
Enabling Decision Making with the Modified Causal Forest: Policy Trees for Treatment Assignment


Abstract
1. Introduction
2. Framework
| Algorithm 1 Policy Tree |
|
3. Empirical Studies
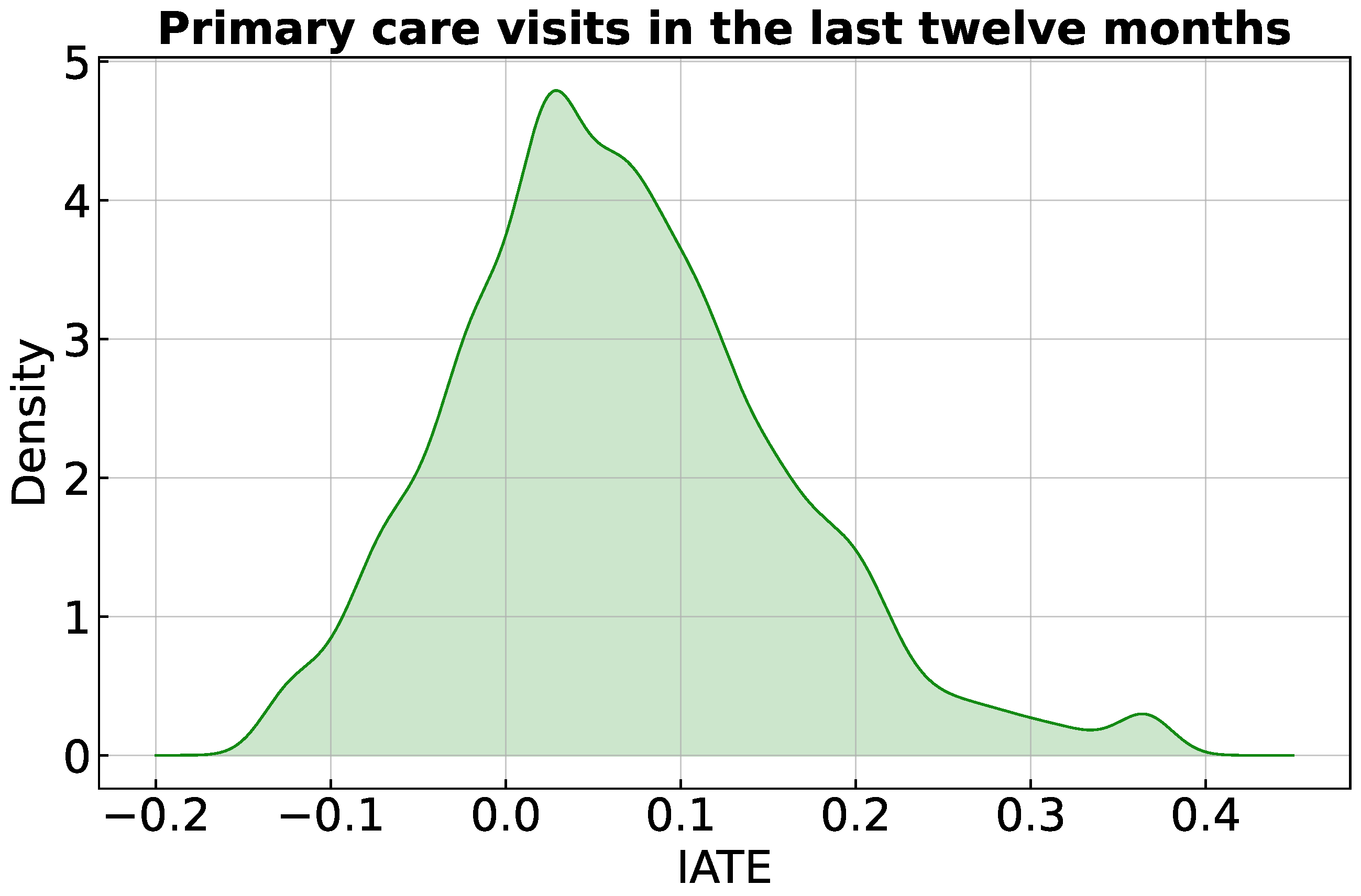
3.1. Study 1: Oregon Health Insurance Experiment
3.2. Study 2: Right Heart Catheterisation
3.3. Study 3: Interest Rates and Loan Returns
4. Technical Considerations and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Codebooks

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description |
|---|---|
| doc_any_12m | any primary care visits |
| treatment | indicator equal to 1 if extracted for the lottery |
| age | in years, calculated as difference between 2008 and birth year |
| numhh_list | number of people in household on lottery list |
| draw | survey mailing wave |
| birthyear_list | birth year: lottery list data |
| have_phone_list | gave a phone number on lottery sign up: lottery list data |
| pobox_list | gave a PO Box as an address: lottery list data |
| english_list | individual requested english-language materials: lottery list data |
| female_list | indicator for female: lottery list data |
| zip_msa | zip code from lottery list is a metropolitan statistical area |
| Variable | Description |
|---|---|
| adld3pc | index of activities of daily living 2 weeks prior to admission |
| age | age in years |
| alb1 | albumin level in grams per deciliter |
| amihx | indicator for definite myocardial infarction |
| aps1 | acute physiology and chronic health evaluation score (APACHE III) |
| bili1 | bilirubin level in milligrams per deciliter |
| ca | cancer; 3 categories: metastatic cancer (Metastatic), no cancer (No), cancer (Yes) |
| card | indicator for cardiovascular diagnosis |
| cardiohx | indicator for acute myocardial infarction, peripheral vascular disease, severe, and very severe cardiovascular symptoms (NYHA-classes III and IV) |
| cat1 | primary disease; 9 categories: acute respiratory failure (0), congestive heart failure (1), chronic obstructive pulmonary disease (2), cirrhosis (3), colon cancer metastatic to the liver (4), non-traumatic coma (5), non-small-cell cancer of the lung, stage III or IV (6), multiorgan system failure with malignancy (7), indicator for multiorgan system failure with sepsis (8) |
| cat2 | secondary disease; 3 categories: missings or others (0), multiorgan system failure with malignancy (1), multiorgan system failure with sepsis (2) |
| cat2_miss | indicator for missings in cat2 |
| chfhx | indicator for congestive heart failure |
| chrpulhx | indicator for chronic, severe, or very severe pulmonary disease |
| crea1 | creatinine level in milligrams per deciliter |
| das2d3pc | Duke activity status index (DASI) two weeks before admission |
| dementhx | indicator for dementia, stroke or cerebral infarct, Parkinson’s disease |
| dnr1 | indicator for do not resuscitate status on the first day |
| dth30 | outcome indicator for mortality within 6 months |
| edu | education in years |
| gastr | indicator for gastrointestinal diagnosis |
| gibledhx | indicator for upper gastrointestinal bleeding |
| hema | indicator for hematologic diagnosis |
| hema1 | hematocrit levels in percent |
| hrt1 | heart rate in beats per minute |
| immunhx | indicator for immunosuppression, organ transplant, HIV positivity, diabetes mellitus with or without end organ damage, connective tissue disease |
| income | income in US dollars; 4 categories: below 11 k (0), 11–25 k (1), 25–50 k (2), above 50 k (3) |
| liverhx | indicator for cirrhosis, hepatic failure |
| malighx | indicator for solid tumor, metastatic disease, chronic leukemia/myeloma, acute leukemia, lymphoma |
| meanbp1 | mean blood pressure in millimeters of mercury |
| meta | indicator for metabolic diagnosis |
| neuro | indicator for neurological diagnosis |
| ninsclas | medical insurance; 6 categories: Medicaid (0), Medicare (1), Medicare and Medicaid (2), no medical insurance (3), private medical insurance (4), private medical insurance and Medicaid (5) |
| ortho | indicator for orthopedic diagnosis |
| paco21 | partial pressure of arterial carbon dioxide in millimeters of mercury |
| pafi1 | ratio between partial pressure of arterial oxygen in millimeters of mercury and fraction of inspired oxygen |
| ph1 | potential of hydrogen (pH) at logarithmic scale |
| pot1 | blood potassium level in millimoles per liter |
| psychhx | indicator for psychiatric history, active psychosis or severe depression |
| race | race; 3 categories: African American (0), other race (1), Caucasian (2) |
| renal | indicator for renal diagnosis |
| renalhx | indicator for chronic renal disease, chronic hemodialysis, or peritoneal dialysis |
| resp | indicator for respiratory diagnosis |
| resp1 | respiratory rate |
| scoma1 | Glasgow coma score |
| seps | indicator for sepsis diagnosis |
| sex | indicator for gender (1 = male) |
| sod1 | sodium level in milliequivalents per liter |
| surv2md1 | probability of surviving two months (based on support model estimations) |
| swang1 | treatment indicator for right heart catheterisation |
| temp1 | body temperature in degrees Celsius |
| transhx | indicator for transfer exceeding 24 h from another hospital |
| trauma | indicator for trauma diagnosis |
| urin1 | urine output per day in milliliters |
| urin1_miss | indicator for missings in urin1 |
| wblc1 | white blood cells in thousands per cubic millimeter |
| wtkilo1 | weight in kilograms |
| Variable | Description |
|---|---|
| adj_loan | loan size (loansize variable) multiplied by the interest rate (final4 variable) applied to calculate returns. |
| offer_risk | treatment, based on the original offered interest rate (offer4); offer_risk is equal to 1 for the offers with a value less than or equal to 7.75, indicating an associated low risk; offers with values greater than 7.75 but less than or equal to 9.75 are categorised as 2, associated to moderate risk; offers with a value greater than 9.75 are categorised as 3, associated to high risk. |
| age | age in years |
| dependants | number of individuals who rely on the primary household for economic support and care |
| qnt_income | quintiles of gross income |
| wave | number indicating in which wave the offer letter has been sent |
| risk_num | number from 1 to 3 indicating the client’s risk category |
| female | indicator for gender, equal to 1 if female |
| married | indicator for civil status, equal to 1 if married |
| edhi | indicator for higher education, equal to 1 if this level is achieved |
| rural | indicator for living in rural area |
Appendix A.2. Data
| Variable | No Medicaid | Medicaid | |
|---|---|---|---|
| Mean | Mean | Std. Diff. | |
| age | 42.31 | 42.20 | (0.90) |
| numhh_list | 1.25 | 1.35 | (20.22) |
| draw | 3.91 | 4.33 | (16.75) |
| birthyear_list | 1966 | 1966 | (0.90) |
| have_phone_list | 0.89 | 0.90 | (2.52) |
| pobox_list | 0.13 | 0.13 | (0.04) |
| english_list | 0.92 | 0.91 | (3.53) |
| female_list | 0.60 | 0.58 | (2.94) |
| zip_msa | 0.75 | 0.75 | (1.01) |
| doc_any_12m | 0.49 | 0.51 | (3.85) |
| N. observations | 11,844 | 11,683 | |
| Variable | No RHC | RHC | |
|---|---|---|---|
| Mean | Mean | Std. Diff. | |
| adld3pc | 1.63 | 1.47 | (11.36) |
| age | 61.76 | 60.75 | (6.14) |
| alb1 | 3.16 | 2.96 | (27.85) |
| amihx | 0.03 | 0.04 | (7.43) |
| aps1 | 50.93 | 60.74 | (50.14) |
| bili1 | 1.93 | 2.64 | (16.25) |
| card | 0.28 | 0.42 | (29.49) |
| cardiohx | 0.16 | 0.20 | (11.56) |
| cat2_miss | 0.81 | 0.77 | (9.93) |
| chfhx | 0.17 | 0.19 | (6.95) |
| chrpulhx | 0.22 | 0.14 | (19.23) |
| crea1 | 1.92 | 2.47 | (27.78) |
| das2d3pc | 20.37 | 20.70 | (6.26) |
| dementhx | 0.12 | 0.07 | (16.31) |
| edu | 11.57 | 11.86 | (9.14) |
| gastr | 0.15 | 0.19 | (12.09) |
| gibledhx | 0.04 | 0.02 | (7.04) |
| hema | 0.07 | 0.05 | (6.17) |
| hema1 | 32.70 | 30.51 | (26.93) |
| hrt1 | 112.87 | 118.93 | (14.69) |
| immunhx | 0.26 | 0.29 | (8.04) |
| income | 0.70 | 0.83 | (13.52) |
| liverhx | 0.07 | 0.06 | (4.89) |
| malighx | 0.25 | 0.20 | (10.14) |
| meanbp1 | 84.87 | 68.20 | (45.51) |
| meta | 0.05 | 0.04 | (2.81) |
| neuro | 0.16 | 0.05 | (35.30) |
| ortho | 0.00 | 0.00 | (2.70) |
| paco21 | 39.78 | 36.71 | (25.57) |
| pafi1 | 240.18 | 192.39 | (43.40) |
| ph1 | 7.39 | 7.38 | (11.98) |
| pot1 | 4.08 | 4.05 | (2.71) |
| psychhx | 0.08 | 0.05 | (14.32) |
| renal | 0.04 | 0.07 | (11.63) |
| renalhx | 0.04 | 0.05 | (3.16) |
| resp | 0.42 | 0.29 | (26.95) |
| resp1 | 28.91 | 26.59 | (16.69) |
| scoma1 | 22.25 | 18.97 | (10.98) |
| seps | 0.15 | 0.24 | (23.38) |
| sex | 0.54 | 0.59 | (9.31) |
| sod1 | 137.04 | 136.33 | (9.22) |
| surv2md1 | 0.61 | 0.57 | (19.85) |
| temp1 | 37.63 | 37.59 | (2.14) |
| transhx | 0.09 | 0.15 | (16.98) |
| trauma | 0.01 | 0.02 | (10.40) |
| urin1 | 993.38 | 1102.33 | (7.12) |
| urin1_miss | 0.55 | 0.49 | (10.69) |
| wblc1 | 15.24 | 16.19 | (8.24) |
| wtkilo1 | 64.93 | 72.21 | (25.83) |
| dnr1 | 0.14 | 0.07 | (22.76) |
| ca | 1.11 | 1.10 | (2.03) |
| cat1 | 2.65 | 3.52 | (25.79) |
| cat2 | 0.28 | 0.41 | (18.49) |
| ninsclas | 2.70 | 2.99 | (16.25) |
| race | 1.61 | 1.63 | (2.37) |
| dth30 | 0.69 | 0.62 | (15.56) |
| N. observations | 3551 | 2184 | |
| Variable | Low Rate | Medium Rate | High Rate | |||
|---|---|---|---|---|---|---|
| Mean | Mean | Std. Diff. | Mean | Std. Diff. | Std. Diff. | |
| (vs. Low) | (vs. Low) | (vs. Medium) | ||||
| age | 41.63 | 41.07 | (5.00) | 41.16 | (4.23) | (0.76) |
| dependants | 1.73 | 1.55 | (10.02) | 1.44 | (16.61) | (6.66) |
| qnt_income | 1.53 | 1.47 | (5.41) | 1.47 | (5.18) | (0.24) |
| wave | 2.58 | 2.62 | (7.05) | 2.60 | (4.31) | (2.73) |
| risk_num | 2.41 | 2.84 | (65.55) | 3.00 | (96.93) | (60.70) |
| female | 0.48 | 0.48 | (0.70) | 0.48 | (0.04) | (0.74) |
| married | 0.45 | 0.44 | (1.88) | 0.44 | (1.07) | (0.80) |
| edhi | 0.39 | 0.39 | (0.06) | 0.39 | (1.21) | (1.15) |
| rural | 0.18 | 0.17 | (1.05) | 0.17 | (1.89) | (0.84) |
| adj_loan | 795.33 | 639.65 | (4.59) | 463.75 | (10.23) | (5.98) |
| N. observations | 22,011 | 14,107 | 12,734 | |||
Appendix A.3. Policy Trees Runtime Comparison
Appendix A.3.1. Policy Trees Running Time: Oregon Health Insurance Experiment
| Task and Sample | Running Time | ||
| Unconstrained tree depth | 2 | 3 | |
| Policy tree training data: | 0:02.116 | 0:08.093 | |
| Evaluation of training data: | 0:00.172 | 0:00.125 | |
| Policy tree allocation data: | 0:00.534 | 0:00.424 | |
| Evaluation of test data | 0:00.109 | 0:00.093 | |
| Constrained tree depth | 2 | 3 | 4 |
| Policy tree training data: | 0:02.686 | 0:10.297 | 3:03.169 |
| Evaluation of training data: | 0:00.156 | 0:00.140 | 0:00.141 |
| Policy tree allocation data: | 0:00.486 | 0:00.486 | 0:00.534 |
| Evaluation of test data: | 0:00.158 | 0:00.079 | 0:00.110 |
| Constrained sequential trees depth | 2+1 | 3+1 | |
| Policy tree training data: | 0:03.093 | 0:29.504 | |
| Evaluation of training data: | 0:00.141 | 0:00.267 | |
| Policy tree allocation data: | 0:00.580 | 0:01.098 | |
| Evaluation of test data: | 0:00.141 | 0:00.320 | |
Appendix A.3.2. Policy Trees Running Time: Right Heart Catheterisation Study
| Task and Sample | Running Time | |||
| Tree depth | 2 | 3 | 2+1 | 3+1 |
| Policy tree training: | 0:08.327 | 13:23.021 | 0:28.872 | 11:18.153 |
| Evaluation of training: | 0:00.126 | 0:00.137 | 0:00.152 | 0:00.177 |
| Policy tree allocation: | 0:00.258 | 0:00.287 | 0:00.508 | 0:00.388 |
| Evaluation of allocation: | 0:00.079 | 0:00.125 | 0:00.139 | 0:00.168 |
Appendix A.3.3. Policy Trees Running Time: Interest Rates and Loan Returns Study
| Task and Sample | Running Time | ||
| Unconstrained tree depth | 2 | 3 | 4 |
| Policy tree training data: | 0:08.334 | 0:29.838 | 10:22.988 |
| Evaluation of training data: | 0:00.172 | 0:00.221 | 0:00.173 |
| Policy tree allocation data: | 0:00.571 | 0:00.528 | 0:00.543 |
| Evaluation of test data: | 0:00.140 | 0:00.115 | 0:00.165 |
| Unconstrained sequential trees depth | 2+1 | 3+1 | 4+1 |
| Policy tree training data: | 0:7.667 | 0:25.610 | 5:53.018 |
| Evaluation of training data: | 0:0.236 | 0:0.189 | 0:0.220 |
| Policy tree allocation data: | 0:1.670 | 0:1.733 | 0:1.472 |
| Evaluation of test data: | 0:0.157 | 0:0.157 | 0:0.110 |
| Unconstrained sequential trees depth | 2+2 | 3+2 | 4+2 |
| Policy tree training data: | 0:09.591 | 0:25.590 | 3:45.807 |
| Evaluation of training data: | 0:00.252 | 0:00.284 | 0:00.236 |
| Policy tree allocation data: | 0:01.887 | 0:02.141 | 0:02.010 |
| Evaluation of test data: | 0:00.157 | 0:00.173 | 0:00.173 |
Appendix A.4. Policy Trees Rules
Appendix A.4.1. Policy Rules: Oregon Health Insurance Experiment
| Splitting variables and values |
| female_list = 0, numhh_list = 1 |
| female_list = 0, numhh_list > 1 |
| female_list = 0, age ≤ 47 |
| female_list = 0, age > 47 |
| Splitting variables and values |
| age ≤ 50, age ≤ 31, age ≤ 26 |
| age ≤ 50, age ≤ 31, age > 26 |
| age ≤ 50, age > 31, age ≤ 38 |
| age ≤ 50, age > 31, age > 38 |
| age > 50, numhh_list = 1, age ≤ 60 |
| age > 50, numhh_list = 1, age > 60 |
| age > 50, numhh_list > 1, age ≤ 59 |
| age > 50, numhh_list > 1, age > 59 |
| Splitting variables and values |
| age ≤ 51, age > 36 |
| age > 51, numhh_zip_msa = 0 |
| Splitting variables and values |
| numhh_list = 1, age ≤ 51, age > 37 |
| numhh_list = 1, age > 51, zip_msa = 0 |
| numhh_list > 1, female_list = 0, age > 25 |
| numhh_list > 1, female_list = 1, zip_msa = 0 |
| Splitting variables and values |
| age ≤ 50, age > 39, age ≤ 40 |
| age ≤ 50, age > 39, age > 40 |
| age > 50, numhh_zip_msa = 0, age ≤ 53 |
| age > 50, numhh_zip_msa = 0, age > 53 |
| age > 50, zip_msa = 1 numhh_list > 1 |
| Splitting variables and values |
| numhh_list = 1, zip_msa = 0, female_list = 0, age > 28 |
| numhh_list = 1, zip_msa = 0, female_list > 0.500, age > 35 |
| numhh_list = 1, zip_msa = 1, age > 39, age ≤ 51 |
| numhh_list > 1, female_list = 0, zip_msa < 0, age ≤ 36 |
| numhh_list > 1, female_list = 0 zip_msa = 0, age > 36 |
| numhh_list > 1, female_list = 0, zip_msa = 1, age > 28 |
| numhh_list > 1, female_list = 1, english_list = 0, age ≤ 42 |
| numhh_list > 1, female_list = 1, english_list = 1, zip_msa = 0 |
| Splitting variables and values |
| numhh_list > 1, female_list = 0, age > 27 |
| numhh_list = 1, age ≤ 51, age > 37, age < 39 |
| numhh_list = 1, age ≤ 51, age > 37, age > 39 |
| numhh_list = 1, age > 51, zip_msa = 0, age ≤ 53 |
| numhh_list = 1, age > 51, zip_msa = 0, age > 53 |
| numhh_list > 1, female_list = 1, zip_msa = 0, age ≤ 53 |
| numhh_list > 1, female_list = 1, zip_msa = 0, age > 53 |
| numhh_list > 1, female_list = 1, zip_msa = 1, english_list = 0 |
Appendix A.4.2. Policy Rules: Right Heart Catheterisation Study
| Splitting variables and values |
| age ≤ 65, surv2md1 ≤ 0.480 |
| age > 65, surv2md1 ≤ 0.402 |
| Splitting variables and values |
| cat1 in: 0 1 2 6 8, age ≤ 70, surv2md1 ≤ 0.450 |
| cat1 in: 0 1 2 6 8, age > 70, surv2md1 ≤ 0.402 |
| cat1 not in: 0 1 2 6 8, cat1 in: 3 5, aps1 > 64 |
| cat1 not in: 0 1 2 6 8, cat1 not in: 3 5, surv2md1 ≤ 0.467 |
| Splitting variables and values |
| age ≤ 65, surv2md1 ≤ 0.480, aps1 ≤ 80 |
| age ≤ 65, surv2md1 ≤ 0.480, aps1 > 80 |
| age > 65, surv2md1 ≤ 0.402, aps1 > 50 |
| Splitting variables and values |
| cat1 in: 0 2 8, age ≤ 69, surv2md1 ≤ 0.450, cat1 = 0 |
| cat1 in: 0 2 8, age ≤ 69, surv2md1 ≤ 0.450, cat1 not in: 0 |
| cat1 in: 0 2 8, age > 69, surv2md1 ≤ 0.402, aps1 > 61 |
| cat1 not in: 0 2 8, cat1 in: 3 5, aps1 > 64, aps1 ≤ 77 |
| cat1 not in: 0 2 8, cat1 in: 3 5, aps1 > 64, aps1 > 77 |
| cat1 not in: 0 2 8, cat1 not in: 3 5, surv2md1 ≤ 0.467, surv2md1 ≤ 0.384 |
| cat1 not in: 0 2 8, cat1 not in: 3 5, surv2md1 ≤ 0.467, surv2md1 > 0.384 |
Appendix A.4.3. Policy Rules: Interes Rates and Loan Returns Study
| Splitting variables and values | Treatment allocation |
| age ≤ 50, age > 36 | HR |
| age > 50, qnt_income ≤ 2 | HR |
| age ≤ 50, age ≤ 36 | MR |
| age > 50, qnt_income > 2 | LR |
| Splitting variables and values | Treatment allocation |
| age > 46, qnt_income > 2, age > 50 | LR |
| age ≤ 46, age ≤ 28, female = 0 | MR |
| age ≤ 46, age ≤ 28, female = 1 | HR |
| age ≤ 46, age > 28, age ≤ 36 | MR |
| age > 46, qnt_income ≤ 2, age ≤ 53 | MR |
| age ≤ 46, age > 28, age > 36 | HR |
| age > 46, qnt_income ≤ 2, age > 53 | HR |
| age > 46, qnt_income > 2, age ≤ 50 | HR |
| Splitting variables and values | Treatment allocation |
| age > 43, qnt_income > 2, age > 46, age > 50 | LR |
| age ≤ 43, age ≤ 33, age > 28, age > 32 | LR |
| age ≤ 43, age > 33, edhi = 0, age ≤ 35 | LR |
| age > 43, qnt_income > 2, age ≤ 46, female = 1 | LR |
| age ≤ 43, age ≤ 33, age ≤ 28 female = 1 | MR |
| age ≤ 43, age ≤ 33, age > 28, age ≤ 32 | MR |
| age ≤ 43, age > 33, edhi =1, age ≤ 37 | MR |
| age > 43, qnt_income ≤ 2, age ≤ 50, female = 0 | MR |
| age > 43, qnt_income ≤ 2, age > 50, age ≤ 53 | MR |
| age ≤ 43, age ≤ 33, age ≤ 28, female = 0 | HR |
| age ≤ 43, age > 33, edhi = 0, age > 35 | HR |
| age ≤ 43, age > 33, edhi = 1, age > 37 | HR |
| age > 43, qnt_income ≤ 2, age ≤ 50, female = 1 | HR |
| age > 43, qnt_income ≤ 2, age > 50, age > 53 | HR |
| age > 43, qnt_income > 2, age ≤ 46, female = 0 | HR |
| age > 43, qnt_income > 2, age > 46, age ≤ 50 | HR |
| Splitting variables and values | Treatment allocation |
| age ≤ 50, age ≤ 36, age > 32 | LR |
| age > 50, qnt_income > 2, age ≤ 57 | LR |
| age > 50, qnt_income > 2, age > 57 | LR |
| age ≤ 50, age ≤ 36, age ≤ 32 | MR |
| age > 50, qnt_income ≤ 2, age ≤ 53 | MR |
| age ≤ 50, age > 36, age ≤ 38 | HR |
| age ≤ 50, age > 36, age > 38 | HR |
| age > 50, qnt_income ≤ 2, age > 53 | HR |
| Splitting variables and values | Treatment allocation |
| age ≤ 46, age ≤ 28, female = 0, age ≤ 27 | MR |
| age ≤ 46, age ≤ 28, female = 0, age > 27 | HR |
| age ≤ 46, age ≤ 28, female = 1, age ≤ 25 | HR |
| age ≤ 46, age ≤ 28, female = 1, age > 25 | HR |
| age ≤ 46, age > 28, age ≤ 36, age ≤ 32 | MR |
| age ≤ 46, age > 28, age ≤ 36, age > 32 | LR |
| age ≤ 46, age > 28, age > 36, age ≤ 37 | HR |
| age ≤ 46, age > 28, age > 36, age > 37 | HR |
| age > 46, qnt_income ≤ 2, age ≤ 53, qnt_income = 0 | HR |
| age > 46, qnt_income ≤ 2, age ≤ 53, qnt_income > 0 | MR |
| age > 46, qnt_income ≤ 2, age > 53, rural = 0 | HR |
| age > 46, qnt_income ≤ 2, age > 53, rural = 1 | HR |
| age > 46, qnt_income > 2, age ≤ 50, female = 0 | LR |
| age > 46, qnt_income > 2, age ≤ 50, female = 1 | HR |
| age > 46, qnt_income > 2, age > 50, age ≤ 58 | LR |
| age > 46, qnt_income > 2, age > 50, age > 58 | LR |
| Splitting variables and values | Treatment allocation |
| age > 44, female = 0, qnt_income > 2, age ≤ 50 | HR |
| age > 44, female = 0, qnt_income > 2, age > 50 | LR |
| age ≤ 44, age ≤ 33, age ≤ 28, female = 0, age ≤ 27 | MR |
| age ≤ 44, age ≤ 33, age ≤ 28, female = 0, age > 27 | HR |
| age ≤ 44, age ≤ 33, age ≤ 28, female = 1, age ≤ 25 | HR |
| age ≤ 44, age ≤ 33, age ≤ 28, female = 1, age > 25 | HR |
| age ≤ 44, age ≤ 33, age > 28, age ≤ 32, rural = 0 | MR |
| age ≤ 44, age ≤ 33, age > 28, age ≤ 32, rural = 1 | MR |
| age ≤ 44, age ≤ 33, age > 28, age > 32, female = 0 | LR |
| age ≤ 44, age ≤ 33, age > 28, age > 32, female = 1 | LR |
| age ≤ 44, age > 33, edhi = 0, age ≤ 35, qnt_income = 0 | HR |
| age ≤ 44, age > 33, edhi = 0, age ≤ 35, qnt_income > 0 | LR |
| age ≤ 44, age > 33, edhi = 0, age > 35, qnt_income ≤ 2 | HR |
| age ≤ 44, age > 33, edhi = 0, age > 35, qnt_income > 2 | HR |
| age ≤ 44, age > 33, edhi = 1, age ≤ 37, qnt_income = 0 | MR |
| age ≤ 44, age > 33, edhi = 1, age ≤ 37, qnt_income > 0 | MR |
| age ≤ 44, age > 33, edhi = 1, age > 37, rural = 0 | HR |
| age ≤ 44, age > 33, edhi = 1, age > 37, rural = 1 | HR |
| age > 44, female = 0, qnt_income ≤ 2, age ≤ 53, qnt_income = 0 | HR |
| age > 44, female = 0, qnt_income ≤ 2, age ≤ 53, qnt_income > 0 | MR |
| age > 44, female = 0, qnt_income ≤ 2, age > 53, age ≤ 55 | HR |
| age > 44, female = 0, qnt_income ≤ 2, age > 53, age > 55 | HR |
| age > 44, female = 1, age ≤ 53, age ≤ 50, age ≤ 47 | HR |
| age > 44, female = 1, age ≤ 53, age ≤ 50, age > 47 | HR |
| age > 44, female = 1, age ≤ 53, age > 50, edhi = 0 | HR |
| age > 44, female = 1, age ≤ 53, age > 50, edhi = 1 | MR |
| age > 44, female = 1, age > 53, edhi = 0, age ≤ 65 | HR |
| age > 44, female = 1, age > 53, edhi = 0, age > 65 | MR |
| age > 44, female = 1, age > 53, edhi = 1, age ≤ 58 | LR |
| age > 44, female = 1, age > 53, edhi = 1, age > 58 | LR |
| Splitting variables and values | Treatment allocation |
| age ≤ 48, age ≤ 36, age ≤ 28, female = 0 | MR |
| age ≤ 48, age ≤ 36, age ≤ 28, female > 0 | HR |
| age ≤ 48, age ≤ 36, age > 28, age ≤ 32 | MR |
| age ≤ 48, age ≤ 36, age > 28, age > 32 | LR |
| age ≤ 48, age > 36, female = 0, age ≤ 46 | HR |
| age ≤ 48, age > 36, female = 0, age > 46 | MR |
| age ≤ 48, age > 36, female > 0, age ≤ 37 | MR |
| age ≤ 48, age > 36, female > 0, age > 37 | HR |
| age > 48, qnt_income ≤ 2, qnt_income = 0, age ≤ 52 | HR |
| age > 48, qnt_income ≤ 2, qnt_income = 0, age > 52 | HR |
| age > 48, qnt_income ≤ 2, qnt_income > 0, age ≤ 53 | MR |
| age > 48, qnt_income ≤ 2, qnt_income> 0, age > 53 | HR |
| age > 48, qnt_income > 2, age ≤ 51 | LR |
| age > 48, qnt_income > 2, age > 51 | LR |
| Splitting variables and values | Treatment allocation |
| age ≤ 44, age ≤ 28, female = 0, age ≤ 26, qnt_income ≤ 1 | MR |
| age ≤ 44, age ≤ 28, female = 0, age ≤ 26, qnt_income > 1 | MR |
| age ≤ 44, age ≤ 28, female = 0, age > 26, qnt_income ≤ 1 | HR |
| age ≤ 44, age ≤ 28, female = 0, age > 26, qnt_income > 1 | MR |
| age ≤ 44, age ≤ 28, female = 1, qnt_income ≤ 1, qnt_income = 0 | HR |
| age ≤ 44, age ≤ 28, female = 1, qnt_income ≤ 1, qnt_income > 0 | HR |
| age ≤ 44, age ≤ 28, female = 1, qnt_income > 1, qnt_income ≤ 2.5 | HR |
| age ≤ 44, age ≤ 28, female > 1, qnt_income > 1, qnt_income > 2.5 | HR |
| age ≤ 44, age > 28, age ≤ 36, age ≤ 33, age ≤ 32 | MR |
| age ≤ 44, age > 28, age ≤ 36, age ≤ 33, age > 32 | LR |
| age ≤ 44, age > 28, age ≤ 36, age > 33, edhi = 0 | LR |
| age ≤ 44, age > 28, age ≤ 36, age > 33, edhi = 1 | MR |
| age ≤ 44, age > 28, age > 36, female = 0, qnt_income ≤ 1 | HR |
| age ≤ 44, age > 28, age > 36, female = 0, qnt_income > 1 | HR |
| age ≤ 44, age > 28, age > 36, female = 1, qnt_income ≤ 2 | HR |
| age ≤ 44, age > 28, age > 36, female = 1, qnt_income > 2. | MR |
| age > 44, qnt_income ≤ 2, female = 0, age ≤ 55, qnt_income = 0 | HR |
| age > 44, qnt_income ≤ 2, female = 0, age ≤ 55, qnt_income > 0 | MR |
| age > 44, qnt_income ≤ 2, female = 0, age > 55, age ≤ 61 | HR |
| age > 44, qnt_income ≤ 2, female = 0, age > 55, age > 61 | HR |
| age > 44, qnt_income ≤ 2, female = 1, age ≤ 50, age ≤ 46 | HR |
| age > 44, qnt_income ≤ 2, female = 1, age ≤ 50, age > 46 | HR |
| age > 44, qnt_income ≤ 2, female = 1, age > 50, age ≤ 53 | MR |
| age > 44, qnt_income ≤ 2, female = 1, age > 50, age > 53 | HR |
| age > 44, qnt_income > 2, age ≤ 50, age ≤ 47 | HR |
| age > 44, qnt_income > 2, age ≤ 50 age > 47 | HR |
| age > 44, qnt_income > 2, age > 50, age ≤ 59 | LR |
| age > 44, qnt_income > 2, age > 50, age > 59 | LR |
| Splitting variables and values | Treatment allocation |
| age ≤ 44, age ≤ 33, age ≤ 28, female = 0, age ≤ 26, qnt_income ≤ 1 | MR |
| age ≤ 44, age ≤ 33, age ≤ 28, female = 0, age ≤ 26, qnt_income > 1 | MR |
| age ≤ 44, age ≤ 33, age ≤ 28, female = 0, age > 26, qnt_income ≤ 1 | HR |
| age ≤ 44, age ≤ 33, age ≤ 28, female = 0, age > 26, qnt_income > 1 | MR |
| age ≤ 44, age ≤ 33, age ≤ 28, female > 1, qnt_income ≤ 1, qnt_income = 0 | HR |
| age ≤ 44, age ≤ 33, age ≤ 28, female = 1, qnt_income ≤ 1, qnt_income > 0 | HR |
| age ≤ 44, age ≤ 33, age ≤ 28, female = 1, qnt_income > 1, qnt_income ≤ 2.5 | HR |
| age ≤ 44, age ≤ 33, age ≤ 28, female = 1, qnt_income > 1, qnt_income > 2.5 | HR |
| age ≤ 44, age ≤ 33, age > 28, age ≤ 32, edhi = 0, age ≤ 30 | MR |
| age ≤ 44, age ≤ 33, age > 28, age ≤ 32, edhi = 0, age > 30 | HR |
| age ≤ 44, age ≤ 33, age > 28, age ≤ 32, edhi = 1, qnt_income = 0 | HR |
| age ≤ 44, age ≤ 33, age > 28, age ≤ 32, edhi = 1, qnt_income > 0 | MR |
| age ≤ 44, age ≤ 33, age > 28, age > 32, female = 0 | LR |
| age ≤ 44, age ≤ 33, age > 28, age > 32, female > 0 | LR |
| age ≤ 44, age > 33, edhi = 0, age ≤ 35, qnt_income = 0 | HR |
| age ≤ 44, age > 33, edhi = 0, age ≤ 35, qnt_income > 0 | LR |
| age ≤ 44, age > 33, edhi = 0, age > 35, qnt_income ≤ 2, age ≤ 36 | LR |
| age ≤ 44, age > 33, edhi = 0, age > 35, qnt_income ≤ 2, age > 36 | HR |
| age ≤ 44, age > 33, edhi = 0, age > 35, qnt_income > 2, age ≤ 39 | HR |
| age ≤ 44, age > 33, edhi = 0, age > 35, qnt_income > 2, age > 39 | HR |
| age ≤ 44, age > 33, edhi = 1, age ≤ 37, qnt_income ≤ 2, qnt_income ≤ 1 | MR |
| age ≤ 44, age > 33, edhi = 1, age ≤ 37, qnt_income ≤ 2, qnt_income > 1 | LR |
| age ≤ 44, age > 33, edhi = 1, age ≤ 37, qnt_income > 2, female = 0 | MR |
| age ≤ 44, age > 33, edhi = 1, age ≤ 37 qnt_income > 2, female = 1 | MR |
| age ≤ 44, age > 33, edhi = 1, age > 37, qnt_income ≤ 2, qnt_income ≤ 1 | HR |
| age ≤ 44 age > 33, edhi = 1, age > 37, qnt_income ≤ 2, qnt_income 1 | HR |
| age ≤ 44, age > 33, edhi = 1, age > 37, qnt_income > 2, female = 0 | HR |
| age ≤ 44, age > 33, edhi = 1, age > 37, qnt_income > 2, female = 1 | MR |
| age > 44, qnt_income ≤ 1, age ≤ 52, female = 0, qnt_income = 0 | HR |
| age > 44, qnt_income ≤ 1 age ≤ 52, female = 0, qnt_income > 0 | MR |
| age > 44, qnt_income ≤ 1, age ≤ 52, female = 1, age ≤ 47, qnt_income = 0 | HR |
| age > 44, qnt_income ≤ 1, age ≤ 52, female = 1, age ≤ 47, qnt_income > 0 | MR |
| age > 44, qnt_income ≤ 1, age ≤ 52, female = 1, age > 47, qnt_income = 0 | MR |
| age > 44, qnt_income ≤ 1 age ≤ 52, female= 1, age > 47, qnt_income > 0 | MR |
| age > 44, qnt_income ≤ 1, age > 52, age ≤ 60, qnt_income = 0, age ≤ 56 | HR |
| age > 44, qnt_income ≤ 1, age > 52, age ≤ 60, qnt_income = 0, age > 56 | HR |
| age > 44, qnt_income ≤ 1, age > 52, age ≤ 60, qnt_income > 0, age ≤ 55 | MR |
| age > 44, qnt_income ≤ 1, age > 52, age ≤ 60, qnt_income > 0, age > 55 | HR |
| age , qnt_income , age , age , age , age | HR |
| age , qnt_income , age , age , age , age | HR |
| age , qnt_income , age , age , age , age | HR |
| age , qnt_income , age , age , age , age | HR |
| age , qnt_income , qnt_income , female = 0, age , age | MR |
| age , qnt_income , qnt_income , female = 0, age , age | MR |
| age , qnt_income , qnt_income , female = 0, age , age | LR |
| age , qnt_income , qnt_income , female = 0, age , age | HR |
| age , qnt_income , qnt_income , female = 1, age , age | HR |
| age , qnt_income , qnt_income , female = 1, age , age | MR |
| age , qnt_income , qnt_income , female = 1, age , age | HR |
| age , qnt_income , qnt_income , female = 1, age , age | HR |
| age , qnt_income , qnt_income , age , age , female = 0 | HR |
| age , qnt_income , qnt_income , age , age , female = 1 | LR |
| age , qnt_income , qnt_income , age , age , female = 0 | LR |
| age , qnt_income , qnt_income , age , age , female | HR |
| age , qnt_income , qnt_income , age , age , female = 0 | LR |
| age , qnt_income , qnt_income , age , age , female = 1 | LR |
| age , qnt_income , qnt_income , age , age , female = 0 | LR |
| age , qnt_income , qnt_income , age , age , female = 1 | LR |
References
- Athey, S.; Imbens, G.W. The state of applied econometrics: Causality and policy evaluation. J. Econ. Perspect. 2017, 31, 3–32. [Google Scholar] [CrossRef]
- Baiardi, A.; Naghi, A.A. The value added of machine learning to causal inference: Evidence from revisited studies. Econom. J. 2024, 27, utae004. [Google Scholar] [CrossRef]
- Künzel, S.R.; Sekhon, J.S.; Bickel, P.J.; Yu, B. Metalearners for estimating heterogeneous treatment effects using machine learning. Proc. Natl. Acad. Sci. USA 2019, 116, 4156–4165. [Google Scholar] [CrossRef] [PubMed]
- Manski, C.F. Statistical treatment rules for heterogeneous populations. Econometrica 2004, 72, 1221–1246. [Google Scholar] [CrossRef]
- Kitagawa, T.; Tetenov, A. Who should be treated? empirical welfare maximization methods for treatment choice. Econometrica 2018, 86, 591–616. [Google Scholar] [CrossRef]
- Mbakop, E.; Tabord-Meehan, M. Model selection for treatment choice: Penalized welfare maximization. Econometrica 2021, 89, 825–848. [Google Scholar] [CrossRef]
- Athey, S.; Wager, S. Policy learning with observational data. Econometrica 2021, 89, 133–161. [Google Scholar] [CrossRef]
- Kitagawa, T.; Tetenov, A. Equality-minded treatment choice. J. Bus. Econ. Stat. 2021, 39, 561–574. [Google Scholar] [CrossRef]
- Zhou, Z.; Athey, S.; Wager, S. Offline multi-action policy learning: Generalization and optimization. Oper. Res. 2023, 71, 148–183. [Google Scholar] [CrossRef]
- Lechner, M.; Mareckova, J. Comprehensive Causal Machine Learning. arXiv 2024, arXiv:2405.10198. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Series in Statistics; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Imbens, G.W.; Wooldridge, J.M. Recent Developments in the Econometrics of Program Evaluation. J. Econ. Lit. 2009, 47, 5–86. [Google Scholar] [CrossRef]
- Bodory, H.; Busshoff, H.; Lechner, M. High resolution treatment effects estimation: Uncovering effect heterogeneities with the modified causal forest. Entropy 2022, 24, 1039. [Google Scholar] [CrossRef] [PubMed]
- Finkelstein, A.; Taubman, S.; Wright, B.; Bernstein, M.; Gruber, J.; Newhouse, J.P.; Allen, H.; Baicker, K.; the Oregon Health Study Group. The Oregon health insurance experiment: Evidence from the first year. Q. J. Econ. 2012, 127, 1057–1106. [Google Scholar] [CrossRef] [PubMed]
- Baicker, K.; Taubman, S.L.; Allen, H.L.; Bernstein, M.; Gruber, J.H.; Newhouse, J.P.; Schneider, E.C.; Wright, B.J.; Zaslavsky, A.M.; Finkelstein, A.N. The Oregon experiment—effects of Medicaid on clinical outcomes. N. Engl. J. Med. 2013, 368, 1713–1722. [Google Scholar] [CrossRef] [PubMed]
- Finkelstein, A.N.; Taubman, S.L.; Allen, H.L.; Wright, B.J.; Baicker, K. Effect of Medicaid coverage on ED use—Further evidence from Oregon’s experiment. N. Engl. J. Med. 2016, 375, 1505–1507. [Google Scholar] [CrossRef] [PubMed]
- Baicker, K.; Allen, H.L.; Wright, B.J.; Finkelstein, A.N. The effect of Medicaid on medication use among poor adults: Evidence from Oregon. Health Aff. 2017, 36, 2110–2114. [Google Scholar] [CrossRef]
- Carcillo, S.; Grubb, D. From Inactivity to Work. 2006. Available online: https://www.oecd-ilibrary.org/social-issues-migration-health/from-inactivity-to-work_687686456188 (accessed on 10 July 2024).
- Baicker, K.; Finkelstein, A. The Impact of Medicaid Expansion on Voter Participation: Evidence from the Oregon Health Insurance Experiment; Technical Report; National Bureau of Economic Research: Cambridge, MA, USA, 2018. [Google Scholar]
- Finkelstein, A.; Hendren, N.; Luttmer, E.F. The value of medicaid: Interpreting results from the oregon health insurance experiment. J. Political Econ. 2019, 127, 2836–2874. [Google Scholar] [CrossRef] [PubMed]
- Baicker, K.; Finkelstein, A.; Song, J.; Taubman, S. The impact of health insurance expansions on other social safety net programs. Am. Econ. Rev. 2014, 104, 322–328. [Google Scholar] [CrossRef]
- Sverdrup, E.; Kanodia, A.; Zhou, Z.; Athey, S.; Wager, S. Policytree: Policy Learning via Doubly Robust Empirical Welfare Maximization over Trees. J. Open Source Softw. 2023, 5, 2232. [Google Scholar] [CrossRef]
- Connors, A.F.; Speroff, T.; Dawson, N.V.; Thomas, C.; Harrell, F.E.; Wagner, D.; Desbiens, N.; Goldman, L.; Wu, A.W.; Califf, R.M.; et al. The effectiveness of right heart catheterization in the initial care of critically III patients. JAMA 1996, 276, 889–897. [Google Scholar] [CrossRef]
- Knaus, W.A.; Harrell, F.E.; Lynn, J.; Goldman, L.; Phillips, R.S.; Connors, A.F.; Dawson, N.V.; Fulkerson, W.J.; Califf, R.M.; Desbiens, N.; et al. The SUPPORT prognostic model: Objective estimates of survival for seriously ill hospitalized adults. Ann. Intern. Med. 1995, 122, 191–203. [Google Scholar] [CrossRef] [PubMed]
- Ramsahai, R.R.; Grieve, R.; Sekhon, J.S. Extending iterative matching methods: An approach to improving covariate balance that allows prioritisation. Health Serv. Outcomes Res. Methodol. 2011, 11, 95–114. [Google Scholar] [CrossRef]
- Keele, L.; Small, D.S. Pre-analysis Plan for a Comparison of Matching and Black Box-based Covariate Adjustment. Obs. Stud. 2018, 4, 97–110. [Google Scholar] [CrossRef]
- Keele, L.; Small, D.S. Comparing covariate prioritization via matching to machine learning methods for causal inference using five empirical applications. Am. Stat. 2021, 75, 355–363. [Google Scholar] [CrossRef]
- Karlan, D.S.; Zinman, J. Credit elasticities in less-developed economies: Implications for microfinance. Am. Econ. Rev. 2008, 98, 1040–1068. [Google Scholar] [CrossRef]
- Kallus, N.; Zhou, A. Fairness, welfare, and equity in personalized pricing. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, Toronto, ON, Canada, 3–10 March 2021; pp. 296–314. [Google Scholar]





| Policy | Welfare (%) | Treatment Shares (%) | |
|---|---|---|---|
| Primary Care Visits | Medicaid No | Medicaid Yes | |
| Observed | 51.70 | 49.98 | 50.02 |
| Random | 51.45 | 50.16 | 49.84 |
| Unconstrained optimal policy tree | |||
| Depth-2 | 54.97 | 0 | 100 |
| Depth-3 | 54.97 | 0 | 100 |
| Constrained optimal policy tree | |||
| Depth-2 | 52.88 | 53.56 | 46.44 |
| Depth-3 | 53.48 | 51.75 | 48.25 |
| Depth-4 | 53.51 | 52.18 | 47.82 |
| Constrained sequentially optimal policy trees | |||
| Depth-2+1 | 52.68 | 57.06 | 42.93 |
| Depth-3+1 | 53.54 | 50.30 | 49.69 |
| Policy | Welfare (%) | Treatment Shares (%) | |
|---|---|---|---|
| Survival Rate | No RHC | Yes RHC | |
| Observed | 68.23 | 60.51 | 39.49 |
| Random | 67.88 | 59.00 | 40.99 |
| Unconstrained optimal policy tree | |||
| Depth-2 | 69.99 | 80.78 | 19.21 |
| Depth-3 | 69.95 | 82.73 | 17.27 |
| Unconstrained sequentially optimal policy trees | |||
| Depth-2+1 | 69.98 | 82.88 | 17.11 |
| Depth-3+1 | 69.97 | 83.78 | 16.22 |
| Policy | Welfare (ZAR) | Treatment Shares (%) | ||
|---|---|---|---|---|
| Average Returns | Low Rate | Medium Rate | High Rate | |
| Observed | 497 | 39.84 | 28.40 | 31.75 |
| Random | 497 | 39.84 | 28.85 | 31.10 |
| Unconstrained optimal policy tree | ||||
| Depth-2 | 652 | 4.62 | 40.25 | 55.12 |
| Depth-3 | 678 | 4.62 | 44.62 | 50.76 |
| Depth-4 | 701 | 13.74 | 36.02 | 50.23 |
| Unconstrained sequentially optimal policy trees | ||||
| Depth-2+1 | 663 | 19.58 | 28.89 | 51.53 |
| Depth-3+1 | 686 | 20.95 | 25.14 | 53.90 |
| Depth-4+1 | 703 | 11.68 | 31.23 | 57.09 |
| Depth-2+2 | 685 | 20.84 | 28.67 | 50.50 |
| Depth-3+2 | 710 | 14.74 | 34.66 | 50.60 |
| Depth-4+2 | 717 | 17.45 | 28.87 | 53.68 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bodory, H.; Mascolo, F.; Lechner, M. Enabling Decision Making with the Modified Causal Forest: Policy Trees for Treatment Assignment. Algorithms 2024, 17, 318. https://doi.org/10.3390/a17070318
Bodory H, Mascolo F, Lechner M. Enabling Decision Making with the Modified Causal Forest: Policy Trees for Treatment Assignment. Algorithms. 2024; 17(7):318. https://doi.org/10.3390/a17070318
Chicago/Turabian StyleBodory, Hugo, Federica Mascolo, and Michael Lechner. 2024. "Enabling Decision Making with the Modified Causal Forest: Policy Trees for Treatment Assignment" Algorithms 17, no. 7: 318. https://doi.org/10.3390/a17070318
APA StyleBodory, H., Mascolo, F., & Lechner, M. (2024). Enabling Decision Making with the Modified Causal Forest: Policy Trees for Treatment Assignment. Algorithms, 17(7), 318. https://doi.org/10.3390/a17070318