1. Introduction
With the swift advancement of artificial intelligence technology, reinforcement learning, a significant subset of machine learning, has exhibited remarkable applicability in numerous domains, including automotive systems categorization [
1], object detection [
2], and scene parsing [
3].
Presently, the approaches to behavioral decision-making in autonomous driving are primarily categorized into two types: rule-based decision-making and decision-making based on reinforcement learning [
4]. The finite state machine approach, introduced by Talebpour et al. [
5], is a typical rule-based decision-making method with high stability. Numerous teams participating in the US DARPA Urban Challenge utilized it as the decision-making control system for autonomous vehicles. The rule-based method relies on preset conditions and logic, which can achieve rapid response to specific traffic conditions, but this method has limited flexibility and adaptability when dealing with unknown or complex environments. Bojarski et al. [
6] proposed a decision-making algorithm based on deep learning, which simplifies the complexity of traditional autonomous driving systems by directly predicting control commands from input images and realizes end-to-end control of autonomous vehicles. Conversely, methods grounded in reinforcement learning, particularly those utilizing deep reinforcement learning, can enhance decision-making strategies through continuous environmental learning, demonstrating superior generalization and the capacity to handle intricate driving scenarios.
Among various reinforcement learning algorithms, the Q-learning algorithm [
7] is frequently employed to address a wide range of sequential decision-making problems because of its straightforwardness and efficacy. Nevertheless, issues such as its slow convergence and poor sample efficiency pose limitations on its applicability in real-world complex environments. In recent years, to enhance the efficiency and effectiveness of the algorithm, scholars have introduced the deep Q-network (DQN) [
8], which builds upon the Q-learning framework. By incorporating deep neural networks, DQN markedly improves performance and generalization. However, issues such as inadequate sample utilization and suboptimal training stability persist in the DQN algorithm. Drawing from this, scholars have suggested several enhancement techniques, such as the double deep Q-network (DDQN) [
9], dueling deep Q-network (Dueling DQN) [
10], and Noisy Deep Q-Network (Noisy DQN) [
11]. These improvement methods have made some progress in improving sample efficiency and algorithm stability, but they are still not safe and stable enough in complex scenarios and have not shown a higher upper limit of decision efficiency. Therefore, improving learning efficiency and decision-making quality remains a key focus of the current research. To address issues such as slow convergence and unstable training, this paper utilizes the dueling double deep Q-network (D3QN) [
12], which integrates DDQN and Dueling DQN, as the foundational model for enhancement to achieve an algorithm that converges more rapidly and with greater stability.
Prioritized experience replay (PER) [
13] is a method employed in reinforcement learning (RL) to enhance the efficiency of experience replay [
14]. Experience replay involves accumulating the agent’s experiences—comprising states, actions, rewards, and subsequent states—from its interaction with the environment and subsequently sampling these experiences randomly for training purposes during the training process.
Although algorithms such as DQN, DDQN, and Dueling DQN use uniform random sampling for experience replay, the importance of experience samples can vary significantly. Since the samples in the experience replay unit are continuously updated, if uniform random sampling is used to extract a small number of samples from the experience replay unit as model input, some highly important experience samples may not be fully utilized, thereby reducing the training efficiency of the model. In response to the problems of low data quality and low sample utilization in the experience replay mechanism of previous algorithms, and in combination with the needs of autonomous driving, this paper designs dual prioritized experience replay, DPER, and uses it as the basis for sample classification. It gives different priorities to each experience through dual-layer selection, and based on this, proposes a method based on priority experience replay, DPER.
The main contributions of this paper include the following:
This study presents a streamlined decision-making framework for autonomous vehicles, utilizing a dual-network architecture that separates ego-vehicle and environmental vehicle state processing. The design decouples action selection from evaluation through distinct parameter updating protocols, achieving precise motion control while enhancing system stability. Experimental results confirm its effectiveness in reducing Q-value overestimation and maintaining operational consistency in dynamic traffic scenarios.
The dueling network is incorporated into the double deep Q-network, merging their respective benefits and reconfiguring the original network’s output layer. This integration enhances the driverless car’s capacity to comprehend the current state and refines the precision of action value estimation. By separately assessing the state value and action advantage, the dueling network boosts the accuracy of these estimations. The double deep Q-network further reduces the overestimation bias, making the decision more robust. This structure improves the performance of traditional algorithms at multiple levels.
A new dual-priority experience replay mechanism is proposed. This paper introduces an innovative dual-priority experience replay mechanism that combines TD error priority and segmented sampling priority. The mechanism significantly improves the learning frequency and quality of key states by giving higher priority to recent experience on TD error and dynamically adjusting the state importance on segmented sampling. A comprehensive priority—that is, dual priority—is calculated based on TD error and segmented sampling. Dual-priority experience replay effectively solves the problems of low sample utilization and sparse rewards in traditional experience replay and can more effectively utilize experience replay data in unmanned highway scenarios, especially when dealing with rare but important scenarios (such as high-speed lane changes and emergency braking), which can help the DPD3QN better learn these key decisions.
The remainder of this paper is organized as follows.
Section 2 introduces related work in the field of deep reinforcement learning and autonomous driving.
Section 3 presents the proposed DPD3QN method, including the network structure and dual-priority experience replay mechanism.
Section 4 describes the simulation environment and experimental setup.
Section 5 provides the simulation results and comparative performance analysis. Finally,
Section 6 concludes this study and outlines future research directions.
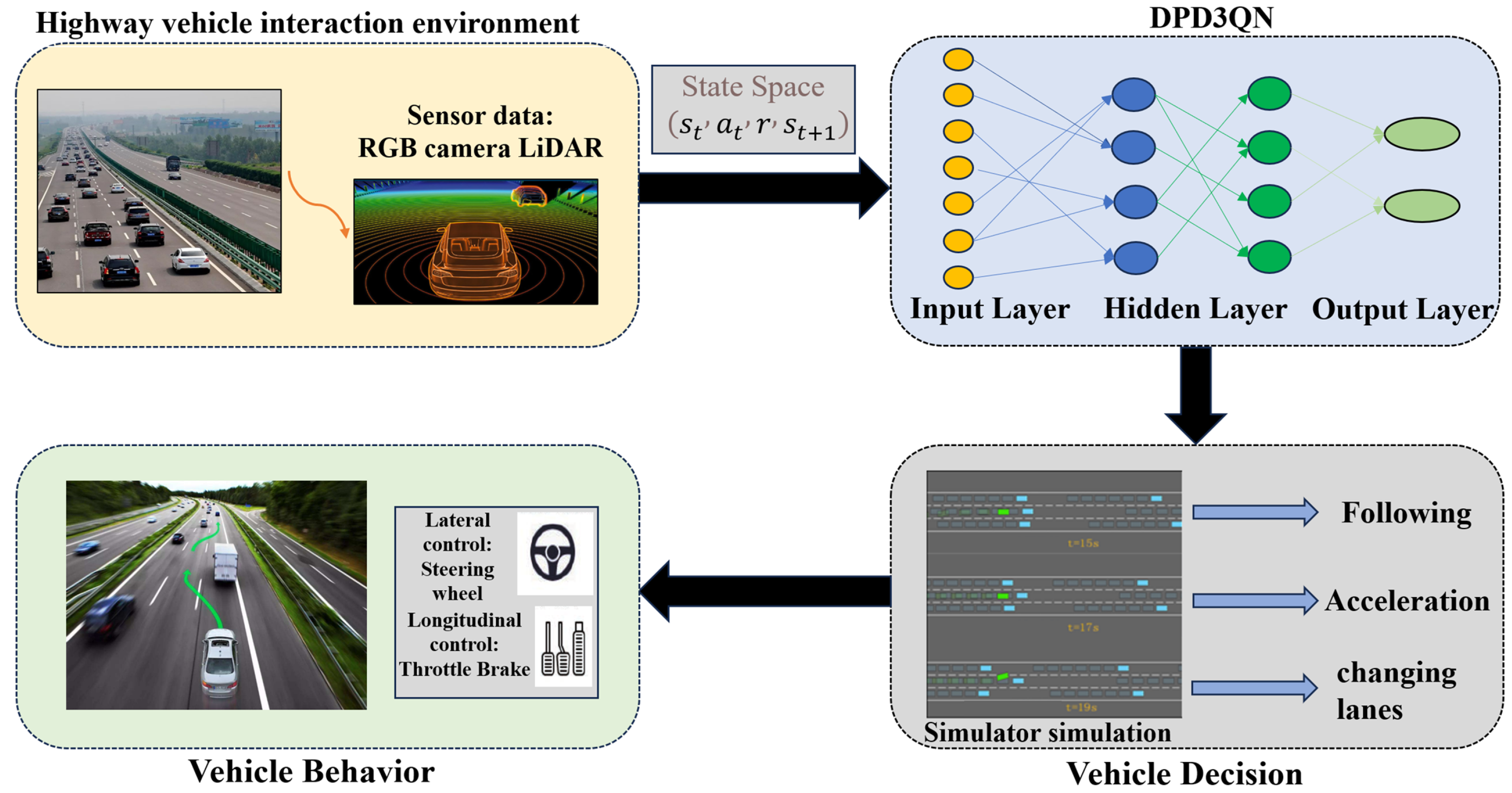
3. DPD3QN
To enhance decision-making efficiency and address the limitations of uniform experience replay in the existing algorithms, this section proposes a dueling double deep Q-network (D3QN) integrated with a dual-priority experience replay mechanism (illustrated in
Figure 2), which is then trained and tested in a highway scenario. Specifically, a four-lane highway simulation environment is created, and a hierarchical structure is used to control the movement of surrounding vehicles. In this structure, high-level modules determine general driving intentions—such as lane keeping, lane changing, or overtaking—while low-level modules handle specific motion control tasks, like acceleration, deceleration, and steering. This layered design improves modularity and enables more realistic and flexible traffic behavior modeling. The autonomous driving vehicle’s sensors capture real-time environmental information from the current scene and input the state data into the experience replay pool. This state is then passed to the dueling double deep Q-network. The input layer of the neural network processes the state information through intermediate layers, and the output layer translates the computed values into potential actions within the specified context. The bottom-level controller then selects and executes the optimal action based on this output.
3.1. Network Structure
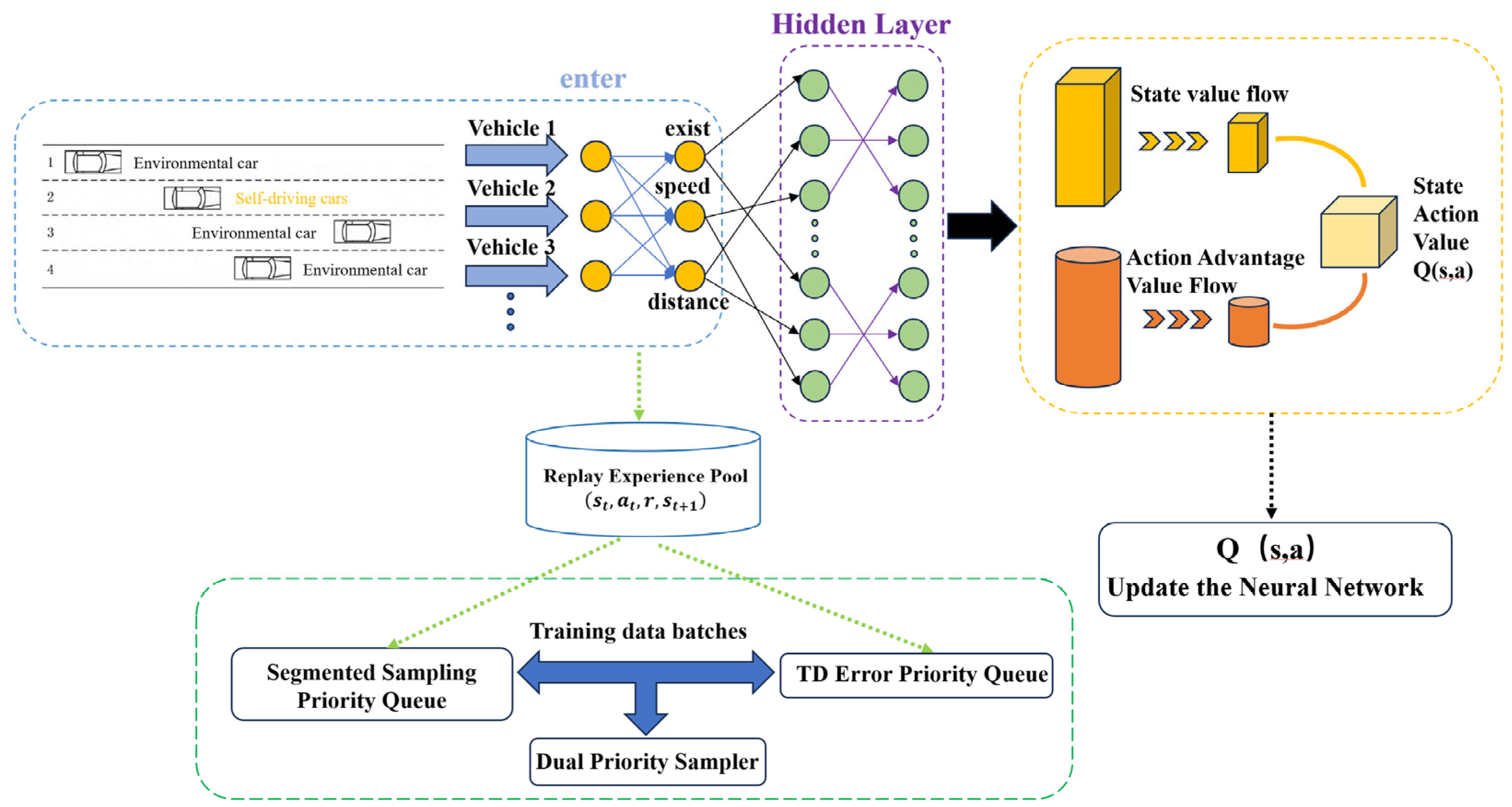
DPD3QN is a dueling double deep Q-network that integrates dual-priority experience replay; its structure is shown in
Figure 3. The primary objective is to enhance the accuracy of state and action estimations via the dueling network architecture, and to improve sample efficiency and expedite the training process through a dual-priority experience replay mechanism. This approach is especially well-suited for sequential decision-making tasks, such as autonomous driving.
Figure 2 shows a reinforcement learning architecture of a dueling double deep Q-network based on dual-priority experience replay, aimed at enhancing learning efficiency and decision-making precision. The entire procedure can be segmented into the subsequent components:
In the input module, this paper employs the state information from multiple vehicles, encompassing attributes like vehicle presence, speed, and distance. Each vehicle’s characteristics are vectorized to create a state representation, which is then fed into the neural network’s hidden layer.
The experience replay buffer stores the experience tuples generated by the agent as it interacts with the environment. Utilizing this replay buffer efficiently disrupts the temporal correlation among data samples, enhances sample utilization, and mitigates overfitting. This module ensures the stability of the training process by storing past experience data.
Priority sampling method: To enhance learning efficiency even more, the replay pool adopts a dual-priority sampling mechanism. First, the TD error is used to measure the importance of the sample, and the empirical samples are sorted through the priority queue, giving priority to samples with larger errors for training. At the same time, a segmented sampling mechanism is used to extract samples from different priority queues to ensure the diversity of the training samples. This method can accelerate model convergence and improve sample utilization.
Neural network structure: As shown in
Figure 3, the hidden layer of the network is responsible for extracting high-dimensional features of the input state. Following the hidden layer, the network bifurcates into two streams: one for state value and another for action advantage. The state value stream V assesses the worth of the current state
, whereas the action advantage stream A evaluates the relative benefits of each action
within this state. This design is based on the dueling network structure, which enables the model to better distinguish action choices under different states, thereby improving decision quality. Ultimately, the two streams are combined to produce the Q-value, denoted as
, which the agent utilizes to determine the optimal action.
Q-network update: The network parameters are adjusted by computing the discrepancy between the predicted Q-value and the target Q-value. Specifically, the TD error is determined using the Bellman equation to inform the modification of the network weights. This procedure is iterated numerous times, enabling the model to progressively converge and allowing the agent to learn the optimal strategy in a dynamic environment.
3.2. Priority Experience Replay
3.2.1. Prioritization Based on TD Error
Experience replay was first proposed by Schual [
13] and applied to DQN. This method determines the importance of each sample based on temporal difference (TD). Samples with higher priority are more likely to be selected for training. This priority can be calculated based on TD error. TD error signifies the discrepancy between the anticipated value and the actual reward value. Its calculation formula is shown in Equation (17):
where
is the immediate reward,
is the discount factor,
is the target network output, and
is the output of the current network. The sum of the two TD errors generated by the dual networks and the immediate reward is used as the basis for dividing the importance. The empirical priority value
can be defined as Equation (18):
where
is a small constant that prevents the priority of the data from being zero. The hyperparameter
determines the degree of influence of the TD error
on the sample selection and controls the sensitivity to the error during sampling. Experience with high priority will have a greater chance of being sampled. The larger the TD error, the higher the priority. In the early training process, the TD error may be inaccurate. In light of the aforementioned factors, it is necessary to decrease the priority weight when selecting training data during the initial phase of the training process. At the same time, in order to ensure that even samples with extremely low priority can be selected, we add a bias to the priority compared to the traditional priority approximate distribution
[
13]. In our experiments, the value of the bias term
b is set to 0.01, which helps avoid zero probability and ensures sufficient sample diversity. The approximate distribution of an experience sample being taken is improved to Equation (19):
The sampling probability for the i-th experience is determined by the parameter α through the priority mechanism, where α serves as a balancing coefficient between prioritized and uniform sampling. Specifically, α ∈ [0,1] controls the degree of priority emphasis in the probability distribution , which represents the priority of the i-th transition—typically defined based on the magnitude of its temporal difference (TD) error, such as pi = ∣δi∣ + ε, where δi is the TD error and ε is a small positive constant to ensure a non-zero probability. When α approaches 1, the selection process predominantly follows the temporal difference error ranking, while values near 0 implement conventional random sampling. To mitigate potential overfitting caused by repeatedly selecting similar high-priority transitions, the algorithm incorporates a baseline probability adjustment through hyperparameter ε. This safeguard prevents the sampling distribution from becoming excessively skewed toward historically high-priority experiences, thereby maintaining the diversity of training samples and improving generalization capability. The parameter α essentially operates as a continuous interpolation regulator between two sampling paradigms: complete priority dominance (α = 1) and pure stochastic selection (α = 0).
Since the agent tends to replay experiences with higher TD errors more frequently, it will undoubtedly change the frequency of state visits. This change may cause the training process of the neural network to oscillate or even diverge [
19]. To solve this problem, this paper uses importance sampling weights, as shown in Equation (20), when calculating weight changes:
where β represents the parameter governing bias correction in prioritized sampling, and N denotes the total capacity of the experience replay buffer. During agent–environment interactions, β is progressively annealed from its initial value to 1. To counteract sampling bias, the loss function integrates importance sampling weights (β-adjusted), and gradients are optimized to minimize distortions caused by prioritized experience selection.
3.2.2. Prioritization Based on Segment Sampling
Based on the TD error-based priority, this paper further introduces Stochastic Prioritization [
20], which is inspired by the mini-batch gradient descent [
21] in the Deep Deterministic Policy Gradient (DDPG) deep reinforcement learning algorithm. By dividing the data into multiple small batches, segmented sampling can achieve efficient learning and stability in complex environments. This method effectively improves the utilization of data in the experience pool and enables samples of different priorities to be effectively extracted, thereby accelerating the convergence of the model and avoiding overfitting or insufficient data utilization in a high-dimensional continuous action space.
The specific steps of segmented sampling priority are as follows: First, the features are divided into two main segments: the position segment, including the distance to the preceding vehicle or the relative lane position, and the speed segment, covering the vehicle speed range. The data of the entire experience replay buffer are divided into different segments according to these features. Then, the segment to which each sample belongs is defined as and a weight is set for each segment.
For the position segment, the priority can be set according to the scarcity and importance of the preceding vehicle distance. In certain specific distance ranges (such as close or far distances), the number of samples is small, and a higher weight should be given to ensure that the scenes of these critical distances are fully paid attention to. This diversity can be captured by measuring the standard deviation of samples within a position segment. The specific weight setting can be expressed as Equation (21):
where
is the weight of the position segment
,
is the number of samples in segment
, and
is the standard deviation of the distance to the preceding vehicle in segment
. A higher standard deviation indicates that the scene changes more within the segment, so more attention is needed. The function g(⋅) is a mapping function that combines the number of samples and the variability in position to determine the importance of the position segment. It typically increases with larger
and may decrease or normalize based on
, thereby balancing between data abundance and scene dynamics.
Meanwhile, the weight of the speed segment can be expressed as Equation (22):
where
is the weight of speed segment
and
variability is determined by the standard deviation of the speed measurements within segment
. In addition, emergency situations on highways (such as emergency braking or avoidance) are more important than ordinary driving scenarios, so these segments are artificially given higher weights. The function h(⋅) is similar to g(⋅), serving as a mapping from the speed variability and the segment size to a scalar importance value, emphasizing segments with abrupt speed changes or rare events.
The weight of ordinary driving can be set to , the weight of emergency braking to , the weight of lane change operation to , and the weight of close driving to . By setting priorities in this way, we ensure that important scenarios are fully paid attention to during training, thereby improving the overall performance and adaptability of the model.
3.2.3. Dual Priority Calculation
Based on the TD error priority and the segment sampling priority, a comprehensive priority is calculated—that is, a dual priority. For each sample
, its comprehensive priority
can be calculated by combining the TD error priority and the segment weight. The comprehensive priority can be expressed as Equation (23):
where
is the TD error priority of sample
,
and
are the weights of the position information and velocity information segments to which the sample belongs, respectively, and
and
are hyperparameters that control the influence of their respective weights. Based on the dual priority
, we then perform weighted sampling to ensure that the model can pay more attention to important samples. Specifically, the sampling probability of sample
can be determined by the following Equation (24):
where the numerator
is the comprehensive priority of sample
and the denominator
is the sum of the comprehensive priorities of all samples. Thus, the likelihood of sample
being selected is proportional to its overall priority.
It is important to note that α + β is not strictly constrained to equal 1. This design provides greater flexibility, allowing the relative importance of TD error and segment-based priority to be dynamically adjusted during different training stages. For example, in the early stages of training, when the model has not yet learned an effective policy and the TD error tends to fluctuate significantly, a higher α can be used to emphasize learning from large-value errors and accelerate policy correction. In contrast, during the later stages—when the policy becomes more stable—β can be increased to direct the model’s attention to rare but critical driving scenarios, such as high-speed lane changes or emergency braking. This helps improve the generalization and real-world adaptability of the learned policy.
Moreover, since both the TD error and the segment weights are not inherently bounded, the combined priority value may theoretically exceed 1. To address this, we apply a normalization process during the sampling stage by dividing each priority by the total priority sum , resulting in the normalized sampling probability. This ensures that each sample is selected according to its relative importance, regardless of the absolute value. At the same time, it prevents high-priority samples from dominating the training process, thereby reducing the risk of overfitting or biased learning.
This approach not only maintains training efficiency but also enhances the model’s ability to learn from diverse types of scenarios with increased robustness. By adjusting α and β, researchers and developers can fine-tune the training process based on specific task demands and environmental complexities. In future versions, we also plan to include a schematic illustration and a numerical example to further improve the transparency and interpretability of the dual-priority formula. A simple calculation example is added in this section to enhance the understanding of the formula, as shown in
Table 1.
This example clearly demonstrates how to combine the TD error and semantic segment weights to compute the comprehensive priority and normalize it into a sampling probability.
This priority sampling method, which combines TD error and segment weights, namely, dual-priority sampling, can more effectively utilize experience playback data in unmanned highway scenarios, especially when dealing with rare but important scenarios (such as high-speed lane changes and emergency braking), which can help the DPD3QN better learn these key decisions and ensure the stability and convergence speed of the training process.
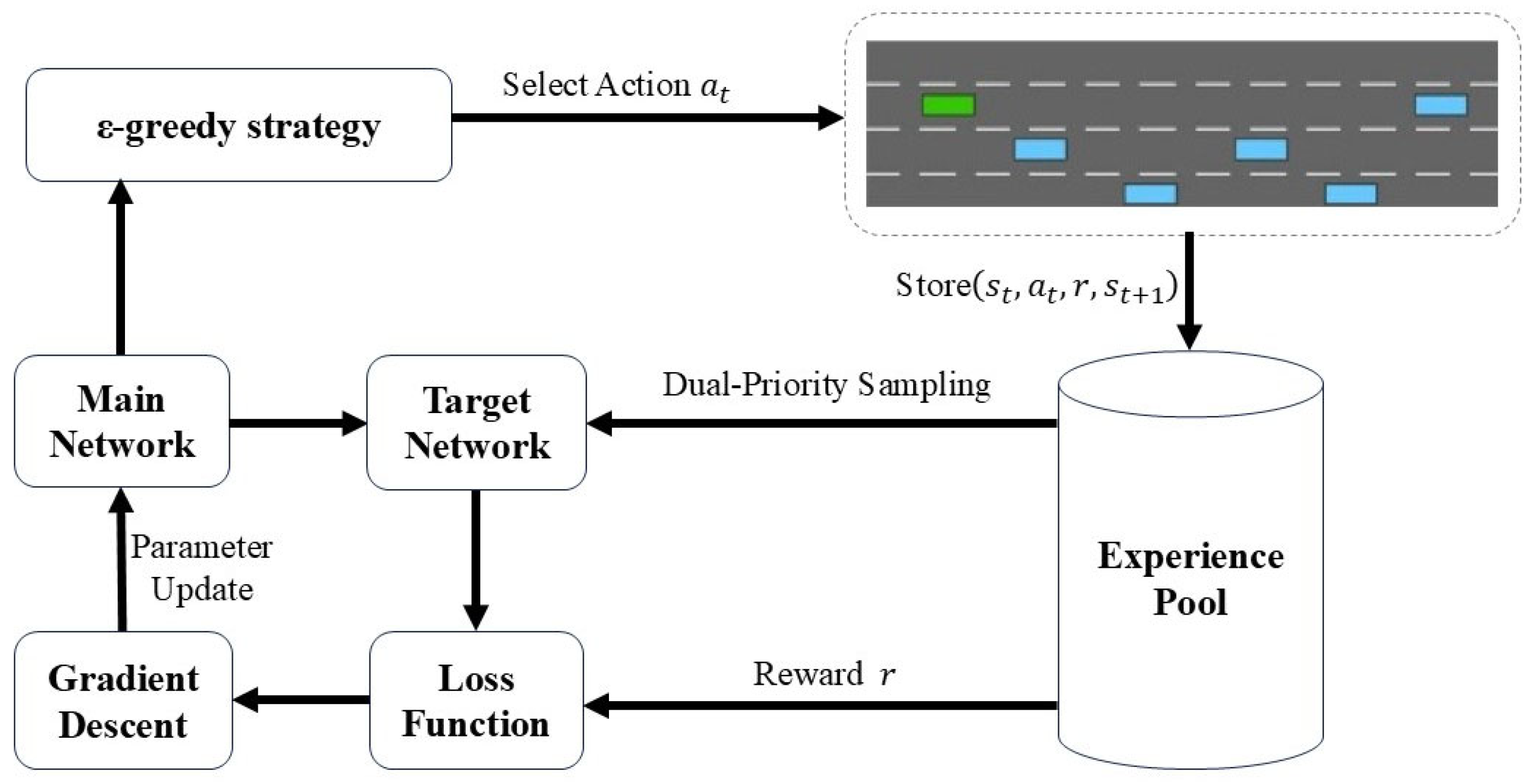
Based on the integration of the dueling network and the DDQN structure, this paper uses dual-priority experience replay to update the experience pool and update the parameters of the neural network, as shown in
Figure 4.
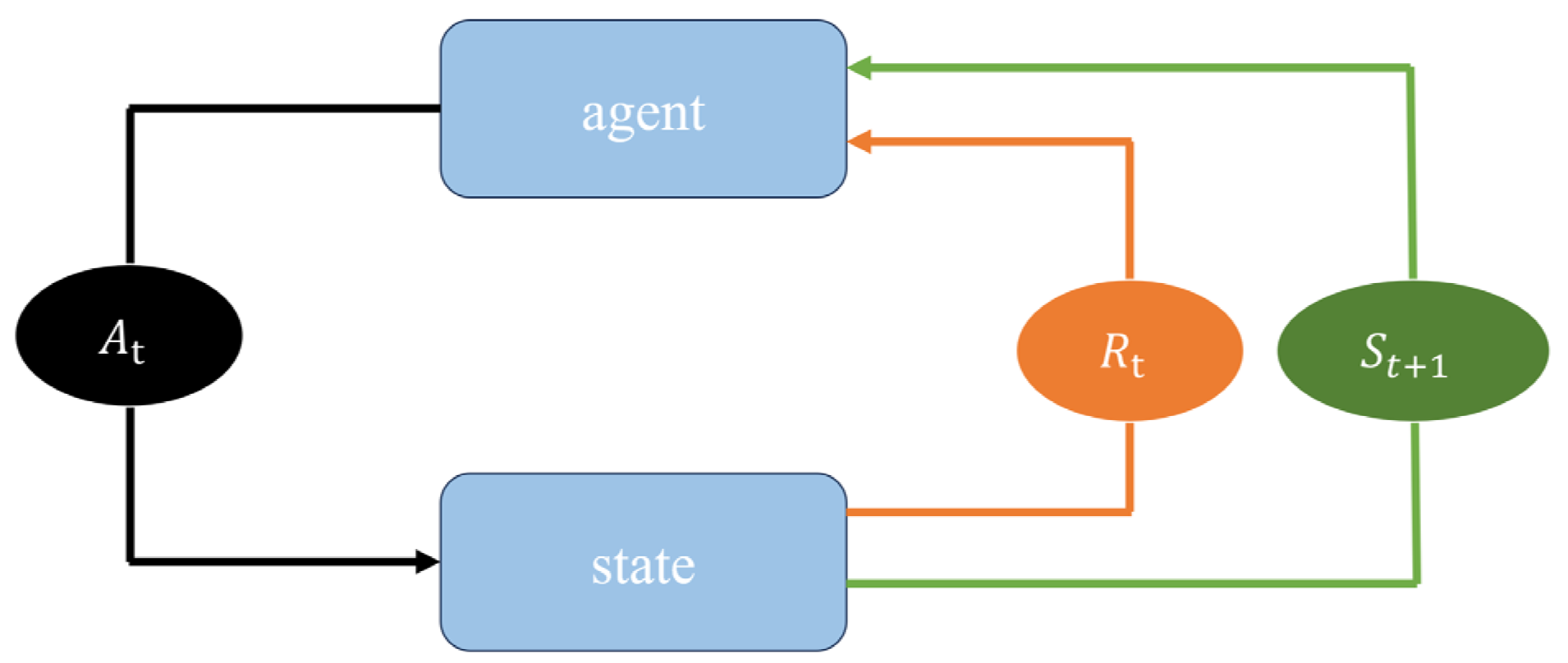
During the autonomous driving process, the system first selects the current action
from the main network using the ϵ-greedy strategy [
22]. This strategy strikes a balance between exploration (selecting random actions) and exploitation (selecting the best action), exploring new strategies by randomly selecting actions with a small probability and selecting the best action evaluated by the main network at other times. Once the action has been chosen, the system executes
and then engages with the simulated driving scenario and interacts within it to generate the next state
and reward value
. This information (current state
, action
, reward
, and next state
) is stored in the experience pool. The experience pool is used to record multiple historical data for experience playback during training. The system extracts samples from the experience pool and calculates the TD error of these samples through the target network to calculate the loss function. The TD error reflects the gap between the prediction and the actual reward and is the core optimization target of training. The main network’s parameters are refined via the gradient descent method, employing the backpropagation algorithm to reduce the loss function, thereby enhancing the network’s predictive performance progressively. To ensure stability, the target network’s parameters are not adjusted in real time but are periodically updated to match those of the main network. This structure helps prevent the target value from fluctuating too much, thereby improving the stability of training. The system repeats the above process continuously, gradually updating the network parameters and improving the strategy, thereby achieving more intelligent decision-making in unmanned driving scenarios.
The ϵ-greedy [
22] strategy facilitates the equilibrium between exploration and exploitation throughout the reinforcement learning training phase, ensuring that the agent both investigates novel states and actions and leverages accumulated knowledge to choose the most advantageous action. The implementation proceeds as follows: at each time step, an action is chosen randomly with probability ϵ, while the action deemed optimal by the current Q-network is selected with probability 1 − ϵ. Following a set number of training iterations, the approach is assessed, and adjustments are made to the exploration strategy or algorithm parameters in accordance with the evaluation outcomes. The exploration process usually gradually reduces the value of ϵ so that the agent explores more in the early stage of training and exploits more in the later stage of training. The algorithm is shown in Equation (25):
where
is the exploration rate at time step t,
is the minimum value of the exploration rate,
is the decay factor of the exploration rate, and
is the exploration rate at time step t − 1. Equation (25) indicates that at each time step t, the exploration rate ϵ will decay with a fixed decay factor
but will not fall below the preset minimum value
.
4. Experiment and Its Simulation Environment
This section analyzes the operational framework for multi-lane highway environments and the hierarchical control architecture regulating vehicle motion across lateral (steering) and longitudinal (acceleration/braking) axes. At the actuation level, proportional-derivative (PD) controllers enable accurate trajectory tracking and speed adjustment. The experimental setup leverages the Highway-env platform [
23], a simulation tool integrated with OpenAI Gym, to model a four-lane highway environment. This platform emulates real-world traffic dynamics, facilitating structured testing of autonomous driving algorithms under diverse yet controlled highway scenarios. Parameters such as traffic flow variability and control precision are systematically configured to validate strategy robustness.
4.1. Highway Environment
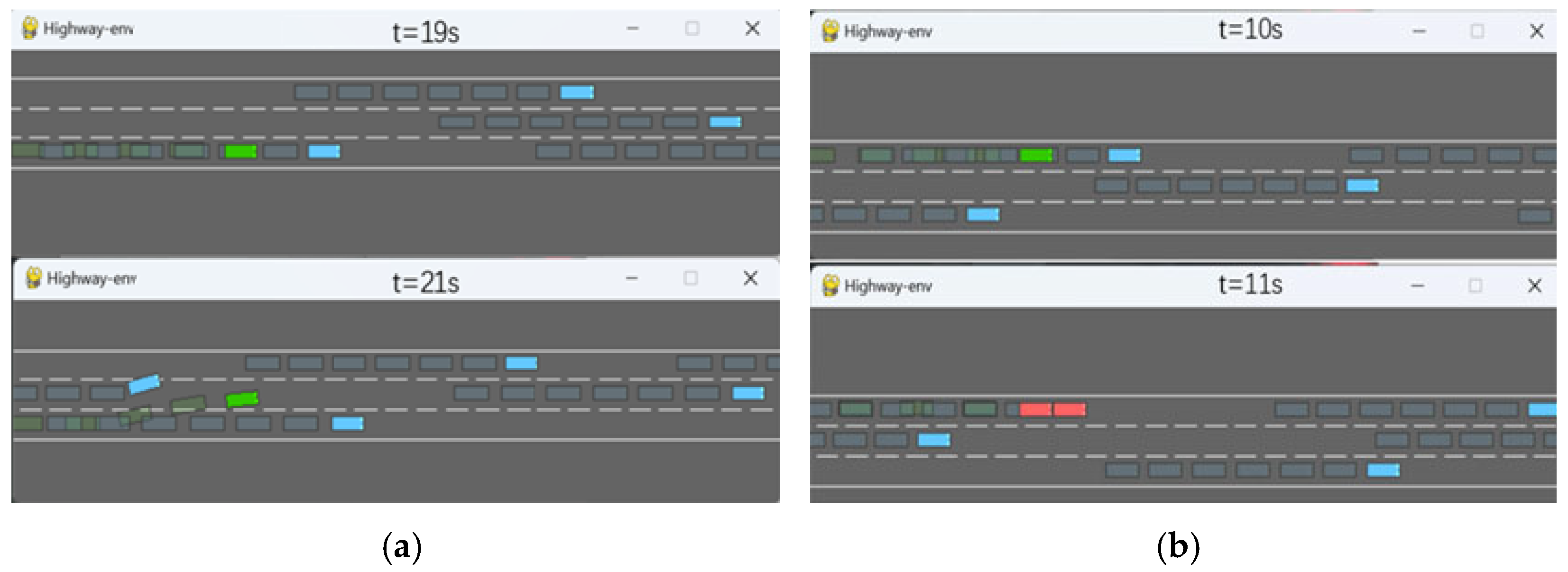
This section analyzes operational decision-making frameworks for autonomous navigation, focusing on achieving specific navigational goals through strategic action sequences. Within the controlled expressway environment, these core operational modalities manifest as propulsion adjustments (speed modulation), lateral maneuvers (lane transitions), and velocity maintenance. The simulation environment is shown in
Figure 5. The experimental setup adopts a dual-agent system, consisting of a self-driving vehicle and several environment vehicles that mimic human driving behavior. All vehicles operate based on the previously mentioned motion model and environmental configuration, aiming to study the interactive dynamics under standardized highway conditions. The investigation employs a parametric analysis approach, quantifying control responses through measurable kinematic variables including relative velocities, inter-vehicle spacing, and trajectory deviation metrics.
To enhance the realism and unpredictability of the driving scenario, this paper randomly determines the initial speed and starting position of the environmental vehicle. This practice helps to simulate the actual driving situation more realistically and enhance the adaptability of the autonomous vehicle in complex environments. In addition, in order to better imitate human driving habits, we set the autonomous vehicle to drive as far to the right as possible when there is no need to overtake. These settings are designed to improve the realism of the driving scene.
Prior to initiating the driving task, 60 environmental vehicles are randomly positioned on a four-lane highway ahead of the autonomous vehicle. Each simulation cycle, termed a round, commences with the autonomous vehicle’s activation and concludes upon either its successful completion of the journey within a 30 s timeframe or collision with surrounding vehicles. Vehicle configurations follow standardized parameters: all units measure 5 m in length and 2 m in width. Environmental vehicles are assigned randomized initial speeds between 20 and 30 m·s
−1, while the autonomous vehicle starts at 25 m·s
−1. Operating at a 10 Hz simulation frequency [
24], rounds are automatically reset upon meeting termination criteria, ensuring iterative scenario testing under controlled temporal constraints. For the specific settings of vehicle parameters, see
Table 2.
4.2. Vehicle Behavior Control
In this research, the environmental vehicles are governed by the intelligent driving model (IDM) [
25] and the overall braking model (MOBIL) [
26]. In addition, this paper uses deep reinforcement learning methods to control the behavior of the autonomous driving vehicle.
The IDM is a common microscopic model used to control the longitudinal behavior of the vehicle. The model accomplishes vehicle following and collision prevention by assessing the spacing and relative velocity between vehicles. Generally, the longitudinal acceleration in the IDM can be described by Equations (26) and (27).
The IDM defines vehicle dynamics through the following critical variables: denotes the current velocity of the subject vehicle, while specifies the peak acceleration capability. The parameter quantifies the gap distance to the leading vehicle, and indicates the desired cruising speed. A nonlinear velocity regulation coefficient, denoted as δ, governs speed adaptation responsiveness. Safety constraints are enforced via T, a temporal safety buffer defining the minimum acceptable time-to-collision threshold, and captures the relative velocity differential between vehicles. The model further incorporates as the mandatory minimum inter-vehicle spacing and as the maximum emergency braking capacity. The parameters are configured as follows: the maximum acceleration is 6 m·s−2, the speed index parameter is 5, the required time interval T is 1.5 s, the maximum deceleration is −5 m·s−2, and the minimum distance is 12 m.
By contrast, the MOBIL model governs the vehicle’s decision to change lanes laterally. This model takes into account the safety and incentive criteria between vehicles to ensure that when changing lanes, the new following vehicle does not cause a collision risk due to sudden deceleration. Within the mobility-oriented lane-changing decision framework, the kinematic response of the target lane’s following vehicle is quantitatively evaluated through Equation (28), where the critical parameter
characterizes the maximum emergency braking intensity imposed on the following vehicle during lane changes. To ensure operational safety, the system employs a dual-layer constraint mechanism: Equation (29) rigorously defines the acceleration threshold
for safety criteria, which holistically integrates vehicular dynamic constraints and traffic flow stability requirements. This threshold enables optimal decision-making by dynamically balancing traffic throughput efficiency and risk mitigation requirements.
The coordinated velocity optimization mechanism, governed by Equations (28) and (29), ensures systematic speed improvements for the ego vehicle, its immediate follower, and downstream traffic participants in both original and target lanes. Within the MOBIL decision framework, critical operational parameters are calibrated as follows: the social compliance coefficient (p = 2 × 10−4) modulates cooperative interaction intensity between vehicles, while the safety-critical deceleration boundary ( = 2.5 m·s−2) establishes emergency braking limits to prevent collision risks. Concurrently, the maneuver benefit threshold ( = 0.25 m·s−2) enforces a minimum acceleration advantage requirement for lane-change authorization.
4.3. Vehicle Motion Control
Upon completion of the vehicle motion decision process, the lower control layer primarily governs the vehicle’s longitudinal and lateral movements via proportional and proportional-differential controllers [
27]. The longitudinal motion is managed by the proportional controller with acceleration, which is mathematically defined as Equation (30), where
denotes the vehicle’s present longitudinal acceleration,
signifies the vehicle’s current speed,
is the set speed, and
represents the controller’s proportional gain:
In the context of lateral movement, the proportional-derivative controller governs the vehicle’s lateral position. Its expression is characterized as presented in Equations (31) and (32), where
is the lateral velocity command,
is the position gain, and
is the lateral position of the vehicle relative to the centerline of the lane:
In this scenario, all environmental vehicles realize their behavior and motion management through the above two-layer control framework.
4.4. Experimental Parameter Settings
This experiment assumes that the autonomous vehicle can sense the 10 nearest environmental vehicles within 250 m before and after its position and accurately obtain the distance and speed information of these vehicles relative to the autonomous vehicle, which is used as an important part of the environmental state. The definition of its environmental state is Equations (33) and (34):
The policy update frequency is set to 1 Hz. The road in the experiment is divided into four lanes, and the surrounding environment contains 50 other vehicles. The discount factor γ is set to 0.95, indicating that future rewards decay exponentially, and the learning rate α is 0.0002, which controls the step size of the state change in each update. Both the value network and the advantage network feature layers with 64 neurons each, defining the network’s width. The training process lasts for 5000 rounds, during which ϵ is gradually reduced from 1 to 0.05. As the training progresses, exploration is reduced, and action selection is based more on the currently learned strategy.
The reward function
consists of the optimal control goal, which is to avoid collisions during driving and drive in the right lane as fast as possible. To achieve this control goal, the round reward function is set as shown in Equation (35):
where
∈ [0,1] (0 means no collision, 1 means collision),
is the speed reward,
∈ [24,30], and L is the lane position.
6. Conclusions
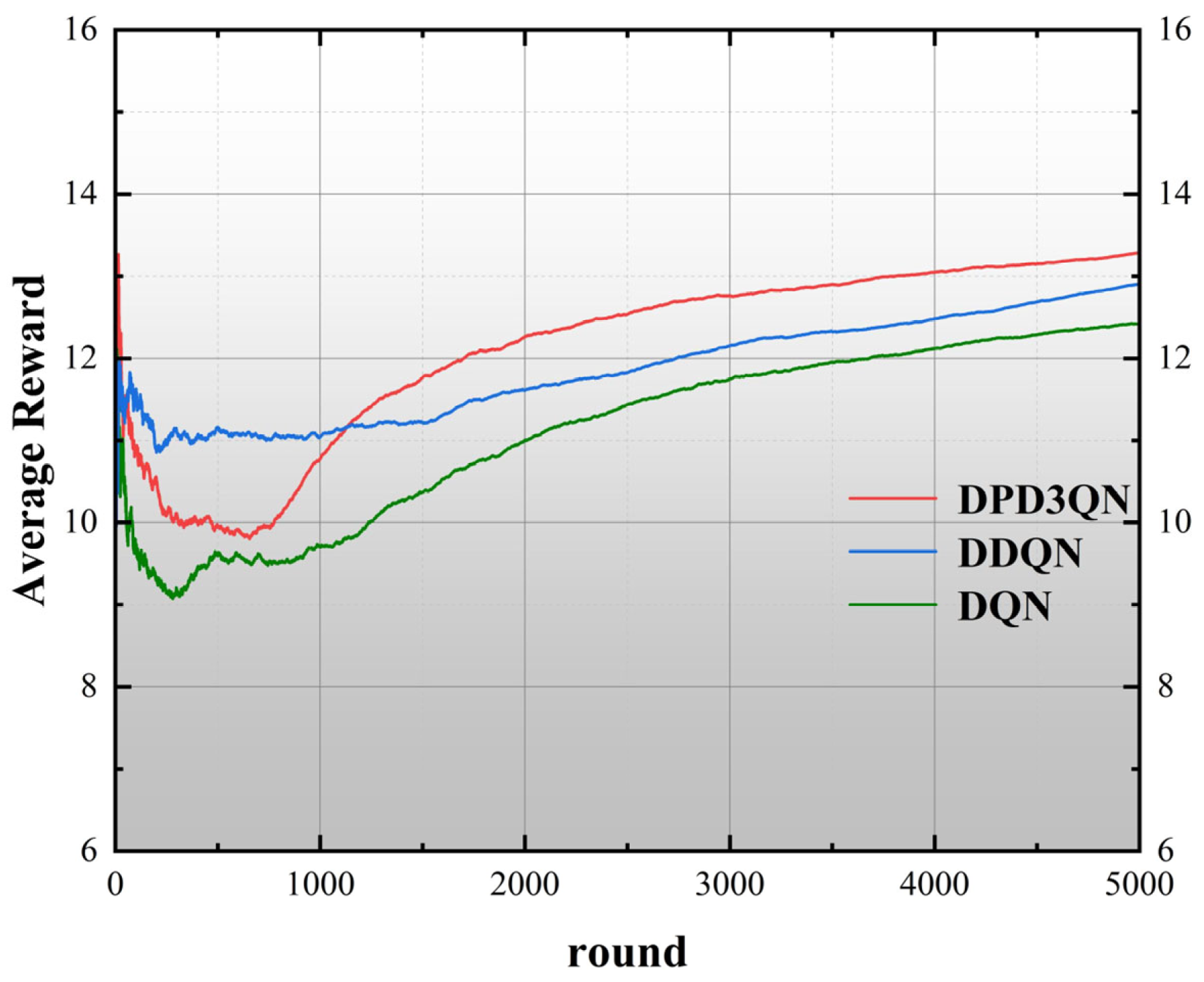
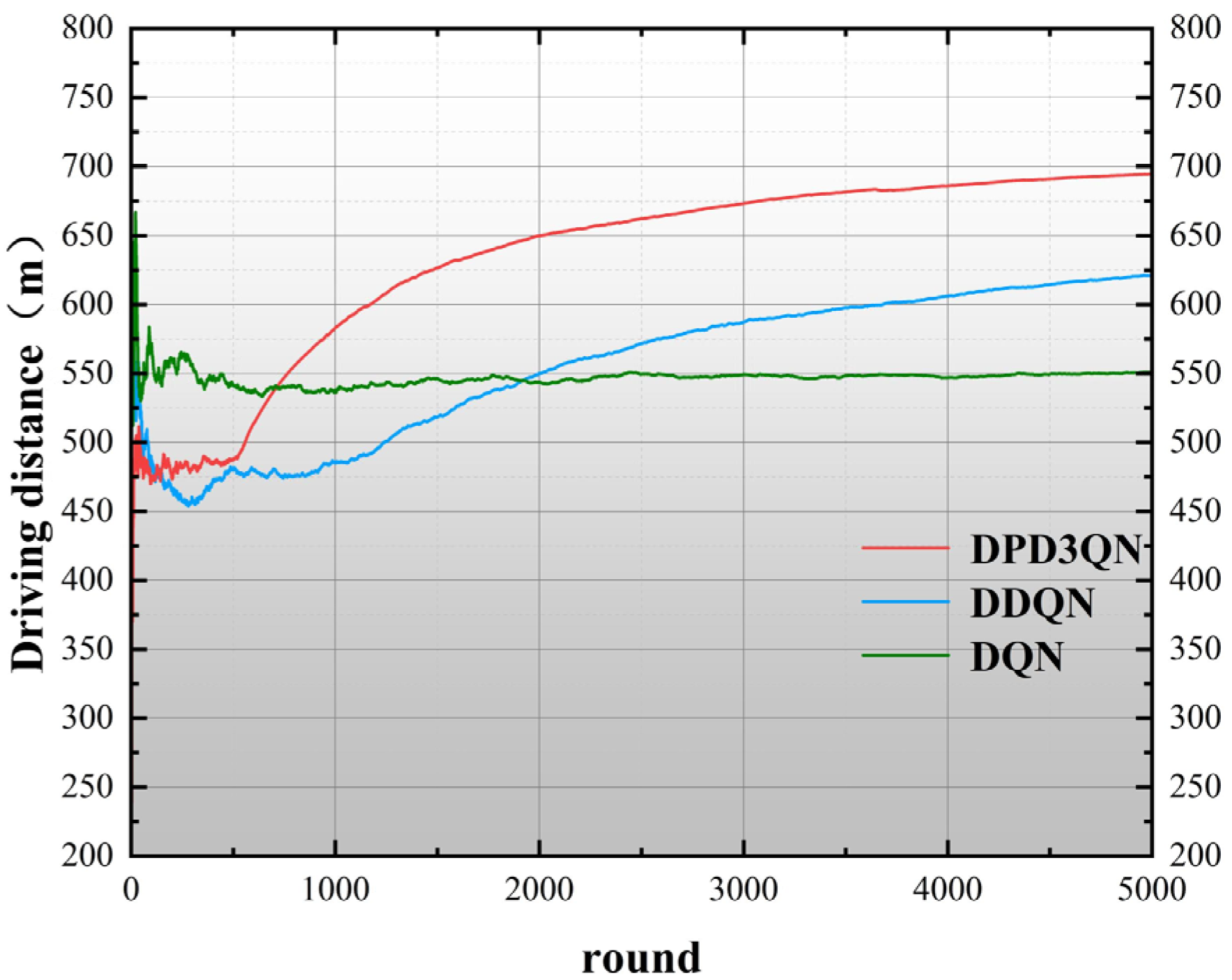
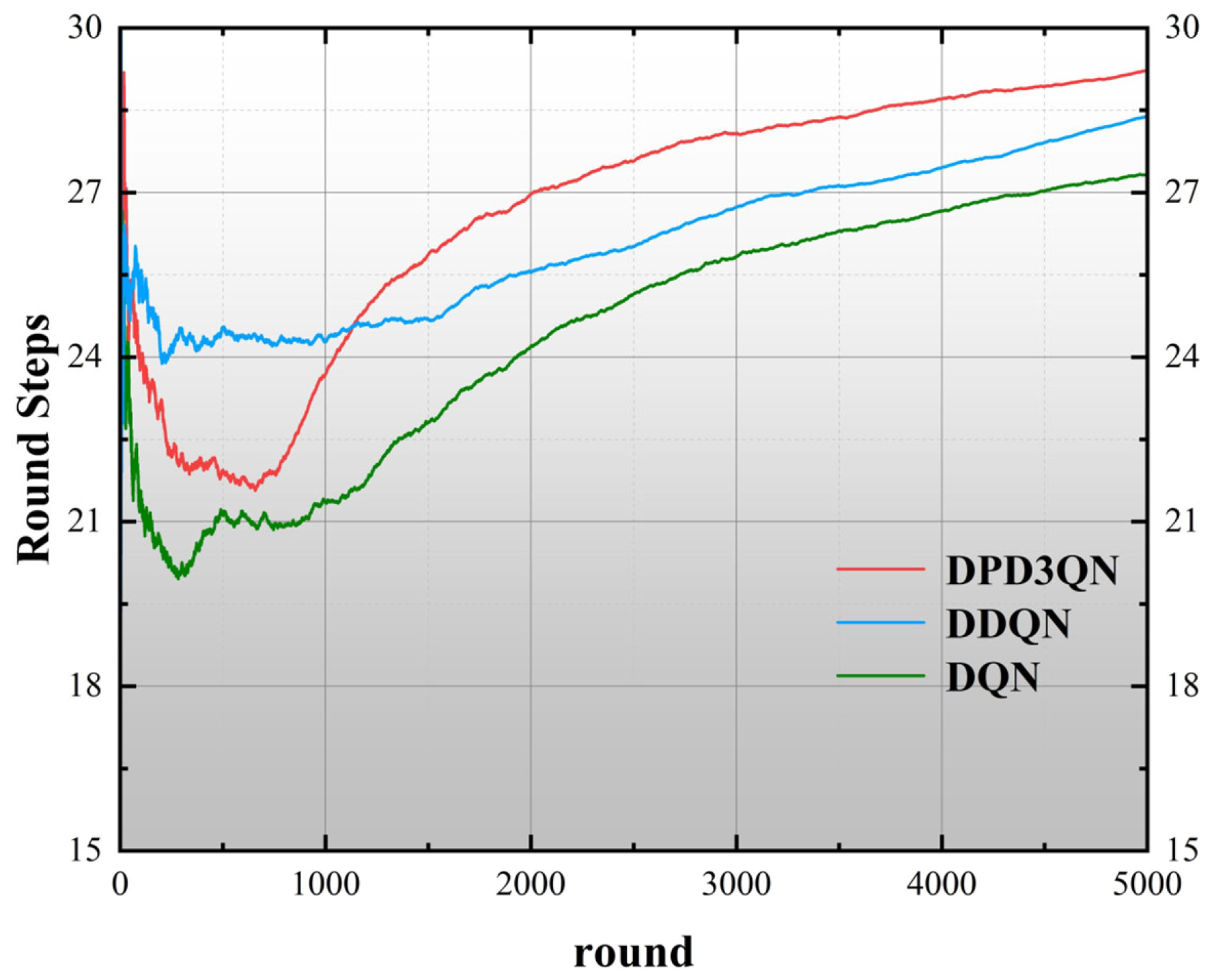
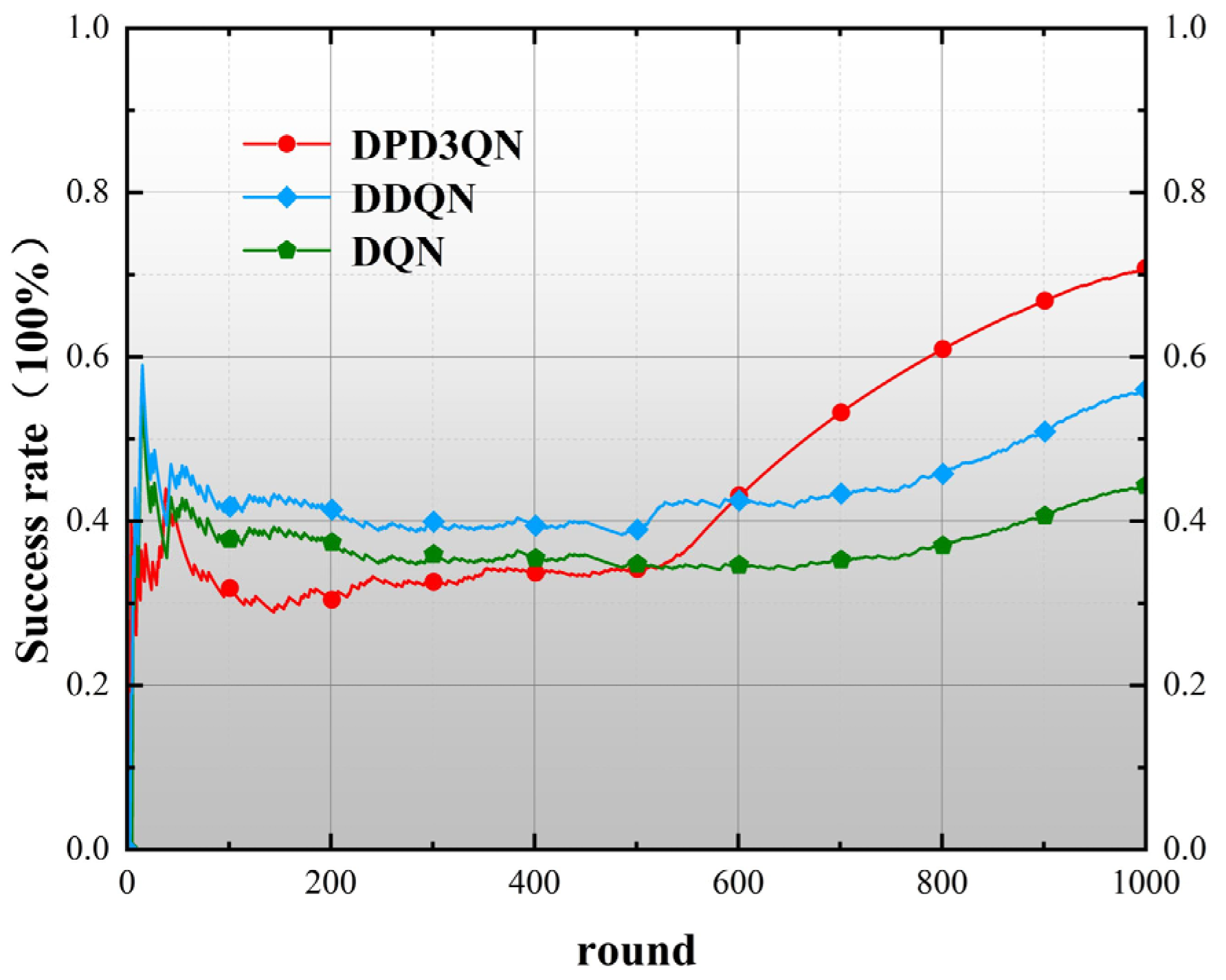
This study employs deep reinforcement learning techniques to examine the decision-making processes of autonomous vehicles in highway settings and introduces a dueling double deep Q-network utilizing dual-priority experience replay (DPD3QN). Through theoretical comparison with the traditional DQN and DDQN methods, it is proved that the proposed adaptive optimal autonomous driving behavior decision-making method has significant advantages in decision-making performance and applicability.
(1) An efficient and safe decision network framework is constructed. By combining the dueling network with the double deep Q-network, this paper reconstructs the output layer of the original network, enhances the autonomous driving system’s ability to understand the current state, and improves the accuracy of the estimation of action value.
(2) A dual-priority experience playback mechanism is introduced, allowing the system to identify and utilize key experiences faster. When updating network parameters, the weight distribution of old and new experiences can be better balanced, thereby significantly improving the update efficiency and convergence speed of the network.
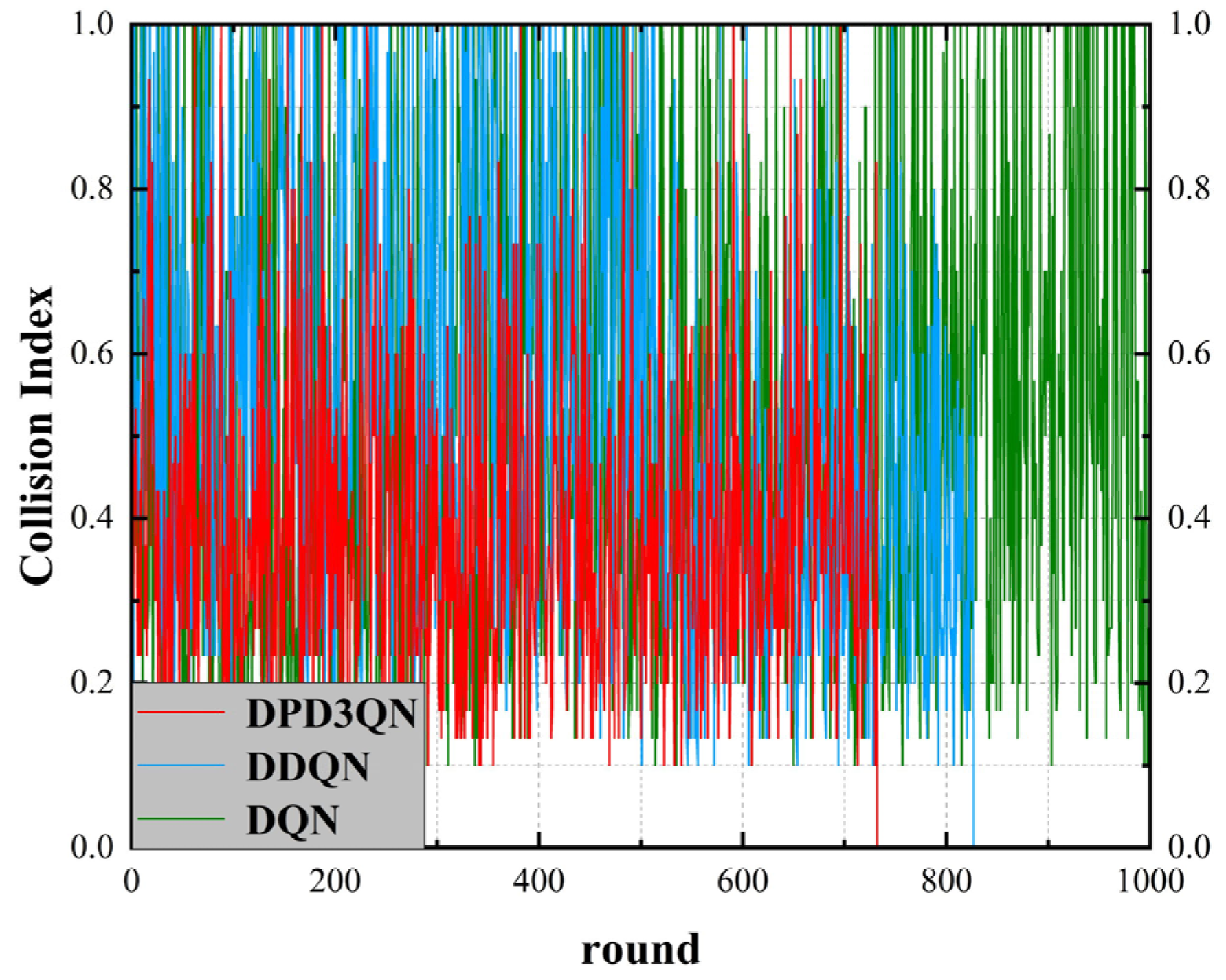
(3) After detailed training and testing experiments, it is verified that this method is superior to traditional deep reinforcement learning methods in terms of convergence speed and security. Through extensive experiments in multiple standardized environments, it is proven that DPD3QN significantly improves learning efficiency, decision-making quality, and stability compared with the existing technologies and can effectively cope with complex and challenging scenarios in autonomous driving.
The experimental results show that compared with DDQN and DQN algorithms, DPD3QN improves the decision success rate by 11.8 and 25.8 percentage points in scenario I and by 8.8 and 22.2 percentage points in scenario II, respectively. In addition, DPD3QN also outperforms the comparison algorithms in terms of average reward and average driving speed, further demonstrating its advantages in complex driving tasks.
The realism of the simulation environment is limited, and the generalization capability to real-world scenarios still needs to be validated. Gaps remain compared to real road environments in terms of perception errors, behavioral uncertainty, and the complexity of traffic rules. Future research could incorporate higher-fidelity simulation platforms (such as CARLA or LGSVL) or real-world driving data for further validation. The modeling capability for multi-agent interactions needs to be improved. The current method primarily focuses on single-vehicle decision-making tasks and does not fully account for the dynamic impact of complex games and collaborative behaviors among multiple vehicles.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}