

Official International Mahjong: A New Playground for AI Research

Abstract
1. Introduction
- We are the first to hold AI competitions of Official International Mahjong. We provide the judge program that implements the rules of this Mahjong variant and open source libraries to calculate scoring patterns. We also build match datasets from both humans and top AI agents for further research.
- We innovatively adopt the duplicate format in the evaluation of AI agents to reduce the high variance introduced by the randomness of the game, which is commonly used in top-level human competitions but rarely used in AI competitions.
- We promote Official International Mahjong as a challenge and benchmark for AI research. We summarize the algorithms of AI agents in the two AI competitions and conclude that modern game AI algorithms based on deep learning are the current state-of-the-art methods. We claim that more powerful algorithms are needed to beat professional human players in this game.
2. Background
2.1. AI and Games
2.2. Game AI Algorithms
2.3. Mahjong
3. Official International Mahjong
4. AI Competitions
4.1. Botzone
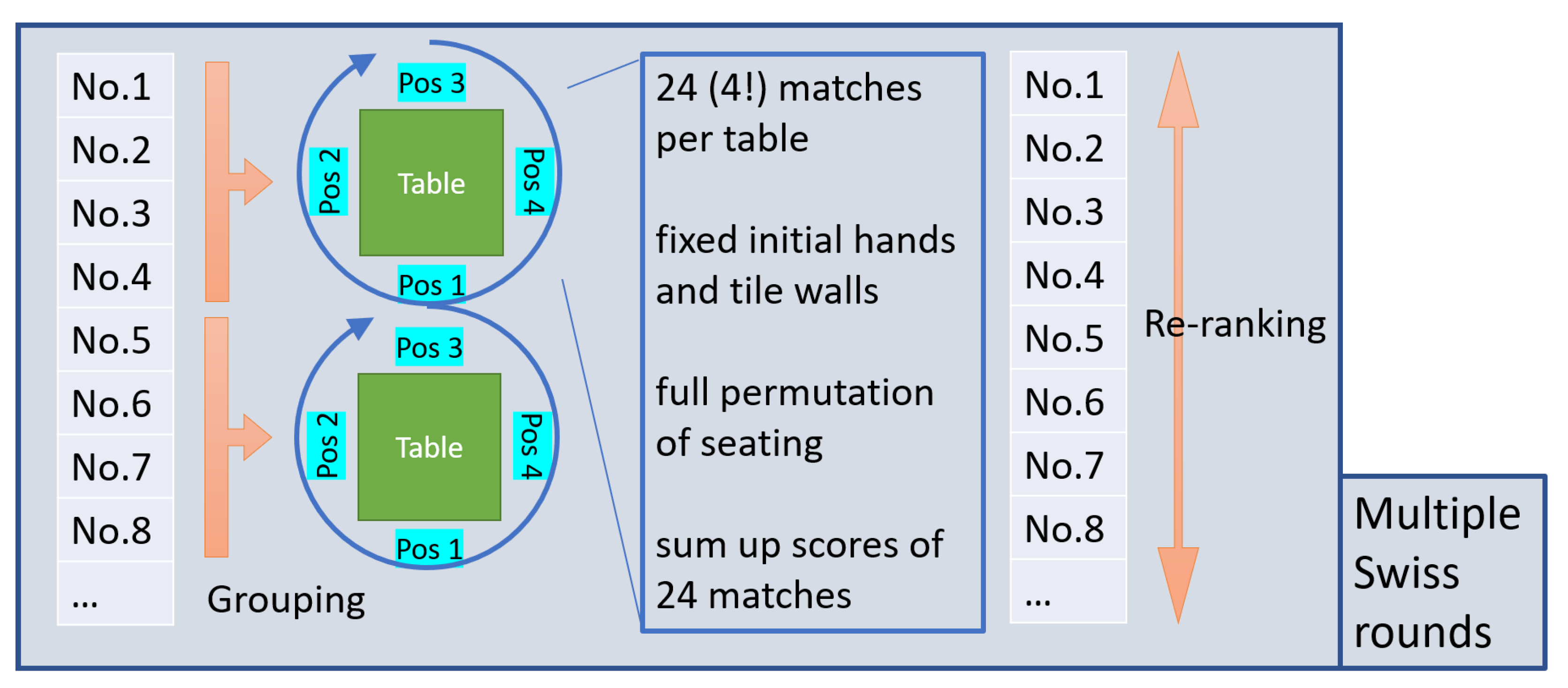
4.2. Competition Format
4.3. Mahjong AI Competition
4.4. Human-versus-AI Competition
5. AI Algorithms
5.1. Heuristic Methods
5.2. Supervised Learning
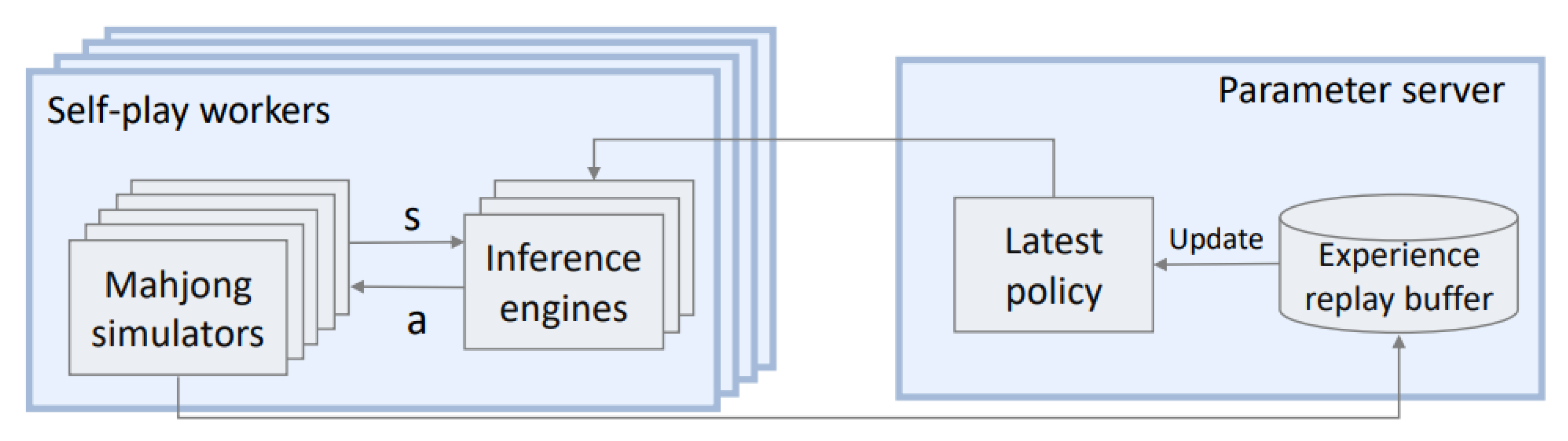
5.3. Reinforcement Learning
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Scoring system in Official International Mahjong
Appendix A.1. Scoring Principles
- The Non-Repeat Principle: When a scoring pattern is inevitably implied or included by another pattern, the pattern with a lower fan value is not counted.
- The Non-Separation Principle: After combining some melds to match a scoring pattern, these melds cannot be separated and rearranged to match another pattern.
- The Non-Identical Principle: Once a meld has been used to match a scoring pattern, the player is not allowed to use the same meld together with other melds to match the same pattern.
- The High-versus-Low Principle: When there are multiple ways to break the hand to match different sets of scoring patterns, the way with the highest total fan value is chosen.
- The Account-Once Principle: When a player has combined some melds to match a scoring pattern, they can only combine any remaining melds once with a meld that has already been used to match other patterns.
Appendix A.2. Scoring Patterns
- Patterns worth 88 fans


 .
.
 +
+ 
 ) (
) ( ) (
) ( ) (
) ( )
) 


- Patterns worth 64 fans





- Patterns worth 48 fans


- Patterns worth 32 fans

 ) (
) ( ) (
) ( )
) 

- Patterns worth 24 fans









- Patterns worth 16 fans





- Patterns worth 12 fans





- Patterns worth 8 fans


 .
.


 ) (
) ( )
)  +
+ 
- Patterns worth 6 fans




- Patterns worth 4 fans
- Patterns worth 2 fans
- Patterns worth 1 fan
References
- Schaeffer, J.; Lake, R.; Lu, P.; Bryant, M. Chinook the world man-machine checkers champion. AI Mag. 1996, 17, 21. [Google Scholar]
- Campbell, M.; Hoane, A.J., Jr.; Hsu, F.h. Deep blue. Artif. Intell. 2002, 134, 57–83. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef]
- Moravčík, M.; Schmid, M.; Burch, N.; Lisỳ, V.; Morrill, D.; Bard, N.; Davis, T.; Waugh, K.; Johanson, M.; Bowling, M. Deepstack: Expert-level artificial intelligence in heads-up no-limit poker. Science 2017, 356, 508–513. [Google Scholar] [CrossRef]
- Brown, N.; Sandholm, T. Superhuman AI for heads-up no-limit poker: Libratus beats top professionals. Science 2018, 359, 418–424. [Google Scholar] [CrossRef]
- Brown, N.; Sandholm, T. Superhuman AI for multiplayer poker. Science 2019, 365, 885–890. [Google Scholar] [CrossRef]
- Vinyals, O.; Babuschkin, I.; Chung, J.; Mathieu, M.; Jaderberg, M.; Czarnecki, W.M.; Dudzik, A.; Huang, A.; Georgiev, P.; Powell, R.; et al. Alphastar: Mastering the real-time strategy game starcraft ii. DeepMind Blog 2019, 2. [Google Scholar]
- Berner, C.; Brockman, G.; Chan, B.; Cheung, V.; Debiak, P.; Dennison, C.; Farhi, D.; Fischer, Q.; Hashme, S.; Hesse, C.; et al. Dota 2 with large scale deep reinforcement learning. arXiv 2019, arXiv:1912.06680. [Google Scholar]
- Ye, D.; Chen, G.; Zhang, W.; Chen, S.; Yuan, B.; Liu, B.; Chen, J.; Liu, Z.; Qiu, F.; Yu, H.; et al. Towards playing full moba games with deep reinforcement learning. ADvances Neural Inf. Process. Syst. 2020, 33, 621–632. [Google Scholar]
- Li, J.; Koyamada, S.; Ye, Q.; Liu, G.; Wang, C.; Yang, R.; Zhao, L.; Qin, T.; Liu, T.Y.; Hon, H.W. Suphx: Mastering mahjong with deep reinforcement learning. arXiv 2020, arXiv:2003.13590. [Google Scholar]
- Copeland, B.J. The Modern History of Computing. Available online: https://plato.stanford.edu/entries/computing-history/ (accessed on 28 April 2023).
- Wikipedia. World Series of Poker—Wikipedia, The Free Encyclopedia. 2023. Available online: http://en.wikipedia.org/w/index.php?title=World%20Series%20of%20Poker&oldid=1133483344 (accessed on 8 February 2023).
- Bard, N.; Hawkin, J.; Rubin, J.; Zinkevich, M. The annual computer poker competition. AI Mag. 2013, 34, 112. [Google Scholar] [CrossRef]
- Lu, Y.; Li, W. Techniques and Paradigms in Modern Game AI Systems. Algorithms 2022, 15, 282. [Google Scholar] [CrossRef]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A formal basis for the heuristic determination of minimum cost paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Stockman, G.C. A minimax algorithm better than alpha-beta? Artif. Intell. 1979, 12, 179–196. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Heinrich, J.; Lanctot, M.; Silver, D. Fictitious self-play in extensive-form games. In Proceedings of the International Conference on Machine Learning. PMLR, Lille, France, 7–9 July 2015; pp. 805–813. [Google Scholar]
- McMahan, H.B.; Gordon, G.J.; Blum, A. Planning in the presence of cost functions controlled by an adversary. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 536–543. [Google Scholar]
- Lanctot, M.; Zambaldi, V.; Gruslys, A.; Lazaridou, A.; Tuyls, K.; Pérolat, J.; Silver, D.; Graepel, T. A unified game-theoretic approach to multiagent reinforcement learning. Adv. Neural Inf. Process. Syst. 2017, 30, 4193–4206. [Google Scholar]
- Wikipedia. Mahjong solitaire—Wikipedia, The Free Encyclopedia. 2023. Available online: http://en.wikipedia.org/w/index.php?title=Mahjong%20solitaire&oldid=1129612325 (accessed on 8 February 2023).
- Osborne, M.J.; Rubinstein, A. A Course in Game Theory; MIT Press: Cambridge, MA, USA, 1994. [Google Scholar]
- Sloper, T. FAQ 10: Simplified Rules for Mah-Jongg—sloperama.com. Available online: https://sloperama.com/mjfaq/mjfaq10.html (accessed on 8 February 2023).
- Zhou, H.; Zhang, H.; Zhou, Y.; Wang, X.; Li, W. Botzone: An online multi-agent competitive platform for ai education. In Proceedings of the 23rd Annual ACM Conference on Innovation and Technology in Computer Science Education, Larnaca, Cyprus, 2–4 July 2018; pp. 33–38. [Google Scholar]
- IJCAI 2020 Mahjong AI Competition—botzone.org.cn. Available online: https://botzone.org.cn/static/gamecontest2020a.html (accessed on 8 February 2023).
- IJCAI 2022 Mahjong AI Competition—botzone.org.cn. Available online: https://botzone.org.cn/static/gamecontest2022a.html (accessed on 8 February 2023).
- GitHub—ailab-pku/PyMahjongGB: Python Fan Calculator for Chinese Standard Mahjong—github.com. Available online: https://github.com/ailab-pku/PyMahjongGB (accessed on 8 February 2023).
- Yata. SuperJong. Available online: https://botzone.org.cn/static/IJCAI2020MahjongPPT/03-SuperJong-yata.pdf (accessed on 8 February 2023).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Heinrich, J.; Silver, D. Deep reinforcement learning from self-play in imperfect-information games. arXiv 2016, arXiv:1603.01121. [Google Scholar]
- Zhao, E.; Yan, R.; Li, J.; Li, K.; Xing, J. AlphaHoldem: High-Performance Artificial Intelligence for Heads-Up No-Limit Texas Hold’em from End-to-End Reinforcement Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 22 February–1 March 2022; Volume 36, pp. 4689–4697. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, New York City, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Guan, Y.; Liu, M.; Hong, W.; Zhang, W.; Fang, F.; Zeng, G.; Lin, Y. PerfectDou: Dominating DouDizhu with Perfect Information Distillation. arXiv 2022, arXiv:2203.16406. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Suited Tiles | Numbers | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| One | Two | Three | Four | Five | Six | Seven | Eight | Nine | ||
| Suits | Characters |  |  |  |  |  |  |  |  |  |
| Bamboos |  |  |  |  |  |  |  |  |  | |
| Dots |  |  |  |  |  |  |  |  |  | |
| Honor tiles | Winds | Dragons | ||||||||
| East | South | West | North | Red | Green | White | ||||
 |  |  |  |  |  |  | ||||
| Flower tiles | Plants | Seasons | ||||||||
| Plum blossom | Orchid | Daisy | Bamboo | Spring | Summer | Fall | Winter | |||
 |  |  |  |  |  |  |  | |||
| Winning Patterns | Explanation with an Example |
|---|---|
| Basic pattern | Four melds and a pair, with fan value no less than 8. |
              | |
| Thirteen orphans | 1 and 9 of each suit, one of each wind, one of each dragon, and one duplicate tile of any. |
              | |
| Seven pairs | A hand with seven pairs. |
              | |
| Honors and knitted tiles | A hand of 14 tiles from these 16 tiles: number 1, 4, 7 of one suit; number 2, 5, 8 of second suit; number 3, 6, 9 of third suit; and all honor tiles. |
              | |
| Knitted Straight | Number 1, 4, 7 of one suit, number 2, 5, 8 of second suit, number 3, 6, 9 of third suit, plus a meld and a pair. |
              |
| Year | Qualification Round | Elimination Round | Final Round | Dataset | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Time | Teams | Rounds | Time | Teams | Rounds | Time | Teams | Rounds | ||
| 2020–2021 | 31 November | 37 | 1 January | 16 | 6 January | 4 | Human data | |||
| 2022 | 22 May | 25 | 128 | 3 July | 16 | 128 | 4 July | 4 | 512 | AI data |
| Player | East Wind | South Wind | West Wind | North Wind | Total | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Li | −22 | 32 | 51 | −19 | 54 | 99 | −8 | −17 | 34 | −8 | 34 | −8 | 34 | −27 | −8 | −16 | 205 |
| Zhang | −22 | 60 | 54 | −19 | 54 | −8 | −8 | −30 | 37 | 33 | 66 | −8 | 35 | −16 | −8 | −16 | 204 |
| Kima (AI) | −22 | 60 | −8 | −19 | 54 | −8 | −8 | −28 | −8 | −8 | 66 | −8 | 35 | −8 | −8 | −16 | 66 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, Y.; Li, W.; Li, W. Official International Mahjong: A New Playground for AI Research. Algorithms 2023, 16, 235. https://doi.org/10.3390/a16050235
Lu Y, Li W, Li W. Official International Mahjong: A New Playground for AI Research. Algorithms. 2023; 16(5):235. https://doi.org/10.3390/a16050235
Chicago/Turabian StyleLu, Yunlong, Wenxin Li, and Wenlong Li. 2023. "Official International Mahjong: A New Playground for AI Research" Algorithms 16, no. 5: 235. https://doi.org/10.3390/a16050235
APA StyleLu, Y., Li, W., & Li, W. (2023). Official International Mahjong: A New Playground for AI Research. Algorithms, 16(5), 235. https://doi.org/10.3390/a16050235