



An Approach to Trustworthy Article Ranking by NLP and Multi-Layered Analysis and Optimization



Abstract
1. Introduction
2. Related Work
2.1. Similarity Comparison
2.2. Trustworthiness in Article Discovery
2.3. Classification Models for Trust Assessment
2.4. Ranking Systems in Academic Article Repositories
- Integrated Semantic Relevance and Trust Assessment: Combines BERT-based semantic matching with trustworthiness evaluation to retrieve articles that are both topically relevant and scientifically reliable.
- Robust Problematic Article Filtering: Applies a Random Forest classifier trained on retracted and non-retracted articles to effectively eliminate unreliable publications with 90% overall accuracy.
- Transparent Multi-factor Ranking Strategy: Introduces a scoring model that merges citation, Altmetric, and impact factor data to produce an interpretable and adjustable trustworthiness ranking.
- Validated on Large Cross-domain Dataset: Demonstrates a consistent performance using over 16,000 articles across diverse scientific fields, supporting generalizability and applicability to real-world literature discovery tasks.
3. Data Retrieval and Pre-Processing
- Photosynthesis and Cellular Respiration;
- Quantum Mechanics and Quantum Computing;
- Ecology and Environmental Science;
- Virology and Epidemiology;
- Bacteria and Viruses.
- Altmetric Data Integration: We utilized the Altmetric API to retrieve attention scores for articles using their Digital Object Identifiers (DOIs).
- Impact Factor Collection: Journal impact factors were obtained through the Journal Citation Reports (JCR) database, supplemented by direct extraction from journal websites when necessary.
4. Methodology
4.1. BERT Embedding and Similarity Comparison
4.2. Elimination of Problematic Articles
4.3. Final Result Ranking
5. Expanded Experiments, Results, and Discussion
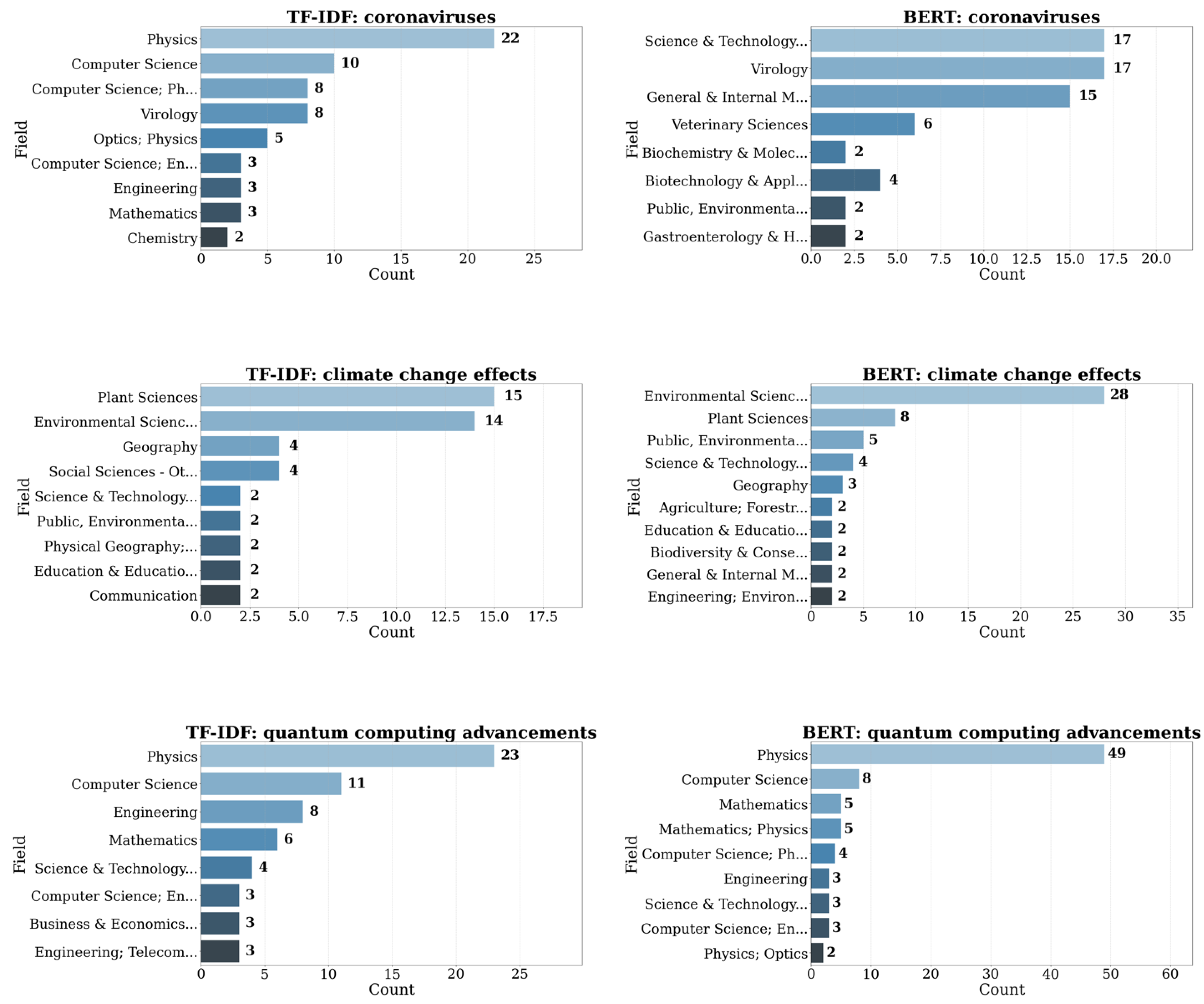
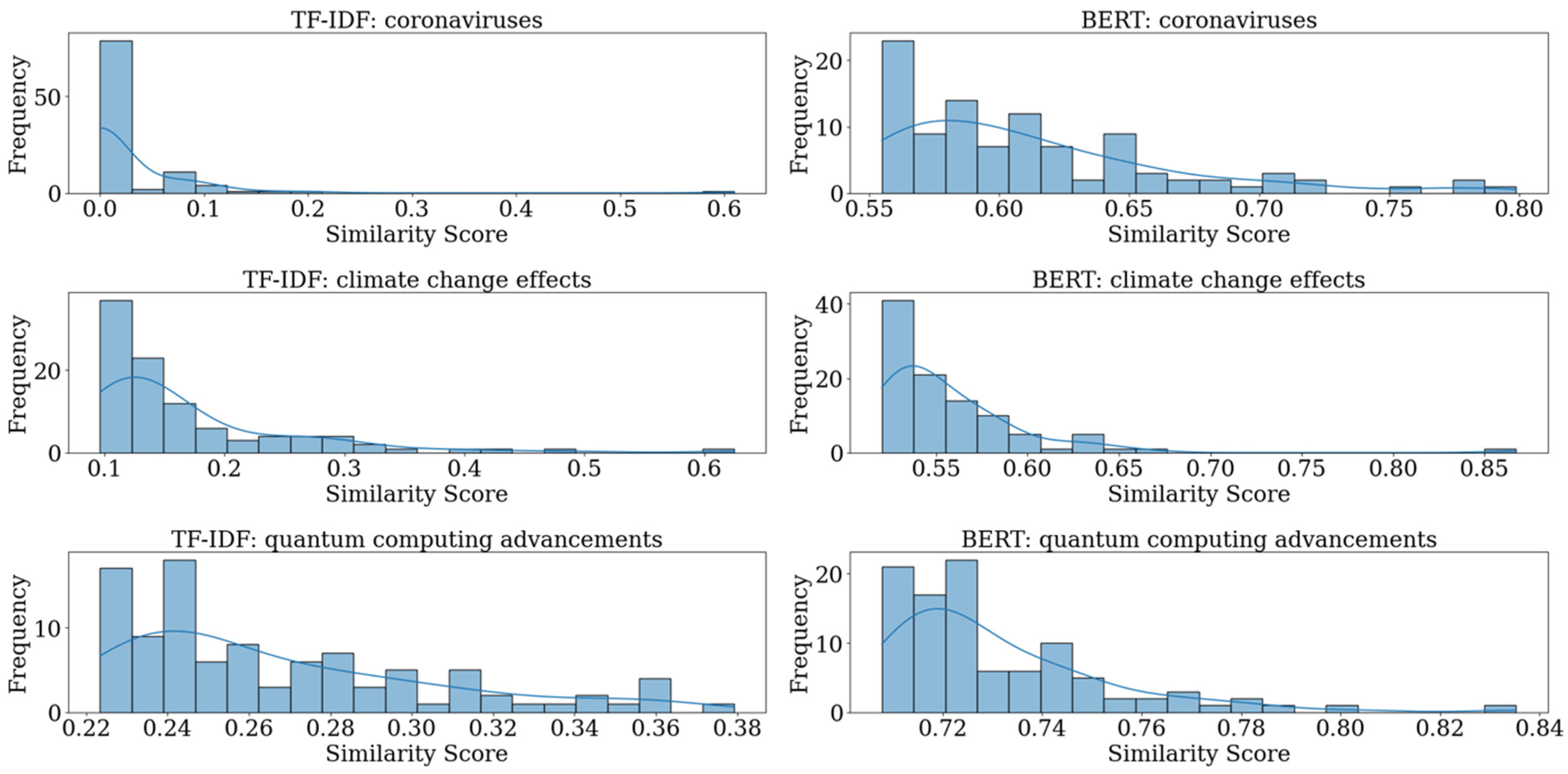
5.1. Evaluation of TF-IDF and BERT Model Performance
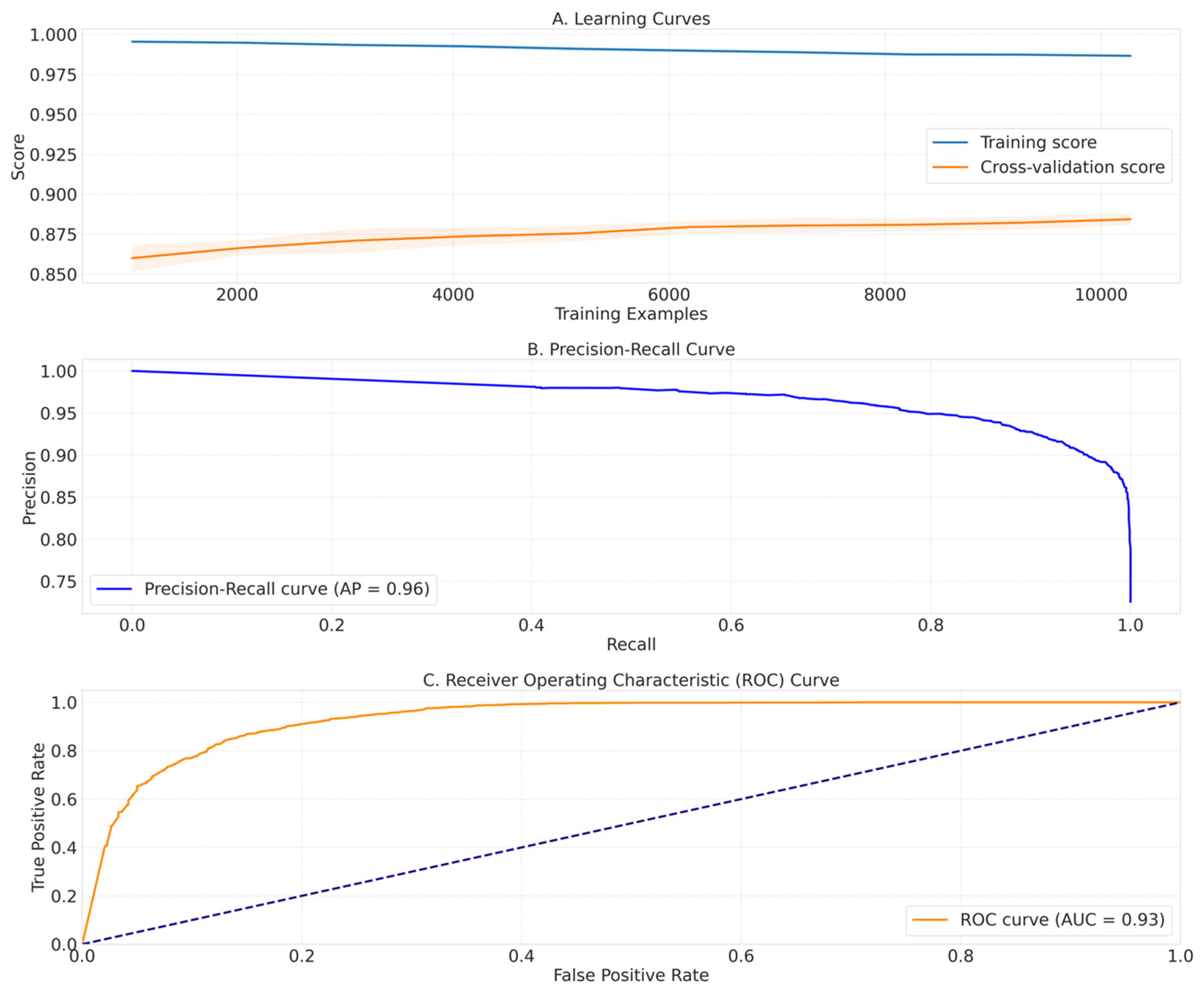
5.2. Evaluation of Random Forest Model Performance
5.3. Random Forest Model Validation
5.4. Class Imbalance Mitigation and Impact Assessment
5.5. Exemplar Result and Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fire, M.; Guestrin, C. Over-optimization of academic publishing metrics: Observing Goodhart’s Law in action. GigaScience 2019, 8, giz053. [Google Scholar] [CrossRef] [PubMed]
- Kelly, J.; Sadeghieh, T.; Adeli, K. Peer Review in Scientific Publications: Benefits, Critiques, & A Survival Guide. EJIFCC 2014, 25, 227–243. Available online: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4975196/ (accessed on 28 March 2025). [PubMed]
- Pal, S. What is Text Similarity and How to Implement it ? MLSAKIIT. Available online: https://medium.com/msackiit/what-is-text-similarity-and-how-to-implement-it-c74c8b641883 (accessed on 28 March 2025).
- Intellica.AI. Comparison of Different Word Embeddings on Text Similarity—A Use Case in NLP. Medium. Available online: https://intellica-ai.medium.com/comparison-of-different-word-embeddings-on-text-similarity-a-use-case-in-nlp-e83e08469c1c (accessed on 28 March 2025).
- Liberti, L.; Lavor, C.; Maculan, N.; Mucherino, A. Euclidean distance geometry and applications. arXiv 2012, arXiv:1205.0349. [Google Scholar] [CrossRef]
- Steck, H.; Ekanadham, C.; Kallus, N. Is Cosine-Similarity of Embeddings Really About Similarity? In Proceedings of the Companion ACM Web Conference, Singapore, 13–17 May 2024; pp. 887–890. [Google Scholar] [CrossRef]
- Neha. A Simple Guide to Metrics for Calculating String Similarity. Analytics Vidhya. Available online: https://www.analyticsvidhya.com/blog/2021/02/a-simple-guide-to-metrics-for-calculating-string-similarity/ (accessed on 28 March 2025).
- Qian, G.; Sural, S.; Gu, Y.; Pramanik, S. Similarity Between Euclidean and Cosine Angle Distance for Nearest Neighbor Queries. In Proceedings of the 2004 ACM Symposium on Applied Computing, in SAC ’04, Nicosia, Cyprus, 14–17 March 2004; Association for Computing Machinery: New York, NY, USA, 2004; pp. 1232–1237. [Google Scholar] [CrossRef]
- Bosker, H.R. Using fuzzy string matching for automated assessment of listener transcripts in speech intelligibility studies. Behav. Res. Methods 2021, 53, 1945–1953. [Google Scholar] [CrossRef] [PubMed]
- Shimomura, L.C.; Oyamada, R.S.; Vieira, M.R.; Kaster, D.S. A survey on graph-based methods for similarity searches in metric spaces. Inf. Syst. 2021, 95, 101507. [Google Scholar] [CrossRef]
- Sammut, C.; Webb, G.I. (Eds.) TF–IDF. In Encyclopedia of Machine Learning; Springer: Boston, MA, USA, 2010; pp. 986–987. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar] [CrossRef]
- Le, Q.V.; Mikolov, T. Distributed Representations of Sentences and Documents. arXiv 2014, arXiv:1405.4053. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Bornmann, L.; Daniel, H. What do citation counts measure? A review of studies on citing behavior. J. Doc. 2008, 64, 45–80. [Google Scholar] [CrossRef]
- Ioannidis, J.P.A. Why Most Published Research Findings Are False. PLoS Med. 2005, 2, e124. [Google Scholar] [CrossRef] [PubMed]
- Kousha, K.; Thelwall, M. Are wikipedia citations important evidence of the impact of scholarly articles and books? J. Assoc. Inf. Sci. Technol. 2017, 68, 762–779. [Google Scholar] [CrossRef]
- Castillo, C.; Mendoza, M.; Poblete, B. Information Credibility on Twitter. In Proceedings of the 20th International Conference on World Wide Web, in WWW ’11, Hyderabad, India, 28 March–1 April 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 675–684. [Google Scholar] [CrossRef]
- Pérez-Rosas, V.; Kleinberg, B.; Lefevre, A.; Mihalcea, R. Automatic Detection of Fake News. In Proceedings of the 27th International Conference on Computational Linguistics; Bender, E.M., Derczynski, L., Isabelle, P., Eds.; Association for Computational Linguistics: Santa Fe, NM, USA, 2018; pp. 3391–3401. Available online: https://aclanthology.org/C18-1287/ (accessed on 28 March 2025).
- Beel, J.; Gipp, B. Google Scholar’s Ranking Algorithm: The Impact of Citation Counts (An Empirical Study). In Proceedings of the 2009 Third International Conference on Research Challenges in Information Science, Fez, Morocco, 22–24 April 2009; pp. 439–446. [Google Scholar] [CrossRef]
- Falagas, M.E.; Pitsouni, E.I.; Malietzis, G.A.; Pappas, G. Comparison of PubMed, Scopus, Web of Science, and Google Scholar: Strengths and weaknesses. FASEB J. Off. Publ. Fed. Am. Soc. Exp. Biol. 2008, 22, 338–342. [Google Scholar] [CrossRef] [PubMed]
- Lu, Z. PubMed and beyond: A survey of web tools for searching biomedical literature. Database J. Biol. Databases Curation 2011, 2011, baq036. [Google Scholar] [CrossRef] [PubMed]
- Retraction Watch. Available online: https://retractionwatch.com/ (accessed on 28 March 2025).
- Nature Editorial. Why retractions data could be a powerful tool for cleaning up science. Nature 2025, 638, 581. [Google Scholar] [CrossRef] [PubMed]
- Gu, J.; Jiang, X.; Shi, Z.; Tan, H.; Zhai, X.; Xu, C.; Li, W.; Shen, Y.; Ma, S.; Liu, H.; et al. A Survey on LLM-as-a-Judge. arXiv 2025, arXiv:2411.15594. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Article Title | Cited | Impact Factor | Altmetric Score | DOI | Retracted | Severity Category |
|---|---|---|---|---|---|---|
| Zika virus: Current concerns in India | 29.0 | 2.7 | 6.6 | 10.4103/ijmr.IJMR_1160_17 | no | good |
| Emergence of H3N2pM-like and novel reassortant H3N1 swine viruses possessing segments derived from the A (H1N1)pdm09 influenza virus, Korea | 17.0 | 4.3 | 8.242 | 10.1111/irv.12154 | no | good |
| ICTV Virus Taxonomy Profile: Virgaviridae | 85.0 | 3.6 | 3.0 | 10.1099/jgv.0.000884 | no | good |
| Taming influenza viruses | 13.0 | 2.5 | 0.5 | 10.1016/j.virusres.2011.09.035 | no | good |
| Down-regulation of the long noncoding RNA-HOX transcript antisense intergenic RNA inhibits the occurrence and progression of glioma | 3.0 | 3 | 1.0 | 10.1002/jcb.30040 | yes | critical |
| Interleukin-6 promotes the migration and cellular senescence and inhibits apoptosis of human intrahepatic biliary epithelial cells | 2.0 | 3 | 1.0 | 10.1002/jcb.30039 | yes | critical |
| MicroRNA-205 acts as a tumor suppressor in osteosarcoma via targeting RUNX2 | 2.0 | 3.8 | 7.33 | 10.3892/or.2021.8106 | yes | critical |
| MiR-132 inhibits cell proliferation, invasion, and migration of hepatocellular carcinoma by targeting PIK3R3 | 1.0 | 4.5 | 0.25 | 10.3892/ijo.2021.5238 | yes | critical |
| Classification Report | ||||
|---|---|---|---|---|
| Class | Precision | Recall | F1-Score | Support |
| 0 | 0.89 | 0.71 | 0.79 | 881 |
| 1 | 0.90 | 0.97 | 0.93 | 2330 |
| Accuracy | 0.89 | 3211 | ||
| Macro Avg. | 0.88 | 0.84 | 0.86 | 3211 |
| Weighted Avg. | 0.89 | 0.90 | 0.89 | 3211 |
| Model | CV F1-Score | Test F1-Score | AUC | Rank |
|---|---|---|---|---|
| Gradient Boosting | 0.9304 | 0.9336 | 0.9477 | 1 |
| XGBoost | 0.9296 | 0.9333 | 0.9452 | 2 |
| Random Forest | 0.9275 | 0.9305 | 0.9377 | 3 |
| Decision Tree | 0.9185 | 0.9266 | 0.8942 | 4 |
| AdaBoost | 0.9061 | 0.9118 | 0.8969 | 5 |
| K-Nearest Neighbors | 0.9055 | 0.9114 | 0.8931 | 6 |
| Neural Network | 0.9052 | 0.9092 | 0.8657 | 7 |
| SVM | 0.8706 | 0.8685 | 0.7956 | 8 |
| Logistic Regression | 0.8485 | 0.8481 | 0.7476 | 9 |
| Naive Bayes | 0.1227 | 0.1286 | 0.5821 | 10 |
| Configuration | Features | Test F1 | Performance Drop |
| Full Model | Citations + Altmetric + Impact | 0.9305 | - |
| Best Two-Feature | Citations + Altmetric | 0.9334 | 0.29% |
| Without Citations | Altmetric + Impact | 0.831 | −10.70% |
| Without Altmetric Score | Citations + Impact | 0.888 | −4.58% |
| Without Impact Factor | Citations + Altmetric | 0.9334 | 0.31% |
| Citations Only | Citations | 0.869 | −6.62% |
| Altmetric Score Only | Altmetric Score | 0.8246 | −11.38% |
| Impact Factor Only | Impact Factor | 0.8348 | −10.29% |
| Approach | F1-Score | Precision (Non-Retracted) | Recall (Non-Retracted) | Precision (Retracted) | Recall (Retracted) | Balanced Accuracy |
|---|---|---|---|---|---|---|
| No Weights (Original) | 0.9305 | 0.8876 | 0.7083 | 0.8975 | 0.9661 | 0.8372 |
| Balanced Weights | 0.9243 | 0.8094 | 0.7809 | 0.9183 | 0.9305 | 0.8557 |
| Custom Weights (Conservative) | 0.9203 | 0.7909 | 0.7855 | 0.9191 | 0.9215 | 0.8535 |
| Custom Weights (Moderate) | 0.9266 | 0.8344 | 0.7548 | 0.9105 | 0.9433 | 0.8491 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Zhang, J.; Chen, W.; Ma, X. An Approach to Trustworthy Article Ranking by NLP and Multi-Layered Analysis and Optimization. Algorithms 2025, 18, 408. https://doi.org/10.3390/a18070408
Li C, Zhang J, Chen W, Ma X. An Approach to Trustworthy Article Ranking by NLP and Multi-Layered Analysis and Optimization. Algorithms. 2025; 18(7):408. https://doi.org/10.3390/a18070408
Chicago/Turabian StyleLi, Chenhao, Jiyin Zhang, Weilin Chen, and Xiaogang Ma. 2025. "An Approach to Trustworthy Article Ranking by NLP and Multi-Layered Analysis and Optimization" Algorithms 18, no. 7: 408. https://doi.org/10.3390/a18070408
APA StyleLi, C., Zhang, J., Chen, W., & Ma, X. (2025). An Approach to Trustworthy Article Ranking by NLP and Multi-Layered Analysis and Optimization. Algorithms, 18(7), 408. https://doi.org/10.3390/a18070408