1. Introduction
Many real-world pattern classification and data mining applications are often confronted with a typical problem that is lacking of sufficient labeled data, since labeling samples usually requires domain-specific experts [
1,
2]. Supervised classifiers, trained only on such scarcely labeled samples, often can not have a good generalization ability. With the development of high-throughput techniques, a large number of unlabeled data can be easily accumulated. If we take these labeled samples as unlabeled ones and train unsupervised learners (
i.e., clustering) on all the unlabeled samples, the valuable information in labeled samples is wasted. That is because the label information should be regarded as prior information, which can be used to boost the performance of a classifier [
3]. Therefore, it is important to develop techniques that leverage both labeled and unlabeled samples.
Semi-supervised learning aims to leverage labeled and unlabeled samples to achieve a learner with good generalization ability [
1]. In this paper, we focus on semi-supervised classification, and more specifically on graph-based semi-supervised classification (GSSC). In GSSC, labeled and unlabeled samples are taken as nodes (or vertices) of a weighted graph, and the edge weights reflect the similarity between samples [
1]. Various effective GSSC methods have been proposed in the last decade. To name a few, Zhu
et al. [
4] utilized Gaussian fields and harmonic functions (GFHF) on a
k nearest neighborhood (
kNN) graph to predict the labels of unlabeled samples via label propagation on the graph. Zhou
et al. [
5] studied a learning with local and global consistence (LGC) approach on a completely connected graph based on the consistency assumption. These two methods can be regarded as label propagation on a graph under different assumptions or schemes [
1]. Most GSSC methods focus on how to leverage labeled and unlabeled samples but pay little attention to construct a well-structure graph that faithfully reflects the distribution of samples. For low dimensional samples, these GSSC methods can achieve good performance by using a simple
kNN graph. When dealing with high dimensional instances, their performance often drops sharply, since the noisy and redundant features of high dimensional samples destroy the underlying distance (or similarity) between samples [
3,
6].
Recently, researchers recognized the importance of graph in GSSC and proposed various graph optimization based semi-supervised classification methods [
1,
7,
8,
9,
10]. Zhu [
1] gave a comprehensive literature review on semi-supervised learning. Here, we just name a few most related and representative methods, which will be used for experimental comparison. Wang
et al. [
11] used an
graph [
12], optimized by minimizing the
-norm regularized reconstruction error of locally linear embedding [
13], and studied a linear neighborhood propagation (LNP) approach. Liu
et al. [
7] took advantage of iterative nonparametric matrix learning to construct a symmetric adjacent graph and proposed a robust multi-class graph transductive (RMGT) classification method. In addition, Fan
et al. [
9] constructed an
graph by the coefficients of
-norm regularized sparse representation [
14] to perform semi-supervised classification. Zhao
et al. [
10] suggested a compact graph based semi-supervised learning (CGSSL) method for image annotation. This method constructs a compact
graph by utilizing not only the neighborhood samples of a sample, but also the neighborhood samples of its reciprocal neighbors. However, the effectiveness of these methods is not as good as expected when dealing with high dimensional data, since high dimensional data have a lot of noisy and redundant features, and it is difficult to optimize a graph distorted by these noisy features [
2,
15].
More recently, some researchers studied how to synthesize multiple graphs, derived from multiple data sources or multiple modules data, for semi-supervised classification [
16]. Wang
et al. [
17], Karasuyama and Mamitsuka [
18], Shiga and Mamitsuka [
19] and Yu
et al. [
20] explored different techniques (
i.e., multiple kernel learning [
21], kernel target alignment [
22]) to assign different weights to the graphs and then weighted combined these graphs into a composite graph for semi-supervised classification. A number of researchers have applied the random subspace method (RSM) [
23] to semi-supervised classification [
2,
15] and dimensionality reduction [
24]. Particularly, Yu
et al. [
2] proposed a GSSC method called semi-supervised ensemble classification in subspaces (SSEC in short). SSEC firstly constructs several
kNN graphs in the random subspaces of samples; then, it trains several semi-supervised linear classifiers on these graphs, one classifier for each graph; next, it combines these classifiers into an ensemble classifier for prediction. The empirical study shows that the base classifiers trained on these simple
kNN graphs outperform the classifier trained in the original space, and the ensemble classifier also works better than other graph optimization based semi-supervised classifiers (
i.e., LNP and RMGT) and some representative ensemble classifiers (
i.e., Random Forest [
25] and Rotation Forest [
26]).
In this paper, motivated by these observations, we investigate a mixture graph combined by multiple
kNN graphs constructed in the subspaces, and study a semi-supervised classification method on this mixture graph ((semi-supervised classification based on mixture graph SSCMG)). Particularly, SSCMG first constructs multiple
kNN graphs in different random subspaces (like the random subspace scheme in [
23]) of samples, and then combines these graphs into a mixture graph. Finally, SSCMG incorporates this mixture graph into GFHF [
4], a representative GSSC method, for semi-supervised classification. Since the distance metric is more reliable in the subspace than that in the original space and the mixture graph is constructed in subspaces, the mixture graph is less suffered from the noisy samples and features. Besides, it is able to hold complicated geometric distribution as the diversity of random subspaces. Experimental comparison with other related methods shows that SSCMG not only has higher classification accuracy, but also has wide ranges of effective input parameters. The main difference between SSCMG and aforementioned GFHF, LGC, LNP, RMGT and CGSSL is that SSCMG uses a mixture graph combined by multiple
kNN graphs constructed in the subspaces, whereas the other methods just utilize (or optimize) a single graph alone. SSEC trains several semi-supervised linear classifiers based on
kNN graphs constructed in randomly partitioned subspaces and incorporates these classifiers into an ensemble classifier for prediction. In contrast, SSCMG integrates multiple
kNN graphs constructed in random subspaces into a mixture graph, and then trains one semi-supervised classifier based on the mixture graph.
In summary, the main contributions of this paper are summarized as follows: (1) A semi-supervised classification based on mixture graph (SSCMG) method is proposed for high-dimensional data classification; (2) Extensive experimental study and analysis demonstrate that SSCMG achieves higher accuracy and it can be more robust to input parameters than other related methods; (3) Mixture graph works better than the graph optimized by a single kNN graph alone, and it can be used as a good alternative graph for GSSC methods on high dimensional data.
The rest of this paper is structured as follows:
Section 2 describes the procedure of GFHF and introduces the construction of mixture graph. In
Section 3, extensive experiments are conducted to study the performance and parameter sensitivity of SSCMG. Conclusions and future work are provided in
Section 4.
3. Experiment
In this section, we conduct experiments on four publicly available face datasets to study the effectiveness of SSCMG. The face datasets used in the experiments are ORL [
33], CMU PIE [
34], AR [
35], and extended YaleB [
36]. ORL consists of 40 individuals with 10 images per person. We aligned and resized ORL images into 64 × 64 pixels in grey scale, thus each image can be viewed as a point in the 4096-dimensional space. CMU PIE face dataset contains 41,368 face images from 68 individuals. The face images were captured under varying pose, illumination and expression conditions, and we chose a subset (Pose27) of CMU PIE as the second dataset. Pose27 includes 3329 face images from 68 individuals. Before the experiments, we resized the images to 64 × 64 pixels and each image is an 8 bit grayscale image. AR face dataset includes over 4000 color face images from 126 people (70 men and 56 women). In the experiments, 2600 images of 100 people (50 men and 50 women) were used. We aligned and resized these images into 42 × 30 pixels and then normalized them into 8 bit grayscale, thus each image is a point in the 1260-dimensional space. YaleB consists of 21,888 single light source images of 38 individuals each captured under 576 viewing conditions (9 × 64 illumination conditions). We chose a subset that contains 2414 images and resized these images into 32 × 32 pixels, with 256 gray level per pixel, so each image is a 1024-dimensional vector. ORL and extended yaleB can be downloaded from the link in reference [
37].
To comparatively study the performance of SSCMG, we take several representative methods as comparing methods, which include GFHF [
4], LNP [
11], RMGT [
7], LGC [
5], CGSSL [
10]. We regard the classification accuracy on testing samples as the comparative index, and the higher the accuracy, the better the performance. Gaussian kernel used for graph construction can often be improved upon by using the ‘local scaling’ method [
31,
38]. We utilize local scaling to adjust the graph defined in Equation (
1) and name GFHF on the adjusted graph as LGFHF. The diffuse interfaces model in [
31] is proposed for binary classification and it is not so straightforward for multi-class datasets. Since the target of this study is to investigate the effectiveness of mixture graph for semi-supervised classification and the proposed SSCMG is a special case of
p-Laplacian with
, we do not compare SSCMG with the diffuse interfaces model and
p-Laplacian with different
p values. In the following experiments, we firstly apply principal component analysis (PCA) [
3] to project each facial image into a 100-dimensional vector, and then use different methods to predict the labels of unlabeled images. For convenience, notations used in the experiments are listed in
Table 1.
Table 1.
Notations used in the experiments.
Table 1.
Notations used in the experiments.
| Notation | Means |
|---|
| n | Number of labeled and unlabeled samples |
| l | Number of labeled samples |
| C | Number of classes |
| k | Neighborhood size |
| T | Number of subspaces |
| d | Dimensionality of random subspace |
| Number of labeled samples per class |
In the experiments, if without extra specification,
α in LGC [
5] is set to 0.01,
σ in Equation (
1) is set to the average Euclidean distance between
n samples, and
k is fixed as 3 for all the methods that based on a
kNN graph.
T and
d are set to 70 and 40, respectively. Other parameters of these comparing methods are kept the same as reported in the original papers. The sensitivity of these input parameters will be studied later. To reduce random effect, all reported results are the average of 20 independent runs. In each run, the training set and testing set are randomly partitioned.
3.1. Performance on Different Datasets
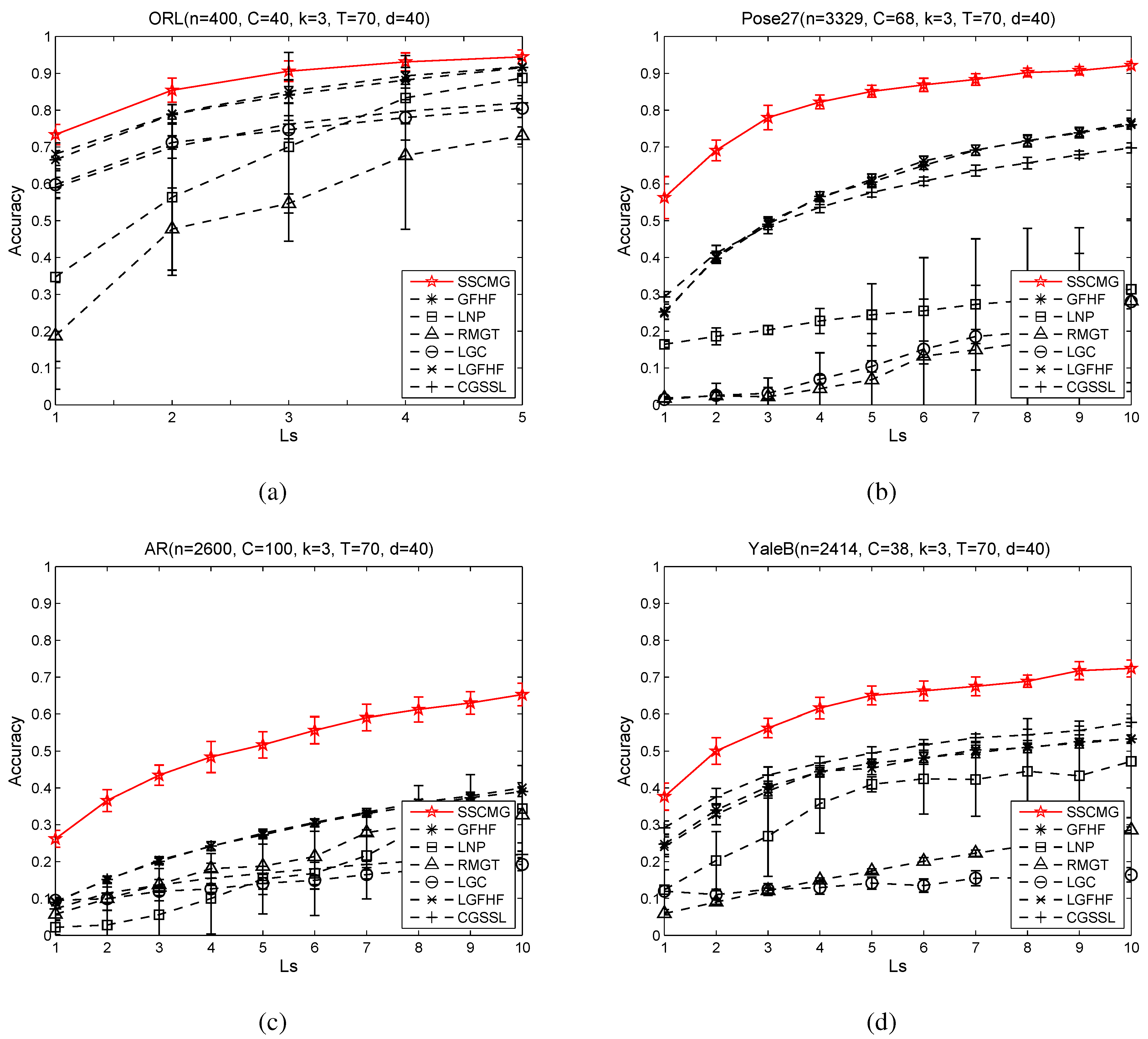
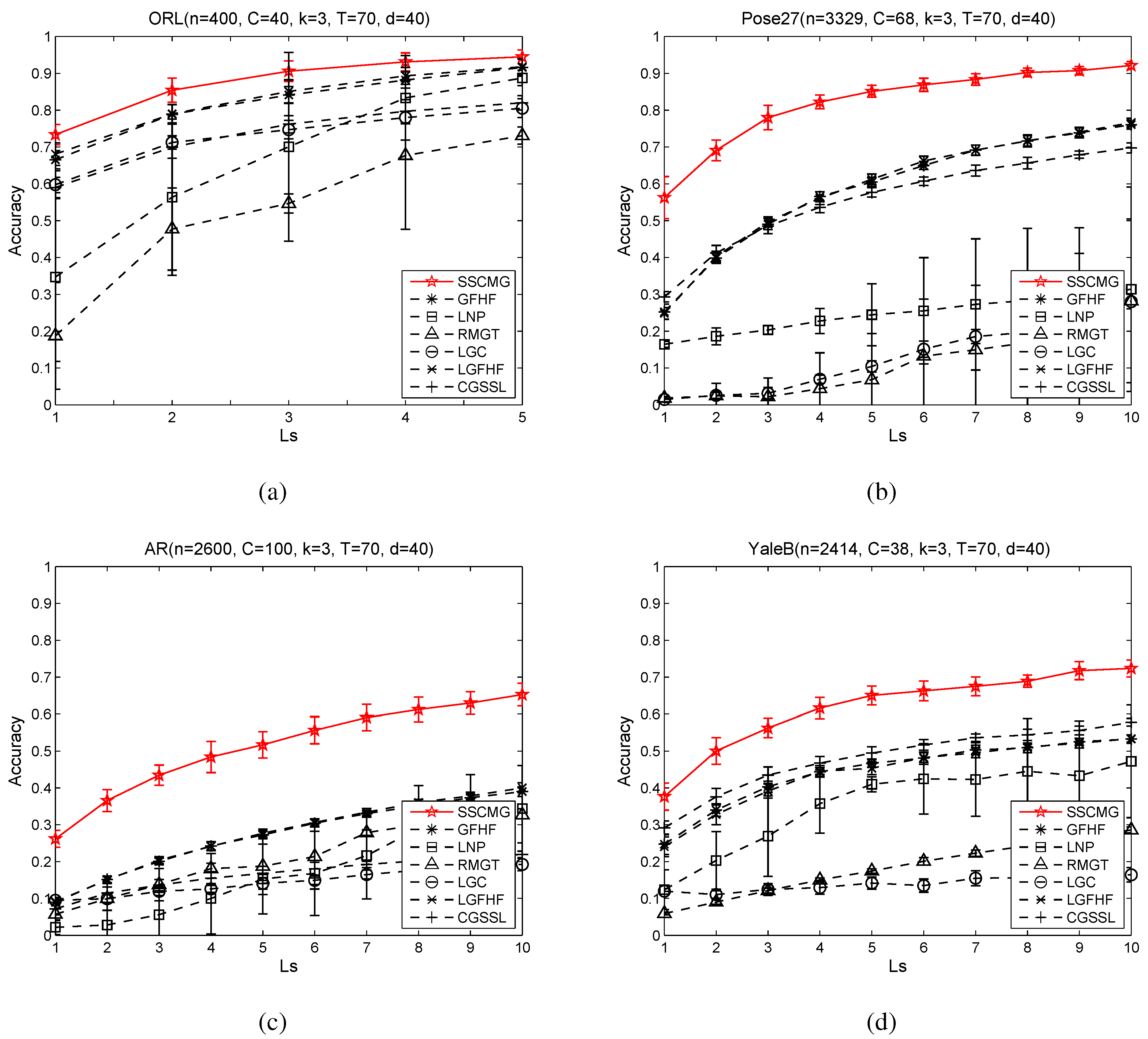
In order to study the performance of SSCMG under different number of labeled images per people, we conduct experiments on ORL with
rising from 1 to 5, and on the other three datasets with
increasing from 1 to 10. The corresponding results are revealed in
Figure 1. Each class in the four datasets has an equal (or nearly equal) number of samples as other classes, so the classes are balanced. Each dataset has more than 30 classes and the accuracy per class cannot be visualized in
Figure 1. Given these reasons, we report the average accuracy for all the classes on each dataset.
Figure 1.
The performance of SSCMG on different values. (a) Accuracy vs. (ORL); (b) Accuracy vs. (Pose27); (c) Accuracy vs. (AR); (d) Accuracy vs. (YaleB).
Figure 1.
The performance of SSCMG on different values. (a) Accuracy vs. (ORL); (b) Accuracy vs. (Pose27); (c) Accuracy vs. (AR); (d) Accuracy vs. (YaleB).
From these four sub-figures, it is easy to observe that SSCMG achieves better performance than these comparing methods on all facial datasets and GFHF almost ranks second among these comparing methods. Although SSCMG, LGFHF and GFHF are based on the same objective function, SSCMG always outperforms the latter two. That is because SSCMG utilizes a mixture graph combined by multiple kNN graphs defined in the subspaces, whereas the latter two depend on a single kNN graph constructed in the PCA reduced space. This observation not only justifies the statement that graph determines the performance of GSSC methods, but also supports our motivation to utilize mixture graph for semi-supervised classification. LGFHF is slightly superior to GFHF. This fact indicates local scaling technique can only improve the kNN graph in a small scale. LGC often loses to other methods. The reason is that LGC utilizes a fully connected graph rather than a kNN graph, and this fully connected graph is more heavily distorted by noisy features. RMGT and LNP apply different techniques to optimize a kNN graph, but their accuracies are almost always lower than that of SSCMG. The cause is that optimizing a kNN graph that distorted by noisy features is rather difficult. CGSSL uses a compact graph and it often outperforms LNP, which is based on a non-compact graph, but CGSSL is always outperformed by SSCMG. These facts suggest that optimizing an graph alone can only improve the performance in a small range, and it may not result in an optimal graph for semi-supervised classification.
As the number of labeled samples () increasing, the accuracy of SSCMG and other methods climbs steadily, for more labeled samples can often help to acquire a more accurate classifier. RMGT asks for a number of labeled samples to learn an optimized graph, but available labeled samples are not sufficient to optimize a good graph for RMGT. From these observations, we can conclude that mixture graphs can be used as a good alternative graph for GSSC methods on high dimensional data.
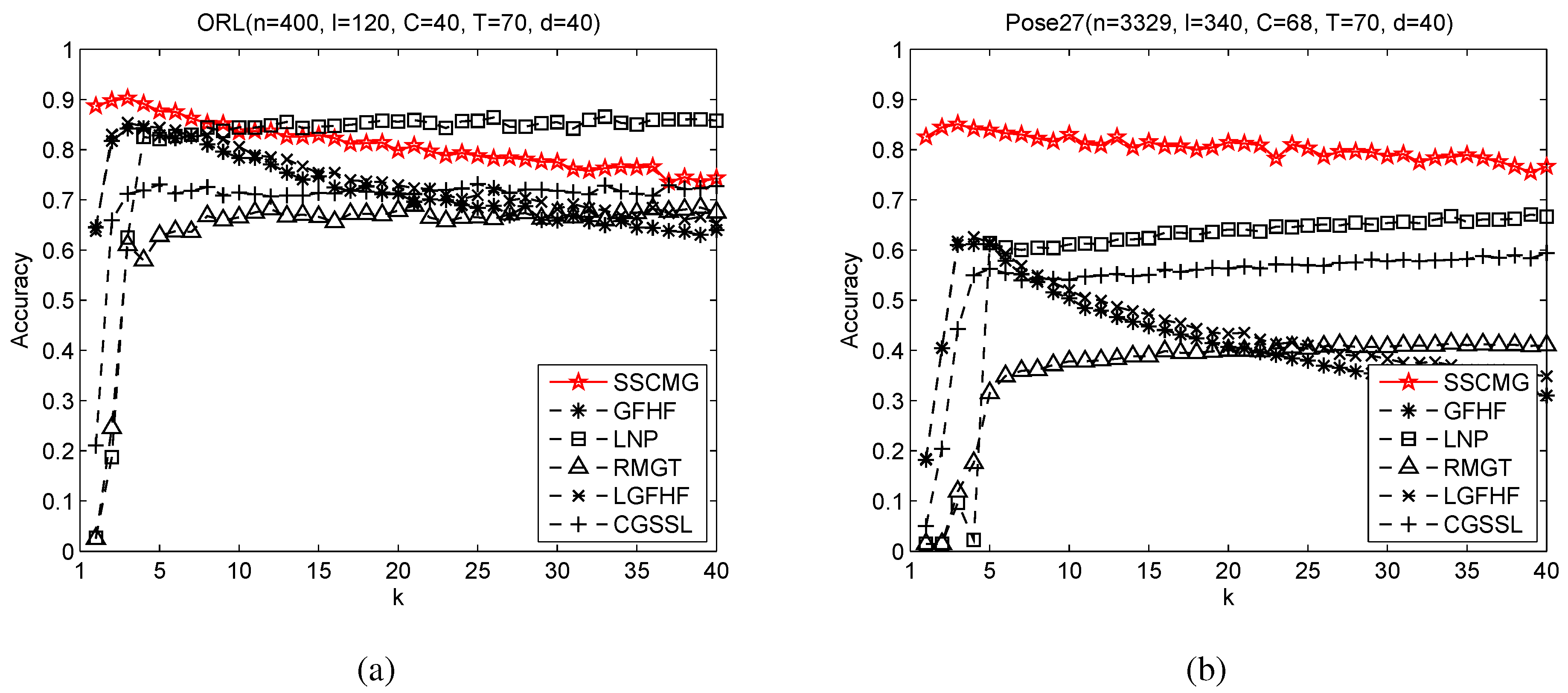
3.2. Sensitivity Analysis with Respect to Neighborhood Size
It is found that neighborhood size
k of
kNN graph can influence the results of GSSC. To investigate the sensitivity of SSCMG under different
k values, we conduct experiments on ORL and Pose27. In the experiments, we fix
as 3 on ORL and as 5 on Pose27, we then vary
k from 1 to 40. We also include the results of other comparing methods that utilize a
kNN graph and report the results in
Figure 2.
Figure 2.
Sensitivity under different values of k. (a) Accuracy vs. k (ORL); (b) Accuracy vs. k (Pose27).
Figure 2.
Sensitivity under different values of k. (a) Accuracy vs. k (ORL); (b) Accuracy vs. k (Pose27).
From
Figure 2, we can observe that SSCMG achieves better performance and it is less sensitive to
k than other comparing methods when
. However, as
k increasing, its accuracy downgrades gradually. This is because a large value of
k means choosing more neighbors of a sample, so the constructed mixture graph is becoming denser and more noisy edges are included. On the other hand, the accuracy of GFHF and LGFHF first rise sharply as
k increasing and then reduce gradually. The accuracy of LNP, RMGT and CGSSL increase as
k rising and become relatively stable, and these methods sometimes get comparable (or better) results with SSCMG on ORL. The reason is that these three methods need a large number of neighbors to optimize a
kNN graph for semi-supervised classification. CGSSL utilizes a compact
graph by using the direct neighborhood samples of a sample and the neighborhood samples of its reciprocal neighbors. As
k increasing, more neighborhood samples are included and thus the similarity between samples is more distorted by noisy neighbors. Given that, CGSSL loses to LNP, which is also based on an
graph, but LNP only utilizes the direct neighborhood samples of a sample. As
k increasing, the accuracy of GFHF and LGFHF on ORL and Pose27 downgrades much more than that of SSCMG, this observation suggests that mixture graph is less suffered from the choice of
k than a single
kNN graph.
Figure 2 also shows that it is difficult to set a suitable
k for GSSC methods. In contrast, there is a clear pattern and it is easy to select a suitable
k for SSCMG. Although SSCMG, LGFHF and GFHF share the same classifier, the performance of SSCMG is always more stable than LGFHF and GFHF. This observation also justifies the advantage of mixture graph for GSSC.
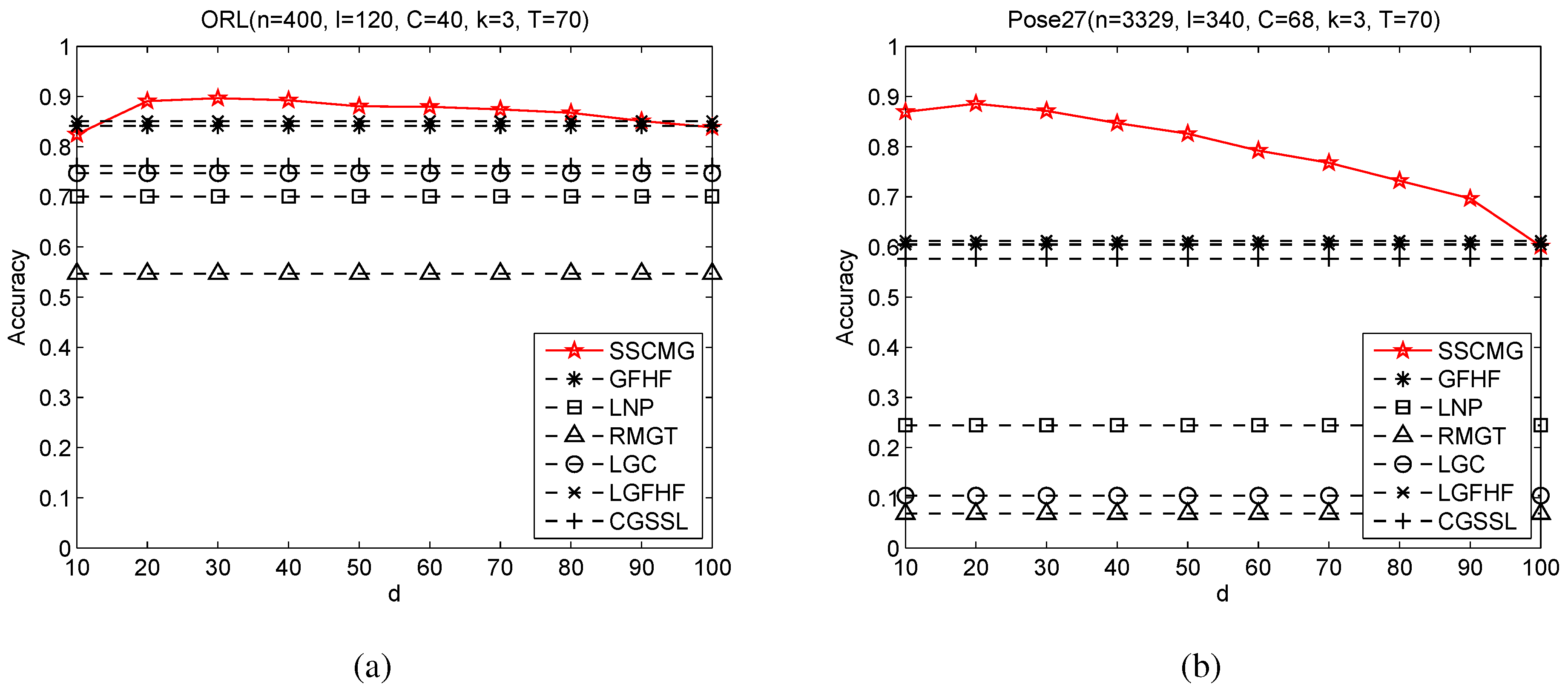
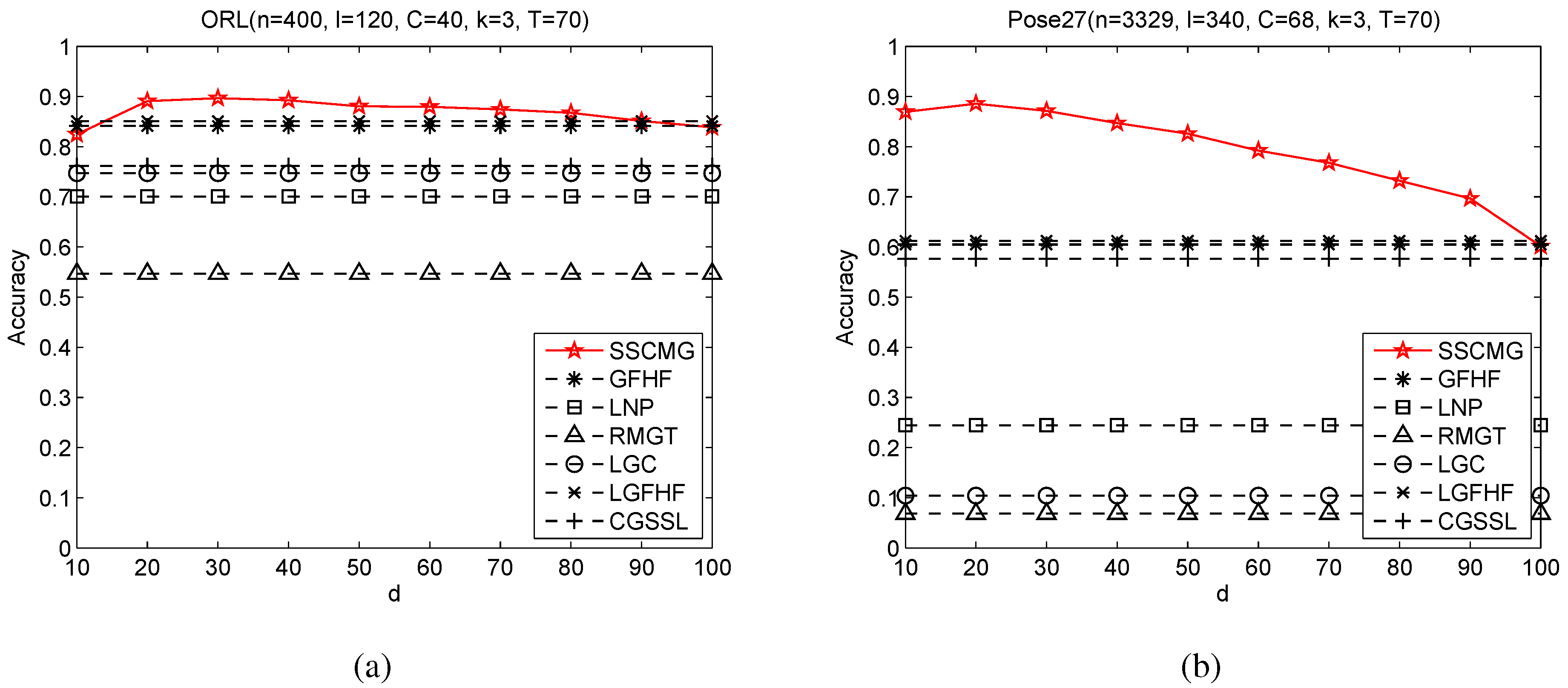
3.3. Sensitivity Analysis with Respect to Dimensionality of Random Subspace
The dimensionality of random subspace is an influential parameter for the random subspace method [
2,
23]. To study the sensitivity of mixture graph with respect to the dimensionality of random subspace, we conduct two experiments on ORL and Pose27 with
d varying from 10 to 100. The corresponding experimental results are reported in
Figure 3. For reference, we also include the results of GFHF, LGFHF, LNP, RMGT, LGC and CGSSL in
Figure 3.
Figure 3.
Sensitivity under different values of d. (a) Accuracy vs. d (ORL); (b) Accuracy vs. d (Pose27).
Figure 3.
Sensitivity under different values of d. (a) Accuracy vs. d (ORL); (b) Accuracy vs. d (Pose27).
From
Figure 3, we can observe that the accuracy of SSCMG increases slightly as
d rising at first and then turns to downgrade, especially on Pose27. The reason is twofold: (i) when
d is very small (
i.e.,
), there are too few features to construct a graph that describes the distribution of samples projected in that subspace; (ii) as
d is close to 100, more and more noisy features are included into the subspace and hence the graph is more and more distorted by noisy features. When
all the features are included, these
T graphs are the same, and thus the performance of SSCMG is similar to that of GFHF. Overall, irrespective of the setting of
d, the performance of SSCMG is always no worse than that of GFHF. However, how to choose an effective value of
d (or design a graph less suffered from
d) is still a future pursue.
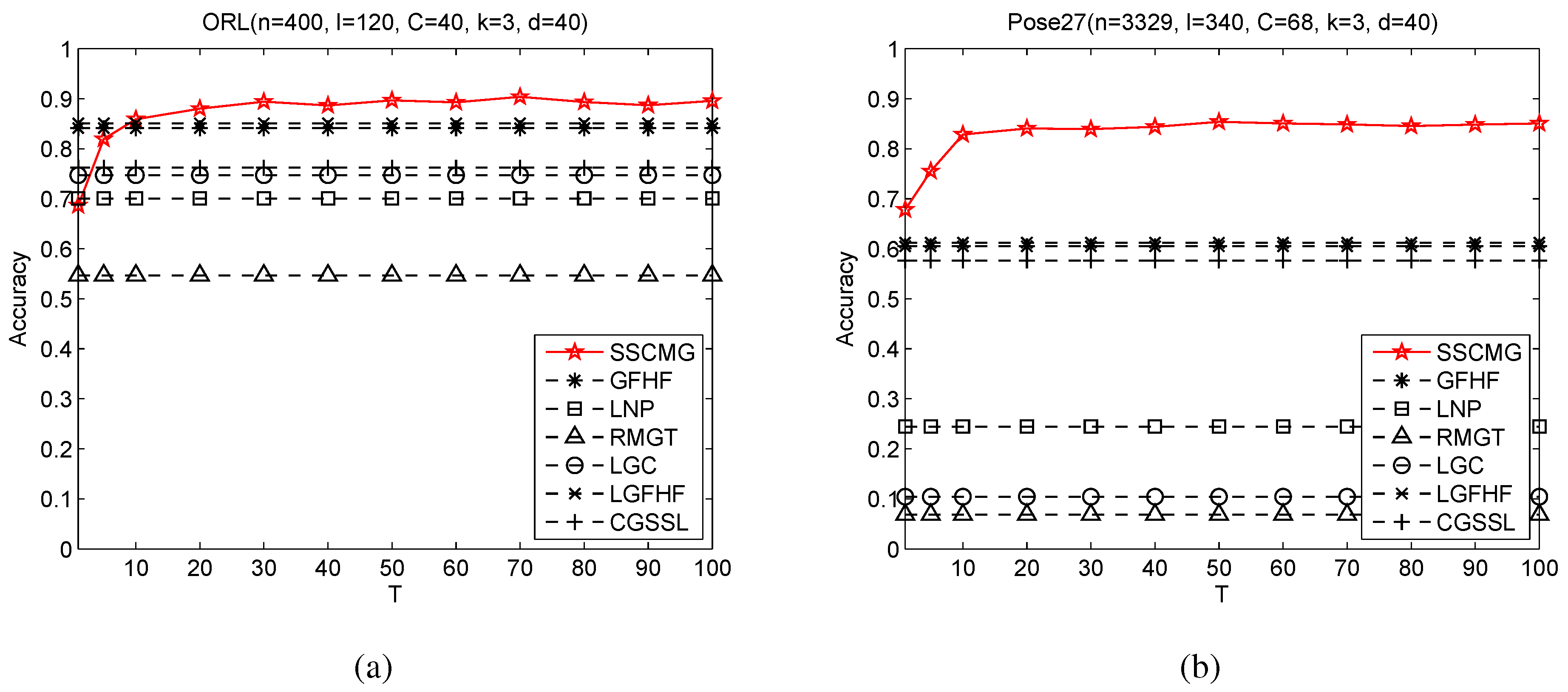
3.4. Sensitivity Analysis with Respect to Number of Random Subspaces
The number of random subspaces is another influential parameter of random subspace method. To explore the performance of SSCMG under different number of random subspaces, additional experiments are conducted on ORL and Pose27 with
T rising from 1 to 100, and the corresponding results are shown in
Figure 4.
Figure 4.
Sensitivity under different values of T. (a) Accuracy vs. T (ORL); (b) Accuracy vs. T (Pose27).
Figure 4.
Sensitivity under different values of T. (a) Accuracy vs. T (ORL); (b) Accuracy vs. T (Pose27).
From
Figure 4, we can clearly observe that when
, the accuracy of SSCMG is relatively low, even lower than that of GFHF on ORL. The accuracy of SSCMG increases as
T rising, and it reaches to relatively stable when
. The cause is that too few
kNN graphs in the subspaces can not capture the distribution of samples. Overall, these experimental results suggest that SSCMG can easily choose a suitable value of
T in a wide range.




{kind=link}
{kind=link}
{kind=link}
{kind=link}