
A Novel Algorithm for Personalized Federated Learning: Knowledge Distillation with Weighted Combination Loss



Abstract
1. Introduction
2. Materials and Methods
2.1. Conventional FL Model
2.2. Knowledge Distillation
2.3. Proposed Method
2.3.1. Problem Formulation
2.3.2. Algorithm Description
| Algorithm 1 pFedKD-WCL Algorithm |
| 1: Input: T (rounds), R (local steps), S (clients per round), (learning rate), (KD weight), (initial global model) 2: for to do 3: Server samples subset of S clients 4: Server broadcasts to all clients in 5: for each client in in parallel do 6: for to do 7: Sample mini-batch from 8: Compute loss using Equation (3) 9: Update 10: end for 11: Set 12: end for 13: Clients in send to server 14: Server updates with Equation (4) 15: end for 16: Output: Global model , personalized models |
3. Experiments and Results
3.1. Experimental Setting
3.2. Experimental Hyperparameter Settings
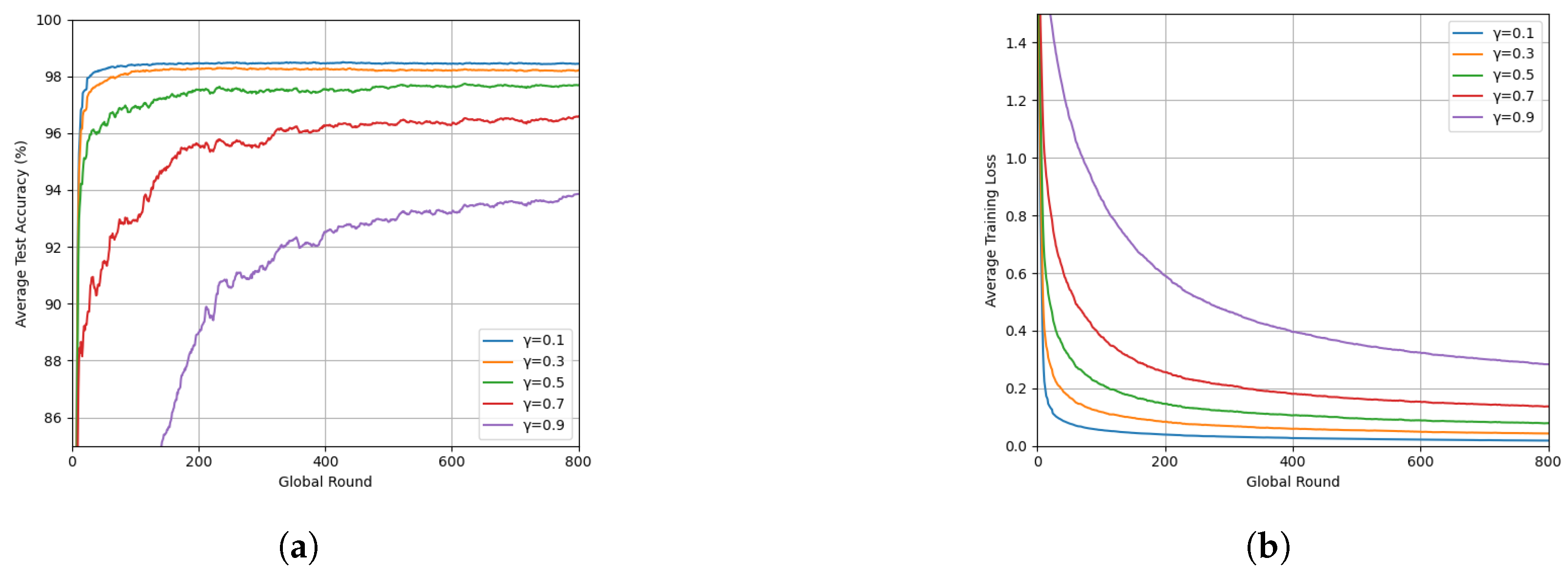
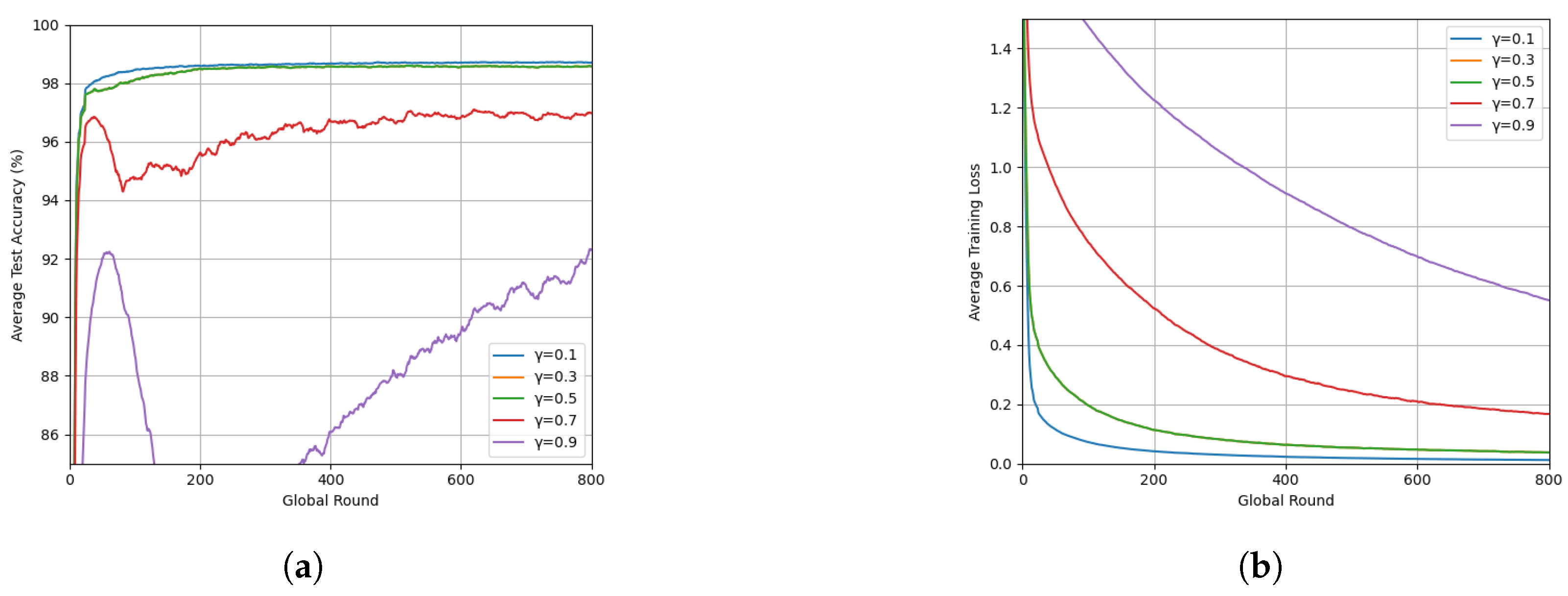
3.3. Effect of the Hyperparameter
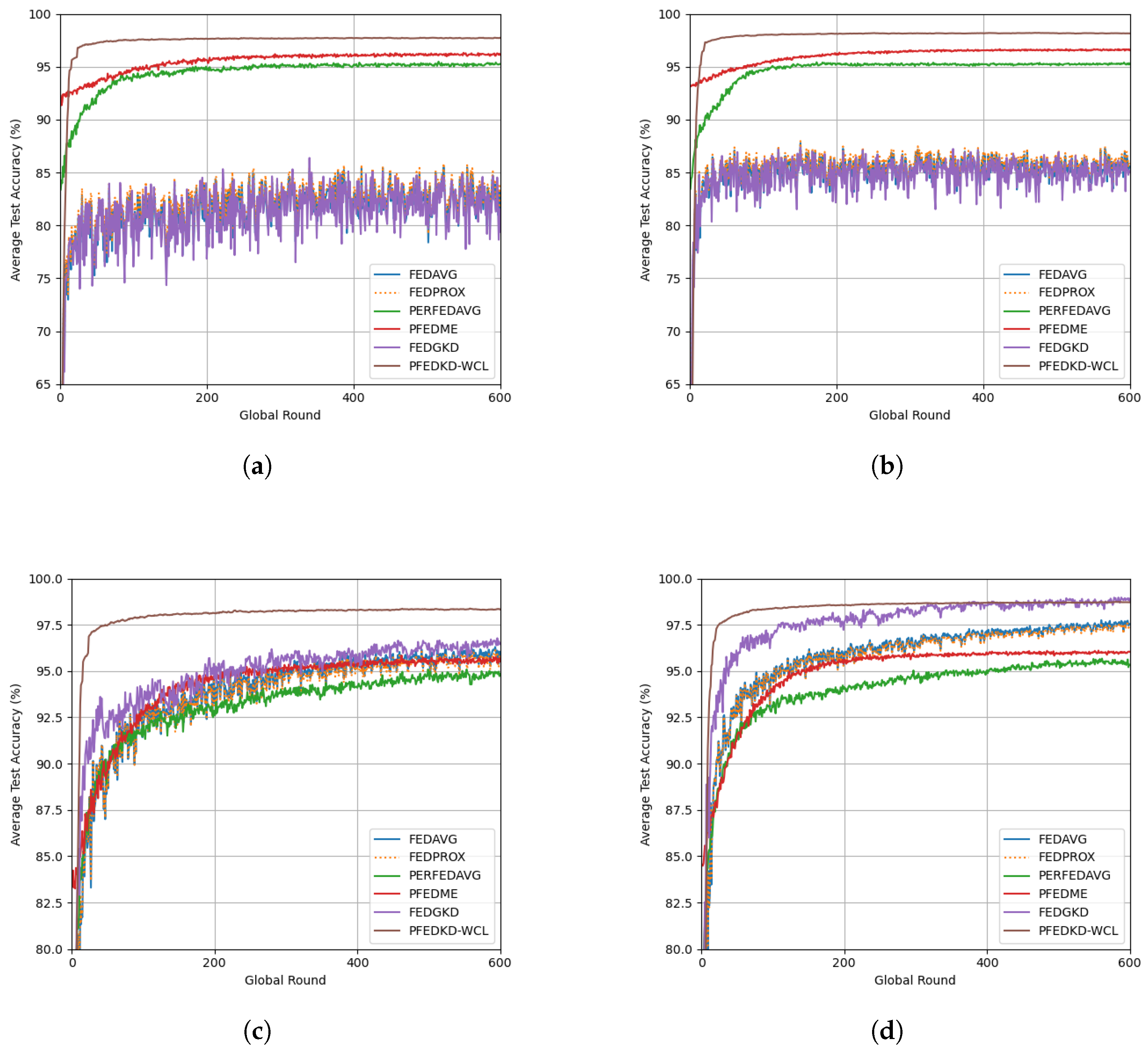
3.4. Performance Comparison Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Nitin Bhagoji, A.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and Open Problems in Federated Learning. Found. Trends® Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Sattler, F.; Wiedemann, S.; Müller, K.R.; Samek, W. Robust and communication-efficient federated learning from non-iid data. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 3400–3413. [Google Scholar] [CrossRef]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.; Stich, S.; Suresh, A.T. Scaffold: Stochastic controlled averaging for federated learning. In Proceedings of the International Conference on Machine Learning, Online, 13–18 July 2020; pp. 5132–5143. [Google Scholar]
- Wang, J.; Liu, Q.; Liang, H.; Joshi, G.; Poor, H.V. Tackling the objective inconsistency problem in heterogeneous federated optimization. Adv. Neural Inf. Process. Syst. 2020, 33, 7611–7623. [Google Scholar]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated learning with non-iid data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Chen, H.Y.; Chao, W.L. On bridging generic and personalized federated learning for image classification. arXiv 2021, arXiv:2107.00778. [Google Scholar]
- Li, T.; Hu, S.; Beirami, A.; Smith, V. Ditto: Fair and robust federated learning through personalization. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 6357–6368. [Google Scholar]
- Tan, A.Z.; Yu, H.; Cui, L.; Yang, Q. Towards personalized federated learning. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 9587–9603. [Google Scholar] [CrossRef]
- Arivazhagan, M.G.; Aggarwal, V.; Singh, A.K.; Choudhary, S. Federated learning with personalization layers. arXiv 2019, arXiv:1912.00818. [Google Scholar]
- T Dinh, C.; Tran, N.; Nguyen, J. Personalized federated learning with moreau envelopes. Adv. Neural Inf. Process. Syst. 2020, 33, 21394–21405. [Google Scholar]
- Fallah, A.; Mokhtari, A.; Ozdaglar, A. Personalized federated learning: A meta-learning approach. arXiv 2020, arXiv:2002.07948. [Google Scholar]
- Jiang, Y.; Konečnỳ, J.; Rush, K.; Kannan, S. Improving federated learning personalization via model agnostic meta learning. arXiv 2019, arXiv:1909.12488. [Google Scholar]
- Smith, V.; Chiang, C.K.; Sanjabi, M.; Talwalkar, A.S. Federated multi-task learning. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Deng, Y.; Kamani, M.M.; Mahdavi, M. Adaptive personalized federated learning. arXiv 2020, arXiv:2003.13461. [Google Scholar]
- Ghosh, A.; Chung, J.; Yin, D.; Ramchandran, K. An efficient framework for clustered federated learning. Adv. Neural Inf. Process. Syst. 2020, 33, 19586–19597. [Google Scholar] [CrossRef]
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A survey on federated learning. Knowl.-Based Syst. 2021, 216, 106775. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Li, D.; Wang, J. Fedmd: Heterogenous federated learning via model distillation. arXiv 2019, arXiv:1910.03581. [Google Scholar]
- Lin, T.; Kong, L.; Stich, S.U.; Jaggi, M. Ensemble distillation for robust model fusion in federated learning. Adv. Neural Inf. Process. Syst. 2020, 33, 2351–2363. [Google Scholar]
- Jeong, E.; Kountouris, M. Personalized decentralized federated learning with knowledge distillation. In Proceedings of the ICC 2023-IEEE International Conference on Communications, Rome, Italy, 28 May–1 June 2023; pp. 1982–1987. [Google Scholar]
- Seo, H.; Park, J.; Oh, S.; Bennis, M.; Kim, S.L. 16 federated knowledge distillation. Mach. Learn. Wirel. Commun. 2022, 457. [Google Scholar]
- Zhu, Z.; Hong, J.; Zhou, J. Data-free knowledge distillation for heterogeneous federated learning. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 12878–12889. [Google Scholar]
- Zheng, S.; Hu, J.; Min, G.; Li, K. Mutual Knowledge Distillation based Personalized Federated Learning for Smart Edge Computing. IEEE Trans. Consum. Electron. 2024. [Google Scholar] [CrossRef]
- Zheng, M.; Liu, Z.; Chen, B.; Hu, Z. PFedSKD: Personalized Federated Learning via Self-Knowledge Distillation. In Proceedings of the 2024 IEEE International Symposium on Parallel and Distributed Processing with Applications (ISPA), Kaifeng, China, 30 October–2 November 2024; pp. 1591–1598. [Google Scholar]
- Yao, D.; Pan, W.; Dai, Y.; Wan, Y.; Ding, X.; Yu, C.; Jin, H.; Xu, Z.; Sun, L. FedGKD: Toward heterogeneous federated learning via global knowledge distillation. IEEE Trans. Comput. 2023, 73, 3–17. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Hsu, T.M.H.; Qi, H.; Brown, M. Measuring the Effects of Non-Identical Data Distribution for Federated Visual Classification. arXiv 2019, arXiv:1909.06335. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Algorithm | Model | with Top-2 Classes | |||
|---|---|---|---|---|---|
| N = 20 | N = 50 | N = 20 | N = 50 | ||
| FedAvg | MLR | ||||
| FedProx | MLR | ||||
| PerFedAvg | MLR | ||||
| pFedMe | MLR | ||||
| FedGKD | MLR | ||||
| pFedKD-WCL | MLR | ||||
| FedAvg | MLP | ||||
| FedProx | MLP | ||||
| PerFedAvg | MLP | ||||
| pFedMe | MLP | ||||
| FedGKD | MLP | ||||
| pFedKD-WCL | MLP | ||||
| Algorithm | Model | Accuracy |
|---|---|---|
| FedAvg | MLR | |
| FedProx | MLR | |
| PerFedAvg | MLR | |
| pFedMe | MLR | |
| FedGKD | MLR | |
| pFedKD-WCL | MLR | |
| FedAvg | MLP | |
| FedProx | MLP | |
| PerFedAvg | MLP | |
| pFedMe | MLP | |
| FedGKD | MLP | |
| pFedKD-WCL | MLP |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, H.; Kothari, A.N.; Banerjee, A. A Novel Algorithm for Personalized Federated Learning: Knowledge Distillation with Weighted Combination Loss. Algorithms 2025, 18, 274. https://doi.org/10.3390/a18050274
Hu H, Kothari AN, Banerjee A. A Novel Algorithm for Personalized Federated Learning: Knowledge Distillation with Weighted Combination Loss. Algorithms. 2025; 18(5):274. https://doi.org/10.3390/a18050274
Chicago/Turabian StyleHu, Hengrui, Anai N. Kothari, and Anjishnu Banerjee. 2025. "A Novel Algorithm for Personalized Federated Learning: Knowledge Distillation with Weighted Combination Loss" Algorithms 18, no. 5: 274. https://doi.org/10.3390/a18050274
APA StyleHu, H., Kothari, A. N., & Banerjee, A. (2025). A Novel Algorithm for Personalized Federated Learning: Knowledge Distillation with Weighted Combination Loss. Algorithms, 18(5), 274. https://doi.org/10.3390/a18050274