
Twenty Years of Machine-Learning-Based Text Classification: A Systematic Review



Abstract
1. Introduction
- 1.
- What is the most frequently used dataset for machine-learning-based text classification?
- 2.
- What are the frequencies at which machine learning models are used?
- 3.
- What is the maximum accuracy for each dataset?
- 4.
- What is the most frequently used performance evaluation metric?
- 5.
- What is the most successful train–test split method?
- 6.
- How do different machine learning models compare?
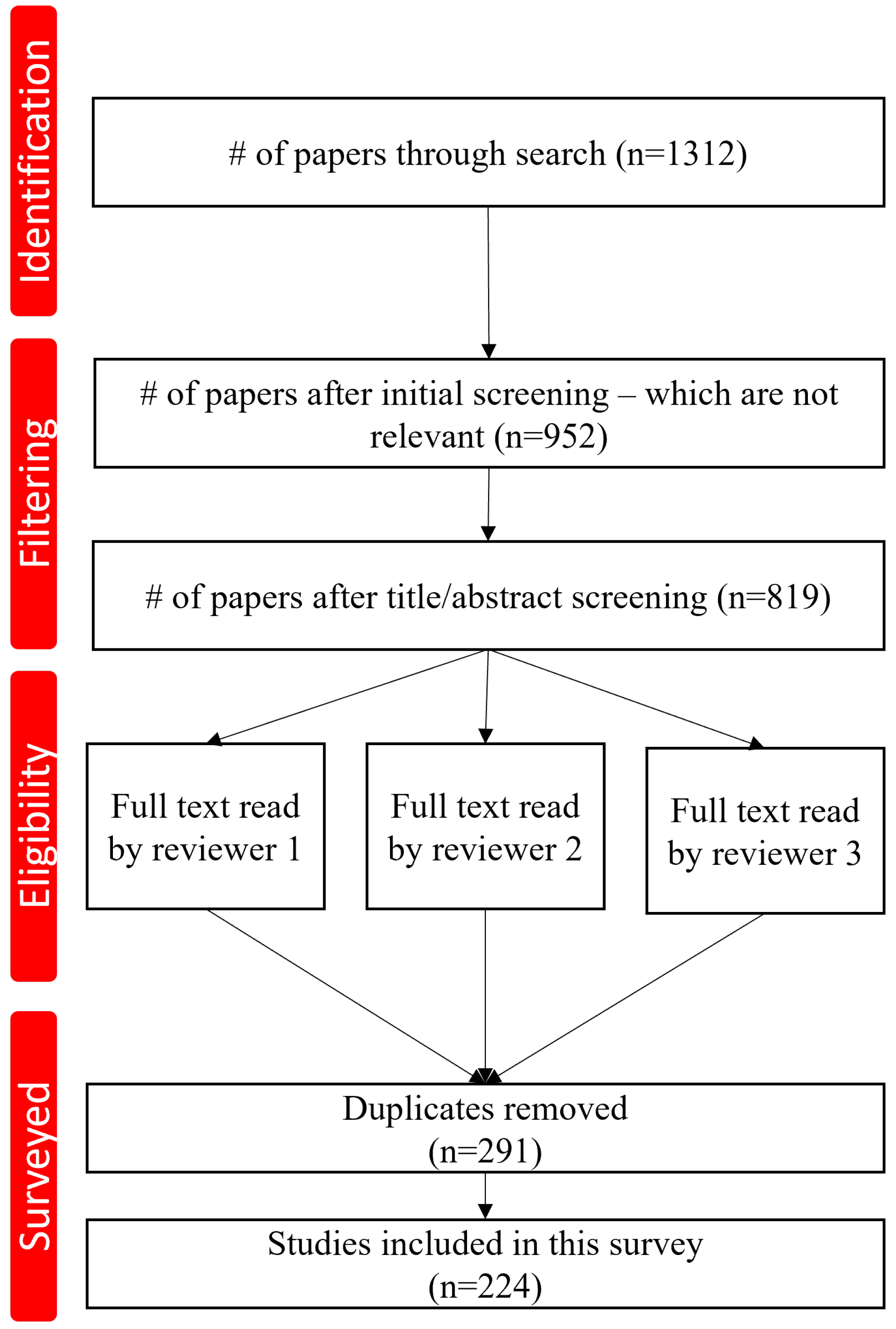
2. Survey Methodology
3. Overview of the Survey Results
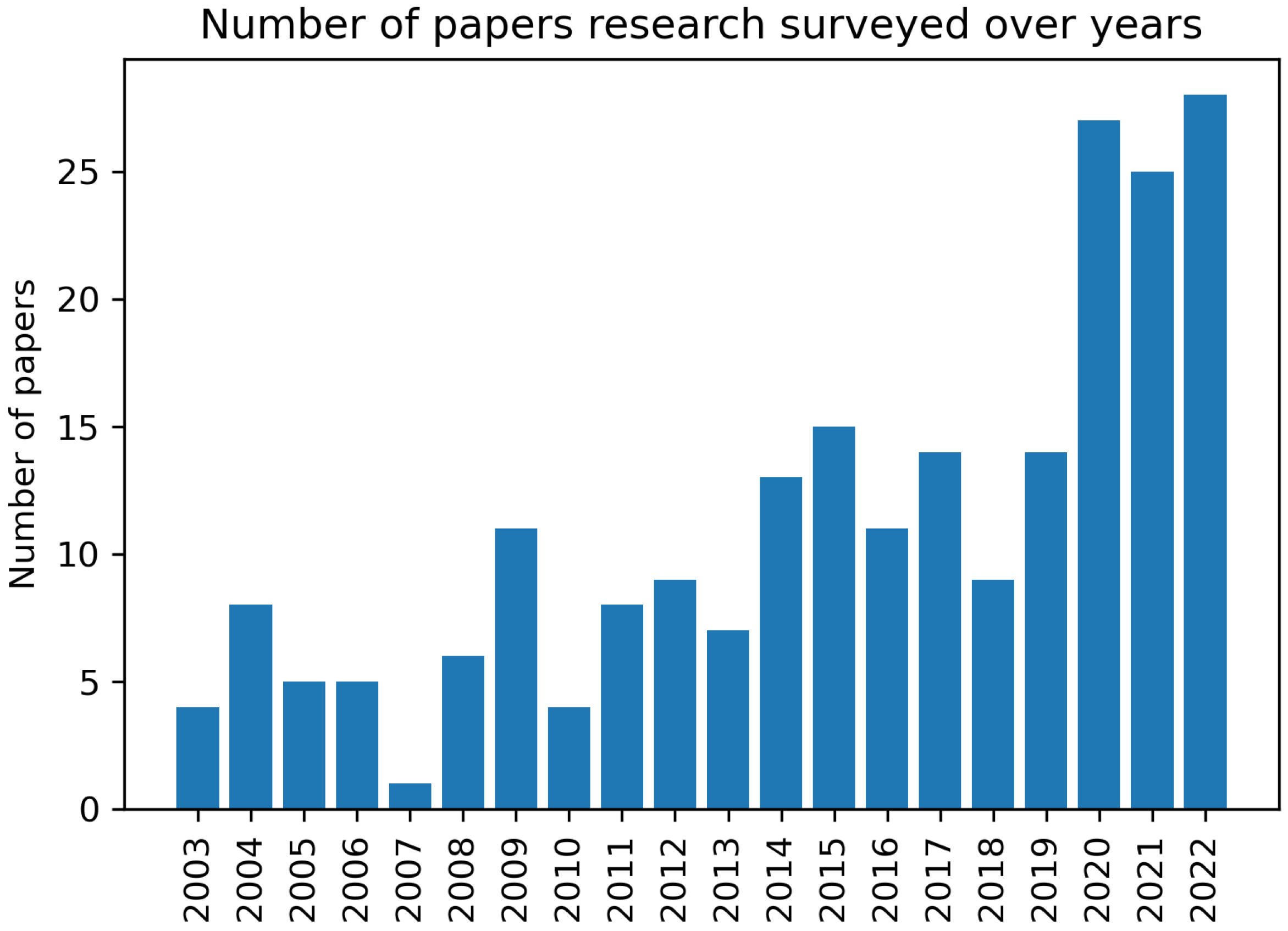
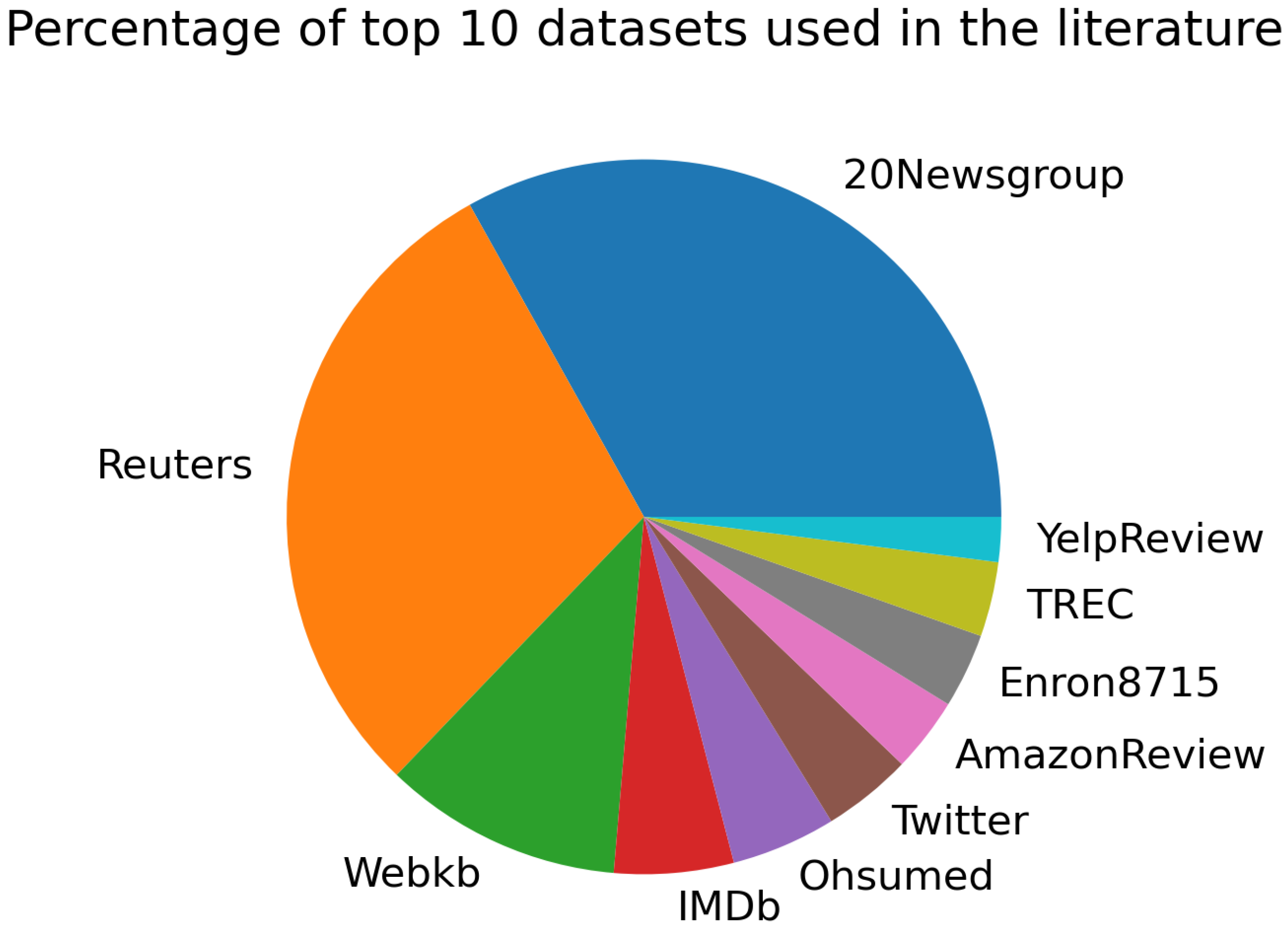
3.1. Study on the Dataset
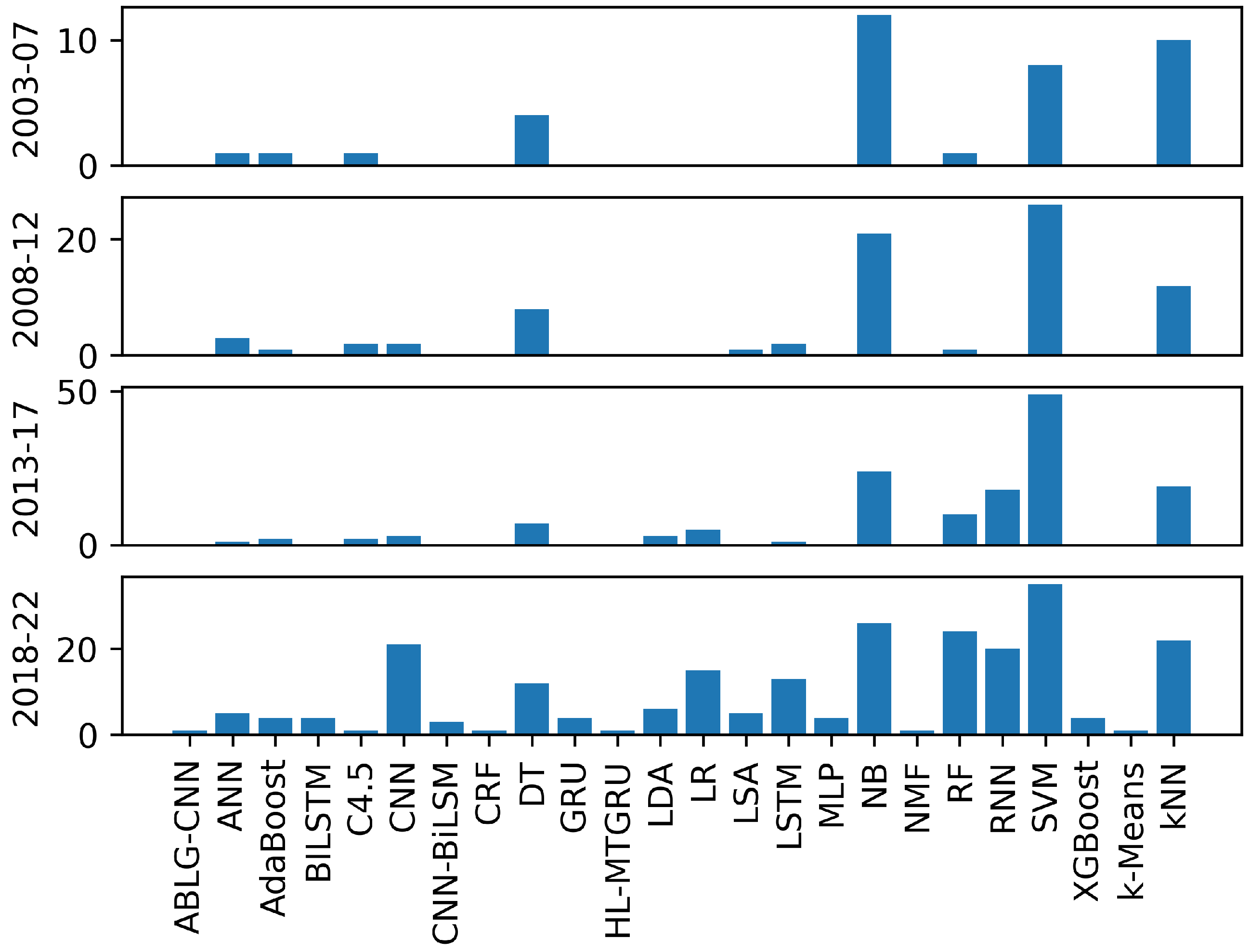
3.2. Study on Machine Learning Models
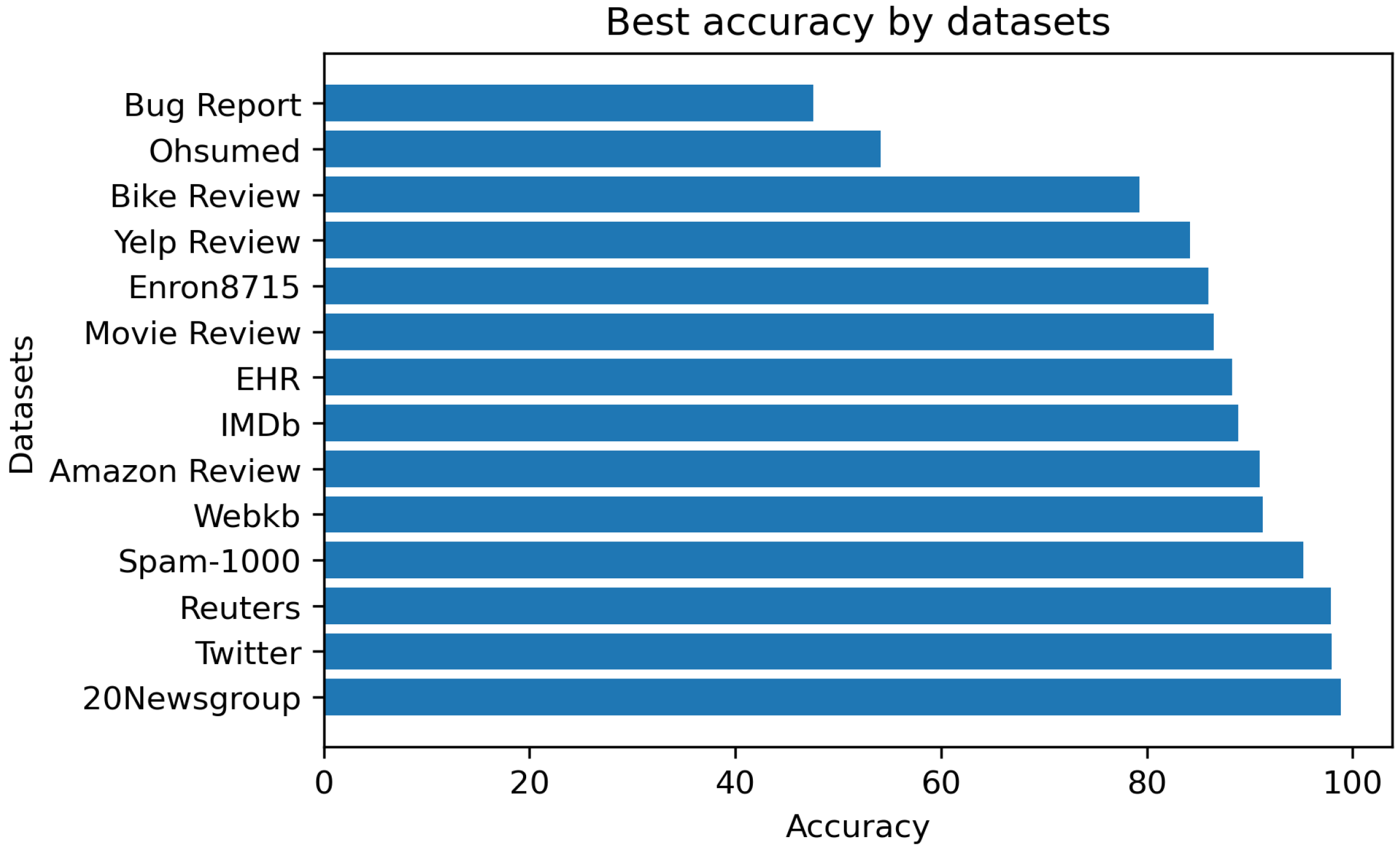
3.3. Study on Accuracy
3.4. Study on Performance Evaluation
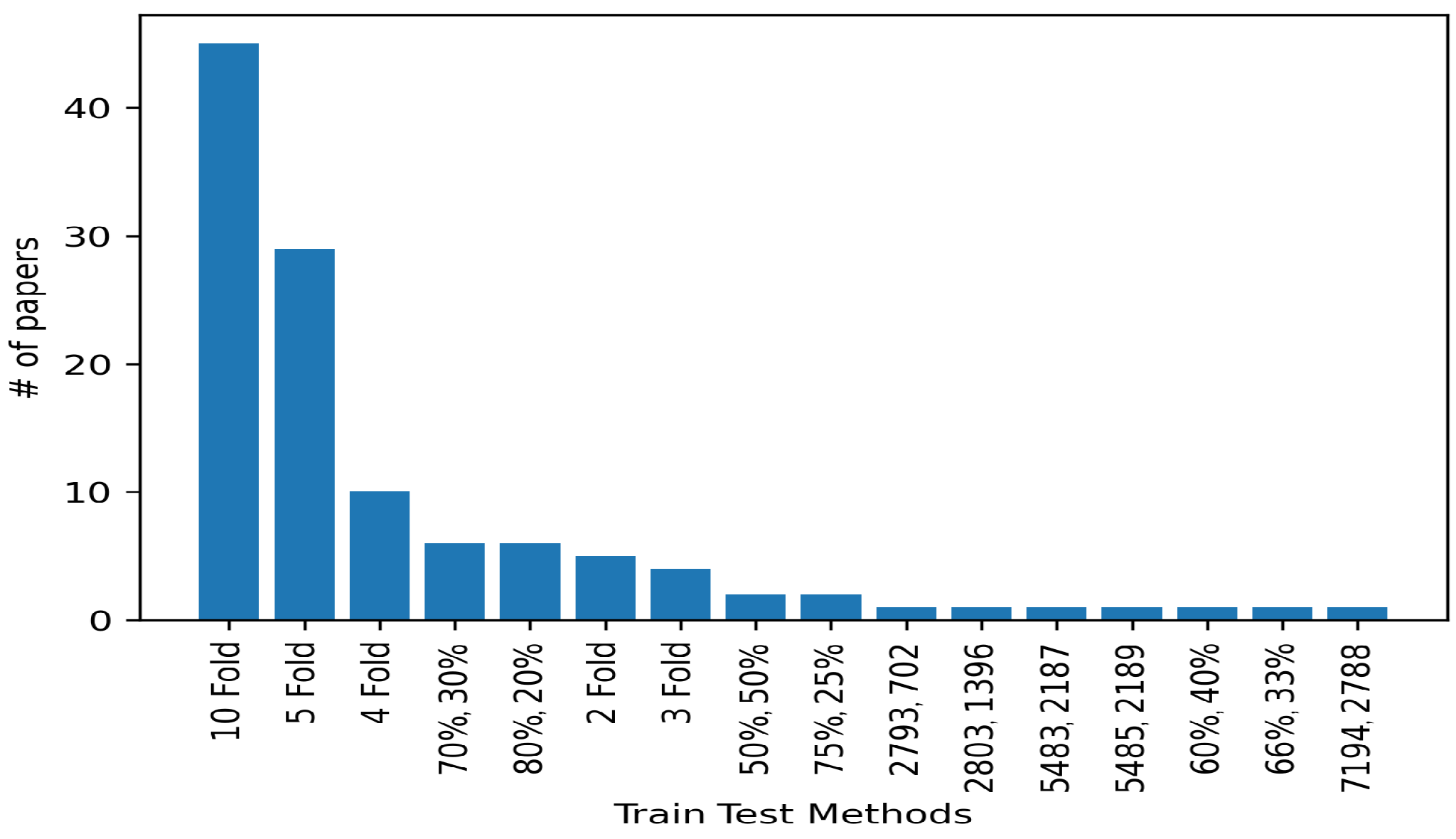
3.5. Study on Train–Test Splits
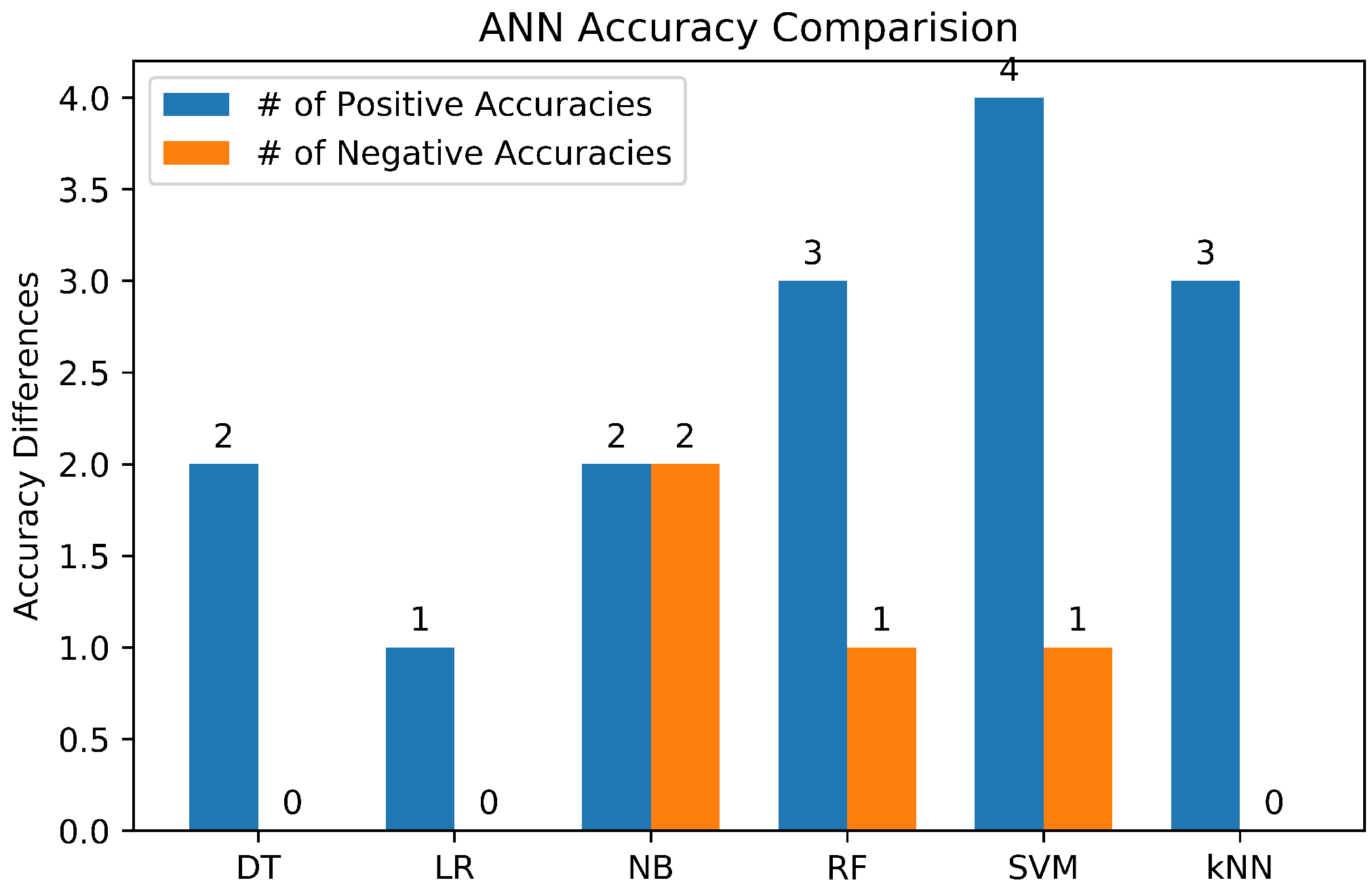
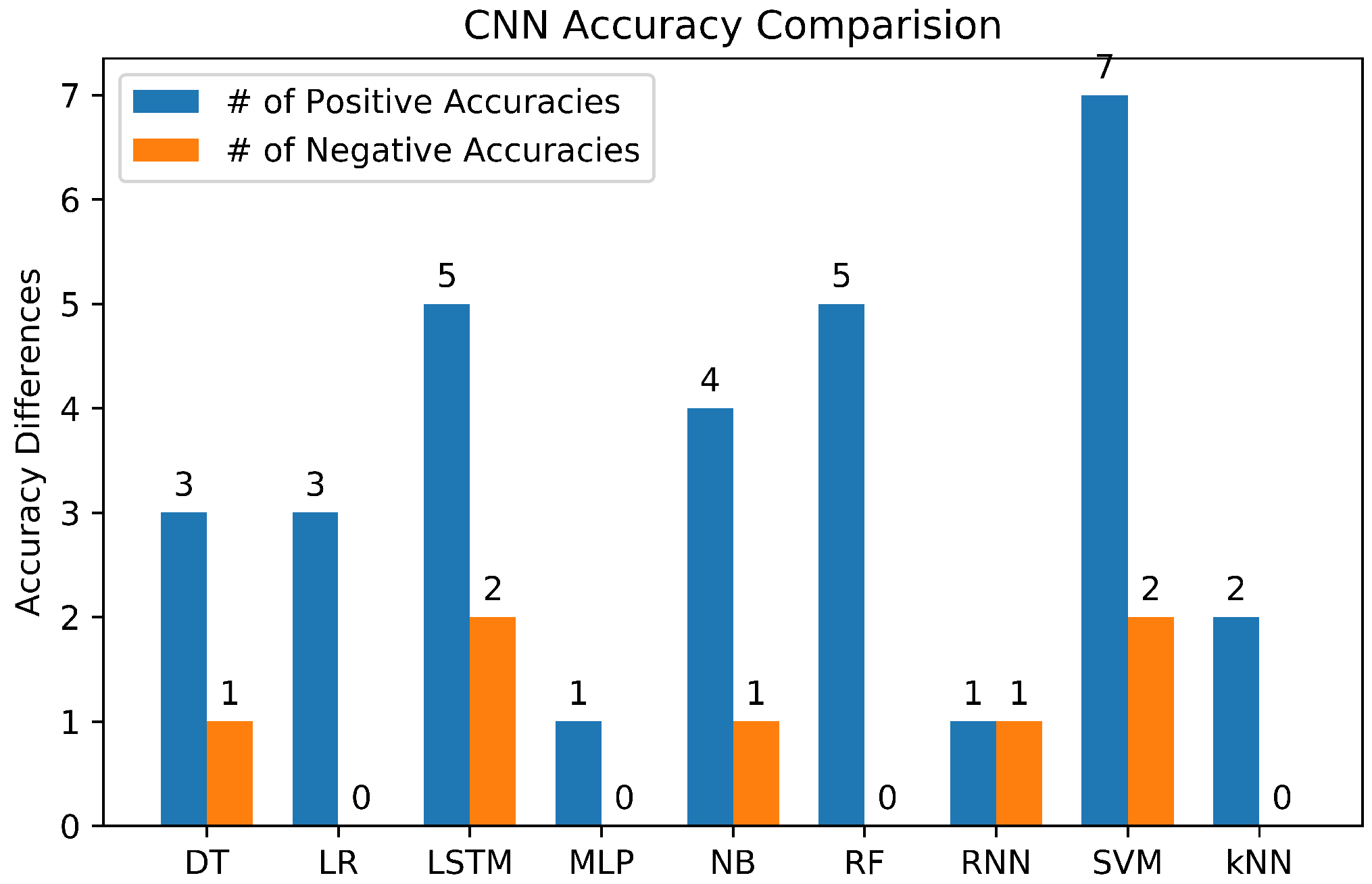
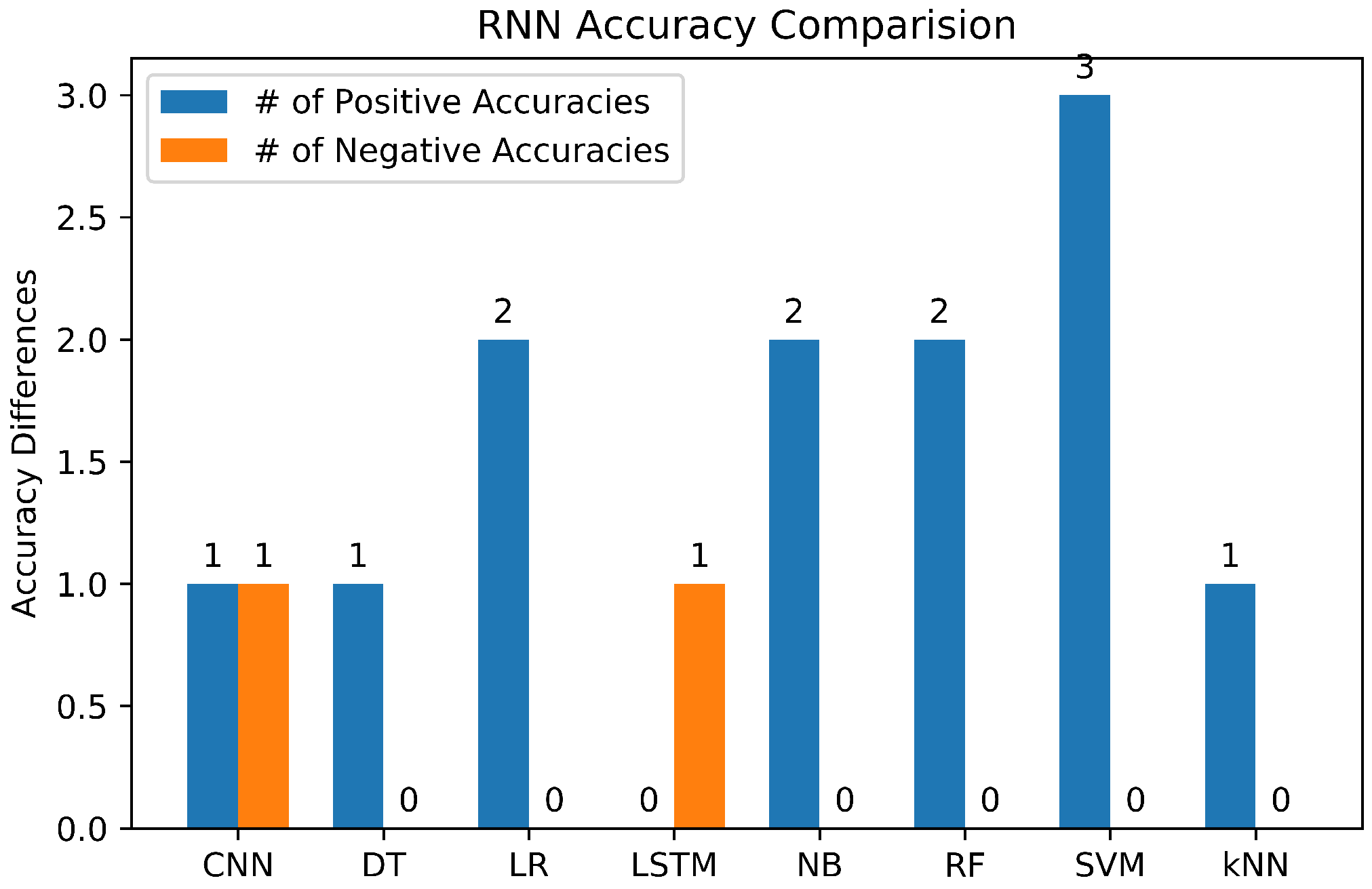
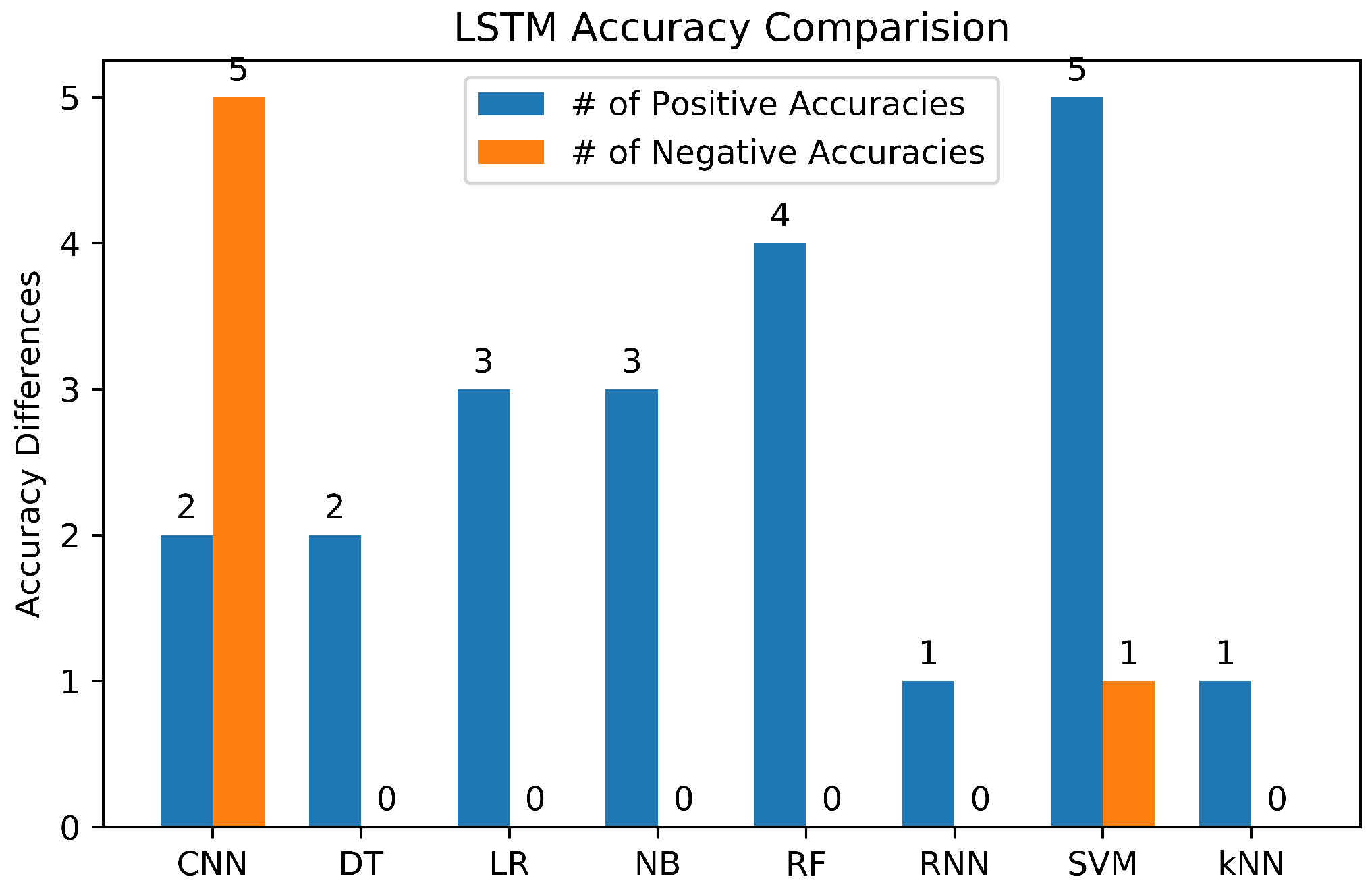
3.6. Study on Machine Learning Algorithms
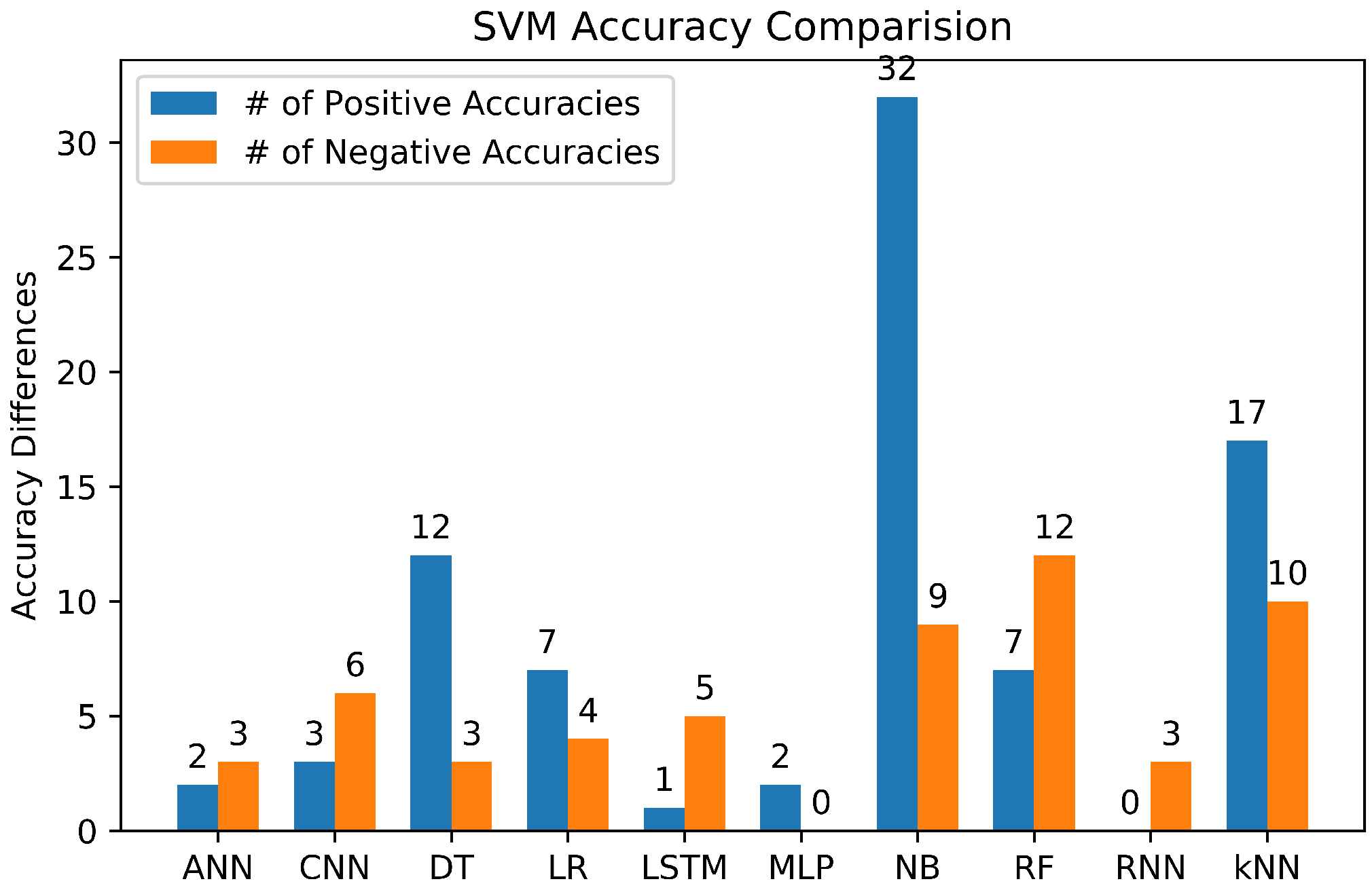
3.6.1. Support Vector Machine (SVM)
- (a)
- It is more accurate than other classifiers;
- (b)
- It works well with nonlinear distributions;
- (c)
- The overfitting chances are very low.
- (a)
- Choosing the correct kernel is challenging;
- (b)
- There is a long training time;
- (c)
- It occupies more memory.
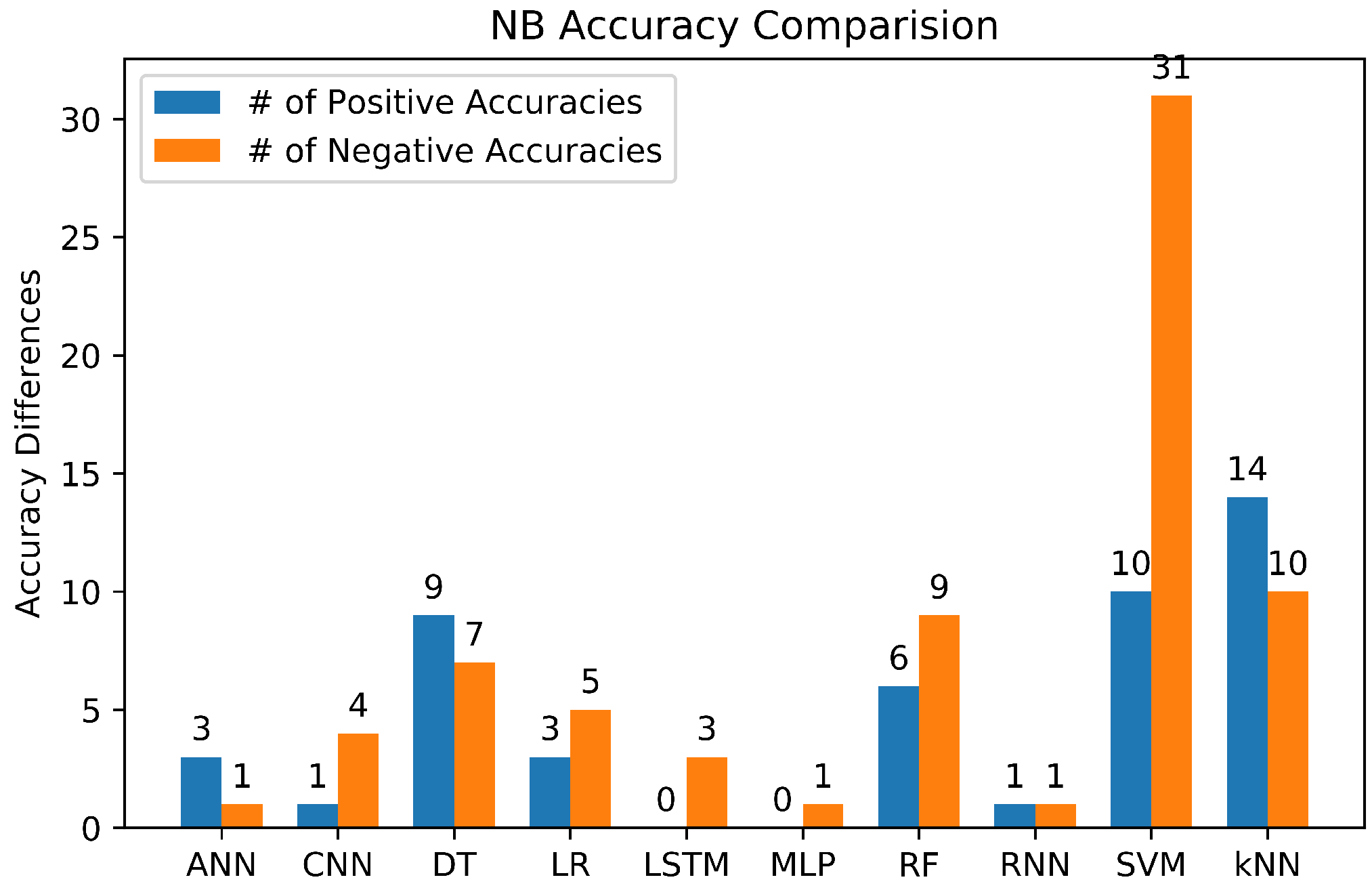
3.6.2. Naive Bayes (NB)
- (a)
- If the training set is very small, then NB can produce a good performance;
- (b)
- NB can be used for multi-class classification;
- (c)
- It does not require much training data.
- (a)
- It is not suited for small datasets [61];
- (b)
- If the features are not independent, NB is not the best choice for classification.
3.6.3. k Nearest Neighbor (kNN)
- (a)
- It needs more storage space;
- (b)
- It is highly sensitive to errors.
3.6.4. Decision Tree (DT)
3.6.5. Random Forest (RF)
3.6.6. Logistic Regression (LR)
3.6.7. Summary of Machine Learning Classifiers
3.7. Deep-Learning-Based Models for Text Classification
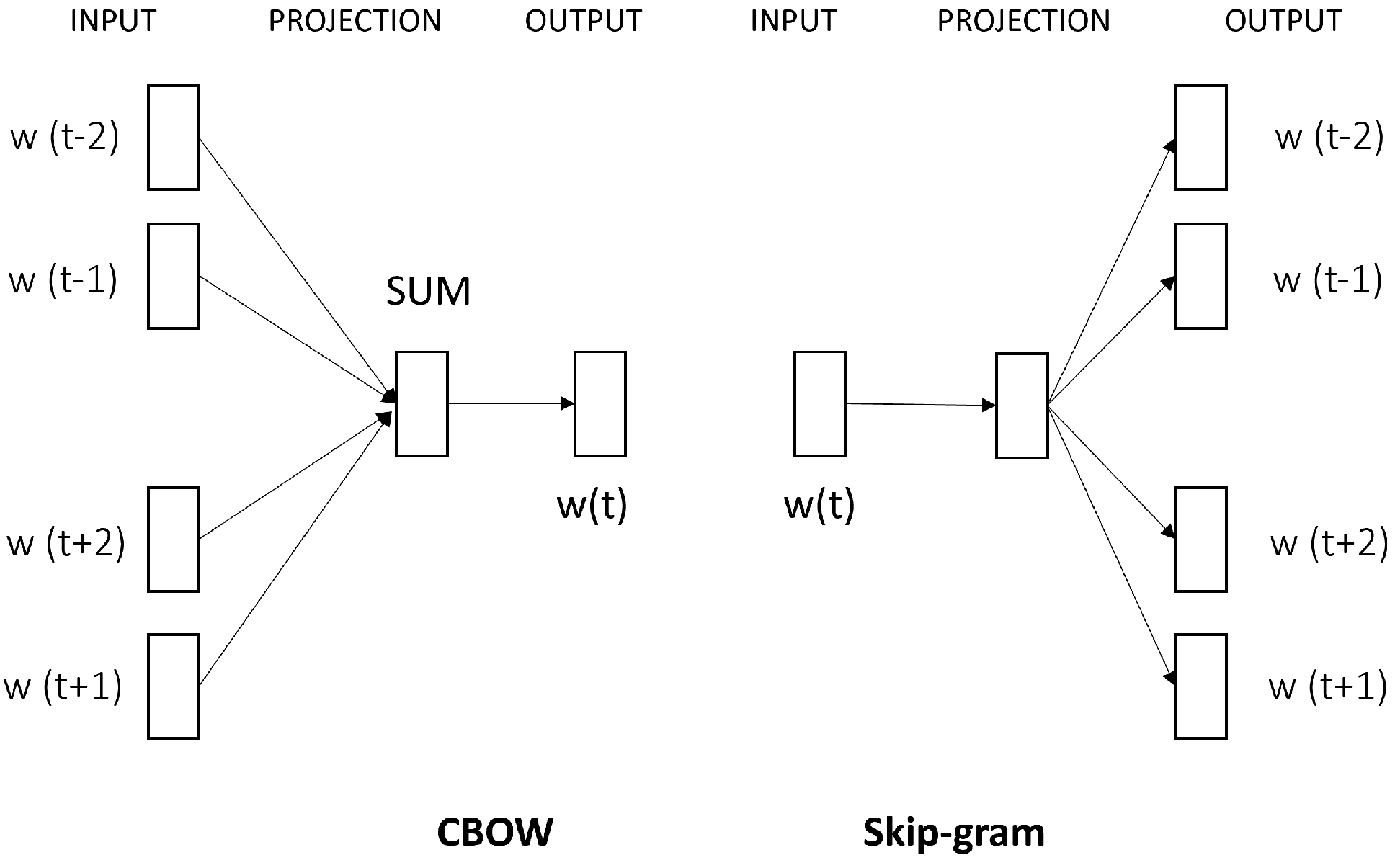
3.7.1. Word2Vec
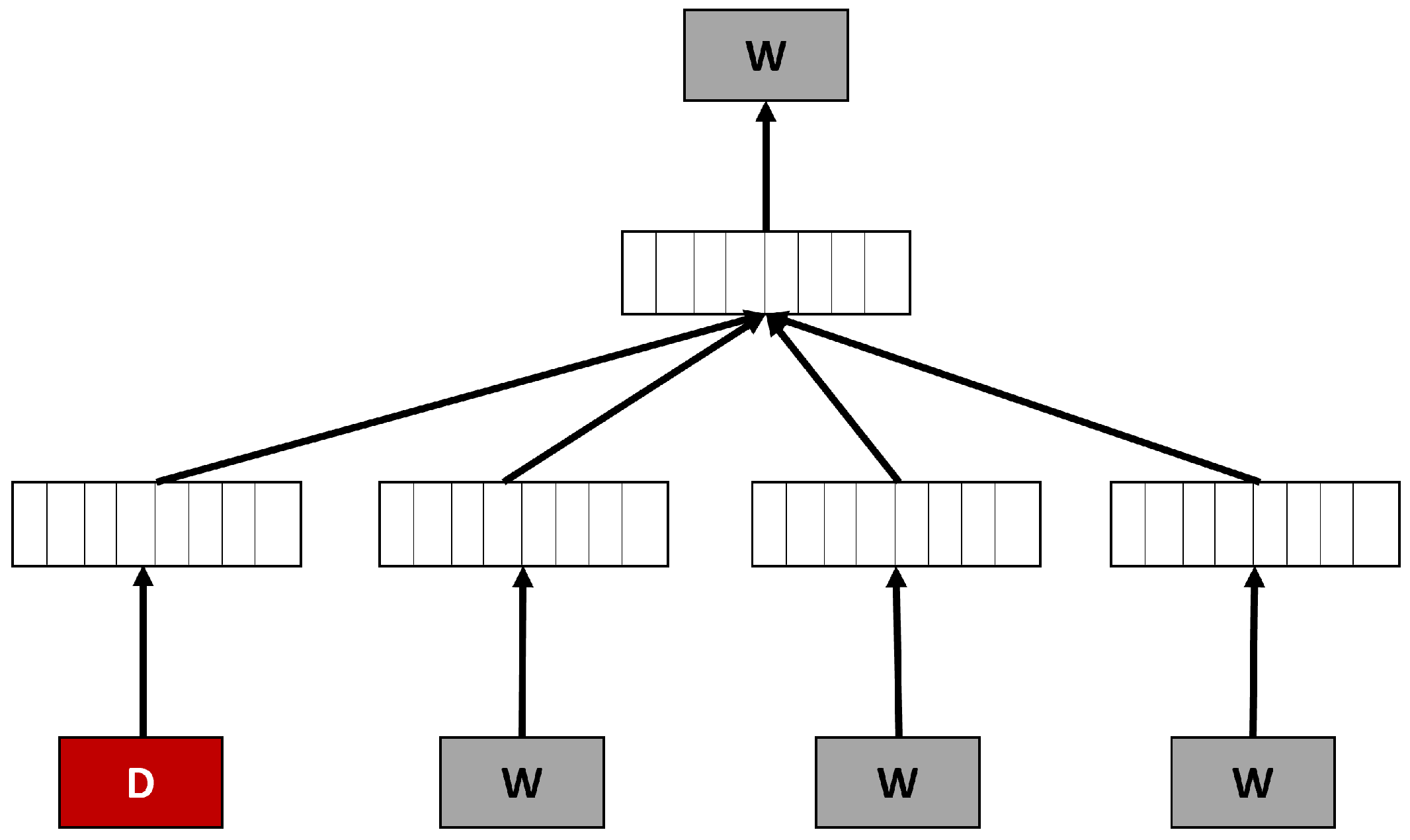
3.7.2. Doc2Vec
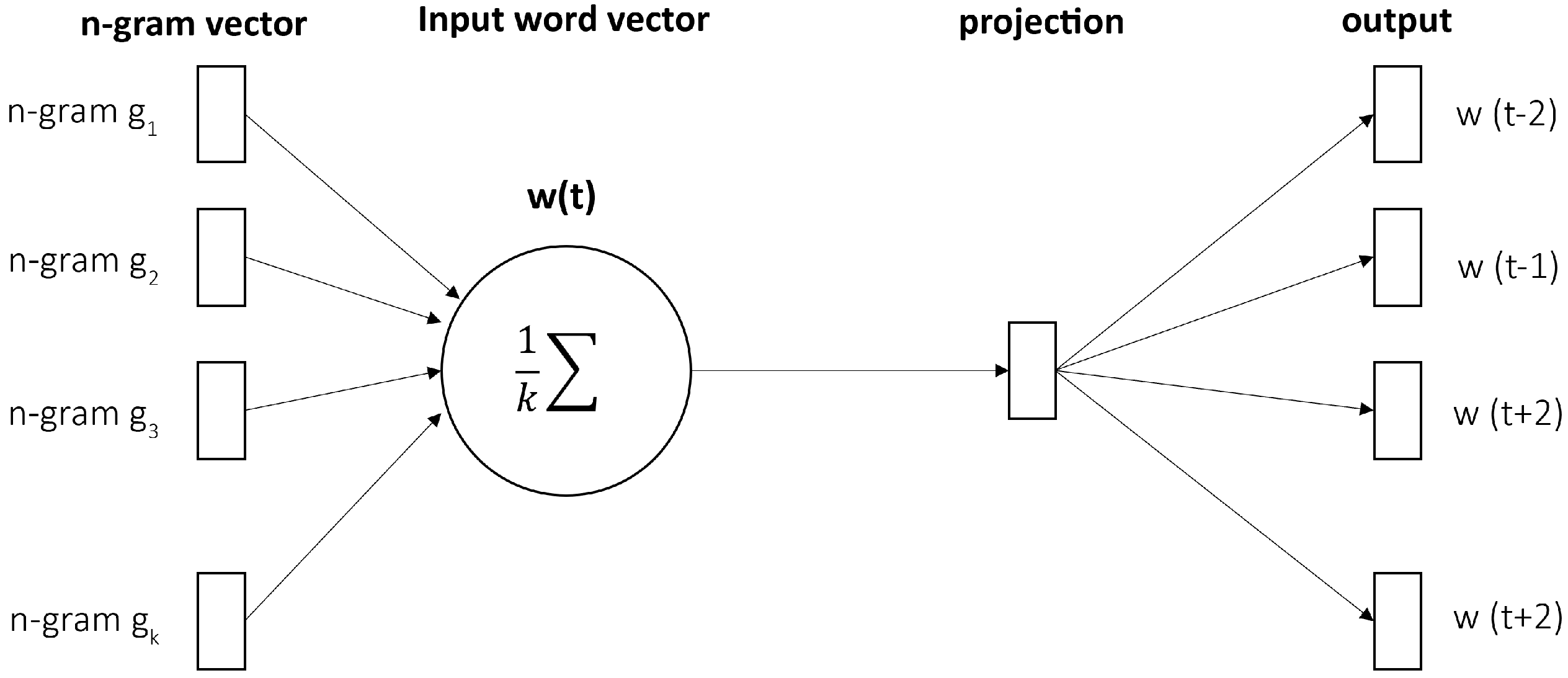
3.7.3. FastText
3.7.4. Transformers
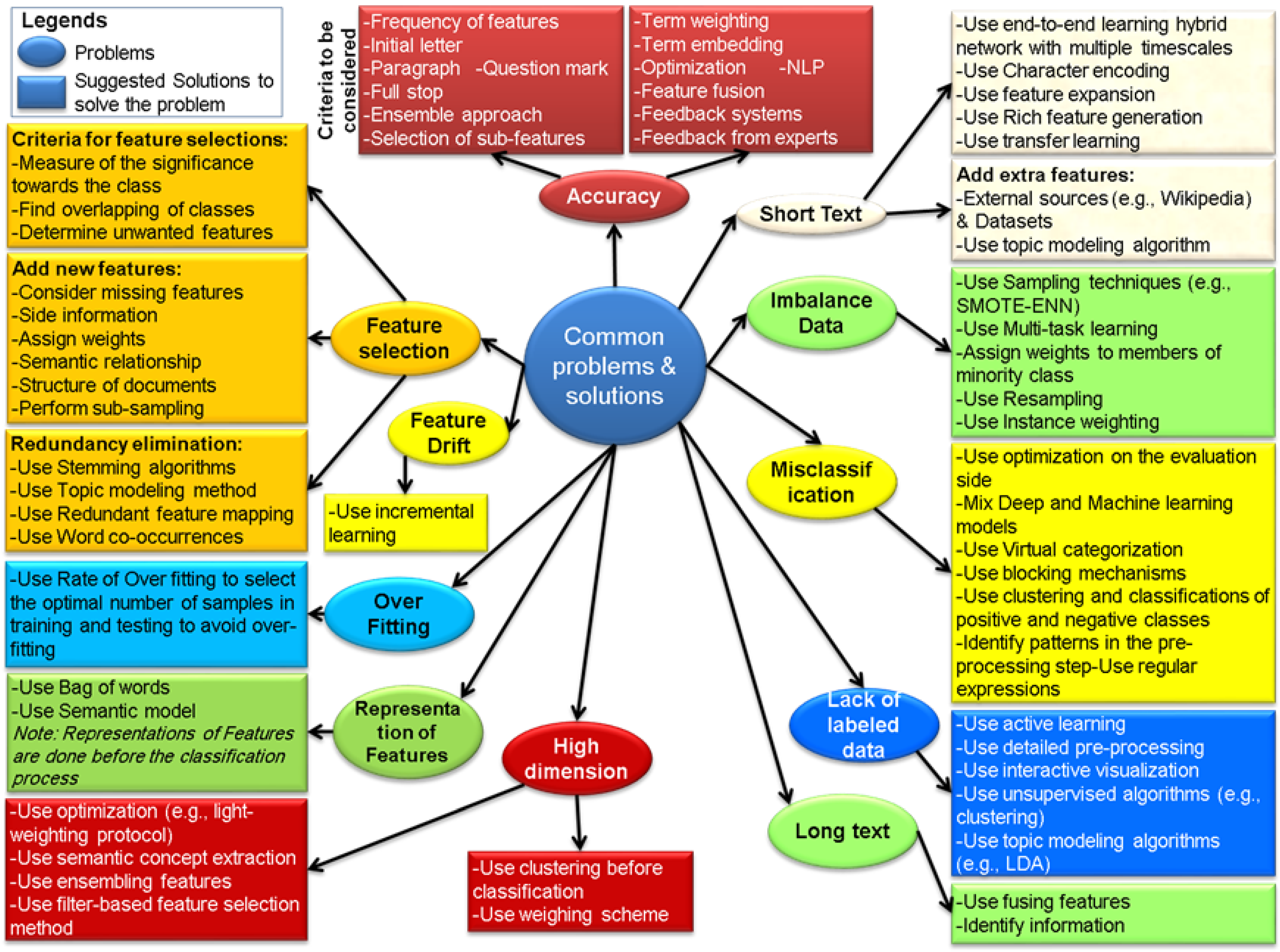
4. Problems in Text Classification
4.1. Increased Accuracy
4.2. Feature Selection
4.3. Feature Drift
4.4. Representation of Features
4.5. Overfitting
4.6. Short Text
4.7. Imbalanced Data
4.8. Misclassification
4.9. Lack of Labeled Data
4.10. High Dimensional Data
4.11. Long Text
5. Discussion
5.1. Notable Observations
- A good correlation factor can be found between a pre-classified dataset and a classified dataset. This can enable a transfer learning approach that can easily classify an unmapped instance;
- Efficient feature extraction by incorporating textual algorithms (such as sentiment analysis, NLP) can focus on finding important terms (e.g., Smiley in social text classification);
- Implementing the GAN model for generating dummy text can convert a short-text input to a normal-sized input.
5.2. Research Gaps
- Many research studies have focused on self-generated datasets. However, many datasets exist for a given domain. All of these datasets differ in terms of the format and structure of data. Thus, a multi-model classification should be developed to address this issue.
- A publicly available database that contains the federated-based classifiers of the top datasets should be created. This will significantly help future researchers to develop high-quality and fast outcomes. This step will also enable researchers to compare their local results with community results.
- The use of active learning can improve the performance of classification by using only a few inputs. The majority of the papers skip the use of active learning. Thus, future research works can focus on including active learning in the classification.
- Text representation still requires improvement. Many research works should focus on labeling or segmenting the features. For example, there may be a pronoun that represents the noun from the previous sentence. Thus, a good labeling scheme should be developed.
- The majority of research included in this survey focused on ranking features based on their frequencies. Highly frequent features are ranked the highest. However, this may not be a generalized case. This limitation can be overcome with the help of domain experts who rank the least frequent words based on their importance.
5.3. Recommendations
- Increase Accuracy: Embedding methods can be improved by incorporating graph-based embedding approaches [83].The SVM classifier can significantly increase the accuracy by focusing on improvements in kernels [136];
- Misclassification: To reduce the rate of misclassification, fusion models [119] can be improved by assigning different weights to each model and by using some recent fusion models, such as hierarchical deep genetic networks and transfer-learning-based deep models. Creating a hybrid classification model by mixing both instance selection and feature selection could be done in the future [137];
- Feature Drift: In the future, work will determine whether a feature has significant importance in the upcoming period or not [103], thus removing very old features to improve the classification.
- Long Text: To improve the speed of classification on long-text information, the authors of [135] proposed the use of parallel computing.
5.4. Strengths and Weaknesses
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sebastiani, F. Machine Learning in Automated Text Categorization. ACM Comput. Surv. 2002, 34, 1–47. [Google Scholar] [CrossRef]
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text Classification Algorithms: A Survey. Information 2019, 10, 150. [Google Scholar] [CrossRef]
- Kapočiute-Dzikiene, J. A domain-specific generative chatbot trained from little data. Appl. Sci. 2020, 10, 2221. [Google Scholar] [CrossRef]
- Rogers, D.; Preece, A.; Innes, M.; Spasić, I. Real-Time Text Classification of User-Generated Content on Social Media: Systematic Review. IEEE Trans. Comput. Soc. Syst. 2022, 9, 1154–1166. [Google Scholar] [CrossRef]
- Karayigit, H.; Akdagli, A.; Acı, Ç.İ. BERT-based Transfer Learning Model for COVID-19 Sentiment Analysis on Turkish Instagram Comments. Inf. Technol. Control 2022, 51, 409–428. [Google Scholar] [CrossRef]
- Kapočiūtė-Dzikienė, J.; Damaševičius, R.; Woźniak, M. Sentiment analysis of Lithuanian texts using traditional and deep learning approaches. Computers 2019, 8, 4. [Google Scholar] [CrossRef]
- Tesfagergish, S.G.; Kapočiūtė-Dzikienė, J.; Damaševičius, R. Zero-Shot Emotion Detection for Semi-Supervised Sentiment Analysis Using Sentence Transformers and Ensemble Learning. Appl. Sci. 2022, 12, 8662. [Google Scholar] [CrossRef]
- Karayigit, H.; Akdagli, A.; Aci, Ç.İ. Homophobic and Hate Speech Detection Using Multilingual-BERT Model on Turkish Social Media. Inf. Technol. Control 2022, 51, 356–375. [Google Scholar] [CrossRef]
- Aldjanabi, W.; Dahou, A.; Al-Qaness, M.A.A.; Elaziz, M.A.; Helmi, A.M.; Damaševičius, R. Arabic offensive and hate speech detection using a cross-corpora multi-task learning model. Informatics 2021, 8, 69. [Google Scholar] [CrossRef]
- Kapociute-Dzikiene, J.; Venckauskas, A.; Damasevicius, R. A comparison of authorship attribution approaches applied on the Lithuanian language. In Proceedings of the 2017 Federated Conference on Computer Science and Information Systems, FedCSIS 2017, Prague, Czech Republic, 3–6 September 2017; pp. 347–351. [Google Scholar]
- Mathews, A.; Sejal, N.; Venugopal, K.R. Text Based and Image Based Recommender Systems: Fundamental Concepts, Comprehensive Review and Future Directions. Int. J. Eng. Trends Technol. 2022, 70, 124–143. [Google Scholar] [CrossRef]
- Ji, Z.; Pi, H.; Wei, W.; Xiong, B.; Wozniak, M.; Damasevicius, R. Recommendation Based on Review Texts and Social Communities: A Hybrid Model. IEEE Access 2019, 7, 40416–40427. [Google Scholar] [CrossRef]
- Sun, G.; Wang, Z.; Zhao, J. Automatic text summarization using deep reinforcement learning and beyond. Inf. Technol. Control 2021, 50, 458–469. [Google Scholar] [CrossRef]
- Jiang, M.; Zou, Y.; Xu, J.; Zhang, M. GATSum: Graph-Based Topic-Aware Abstract Text Summarization. Inf. Technol. Control 2022, 51, 345–355. [Google Scholar] [CrossRef]
- Shrivas, A.K.; Dewangan, A.K.; Ghosh, S.M.; Singh, D. Development of proposed ensemble model for spam e-mail classification. Inf. Technol. Control. 2021, 50, 411–423. [Google Scholar] [CrossRef]
- Salloum, S.; Gaber, T.; Vadera, S.; Shaalan, K. A Systematic Literature Review on Phishing Email Detection Using Natural Language Processing Techniques. IEEE Access 2022, 10, 65703–65727. [Google Scholar] [CrossRef]
- Kapočiūtė-Dzikienė, J.; Balodis, K.; Skadiņš, R. Intent detection problem solving via automatic DNN hyperparameter optimization. Appl. Sci. 2020, 10, 7426. [Google Scholar] [CrossRef]
- Iqbal, W.; Malik, W.I.; Bukhari, F.; Almustafa, K.M.; Nawaz, Z. Big data full-text search index minimization using text summarization. Inf. Technol. Control 2021, 50, 375–389. [Google Scholar] [CrossRef]
- Dogra, V.; Verma, S.; Kavita; Chatterjee, P.; Shafi, J.; Choi, J.; Ijaz, M.F. A Complete Process of Text Classification System Using State-of-the-Art NLP Models. Comput. Intell. Neurosci. 2022, 2022, 1883698. [Google Scholar] [CrossRef] [PubMed]
- Ashokkumar, P.; Arunkumar, N.; Don, S. Intelligent optimal route recommendation among heterogeneous objects with keywords. Comput. Electr. Eng. 2018, 68, 526–535. [Google Scholar] [CrossRef]
- Haque, R.; Islam, N.; Tasneem, M.; Das, A.K. Multi-class sentiment classification on Bengali social media comments using machine learning. Int. J. Cogn. Comput. Eng. 2023, 4, 21–35. [Google Scholar] [CrossRef]
- Gupta, A.; Dengre, V.; Kheruwala, H.A.; Shah, M. Comprehensive review of text-mining applications in finance. Financ. Innov. 2020, 6, 39. [Google Scholar] [CrossRef]
- Li, Q.; Li, S.; Zhang, S.; Hu, J.; Hu, J. A review of text corpus-based tourism big data mining. Appl. Sci. 2019, 9, 3300. [Google Scholar] [CrossRef]
- Omoregbe, N.A.I.; Ndaman, I.O.; Misra, S.; Abayomi-Alli, O.O.; Damaševičius, R. Text messaging-based medical diagnosis using natural language processing and fuzzy logic. J. Healthc. Eng. 2020, 2020, 8839524. [Google Scholar] [CrossRef]
- Tesfagergish, S.G.; Damaševičius, R.; Kapočiūtė-Dzikienė, J. Deep Fake Recognition in Tweets Using Text Augmentation, Word Embeddings and Deep Learning; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2021; Volume 12954, pp. 523–538. [Google Scholar]
- Thangaraj, M.; Sivakami, M. Text Classification Techniques: A Literature Review. Interdiscip. J. Inf. Knowl. Manag. 2018, 13, 117–135. [Google Scholar] [CrossRef]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep Learning–based Text Classification. ACM Comput. Surv. 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Bayer, M.; Kaufhold, M.A.; Reuter, C. A Survey on Data Augmentation for Text Classification. ACM Comput. Surv. 2022, 55, 3544558. [Google Scholar] [CrossRef]
- Li, Q.; Peng, H.; Li, J.; Xia, C.; Yang, R.; Sun, L.; Yu, P.S.; He, L. A Survey on Text Classification: From Traditional to Deep Learning. ACM Trans. Intell. Syst. Technol. 2022, 13, 1–41. [Google Scholar] [CrossRef]
- Wu, H.; Liu, Y.; Wang, J. Review of text classification methods on deep learning. Comput. Mater. Contin. 2020, 63, 1309–1321. [Google Scholar] [CrossRef]
- Mirończuk, M.M.; Protasiewicz, J. A recent overview of the state-of-the-art elements of text classification. Expert Syst. Appl. 2018, 106, 36–54. [Google Scholar] [CrossRef]
- Moher, D.; Shamseer, L.; Clarke, M.; Ghersi, D.; Liberati, A.; Petticrew, M.; Shekelle, P.; Stewart, L.A. Preferred reporting items for systematic review and meta-analysis protocols (PRISMA-P) 2015 statement. Syst. Rev. 2015, 4, 1. [Google Scholar] [CrossRef]
- Isa, D.; Lee, L.H.; Kallimani, V.P.; RajKumar, R. Text Document Preprocessing with the Bayes Formula for Classification Using the Support Vector Machine. IEEE Trans. Knowl. Data Eng. 2008, 20, 1264–1272. [Google Scholar] [CrossRef]
- Han, H.; Ko, Y.; Seo, J. Using the revised EM algorithm to remove noisy data for improving the one-against-the-rest method in binary text classification. Inf. Process. Manag. 2007, 43, 1281–1293. [Google Scholar] [CrossRef]
- Haneczok, J.; Piskorski, J. Shallow and deep learning for event relatedness classification. Inf. Process. Manag. 2020, 57, 102371. [Google Scholar] [CrossRef]
- Wang, T.Y.; Chiang, H.M. Fuzzy support vector machine for multi-class text categorization. Inf. Process. Manag. 2007, 43, 914–929. [Google Scholar] [CrossRef]
- Devaraj, A.; Murthy, D.; Dontula, A. Machine-learning methods for identifying social media-based requests for urgent help during hurricanes. Int. J. Disaster Risk Reduct. 2020, 51, 101757. [Google Scholar] [CrossRef]
- Chukwuocha, C.; Mathu, T.; Raimond, K. Design of an Interactive Biomedical Text Mining Framework to Recognize Real-Time Drug Entities Using Machine Learning Algorithms. Procedia Comput. Sci. 2018, 143, 181–188. [Google Scholar] [CrossRef]
- Elnagar, A.; Al-Debsi, R.; Einea, O. Arabic text classification using deep learning models. Inf. Process. Manag. 2020, 57, 102121. [Google Scholar] [CrossRef]
- Sboev, A.; Litvinova, T.; Gudovskikh, D.; Rybka, R.; Moloshnikov, I. Machine Learning Models of Text Categorization by Author Gender Using Topic-independent Features. Procedia Comput. Sci. 2016, 101, 135–142. [Google Scholar] [CrossRef]
- Zhao, R.; Mao, K. Fuzzy Bag-of-Words Model for Document Representation. IEEE Trans. Fuzzy Syst. 2018, 26, 794–804. [Google Scholar] [CrossRef]
- Xu, D.; Tian, Z.; Lai, R.; Kong, X.; Tan, Z.; Shi, W. Deep learning based emotion analysis of microblog texts. Inf. Fusion 2020, 64, 1–11. [Google Scholar] [CrossRef]
- Baker, L.D.; McCallum, A.K. Distributional Clustering of Words for Text Classification. In Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’98, Melbourne, Australia, 24–28 August 1998; Association for Computing Machinery: New York, NY, USA, 1998; pp. 96–103. [Google Scholar] [CrossRef]
- Zhu, Y.; Li, Y.; Yue, Y.; Qiang, J.; Yuan, Y. A Hybrid Classification Method via Character Embedding in Chinese Short Text With Few Words. IEEE Access 2020, 8, 92120–92128. [Google Scholar] [CrossRef]
- Halim, Z.; Waqar, M.; Tahir, M. A machine learning-based investigation utilizing the in-text features for the identification of dominant emotion in an email. Knowl.-Based Syst. 2020, 208, 106443. [Google Scholar] [CrossRef]
- Lopes, F.; Agnelo, J.; Teixeira, C.A.; Laranjeiro, N.; Bernardino, J. Automating orthogonal defect classification using machine learning algorithms. Future Gener. Comput. Syst. 2020, 102, 932–947. [Google Scholar] [CrossRef]
- Goodrum, H.; Roberts, K.; Bernstam, E.V. Automatic classification of scanned electronic health record documents. Int. J. Med. Inform. 2020, 144, 104302. [Google Scholar] [CrossRef]
- Vijayakumar, B.; Fuad, M.M.M. A New Method to Identify Short-Text Authors Using Combinations of Machine Learning and Natural Language Processing Techniques. Procedia Comput. Sci. 2019, 159, 428–436. [Google Scholar] [CrossRef]
- Singh, A.; Tucker, C.S. A machine learning approach to product review disambiguation based on function, form and behavior classification. Decis. Support Syst. 2017, 97, 81–91. [Google Scholar] [CrossRef]
- Park, E.L.; Cho, S.; Kang, P. Supervised Paragraph Vector: Distributed Representations of Words, Documents and Class Labels. IEEE Access 2019, 7, 29051–29064. [Google Scholar] [CrossRef]
- Rashid, J.; Adnan Shah, S.M.; Irtaza, A.; Mahmood, T.; Nisar, M.W.; Shafiq, M.; Gardezi, A. Topic Modeling Technique for Text Mining Over Biomedical Text Corpora Through Hybrid Inverse Documents Frequency and Fuzzy K-Means Clustering. IEEE Access 2019, 7, 146070–146080. [Google Scholar] [CrossRef]
- Liu, C.; Hsaio, W.; Lee, C.; Lu, G.; Jou, E. Movie Rating and Review Summarization in Mobile Environment. IEEE Trans. Syst. Man Cybern. Part Appl. Rev. 2012, 42, 397–407. [Google Scholar] [CrossRef]
- Yu, B.; Xu, Z.B. A comparative study for content-based dynamic spam classification using four machine learning algorithms. Knowl.-Based Syst. 2008, 21, 355–362. [Google Scholar] [CrossRef]
- Espejo-Garcia, B.; Martinez-Guanter, J.; Pérez-Ruiz, M.; Lopez-Pellicer, F.J.; Javier Zarazaga-Soria, F. Machine learning for automatic rule classification of agricultural regulations: A case study in Spain. Comput. Electron. Agric. 2018, 150, 343–352. [Google Scholar] [CrossRef]
- Ligthart, A.; Catal, C.; Tekinerdogan, B. Analyzing the effectiveness of semi-supervised learning approaches for opinion spam classification. Appl. Soft Comput. 2021, 101, 107023. [Google Scholar] [CrossRef]
- Song, D.; Vold, A.; Madan, K.; Schilder, F. Multi-label legal document classification: A deep learning-based approach with label-attention and domain-specific pre-training. Inf. Syst. 2021, 106, 101718. [Google Scholar] [CrossRef]
- Rostam, N.A.P.; Malim, N.H.A.H. Text categorisation in Quran and Hadith: Overcoming the interrelation challenges using machine learning and term weighting. J. King Saud Univ.-Comput. Inf. Sci. 2019, 33, 658–667. [Google Scholar] [CrossRef]
- Altınel, B.; Can Ganiz, M.; Diri, B. A corpus-based semantic kernel for text classification by using meaning values of terms. Eng. Appl. Artif. Intell. 2015, 43, 54–66. [Google Scholar] [CrossRef]
- Shafiabady, N.; Lee, L.; Rajkumar, R.; Kallimani, V.; Akram, N.A.; Isa, D. Using unsupervised clustering approach to train the Support Vector Machine for text classification. Neurocomputing 2016, 211, 4–10. [Google Scholar] [CrossRef]
- Sabbah, T.; Selamat, A.; Selamat, M.H.; Al-Anzi, F.S.; Viedma, E.H.; Krejcar, O.; Fujita, H. Modified frequency-based term weighting schemes for text classification. Appl. Soft Comput. 2017, 58, 193–206. [Google Scholar] [CrossRef]
- Milosevic, N.; Dehghantanha, A.; Choo, K.K.R. Machine learning aided Android malware classification. Comput. Electr. Eng. 2017, 61, 266–274. [Google Scholar] [CrossRef]
- Akhter, M.P.; Jiangbin, Z.; Naqvi, I.R.; Abdelmajeed, M.; Mehmood, A.; Sadiq, M.T. Document-Level Text Classification Using Single-Layer Multisize Filters Convolutional Neural Network. IEEE Access 2020, 8, 42689–42707. [Google Scholar] [CrossRef]
- Huang, L.; Song, T.; Jiang, T. Linear regression combined KNN algorithm to identify latent defects for imbalance data of ICs. Microelectron. J. 2023, 131, 105641. [Google Scholar] [CrossRef]
- Li, W.; Miao, D.; Wang, W. Two-level hierarchical combination method for text classification. Expert Syst. Appl. 2011, 38, 2030–2039. [Google Scholar] [CrossRef]
- Wan, C.H.; Lee, L.H.; Rajkumar, R.; Isa, D. A hybrid text classification approach with low dependency on parameter by integrating K-nearest neighbor and support vector machine. Expert Syst. Appl. 2012, 39, 11880–11888. [Google Scholar] [CrossRef]
- Vo, D.T.; Ock, C.Y. Learning to classify short text from scientific documents using topic models with various types of knowledge. Expert Syst. Appl. 2015, 42, 1684–1698. [Google Scholar] [CrossRef]
- Khabbaz, M.; Kianmehr, K.; Alhajj, R. Employing Structural and Textual Feature Extraction for Semistructured Document Classification. IEEE Trans. Syst. Man Cybern. Part Appl. Rev. 2012, 42, 1566–1578. [Google Scholar] [CrossRef]
- Asim, Y.; Shahid, A.R.; Malik, A.K.; Raza, B. Significance of machine learning algorithms in professional blogger’s classification. Comput. Electr. Eng. 2018, 65, 461–473. [Google Scholar] [CrossRef]
- Hartmann, J.; Huppertz, J.; Schamp, C.; Heitmann, M. Comparing automated text classification methods. Int. J. Res. Mark. 2019, 36, 20–38. [Google Scholar] [CrossRef]
- Ngejane, C.; Eloff, J.; Sefara, T.; Marivate, V. Digital forensics supported by machine learning for the detection of online sexual predatory chats. Forensic Sci. Int. Digit. Investig. 2021, 36, 301109. [Google Scholar] [CrossRef]
- Tesfagergish, S.G.; Kapočiūtė-Dzikienė, J. Part-of-speech tagging via deep neural networks for northern-Ethiopic languages. Inf. Technol. Control 2020, 49, 482–494. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.S.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Le, Q.V.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2016, 5, 135–146. [Google Scholar] [CrossRef]
- Choi, J.; Lee, S.W. Improving FastText with inverse document frequency of subwords. Pattern Recognit. Lett. 2020, 133, 165–172. [Google Scholar] [CrossRef]
- Athiwaratkun, B.; Wilson, A.G.; Anandkumar, A. Probabilistic FastText for Multi-Sense Word Embeddings. In Proceedings of the ACL, Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the NAACL, New Orleans, LA, USA, 1–6 June 2018. [Google Scholar]
- Damasevicius, R.; Valys, R.; Wozniak, M. Intelligent tagging of online texts using fuzzy logic. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence, SSCI, Athens, Greece, 6–9 December 2016. [Google Scholar]
- Khasanah, I.N. Sentiment Classification Using fastText Embedding and Deep Learning Model. Procedia Comput. Sci. 2021, 189, 343–350. [Google Scholar] [CrossRef]
- Ait Hammou, B.; Ait Lahcen, A.; Mouline, S. Towards a real-time processing framework based on improved distributed recurrent neural network variants with fastText for social big data analytics. Inf. Process. Manag. 2020, 57, 102122. [Google Scholar] [CrossRef]
- Fang, Y.; Huang, C.; Su, Y.; Qiu, Y. Detecting malicious JavaScript code based on semantic analysis. Comput. Secur. 2020, 93, 101764. [Google Scholar] [CrossRef]
- Luo, X. Efficient English text classification using selected Machine Learning Techniques. Alex. Eng. J. 2021, 60, 3401–3409. [Google Scholar] [CrossRef]
- Ibrahim, M.A.; Ghani Khan, M.U.; Mehmood, F.; Asim, M.N.; Mahmood, W. GHS-NET a generic hybridized shallow neural network for multi-label biomedical text classification. J. Biomed. Inform. 2021, 116, 103699. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Mou, L.; Cui, H.; Lu, Z.; Song, S. Finding decision jumps in text classification. Neurocomputing 2020, 371, 177–187. [Google Scholar] [CrossRef]
- Ye, X.; Dai, H.; Dong, L.A.; Wang, X. Multi-view ensemble learning method for microblog sentiment classification. Expert Syst. Appl. 2021, 166, 113987. [Google Scholar] [CrossRef]
- Fragos, K.; Belsis, P.; Skourlas, C. Combining Probabilistic Classifiers for Text Classification. Procedia-Soc. Behav. Sci. 2014, 147, 307–312. [Google Scholar] [CrossRef]
- Shang, C.; Li, M.; Feng, S.; Jiang, Q.; Fan, J. Feature selection via maximizing global information gain for text classification. Knowl.-Based Syst. 2013, 54, 298–309. [Google Scholar] [CrossRef]
- Matošević, G.; Dobša, J.; Mladenić, D. Using Machine Learning for Web Page Classification in Search Engine Optimization. Future Internet 2021, 13, 9. [Google Scholar] [CrossRef]
- Mesleh, A.M. Feature sub-set selection metrics for Arabic text classification. Pattern Recognit. Lett. 2011, 32, 1922–1929. [Google Scholar] [CrossRef]
- Santucci, V.; Santarelli, F.; Forti, L.; Spina, S. Automatic Classification of Text Complexity. Appl. Sci. 2020, 10, 7285. [Google Scholar] [CrossRef]
- Ganiz, M.C.; Lytkin, N.I.; Pottenger, W.M. Leveraging Higher Order Dependencies between Features for Text Classification. Mach. Learn. Knowl. Discov. Databases Lect. Notes Comput. Sci. 2009, 5781, 375–390. [Google Scholar] [CrossRef]
- Sabbah, T.; Selamat, A.; Selamat, M.H.; Ibrahim, R.; Fujita, H. Hybridized term-weighting method for Dark Web classification. Neurocomputing 2016, 173, 1908–1926. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Zhao, Y.; Yu, P.S. On the Use of Side Information for Mining Text Data. IEEE Trans. Knowl. Data Eng. 2014, 26, 1415–1429. [Google Scholar] [CrossRef]
- Ojewumi, T.; Ogunleye, G.; Oguntunde, B.; Folorunsho, O.; Fashoto, S.; Ogbu, N. Performance evaluation of machine learning tools for detection of phishing attacks on web pages. Sci. Afr. 2022, 16, e01165. [Google Scholar] [CrossRef]
- Moreo, A.; Esuli, A.; Sebastiani, F. Learning to Weight for Text Classification. IEEE Trans. Knowl. Data Eng. 2020, 32, 302–316. [Google Scholar] [CrossRef]
- Hasan, M.; Kotov, A.; Idalski Carcone, A.; Dong, M.; Naar, S.; Brogan Hartlieb, K. A study of the effectiveness of machine learning methods for classification of clinical interview fragments into a large number of categories. J. Biomed. Inform. 2016, 62, 21–31. [Google Scholar] [CrossRef]
- Galitsky, B. Machine learning of syntactic parse trees for search and classification of text. Eng. Appl. Artif. Intell. 2013, 26, 1072–1091. [Google Scholar] [CrossRef]
- Liang, J.; Zhou, X.; Liu, P.; Guo, L.; Bai, S. An EMM-based Approach for Text Classification. Procedia Comput. Sci. 2013, 17, 506–513. [Google Scholar] [CrossRef]
- He, J.; Wang, L.; Liu, L.; Feng, J.; Wu, H. Long Document Classification From Local Word Glimpses via Recurrent Attention Learning. IEEE Access 2019, 7, 40707–40718. [Google Scholar] [CrossRef]
- Alhaj, Y.A.; Dahou, A.; Al-Qaness, M.A.A.; Abualigah, L.; Abbasi, A.A.; Almaweri, N.A.O.; Elaziz, M.A.; Damaševičius, R. A Novel Text Classification Technique Using Improved Particle Swarm Optimization: A Case Study of Arabic Language. Future Internet 2022, 14, 194. [Google Scholar] [CrossRef]
- Lin, Y.; Jiang, J.; Lee, S. A Similarity Measure for Text Classification and Clustering. IEEE Trans. Knowl. Data Eng. 2014, 26, 1575–1590. [Google Scholar] [CrossRef]
- Figueiredo, F.; Rocha, L.; Couto, T.; Salles, T.; Gonçalves, M.A.; Meira, W., Jr. Word co-occurrence features for text classification. Inf. Syst. 2011, 36, 843–858. [Google Scholar] [CrossRef]
- Chen, C.; Wang, Y.; Zhang, J.; Xiang, Y.; Zhou, W.; Min, G. Statistical Features-Based Real-Time Detection of Drifted Twitter Spam. IEEE Trans. Inf. Forensics Secur. 2017, 12, 914–925. [Google Scholar] [CrossRef]
- Babapour, S.M.; Roostaee, M. Web pages classification: An effective approach based on text mining techniques. In Proceedings of the 2017 IEEE 4th International Conference on Knowledge-Based Engineering and Innovation (KBEI), Tehran, Iran, 22 December 2017; pp. 0320–0323. [Google Scholar] [CrossRef]
- Kim, H.J.; Kim, J.; Kim, J.; Lim, P. Towards perfect text classification with Wikipedia-based semantic Naïve Bayes learning. Neurocomputing 2018, 315, 128–134. [Google Scholar] [CrossRef]
- Fesseha, A.; Xiong, S.; Emiru, E.D.; Diallo, M.; Dahou, A. Text Classification Based on Convolutional Neural Networks and Word Embedding for Low-Resource Languages: Tigrinya. Information 2021, 12, 52. [Google Scholar] [CrossRef]
- Lilleberg, J.; Zhu, Y.; Zhang, Y. Support vector machines and Word2vec for text classification with semantic features. In Proceedings of the 2015 IEEE 14th International Conference on Cognitive Informatics Cognitive Computing (ICCI*CC), Beijing, China, 6–8 July 2015; pp. 136–140. [Google Scholar] [CrossRef]
- Ganiz, M.C.; George, C.; Pottenger, W.M. Higher Order Naive Bayes: A Novel Non-IID Approach to Text Classification. IEEE Trans. Knowl. Data Eng. 2011, 23, 1022–1034. [Google Scholar] [CrossRef]
- Feng, X.; Liang, Y.; Shi, X.; Xu, D.; Wang, X.; Guan, R. Overfitting Reduction of Text Classification Based on AdaBELM. Entropy 2017, 19, 330. [Google Scholar] [CrossRef]
- Moirangthem, D.S.; Lee, M. Hierarchical and lateral multiple timescales gated recurrent units with pre-trained encoder for long text classification. Expert Syst. Appl. 2021, 165, 113898. [Google Scholar] [CrossRef]
- Wang, P.; Xu, B.; Xu, J.; Tian, G.; Liu, C.L.; Hao, H. Semantic expansion using word embedding clustering and convolutional neural network for improving short text classification. Neurocomputing 2016, 174, 806–814. [Google Scholar] [CrossRef]
- Li, J.; Rao, Y.; Jin, F.; Chen, H.; Xiang, X. Multi-label maximum entropy model for social emotion classification over short text. Neurocomputing 2016, 210, 247–256. [Google Scholar] [CrossRef]
- Wang, X.; Chen, R.; Jia, Y.; Zhou, B. Short Text Classification Using Wikipedia Concept Based Document Representation. In Proceedings of the 2013 International Conference on Information Technology and Applications, Chengdu, China, 16–17 November 2013; pp. 471–474. [Google Scholar] [CrossRef]
- Xu, J.; Du, Q. Learning transferable features in meta-learning for few-shot text classification. Pattern Recognit. Lett. 2020, 135, 271–278. [Google Scholar] [CrossRef]
- Kim, N.; Hong, S. Automatic classification of citizen requests for transportation using deep learning: Case study from Boston city. Inf. Process. Manag. 2021, 58, 102410. [Google Scholar] [CrossRef]
- Liu, Y.; Loh, H.T.; Sun, A. Imbalanced text classification: A term weighting approach. Expert Syst. Appl. 2009, 36, 690–701. [Google Scholar] [CrossRef]
- Sun, A.; Lim, E.P.; Liu, Y. On strategies for imbalanced text classification using SVM: A comparative study. Decis. Support Syst. 2009, 48, 191–201. [Google Scholar] [CrossRef]
- Triantafyllou, I.; Drivas, I.C.; Giannakopoulos, G. How to Utilize My App Reviews? A Novel Topics Extraction Machine Learning Schema for Strategic Business Purposes. Entropy 2020, 22, 1310. [Google Scholar] [CrossRef]
- Basiri, M.E.; Abdar, M.; Cifci, M.A.; Nemati, S.; Acharya, U.R. A novel method for sentiment classification of drug reviews using fusion of deep and machine learning techniques. Knowl.-Based Syst. 2020, 198, 105949. [Google Scholar] [CrossRef]
- Stein, R.A.; Jaques, P.A.; Valiati, J.F. An analysis of hierarchical text classification using word embeddings. Inf. Sci. 2019, 471, 216–232. [Google Scholar] [CrossRef]
- Sun, A.; Lim, E.; Ng, W.; Srivastava, J. Blocking reduction strategies in hierarchical text classification. IEEE Trans. Knowl. Data Eng. 2004, 16, 1305–1308. [Google Scholar] [CrossRef]
- Alsmadi, I.; Alhami, I. Clustering and classification of email contents. J. King Saud Univ.-Comput. Inf. Sci. 2015, 27, 46–57. [Google Scholar] [CrossRef]
- Galgani, F.; Compton, P.; Hoffmann, A. LEXA: Building knowledge bases for automatic legal citation classification. Expert Syst. Appl. 2015, 42, 6391–6407. [Google Scholar] [CrossRef]
- Hu, R.; Mac Namee, B.; Delany, S.J. Active learning for text classification with reusability. Expert Syst. Appl. 2016, 45, 438–449. [Google Scholar] [CrossRef]
- Jung, N.; Lee, G. Automated classification of building information modeling (BIM) case studies by BIM use based on natural language processing (NLP) and unsupervised learning. Adv. Eng. Inform. 2019, 41, 100917. [Google Scholar] [CrossRef]
- Heimerl, F.; Koch, S.; Bosch, H.; Ertl, T. Visual Classifier Training for Text Document Retrieval. IEEE Trans. Vis. Comput. Graph. 2012, 18, 2839–2848. [Google Scholar] [CrossRef]
- Palanivinayagam, A.; Nagarajan, S. An optimized iterative clustering framework for recognizing speech. Int. J. Speech Technol. 2020, 23, 767–777. [Google Scholar] [CrossRef]
- Pavlinek, M.; Podgorelec, V. Text classification method based on self-training and LDA topic models. Expert Syst. Appl. 2017, 80, 83–93. [Google Scholar] [CrossRef]
- Silva, R.M.; Almeida, T.A.; Yamakami, A. MDLText: An efficient and lightweight text classifier. Knowl.-Based Syst. 2017, 118, 152–164. [Google Scholar] [CrossRef]
- Hoai Nam, L.N.; Quoc, H.B. Integrating Low-rank Approximation and Word Embedding for Feature Transformation in the High-dimensional Text Classification. Procedia Comput. Sci. 2017, 112, 437–446. [Google Scholar] [CrossRef]
- Onan, A.; Korukoğlu, S.; Bulut, H. Ensemble of keyword extraction methods and classifiers in text classification. Expert Syst. Appl. 2016, 57, 232–247. [Google Scholar] [CrossRef]
- Uysal, A.K.; Gunal, S. A novel probabilistic feature selection method for text classification. Knowl.-Based Syst. 2012, 36, 226–235. [Google Scholar] [CrossRef]
- Seara Vieira, A.; Borrajo, L.; Iglesias, E. Improving the text classification using clustering and a novel HMM to reduce the dimensionality. Comput. Methods Programs Biomed. 2016, 136, 119–130. [Google Scholar] [CrossRef]
- Selamat, A.; Omatu, S. Web page feature selection and classification using neural networks. Inf. Sci. 2004, 158, 69–88. [Google Scholar] [CrossRef]
- Deng, J.; Cheng, L.; Wang, Z. Attention-based BiLSTM fused CNN with gating mechanism model for Chinese long text classification. Comput. Speech Lang. 2021, 68, 101182. [Google Scholar] [CrossRef]
- Liu, Y.; Bi, J.W.; Fan, Z.P. Multi-class sentiment classification: The experimental comparisons of feature selection and machine learning algorithms. Expert Syst. Appl. 2017, 80, 323–339. [Google Scholar] [CrossRef]
- Tsai, C.F.; Chen, Z.Y.; Ke, S.W. Evolutionary instance selection for text classification. J. Syst. Softw. 2014, 90, 104–113. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Search Keywords Used | ||
|---|---|---|
| Machine-learning-based classification | text classification | text mining |
| text analysis | text categorization | document classification |
| sentiment analysis | natural language processing | Data mining |
| Dataset | # | Model Wise Count | |||||||
|---|---|---|---|---|---|---|---|---|---|
| ANN | CNN | DT | kNN | LR | NB | RF | SVM | ||
| 20Newsgroup | 49 | 1 | 4 | 5 | 17 | 2 | 23 | 5 | 29 |
| Reuters | 44 | 2 | 4 | 4 | 20 | 2 | 17 | 6 | 27 |
| Webkb | 16 | - | - | - | 9 | - | 7 | - | 10 |
| IMDb | 8 | 1 | 1 | - | 1 | 1 | 3 | 1 | 5 |
| Ohsumed | 7 | - | - | - | 4 | 1 | 2 | 1 | 4 |
| 6 | 1 | 2 | 3 | 2 | 2 | 3 | 3 | 4 | |
| AmazonReview | 5 | - | - | - | 2 | 1 | 1 | - | 2 |
| Enron8715 | 5 | 2 | - | 2 | 1 | - | 2 | 2 | 4 |
| TREC | 5 | - | 1 | - | 1 | - | 2 | - | 4 |
| YelpReview | 3 | - | - | - | - | 1 | 2 | 1 | 2 |
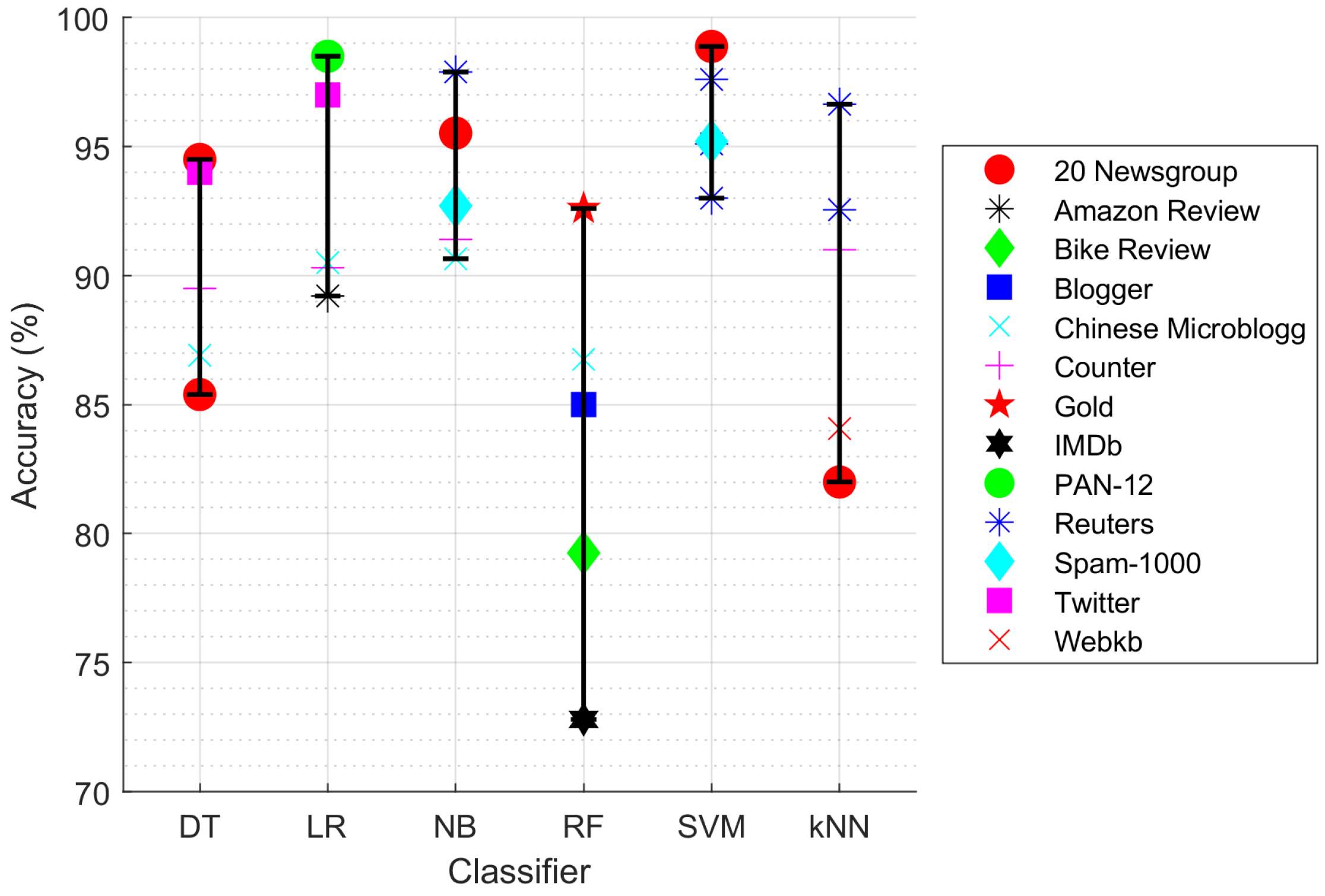
| Model | # of Papers | Max Accuracy (%) | Dataset | Reference |
|---|---|---|---|---|
| SVM | 118 | 98.88 | 20Newsgroup | [33] |
| NB | 92 | 97.89 | Reuters | [34] |
| kNN | 66 | 96.64 | Reuters | [34] |
| RF | 42 | 92.60 | Gold | [35] |
| DT | 34 | 94.50 | 20Newsgroup | [36] |
| CNN | 27 | 98 | [37] | |
| LR | 23 | 98.50 | PubMed | [38] |
| LSTM | 16 | 96.54 | Arabiya | [39] |
| ANN | 10 | 86 | RusPersonality | [40] |
| LDA | 10 | 96.20 | Reuters | [41] |
| Ada Boost | 9 | 97 | [37] | |
| RNN | 6 | 90.65 | Chinese Microblogg | [42] |
| C4.5 | 6 | 74 | 20Newsgroup | [43] |
| LSA | 6 | 96.50 | Reuters | [41] |
| BILSTM | 5 | 98 | [37] | |
| GRU | 4 | 96.76 | Arabiya | [39] |
| XGBoost | 4 | 98 | [37] | |
| CNN-BiLSM | 3 | 81.90 | THUCNews | [44] |
| CRF | 1 | 98.75 | PubMed | [38] |
| Dataset | Accuracy (%) | Algorithm | Train-Test | Reference |
|---|---|---|---|---|
| Enron8715 | 86 | ANN | 70–30% | [45] |
| Bug Report | 47.60 | RNN | 10 Fold | [46] |
| EHR | 88.30 | RF | 90–10% | [47] |
| Yelp Review | 84.20 | SVM | 10 Fold | [48] |
| 98 | CNN | 10 Fold | [37] | |
| Bike Review | 79.25 | RF | 10 Fold | [49] |
| 20Newsgroup | 98.88 | SVM | 10 Fold | [33] |
| Amazon Review | 91 | LSA | 60–40% | [41] |
| IMDb | 88.87 | LR | 50–50% | [50] |
| Ohsumed | 54.10 | LDA | 10 Fold | [51] |
| Movie Review | 86.50 | SVM | 5 Fold | [52] |
| Spam-1000 | 95.20 | SVM | 60–40% | [53] |
| Reuters | 97.89 | NB | 5 Fold | [34] |
| Webkb | 91.30 | SVM | 5 Fold | [34] |
| Parameter | Count |
|---|---|
| Accuracy | 107 |
| F1 | 99 |
| Precision | 64 |
| Recall | 55 |
| Execution time | 15 |
| AUC | 5 |
| Kappa Coefficient | 4 |
| FP Rate | 4 |
| Sensitivity | 4 |
| Specificity | 3 |
| Classification error | 3 |
| Hamming Loss | 3 |
| Variance | 2 |
| TP Rate | 2 |
| FN Rate | 1 |
| MAE | 1 |
| Ranking loss | 1 |
| AULC | 1 |
| ROC | 1 |
| Jaccard Similarity Score | 1 |
| Reliability | 1 |
| ARI | 1 |
| RMSE | 1 |
| Validation Combination | No. of Papers |
|---|---|
| Accuracy | 56 |
| F1 | 37 |
| F1, Precision, Recall | 26 |
| Accuracy, F1, Precision, Recall | 12 |
| Accuracy, Execution time | 8 |
| Accuracy, F1 | 8 |
| Precision | 6 |
| Accuracy, Precision, Recall | 3 |
| Precision, Recall | 3 |
| Accuracy, Recall | 2 |
| Classification error | 2 |
| Dataset | Accuracy (%) | Other Model Performance (%) | Reference |
|---|---|---|---|
| 20Newsgroup | 98.88 | NB (95.52) | [46] |
| Reuters | 97.60 | NB (97.89), kNN (96.64) | [34] |
| Spam-1000 | 95.20 | NB (92.70), ANN (85.30) | [53] |
| Reuters | 95.10 | Traditional SVM (82.76) | [59] |
| Reuters | 93 | kNN (53), NB (24) | [60] |
| Dataset | Accuracy (%) | Other Model Performance (%) | Reference |
|---|---|---|---|
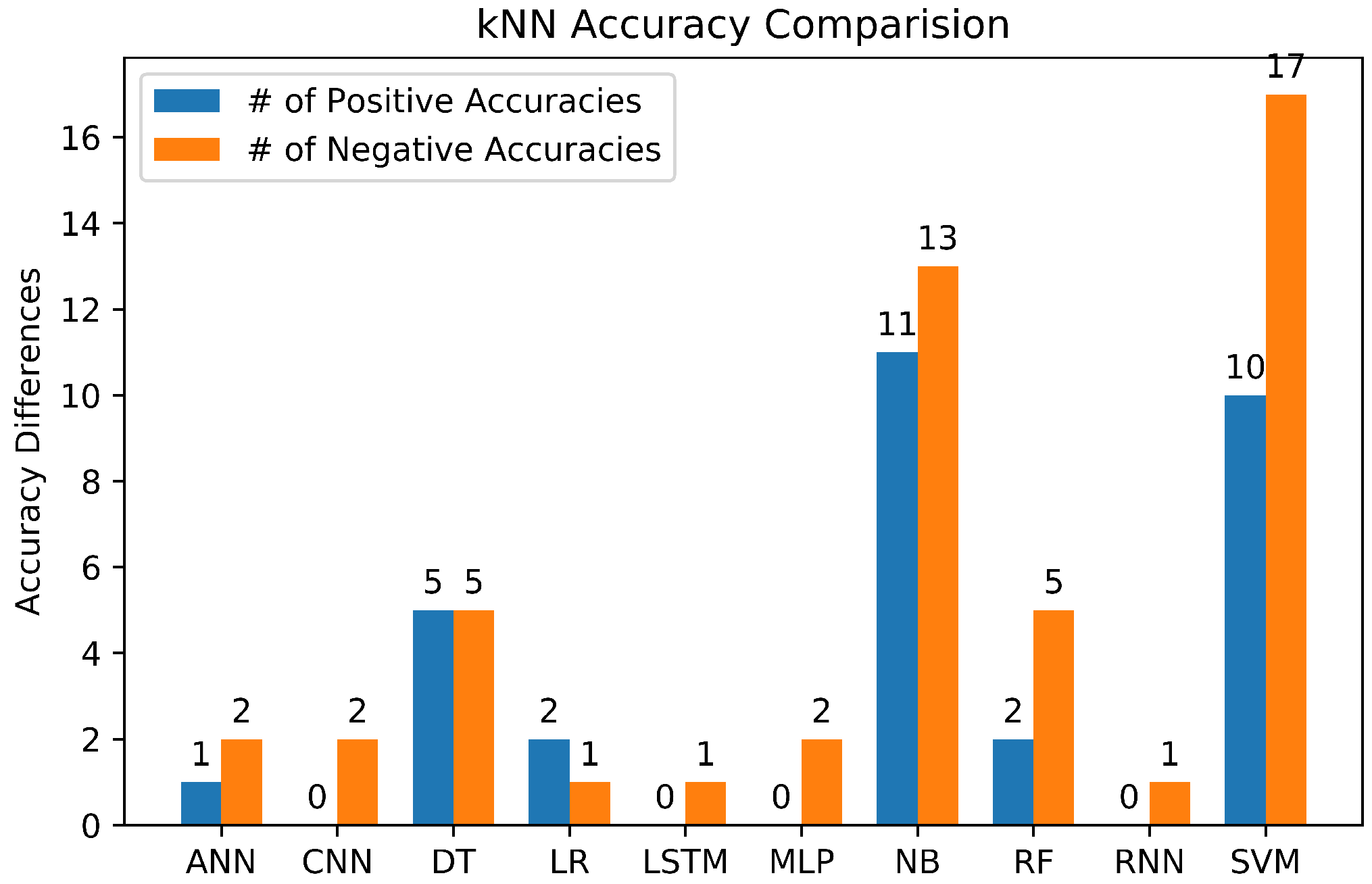
| Reuters | 97.89 | SVM (97.60), kNN (96.64) | [34] |
| 20Newsgroup | 95.52 | SVM (98.88) | [33] |
| Spam-1000 | 92.70 | SVM (95.20), ANN (85.30) | [53] |
| Counter | 91.40 | LR (90.30), DT (89.50), kNN (91), SVM(71.70) | [62] |
| Chinese Microblogg | 90.65 | CNN (97.60), SVM (90.60), LR (90.50), DT (86.91), RF (86.75) | [42] |
| Dataset | Accuracy (%) | Other Model Performance (%) | Reference |
|---|---|---|---|
| Reuters | 96.64 | NB (97.89), SVM (97.60) | [34] |
| Reuters | 92.55 | SVM (81.48) | [65] |
| Counter | 91 | NB (91.40), LR (90.30), DT (89.50), SVM(71.70) | [62] |
| Webkb | 84.07 | SVM (91.30), NB (85.67) | [34] |
| 20Newsgroup | 82 | SVM (84), NB (83) | [66] |
| Dataset | Accuracy (%) | Other Model Performance (%) | Reference |
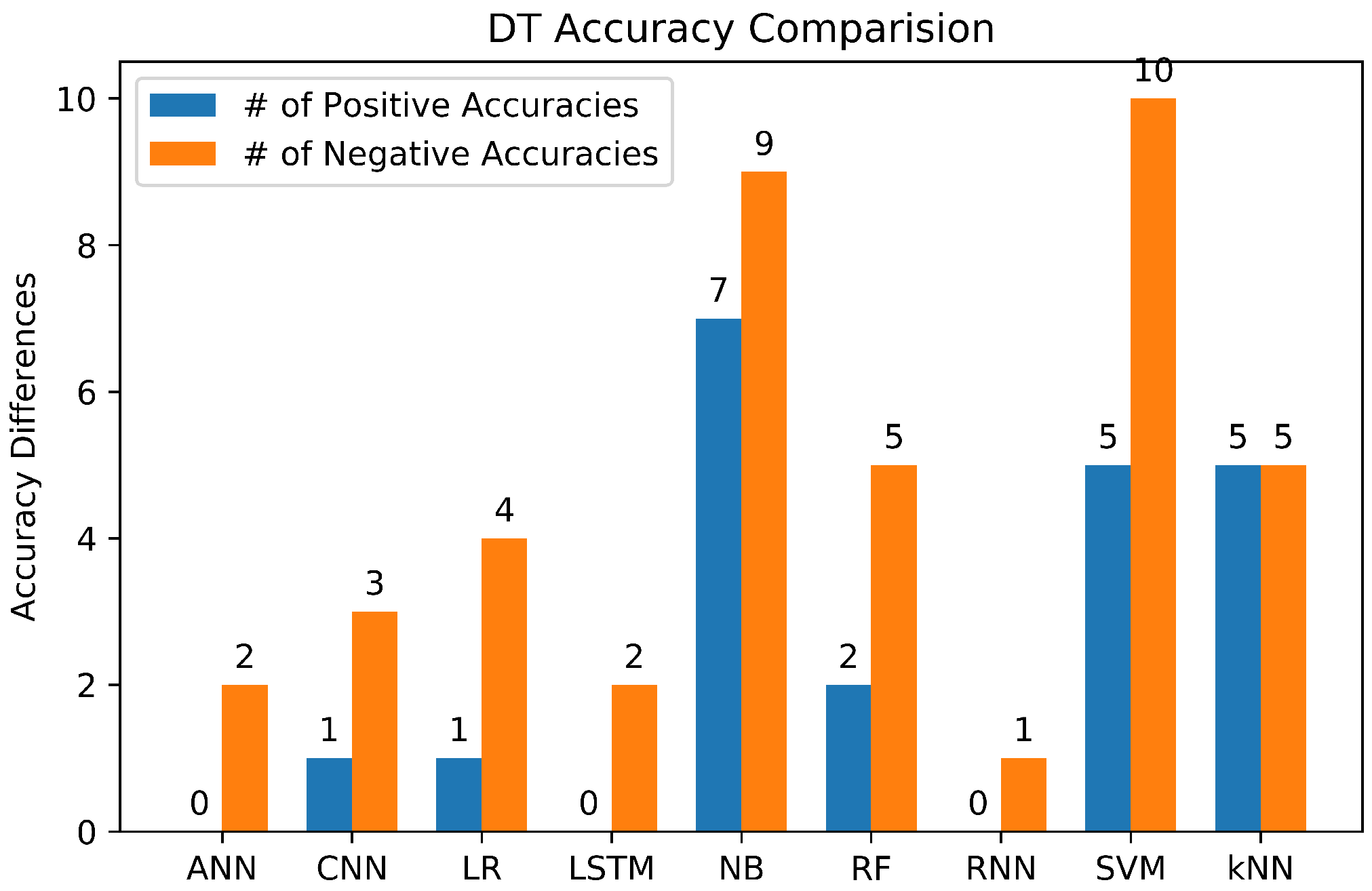
|---|---|---|---|
| 20Newsgroup | 94.50 | - | [36] |
| 94 | CNN (98), SVM (98), LR (97), NB (86) | [37] | |
| Counter | 89.50 | NB (91.40), kNN (91), LR (90.30), SVM(71.70) | [62] |
| Chinese Microblogg | 86.91 | CNN (97.60), NB (90.65), SVM (90.60), LR (90.50), RF (86.75) | [42] |
| 20Newsgroup | 85.39 | SVM (85.88) | [67] |
| Dataset | Accuracy (%) | Other Model Performance (%) | Reference |
|---|---|---|---|
| Gold | 92.60 | LSTM (95.90), SVM (91.90), LR (70.70) | [35] |
| Chinese Microblogg | 86.75 | CNN (97.60), NB (90.65), SVM (90.60), LR (90.50), DT (86.91) | [42] |
| Blogger | 85 | DT (77) | [68] |
| Bike Review | 79.25 | NB (79.05) | [49] |
| IMDb | 72.80 | NB (77.50), ANN (72), SVM (68.30), kNN (63) | [69] |
| Dataset | Accuracy (%) | Other Model Performance (%) | Reference |
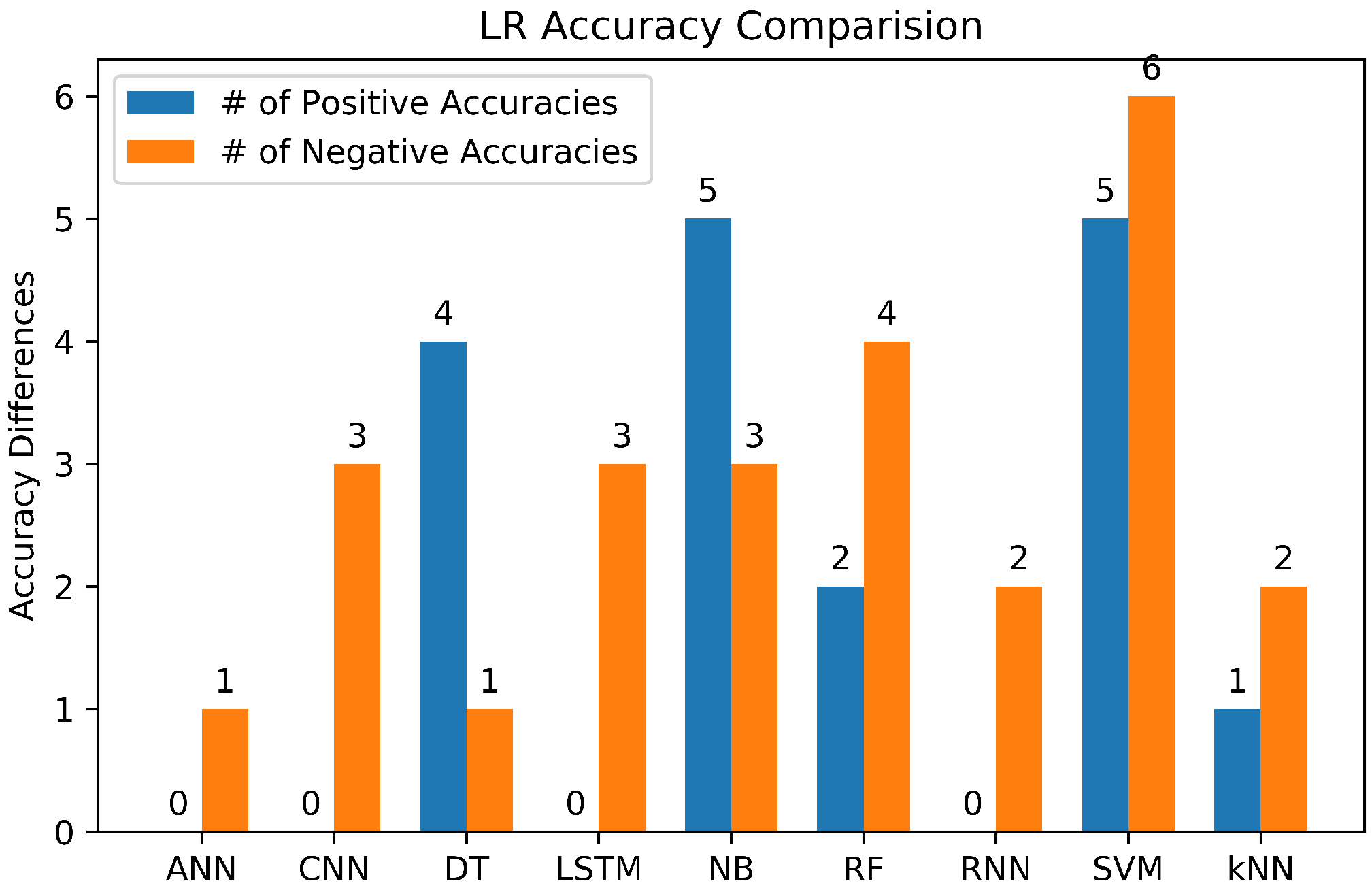
|---|---|---|---|
| PAN-12 | 98.50 | LSTM (98) | [70] |
| 97 | CNN (98), SVM (98), DT (94), NB (86) | [37] | |
| Chinese Microblogg | 90.50 | CNN (97.60), NB (90.65), SVM (90.60), DT (86.91), RF (86.75) | [42] |
| Counter | 90.30 | NB (91.40), kNN (91), DT (89.50), SVM(71.70) | [62] |
| Amazon Review | 89.21 | Others (88) | [50] |
| Year | Popular Text Representation Method |
|---|---|
| 2013 | Word2Vec |
| 2014 | Doc2Vec |
| 2015 | Character Embedding |
| 2016 | Subword Embedding |
| 2017 | FastText |
| 2018 | Transformer |
| 2019 | BERT |
| 2020 | ALBERT |
| 2021 | GPT |
| 2022 | GPT |
| Considerations for Improving the Accuracy of Text Clarifications | References |
|---|---|
| Frequency of features Initial letter Paragraph Question mark Full stop | [82] |
| Term weighting | [57] |
| Term embedding | [83] |
| Optimization | [84] |
| NLP | [54] |
| Feature fusion | [85] |
| Ensemble approach | [33,85,86] |
| Feedback systems | [87] |
| Feedback from experts | [88] |
| Selection of sub-features | [89] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Palanivinayagam, A.; El-Bayeh, C.Z.; Damaševičius, R. Twenty Years of Machine-Learning-Based Text Classification: A Systematic Review. Algorithms 2023, 16, 236. https://doi.org/10.3390/a16050236
Palanivinayagam A, El-Bayeh CZ, Damaševičius R. Twenty Years of Machine-Learning-Based Text Classification: A Systematic Review. Algorithms. 2023; 16(5):236. https://doi.org/10.3390/a16050236
Chicago/Turabian StylePalanivinayagam, Ashokkumar, Claude Ziad El-Bayeh, and Robertas Damaševičius. 2023. "Twenty Years of Machine-Learning-Based Text Classification: A Systematic Review" Algorithms 16, no. 5: 236. https://doi.org/10.3390/a16050236
APA StylePalanivinayagam, A., El-Bayeh, C. Z., & Damaševičius, R. (2023). Twenty Years of Machine-Learning-Based Text Classification: A Systematic Review. Algorithms, 16(5), 236. https://doi.org/10.3390/a16050236