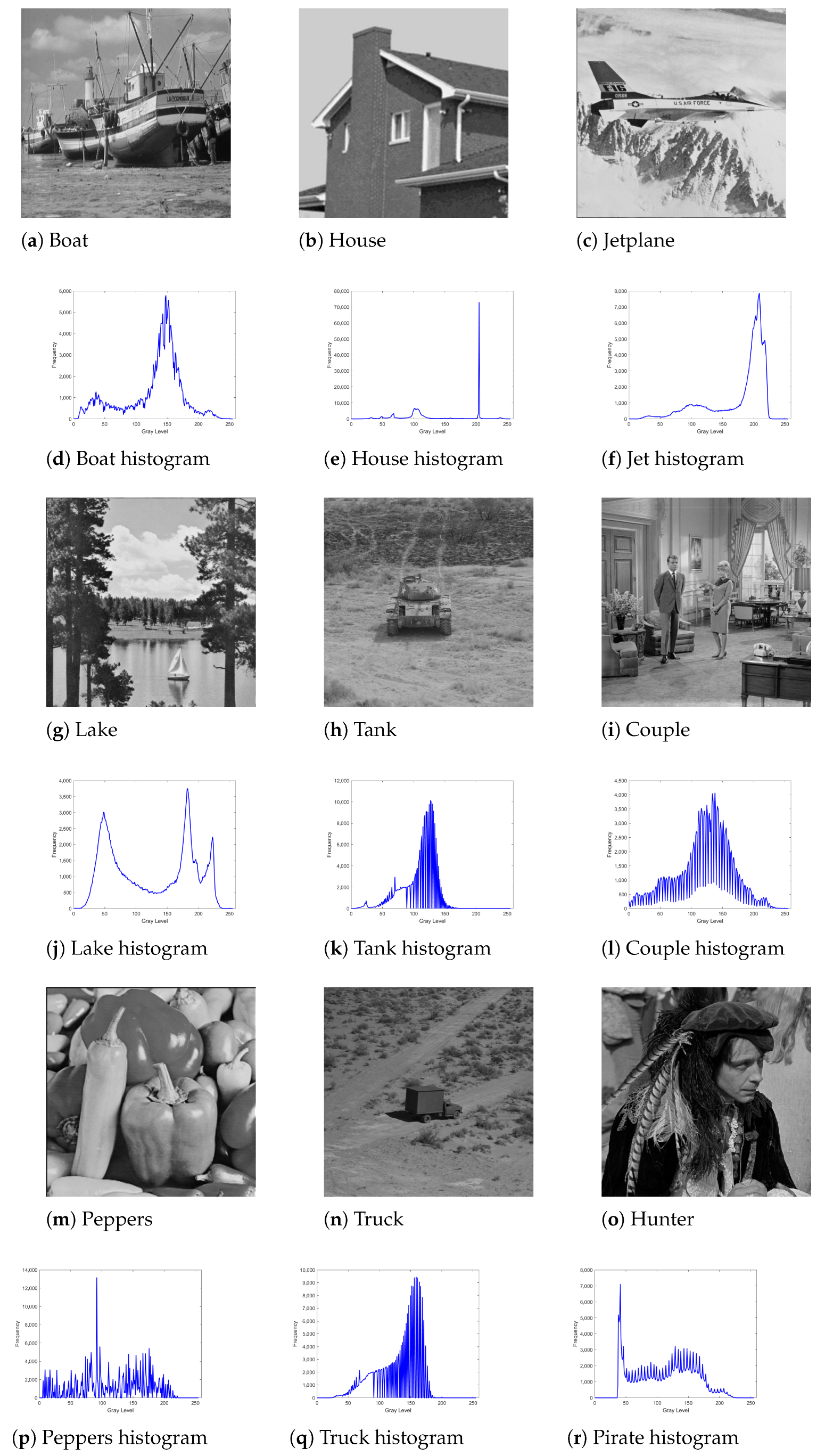
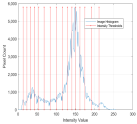
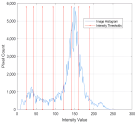
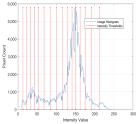
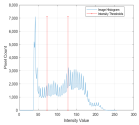
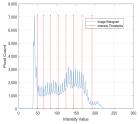
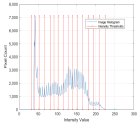
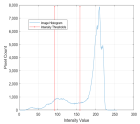
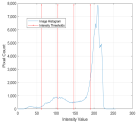
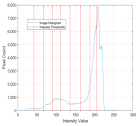
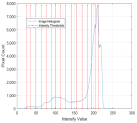
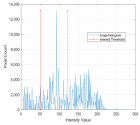
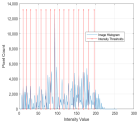
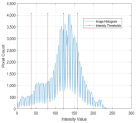
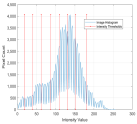
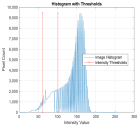
1. Introduction
The “No Free Lunch” theorem asserts that no single algorithm can universally outperform all others across every possible problem [
1]. Consequently, a diverse range of metaheuristic algorithms (MAs) has been developed, including Evolutionary Algorithms (EAs) and Swarm Intelligence Algorithms (SAs) [
2]. Among the most prominent MAs are Differential Evolution (DE) [
3], Artificial Bee Colony (ABC) [
4], Particle Swarm Optimization (PSO) [
5], Genetic Algorithm (GA) [
6], and Ant Colony Optimization (ACO) [
7].
Recent advancements have introduced innovative particle-based algorithms with notable performance. These include the Artificial Hummingbird Algorithm (AHA), which emulates the foraging and flight behaviors of hummingbirds [
8]; Colliding Bodies Optimization (CBO), which models solutions as physical bodies undergoing one-dimensional collisions [
9]; and Enhanced Colliding Bodies Optimization (ECBO), an improved variant of CBO that incorporates mass and velocity to refine collision dynamics [
10]. Additionally, hybrid approaches like the Artificial Hummingbird Algorithm with Aquila Optimization (AHA-AO) [
11] and Social Network Search (SNS) have gained traction. SNS simulates social media interactions, where users influence one another through mood-driven behaviors such as Imitation, Conversation, Disputation, and Innovation, mirroring real-world opinion dynamics [
12].
Metaheuristic algorithms (MAs) generate solutions by efficiently exploring the search space while progressively narrowing the search area. Their performance hinges on the ability to balance exploration, i.e., searching globally for diverse solutions, and exploitation, i.e., refining solutions within promising regions. Initially, when no prior information about the search space is available, MAs prioritize exploration to identify a wide range of potential solutions. As the algorithm progresses and converges toward potential optima, the focus shifts to exploitation, enhancing solution precision and accuracy [
13].
Modern real-life optimization problems are often highly complex, making them difficult to solve using traditional exact methods. This complexity stems from factors such as high dimensionality, intricate parameter interactions, and multimodality [
13]. Metaheuristic algorithms (MAs) have emerged as a robust alternative, offering effective solutions to these challenging problems [
14].
Parametric identification is a crucial application in automatic control, but it presents significant challenges due to the complexity of the models involved. These models often include numerous parameters and multiple ordinary differential equations, making traditional identification methods inadequate. While parametric estimation techniques for linear systems are well-established [
15], they often fail to address the complexities of non-linear systems. Conventional approaches are limited by their reliance on assumptions, such as unimodality, continuity, and differentiability of the objective function, which rarely apply to non-linear systems [
16]. Another important application is in image analysis, where image segmentation remains a critical and extensively researched task [
17].
This process is a critical preliminary step in image analysis, aiming to divide an image into meaningful and homogeneous regions based on characteristics such as gray values, edge information, and texture. Framing this as an optimization problem involves minimizing the cross-entropy between the object and the background. However, this approach often encounters multiple local minima, complicating the computational process. Furthermore, the computational time grows exponentially with the number of thresholds, making it a challenging and resource-intensive task.
To address key limitations, particularly the high computational cost of threshold searches, numerous algorithms have been developed. In scenarios where traditional methods fall short, metaheuristic algorithms (MAs) offer a promising alternative. Unlike conventional approaches, MAs do not depend on simplifying assumptions such as unimodality, continuity, or differentiability, making them highly effective for complex nonlinear systems with multiple parameters and time-varying dynamics. Their success has been demonstrated in various real-world applications [
16], including the identification of unknown parameters in biological models [
18].
In this study, we propose a novel population-based algorithm, the Gaslike Social Motility Algorithm (GSM), for solving optimization problems. Inspired by the movement patterns of gas motility [
19], GSM dynamically adapts its search process to efficiently explore the solution space. This model is characterized by its deterministic nature, minimal parameter requirements, and ability to replicate social behaviors, such as: (1) attraction between similar particles, (2) formation of stable groups, (3) division of groups into smaller units upon reaching a critical size, (4) modification of particle distributions through inter-group interactions during the search process, and (5) changes in particles’ internal states through local interactions. The proposed algorithm was evaluated using 22 benchmark optimization functions and compared against the performance of the PSO, DE, BA, ABC, AHA, AHA-AO, CBO, ECBO, and SNS algorithms. The GSM algorithm demonstrated superior performance, achieving optimal results for all benchmark functions with significantly fewer computational iterations than its counterparts.
The key contributions of this paper are: (1) the introduction of a novel swarm-based optimization algorithm, (2) a comprehensive comparison of various metaheuristic algorithms, and (3) the application of the proposed algorithm to image thresholding segmentation. These contributions underscore the significance of this work in advancing the field of metaheuristic algorithms (MAs).
The paper is structured as follows: first, the GSM algorithm is described in detail; next, a comparative analysis is conducted between GSM and state-of-the-art algorithms, including PSO, DE, BA, ABC, AHA, AHA-AO, CBO, ECBO, and SNS; then, the application of GSM to image thresholding segmentation is presented; and finally, the conclusions are discussed.
2. The Proposed Gaslike Social Motility (GSM) Algorithm
We propose a novel swarm-based algorithm for global optimization, inspired by the principles of gaslike social motility as described in [
19].
This algorithm is based on the concept of collective movement, commonly observed in systems such as bird flocks, bee swarms, and animal herds. Each particle is characterized by an internal state that evolves through interactions with neighboring particles, where the interaction strength depends on the internal states of the neighbors. Specifically, a particle i responds to particle j by either approaching or retreating, requiring an evaluation of the local environment to determine the appropriate action.
The behavior of gas particles is described below, along with its adaptation to develop a global optimization strategy inspired by their dynamics.
2.1. Gaslike Social Motility Behavior: Inspiration and Application
In [
19], each particle
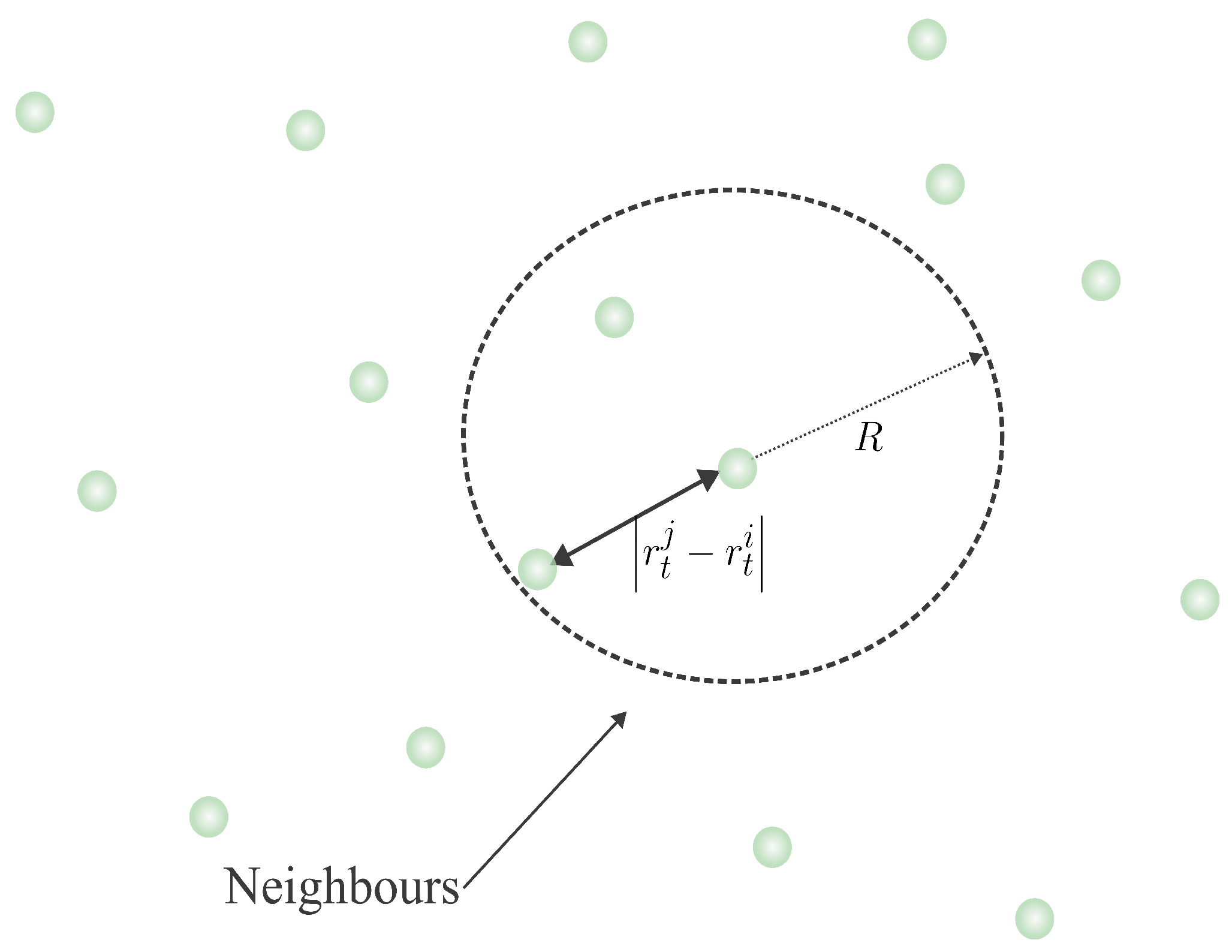
i interacts within a bounded, time-varying neighborhood defined by the proximity and affinity between the gas particle
i and its surrounding particles. These interactions determine whether a particle
i forms groups with its neighbors or moves away from them. The behavior of each particle is governed by the following dynamic rules:
Here, denotes the feature (state or mood) of the i-th particle at the time step t, where i ranges from 1 to N, the total number of particles. The position vector lies in a d-dimensional space, and the neighborhood of each particle is defined as , with representing its cardinality. The parameter controls the coupling strength, determining how quickly a particle adjusts its position to approach or retreat from others. The constant R defines the interaction radius for each particle, while represents the bounded coupling strength within the range .
The state of the particle is influenced not only by its own mood but also by the moods of its neighboring particles. The parameter determines the extent of this influence: a higher value of increases the contribution from neighbors, while a lower value diminishes it. This dynamic models a highly relevant social interaction mechanism, making it particularly suitable for application in metaheuristic algorithms.
In Equation (
1), the function
governs the internal behavior of each particle and is applied across the entire network. The dynamics are coupled through a weighted sum of the influences exerted by the neighboring particles of the particle
i. In this work, a network is defined as the set of relationships or connections that particles establish with their neighbors within their environment.
From Equation (
2), it is clear that the particle
i evaluates its environment globally before deciding whether to stay close to or move away from its neighbors. This decision is primarily determined by the two factors on the right-hand side of (
2). The movement, which can be either inward or outward, is driven by the term
. Here, particles exchange information about their “affinity” with their neighboring group, reflecting the similarity of their characteristics at time
. The direction of movement is influenced by the first factor in the equation, which assesses the angular distribution of neighbors relative to the particle
i. Greater asymmetry in the angular distribution of neighbors results in a larger displacement magnitude for
i.
2.2. Gaslike Social Motility Algorithm
The emergent behavior described by Equations (
1) and (
2) is well-suited for use as an optimization algorithm. To adapt this behavior for optimization, we introduced modifications while retaining the core principles of the original model. As a result, (
1) and (
2) are reformulated as follows:
Here, we consider a population of
N motile particles, each with a continuous position
. Each particle
i navigates the
D-dimensional search space, where
represents the state (or “mood”) of the
i-th gas particle, reflecting its perception of the environment. The evolution of the particle’s state depends on its interactions with its neighborhood. In particular, when
, the best position achieved by the neighboring particle
coincides with the position of particle
. In this case, the neighbor does not provide any meaningful contribution and is therefore ignored.
Figure 1 illustrates an example of neighbor selection for the particle
within the search space.
The primary objective is to optimize the function by adjusting the position of the gas particles. The optimization process depends entirely on the position at the time step t, which is influenced by the particle’s mood . The factor is computed to determine the direction of motion for the particle.
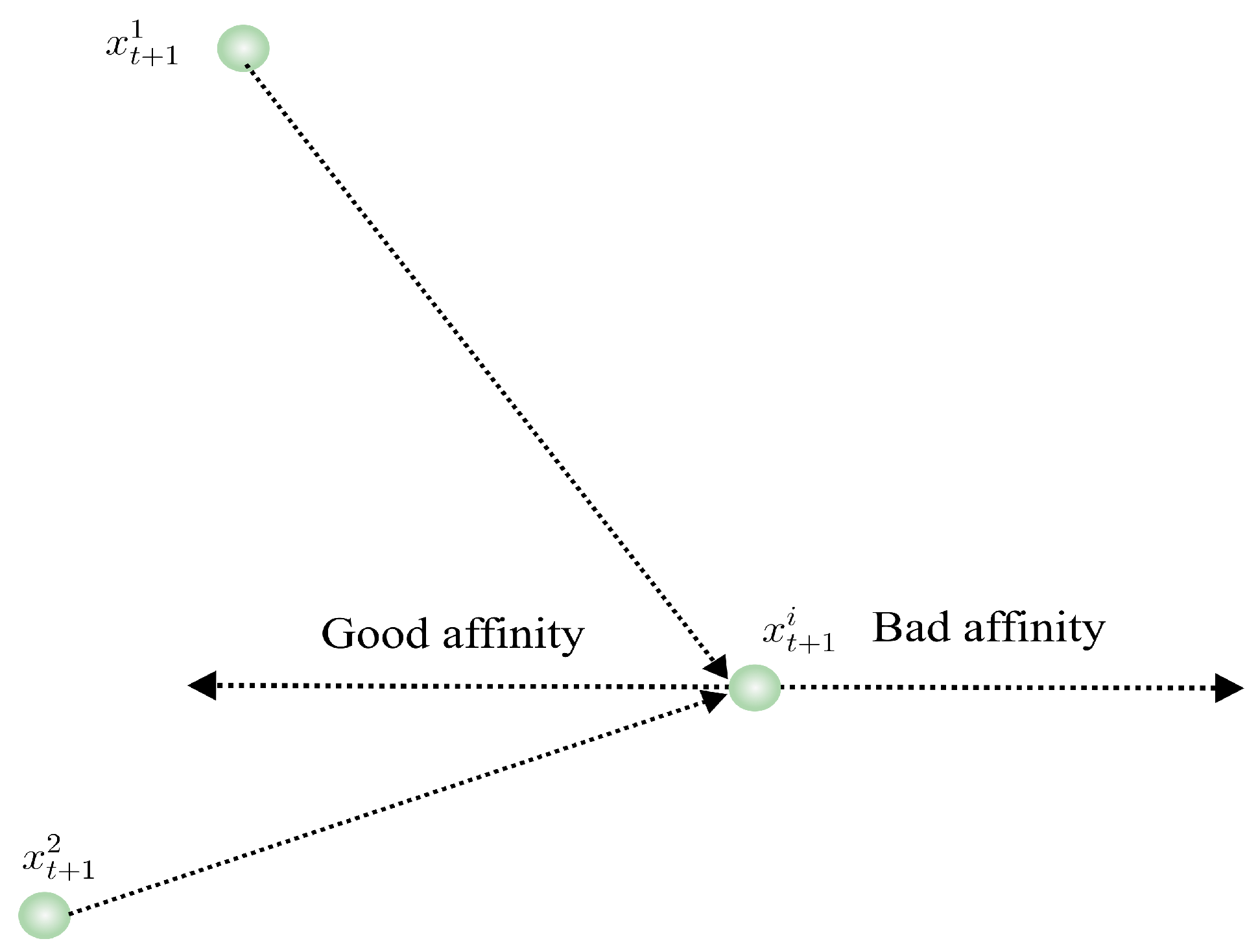
This equation quantifies the affinity of the particle
i with its neighborhood. If the affinity is “good”, the particle
i moves toward the dense region of the normal distribution corresponding to the best global position of the particles. If the affinity is “bad”, it moves in the opposite direction.
Figure 2 illustrates whether the displacement is positive or negative based on the contributions of neighboring particles.
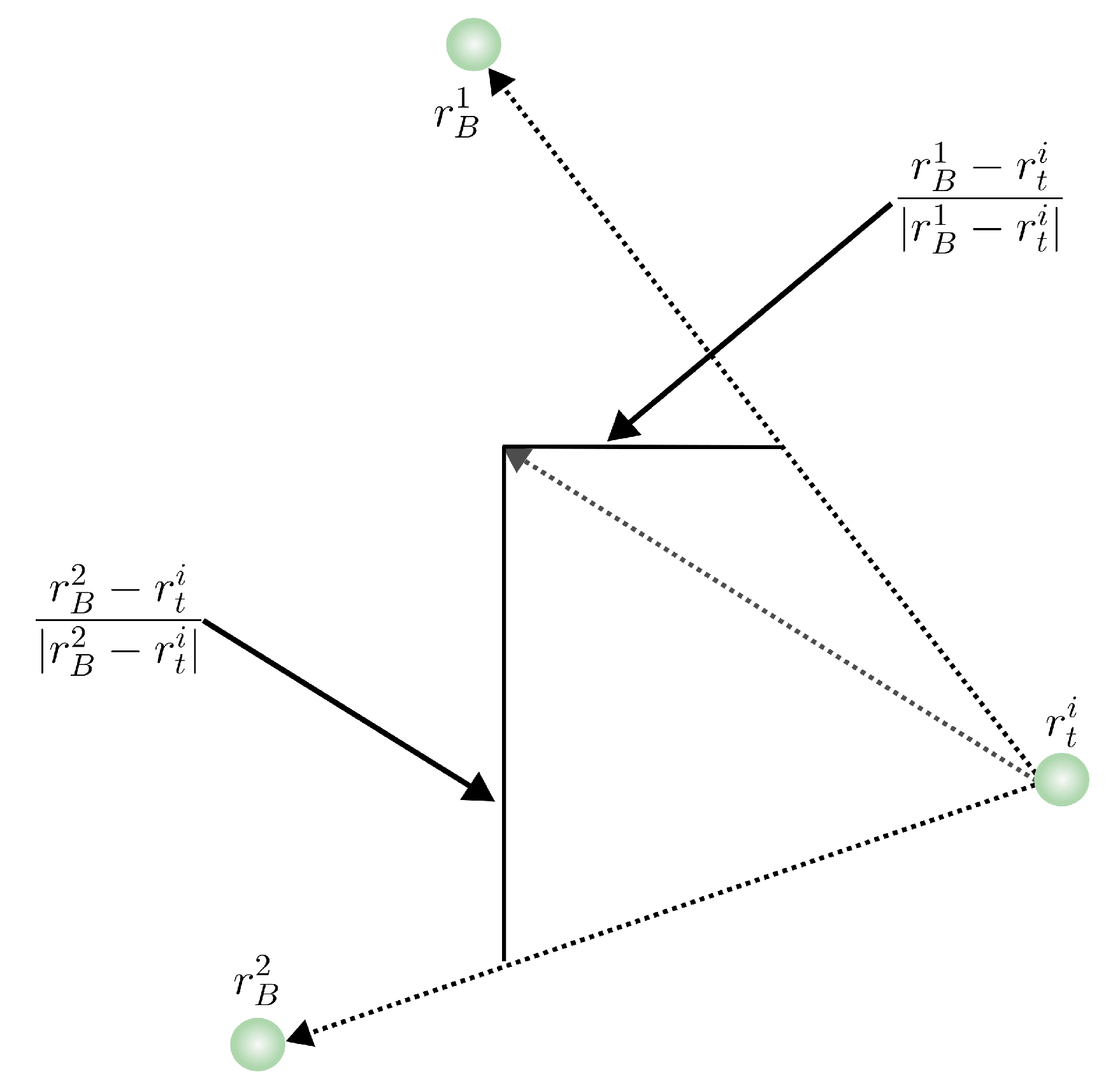
Moreover, in Equation (
4), the direction of movement for particle
i depends on the distribution of the best-visited positions
of all particles in the set
, relative to the position of
i, as illustrated in
Figure 3.
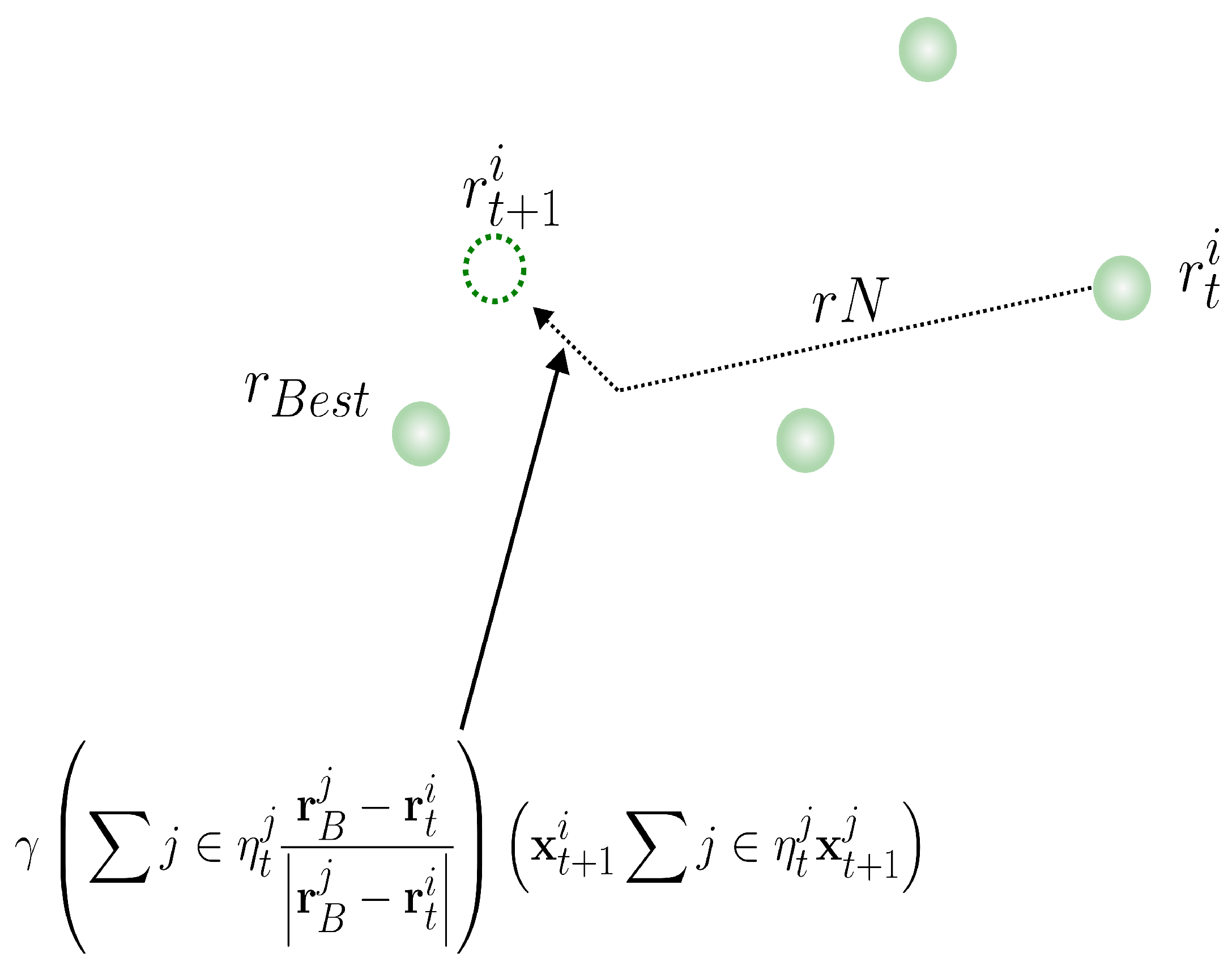
Finally, the term
is a vector generated as
, where
. This introduces a randomness factor that models the uncertainty and variability inherent in social systems, where particles may act unpredictably in response to external influences. In the context of the model, this term can produce effects contrary to expectations, generating deviations in particle displacement and reflecting behavioral diversity within the network. This reinforces the analogy to real social systems, where interactions between agents are not always deterministic. Here,
is a normal distribution centered on the best global position
, and
is the standard deviation of the best positions of
particles, where
. This term represents the leadership of the best-performing particle, guiding collective movement toward feasible regions with optimal solutions. However, particles may choose to move closer or farther depending on interactions with nearby particles, as illustrated in
Figure 4.
In summary, the displacement of the particles depends on how the position relates to the best positions found by the set and how similar the next state is to the corresponding i-th component. Specifically, if a particle is far from the best positions, it will move more significantly than if it is near them. The particle is attracted to remain in the vicinity of the best positions only if its state is comparable to those of its neighbors. If a particle has no neighbors (), its position is determined solely by the random variable from , and its internal state is defined by the objective function at . To avoid this scenario, an appropriate choice of R is crucial to ensure particles maintain interactions within the network, tailored to the properties of the objective function.
The selection of the parameters , , and R should be guided by the following considerations: regulates the coupling between a particle’s internal state and that of its neighbors. Larger values () increase the tendency to resemble neighboring particles, while causes the particle to evolve independently of its neighborhood. should be small enough to allow cluster formation, as results in no motion. R depends on the size of the search space. If the space is large and R is small, particles may become too dispersed, preventing cluster formation. Conversely, if the space is small and R is large, particles will have nearly all others as neighbors. The interaction radius R defines the neighborhood size, and dynamically adjusting R allows the algorithm to balance local exploitation (small R) and global exploration (large R). When a particle has no useful neighbors (i.e., ), it acts independently, enabling it to escape local optima.
In this way, we preserve the original property, where individuals evaluate their internal state to determine how much they want to resemble their neighborhood and, in terms of position, how they are located relative to the best position of their neighbors and how similar they are to their surroundings.
Table 1 shows the list of GSM algorithm terms. The complete GSM algorithm is found in Algoritm 1.
| Algorithm 1 GSM algorithm to solve minimization problems. f is the Objective Function, N the total number of particles and D the dimension of the problem. |
- 1:
R, , , ← define parameters - 2:
← initialize i ∈ N state of the particles randomly - 3:
← initialize random position such that - 4:
←, initialization of best particle positions - 5:
initialize neighbors at zero such that - 6:
do - 7:
for do - 8:
if then - 9:
- 10:
Choose particle with best swarm position - 11:
Selection of the best particles bs from rt - 12:
for do - 13:
- 14:
for do - 15:
if then - 16:
- 17:
- 18:
for do - 19:
- 20:
-
- 21:
while Total number of iterations G is fulfilled
|
3. GSM Algorithm Performance Results
To evaluate the efficiency of the GSM algorithm, it was implemented and tested on a set of benchmark functions. The GSM algorithm was compared on equal terms with several well-known optimization algorithms, including PSO, DE, BA, ABC, AHA, AHA-AO, CBO, ECBO, and SNS. The benchmark functions were selected to represent a diverse range of problem types, such as unimodal, multimodal, regular, irregular, separable, non-separable, and multidimensional functions. The parameters used for each algorithm in this study are provided in
Table 2.
A unimodal function has a single global optimum with no or only one local optimum, while a multimodal function features multiple local optima. Optimization algorithms are often tested on multimodal functions to assess their ability to avoid local optima. Algorithms with poor exploration capabilities may struggle to search the space thoroughly and may converge to suboptimal solutions. Additionally, flat search spaces pose challenges as they lack gradient information to guide the algorithm toward the global optimum [
20]. Both separable and non-separable functions were included in the tests to further evaluate algorithm performance [
20].
High-dimensional search spaces present another significant challenge for optimization algorithms. As the dimensionality of a problem increases, the search space volume grows exponentially, making it harder to locate the global optimum. Algorithms that perform well in low-dimensional spaces may struggle in high-dimensional environments. Therefore, global optimization algorithms are rigorously tested in high-dimensional search spaces to ensure robustness [
21].
Scaling problems also pose difficulties for optimization algorithms. These problems involve significant variations in magnitude between the domain and the frequency of the hypersurface, complicating the search process [
22]. For instance, Langerman functions are nonsymmetrical with randomly distributed local optima, making them particularly challenging to optimize. The quartic function introduces random noise (Gaussian or uniform), requiring algorithms to handle noisy data effectively. Algorithms that fail to perform well on noisy functions are likely to struggle in real-world applications where noise is prevalent. The benchmark functions used in this study are summarized in
Table 3 and
Table 4, categorized by unimodal and multimodal functions, respectively. These functions are further classified based on characteristics such as continuity, separability, scalability, and differentiability.
The GSM algorithm was compared against PSO, DE, BA, ABC, AHA, AHA-AO, CBO, ECBO, and SNS using the 22 benchmark functions listed in
Table 3 and
Table 4. Each algorithm was executed 100 times, and the mean, standard deviation, and optimal values were recorded. The number of iterations and population size for each algorithm are detailed in
Table 3 and
Table 4. All algorithms were implemented in MATLAB 24.2.0.2871072 (R2024b) Update 5 (The MathWorks, Inc., Natick, MA, USA), and the results are presented in
Table 5 and
Table 6. The findings indicate that the GSM algorithm converges to optimal values with high precision, requiring fewer iterations and smaller population sizes compared to other algorithms.
In
Table 7, a ‘‘+’’ denotes cases where the GSM algorithm outperformed the other algorithms in terms of mean values, while a ‘‘−’’ indicates inferior performance. Overall, the GSM algorithm demonstrated superior performance on most benchmark functions compared to PSO, DE, BA, ABC, AHA, AHA-AO, CBO, ECBO, and SNS.
Table 2.
Parameters of the algorithms.
Table 2.
Parameters of the algorithms.
| Algorithm | Parameters | Reference |
|---|
| GSM | ,
| |
| PSO | , , and
| [23] |
| DE | and | [24] |
| BA | ,,
, , , | [25] |
| ABC | Food sources = 10 | [20] |
| AHA | , Flight Step
size and
| [8] |
| CBO | no parameters | [9] |
| ECBO | | [10] |
| AHA-AO | ,, and
| [11] |
| SNS | no parameters | [12] |
Table 3.
Unimodal benchmark functions used in experiments F, the number of iterations I, population P, and dimension D.
Table 3.
Unimodal benchmark functions used in experiments F, the number of iterations I, population P, and dimension D.
| No | Function (F) | Type | D | Range | Formulation | P | I |
|---|
| BOOTH | U, C, Di, NS, NSc | 2 | [−10, 10] | | 50 | 100 |
| SPHERE | U, S | 2 | [−5.12, 5.12] | | 50 | 50 |
| SPHERE | U, S | 10 | [−5.12, 5.12] | | 150 | 100 |
| SPHERE | U, S | 20 | [−5.12, 5.12] | | 150 | 150 |
| BEALE | U, C, Di, NS, NSc, S | 2 | [−4.5, 4.5] | | 50 | 100 |
| ROTATED HYPER-ELLIPSOID | U, C, Di, NS, NSc | 2 | [−65.536, 65.536] | | 50 | 250 |
| SUM SQUARES | U, C, Di, S, Sc | 20 | [−5.12, 5.12] | | 200 | 500 |
| QUARTIC | U, C, Di, S, Sc | 2 | [−1.28, 1.28] | | 50 | 100 |
The GSM algorithm demonstrates superior performance on unimodal, continuous, differentiable, nonseparable, and nonscalable functions , , and , outperforming the compared algorithms, including the most recent ones in the literature. Notably, for , the GSM algorithm consistently finds the global optimum with few iterations. For unimodal and separable functions such as , , and , algorithms like AHA, AHA-AO, and SNS exhibit better performance in high-dimensional spaces, indicating their ability to converge quickly on smooth functions. However, in low-dimensional settings, the GSM algorithm shows a slight improvement over these algorithms. Functions and are unimodal, continuous, differentiable, separable, and scalable. For , the AHA, AHA-AO, and SNS algorithms achieve the best results. In the case of , the GSM, AHA, AHA-AO, and SNS algorithms perform similarly, making it difficult to determine which algorithm is superior for this function.
Table 4.
Multimodal benchmark functions used in experiments F, the number of iterations I, population P, and dimension D.
Table 4.
Multimodal benchmark functions used in experiments F, the number of iterations I, population P, and dimension D.
| No | Function (F) | Type | D | Range | Formulation | P | I |
|---|
| SIX-HUMP CAMEL | M, C, Di, NS, NSc | 2 | [−3, 3], [−2, 2] | | 15 | 20 |
| ACKLEY | M, C, Di, NS, Sc | 2 | [−32.768, 32.768] | | 50 | 100 |
| MICHALEWICZ | M, S | 2 | [0, ] | | 50 | 15 |
| MICHALEWICZ | M, S | 5 | [0, ] | | 200 | 100 |
| MICHALEWICZ | M, S | 10 | [0, ] | | 150 | 40 |
| GRIEWANK | M, C, Di, NS, Sc | 2 | [−600, 600] | | 150 | 100 |
| CROSS-IN-TRAY | M, C, NS, NSc | 2 | [-10, 10] | | 50 | 15 |
| LEVY | M, NS | 5 | [−10, 10] | | 50 | 100 |
| | | | | | where for all | | |
| EASOM | M, C, Di, S, NSc | 2 | [- | | 50 | 25 |
| BRANIN | M, C, Di, NS, NSc | 2 | [−5, 10], [0, 15] | | 50 | 15 |
| BOHACHEVSKY | M, C, Di, S, NSc | 2 | [−100, 100] | | 50 | 50 |
| SCHWEFEL | M, C, Di, S, Sc | 2 | [−500, 500] | | 50 | 100 |
| SHUBERT | M, C, Di, S, NSc | 2 | [−10, 10] | | 50 | 50 |
| LANGERMANN | M, NS | 2 | [0, 10] | | 50 | 100 |
On the other hand, functions and are multimodal, continuous, differentiable, non-separable, and non-scalable, featuring multiple local minima. For these functions, the GSM algorithm achieves the best results with a low standard deviation, indicating high precision. Functions and are multimodal, continuous, differentiable, non-separable, and scalable. For , the GSM algorithm performs slightly better than the other algorithms. However, for , the AHA and AHA-AO algorithms demonstrate superior performance. Functions , , and are multimodal and separable, posing challenges for all algorithms in locating the global optimum. For and , the GSM algorithm produces results closest to the optimum, while for , the DE algorithm outperforms the others. For the non-scalable function , the GSM algorithm surpasses all competing algorithms. Similarly, for , a multimodal and non-separable function, the GSM algorithm proves to be the best. In the case of , a continuous, differentiable, non-scalable, and multimodal function, both the GSM and ABC algorithms deliver strong results, with GSM performing slightly better. Functions and are multimodal, continuous, separable, non-scalable, and differentiable. While most algorithms perform well on these functions, the GSM algorithm stands out as the best. In contrast, is a scalable function where all algorithms struggle to find the optimum, with the best results achieved by SNS, AHA, AHA-AO, and GSM. Finally, for , a multimodal and non-separable function, most algorithms fail to optimize effectively. However, the closest results to the optimum are obtained by CBO, ECBO, and GSM.
Table 5.
Results of all proposed algorithms for unimodal functions.
Table 5.
Results of all proposed algorithms for unimodal functions.
| No | | | GSM | PSO | DE | BA | ABC | AHA | CBO | ECBO | AHA-AO | SNS |
|---|
| 0 | Best | 0 | 4.7161 | 1.5620 | 1.9285 | 5.4342 | 2.2249 | 2.1592 | 1.4831 | 1.0684 | 7.2601 |
| | | Mean | 0 | 3.3472 | 6.2692 | 8.4600 | 5.8342 | 1.5434 | 2.1668 | 8.3649 | 3.9487 | 8.1263 |
| | | StdDev | 0 | 1.0584 | 1.7007 | 9.9731 | 1.7111 | 2.5825 | 4.6605 | 1.0683 | 3.4400 | 1.2731 |
| 0 | Best | 7.0223 | 5.211 | 6.6253 | 2.3480 | 8.1189 | 4.0049 | 1.8585 | 1.0575 | 2.9348 | 1.8608 |
| | | Mean | 4.8067 | 1.0242 | 1.6800 | 3.6863 | 3.1458 | 3.3871 | 1.4750 | 1.2829 | 5.8306 | 4.2709 |
| | | StdDev | 1.5200 | 3.2126 | 1.4829 | 3.9603 | 5.4034 | 4.6770 | 2.3268 | 1.3716 | 1.5306 | 8.0683 |
| 0 | Best | 1.8983 | 1.2195 | 3.2206 | 2.6370 | 0.0143 | 2.2838 | 2.6720 | 0.0144 | 1.5281 | 4.3313 |
| | | Mean | 5.5377 | 3.0311 | 5.6897 | 3.7566 | 0.0303 | 2.9439 | 2.6527 | 0.0170 | 4.3047 | 3.5935 |
| | | StdDev | 6.4917 | 6.1127 | 1.8035 | 3.7826 | 0.0189 | 6.7651 | 1.1917 | 0.0060 | 8.1642 | 2.3942 |
| 0 | Best | 5.4565 | 9.0912 | 1.0301 | 7.9196 | 0.1569 | 1.0626 | 0.0039 | 0.1433 | 1.0605 | 2.3915 |
| | | Mean | 4.4192 | 2.4432 | 1.8558 | 2.6131 | 0.4346 | 8.8246 | 0.0090 | 0.1320 | 3.9312 | 1.1474 |
| | | StdDev | 1.3878 | 3.9384 | 6.3749 | 1.0577 | 0.2315 | 1.3711 | 0.0027 | 0.0457 | 1.0593 | 6.7661 |
| 0 | Best | 0 | 2.6321 | 8.9583 | 5.7992 | 2.9569 | 2.1248 | 9.5145 | 2.9519 | 3.6675 | 1.0593 |
| | | Mean | 2.7733 | 9.6230 | 5.2257 | 0.0909 | 6.9116 | 7.7244 | 1.3407 | 2.2842 | 2.8535 | 1.7591 |
| | | StdDev | 8.7700 | 0.0030 | 1.2922 | 0.1917 | 1.4852 | 1.0677 | 3.3844 | 5.1538 | 4.5641 | 5.1523 |
| 0 | Best | 6.0353 | 1.2180 | 1.6365 | 3.8400 | 3.6787 | 4.3497 | 5.1664 | 2.8114 | 2.7457 | 8.2010 |
| | | Mean | 3.0077 | 7.3249 | 4.9137 | 9.9511 | 2.2754 | 3.8621 | 4.8796 | 2.3092 | 2.4815 | 2.8823 |
| | | StdDev | 0 | 2.1958 | 1.0362 | 2.8837 | 5.0686 | 6.6999 | 7.6559 | 2.6735 | 7.2763 | 7.6906 |
| 0 | Best | 4.6778 | 9.7328 | 4.4776 | 3.0762 | 0.6562 | 2.4692 | 1.9993 | 0.0678 | 1.7838 | 3.5424 |
| | | Mean | 5.9890 | 5.7186 | 6.9886 | 8.4214 | 2.1627 | 2.8594 | 6.7964 | 0.1077 | 5.1417 | 1.0878 |
| | | StdDev | 1.0477 | 1.5996 | 2.2506 | 2.1557 | 1.1511 | 7.9217 | 3.4927 | 0.0610 | 1.6259 | 1.0818 |
| 0 | Best | 8.9795 | 0.0188 | 4.7591 | 9.5197 | 0.5218 | 0.000604 | 2.8205 | 0.0021 | 0.0013 | 4.1045 |
| | | Mean | 6.1556 | 0.0192 | 0.0011 | 0.0119 | 0.3278 | 5.5981 | 5.8584 | 0.0018 | 6.1085 | 5.7738 |
| | | StdDev | 6.9240 | 0.0125 | 7.2484 | 0.0228 | 0.0642 | 3.2712 | 2.9234 | 0.0016 | 7.7823 | 6.8678 |
Table 6.
Results of all proposed algorithms for multimodal functions.
Table 6.
Results of all proposed algorithms for multimodal functions.
| No | | | GSM | PSO | DE | BA | ABC | AHA | CBO | ECBO | AHA-AO | SNS |
|---|
| −1.0316 | Best | −1.0316 | −1.0315 | −1.0316 | −1.0316 | −0.8995 | −1.0289 | −1.0270 | −1.0316 | −1.0229 | −1.0296 |
| | | Mean | −1.0316 | −0.9268 | −1.0315 | −1.0251 | 4.2389 | −1.0269 | −1.0234 | −1.0300 | −1.0245 | −1.0301 |
| | | StdDev | 4.7291 | 0.2331 | 1.4627 | 0.0206 | 5.7466 | 0.0064 | 0.0151 | 0.0026 | 0.0063 | 0.0023 |
| 0 | Best | 8.8817 | 0.0689 | 8.8817 | 3.0121 | 4.6990 | 8.8818 | 7.9670 | 0.0410 | 7.9936 | 7.9936 |
| | | Mean | 1.2434 | 2.9340 | 5.5067 | 1.1846 | 1.3126 | 8.8818 | 5.7216 | 0.0448 | 3.6840 | 5.8620 |
| | | StdDev | 0 | 5.6339 | 4.4468 | 1.5798 | 1.3306 | 0 | 8.0797 | 0.0407 | 1.0636 | 2.4841 |
| −1.8013 | Best | −1.8013 | −1.8007 | −1.8012 | −1.8013 | −1.7612 | −1.7835 | −1.8009 | −1.8010 | −1.7994 | −1.8005 |
| | | Mean | −1.8013 | −1.7328 | −1.8012 | −1.6382 | −1.1260 | −1.7933 | −1.7693 | −1.7929 | −1.7972 | −1.8000 |
| | | StdDev | 4.2321 | 0.1810 | 9.0472 | 0.3365 | 0.5213 | 0.0107 | 0.0780 | 0.0114 | 0.0070 | 0.0018 |
| −4.6876 | Best | −4.6876 | −4.4186 | −4.6876 | −4.6984 | −4.6455 | −4.6677 | −3.0771 | −2.6610 | −4.6848 | −4.6795 |
| | | Mean | −4.5648 | −4.5497 | −4.6876 | −4.0940 | −3.9823 | −4.6835 | −3.1844 | −3.1365 | −4.6822 | −4.6792 |
| | | StdDev | 0.1205 | 0.2592 | 5.4176 | 0.5330 | 0.6404 | 0.0060 | 0.1568 | 0.3326 | 0.0086 | 0.3155 |
| −9.6601 | Best | −9.3481 | −7.3345 | −8.6679 | −7.4825 | −4.0441 | −6.5437 | −4.2352 | −5.3466 | −7.1608 | −4.0027 |
| | | Mean | −8.4376 | −5.6146 | −7.5020 | −6.1008 | −2.7108 | −6.9682 | −4.0461 | −4.6553 | −6.9637 | −3.9526 |
| | | StdDev | 0.675264 | 1.5458 | 0.4730 | 1.1223 | 1.0923 | 0.3616 | 0.2349 | 0.4807 | 0.2925 | 0.4216 |
| 0 | Best | 0 | 0.0503 | 1.7840 | 0.0073 | 0.0249 | 0 | 8.0040 | 0.0340 | 0 | 1.6239 |
| | | Mean | 2.5455 | 0.0188 | 3.2405 | 0.0182 | 0.7264 | 0 | 0.0018 | 0.0204 | 0 | 1.1947 |
| | | StdDev | 8.0449 | 0.0276 | 1.7840 | 0.0189 | 0.5711 | 0 | 0.0018 | 0.0094 | 0 | 2.7079 |
| −2.06261 | Best | −2.06261 | −2.06261 | −2.06260 | −2.06261 | −2.05771 | −2.0622 | 6.5049 | −2.0625 | −2.0622 | −2.06197 |
| | | Mean | −2.06261 | −2.05583 | −2.06256 | −2.06260 | −1.91421 | −2.0623 | 1.1164e-04 | −2.0622 | −2.0622 | −2.06232 |
| | | StdDev | 6.51894e-12 | 0.01216 | 3.81885 | 7.3581 | 0.2170 | 2.8316 | 7.3258 | 2.9582 | 3.3633 | 2.8401 |
| 0 | Best | 1.49 | 6.3494 | 2.7875 | 0.0895 | 1.4886 | 8.0073 | 2.1805 | 5.8909 | 5.7749 | 1.2099 |
| | | Mean | 5.0346 | 1.4721 | 9.7101 | 1.7433 | 0.0159 | 8.5798 | 9.3221 | 7.2814 | 5.5570 | 6.8459 |
| | | StdDev | 1.5907 | 4.6030 | 1.0476 | 2.1265 | 0.0359 | 6.6270 | 1.2289 | 5.8909 | 4.3407 | 1.3644 |
| −1 | Best | −1 | −0.9957 | −0.9263 | −1.0000 | −1.0144 | −0.99207 | −0.974192 | −0.85191 | −0.9237 | −0.8505 |
| | | Mean | −0.9999 | −0.5063 | −0.2893 | −0.8000 | −1.0014 | −0.9435 | −7.4192 | −8.5191 | −0.7494 | −0.9566 |
| | | StdDev | 8.7416 | 0.4702 | 0.3795 | 0.4216 | 0.0046 | 0.0863 | 1.6793 | 0 | 0.2578 | 0.0465 |
| 0.3978 | Best | 0.3978 | 0.3979 | 0.3980 | 0.3979 | 0.3500 | 0.42234 | 0.4014 | 0.4003 | 0.4240 | 0.3984 |
| | | Mean | 0.3978 | 1.04669 | 0.4111 | 0.3979 | 0.4844 | 0.4116 | 0.4110 | 0.4053 | 0.4205 | 0.4020 |
| | | StdDev | 8.8638 | 0.80193 | 0.0152 | 2.8015 | 0.00623 | 0.0125 | 0.0209 | 0.0087 | 0.0168 | 0.0055 |
| 0 | Best | 0 | 6.4181 | 2.8421 | 3.0285 | 2.4448 | 0 | 3.3798 | 0.3129 | 1.3847 | 7.2187 |
| | | Mean | 0 | 1.6284 | 1.9197 | 0.0413 | 0.2298 | 4.1744 | 2.4281 | 0.1556 | 2.2589 | 1.2476 |
| | | StdDev | 0 | 5.1098 | 3.0728 | 0.1306 | 0.5022 | 1.3123 | 3.2786 | 0.1604 | 4.7812 | 1.3407 |
| 0 | Best | 2.5455 | 2.5451 | -5.5072 | -2.1668 | -4.2575 | 3.5033 | -8.6854 | 3.876 | 5.6815 | 2.5455 |
| | | Mean | 9.6119 | 1.1175 | −1.3876 | −2.1682 | −6.3527 | 9.1733 | −4.1821 | −1.9261 | 2.1051 | 2.5455 |
| | | StdDev | 3.0395 | 2.7290 | 2.0601 | 6.8514 | 1.3092 | 2.6225 | 1.3221 | 3.0815 | 2.9967 | 6.3251 |
| −186.7309 | Best | −186.7309 | −186.7309 | −186.7309 | −186.7309 | −186.6556 | −186.4788 | −176.6064 | −184.3464 | −186.4394 | −186.7299 |
| | | Mean | −186.7309 | −181.1768 | −186.7197 | −156.2154 | −154.1955 | −186.0850 | −180.0691 | −178.6231 | −186.2692 | −186.7201 |
| | | StdDev | 4.4613 | 11.3440 | 0.0188 | 51.9967 | 39.2589 | 0.6731 | 5.8514 | 11.1027 | 0.4619 | 0.0140 |
| −1.4 | Best | −1.7541 | −1.7546 | −1.7546 | −1.7547 | −1.7547 | −1.0809 | −1.2551 | −1.6272 | −0.6639 | −1.7547 |
| | | Mean | −1.4259 | −1.6439 | −1.7546 | −1.3612 | −0.9023 | −1.0809 | −1.4072 | −1.4337 | −0.6639 | −1.7547 |
| | | StdDev | 0.5258 | 0.3464 | 3.5298 | 0.5147 | 0.9375 | 1.2794 | 0.1897 | 0.2222 | 2.2680 | 4.3274 |
Table 7.
Results of all proposed algorithms for multimodal functions.
Table 7.
Results of all proposed algorithms for multimodal functions.
| No | GSM vs. PSO | GSM vs. DE | GSM vs. BA | GSM vs. ABC | GSM vs. AHA | GSM vs. CBO | GSM vs. ECBO | GSM vs. AHA-AO | GSM vs. SNS |
|---|
| + | + | + | + | + | + | + | + | + |
| + | + | + | + | + | + | + | + | + |
| + | + | + | + | − | + | + | + | + |
| + | + | − | + | − | + | + | − | − |
| + | + | + | + | + | + | + | + | + |
| + | + | + | + | + | + | + | + | + |
| + | + | + | + | − | + | + | − | − |
| + | + | + | + | − | − | + | − | − |
| + | + | + | + | + | + | + | + | + |
| + | + | + | + | + | + | + | + | + |
| + | + | + | + | + | + | + | + | + |
| + | − | + | + | − | + | + | − | + |
| + | + | + | + | + | + | + | + | + |
| + | + | + | + | − | + | + | − | + |
| + | + | + | + | + | + | + | + | + |
| + | + | + | + | + | + | + | + | + |
| + | + | + | + | + | + | + | + | + |
| + | + | + | + | + | + | + | + | + |
| + | + | + | + | + | + | + | + | + |
| + | + | + | + | + | + | + | + | + |
| + | + | + | + | + | + | + | + | + |
| + | + | + | + | + | − | + | + | + |
Wilcoxon Sing Rank Test
The statistical results presented in
Table 5 and
Table 6 do not provide sufficient evidence to determine whether there are significant differences between the algorithms. To address this, a pairwise statistical test is often employed for more robust comparisons. In this study, the Wilcoxon Signed-Rank Test is applied to the results obtained from 100 runs of each algorithm to assess their relative efficiency across the set of benchmark functions. This statistical technique is widely used for comparing paired samples in optimization studies [
1]. The test assumes
n experimental data sets, each with two observations,
and
, corresponding to the performance of two algorithms on function
i. This results in two paired samples:
and
. The
T-statistic is calculated as the sum of the negative ranks derived from the differences
for all
. The null hypothesis for this test is defined as follows:
: There is no significant difference between the mean solutions produced by algorithm
A and algorithm
B for the set of benchmark functions. The ranks provided by the Wilcoxon Signed-Rank Test, denoted as
and
, are then examined to evaluate this hypothesis, as described in [
1]. The critical values for the
T-statistic are evaluated using a normal distribution
Z. A 95% significance level (
) is applied, with
(the number of benchmark functions).
Table 8 presents the pairwise statistical results comparing the GSM algorithm to the other algorithms.
The GSM algorithm demonstrates superior performance compared to the PSO, DE, BA, ABC, AHA, AHA-AO, CBO, ECBO, and SNS algorithms. In all pairwise comparisons, the null hypothesis is rejected, indicating significant differences in performance. Specifically, the PSO algorithm underperforms relative to the GSM algorithm. While the DE algorithm is highly competitive, the statistical test results confirm that GSM outperforms it. The BA algorithm, a powerful swarm-based approach, has been successfully applied to various problems. However, its performance falls short when compared to the GSM algorithm. As shown in
Table 8, the key difference between the GSM and ABC algorithms lies in their exploration capabilities. The ABC algorithm struggles with certain functions, resulting in poorer performance. The AHA algorithm, another swarm-based approach, delivers excellent results and excels in optimizing smooth functions, often finding the optimum quickly. However, it faces challenges with multimodal functions, where the GSM algorithm achieves better results.
Table 8.
Wilcoxon signed-rank test results.
Table 8.
Wilcoxon signed-rank test results.
| GSM vs | PSO | DE | BA | ABC | AHA | CBO | ECBO | AHA-AO | SNS |
|---|
| 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 |
| 253 | 235 | 246 | 253 | 199 | 229 | 253 | 205 | 229 |
| 0 | 18 | 7 | 0 | 54 | 24 | 0 | 48 | 24 |
| rejected | rejected | rejected | rejected | rejected | rejected | rejected | rejected | rejected |
Swarm-based algorithms CBO and ECBO exhibit lower performance in most problems, even underperforming compared to older algorithms. The AHA-AO algorithm, an improved version of AHA, delivers results very similar to its predecessor. It excels in optimizing smooth functions and performs slightly better in multimodal functions. The SNS algorithm, a recent swarm-based approach, demonstrates strong performance across various test functions. However, its performance declines in non-separable functions, such as the Six-Hump Camel and Easom functions, where the proposed GSM algorithm proves superior. Overall, the GSM algorithm performs well across a wide range of functions, including continuous, non-continuous, separable, non-separable, scalable, non-scalable, differentiable, and non-differentiable problems. Specifically, it outperforms other algorithms in unimodal separable functions and also delivers strong results for unimodal non-separable functions, surpassing PSO, DE, BA, ABC, AHA, AHA-AO, CBO, ECBO, and SNS. While its performance is slightly lower for multimodal separable functions compared to unimodal separable ones, it still outperforms most population-based algorithms. For non-separable multimodal functions, the GSM algorithm maintains acceptable performance without significant issues. These results suggest that the GSM algorithm is particularly effective for separable functions. The GSM algorithm successfully optimized all implemented functions, which include challenging problems such as the QUARTIC function with random noise—useful for testing real-world applications—and functions with large search spaces like SCHWEFEL and GRIEWANK. This highlights the algorithm’s robustness and strong performance across diverse problem types.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}