1. Introduction
Job recommendation systems have become increasingly useful in modern recruitment processes, offering a more efficient and personalized way to match candidates with suitable job opportunities. The trend towards personalization in recommendation systems is particularly pronounced in job markets, where understanding individual preferences and characteristics can significantly enhance the effectiveness of these systems. Traditional job recommendation systems often focus on skills, qualifications, and past behavior, but they frequently overlook deeper personal factors such as personality traits [
1]. This oversight is significant because personality plays a pivotal role in determining career satisfaction, productivity, and long-term job retention. Job recommendation systems have become increasingly useful in modern recruitment processes, offering a more efficient and personalized way to match candidates with suitable job opportunities. The trend towards personalization in recommendation systems is particularly pronounced in job markets, where understanding individual preferences and characteristics can significantly enhance the effectiveness of these systems. Traditional job recommendation systems often focus on skills, qualifications, and past behavior, but they frequently overlook deeper personal factors such as personality traits [
1]. This oversight is significant because personality plays a pivotal role in determining career satisfaction, productivity, and long-term job retention. In this work, we propose a novel approach to job recommendations that leverages the Gallup CliftonStrengths personality assessment to enable more meaningful job–candidate matches. We apply GPT-4 and distance-based ranking methods to produce interpretable and fair recommendations, validated in a real-world setting.
The Big Five personality traits—openness, conscientiousness, extraversion, agreeableness, and neuroticism—have been shown to influence user behavior and preferences in various contexts, including recommendation systems [
2,
3]. By integrating personality traits into job recommendation systems, we can address the shortcomings of traditional systems and potentially improve career satisfaction and long-term job retention. This approach could also help employers identify candidates who are more likely to thrive in their work environment, leading to better talent acquisition and retention strategies. While prior work has largely relied on broad personality constructs like the Big Five (e.g., [
2]), our use of Gallup’s 34 themes enables finer-grained recommendations by mapping specific strengths to job requirements. For instance, a role requiring ‘Relationship Building’ may prioritize traits like ‘Empathy’ or ‘Includer’, which are not captured by generic extraversion or agreeableness measures.
The Gallup Personality Test, specifically the CliftonStrengths assessment (
https://www.gallup.com/cliftonstrengths/en/home.aspx, accessed on 1 May 2025), offers a unique approach to evaluating personality traits by focusing on 34 distinct strengths or talents that individuals naturally exhibit. This assessment is based on the premise that understanding and leveraging these strengths can enhance personal and professional performance. Unlike traditional personality assessments, like the Big Five, which categorize individuals into broad traits, the Gallup test provides a more nuanced view by identifying specific talents that can be developed and utilized effectively in various contexts. This granularity makes it particularly useful for job recommendation systems, as it allows for more precise matching of individuals with job roles that align with their natural strengths. Throughout this paper, we use the term
traits to refer to the 34 distinct themes identified by the CliftonStrengths assessment, which Gallup often refers to interchangeably as talents or strengths depending on the context. We do not use traits in the broader sense defined by psychological models like the Big Five.
To avoid confusion between commonly used psychological constructs and the terminology of the CliftonStrengths framework, we clarify the following distinctions. In this work we use the following terms:
Personality traits refer to broad, stable dispositions that influence behavior across situations. This includes models like the Big Five (e.g., extraversion, conscientiousness), which provide a general psychological profile.
Strengths are defined, following the Gallup CliftonStrengths framework, as a person’s consistent near-perfect performance in a specific activity. Strengths emerge when innate talents are refined through practice and knowledge.
Talents are naturally recurring patterns of thought, feeling, or behavior that can be productively applied. They represent the raw potential that, when invested in, develops into a strength.
By incorporating the Gallup test’s insights into job matching, our method seeks to provide a more holistic and personalized approach to recruitment. This integration can help ensure that job seekers are matched with roles that not only align with their skills and qualifications but also resonate with their natural strengths and talents. Ultimately, this novel approach has the potential to enhance career satisfaction, productivity, and long-term job retention by creating a better fit between individuals and their work environments.
This paper makes several key contributions to the field of job recommendation systems. Firstly, it introduces a unique approach for incorporating personality traits, as evaluated by the Gallup CliftonStrengths assessment, into job recommendation systems. This framework provides a more nuanced approach to matching candidates with job opportunities by considering their natural strengths and talents. In contrast to traditional methods that rely on manual trait–job pairing, our work employs GPT-4 to dynamically infer rankings, adapting to evolving job markets. In addition, it applies a bias detection/mitigation technique to the LLM-based results to ensure fairness across demographics. Secondly, the paper validates the effectiveness of the proposed method through empirical experiments, demonstrating how integrating personality traits can improve the accuracy and relevance of job recommendations. It integrates different distance metrics, including a sigmoid-weighted Manhattan distance to prioritize mismatches in high-impact traits. Last and most importantly, it incorporated the proposed approach in an actual job recommendation platform in Kazakhstan that is used by several companies and hundreds of candidates.
The paper is structured to provide a comprehensive overview of our novel method for integrating personality traits into job recommendation systems. Following this introduction,
Section 2 discusses related work and the role of personality in job recommendations, highlighting the importance of personalization and the limitations of existing systems.
Section 3 presents the proposed method, including data processing and model design, detailing how the Gallup CliftonStrengths assessment is integrated into the recommendation framework.
Section 4 details the experimental setup and provides an overview of the application that currently supports our approach.
Section 5 presents the results, providing an analysis of the effectiveness of our approach compared to traditional methods. Finally,
Section 6 concludes the paper and outlines future work, discussing potential extensions and applications of our framework in broader recruitment contexts.
2. Related Work
The literature on recommender systems and their various applications is full of variations of collaborative filtering, such as content-based or hybrid methods [
4], which take advantage of the available information expressed as user or item content, user-to-item preferences, etc. to recommend the most appropriate choices for each individual user or group of users [
5]. Content-based approaches, in the case of job recommendations, try to match resume information with job descriptions by quantifying the similarity of the respective texts. This was traditionally performed using cosine similarity at the high-dimensional vector space of keywords [
6]. However, recent advances in transformers and embeddings allow more proficient semantic-based matching to be employed and improve matching performance [
7].
A recent survey on e-recruitment recommendation systems [
8] examines the more practical aspects of job recommendations and focuses on the challenges that e-recruitment systems have to resolve. As shown in the survey, job recommendation systems differ significantly from traditional general-purpose recommender systems due to several distinct characteristics. Unlike traditional systems, job recommenders adhere to the “one worker, one job” principle, where job seekers and positions are typically limited to singular matches, creating competition and necessitating a small, highly selective set of recommendations. These systems also operate on a two-sided engagement model, requiring mutual actions from job seekers and employers, unlike unilateral user actions in traditional domains like movie recommendations. Additionally, job recommenders emphasize both suitability and user preferences, integrating multi-faceted data such as skills, experience, and cultural fit, while addressing challenges like fairness and trustworthiness in this high-stakes domain. Furthermore, the transient nature of job listings and episodic engagement of users result in short interaction histories, making it harder to gather and utilize data compared to other domains. According to the same survey, job recommendation systems face challenges, including data quality issues like noise, semantic gaps, multilingual data, and sparsity, which complicate feature extraction and matching.
A different group of recommender systems in the recruitment industry comprises works that aim to generate career improvement recommendations via upskilling or reskilling actions based on user profiles and their desired positions [
9,
10,
11]. The various methods used for tackling this task comprise content-based matching between user profiles and training courses [
11], the use of knowledge graphs in order to perform information-rich matching [
10], or even dynamic programming [
9] and other matching optimization techniques. Another recent survey [
12] summarizes the techniques that can be employed for recommending skills for upskilling or reskilling, to Content-Based Filtering (CBF), which identifies skills similar to a user’s profile by analyzing their history and preferences; Collaborative Filtering (CF), which leverages the preferences of other users, either through memory-based approaches using similarity measures or model-based methods for predicting new skills; Knowledge-Based techniques (KB), which infer skills based on predefined rules and user preferences; Utility-Based techniques (UB), which calculate the utility of skills based on multi-attribute preferences; Rule-Based techniques (RB) that use if–then rules to match users with relevant skills; and Hybrid Filtering (HF), which combines these methods to enhance accuracy and address limitations like sparsity, scalability, and cold-start issues.
According to another recent survey [
13], deep learning techniques in job recommendation systems include Convolutional Neural Networks (CNNs) for extracting features like keywords from job descriptions, Recurrent Neural Networks (RNNs) for analyzing sequential text data to predict user preferences, Autoencoders for creating compact representations of job descriptions to identify similar roles, and Generative Adversarial Networks (GANs) for generating new job descriptions aligned with user interests, offering sophisticated, personalized, and adaptable recommendations at the cost of higher computational and training complexity. Finally, Graph Neural Networks (GNNs) combined with knowledge-graph-based techniques [
14] are gaining hype for providing better skills, experience, and education matching between candidates and positions.
Recommending a job that matches the user’s profile is very important since it can reduce underemployment or unemployment and, indirectly, contribute to social and economic development. In this direction, the work of [
7] presents an interesting approach that employs Large Language Models and, more specifically, BERT to generate content-based job recommendations based on user resumes and job descriptions. Simpler NLP techniques have been employed in [
15] to find matching between user profiles and job descriptions. However, these approaches stick to the matching of hard skills and ignore soft skills and personality traits that can either be hidden behind the words of a job description text or a user resume. The importance of soft skills is recognized by the CareProfSys system [
16], which collects demographic and personality data from users, along with skill information from the user’s CV and professional social media (i.e., LinkedIn). Manual extraction of text segments from the above sources is performed, and rule-based and BERT-based mapping is employed to map texts into specific skill codes from a manually compiled lexicon. Some filtering steps limit the candidates that match each job, and finally, an ontology is employed to perform the matching between the positions’ requirements and the candidate profiles. Another job recommendation engine, JobFit [
17], processes job descriptions and applicants’ profiles and generates a JobFit score indicating how well the applicant fits a position. Once again, the job inputs comprise required skills, experience, and qualification, and while experience and qualification act as filters, skills are matched to the applicant’s skills using NLP techniques. The system also considers the applicant’s personality (the big 5 traits) by measuring the correlation of the user’s personality with the personality of employees who work in this job and by using it to measure the possible satisfaction from the job. Prior work on personality-aware job recommendations (e.g., [
17]) often relies on the Big Five model, which, while useful for broad trait alignment, lacks granularity for specific strength-based matching. In contrast, Gallup’s 34 themes—such as ‘Achiever’, ‘Communication’, or ‘Strategic’—provide actionable insights into how innate talents align with role-specific demands (e.g., ‘Strategic’ for consulting roles). This fine-grained approach bridges a gap left by broader psychological models and manual skill-mapping methods (e.g., [
16]), enabling dynamic, scalable recommendations.
In recent years, transparent and explainable recommender systems have attracted considerable attention. He et al.’s TriRank [
18] models aspect-level interactions in a tripartite graph to enable users to inspect, which review-derived aspects drive each recommendation, thus improving transparency and scrutability. Chen et al.’s GREASE [
19] generates both factual and counterfactual explanations for GNN-based recommenders by optimizing adjacency perturbations, offering concise, user-understandable reasons for item rankings. More recently, Mohammadi et al. [
20] highlighted the need to incorporate recommender performance metrics when evaluating explanation methods, demonstrating that ignoring recommendation accuracy can lead to misleading assessments of explainer quality.
The use of Gallup tests that we adopt in our study allows us to better understand user personality, since it provides a more fine-grained analysis than the big 5 traits, and also covers several soft skills, which are of equal, if not higher, importance than the hard skills that are explicitly stated in a job description and can be easily used to filter out non-relevant candidates. In addition, we automate the process of skill matching, as well as the mapping of textual descriptions to skills, using a Large Language Model (i.e., chatGPT).
In summary, while prior work has extensively explored various techniques for job recommendations—including content-based and collaborative filtering methods, deep learning approaches, knowledge graphs, and hybrid systems—most approaches primarily focus on hard skill matching or leverage user preferences in a limited way. Recent efforts have begun to consider soft skills and personality traits, yet often rely on coarse models like the Big Five or manual extraction and mapping processes which lack scalability and granularity for strength-based role alignment. Our work distinguishes itself by integrating Gallup’s 34 themes (e.g., ‘Achiever’, ‘Strategic’) as first-class features, enabling fine-grained matching of innate talents to job demands. Furthermore, we employ Large Language Models to automate semantic matching, overcoming the limitations of manual ontology-based systems while offering richer trait-to-role alignment than traditional content-based methods. This combination enables a more nuanced and holistic recommendation process that addresses key limitations in existing systems, particularly around dynamic soft skill identification and scalable trait-aware recommendations.
3. Proposed Approach
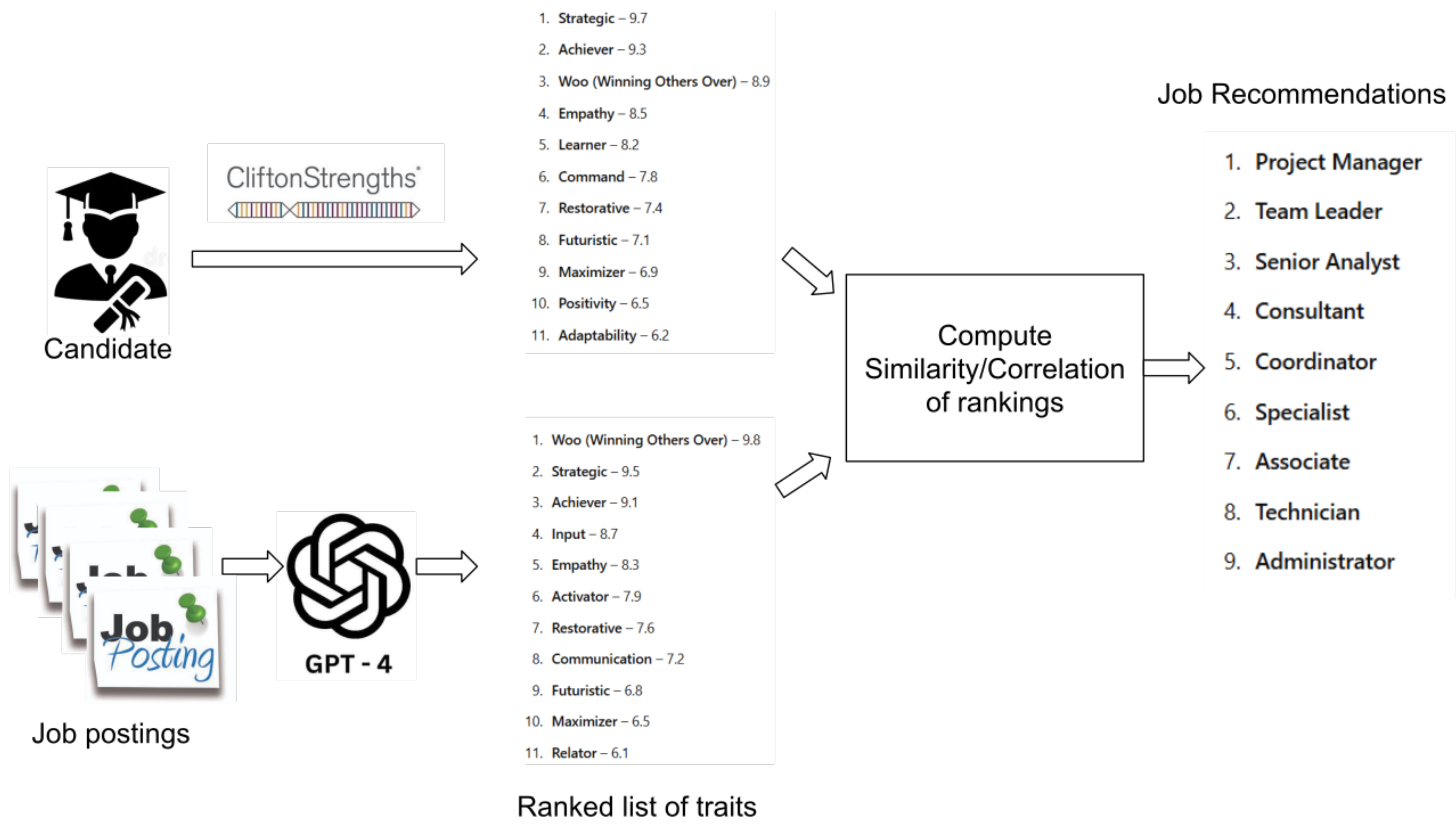
The proposed approach has been designed to generate job recommendations for graduate students who perform the Gallup test in order to evaluate their skills and help them find the most appropriate jobs out of a wide range of positions. The input it considers is the graduates’ evaluation using the CliftonStrengths test and a text that describes each job position. The overall process is depicted in
Figure 1.
The first step in the proposed approach is to utilize the GPT-4 model to process job positions within specific sectors of a broader industry and identify the most important personality traits from the 34 official CliftonStrengths themes. This is achieved by constructing a precise and context-aware prompt (see
Figure 2) designed to simulate the role of a Career Counselor. The prompt incorporates detailed information about the job title, sector, and industry, asking the AI to rank the CliftonStrengths themes from most relevant to least relevant for the specific role.
The ranking process considers the job’s specific requirements, necessary personality traits, and the strengths typically associated with success in the given position. By iteratively evaluating each of the traits in a step-by-step manner, the AI provides a ranked list in a standardized format, ensuring that every skill is used exactly once. This ranking is then used to assign a weight to each of the 34 CliftonStrengths traits, reflecting their relative importance for the given role. These weighted traits serve as the foundation for further processing and analysis in the workflow.
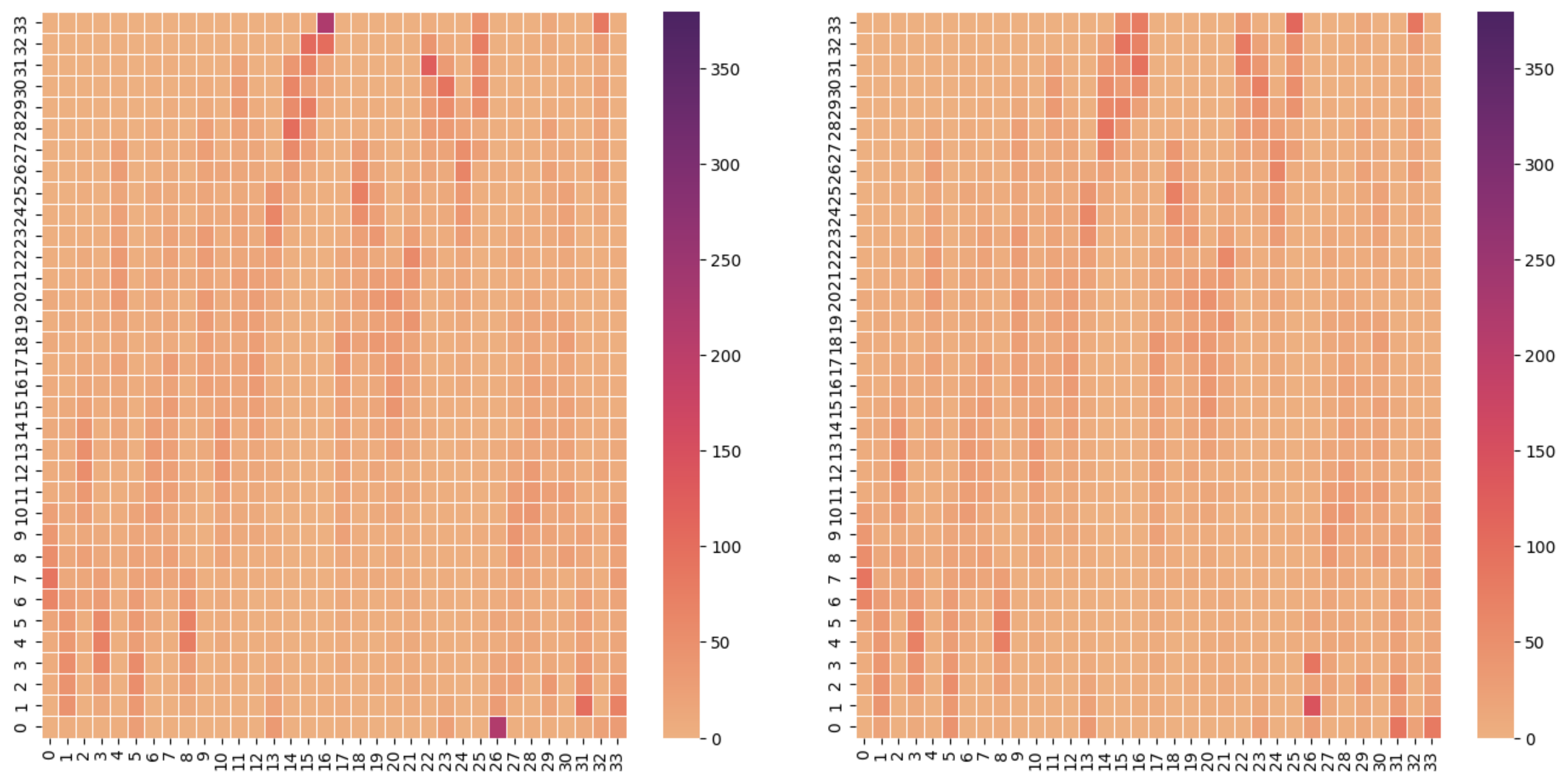
The next step is to evaluate whether the LLM-based extraction process introduces any bias in the weighting of CliftonStrengths traits across all job positions. To achieve this, we construct a 34 × 34 matrix, where each element represents the cumulative weight of a specific trait across all analyzed job positions. This matrix provides a comprehensive overview of how each trait is ranked and weighted on a global scale.
By analyzing the matrix, we identify cases where certain traits have a total weight that exceeds a predefined threshold, indicating a potential bias introduced by the LLM-based ranking process. For such traits, a normalization function is applied to adjust the weights, smoothing out the overemphasis and ensuring that the distribution of trait importance aligns more evenly across the dataset.
Let
be the cumulative weight matrix, where
is the total weight of trait
i across all job positions. We first compute, for each trait
i,
We then identify any trait
i for which
(our chosen bias threshold). For these “overemphasized” traits, we apply a min–max rescaling to cap the maximum at 100:
This transformation ensures and , preserving relative differences while smoothing extreme peaks. We selected simple min–max scaling for its transparency and ease of reproduction and because it retains monotonicity—ensuring that more important traits remain more heavily weighted even after correction.
The impact of this normalization process is visualized in two plots (see
Figure 3): the “before” figure, which illustrates the raw cumulative weights of the traits, and the “after” figure, which shows the adjusted weights following normalization. These visualizations provide insight into the effectiveness of the bias correction process and ensure that the workflow maintains a fair and balanced assessment of the CliftonStrengths traits.
The third step of the process is to employ the CliftonStrengths questionnaire and analyze all the candidate profiles. The result of this process is that every candidate is associated with a vector of 34 weights that correspond to the importance of each trait in the candidate’s personality. In this step, we take advantage of the power of the Gallup test methodology in capturing the importance of each trait in a person’s character.
The final step of the recommendation process is to compare the job description traits with the candidate traits and rank jobs accordingly for each candidate. This step employs a vector similarity metric to compute the similarity (or distance) between the job and the candidate vector. Any of the common metrics (e.g., cosine similarity, manhattan, or Euclidean distance) can be applied at this step. Alternatively, we could rank the traits by their importance for the candidate and the position and compare the correlation of the two rankings using a correlation metric.
When the process finishes, each candidate gets as an output a ranked list of positions that match their personality traits. Algorithm 1 summarizes the main steps of our approach.
| Algorithm 1 Job Recommendation Based on Gallup Test Scores |
| Require: Set of job descriptions J, Set of candidate profiles C |
| Ensure: Ranked job list for each candidate |
| 1: Initialize trait matrix | ▹ Store trait weights per job |
| 2: Initialize global trait bias matrix |
| 3: for all job j in J do |
| 4: Construct GPT-4 prompt with job title, sector, and industry |
| 5: | ▹ Return ranking of 34 traits |
| 6: | ▹ Assign weights based on ranking |
| 7: |
| 8: end for |
| 9: | ▹ Apply normalization if bias threshold is exceeded |
| 10: for all candidate c in C do |
| 11: | ▹ Obtain vector of 34 weighted traits |
| 12: Initialize | ▹ Recommended job scores |
| 13: for all job j in J do |
| 14: |
| 15: | ▹ Use weighted Manhattan, Euclidean or cosine |
| 16: |
| 17: end for |
| 18: |
| 19: end for |
| 20: return RankJobs |
3.1. Similarity/Distance Metrics
To compare the matching between the weighted traits of the candidate and a position, several metrics were used. Below are a few of these metrics, including their equations and brief descriptions.
3.1.1. Weighted Manhattan Distance
Manhattan distance, also known as the L1 distance, measures the absolute difference between corresponding elements of two vectors. In our problem, it is defined as:
where
is the user profile vector, and
is the respective position profile vector. Both vectors are of size 34, and
and
represent the
i-th components of the vectors
and
, respectively.
is the weight assigned to the
i-th trait. The weights are assigned to each trait depending on how high it ranks for the user
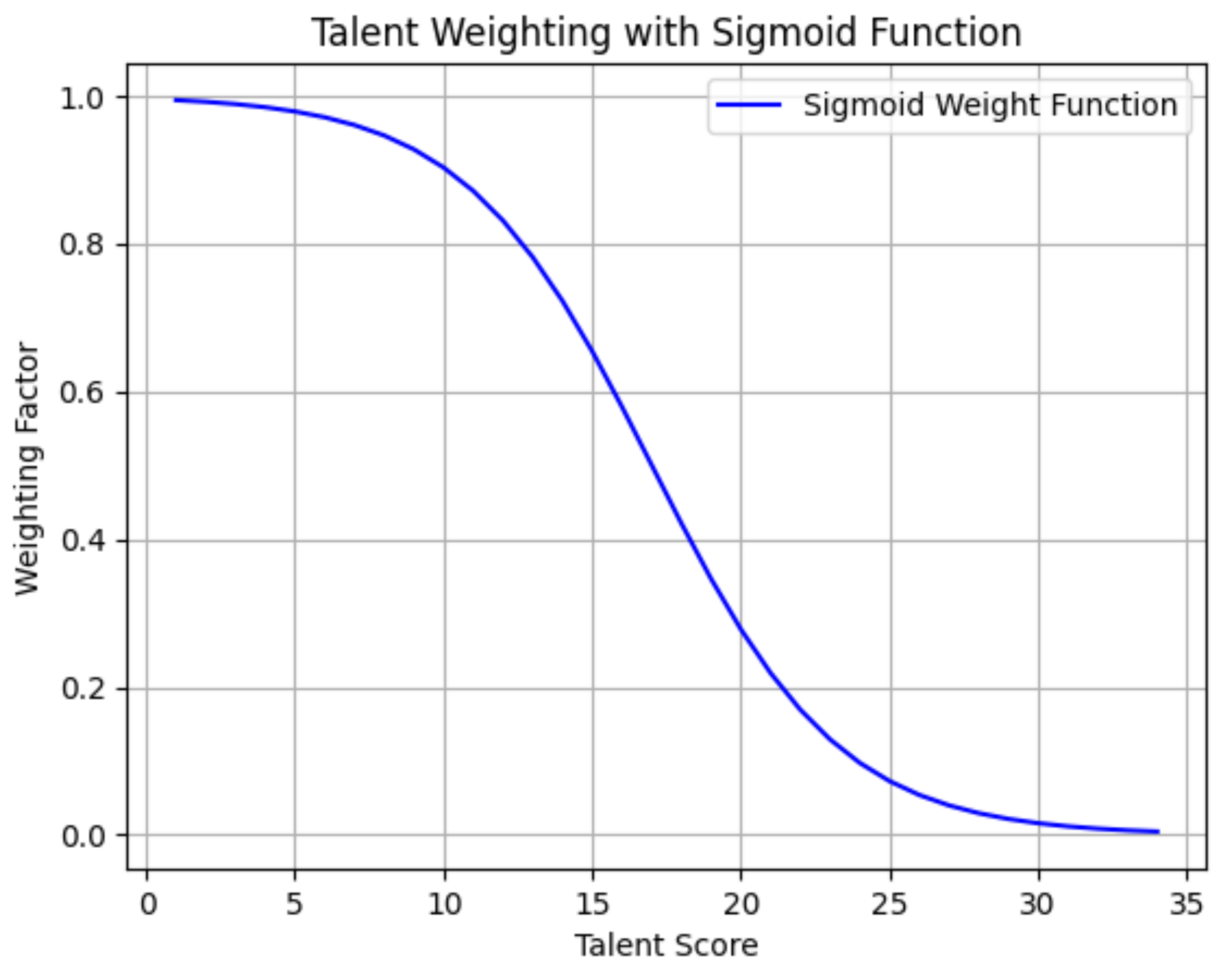
U, using a sigmoid function, as depicted in
Figure 4 and Equation (
4). The differences in highly ranked traits for the user are weighted more than those in lower ranked personality traits.
A smaller Manhattan distance indicates higher similarity between the vectors.
3.1.2. Weighted Euclidean Distance
Euclidean distance is a straight-line distance between two points (vectors) in a multidimensional space. It is commonly used to measure the dissimilarity between two weight vectors. The formula with weights used in our case is:
where
and
represent the
i-th components of the vectors
and
, for the user and the position profile respectively, and
is the corresponding weight, based on the importance of the trait for the user, as before. A smaller Euclidean distance indicates a higher similarity between the vectors.
3.1.3. Cosine Similarity
Cosine similarity measures the cosine of the angle between two vectors, which gives an indication of how similar they are in direction. The formula is defined as:
where
and
are the weight vectors of the two trait lists, and
is the dot product of the vectors. The magnitude of each vector is represented by
and
.
This metric gives a value between (completely opposite directions) and 1 (completely similar directions), with 0 indicating orthogonality (no similarity).
These metrics provide diverse ways to analyze the relationship between the two lists, whether focusing on vector similarity, or distance of rankings. Depending on the application, one metric may be more suitable than another based on the specific nature of the data and the desired outcome.
The three distance/similarity metrics each have distinct characteristics that make them suitable for different aspects of trait-based matching:
Manhattan distance (L1 norm) provides a linear, robust measure of absolute differences between corresponding trait weights. Its weighted variant (Equation (
2)) can emphasize specific trait mismatches through customizable weighting functions (
Figure 4), making it particularly suitable for rank-sensitive comparisons, where the magnitude of individual trait discrepancies matters.
Euclidean distance (L2 norm) measures the straight-line distance between trait vectors in the multidimensional space. While sensitive to large individual differences (due to its quadratic nature), it provides a comprehensive view of overall vector dissimilarity that accounts for both the direction and magnitude of trait weight variations.
Cosine similarity evaluates the angular alignment between trait vectors, focusing purely on their directional similarity regardless of magnitude. This makes it effective for identifying patterns in relative trait importance while being invariant to absolute weight scaling differences.
Each metric offers unique advantages: Manhattan distance’s robustness to outliers, Euclidean distance’s comprehensive dissimilarity measurement, and cosine similarity’s focus on directional alignment. The choice between them depends on whether the matching process prioritizes individual trait discrepancies (Manhattan), overall dissimilarity (Euclidean), or proportional similarity (cosine).
The experimental evaluation that follows demonstrates the differences between these metrics.
4. Experimental Evaluation
In order to evaluate the performance of the proposed approach, we collected descriptions for 256 job postings and passed 100 graduates from the CliftonStrength test. Then, we run the process presented in
Section 3 using Euclidian and Manhattan distance to measure the similarity of lists.
4.1. Participant Demographics
To better understand our evaluation sample, we collected and analyzed demographic information from all participants, who are recent graduates from various disciplines in Kazakhstan.
Study and Profession Backgrounds: Participants’ fields of study spanned 45 unique disciplines. The most common study backgrounds were Teacher (10 participants), and Translator (4). Their current professions were equally diverse, with top roles including English Teachers (8) and Other Teachers (5).
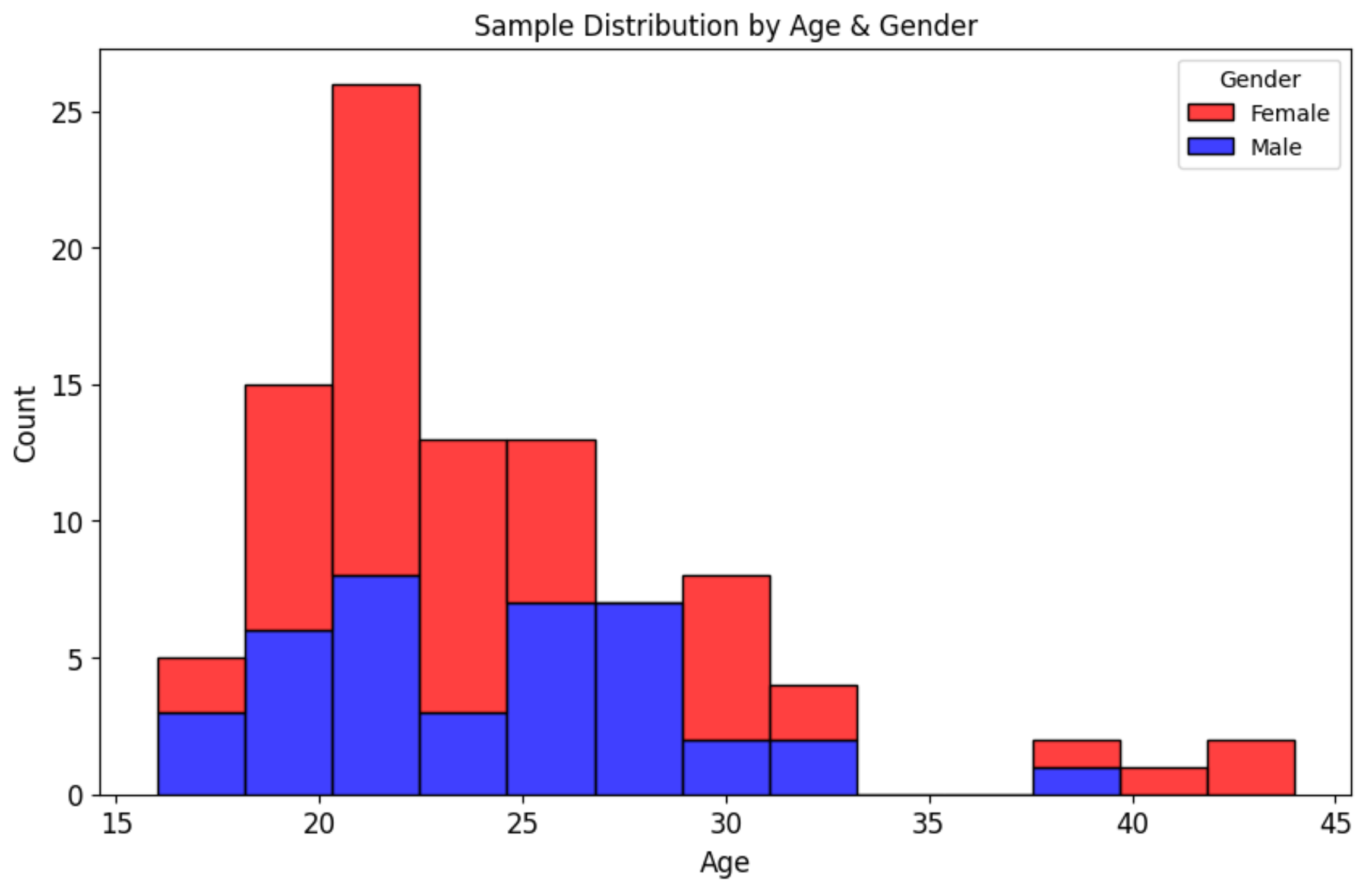
Age and Gender Distribution: The sample consisted of 59 female and 41 male graduates, with ages ranging from 16 to 44 years (mean = 24.4, SD = 5.54).
Figure 5 illustrates the age distribution by gender.
Job Matching and Experience: Only 5% of participants reported prior work experience outside their current roles. Additionally, 46 participants (48%) are employed in the same profession they studied, which may influence their evaluation of job recommendations.
4.2. Pre-Processing
Before analysis, input data undergoes rigorous preprocessing:
Job Descriptions:
- -
Raw text is cleaned (stopword removal, lemmatization) and structured into (title, sector, industry) tuples.
- -
GPT-4 processes these tuples using the prompt in
Figure 2 to produce a ranked list of the 34 CliftonStrengths traits per job.
- -
Trait weights are min–max scaled to [1, 100] to prevent magnitude dominance in Euclidean distance calculations.
Gallup Test Results:
- -
Global trait weights are monitored via a 34 × 34 matrix tracking cumulative weights across jobs.
- -
Traits exceeding
from the mean undergo log-normalization (Equation (
2)) to mitigate skew that could disproportionately affect Euclidean distances.
- -
Corrected weights are clipped to [5, 95] to preserve ordinal relationships while limiting extreme values.
We also have a baseline method that follows a different approach: First, it collects user test responses to the Strengths Assessment Test and sends them to GPT-4, which generates a concise personality summary. This summary is then converted into a numerical embedding using SentenceTransformers. Each profession’s description is also converted to vector embeddings. We then calculate the cosine similarity between the user’s embedding and the embedding of each profession to measure how closely they match. The professions are ranked by similarity, allowing the system to suggest careers based on a deep semantic understanding. By comparing our proposed method with this baseline, we aim to assess the benefits of incorporating personality traits into job recommendations using different distance metrics.
The preprocessing pipeline was designed to ensure equitable performance across all distance metrics. For instance, min–max scaling and outlier clipping mitigate Euclidean distance’s sensitivity to magnitude variations, while L2 normalization of baseline embeddings guarantees cosine similarity and focuses solely on angular similarity. These steps enable meaningful comparisons between our trait-based method and the semantic-search baseline.
4.3. Experiments’ UI
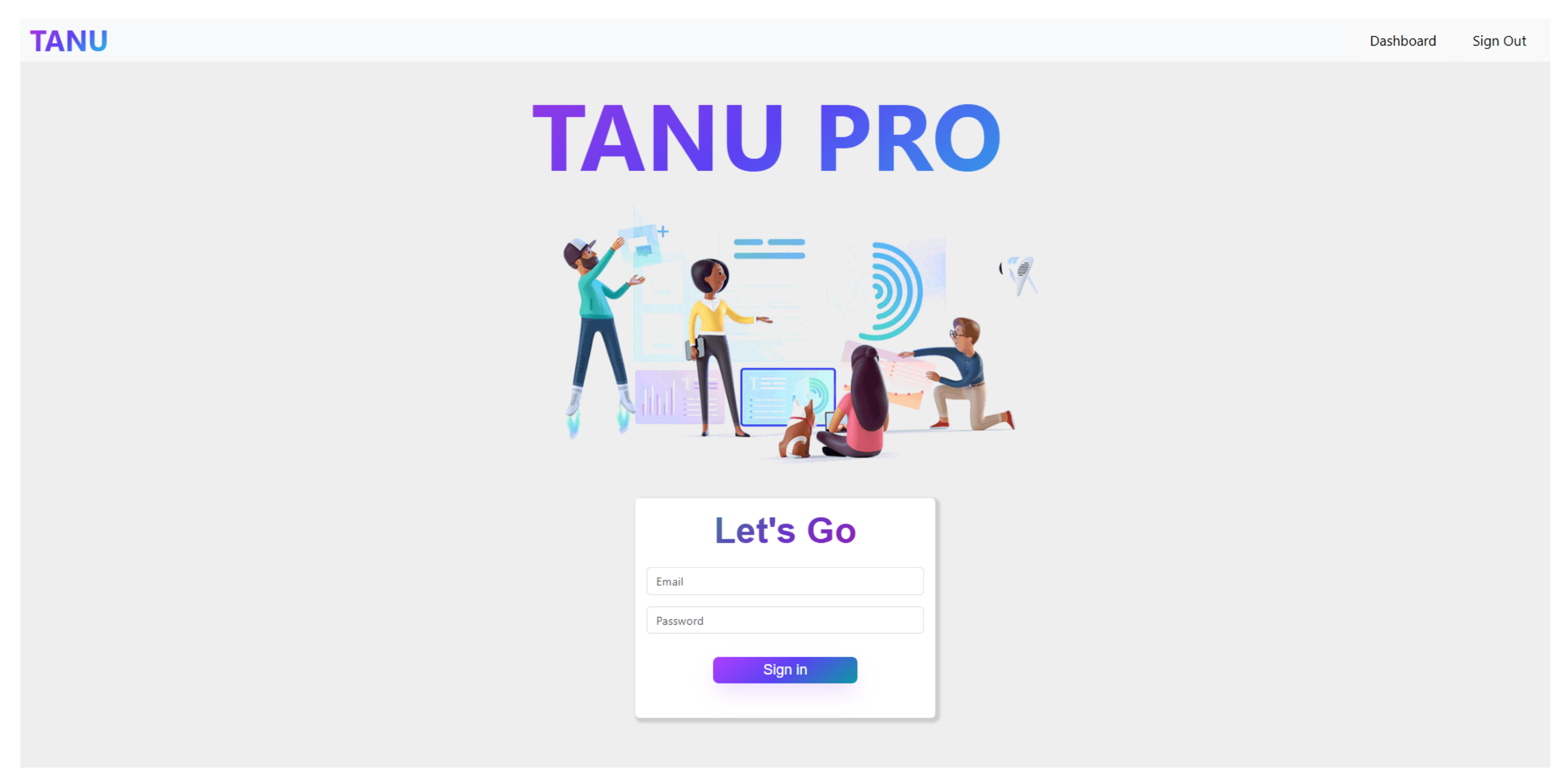
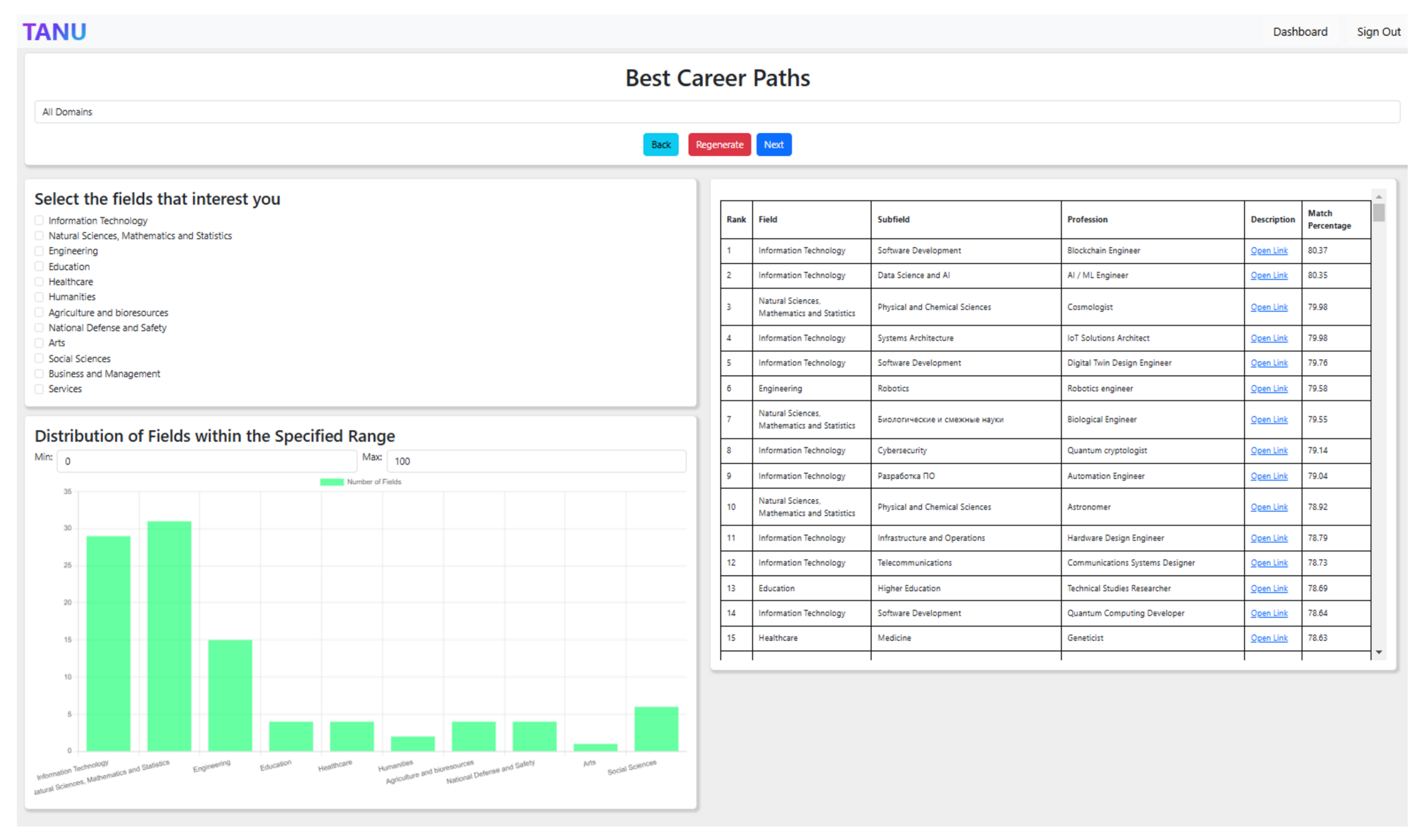
In order to compare the three alternatives and evaluate the overall performance of the proposed approach, we developed a web-based application that streamlines the job recommendation process. Career counselors must first login through the Login Page (
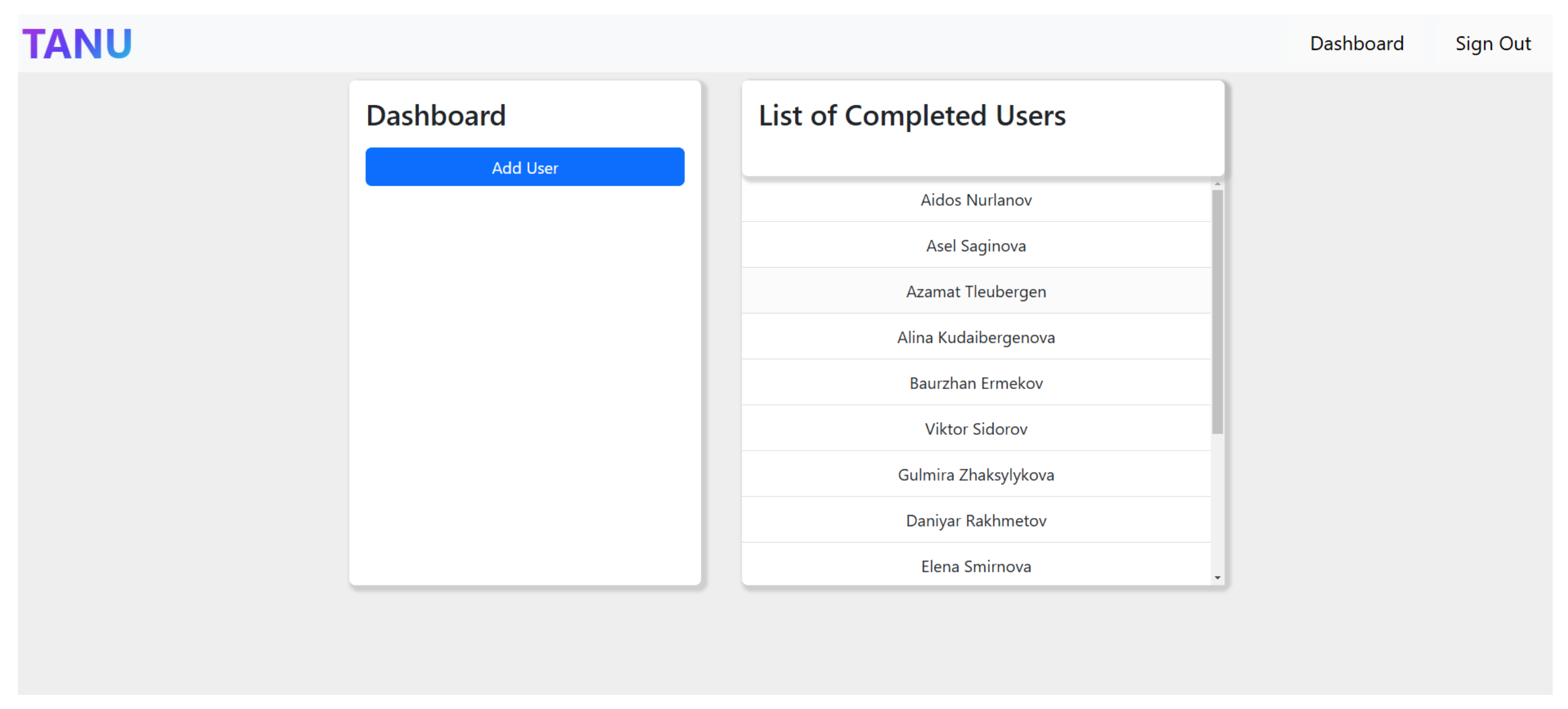
Figure 6) using their credentials. Once authenticated, they are redirected to the Dashboard (
Figure 7), which serves as the main hub for managing users and career reports. From the dashboard, counselors can add new users, access completed career tests, and navigate to individual user profiles.
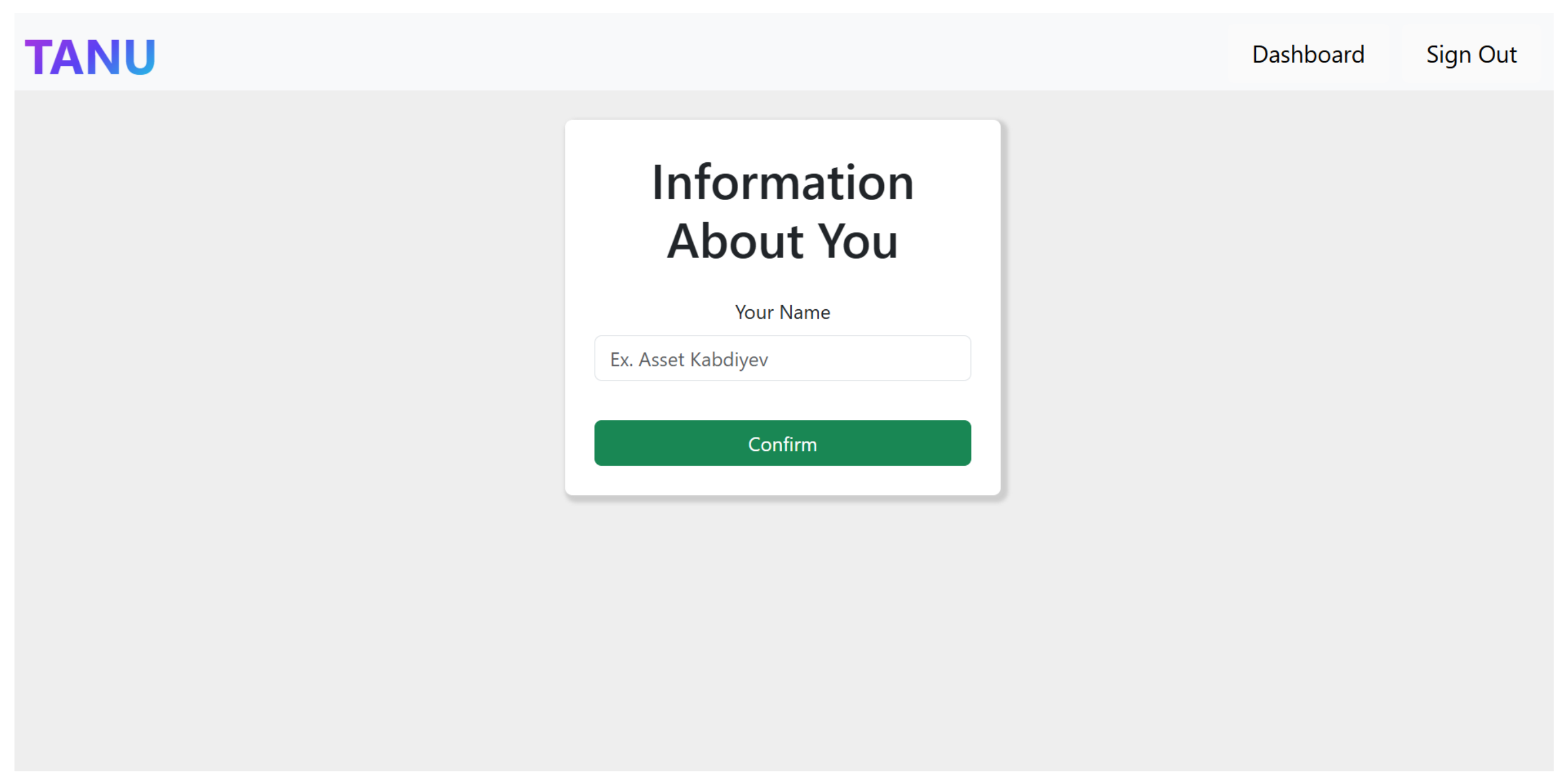
Each candidate begins the process by entering their name on the Information Page (
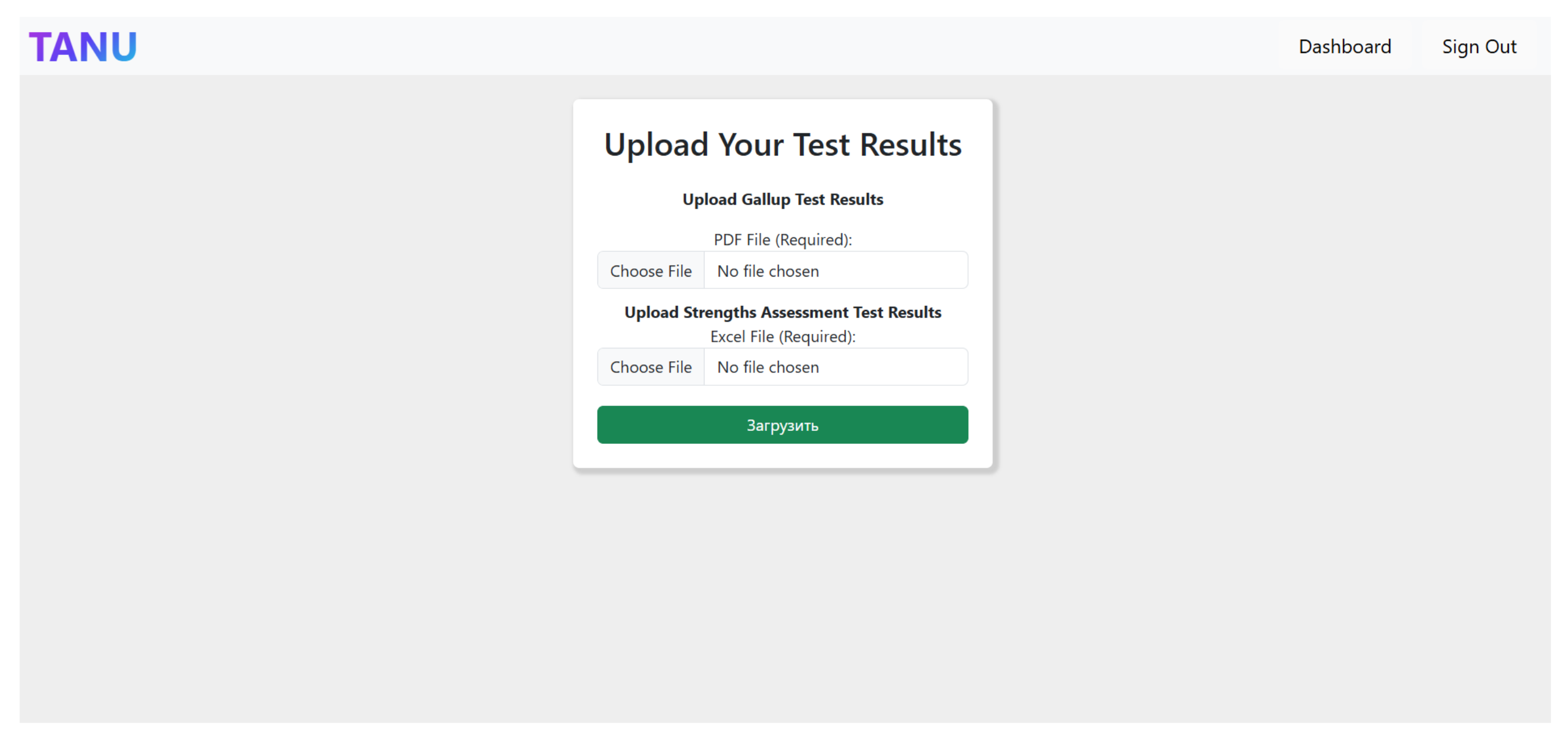
Figure 8) before proceeding to the Upload Page (
Figure 9), where they submit their Gallup test results (PDF) and Strengths Assessment Test results (Excel file). Upon successful submission, the system automatically processes the data and redirects the user to the Career Report Page.
On the career report page (
Figure 10), candidates are presented with three separate lists of potential job recommendations, generated using different similarity metrics (Cosine Similarity, Euclidean Distance, and Manhattan Distance). These lists are displayed in a randomized order to minimize selection bias and prevent candidates from being influenced by list positioning. Users can interact with the recommendations by filtering career fields, adjusting match scores, and exploring detailed profession descriptions through embedded links.
To assess the effectiveness of each similarity method, candidates are asked to review all three lists and select the one they believe best represents their career preferences and aspirations. This structured process allows for a more objective comparison of the different methods while providing career counselors with insights into which metric yields the most relevant recommendations. The navigation features within the application also allow users to refine their selections, revisit results, or proceed to further career exploration, ensuring a seamless and user-friendly experience.
4.4. Computational Efficiency Analysis
While our approach prioritizes recommendation quality over training speed, we evaluate its computational demands:
GPT-4 Processing: Requires ∼3 s per job description (256 jobs = ∼13 min. total).
Bias Correction: The 34 × 34 matrix normalization adds negligible overhead (<1 min).
Recommendation Generation: Scales linearly with candidates (100 candidates × 256 jobs = 25,600 comparisons at ∼0.1 ms each = ∼2.5 s total).
The numbers above demonstrate practical deployability despite not being optimized purely for training speed.
5. Results and Discussion
The evaluation process engaged 100 university graduates who took the personality test. This section presents and discusses the main results of the evaluation process in a comparative manner, highlighting the overall performance of the method using different metrics and the respective performance in various user subgroups depending on the domain of studies.
Specifically, the graduates evaluated three distinct job recommendation methods—Weighted Manhattan, Weighted Euclidean, and Baseline—by scoring each method on a scale from 1 to 10. The analysis focuses on comparing the performance of the three approaches by examining their score distributions across participants. The dataset also includes additional attributes such as the graduates’ current specialty, the broader area of their work, their initial field of study, and whether their current job aligns with their studied specialty. The analysis that follows aims to uncover patterns, strengths, and weaknesses of each method across different graduate subgroups and provide actionable insights for improving job recommendation systems. This comparative assessment provides insights into the effectiveness of each approach in capturing meaningful patterns related to personality traits and professional alignment and satisfaction.
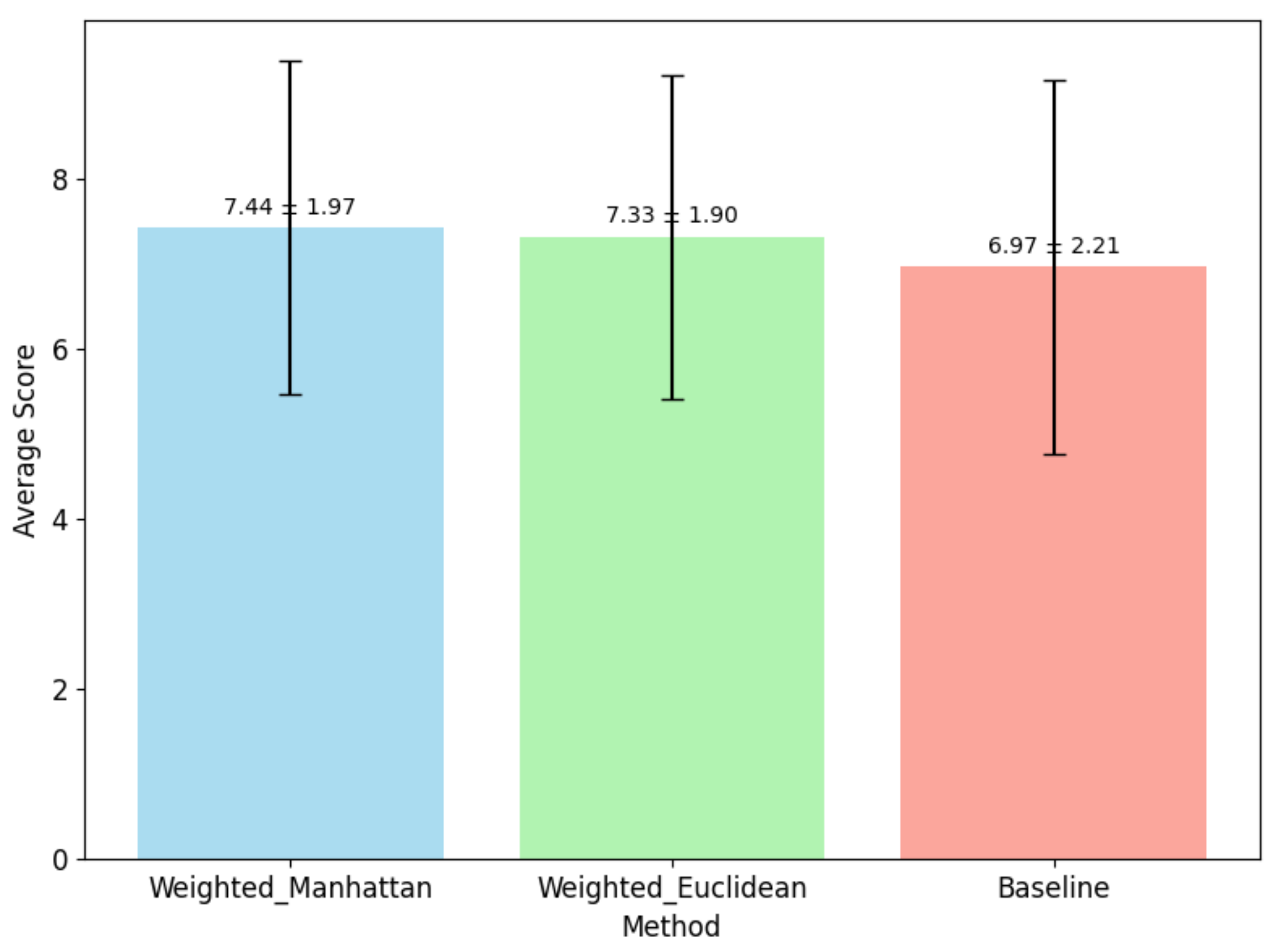
The first comparison examines the performance of the two proposed alternatives versus the baseline method. As shown in
Figure 11, which displays the average score and the standard deviation for each method, the two proposed alternatives outperform the baseline. The weighted Manhattan method is almost 0.5 degrees better than the baseline, on average, based on the evaluation of the 100 graduates. This means that the method is statistically significantly better than the baseline, almost at the 90% confidence interval.
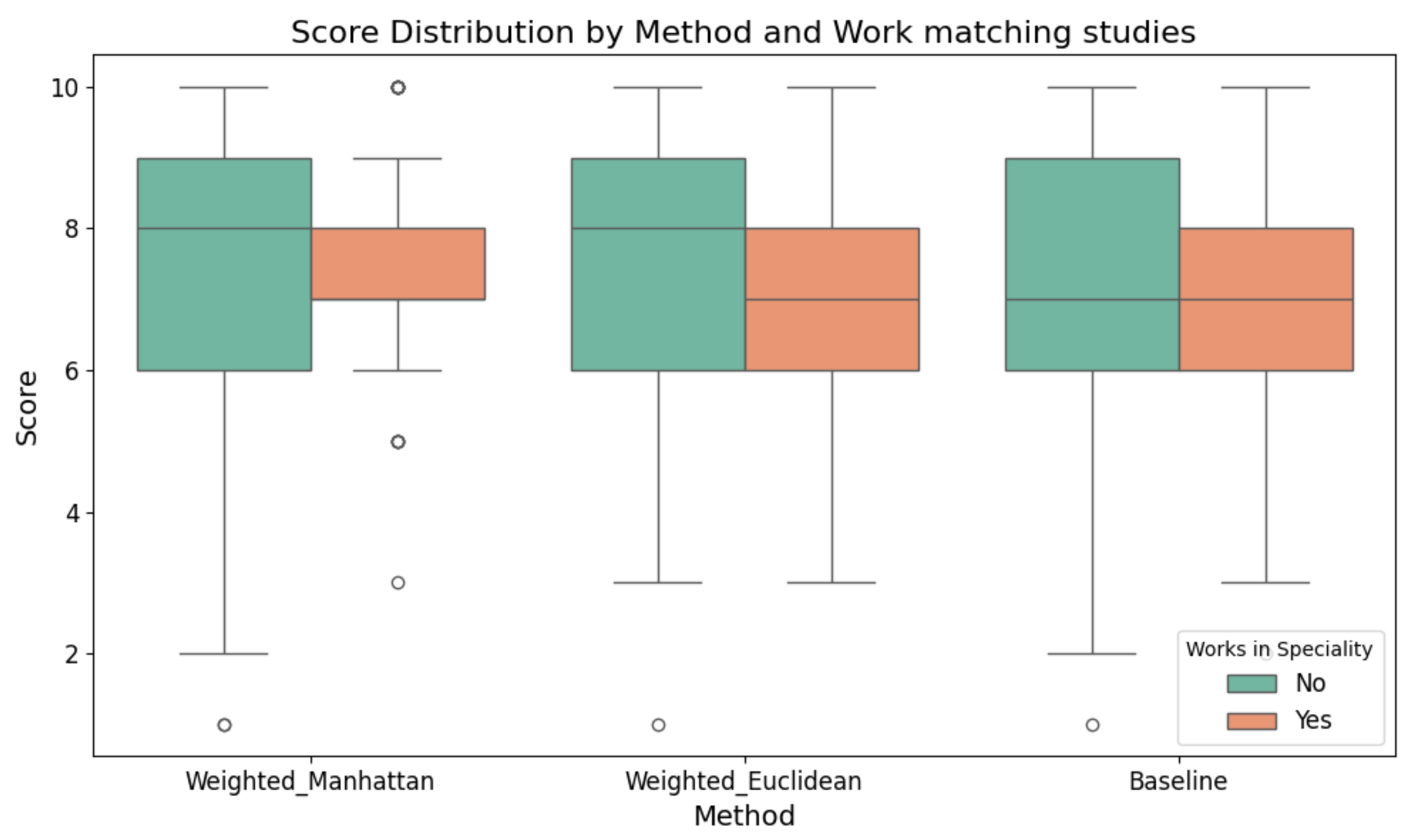
Following the overall performance comparison, we would like to examine the differences in the distribution of scores to the three methods between graduates who are working on the specialization they studied and those who do not. As shown in
Figure 12 the scores are more dispersed for all metrics among graduates working outside their specialty (interquartile range [IQR]: 3.5–6.5 for Manhattan, 3–6 for Euclidean) compared to those within their specialty (IQR: 6–8 for Manhattan, 5–7 for Euclidean). The average score for the two proposed methods is higher than the baseline.
The group of graduates who work in the same domain that they studied has a more clear opinion of the quality of the results of each method and a more cohesive evaluation. Apart from a few outliers, they rank the weighted Manhattan-based alternative higher than the other two methods, giving scores that are either 7 or 8 out of 10. More specifically, in the within-specialty group, the weighted Manhattan method achieved a median score of 7.5 (IQR = 6–8), with 75% of ratings being 7 or higher. The weighted Euclidean method showed a slightly lower consensus with a median of 6 (IQR = 5–7). Baseline scores were consistently the lowest with a median of 4 (IQR = 3–5). In the outside-specialty group, both proposed methods outperformed the baseline (median scores of 5 vs. 3 respectively), but exhibited wider score distributions (Manhattan IQR = 3.5–6.5; Euclidean IQR = 3–6). The baseline method showed the poorest performance with a median of 3 (IQR = 2–4). The greater variance in scores for this group suggests more variability in how relevant the recommendations were perceived to be. These numerical results demonstrate that graduates working in their field of study showed both higher satisfaction and greater consensus in their evaluations, particularly favoring the weighted Manhattan approach. The wider score ranges among those working outside their specialty may reflect more diverse career trajectories or differing expectations from the recommendation system.
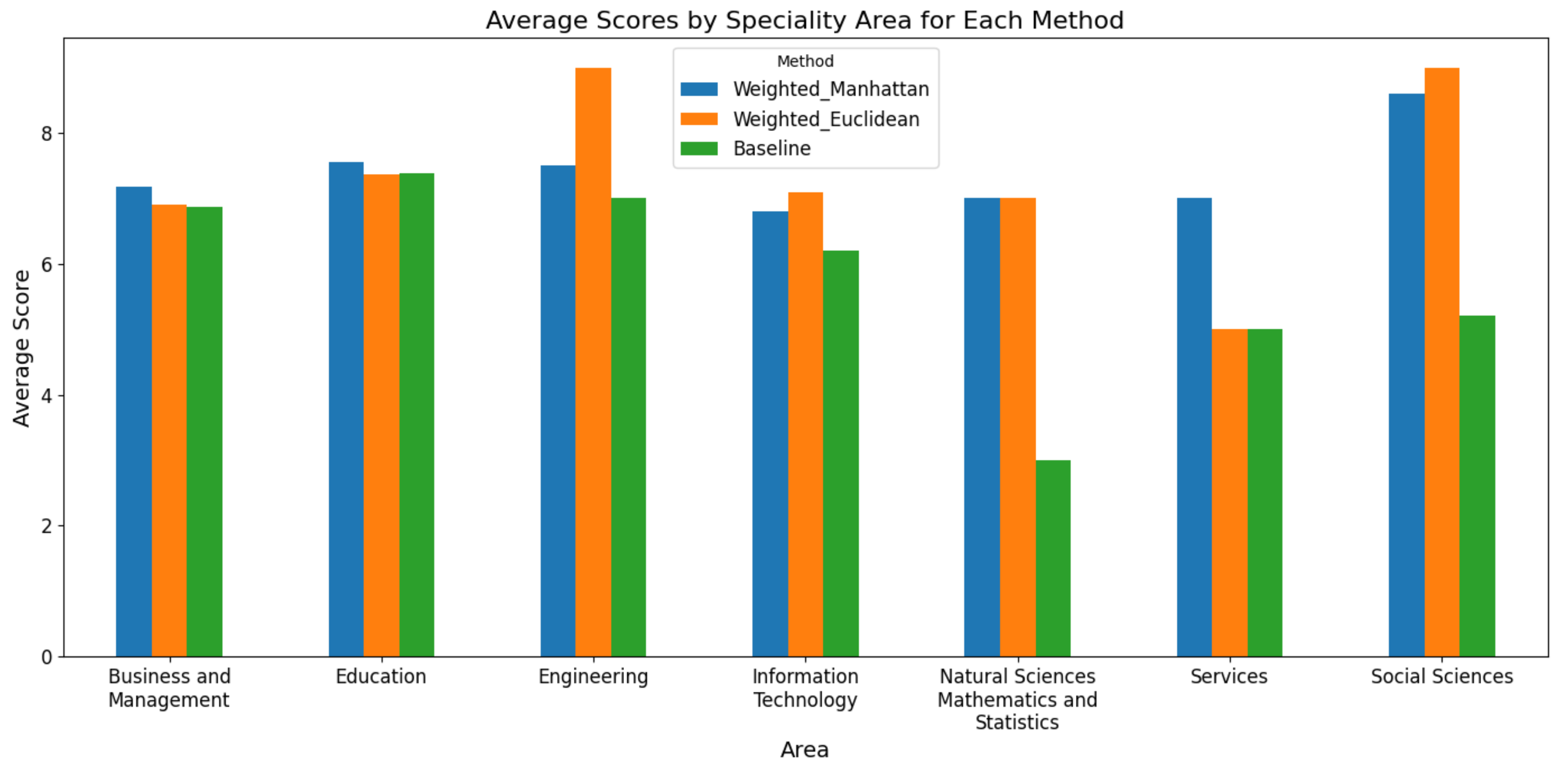
The next set of results highlights whether certain methods perform better than others for specific work specializations. From what is shown in
Figure 13, our proposed approach outperforms the text similarity-based baseline in all specialization areas. However, the weighted Manhattan method is preferred among graduates who work in Business and Management, Education, and Services, whereas the weighted Euclidian method is preferred among graduates who work in Engineering, Information Technology, and Social Sciences. The two methods are equally valued among graduates who work in Natural Sciences, Mathematics, and Statistics.
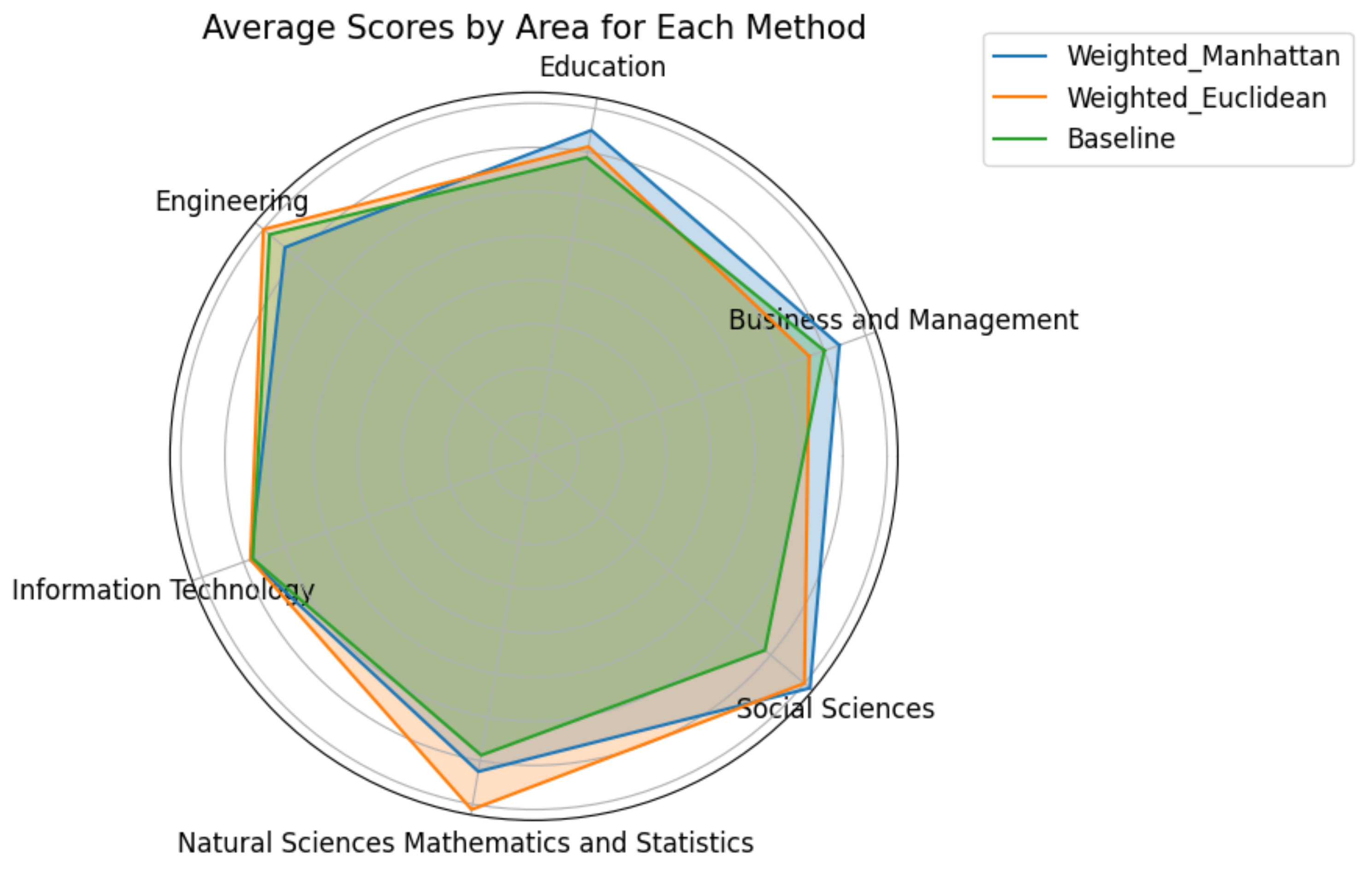
Similar results are found in the radar plot of
Figure 14, which displays the respective average score per group of graduates, based on the area they have studied. Once again, the two proposed alternatives outperform the baseline in all areas apart from the group of graduates of Information Technology for which the three methods have comparable performance.
While the study provides valuable insights into the performance of job recommendation methods, several limitations should be acknowledged. First, the sample size of 100 graduates, though sufficient for initial comparisons, may lack the diversity and statistical power to generalize findings across broader populations or niche specializations. For instance, subgroups like graduates in Natural Sciences or Information Technology were underrepresented, potentially skewing results (e.g., the comparable performance of methods in IT). Second, the evaluation relied on self-reported scores, which may introduce subjective bias, and the analysis focused narrowly on specialty alignment and domain areas, overlooking other factors like demographic diversity, job market dynamics, or longitudinal satisfaction. Finally, while the proposed methods outperformed the baseline, their reliance on Manhattan and Euclidean metrics may oversimplify the complexity of personality–job alignment.
To address these limitations, future work could expand the participant pool to include more graduates across diverse specializations and geographic regions, ensuring robust subgroup analyses. Testing advanced similarity methods (e.g., machine learning-driven metrics, hybrid models combining personality traits with contextual job-market data) could enhance recommendation accuracy. Additionally, incorporating objective metrics (e.g., job retention rates, employer feedback) and longitudinal studies would strengthen validity, while explainability frameworks could clarify why certain methods succeed in specific domains (e.g., Manhattan’s dominance in Business vs. Euclidean in Engineering).
6. Conclusions and Future Work
This study introduced a novel job recommendation system that integrates personality traits evaluated through the Gallup CliftonStrengths assessment, offering a more holistic approach to career matching by aligning users’ natural strengths with job requirements. Empirical evaluations involving 100 graduates demonstrated that the proposed methods significantly outperformed the baseline text-similarity approach, showing a 0.5-point average improvement in user satisfaction. Notably, graduates working in their studied specializations exhibited more cohesive evaluations, consistently favoring the proposed approach, while the performance of the two proposed variants varied across domains. These results underscore the value of incorporating personality traits into recommendation systems, particularly for enhancing alignment between users’ intrinsic strengths and job roles.
However, the study has several limitations. First, the sample size, though sufficient for initial validation, limits generalizability to niche specializations (e.g., underrepresented groups in IT or Natural Sciences). Second, reliance on self-reported scores introduces potential subjective bias, and the analysis focused narrowly on specialty alignment rather than demographic or job-market dynamics.
Future work should expand the participant pool to include diverse specializations and geographic regions to validate robustness. Testing advanced similarity methods, such as machine learning-driven metrics or hybrid models integrating contextual job-market data, could further refine accuracy. As part of future work, we plan to conduct a rigorous ablation study to isolate and quantify the impact of each pipeline component—especially the CliftonStrengths-derived personality vectors—on recommendation performance. In addition, we plan to incorporate comparisons with other recommendation techniques, such as collaborative filtering and hybrid recommenders, to further validate our approach in a broader algorithmic context. We also aim to explore the use of standard evaluation metrics, including AUC and precision/recall, to provide a more comprehensive view of accuracy and performance trade-offs.
Furthermore, recognizing the importance of adaptability in both individuals and systems, we aim to investigate how dynamic, future-oriented strengths—such as those captured by the Gallup Adaptability, Learner, and Strategic themes—can be leveraged to match users with roles that are themselves evolving. This may include hybridizing narrow strength-based models with broader frameworks like the Big Five to better address the multidimensional nature of jobs that demand both technical precision and socio-emotional intelligence. Incorporating objective metrics like job retention rates or employer feedback, alongside longitudinal studies, would strengthen validity. For this reason, we plan to conduct a longitudinal follow-up incorporating objective indicators such as job placement outcomes, employer feedback, and career retention rates, to more robustly evaluate the long-term impact of the proposed method. Additionally, explainability frameworks could clarify why certain methods excel in specific domains. By addressing these challenges, personality-based recommendation systems can evolve into indispensable tools for fostering career satisfaction and talent retention.





 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}