1. Introduction
The Markov Chain Monte Carlo (MCMC) method is one of the most frequently used algorithms to solve hard counting, sampling and optimization problems. This is relevant for many areas, including complex networks, physics, communication systems, computational biology, optimization, data mining, big data analysis, forecast problems, prediction tasks, and innumerable others. The success and influence of the method is shown by the fact that it has been selected as one of the top 10 of all algorithms in the 20th century, see [
1].
The MCMC algorithm also plays an important role in large, complex networks. In this paper, building on our earlier conference presentations [
2,
3], we consider the following regularly occurring application of the MCMC method:
Consider a very large graph
G, with node set
S, and let
be a subset of the nodes. We would like to estimate the relative size of
A, that is, the goal is to obtain a good estimate of the value
More generally, if a random walk is considered on the graph, with stationary distribution π, then we would like to estimate , the stationary probability of being in A. In the special case when π is the uniform distribution, we get back the formula (1).
If we can take random samples from S, according to the stationary distribution, then an obvious estimate with good properties is the relative frequency of the event that the sample falls in A. Unfortunately, in most nontrivial cases of interest, this sampling task is not feasible. The reason is that often the large set S is defined implicitly. Examples are the set of all cliques in a graph, or the set of all feasible solutions to an optimization problem, and many others. No efficient general method is known to sample uniformly at random from such complex sets.
An important application in telecommunication networks is to estimate blocking probabilities, see [
4,
5]. More generally, if we have a large system, with an enormous state space, we may want to estimate that the actual state falls in a specific subset. For example, if the state space consists of all possible load values of the network links, which leads to a state space of astronomical size, we may want to know what the probability is that at most
k links are overloaded, for some value of
k.
At this point, the MCMC does a very good service. If we define a Markov chain in which the states are the elements of S and the transitions are based on simple local operations, then we can very often obtain a Markov chain with uniform, or some other simple stationary distribution over S. Then, if we run this chain long enough so that it gets close to the stationary distribution, then the state where we stop the chain will be a good approximation of a random sample over S, distributed according to the stationary distribution. Then by repeating the process sufficiently many times, and by counting the relative frequency that the random sample falls in A, we can get a good estimate of the probability measure of A.
The key difficulty is, however, that we should run the chain long enough to get sufficiently close to the stationary distribution. This time is often referred to as
mixing time [
6]. If the mixing time grows only polynomially with the size of the problem, e.g. with the size of the graph, then we say that the chain is
rapidly mixing. Unfortunately, in many cases of interest the mixing time grows exponentially with the problem parameters, so in many important cases the Markov chain is mixing very slowly.
What we are interested in is whether it is possible to speed up the running time. It is clear that if we want to estimate the size of any possible subset, then we really need to get close to the stationary distribution, since only this distribution can guarantee that the probability of the random state falling in the set is really the relative size of the set. On the other hand, if we only want to estimate the relative size of a specific subset A, then it is enough for us if we reach a distribution in which the measure of A is close to the stationary measure, but this does not have to hold for every other set. In other words, if denotes the state distribution after t steps and π is the stationary distribution, then we want to choose t such that is small, but the same does not have to hold for all other sets. This makes it possible to reduce the required value of t, that is, to speed up the algorithm. In this paper we investigate under what conditions it is possible to obtain such a speed-up.
The main result is that the structure of the chain, that is, the network structure, can significantly help, if it has some special properties. Specifically, if the Markov chain is close to a so called lumpable chain, then remarkable speedup is possible. In other words, in this case we can indeed capitalize on the particular network structure to accelerate the method. Below we informally explain what the concept of lumpability means. The formal definition will follow in the next section.
The concept of lumpability stems from the following observation: it is very useful if the state space can be
partitioned such that the states belonging to the same partition class “behave the same way,” in the sense defined formally in the next section. This is the concept of
lumpability [
7]. Informally speaking, it means that some sets of states can be lumped together (aggregated) and replaced by a single state, thus obtaining a Markov chain which has a much smaller state space, but its essential behavior is the same as the original.
In some cases, the lumpability of the Markov chain can have a very significant effect on the efficiency of the model. A practical example is discussed in [
8,
9], where the authors present a fast algorithm to compute the PageRank vector, which is an important part of search engine algorithms in the World Wide Web. The PageRank vector can be interpreted as the stationary distribution of a Markov chain. This chain has a huge state space, yielding excessive computation times. This Markov chain, however, is lumpable. Making use of the lumpability, the computation time can be reduced to as low as 20% of the original, according to the experiments presented in [
8].
Unfortunately, it happens relatively rarely that the Markov chain satisfies the definition of lumpability
exactly. This motivates the concept of
quasi-lumpability [
10,
11]. Informally, a Markov chain is quasi-lumpable if its transition matrix is obtainable by a small
perturbation from a matrix that exactly satisfies the lumpability condition (see the formal definition in the next section).
In this paper we are interested in the following problem, which is often encountered in applications: how long do we have to run the Markov chain if we want to get close to the stationary distribution within a prescribed error? While the general question is widely discussed in the literature (see, e.g., [
6,
12]), we focus here on a less researched special case: how much gain can the convergence speed enjoy, if we can capitalize on the special structure of
quasi-lumpability. 2. Aggregation in Markov Chains
We assume the reader is familiar with the basic concepts of Markov chains. We adopt the notation that a Markov chain is given by a set S of states and by a transition probability matrix P, so we write . This notation does not include the initial distribution, because it is assumed arbitrary.
Let us first define the concept lumpability of a Markov chain. Informally, as mentioned in the Introduction, a chain is lumpable if its states can be aggregated into larger subsets of S, such that the aggregated (lumped) chain remains a Markov chain with respect to the set-transition probabilities (i.e., it preserves the property that the future depends on the past only through the present). Note that this is generally not preserved by any partition of the state space. Let us introduce now the formal definition.
Definition 1. (Lumpability of Markov chain) Let
be a Markov chain. Let
be a partition of
S. The chain
is called
lumpable with respect to the partition
if for any initial distribution the relationship
holds for any
, whenever these conditional probabilities are defined (i.e., the conditions occur with positive probability). If the chain is lumpable, then the state set of the lumped chain is
and its state transition probabilities are defined by
Checking whether a Markov chain is lumbable would be hard to do directly from the definition. That is why it is useful to have the following characterization, which is fundamental result on the lumpability of Markov chains, see [
7]. For simple description, we use the notation
to denote the probability that the chain moves into a set
in the next step, given that currently it is in the state
. Note that
x itself may or may not be in
A.
Theorem 1. (Necessary and sufficient condition for lumpability, see [7]) A Markov chain is lumpable with respect to a partition of S if and only if for any the value of is the same for every These common values define the transition probabilities for the lumped chain,
which is a Markov chain with state set and state transition probabilities where x is any state in Informally, the condition means that a move from a set to another set happens with probability , no matter which is chosen. That is, any has the property that the probability of moving from this x to the set in the next step is the same for every . The sets are partition classes of . We also allow , so they may coincide.
Whenever our Markov chain is lumpable, we can reduce the number of states by the above aggregation, and it is usually advantageous for faster convergence (a specific bound will be proven in
Section 3).
It is worth noting that lumpability is a rather special property, and one has to be quite lucky to encounter a real-life Markov chain that actually has this property. Sometimes it happens (see, e.g., the example in the Introduction about PageRank computation), but it is not very common. Therefore, let us now relax the concept of lumpability to broaden the family of the considered Markov chains. The extended condition, as explained below, is called quasi-lumbability.
Informally, a Markov chain is called
quasi-lumpable or
ϵ-quasi-lumpable or simply
ϵ-lumpable, if it may not be perfectly lumpable, but it is “not too far" from that. This “
ϵ-closeness" is defined in [
10,
11] in a way that the transition matrix can be decomposed as
. Here
is a component-wise non-negative lower bound for the original transition matrix
P, such that
satisfies the necessary and sufficient condition of Theorem 1. The other matrix,
, represents a
perturbation. It is an arbitrary non-negative matrix in which each entry is bounded by
ϵ. This definition is not very easy to visualize, therefore, we use the following simpler but equivalent definition.
Definition 2. (ϵ-lumpability) Let
A Markov chain
is called
ϵ-lumpable with respect to a partition
of
S if
holds for any
and for any
.
Note that if we take
, then we get back the ordinary concept of lumpability. Thus, quasi-lumpability is indeed a relaxation of the original concept. It can also be interpreted in the following way. If
, then the original definition of lumpability may not hold. This means, the aggregated process may not remain Markov. i.e., it does not satisfy (
2). On the other hand, if
ϵ is small, then the aggregated process will be, in a sense, “close" to being Markov, that is, to satisfying (
2).
What we are interested in is the convergence analysis of quasi-lumpable Markov chains, typically for a small value of ϵ. For the analysis we need to introduce another definition.
Definition 3. (Lower and upper transition matrices) Let
be a Markov chain which is
ϵ-lumpable with respect to a partition
. The lower and upper transition matrices
and
are defined as
matrices with entries
respectively, for
Note that it always holds (component-wise) that . If the chain is lumpable, then these matrices coincide, so then , where is the transition matrix of the lumped chain. If the chain is ϵ-lumpable, then L and U differ at most by ϵ in each entry.
Generally, L and U are not necessarily stochastic matrices (A vector is called stochastic if each coordinate is non-negative and their sum is 1. A matrix is called stochastic if each row vector of it is stochastic.), as their rows may not sum up to 1.
3. Convergence Analysis
An important concept in Markov chain convergence analysis is the
ergodic coefficient, see, e.g., [
12]. It is also called
coefficient of ergodicity.Definition 4. (Ergodic coefficient) Let
be an
matrix. Its
ergodic coefficient is defined as
The ergodic coefficient is essentially the largest
distance that occurs between different row vectors of the matrix
P. That is, in a sense, it captures how diverse are the row vectors of the matrix. The 1/2 factor is only for normalization purposes. For stochastic matrices two important properties of the ergodic coefficient are the following [
12]:
- (i)
- (ii)
The importance of the ergodic coefficient lies in its relationship to the convergence rate of the Markov chain. It is well known that the convergence rate is determined by the second largest eigenvalue of the transition matrix (that is, the eigenvalue which has the largest absolute value less than 1), see, e.g., [
6]. If this eigenvalue is denoted by
, then the convergence to the stationary distribution happens at a rate of
, where
t is the number of steps, see [
12]. It is also known [
12] that the ergodic coefficient is always an upper bound on this eigenvalue, it satisfies
. Therefore, the distance to the stationary distribution is also bounded by
Thus, the smaller is the ergodic coefficient, the faster convergence we can expect. Of course it only provides any useful bound if
If
happens to be the case, then it does not directly provide a useful bound on the convergence rate, since then
remains 1. In this situation a possible way out is considering the
k-step transition matrix
for some constant integer
k. If
k is large enough, then we can certainly achieve
, since it is known [
12] that
.
Now we are ready to present our main result, which is a bound on how fast will an ϵ-lumpable Markov chain converge to its stationary distribution on the sets that are in the partition, which is used in defining the ϵ-lumpability of the chain. We are going to discuss the applicability of the result in the next section.
Theorem 2. Let and be an irreducible, aperiodic Markov chain with stationary distribution π. Assume the chain is ϵ-lumpable with respect to a partition of S. Let ρ be any upper bound on the ergodic coefficient of the lower transition matrix L (Definition 3), that is, . Let be any initial probability distribution on S, such that holds for any i, and , whenever the chain starts from . Then for every the following estimation holds: assuming . Remark: Recall that the parameter ϵ quantifies how much the Markov chain deviates from the ideal lumpable case, see Definition 2. In the extreme case, when , every Markov chain satisfies the definition. This places an“upward pressure” on ϵ: the larger it is, the broader is the class of Markov chains to which ϵ-lumpability applies. On the other hand, a downward pressure is put on ϵ by Theorem 2: the convergence bound is only meaningful, if holds. This inequality can be checked for any particular ϵ, since it is assumed that ρ and m are known parameters. Furthermore, the smaller is ϵ, the faster is the convergence. Therefore, the best value of ϵ is the smallest value which still satisfies Definition 2 for the considered state partition.
For the proof of Theorem 2 we need a lemma about stochastic vectors and matrices (Lemma 3.4 in [
13], see also [
14]):
Lemma 1. (Hartfiel [
13,
14])
Let be n-dimensional stochastic vectors and be stochastic matrices. If and for all then where The vector norm used is the -norm and the matrix norm is for any real matrix Lemma 1 can be proved via induction on
k, see [
13,
14]. Now, armed with the lemma, we can prove our theorem.
Proof of Theorem 2. Let be an initial state distribution of the Markov chain , let be the corresponding distribution after t steps and be the (unique) stationary distribution of . For a set of states the usual notations are adopted.
Using the sets
of the partition
, let us define the stochastic vectors
for
and the
stochastic matrices
for
. Let us call them aggregated state distribution vectors and aggregated transition matrices, respectively. Note that although the entries in (4) involve only events of the form
they may also depend on the detailed state distribution within these sets, which is in turn determined by the initial distribution
In other words, if two different initial distributions give rise to the same probabilities for the events
for some
t, they may still result in different conditional probabilities of the form
since the chain is not assumed lumpable in the ordinary sense. This is why the notations
are used. Also note that the conditional probabilities are well defined for any initial distribution allowed by the assumptions of the lemma, since then
For any fixed
t the events
are mutually exclusive with total probability 1, therefore, by the law of total probability,
holds. This implies
, from which
follows.
We next show that for any
the matrix
falls between the lower and upper transition matrices, i.e.,
holds. Let us use short notations for certain events: for any
and for a fixed
set
and for
let
Then
holds for any
and
Applying the definition of conditional probability and the law of total probability, noting that
is provided by the assumptions of the lemma, we get
Whenever
we have
Therefore, it is enough to take the summation over
, instead of the entire
For
however,
holds, so we obtain
Thus,
is a weighted average of the
probabilities. The weights are
so they are non-negative and sum up to 1. Further,
must hold, since
are defined as the minimum and maximum values, respectively, of
over
Since the weighted average must fall between the minimum and the maximum, therefore, we have
that is,
for any
and for any initial distribution
allowed by the conditions of the Theorem.
Let us now start the chain from an initial distribution that satisfies the conditions of the Theorem. We are going to compare the arising aggregated state distribution vectors (3) with the ones resulting from starting the chain from the stationary distribution Note that, due to the assumed irreducibility of the original chain, for all , so π is also a possible initial distribution that satisfies the conditions .
When the chain is started from the stationary distribution
π, then, according to (5), the aggregated state distribution vector at time
t is
where
is given as
On the other hand,
remains the same for all
if the chain starts from the stationary distribution. Therefore, we have
When the chain starts from
then we obtain the aggregated state distribution vector
after
t steps. Now we can apply Lemma 1 for the comparison of (8) and (9). The roles for the quantities in Lemma 1 are assigned as
and, for every
To find the value of
recall that by (7) we have
and
. Since any entry of
U exceeds the corresponding entry of
L at most by
ϵ, therefore, by the definition of the ergodic coefficient,
and
hold, where
ρ is the upper bound on
. Thus, we can take
. With these role assignments we obtain from Lemma 1
where
and the norms are as in Lemma 1. Taking (8) and (9) into account yields
Thus, it only remains to estimate
and
. Given that
are both stochastic vectors, we have
Further,
since (6) holds for any considered
(including
π), and, by the definition of
ϵ-lumpability,
Substituting the estimations into (10), we obtain
proving the Theorem. ☐
If the chain happens to be exactly lumpable, then we get a “cleaner" result. Let
be the state distribution of the lumped chain after
t steps and let
be its stationary distribution. For concise description let us apply a frequently used distance concept among probability distributions. If
are two discrete probability distributions on the same set
S, then their
total variation distance is defined as
It is well known that holds for any two probability distributions. It is also clear from the definition of the ergodic coefficient that it is the same as the maximum total variation distance occurring between any two row vectors of the transition matrix.
Note that exact lumpability is the special case of ϵ-lumpability with . Therefore, we immediately obtain the following corollary.
Corollary 1. If the Markov chain in Theorem 2 is exactly lumpable, then in the lumped chain for any the following holds: where is the ergodic coefficient of the transition matrix of the lumped chain. Proof. Take the special case in Theorem 2. ☐
4. Numerical Demonstration
Let us consider the following situation. Let
be a Markov chain with state space
S. Assume we want to estimate the stationary measure
of a subset
. A practical example of such a situation is to estimate the probability that there is at most
k blocked links, for some constant
k, in a large communication network. Here the state space is the set
S of all possible states of all the links. The state of a link is the current traffic load of the link, and it is blocked if the load is equal to the link capacity, so it cannot accept more traffic. Within this state space the considered subset
A is the subset of states in which among all links at most
k are blocked. Therefore, the relevant partition of
S is
. This is motivated by real-world application, since the number of blocked links critically affects network performance. When considering the loss of traffic due to blocking, the models of these networks are often called
loss networks. For detailed background information on loss networks, see [
4,
15,
16]. Of course, we can also consider other events in the network. For example, at most a given percentage of traffic is blocked, without specifying how many links are involved in the blocking.
In many cases we are unable to directly compute
. This task frequently has enormous complexity, for the theoretical background see [
5]. Then a natural way to obtain an estimation of
is simulation. That is, we run the chain from some initial state, stop it after
t steps and check out whether the stopping state is in
A or not. Repeating this experiment a large enough number of times, the relative frequency of ending up in
A will give a good estimation of the measure of
. If
t is chosen such that
is close enough to the stationary distribution
π for any initial state, then we also obtain a good estimation for
. This is the core idea of the Markov Chain Monte Carlo approach.
Unfortunately, Markov chains with large state space often converge extremely slowly. Therefore, we may not get close enough to π after a reasonable number of steps. In such a case our result can do a good service, at least when the chain satisfies some special requirements. As an example, let us consider the following case. First we examine it using our bounds, then we also study it through numerical experiments.
Assume the set
has the property that its elements behave similarly in the following sense: for any state
the probability to move out of
A in the next step, given that the current state is
x, is
approximately the same. Similarly, if
, then moving into
A in the next step from the given
x has approximately the same probability for any
. To make this assumption formal, assume there are values
, such that the following conditions hold:
- (A)
If then where . This means, the smallest probability of moving out of A from any state in is at least , and the largest such probability is at most .
- (B)
If then . Similarly to the first case, this means that the smallest probability of moving into A from any state in is at least , and the largest such probability is at most . (We choose ϵ such that it can serve for this purpose in both directions.)
- (C)
To avoid degenerated cases, we require that the numbers satisify , and The other state transition probabilities (within A and ) can be completely arbitrary, assuming, of course, that at any state the outgoing probabilities must sum up to 1.
Let us now apply our main result, Theorem 2, for this situation. The parameters will be as follows:
m, the number of sets in the partition, is 2, since the partition is
. The matrices
become the following:
Furthermore, we can take
as an upper bound on the ergodic coefficient of
L. Then we obtain from Theorem 2, expressing the estimation in terms of the total variation distance:
where the distributions
are over the sets of the partition (
), not on the original state space. Note that in our case we actually have
, due to the fact that
. Therefore, we obtain the estimation directly for the set
A:
If
is not extremely small, then the term
will quickly vanish, as it approaches 0 at an exponential rate. Therefore, after a reasonably small number of steps, we reach a distribution
from
any initial state, such that approximately the following bound is satisfied:
It is quite interesting to note that neither the precise estimation (
11), nor its approximate version (
12) depend on the size of the state space.
Now we demonstrate via numerical results that the obtained bounds indeed hold. Moreover, they are achievable after a small number of Markov chain steps, that is, with fast convergence. We simulated the example with the following parameters: states, , and . The set A was a randomly chosen subset of 50 states. The transition probabilities were also chosen randomly, with the restriction that together with the other parameters they had to satisfy conditions (A), (B), (C).
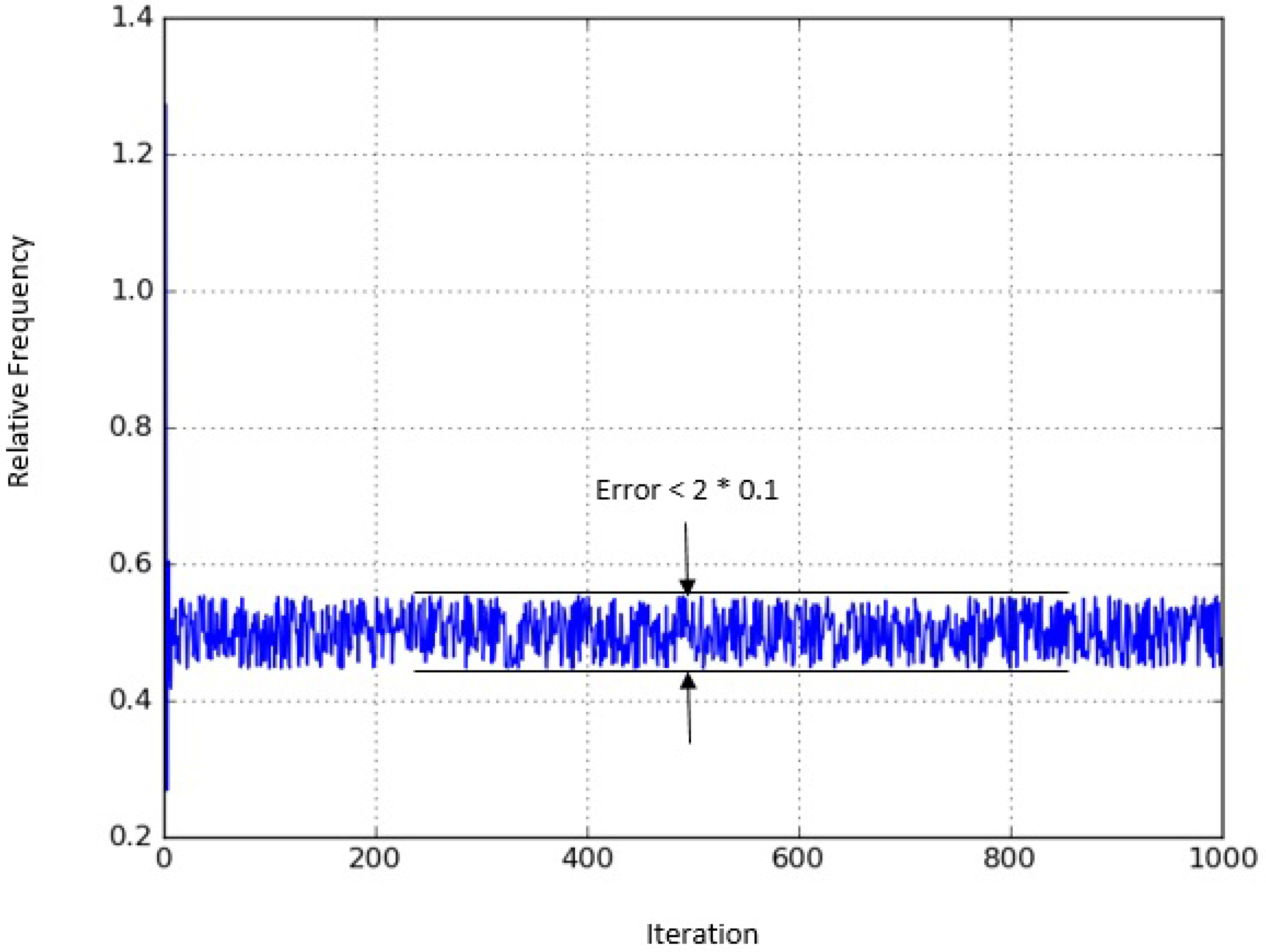
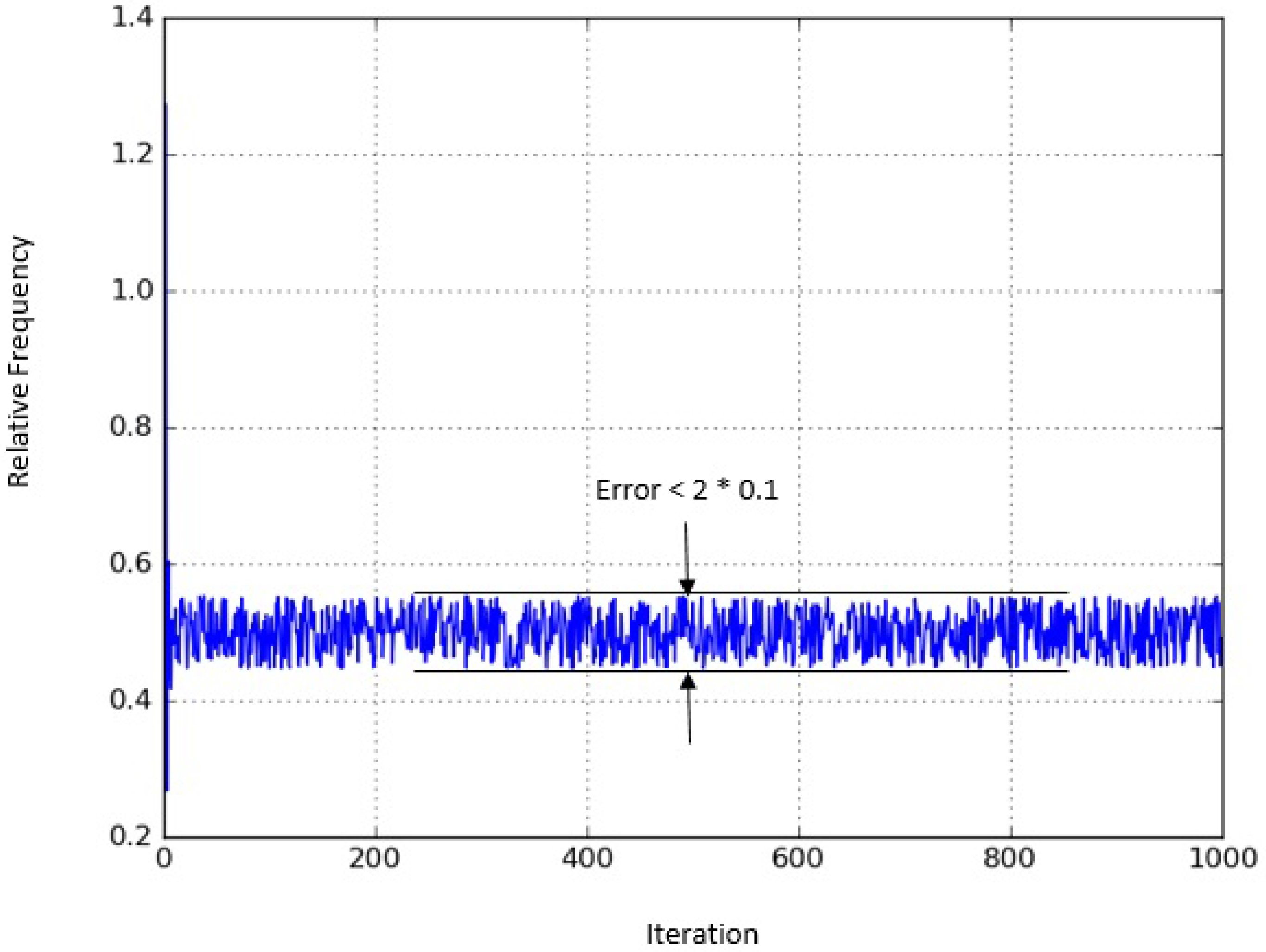
Figure 1 shows the relative frequency of visiting
A, as function of the number of Markov chain steps. It is well detectable that the chain converges quite slowly. Even after many iterations the deviation from the stationary probability
does not visibly tend to 0. On the other hand, it indeed stays within our error bound:
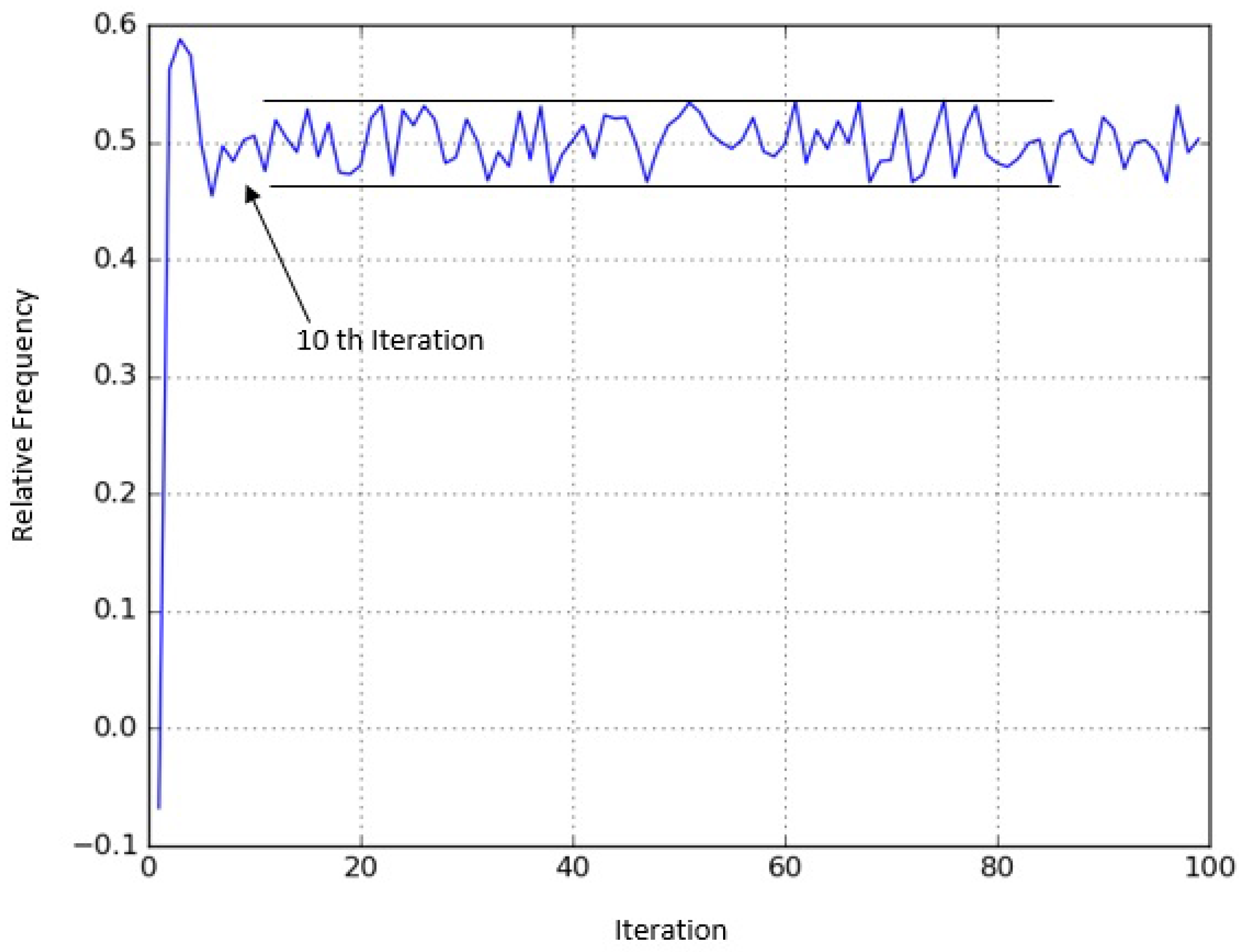
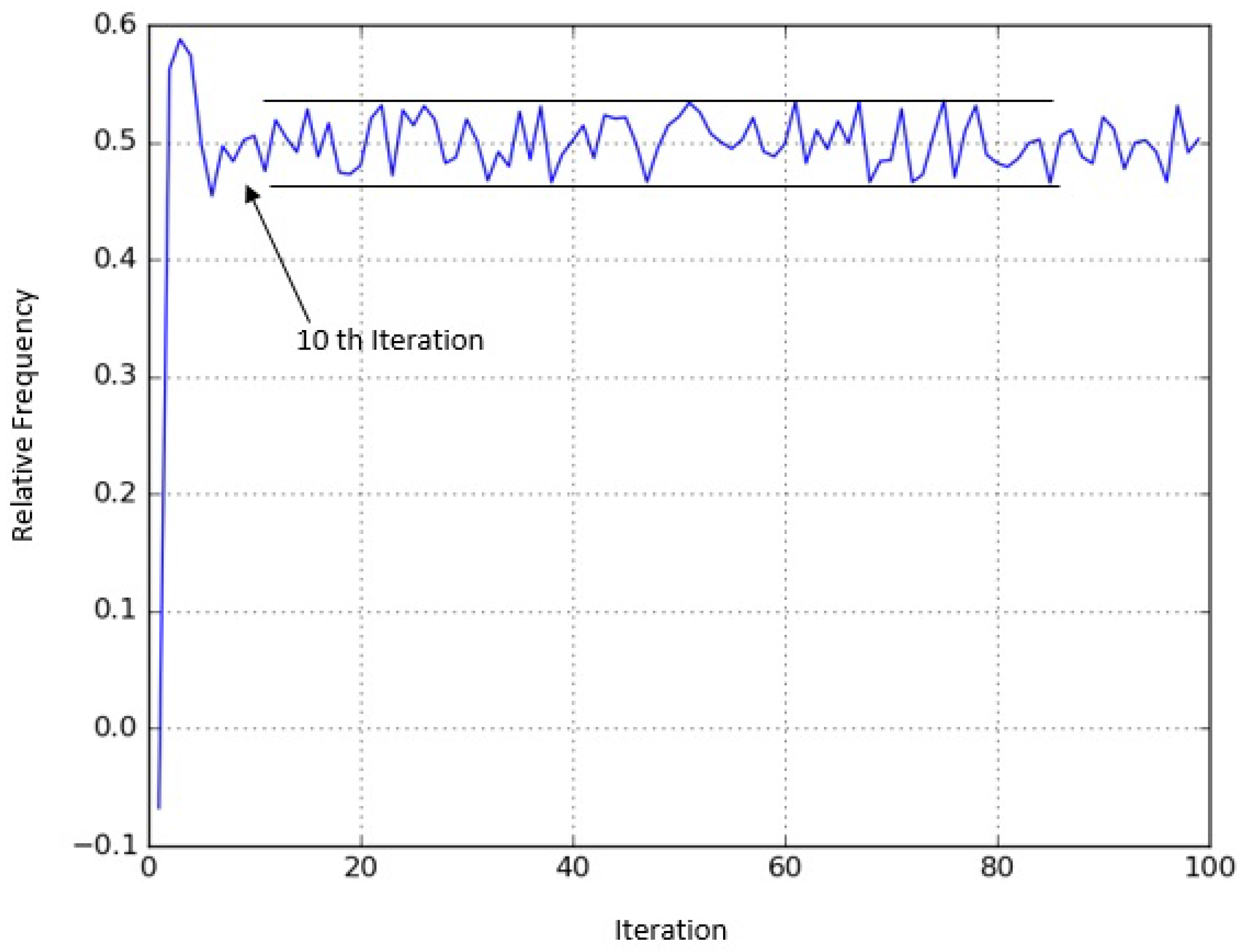
as promised. Having observed this, it is natural to ask, how soon can we reach this region, that is, how many steps are needed to satisfy the bound? This is shown in
Figure 2. We can see that after only 10 iterations, the error bound is already satisfied. Note that this is very fast convergence, since the number of steps to get within the bound was as little as 10% of the number of states.




{kind=link}
{kind=link}