Detection and Modeling of Unstructured Roads in Forest Areas Based on Visual-2D Lidar Data Fusion



Abstract
:1. Introduction
2. Materials and Methods
2.1. Autonomous Navigation Platform of Vision and Lidar Cooperation
2.2. Unstructured Road Detection Based on Vision
2.2.1. Superpixel Segmentation
- Preliminary segmentation;
- 2.
- Energy function construction.
- 3.
- Color distribution item ;
- 4.
- Boundary term ;
- 5.
- Compactness term .
2.2.2. Road Detection Based on Online SVM
- Superpixel feature extraction;
- 2.
- Construction and training of SVM model
- Construction of SVM model;
- Data set construction.
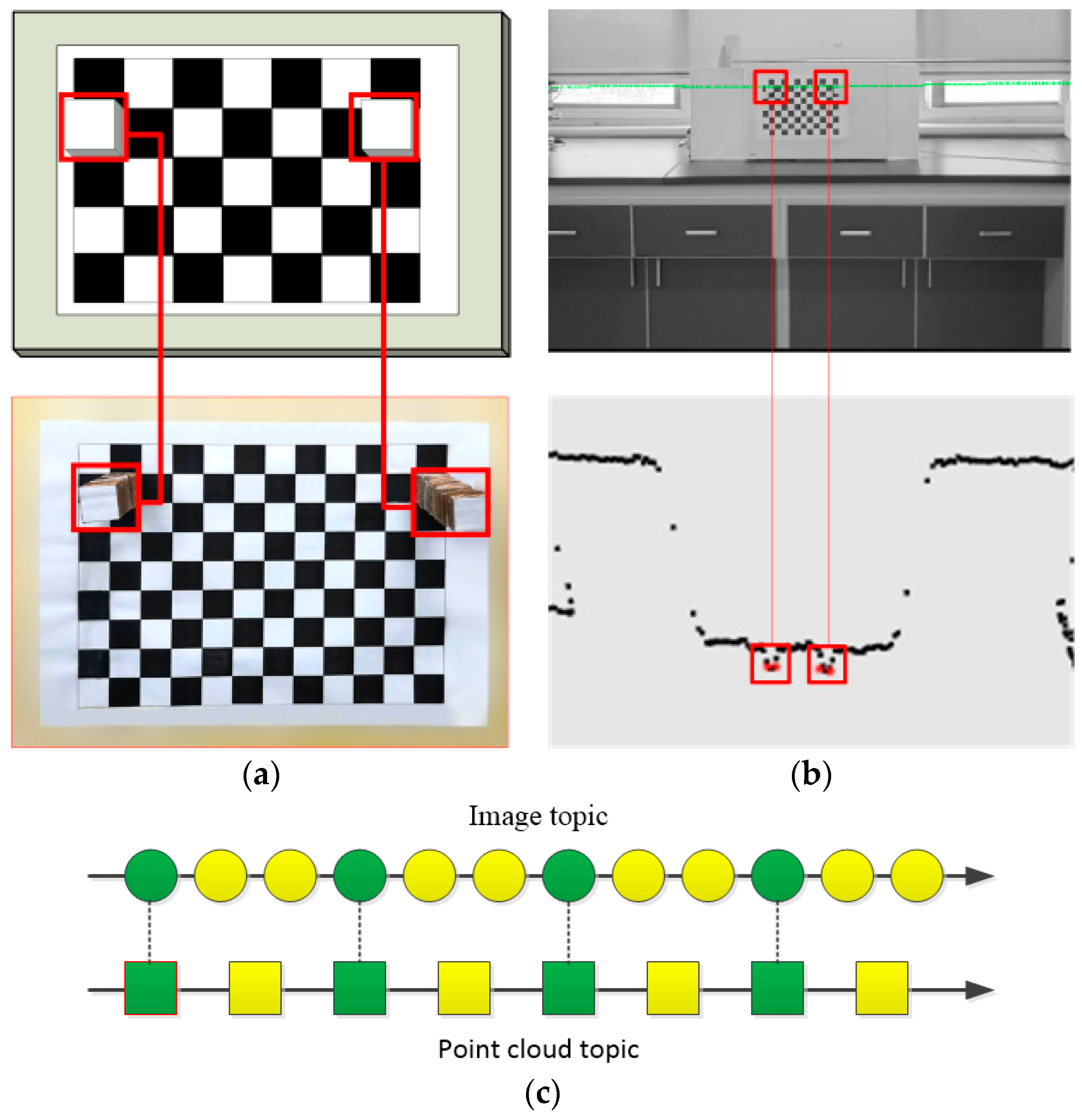
2.3. Description of Unstructured Road Structure Based on 2D Lidar
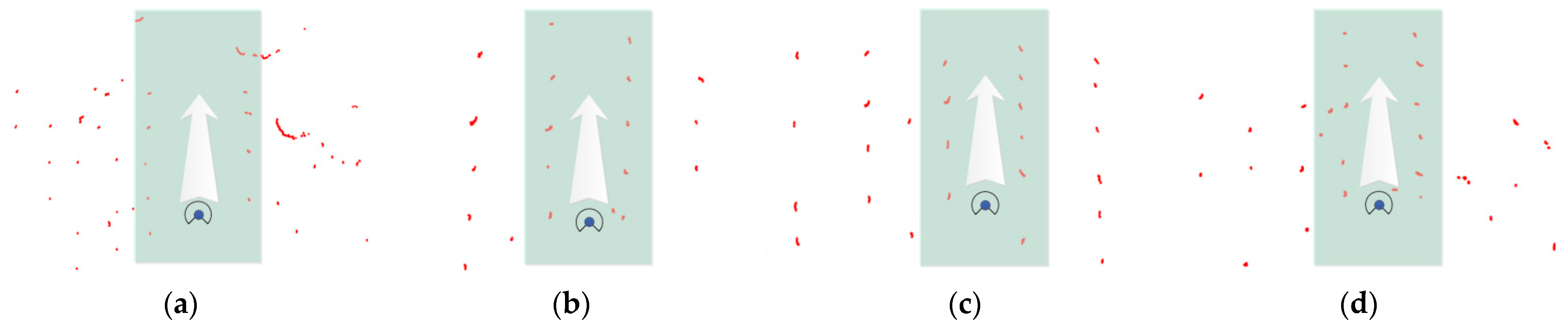
2.3.1. Lidar Point Cloud Acquisition and Processing
2.3.2. Remap Transformation
3. Experimental Results and Analysis
3.1. Experimental Environment Configuration
3.2. Visual Image Processing
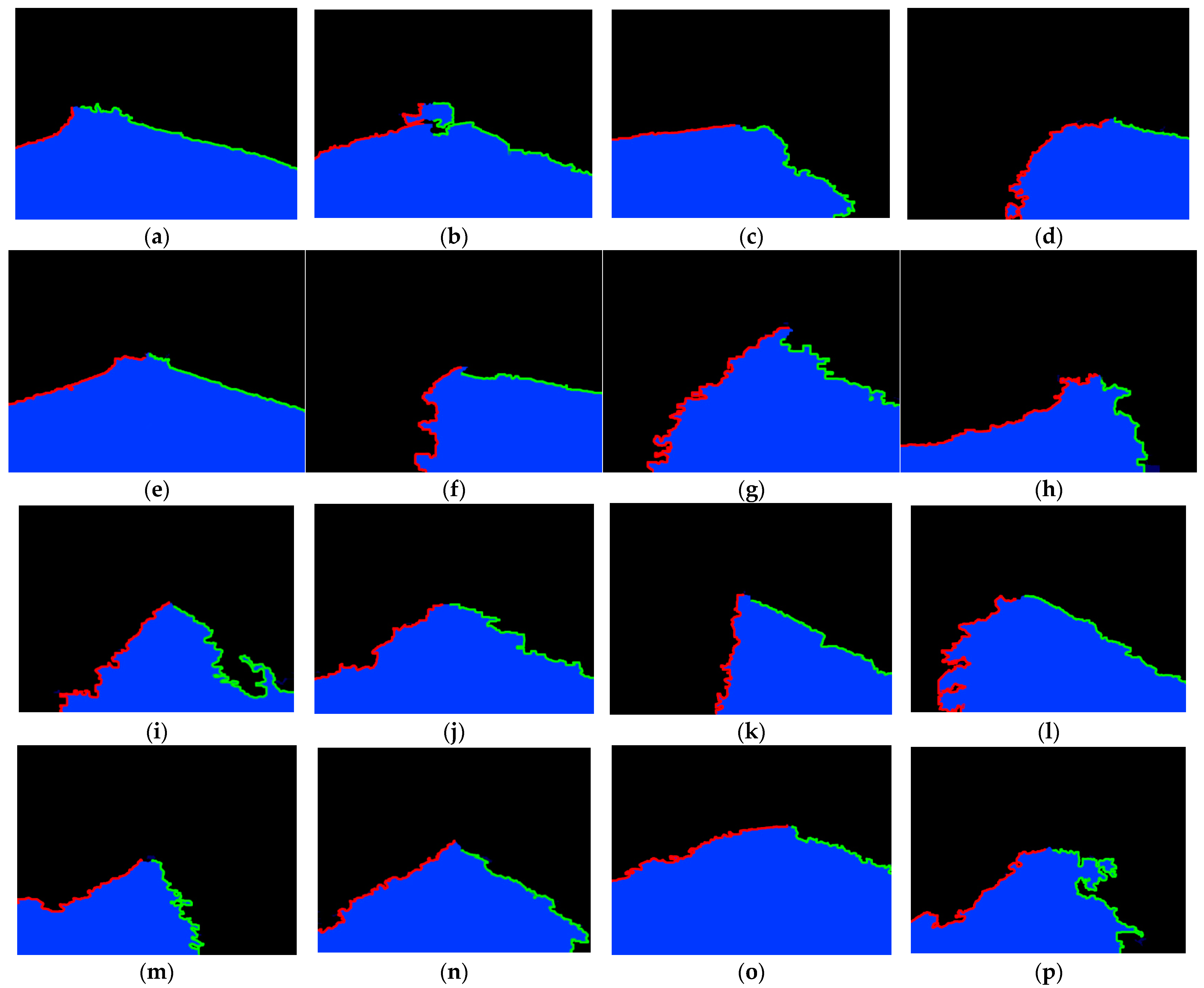
3.2.1. Superpixel Segmentation in Real-Time
3.2.2. Online Recognition of Road Area
3.2.3. Road Model Establishment
4. Discussion
4.1. Road Structure Evaluation
4.2. Algorithm Real-Time Evaluation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kim, J.S.; Jeong, J.H.; Park, J.H. Boundary detection with a road model for occupancy grids in the curvilinear coordinate system using a downward-looking lidar sensor. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2016, 230, 1351–1363. [Google Scholar] [CrossRef]
- Yang, M.Y.; Cao, Y.P.; McDonald, J. Fusion of camera images and laser scans for wide baseline 3D scene alignment in urban environments. ISPRS J. Photogramm. Remote Sens. 2011, 66, S52–S61. [Google Scholar] [CrossRef] [Green Version]
- Che, E.Z.; Olsen, M.J.; Jung, J. Efficient segment-based ground filtering and adaptive road detection from mobile light detection and ranging (LiDAR) data. Int. J. Remote Sens. 2021, 42, 3633–3659. [Google Scholar] [CrossRef]
- Cao, J.W.; Song, C.X.; Song, S.X.; Xiao, F.; Peng, S.L. Lane detection algorithm for intelligent vehicles in complex road conditions and dynamic environments. Sensors 2019, 19, 3166. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, M.; Zhang, J.; Fang, Z.J. Unstructured road detection algorithm based on adaptive road model. Trans. Micro. Technol. 2020, 39, 132–135. [Google Scholar]
- Zuo, W.H.; Yao, T.Z. Road model prediction based unstructured road detection. J. Zhejiang Univ. Sci. C 2013, 14, 822–834. [Google Scholar] [CrossRef]
- Haeselich, M.; Arends, M.; Wojke, N. Probabilistic terrain classification in unstructured environments. Robot. Auton. Syst. 2013, 61, 1051–1059. [Google Scholar] [CrossRef]
- Lin, C.Y.; Lian, F.L. System integration of sensor-fusion localization tasks using vision-based driving lane detection and road-marker recognition. IEEE Syst. J. 2020, 14, 144523–144534. [Google Scholar] [CrossRef]
- Bayoudh, K.; Hamdaoui, F.; Mtibaa, A. Transfer learning based hybrid 2D-3D CNN for traffic sign recognition and semantic road detection applied in advanced driver assistance systems. Appl. Intell. 2021, 51, 124–142. [Google Scholar] [CrossRef]
- Jayaprakash, A.; KeziSelvaVijila, C. Feature selection using Ant Colony Optimization (ACO) and Road Sign Detection and Recognition (RSDR) system. Cogn. Syst. Res. 2019, 58, 123–133. [Google Scholar] [CrossRef]
- Han, J.M.; Yang, Z.; Hu, G.X.; Zhang, T.Y.; Song, J.R. Accurate and robust vanishing point detection method in unstructured road scenes. J. Intell. Robot. Syst. 2018, 94, 143–158. [Google Scholar] [CrossRef]
- Li, Y.; Tong, G.F.; Sun, A.A.; Ding, W.L. Road extraction algorithm based on intrinsic image and vanishing point for unstructured road image. Robot. Auton. Syst. 2018, 109, 86–96. [Google Scholar] [CrossRef]
- Shi, J.J.; Wang, J.X.; Fu, F.F. Fast and robust vanishing point detection for unstructured road following. IEEE Trans. Intell. Transp. Syst. 2018, 17, 970–979. [Google Scholar] [CrossRef]
- Feng, M.Y.; Jia, P.; Wang, X.; Liu, H.Q.; Cao, J. Structural road detection for intelligent vehicle based on a 2d laser radar. In Proceedings of the 2012 4th International Conference on Intelligent Human-Machine Systems and Cybernetics, Nanchang, China, 26–27 August 2012. [Google Scholar]
- Wang, E.D.; Sun, A.A.; Li, Y.; Hou, X.K.; Zhu, Y.L. Fast vanishing point detection method based on road border region estimation. IET Image Process. 2017, 12, 361–373. [Google Scholar] [CrossRef]
- Shang, E.K.; An, X.J.; Li, J.; Ye, L.; He, H.G. Robust unstructured road detection: The importance of contextual information. Int. J. Adv. Robot. Syst. 2013, 10, 179. [Google Scholar] [CrossRef]
- Wang, Q.D.; Wei, Z.Y.; Wang, J.E. Curve recognition algorithm based on edge point curvature voting. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2020, 234, 1006–1019. [Google Scholar] [CrossRef]
- Husain, A.; Vaishya, R.C. Road surface and its center line and boundary lines detection using terrestrial Lidar data. Egyp. J. Remote Sen.Space Sci. 2020, 24, 331. [Google Scholar] [CrossRef]
- Lee, I.; Oh, J.; Kim, I.; Oh, J.H. Camera-laser fusion sensor system and enviromental recognition for humanoids in disaster scenarios. J. Mech. Sci. Technol. 2017, 31, 2997–3003. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Zhou, M.; Qiu, P. Radar and vision fusion for the real-time obstacle detection and identification. Ind. Robot. 2019, 46, 391–395. [Google Scholar] [CrossRef]
- Budzan, S.; Wyzgolik, R.; Ilewicz, W. Improved human detection with a fusion of laser scanner and vision/infrared information for mobile applications. Appl. Sci. 2018, 8, 1967. [Google Scholar] [CrossRef] [Green Version]
- Deng, F.C.; Zhu, X.R.; He, C. Vision-based real-time traversable region detection for mobile robot in the outdoors. Sensors 2017, 17, 2101. [Google Scholar] [CrossRef] [Green Version]
- Cheng, H.Y.; Yu, C.C.; Tseng, C.C.; Fan, K.C.; Hwang, J.N.; Jeng, B.S. Environment classification and hierarchical lane detection for structured and unstructured roads. IET Comput. Vis. 2010, 4, 37–49. [Google Scholar] [CrossRef]
- Caltagirone, L.; Bellone, M.; Svensson, L.; Wahde, M. Lidar–camera fusion for road detection using fully convolutional neural networks. Robot. Auton. Syst. 2019, 111, 125–131. [Google Scholar] [CrossRef] [Green Version]
- Wei, Y.; Zhang, K.S.P.; Ji., S. Simultaneous road surface and centerline extraction from large-scale remote sensing images using CNN-based segmentation and tracing. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8919–8931. [Google Scholar] [CrossRef]
- Kurosh, M.; Dimitri, P.; Oleg, G. Informatics in Control, Automation and Robotics, 13th ed.; Springer: Lisbon, Portugal, 2018; pp. 312–330. [Google Scholar]
- Liu, H.F.; Yao, Y.Z.; Sun, Z. Road segmentation with image-LiDAR data fusion in deep neural network. Multimed. Tools Appl. 2020, 79, 35503–35518. [Google Scholar] [CrossRef]
- Vera-Olmos, F.J.; Pardo, E.; Melero, H. DeepEye: Deep convolutional network for pupil detection in real environments. Integr. Comput. Aided Eng. 2019, 26, 85–95. [Google Scholar] [CrossRef]
- Khalilullah, K.M.I.; Ota, S.; Yasuda, T.; Jindai, M. Road area detection method based on DBNN for robot navigation using single camera in outdoor environments. Ind. Robot. 2018, 45, 275–286. [Google Scholar] [CrossRef]
- Sabu, M.T.; Sri, K.; Rajesh, M.H.; Domenico, C.; Thomas, H.; Jagadeesh, K.R. Advances in Signal Processing and Intelligent Recognition Systems, 6th ed.; Springer: Chennai, India, 2020; pp. 256–291. [Google Scholar]
- Tsogas, M.; Floudas, N.; Lytrivis, P.; Amditis, A.; Polychronopoulos, A. Combined lane and road attributes extraction by fusing data from digital map, laser scanner and camera. Inf. Fusion 2011, 12, 28–36. [Google Scholar] [CrossRef]
- Jung, J.Y.; Bae, S.H. Real-time road lane detection in urban areas using lidar data. Electronics 2018, 7, 276. [Google Scholar] [CrossRef] [Green Version]
- Waga, K.; Tompalski, P.; Coops, N.C. Forest road status assessment using airborne laser scanning. For. Sci. 2020, 66, 501–508. [Google Scholar] [CrossRef]
- Buján, S.; Guerra-Hernández, J.; González-Ferreiro, E.; Miranda, D. Forest road detection using lidar data and hybrid classification. Remote Sens. 2021, 13, 393. [Google Scholar] [CrossRef]
- Yao, R.T.; Zheng, Y.L.; Chen, F.J.; Wu, J.; Wang, H. Research on vision system calibration method of forestry mobile robots. Int. J. Circuits Syst. Signal Proces. 2020, 14, 1107–1114. [Google Scholar] [CrossRef]
- Van den Bergh, M.; Boix, X.; Roig, G.; Van Gool, L. SEEDS: Superpixels extracted via energy-driven sampling. Int. J. Comput. Vis. 2015, 111, 298–314. [Google Scholar] [CrossRef]
- Wigness, M.; Eum, S.M.; Rogers, J.G.; Han, D.; Kwon, H. A RUGD dataset for autonomous navigation and visual perception in unstructur. IEEE Inter. Conf. Intell. Robots Sys. 2016, 1, 5000–5007. [Google Scholar]
- Lee, S.W.; Lee, B.H.; Lee, J.E. Statistical characteristic-based road structure recognition in automotive FMCW radar systems. IEEE Trans. Intell. Transp. Syst. 2019, 20, 2418–2429. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Sources | MIoU | Precision | Recall | F1 | MAE | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| SLIC | Improved SEEDS | SLIC | Improved SEEDS | SLIC | Improved SEEDS | SLIC | Improved SEEDS | SLIC | Improved SEEDS | |
| RUGD | 0.8649 | 0.9005 | 0.8704 | 0.9097 | 0.9346 | 0.9618 | 0.9013 | 0.9332 | 0.0598 | 0.0301 |
| Jiufeng National Forest Park | 0.8762 | 0.9028 | 0.8843 | 0.9125 | 0.9398 | 0.9746 | 0.9112 | 0.9425 | 0.0465 | 0.0297 |
| Liaocheng Forest Farm | 0.8835 | 0.9173 | 0.8961 | 0.9241 | 0.9502 | 0.9795 | 0.9224 | 0.9526 | 0.0328 | 0.0216 |
| Distance | Eup (pixel) | Evp (pixel) | Eud (m) | Evd (m) | Eξ (m) |
|---|---|---|---|---|---|
| 1 m–2 m | 25.4572 | 3.1517 | 0.0833 | 0.0086 | 0.0390 |
| 2 m–3 m | 28.3554 | 3.6740 | 0.1309 | 0.0127 | 0.0584 |
| 3 m–4 m | 32.3748 | 4.0512 | 0.1971 | 0.0221 | 0.0831 |
| 4 m–5 m | 35.9710 | 4.3476 | 0.2564 | 0.0272 | 0.1190 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, G.; Yao, R.; Zhao, Y.; Zheng, Y. Detection and Modeling of Unstructured Roads in Forest Areas Based on Visual-2D Lidar Data Fusion. Forests 2021, 12, 820. https://doi.org/10.3390/f12070820
Lei G, Yao R, Zhao Y, Zheng Y. Detection and Modeling of Unstructured Roads in Forest Areas Based on Visual-2D Lidar Data Fusion. Forests. 2021; 12(7):820. https://doi.org/10.3390/f12070820
Chicago/Turabian StyleLei, Guannan, Ruting Yao, Yandong Zhao, and Yili Zheng. 2021. "Detection and Modeling of Unstructured Roads in Forest Areas Based on Visual-2D Lidar Data Fusion" Forests 12, no. 7: 820. https://doi.org/10.3390/f12070820
APA StyleLei, G., Yao, R., Zhao, Y., & Zheng, Y. (2021). Detection and Modeling of Unstructured Roads in Forest Areas Based on Visual-2D Lidar Data Fusion. Forests, 12(7), 820. https://doi.org/10.3390/f12070820