1. Introduction
In order to communicate with computers in more effective and natural ways, researchers have experimented with various methods for more than half of the last century. Over time, human interaction was made mainly via a keyboard and mouse. Most of the time, we interact with computers using our fingers and eyes, but other body parts, including our legs, arms, and mouth, are underutilized or never used at all. This is inconvenient since it is like composing emails with just one finger. Standard image processing methods do not produce excellent results, so machine learning is required for gesture detection to reach its full potential. Gestures are meaningful, expressive body motions that involve physical movements of the body, hands, arms, head, face, and fingers. Gesture recognition is the process that seeks to identify gestures and translate them into commands that can facilitate effective communication between humans and computers. Hand gestures are either dynamic or static. Implicit hand gestures and postural behavior are considered for the recognition of emotional states [
1,
2]. However, this paper is meant to focus more on the recognition of static, explicit hand gestures.
At present, there are some problems in visual gesture recognition, such as accuracy, real-time, and poor robustness. Although there are many methods of gesture recognition, vision-based gesture recognition still faces many serious problems in practice. It is mainly reflected in a low recognition rate, poor robustness, insensitivity in real-time, and poor practicability. Gesture recognition should bring great results no matter the background; it should work whether you are in the car, at home, or walking down the street. Using CNN helps overcome the problem of identifying gestures in complex backgrounds with very high accuracy.
Advancements in
CNN and the recently emerged deep learning techniques avoid the need for deriving complex handcrafted feature descriptors from images, so they outweigh the classical approach to hand gesture recognition [
3,
4,
5,
6]. By learning the high-level abstractions in images,
CNN automates the feature extraction process and uses hierarchical architecture to capture the most discriminative feature values [
7,
8].
In ref. [
9], Gao et al. proposed a parallel
CNN model that used
RGB and depth images as input. Parallel
CNN consists of two
CNNs, namely depth-
CNN and
RGB-
CNN, where one takes a depth image as input while the other takes an
RGB image as input. A prediction probability was weighted on the last layer of each
CNN output and concatenated to have the input to a softmax classifier layer. The dataset used contains a total of 24 hand gestures, representing the 24 letters (except J and Z, because J and Z are dynamic hand gestures). Each gesture contains 5000 sample images, which are 2500 RGB images and 2500 depth images, completed by 5 people in different backgrounds with different illumination. So there are a total of 120,000 pictures, which are 60,000 RGB images and 60,000 depth images. The model accuracy has reached 93.3% for American Sign Language (
ASL). The advantage of this approach is its ability to capture both appearance and depth information.
In ref. [
10], Oliveira et al. proposed
CNN with four convolutional layers, with a max-pooling layer affixed to each convolutional layer, followed by a fully connected layer and a softmax classifier. The proposed
CNN was able to attain 99% for Irish Sign Language (ISL). The dataset was collected by filming human subjects performing ISL hand shapes and movements and then extracting frames from the videos. This produced a total of 52,688 images for the 23 common hand- shapes from ISL. The very high accuracy can be explained by the simple image black backgrounds, which make it so easy and unchallenging to identify images and gestures. However, this method may struggle when applied to real-world scenarios with complex backgrounds and lighting variations, which is a disadvantage. In the proposed method, we will solve that by working on datasets with complex backgounds. Arenas et al. [
11] derived a
CNN architecture from a directed acyclic graph (
DAG) structure (
DAG-
CNN). A self-constructed dataset was used to experiment with the model on. The dataset consists of 10 gestures for controlling the robotic arm, and model accuracy was 84.5%. However, the model’s performance may vary when applied to different gesture recognition tasks.
Using fully connected layers of a pre-trained artificial neural network (AlexNet), Sahoo et al. [
12] proposed a deep
CNN feature-based static hand gesture recognition system. This system reduces redundant features using principal component analysis after deep features are extracted using fully connected layers of AlexNet (
PCA). An
SVM was then used as a classifier to categorize the poses of hand motions. The dataset was developed from five subjects with 36 gesture poses (10 ASL digits and 26 ASL alphabets). The dataset has variations in illumination in five different directions, such as left, right, top, bottom, and diffuse. The gesture poses are performed with variation in hand rotation, scale, and articulation. The American Sign Language dataset was used to test the system’s performance on 36 gesture postures, and the average accuracy score was 87.83%. Wadhawan et al. [
13] proposed a generic
CNN architecture for static sign language recognition. The dataset used comprises 35,000 images, which include 350 images for each of the static signs. There are 100 distinct sign classes that include 23 alphabets of English, 0–10 digits, and 67 commonly used words (e.g., bowl, water, stand, hand, fever, etc.). The network had an accuracy of 98.85% on the Indian sign language dataset. However, this approach may face challenges when applied to complex backgrounds, as the dataset consists of images captured on a simple white background that can be identified as relatively unchallenging.
For the purpose of assessing human behavior in the context of classroom learning and instruction with two teachers, Wang et al. [
14] introduced a recognition model of hand gestures based on
CNN. The analysis of the teacher’s nonverbal behaviors that improve the learning results of learners and attract their attention is achieved by exploiting the recognized instructors’ hand gestures. A non-linear neural network with four convolutional layers is used in this model to extract the features of hand gesture images. For achieving robust recognition, three convolution layers of
CNN are designed. A dataset of 38,425 infrared hand gesture images extracted from 100 short infrared videos is used to test and evaluate the model. The model has reached an accuracy of more than 92%. The model has the advantage of using a dataset that gives good results. Nevertheless, the images are also simple, with simple infrared backgrounds.
In ref. [
15], Zuocai Wang et al. suggested a method for identifying hand gestures through the use of particle filtering. By implementing this filtering technique on hand gesture images with identical backgrounds, the researchers achieved an accuracy of 90.6%. However, it has the disadvantage that performance may degrade when backgrounds are not stationary. In ref. [
16], Suguna and Neethu utilized shape features obtained from hand gesture images to categorize them into different classes. The extracted features were then taught and sorted into clusters using the k-means clustering algorithm. This approach offers simplicity but may struggle with complex hand gestures. In ref. [
17], Marium et al. put forward a method for hand gesture recognition that involved the use of a convexity algorithm approach. The researchers tested this technique on hand gesture images with identical backgrounds and obtained an accuracy of 87.5%. However, the approach was limited by the fact that the algorithm worked best when the background of the hand gesture image was stationary.
In ref. [
18], Ashfaq and Khurshid converted spatial domain-format hand gesture images into multi-class domain-format images using the Gabor filtering approach. They employed both Bayesian and Naive Bayes classifiers to categorize the test hand gesture images into different classes. The researchers found that the naive Bayes classifier produced higher levels of classification accuracy than the Bayesian classification methodology, owing to its straightforward architecture pattern. The data is acquired by a 7-megapixel camera. The dataset used has a total of ten hand gestures. For each hand gesture, there are 18 images, of which 5 are used for training and 13 for final testing. The model has an accuracy of 90%. In [
19], Rahman and Afrin used an
SVM classification approach in 2013 to categorize hand gesture images into various classes. The training set for the detection phase consisted of over 800 positive samples and 1500 negative image samples. The researchers achieved a sensitivity of 89.6%, a specificity of 79.9%, and an accuracy of 85.7%. However, the error rate was high in this method, and it was not suitable for fast-moving background and foreground object images.
In ref. [
20,
21], Authors utilized naive Bayes Classifier and
SVM approaches for recognizing gestures, but these methods were unable to handle large training datasets and needed a large number of training samples. To overcome these limitations, the current study introduces a
CNN classifier, which does not require a large number of training samples and has a low complexity level. In ref. [
22], Rao et al. developed a hand gesture recognition system using a hidden Markov model. The authors constructed a Markov model for the foreground fingers in a hand gesture image. This model was used in both the training and testing of the binary classification approach, giving it an accuracy of 90.1%.
In ref. [
23], the hand postures are classified using the shape, texture, and color features with an
SVM classifier. The proposed system utilizes a Bayesian model of visual attention to generate a saliency map and to detect and identify the hand region, and they reported an accuracy of 94.36% on the NUS II dataset that we use in our research. In ref. [
24], the authors proposed a
CNN model with two convolutional layers, two max-pooling layers, and one last fully connected layer. Dropout and activation functions are optional. However, they reported better results using both of them. The best accuracy reported on the NUS-II dataset was 89.1% by adding the dropout and activation functions. In our research paper, we will compare our results with the ones in refs. [
23,
24] as they reported results on the same challenging dataset we use and they also use
CNN.
In this research, we propose a CNN to recognize static hand gestures against complex backgrounds. The objective is to increase the accuracy of correctly identified gestures. Testing the accuracy of the model is achieved by comparing the true label of the image with the predicted label. The efficiency of deep learning in extracting and classifying high-level aspects of data has recently been the focus of existing research.
In summary, the contributions of this paper are adding the power of newly proposed preprocessing techniques in this research for the images using skin segmentation and data augmentation with the power of using CNN for classifying images. To the best of our knowledge, there has been no previous publication that has performed skin segmentation on the NUS II dataset using the same methodology we used. In addition, there is no paper that reported any results of combining both the CNN model and skin segmentation on a complex dataset such as the NUS II dataset, as we performed.
We compare our accuracy on the NUS II dataset to the one in refs. [
23,
24], as they both use different state-of-the-art methods on the same dataset. The accuracy of our proposed method has improved from the one in ref. [
24], going from 89.1% to 96.5%, as the number of misclassified images has decreased from representing 10.9% of the test dataset to only 3.5%. We also compare our accuracy on the Marcel dataset to the one in refs. [
24,
25], as they also both use different state-of-the-art methods on the same dataset. The accuracy of our proposed method has improved from the one in ref. [
24], going from 85.59% to 96.57%, as the number of misclassified images has decreased from representing 14.41% of the test dataset to only 3.43%.
In
Section 2, the concepts of skin segmentation, data augmentation, cross-entropy loss function, and the structure of the newly proposed
CNN are introduced. We also discuss the training details and analysis of different methods and tools used in different training experiments. In
Section 3, we discuss the results of the proposed experiments. Finally, In
Section 4 and
Section 5, we discuss how the results can be interpreted from the previous state-of-the-art methods in refs. [
23,
24,
25], how well they have improved, and our conclusion.
2. Materials and Methods
2.1. Introduction
In spite of the advances in image processing techniques and gesture recognition, an essential challenge is still unsolved: how can we recognize gestures in complex backgrounds without using hardware with a high level of accuracy? It turns out that using CNN helps us a lot to achieve that with very high accuracy by using the right dimensions for the CNN layers and choosing the best optimization techniques.
Identifying the right label for the test image is the optimization aim of our CNN model. We can achieve this by minimizing the loss function for the training and validation datasets to achieve as much accuracy as possible. To train the model, skin segmentation is used to reduce the data in the image and remove unwanted pixels that do not have skin HSV values. The challenge with this technique is that some pixels in the background already have skin colors, but it helps reduceing the data in the image and reduces the loss significantly.
Softmax is used to measure the predicted probabilities of each class by assigning them values between 0 and 1. As a consequence of using softmax, the cross-entropy loss function is used to measure the loss for the training dataset. Cross-entropy loss, or log loss, measures the performance of a classification model whose output is a probability value between 0 and 1. Cross-entropy loss increases as the predicted probability diverges from the actual label. Data augmentation is used to increase the dimensions of our training dataset, but validation and test datasets are not affected, and it has shown a significant increase in accuracy and decrease in the loss function as it helps in reducing overfitting and giving the model more data to train on.
2.2. Structure of the CNN
The motivation for proposing the chosen
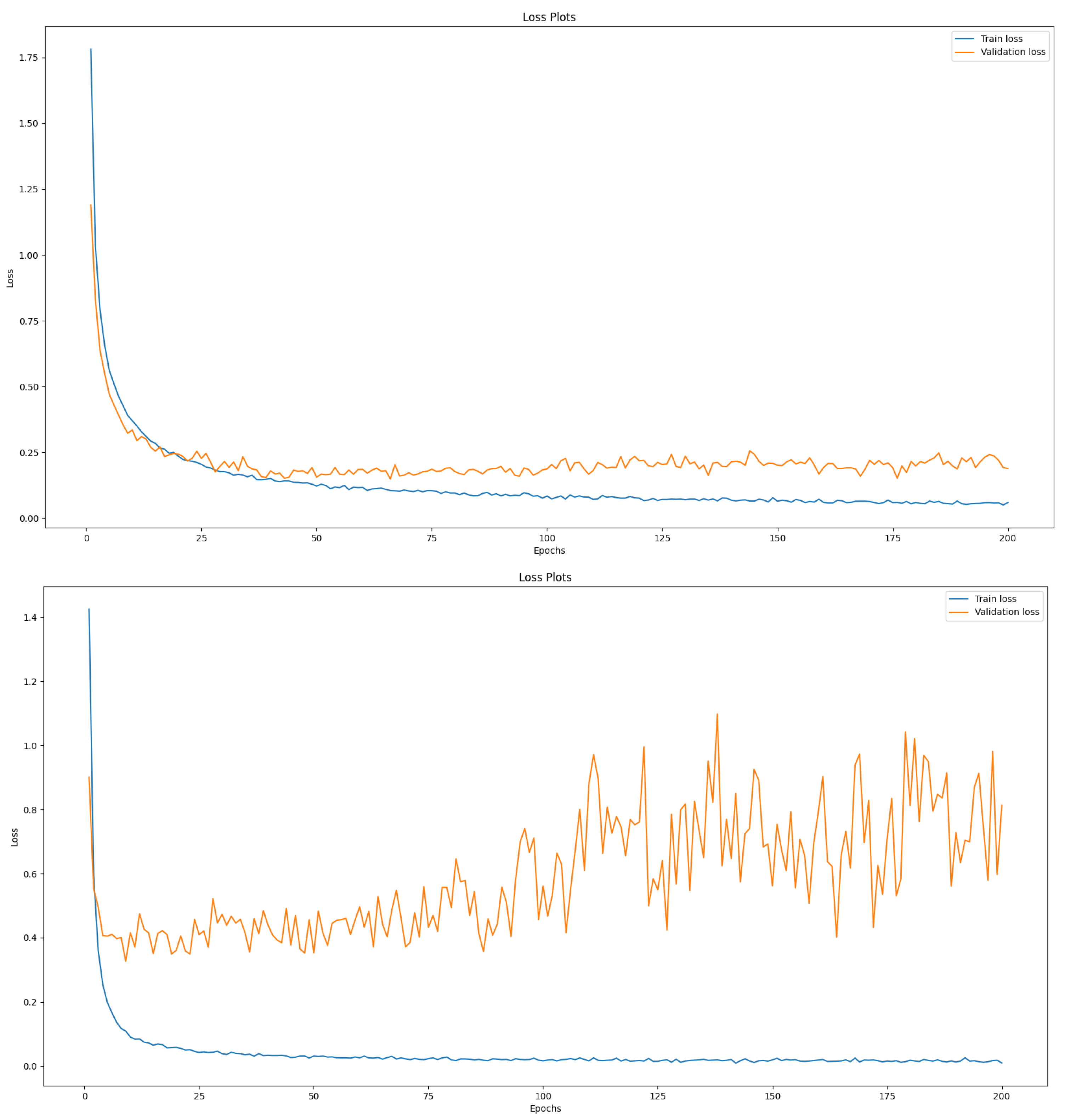
CNN architecture is the aim to leverage the hierarchical features of hand gestures, exploit translation invariance, reduce dimensionality, and efficiently extract discriminative features. The cascaded layers of convolutional and max-pooling operations in the architecture allow the network to progressively learn and extract increasingly complex features from the input images as a hierarchical feature extraction. The initial convolutional layer with 15 output maps captures low-level visual patterns, while subsequent layers with increasing output maps can learn more abstract and high-level features relevant to hand gesture recognition. This hierarchical feature extraction enables the network to effectively model the intricate details and variations present in hand gestures. The max-pooling layers in the architecture help reduce the spatial dimensions of the feature maps, resulting in a more compact representation of the learned features. By downsampling the feature maps, the max-pooling layers retain the most salient information while discarding less relevant or redundant details. This dimensionality reduction helps to mitigate the impact of background noise, variations in hand pose, and other sources of variability in hand gesture images, making the model more robust and efficient. We resize the input size of images to 32 × 32 to reduce overfitting. If we use a bigger size, the model will overfit, as we will show in the results of
Section 3.6 by using image sizes of
and showing the increase in the overfitting.
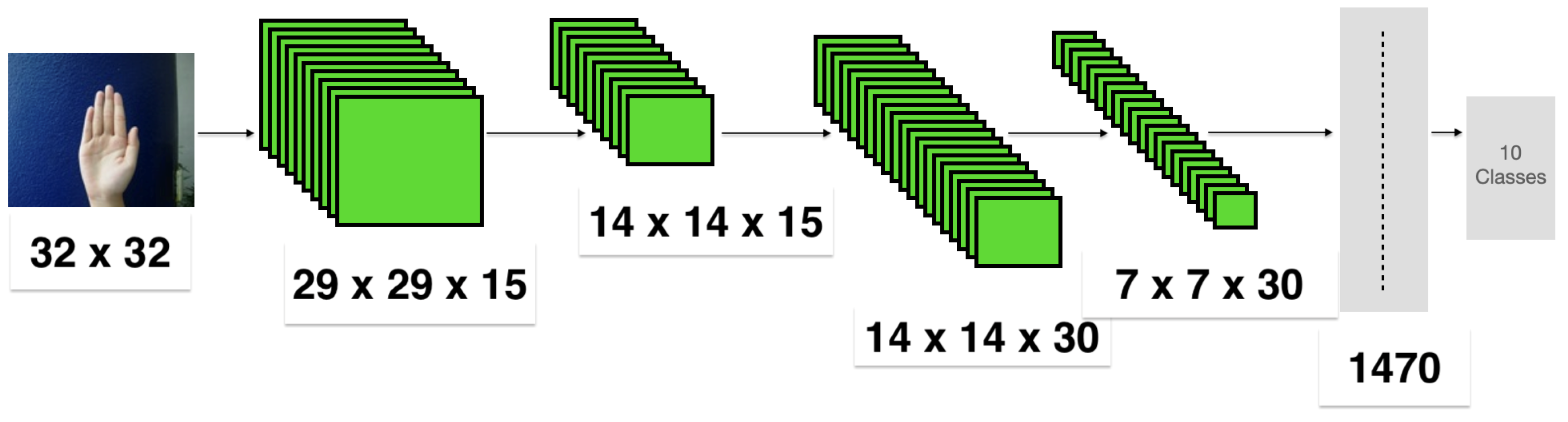
As shown in
Figure 1, the
CNN model consists of two convolutional layers, followed by a
ReLU activation function for each one, and two pooling layers apart from the input and output layers. As shown in
Figure 1, the input image of
pixels is convolved with 15 filter maps of size
to produce 15 output maps of
in the first layer. These output maps are operated upon with a
ReLU activation function. Downsampling of the output convolutional maps is completed with max-pooling of
regions to yield 15 output maps of
in layer 2. The 10 output maps of layer 2 are convolved with each of the 30 kernels of size
to obtain 30 maps of size
. These maps are further downsampled by a factor of 2 by max-pooling to produce 30 output maps of size
of layer 4. The output maps from layer 4 are concatenated to form a single vector during training and fed to the next layer, which is the fully connected layer. A dropout probability of 0.5 is used to reduce overfitting.
2.3. Skin Segmentation
The first technique we use to try to make the model learn better and increase its accuracy is skin segmentation, which will be used in the second experiment. Segmentation aims at partitioning areas in the image based on color, shape, and textures. It is useful in many computer vision applications. such as medical image analysis, object detection, and content-based image retrieval
CBIR [
26].
The skin segmentation technique is completed using the OpenCV python binary extension loader module. The segmentation is achieved by first converting the image from RGB to HSV color space to be able to extract the hue values for skin colors. In the OpenCV library in python, the measuring unit of hue values in the HSV (Hue, Saturation, Value) color space is typically 8-bit unsigned integers, ranging from 0 to 179. This means that hue values are quantized into discrete values, where each integer represents a specific hue bin or hue category. The 0 to 179 range is used to represent the full 360 degrees of hue values typically used in other systems, where each bin or category corresponds to a hue angle increment of approximately 2 degrees (360 degrees divided by 180 bins). This integer representation allows for efficient storage and processing of hue values in digital images and computer vision applications.
Hue values for skin colors are found to range from 0 to 38, which means they are ranging from 0 to 76 degrees in the normal HSV color space. The saturation and value (also known as brightness) are given a complete range from 0 to 255. This is completed to overcome the complex background, which has a wide range of brightness values that can be very dark or very bright. We only truncate the values for hue, which give us the true skin pixels, whatever the value of the saturation of light or brightness. Note also that images have a complex background, which includes skin-colored surfaces. Therefore, any skin-colored surface in the background is included in the image. Nevertheless, overall, it is better than the normal image, as there are a lot of unwanted pixels in the background that are removed, which makes us use only pixels that we can learn the most from during the training and validation phases.
2.4. Data Augmentation
Data augmentation is a very powerful technique for constructing better datasets. Many augmentations have been proposed, which can generally be classified as oversampling techniques. Deep learning models rely on big data generated from data augmentation to avoid overfitting. Artificially inflating datasets using methods of data augmentation achieves the benefit of big data in the limited data domain [
27].
Data augmentation is used on the training data of two datasets used (NUS II and Marcel datasets) to increase the size of each by 10 times. The data augmentation is performed by randomly rotating each image by an angle that ranges from 20 degrees to the left to 20 degrees to the right.
2.5. Dropout
Dropout is a regularization technique that helps address the issue of overfitting in neural networks. During training, standard backpropagation learning can result in brittle co-adaptations that only work well on the training data and do not generalize to new, unseen data. By randomly dropping out or deactivating a fraction of hidden units during each training iteration, dropout disrupts these co-adaptations, making the presence of any particular hidden unit less reliable. This technique has been found to be effective in improving the performance of neural networks in various application domains, such as object classification, digit recognition, speech recognition, document classification, and computational biology data analysis [
28]. In our proposed
CNN, The dropout is added at the end of our model before the last fully connected layer to reduce the overfitting that is reaching the final layer and make the model generalize to new, unseen data.
2.6. Loss Function
The loss function that has been used is the logarithmic loss, log loss, or logistic loss. Each predicted class probability is compared with the actual class desired output of 0 or 1, and a score/loss is calculated that penalizes the probability based on how far it is from the actual expected value. The penalty is logarithmic in nature, yielding a large score for large differences close to 1 and a small score for small differences tending to 0.
Cross-entropy loss is used when adjusting model weights during training. The aim is to minimize the loss, i.e., the smaller the loss, the better the model. A perfect model has a cross-entropy loss of 0. Cross Entropy is defined as follows:
Here,
n is the number of classes,
the true probability of the
ith class in the target, and
the softmax probability for the
ith class.
Here, if we look at Equation (
1), we can see that loss is calculated for each training example by calculating the negative natural logarithm for the output of the softmax function (
) multiplied by the true probability of the target, which is 0 or 1 (
). After calculating the loss for every training example, we sum all of them to get the training loss of the whole training dataset.
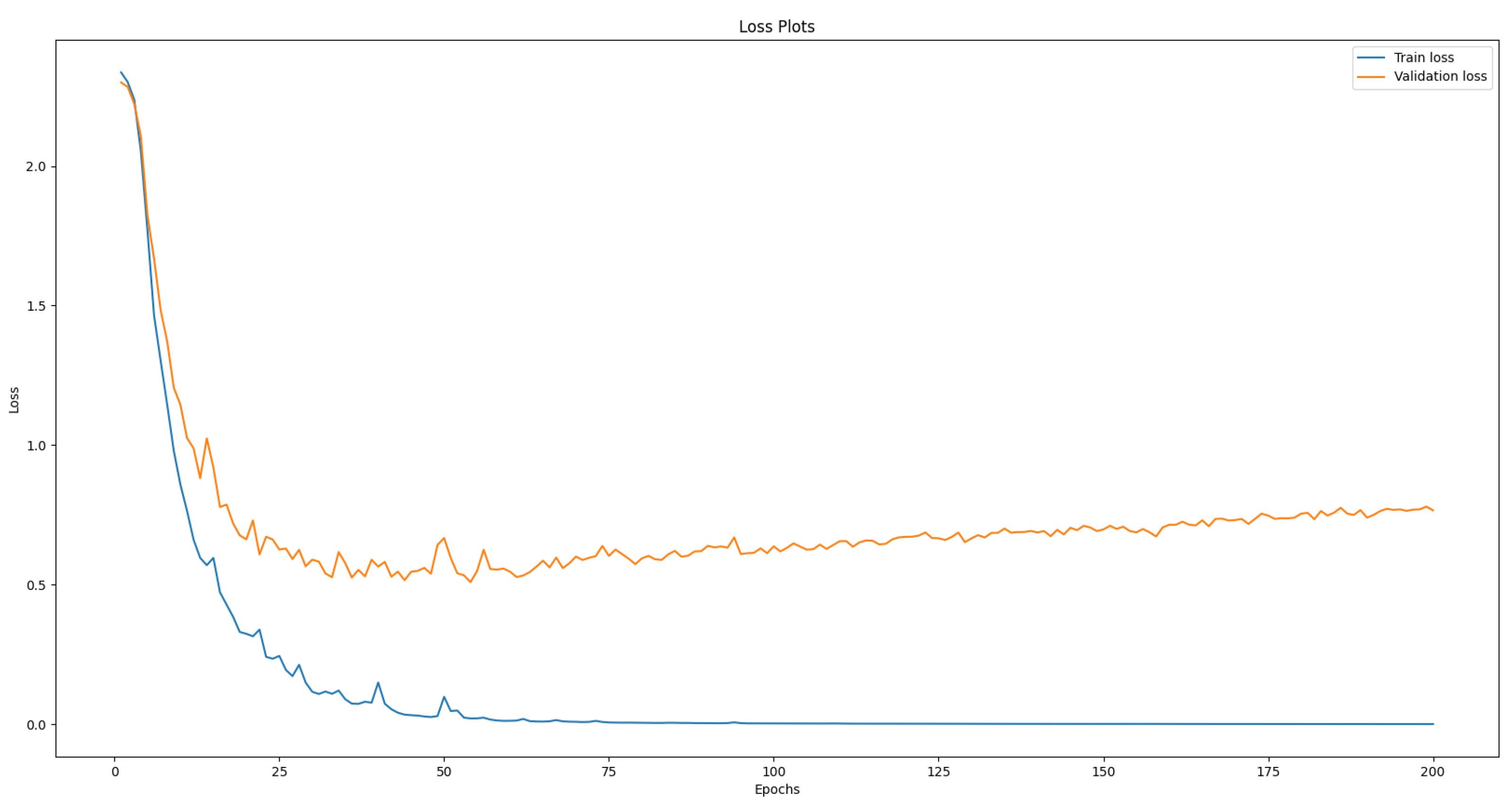
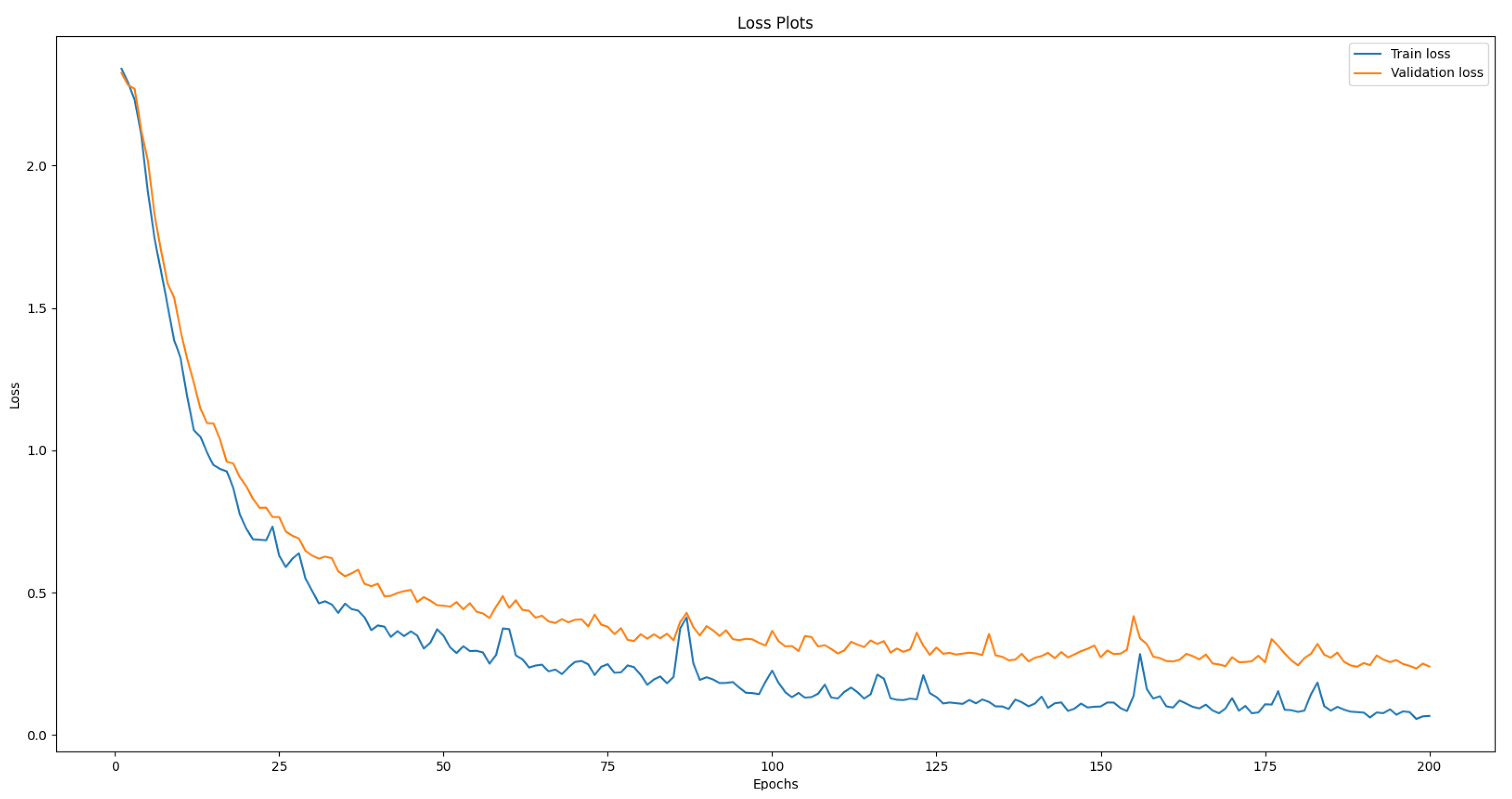
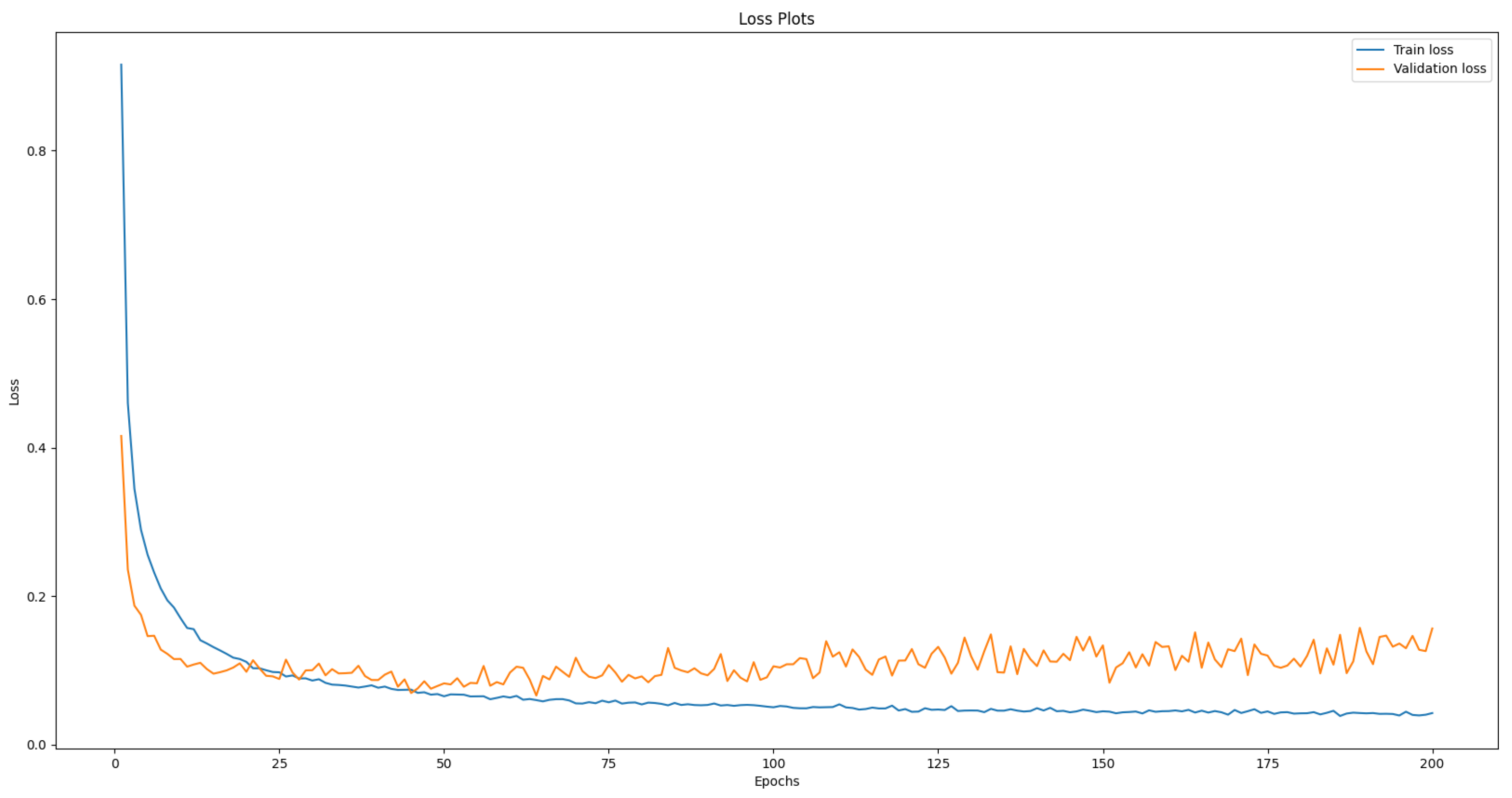
2.7. Training Details
All the experiments were completed on the Google colab CPU. Before training, the images are resized to 32 × 32. A batch size of 64 is used for the training set, and a batch size of 32 is used for both the validation set and the test set. Each image is resized into 32 × 32 and then enters the first convolution layer for the training phase. A learning rate of 0.001 is used with Adam optimizer as our optimization function.
NUS II Dataset and Marcel datasets are the two dataset used for the training. NUS II dataset is a 10-class hand posture dataset, as shown in
Figure 2. The postures are shot in and around the National University of Singapore (NUS), against complex natural backgrounds, with various hand shapes and sizes, which makes it a challenging dataset, as shown in
Figure 3. The postures are performed by 40 subjects of different ethnicities from different complex backgrounds. The subjects include both males and females in the age range of 22 to 56 years. The subjects are asked to show the 10 hand postures five times each. They are asked to loosen the hand muscles after each shot in order to incorporate the natural variations in the postures. The dataset consists of 2000 images; each image has a size of 160 × 120. Marcel dataset [
25] is a 6-class hand posture dataset, as shown in
Figure 4. For Marcel dataset there are 4872 training images and 659 testing images with complex and uniform backgrounds. To ensure random shuffling for the Marcel dataset, we combine both training and test datasets in the original one to be a total of 5531 images. For both datasets, they are divided into two phases. In the first phase, each one is shuffled randomly and then separated into train and test sets, maintaining the ratio of each class in both of them as the same ratio of splitting by using stratify in the train_test_Split function used to split them. In the second phase, the training set from the first phase is split again into training and validation sets by maintaining the same ratio of classes in both of them as we have already achieved in the first phase by using stratify.
2.8. Training Experiments Details
These are the details of the experiments that have been conducted and will be referenced in the following sections. In all the experiments, the model has been trained for 200 epochs using
Adam optimizer.
Table 1 and
Table 2 show the number of images in each of the training validation and testing datasets for each of the NUS II and Marcel datasets. The images column shows the total number of images; the total number of batches is represented in the batches column. In the batch images column is the number of images in all batches except for the last batch. The last batch images column shows the images in the last batch. For example, in
Table 1, the first row shows that in the training dataset of NUS II without augmentation, the number of images is 1602 divided into 26 batches, where the first 25 batches contain 64 images and the last batch contains 2 images. The same follows for the two
Table 1 and
Table 2.
2.9. Validation Details
Validation is achieved by evaluating our model on the validation dataset using the eval function in the model library in Python. The prediction of the validation is achieved on every image by iterating over them and computing the gradient by giving both the prediction and the original labels to a criterion function, which computes the gradient from the cross-entropy loss function that we used. After getting the validation loss, we do backpropagation to learn how to update the weights and get a better validation loss for the next iteration. A softmax function is then applied to the predicted variables to make the predicted variables for each class sum up to 1. The validation accuracy is completed by enumerating over the validation data loader and then comparing the original labels of the image with the labels predicted from our model. After every iteration, we check if the original label equals the predicted label. If they are equal, we increment our variable and then see at the end how much our testing accuracy is by dividing the number of correct predictions by the number of images in the validation dataset as follows:
After every epoch, if the validation loss is less than the least validation loss so far, we save a new model state dictionary. We then update our variable to be the least validation loss for the next epoch to do the same thing again. As a result, we can know which are the best weights to use for the testing phase as we finish.
2.10. Testing Details
The testing dataset has been derived from the NUS II and Marcel datasets by shuffling the datasets and taking 10% of it. A softmax function is applied to the predicted variables to make the predicted variables for each class sum up to 1. The testing is completed by enumerating over the test data loader and then comparing the original labels of the image with the labels predicted from our model, and then after every iteration we check if the original label equals the predicted label; if yes, we increment our variable, and then we see at the end how much our testing accuracy is by dividing the number of correct predictions by the whole number of images in the test dataset as follows:

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}