1. Introduction
Let
be a
binary matrix. We say that
S is a
segment if for each row
, the following
consecutive ones property holds [
1]:
Given an nonnegative integer matrix , the Minimum Cardinality Segmentation Problem (MCSP) consists in finding a decomposition such that , is a segment, for all , and K is minimum.
For example, consider the following nonnegative integer matrix:
then a possible decomposition of
A into segments is [
2]:
The MCSP arises in intensity modulated radiation therapy, currently considered one of the most powerful tools to treat solid tumors (see [
3,
4,
5,
6,
7]). In this application, the matrix
A usually encodes the intensity of the particle beam that has to be emitted by a linear accelerator at each instant of a radiation therapy session (see
Figure 1). As the linear accelerator can only emit, instant per instant, a particle beam having a fixed intensity value rather than those encoded in
A, the intensity matrix has to be decomposed into a set of segments, each encoding those elementary quantities of radiation, in order to deliver entry per entry the requested amount of radiation (see [
7] for further details).
The MCSP is known to be
-hard even if the matrix
A has only one row [
1] or one column [
8]. It is worth noting that the two restrictions mainly differ from each other for the type of segments considered. Specifically, in the one row case the segments are binary vector rows satisfying the consecutive ones property; in the one column case segments are just binary column vectors.
The
-hardness of the MCSP has justified the development of exact and approximate solution approaches aiming at solving larger and larger instances of the problem. These approaches have been recently reviewed in [
7,
9,
10], and we refer the interested reader to these articles for further information. Here, we just focus on the exact solution approaches for the MCSP.
The literature on the MCSP reports on a number of studies focused on a specific restriction of the problem characterized by having the highest entry value of the matrix
A, denoted as
, bounded by a positive constant
H. This assumption is generally exploited e.g., in [
1,
11,
12,
13] to develop pseudo-polynomial exact solution algorithms for the considered restriction. A recent survey of these algorithms can be found in [
7]. Surprisingly enough, however, in the last decade only a limited number of exact solution approaches have been proposed in the literature for the general problem. These approaches are restricted to the pseudo-polynomial solution algorithm described in [
14], the Constraint Programming (CP) approaches described in [
9,
15], and the Integer Linear Programming (ILP) approaches described in [
16,
17,
18,
19]. Specifically, the algorithm proposed in [
14] is based on an iterative process that exploits the pseudo-polynomial solution algorithm of [
13] to solve at each step an instance of the MCSP characterized by having
. The author shows that the algorithm is able to solve an instance of the general problem with an overal computational complexity
. However, as shown in the computational experiments performed in [
9], the algorithm proves to be very slow in practice.
The CP approach described in [
15] was not initially conceived to solve the MCSP. In fact, the authors consider an objective function that minimizes at the same time a linear weighted combination of the number of segments involved in the decomposition and the sum of the coefficients used in the decomposition. As shown in [
10], this approach can be adapted to solve the MCSP. However, the performances (in terms of solution times) so obtained are poorer than those relative to the CP approach described in [
9]. Specifically, the authors of [
9] first use an heuristic to find an initial feasible solution to the problem. Then, they attempt to find either a solution that uses less segments or to prove that the current solution is optimal. The certificate of optimality of the proposed algorithm is based on the use of an exhaustive search on the space of segments and coefficients compatible with the decomposition. As far as we are aware, this approach currently constitutes the fastest exact solution algorithm for the MCSP.
Figure 1.
An example of discretization of the particle beam emitted by a linear accelerator (from [
2]). The matrix on the right encodes the discretized intensity values of the radiation field shown on the left.
Figure 1.
An example of discretization of the particle beam emitted by a linear accelerator (from [
2]). The matrix on the right encodes the discretized intensity values of the radiation field shown on the left.
The ILP formulations described in the literature are usually characterized by worse performances than the constraint programming approach presented in [
9]. The earliest ILP formulation was presented in [
16] and is characterized by a polynomial number of variables and constraints. Specifically, provided an upper bound on the overall number of segments is used, the authors introduce a variable for each entry of each segment in the decomposition of the matrix
A. This choice gives rise to multiple drawbacks: it may lead to very large formulations, it does not cut out the numerous equivalent (symmetric) solutions to the problem, and it is characterized by very poor performances in terms of solution times and size of the instances of the MCSP that can be analyzed [
9,
10]. The mixed integer linear programming formulation presented in [
19] arises from an adaptation of the formulation used for a version Cutting Stock Problem [
10]. As for [
16], the formulation contains a polynomial number of variables and constraints and requires an upper bound on the overall number of segments used. As shown in [
10], the formulation is characterized by better performances than the one presented in [
16]. However, it proves unable to solve instances of the MCSP containing more than seven rows and seven columns. The polynomial-sized formulation presented in [
18] has a strength point the fact that does not explicitly attempt at reconstructing the segments of the decomposition. This fact allows for both the reduction of the number of involved variables and a break in the symmetry introduced by the search of equivalent sets of segments. However, computational experiments carried out in [
10] have shown that the linear relaxation of this formulation is usually very poor. This fact in turn leads to very long solution times [
10]. A similar idea was used in [
17]. In particular, the proposed polynomial-sized formulation minimizes the number of segments required in the decomposition of the matrix
A, without explicitly computing them. This last step is possible in a subsequent moment via a post-processing of the optimal solution. However, also in this case, the formulation is characterized by poor computational performances when compared to the constraint programming approach described in [
9], mainly due to the poor lower bounds provided by the linear relaxation.
Starting from the results described in C. Engelbeen’s Ph.D. thesis [
20], in this article we investigate the problem of providing tighter lower bounds to the MCSP. Specifically, by using some results related to the one row restriction of the MCSP (see [
2,
20]), we transform the MCSP into a combinatorial optimization problem on a particular class of directed weighted networks and we present an exponential-sized ILP formulation to exactly solve it. Computational experiments show that the performances (in terms of solution times) of the formulation are still far from the CP approach described in [
9]. However, the lower bounds obtained by the linear relaxation of the considered formulation generally improve upon those currently described in the literature. Thus, the theoretical and computational results discussed in this article may suggest new directions for the development of future exact solution approaches to the problem.
The article is organized as follows. After introducing some notation and definitions, in
Section 2 we investigate the one row restriction of the MCSP. In particular, we transform the restriction into a combinatorial optimization problem on a weighted directed network and we investigate the optimality conditions that correlate both problems. In
Section 3, we show how to generalize this transformation for generic intensity matrices and in
Section 4 we present an ILP formulation for the MCSP based on this transformation. Finally, in
Section 5 we present the computational results of the formulation, by providing some perspectives on future exact solution approaches to the problem.
2. The One Row Restriction of the MCSP as a Network Optimization Problem
In this section, we consider a restriction of the MCSP to the case in which the matrix
A is a row vector. By following an approach similar to [
15,
20], we transform this restriction into a combinatorial optimization problem consisting of finding a shortest path in a particular weighted directed network. The insights provided by this transformation will prove useful both to extend the transformation to general matrices and to develop an ILP formulation for the general case of the MCSP. Before proceeding, we first introduce some notation and definitions similar to those already used in [
2,
9,
20] and that will prove useful throughout the article.
Let
q be a positive integer. We define a partition of
q as a possible way of writing it as a sum of positive integers,
i.e.,
for some
(see [
21]). For example, if we consider
and we set
and
and
then a possible partition of 4 is
. We call Equation (
4) the extended form of this particular partition of
q. Interestingly, we also observe that an alternative way to partition
q consists in writing it as a nonnegative integer linear combination of nonnegative integers,
i.e.,
for some
. For example, if we set
,
,
,
,
, then an alternative way to encode the considered partition is
. We call Equation (
5) the compact form of this particular partition of
q. The definition of a partition of a positive integer proves useful to investigate the one row restriction of the MCSP. In particular, it is worth noting that any decomposition of a row vector
A into a sum of positive integers implicitly implies partitioning the entries of
A. Then, a possible approach to solve the considered restriction consists in finding from among all of the possible partitions of each entry of
A the ones that, appropriately combined, lead to the searched optimal decomposition.
To this end, we denote
,
as the set
, for some positive integer
K, and we associate to the row vector
A a particular weighted directed network
, called partition network, built as follows. Given an entry
of
A and a generic partition of
, let
be the number of terms equal to
w in the extended form of the considered partition or, equivalently, the coefficient associated to the term
w in its compact form. Let
V be the set of vertices including a source vertex
s, a sink vertex
t and a vertex for each partition of each entry of
A:
Let
be the set of arcs of
D defined as follows:
Note that the construction of the partition network
D is such that a decomposition of
A corresponds to a path from the source to the sink in
D. In particular, traversing a vertex
means that in the decomposition there are exactly
segments with a coefficient equal to
w and a 1 in position
j, for all
. Traversing an arc
in the network means that in the corresponding decomposition of
A there are exactly
segments with a coefficient equal to
w and a 1 in position
j and exactly
segments with a coefficient equal to
w and a 1 in position
, for all
. As an example,
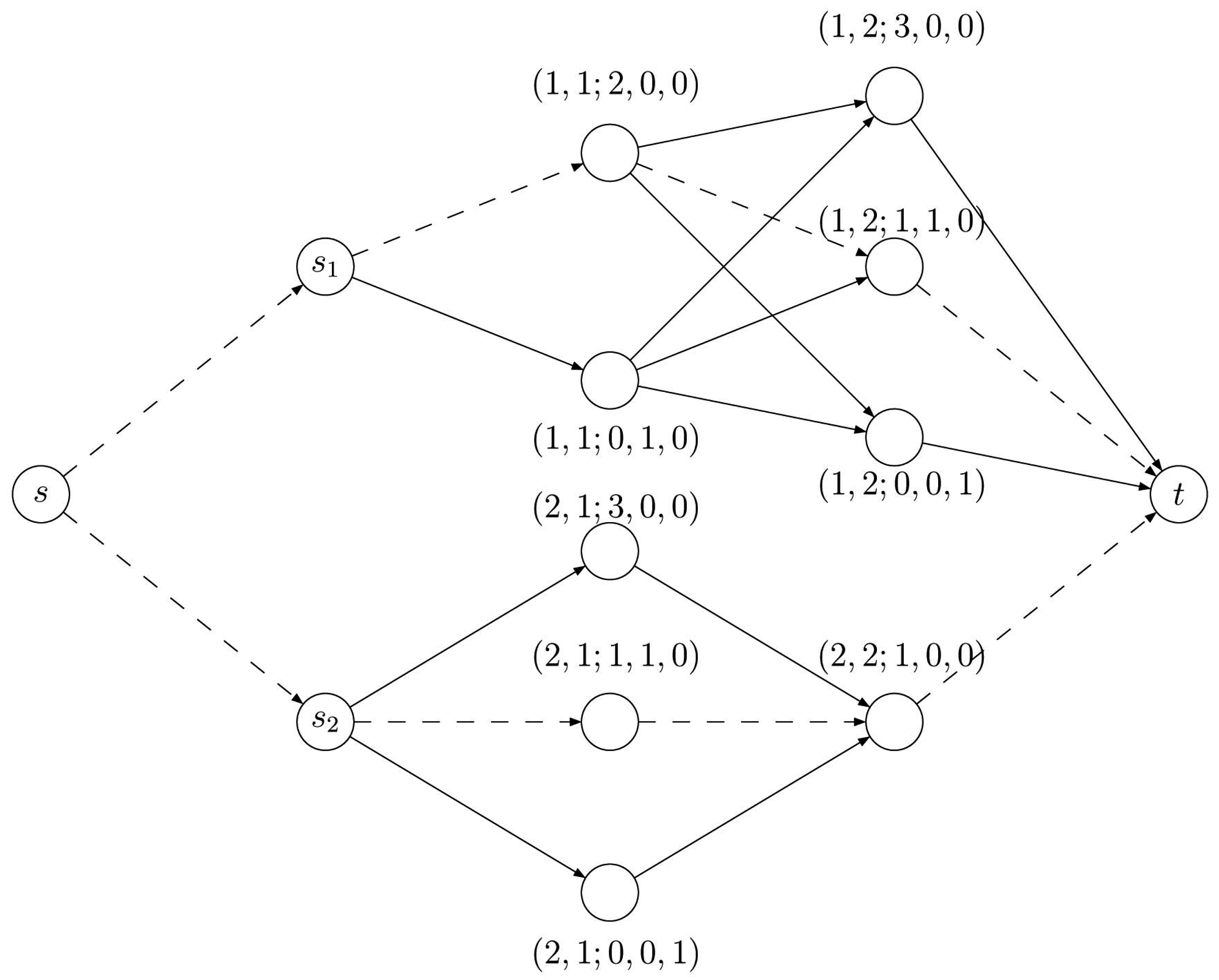
Figure 2 shows the network corresponding to the row vector
Figure 2.
The partition network corresponding to the row with some lengths on arcs. The first two vertices on the right of s correspond to the two possible partitions of 2 (i.e., and ). The subsequent three vertices on the right correspond to the three possible partitions of 3 (i.e., , , ), and so on. Note that the entries of two subsequent columns, say j and , in the row vector A induce a bipartite subnetwork in D. The dotted arcs represent the shortest path in D.
Figure 2.
The partition network corresponding to the row with some lengths on arcs. The first two vertices on the right of s correspond to the two possible partitions of 2 (i.e., and ). The subsequent three vertices on the right correspond to the three possible partitions of 3 (i.e., , , ), and so on. Note that the entries of two subsequent columns, say j and , in the row vector A induce a bipartite subnetwork in D. The dotted arcs represent the shortest path in D.
It is worth noting that, as we want to minimize the number of segments in the decomposition, whenever we cross arc
we use
segments with a coefficient equal to
w, a 1 in position
j and a zero in position
;
segments with a coefficient equal to
w and a 1 in both positions
j and
and finally
segments with a coefficient equal to
w, a zero in position
j and a 1 in position
. Hence, passing from the vertex
to the vertex
implies to add
new segments with a coefficient equal to
w. In the light of these observations, consider a length function
defined as follows:
Then, finding a decomposition of the row vector
A into the minimum number of segments is equivalent to compute the length of any shortest
path, denoted as
, in the corresponding weighted directed network
D. Note that, due to the particular structure of the partition network
D, such a problem is fixed-parameter tractable in
H [
2,
20,
22]. Once computed
, we can build the segments and the corresponding coefficients involved in the decomposition by iteratively applying the following approach. For all integers
ℓ and
r such that
, let
. Set
and build a segment
S having the generic entry
equal to 1 if
and 0 otherwise. Associate to
S a coefficient equal to
w. Remove one unit in component
from each vertex of the path that corresponds to an entry
and iterate the procedure. As an example, the application of this procedure to the row vector Equation (
12) leads to the following optimal solution:
In the next section, we show how to generalize this transformation to generic intensity matrices. This transformation will prove useful to develop an ILP formulation for the general version of the problem.
3. The MCSP as a Network Optimization Problem
Let
A be a generic
nonnegative integer matrix. For each row
we build a partition network
in a way similar to the procedure described in
Section 2. Specifically, for each row
, the set
includes a source vertex
and a vertex for each partition of each entry of the
i-th row of
A:
Similarly, the set
includes an arc for each pair of vertices corresponding to consecutive entries on the same row:
Consider the combined partition network
having as vertexset
and as arcset
D contains a vertex corresponding to each possible partition of each entry
of
A. Each of these vertices is denoted by
, where
denotes the position of
in
A, and
denotes the number of terms equal to
w in the extended form of the corresponding partition of
or, equivalently, the coefficient of
w in its compact form, meaning
. As an example,
Figure 3 shows the combined partition network corresponding to the intensity matrix
Figure 3.
The combined partition network for matrix Equation (
23). The dotted arcs represent a flow in the network that encodes a possible decomposition of
A.
Figure 3.
The combined partition network for matrix Equation (
23). The dotted arcs represent a flow in the network that encodes a possible decomposition of
A.
It is worth noting that, as for the one row restriction, a decomposition of the i-th row of A corresponds by construction to a path in the network . In particular, traversing a vertex means that in the decomposition, there are exactly matrices with a coefficient equal to w and a 1 in position , for all .
Let
be a function that associate a
H-dimensional
length vector to each arc
according to the following law:
In particular, we use the convention to associate the length vector
to both the arcs leaving the source vertex
s and the arcs entering the sink vertex
t. For all the remaining arcs, the
w-th entry of the length vector, denoted as
, represents the coefficient of
w in the compact form of the corresponding partition of
minus the coefficient of
w in the compact form of the corresponding partition of
,
i.e.,
. As an example,
Figure 4 provides the length vector of (certain arcs of) the partition network corresponding to the first row of matrix Equation (
23), namely
.
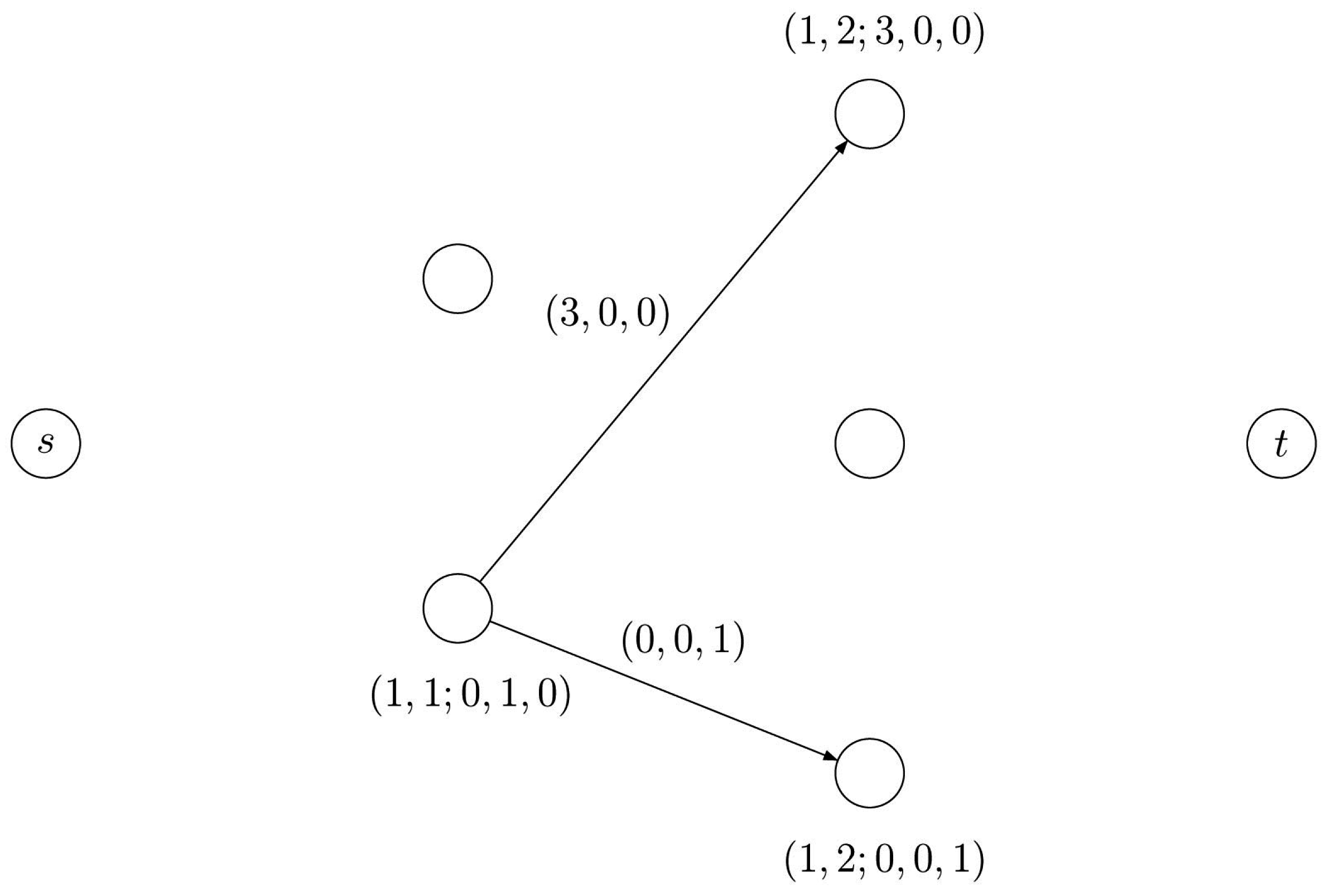
Figure 4.
The arc represents a decomposition of the row vector in which entry 2 is decomposed by means of one segment having coefficient 2 and entry 3 is decomposed by means of three segments having coefficients 1. In order to move from partition to partition , we need three new segments with a coefficient 1 and no segment with coefficient 2 or 3.
Figure 4.
The arc represents a decomposition of the row vector in which entry 2 is decomposed by means of one segment having coefficient 2 and entry 3 is decomposed by means of three segments having coefficients 1. In order to move from partition to partition , we need three new segments with a coefficient 1 and no segment with coefficient 2 or 3.
It is easy to realize that any integral
flow of value
m in the combined partition network
D associated to a given intensity matrix
A,
i.e., a
flow in
D composed by a family of
flows, each lying in the subnetwork
, corresponds to a decomposition of the intensity matrix
A. Any such flow is a combination of
m paths
such that each
is a
path in the network
, for all
. The length vector associated to this
flow is
Note that the
w-th component of vector Equation (
25) provides the overall number of segments with a coefficient
w in the decomposition of
A. Hence, solving the MCSP is equivalent to find a
flow of value
m (that is, paths
) such that the sum of all components of Equation (
25) is minimized, or equivalently
over all
paths
in
.
By referring to matrix Equation (
23) and to the corresponding combined partition network shown in
Figure 3, the length vector of the top-most dotted path
equals
and the length vector of the bottom-most dotted path
equals
+
=
. The length vector of the whole flow equals
. Given paths
and
, we can build the corresponding decomposition of the matrix
A in the following way. For each component
w, consider a nonnegative integer
matrix
having the generic entry
equal to the component
in vertex
belonging to
. Then, the matrix
A can be decomposed as
As an example, by referring to the matrix Equation (
23) and to the corresponding combined partition network shown in
Figure 3, this procedure leads to the following decomposition of
A:
It is worth noting that the matrices in general are not segments. However, it is possible to prove that each matrix can be in turn decomposed into a sum of segments, in such a way that the resulting decomposition is optimal for the MCSP. To this end, we introduce the following auxiliary problem:
The Beam-On Time Problem (BOTP). Given a nonnegative integer matrix A, find a decomposition such that , is a segment, for all , and is minimum.
The BOTP is polynomially solvable via the algorithms described in [
1,
20] and differs from the MCSP for the fact that it searches from among all the possible decompositions of the matrix
A the one for which the sum of the coefficients is minimal.
Given a decomposition of
A as in Equation (
27), let us decompose
, for each
, into a nonnegative integer linear combination of segments minimizing the BOTP. Then, Equation (
27) can be rewritten as
where
. The minimality of
K in this new decomposition (
i.e., the optimality of Equation (
29) for the MCSP) is then proved by the following proposition:
Proposition 1. Let K be the optimal value to the MCSP. Then, the following equality holds:where denotes the minimum sum of in the decomposition of .
Proof. Let
denote
,
i.e., the sum of the coefficients in the decomposition of
, for all
. Then, it holds that
, for all
. Hence, we have that
To prove that in Equation (
30) the strict equality holds, assume by contradiction that for some
,
. Then, it is possible to obtain a smaller value of
by replacing
with the decomposition provided by the optimal solution of the BOTP with input
. However,
is defined as the optimal solution to the BOTP with input
, hence this would contradict its optimality. Thus, the statement follows. ☐
As an example, by using the decomposition algorithm for the BOTP described in [
1,
20] on the matrices
in Equation (
28), we obtain the following decomposition for Equation (
23)
which is optimal due to Proposition 1.
The transformation of the MCSP into a network optimization problem and the result provided by Proposition 1 constitute the fundation for the ILP formulation that will be presented in the next section.
4. An Integer Linear Programming Formulation for the MCSP
In this section, we develop an exponential-sized integer linear programming formulation for the MCSP. Unless not stated otherwise, throughout this section we will assume that A is a generic nonnegative integer matrix.
Let
be the combined partition network associated to
A and let
be the set of all of the
paths whose internal vertices belong to the subnetwork
, for all
. We associate to each path
,
, a length vector
of dimension
obtained by summing over the lengths of the arcs belonging to
p:
where
are the length vectors defined in
Section 3. Let
be a decision variable equal to 1 if path
,
, is considered in the optimal solution to the problem and 0 otherwise. Finally, let
be an integer variable equal to the number of segments with a coefficient
w needed to decompose the matrix
A. Then, a possible integer linear programming formulation for the MCSP is:
Formulation 1. – Integer Master Problem (IMP) The objective function Equation (33a) accounts for the number of segments involved in the decomposition of the matrix
A. Constraints Equation (33b) impose that for each row
, the number of segments with coefficient
w has to be greater than or equal to
, which corresponds to the
w-th component of the length vector associated to the
flow in
D. Constraints Equation (33c) impose to choose exactly one path in each partition network
. Finally, constraints Equations (33d) and (33e) impose the integrality constraint on the considered variables. The validity of Formulation 1 is guaranteed by the transformation described in
Section 3. It is worth noting that we need not to impose the integrality constraint on variables
. In fact, it is easy to see that in an optimal solution to IMP, the integrality of variables
together with Equation (33b) suffice to guarantee the integrality of variables
. Formulation 1 includes an exponential number of (path) variables and a number of constraints that grows pseudo-polynomially in function of
H. A possible approach to solve it consists of using column generation and branch-and-price techniques [
23].
In order to study the pricing oracle, consider the following formulation:
Formulation 2. – Restricted Linear Program Master (RLPM)
where
is a strict subset of
,
, and let
and
be the dual variables associated to constraints Equations (33b) and (33c), respectively. Then, the dual problem associated to the IMP is:
A variable with negative reduced cost in the RLPM corresponds to a dual constraint violated by the current dual solution. As variables
are always present in the RLPM, constraints Equation (35c) will never be violated. To check the existence of violated constraints, Equation (35b) means searching for the existence of a row
and a path
such that
Let
and
be the values of variables
and
in the current dual solution. Consider a new length function
defined as
and let
be the partition network
with lengths provided by Equation (
37). By definition, the length
of a
path
in
D is equal to
Then, determining the existence of a path violating Equation (35b) implies to check whether the shortest
path in
has an overall length shorter than
,
i.e., to check if it holds that
Since all length values are nonnegative, this task can be performed by using a standard implementation of Dijkstra’s algorithm [
22].





{kind=link}
{kind=link}
{kind=link}
{kind=link}