Exact Algorithms for Maximum Clique: A Computational Study

Abstract
:1. Introduction
1.1. The Maximum Clique Problem (MCP)
1.2. Exact Algorithms for MCP
1.3. Structure of the Paper
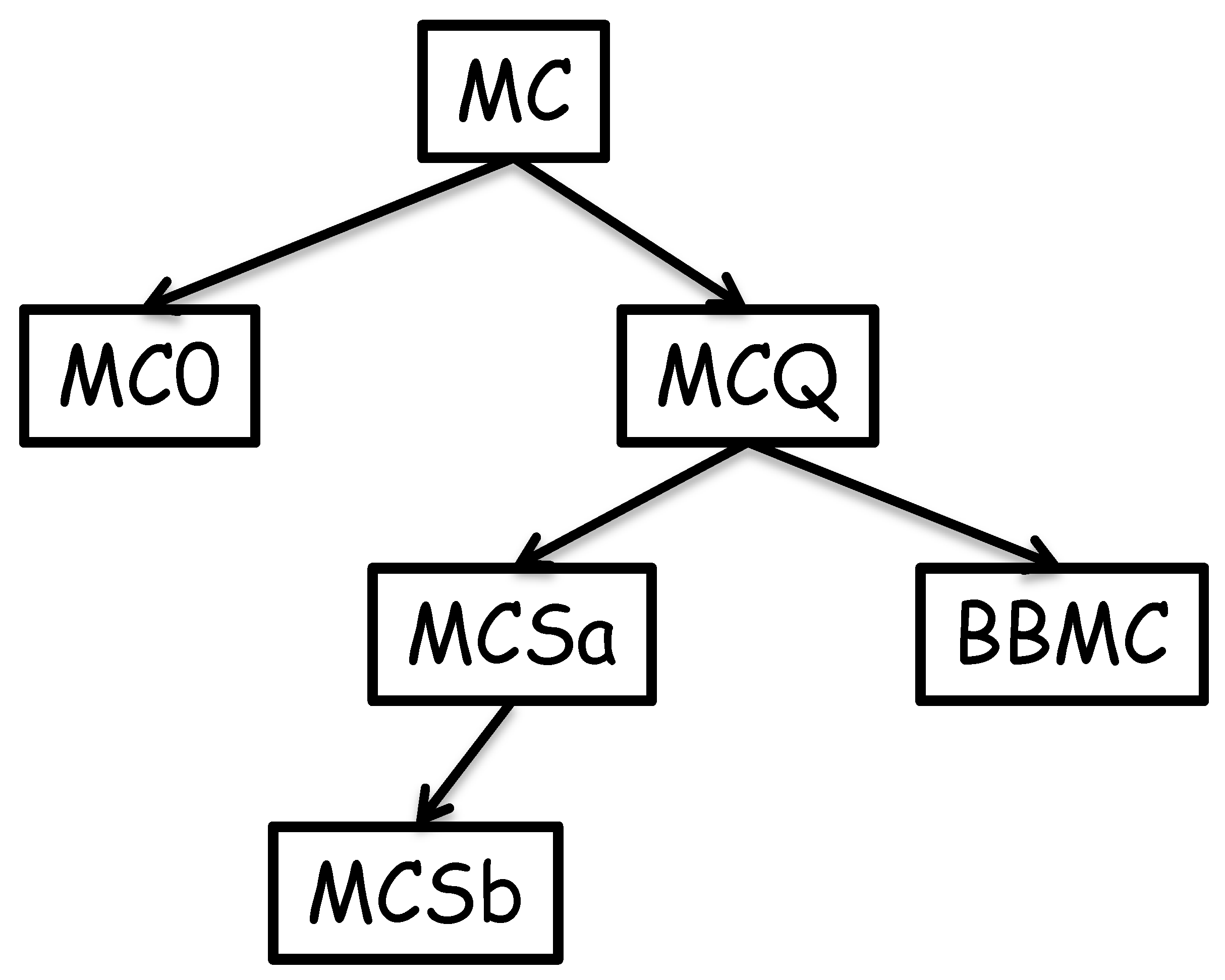
2. The Algorithms: MC, MCQ, MCR, MCS and BBMC
2.1. MC
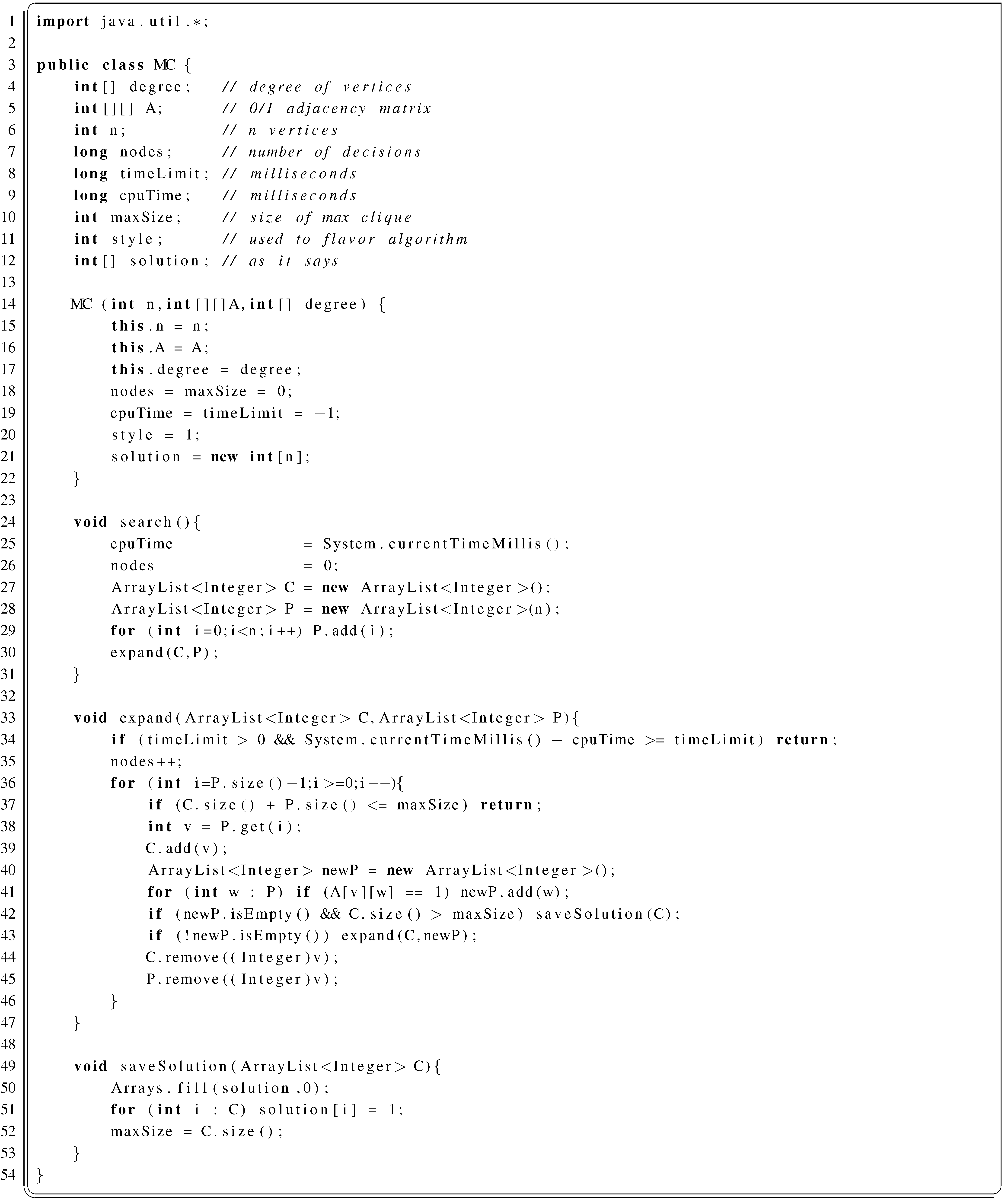
2.1.1. MC in Java
2.1.2. Observations on MC


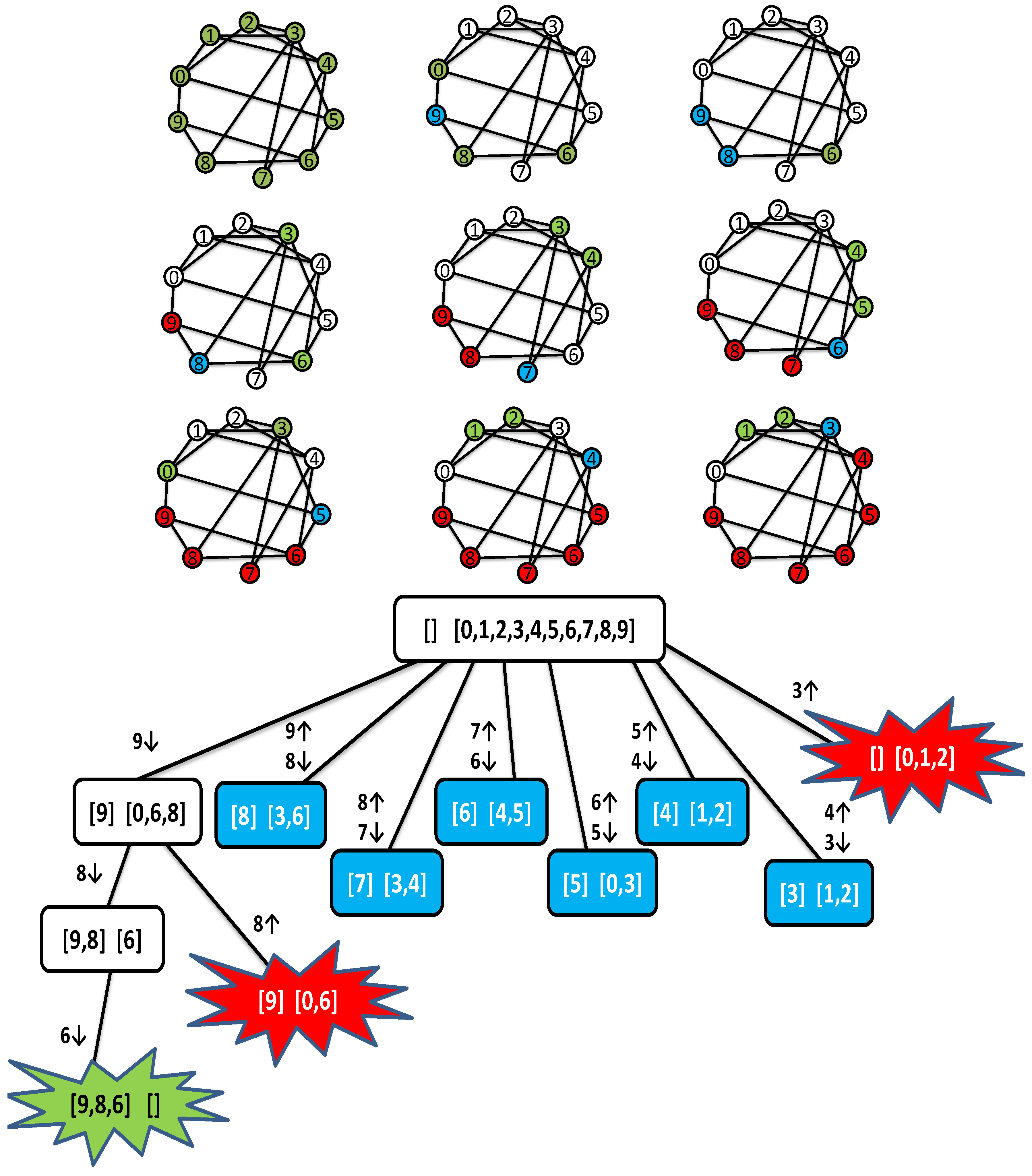
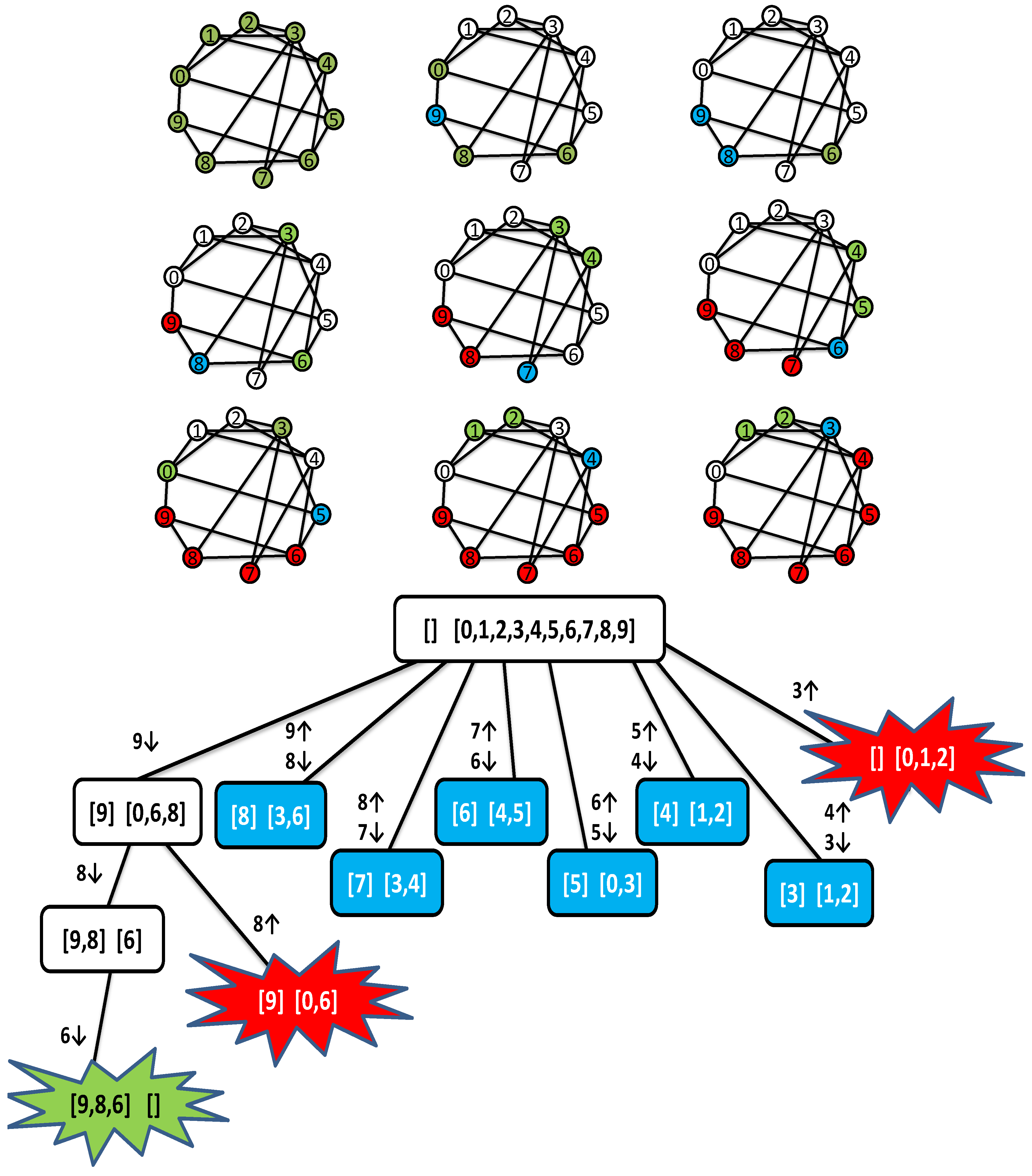
2.1.3. A Trace of MC
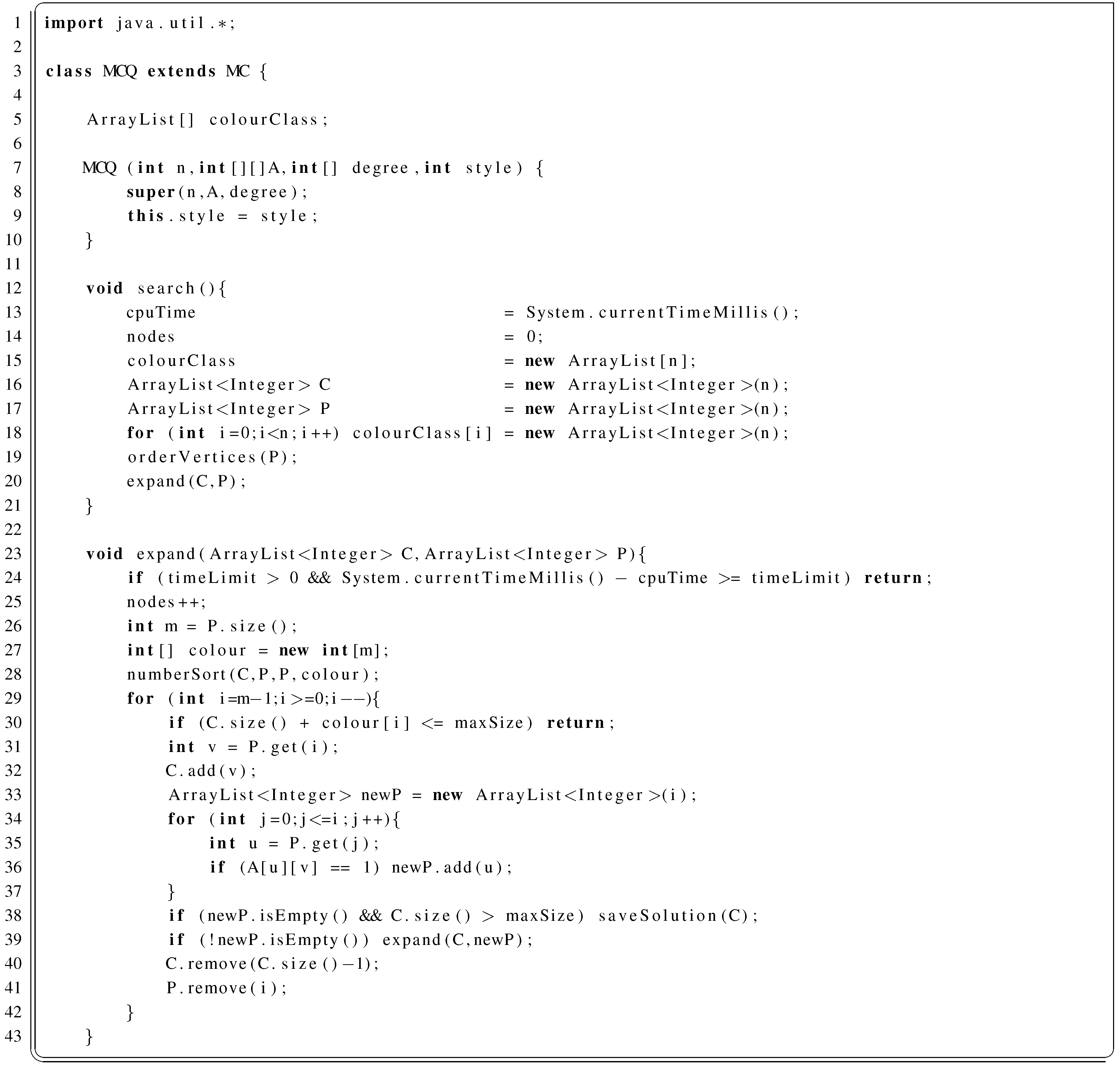
2.2. MCQ and MCR
2.2.1. MCQ in Java




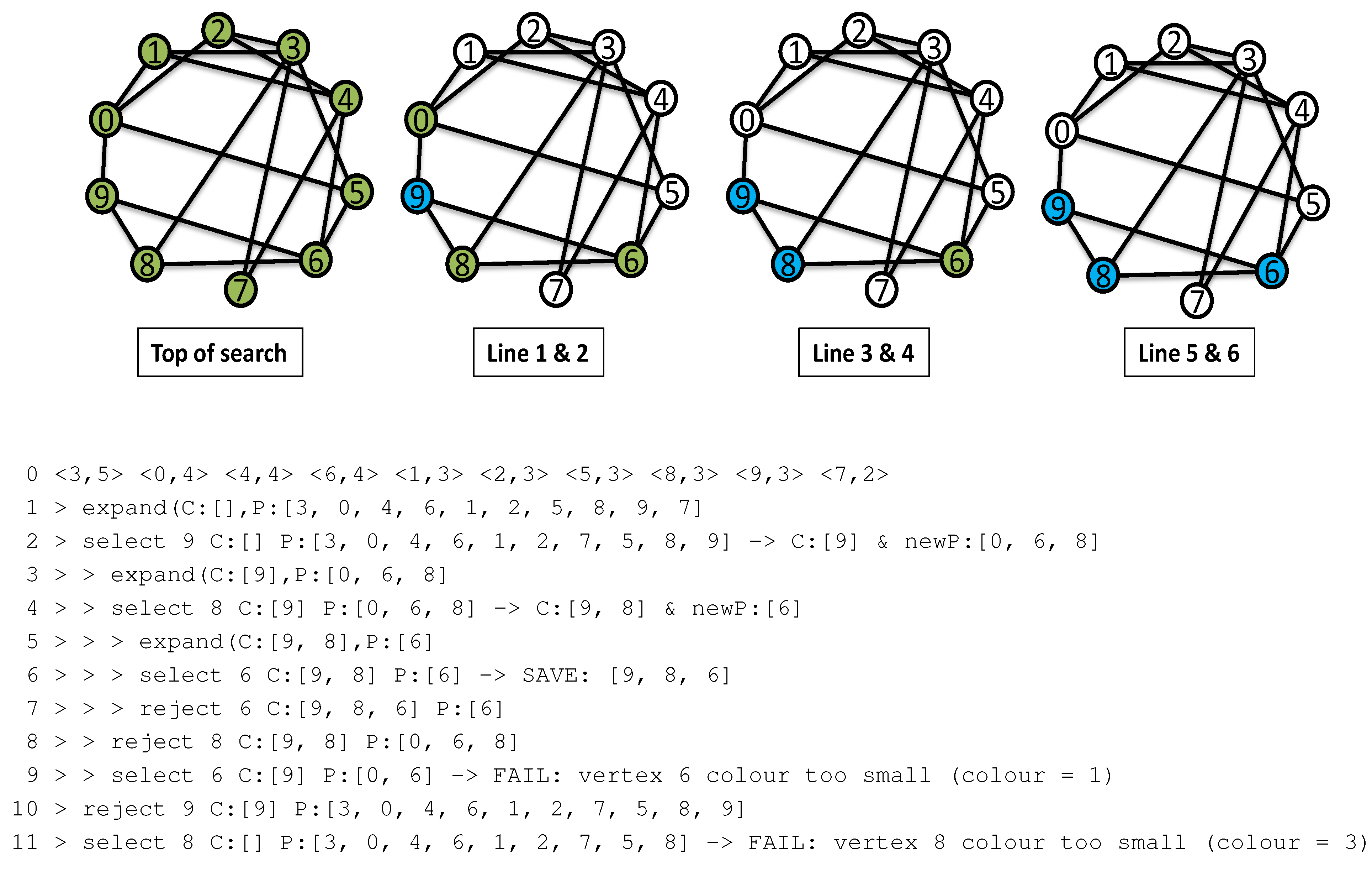
2.2.2. A Trace of MCQ
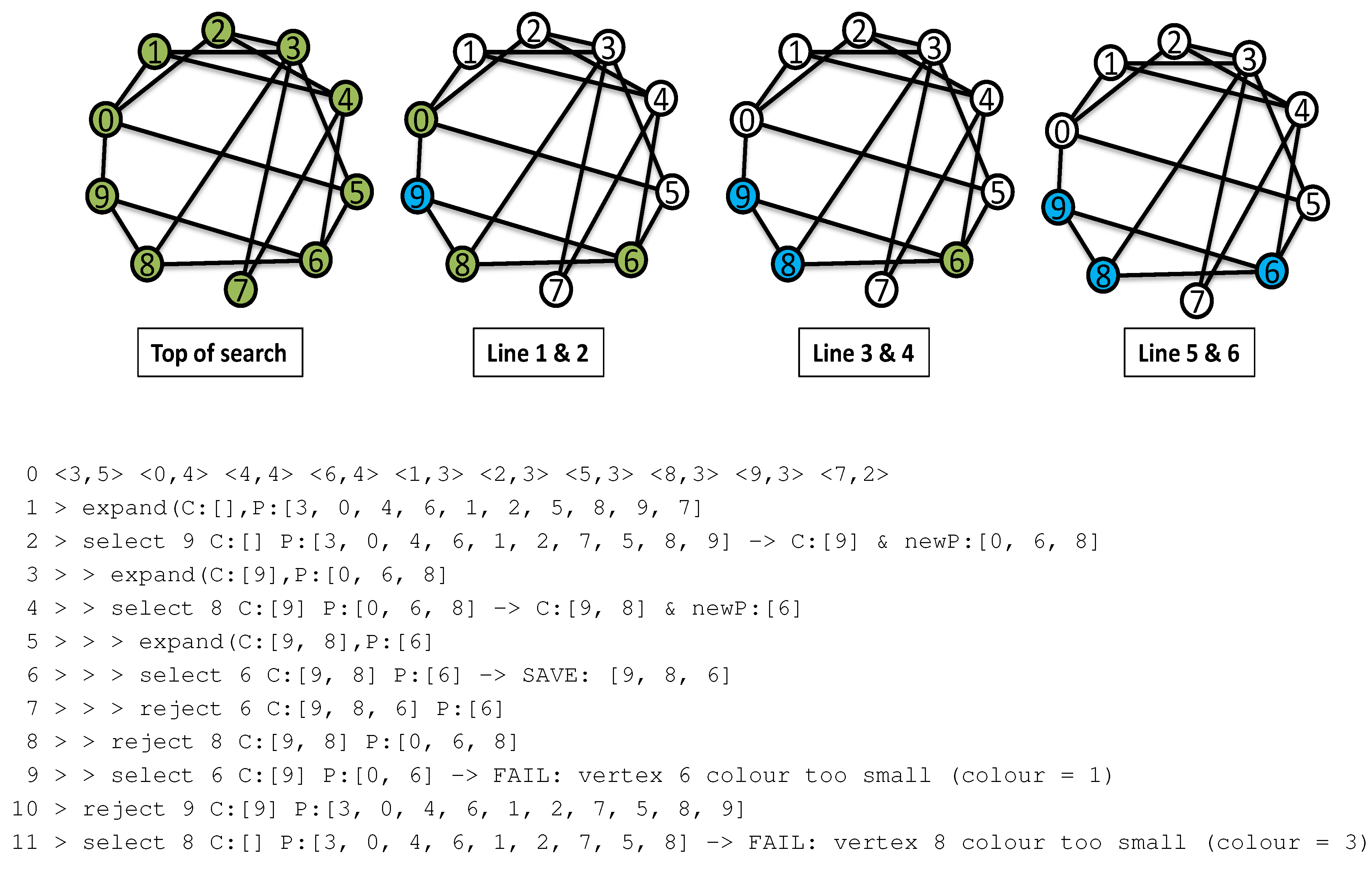
2.2.3. Observations on MCQ
2.3. MCS
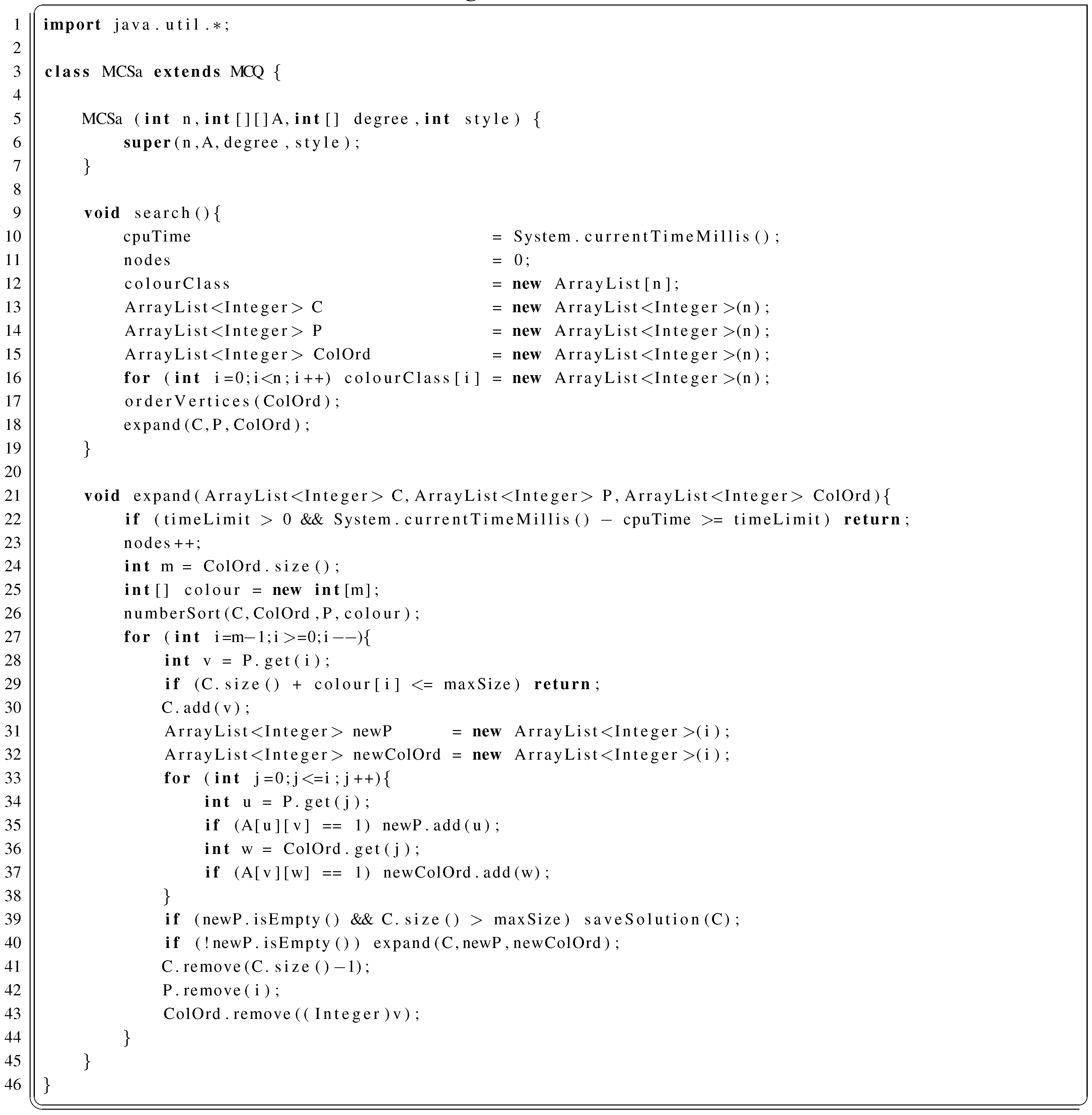
2.3.1. MCSa in Java
2.3.2. MCSb in Java

2.3.3. Observations on MCS
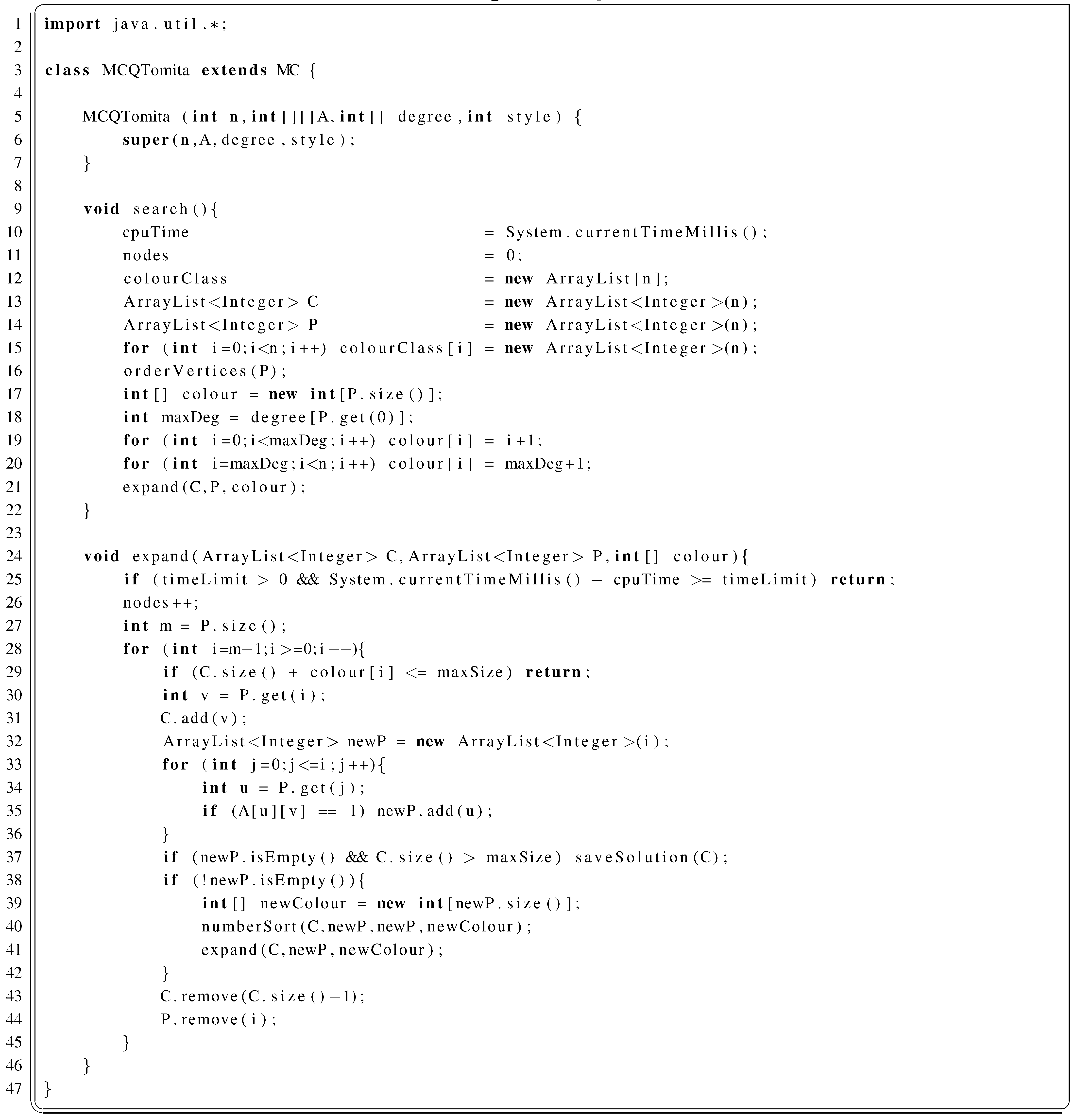
2.4. BBMC
- The “BB” in “BB-MaxClique” is for “Bit Board”. Sets are represented using bit strings.
- BBMC colours the candidate set using a static sequential ordering, the ordering set at the top of search, the same as MCSa.
- BBMC represents the neighbourhood of a vertex and its inverse neighbourhood as bit strings, rather than using a row of an adjacency matrix and its complement.
2.4.1. BBMC in Java



2.4.2. Observations on BBMC
2.5. Summary of MCQ, MCR, MCS and BBMC
3. Exact Algorithms for Maximum Clique: A Brief History
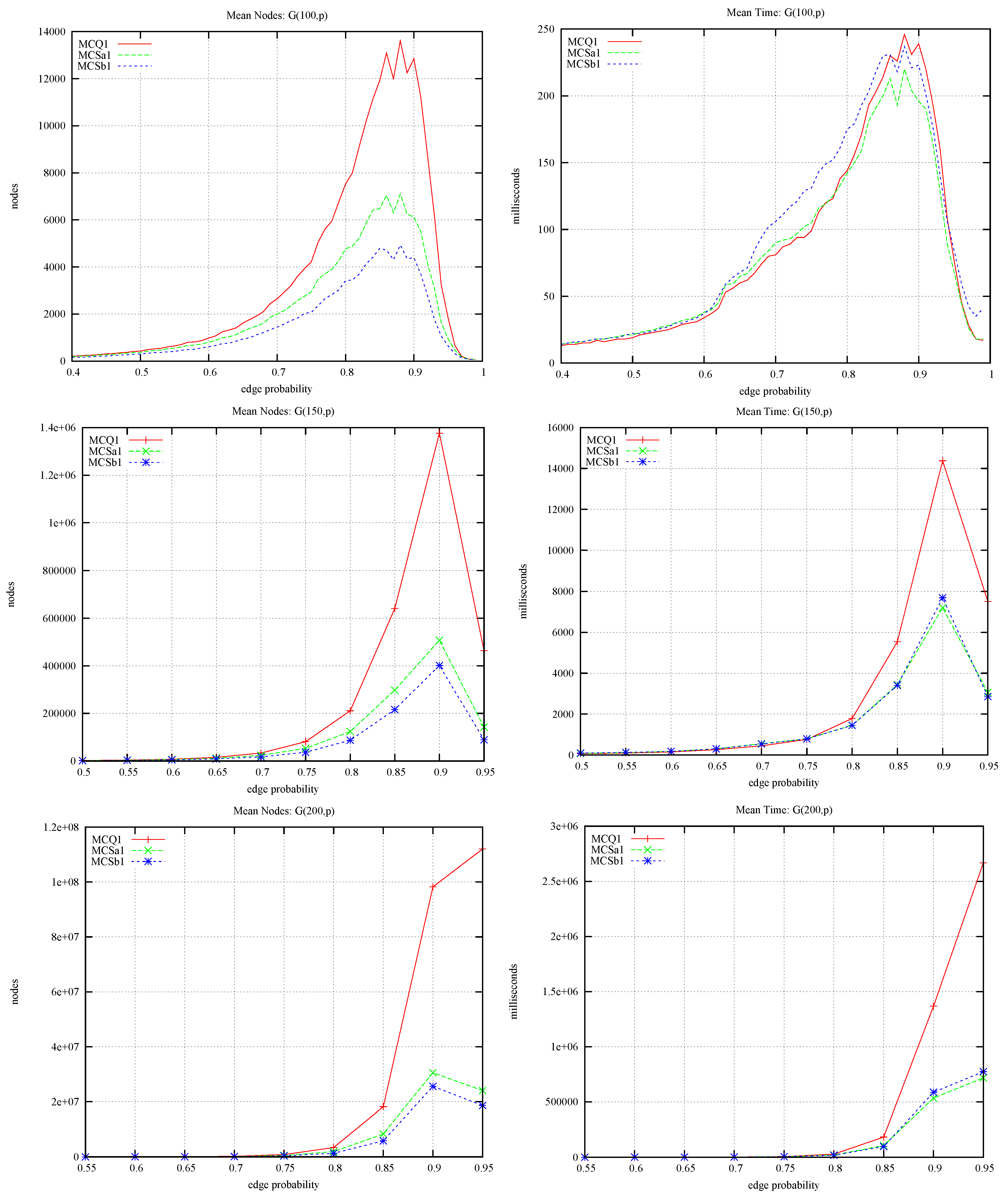
4. The Computational Study
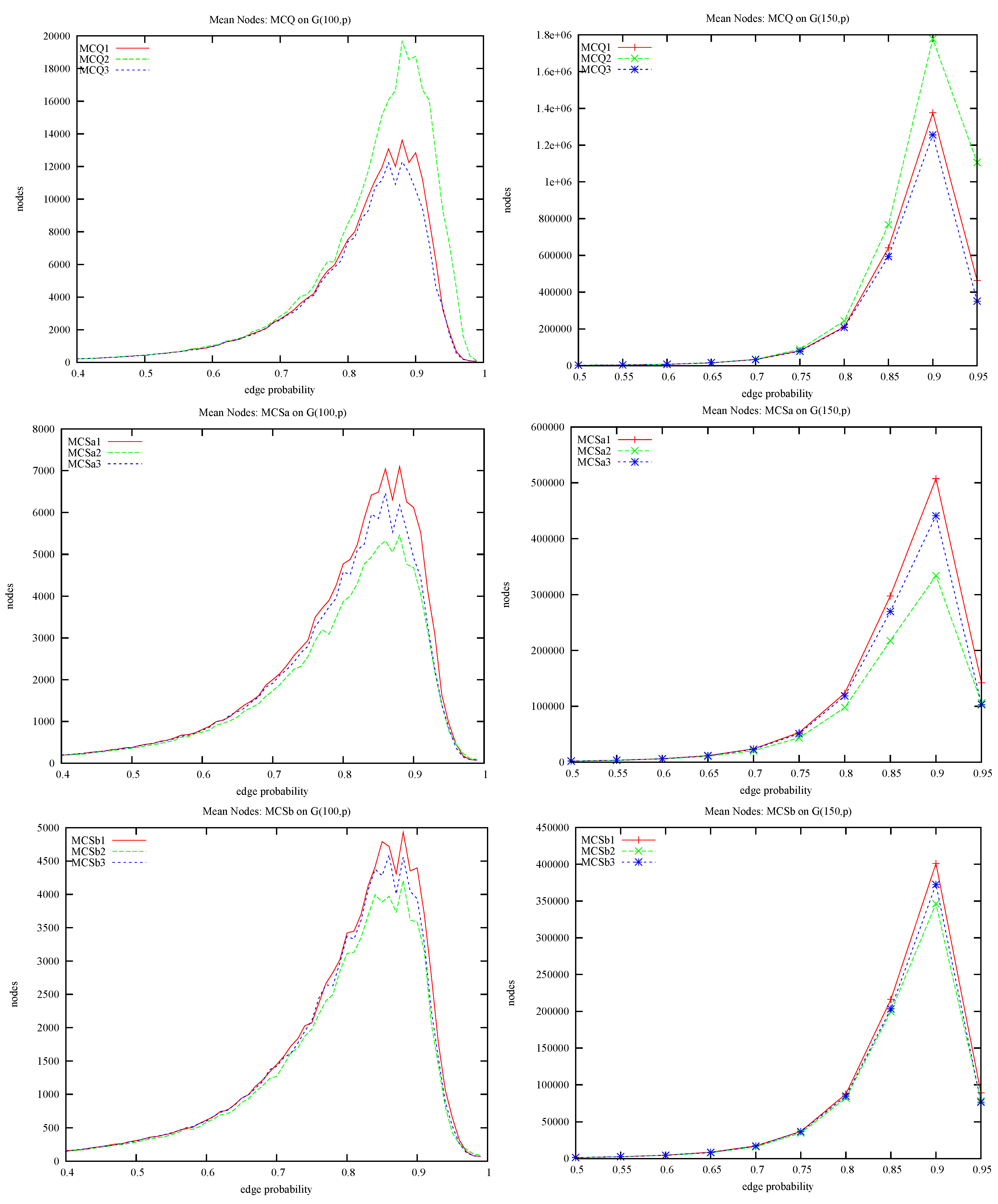
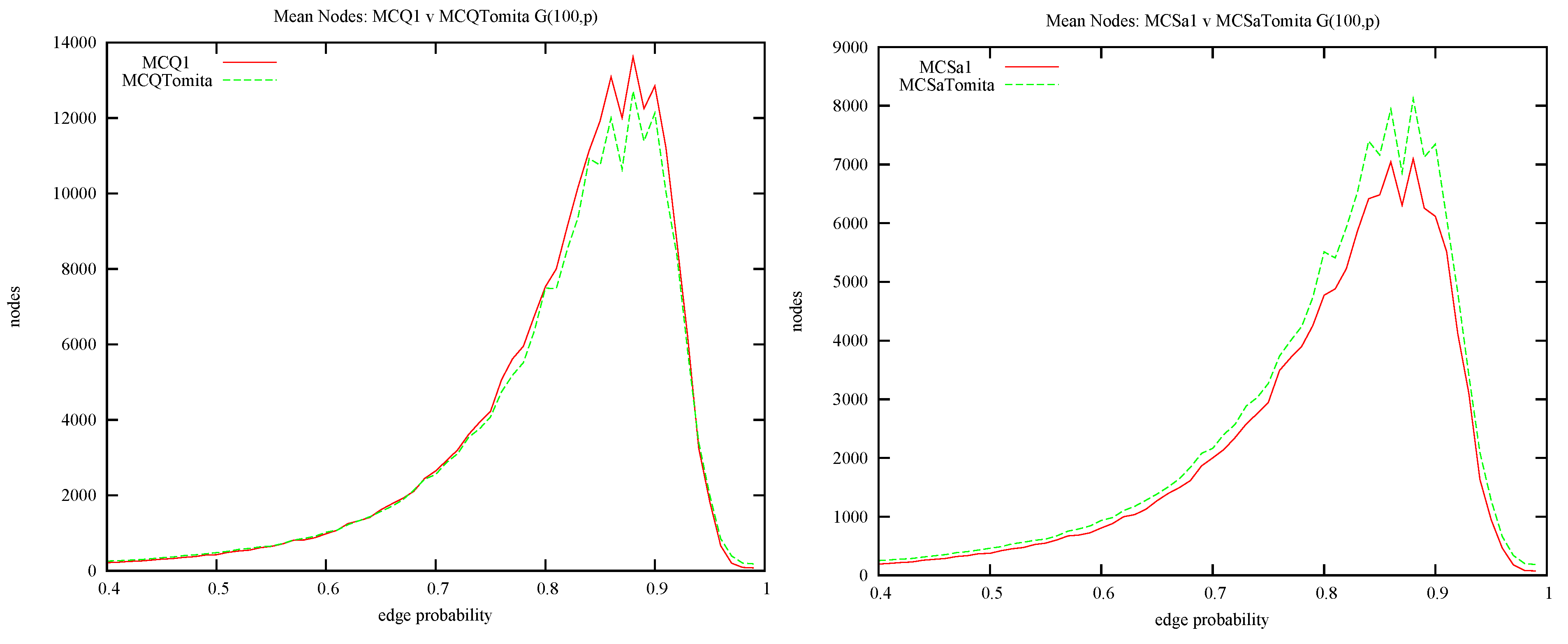
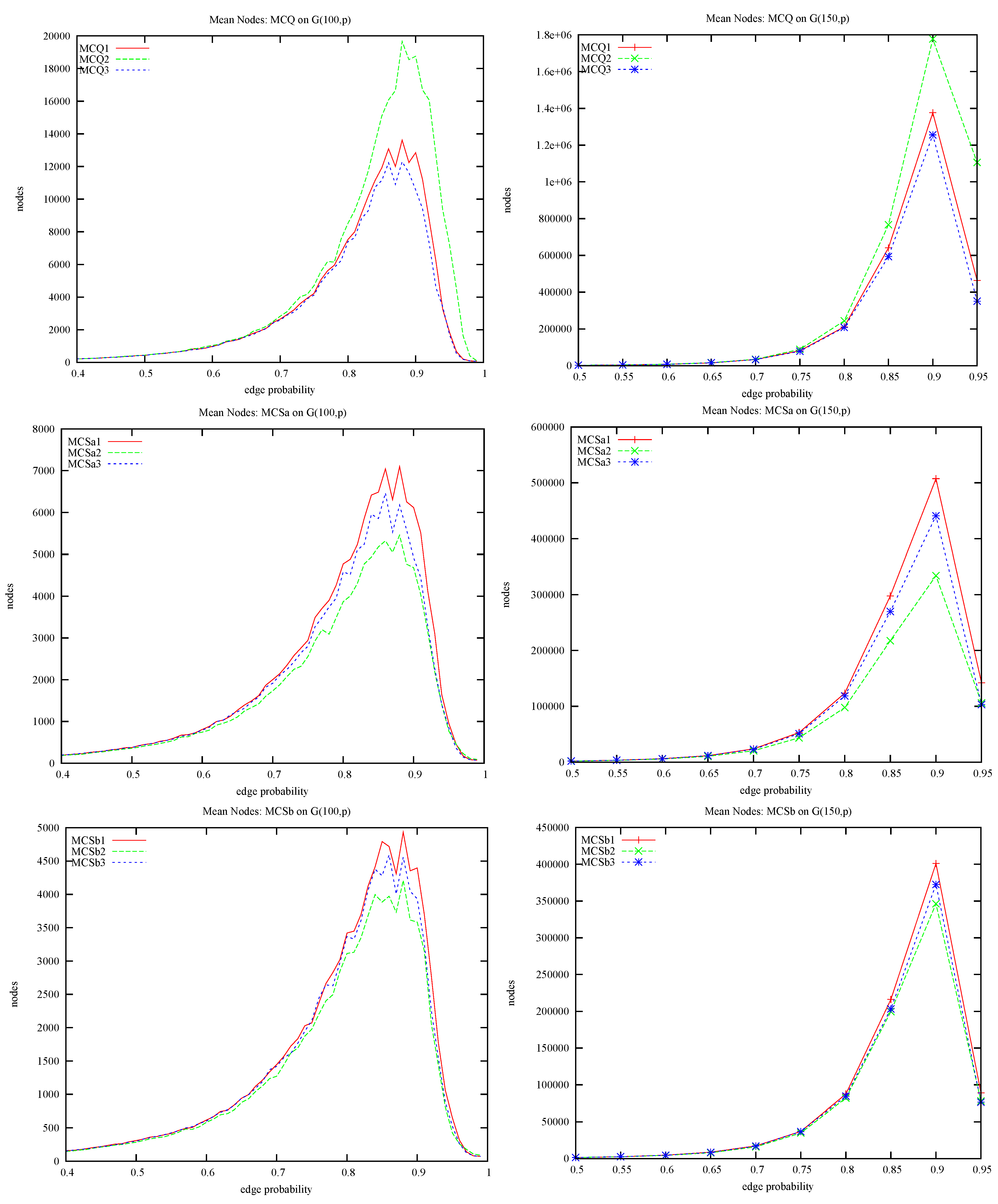
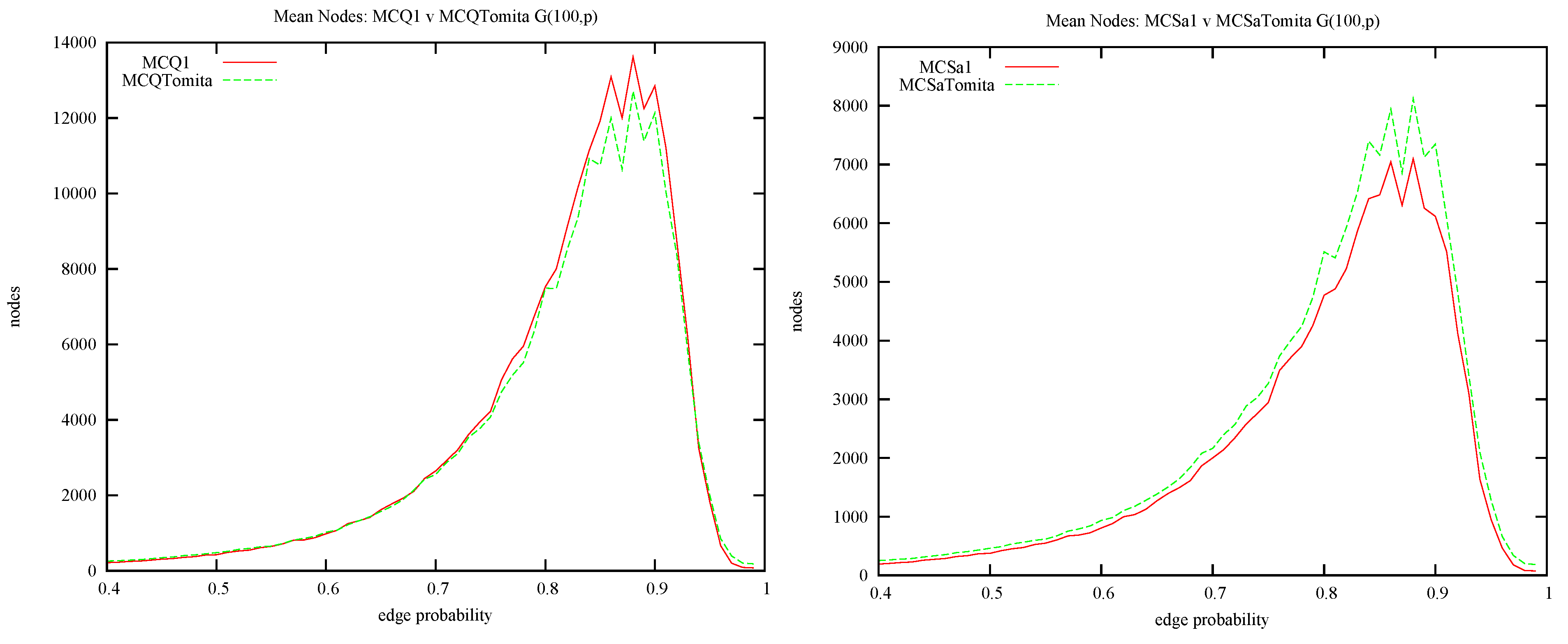
- Where does the improvement in MCS come from? By comparing MCQ with MCSa we can measure the contribution due to static colouring, and by comparing MCSa with MCSb we can measure the contribution due to colour repair.
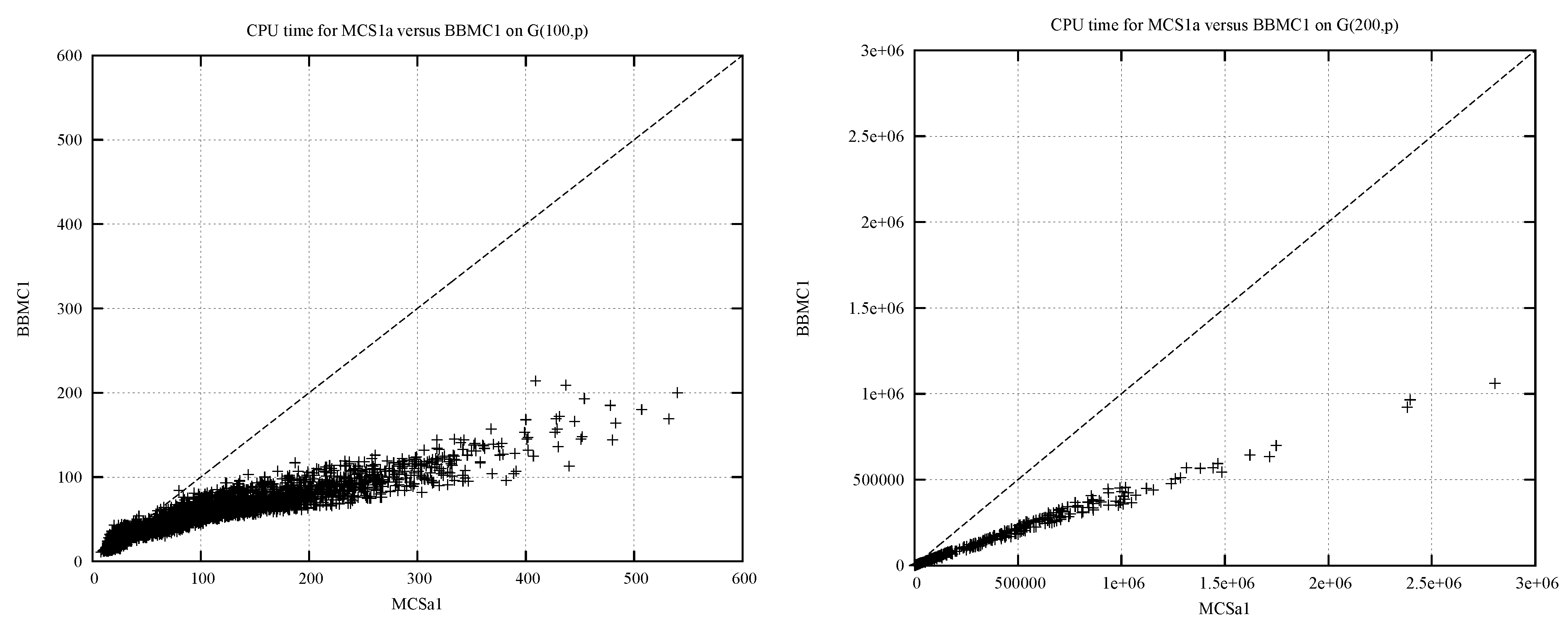
- How much benefit can be obtained from the BitSet encoding? We compare MCSa with BBMC over a variety of problems.
- We have three possible initial orderings (styles). Is any one of them better than the others and is this algorithm independent?
- Most papers use only random problems and the DIMACS benchmarks. What other problems might we use in our investigation?
- Is it safe to recalibrate published results?
4.1. MCQ vs. MCS: Static Ordering and Colour Repair

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| instance | MCQ1 | MCSa1 | MCSb1 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| brock200-1 | 868,213 | 7 | (21) | 524,723 | 4 | (21) | 245,146 | 3 | (21) |
| brock400-1 | 342,473,950 | 4,471 | (27) | 198,359,829 | 2,888 | (27) | 142,253,319 | 2,551 | (27) |
| brock400-2 | 224,839,070 | 2,923 | (29) | 145,597,994 | 2,089 | (29) | 61,327,056 | 1,199 | (29) |
| brock400-3 | 194,403,055 | 2,322 | (31) | 120,230,513 | 1,616 | (31) | 70,263,846 | 1,234 | (31) |
| brock400-4 | 82,056,086 | 1,117 | (33) | 54,440,888 | 802 | (33) | 68,252,352 | 1,209 | (33) |
| brock800-1 | 1,247,519,247 | — | (23) | 1,055,945,239 | — | (23) | 911,465,283 | — | (21) |
| brock800-2 | 1,387,973,191 | — | (21) | 1,171,057,646 | — | (24) | 914,638,570 | — | (21) |
| brock800-3 | 1,332,309,827 | — | (21) | 1,159,165,900 | — | (21) | 914,235,793 | — | (21) |
| brock800-4 | 804,901,115 | — | (26) | 640,444,536 | 12,568 | (26) | 659,145,642 | 13,924 | (26) |
| hamming10-4 | 636,203,658 | — | (40) | 950,939,457 | — | (37) | 858,347,653 | — | (37) |
| johnson32-2-4 | 10,447,210,976 | — | (16) | 8,269,639,389 | — | (16) | 7,345,343,221 | — | (16) |
| keller5 | 603,233,453 | — | (27) | 596,150,386 | — | (27) | 523,346,613 | — | (27) |
| keller6 | 285,704,599 | — | (48) | 226,330,037 | — | (52) | 240,958,450 | — | (54) |
| MANN-a27 | 38,019 | 9 | (126) | 38,019 | 6 | (126) | 38,597 | 8 | (126) |
| MANN-a45 | 2,851,572 | 4,989 | (345) | 2,851,572 | 3,766 | (345) | 2,545,131 | 4,118 | (345) |
| MANN-a81 | 550,869 | — | (1100) | 631,141 | — | (1100) | 551,612 | — | (1100) |
| p-hat1000-1 | 237,437 | 2 | (10) | 176,576 | 2 | (10) | 151,033 | 2 | (10) |
| p-hat1000-2 | 466,616,845 | — | (45) | 34,473,978 | 1,401 | (46) | 166,655,543 | 7,565 | (46) |
| p-hat1000-3 | 440,569,803 | — | (52) | 345,925,712 | — | (55) | 298,537,771 | — | (56) |
| p-hat1500-1 | 1,642,981 | 16 | (12) | 1,184,526 | 14 | (12) | 990,246 | 14 | (12) |
| p-hat1500-2 | 414,514,960 | — | (52) | 231,498,292 | — | (60) | 259,771,137 | — | (57) |
| p-hat1500-3 | 570,637,417 | — | (56) | 220,823,126 | — | (69) | 176,987,047 | — | (69) |
| p-hat300-3 | 3,829,005 | 74 | (36) | 624,947 | 13 | (36) | 713,107 | 21 | (36) |
| p-hat500-2 | 1,022,190 | 23 | (36) | 114,009 | 3 | (36) | 137,568 | 5 | (36) |
| p-hat500-3 | 515,071,375 | — | (47) | 39,260,458 | 1,381 | (50) | 104,684,054 | 4,945 | (50) |
| p-hat700-2 | 18,968,155 | 508 | (44) | 750,903 | 27 | (44) | 149,0522 | 74 | (44) |
| p-hat700-3 | 570,423,439 | — | (48) | 255,745,746 | — | (62) | 243,836,191 | — | (62) |
| san1000 | 302,895 | 20 | (15) | 150,725 | 10 | (15) | 53,215 | 3 | (15) |
| san200-0.9-2 | 1,149,564 | 20 | (60) | 229,567 | 5 | (60) | 62,776 | 1 | (60) |
| san200-0.9-3 | 8,260,345 | 154 | (44) | 6,815,145 | 111 | (44) | 1,218,317 | 32 | (44) |
| san400-0.7-1 | 55,010 | 1 | (40) | 119,356 | 2 | (40) | 134,772 | 3 | (40) |
| san400-0.7-2 | 606,159 | 14 | (30) | 889,125 | 19 | (30) | 754,146 | 16 | (30) |
| san400-0.7-3 | 582,646 | 11 | (22) | 521,410 | 10 | (22) | 215,785 | 5 | (22) |
| san400-0.9-1 | 523,531,417 | — | (56) | 4,536,723 | 422 | (100) | 582,445 | 54 | (100) |
| sanr200-0.7 | 206,262 | 1 | (18) | 152,882 | 1 | (18) | 100,977 | 1 | (18) |
| sanr200-0.9 | 44,472,276 | 892 | (42) | 14,921,850 | 283 | (42) | 9,730,778 | 245 | (42) |
| sanr400-0.5 | 380,151 | 2 | (13) | 320,110 | 2 | (13) | 190,706 | 2 | (13) |
| sanr400-0.7 | 101,213,527 | 979 | (21) | 64,412,015 | 711 | (21) | 46,125,168 | 650 | (21) |
4.2. BBMC vs. MCSa: A Change of Representation
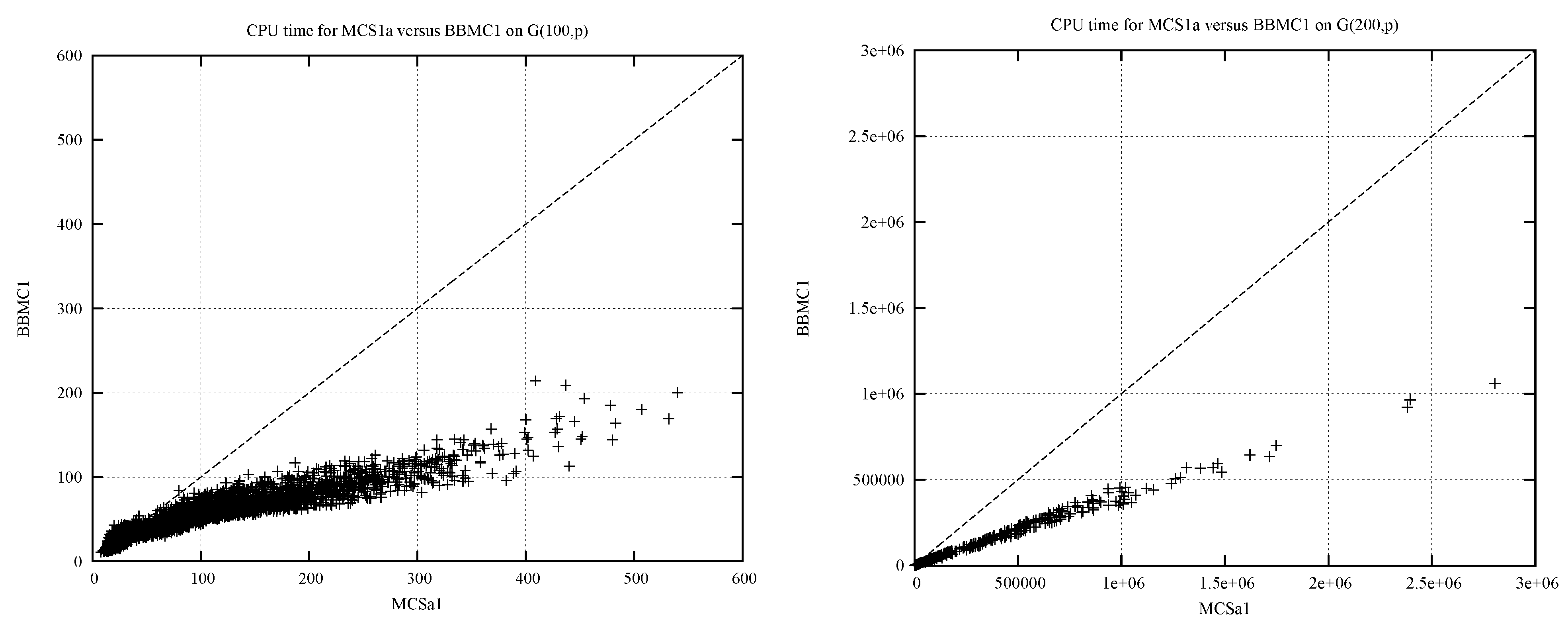
| instance | MCSa1 | BBMC1 | MCSa1/BBMC1 | ||||
|---|---|---|---|---|---|---|---|
| brock200-1 | 524,723 | 4 | (21) | 524,723 | 2 | (21) | 2.03 |
| brock400-1 | 198,359,829 | 2,888 | (27) | 198,359,829 | 1,421 | (27) | 2.03 |
| brock400-2 | 145,597,994 | 2,089 | (29) | 145,597,994 | 1,031 | (29) | 2.03 |
| brock400-3 | 120,230,513 | 1,616 | (31) | 120,230,513 | 808 | (31) | 2.00 |
| brock400-4 | 54,440,888 | 802 | (33) | 54,440,888 | 394 | (33) | 2.03 |
| brock800-4 | 640,444,536 | 12,568 | (26) | 640,444,536 | 6,908 | (26) | 1.82 |
| MANN-a27 | 38,019 | 6 | (126) | 38,019 | 1 | (126) | 4.12 |
| MANN-a45 | 2,851,572 | 3,766 | (345) | 2,851,572 | 542 | (345) | 6.94 |
| p-hat1000-1 | 176,576 | 2 | (10) | 176,576 | 1 | (10) | 1.80 |
| p-hat1000-2 | 34,473,978 | 1,401 | (46) | 34,473,978 | 720 | (46) | 1.95 |
| p-hat1500-1 | 1,184,526 | 14 | (12) | 1,184,526 | 9 | (12) | 1.52 |
| p-hat300-3 | 624,947 | 13 | (36) | 624,947 | 5 | (36) | 2.36 |
| p-hat500-2 | 114,009 | 3 | (36) | 114,009 | 1 | (36) | 2.56 |
| p-hat500-3 | 39,260,458 | 1,381 | (50) | 39,260,458 | 606 | (50) | 2.28 |
| p-hat700-2 | 750,903 | 27 | (44) | 750,903 | 12 | (44) | 2.20 |
| san1000 | 150,725 | 10 | (15) | 150,725 | 5 | (15) | 1.76 |
| san200-0.9-2 | 229,567 | 5 | (60) | 229,567 | 2 | (60) | 2.36 |
| san200-0.9-3 | 6,815,145 | 111 | (44) | 6,815,145 | 50 | (44) | 2.20 |
| san400-0.7-1 | 119,356 | 2 | (40) | 119,356 | 1 | (40) | 2.04 |
| san400-0.7-2 | 889,125 | 19 | (30) | 889,125 | 9 | (30) | 2.12 |
| san400-0.7-3 | 521,410 | 10 | (22) | 521,410 | 5 | (22) | 2.10 |
| san400-0.9-1 | 4,536,723 | 422 | (100) | 4,536,723 | 125 | (100) | 3.37 |
| sanr200-0.9 | 14,921,850 | 283 | (42) | 14,921,850 | 123 | (42) | 2.30 |
| sanr400-0.5 | 320,110 | 2 | (13) | 320,110 | 1 | (13) | 1.85 |
| sanr400-0.7 | 64,412,015 | 711 | (21) | 64,412,015 | 365 | (21) | 1.95 |
4.3. MCQ and MCS: The Effect of Initial Ordering
| MCQ | MCSa | MCSb | BBMC | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| instance | ||||||||||||
| brock200-1 | 7 | 5 | 4 | 4 | 3 | 3 | 3 | 3 | 3 | 2 | 1 | 1 |
| brock400-1 | 4,471 | 3,640 | 5,610 | 2,888 | 1,999 | 3,752 | 2,551 | 3,748 | 2,152 | 1,421 | 983 | 1,952 |
| brock400-2 | 2,923 | 4,573 | 1,824 | 2,089 | 2,415 | 1,204 | 1,199 | 2,695 | 2,647 | 1,031 | 1,230 | 616 |
| brock400-3 | 2,322 | 2,696 | 1,491 | 1,616 | 1,404 | 1,027 | 1,234 | 2,817 | 2,117 | 808 | 711 | 534 |
| brock400-4 | 1,117 | 574 | 1,872 | 802 | 338 | 1,283 | 1,209 | 1,154 | 607 | 394 | 158 | 651 |
| brock800-1 | — | — | — | — | — | — | — | — | — | — | — | — |
| brock800-2 | — | — | — | — | — | — | — | — | — | — | — | — |
| brock800-3 | — | — | — | — | — | — | — | — | — | — | 9,479 | 12,815 |
| brock800-4 | — | — | — | 12,568 | 13,502 | — | 13,924 | — | — | 6,908 | 7,750 | 12,992 |
| hamming10-4 | — | — | — | — | — | — | — | — | — | — | — | — |
| johnson32-2-4 | — | — | — | — | — | — | — | — | — | — | — | — |
| keller5 | — | — | — | — | — | — | — | — | — | — | — | — |
| keller6 | — | — | — | — | — | — | — | — | — | — | — | — |
| MANN-a27 | 9 | 9 | 9 | 6 | 7 | 6 | 8 | 7 | 8 | 1 | 1 | 1 |
| MANN-a45 | 4,989 | 5,369 | 4,999 | 3,766 | 3,539 | 3,733 | 4,118 | 3,952 | 4,242 | 542 | 580 | 554 |
| MANN-a81 | — | — | — | — | — | — | — | — | — | — | — | — |
| p-hat1000-1 | 2 | 2 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 1 | 1 |
| p-hat1000-2 | — | — | — | 1,401 | 861 | 1,481 | 7,565 | 8,459 | 6,606 | 720 | 431 | 763 |
| p-hat1000-3 | — | — | — | — | — | — | — | — | — | — | — | — |
| p-hat1500-1 | 16 | 16 | 15 | 14 | 15 | 15 | 14 | 14 | 16 | 9 | 9 | 10 |
| p-hat1500-2 | — | — | — | — | — | — | — | — | — | — | — | — |
| p-hat300-3 | 74 | 127 | 69 | 13 | 10 | 12 | 21 | 24 | 18 | 5 | 4 | 5 |
| p-hat500-3 | — | — | — | 1,381 | 660 | 1,122 | 4,945 | 6,982 | 5,167 | 606 | 282 | 500 |
| p-hat700-2 | 508 | 551 | 353 | 27 | 25 | 24 | 74 | 93 | 108 | 12 | 11 | 11 |
| p-hat700-3 | — | — | — | — | 12,244 | — | — | — | — | 6,754 | 5,693 | 7,000 |
| san1000 | 20 | 19 | 18 | 10 | 10 | 10 | 3 | 3 | 3 | 5 | 5 | 5 |
| san200-0.9-2 | 20 | 73 | 35 | 5 | 1 | 5 | 1 | 1 | 1 | 2 | 0 | 2 |
| san200-0.9-3 | 154 | 4 | 59 | 111 | 0 | 65 | 32 | 3 | 8 | 50 | 0 | 27 |
| san400-0.7-1 | 1 | 5 | 2 | 2 | 17 | 4 | 3 | 0 | 1 | 1 | 8 | 1 |
| san400-0.7-2 | 14 | 47 | 16 | 19 | 26 | 23 | 16 | 9 | 4 | 9 | 11 | 10 |
| san400-0.7-3 | 11 | 38 | 41 | 10 | 22 | 39 | 5 | 13 | 19 | 5 | 9 | 18 |
| san400-0.9-1 | — | — | — | 422 | — | 8,854 | 54 | 0 | — | 125 | — | 3,799 |
| sanr200-0.7 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| sanr200-0.9 | 892 | 1,782 | 1,083 | 283 | 229 | 364 | 245 | 227 | 444 | 123 | 104 | 164 |
| sanr400-0.5 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 1 | 1 |
| sanr400-0.7 | 979 | 1,075 | 975 | 711 | 608 | 719 | 650 | 660 | 674 | 365 | 326 | 369 |
| MCQ | MCSa | MCSb | BBMC | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| instance | ||||||||||||
| brock200-1 | 0.86 | 0.59 | 0.51 | 50.52 | 0.30 | 0.32 | 0.24 | 0.26 | 0.27 | 0.52 | 0.30 | 0.32 |
| brock400-1 | 342.5 | 266.2 | 455.3 | 198.4 | 132.8 | 278.9 | 142.3 | 208.6 | 114.8 | 198.4 | 132.8 | 278.9 |
| brock400-2 | 224.8 | 381.9 | 125.2 | 145.6 | 178.5 | 76.4 | 61.3 | 151.8 | 154.3 | 145.6 | 178.5 | 76.4 |
| brock400-3 | 194.4 | 214.0 | 114.7 | 120.2 | 101.6 | 72.8 | 70.3 | 163.5 | 125.5 | 120.2 | 101.6 | 72.8 |
| brock400-4 | 82.1 | 36.5 | 148.3 | 54.4 | 19.3 | 90.9 | 68.3 | 62.7 | 31.9 | 54.4 | 19.3 | 90.9 |
| brock800-1 | — | — | — | — | — | — | — | — | — | — | — | — |
| brock800-2 | — | — | — | — | — | — | — | — | — | — | — | — |
| brock800-3 | — | — | — | — | — | — | — | — | — | — | 949.4 | 1,369.1 |
| brock800-4 | — | — | — | 640.4 | 773.3 | — | 659.1 | — | — | 640.4 | 773.3 | 1,440.8 |
| hamming10-4 | — | — | — | — | — | — | — | — | — | — | — | — |
| johnson32-2-4 | — | — | — | — | — | — | — | — | — | — | — | — |
| keller5 | — | — | — | — | — | — | — | — | — | — | — | — |
| keller6 | — | — | — | — | — | — | — | — | — | — | — | — |
| MANN-a27 | 0.038 | 0.038 | 0.038 | 0.038 | 0.038 | 0.038 | 0.038 | 0.034 | 0.038 | 0.038 | 0.038 | 0.038 |
| MANN-a45 | 2.9 | 2.9 | 2.9 | 2.9 | 2.9 | 2.8 | 2.5 | 2.4 | 2.5 | 2.9 | 2.9 | 2.8 |
| MANN-a81 | — | — | — | — | — | — | — | — | — | — | — | — |
| p-hat1000-1 | 2.4 | 2.5 | 2.4 | 1.8 | 1.7 | 1.8 | 1.5 | 1.48 | 1.48 | 1.8 | 1.7 | 1.8 |
| p-hat1000-2 | — | — | — | 34.5 | 19.2 | 36.9 | 166.7 | 177.9 | 142.0 | 34.5 | 19.2 | 36.9 |
| p-hat1000-3 | — | — | — | — | — | — | — | — | — | — | — | — |
| p-hat1500-1 | 1.6 | 1.8 | 1.9 | 1.2 | 1.2 | 1.4 | 1.0 | 0.9 | 1.2 | 1.2 | 1.2 | 1.4 |
| p-hat1500-2 | — | — | — | — | — | — | — | — | — | — | — | — |
| p-hat300-3 | 3.8 | 7.1 | 4.0 | 0.62 | 0.49 | 0.64 | 0.71 | 0.82 | 0.64 | 0.62 | 0.49 | 0.64 |
| p-hat500-3 | — | — | — | 39.3 | 16.9 | 30.9 | 104.7 | 152.8 | 111.6 | 39.3 | 16.9 | 30.9 |
| p-hat700-2 | 18.9 | 19.0 | 12.8 | 0.75 | 0.63 | 0.59 | 1.5 | 1.9 | 2.2 | 0.75 | 0.63 | 0.59 |
| p-hat700-3 | — | — | — | — | 216.5 | — | — | — | — | 282.4 | 216.5 | 297.1 |
| san1000 | 0.30 | 0.31 | 0.29 | 0.15 | 0.15 | 0.15 | 0.05 | 0.05 | 0.05 | 0.15 | 0.15 | 0.15 |
| san200-0.9-2 | 1.1 | 4.3 | 2.1 | 0.23 | 0.06 | 0.24 | 0.06 | 0.05 | 0.03 | 0.23 | 0.06 | 0.23 |
| san200-0.9-3 | 8.3 | 0.23 | 3.2 | 6.8 | 0.01 | 3.6 | 1.2 | 0.12 | 0.24 | 6.8 | 0.01 | 3.6 |
| san400-0.7-1 | 0.06 | 0.12 | 0.09 | 0.12 | 0.66 | 0.15 | 0.13 | 0.01 | 0.05 | 0.12 | 0.66 | 0.15 |
| san400-0.7-2 | 0.61 | 1.7 | 0.67 | 0.89 | 0.88 | 0.93 | 0.75 | 0.31 | 0.16 | 0.89 | 0.88 | 0.93 |
| san400-0.7-3 | 0.58 | 1.9 | 2.3 | 0.52 | 0.92 | 1.9 | 0.22 | 0.55 | 0.99 | 0.52 | 0.92 | 1.9 |
| san400-0.9-1 | — | — | — | 4.5 | — | 220.2 | 0.58 | 0.02 | — | 4.5 | — | 220.2 |
| sanr200-0.7 | 0.21 | 0.29 | 0.22 | 0.15 | 0.18 | 0.16 | 0.10 | 0,12 | 0.11 | 0.15 | 0.18 | 0.16 |
| sanr200-0.9 | 44.5 | 101.0 | 62.2 | 14.9 | 12.5 | 20.6 | 9.7 | 8.1 | 19.0 | 14.9 | 12.5 | 20.6 |
| sanr400-0.5 | 0.38 | 0.42 | 0.35 | 0.32 | 0.32 | 0.30 | 0.19 | 0.18 | 0.20 | 0.32 | 0.32 | 0.30 |
| sanr400-0.7 | 101.2 | 106.7 | 101.5 | 64.4 | 54.4 | 64.1 | 46.1 | 44.9 | 48.7 | 64.4 | 54.4 | 64.1 |
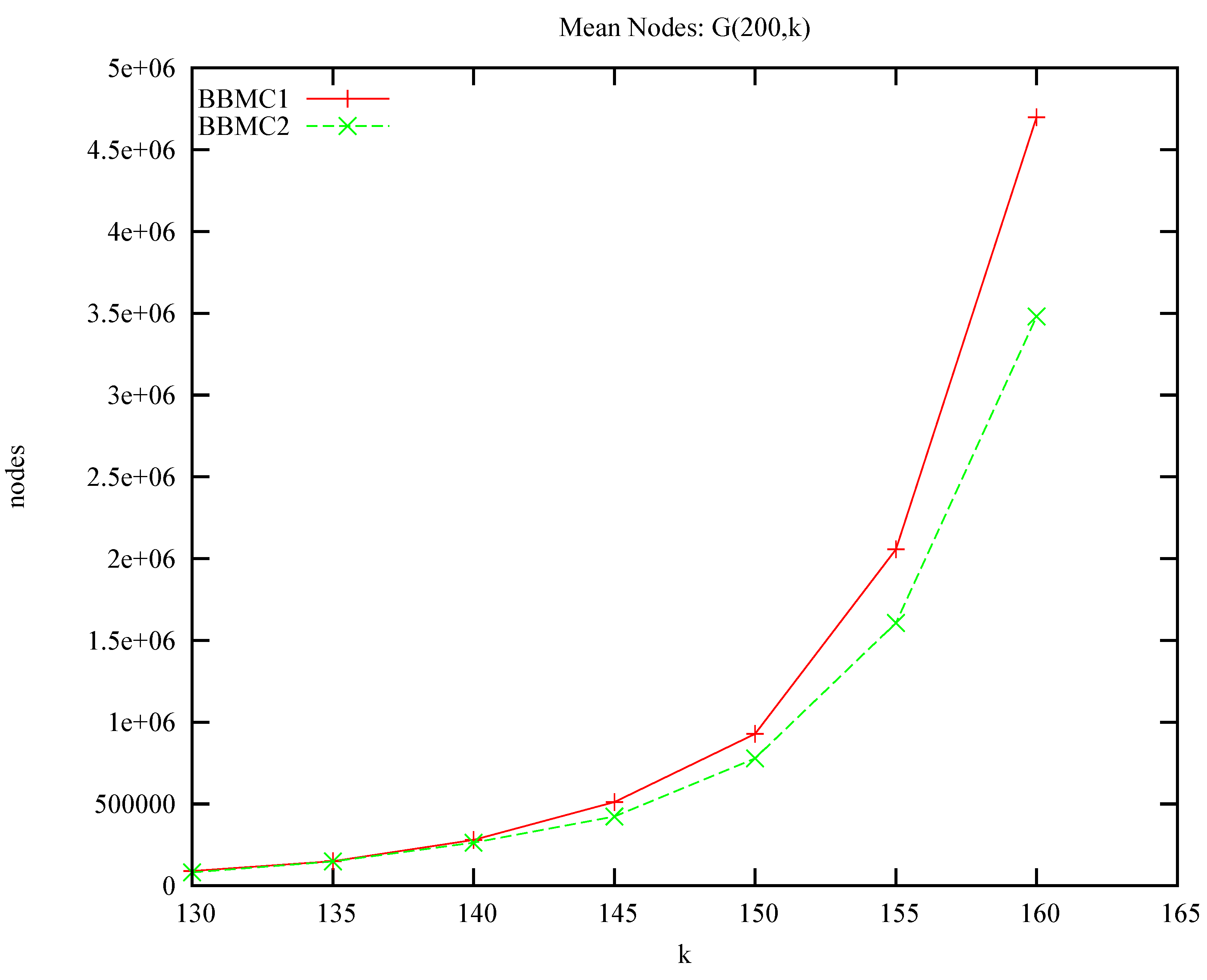
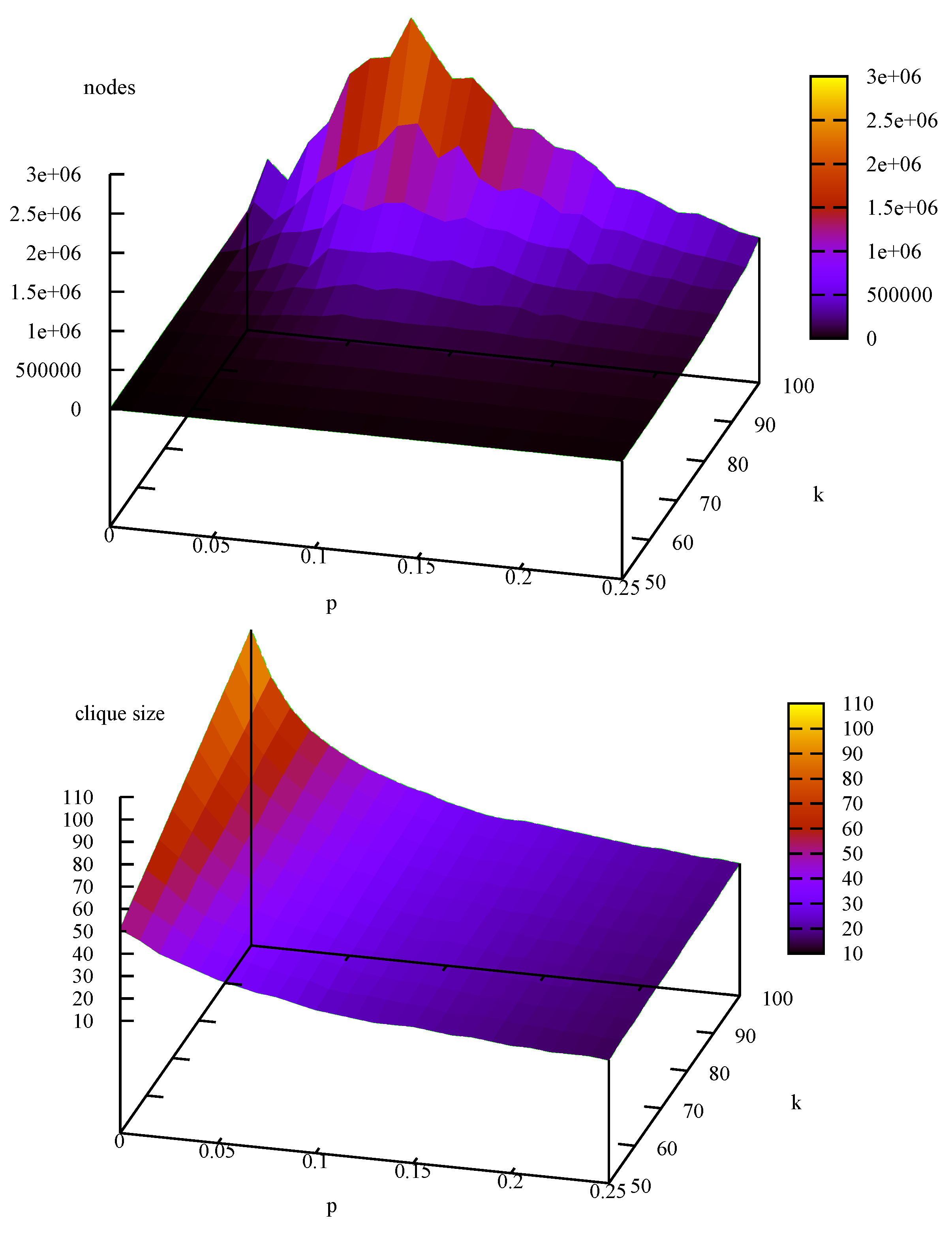
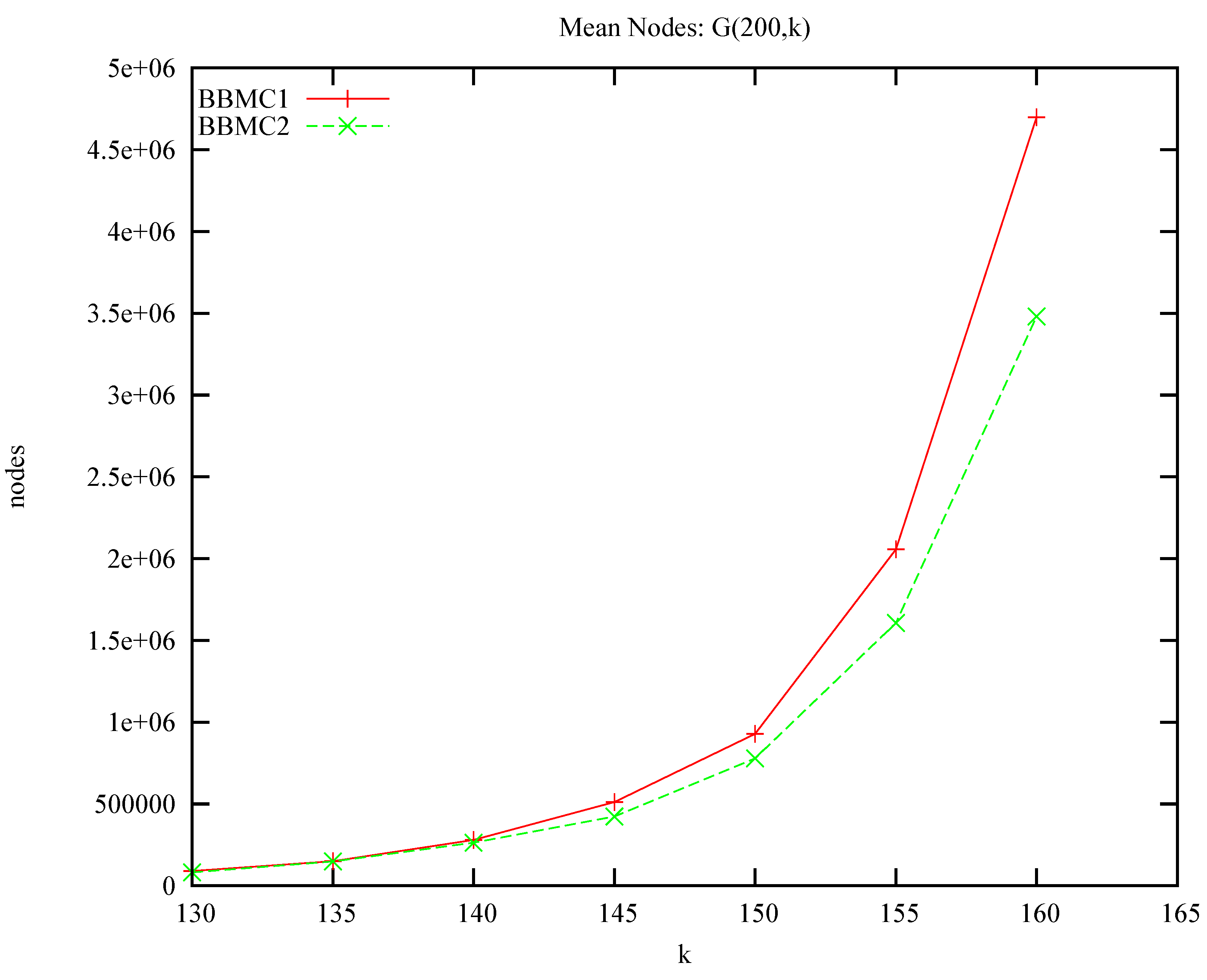
4.4. More Benchmarks (not DIMACS)
| instance | n | edges | BBMC1 | BBMC2 | BBMC3 | |||
|---|---|---|---|---|---|---|---|---|
| frb30-15-1 | 450 | 83,198 | 292,095 | 3,099 | 626,833 | 6,503 | 361,949 | 3,951 |
| frb30-15-2 | 450 | 83,151 | 557,252 | 5,404 | 599,543 | 6,136 | 436,110 | 4,490 |
| frb30-15-3 | 450 | 83,126 | 167,116 | 1,707 | 265,157 | 2,700 | 118,495 | 1,309 |
| frb30-15-4 | 450 | 83,194 | 991,460 | 9,663 | 861,391 | 8,513 | 1,028,129 | 9,781 |
| frb30-15-5 | 450 | 83,231 | 282,763 | 2,845 | 674,987 | 7,033 | 281,152 | 2,802 |
| instance | nodes | MCSa | BBMC | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| n | p | |||||||||
| 1,000 | 0.1 | 4,536 | 4,472 | 4,563 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.2 | 39,478 | 38,250 | 38,838 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0.3 | 400,018 | 371,360 | 404,948 | 4 | 4 | 4 | 2 | 2 | 2 | |
| 0.4 | 3,936,761 | 3,780,737 | 4,052,677 | 40 | 39 | 38 | 26 | 25 | 26 | |
| 0.5 | 79,603,712 | 75,555,478 | 80,018,645 | 860 | 910 | 859 | 570 | 574 | 604 | |
| 3,000 | 0.1 | 144,375 | 142,719 | 145,487 | 3 | 3 | 3 | 2 | 2 | 2 |
| 0.2 | 2,802,011 | 2,723,443 | 2,804,830 | 38 | 38 | 38 | 32 | 32 | 32 | |
| 0.3 | 73,086,978 | 71,653,889 | 73,354,584 | 964 | 960 | 978 | 926 | 930 | 931 | |
| 10,000 | 0.1 | 5,351,591 | 5,303,615 | 5,432,812 | 236 | 252 | 245 | 212 | 216 | 214 |
| 15,000 | 0.1 | 22,077,212 | 21,751,100 | 21,694,036 | 1,179 | 1,117 | 1,081 | 1,249 | 1,235 | 1,208 |
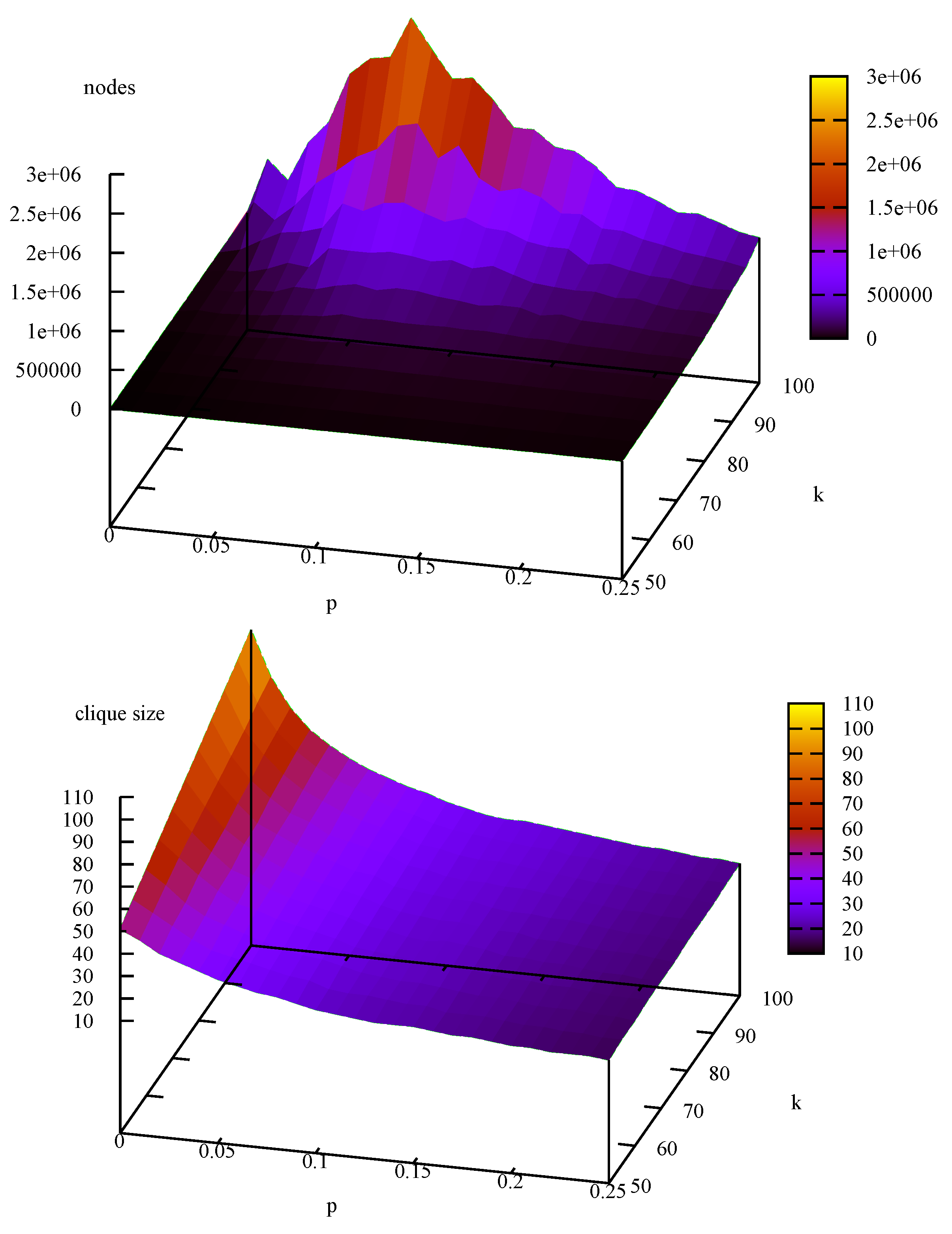
4.5. Calibration of Results
| machine | r100.5 | r200.5 | r300.5 | r400.5 | r500.5 | Intel(R) | GHz | cache | Java | scaling factor |
|---|---|---|---|---|---|---|---|---|---|---|
| Cyprus | 0.0 | 0.02 | 0.24 | 1.49 | 5.58 | Xeon(R) E5620 | 2.40 | 12,288KB | 1.6.0_07 | 1 |
| Fais | 0.0 | 0.08 | 0.58 | 3.56 | 13.56 | XEON(TM) CPU | 2.40 | 512KB | 1.5.0_06 | 0.41 |
| Daleview | 0.0 | 0.09 | 0.53 | 3.00 | 10.95 | Atom(TM) N280 | 1.66 | 512KB | 1.6.0_18 | 0.50 |
| MCSa1 | BBMC1 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| instance | Fais | Daleview | Cyprus | Fais | Daleview | Cyprus | ||||||
| brock200-1 | 0.25 | (19,343) | 0.27 | (17,486) | 1.00 | (4,777) | 0.15 | (15,365) | 0.09 | (25,048) | 1.00 | (2,358) |
| brock200-4 | 0.40 | (1,870) | 0.43 | (1,765) | 1.00 | (755) | 0.20 | (1,592) | 0.13 | (2,464) | 1.00 | (321) |
| hamming10-2 | 0.18 | (1,885) | 0.14 | (2,299) | 1.00 | (333) | 0.25 | (608) | 0.21 | (710) | 1.00 | (151) |
| hamming8-4 | 0.24 | (1,885) | 0.28 | (1,647) | 1.00 | (455) | 0.23 | (1,625) | 0.19 | (1,925) | 1.00 | (367) |
| johnson16-2-4 | 0.35 | (2,327) | 0.38 | (2,173) | 1.00 | (823) | 0.26 | (1,896) | 0.14 | (3,560) | 1.00 | (495) |
| MANN-a27 | 0.21 | (32,281) | 0.22 | (31,874) | 1.00 | (6,912) | 0.14 | (12,335) | 0.10 | (16,491) | 1.00 | (1,676) |
| p-hat1000-1 | 0.25 | (8,431) | 0.28 | (7,413) | 1.00 | (2,108) | 0.14 | (8,359) | 0.12 | (9,389) | 1.00 | (1,169) |
| p-hat1500-1 | 0.19 | (77,759) | 0.22 | (66,113) | 1.00 | (14,421) | 0.11 | (90,417) | 0.10 | (92,210) | 1.00 | (9,516) |
| p-hat300-3 | 0.25 | (53,408) | 0.26 | (51,019) | 1.00 | (13,486) | 0.14 | (41,669) | 0.09 | (60,118) | 1.00 | (5,711) |
| p-hat500-2 | 0.27 | (13,400) | 0.30 | (12,091) | 1.00 | (3,659) | 0.14 | (10,177) | 0.11 | (13,410) | 1.00 | (1,428) |
| p-hat700-1 | 0.40 | (1,615) | 0.51 | (1,251) | 1.00 | (641) | 0.29 | (1,169) | 0.24 | (1,422) | 1.00 | (344) |
| san1000 | 0.11 | (94,107) | 0.12 | (89,330) | 1.00 | (10,460) | 0.10 | (57,868) | 0.11 | (54,816) | 1.00 | (5,927) |
| san200-0.9-1 | 0.29 | (4,918) | 0.31 | (4,705) | 1.00 | (1,444) | 0.18 | (4,201) | 0.11 | (6,588) | 1.00 | (748) |
| san200-0.9-2 | 0.22 | (23,510) | 0.25 | (20,867) | 1.00 | (5,240) | 0.15 | (14,572) | 0.09 | (23,592) | 1.00 | (2,218) |
| san400-0.7-1 | 0.25 | (10,230) | 0.27 | (9,607) | 1.00 | (2,573) | 0.15 | (8,314) | 0.12 | (10,206) | 1.00 | (1,260) |
| san400-0.7-2 | 0.23 | (84,247) | 0.27 | (72,926) | 1.00 | (19,565) | 0.13 | (71,360) | 0.11 | (87,325) | 1.00 | (9,219) |
| san400-0.7-3 | 0.24 | (45,552) | 0.27 | (40,792) | 1.00 | (10,839) | 0.13 | (39,840) | 0.11 | (46,818) | 1.00 | (5,162) |
| sanr200-0.7 | 0.31 | (5,043) | 0.33 | (4,676) | 1.00 | (1,548) | 0.19 | (4,079) | 0.12 | (6,652) | 1.00 | (795) |
| sanr200-0.9 | 0.23 | (1,249,144) | 0.23 | (1,211,762) | 1.00 | (283,681) | 0.15 | (844,487) | 0.09 | (1,409,428) | 1.00 | (123,461) |
| sanr400-0.5 | 0.28 | (9,898) | 0.31 | (8,754) | 1.00 | (2,745) | 0.16 | (9,177) | 0.12 | (12,658) | 1.00 | (1,484) |
| sanr400-0.7 | 0.10 | (7,292,771) | 0.28 | (2,544,196) | 1.00 | (711,861) | 0.14 | (2,698,444) | 0.10 | (3,737,833) | 1.00 | (365,629) |
| ratio (total) | 0.12 | (9,033,624) | 0.26 | (4,202,746) | 1.00 | (1,098,326) | 0.14 | (3,937,554) | 0.10 | (5,622,663) | 1.00 | (539,439) |
4.6. Relative Algorithmic Performance on Different Machines
| Cliquer | dfmax | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| instance | Fais | Daleview | Cyprus | Fais | Daleview | Cyprus | ||||||
| brock200-1 | 0.66 | (9,760) | 0.43 | (18,710) | 1.00 | (6,490) | 0.39 | (25,150) | 0.42 | (23,020) | 1.00 | (9,730) |
| brock200-4 | 0.64 | (690) | 0.47 | (1,190) | 1.00 | (440) | 0.41 | (1,510) | 0.46 | (1,360) | 1.00 | (620) |
| p-hat1000-1 | 0.62 | (1,750) | 0.36 | (3,020) | 1.00 | (1,090) | 0.41 | (1,680) | 0.45 | (1,540) | 1.00 | (690) |
| p-hat700-1 | 0.67 | (150) | 0.37 | (270) | 1.00 | (100) | — | — | — | — | — | — |
| san1000 | 0.75 | (120) | 0.30 | (300) | 1.00 | (90) | — | — | — | — | — | — |
| san200-0.7-1 | 0.48 | (1,750) | 0.20 | (4,220) | 1.00 | (840) | — | — | — | — | — | — |
| san200-0.9-2 | 0.61 | (18,850) | 0.21 | (53,970) | 1.00 | (11,530) | — | — | — | — | — | — |
| san400-0.7-3 | 0.62 | (6,800) | 0.26 | (16,100) | 1.00 | (4,230) | — | — | — | — | — | — |
| sanr200-0.7 | 0.65 | (2,940) | 0.36 | (5,270) | 1.00 | (1,900) | 0.40 | (5,240) | 0.44 | (4,770) | 1.00 | (2,080) |
| sanr400-0.5 | 0.62 | (1,490) | 0.38 | (2,420) | 1.00 | (930) | 0.41 | (3,550) | 0.47 | (3,080) | 1.00 | (1,460) |
| ratio (total) | 0.62 | (44,300) | 0.26 | (105,470) | 1.00 | (27,640) | 0.39 | (37,130) | 0.43 | (33,770) | 1.00 | (14,580) |
5. Conclusions
| instance | Fais | Daleview | Cyprus |
|---|---|---|---|
| brock200-1 | 1.26 | 0.70 | 2.03 |
| brock200-4 | 1.17 | 0.72 | 2.35 |
| hamming10-2 | 3.10 | 3.24 | 2.21 |
| hamming8-4 | 1.16 | 0.86 | 1.24 |
| johnson16-2-4 | 1.23 | 0.61 | 1.66 |
| MANN-a27 | 2.62 | 1.93 | 4.12 |
| p-hat1000-1 | 1.01 | 0.79 | 1.80 |
| p-hat1500-1 | 0.86 | 0.72 | 1.52 |
| p-hat300-3 | 1.28 | 0.85 | 2.36 |
| p-hat500-2 | 1.32 | 0.90 | 2.56 |
| p-hat700-1 | 1.38 | 0.88 | 1.86 |
| san1000 | 1.63 | 1.63 | 1.76 |
| san200-0.9-1 | 1.17 | 0.71 | 1.93 |
| san200-0.9-2 | 1.61 | 0.88 | 2.36 |
| san400-0.7-1 | 1.23 | 0.94 | 2.04 |
| san400-0.7-2 | 1.18 | 0.84 | 2.12 |
| san400-0.7-3 | 1.14 | 0.87 | 2.10 |
| sanr200-0.7 | 1.24 | 0.70 | 1.95 |
| sanr200-0.9 | 1.48 | 0.86 | 2.30 |
| sanr400-0.5 | 1.08 | 0.69 | 1.85 |
| sanr400-0.7 | 2.70 | 0.68 | 1.95 |
Appendix
Acknowledgements
References
- Garey, M.R.; Johnson, D.S. Computers and Intractability; W.H. Freeman and Co.: New York, NY, USA, 1979. [Google Scholar]
- Renato, C.; Alexandre, P. Z. Branch and bound algorithms for the maximum clique problem under a unified framework. J. Braz. Comp. Soc. 2012, 18, 137–151. [Google Scholar]
- Randy, C.; Panos, M.P. An exact algorithm for the maximum clique problem. Oper. Res. Lett. 1990, 9, 375–382. [Google Scholar]
- Torsten, F. Simple and Fast: Improving a Branch-and-Bound Algorithm for Maximum Clique. In Proceedings of the ESA 2002, LNCS 2461, Rome, Italy, 17–21 September 2002; pp. 485–498.
- Janez, K.; Dušanka, J. An improved branch and bound algorithm for the maximum clique problem. MATCH Commun. Math. Comput. Chem. 2007, 58, 569–590. Available online: http://www.sicmm.org/ konc/ (accessed on 12 November 2012). [Google Scholar]
- Chu, M.; Li, Z.Q. An Efficient Branch-and-Bound Algorithm Based on Maxsat for the Maximum Clique Problem. In Proceedings of the AAAI’10, Atlanta, GA, USA, 11–15 July 2010; pp. 128–133.
- Östergård, P.R.J. A fast algorithm for the maximum clique problem. Discret. Appl. Math. 2002, 120, 197–207. Available online: http://users.tkk.fi/pat/cliquer.html/ (accessed on 12 November 2012). [Google Scholar] [CrossRef]
- Pardalos, P.M.; Rodgers, G.P. A branch and bound algorithm for the maximum clique problem. Comput. Oper. Res. 1992, 19, 363–375. [Google Scholar] [CrossRef]
- Régin, J.-C. Using Constraint Programming to Solve the Maximum Clique Problem. In Proceedings CP 2003, LNCS 2833, Kinsale, Ireland, 29 September–3 October 2003; pp. 634–648.
- Segundo, P.S.; Matia, F.; Diego, R.-L.; Miguel, H. An improved bit parallel exact maximum clique algorithm. Optim. Lett. 2011. [Google Scholar] [CrossRef]
- Segundo, P.S.; Diego, R.-L.; Augustín, J. An exact bit-parallel algorithm for the maximum clique problem. Comput. Oper. Res 2011, 38, 571–581. [Google Scholar] [CrossRef]
- Tomita, E.; Sutani, Y.; Higashi, T.; Takahashi, S.; Wakatsuki, M. An Efficient Branch-and-Bound Algorithm for Finding a Maximum Clique. In Proceedings of the DMTCS 2003, LNCS 2731, Dijon, France, 7–12 July 2003; pp. 278–289.
- Tomita, E.; Sutani, Y.; Higashi, T.; Takahashi, S.; Wakatsuki, M. A Simple and Faster Branch-and-Bound Algorithm for Finding Maximum Clique. In Proceedings of the WALCOM 2010, LNCS 5942, Dhaka, Bangladesh, 10–12 February 2010; pp. 191–203.
- Wood, D.R. An algorithm for finding a maximum clique in a graph. Oper. Res. Lett. 1997, 21, 211–217. [Google Scholar] [CrossRef]
- Tomita, E.; Toshikatsu, K. An efficient branch-and-bound algorithm for finding a maximum clique and computational experiments. J. Glob. Optim. 2007, 37, 95–111. [Google Scholar] [CrossRef]
- David, E.; Darren, S. Listing all maximal cliques in large sparse real-world graphs. Experimental Algorithms, LNCS 6630. Comput. Sci. 2011, 6630, 364–375. [Google Scholar]
- Knuth, D.E. Generating all Combinations and Permutations. In The Art of Computer Programming; Pearson Education Inc.: Stoughton, MA, USA, January 2006; Volume 4, pp. 1–3. [Google Scholar]
- Li, C.M.; Quan, Z. Combining Graph Structure Exploitation and Propositional Reasoning for the Maximum Clique Problem. In Proceedings of the ICTAI’10, Arras, France, 27–29 October 2010; Volume 1, pp. 344–351.
- Bentley, J.L.; McIlroy, M.D. Engineering a sort function. Softw.-Pract. Exp. 1993, 23, 1249–1265. [Google Scholar] [CrossRef]
- Eugene, C.F. A sufficient condition for backtrack-free search. J. Assoc. Comput. Mach. 1982, 29, 24–32. [Google Scholar]
- David, W.M.; Beck, L.L. Smallest-Last ordering and clustering and graph coloring algorithms. J. Assoc. Comput. Mach. 1983, 30, 417–427. [Google Scholar]
- Pardalos, P.M.; Xue, J. The maximum clique problem. J. Glob. Optim. 1994, 4, 301–324. [Google Scholar] [CrossRef]
- Bron, C.; Kerbosch, J. Algorithm 457: Finding all cliques of an undirected graph [h]. Commun. ACM 1973, 16, 575–579. [Google Scholar] [CrossRef]
- Akkoyunlu, E.A. The enumeration of maximal cliques of large graphs. SIAM J. Comput. 1973, 2, 1–6. [Google Scholar] [CrossRef]
- Tomita, E.; Tanaka, A.; Takahashi, H. The worst-case time complexity for generating all maximal cliques and computational experiments. Theor. Comput. Sci. 2006, 363, 28–42. [Google Scholar] [CrossRef]
- Abu-Khzam, F.N.; Collins, R.L.; Fellows, M.R.; Langston, M.A.; Suters, W.H.; Symons, C.T. Kernelization algorithms for the vertex cover problem: Theory and experiments. In ALENEX/ANALC, New Orleans, LA, USA, 10–13 January 2004; pp. 62–69.
- Segundo, P.S.; Tapia, C. A New Implicit Branching Strategy for Exact Maximum Clique. In Proceedings of ICTAI’10, Arras, France, 27–29 October 2010; Volume 1, pp. 352–357.
- Cheeseman, P.; Kanefsky, B.; Taylor, W.M. Where the Really Hard Problems are. In Proceedings of the IJCAI’91, Sidney, Australia, 24–30 August 1991; pp. 331–337.
- Gent, I.P.; MacIntyre, E.; Prosser, P.; Walsh, T. The Constrainednss of Search. In Proceedings of the AAAI’96, Portland, OR, USA, 4–8 August 1996; pp. 246–252.
- Zweig, K.A.; Palla, G.; Vicsek, T. What makes a phase transition? Analysis of the random satisfiability problem. Physica A 2010, 389, 1501–1511. [Google Scholar]
- DIMACS instances. Available online: ftp://dimacs.rutgers.edu/pub/challenge/graph/benchmarks/clique (accessed on 12 November 2012).
- Watts, D.J.; Strogatz, S.H. Collective dynamics of small world networks. Nature 1998, 394, 440–442. [Google Scholar] [CrossRef] [PubMed]
- Sewell, E.C. A branch and bound algorithm for the stability number of a sparse graph. INFORMS J. Comput. 1998, 10, 438–447. [Google Scholar] [CrossRef]
- Prosser, P. Maximum Clique Algorithms in Java. Available online: http://www.dcs.gla.ac.uk/ pat/maxClique (accessed on 12 November 2012).
- Stanford Large Network Dataset Collection. Available online: http://snap.stanford.edu/data/index.html (accessed on 12 November 2012).
- Benchmarks with Hidden Optimum Solutions. Available online: http://www.nlsde.buaa.edu.cn/kexu/benchmarks/graph-benchmarks.htm (accessed on 12 November 2012).
- Dfmax. Available online: ftp://dimacs.rutgers.edu/pub/dsj/clique (accessed on 12 November 2012).
© 2012 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Prosser, P. Exact Algorithms for Maximum Clique: A Computational Study . Algorithms 2012, 5, 545-587. https://doi.org/10.3390/a5040545
Prosser P. Exact Algorithms for Maximum Clique: A Computational Study . Algorithms. 2012; 5(4):545-587. https://doi.org/10.3390/a5040545
Chicago/Turabian StyleProsser, Patrick. 2012. "Exact Algorithms for Maximum Clique: A Computational Study " Algorithms 5, no. 4: 545-587. https://doi.org/10.3390/a5040545
APA StyleProsser, P. (2012). Exact Algorithms for Maximum Clique: A Computational Study . Algorithms, 5(4), 545-587. https://doi.org/10.3390/a5040545