

Inverse Kinematics-Augmented Sign Language: A Simulation-Based Framework for Scalable Deep Gesture Recognition



Abstract
1. Introduction
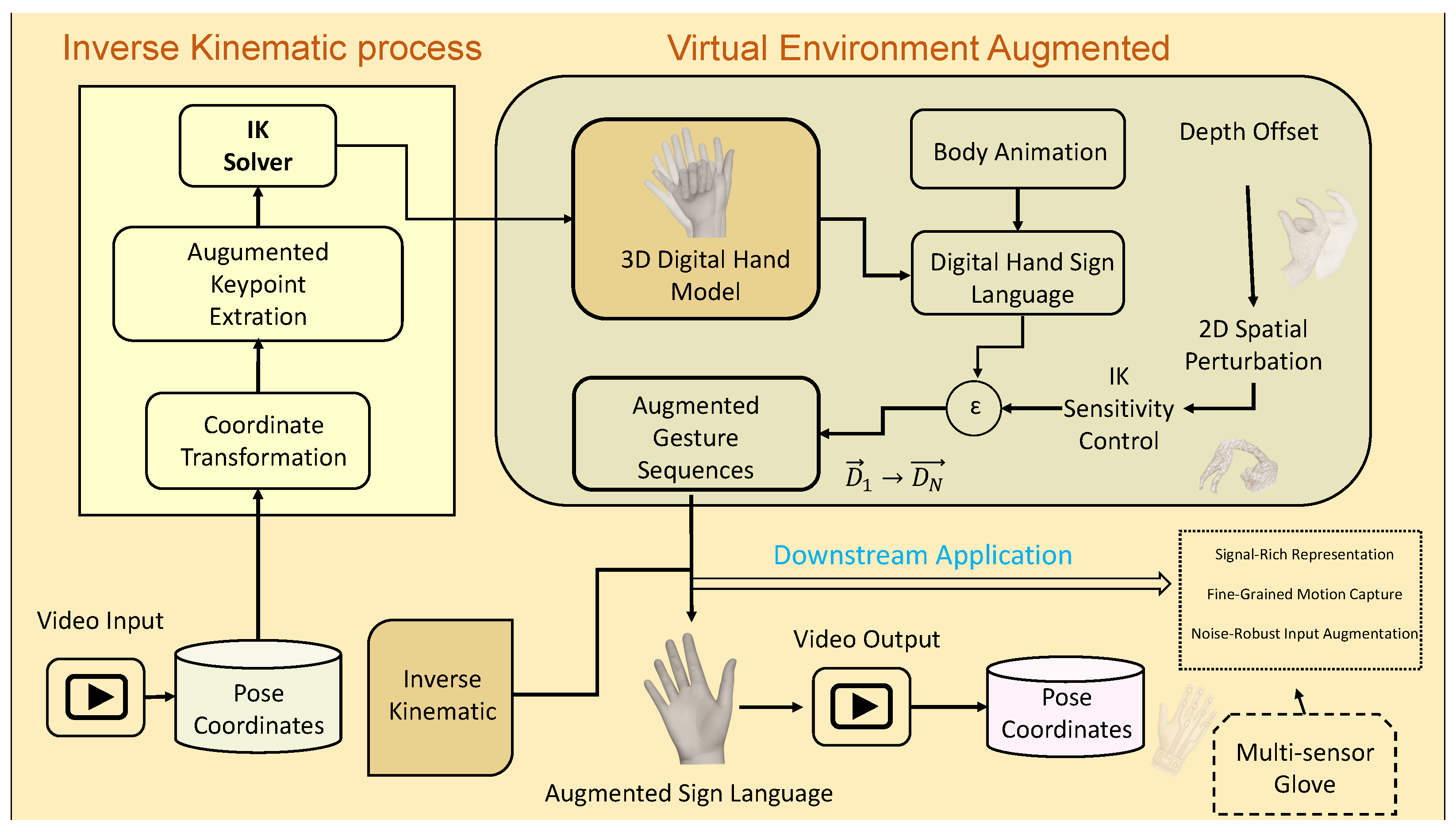
- We propose IK-AUG, a unified algorithmic framework that leverages inverse kinematics within a virtual simulation environment to generate anatomically and temporally coherent sign language sequences from sparse 3D inputs.
- We design a set of differentiable perturbation operators including depth modulation, spatial displacement, and solver sensitivity variation that systematically inject realistic variability while preserving semantic consistency, forming a domain-specific augmentation module.
- We conduct comprehensive empirical evaluations across five deep sequence models (CNN3D, TCN, Transformer, Informer, Sparse Transformer), demonstrating that IK-AUG consistently enhances convergence efficiency and classification performance, particularly in attention-based architectures.
- We establish a foundation for future hybrid gesture learning systems by outlining a scalable pathway to integrate multi-sensor modalities (e.g., inertial and haptic glove data) into a unified simulation–supervision loop.
2. Related Work
2.1. Virtual and Immersive Environments for Sign Language Learning and Recognition
2.2. Inverse Kinematics for Motion Reconstruction
2.3. Data Augmentation for Sign Language Recognition
2.4. Skeleton-Based and Adversarial Augmentation Techniques
2.5. Multimodal and Glove-Enhanced Recognition Systems
3. Methodology and Algorithms
3.1. Theoretical Foundation
3.1.1. Virtual Environments for Structured Simulation and Data Augmentation
3.1.2. Inverse Kinematics (IK) for Motion Modeling
3.1.3. Deep Learning Architectures for Sign Language Recognition
3.2. Proposed Augmentation Framework via Kinematic Gesture Simulation
3.2.1. Overview of the Synthetic–Real Gesture Loop
| Algorithm 1 IK-AUG: Inverse Kinematic-Augmented Gesture Synthesis Framework |
| Require:
Raw video sequence V, pose estimator , transformation module , IK solver , perturbation config , number of augmentations N |
| Ensure: Augmented dataset |
| 1: ▹ Extract 3D keypoints from raw video |
| 2: ▹ Transform to virtual space: normalization, filtering, re-alignment |
| 3: ▹ Apply IK solver to reconstruct skeletal pose sequence |
| 4: Initialize |
| 5: for to N do |
| 6: Sample perturbation config |
| 7: ▹ Apply spatial, depth, and kinematic variation |
| 8: |
| 9: |
| 10: |
| 11: end for |
| 12: return |
3.2.2. Inverse Kinematics Solver for Hand Pose Reconstruction
| Algorithm 2 Finger Rig-Based IK Solver |
| Input:
Target position , joint positions (MCP → PIP → DIP), segment lengths , convergence threshold |
| Output: Joint rotations |
| 1: ifthen |
| 2: // Target unreachable: fully extend finger |
| 3: |
| 4: |
| 5: |
| 6: else |
| 7: repeat |
| 8: // Backward pass |
| 9: |
| 10: |
| 11: |
| 12: // Forward pass (optional if root fixed) |
| 13: |
| 14: |
| 15: |
| 16: until |
| 17: end if |
| 18: Compute joint angles from final |
| 19: Apply joint rotations to digital hand model |
3.2.3. Sign Language Diversity Enhancement Strategy Driven by Multimodal Perturbation
- Depth Offset: Simulates variations in camera-to-subject distance by perturbing the depth plane of the virtual viewpoint.
- 2D Spatial Perturbation: Introduces localized shifts in the image plane (X-Y), mimicking tracking noise, occlusions, or signer-dependent expressive differences.
- IK Sensitivity Control: Adjusts solver hyperparameters such as target weight and damping, enabling variability in articulation flexibility and gesture expressiveness.
4. Experiments
4.1. Experimental Setup
4.2. Experimental Results
4.3. Evaluation
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Bragg, D.; Koller, O.; Bellard, M.; Berke, L.; Boudreault, P.; Braffort, A.; Caselli, N.; Huenerfauth, M.; Kacorri, H.; Verhoef, T.; et al. Sign language recognition, generation, and translation: An interdisciplinary perspective. In Proceedings of the 21st International ACM Special Interest Group on Accessibility and Computing Conference on Computers and Accessibility, Pittsburgh, PA, USA, 28–30 October 2019; pp. 16–31. [Google Scholar]
- Camgoz, N.C.; Koller, O.; Hadfield, S.; Bowden, R. Sign language transformers: Joint end-to-end sign language recognition and translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: New York, NY, USA, 2020; pp. 10023–10033. [Google Scholar]
- Maiorana-Basas, M.; Pagliaro, C.M. Technology use among adults who are deaf and hard of hearing: A national survey. J. Deaf. Stud. Deaf. Educ. 2014, 19, 400–410. [Google Scholar] [CrossRef] [PubMed]
- Koller, O.; Zargaran, S.; Ney, H.; Bowden, R. Deep sign: Enabling robust statistical continuous sign language recognition via hybrid CNN-HMMs. Int. J. Comput. Vis. 2018, 126, 1311–1325. [Google Scholar] [CrossRef]
- Li, D.; Rodriguez, C.; Yu, X.; Li, H. Word-level deep sign language recognition from video: A new large-scale dataset and methods comparison. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; IEEE: New York, NY, USA, 2020; pp. 1459–1469. [Google Scholar]
- Ge, L.; Ren, Z.; Li, Y.; Xue, Z.; Wang, Y.; Cai, J.; Yuan, J. 3D hand shape and pose estimation from a single RGB image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, NY, USA, 2019; pp. 10833–10842. [Google Scholar]
- Khan, A.; Jin, S.; Lee, G.H.; Arzu, G.E.; Nguyen, T.N.; Dang, L.M.; Choi, W.; Moon, H. Deep learning approaches for continuous sign language recognition: A comprehensive review. IEEE Access 2025, 13, 55524–55544. [Google Scholar] [CrossRef]
- Duarte, A.; Palaskar, S.; Ventura, L.; Ghadiyaram, D.; DeHaan, K.; Metze, F.; Torres, J.; Giro-i Nieto, X. How2Sign: A large-scale multimodal dataset for continuous American Sign Language. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: New York, NY, USA, 2021; pp. 2735–2744. [Google Scholar]
- Forster, J.; Schmidt, C.; Hoyoux, T.; Koller, O.; Zelle, U.; Piater, J.H.; Ney, H. Rwth-phoenix-weather: A large vocabulary sign language recognition and translation corpus. Int. Conf. Lang. Resour. Eval. 2012, 9, 3785–3789. [Google Scholar]
- Al-Qurishi, M.; Khalid, T.; Souissi, R. Deep learning for sign language recognition: Current techniques, benchmarks, and open issues. IEEE Access 2021, 9, 126917–126951. [Google Scholar] [CrossRef]
- Jiang, S.; Sun, B.; Wang, L.; Bai, Y.; Li, K.; Fu, Y. Skeleton-aware multi-modal sign language recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: New York, NY, USA, 2021; pp. 3413–3423. [Google Scholar]
- Barve, P.; Mutha, N.; Kulkarni, A.; Nigudkar, Y.; Robert, Y. Application of deep learning techniques on sign language recognition A survey. In Data Management, Analytics and Innovation, Proceedings of the International Conference on Discrete Mathematics, Rupnagar, India, 11–13 February 2021; Springer: Singapore, 2021; Volume 70, pp. 211–227. [Google Scholar]
- Kumar, D.A.; Sastry, A.; Kishore, P.; Kumar, E.K. 3D sign language recognition using spatio-temporal graph kernels. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 143–152. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Lea, C.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal convolutional networks: A unified approach to action segmentation. In Proceedings of the European Conference on Computer Vision 2016 Workshops, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; Part III. Springer: Cham, Switzerland, 2016; pp. 47–54. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the The Association for the Advancement of Artificial Intelligence (AAAI) Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 11106–11115. [Google Scholar]
- Child, R.; Gray, S.; Radford, A.; Sutskever, I. Generating long sequences with sparse transformers. arXiv 2019, arXiv:1904.10509. [Google Scholar]
- Alam, M.S.; Lamberton, J.; Wang, J.; Leannah, C.; Miller, S.; Palagano, J.; de Bastion, M.; Smith, H.L.; Malzkuhn, M.; Quandt, L.C. ASL champ!: A virtual reality game with deep-learning driven sign recognition. Comput. Educ. X Real. 2024, 4, 100059. [Google Scholar] [CrossRef]
- Vaitkevičius, A.; Taroza, M.; Blažauskas, T.; Damaševičius, R.; Maskeliūnas, R.; Woźniak, M. Recognition of American sign language gestures in a virtual reality using leap motion. Appl. Sci. 2019, 9, 445. [Google Scholar] [CrossRef]
- Schioppo, J.; Meyer, Z.; Fabiano, D.; Canavan, S. Sign language recognition: Learning American sign language in a virtual environment. In Proceedings of the Extended Abstracts of the 2019 Conference on Human Factors in Computing Systems, Glasgow, Scotland, UK, 4–9 May 2019; pp. 1–6. [Google Scholar]
- Papadogiorgaki, M.; Grammalidis, N.; Makris, L.; Strintzis, M.G. Gesture synthesis from sign language notation using MPEG-4 humanoid animation parameters and inverse kinematics. In Proceedings of the 2nd IET International Conference on Intelligent Environments, Athens, Greece, 5–6 July 2006; pp. 151–160. [Google Scholar]
- Ponton, J.L.; Yun, H.; Aristidou, A.; Andujar, C.; Pelechano, N. Sparseposer: Real-time full-body motion reconstruction from sparse data. ACM Trans. Graph. 2023, 43, 5. [Google Scholar] [CrossRef]
- Nunnari, F.; España-Bonet, C.; Avramidis, E. A data augmentation approach for sign-language-to-text translation in-the-wild. In Proceedings of the 3rd Conference on Language, Data and Knowledge. Schloss Dagstuhl–Leibniz-Zentrum für Informatik, Zaragoza, Spain, 1–3 September 2021; pp. 36:1–36:8. [Google Scholar]
- Awaluddin, B.A.; Chao, C.T.; Chiou, J.S. A hybrid image augmentation technique for user-and environment-independent hand gesture recognition based on deep learning. Mathematics 2024, 12, 1393. [Google Scholar] [CrossRef]
- Perea-Trigo, M.; López-Ortiz, E.J.; Soria-Morillo, L.M.; Álvarez García, J.A.; Vegas-Olmos, J. Impact of face swapping and data augmentation on sign language recognition. Univers. Access Inf. Soc. 2024, 24, 1283–1294. [Google Scholar] [CrossRef]
- Brock, H.; Law, F.; Nakadai, K.; Nagashima, Y. Learning three-dimensional skeleton data from sign language video. ACM Trans. Intell. Syst. Technol. 2020, 11, 1–24. [Google Scholar] [CrossRef]
- Nakamura, Y.; Jing, L. Skeleton-based data augmentation for sign language recognition using adversarial learning. IEEE Access 2024, 13, 15290–15300. [Google Scholar] [CrossRef]
- Wen, F.; Zhang, Z.; He, T.; Lee, C. AI enabled sign language recognition and VR space bidirectional communication using triboelectric smart glove. Nat. Commun. 2021, 12, 5378. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Batch Size | Learning Rate | Weight Decay | Dropout | Hidden Dim | Notes |
|---|---|---|---|---|---|---|
| CNN3D | 16 | 0.395 | 320 | |||
| TCN | 32 | 0.266 | 256 | Kernel size = 3, 6 layers | ||
| Transformer | 32 | 0.102 | 32 | 2 layers, 8 heads | ||
| Informer | 32 | 0.422 | 256 | Kernel size = 0, 4 layers | ||
| Sparse Transformer | 16 | 0.458 | 384 |
| Model | Original Data Accuracy | Augmented Data Accuracy |
|---|---|---|
| CNN3D | 85% | 90% |
| TCN | 83% | 89% |
| Transformer | 90% | 92% |
| Informer | 91% | 94% |
| Sparse Transformer | 89% | 92% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, B.; Jing, L.; Li, X. Inverse Kinematics-Augmented Sign Language: A Simulation-Based Framework for Scalable Deep Gesture Recognition. Algorithms 2025, 18, 463. https://doi.org/10.3390/a18080463
Wang B, Jing L, Li X. Inverse Kinematics-Augmented Sign Language: A Simulation-Based Framework for Scalable Deep Gesture Recognition. Algorithms. 2025; 18(8):463. https://doi.org/10.3390/a18080463
Chicago/Turabian StyleWang, Binghao, Lei Jing, and Xiang Li. 2025. "Inverse Kinematics-Augmented Sign Language: A Simulation-Based Framework for Scalable Deep Gesture Recognition" Algorithms 18, no. 8: 463. https://doi.org/10.3390/a18080463
APA StyleWang, B., Jing, L., & Li, X. (2025). Inverse Kinematics-Augmented Sign Language: A Simulation-Based Framework for Scalable Deep Gesture Recognition. Algorithms, 18(8), 463. https://doi.org/10.3390/a18080463