Abstract
LR parsing is a popular parsing strategy for variants of Context-Free Grammar (CFG). It has also been used for mildly context-sensitive formalisms, such as Tree-Adjoining Grammar. In this paper, we present the first LR-style parsing algorithm for Linear Context-Free Rewriting Systems (LCFRS), a mildly context-sensitive extension of CFG which has received considerable attention in the last years in the context of natural language processing.
1. Introduction
In computational linguistics, the modeling of discontinuous structures in natural language, i.e., of structures that span two or more non-adjacent portions of the input string, is an important issue. In recent years, Linear Context-Free Rewriting System (LCFRS) [1] has emerged as a formalism which is useful for this task. LCFRS is a mildly context-sensitive [2] extension of CFG in which a single non-terminal can cover continuous blocks of terminals. CFG is a special case of LCFRS where . In CFG, only embedded structures can be modelled. In LCFRS, in contrast, yields can be intertwined. The schematically depicted derivation trees in Figure 1 illustrate the different domains of locality of CFG and LCFRS. As can be seen, in the schematic CFG derivation, X contributes a continuous component β to the full yield. In the schematic LCFRS derivation, however, X contributes three non-adjacent components to the full yield. Intuitively speaking, the difference between LCFRS and CFG productions is that the former allow for arguments on their non-terminals. Each argument spans a continuous part of the input string, i.e., an argument boundary denotes a discontinuity in the yield of the non-terminal. The production itself specifies how the lefthand side non-terminal yield is built from the yields of the righthand side non-terminals. In the example, the X node in the schematic LCFRS tree would be derived from a production which, on its left hand side, has a terminal . Note that CFG non-terminals can consequently be seen as LCFRS non-terminals with an implicit single argument.
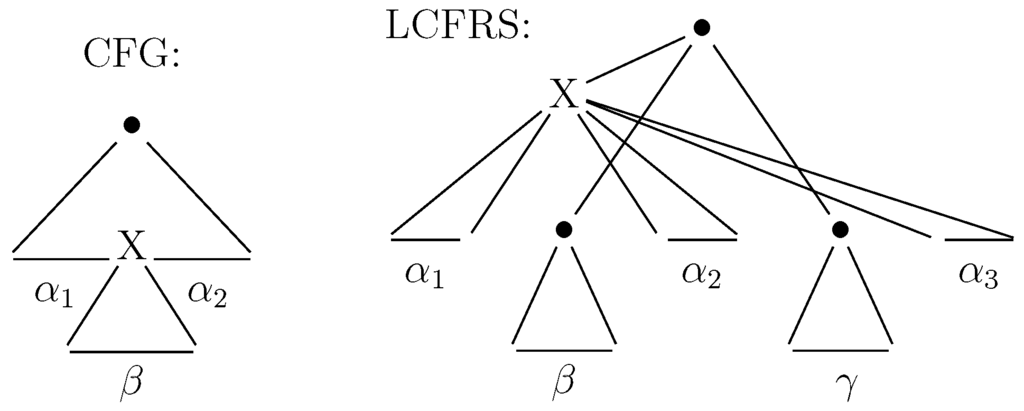
Figure 1.
Locality in CFG vs. LCFRS derivation.
LCFRS has been employed in various subareas of computational linguistics. Among others, it has been used for syntactic modeling. In syntax, discontinuous structures arise when a displacement occurs within the sentence, such as, e.g., with topicalization. Constructions causing discontinuities are frequent: In the German TiGer treebank [3], about a fourth of all sentences contains at least one instance of discontinuity [4]; in the English Penn Treebank (PTB) [5], this holds for about a fifth of all sentences [6]. Below, three examples for discontinuities are shown. In (1), the discontinuity is due to the fact that a part of the VP is moved to the front. In (2), the discontinuity comes from the topicalization of the pronoun Darüber. (3), finally, is an example for a discontinuity which has several parts. It is due to a topicalization of the prepositional phrase Ohne internationalen Schaden, and scrambling [7] of elements after the verb.
- (1)
- Selbst besucht hat er ihn niePersonally visited has he him never“He has never visited him personally”
- (2)
- Darüber muss nachgedacht werdenAbout it must thought be“One must think about that”
- (3)
- Ohne internationalen Schaden könne sich Bonn von dem Denkmal nicht distanzierenWithout international damage could itself Bonn from the monument not distance“Bonn could not distance itself from the monument without international damage.”
The syntactic annotation in treebanks must account for discontinuity. In a constituency framework, this can be done by allowing crossing branches and grouping all parts of a discontinuous constituent under a single node. Similarly in dependency syntax [8], words must be connected such that edges end up crossing. As an example, Figure 2 shows both the constituency and dependency annotations of (2). While the discontinuous yields inhibit an interpretation of either structure as a CFG derivation tree, both can immediately been modeled as the derivation of an LCFRS [4,9].

Figure 2.
Discontinuity and non-projectivity in NeGra annotation (see (2)) [10].
In grammar engineering, LCFRS and related formalisms have been employed in two ways. Grammatical Framework (GF) is actively used for multilingual grammar development and allows for an easy treatment of discontinuities, see [11] for details. GF is an extension of Parallel Multiple Context-Free Grammar, which itself is a generalization of LCFRS [12]. TuLiPA [13] is a multi-formalism parser used in a development environment for variants of Tree Adjoining Grammar (TAG). It exploits the fact that LCFRS is a mildly context-sensitive formalism with high expressivity. LCFRS acts as a pivot formalism, i.e., instead of parsing directly with a TAG instance, TuLiPA parses with its equivalent LCFRS, obtained through a suitable grammar transformation [14].
LCFRS has also been used for the modeling of non-concatenative morphology, i.e., for the description of discontinuous phenomena below word level, such as stem derivation in Semitic languages. In such languages, words are derived by combining a discontinuous root with a discontinuous template. In Arabic, for instance, combining the root k-t-b with the template i-a results in kitab (“book”), combining it with a-i results in katib (“writer”), and combining it with ma-∅-a results in maktab (“desk”). Authors of [15,16] use LCFRS for the modeling of such processes. Finally, in machine translation, suitable versions of LCFRS, resp. equivalent formalisms, have been proposed for the modeling of translational equivalence [17,18]. They offer the advantage that certain alignment configurations that cannot be modeled with synchronous variants of CFG can be induced by LCFRS [19]. As an example, see Figure 3, which shows an English sentence with its French translation, along with a grammar that models the alignment between both.
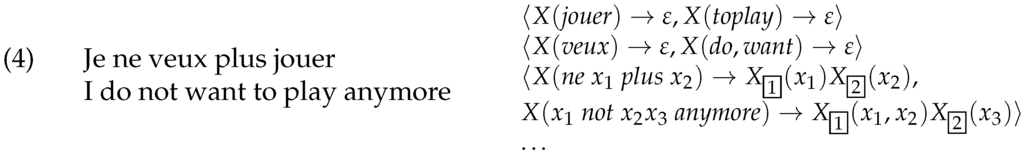
Figure 3.
LCFRS for machine translation alignments.
Parsing is a key task since it serves as a backend in many practical applications such as the ones mentioned above. The parsing of LCFRS has received attention both on the symbolic and on the probabilistic side. Symbolic parsing strategies, such as CYK and Earley variants have been presented [20,21,22], as well as automaton-based parsing [23] and data-driven probabilistic parsing techniques [24,25,26]. To our knowledge, however, no LR strategy for LCFRS has so far been presented in the literature. LR parsing is an incremental shift-reduce parsing strategy in which the transitions between parser states are guided by an automaton which is compiled offline. LR parsers were first introduced for deterministic context-free languages [27] and later generalized to context-free languages [28,29] and tree-adjoining languages [30,31]. Also for conjunctive grammars and boolean grammars, LR parsing algorithms exist [32,33,34]. In this paper, we present an LR-style parser for LCFRS, extending our earlier work [35]. Our parsing strategy is based on the incremental parsing strategy implemented by Thread Automata [23].
The remainder of the article is structured as follows. In the following section, we introduce LCFRS and thread automata. Section 3 introduces LR parsing for the context-free case. Section 4 presents the LR algorithm for LCFRS along with an example. In particular, Section 4.1 gives the intuition behind the algorithm, Section 4.2 introduces the algorithms for automaton and parse table constructions, and Section 4.3 presents the parsing algorithm. Section 5 concludes the article.
2. Preliminaries
2.1. Linear Context-Free Rewriting Systems
We now introduce Linear Context-Free Rewriting Systems (LCFRS). In LCFRS, a single non-terminal can span continuous blocks of a string. A CFG is simply a special case of an LCFRS in which . We notate LCFRS with the syntax of Simple Range Concatenation Grammars (SRCG) [36], a formalism equivalent to LCFRS. Note that we restrict ourselves to the commonly used string rewriting version of LCFRS and omit the more general definition of LCFRS of [37]. Furthermore, we assume that our LCFRSs are monotone (see condition 3 below) and ε-free (we can make this assumption without loss of generality see [20,38]).
Definition 1 (LCFRS).
An Linear Context-Free Rewriting System (LCFRS) [1,20] is a tuple where
- N is a finite set of non-terminals with a function dim: determining the fan-out of each ;
- T and V are disjoint finite sets of terminals and variables;
- is the start symbol with ; and
- P is a finite set of rewriting rules (or productions). For all , the following holds.
- γ has the formwhere , being the rank of γ; for ; and for ; all and are called arguments or components. γ may be abridged as ; and we define .
- For all there is at most one unique occurrence of x on each lefthand side and righthand side of γ; furthermore, there exists an lefthand side occurrence iff there exists a righthand side occurrence.
- Variable occurrences in γ are ordered by a strict total order ≺ which is such that for all with occurrences in γ, if precedes in any , , then also precedes in α.
The rank of G is given by and written as . G is of fan-out k if and is written as . The set is defined as (subscript G can be omitted if clear from the context).
The LCFRS derivation is based on the instantiation of rules, the replacement of variable occurrences by strings of terminals.
Definition 2 (Instantiation).
An instantiation of a production with is given by a function , where the set of all occurring in γ. γ is instantiated if all variable occurrences x have been replaced by . A non-terminal in an instantiated production is an instantiated non-terminal.
We now describe the LCFRS derivation process. A (partial) derivation is specified as a pair called item. Thereby, specifies the yield and D is the derivation tree. We use a bracketed representation of trees, e.g., is a tree with a root node labeled that has two daughters, a left daughter labeled and a right daughter labeled .
Definition 3 (Derivation).
Let be an LCFRS. The set of derivable items with respect to G contains all and only those items that can be deduced with the following deduction rules (the subscript G on may be omitted if clear from the context).
We can now define the string language of an LCFRS G on the basis of the yield of a non-terminal.
Definition 4 (Yield, String Language, and Tree Language).
Let be an LCFRS.
- For every we define .
- The string language of G is defined as .
- The derivation tree language of G is defined as .
Note that this definition of a tree language captures the set of derivation trees, not the derived trees with crossing branches along the lines of Figure 1 and Figure 2.
Example 1 (LCFRS Derivation).

Figure 4 shows an LCFRS that generates the language , , together with a derivation of the string . The derivation works as follows. First, the leaf nodes of the derivation tree are produced using the first deduction rule with the productions and . They introduce the first three as and the two bs. In order to insert three more as, we use the second deduction rule with production . This leads to a derivation tree with a root labeled that has the node as its single daughter. Finally the as and the bs are combined with the second deduction rule and production . This leads to a derivation tree with root label that has two daughters, the first one is the -derivation tree and the second one the node. The order of the daughters reflects the order of elements in the righthand sides of productions.
Figure 4.
LCFRS example derivation of with grammar for .
Finally, we define some additional notation that we will need later: Let be a production.
- gives A, gives and the jth symbol of ; gives , and gives the kth component of the lth RHS element. Thereby, i, j and k start with index 0, and l starts with index 1. These functions have value ⊥ whenever there is no such element.
- In the sense of dotted productions, we define a set of symbols denoting computation points of γ as .
2.2. Thread Automata
Thread automata TA [23] are a generic automaton model which can be parametrized to recognize different mildly context-sensitive languages. The TA for LCFRS (LCFRS-TA) implements a prefix-valid top-down incremental parsing strategy similar to the ones of [21,22]. In this paper, we restrict ourselves to introducing this type of TA.
As an example, let us consider the derivation of the word with the LCFRS from Figure 5 and Figure 6 shows a sample run of a corresponding TA where only the successful configurations are given. We have one thread for each rule instantiation that is used in a parse. In our case, the derivation is , we therefore have one thread for the α-rule, one for β and one for γ. The development of these threads is given in the three columns of Figure 6.
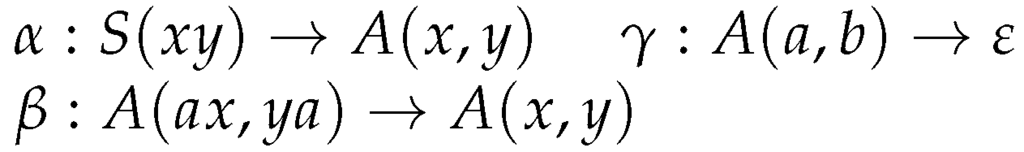
Figure 5.
LCFRS for .
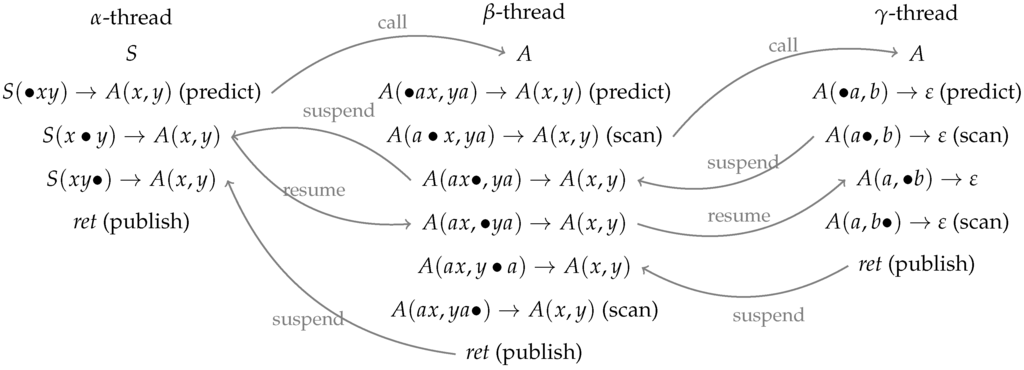
Figure 6.
Sample TA-run for .
Each thread contains at each moment of the TA run only a single symbol, either a non-terminal or a dotted production. The TA starts with the α-thread containing the start symbol. In a predict step, this is replaced with the dotted production corresponding to starting the α-rule. Now the dot precedes the first variable of the non-terminal A in the righthand side. We therefore start a new A-thread (we “call” a new A). In this thread, rule β is predicted, and the dot is moved over the terminal a in a scan step, leading to as content of the thread. Now, since the dot again precedes the first component of a righthand side non-terminal A, we call a new A-thread, which predicts γ this time. A scan allows to complete the first component of the γ-rule (thread content ). Here, since the dot is at the end of a component, i.e., precedes a gap, the γ-thread is supended and its mother thread, i.e. the one that has called the γ-thread, becomes the active thread with the dot now moved over the variable for the firsts γ-component (). Similarly, a second suspend operation leads to the α-thread becoming the active thread again with the dot moved over the finished component of the righthand side A (). The dot now precedes the variable of the second component of this A, therefore the β-thread is resumed with the dot moving on to the second component (). Similarly, a second resume operation leads to the γ-thread becoming active with content . The subsequent scan yields a completed A-item that can be published, which means that the mother thread becomes active with the dot moved over the variable for the last righthand side component. After another scan, again, we have a completed item and the α-thread becomes active with a content that signifies that we have found a complete S-yield. Since the entire input has been processed, the TA run was successful and the input is part of the language accepted by the TA.
More generally, an LCFRS-TA for some LCFRS works as follows. As we have seen, the processing of a single instantiated rule is handled by a single thread which will traverse the lefthand side arguments of the rule. A thread is given by a pair , where with m the rank of G is the address, and where is the content of the thread. In our example in Figure 6, addresses were left aside. They are, however, crucial for determining the mother thread to go back to in a suspend step. In Figure 6, the α-thread has address ε, the β-thread address 1 and the γ-thread address 11, i.e., the address of the mother thread is a prefix of the address of the child thread, respectively. This is why a thread knows where to go back to in a suspend step. An automaton state is given by a tuple where is a set of threads, the thread store, p is the address of the active thread, and indicates that i tokens have been recognized. We use as start state.
Definition 5 (LCFRS-TA).
Let be a LCFRS. The LCFRS thread automaton for G is a tuple with
- ;
- δ is a function from to such that if there is a l such that , and if ; and
- Θ is a finite set of transitions as defined below.
Intuitively, a δ value j tells us that the next symbol to process is a variable that is an argument of the j-th righthand side non-terminal.
Definition 6 (Transitions of a LCFRS-TA).
The transition set Θ of a LCFRS-TA as in Definition 5 contains the following transitions:
- Call: if and where .
- Predict: if .
- Scan: if .
- Publish: if and .
- Suspend:
- (i)
- if .
- (ii)
- if , , and .
- Resume: if , and .
These are all thransitions in Θ.
A transition roughly indicates that in the current thread store, α can be replaced with β while scanning a. Square brackets in α and β indicate parts that do not belong to the active thread. Call transitions start a new thread for a daughter non-terminal, i.e., a righthand side non-terminal. They move down in the parse tree. Predict transitions predict a new rule for a non-terminal A. Scan transitions read a lefthand side terminal while scanning the next input symbol. Publish marks the completion of a production, i.e., its full recognition. Suspend transitions suspend a daughter thread and resume the parent. i.e., move up in the parse tree. There are two cases: Either (i) the daughter is completely recognized (thread content ) or (ii) the daughter is not yet completely recognized, we have only finished one of its components. Resume transitions resume an already present daughter thread, i.e., move down into some daughter that has already been partly recognized.
Figure 7 shows the transitions for our sample grammar. Let us explain the semantics of these rules with these examples before moving to the general deduction rules for TA configurations. As already mentioned, a rule with and expresses that with being the content of the active thread, we can replace with while scanning t. The predict, scan and publish rules are instances of this rule type. in square brackets to the left characterize the content of the mother of the active thread while in square brackets to the right characterize the content of a daughter thread where the address of the daughter depends on the one of the active thread and the δ-value of the content of the active thread. Consider for instance the last suspend rule. It signifies that if the content of the active thread is and its mother thread has content , this mother thread becomes the new active thread with its content changed to while the daughter thread does not change content. The resume rules, in contrast to this, move from the active thread to one of its daughters. Take for instance the last rule. It expresses that, if the active thread has content and if this thread has a th daughter thread with content , we make this daughter thread the active one and change its content to , i.e., move its dot over a gap.
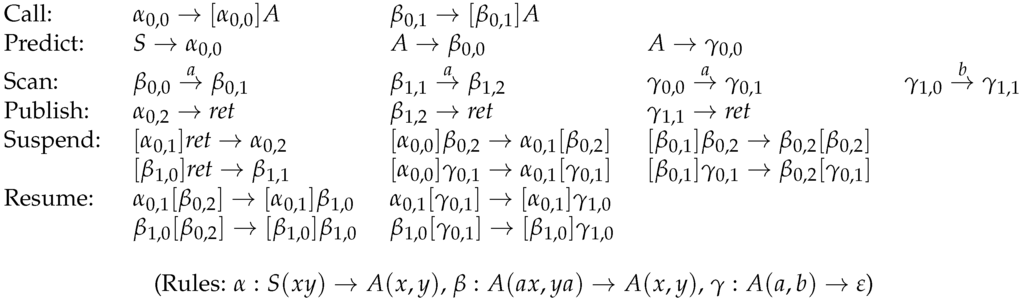
Figure 7.
TA transitions for the LCFRS from Figure 5.
This is not exactly the TA for LCFRS proposed in [23] but rather the one from [39], which is close to the Earley parser from [21].
The set of configurations for a given input is then defined by the deduction rules in Figure 8 (the use of set union in these rules assumes that ). The accepting state of the automaton for some input w is .

Figure 8.
Deduction rules for TA configurations.
3. LR Parsing
In an LR parser (see [40] chapter 9), the parser actions are guided by an automaton, resp. a parse table which is compiled offline. Consider the context-free case. An LR parser for CFG is a guided shift-reduce parser, in which we first build the LR automaton. Its states are sets of dotted productions closed under prediction, and its transitions correspond to having recognized a part of the input, e.g., to moving the dot over a righthand side element after having scanned a terminal or recognized a non-terminal.
Consider for instance the CFG . Its LR automaton is given in Figure 9. The construction of this automaton starts from the prediction closure of , which contains the two S-productions with the dot at the beginning of the righthand side. The prediction closure of a set of dotted productions q is defined as follows: if , then for all B-productions in the grammar. From a state q, a new state can be obtained by computing all items that can be reached by moving the dot over a certain in any of the dotted productions in q and then, again, building the prediction closure. The new state can be reached from the old one by an edge labeled with x. This process is repeated until all possible states have been constructed. In our example, when being in , we can for instance reach by moving the dot over an a, and we can reach (the acceptance state) by moving the dot over an S.
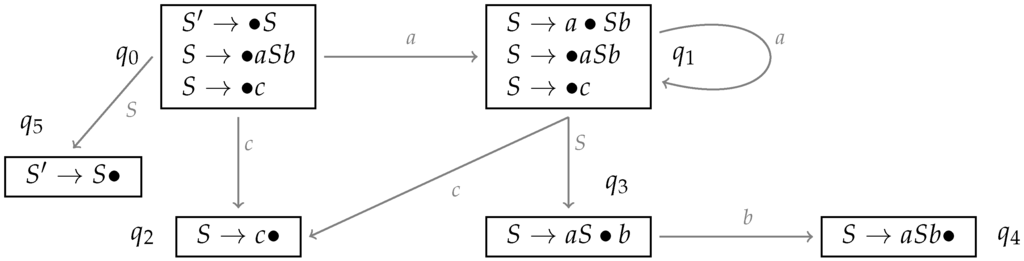
Figure 9.
Sample LR automaton for a CFG.
This automaton guides the shift-reduce parsing in the following way: At every moment, the parser is in one of the states. We can shift an if there is an outgoing a-transition. The state changes according to the transition. We can reduce if the state contains a completed . We then reduce with . The new state is obtained by following the A-transition, starting from the state reached before processing that rule.
The information about possible shift and reduce operations in a state is precompiled into a parse table: Given an LR automaton with n states, we build a parse table with n rows. Each row i, , describes the possible parser actions associated with the state , i.e., for each state and each possible shift or reduce operation, it tells us in which state to go after the operation. The table has columns where the first are indexed with the terminals, then follows a column for reduce operations and then a column for each of the non-terminals. For every pair of states , that are linked by an a-edge for some , the field of and a contains sj, which indicates that in , one can shift an a and then move to . For every state that contains rule number j with a dot at the end of the righthand side, we add rj to the reduce field of . Finally, for every pair of states , that are linked by an A-edge for some , the field of and A contains j, which indicates that in , after having completed an A, we can move to . On the left of Figure 10, we see the parse table resulting from the automaton in Figure 9. The first columns are the so-called action-part of the table while the last columns form the goto-part.

Figure 10.
Parse table and sample parse (rule 1 = , rule 2 = ).
The parse table determines the possible reductions and shifts we can do at every moment. We start parsing with a stack containing only . In a shift, we push the new terminal followed by the state indicated in the table on the stack. In a reduction, we use the production indicated in the table. We pop its righthand side (in reverse order) and push its lefthand side onto the stack. The new state is the state indicated in the parse table field for the state preceding the lefthand side of this production on the stack and the lefthand side category of the production. On the right of Figure 10, we see a sample trace of a parse according to our LR parse table. Note that this example allowed for deterministic LR parsing, which is not the case in general. There might be shift-reduce or reduce-reduce conflicts.
4. LR for LCFRS
4.1. Intuition
We will now adapt the ideas underlying LR parsing for CFG to the case of LCFRS. The starting point is the set of possible threads that can occur in a TA for a given LCFRS. Our LR automaton for LCFRS precompiles predict, call and resume steps into single states, i.e., states are closed under these three operations.
As an example, consider the TA from Section 2.2. Figure 11 sketches some of the states one obtains for this TA.
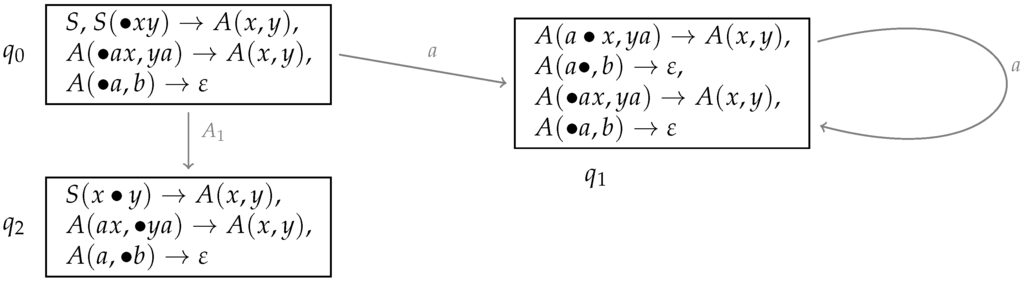
Figure 11.
Sample LR states for the TA in Figure 6.
As in the CFG case, we start with a state for the start symbol S and, in this state, add all predictions of S-rules with the dot at the left of the lefthand side component. Furthermore, for every item in some state q where the dot precedes a variable: If this variable is the ith component of a righthand side non-terminal A, we add to q all A-rules with the dot at the beginning of the ith component in the lefthand side. For , this is a call-and-predict operation, for a resume operation.
Moving the dot over a terminal symbol a leads to a transition labeled with a that yields a new state. And moving the dot over the variable that is the ith component of some righthand side symbol A leads to a transition labeled with .
Our parser then has shift operations and two kinds of reduce operations (the two types of suspend operations in the TA). Either we reduce the ith component of some A where or we reduce the last component of some A. In the first case, we have to keep track of the components we have already found, in particular of their derivation tree addresses. This is why we have to extend the states sketched in Figure 11 to using dotted productions with addresses.
Our predict/resume closure operations then have to add the index of the daughter that gets predicted/resumed to the address. A problem here is that this can lead to states containing infinitely many items. An example is in Figure 11. The dotted production leads, via the resume closure, to new instances of and , this time with a different address since these are daughters of the first. Consequently, would be the set , , , , , , , ...}. Such a problem of an infinite loop of predict or resume steps occurs whenever there is a left recursion in one of the components of a rule. We do not want to exclude such recursions in general. Therefore, in order to keep the states finite nevertheless, we allow the addresses to be regular expressions. Then for instance becomes , , . Concerning the transitions, here as well, we add the addresses of the item(s) that have triggered that transition. See Figure 12 for an example. A new state always starts with an item with address ε.
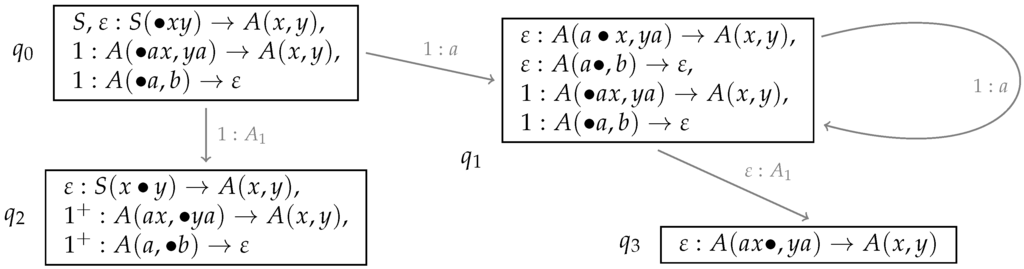
Figure 12.
Sample LR states for the TA in Figure 6 including addresses.
Once the automaton is constructed, the shift-reduce parser proceeds as follows: A configuration of the parser consists of a stack, a set of completed components and the remaining input. The completed components are of the form where r is a regular expression, is a pointer to the derivation tree node for this use of the rule and i is the component index. The stack has the form where is a regular expression followed by a state and points at a derivation tree node for a rule γ with .
For the input for instance, we would start with a stack and then, following the corresponding transition in the automaton, we can shift an a and move to . Since the shift transition tells us that this shift refers to the daughter with address 1, this address is concatenated to the preceding address. The new stack would be and, after a second shift, . In we can not only shift as but we can also reduce since there is an item with the dot at the end of the first A-component, . Such a reduce means that we remove this component (here a single a) from the stack, then create a node as part of the set of completed components, and then push its pointer and index (here ). The transition from the state preceding the a that is labeled gives the new state and address. The stack is then , and the set of completed components is . also tells us that a first component of a rule, this time , has been completed. It consists of a followed by a first A-component, therefore we have to remove a and (in reverse order) from the stack and then follow the transition from . The result is a stack and a completed components set . The completed components are, furthermore, equipped with an immediate dominance relation. In this example, immediately dominates . Whenever a reduce state concerns a component that is not the first one, we check in our set of completed components that we have already found a preceding component with the same address or (if it is a regular expression denoting a set) a compatible address. In this case, we increment the component index of the corresponding derivation tree node. In the end, in case of a successful parse, we have a stack and a component set giving the entire derivation tree with root node .
4.2. Automaton and Parse Table Construction
The states of the LR-automaton are sets of pairs where r is a regular expression over , and . They represent predict and resume closures.
Definition 7.
We define the predict/resume closure of some set by the following deduction rules:
- Initial predict:
- Predict/resume:
This closure is not always finite. However, if it is not, we obtain a set of items that can be represented by a finite set of pairs plus eventually such that r is a regular expression denoting a set of possible addresses. As an example for such a case, see in Figure 12. Let be the set of all regular expressions over .
Lemma 8.
For every , it holds that if is infinite, then there is a finite set such that .
Proof.
is finite. For each , the set of possible addresses it might be combined with in a state that is the closure of is generated by the CFG with
- ,
- , and
- P contains the following rules:
- -
- for all ,
- -
- for all instances of deduction rules,
- -
- and .
This is a regular grammar, its string language can thus be characterized by a regular expression.
The construction of the set of states starts with . From this state, follwing a-transitions or -transitions as sketched above, we generate new states. We first formalize these transitions:
Definition 9.
Let be a LCFRS. Let .
- For every , every and every , we define
- -
- and there is some l such that and and
- -
- .
- For every and every , we define
- -
- and and
- -
- .
The set of states of our automaton is then the closure of under the application of the -functions. The edges in our automaton correspond to -transitions, where each edge is labeled with the corresponding pair or respectively. Furthermore, we add a state and an edge labeled from the start state to this state, which is the acceptance state.
The complete automaton we obtain for the grammar in Figure 5 is shown in Figure 13. For the sake of readability, we use dotted productions instead of the computation points .
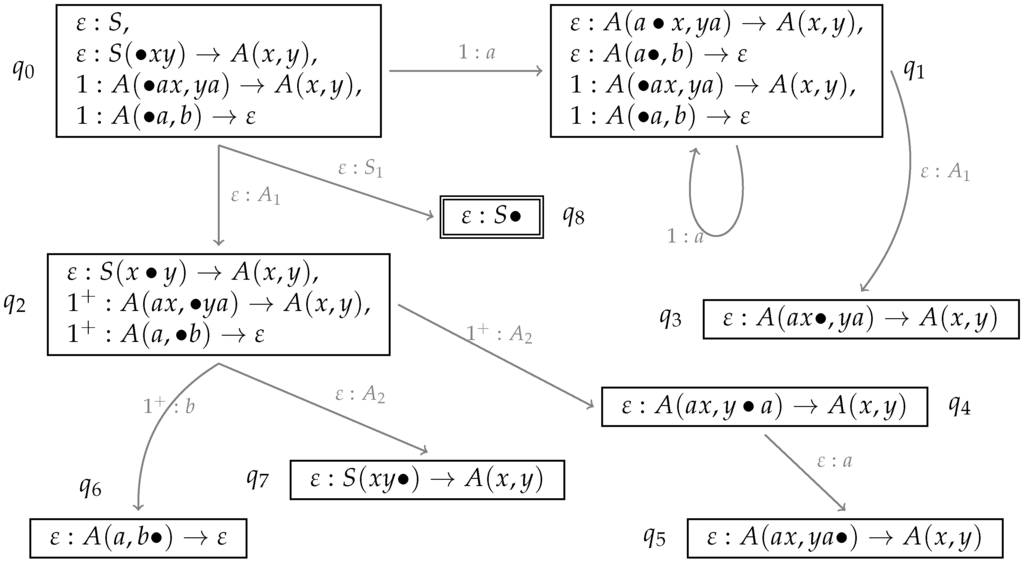
Figure 13.
The automaton for the LCFRS in Figure 5.
The number of possible states is necessarily finite since each state is the closure of some set containing only items with address ε. There are only finitely many such sets.
In the parse table, our operations are for shifting some terminal a followed by the old address concatenated with p and state q and for reducing the ith component of rule α. The two reduce operations can be distinguished by the component indices. These operations are entered into the first columns of the table, the so-called action part. Furthermore, the goto-part of the table tells where to go when traversing a component edge and which address to add then.
The parse table can be read off the automaton as follows:
Definition 10.
Let be a LCFRS, M its LR-automaton with state set Q. Then we define the corresponding LR parse table as a pair with a table and a table. The content of these tables is as follows:
- iff ;
- iff there is some such that .
- iff .
- Nothing else is in these tables.
Figure 14 shows the parse table for our example.

Figure 14.
The parse table.
4.3. Parsing Algorithm
The parser has slightly more complex configurations than the CFG shift-reduce parser. Let Q be the set of states of the LR automaton for a given LCFRS G, the state containing and the accepting state containing . Furthermore, let be the set of possible pointers to derivation tree nodes. The parser configurations are then triples consisting of
- a stack ,
- a set of constraints C that are either of the form with , , and or of the form with , .
- and the index j up to which the input w has been recognized, .
Concerning the constraint set C, the first type of constraints describes nodes in the derivation tree while the second describes immediate dominance relations between them, more precisely the fact that one node is the dth daughter of another node. There is an immediate relation between the two: if , then the address of must be the regular expression of concatenated with the daughter index d of . Let be the set of indices from occurring in C.
The initial configuration is . From a current configuration, a new one can be obtained by one of the following operations:
- Shift: Whenever we have on top of the stack, the next input symbol is a and in our parse table we have , we push a followed by onto the stack and increment the index j.
- Reduce: Whenever the top of the stack is and we have a parse table entry , we can reduce the ith component of γ, i.e, suspend γ. Concretely, this means the following:
- -
- Concerning the constraint set C, if , we add to C where is a new pointer.
- -
- If , we check whether there is a in C such that the intersection of the languages denoted by and , and , is not empty. We then replace in C with where p is a regular expression denoting .
- -
- Concerning the stack Γ, we remove elements (i.e., terminals/component pointers and their regular expressions and states) from Γ. Suppose the topmost state on the stack is now . If , we push followed by on the stack.
- -
- Concerning the dominance relations, for every among the symbols we removed from the stack, we add where d is the corresponding daughter index.
- -
- It can happen that, thanks to the new dominance relations, we can further restrict the regular expressions characterizing the addresses in C. For instance, if we had , and in our set, we would replace the address of with .
- -
- The index j remains unchanged in reduce steps.
Note that the intersection of two deterministic finite state automata is quadratic in the size of the two automata. In LCFRS without left recursion in any of the components, the intersection is trivial since the regular expressions denote only a single path each.
As an example, we run the parser from Section 4.2 with an input . The trace is shown in Figure 15. In this example, the immediate dominance constraints in C are depicted as small trees. We start in , and shift two as, which leads to . We have then fully recognized the first components of γ and β: We suspend them and keep them in the set of completed components, which takes us to . Shifting the b takes us to , from where we can reduce, which finally takes us to . From there, we can shift the remaining a (to ), with which we have fully recognized β. We can now reduce both β and with that, α, which takes us to the accepting state .
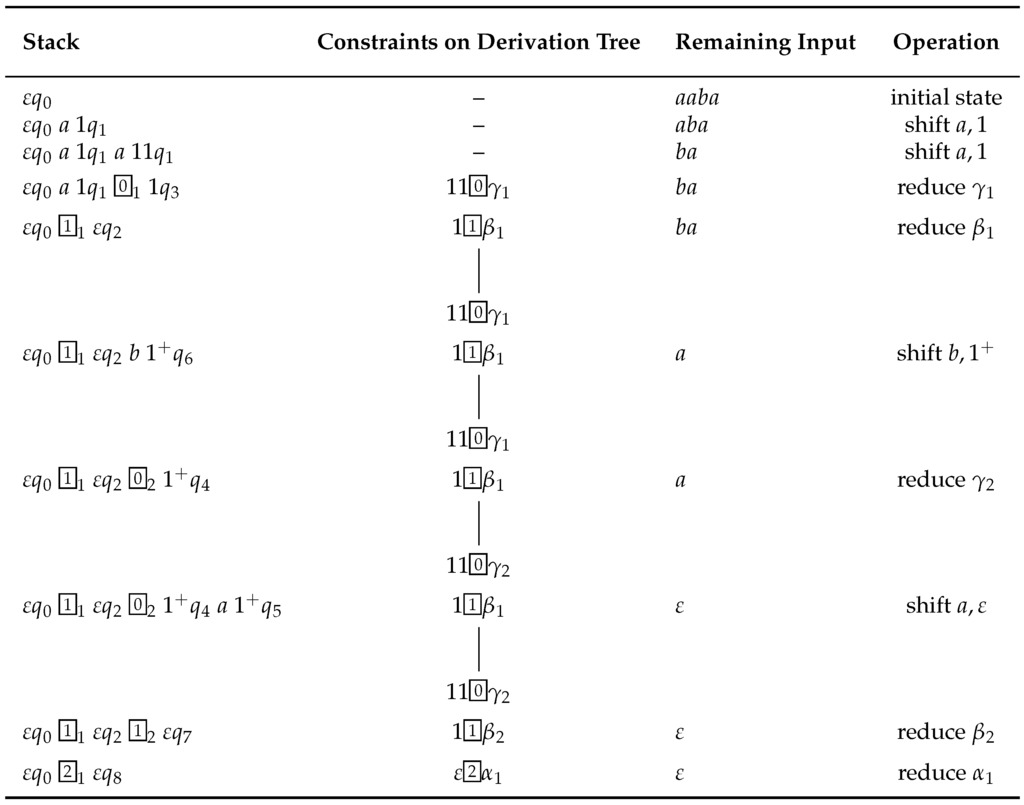
Figure 15.
Sample LR parser run with .
The way the different parsing operations can lead to new configurations can be described by a corresponding parsing schema, i.e., a set of deduction rules and a goal item specification. This is given in the following definition (the use of set union in these rules assumes ) (comparing the configurations of a LCFRS-TA to the configurations of our parser, it becomes clear that one problem of the TA is that, because of possible call-predict loops, we can have infinitely many configurations in a TA. [23] avoids this problem by a dynamic programming implementation of TAs. In our automata, this problem does not occur because of the regular expressions we use as addresses).
Definition 11 (LR Parsing: Deduction Rules).
Let be a LCFRS, its LR parse table, and and as introduced above.
The set of possible configurations for the LR parser is then defined by the following deduction rules:
- Initial configuration:
- Shift:Reduce 1:Reduce 2:where in both reduce operations,
- for some stands for the nth component of the dth righthand side element of γ for some and .
- is defined as the closure of C under application of the following rules:
- (a)
- Compilation of address information:
- (b)
- Removal of daughters of completed rules:
- Goal items: for some and with .
4.4. An Example with Crossing Dependencies
The running example we have considered so far generates only a context-free language. It was chosen for its simplicity and for the fact that it has a non-terminal with a fan-out and a left recursion in one of the components, which requires the use of regular expressions. Let us now consider the LCFRS in Figure 16, an LCFRS for a language that is not context-free with a cross-serial dependency structure. We have again left recursions, this time in all components of the rules and . And the rank of the grammar is 2, not 1 as in the running example we have considered so far. This gives us more interesting derivation trees.
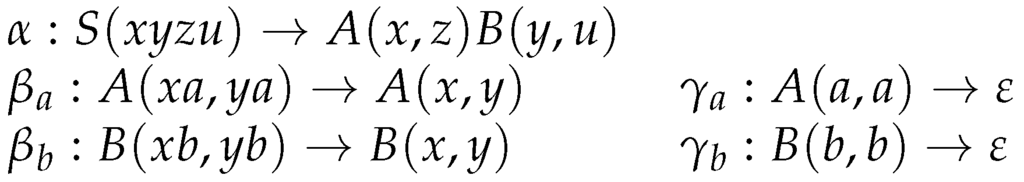
Figure 16.
A LCFRS for .
The LR automaton for this grammar is given in Figure 17. Since we have a left recursion in both components of the β rules, the predict and resume closures of the items that start the traversal of these components contain each an infinite number of addresses in the derivation tree, encoded in a regular expression ( or ). This automaton leads then to the parse table in Figure 18. As can be seen, the grammar does not allow for a deterministic parsing since, when being in for instance and having completed the first component of an A, this can lead to or , consequently there are several entries in the corresponding goto-field.
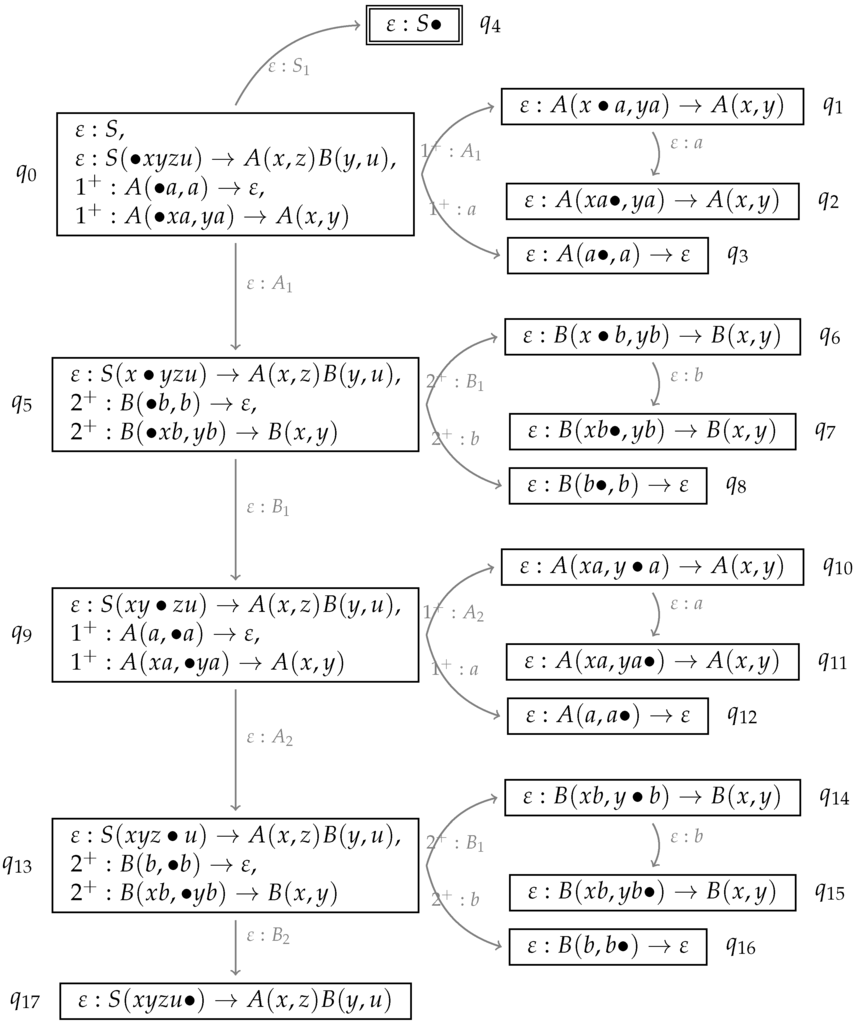
Figure 17.
LR automaton for .

Figure 18.
Parse table obtained from the LR automaton for .
Figure 19 gives a sample parse (only successful configurations) for the input . When reducing the components of the A yields (nodes and ) and of the components of the B yields (), we do not know the exact address of these elements in the derivation tree. Only in the last reduce step, it becomes clear that the and nodes are immediate daughters of the root of the derivation tree, and their addresses are resolved to 1 and 2 respectively.

Figure 19.
Sample LR parser run with (only successful configurations).
As mentioned, this grammar does not allow for a deterministic parsing. With one additional lookahead, the grammar would become deterministic (the ε-possibility is to be taken when being at the end of one of the or substrings of the input).
4.5. Deterministic Parsing
As mentioned, with one lookahead, LR parsing of the LCFRS in the previous example would become deterministic.
In general, when doing natural language processing, the grammars will always be ambiguous and a deterministic parsing is not possible. Instead, some way to share structure in the style of generalized LR [29] parsing has to be found. In other applications, however, we might have LCFRSs that allow for a deterministic parsing, similar to LR(k) parsing as in [27].
Non-determinism with LCFRS can arise not only from shift-reduce or reduce-reduce conflicts as in CFGs but also from a conflict between different transitions that have the same component non-terminal but different node addresses (see the multiple entries in the table of our example). We therefore need lookaheads not only for reduce (and, if , shift) but also for the entries.
We now define, similar to the CFG case [27], sets of symbols for dotted productions, which contain all terminals that are reachable as first element of the yield, starting from the dotted production. For every , let us define as follows. (Remember that gives the jth symbol of the ith component in the lefthand side of γ, i.e., the element following the dot.)
- if is not defined (i.e, the dot is at the end of the ith component);
- if (i.e., the dot precedes a);
- if , x is the lth component in a righthand side element of γ with non-terminal B, and there is a with such that .
- Nothing else is in .
Besides this, we also need the notion of . sets are defined for all component nonterminals () of our LCFRS. They contain the terminals that can immediately follow the yield of such a component nonterminal.
- where S is the start symbol and is a new symbol marking the end of the input.
- For every production γ with being the jth element of the ith lefthand side component (indices start with and ) and x being the lth element of the yield of a nonterminal B in the righthand side (also starting with ), we have , provided is defined.
- For every production γ with and with being the last element of the ith lefthand side component (indices start with ) and the lth element of the yield of a nonterminal B in the righthand side (also starting with ), we have .
- Nothing else is in the sets of our component nonterminals.
For parsing, i.e., LR parsing with 1 lookahead, we replace the items in our states with triples consisting of the adress (regular expression), the dotted production and the possible next terminal symbols. To this end, we define sets that are the sets for dots that are not at the end of components and otherwise the -sets of the component non-terminal:
if exists and otherwise.
A simple way to extend our automaton to is by extending the items in the states as follows: Every item with dotted production is equipped with the lookahead set . Furthermore, transitions are also labeled with triples where the new third element that is added is the terminal in case of a shift transition and, in case of a transition that moves the dot over a non-terminal, the set of the result of moving the dot according to the transition.
Consider the sample automaton in Figure 17. has two outgoing edges with different addresses. One (derivation tree node address ε) arises from moving the dot over the variable x in . We have , therefore this transition would be relabeled . The other transition (address ) leads to , the set is and therefore this transition would be relabeled .
Consequently, the part of the parse table, that would now have entries for every combination of component non-terminal and lookahead symbol, would have at most one entry per field. Hence, LR(1) parsing of our sample grammar is deterministic.
Concerning the reduce steps in the parse table, we would also have a lookahead. Here we can use the elements from the set of the reduced components as lookaheads. The reduce entry for state for instance would have the lookaheads from .
Instead of this simple LR technique one can also compute the lookahead sets while constructing the automaton, in the style of canonical LR parsing for CFGs. This would allow for more precise predictions of next moves.
There are LCFRSs that do not allow for a deterministic parsing, no matter how long the length k of the lookahead strings (the non-deterministic CFGs, which are 1-LCFRSs are such grammars). But a precise characterization of the class of deterministic LCFRSs and an investigation of whether, for every LCFRS, we can find a weakly equivalent LCFRS (as is the case for CFG), is left for further research.
4.6. Soundness and Completeness of the LR Algorithm
In order to show soundness and completeness of the LR algorithm, we will relate it to the LCFRS-TA for the same grammar. We will slightly modify the deduction rules for TA by assuming that (1) call and predict steps are combined and the initial configuration is omitted, i.e., we start with the result of the first predict steps; (2) we omit the publish steps; and (3) we don’t delete threads of finished rules. The modified rules are given Figure 20. Concerning the LR automaton, we replace the regular expressions in our parsing configurations with concrete addresses. In principal we can then have infinitely many configurations in cases of left recursions (just like in the TA case), i.e., in cases where a shift or goto transition comes with a regular expression denoting an infinite language. Furthermore, we do not delete daughters of completed rules in the constraint set either, i.e., we assume that the rule 2(b) in Definition 11 concerning the application of to the constraint set does not apply. Clearly, this does not change the languages recognized by these automata, it just increases the set of possible configurations. Since we use no longer regular expressions but single addresses, the deduction rules of the LR parser get simpler. Immediate dominance constraints are no longer needed since they follow from the addresses. The relevant deduction rules are given in Figure 21.
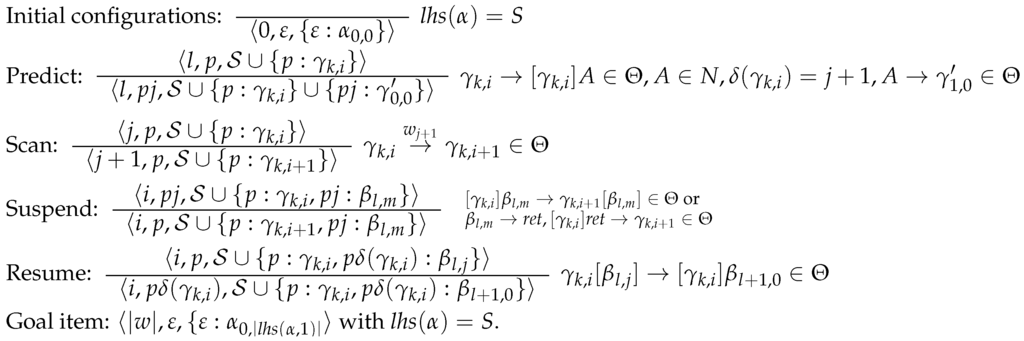
Figure 20.
Revised deduction rules for TA configurations.

Figure 21.
LR deduction rules without regular expressions.
Figure 22 shows the correspondence between TA configurations and LR configurations for our sample derivation of .
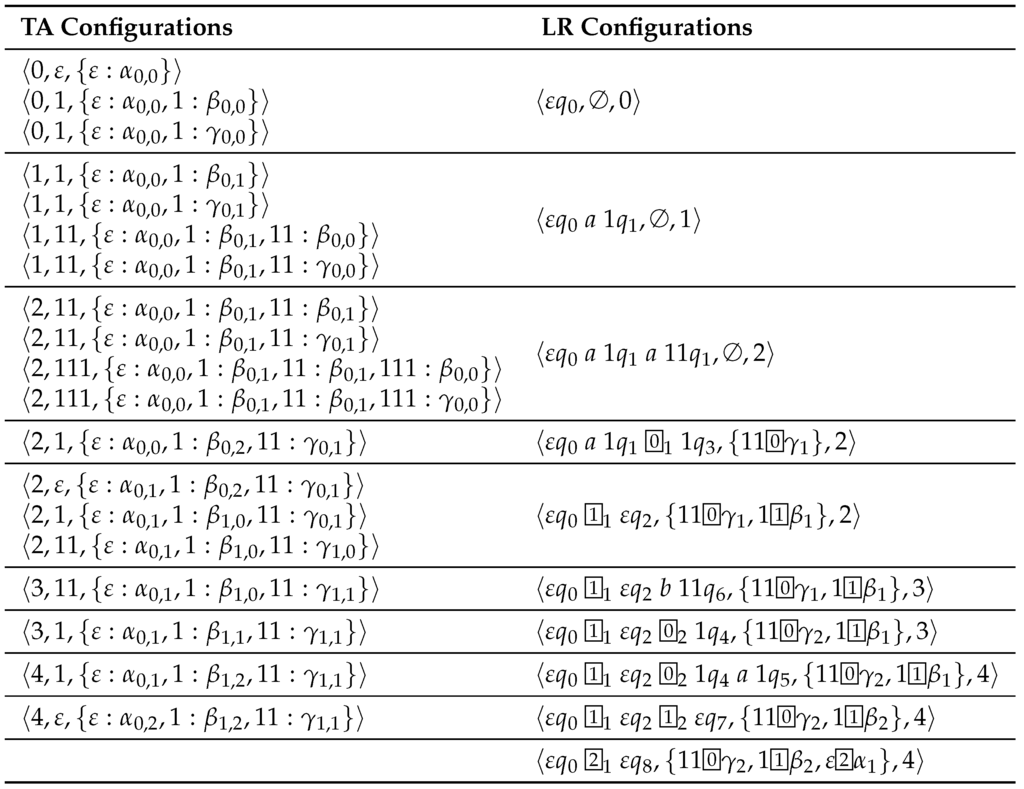
Figure 22.
TA configurations and corresponding LR configurations for our sample parse of .
We now define a function that gives for every LR configuration the set of corresponding TA configurations. The idea is the following: An LR configuration describes a path in our LR automaton. This path yields several possible thread contents.
Before giving the formal definition, let us consider two examples from Figure 22 for illustration. Take as a first example the LR configuration . The corresponding path in our automaton is
Each thread store in the corresponding TA configuration corresponds to a possible path through these states.
- For every ε-element in the last state of this path (here or ), we compute the TA configurations and respectively for these elements:Let us consider first the case of . We first define a set , starting with :
- -
- Since was obtained via the a-transition, from in , we add to .
- -
- in turn is in the second state on the path since we obtained it via prediction from , which is added to as well.
- -
- Again, arose out of a shift of a from , which is added as well and then, because of predict in , we add . This gives .
- -
- We then remove all items where there is an item with the same address and rule in the set but with a lefthand side index that is more advanced. This yields , which is the thread set we were looking for.
- -
- In a similar way, for the γ case, we obtain
- In addition, we add all configurations that we can reach from the ones constructed so far via predict or resume. These are reflected in corresponding items in the last state of our path. In our sample case, and are both elements of the last state and arose directly out of via predict. Therefore, we add these to the thread store with being the active thread, which leads to and .
- These are all configurations in .
Now consider as a second example , corresponding to the following path:
Again, we have to go back from the ε-element in the last state in order to construct the thread store. The last element gives us .
Consequently, the configuration is and we construct starting with . Following the shift transition back adds to . , in turn, arose from a resume applied to , which is therefore added as well. was predicted from , which is added as well. Now we follow the -transition backwards and therefore add . Finally, since for a specific address and rule, we keep only the most advanced position, we obtain .
In order to define the corresponding TA-sets, we annotate the LR automaton with pointers that show for each element c in any of the states, which other element has lead to c, either because of moving the dot over a terminal or a component variable or because of a predict/resume closure operation. In the latter case, the pointer is labeled with the daughter index of the predict/resume operation. For this annotation, we assume that instead of pairs of regular expression and comutation point, we use onyl pairs of address and computation point. This means of course, that we have potentially infinite states and potentially infinite predecessor paths through a state and from one state to another.
Definition 12 (Predecessor Annotation).
Let M be an LR-automaton with state set Q constructed from an LCFRS G. .
We define the predecessor annotation of M as a labeled relation such that for every and every :
- If there is a such that and can be deduced from by the predict/resume rule from Definition 7, .
- If and there is a and a such that for some , then .
Nothing else is in .
Now we can define the set of possible TA stores for a given LR-configuration.
For every set of constraints C, we define as the set of pointers in C. Furthermore, for every pointer , we define as the address associated with , and as its label .
For a given LR configuration, we compute the corresponding TA configurations via deduction rules. The items in these rules have the form with a thread store, a LR configuration, i the index in the input, p an address and an element of the topmost state in Γ. We start with an empty thread store and our LR configuration. The deduction rules then either move backwards inside the topmost Γ state or remove elements from Γ while adding corresponding threads to the thread store. In the end, we will have an empty stack Γ and then, the thread store together with the index i and the address p of the current thread gives us one of the TA configurations corresponding to the LR configuration we started with. p stays constant throughout the entire computation. represents the address of the daughter that has lead to moving into the current state.
Definition 13.
Let G be an LCFRS, its LR automaton. For every input and every configuration that can be deduced via for the input w, we define can be deduced from via the following deduction rules}.
- Current thread:
- Predict/resume backwards:
- Shift backwards:
- Shift non-terminal backwards:
- Empty stack:
- Add completed components:
Current thread picks one element from the topmost state q in Γ as the starting element. The address of the corresponding thread is a concatenation of the address preceding q on the stack and the address of the chosen state element. Predict/resume backwards applies whenever the address of the current state element is not ε, we then follow the link and add a corresponding new thread to our thread store. Shift backwards follows a link that corresonds to a reversed edge in the automaton labeled with a terminal. In this case, we do not change the thread store since we already have a thread for the rule application in question with a more advanced index. We only remove the shifted terminal and state from the LR stack and we split the address of the state and the element within it according to the link. Shift non-terminal backwards is a similar move following a link that corresonds to a reversed edge in the automaton labeled with a component non-terminal. These four rules serve to reduce the LR stack while constructing threads out of it. This process terminates with a single application of Empty stack. Once the stack is empty, we have to take care of the components described in C. For all of these, if no corresponding thread exists, wee add it by applying Add completed component.
Lemma 14.
Let be a LCFRS of rank m. Let be the LCFRS-TA of G, and let M be the LR-automaton constructed for G with being the LR parse table one can read off M.
For every input word , with being the set of TA configurations, the set of LR configurations arising from parsing w with the TA or the LR parser:
Proof.
Proof by induction over the deduction rules of the TA automaton and the LR parser:
- Initial configurations: can be added as initial configuration in the LR parser iff for every with are initial configurations in the TA and, furthermore, for any configuration one can obtain from one of these initial TA configurations via applications of Predict it holds that there is a corresponding element in . Conversely, except for , for every element in , there is a corresponding configuration in the TA containing this element and all its predecessors as threads.Predict in the TA starting from any of the :Elements in are obtained by
- -
- Initial predict:
- -
- Predict closure on in the LR automaton:with a link labeled j from the consequent item to the antecedent item.
Consequently, we obtain that the set of TA configurations we get by using only the initial rule and Predict is exactly , i.e., the union of all for LR configurations we can obtain by the initial rule. - Scan and Shift: We now assume that we have sets of TA configurations and of LR configurations such that .To show: For any pair contained in the two sets and for any terminal a and any address p: are all the configurations in with current thread address p that allow for an application of Scan with a, the new configurations being iff allows to derive a new configuration via an application of Shift with the terminal a and address p, such that the following holds: where is the closure of under applications of Predict and Resume.Let us repeat the operations Scan and Shift:Scan in the TA:Shift in the LR automaton:Let for . According to our induction assumption, has a form such that there exist a with for all . Furthermore, the dot in precedes a terminal , we consequently can perform scans on and there is a shift transition . Consequently, we can obtain new TA configurations and a new LR configuration in the LR automaton.According to the LR automaton construction, with having a predecessor link pointing to in q. Further elements in are obtained by predict and resume and are linked to the elements with address ε by a predecessor chain. The same predict and resume operations can be applied to the corresponding TA configurations as well. Therefore our induction assumption holds.
- Suspend and Reduce: We assume again that we have sets of TA configurations and of LR configurations such that .To show: For any pair contained in the two sets: there is a that allows to derive a new configuration via an application of suspend iff allows to derive a new configuration via an application of reduce 1/2 such that .Let such that a suspend can be applied resulting in . According to our induction assumption, has a form such that there exists a (without loss of generality, we assume our grammars to be ε-free. Consequently, computation points with the dot at the end of a component cannot arise from predict or resume operations and therefore always have address ε). Furthermore, since in , the dot is at the end of the th component, we have .Let us remind the suspend and reduce operations:TA Suspend:LR Reduce 1:LR Reduce 2:where for both reduce steps, any component pointer among the has an address for some .The only difference between the two reduce steps is that in the first, a first component is found and therefore a new pointer added to C, while in the second, only the component index of an already present pointer in C is incremented.In our case, there must be elements such that and . This means that for the resulting LR configuration, we obtain exactly the TA thread store plus eventually additional store entries obtained from predict or resume operations.
4.7. Comparison to TAG Parsing
As mentioned in the beginning, LR parsing has also been proposed for TAG [31,41]. The LR states in this case contain dotted productions that correspond to small subtrees (a node and its daughters) in the TAG elementary trees. They are closed under moving up and down in these trees, predicting adjunctions and predicting subtrees below foot nodes. There are two different transitions labeled with non-terminal symbols in the LR automata constructed for TAG: Transitions that correspond to having finished a subtree and moving the dot over the corresponding non-terminal node and transitions that correspond to having finished the part below a foot node and moving back into the adjoined auxiliary tree. The latter transitions are labeled with the adjunction site. In the parser, when following such a transition, the adjunction site is stored on the stack of the parser. Adjunctions can be nested, consequently, we can have a list (actually a stack) of such adjunction sites that we have to go back to later. This way to keep track of where to go back to once the adjoined tree is entirely processed corresponds to the derivation node addresses we have in the thread automata and the LCFRS LR parser since both mechanisms capture the derivation structure. The difference is that with TAG, we have a simple nested structure without any interference of nested adjunctions in different places. And the contribution of auxiliary trees in the string contains only a single gap, consequently only a single element in the daughter list of a node contains such information about where to go back to when having finished the auxiliary tree. Therefore each of these chains of adjunctions can be kept track of locally on the parser stack.
Restricting our LR parser to well-nested 2-LCFRS amounts to restricting it to TAG. This restriction means that our LCFRS rules have the following form: Assume that is a rule in such an LCFRS. Then we can partition the righthand side into minimal subsequences , ..., such that a) the yields of these subsequences do not cross; b) every subsequence either (i) contains only a single non-terminal or (ii) has a first element of fan-out 2 that wraps around the yields of the other non-terminals. In this latter case, the yield of the second to last non-terminals can again be partitioned in the same way. Consider as an example a rule . Here, we can partition the righthand side into the daughter sequences B and and F that can be parsed one after the other without having to jump back and forth between them. Concering , the C wraps around and, concerning this shorter sequence, D wraps around E. This means that during parsing, when processing the yield of one of these subsequences, we have to keep track of the last first component of some non-terminal that we have completed since this will be the first one for which we have to find a second component. We can push this information on a stack and have to access only the top-most element. There is no need to search through the entire partial derivation structure that has already been built in order to find a matching first component when reducing a second one. On the parse stack, it is enough to push the rule names for which we have completed a first component and still need to find a second. Pointers to the derivation structure are no longer needed. And node addresses are not needed either. Besides nestings between sisters as in this example, we can also have embedded nestings in the sense that a first comoponent is part of some other component. In this case, we have to finish the lower non-terminal before finishing the higher. In reductions of first components, we keep can keep track of embedded first components by removing them from the stack and popping them again after having added the new element. This makes sure that the second component of the most deeply embedded first component inside the rightmost first component of what we have processed so far must be completed next.
The LR automaton does not need node addresses any longer. Besides this, it looks exactly like the automata we have built so far. As an example consider the LR automaton in Figure 23.
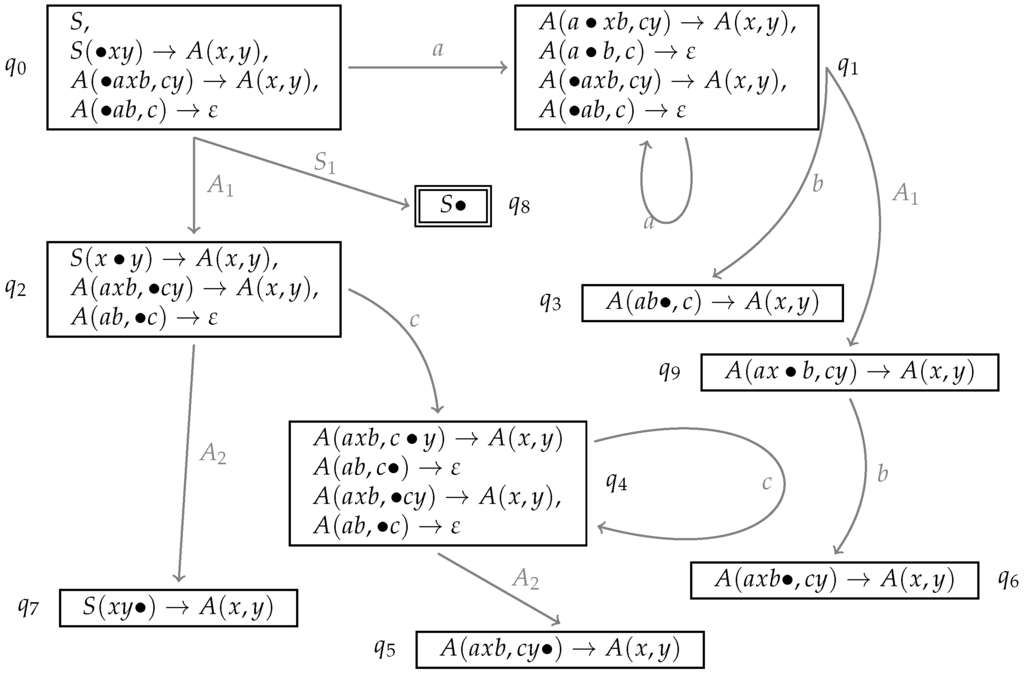
Figure 23.
LR automaton for an LCFRS with rules , , .
Whenever we reduce a first component of a rule with fan-out 2, we push the rule name on the component stack and any stack symbols corresponding to daughters of this component (i.e., the first component non-terminals are part of the reduced yield but not the corresponding second one) are taken from this stack and then pushed on an extra stack attached to the new rule symbol, such that the rightmost daughter is the highest element on this embedded stack. Whenever we reduce a second component, we must have the corresponding rule name as the top stack element and then we can delete it. The top is defined as follows: If the top is an element without attached stack, it is itself the top of the entire stack. If not, the top of its attached stack is the top of the entire stack structure. An example is given in Figure 24. This example involves two reduce steps with first components, the first in state where the rule name γ is pushed on the stack. In the second reduce step, we reduce the first component of β. This contains a non-terminal for which we have not seen the corresponding yet. Therefore, one symbol is popped from the stack (for ), and the new β is pushed with an attached stack containing the removed γ. Whenever we reduce a second component of a rule, the top-most stack element must be the name of that rule.

Figure 24.
Parsing trace for (only successful configurations), well-nested 2-LCFRS parsing.
5. Conclusions
This paper presents the first LR style algorithm for LCFRS parsing. It extends the well-known LR parsing techniques from CFG to the case of LCFRS where a single non-terminal can span several non-adjacent strings in the input. Even though the derivation structure needs to be kept track off during parsing in order to make sure that the correct components are related to each other, the proposed algorithm constructs only a finite automaton, by capturing derivation tree addresses in regular expressions whenever left recursions occur in some component.
The resulting parsing algorithm extends previous work on incremental Earley-style LCFRS parsing and on Thread Automata, an automaton model for LCFRS that proceeds in an incremental way but that does not precompile predict and resume steps the way it is proposed for the LR construction in this paper.
Acknowledgments
The research presented in this paper was partly funded by the German Science Foundation (DFG). We are grateful to anonymous reviewers of this paper and of a previous short version of this work that has been presented at NAACL-HLT 2015. Their comments and suggestions helped considerably to improve the paper.
Author Contributions
This work is an extension of previous research of the authors. The underlying ideas emerged from mutual discussion, to which both authors have contributed substantially. The present paper was mostly written by Laura Kallmeyer. Wolfgang Maier contributed the introduction and the first part of the second section.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Vijay-Shanker, K.; Weir, D.; Joshi, A.K. Characterising structural descriptions used by various formalisms. In Proceedings of the 25th Annual Meeting of the Association for Computational Linguistics, Stanford, CA, USA, 6–9 July 1987; pp. 104–111.
- Joshi, A. How much context-sensitivity is necessary for characterizing structural descriptions? In Natural Language Processing: Theoretical, Computational and Psychological Perspectives; Dowty, D., Karttunen, L., Zwicky, A., Eds.; Cambridge University Press: New York, NY, USA, 1985; pp. 206–250. [Google Scholar]
- Brants, S.; Dipper, S.; Hansen, S.; Lezius, W.; Smith, G. The TIGER treebank. In Proceedings of the 1st Workshop on Treebanks and Linguistic Theories, Sofia, Bulgaria, 13–14 December 2002; pp. 24–42.
- Maier, W.; Lichte, T. Characterizing discontinuity in constituent treebanks. In Proceedings of the 14th International Conference, Bordeaux, France, 25–26 July 2009; pp. 167–182.
- Marcus, M.P.; Santorini, B.; Marcinkiewicz, M.A. Building a large annotated corpus of english: The penn treebank. Comput. Linguist. 1993, 19, 313–330. [Google Scholar]
- Evang, K.; Kallmeyer, L. PLCFRS parsing of english discontinuous constituents. In Proceedings of the 12th International Conference on Parsing Technologies (IWPT 2011), Dublin, Ireland, 5–7 October 2011; pp. 104–116.
- Haider, H.; Rosengren, I. Scrambling; Sprache und Pragmatik: Lund, Sweden, 1998. [Google Scholar]
- Kübler, S.; McDonald, R.; Nivre, J. Dependency parsing. Synth. Lect. Hum.Lang. Technol. 2009, 1, 1–127. [Google Scholar] [CrossRef]
- Kuhlmann, M. Mildly non-projective dependency grammar. Comput. Linguist. 2013, 39, 355–387. [Google Scholar] [CrossRef]
- Skut, W.; Krenn, B.; Brants, T.; Uszkoreit, H. An annotation scheme for free word order languages. In Proceedings of the 5th Applied Natural Language Processing Conference, 31 March–3 April 1997; pp. 88–95.
- Ranta, A. Grammatical Framework: Programming with Multilingual Grammars; CSLI Publications: Stanford, CA, USA, 2011. [Google Scholar]
- Ljunglöf, P. Expressivity and Complexity of the Grammatical Framework. Ph.D. Thesis, Göteborg University, Gothenburg, Sweden, 2004. [Google Scholar]
- Kallmeyer, L.; Maier, W.; Parmentier, Y.; Dellert, J. TuLiPA-Parsing extensions of TAG with range concatenation grammars. Bull. Pol. Acad. Sci. 2010, 58, 377–391. [Google Scholar] [CrossRef]
- Kallmeyer, L.; Parmentier, Y. On the relation between multicomponent tree adjoining grammars with tree tuples (TT-MCTAG) and range concatenation grammars (RCG). In Proceedings of the Second International Conference on Language and Automata Theory and Applications (LATA 2008), Tarragona, Spain, 13–19 March 2008; pp. 263–274.
- Dada, A.; Ranta, A. Implementing an open source arabic resource grammar in GF. In Perspectives on Arabic Linguistics: Papers from the Annual Symposium on Arabic Linguistics; John Benjamins Publishing: Amsterdam, The Netherlands, 2007; pp. 209–231. [Google Scholar]
- Botha, J.A.; Blunsom, P. Adaptor grammars for learning non-concatenative morphology. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Washington, DC, USA, 18–21 October 2013; pp. 345–356.
- Melamed, I.D.; Satta, G.; Wellington, B. Generalized multitext grammars. In Proceedings of the 42nd Meeting of the Association for Computational Linguistics (ACL’04), Barcelona, Spain, 21–26 July 2004; pp. 661–668.
- Kaeshammer, M. Hierarchical machine translation with discontinuous phrases. In Proceedings of the Tenth Workshop on Statistical Machine Translation, Lisbon, Portugal, 17–18 September 2015.
- Kaeshammer, M. Synchronous linear context-free rewriting systems for machine translation. In Proceedings of the Seventh Workshop on Syntax, Semantics and Structure in Statistical Translation, Atlanta, GA, USA, 13 June 2013; pp. 68–77.
- Seki, H.; Matsumura, T.; Fujii, M.; Kasami, T. On multiple context-free grammars. Theor. Comput. Sci. 1991, 88, 191–229. [Google Scholar] [CrossRef]
- Burden, H.; Ljunglöf, P. Parsing linear context-free rewriting systems. In Proceedings of the Ninth International Workshop on Parsing Technology, Vancouver, BC, Canada, 9–10 October 2005; pp. 11–17.
- Kallmeyer, L.; Maier, W. An incremental earley parser for simple range concatenation grammar. In Proceedings of the 11th International Conference on Parsing Technologies (IWPT’09), Paris, France, 7–9 October 2009; pp. 61–64.
- Villemonte de la Clergerie, E. Parsing mildly context-sensitive languages with thread automata. In Proceedings of the COLING 2002: The 19th International Conference on Computational Linguistics, Taipei, Taiwan, 26–30 August 2002.
- Kallmeyer, L.; Maier, W. Data-driven parsing using probabilistic linear context-free rewriting systems. Comput. Linguist. 2013, 39, 87–119. [Google Scholar] [CrossRef]
- Van Cranenburgh, A. Efficient parsing with linear context-free rewriting systems. In Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics, Avignon, France, 23–27 April 2012; pp. 460–470.
- Angelov, K.; Ljunglöf, P. Fast statistical parsing with parallel multiple context-free grammars. In Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, Gothenburg, Sweden, 26–30 April 2014; pp. 368–376.
- Knuth, D.E. On the translation of languages from left to right. Inf. Control 1965, 8, 607–639. [Google Scholar] [CrossRef]
- Tomita, M. LR parsers for natural languages. In Proceedings of the COLING 1984: The 10th International Conference on Computational Linguistics, Stanford, CA, USA, 2–6 July 1984; pp. 354–357.
- Tomita, M. An efficient augmented context-free parsing algorithm. Comput. Linguist. 1987, 13, 31–46. [Google Scholar]
- Nederhof, M.J. An alternative LR algorithm for TAGs. In Proceedings of the 36th Annual Meeting of the Association for Computational Linguistics and 17th International Conference on Computational Linguistics, Montreal, QC, Canada, 10–14 August 1998; pp. 946–952.
- Prolo, C.A. LR Parsing for Tree Adjoining Grammars and Its Application to Corpus-Based Natural Language Parsing. Ph.D. Thesis, Department of Computer and Information Science, University of Pennsylvania, Philadelphia, PA, USA, 2003. [Google Scholar]
- Aizikowitz, T.; Kaminski, M. LR(0) conjunctive grammars and deterministic synchronized alternating pushdown automata. In Proceedings of the 6th International Computer Science Symposium on Computer Science, Theory and Applications, St. Petersburg, Russia, 14–18 June 2011; pp. 345–358.
- Okhotin, A. Generalized LR parsing algorithm for boolean grammars. Int. J. Found. Comput. Sci. 2006, 17, 629–664. [Google Scholar] [CrossRef]
- Barash, M.; Okhotin, A. Generalized LR parsing algorithm for grammars with one-sided contexts. Theory Comput. Syst. 2016. [Google Scholar] [CrossRef]
- Kallmeyer, L.; Maier, W. LR parsing for LCFRS. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015; pp. 1250–1255.
- Boullier, P. Proposal for a Natural Language Processing Syntactic Backbone; Research Report 3342; INRIA-Rocquencourt: Rocquencourt, France, 1998. [Google Scholar]
- Weir, D. Characterizing Mildly Context-Sensitive Grammar Formalisms. Ph.D. Thesis, University of Pennsylviania, Philadelphia, PA, USA, 1988. [Google Scholar]
- Kracht, M. The Mathematics of Language; Mouton de Gruyter: Berlin, Germany, 2003. [Google Scholar]
- Kallmeyer, L. Parsing beyond Context-Free Grammar; Springer: Heidelberg, Germany, 2010. [Google Scholar]
- Grune, D.; Jacobs, C. Parsing Techniques. A Practical Guide, 2nd ed.; Monographs in Computer Science; Springer: New York, NY, USA, 2008. [Google Scholar]
- Nederhof, M.J. Solving the correct-prefix property for TAGs. In Proceedings of the Fifth Meeting on Mathematics of Language, Schloss Dagstuhl, Germany, 25–28 August 1997; pp. 124–130.
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).