

High-Fidelity Steganography: A Covert Parity Bit Model-Based Approach


Abstract
1. Introduction
- 1.
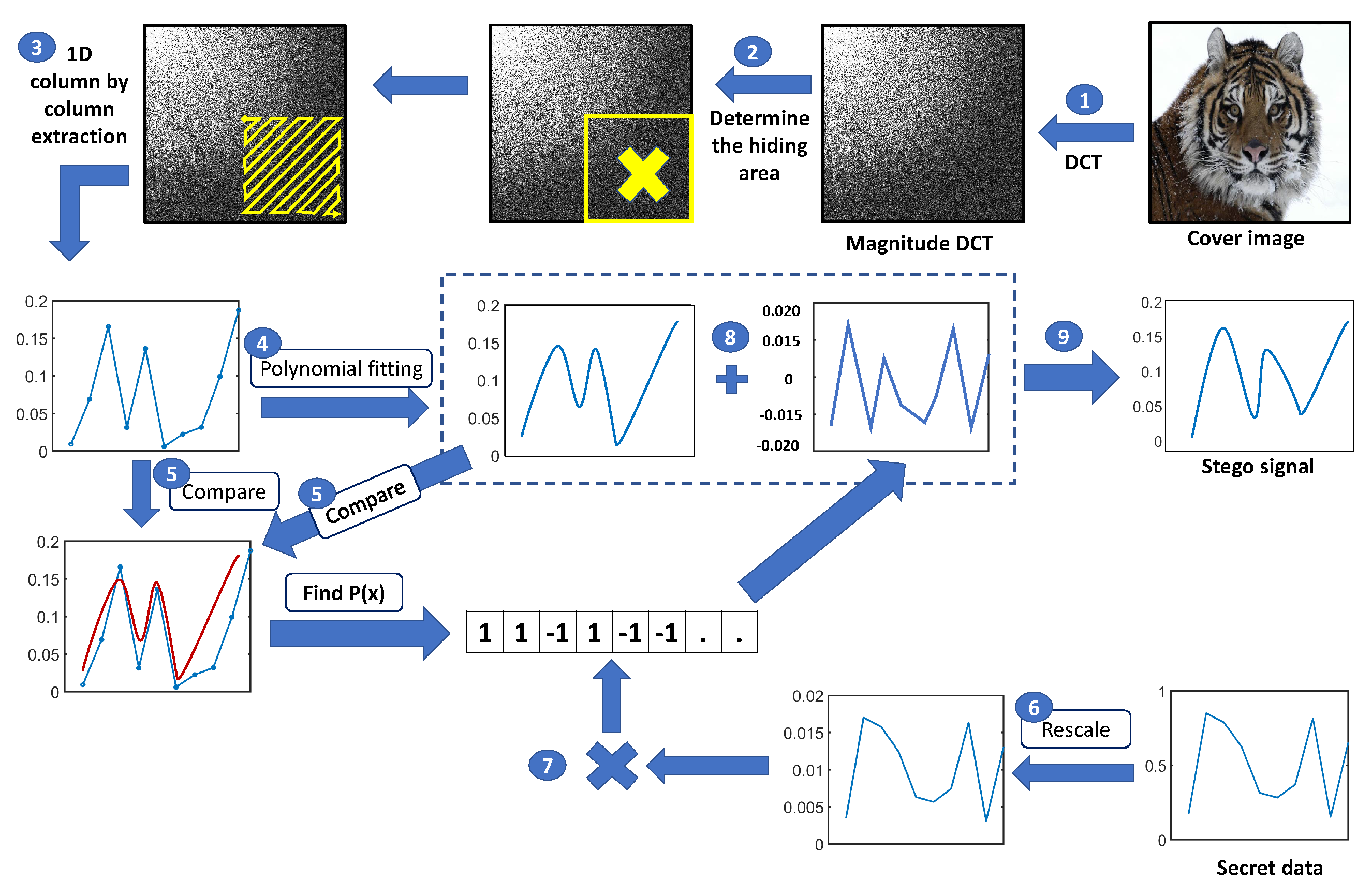
- A new data hiding strategy based on DCT modeling maximizes the similarity between the stego signal and the original cover signal, thereby improving the quality of the stego signal.
- 2.
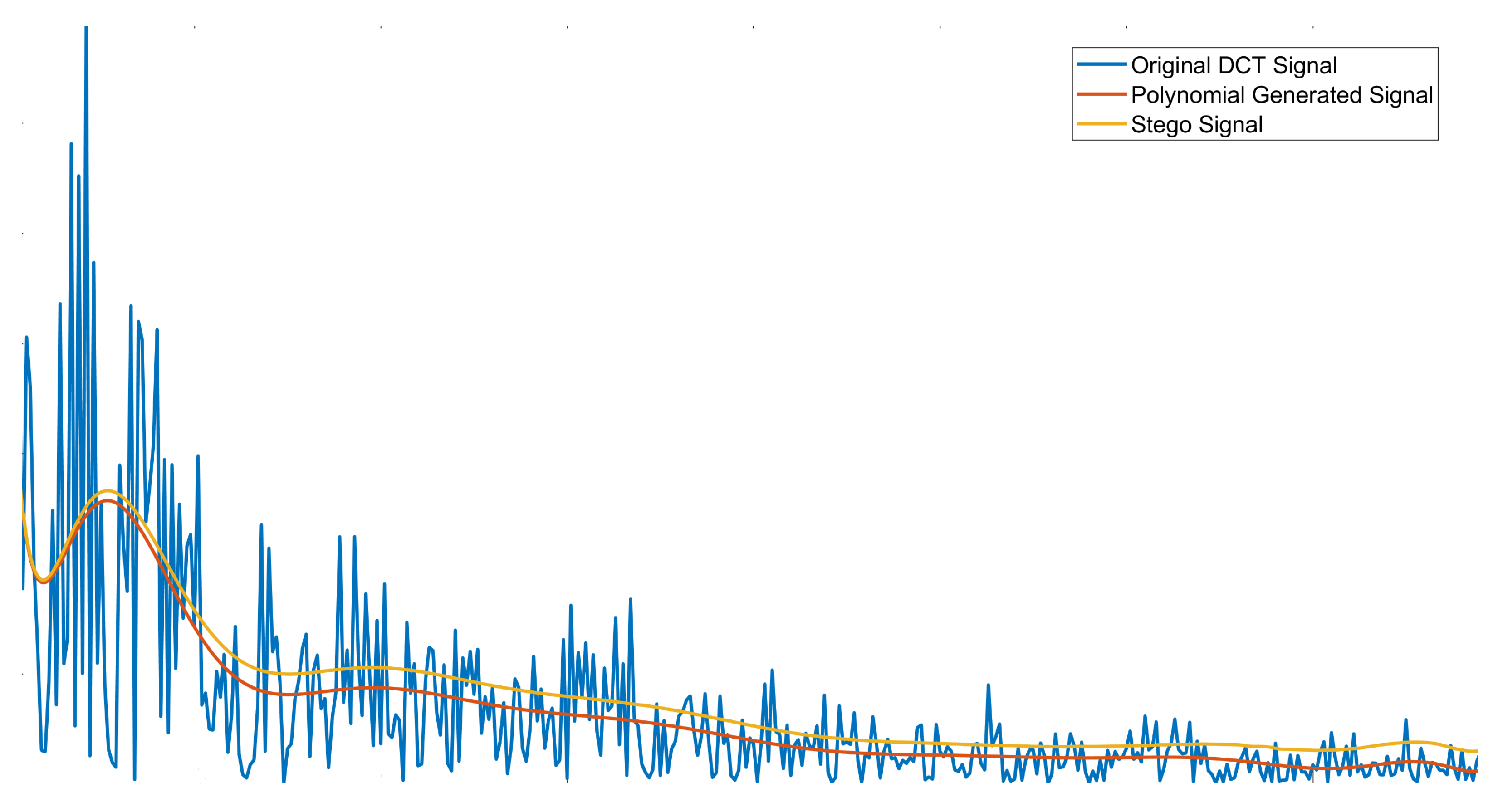
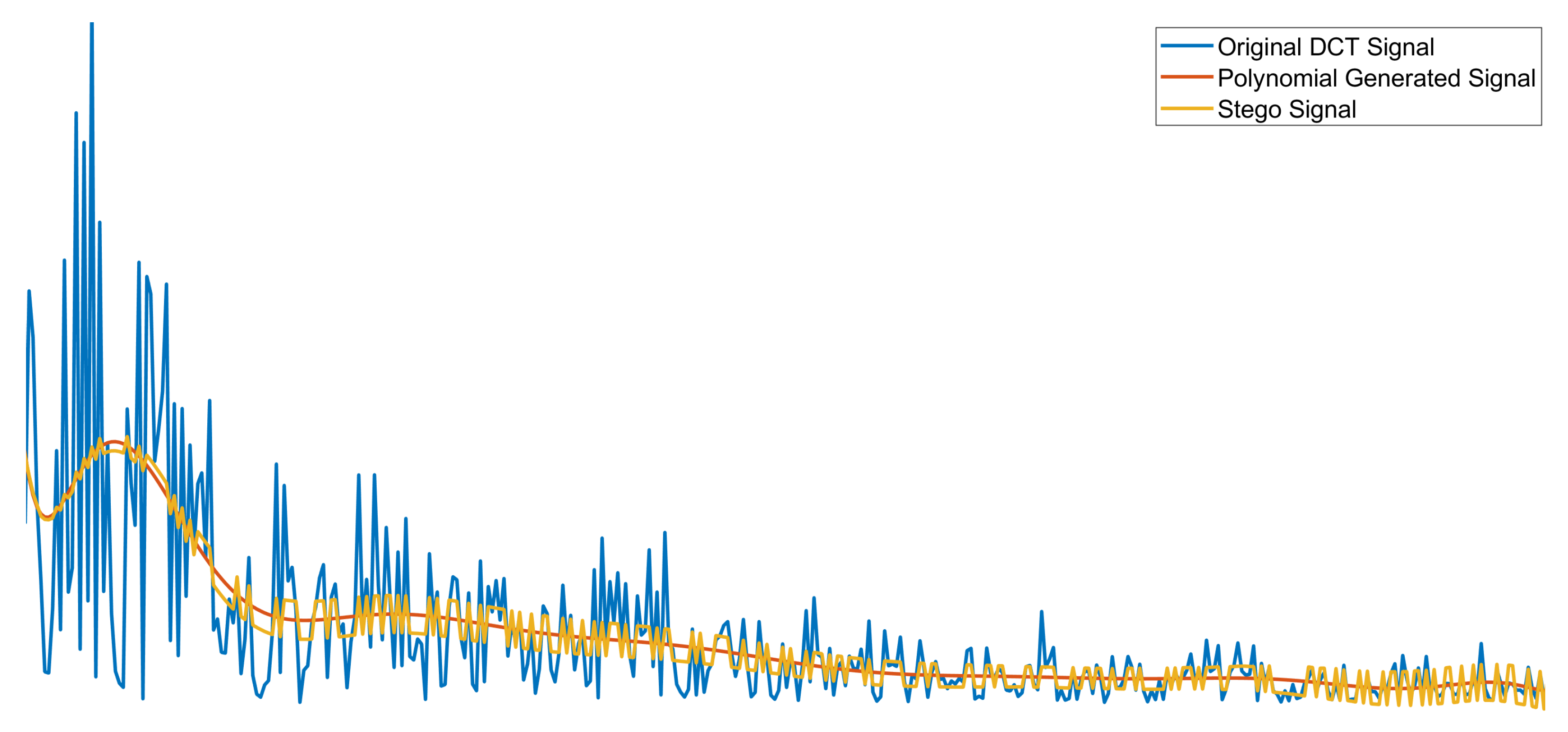
- A new DCT modeling strategy is proposed that is suitable for steganography techniques. The proposed modeling phase adopts a polynomial fitting strategy to generate a signal approximating the cover signal. Unlike other recent approaches such as [21,22] which superimpose the secret signal over the modeled signal to produce the stego signal, the proposed strategy adaptively adds or subtracts secret samples to or from the modeled pixels to match the original DCT coefficients of the cover signal based on the error sign between the modeled signal and the cover signal. This adaptive approach maximizes the similarity between the stego and original cover signals, which enhances the imperceptibility of the stego image.
- 3.
- A new strategy reduces the communication cost between the encoder and decoder. The decoder requires the polynomial coefficients in order to extract the secret data. The default approach in other DCT modeling approaches is to model the DCT region in a column-by-column manner. This approach increases the communication cost. We propose extracting a single DCT signal in a zigzag manner instead of column-by-column.
2. Related Works
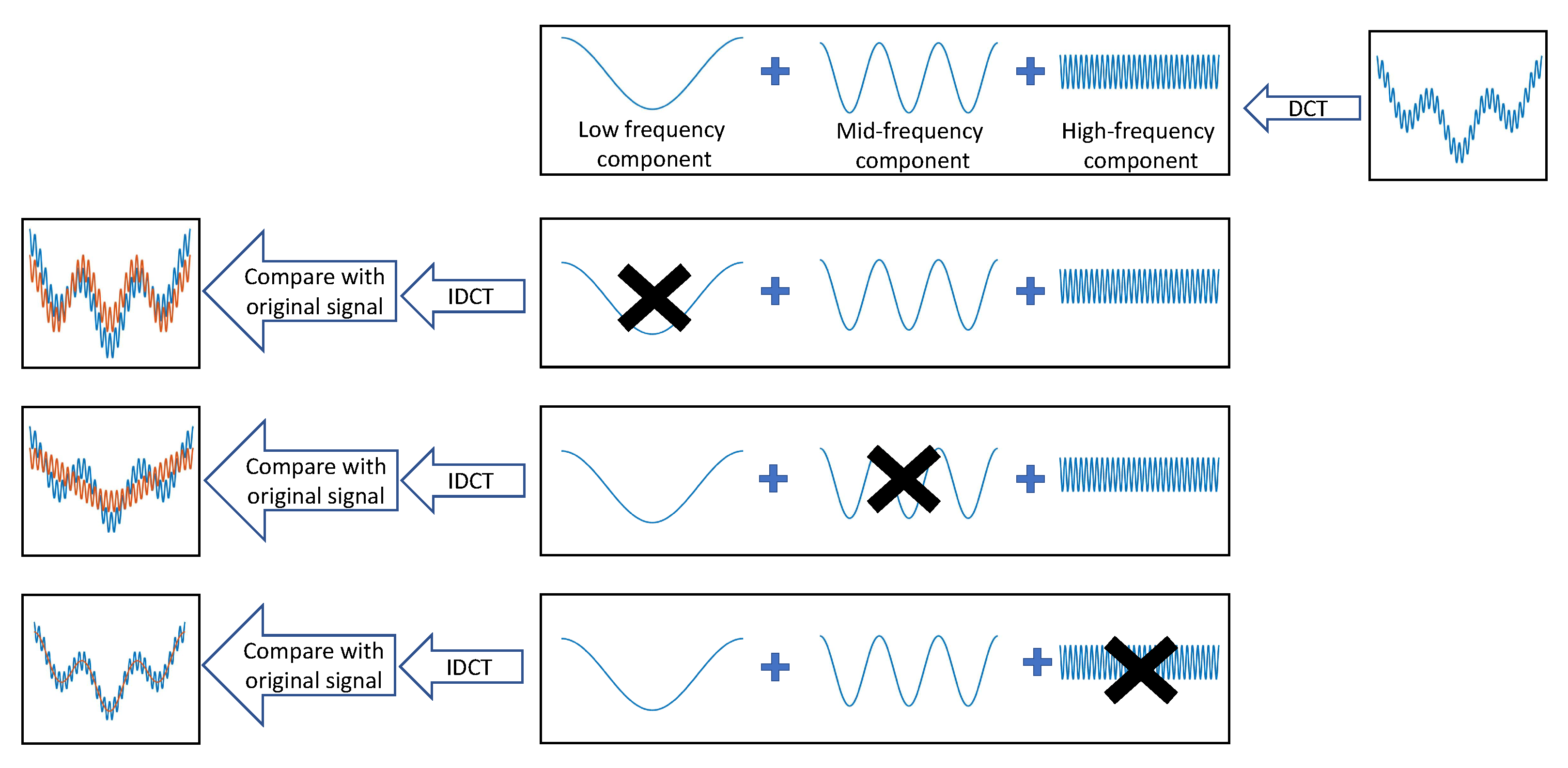
3. The DCT Transform
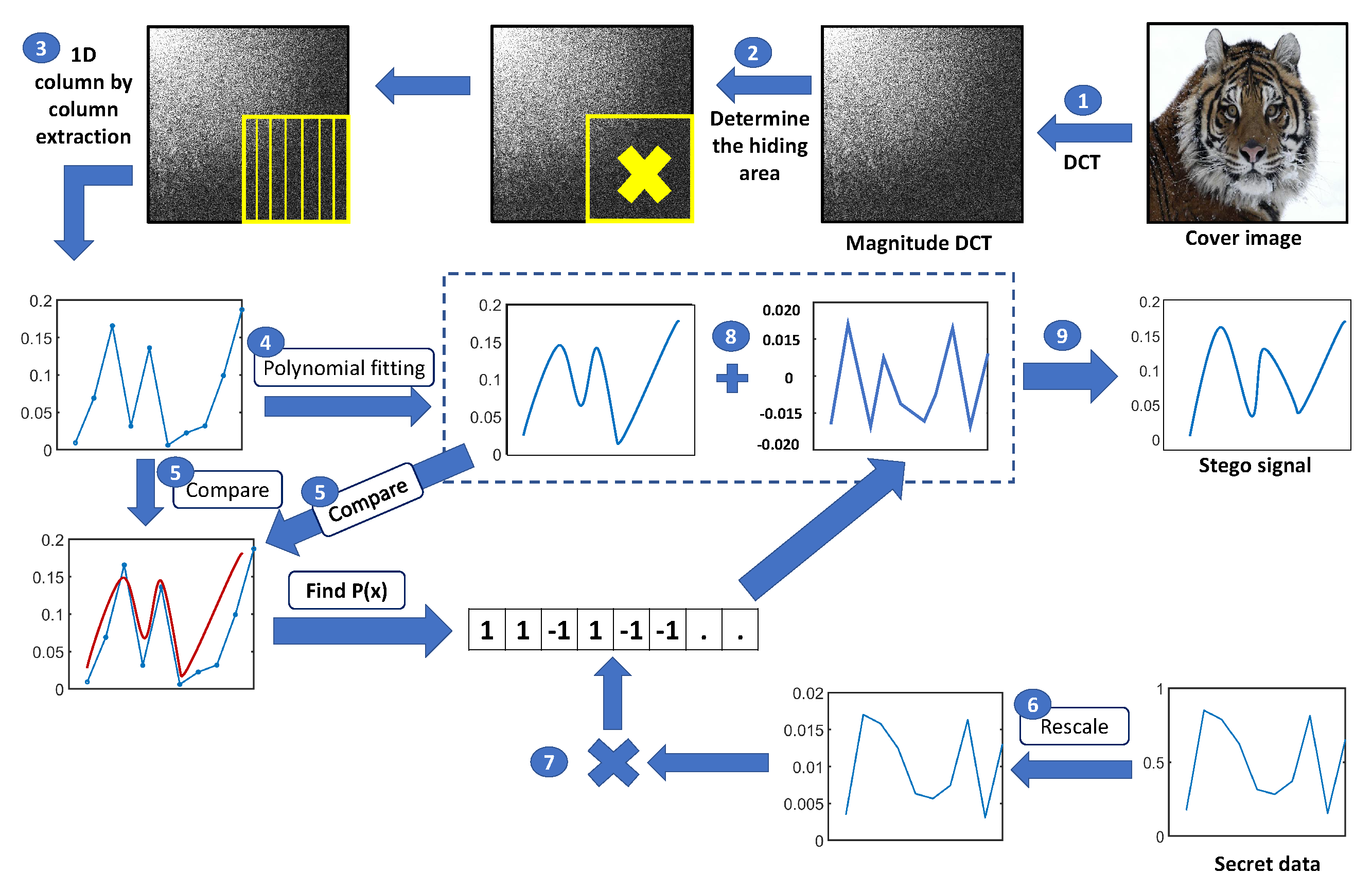
4. Proposed Scheme
4.1. Data Embedding
| Algorithm 1 The algorithm of the proposed embedding scheme |
| 1: Input: |
| 2: cover: The cover image |
| 3: secret: The secret image |
| 4: n: The polynomial degree |
| 5: k: The scaling factor |
| 6: Output: |
| 7: stego: The stego image |
| 8: [coverdct] ← DCT2(cover) ▹ Apply 2D-DCT on the cover image |
| 9: [sec] ← secret*(1/k) ▹ Downscale the secret image using the scaling factor k |
| 10: [column] ← EXTRACT(coverdct) ▹ Extract DCT column (Column-by-column or zigzag) |
| 11: for 1:size(column) do ▹ For every column, do the following: (for zigzag version, we have only 1 column) |
| 12: [column_model] ← polymodel(column,n) ▹ Apply polynomial modeling using a degree of n |
| 13: [steg_column] ← column_model + b*sec ▹ Superimpose sec over column_model |
| 14: end for |
| 15: steg_dct ← Group(steg_column) ▹ Group the columns and place them back into their original locations |
| 16: [stego] ← IDCT2(steg_dct) ▹ Apply the inverse 2D-DCT to obtain the stego image |
Zigzag Method
4.2. Data Extraction
| Algorithm 2 The algorithm of the proposed extraction scheme |
| 1: Input: |
| 2: stego: The stego image |
| 3: p: The polynomial coefficients vector |
| 4: k: The scaling factor |
| 5: Output: |
| 6: secret: The secret image |
| 7: [stegodct] ← DCT2(stego) ▹ Apply 2D-DCT on the stego image |
| 8: [column] ← EXTRACT(stegdct) ▹ Extract DCT column (Column-by-column or zigzag) |
| 9: for 1:size(column) do ▹ For every column, do the following: (for zigzag version, we have only 1 column) |
| 10: [column_model] ← construct(n) ▹ Construct the polynomial signal from the polynomial coefficients vector p |
| 11: [secret_column] ← column – b* column_model ▹ Get the secret column, b can be 0 or 1 |
| 12: end for |
| 13: secret_scaled ← Group(secret_column) ▹ Group the columns and place them back into their original locations |
| 14: [sec] ← secret_scaled*(k) ▹ Upscale the secret image using the scaling factor k |
5. Experimental Results
5.1. Analysis of Results
Capacity–Transparency Analysis
5.2. Comparison with Recent Schemes
5.3. Robustness
5.4. Security
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kunhoth, J.; Subramanian, N.; Al-Maadeed, S.; Bouridane, A. Video steganography: Recent advances and challenges. Multimed. Tools Appl. 2023, 82, 41943–41985. [Google Scholar] [CrossRef]
- Mehic, M.; Michalek, L.; Dervisevic, E.; Burdiak, P.; Plakalovic, M.; Rozhon, J.; Mahovac, N.; Richter, F.; Kaljic, E.; Lauterbach, F.; et al. Quantum cryptography in 5g networks: A comprehensive overview. IEEE Commun. Surv. Tutorials 2023, 26, 302–346. [Google Scholar] [CrossRef]
- Varghese, F.; Sasikala, P. A detailed review based on secure data transmission using cryptography and steganography. Wirel. Pers. Commun. 2023, 129, 2291–2318. [Google Scholar] [CrossRef]
- Subramani, S.; Svn, S.K. Review of security methods based on classical cryptography and quantum cryptography. Cybern. Syst. 2023, 1–19. [Google Scholar] [CrossRef]
- Rabie, T.; Kamel, I.; Baziyad, M. Maximizing embedding capacity and stego quality: Curve-fitting in the transform domain. Multimed. Tools Appl. 2018, 77, 8295–8326. [Google Scholar] [CrossRef]
- Gutub, A. Regulating Kashida Arabic steganography to improve security and capacity performance. Multimed. Tools Appl. 2024, 1–34. [Google Scholar] [CrossRef]
- Chen, T.H.; Yan, J.Y. Enhanced steganography for high dynamic range images with improved security and capacity. Appl. Sci. 2023, 13, 8865. [Google Scholar] [CrossRef]
- Huo, L.; Chen, R.; Wei, J.; Huang, L. A High-Capacity and High-Security Image Steganography Network Based on Chaotic Mapping and Generative Adversarial Networks. Appl. Sci. 2024, 14, 1225. [Google Scholar] [CrossRef]
- Suhail, M.; Sadoun, B.; Obaidat, M.S. Digital Watermarking and Steganography; Wiley: Boston, MA, USA, 2006; Volume 2, pp. 664–678. [Google Scholar]
- Rafidison, M.A.; Rafanantenana, S.H.J.; Rakotomihamina, A.H.; Toky, R.F.M.; Ramafiarisona, H.M. Contribution of neural networks in image steganography, watermarking and encryption. IET Image Process. 2023, 17, 463–479. [Google Scholar] [CrossRef]
- Caballero, H.; Muñoz, V.; Ramos-Corchado, M.A. A comparative study of steganography using watermarking and modifications pixels versus least significant bit. Int. J. Electr. Comput. Eng. IJECE 2023, 13, 6335–6350. [Google Scholar] [CrossRef]
- Dong, L.; Fu, Z.; Chen, L.; Ding, H.; Zheng, C.; Cui, X.; Shen, Z. FDNet: Imperceptible backdoor attacks via frequency domain steganography and negative sampling. Neurocomputing 2024, 583, 127546. [Google Scholar] [CrossRef]
- Kaur, R.; Singh, B. A robust and imperceptible n-Ary based image steganography in DCT domain for secure communication. Multimed. Tools Appl. 2024, 83, 20357–20386. [Google Scholar] [CrossRef]
- Lan, Y.; Shang, F.; Yang, J.; Kang, X.; Li, E. Robust image steganography: Hiding messages in frequency coefficients. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 14955–14963. [Google Scholar]
- Zhou, W.; Wang, Z.; Chen, Z. Image super-resolution quality assessment: Structural fidelity versus statistical naturalness. In Proceedings of the 2021 13th International Conference on Quality of Multimedia Experience (QoMEX), Virtual Event, 14–17 June 2021; pp. 61–64. [Google Scholar]
- Rabie, T.; Kamel, I. Toward optimal embedding capacity for transform domain steganography: A quad-tree adaptive-region approach. Multimed. Tools Appl. 2017, 76, 8627–8650. [Google Scholar] [CrossRef]
- Brisbane, G.; Safavi-Naini, R.; Ogunbona, P. High-capacity steganography using a shared colour palette. IEE Proc. Vis. Image Signal Process. 2005, 152, 787–792. [Google Scholar] [CrossRef]
- Rabie, T.; Kamel, I. On the embedding limits of the discrete cosine transform. Multimed. Tools Appl. 2016, 75, 5939–5957. [Google Scholar] [CrossRef]
- Rabie, T.; Baziyad, M. Visual fidelity without sacrificing capacity: An adaptive Laplacian pyramid approach to information hiding. J. Electron. Imaging 2017, 26, 063001. [Google Scholar] [CrossRef]
- Lee, Y.; Chen, L. High capacity image steganographic model. IEE Proc. Vis. Image Signal Process. 2000, 147, 288–294. [Google Scholar] [CrossRef]
- Rabie, T.; Baziyad, M.; Kamel, I. High Payload Steganography: Surface-Fitting The Transform Domain. In Proceedings of the International Conference on Communications, Signal Processing, and their Applications (ICCSPA), Sharjah, United Arab Emirates, 16–18 March 2019; pp. 1–6. [Google Scholar]
- Rabie, T.; Baziyad, M.; Kamel, I. Secure high payload steganography: A model-based approach. J. Inf. Secur. Appl. 2021, 63, 103043. [Google Scholar] [CrossRef]
- Milosav, P.; Milosavljević, M.; Banjac, Z. Steganographic Method in Selected Areas of the Stego-Carrier in the Spatial Domain. Symmetry 2023, 15, 1015. [Google Scholar] [CrossRef]
- Hussain, M.; Wahab, A.W.A.; Idris, Y.I.B.; Ho, A.T.; Jung, K.H. Image steganography in spatial domain: A survey. Signal Process. Image Commun. 2018, 65, 46–66. [Google Scholar] [CrossRef]
- Rahman, S.; Uddin, J.; Hussain, H.; Ahmed, A.; Khan, A.A.; Zakarya, M.; Rahman, A.; Haleem, M. A Huffman code LSB based image steganography technique using multi-level encryption and achromatic component of an image. Sci. Rep. 2023, 13, 14183. [Google Scholar] [CrossRef] [PubMed]
- Al-Chaab, W.; Abduljabbar, Z.A.; Abood, E.W.; Nyangaresi, V.O.; Mohammed, H.M.; Ma, J. Secure and low-complexity medical image exchange based on compressive sensing and lsb audio steganography. Informatica 2023, 47. [Google Scholar] [CrossRef]
- Sondas, A.; Erturk, N.B. Dynamic data hiding capacity enhancement for the Hybrid Near Maximum Histogram image steganography based on Multi-Pixel-Pair approach. Multimed. Tools Appl. 2024, 1–17. [Google Scholar] [CrossRef]
- Fatman, A.N.; Ahmad, T.; Jean De La Croix, N.; Hossen, M.S. Enhancing Data Hiding Methods for Improved Cyber Security Through Histogram Shifting Direction Optimization. Math. Model. Eng. Probl. 2023, 10, 1508–1514. [Google Scholar] [CrossRef]
- Andono, P.N.; Setiadi, D.R.I.M. Quantization selection based on characteristic of cover image for PVD Steganography to optimize imperceptibility and capacity. Multimed. Tools Appl. 2023, 82, 3561–3580. [Google Scholar] [CrossRef]
- Broumandnia, A. Two-dimensional modified pixel value differencing (2 D-MPVD) image steganography with error control and security using stream encryption. Multimed. Tools Appl. 2024, 83, 21967–22003. [Google Scholar] [CrossRef]
- Ernawan, F. An improved hiding information by modifying selected DWT coefficients in video steganography. Multimed. Tools Appl. 2024, 83, 34629–34645. [Google Scholar] [CrossRef]
- Melman, A.; Evsutin, O. Comparative study of metaheuristic optimization algorithms for image steganography based on discrete Fourier transform domain. Appl. Soft Comput. 2023, 132, 109847. [Google Scholar] [CrossRef]
- Sabeti, V.; Aghabagheri, A. Developing an adaptive DCT-based steganography method using a genetic algorithm. Multimed. Tools Appl. 2023, 82, 19323–19346. [Google Scholar] [CrossRef]
- Saeidi, Z.; Yazdi, A.; Mashhadi, S.; Hadian, M.; Gutub, A. High performance image steganography integrating IWT and Hamming code within secret sharing. IET Image Process. 2024, 18, 129–139. [Google Scholar] [CrossRef]
- Lin, S.; Huang, X. Advanced Research on Computer Education, Simulation and Modeling. In Proceedings of the Conference Proceedings CESM, Wuhan, China, 18–19 June 2011; Springer: Berlin/Heidelberg, Germany, 2011; p. 43. [Google Scholar]
- Kumar, V.; Kumar, D. A modified DWT-based image steganography technique. Multimed. Tools Appl. 2018, 77, 13279–13308. [Google Scholar] [CrossRef]
- Kavitha, S.; Varuna, S.; Ramya, R. A comparative analysis on linear regression and support vector regression. In Proceedings of the 2016 Online International Conference on Green Engineering and Technologies (IC-GET), Coimbatore, India, 19 November 2016; pp. 1–5. [Google Scholar]
- Savithri, G.; Mane, S.; Banu, J.S.; Vinupriya. Parallel Implementation of RSA 2D-DCT Steganography and Chaotic 2D-DCT Steganography. In Proceedings of the International Conference on Computer Vision and Image Processing, Roorkee, India, 9–12 September 2017; Springer: Singapore, 2017; pp. 593–605. [Google Scholar]
- Saidi, M.; Hermassi, H.; Rhouma, R.; Belghith, S. A new adaptive image steganography scheme based on DCT and chaotic map. Multimed. Tools Appl. 2017, 76, 13493–13510. [Google Scholar] [CrossRef]
- Kadhim, I.J.; Premaratne, P.; Vial, P.J.; Halloran, B. Comprehensive survey of image steganography: Techniques, Evaluations, and trends in future research. Neurocomputing 2019, 335, 299–326. [Google Scholar] [CrossRef]
- Rabie, T.; Kamel, I. High-Capacity Steganography: A Global-Adaptive-Region Discrete Cosine Transform Approach. Multimed. Tools Appl. 2016, 75, 6473–6493. [Google Scholar] [CrossRef]
- Sallee, P. Model-based steganography. In Proceedings of the International Workshop on Digital Watermarking, Seoul, Republic of Korea, 20–22 October 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 154–167. [Google Scholar]
- Böhme, R.; Westfeld, A. Breaking Cauchy model-based JPEG steganography with first order statistics. In Proceedings of the European Symposium on Research in Computer Security, Sophia Antipolis, France, 13–15 September 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 125–140. [Google Scholar]
- Chen, C.; Shi, Y.Q. JPEG image steganalysis utilizing both intrablock and interblock correlations. In Proceedings of the 2008 IEEE International Symposium on Circuits and Systems, Seattle, WA, USA, 18–21 May 2008; pp. 3029–3032. [Google Scholar]
- Yang, C.H.; Tsai, M.H. Improving histogram-based reversible data hiding by interleaving predictions. IET Image Process. 2010, 4, 223–234. [Google Scholar] [CrossRef]
- Parah, S.A.; Sheikh, J.A.; Akhoon, J.A.; Loan, N.A.; Bhat, G.M. Information hiding in edges: A high capacity information hiding technique using hybrid edge detection. Multimed. Tools Appl. 2016, 77, 185–207. [Google Scholar] [CrossRef]
- Qin, C.; Chang, C.C.; Hsu, T.J. Reversible data hiding scheme based on exploiting modification direction with two steganographic images. Multimed. Tools Appl. 2015, 74, 5861–5872. [Google Scholar] [CrossRef]
- Bai, J.; Chang, C.C.; Nguyen, T.S.; Zhu, C.; Liu, Y. A High Payload Steganographic Algorithm Based on Edge Detection. Displays 2017, 46, 42–51. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Coefficient Replacement | Proposed | ||||||
|---|---|---|---|---|---|---|---|
| Block Size | Capacity | Cover | PSNR | SSIM | PSNR | SSIM | Cost |
| Airplane | 41.80 | 0.9857 | 44.87 | 0.9858 | 0.75% | ||
| 400 × 400 | 14.67 bpp | Animal | 25.40 | 0.9945 | 31.09 | 0.9973 | 0.75% |
| Vegetables | 31.45 | 0.9947 | 37.92 | 0.9964 | 0.75% | ||
| Airplane | 40.02 | 0.9845 | 43.46 | 0.9780 | 0.71% | ||
| 425 × 425 | 16.54 bpp | Animal | 24.82 | 0.9926 | 29.18 | 0.9964 | 0.71% |
| Vegetables | 29.24 | 0.9926 | 36.50 | 0.9960 | 0.71% | ||
| Airplane | 38.91 | 0.9672 | 41.84 | 0.9686 | 0.67% | ||
| 450 × 450 | 18.54 bpp | Animal | 23.85 | 0.9895 | 27.03 | 0.9953 | 0.67% |
| Vegetables | 27.22 | 0.9878 | 32.73 | 0.9942 | 0.67% | ||
| Airplane | 29.93 | 0.9628 | 38.42 | 0.9655 | 0.63% | ||
| 475 × 475 | 20.66 bpp | Animal | 20.74 | 0.9820 | 23.94 | 0.9922 | 0.63% |
| Vegetables | 25.16 | 0.9744 | 30.91 | 0.9918 | 0.63% | ||
| Airplane | 23.36 | 0.7913 | 30.22 | 0.9230 | 0.60% | ||
| 500 × 500 | 22.89 bpp | Animal | 17.33 | 0.9539 | 18.53 | 0.9801 | 0.60% |
| Vegetables | 18.91 | 0.9560 | 22.75 | 0.9739 | 0.60% | ||
| Coefficient Replacement | Proposed | ||||||
|---|---|---|---|---|---|---|---|
| Block Size | Capacity | Cover | PSNR | SSIM | PSNR | SSIM | Cost |
| Airplane | 41.80 | 0.9856 | 44.87 | 0.9858 | 4.00% | ||
| 400 × 400 | 14.65 | Animal | 25.40 | 0.9945 | 30.53 | 0.9974 | 4.00% |
| Vegetables | 31.45 | 0.9947 | 39.01 | 0.9964 | 4.00% | ||
| Airplane | 40.02 | 0.9845 | 43.72 | 0.9856 | 3.76% | ||
| 425 × 425 | 16.54 | Animal | 24.82 | 0.9926 | 29.05 | 0.9965 | 3.76% |
| Vegetables | 29.24 | 0.9926 | 36.60 | 0.9962 | 3.76% | ||
| Airplane | 38.91 | 0.9672 | 42.41 | 0.9839 | 3.56% | ||
| 450 × 450 | 18.54 | Animal | 23.85 | 0.9895 | 26.99 | 0.9955 | 3.56% |
| Vegetables | 27.22 | 0.9878 | 33.67 | 0.9944 | 3.56% | ||
| Airplane | 29.93 | 0.9628 | 38.64 | 0.9742 | 3.37% | ||
| 475 × 475 | 20.66 | Animal | 20.74 | 0.9820 | 23.45 | 0.9928 | 3.37% |
| Vegetables | 25.16 | 0.9744 | 31.10 | 0.9909 | 3.37% | ||
| Airplane | 23.36 | 0.7913 | 32.91 | 0.9532 | 3.20% | ||
| 500 × 500 | 22.89 | Animal | 17.32 | 0.9539 | 19.34 | 0.9841 | 3.20% |
| Vegetables | 18.91 | 0.9560 | 24.86 | 0.9789 | 3.20% | ||
| Coefficient Replacement | Proposed | ||||||
|---|---|---|---|---|---|---|---|
| Block Size | Capacity | Cover | PSNR | SSIM | PSNR | SSIM | Cost |
| Airplane | 41.80 | 0.9857 | 45.09 | 0.9858 | 4.00% | ||
| 400 × 400 | 14.65 | Animal | 25.40 | 0.9945 | 31.20 | 0.9973 | 4.00% |
| Vegetables | 31.45 | 0.9947 | 37.67 | 0.9963 | 4.00% | ||
| Airplane | 40.02 | 0.9845 | 43.23 | 0.9776 | 3.76% | ||
| 425 × 425 | 16.54 | Animal | 24.81 | 0.9926 | 29.09 | 0.9964 | 3.76% |
| Vegetables | 29.24 | 0.9926 | 36.56 | 0.9959 | 3.76% | ||
| Airplane | 38.91 | 0.9672 | 41.61 | 0.9679 | 3.56% | ||
| 450 × 450 | 18.54 | Animal | 23.86 | 0.9895 | 26.88 | 0.9952 | 3.56% |
| Vegetables | 27.22 | 0.9878 | 32.89 | 0.9941 | 3.56% | ||
| Airplane | 29.93 | 0.9628 | 38.50 | 0.9562 | 3.37% | ||
| 475 × 475 | 20.66 | Animal | 20.74 | 0.9820 | 23.79 | 0.9922 | 3.37% |
| Vegetables | 25.16 | 0.9744 | 30.97 | 0.9906 | 3.37% | ||
| Airplane | 23.36 | 0.7913 | 29.10 | 0.9105 | 3.20% | ||
| 500 × 500 | 22.89 | Animal | 17.33 | 0.9539 | 19.12 | 0.9813 | 3.20% |
| Vegetables | 18.91 | 0.9560 | 24.07 | 0.9780 | 3.20% | ||
| Method | bpp | PSNR (dB) |
|---|---|---|
| [46] | 4.84 | 31.67 |
| [47] | 3.48 | 41.00 |
| [45] | 9.60 | 48.84 |
| [20] | 12.18 | 34.03 |
| [16] (Max. dB) | 15.17 | 35.00 |
| [38] | 1.50 | 25.00 |
| [5]: CF-FB-GAR (Max. dB) | 19.54 | 35.03 |
| [5]: CF-QTAR (Max. dB) | 19.88 | 35.02 |
| [19] | 19.50 | 32.00 |
| [36] | 6.00 | 45.34 |
| Proposed Scheme | 18.54 | 41.84 |
| Proposed Scheme | 18.54 | 42.41 |
| Proposed Scheme | 18.54 | 41.61 |
| Method | bpp | PSNR (dB) |
|---|---|---|
| [48] | 14.38 | 26.20 |
| [18] | 20.22 | 25.00 |
| [41] | 20.83 | 27.00 |
| [16] (Max. bpp) | 21.01 | 27.00 |
| [5] CF-FB-GAR (Max. bpp) | 22.43 | 28.49 |
| [5] CF-QTAR (Max. bpp) | 22.70 | 28.15 |
| [19] (Max. bpp) | 19.30 | 29.10 |
| [19] (Max. bpp) | 19.50 | 32.00 |
| Proposed Scheme | 22.89 | 30.22 |
| Proposed Scheme | 22.89 | 32.91 |
| Proposed Scheme | 22.89 | 29.10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rabie, T.; Baziyad, M.; Kamel, I. High-Fidelity Steganography: A Covert Parity Bit Model-Based Approach. Algorithms 2024, 17, 328. https://doi.org/10.3390/a17080328
Rabie T, Baziyad M, Kamel I. High-Fidelity Steganography: A Covert Parity Bit Model-Based Approach. Algorithms. 2024; 17(8):328. https://doi.org/10.3390/a17080328
Chicago/Turabian StyleRabie, Tamer, Mohammed Baziyad, and Ibrahim Kamel. 2024. "High-Fidelity Steganography: A Covert Parity Bit Model-Based Approach" Algorithms 17, no. 8: 328. https://doi.org/10.3390/a17080328
APA StyleRabie, T., Baziyad, M., & Kamel, I. (2024). High-Fidelity Steganography: A Covert Parity Bit Model-Based Approach. Algorithms, 17(8), 328. https://doi.org/10.3390/a17080328