

Automatic Vertical Parking Reference Trajectory Based on Improved Immune Shark Smell Optimization


Abstract
1. Introduction
- A novel optimization model of a reference trajectory for AVP is constructed. In view of the problems with the existing AVP reference trajectory optimization, such as poor obstacle avoidance, low trajectory smoothness, a long path, and a large parking incline, a novel, reasonable, and feasible optimization model of the reference trajectory for automatic parking is established using cubic spline.
- A novel improved immune shark optimization algorithm is put forward to address the issue of local convergence in the existing shark optimization algorithm. This method organically incorporates refraction, Gaussian variation, and immunity mechanisms, which can effectively improve the global optimization performance and solve the problem of not being able to escape local convergence.
2. Model of Reference Trajectory Optimization and Related Principles for Automatic Vertical Parking
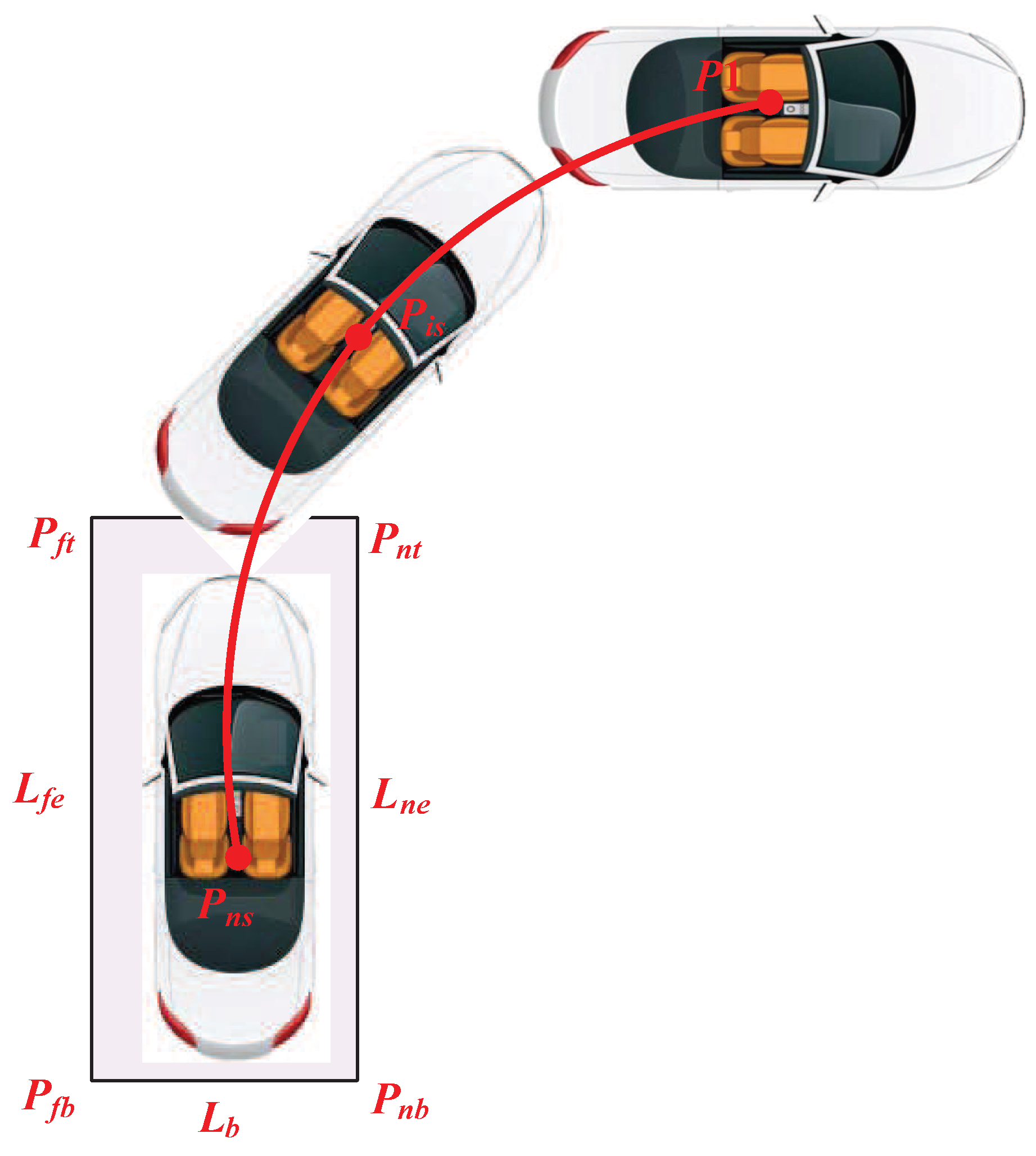
2.1. Basic Principles of Automatic Vertical Parking
2.2. Feasibility Conditions for AVP
2.3. Coordinate Transformation Principle for the Parking Plane
2.4. Reference Trajectory Optimization Model for AVP
2.5. Solution Principle of the Parking Trajectory Length
- Curve segment division: We divide the sampling points’ set into several curve segments. Every curve segment represents consecutive sampling points. The division of the curve segments should ensure that the length of every curve segment is roughly equal, to achieve equal-length quantization.
- Curve segment endpoints extraction: For every curve segment, we extract its two endpoints as the endpoints of the curve segment, and the coordinates of the two endpoints are calculated to determine the length of the curve segment.
- Curve segment length calculation: We calculate the distance between the two endpoints of every curve segment. In the two-dimensional plane coordinate system, the distance between the two endpoints is .
- Result verification: We verify the length of every curve segment to determine whether the length of the curve segment meets the expected error range.
- Quantization result recording: We record the length of every curve segment for the subsequent trajectory length calculation.
- Selection of the encoding method: We select the appropriate encoding method according to the data type to be encoded. For the decimal index value of the parking position reference point set, binary code can be used instead.
- Data conversion: We convert the original data to the encoding format. The index values of the parking position reference points’ set need to be converted into binary numbers.
- Encoding processing: The converted data are encoded according to a fixed length. We fill every binary number to the specified length to ensure that every coding length is the same.
- Verification of the encoding results: We verify whether every encoding length is the same and whether every coding can correctly represent the original data.
- Result recording: We record the encoding results and prepare them for subsequent intelligent algorithm optimization.
3. Improved Shark Optimization Algorithm
3.1. Shark Optimization Algorithm
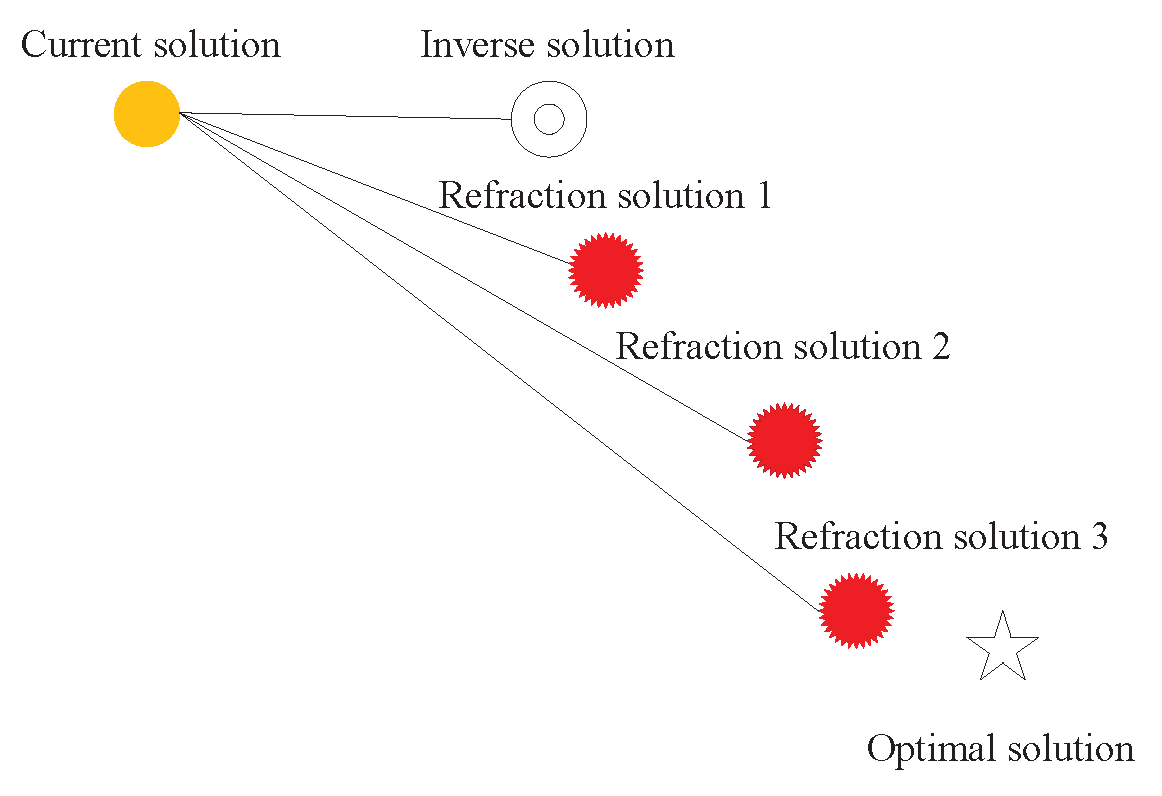
3.2. Refraction Mechanism
3.3. Gaussian Variation Mechanism
- It can effectively expand and strengthen the local search scope and intensity of the shark optimization algorithm, which is conducive to improving its local search ability.
- If the shark optimization algorithm is trapped, risking local convergence, the powerful local perturbation in the region will significantly help it to escape.
3.4. Immune Mechanism
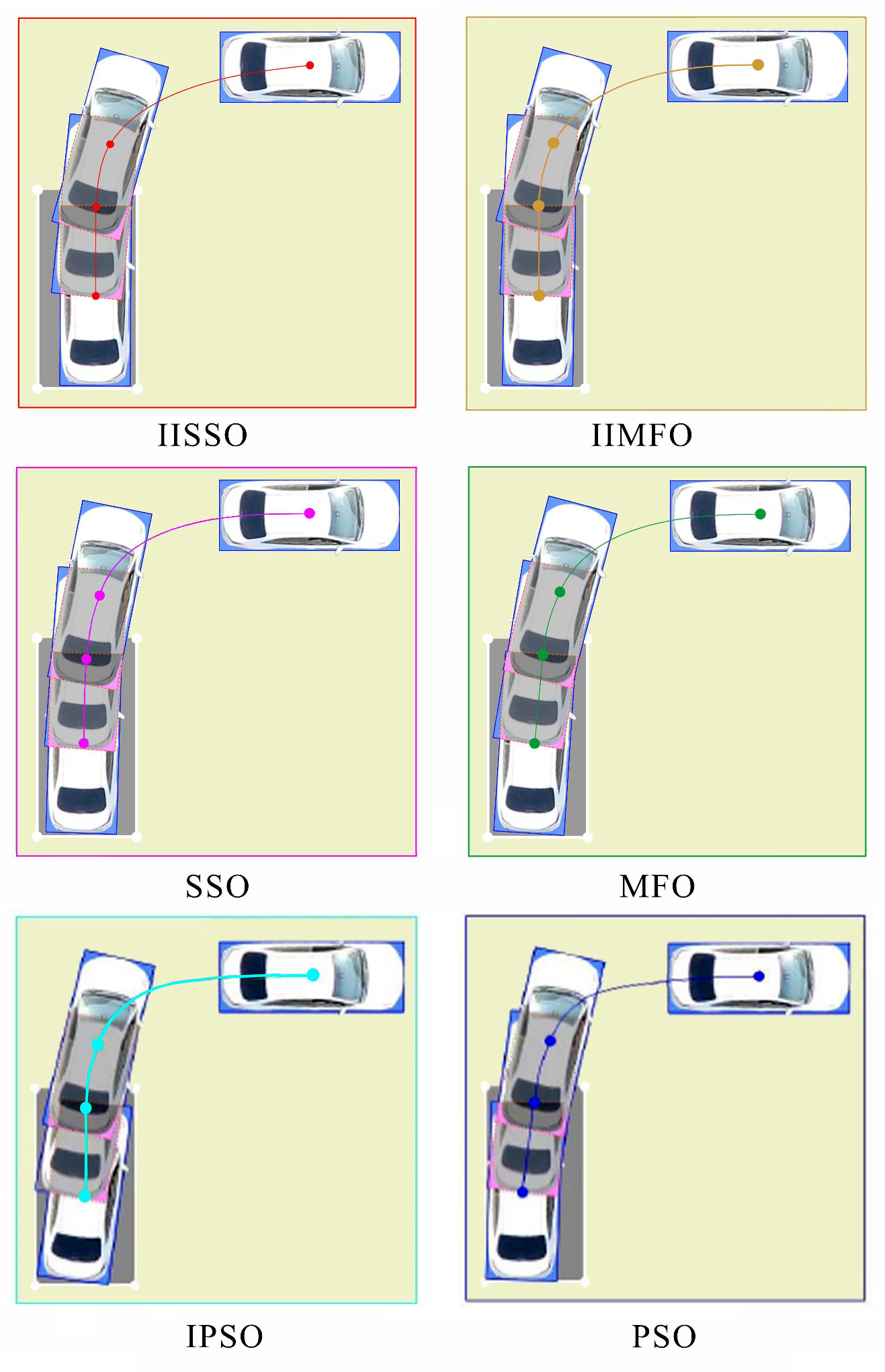
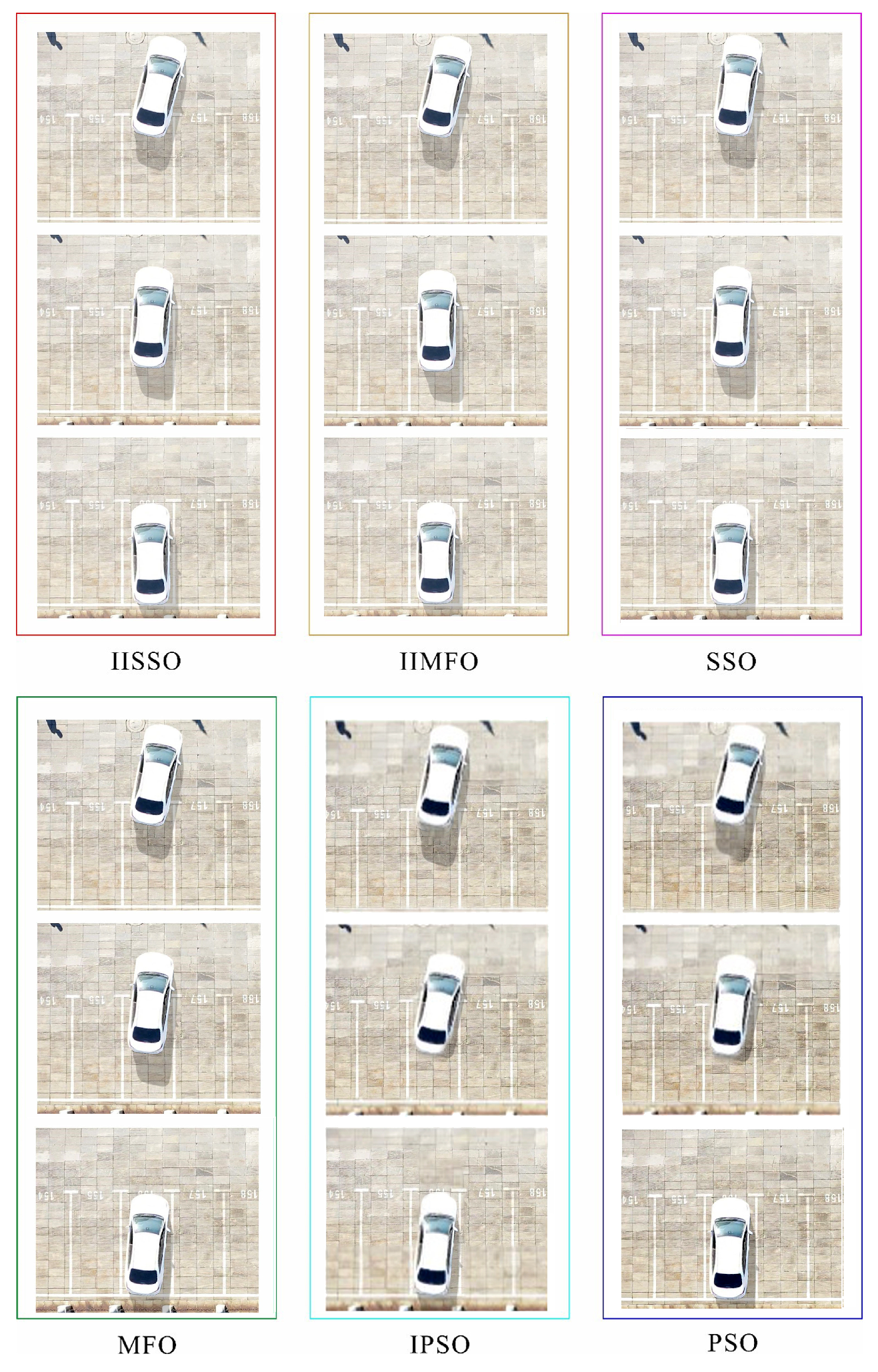
4. Experimental Verification
4.1. Description of the AVP Experiment Scenes
4.2. Overall Design of the Automatic Vertical Parking Experiments
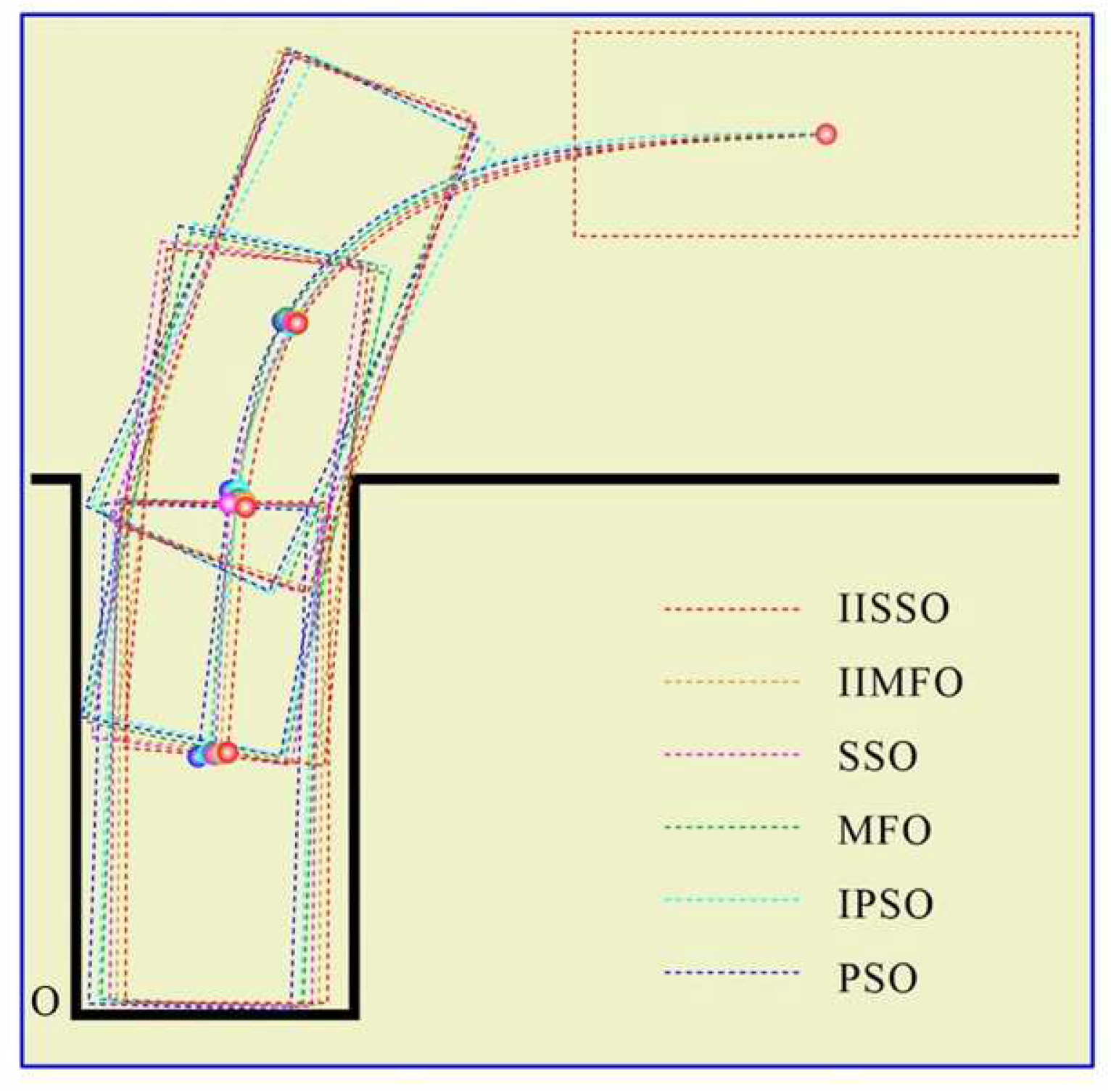
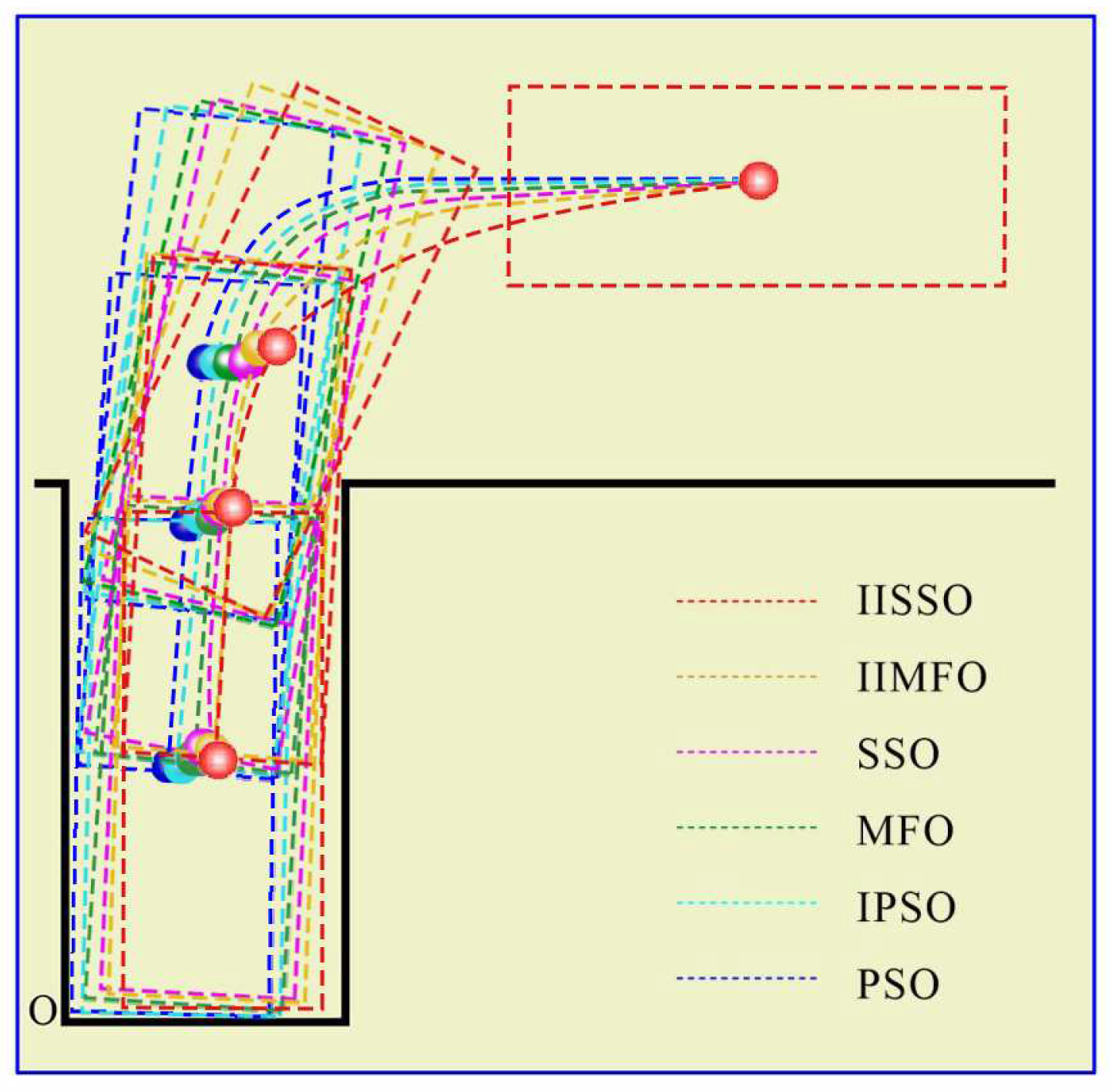
4.3. Results and Analysis of the Automatic Parking Experiment
5. Conclusions
- Real-world parking scenes include dynamic obstacles (e.g., pedestrians and other vehicles). When there are sudden obstacles during parking, the AVP system will trigger the stop command; however, it does not have the ability to continue tracking control and avoid obstacles.
- Our research was limited to ordinary vehicles; hence, it is not applicable to special vehicles, such as trucks, heavy-duty vehicles, large vehicles, and small vehicles.
- There is still room for further improvement of the results, although compared with the existing results, our research results were improved.
- The research presented was still in the experimental stage, which required the configuration of a relatively complex and expensive AVP system; hence, we remain far from having a product that can be mass-produced.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AVP | automatic vertical parking |
| IISSO | improved immune shark smell optimization |
| SSO | shark smell optimization |
| IIMFO | improved immune moth flame optimization |
| MFO | moth flame optimization |
| IPSO | improved particle swarm optimization |
| PSO | particle swarm optimization |
References
- Li, B.; Wang, K.; Shao, Z. Time-Optimal Maneuver Planning in Automatic Parallel Parking Using a Simultaneous Dynamic Optimization Approach. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3263–3274. [Google Scholar] [CrossRef]
- Wang, J.; Li, J.; Yang, J.; Meng, X.; Fu, T. Automatic parking trajectory planning based on random sampling and nonlinear optimization. J. Frankl. Inst. 2023, 360, 9579–9601. [Google Scholar] [CrossRef]
- Suhr, J.K.; Jung, H.G. Automatic parking space detection and tracking for underground and indoor environments. IEEE Trans. Ind. Electron. 2016, 63, 5687–5698. [Google Scholar] [CrossRef]
- Chen, Q.; Gan, L.; Chen, B.; Liu, Q.; Zhang, X. Parallel Parking Path Planning Based on Improved Arctangent Function Optimization. Int. J. Automot. Technol. 2023, 24, 23–33. [Google Scholar] [CrossRef]
- Chai, R.; Tsourdos, A.; Savvaris, A.; Chai, S.; Xia, Y.; Chen, C.L.P. Multiobjective optimal parking maneuver planning of autonomous wheeled vehicles. IEEE Trans. Ind. Electron. 2020, 67, 10809–10821. [Google Scholar] [CrossRef]
- Zips, P.; Böck, M.; Kugi, A. Optimisation based path planning for car parking in narrow environments. Robot. Auton. Syst. 2016, 79, 1–11. [Google Scholar] [CrossRef]
- Ji, J.; Khajepour, A.; Melek, W.; Huang, Y. Path planning and tracking for vehicle collision avoidance based on model predictive control with multiconstraints. IEEE Trans. Veh. Technol. 2017, 66, 952–964. [Google Scholar] [CrossRef]
- Zhao, M.; Shen, T.; Wang, F.; Yin, G.; Li, Z.; Zhang, Y. Automatic Parking Control of Unmanned Vehicle Based on Switching Control Algorithm and Backstepping. IEEE ASME Trans. Mechatronics 2024, 25, 4116–4132. [Google Scholar]
- Gao, H.; Zhu, J.; Li, X.; Kang, Y.; Li, J.; Su, H. APTEN-Planner: Autonomous Parking of Semi-Trailer Train in Extremely Narrow Environments. IEEE Trans. Intell. Transp. Syst. 2022, 27, 1233–1243. [Google Scholar]
- Yang, H.; Xu, X.; Hong, J. Automatic Parking Path Planning of Tracked Vehicle Based on Improved A* and DWA Algorithms. IEEE Trans. Transp. Electrif. 2023, 9, 283–292. [Google Scholar] [CrossRef]
- Chai, R.; Liu, D.; Liu, T.; Tsourdos, A.; Xia, Y.; Chai, S. Deep Learning-Based Trajectory Planning and Control for Autonomous Ground Vehicle Parking Maneuver. IEEE Trans. Autom. Sci. Eng. 2023, 20, 1633–1647. [Google Scholar] [CrossRef]
- Chen, X.; Mai, H.; Zhang, Z.; Gu, F. A novel adaptive pseudospectral method for the optimal control problem of automatic car parking. Asian J. Control. 2022, 24, 1363–1377. [Google Scholar] [CrossRef]
- Cai, L.; Guan, H.; Zhou, Z.; Xu, F.; Jia, X.; Zhan, J. Parking Planning Under Limited Parking Corridor Space. IEEE Trans. Intell. Transp. Syst. 2022, 24, 1962–1981. [Google Scholar] [CrossRef]
- Han, I. Geometric Path Plans for Perpendicular/Parallel Reverse Parking in a Narrow Parking Spot with Surrounding Space. Vehicles 2022, 4, 1195–1208. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, L.; Liu, G.; Xia, B. Automatic Parking Path Optimization based on Immune Moth Flame Algorithm for Intelligent Vehicles. Symmetry 2022, 14, 1923. [Google Scholar] [CrossRef]
- Chen, Y.; Qian, Y. Improved Particle Swarm Optimization Algorithm for Automatic Entering Parking Space Based on Spline Theory. In Proceedings of the 2nd International Conference on Computing and Data Science (CONF-CDS 2021), Stanford, CA, USA, 28–30 January 2021; Volume 28, pp. 136–143. [Google Scholar]
- Dyer, S.A.; Dyer, J.S. Cubic-spline interpolation 1. IEEE Instrum. Meas. Mag. 2001, 4, 44–46. [Google Scholar] [CrossRef]
- Abedinia, O.; Amjady, N.; Ghasemi, A. A new metaheuristic algorithm based on shark smell optimization. Complexity 2014, 21, 97–116. [Google Scholar] [CrossRef]
- Ahmadigorji, M.; Amjady, N. A multiyear DG-incorporated framework for expansion planning of distribution networks using binary chaotic shark smell optimization algorithm. Energy 2016, 102, 199–215. [Google Scholar] [CrossRef]
- Tizhoosh, H.R. Opposition-Based Learning: A New Scheme for Machine Intelligence. In Proceedings of the International Conference on Computational Intelligence for Modelling, Control & Automation, & International Conference on Intelligent Agents, Web Technologies & Internet Commerce, Vienna, Austria, 28–30 November 2005; pp. 695–701. [Google Scholar]
- Xu, L.; Li, Y.; Li, K.; Beng, G.; Jiang, Z.; Wang, C.; Liu, N. Enhanced Moth-flame Optimization Based on Cultural Learning and Gaussian Mutation. J. Bionic Eng. 2018, 15, 751–763. [Google Scholar] [CrossRef]
- Mirjalili, S. Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl.-Based Syst. 2015, 89, 228–249. [Google Scholar] [CrossRef]
- Peng, H.; Li, R.; Cao, L.; Li, L. Multiple Swarms Multi-Objective Particle Swarm Optimization Based on Decomposition. Procedia Eng. 2011, 15, 3371–3375. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Symbol | Value |
|---|---|---|
| Vehicle coverage area collected times | 10 | |
| Parking inclination angle threshold | ||
| Parking process period | s | |
| Parking interval threshold | m |
| Algorithm | Parking Point Vector (m, m) | Path Length (m) | Parking Position Error (m) | Realization Time (s) |
|---|---|---|---|---|
| IISSO | (1.47, 2.50, 0.33) | 9.524 | 0 | 10.11 |
| IIMFO | (1.40, 2.49, 0.67) | 9.640 | −0.01 | 10.38 |
| SSO | (1.35, 2.48, 0.74) | 9.665 | −0.02 | 11.20 |
| MFO | (1.32, 2.49, 2.12) | 9.701 | −0.01 | 10.89 |
| IPSO | (1.28, 2.49, 1.82) | 9.708 | −0.01 | 10.67 |
| PSO | (1.19, 2.46, 1.79) | 9.799 | −0.04 | 10.46 |
| Algorithm | Parking Point Vector (m, m) | Path Length (m) | Parking Position Error (m) |
|---|---|---|---|
| IISSO | (1.44, 2.50, 0.48) | 9.647 | 0 |
| IIMFO | (1.40, 2.49, 1.01) | 9.710 | −0.01 |
| SSO | (1.32, 2.54, 1.53) | 9.725 | 0.04 |
| MFO | (1.31, 2.49, 3.01) | 9.737 | −0.01 |
| IPSO | (1.20, 2.49, 2.65) | 9.758 | −0.01 |
| PSO | (1.16, 2.45, 2.62) | 9.804 | −0.05 |
| Algorithm | Parking Point Vector (m, m) | Path Length (m) | Parking Position Error (m) | Realization Time (s) |
|---|---|---|---|---|
| IISSO | (1.55, 2.39, 0.40) | 9.035 | −0.01 | 9.47 |
| IIMFO | (1.49, 2.43, 1.57) | 9.182 | 0.03 | 9.88 |
| SSO | (1.41, 2.44, 2.82) | 9.293 | 0.04 | 10.62 |
| MFO | (1.33, 2.39, 2.44) | 9.411 | −0.01 | 10.09 |
| IPSO | (1.24, 2.35, 2.07) | 9.498 | −0.05 | 10.44 |
| PSO | (1.17, 2.35, 1.79) | 9.553 | −0.05 | 10.12 |
| Algorithm | Parking Point Vector (m, m) | Path Length (m) | Parking Position Error (m) |
|---|---|---|---|
| IISSO | (1.53, 2.40, 0.53) | 9.109 | 0 |
| IIMFO | (1.47, 2.44, 2.72) | 9.292 | 0.04 |
| SSO | (1.40, 2.46, 2.85) | 9.358 | 0.06 |
| MFO | (1.32, 2.41, 1.51) | 9.443 | 0.01 |
| IPSO | (1.23, 2.38, 1.29) | 9.502 | −0.02 |
| PSO | (1.20, 2.41, 0.72) | 9.544 | 0.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Liu, G.; Wang, L.; Xia, B. Automatic Vertical Parking Reference Trajectory Based on Improved Immune Shark Smell Optimization. Algorithms 2024, 17, 308. https://doi.org/10.3390/a17070308
Chen Y, Liu G, Wang L, Xia B. Automatic Vertical Parking Reference Trajectory Based on Improved Immune Shark Smell Optimization. Algorithms. 2024; 17(7):308. https://doi.org/10.3390/a17070308
Chicago/Turabian StyleChen, Yan, Gang Liu, Longda Wang, and Bing Xia. 2024. "Automatic Vertical Parking Reference Trajectory Based on Improved Immune Shark Smell Optimization" Algorithms 17, no. 7: 308. https://doi.org/10.3390/a17070308
APA StyleChen, Y., Liu, G., Wang, L., & Xia, B. (2024). Automatic Vertical Parking Reference Trajectory Based on Improved Immune Shark Smell Optimization. Algorithms, 17(7), 308. https://doi.org/10.3390/a17070308