
Crack Detection Method for Engineered Bamboo Based on Super-Resolution Reconstruction and Generative Adversarial Network

Abstract
:1. Introduction
2. Materials and Methods
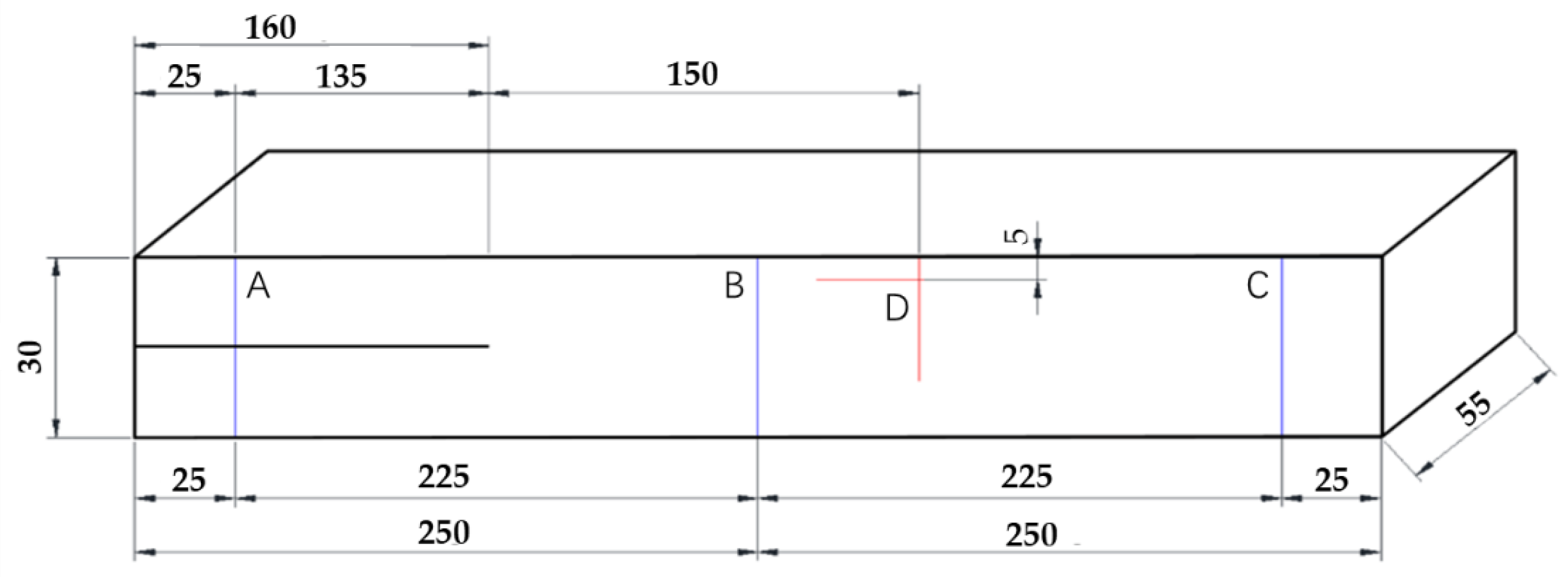
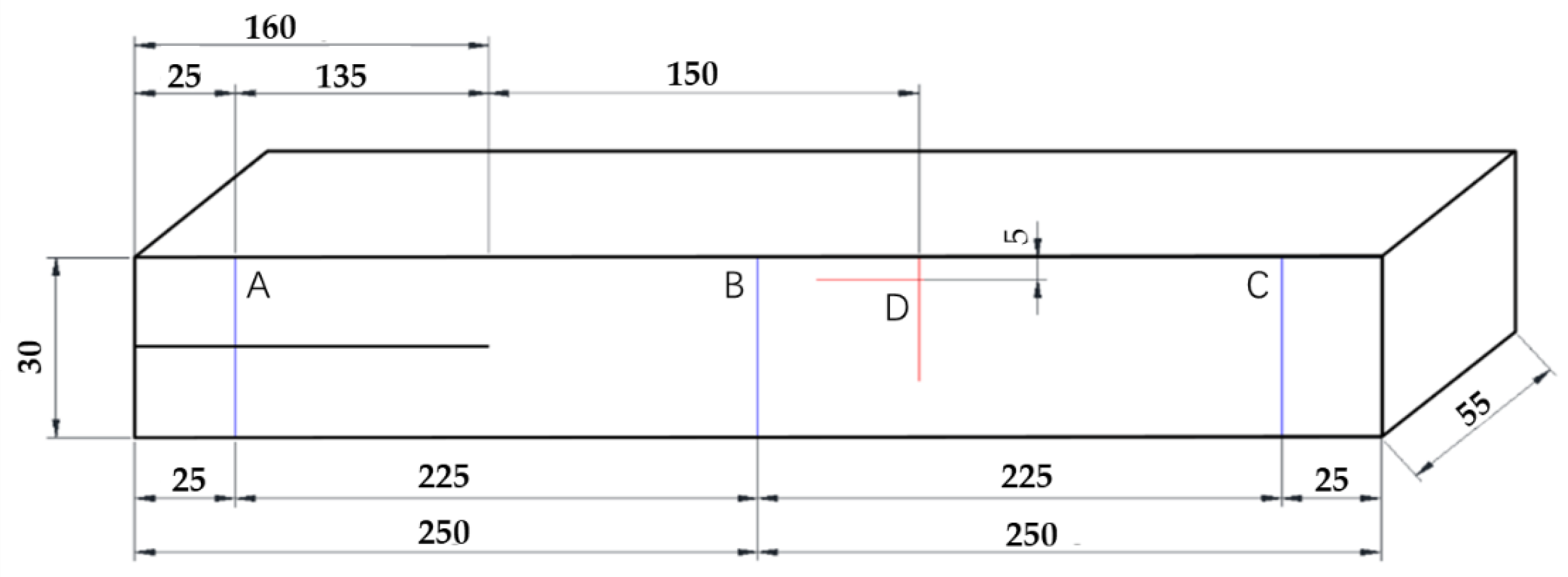
2.1. Imaging
2.2. Image Pre-Processing
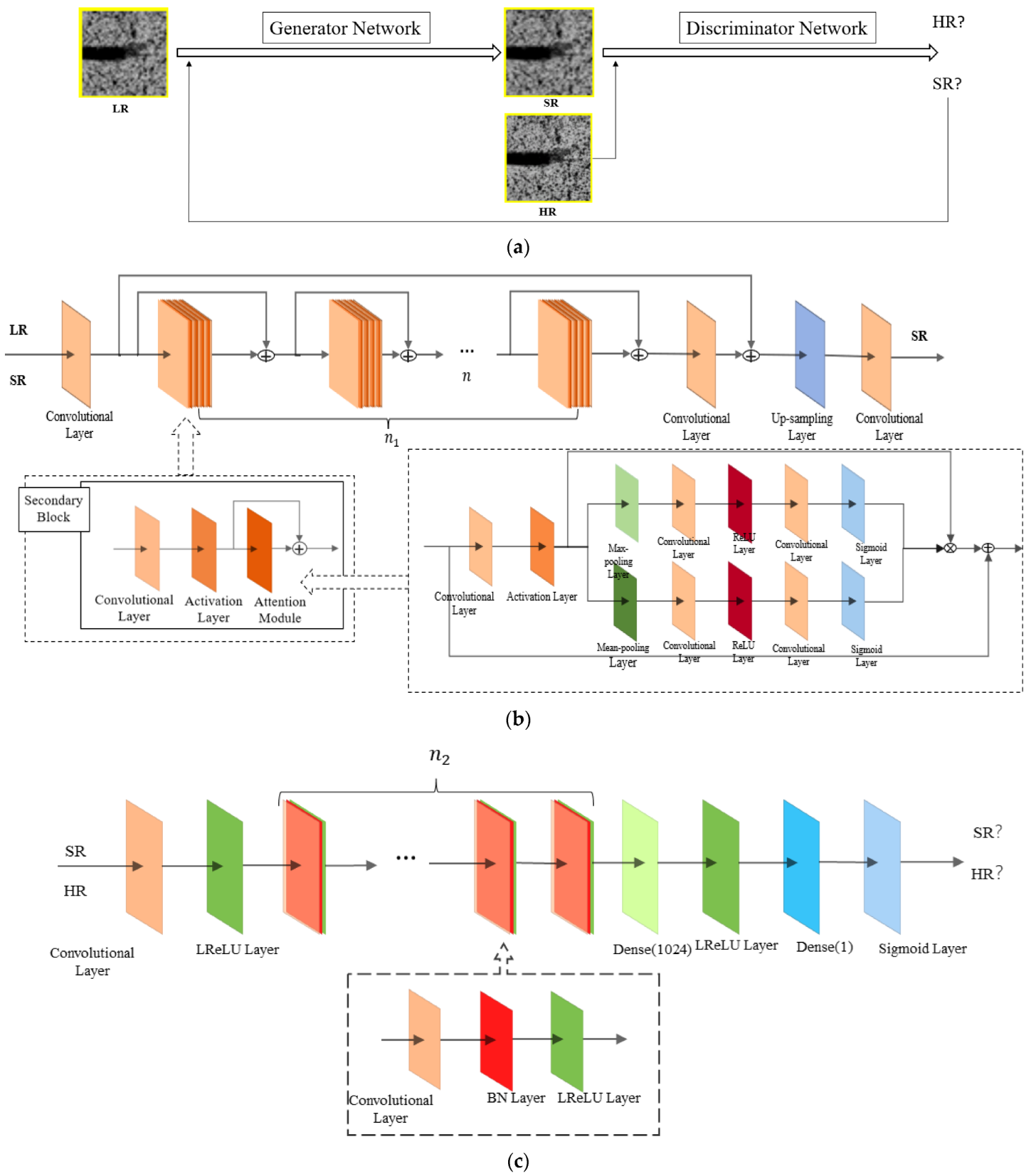
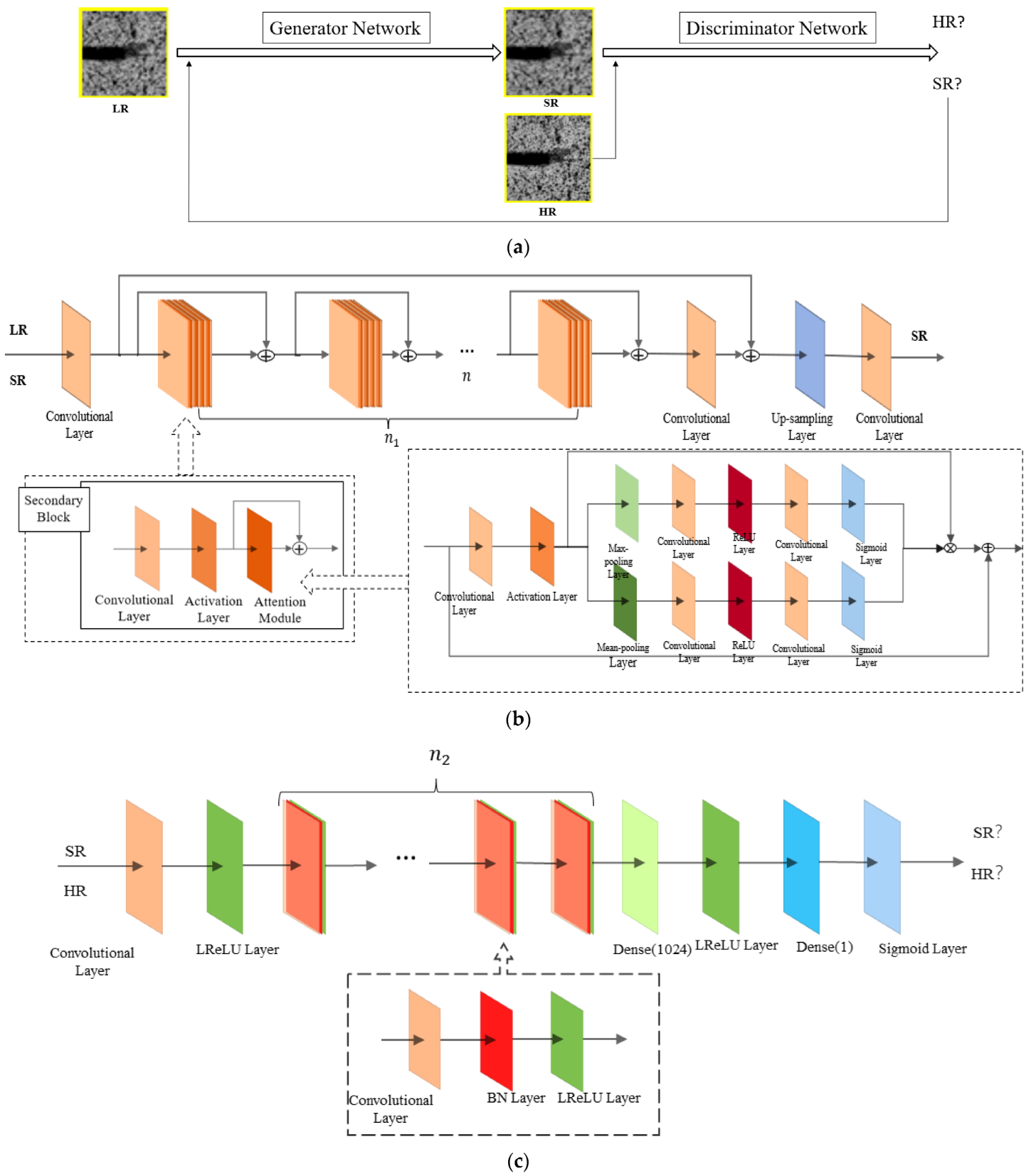
2.3. Super-Resolution Reconstruction Method for Engineered Bamboo Speckle Images Based on Generative Adversarial Network Model
2.3.1. ADRAGAN Network Structure
2.3.2. Relative Mean Discriminator and Loss Function
2.3.3. Network Interpolation
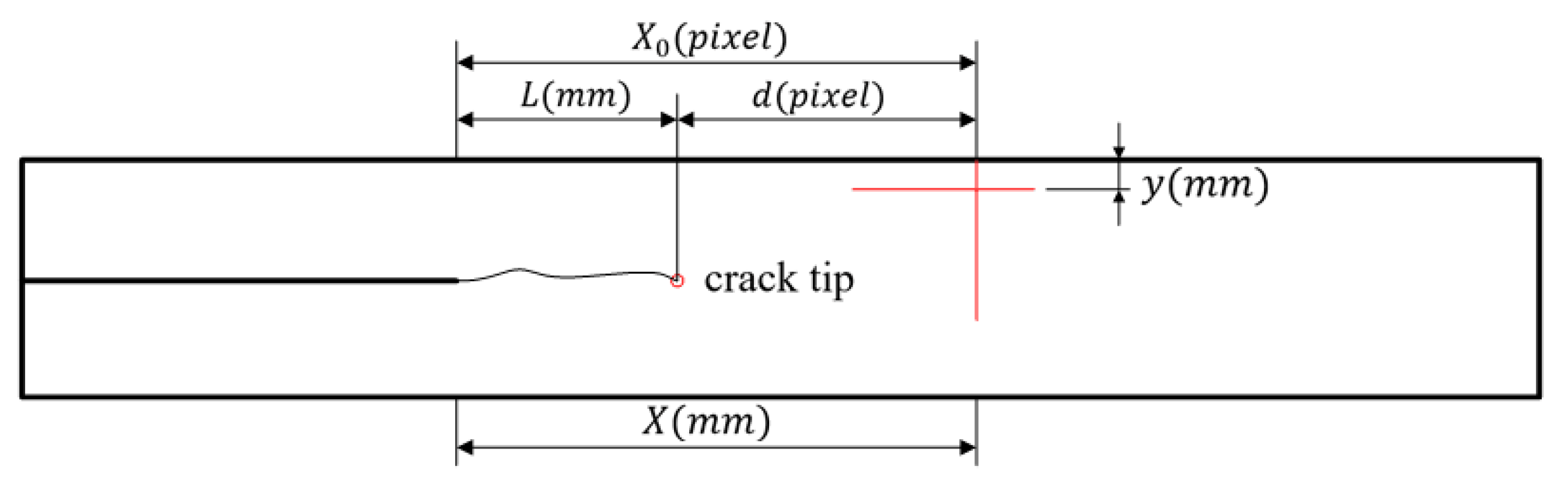
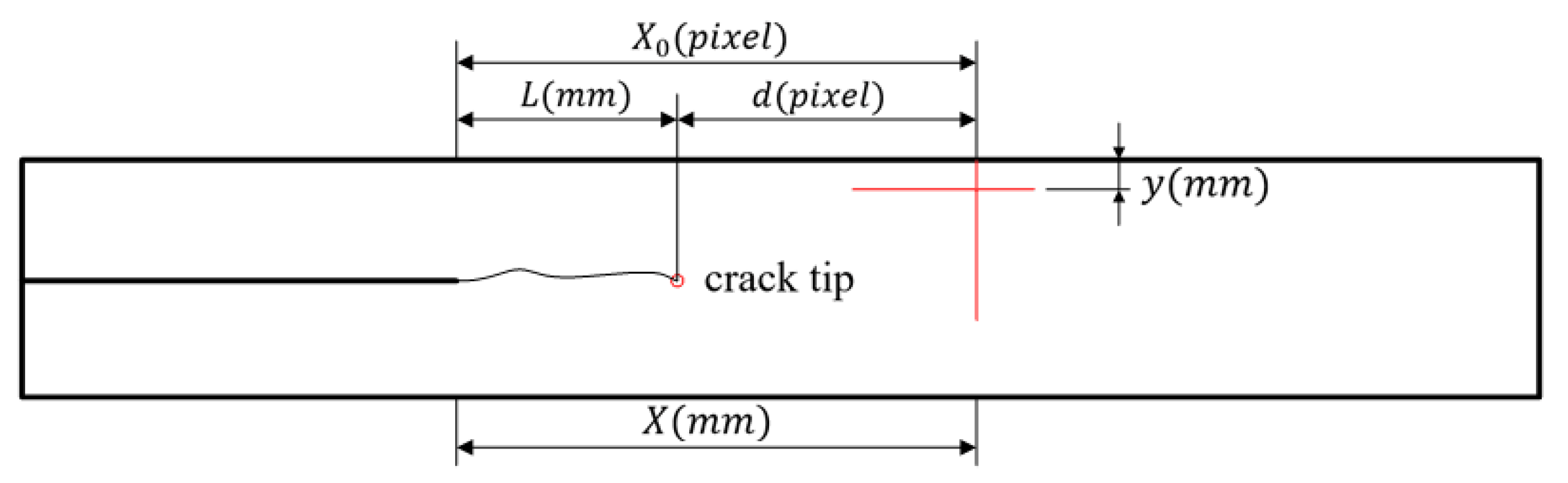
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, Y.; Huang, D.; Zhu, J. Experimental investigation of mixed-mode I/II fracture behavior of parallel strand bamboo. Constr. Build. Mater. 2021, 288, 123127. [Google Scholar] [CrossRef]
- Yan, Y.; Fei, B.; Liu, S. The relationship between moisture content and shrinkage strain in the process of bamboo air seasoning and cracking. Dry. Technol. 2020, 40, 571–580. [Google Scholar] [CrossRef]
- Song, J.; Surjadi, J.U.; Hu, D.; Lu, Y. Fatigue characterization of structural bamboo materials under flexural bending. Int. J. Fatigue 2017, 100, 126–135. [Google Scholar] [CrossRef]
- Wang, X.; Zhong, Y.; Luo, X.; Ren, H. Compressive Failure Mechanism of Structural Bamboo Scrimber. Polymers 2021, 13, 4223. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Zhu, D.; Shao, W.; Jiang, D. Modeling of Internal Geometric Variability and Statistical Property Prediction of Braided Composites. Materials 2022, 15, 5332. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, J.; Wan, Z.; Zhang, D.; Jiang, D. Rotor Fault Diagnosis Using Domain-Adversarial Neural Network with Time-Frequency Analysis. Machines 2022, 10, 610. [Google Scholar] [CrossRef]
- Jiang, D.; Qian, H.; Xu, Y.; Zhang, D.; Zheng, J. Residual strength of C/SiC composite after low-velocity impact. Mater. Today Commun. 2022, 30, 103140. [Google Scholar] [CrossRef]
- Gauss, C.; Savastano, H., Jr.; Harries, K.A. Use of ISO 22157 mechanical test methods and the characterisation of Brazilian P. edulis bamboo. Constr. Build. Mater. 2019, 228, 116728. [Google Scholar] [CrossRef]
- Li, Z.; He, X.Z.; Cai, Z.M.; Wang, R.; Xiao, Y. Mechanical Properties of Engineered Bamboo Boards for Glubam Structures. J. Mater. Civ. Eng. 2021, 33, 04021058. [Google Scholar] [CrossRef]
- Yang, T.-C.; Yang, H.-Y. Strain analysis of Moso bamboo (Phyllostachys pubescens) subjected to longitudinal tensile force. Mater. Today Commun. 2021, 28, 102491. [Google Scholar] [CrossRef]
- Lu, Z.; Wu, C.; Chen, D.; Qi, Y.; Wei, C. Overview on Image Super Resolution Reconstruction. In Proceedings of the 26th Chinese Control and Decision Conference (2014 CCDC), Changsha, China, 31 May–2 June 2014; pp. 2009–2014. [Google Scholar]
- Yu, M.; Wang, H.; Liu, M.; Li, P. Overview of Research on Image Super-Resolution Reconstruction. In Proceedings of the IEEE International Conference on Information Communication and Software Engineering (ICICSE), Chengdu, China, 19–21 March 2021; pp. 131–135. [Google Scholar]
- Tang, H.; Zhu, H.; Tao, H.; Xie, C. An Improved Algorithm for Low-Light Image Enhancement Based on RetinexNet. Appl. Sci. 2022, 12, 7268. [Google Scholar] [CrossRef]
- Tao, H.; Xie, C.; Wang, J.; Xin, Z. CENet: A Channel-Enhanced Spatiotemporal Network With Sufficient Supervision Information for Recognizing Industrial Smoke Emissions. IEEE Internet Things J. 2022, 9, 18749–18759. [Google Scholar] [CrossRef]
- Sun, N.; Li, H. Super Resolution Reconstruction of Images Based on Interpolation and Full Convolutional Neural Network and Application in Medical Fields. IEEE Access 2019, 7, 186470–186479. [Google Scholar] [CrossRef]
- Yang, T.; Jia, S.; Ma, H. Research on the Application of Super Resolution Reconstruction Algorithm for Underwater Image. Comput. Mater. Contin. 2020, 62, 1249–1258. [Google Scholar] [CrossRef]
- Das, V.; Dandapat, S.; Bora, P.K. Unsupervised Super-Resolution of OCT Images Using Generative Adversarial Network for Improved Age-Related Macular Degeneration Diagnosis. IEEE Sens. J. 2020, 20, 8746–8756. [Google Scholar] [CrossRef]
- Tang, Y.; Zhang, J.; Yue, M.; Qu, Z.; Wang, X.; Gui, Y.; Feng, X. Deep learning-based super-resolution images for synchronous measurement of temperature and deformation at elevated temperature. Optik 2021, 226, 165764. [Google Scholar] [CrossRef]
- Xiang, C.; Wang, W.; Deng, L.; Shi, P.; Kong, X. Crack detection algorithm for concrete structures based on super-resolution reconstruction and segmentation network. Automat. Constr. 2022, 140, 104346. [Google Scholar] [CrossRef]
- Lin, C.-Y.; Miki, T.; Kume, T. Potential Factors Canceling Interannual Cycles of Shoot Production in a Moso Bamboo (Phyllostachys pubescens) Stand. Front. For. Glob. Chang. 2022, 5, 913426. [Google Scholar] [CrossRef]
- Xing, X.; Zhang, D. Image-to-Image Translation using a Relativistic Generative Adversarial Network. In Proceedings of the 11th International Conference on Digital Image Processing (ICDIP 2019), Guangzhou, China, 10–13 May 2019. [Google Scholar]
- Zhu, H.; Tang, H.; Hu, Y.; Tao, H.; Xie, C. Lightweight Single Image Super-Resolution with Selective Channel Processing Network. Sensors 2022, 22, 5586. [Google Scholar] [CrossRef]
- Yang, F.; Jiang, Y.; Xu, Y. Design of Bird Sound Recognition Model Based on Lightweight. IEEE Access 2022, 10, 85189–85198. [Google Scholar] [CrossRef]
- Xie, C.; Zhu, H.; Fei, Y. Deep coordinate attention network for single image super-resolution. IET Image Process. 2022, 16, 273–284. [Google Scholar] [CrossRef]
- Nan, F.; Zeng, Q.; Xing, Y.; Qian, Y. Single Image Super-Resolution Reconstruction based on the ResNeXt Network. Multimed. Tools Appl. 2020, 79, 34459–34470. [Google Scholar] [CrossRef]
- Liu, B.; Chen, J. A Super Resolution Algorithm Based on Attention Mechanism and SRGAN Network. IEEE Access 2021, 9, 139138–139145. [Google Scholar] [CrossRef]
- An, Z.; Zhang, J.; Sheng, Z.; Er, X.; Lv, J. RBDN: Residual Bottleneck Dense Network for Image Super-Resolution. IEEE Access 2021, 9, 103440–103451. [Google Scholar] [CrossRef]
- Xie, C.; Liu, Y.; Zeng, W.; Lu, X. An improved method for single image super-resolution based on deep learning. Signal Image Video Porcess. 2019, 13, 557–565. [Google Scholar] [CrossRef]
- Wang, M.; Chen, Z.; Wu, Q.M.; Jian, M. Improved face super-resolution generative adversarial networks. Mach. Vis. Appl. 2020, 31, 22. [Google Scholar] [CrossRef]
- Seif, G.; Androutsos, D. Edge-Based Loss Function for Single Image Super-Resolution. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, Canada, 15–20 April 2018; pp. 1468–1472. [Google Scholar]
- Zhang, C.-Y.; Niu, Y.; Wu, T.-R.; Li, X.M. Color Image Super-Resolution and Enhancement with Inter-Channel Details at Trivial Cost. J. Comput. Sci. Technol. 2020, 35, 889–899. [Google Scholar] [CrossRef]
- Tang, J.; Zhao, Y.; Feng, L.; Zhao, W. Contour-Based Wild Animal Instance Segmentation Using a Few-Shot Detector. Animals 2022, 12, 1980. [Google Scholar] [CrossRef]
- Lu, J.; Zhang, L. Cascaded Deep Hashing for Large-Scale Image Retrieval. In Proceedings of the 25th International Conference on Neural Information Processing (ICONIP), Siem Reap, Cambodia, 13–16 December 2018; pp. 419–429. [Google Scholar]
- Tian, S.; Zou, L.; Yang, Y.; Kong, C.; Liu, Y. Learning image block statistics and quality assessment losses for perceptual image super-resolution. J. Electron. Imaging 2019, 28, 013042. [Google Scholar]
- Nan, Y.; Zhang, H.; Zheng, J.; Yang, K.; Yang, W.; Zhang, M. Research on profiling tracking control optimization of orchard sprayer based on the phenotypic characteristics of tree crown. Comput. Electron. Agric. 2022, 192, 106455. [Google Scholar] [CrossRef]
- Zhang, Z.; Shi, Y.; Zhou, X.; Kan, H.; Wen, J. Shuffle block SRGAN for face image super-resolution reconstruction. Meas. Control 2020, 53, 1429–1439. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Devices | Performance Parameters | |
|---|---|---|
| Universal Testing Machine | Range | 100 kN |
| Sampling Frequency | 20 Hz | |
| Loading Mode | Constant Loading | |
| Loading Speed | 2 mm/min | |
| High-speed Camera | Maximum Resolution | 4000 × 2000 pixel |
| Filming Speed | 4000 × 2000 @ 500 fps | |
| Minimum Exposure Time | 1 µs | |
| Pixel Dimension | 7 µm | |
| Sensitivity | 4.64 V/lux.s @ 525 nm | |
| Support Trigger Mode | Internal trigger, external trigger | |
| Image Acquisition and Parameter Control System | Acquisition Cycle | 50,000–99,999 µs |
| Magnification | 1× | |
| Support Maximum Resolution | 4536 × 3024 pixels | |
| Sampling Frequency | 20 s−1 | |
| Item | Hardware Configuration |
|---|---|
| Processor | Intel Xeon W-2155@3.30 GHz |
| Mainboard | Dell 0 × 8DXD Core i7 |
| Graphics Card | Nvidia GeForce GTX 1080 Ti |
| Video Memory | 8 GB |
| Memory | Hellis DDR4 2666 MHz 64 GB |
| Item | Parameter Settings |
|---|---|
| Operating System | Windows 10 64-bit |
| Programming Language | Python 3.7 |
| Deep Learning Frameworks | Pytorch |
| IDE | Community Edition |
| Initial Learning Rate | |
| Attenuation Rate | , |
| Algorithm | SRResNet | SRGAN | ADRAGAN |
|---|---|---|---|
| Number of residual blocks | 16 | 16 | 16 |
| Training image size | 128 | 128 | 128 |
| Suitable for pre-training model? | No | Yes | Yes |
| Number of feature maps | 64 | 64 | 64 |
| Batch size | 16 | 16 | 16 |
| Algorithm | PSNR (dB) | SSIM | MOS |
|---|---|---|---|
| Bicubic B-spline interpolation | 20.64 | 0.615 | 2.48 |
| SRResNet | 24.66 | 0.827 | 3.77 |
| SRGAN | 28.06 | 0.845 | 3.69 |
| ADRAGAN | 29.38 | 0.869 | 3.8 |
| Algorithm | ||||
|---|---|---|---|---|
| HR | 2080.960 | 59.563 | 0 | 0 |
| LR | 2183.028 | 55.128 | 102.068 | −4.436 |
| BICUBIC | 2138.146 | 57.078 | 57.186 | −2.485 |
| SRResNet | 2108.088 | 58.384 | 27.127 | −1.179 |
| SRGAN | —— | —— | —— | —— |
| ADRAGAN | 2076.235 | 59.769 | −4.725 | 0.205 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, H.; Liu, Y.; Liu, Z.; Zhuang, Z.; Wang, X.; Gou, B. Crack Detection Method for Engineered Bamboo Based on Super-Resolution Reconstruction and Generative Adversarial Network. Forests 2022, 13, 1896. https://doi.org/10.3390/f13111896
Zhou H, Liu Y, Liu Z, Zhuang Z, Wang X, Gou B. Crack Detection Method for Engineered Bamboo Based on Super-Resolution Reconstruction and Generative Adversarial Network. Forests. 2022; 13(11):1896. https://doi.org/10.3390/f13111896
Chicago/Turabian StyleZhou, Haiyan, Ying Liu, Zheng Liu, Zilong Zhuang, Xu Wang, and Binli Gou. 2022. "Crack Detection Method for Engineered Bamboo Based on Super-Resolution Reconstruction and Generative Adversarial Network" Forests 13, no. 11: 1896. https://doi.org/10.3390/f13111896
APA StyleZhou, H., Liu, Y., Liu, Z., Zhuang, Z., Wang, X., & Gou, B. (2022). Crack Detection Method for Engineered Bamboo Based on Super-Resolution Reconstruction and Generative Adversarial Network. Forests, 13(11), 1896. https://doi.org/10.3390/f13111896