
Forest Carbon Density Estimation Using Tree Species Diversity and Stand Spatial Structure Indices


Abstract
1. Introduction
2. Materials and Methods
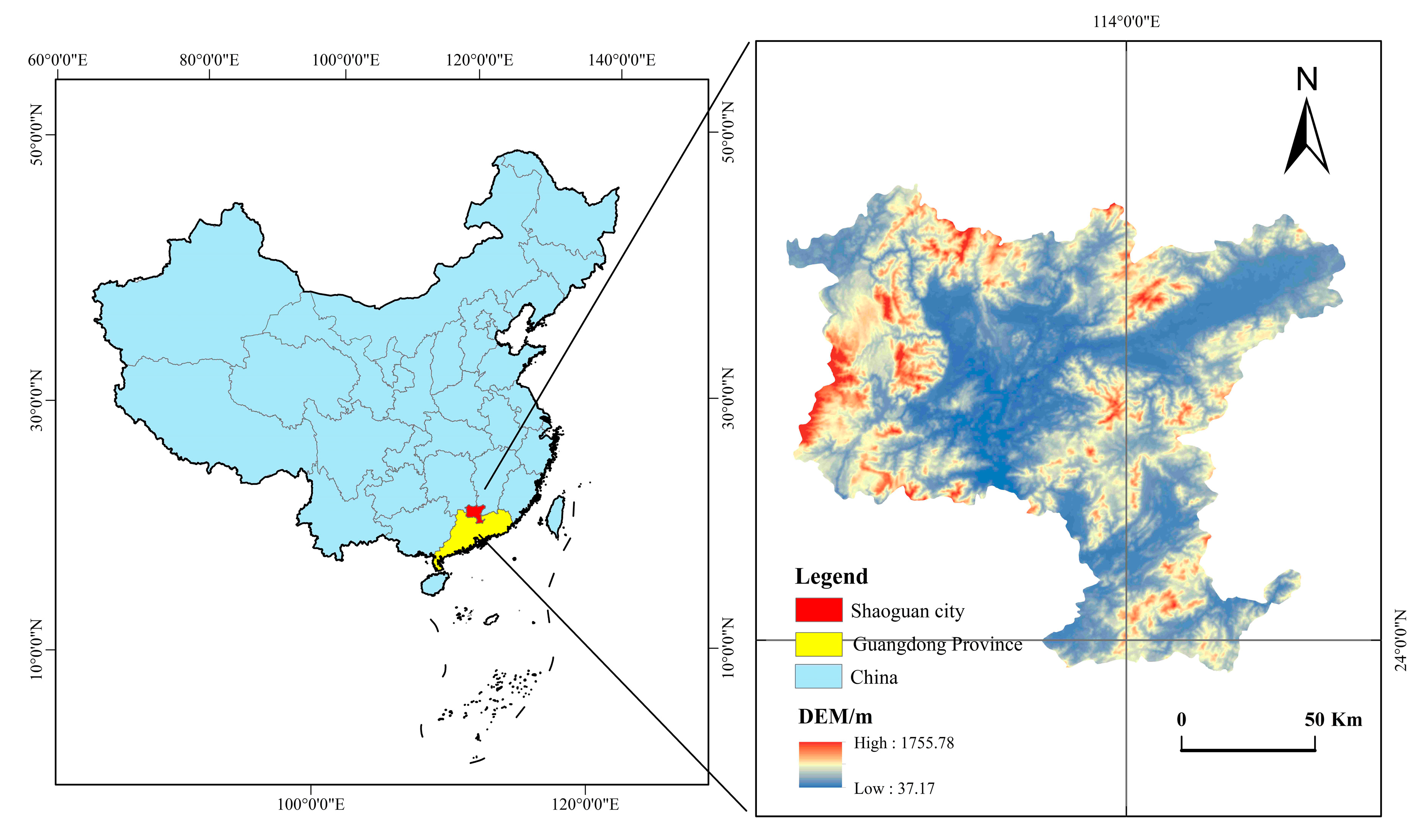
2.1. Study Area
2.2. Data and Preprocessing
2.3. Research Method
2.3.1. Calculation of Species Diversity Index
- (1)
- Richness index
- (2)
- Diversity index
- (3)
- Evenness index
2.3.2. Calculation of Stand Spatial Structure Index
- (1)
- Reineke’s stand density index (SDI)
- (2)
- Hegyi’s competition index (CI)
- (3)
- Simple mingling degree (M)
2.3.3. Structural Equation Model (SEM)
2.3.4. Prediction Model of Forest Carbon Density
- (1)
- Multiple Linear Regression Model (MLR)
- (2)
- Tree-based Piecewise Linear Model (M5P)
- (3)
- Random Forest Model (RF)
- (4)
- Artificial Neural Network Model (ANN)
- (5)
- Support Vector Regression (SVR)
2.3.5. Boruta Algorithm
2.3.6. Model Accuracy Evaluation
2.3.7. Co-Kriging Interpolation
3. Results
3.1. Numerical Distribution of Species Diversity and Stand Spatial Structure Indices
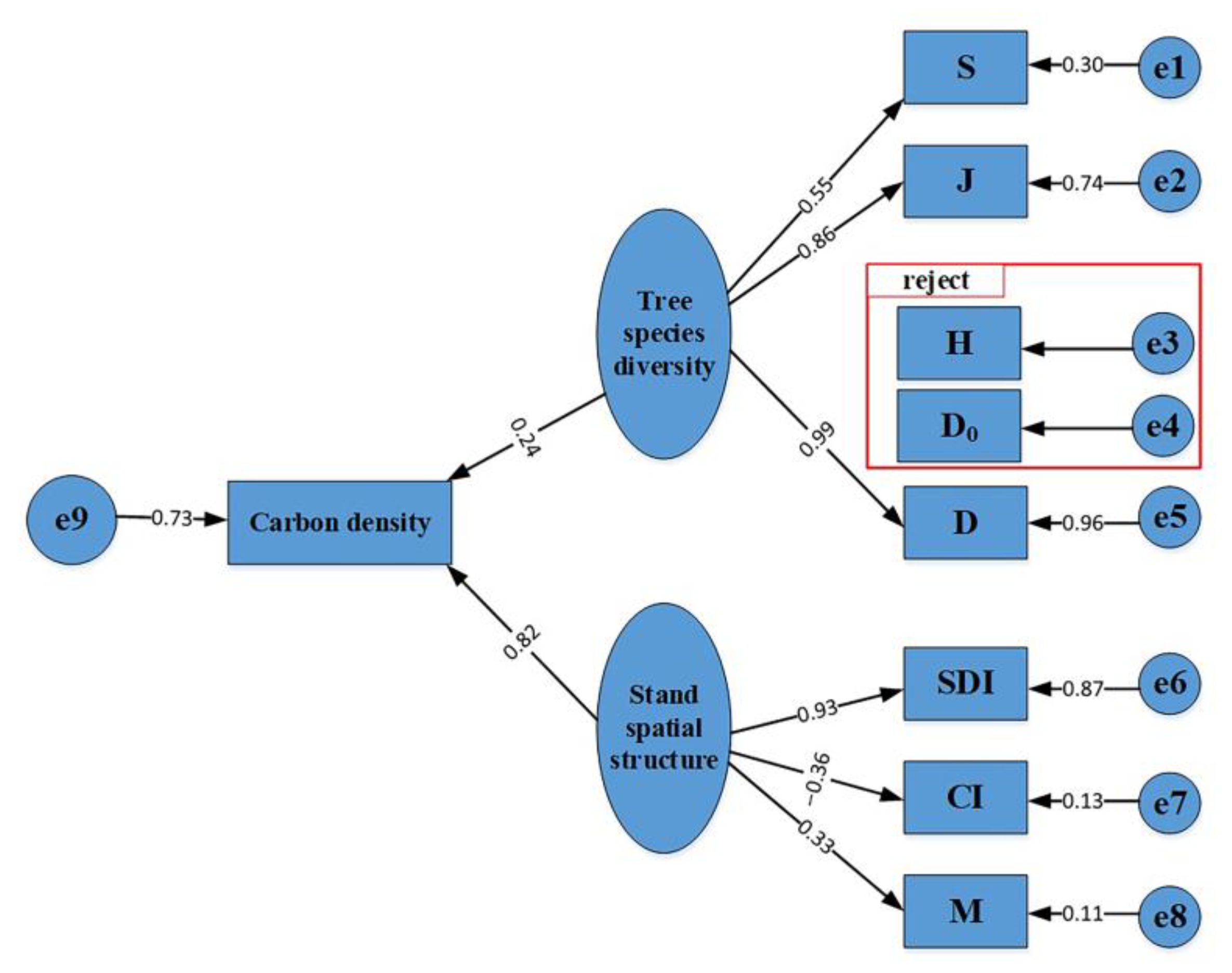
3.2. Impacts of Species Diversity and Stand Spatial Structure on Carbon Density
3.3. Carbon Density Prediction Based on Tree Species Diversity and Stand Spatial Structure Indices
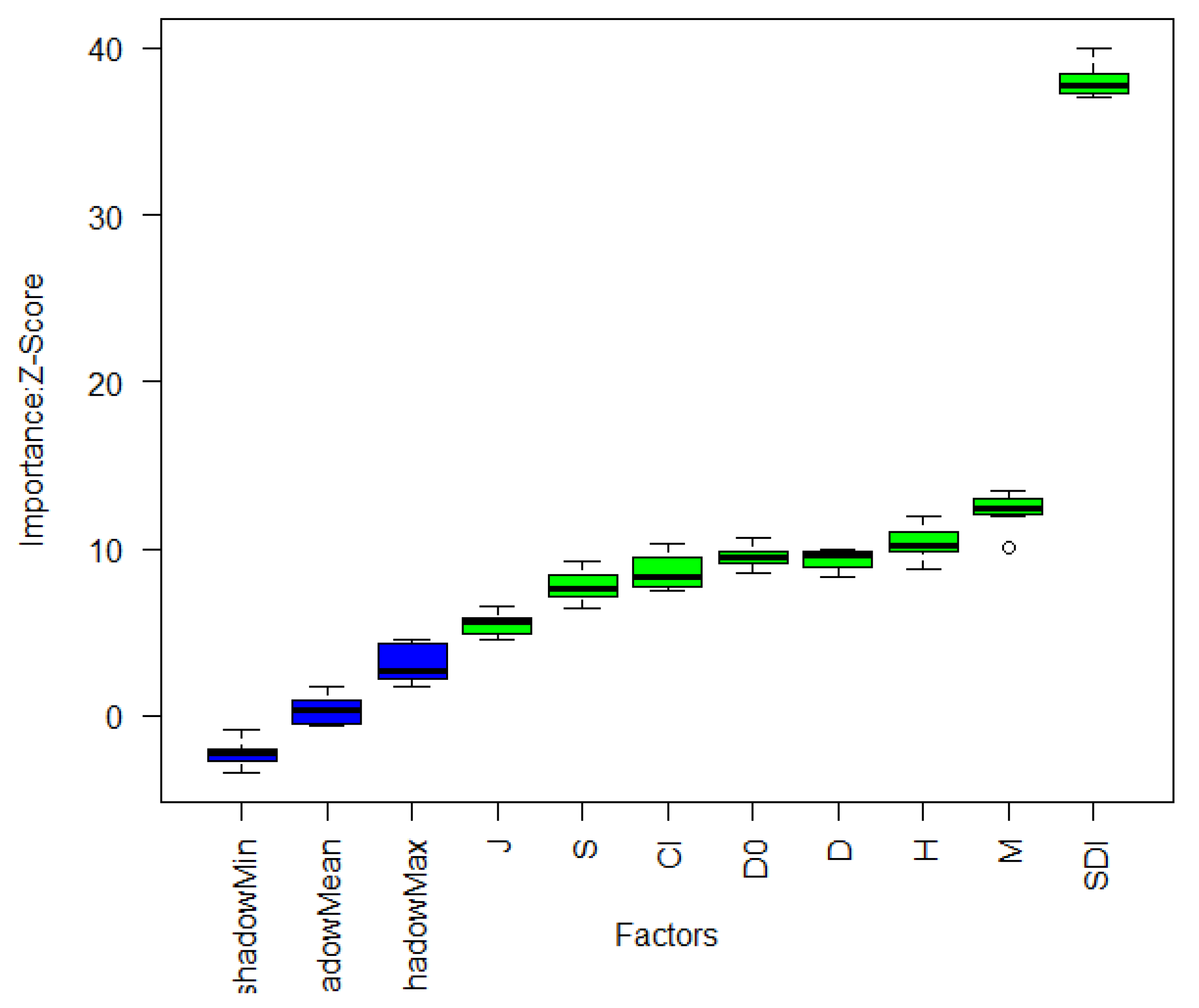
3.3.1. Feature Factor Selection
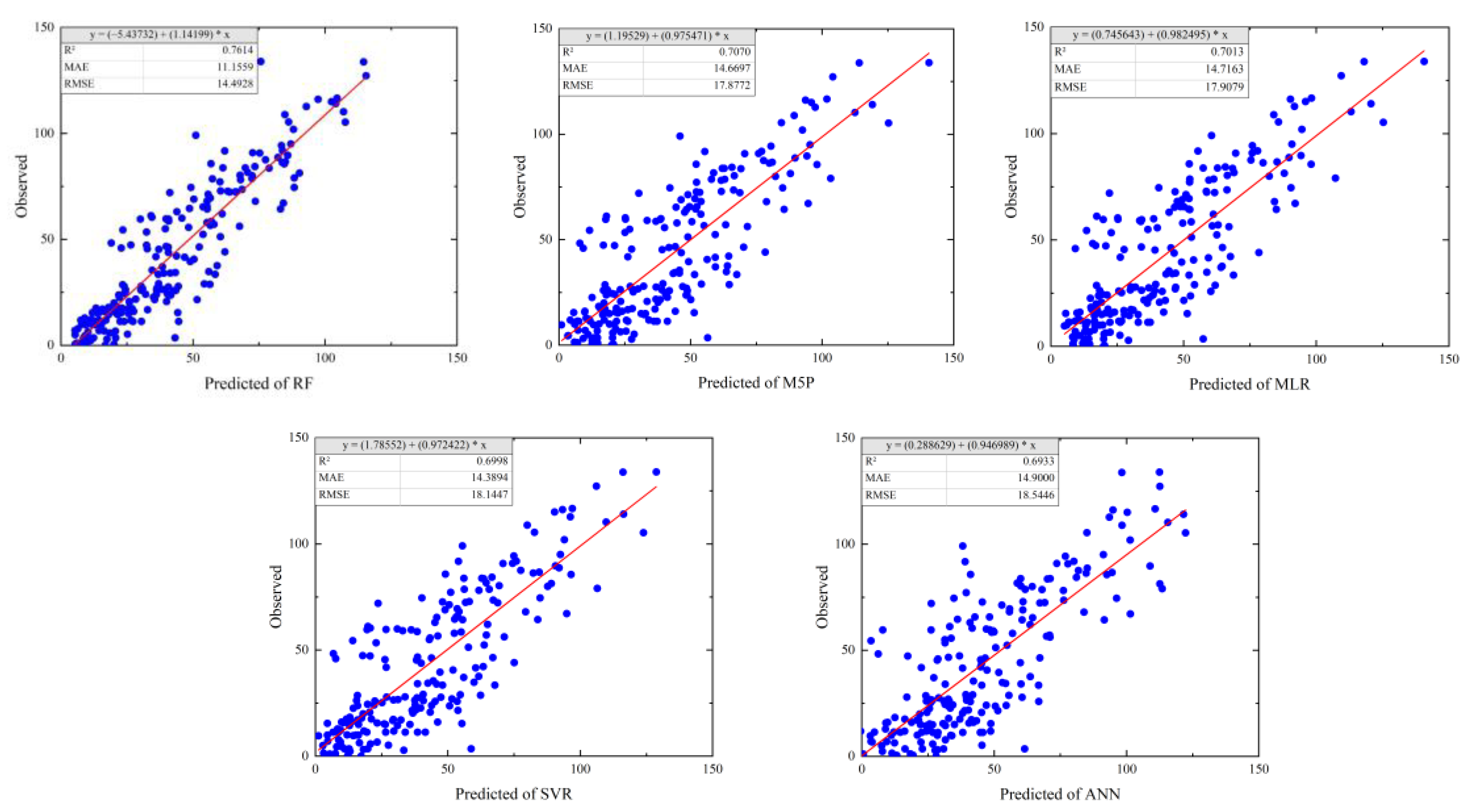
3.3.2. Model Accuracy Evaluation
3.3.3. Carbon Density Estimation Based on RF Model
3.4. Suggestions on Management Measures to Improve Forest Carbon Density
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Winkler, H. Climate change and developing countries. S. Afr. J. Sci. 2005, 101, 355–364. [Google Scholar]
- Kikstra, J.S.; Nicholls, Z.R.J.; Smith, C.J.; Lewis, J.; Lamboll, R.D.; Byers, E.; Sandstad, M.; Meinshausen, M.; Gidden, M.J.; Rogelj, J.; et al. The IPCC Sixth Assessment Report WGIII climate assessment of mitigation pathways: From emissions to global temperatures. Geosci. Model Dev. 2022, 15, 9075–9109. [Google Scholar] [CrossRef]
- Stocker. Climate Change 2013; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Kramer, P.J. Carbon Dioxide Concentration, Photosynthesis, and Dry Matter Production. Bioscience 1981, 31, 29–33. [Google Scholar] [CrossRef]
- Zedaker, S.M. Forest ecosystems: Concepts and management. For. Sci. 1986, 3, 841–842. [Google Scholar] [CrossRef]
- Dixon, R.K.; Solomon, A.M.; Brown, S.; Houghton, R.A.; Trexier, M.C.; Wisniewski, J. Carbon Pools and Flux of Global Forest Ecosystems. Science 1994, 263, 185–190. [Google Scholar] [CrossRef] [PubMed]
- Kurz, W.A.; Apps, M.J. Contribution of Northern Forests to the Global C Cycle: Canada as a Case Study; Springer: Dordrecht, The Netherlands, 1993; pp. 163–176. [Google Scholar] [CrossRef]
- Mi, X.C.; Feng, G.; Zhang, J.; Hu, Y.; Zhu, L.; Ma, K. Review on biodiversity science in China. Bull. Chin. Acad. Sci. 2021, 36, 384–398. [Google Scholar] [CrossRef]
- Liang, J.; Crowther, T.W.; Picard, N.; Wiser, S.; Zhou, M.; Alberti, G.; Schulze, E.-D.; McGuire, A.D.; Bozzato, F.; Pretzsch, H.; et al. Positive biodiversity-productivity relationship predominant in global forests. Science 2016, 354, aaf8957. [Google Scholar] [CrossRef]
- Yin, L.; Bao, W.; Bongers, F.; Chen, B.; Chen, G.; Guo, K.; Jiang, M.; Lai, J.; Lin, D.; Liu, C.; et al. Drivers of tree carbon storage in subtropical forests. Sci. Total Environ. 2019, 654, 684–693. [Google Scholar]
- Huang, Y.; Chen, Y.; Castro-Izaguirre, N.; Baruffol, M.; Brezzi, M.; Lang, A.; Li, Y.; Härdtle, W.; Von Oheimb, G.; Yang, X.; et al. Impacts of species richness on productivity in a large-scale subtropical forest experiment. Science 2018, 362, 80–83. [Google Scholar] [CrossRef]
- Van Con, T.; Thang, N.T.; Ha, D.T.T.; Khiem, C.C.; Quy, T.H.; Lam, V.T.; Van Do, T.; Sato, T. Relationship between aboveground biomass and measures of structure and species diversity in tropical forests of Vietnam. For. Ecol. Manag. 2013, 310, 213–218. [Google Scholar] [CrossRef]
- Vance-Chalcraft, H.D.; Willig, M.R.; Cox, S.B.; Lugo, A.E.; Scatena, F.N. Relationship Between Aboveground Biomass and Multiple Measures of Biodiversity in Subtropical Forest of Puerto Rico. Biotropica 2009, 42, 290–299. [Google Scholar] [CrossRef]
- Shahid, M.; Joshi, S.P. Relationship between Tree Species Diversity and Carbon Stock Density in Moist Deciduous Forest of Western Himalayas, India. J. For. Environ. Sci. 2017, 33, 39–48. [Google Scholar] [CrossRef]
- Kumar, B.M. Species richness and aboveground carbon stocks in the homegardens of central Kerala, India. Agric. Ecosyst. Environ. 2011, 140, 430–440. [Google Scholar] [CrossRef]
- Liu, X.; Trogisch, S.; He, J.-S.; Niklaus, P.; Bruelheide, H.; Tang, Z.; Erfmeier, A.; Scherer-Lorenzen, M.; Pietsch, K.A.; Yang, B.; et al. Tree species richness increases ecosystem carbon storage in subtropical forests. Proc. R. Soc. B Boil. Sci. 2018, 285, 20181240. [Google Scholar] [CrossRef]
- Yang, S.; Zou, W.; Yin, G.; Li, R.S.; Yang, J.C. Species diversity and influencing factors of artificial forest communities in Shunde. Guangdong. Ecol. Sci. 2010, 29, 427–431. [Google Scholar]
- Hall, R.; Skakun, R.; Arsenault, E.; Case, B. Modeling forest stand structure attributes using Landsat ETM+ data: Application to mapping of aboveground biomass and stand volume. For. Ecol. Manag. 2006, 225, 378–390. [Google Scholar] [CrossRef]
- Zheng, G.; Chen, J.M.; Tian, Q.J.; Ju, W.M.; Xia, X.Q. Combining remote sensing imagery and forest age inventory for biomass mapping. J. Environ. Manag. 2007, 85, 616–623. [Google Scholar] [CrossRef]
- Ou, G.L.; Li, C.; Lv, Y.Y.; Wei, A.C.; Xiong, H.X.; Xu, H.; Wang, G.X. Improving aboveground biomass estimation of Pinus densata forests in Yunnan using Landsat 8 Imagery by incorporating age dummy variable and method comparison. Remote Sens. 2019, 11, 738. [Google Scholar] [CrossRef]
- Li, Z.; Huang, H.; Zhang, Y.; Meng, Y. Subtropical evergreen broad-leaved forest: The most diverse subtropical forest in the world. For. Hum. 2022, 008, 66–71. [Google Scholar]
- Xie, X.; Wang, Q.; Dai, L.; Su, D.; Wang, X.; Qi, G.; Ye, Y. Application of China’s National Forest Continuous Inventory Database. Environ. Manag. 2011, 48, 1095–1106. [Google Scholar] [CrossRef]
- Zeng, W. Establishment of a univariate tree biomass model for 34 tree species based on wood density. For. Resour. Manag. 2017, 6, 41–46. [Google Scholar] [CrossRef]
- Zhang, H. Measurement and analysis of carbon content rates of eight tree species in Guangdong province. For. Resour. Manag. 2018, 1, 148–154. [Google Scholar]
- Solow, A.R.; Polasky, S. Measuring biological diversity. Environ. Ecol. Stat. 1994, 1, 95–103. [Google Scholar] [CrossRef]
- Jost, L. Entropy and diversity. Oikos 2006, 113, 363–375. [Google Scholar] [CrossRef]
- GB/T 38590-2020; Technical Regulations for Continuous Forest Inventory. The National Forestry and Grassland Administration: Beijing, China, 2020.
- Vanderschaaf, C.L. Reineke’s stand density index: A quantitative and non-unitless measure of stand density. In Proceedings of the 15th Biennial Southern Silvicultural Research Conference, Hot Springs, AR, USA, 17–20 November 2008; U.S. Department of Agriculture, Forest Service, Southern Research Station: Asheville, NC, USA, 2013. [Google Scholar]
- Marchi, M. Nonlinear versus linearised model on stand density model fitting and stand density index calculation: Analysis of coefficients estimation via simulation. J. For. Res. 2019, 30, 1595–1602. [Google Scholar] [CrossRef]
- Sandoval, S.; Cancino, J. Modeling the edge effect in even-aged Monterrey pine (Pinus radiata D. Don) stands incorporating a competition index. For. Ecol. Manag. 2008, 256, 78–87. [Google Scholar] [CrossRef]
- Hu, Y.B.; Hui, G.Y. A new method for measuring population distribution patterns of forest trees based on the mingling degree. J. Beijing For. Univ. 2015, 37, 9–21. [Google Scholar] [CrossRef]
- Hoyle, R.H. Introduction to the special section: Structural equation modeling in clinical research. J. Consult. Clin. Psychol. 1994, 62, 427–428. [Google Scholar] [CrossRef]
- Wen, Z.L.; Kittai, H.; Marsh, H.W. Structural equation model: Cutoff criteria for goodness of fit indices and chi-square test. Acta Psychol. Sin. 2004, 36, 186–194. [Google Scholar]
- Chen, H.; Qin, Z.; Zhai, D.-L.; Ou, G.; Li, X.; Zhao, G.; Fan, J.; Zhao, C.; Xu, H. Mapping Forest Aboveground Biomass with MODIS and Fengyun-3C VIRR Imageries in Yunnan Province, Southwest China Using Linear Regression, K-Nearest Neighbor and Random Forest. Remote Sens. 2022, 14, 5456. [Google Scholar] [CrossRef]
- He, J.; Fan, C.; Geng, Y.; Zhang, C.; Zhao, X.; von Gadow, K. Assessing scale-dependent effects on Forest biomass productivity based on machine learning. Ecol. Evol. 2022, 12, e9110. [Google Scholar] [CrossRef]
- Li, C.; Li, M.; Li, Y.; Qian, P. Estimating aboveground forest carbon density using Landsat 8 and field-based data: A comparison of modelling approaches. Int. J. Remote Sens. 2020, 41, 4269–4292. [Google Scholar] [CrossRef]
- Liu, Y. Mathematical model of multiple linear regression. J. Shenyang Inst. Eng. 2005, 1, 128–129. [Google Scholar]
- Ross, J. Quinlan: Learning with continuous classes. In Proceedings of the 5th Australian Joint Conference on Artificial Intelligence, Hobart, Tasmania, 16–18 November 1992; World Scientific: Singapore, 1992; pp. 343–348. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Li, T.; Li, M.; Ren, F.; Tian, L. Estimation and Spatio-Temporal Change Analysis of NPP in Subtropical Forests: A Case Study of Shaoguan, Guangdong, China. Remote Sens. 2022, 14, 2541. [Google Scholar] [CrossRef]
- Pavlov, Y.L. Limit distributions of the height of a random forest of plane rooted trees. Discret. Math. Appl. 1994, 4, 73–88. [Google Scholar] [CrossRef]
- Safitri, L.; Mardiyati, S.; Rahim, H. Forecasting the mortality rates of Indonesian population by using neural network. J. Phys. Conf. Ser. 2018, 974, 012030. [Google Scholar] [CrossRef]
- Xiao, F. Forest Coverage Prediction Based on Least Squares Support Vector Regression Algorithm. Adv. Mater. Res. 2012, 446–449, 2978–2982. [Google Scholar] [CrossRef]
- Kursa, M.B.; Rudnicki, W.R. Feature Selection with theBorutaPackage. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef]
- Singh, G.; Panda, R.K. Daily Sediment Yield Modeling with Artificial Neural Network Using 10-fold Cross Validation Method: A Small Agricultural Watershed, Kapgari, India. Int. J. Earth Sci. Eng. 2010, 4, 443–450. [Google Scholar]
- Zheng, B.; Agresti, A. Summarizing the predictive power of a generalized linear model. Stat. Med. 2000, 19, 1771–1781. [Google Scholar] [CrossRef]
- Zimmerman, D.; Pavlik, C.; Ruggles, A.; Armstrong, M. An Experimental Comparison of Ordinary and Universal Kriging and Inverse Distance Weighting. J. Int. Assoc. Math. Geol. 1999, 31, 375–390. [Google Scholar] [CrossRef]
- Myers, D.E. Matrix formulation of co-kriging. J. Int. Assoc. Math. Geol. 1982, 14, 249–257. [Google Scholar] [CrossRef]
- Goovaerts, P. Geostatistical approaches for incorporating elevation into the spatial interpolation of rainfall. J. Hydrol. 2000, 228, 113–129. [Google Scholar] [CrossRef]
- Jiao, W.; Wang, W.; Peng, C.; Lei, X.; Ruan, H.; Li, H.; Yang, Y.; Grabarnik, P.; Shanin, V. Improving a Process-Based Model to Simulate Forest Carbon Allocation under Varied Stand Density. Forests 2022, 13, 1212. [Google Scholar] [CrossRef]
- Cai, H.; Di, X.; Chang, S.X.; Jin, G. Stand density and species richness affect carbon storage and net primary productivity in early and late successional temperate forests differently. Ecol. Res. 2016, 31, 525–533. [Google Scholar] [CrossRef]
- Wu, C.; Chen, D.; Sun, X.; Zhang, S. Contributions of competition on Larix kaempferi tree-ring growth were higher than long-term climate in China. Agric. For. Meteorol. 2022, 320, 108967. [Google Scholar] [CrossRef]
- Hulvey, K.B.; Hobbs, R.J.; Standish, R.J.; Lindenmayer, D.B.; Lach, L.; Perring, M.P. Benefits of tree mixes in carbon plantings. Nat. Clim. Chang. 2013, 3, 869–874. [Google Scholar] [CrossRef]
- Shirima, D.D.; Totland, Ø.; Munishi, P.K.; Moe, S.R. Relationships between tree species richness, evenness and aboveground carbon storage in montane forests and miombo woodlands of Tanzania. Basic Appl. Ecol. 2015, 16, 239–249. [Google Scholar] [CrossRef]
- Ruiz-Jaen, M.C.; Potvin, C. Tree Diversity Explains Variation in Ecosystem Function in a Neotropical Forest in Panama. Biotropica 2010, 42, 638–646. [Google Scholar] [CrossRef]
- Shao, Y.; Zhong, B.; Yang, Z.; Fan, J.; Lu, G.; Xue, L. Distribution of forest resources and carbon storage in Guangdong Province. Hunan For. Sci. Technol. 2013, 40, 34–38. [Google Scholar]
- Chen, L.-C.; Guan, X.; Li, H.-M.; Wang, Q.-K.; Zhang, W.-D.; Yang, Q.-P.; Wang, S.-L. Spatiotemporal patterns of carbon storage in forest ecosystems in Hunan Province, China. For. Ecol. Manag. 2018, 432, 656–666. [Google Scholar] [CrossRef]
- Li, H.; Wang, X.; Meng, J. Research on the dynamic changes of carbon storage at the level of forest management units: A case study of the Hotan Center in Guangxi. J. Zhejiang For. Sci. Technol. 2019, 39, 29–35. [Google Scholar]
- Zhao, M.; Yang, J.; Zhao, N.; Xiao, X.; Yue, T.; Wilson, J.P. Estimation of the relative contributions of forest areal expansion and growth to China’s forest stand biomass carbon sequestration from 1977 to 2018. J. Environ. Manag. 2021, 300, 113757. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Feng, Z.; Ouyang, Z. Vegetation carbon storage and density of forest ecosystems in China. Ying Yong Sheng Tai Xue Bao 2001, 12, 13–16. [Google Scholar]
- Joshi, V.C.; Negi, V.S.; Bisht, D.; Sundriyal, R.; Arya, D. Tree biomass and carbon stock assessment of subtropical and temperate forests in the Central Himalaya, India. Trees For. People 2021, 6, 100147. [Google Scholar] [CrossRef]
- Ali, A.; Ashraf, M.I.; Gulzar, S.; Akmal, M. Estimation of forest carbon stocks in temperate and subtropical mountain systems of Pakistan: Implications for REDD+ and climate change mitigation. Environ. Monit. Assess. 2020, 192, 198. [Google Scholar] [CrossRef]
- Bordin, K.M.; Esquivel-Muelbert, A.; Bergamin, R.S.; Klipel, J.; Picolotto, R.C.; Frangipani, M.A.; Zanini, K.J.; Cianciaruso, M.V.; Jarenkow, J.A.; Jurinitz, C.F.; et al. Climate and large-sized trees, but not diversity, drive above-ground biomass in subtropical forests. For. Ecol. Manag. 2021, 490, 119126. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tree Species or Types | Wood Density (p) | Tree Species or Types | Wood Density (p) |
|---|---|---|---|
| Pinus massoniana | 0.448 | Schima superba | 0.556 |
| Pinus elliottii | 0.412 | Liquidambar formosana | 0.504 |
| Cunninghamia lanceolata | 0.310 | Populus | 0.418 |
| Cryptomeria | 0.349 | Other cedars | 0.394 |
| Cupressus | 0.597 | Other pine | 0.450 |
| Quercus | 0.576 | Other hard width | 0.625 |
| Cinnamomum | 0.460 | Other soft and broad | 0.443 |
| Indices | Max | Min | Mean | SD | Percent below Average (%) |
|---|---|---|---|---|---|
| S | 12.000 | 1.000 | 4.932 | 2.712 | 45.631 |
| J | 1.000 | 0.051 | 0.634 | 0.222 | 41.500 |
| H | 2.450 | 0.000 | 1.021 | 0.709 | 47.500 |
| D | 0.840 | 0.000 | 0.511 | 0.221 | 43.700 |
| D0 | 8.696 | 1.000 | 2.511 | 1.139 | 56.300 |
| SDI | 6655.673 | 30.665 | 1530.739 | 1084.584 | 56.284 |
| CI | 95.893 | 0.280 | 4.578 | 10.428 | 83.060 |
| M | 1.000 | 0.000 | 0.517 | 0.262 | 46.448 |
| Zone | Forest Management Sub-Region | Mean (tC/ha) | Min (tC/ha) | Max (tC/ha) | SD (tC/ha) |
|---|---|---|---|---|---|
| NO. 1 | Evergreen Broad-leaved and Coniferous Broad-leaved Mixed Forest Management Sub-region | 40.004 | 4.654 | 109.069 | 25.058 |
| NO. 2 | Water Conservation Forest and General Timber Forest Management Sub-region | 43.178 | 4.453 | 109.650 | 25.419 |
| Forest Type | Carbon Density (tC/ha) | Percentage of Sample Plots (%) | |||
|---|---|---|---|---|---|
| Min | Max | Mean | SD | ||
| Coniferous pure forest | 2.312 | 133.896 | 24.047 | 19.623 | 29.677 |
| Broad-leaved pure forest | 1.430 | 64.539 | 28.879 | 22.262 | 8.387 |
| Coniferous mixed forest | 17.495 | 74.512 | 42.454 | 20.555 | 3.226 |
| Broad-leaved mixed forest | 45.500 | 133.762 | 77.414 | 20.883 | 47.097 |
| Coniferous and Broad-leaved mixed forest | 14.415 | 81.303 | 36.492 | 22.410 | 11.613 |
| Age Group | Carbon Density (tC/ha) | Percentage of Sample Plots (%) | |||
|---|---|---|---|---|---|
| Min | Max | Mean | SD | ||
| Young forest | 2.313 | 83.781 | 33.459 | 22.877 | 44.118 |
| Middle aged forest | 4.402 | 116.629 | 56.235 | 33.636 | 44.117 |
| Near-mature forest | 21.5436 | 79.006 | 57.399 | 35.082 | 8.824 |
| Mature forest | 25.227 | 133.762 | 73.915 | 38.737 | 1.765 |
| Over-mature forest | 9.675 | 133.896 | 69.325 | 50.771 | 1.176 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Wu, X.-C.; Wu, Y.; Li, M.-Y. Forest Carbon Density Estimation Using Tree Species Diversity and Stand Spatial Structure Indices. Forests 2023, 14, 1105. https://doi.org/10.3390/f14061105
Li T, Wu X-C, Wu Y, Li M-Y. Forest Carbon Density Estimation Using Tree Species Diversity and Stand Spatial Structure Indices. Forests. 2023; 14(6):1105. https://doi.org/10.3390/f14061105
Chicago/Turabian StyleLi, Tao, Xiao-Can Wu, Yi Wu, and Ming-Yang Li. 2023. "Forest Carbon Density Estimation Using Tree Species Diversity and Stand Spatial Structure Indices" Forests 14, no. 6: 1105. https://doi.org/10.3390/f14061105
APA StyleLi, T., Wu, X.-C., Wu, Y., & Li, M.-Y. (2023). Forest Carbon Density Estimation Using Tree Species Diversity and Stand Spatial Structure Indices. Forests, 14(6), 1105. https://doi.org/10.3390/f14061105