

Training of Convolutional Neural Networks for Image Classification with Fully Decoupled Extended Kalman Filter


Abstract
1. Introduction
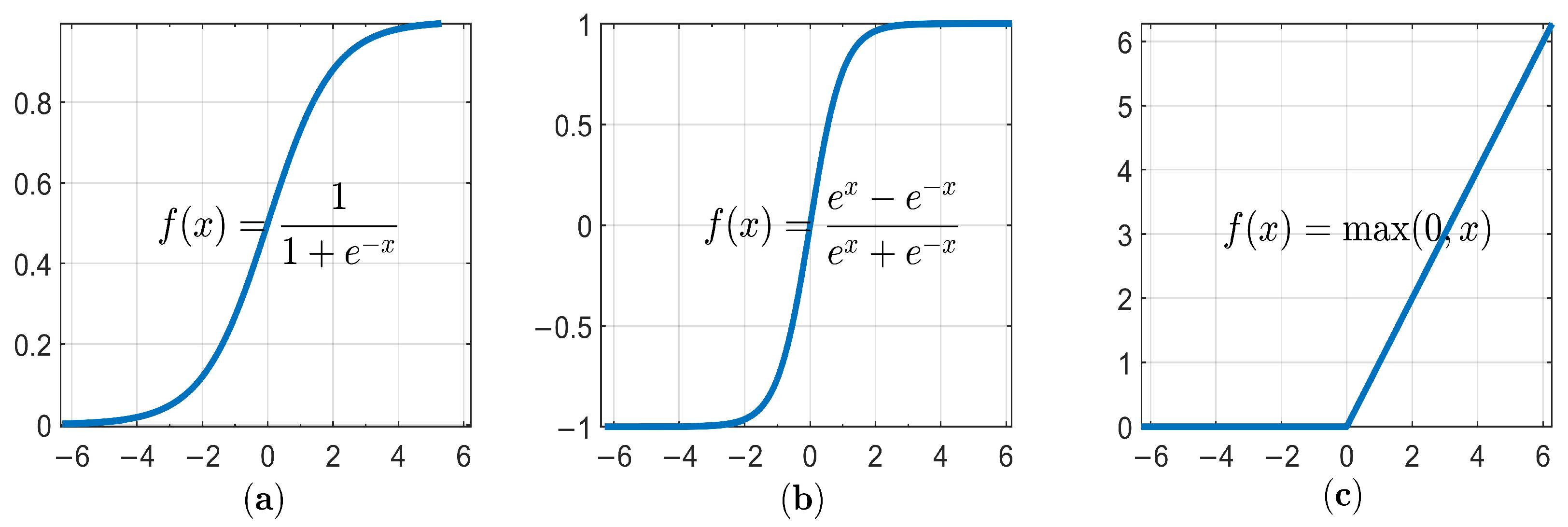
2. Deep Convolutional Neural Networks in Image Classification
3. Fully Decoupled Extended Kalman Filter
3.1. Extended Kalman Filter
3.2. Fully Decoupled Extended Kalman Filter
| Algorithm 1 FDEKF |
| Require: : Initialize diagonal matrix of estimation error covariance Require: : Initialize diagonal matrix of process noise covariance Require: : Initialize measurement noise covariance Require: : Initial parameter vector t ← 0. Initialize timestep while not converged do t ← t + 1 . Get gradients of network output w.r.t. the parameters at timestep t + . Compute a priori state estimation error covariance . Compute output estimation error covariance . Compute Kalman gain . Update parameters . Compute a posteriori state estimation error covariance . Applying a measurement noise covariance update rule end while return . Resulting parameters |
4. Previous Related Work
4.1. Adam Optimizer
| Algorithm 2 Adam Optimizer [17] |
| Require: : Stepsize Require: : Exponential decay rates for the moment estimates Require: : Stochastic objective function with the parameters Require: : Initial parameter vector (Initialize 1st moment vector) (Initialize 2nd moment vector) (Initialize timestep) while not converged do (Get gradients w.r.t. stochastic objective at time-step t) . Update biased 1st moment estimate t . Update biased 2nd raw moment estimate t . Compute bias-corrected 1st moment estimate . Compute bias-corrected 2nd raw moment estimate . Update parameters end while return . Resulting parameters |
4.2. sKAdam Optimizer
| Algorithm 3 sKAdam Optimizer [18] |
| Require: : Stepsize Require: : Exponential decay rates for the moment estimates : Exponentially decay constant for the measurement noise Require: : Stochastic objective function with parameters Require: : Initial parameter vector (Initialize 1st moment vector) (Initialize 2nd moment vector) (Initialize state estimates vector) (Initialize Kalman gains vector) (Initialize covariances vector) (Initialize timestep) while not converged do . Get gradients of stochastic objective w.r.t. parameters at timestep t . Compute a priori state estimate . Compute a priori covariance . Compute measurement noise . Compute Kalman gain . Compute a posteriori state estimate . Set estimated gradient . Compute a posteriori covariance . Update biased 1st moment estimate t . Update biased 2nd raw moment estimate t . Compute bias-corrected 1st moment estimate . Compute bias-corrected 2nd raw moment estimate . Update parameters end while return . Resulting parameters |
4.3. REKF
| Algorithm 4 REKF [19] |
| Require: : Initialize a vector with the estimation error covariances Require: q: process noise covariance, same for all parameters Require: r: measurement noise covariance, scalar value Require: : Initial parameter vector t ← 0. Initialize timestep while not converged do t ← t + 1 . Get gradients of loss function w.r.t. the parameters at timestep t + q. Compute a priori state estimation error covariance . Compute the total scalar value of innovation . Compute a posteriori estimation error covariance . Compute Kalman gain . Update parameters end while return . Resulting parameters |
5. Experiments
5.1. FASHION Classification Experiment with DCNN
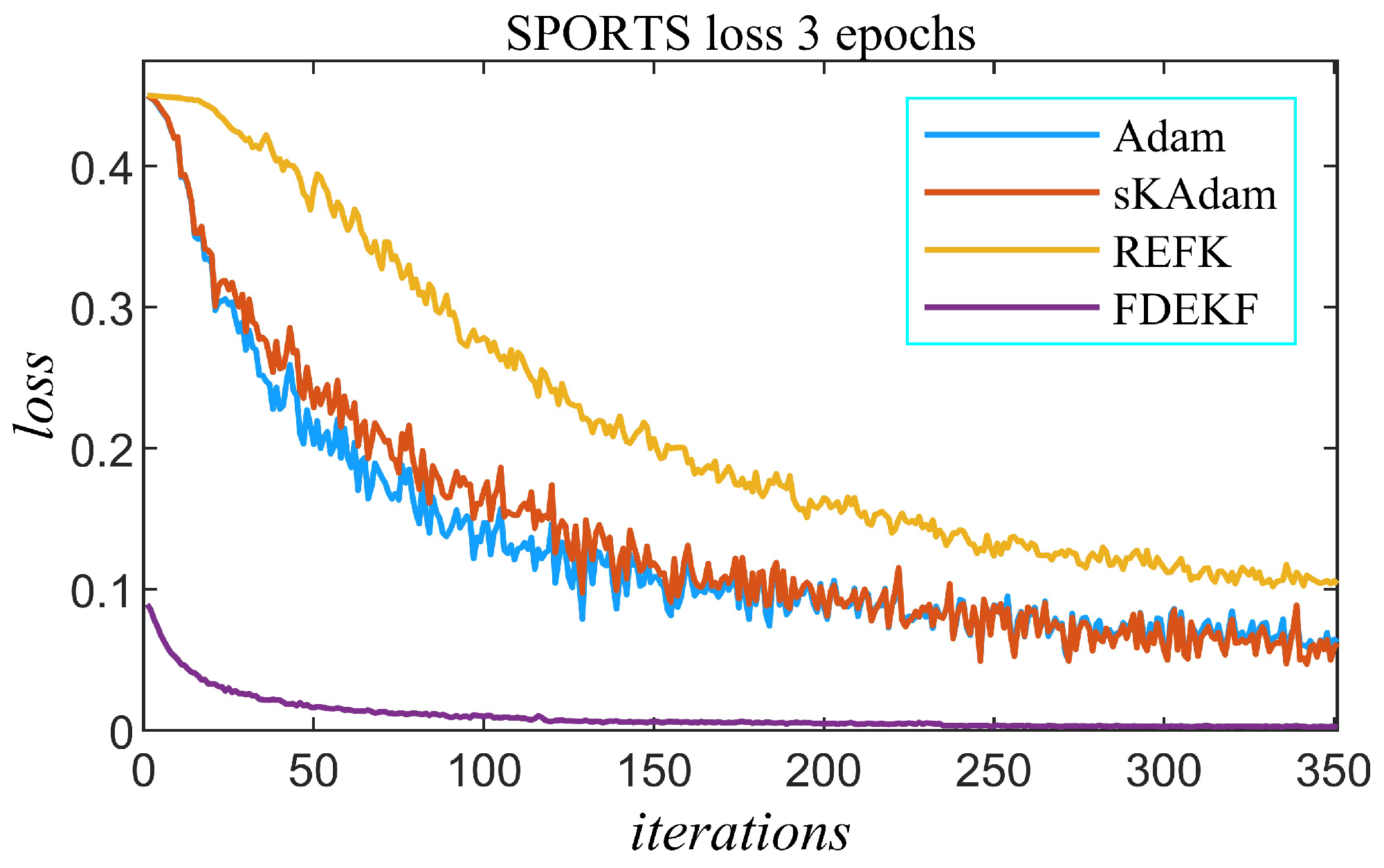
5.2. SPORTS Classification Experiment with DCNN
5.3. MNIST Classification Experiment with DCNN
5.4. Cost Map of Terrain Traversability from Aerial Image with DCNN Experiment
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bosch, J.; Olsson, H.H.; Brine, B.; Crnkovic, I. AI Engineering: Realizing the potential of AI. IEEE Soft. 2022, 39, 23–27. [Google Scholar] [CrossRef]
- Mukhamediev, R.I.; Symagulov, A.; Kuchin, Y.; Yakunin, K.; Yelis, M. From classical machine learning to deep neural networks: A simplified scientometric review. Appl. Sci. 2021, 11, 5541. [Google Scholar] [CrossRef]
- Sharma, N.; Sharma, R.; Jindal, N. Machine learning and deep learning applications—A vision. Glob. Transitions Proc. 2021, 2, 24–28. [Google Scholar] [CrossRef]
- Cao, L. Deep learning applications. IEEE Intell. Syst. 2022, 37, 3–5. [Google Scholar] [CrossRef]
- Sultana, J.; Usha Rani, M.; Farquad, M.A.H. An extensive survey on some deep-learning applications. In Emerging Research in Data Engineering Systems and Computer Communication; Venkata Krishna, P., Obaidat, M., Eds.; Springer: Singapore, 2020; pp. 311–519. [Google Scholar] [CrossRef]
- Zhang, Q.; Yang, L.T.; Chen, Z.; Li, P. A survey on deep learning for big data. Inf. Fusion 2017, 42, 146–157. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. arXiv 2015, arXiv:1404.7828. [Google Scholar] [CrossRef]
- Deng, L.; Yu, D. Deep Learning: Methods and Applications. Found. Trends Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Puskorius, G.V.; Feldkamp, L.A. Decoupled extended Kalman filter training of feedforward layered networks. In Proceedings of the IJCNN-91-Seattle International Joint Conference on Neural Networks, Seattle, WA, USA, 8–12 July 1991. [Google Scholar] [CrossRef]
- Wan, E.A.; Nelson, A.T. Dual extended Kalman filter methods. In Kalman Filtering and Neural Networks; Haykin, S., Ed.; John Wiley & Sons, Inc.: New York, NY, USA, 2001; pp. 123–174. [Google Scholar] [CrossRef]
- Singhal, S.; Wu, L. Training multilayer perceptrons with the extended Kalman algorithm. In Advances in Neural Information Processing Systems 1; Touretzky, D., Ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1988; pp. 133–140. [Google Scholar]
- Shah, S.; Palmieri, F. MEKA-a fast, local algorithm for training feedforward neural networks. In Proceedings of the 1990 IJCNN International Joint Conference on Neural Networks, San Diego, CA, USA, 17–21 June 1990. [Google Scholar] [CrossRef]
- Puskorius, G.V.; Feldkamp, L.A. Parameter-based Kalman filter training: The theory and implementation. In Kalman Filtering and Neural Networks; Haykin, S., Ed.; John Wiley & Sons, Inc.: New York, NY, USA, 2001; pp. 23–68. [Google Scholar] [CrossRef]
- Gaytan, A.; Begovich, O.; Arana-Daniel, N. Node-Decoupled Extended Kalman Filter versus Adam Optimizer in Approximation of Functions with Multilayer Neural Networks. In Proceedings of the 2023 20th International Conference on Electrical Engineering, Computing Science and Automatic Control (CCE), Mexico City, Mexico, 25–27 October 2023. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Camacho, J.; Villaseñor, C.; Alanis, A.Y.; Lopez-Franco, C.; Arana-Daniel, N. sKAdam: An improved scalar extension of KAdam for function optimization. IEEE Intell. Data Anal. 2020, 24, 87–104. [Google Scholar] [CrossRef]
- Ismail, M.; Attari, M.; Habibi, S.; Ziada, S. Estimation theory and neural networks revisited: REFK and RSVSF as optimization for deep-learning. Neural Netw. 2018, 108, 509–526. [Google Scholar] [CrossRef]
- Heimes, F. Extended Kalman filter neural network training: Experimental results and algorithm improvements. In Proceedings of the SMC’98 Conference Proceedings. 1998 IEEE International Conference on Systems, Man, and Cybernetics, San Diego, CA, USA, 14 October 1998. [Google Scholar] [CrossRef]
- Vural, N.M.; Ergüt, S.; Kozart, S.S. An efficient and effective second-order training algorithm for LSTM-based adaptive learning. IEEE Trans. Signal Process. 2021, 69, 2541–2554. [Google Scholar] [CrossRef]
- Fukushima, K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 1980, 36, 193–202. [Google Scholar] [CrossRef]
- Chen, L.; Li, S.; Bai, Q.; Ya, J.; Jiang, S.; Miao, Y. Review of Image Classification Algorithms Based on Convolutional Neural Networks. Remote Sens. 2021, 13, 4712. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.E.; Denke, J.S.; Howard, R.E.; Hubbard, W.E.; Jackel, L.D. Handwritten digit recognition with a back-propagation network. In Advances in Neural Information Processing Systems 2; Touretzky, D., Ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1990; pp. 396–404. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Bengio, Y.; LeCun, Y.; Hinton, G. Deep learning for AI. Commun. ACM 2021, 64, 58–65. [Google Scholar] [CrossRef]
- Galanis, N.-I.; Vafiadis, P.; Mirzaev, K.-G.; Papakostas, G.A. Convolutional Neural Networks: A Roundup and Benchmark of Their Pooling Layer Variants. Algorithms 2022, 15, 391. [Google Scholar] [CrossRef]
- Hinton, G. The forward-forward algorithm: Some preliminary investigations. arXiv 2022, arXiv:2212.13345. [Google Scholar]
- Lu, A.; Honarvar Shakibaei Asli, B. Seismic Image Identification and Detection Based on Tchebichef Moment Invariant. Electronics 2023, 12, 3692. [Google Scholar] [CrossRef]
- Chen, B.; Zhang, L.; Chen, H.; Liang, K.; Chen, X. A novel extended Kalman filter with support vector machine based method for the automatic diagnosis and segmentation of brain tumors. Comput. Methods Programs Biomed. 2021, 200, 105797. [Google Scholar] [CrossRef]
- Kalman, R.E. A new approach to linear filtering and prediction problems. Trans. ASME J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Smith, G.L.; Schmidt, S.F.; McGee, L.A. Application of Statistical Filter Theory to the Optimal Estimation of Position and Velocity on Board a Circumlunar Vehicle; Technical Report R-135; NASA: Moffet Field, CA, USA, 1962.
- Alsadi, N.; Gadsden, S.A.; Yawney, J. Intelligent estimation: A review of theory, applications, and recent advances. Digit. Signal Process. 2023, 135, 103966. [Google Scholar] [CrossRef]
- Ruck, D.W.; Rogers, S.K.; Kabrisky, M.; Maybeck, P.S.; Oxley, M.E. Comparative analysis of backpropagation and the extended Kalman filter for training multilayer perceptrons. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 686–691. [Google Scholar] [CrossRef]
- Chernodub, A.N. Training neural networks for classification using the extended Kalman filter: A Comparative Study. Opt. Mem. Neural Netw. 2014, 23, 96–103. [Google Scholar] [CrossRef]
- Pereira de Lima, D.; Viana Sanchez, R.F.; Pedrino, E.C. Neural network training using unscented and extended Kalman filter. Robot Autom. Eng. J. 2017, 1, 100–105. [Google Scholar] [CrossRef]
- Gomez-Avila, J.; Villaseñor, C.; Hernandez-Barragan, J.; Arana-Daniel, N.; Alanis, A.Y.; Lopez-Franco, C. Neural PD Controller for an Unmanned Aerial Vehicle Trained with Extended Kalman Filter. Algorithms 2020, 13, 40. [Google Scholar] [CrossRef]
- Dubey, S.R.; Chakraborty, S.; Roy, S.K.; Mukherjee, S.; Singh, S.K.; Chaudhuri, B.B. diffGrad: An optimization method for convolutional neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4500–4511. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Hudjakov, R.; Tamre, M. Orthophoto Classification for UGV Path Planning using Heterogeneous Computing. Int. J. Adv. Robot. Syst. 2013, 10, 268. [Google Scholar] [CrossRef]
- Movaghati, S.; Moghaddamjoo, A.; Tavakoli, A. Road Extraction From Satellite Images Using Particle Filtering and Extended Kalman Filtering. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2807–2817. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Mean Accuracy | Standard Deviation |
|---|---|---|
| Adam | 0.8901 | 0.0020 |
| sKAdam | 0.8923 | 0.0021 |
| REKF | 0.8433 | 0.0257 |
| FDEKF | 0.9015 | 0.0025 |
| Algorithm | Mean Accuracy | Standard Deviation |
|---|---|---|
| Adam | 0.9185 | 0.0073 |
| sKAdam | 0.9209 | 0.0082 |
| REKF | 0.8664 | 0.0092 |
| FDEKF | 0.9789 | 0.0024 |
| Algorithm | Mean Accuracy | Standard Deviation |
|---|---|---|
| Adam | 0.8900 | |
| sKAdam | 0.9873 | |
| REKF | 0.9187 | |
| FDEKF | 0.9864 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gaytan, A.; Begovich-Mendoza, O.; Arana-Daniel, N. Training of Convolutional Neural Networks for Image Classification with Fully Decoupled Extended Kalman Filter. Algorithms 2024, 17, 243. https://doi.org/10.3390/a17060243
Gaytan A, Begovich-Mendoza O, Arana-Daniel N. Training of Convolutional Neural Networks for Image Classification with Fully Decoupled Extended Kalman Filter. Algorithms. 2024; 17(6):243. https://doi.org/10.3390/a17060243
Chicago/Turabian StyleGaytan, Armando, Ofelia Begovich-Mendoza, and Nancy Arana-Daniel. 2024. "Training of Convolutional Neural Networks for Image Classification with Fully Decoupled Extended Kalman Filter" Algorithms 17, no. 6: 243. https://doi.org/10.3390/a17060243
APA StyleGaytan, A., Begovich-Mendoza, O., & Arana-Daniel, N. (2024). Training of Convolutional Neural Networks for Image Classification with Fully Decoupled Extended Kalman Filter. Algorithms, 17(6), 243. https://doi.org/10.3390/a17060243