1. Introduction
Facial expressions represent one of the most authentic and biologically significant channels for human emotional communication, providing direct insight into affective states. Facial expression recognition is a technology that analyzes and processes face images by computer to recognize the state of human facial expression [
1]. In 1971, six basic facial expression categories were identified by famous psychologist Ekman [
2]: Angry, Disgust, Fear, Happy, Sad, and Surprise. Neutral emojis have also been proposed as society continues to evolve, resulting in the current mainstream seven emoji states. Face Expression Recognition (FER) recognizes human facial expressions through several steps such as face detection, face alignment, feature extraction, and classification [
3], and has been widely used in the fields of intelligent interaction, medical diagnosis, and security monitoring.
In terms of intelligent interaction, by recognizing the user’s facial expression, a more intelligent and natural interaction experience can be realized. In intelligent driving systems, facial expression recognition technology enables real-time monitoring of driver affective states, facilitating timely interventions to maintain alertness and thereby enhancing road safety. For instance, detection of fatigue or distraction patterns can trigger adaptive warning systems to prevent accidents. In addition, in the field of virtual reality and augmented reality, facial expression recognition technology can also realize a more immersive user experience, providing users with a richer and more vivid interactive experience [
4]. In terms of medical diagnosis, by analyzing patients’ facial expressions, doctors can more accurately understand their emotional state and mental health status, thereby assisting in diagnosis and treatment [
5]. Additionally, facial expression recognition technology can also be used for postoperative rehabilitation monitoring. During the postoperative rehabilitation process, the patient’s facial expressions can reflect their level of pain, comfort, and emotional state. By analyzing this information, doctors can adjust treatment plans in a timely manner and improve the effectiveness of rehabilitation therapy [
6]. In the field of security and surveillance, face expression recognition technology has important application potentials [
7]. By recognizing facial expressions in the surveillance area, the surveillance system can more accurately perceive the emotional state and behavioral intentions of the personnel, thus improving the intelligence and responsiveness of the surveillance system [
8].
Currently, in the field of expression recognition research, the mainstream face expression recognition methods are mainly divided into traditional machine learning-based methods and deep learning-based methods. There are two main traditional machine learning methods for describing faces: geometric feature-based methods and texture feature-based methods. However, conventional machine learning methods often separate facial feature extraction from classification into distinct stages, resulting in complex operations and lack of joint optimization. The effectiveness of recognition depends on the discriminative power and robustness of manually designed features.
The meteoric rise of deep learning technology has injected new vitality into machine learning-based expression recognition methods. Unlike traditional methods, in deep learning methods both the process of feature extraction and classification can be done by the deep learning model itself. The stunning debut of AlexNet [
9] in 2012 provided improvement ideas for neural network development, allowing numerous network models such as VGG-Nets [
10], GoogleNet [
11], ResNet [
12], and DenseNet [
13] to employ deepening of the network and enhancement of convolutional functionality to improve network recognition accuracy. The study in [
14] proposed an identity-aware convolutional neural network using two convolutional neural networks for training, one for training features related to facial expressions and the other for training features related to identity, which improved the accuracy of expression recognition for different faces. Mollahosseini et al. [
15] increased the width and depth of the network based on the Inception layer and achieved good results on datasets such as CK+. Study [
16] proposed a fused convolutional neural network to improve the accuracy and robustness of facial expression recognition by extracting facial features through improved LeNet and ResNet, respectively, and then connecting the two feature vectors for classification. Lee et al. [
17] designed a dual-stream coding network that extracts features from face and background regions, respectively, and combines them with scenarios for expression recognition so that reduces the ambiguity of network and improves the accuracy of emotion recognition. Study [
18] proposed a self-cure network (SCN) that mitigates the problem of inaccurate labeling of large-scale facial expression datasets by weighting each sample in training through ranked regularization. Zhang et al. [
19] proposed an Identity-Expression Dual Branch Network (IE-DBN) that can force the network to generate expression-guided identity-related features while suppressing negative identity factors and outperforms most current techniques. Sidhom et al. [
20] proposed a novel three-phase hybrid feature selection method that leverages the strengths of filter, wrapper, and embedded algorithms. Mukhopadhyay et al. [
21] presents a new facial expressions detection method by exploiting textural image features such as local binary patterns (LBP), local ternary patterns (LTP) and completed local binary pattern (CLBP). Fan et al. [
22] first propose a deeply-supervised attention network (DSAN) to recognize human emotions based on facial images automatically. Based on DSAN, a two-stage training scheme is designed, taking full advantage of the race/gender/age-related information. Li et al. [
23] adopt an Adaptive Confidence Margin (Ada-CM) to fully leverage all unlabeled data for semi-supervised deep facial expression recognition. All unlabeled samples are partitioned into two subsets by comparing their confidence scores with the adaptively learned confidence margin at each training epoch: (1) subset I including samples whose confidence scores are no lower than the margin; (2) subset II including samples whose confidence scores are lower than the margin. For samples in subset I, the predictions are constrained to match pseudo labels. Meanwhile, samples in subset II participate in the feature-level contrastive objective to learn effective facial expression features. Ada-CM is evaluated extensively on four challenging datasets, showing that the method achieves state-of-the-art performance, especially surpassing fully supervised baselines in a semi-supervised manner. The study of ablation further proves the effectiveness of the method.
With the continuous development and application of deep neural network models, the key indicators of network continue to improve, such as the depth, the width, the parameters number, the computation amount and so on. As neural networks become increasingly complex, deploying them on mobile and embedded devices becomes challenging. However, with the increasing demand for real-time, on-device facial expression recognition in mobile and embedded environments, there is an urgent need to develop lightweight FER models that offer competitive accuracy with significantly lower computational cost.
The necessity for lightweight FER models is driven by the rapid proliferation of edge computing and ubiquitous devices such as smartphones, smartwatches, AR/VR headsets, and in-vehicle monitoring systems. In such settings, computational resources, power availability, and memory capacity are often constrained. Heavy models are not suitable for these platforms due to their inference latency and energy consumption. In contrast, lightweight models can perform real-time inference directly on edge devices, reducing latency, enhancing user privacy by avoiding cloud transmission, and lowering bandwidth requirements.
Moreover, many practical FER applications, such as driver drowsiness detection, classroom engagement monitoring, and mobile mental health assessment, require continuous, long-term operation. Lightweight models consume significantly less power, making them ideal for battery-powered or energy-sensitive scenarios. They also facilitate large-scale deployment in scenarios such as intelligent surveillance or retail analytics, where hundreds of devices may need to operate simultaneously with minimal hardware cost.
Lightweight FER models also contribute positively to model generalizability and ethical deployment. By design, these models often have fewer parameters and simpler architectures, which may help mitigate overfitting, especially in scenarios with limited or imbalanced training data. Furthermore, performing emotion recognition locally on-device alleviates privacy concerns, aligning with data protection regulations such as GDPR and addressing growing public scrutiny of biometric technologies.
In summary, designing lightweight FER models is essential for bridging the gap between academic research and real-world applications. These models provide a feasible and scalable solution for deploying emotion recognition in practical, resource-constrained environments without sacrificing performance, making them a cornerstone of future FER systems.
Therefore, numerous researchers have begun to design new lightweight convolutional neural networks. The SqueezeNet proposed by Iandola [
24] pioneered the development of lightweight convolutional neural networks. This model is composed of several FireModels combined with convolutional layers, fully connected layers, etc. The FireModel includes two parts, squeeze and expand, which reduce the number of parameters by first reducing and then increasing the dimensionality of the feature map. In 2017, Google proposed the MobileNet [
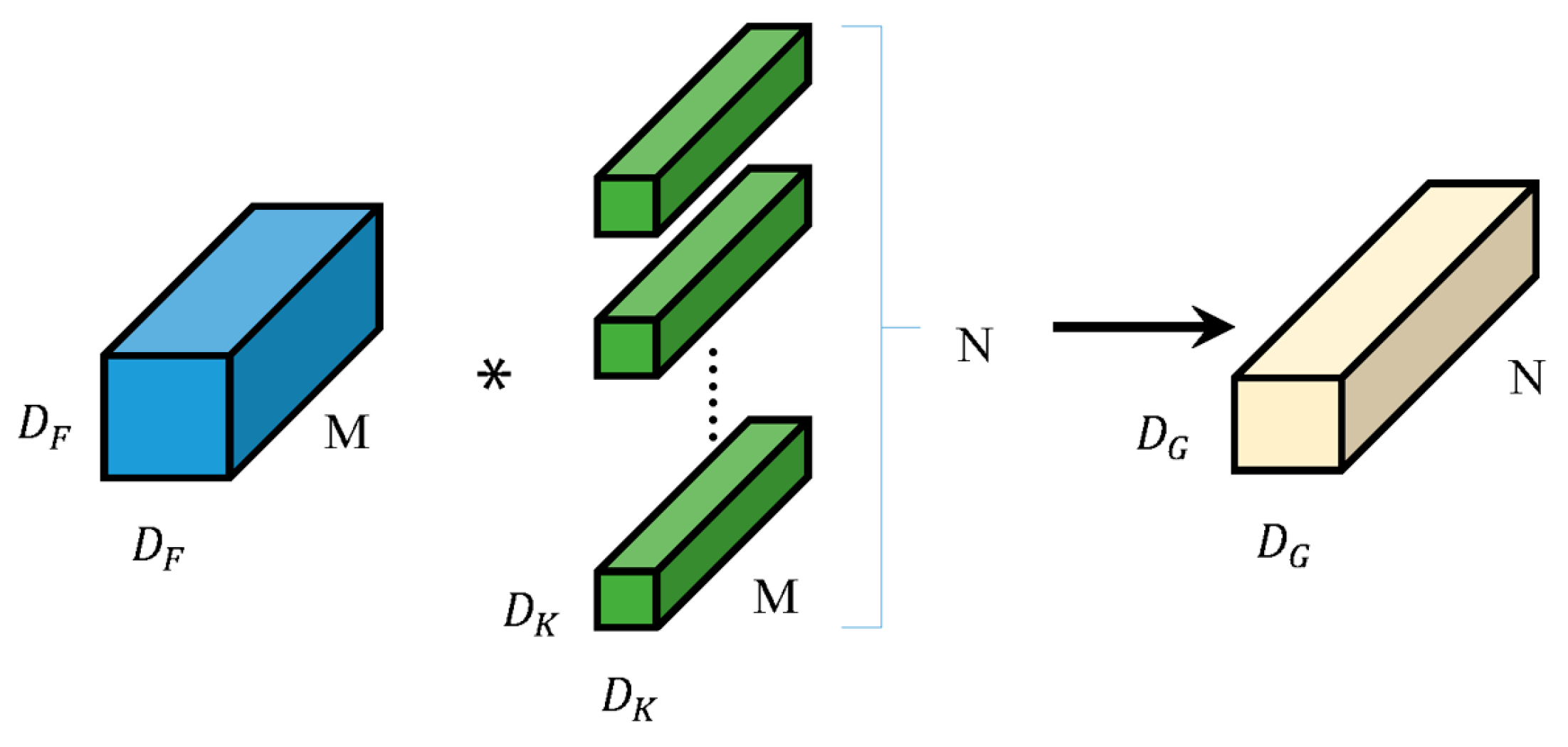
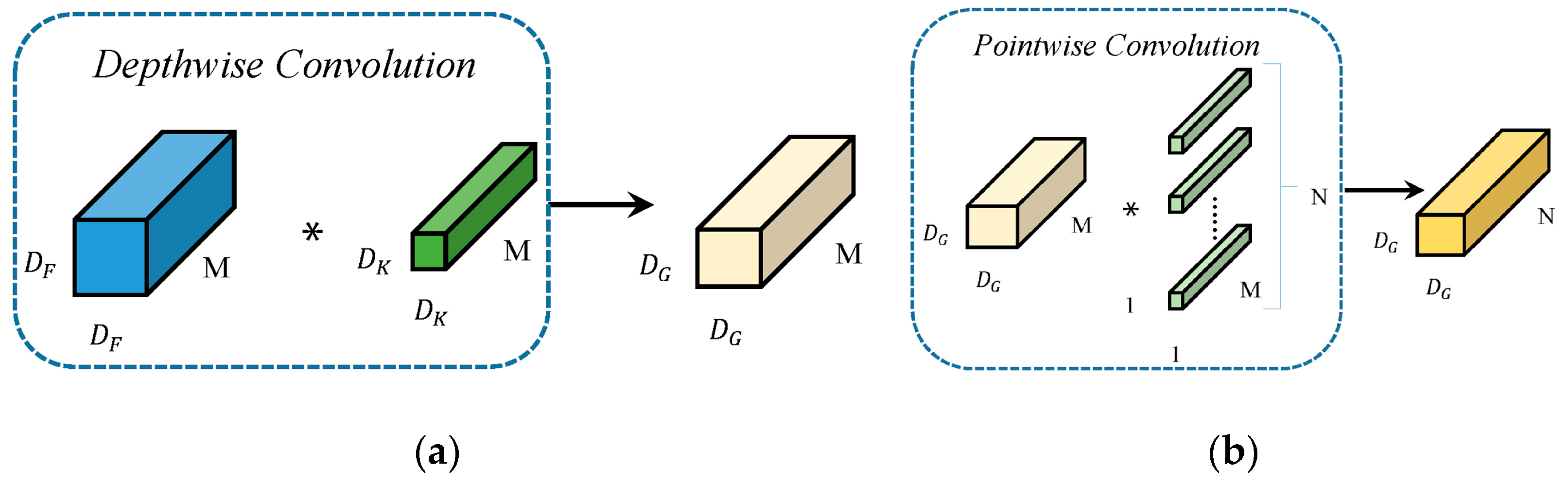
25] model, which uses a depthwise separable convolution to replace traditional convolution operations. Depthwise separable convolution decomposes the traditional convolution layer into two steps, namely, deep convolution first and then point wise convolution. Because MobileNet uses a large number of 3 × 3 convolution kernels, using depthwise separable convolution instead of traditional convolution operations can reduce the computational load by about nine times. At the same time, MobileNet also provides a hyperparameter to control the width of the network, balancing the relationship between model accuracy and model size. Following this, Google proposed the Xception [
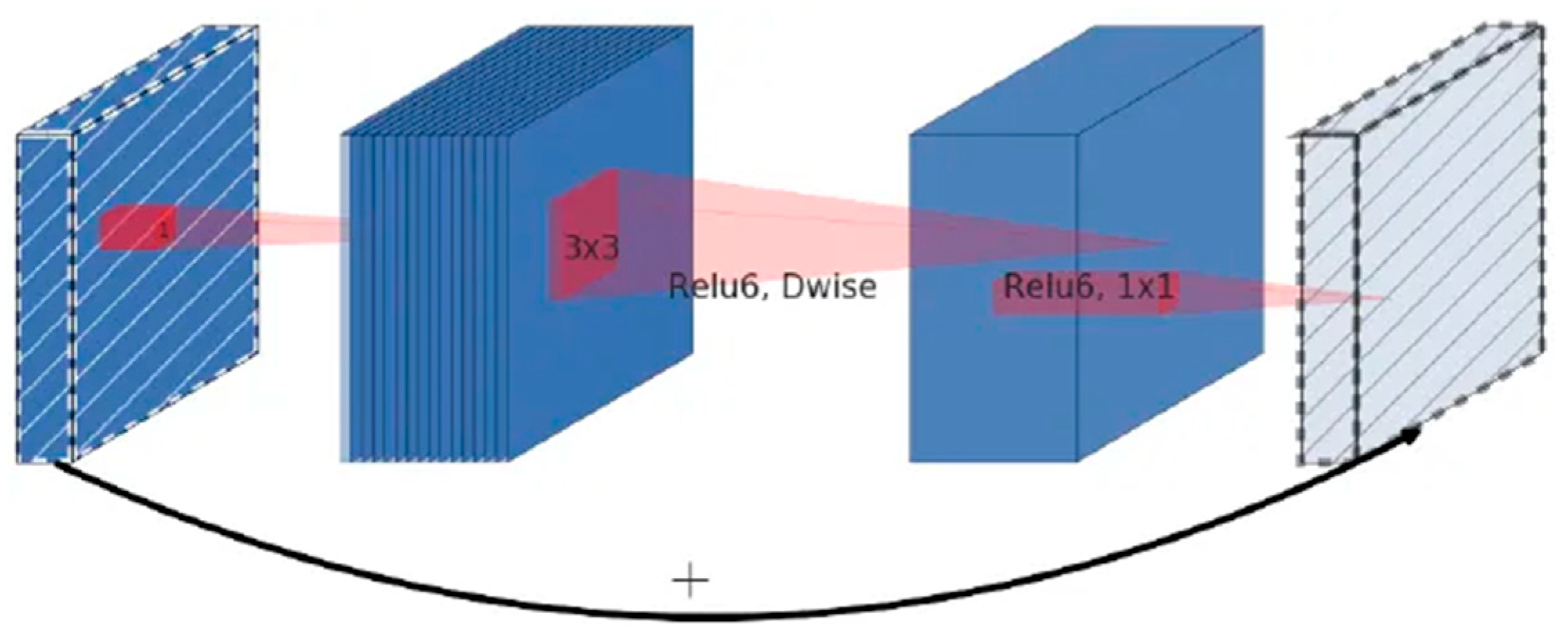
26] model, which is based on the idea of the Inception model and uses depthwise separable convolutions to replace the Inception module, and introduces residual structures. In 2018, the Google team proposed the MobileNetV2 [
27] model. Compared to the MobileNet model, MobileNetV2 introduces an inverted residual structure, which ascends and then descends the dimensions to enhance the propagation of gradients, and removes the ReLU activation function for the second pointwise convolution in the inverted residual module, preserving the diversity of features. ShuffleNet [
28], proposed by Kuangxiang Technology, uses point grouping convolution instead of point convolution operation to reduce the amount of computation, and at the same time proposes a channel shuffle method to solve the problem of not being able to exchange information between different groups due to the use of grouping convolution. The ShuffleNetV2 [
29] model proposed by Ma et al. in 2018 improves ShuffleNet and proposes four principles for designing lightweight networks: the same channel width minimizes the memory access cost (MAC), too many group convolutions increase the memory access cost (MAC), fragmentation operations within the network reduce parallelism, and element-by-element operations increase the memory consumption. According to these four principles, ShuffleNetV2 introduces channel split operation, replaces group convolution in ShuffleNet with point convolution, and postdates the channel mixing operation. In 2020, Han et al. [
30] proposed the GhostNet model, in which they found that the feature maps generated by convolutional neural networks usually contain rich or even redundant feature maps, and thus these redundant feature maps can be generated directly using constant mapping, so that a large number of feature maps can be obtained with a small amount of computation. In 2019, Mingxing Tan et al. [
31] proposed the EfficientNet model, where they used the Neural Architecture Search (NAS) technique to simultaneously explore the effects of input resolution, network depth, and network width on accuracy. There are also many scholars who, based on these lightweight models, have proposed improved algorithms with considerable effects for some specific application scenarios. For example, Zhu et al. [
32] propose an improved strategy for the MobileNetV2 neural network(I-MobileNetV2) in response to problems such as large parameter quantities in existing deep convolutional neural networks and the shortcomings of the lightweight neural network MobileNetV2 such as easy loss of feature information, poor real-time performance, and low accuracy rate in facial emotion recognition tasks. To avoid the overfitting problem of the network model and improve the facial expression recognition effect of partially occluded facial images. Jiang et al. [
33] propose an improved facial expression recognition algorithm based on MobileViT. Firstly, in order to obtain features that are useful and richer for experiments, deep convolution operations are added to the inverted residual blocks of this network, thus improving the facial expression recognition rate. Then, in the process of dimension reduction, the activation function can significantly improve the convergence speed of the model, and then quickly reduce the loss error in the training process, as well as to preserve the effective facial expression features as much as possible and reduce the overfitting problem. In study [
34] as it is difficult to highlight the features of facial expressions in the study of global faces, due to the unique subtleties and complexity of facial expressions. To improve the robustness of expression recognition in natural environments and optimize model parameters, a lightweight facial expression recognition method based on multiregion fusion is proposed, which integrates local details and global features to realize a combination of coarse and fine granularity, thus improving the model’s efficacy in discriminating subtle changes in expressions. Study [
35] presents an expression recognition method based on parallel CNN. Firstly, a series of preprocessing operations is performed on facial expression images. Then, a CNN with two parallel convolution and pooling structures, which can extract subtle expressions, is designed for facial expression images. This parallel structure has three different channels, in which each channel extract different image features and fuse the extracted features, finally, the previously merged features are sent to the Soft Max layer for expression classification. Wang et al. [
36] randomly clipped face faces based on face key points and fed the clipping results into the network, which had many duplicate clipping regions although local details were considered. Mao et al. [
37] propose POSTER++. It improves POSTER in three directions: cross-fusion, two stream, and multi-scale feature extraction. POSTER++ reached 92.21% on RAF-DB, 67.49% on AffectNet (7 cls) and 63.77% on AffectNet (8 cls), respectively, using only 8.4 G floating point operations (FLOPs) and 43.7 M parameters (Param). Zhang et al. [
38] propose CF-DAN which comprises three parts:(1) a cross-fusion grouped dual-attention mechanism to refine local features and obtain global information; (2) a proposed C
2 activation function construction method, which is a piecewise cubic polynomial with three degrees of freedom, requiring less computation with improved flexibility and recognition abilities, which can better address slow running speeds and neuron inactivation problems; and (3) a closed-loop operation between the self-attention distillation process and residual connections to suppress redundant information and improve the generalization ability of the model. The recognition accuracies on the RAF-DB, FERPlus, and AffectNet datasets were 92.78%, 92.02%, and 63.58%, respectively.
Despite these advancements, a significant knowledge gap remains: most existing lightweight FER models are designed by adapting general-purpose lightweight backbones, without specifically optimizing for the unique structural and semantic characteristics of facial expression images. As a result, these models often fail to fully utilize local expression cues—especially from key facial regions such as the eyes, mouth, and eyebrows—which are critical for emotion discrimination. In addition, many approaches either focus solely on architectural compression or rely heavily on post-processing modules, with limited integration of spatial–semantic guidance into the feature extraction process itself.
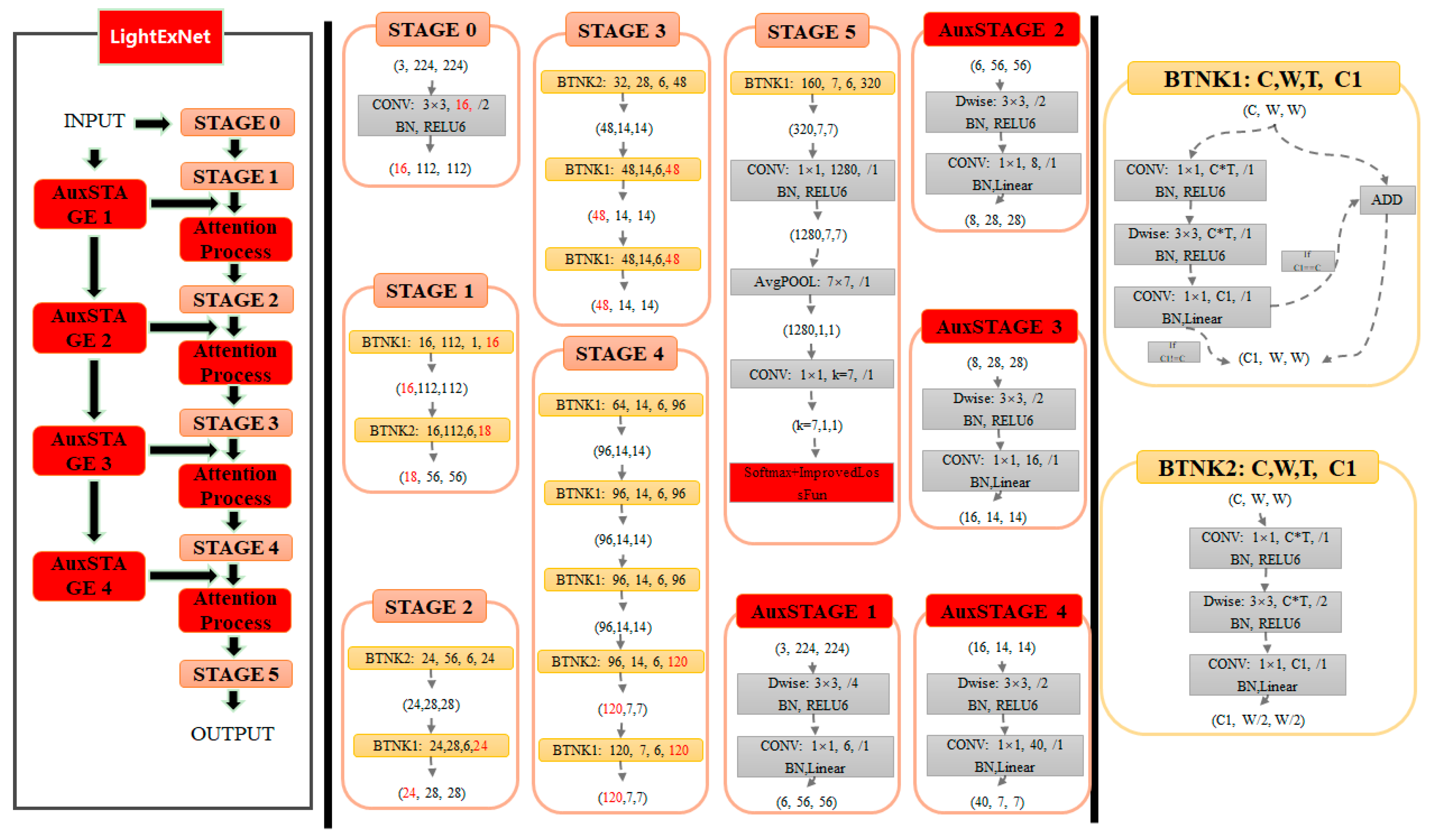
To address these limitations, we propose LightExNet, a novel lightweight CNN tailored specifically for facial expression recognition. The design of LightExNet builds upon the MobileNetV2 backbone, as MobileNet V2 offers both high accuracy and a small number of parameters, making it well suited for lightweight facial expression recognition. But introduces three key innovations to enhance expression-specific feature extraction and classification under constrained computational budgets:
Shallow–Deep Feature Fusion: By integrating low-level shallow features with high-level deep representations, the network retains fine-grained local details while gaining semantic abstraction, thus improving multiscale perception and alleviating gradient vanishing in deeper layers.
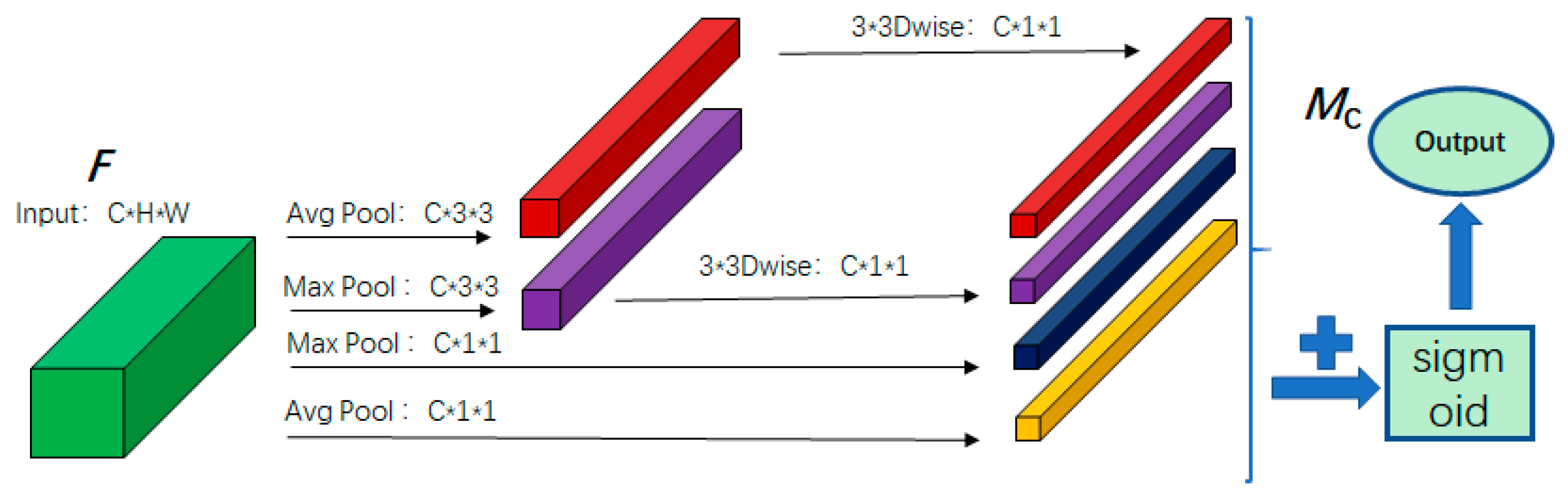
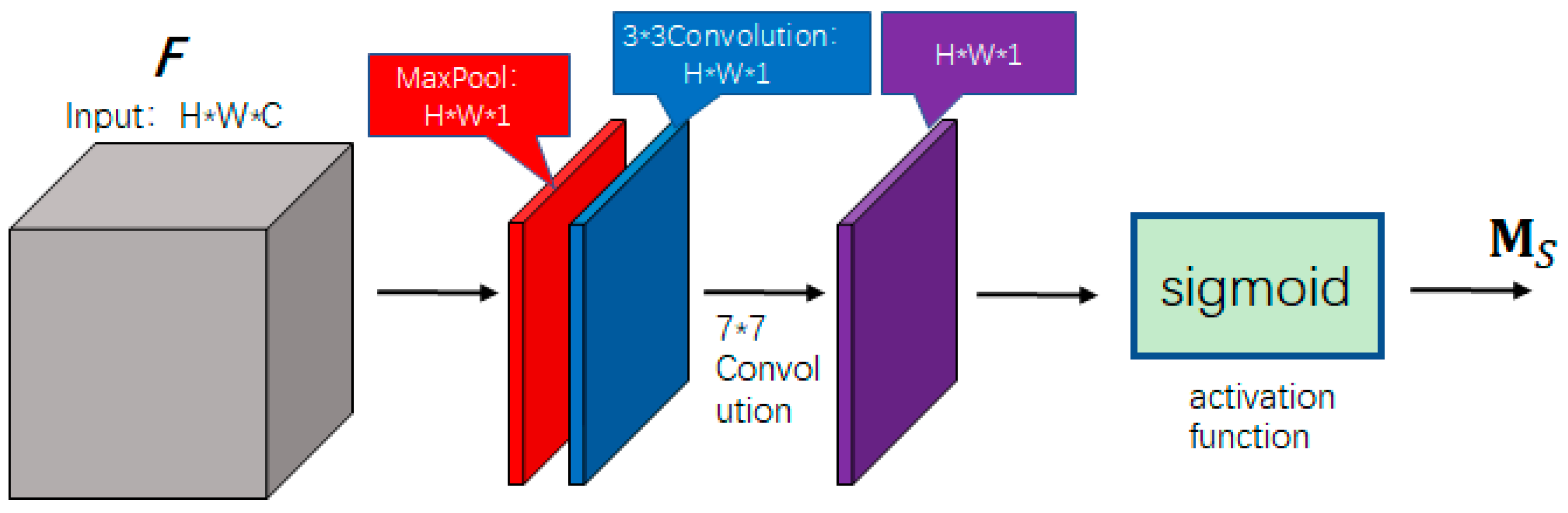
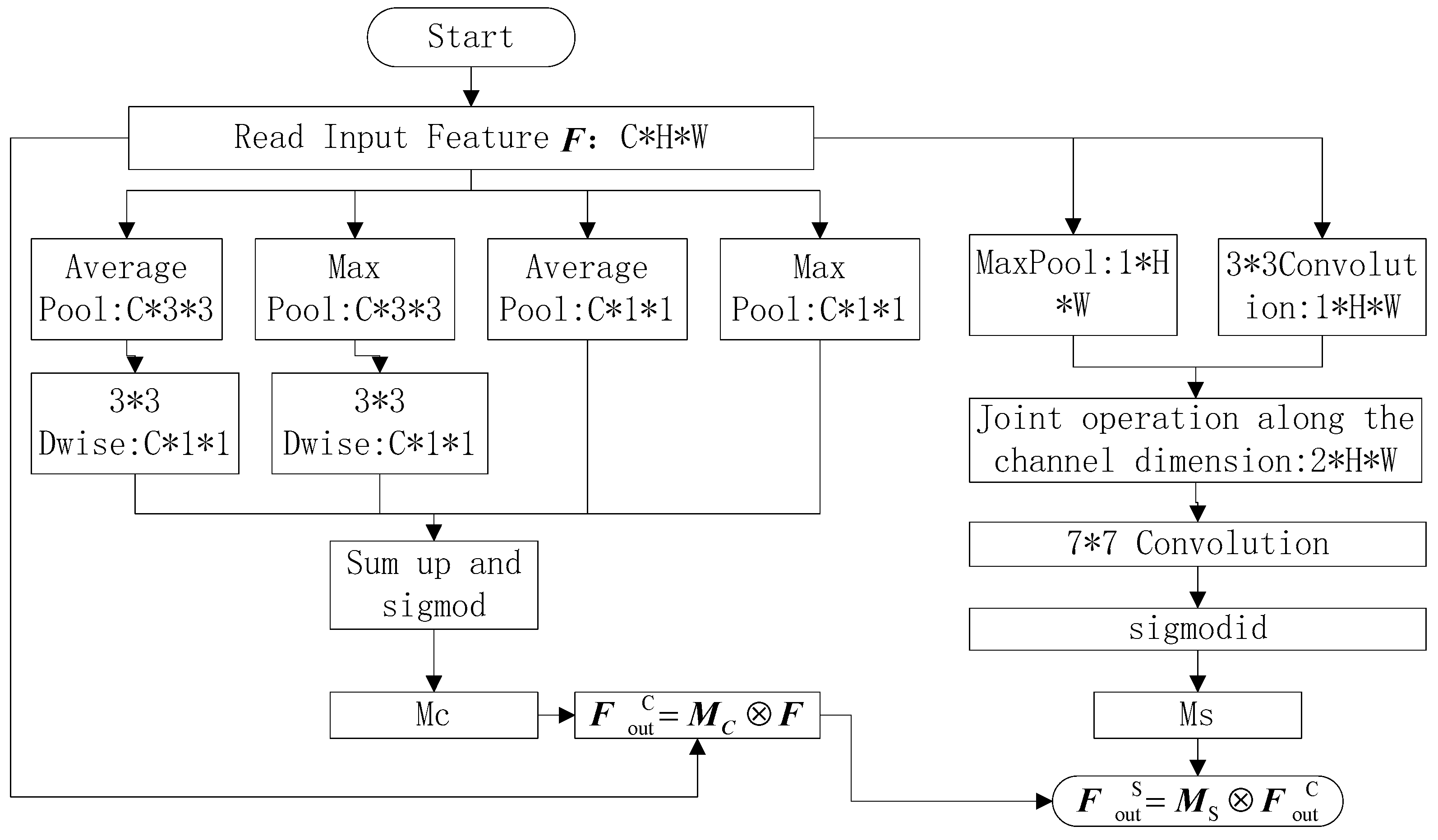
Improved Channel and Spatial Attention Mechanism: A task-specific attention module is introduced to assign higher weights to emotionally salient regions, enhancing the model’s ability to focus on expression-relevant facial components.
Joint Loss Function with Center Loss Optimization: An improved center loss is employed to enhance intra-class compactness and inter-class separability, thereby improving classification performance without increasing model complexity.
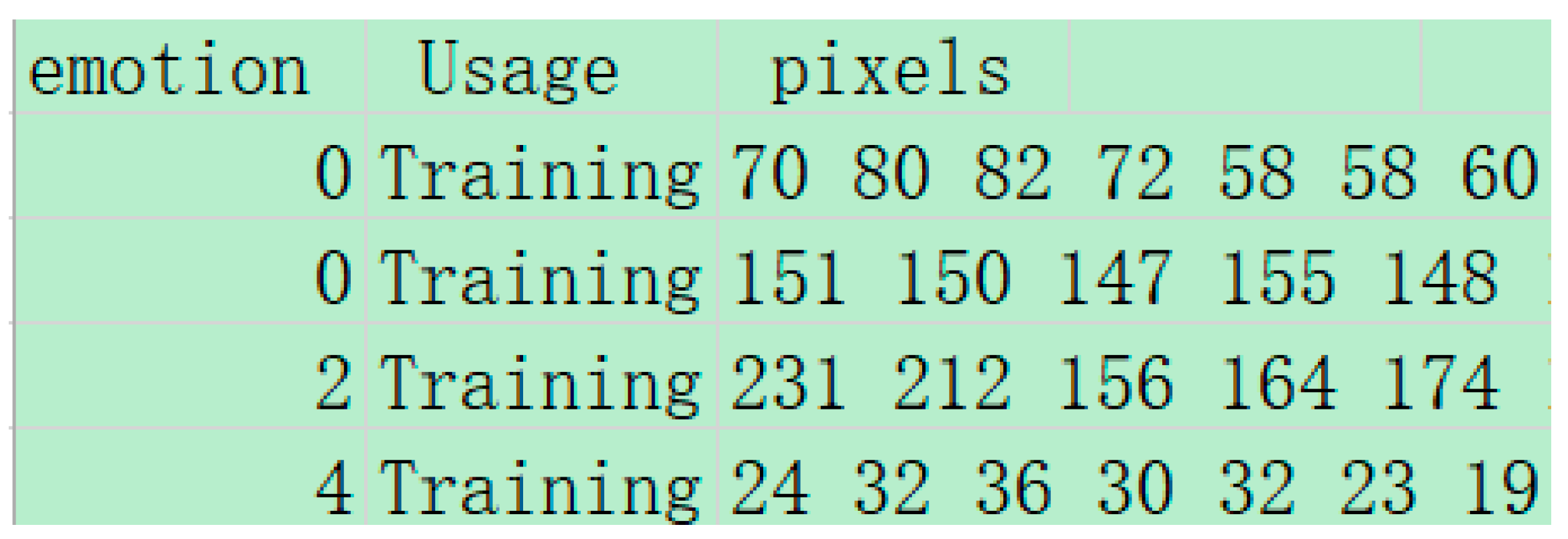
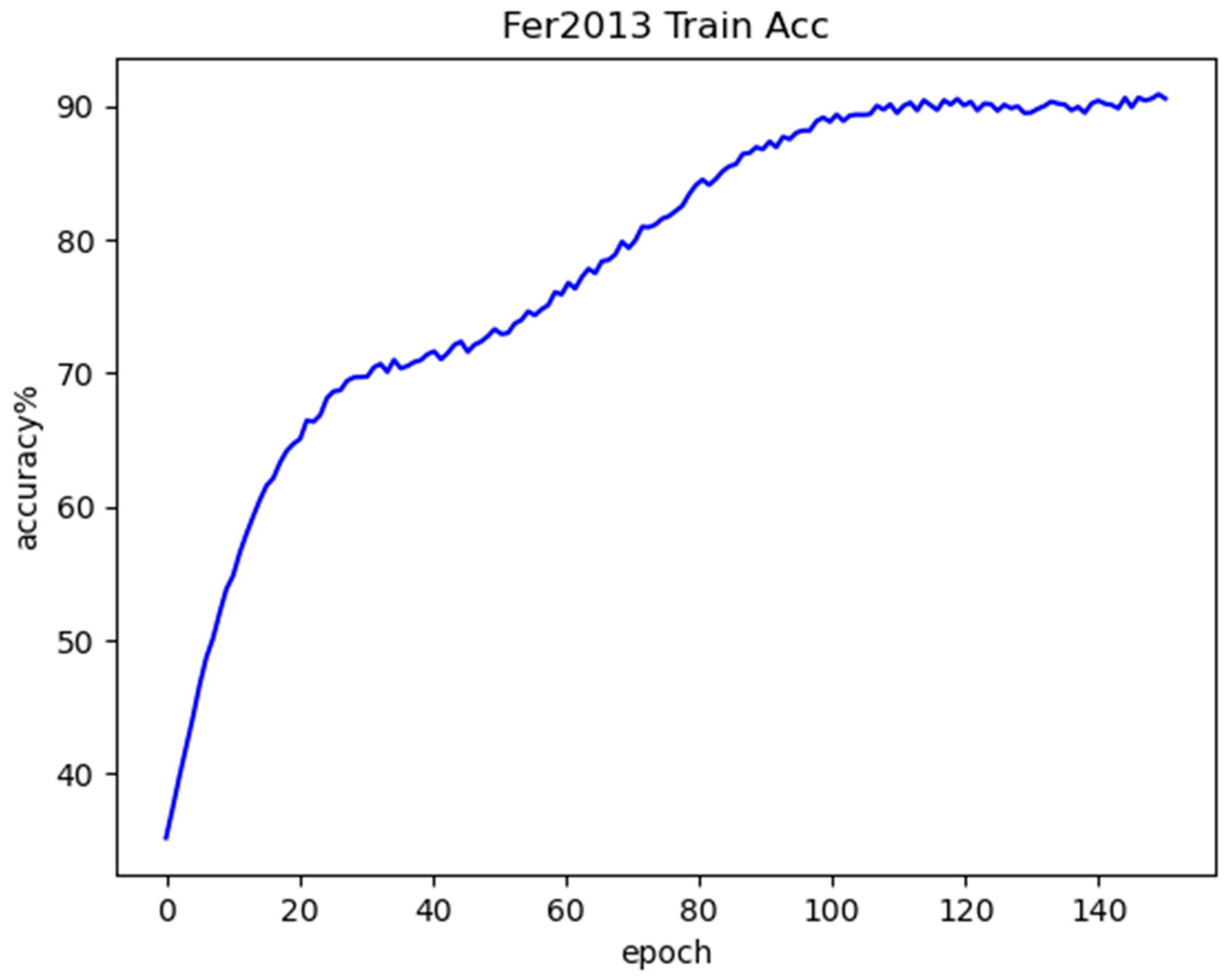
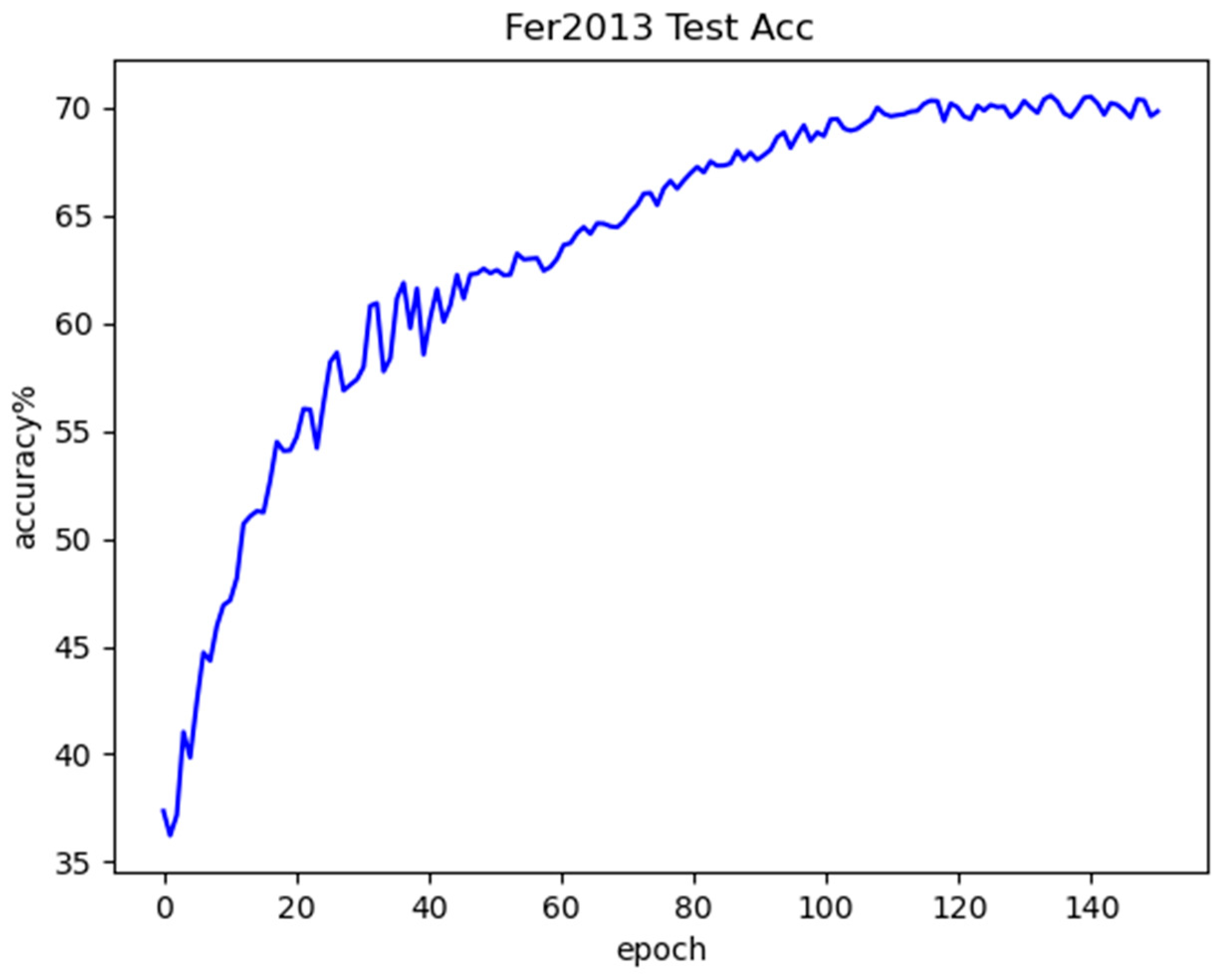
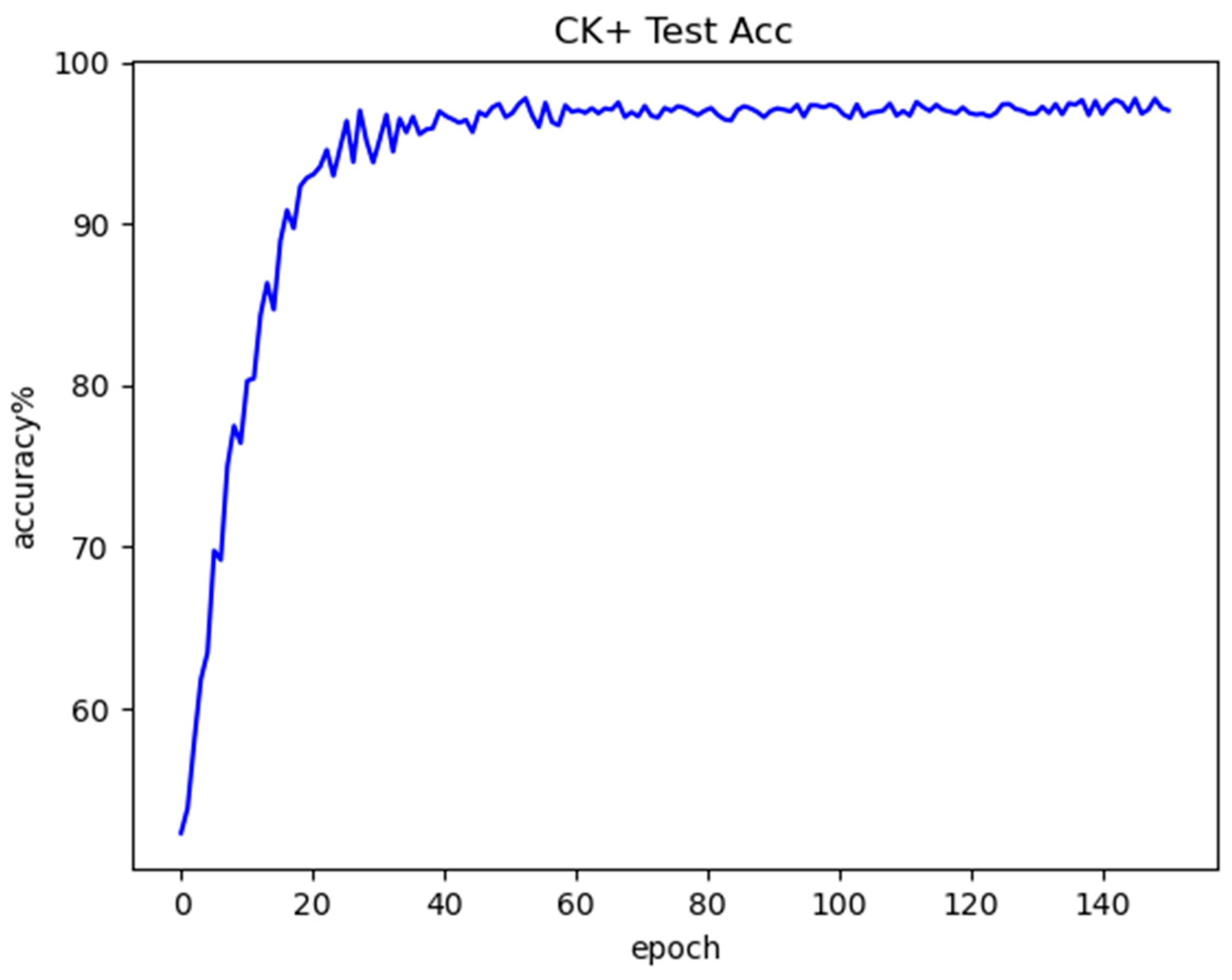
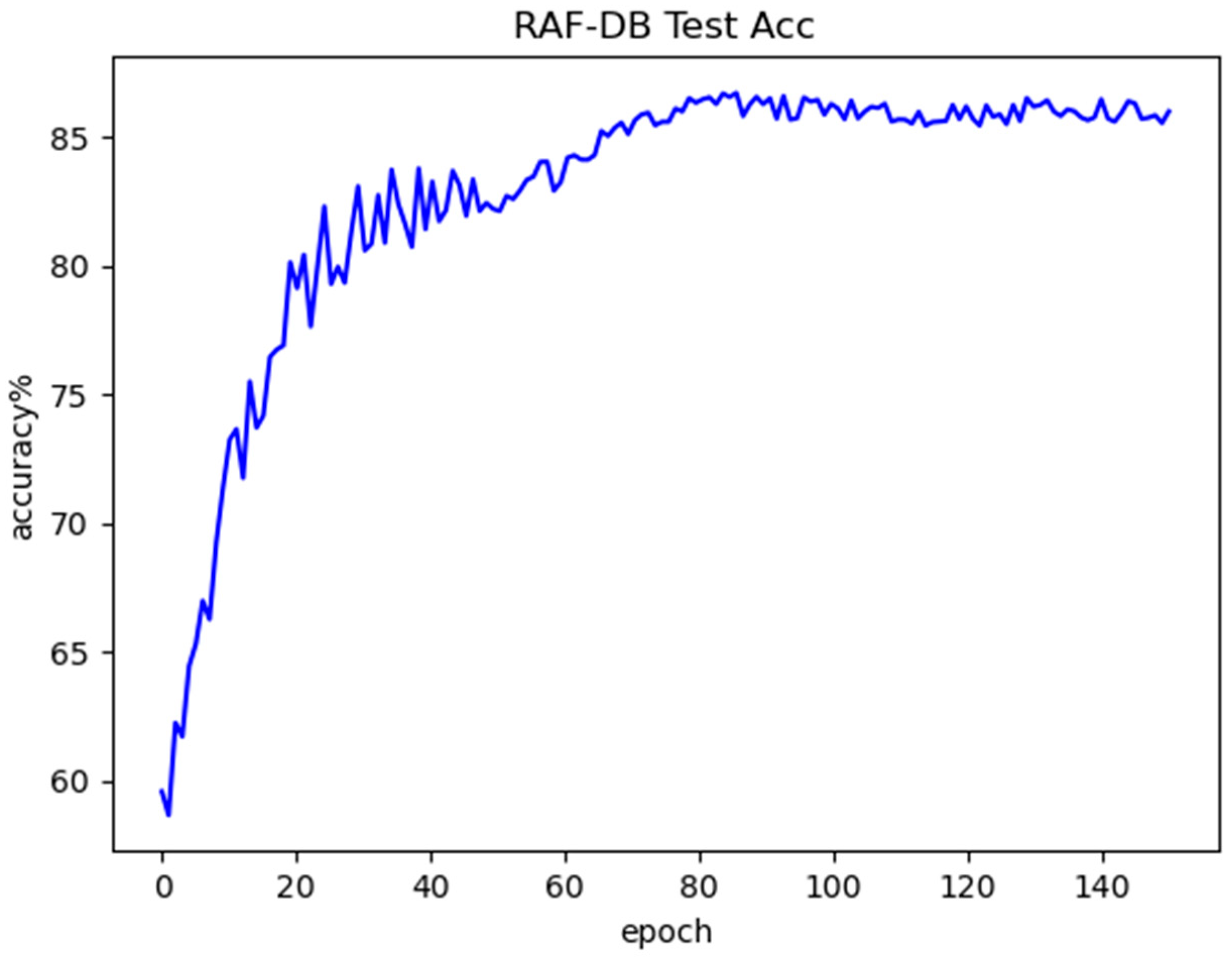
The proposed LightExNet is evaluated on three benchmark datasets: FER2013, CK+, and RAF-DB. Experimental results show that LightExNet achieves competitive accuracy (69.17%, 97.37%, and 85.97%, respectively) with only 3.27 M parameters and 298.27 M FLOPs, outperforming several existing mainstream lightweight FER models in both accuracy and computational efficiency.
In summary, this work bridges the gap between lightweight model design and expression-specific feature optimization, contributing a practical solution for real-time FER deployment on resource-limited devices.
4. Discussion
The comprehensive experimental results across the FER2013, CK+, and RAF-DB datasets highlight both the strengths and limitations of the proposed LightExNet framework in facial expression recognition (FER). The model consistently outperforms several state-of-the-art lightweight FER methods in terms of classification accuracy, parameter efficiency, and computational complexity, underscoring its effectiveness in real-world, resource-constrained applications.
4.1. The Reasons for the Variations in Recognition Accuracy Across Different Facial Expressions
4.1.1. Fer2013 Dataset
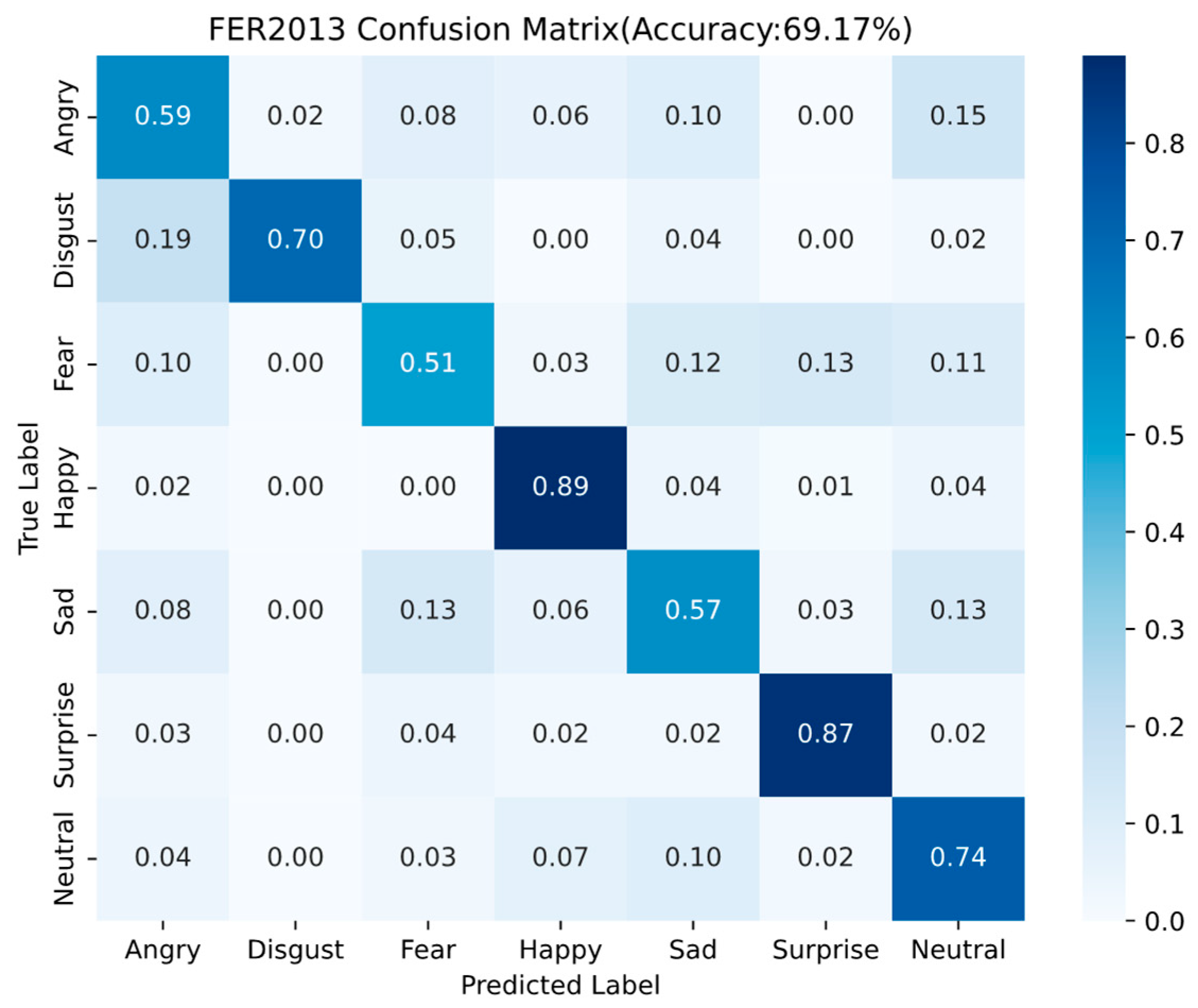
The performance discrepancy of Fer2013 dataset arises because happy and surprised expressions in the FER2013 dataset exhibit more distinctive facial features compared to other emotion categories, enabling superior feature extraction and consequently higher recognition accuracy by the neural network. The facial expression images of faces in the happy state tend to have clearly distinguishable feature information such as the corners of the mouth are raised and lines are created at the corners of the eyes. Face expressions in the state of surprise will also show obvious expression features such as eyes widening and mouth opening. In comparison, the recognition rates of the fear, anger and sadness expressions are relatively low. Fear is the most difficult to recognize, because in the fear expression, there is also the case of mouth opening, only that the mouth opening amplitude is slightly larger, which leads to easy confusion between the two categories of fear and surprise, and at the same time, it is easy to be confused with the sadness category, because there are frowning, forehead tightening, and other similar features in the two categories, so the recognition rate of the fear category of facial expressions is the lowest among all the categories. The remaining two categories of expressions and the fear category are all negative emotional expressions, and there is a strong similarity between the features of the three categories, and the difference between the facial key points is usually very small, which leads to a high probability of confusion, thus resulting in a relatively low recognition accuracy rate for these three categories of expressions.
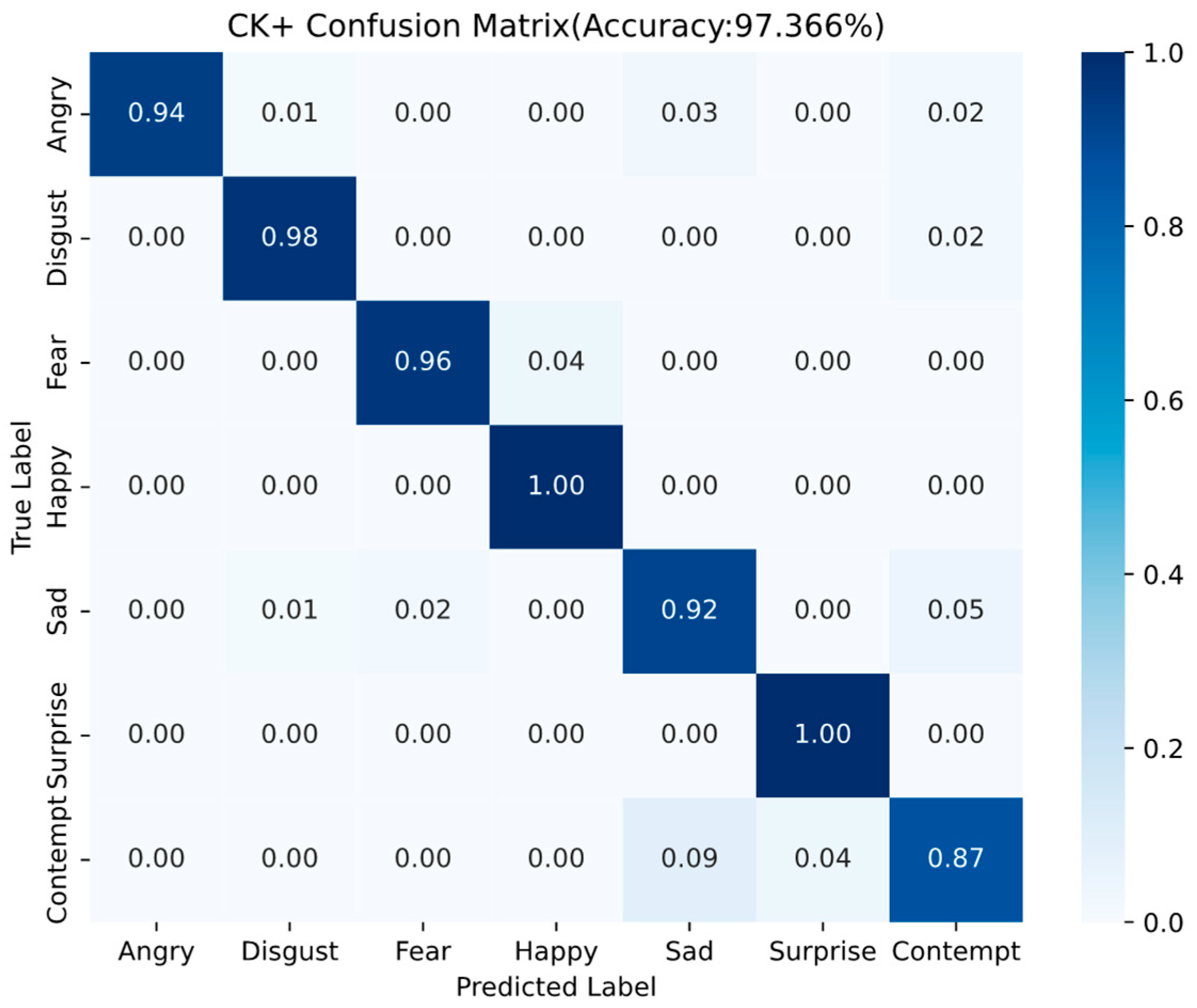
4.1.2. CK+ Dataset
Happy and Surprise expressions are recognized with perfect accuracy (1.00), likely due to their distinct facial features, such as pronounced mouth curvature and wide-open eyes, which make them easily distinguishable from other expressions.
Fear is occasionally misclassified as Happy or Sad, which may be attributed to overlapping facial cues such as widened eyes or tension in the eyebrows.
Angry has a few samples misclassified as Sad and Contempt. This confusion can be explained by the shared facial characteristics among these expressions, such as furrowed brows and downward lip movement.
Sad often confused with Contempt (0.05), possibly due to the subtle and nuanced facial muscle movements involved in expressing sadness, which overlap with negative valence expressions like contempt and fear.
Contempt is often misidentified as Sad (0.09) or Surprise (0.04). This result may stem from the subtlety and asymmetry typically associated with contemptuous expressions (e.g., unilateral lip raise), making them harder to distinguish. Additionally, the relatively limited number of contempt samples in the CK+ dataset may further contribute to the lower classification accuracy.
4.1.3. RAF-DB Dataset
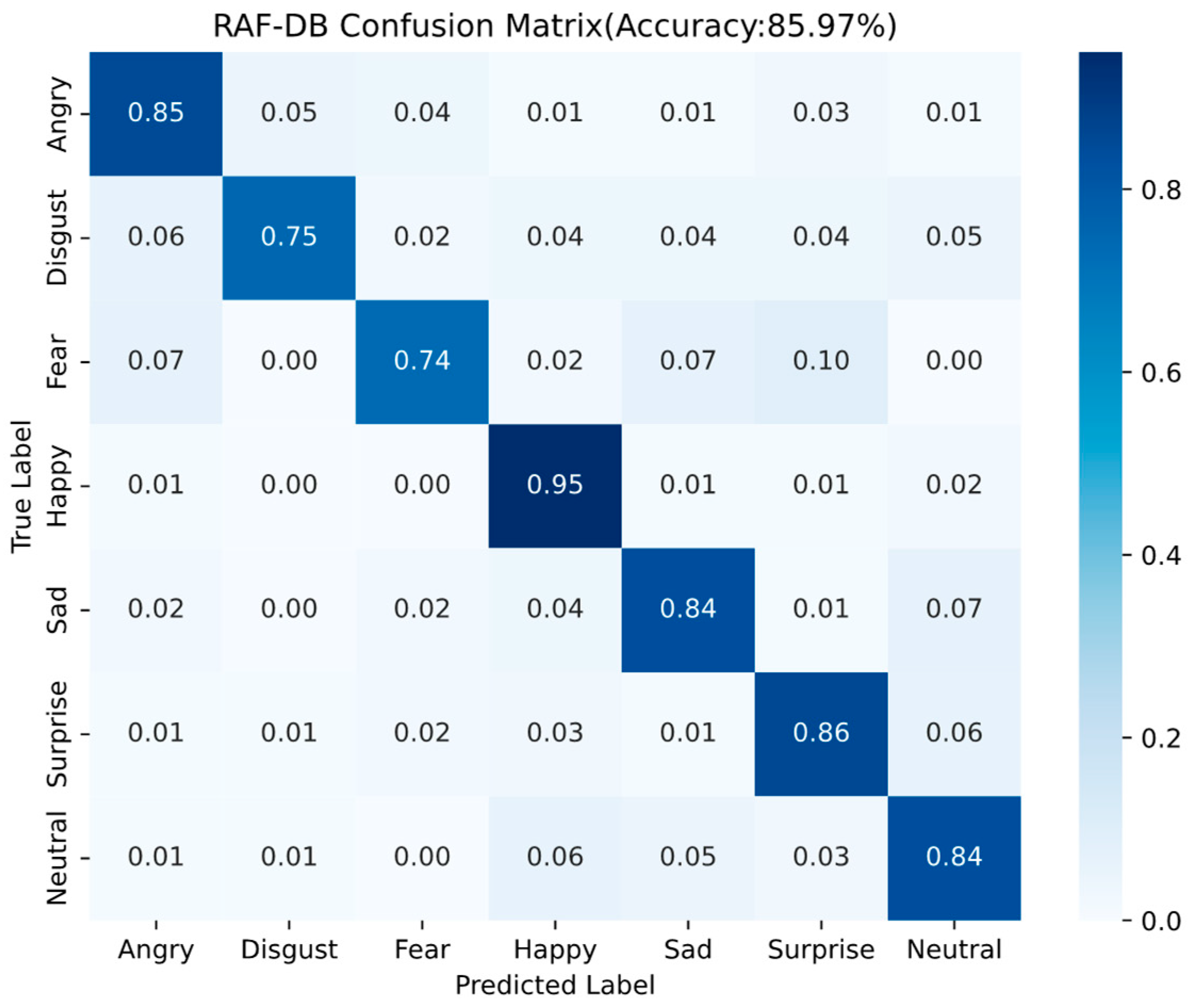
The recognition rate of Happy expression is the highest mainly due to the fact that the happy label has the largest number of images, possesses rich expression features, and is easy to distinguish from other expressions. Disgust and Fear emojis have the lowest recognition rates, and Disgust emoji is easy misrecognized as an Angry emoji, Fear emoji is easy misrecognized as a surprised emoji. This is due to the fact that these expressions share highly similar regional features, making them easy to confuse.
4.2. Generalization Across Datasets
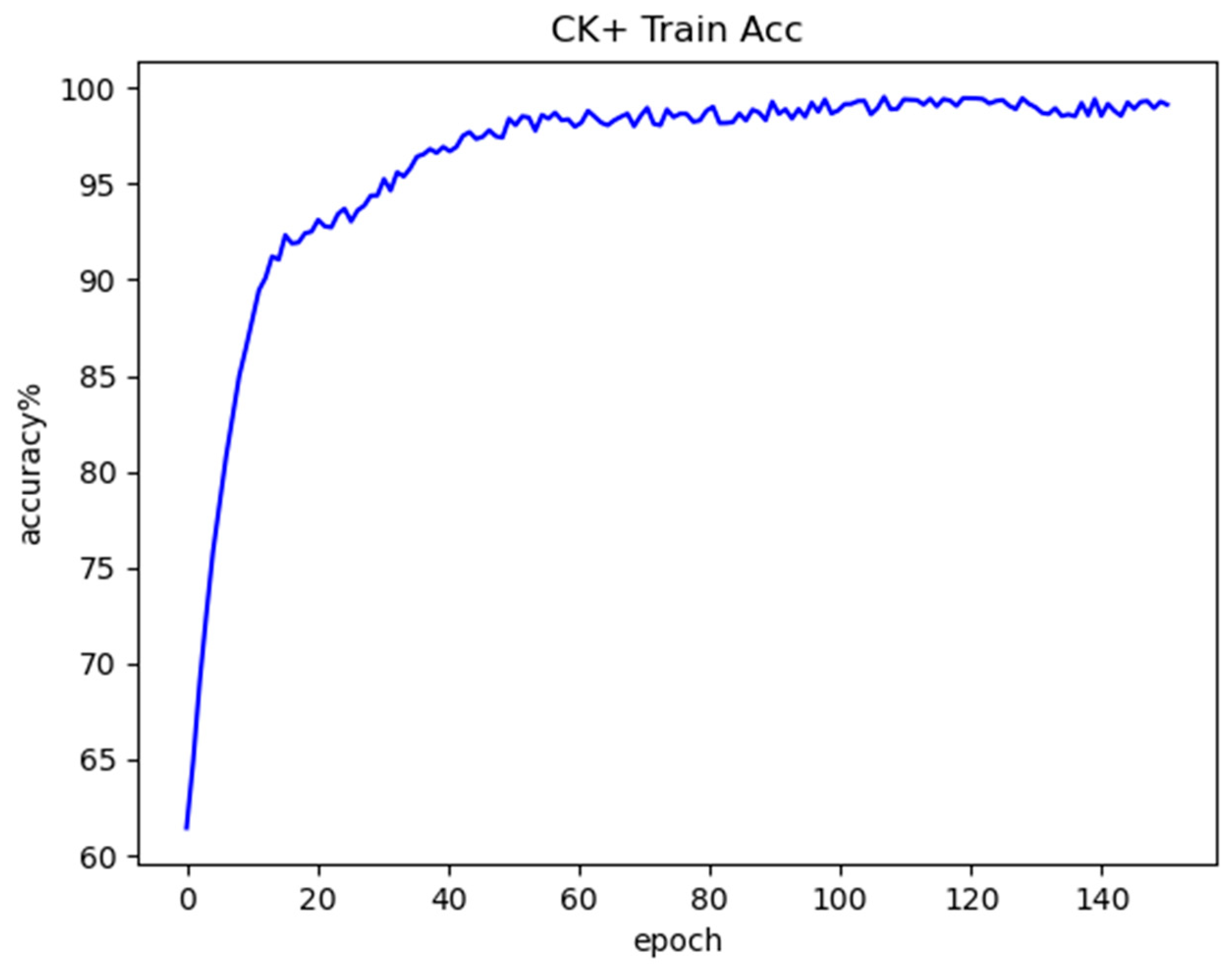
LightExNet achieves the highest overall accuracy on all three datasets compared to a variety of baseline and advanced FER models. On the controlled CK+ dataset, which features high-quality, laboratory-captured images, the model attains a remarkable 97.37% accuracy. This performance illustrates the model’s capacity to leverage clean data for precise expression recognition. On the more challenging, in-the-wild RAF-DB and the class-imbalanced FER2013 datasets, the model still achieves competitive accuracies of 85.97% and 69.17%, respectively. These results confirm that LightExNet generalizes well across domains with varying degrees of noise, occlusion, and class balance.
4.3. Impact of Dataset Characteristics
The observed differences in performance across datasets can be largely attributed to the quality and distribution of the data. For instance, the FER2013 dataset exhibits substantial class imbalance and contains low-resolution, noisy images. This results in skewed performance favoring dominant classes like Happy and Surprise, with poor recognition for underrepresented or ambiguous emotions such as Fear and Disgust. Conversely, the CK+ dataset benefits from well-balanced class representation and consistent image quality, leading to more uniform accuracy across emotion categories. RAF-DB, although collected in unconstrained environments, still provides clearer facial cues and more diverse expressions than FER2013, which contributes to its intermediate performance range.
4.4. Effectiveness of Architectural Enhancements
Ablation studies provide empirical support for the contribution of each architectural component. The fusion of deep and shallow features not only maintains a low parameter count (3.12 M) but also enhances early-stage detail retention, which is particularly beneficial for recognizing subtle expressions. The addition of the channel-spatial attention mechanism further boosts accuracy (up to 96.12% on CK+) by allowing the network to dynamically focus on informative regions of the face. Meanwhile, the integration of an improved center loss function leads to better class separability in the embedding space, especially for visually similar emotions such as Fear and Sad, with minimal computational overhead. When all three components are combined, LightExNet achieves its best performance, demonstrating that these modules synergistically enhance both discriminative power and generalization.
4.5. Efficiency vs. Accuracy Trade-Off
LightExNet strikes a favorable balance between recognition accuracy and model efficiency. Compared with the baseline MobileNet V2 and several other compact models, it achieves higher accuracy while reducing parameter count (3.27 M vs. 3.5 M) and FLOPs (298.27 M vs. 312.86 M). This makes it well suited for deployment in edge-computing scenarios such as mobile devices or embedded systems, where memory and power constraints are critical considerations.
4.6. Limitations and Future Directions
Although LightExNet achieves competitive performance on Fer2013, CK+, and RAF-DB, there are several directions to further enhance its robustness and practicality:
Despite the overall effectiveness of the proposed model, certain limitations remain, particularly when applied to datasets with highly imbalanced class distributions such as FER2013. As illustrated in the confusion matrix, the recognition performance varies significantly across emotion categories. Emotions with more training samples, such as Happy, Surprise, and Neutral, achieve relatively high accuracy (e.g., 0.89, 0.87, and 0.74, respectively). In contrast, underrepresented classes such as Fear and Sad exhibit lower accuracy (0.51 and 0.57), and Disgust is frequently misclassified as Angry (19%) or Fear (5%).
These results suggest that the model tends to be biased toward majority classes, which is a common issue in deep learning when trained on imbalanced data. To address this limitation, future work could explore strategies such as oversampling of minority classes, use of class-balanced loss functions (e.g., focal loss), or synthetic data augmentation techniques to improve the representation of underrepresented emotions. Additionally, transfer learning from more balanced or diverse datasets may help enhance the model’s generalizability across emotion categories.
The current experiments focus on three mainstream datasets, but testing on larger and more diverse datasets (e.g., AffectNet for in-the-wild expressions, or JAFFE for cross-cultural analysis) would better validate the model’s generalization ability. Future work will include these datasets and investigate domain adaptation techniques to address potential distribution shifts.
While the improved center loss in LightExNet effectively enhances feature discrimination, other advanced loss functions (e.g., ArcFace for angular margin optimization or adaptive weight-based losses for imbalanced data) could further refine intra-class compactness. A comparative study of these losses will be conducted to balance accuracy and computational cost.
The current model is trained primarily on datasets with relatively clean facial images. In scenarios involving partial occlusion (e.g., masks, hands, glasses), the model’s accuracy may degrade due to the loss of critical facial features. Future work may incorporate occlusion-aware training strategies or synthetic occlusion augmentation to improve robustness.
The model assumes near-frontal facial alignment for optimal performance. Although some degree of pose variation is tolerated, performance may decrease on non-frontal or profile views. Integrating pose normalization or multi-view learning could help address this issue.
Although LightExNet performs well on mid-tier devices (e.g., Redmi Note 13 5G), its inference time may not fully meet real-time requirements on extremely resource-constrained platforms such as entry-level microcontrollers or legacy smartphones without GPU/NPU support. Future improvements may consider model quantization or dynamic computation strategies.
In summary, LightExNet demonstrates strong performance in static image-based FER tasks, offering a compelling trade-off between accuracy and computational efficiency. The results validate the proposed architectural innovations and provide a solid foundation for future enhancements aimed at broader deployment and improved robustness across complex real-world scenarios.
5. Conclusions
Compared to other lightweight convolutional neural networks, MobileNet V2 is well suited for facial expression recognition. However, it still suffers from several issues, such as feature extraction is relatively blind so the effectiveness of features is relatively low, and the ability to extract spatial and dimensional information hidden in the features is insufficient, etc. In this paper, we propose LightExNet, a lightweight network built upon MobileNet V2, specifically designed to address these challenges in facial expression recognition.
In LightExNet, the deep and shallow feature fusion is firstly fused, in which the deep and shallow feature maps are superposed in the channel dimension rather than simply summed up, which can not only fully extract the shallow features in the original image and reduce the information loss, but also can alleviate the problem of gradient disappearance when the number of convolutional layers increases. Additionally, the sensory field of the deep network is relatively large, and the sensory field of the shallow network is relatively small, and this structure can also achieve the effect of multi-scale feature fusion. At the same time, we streamline the MobileNet V2 architecture to better integrate the deep and shallow networks, facilitating seamless fusion. In addition, in order to more effectively extract the useful information contained in the cascaded feature map, a new channel and spatial attention mechanism is proposed. Based on fully extracting the features of the expression itself, and, as far as possible, obtaining the feature information of different expression regions for encoding, so as to improve the accuracy of expression recognition. In the final classification process, according to the characteristics of face expression recognition classification, the improved center loss function is superimposed to further improve the accuracy of the classification results, and, at the same time, corresponding measures were taken to reduce the computational complexity of the joint loss function.
LightExNet is evaluated on three benchmark datasets: Fer2013, CK+, and RAF-DB. The experimental results show that the Parameters of LightExNet is 3.27 M, the Flops is 298.27 M, and the accuracy is 69.17%, 97.37%, and 85.97% on the three datasets, respectively, and the comprehensive performance is better than the current mainstream lightweight expression recognition algorithms such as MobileNet V2, IE-DBN, Self-Cure Net, Improved MobileViT, MFN, Ada-CM, Parallel CNN etc. So LightExNet is proved to have greater application value and potential in the field of lightweight expression recognition.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}