussion
This study investigated the viability of a novel approach to single-tree segmentation technology by creating point cloud datasets suitable for deep learning applications through an image-based 3D reconstruction methodology, culminating in the utilization of the trained model for single-tree segmentation. This approach offers greater convenience and reduced costs in comparison to traditional methods utilizing LiDAR for data collection. Relative to alternative methodologies, our model demonstrates superior performance in processing datasets generated through image-based 3D reconstruction techniques, while also exhibiting high accuracy when handling LiDAR data.
The fundamental innovation of the model lies in the incorporation of a Sparse 3D U-Net architecture tailored for the specific characteristics of image-based 3D reconstruction data, along with the integration of modules including a multi-head attention mechanism, learnable query vectors, and cyclic prediction, which markedly enhances its capacity to process 3D reconstruction data. Specifically, the Sparse 3D U-Net architecture significantly enhances both the efficiency and accuracy of the model in processing large-scale forest point clouds by minimizing redundant parameters and computational complexity. Meanwhile, inspired by the pioneering work of Vaswani et al. [
26], the multi-head attention mechanism allows the model to simultaneously process multiple feature subspaces during the feature extraction process, thereby adaptively enhancing the expressiveness of key features and effectively mitigating the impact of extraneous information, which notably improves the model’s performance in scenarios characterized by an uneven point cloud distribution. The cyclic prediction module accelerates the convergence speed of the model by iteratively refining the prediction results and retaining only the final output. Furthermore, the overall performance of the model is enhanced by the synergistic interaction among these modules, facilitating efficient and accurate single-tree segmentation across a variety of forest scenarios.
When compared to TreeLearn, our approach demonstrates substantial improvements in feature representation and convergence efficiency. This advantage primarily stems from the multi-head attention mechanism integrated into our model, which allows for simultaneous focus on various segments of input features across multiple subspaces, thereby effectively capturing multi-scale and intricate dependency patterns within the data. Such comprehensive feature representation significantly improves the model’s capacity to identify salient features, mitigate information loss and sparsity issues, and consequently enhance the accuracy and robustness of feature extraction.
Furthermore, the iterative prediction module enables the model to progressively refine its outputs through successive feedback cycles, thereby enhancing feature representations, capturing finer details, and correcting errors more effectively. This iterative mechanism not only amplifies the model’s expressive capacity but also accelerates convergence during training, as each cycle iteratively refines the previous predictions, thereby substantially reducing the training duration required to attain optimal performance.
However, it is possible that the introduction of additional complexity during the optimization process adversely impacts the model’s capacity to fit fine-grained details, thereby leading to a marginal decline in overall accuracy. And owing to limited project funding, the plot size employed in this study (15 × 15 m, totaling 225 m2) is substantially smaller than the plots within the TreeLearn dataset, which span from 1.0 to 2.2 hectares. This disparity in spatial scale imposes notable constraints on direct dataset comparisons.
Specifically, smaller plots tend to provide a more localized snapshot of forest structure and species composition, which may not adequately reflect the heterogeneity inherent at broader spatial scales. As a result, models developed or validated using data from these smaller plots may demonstrate diminished generalizability when applied to larger-scale datasets, such as TreeLearn.
In this study, the TreeLearn dataset was employed for pre-training the model; however, it originates from a different geographical region than the customized dataset. Consequently, this regional discrepancy may adversely affect the model’s performance, exemplified by decreased recall rates observed when substantial heterogeneity exists among trees within the sample plots. When point cloud data collected via LiDAR and image-based 3D reconstruction are obtained from the same region, it can facilitate more effective feature transfer for the target task, thereby enhancing both model performance and training efficiency. In future research, we will consider using both LiDAR and image-based 3D reconstruction techniques to collect data for the same study area in order to improve the performance of the model.
In the context of deep learning models, both the quantity and quality of data are pivotal factors influencing model performance. Therefore, a reduction in the difficulty of data acquisition will contribute positively to the enhancement of model performance. Certainly, alongside the necessity for high-quality data, model optimization represents another critical avenue for enhancing performance. Building upon the existing model, we are contemplating the integration of superpoint features, which are defined as points aggregated from homogeneous neighboring points according to geometric principles [
36]. This methodology effectively circumvents the need for supervised features by utilizing undirected semantic and center distance labels [
37]. Moreover, our approach employs a clustering-based strategy, with potential future explorations incorporating techniques such as bounding box detection or mask prediction.
In conclusion, our methodology adeptly integrates multiple innovative techniques, exploring and validating a new pathway for single-tree segmentation while addressing the challenges encountered by existing single-tree segmentation models in the context of 3D reconstruction data. Despite certain limitations inherent in the model, it is anticipated that, through subsequent optimization and refinement, it will assume a broader role in forest resource management and related fields.

 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}