If we assume some degree of interaction between the compressor and the decompressor then we can exploit the previous knowledge they both have of the source when data compression is used for data transmission. The price we accept to pay, in some cases, is a low probability of communication errors.
The solution of the communication problem, in this case, is an interactive protocol that allows Sender and Receiver to take advantage of the knowledge they have of the source and that exploits the interaction to minimize the communication cost. In real life this could be used in situations in which finite size files are transmitted over a bidirectional communication line, like a telephone line, internet, a satellite link or any other line between two systems that have already available a large number of files of the same type.
As an example consider an internet user that has to frequently download the same kind of file (a newsletter, an image, a report, etc.) from the same source, or a system manager that has to download repetitively an update file for a program or for an antivirus, or an ftp mirroring site that has to be periodically brought up to date, etc. The compression algorithms involved in the communication might be static or dynamic dictionary methods or, in the case of images, Vector Quantization.
4.2. An interactive communication protocol
An efficient communication protocol that allows a Sender and a Receiver to communicate via dictionaries that are built independently from previous (and may be discordant) examples of communication messages that each of the two sides has available is presented by Carpentieri in [
8]. This communication protocol results in an improvement in compression paid with a negligible or almost null possibility of communication errors.
Consider an information source U that emits words over a certain alphabet and for which it is possible to partition the words emitted by the source into two sets: one D of cardinality m that has probability P(D) = 1 − α and another Dcomp with probability P(Dcomp) = α, where α << 1/2, and the words w ∊ D have probability pw such that |(1 − α)/m − pw| < ε for an appropriately chosen ε. The set D might be viewed as the ideal “Dictionary” for the source.
It is possible to recognize this property in many real life situations. As an example consider a source that outputs programs. For this source an ideal set D might include all the keywords and reserved words of the programming language and the set of the most common identifiers.
Consider now a situation in which Sender and Receiver have access to different corpora of the same language: for example different sets of books and/or web pages and/or newspapers, etc. They can use these different corpora to independently construct their own dictionaries.
If the Sender and the Receiver have both knowledge of the source in the form of a large number of messages that are recorded in two files of length approximately n, if n is big enough and nw is the number of occurrences of w in the file and δ is an opportunely chosen number in [0, 1/2], then we have that for each word w, (P|nw/n− pw| < ε) > (1− δ).
The Sender and the Receiver build up, respectively, dictionaries DS and DR of size m. They can estimate the probability of each word w by counting the number of its appearances in the file of length n. Now consider the possibility that a word is in DS but not in DR. This could happen if the frequency count of w done by the Sender does not reflect the probability pw, and therefore w belongs to DS incorrectly and w does not belong to DR correctly, or if the Receiver has a wrong estimate of pw and therefore w belongs to DS correctly but incorrectly does not belong to DR or, finally, if both Sender and Receiver have a wrong estimate of pw. Therefore, if n is big enough the probability of a word w in DS but not in DR is: P(w belongs to DS but does not belong to DR) < 2δ − δ2.
In a practical situation the Sender has to transmit to the Receiver a message that comes from a source whose behavior is well known by both Sender and Receiver: they have available a large number of messages from the source, but not necessarily the same messages. Based on the messages each of them knows, Sender and Receiver independently construct dictionaries DS and DR by including in the dictionaries what they assume are the m most common words of the source.
The Sender transmits the compressed message to the Receiver by using dictionary DS and the Receiver decodes the message by using dictionary DR. The communication line between Sender and Receiver is a bidirectional line: the Receiver has the possibility of sending acknowledgment messages to the Sender, participating actively to the compression/ transmission process.
The Sender will send dictionary words by using Karp and Rabin’s fingerprints (see [
9]) to improve the compression by allowing a small possibility of communication errors. If the current input word is in the Sender’s dictionary than the Sender either sends a previously assigned codeword (if Sender and Receiver have already agreed on that word) or it sends a fingerprint of the current word.
In this second case the Receiver either acknowledges its understanding of the dictionary word (if the Receiver has a single word that matches that fingerprint in its dictionary), or it tells the Sender that there is more than one word in its dictionary for that fingerprint and then invites the Sender to send another, different, fingerprint for the same word, or finally it communicates to the Sender that it does not recognize the word and that the word has to be sent explicitly through a standard compression method. The Sender shall act accordingly.
The Sender will not send more than two fingerprints to identify a word: after two unsuccessful fingerprint trials it sends the word by entropy coding. Every time a new word is acknowledged by the Receiver then a new codeword is independently, but consistently, assigned to that word by both Sender and the Receiver. If the current input word is not in the Sender’s dictionary than the Sender switches to a standard lossless compressor and entropy codes the input word.
This approach exploits compression by taking into account shared data and interaction. It is possible to analyze, as in [
8], the possibility of a communication error,
i.e., the possibility that the Receiver decodes a word incorrectly, and to prove that this probability is very low.
As an example, if we assume that the length in bits of the dictionary words is n = 250, and that t = |D| = 4,000, M = nt2 = 4 × 109, δ = 0.01 then by using this protocol the probability of a false match for the fingerprinting algorithm is less than 2 × 10−8, and the overall communication error probability is less than 4 × 10−10.
The Sender with probability higher than 0.98 will send a word w to the Receiver by using only fingerprints (and it will spend less than 70 bits for word), or otherwise it will send the word by entropy coding (by spending more than 70 + 125 bits per word) with probability less than 0.0199.
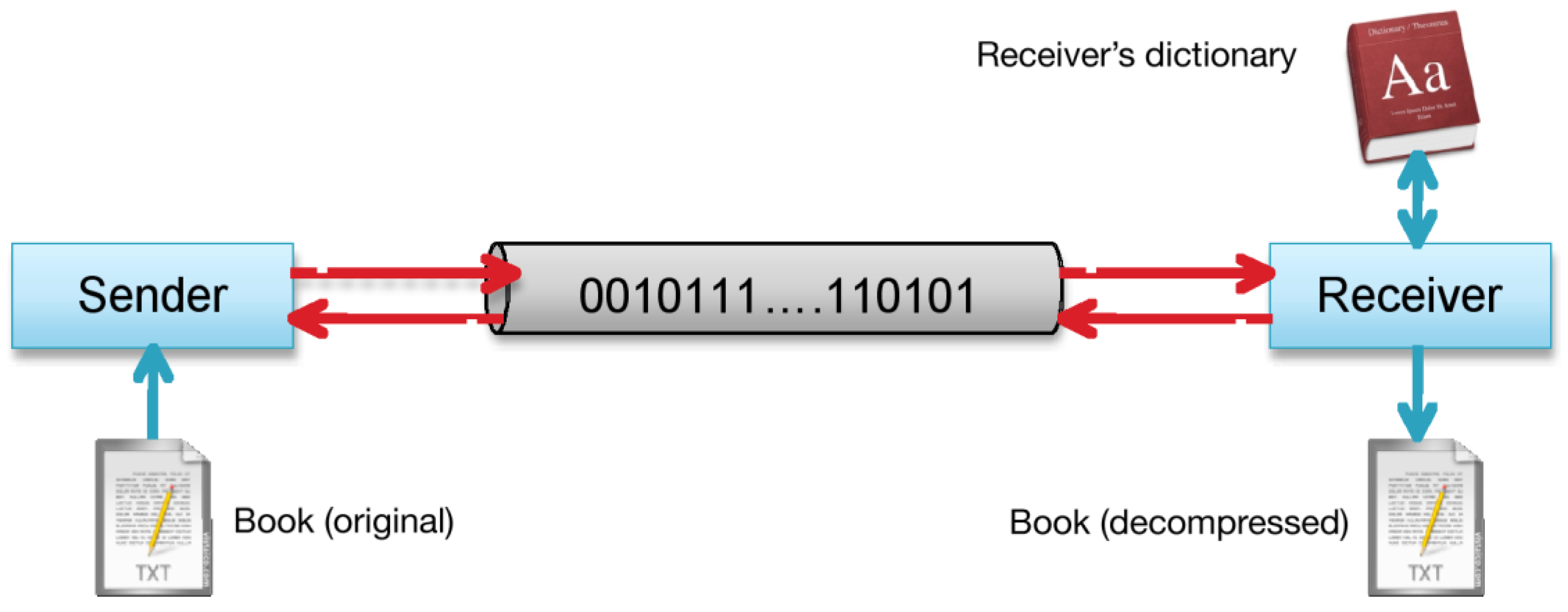
Figure 2.
Sender and Receiver communicate a book.
Figure 2.
Sender and Receiver communicate a book.
In [
8] the protocol is experimentally tested for the compression of source programs in the C programming language. These experimental results show an average improvement of 5–6% with respect to the standard, dictionary based, lossless compressors.
4.3. Interactive compression of books.
A possible application of interactive data compression is in the transmission of natural language textual data, for example electronic newspapers or books, which can be sent from a remote source to a client destination. In this case we can improve the transmission/compression process by taking into account the common rules of the specific natural language (i.e., the set of common words of the natural language, the syntax, etc.). All these rules might be considered as shared knowledge between the Sender (that sends the book) and the Receiver (that receives the data).
For example, when the Receiver receives the book it can use a standard on line dictionary of the language in which the book is written to decode the Sender’s messages. The Sender does not know which static dictionary the Receiver is using. It might try to send the words as pointers that the Receiver could decode by using its dictionary. We have experimented with this dictionary based approach by digitizing ten books: five of them are in the Italian language and the other five are in English.
The Sender sends a book to the Receiver a word at a time. If the word is long enough, instead of the raw word, the Sender sends a token including the initial character of that word, the length of the word and a hash value (for example a Karp and Rabin hash) for that word. The Receiver will receive the token and will try to decode the word by using its local dictionary.
If the token sent by the Sender cannot be decoded because for the hash value that the Sender has sent there is a collision in the Receiver’s dictionary, then the Receiver asks the Sender to send a new token for the same word but with a different letter (may be the middle letter of the word) and a different hash.
Table 1.
Compression results.
Table 1.
Compression results.
| Book Title | Original Dimensions | Interactive Protocol
(12 bits hash) | Zip | Gzip |
|---|
| Compresed size | Compression ratio | Compresed size | Compression ratio | Compresed size | Compression ratio |
|---|
| Angeli e demoni | 948.3 KB | 334.7 KB | 2.83 | 353.3 KB | 2.68 | 339.1 KB | 2.78 |
| Decamerone | 1,638.2 KB | 544.6 KB | 3.00 | 577.2 KB | 2.83 | 551.7 KB | 2.96 |
| Gomorra | 663.0 KB | 240.2 KB | 2.76 | 251.4 KB | 2.63 | 241.3 KB | 2.74 |
| Promessi Sposi | 1,394.9 KB | 490.1 KB | 2.84 | 520.2 KB | 2.68 | 498.5 KB | 2.79 |
| Uomini che odiano le donne | 1,093.5 KB | 373.9 KB | 2.92 | 405.6 KB | 2.69 | 388.1 KB | 2.81 |
| 20,000 Leagues Under The Sea | 875,5 KB | 306.2 KB | 2.85 | 336.1 KB | 2.60 | 323.4 KB | 2.70 |
| The Wealth Of Nations | 2,273.1 KB | 602.9 KB | 3.77 | 688.1 KB | 3.30 | 652.8 KB | 3.48 |
| Catcher in the Rye | 384.3 KB | 122.4 KB | 3.13 | 131.5 KB | 2.92 | 125.6 KB | 3.05 |
| For Whom The Bell Tolls | 937.4 KB | 288.2 KB | 3.25 | 326.3 KB | 2.87 | 310.1 KB | 3.02 |
| The Grapes Of Wrath | 935.3 KB | 310.8 KB | 3.00 | 342.3 KB | 2.73 | 324.8 KB | 2.87 |
If the Receiver finds a unique word that matches the token in the dictionary then it decodes the word and eventually acknowledges the Sender. If the Receiver does not find any word that matches the token in the dictionary, then it sends a request to have the word (entropy coded and) sent directly as raw data to the Sender.
Figure 2 shows the communication line between Sender and Receiver. This communication protocol could introduce errors,
i.e., situations in which the Receiver believes it can decode correctly the word but the word that it finds in its dictionary is not the correct one.
If the probability of an error is very low, as shown in subsection 4.2, then the Receiver might accept to have a few words incorrectly decoded: it will be still possible to read and understand the book. If we assume that the dictionary used by the Receiver is the correct dictionary for that specific book language, then the probability of an error depends on the choice and length of the hash value.
In
Table 1 we show the results obtained by compressing ten books by using, Karp and Rabin, hashes of length 12 bits. The results obtained are compared with the “off of the shelves” standard dictionary based compressors Zip and Gzip.
Table 2.
Compression errors.
Table 2.
Compression errors.
| Angeli e demoni | Deca-merone | Gomorra | Promessi Sposi | Uomini che odiano le donne | 20000 Legues Under The Sea | The Wealth Of Nations | Catcher in the Rye | For Whom The Bell Tolls | The Grapes Of Wrath |
|---|
| 0.031% | 0.047% | 0.096% | 0.087% | 0.083% | 0.036% | 0.004% | 0.012% | 0.032% | 0.025% |
In our experiments the running time of the program that simulates the interaction (if we do not visualize on the computer monitor the messages describing the interaction) is fast enough to be of the same order of the gzip running time on the same input.
These results are very encouraging: with this approach we have implicitly set a strong limit on the length of any matched string that is copied into the output stream (the maximum length of a match will be the length of the longest word in the static Receiver’s dictionary) but nevertheless the results are competitive with respect to the standard zip and gzip compressors. Possible improvements are therefore foreseen if we allow the matches to have longer lengths. The price we pay is the possibility of communication errors.
With the above settings we have a very limited communication error:
i.e., only a very few words (often less than ten) are mismatched in a whole book which therefore maintains its readability.
Table 2 shows the communication error percentage for each book in the previous experiment when the hash value is Karp and Rabin’s hash of length 12 bits. There is a strong relationship between the length of the hash value, the compression results, and the compression errors. With a longer hash we have less compression errors but a worst compression, with a shorter hash we improve compression but we pay the price of more compression errors.
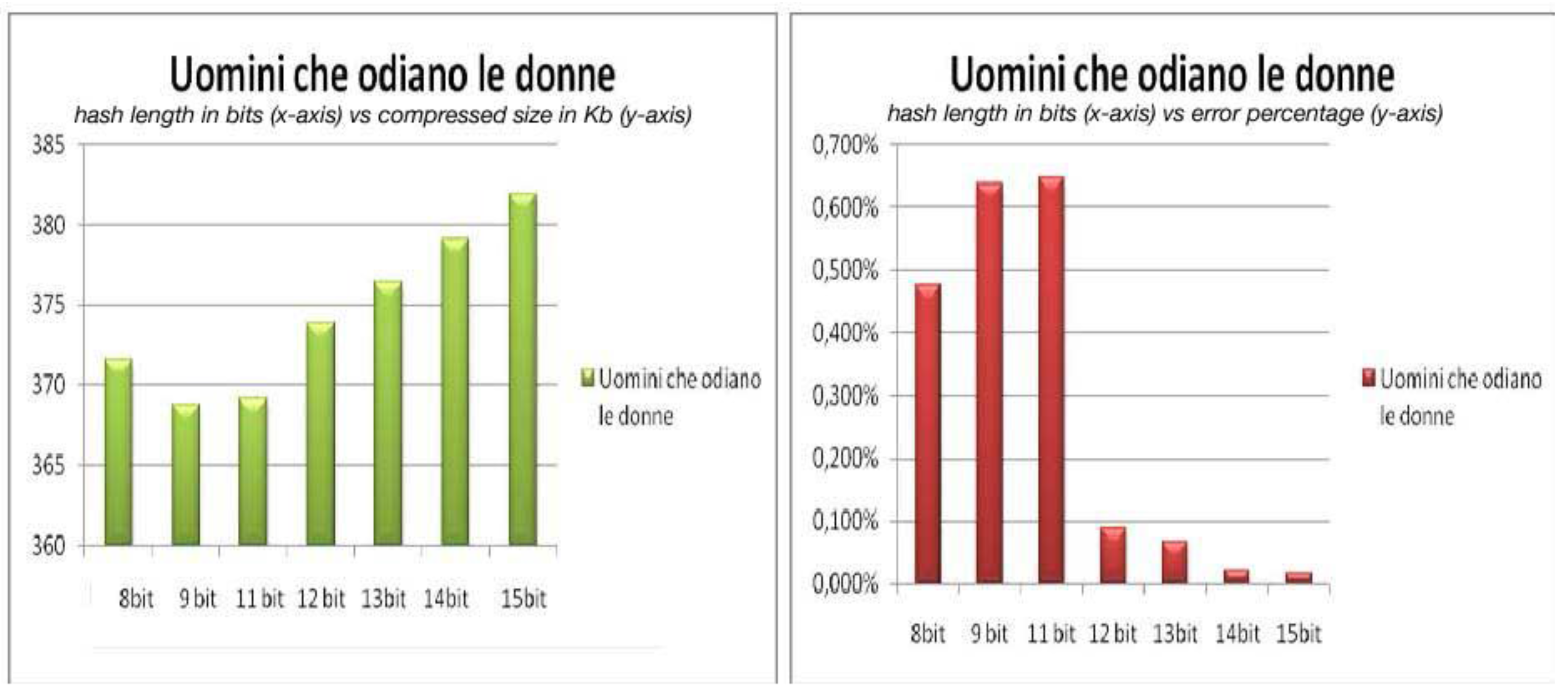
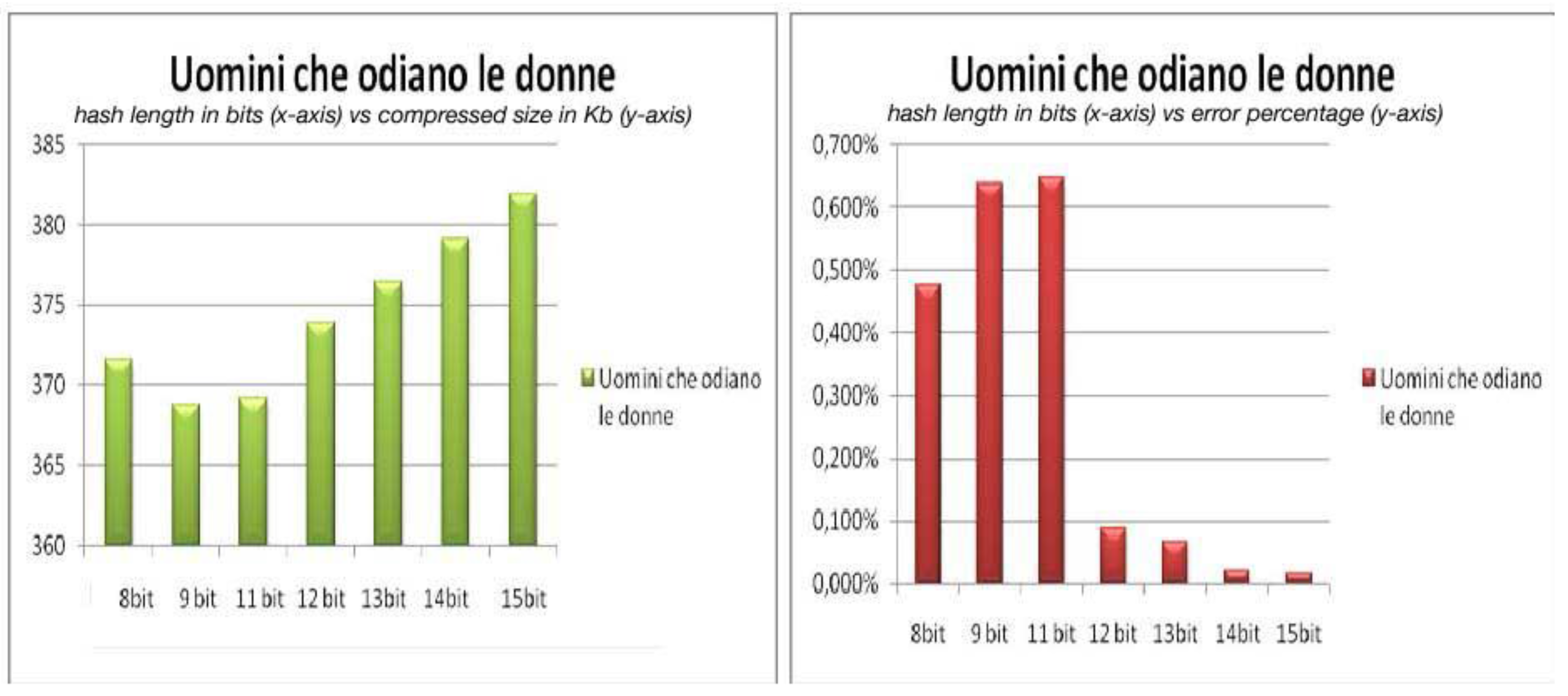
Figure 3 depicts the relationship between the length of the hash value, the size of the compressed file and the error percentage for the book “Uomini che odiano le donne”. In the left part of the picture we have on the x-axis the lengths of the hash value in bits and on the y-axis the corresponding sizes in Kb of the compressed file. In the right part of the picture on the x-axis we have again the lengths of the hash value in bits but on the y-axis we have the corresponding error percentages. The figure shows that the compression results are better for a hash value that has a length of 9 bits, but also that this length is not good enough to cope with transmission errors. Instead a hash of length 15 bits gives a compression that is almost lossless but the compression obtained is not competitive. The right compromise for the hash length here might be 12 bits. The behavior for the other books is very similar to the one in
Figure 3.
Figure 3.
Compression and hash length for “Uomini che odiano le donne”.
Figure 3.
Compression and hash length for “Uomini che odiano le donne”.



{kind=link}
{kind=link}
{kind=link}