

Heterogeneous Treatment Effect with Trained Kernels of the Nadaraya–Watson Regression



Abstract
1. Introduction
- We propose to use the Nadaraya–Watson kernel regression which does not rely on specific regression functions and estimates regression values (outputs of controls and treatments) without any assumptions about the functions. The main feature of the model is that kernels of the Nadaraya–Watson regression are implemented as neural networks, i.e., the kernels are trained on the control and treatment data. In contrast to many CATE estimators based on neural networks, the proposed model uses simple neural networks which implement only kernels, but not the regression functions.
- The proposed model and the neural network architecture allow us to solve the problem of the small numbers of patients in the treatment group. This is a crucial problem especially when new treatments and new drugs are tested. In fact, the proposed model can be considered in the framework of the transfer learning when controls can be viewed as source data (in terms of the transfer learning), but the treatments are target data.
- Neural networks implementing the kernels amplifies the model flexibility. In contrast to the standard kernels, the neural kernels allow us to cope with the possible complex data structure because they are adapted to the structure due to many trainable parameters.
- A specific algorithm of training the neural kernels is proposed. It trains networks on controls and treatments simultaneously in order to memorize the treatment data structure. We show by means of numerical examples that there is an optimal linear combination of two loss functions corresponding to the controls and treatments.
2. Related Work
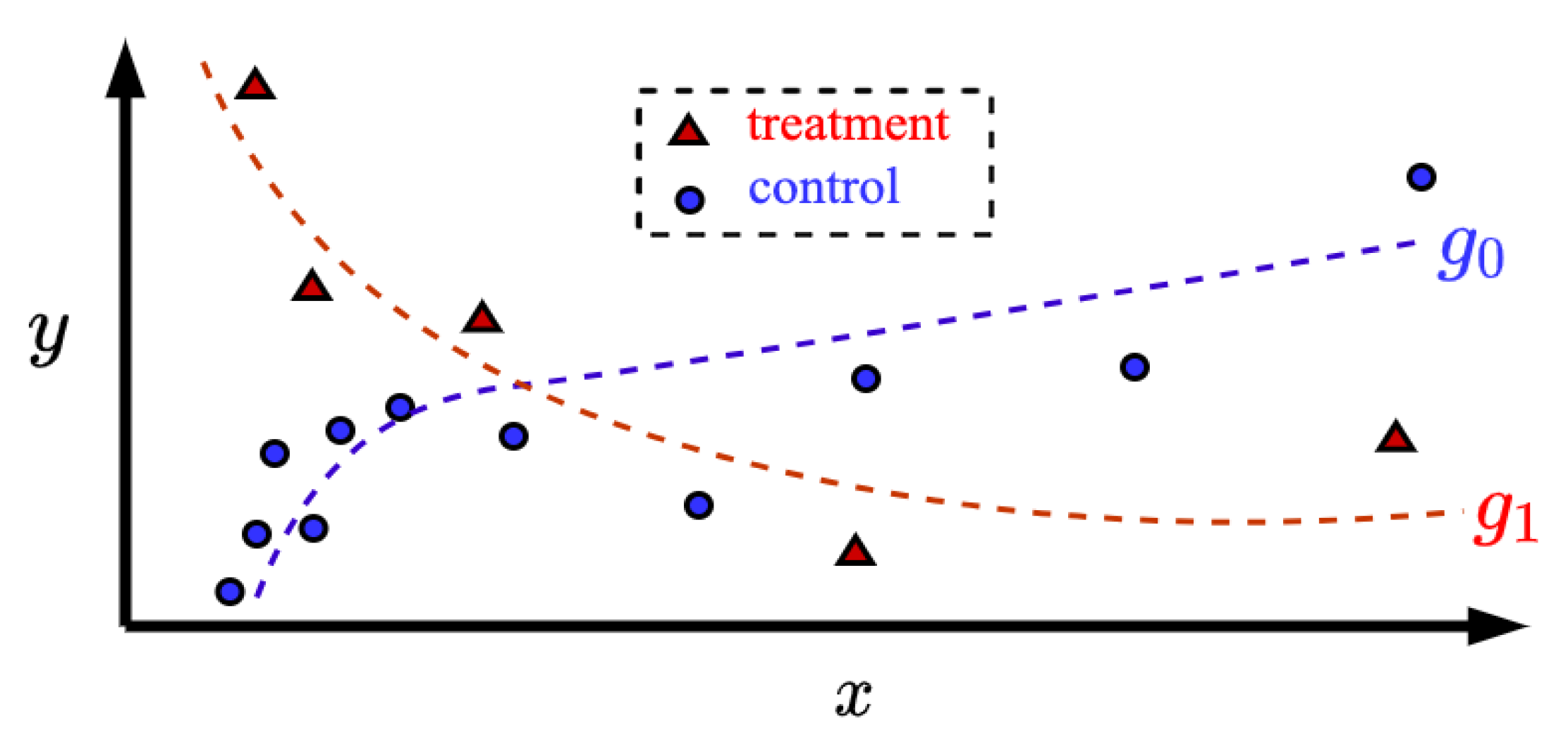
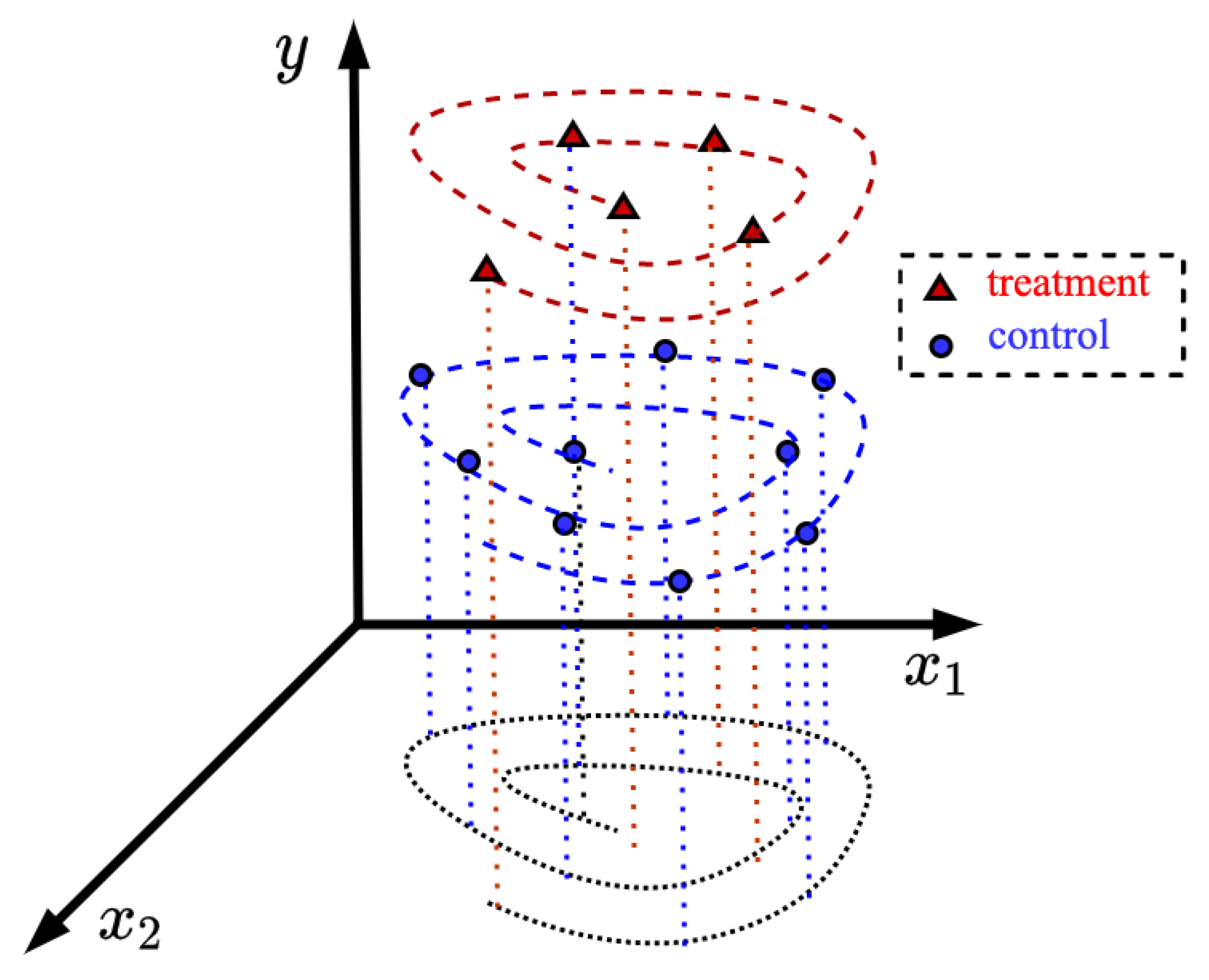
3. A Formal Problem Statement
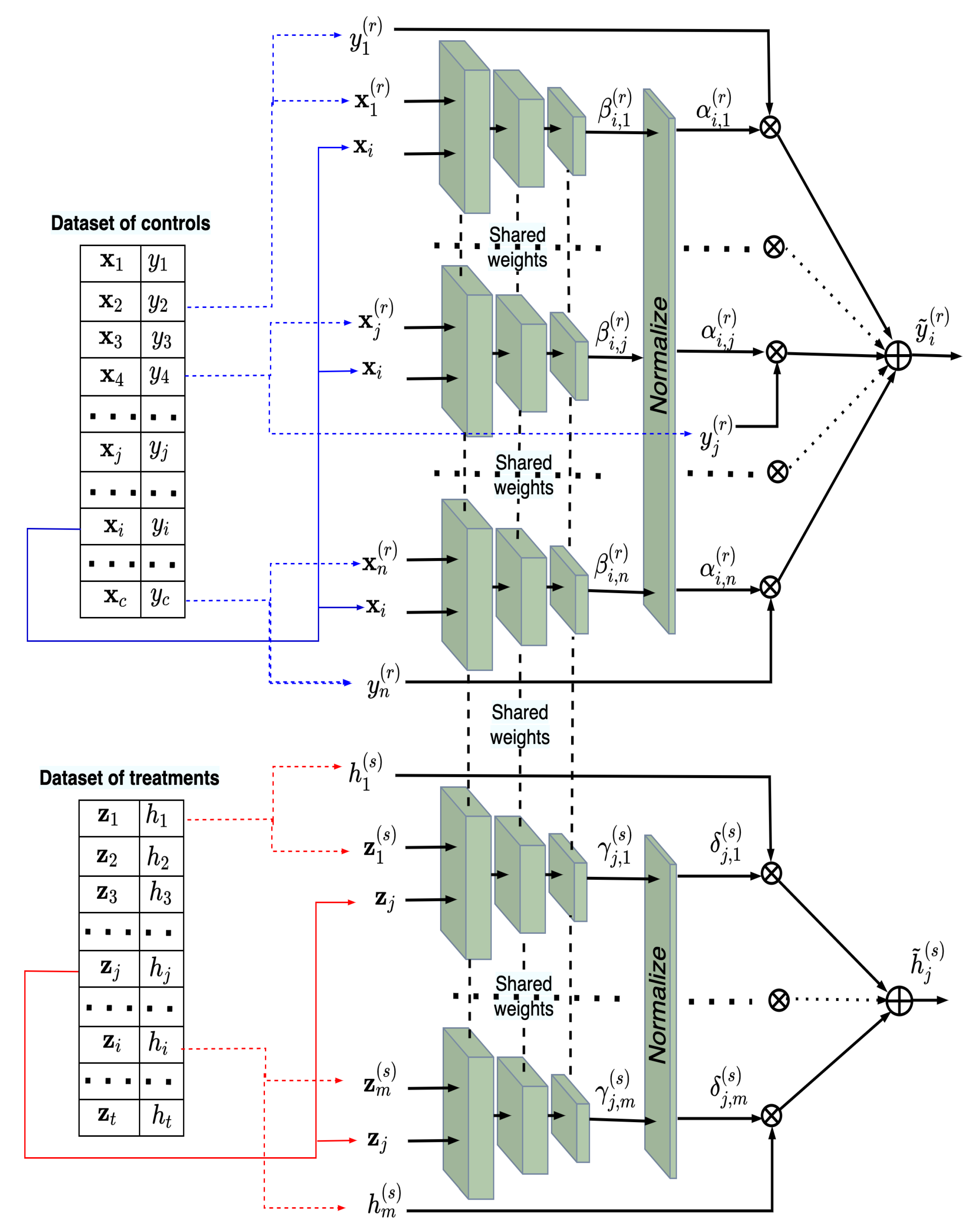
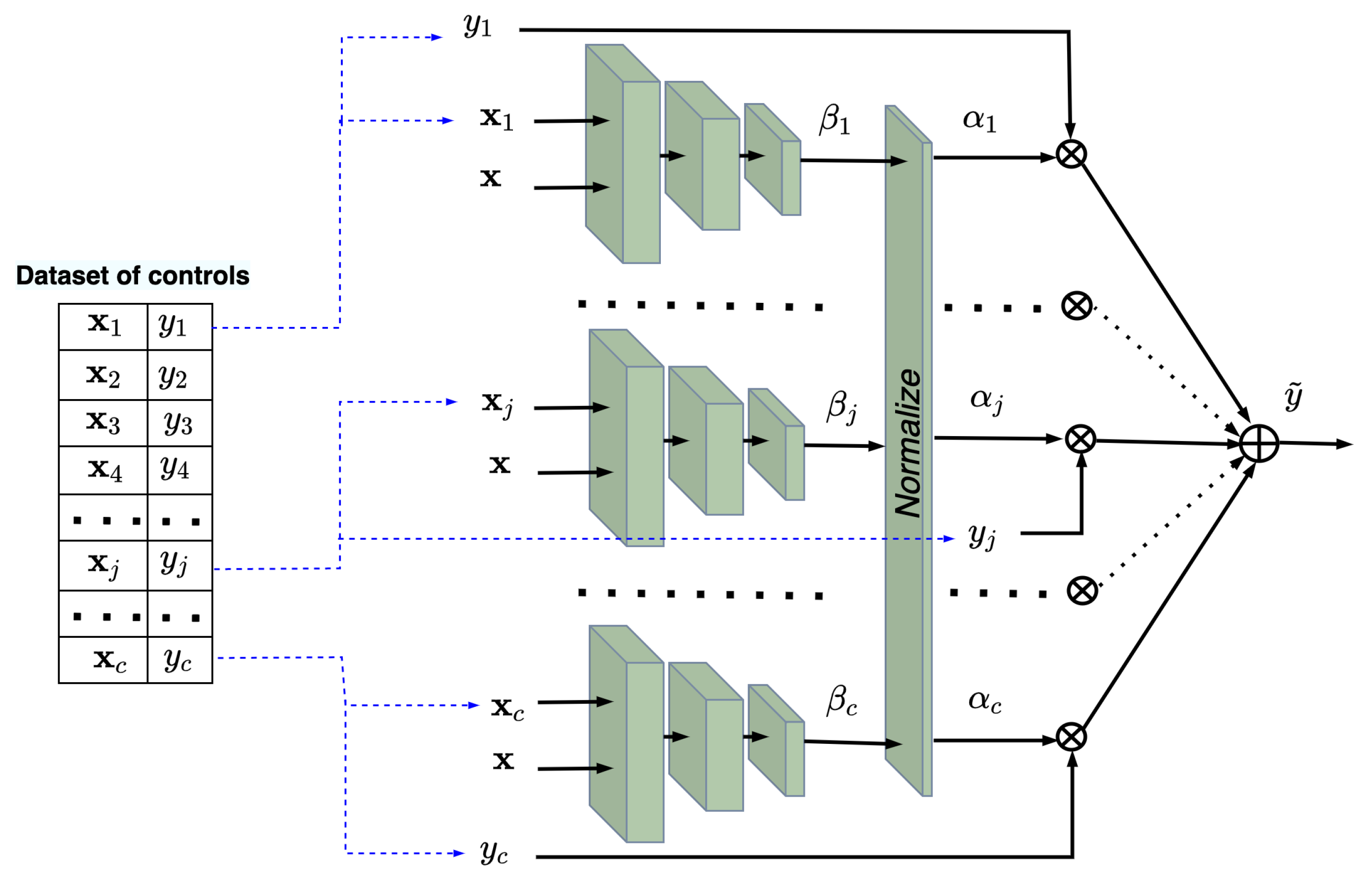
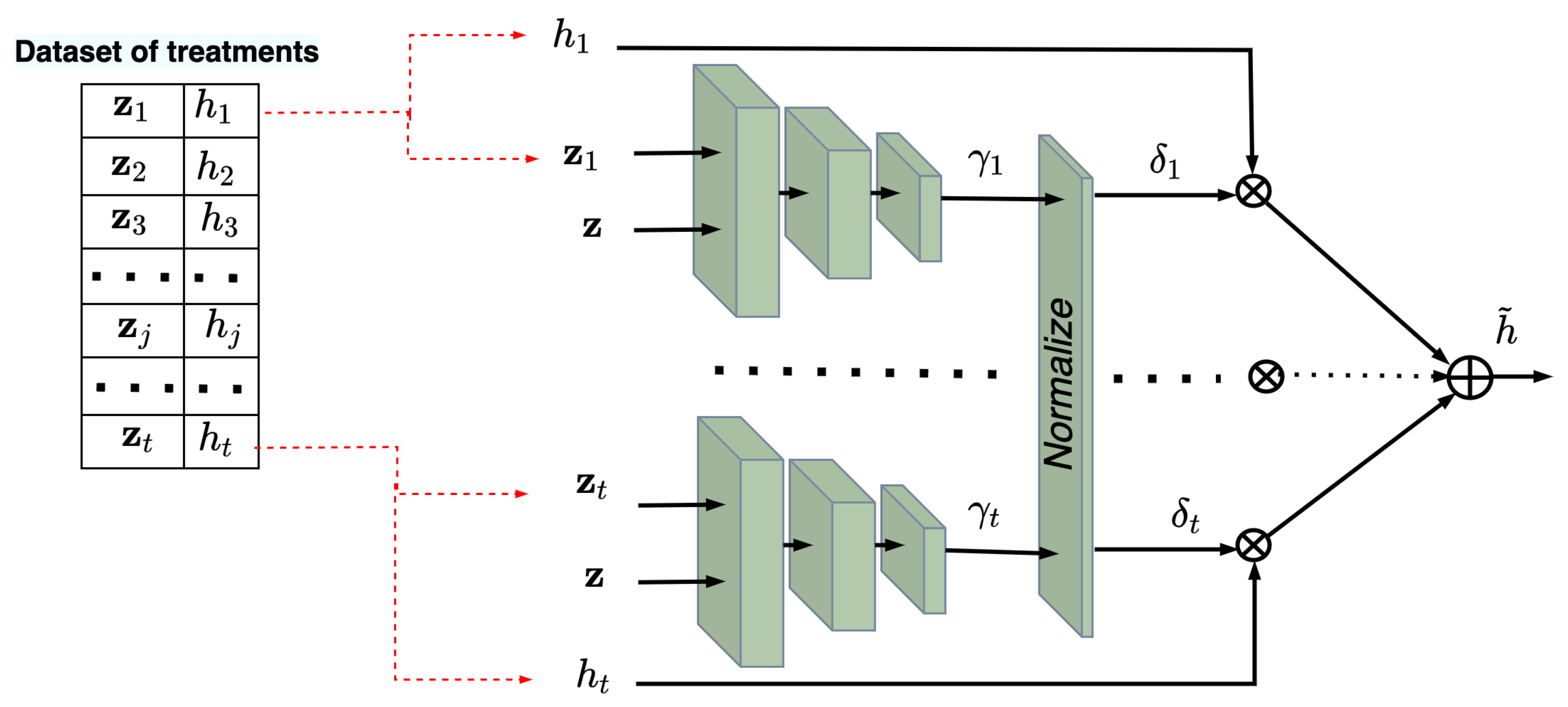
4. The TNW-CATE Description
| Algorithm 1 The algorithm implementing TNW-CATE in the training phase. |
|
| Algorithm 2 The algorithm implementing TNW-CATE in the testing phase. |
|
5. Numerical Experiments
5.1. General Parameters of Experiments
5.1.1. CATE Estimators for Comparison
- The S-learner was proposed in [25] to overcome difficulties and disadvantages of the T-learner. The treatment assignment indicator in the S-learner is included as an additional feature to the feature vector . The corresponding training set in this case is modified as , where if , , and if , . Then the outcome function is estimated by using the training set . The CATE is determined in this case as
- The X-learner [25] is based on computing the so-called imputed treatment effects and is represented in the following three steps. First, the outcome functions and are estimated using a regression algorithm, for example, the random forest. Second, the imputed treatment effects are computed as follows:Third, two regression functions and are estimated for imputed treatment effects and , respectively. CATE for a point is defined as a weighted linear combination of the functions and as , where is a weight which is equal to the ratio of treated patients [13].
5.1.2. Base Models for Implementing Estimators
- The first one is the random forest. It is used as the base regressor to implement the other models for two main reasons. First, we consider the case of the small number of treatments, and usage of neural networks does not allow us to obtain the desirable accuracy of the corresponding regressors. Second, we deal with tabular data for which it is difficult to train a neural network and the random forest is preferable. Parameters of the random forests used in the experiments are as follows:
- Numbers of trees are 10, 50, 100, and 300;
- Depths are 2, 3, 4, 5, 6, and 7;
- The smallest values of examples which fall in a leaf are 1 example, 5%, 10%, and 20% of the training set.
The above values for the hyperparameters are tested, choosing those leading to the best results. - The second base model used for realization different CATE estimators is the Nadaraya–Watson regression with the standard Gaussian kernel. This model is used because it is interesting to compare it with the proposed model that is also based on the Nadaraya–Watson regression but with the trainable kernel in the form of the neural network of the special form. Values , , and values , 5, 50, 100, 200, 500, and 700 of the bandwidth parameter are tested, choosing those leading to the best results.
- T-RF, S-RF, and X-RF are the T-learner, the S-learner, and the X-learner with random forests as the base regression models;
- T-NW, S-NW, and X-NW are the T-learner, the S-learner, and the X-learner with the Nadaraya–Watson regression using the standard Gaussian kernel as the base regression models.
5.1.3. Other Parameters of Numerical Experiments
5.1.4. Functions for Generating Datasets
- Spiral functions: The functions are named spiral because when using two features vectors they are located on the Archimedean spiral. For even d, we write the vector of features asFor odd d, there holdsThe responses are generated as a linear function of t, i.e., they are computed as .Values of parameters a, b, and t for performing numerical experiments with spiral functions areas follows:
- The control group: parameters a, b, and t are uniformly generated from intervals , , and , respectively.
- The treatment group: parameters a, b, and t are uniformly generated from intervals , , and , respectively.
- Logarithmic functions: Features are logarithms of the parameter t, i.e., there holdsThe responses are generated as a logarithmic function with adding an oscillating term to y, i.e., there holds .Values of parameters , b for performing numerical experiments with logarithmic functions are as follows:
- Each parameter from the set is uniformly generated from intervals for controls as well as for treatments.
- Parameter b is uniformly generated from interval for controls and from interval for treatments.
- Values of t are uniformly generated in interval .
- Power functions: Features are represented as powers of t. For arbitrary d, the vector of features is represented asHowever, features which are close to linear ones, e.g., for , are replaced with the Gaussian noise having the unit standard deviation and the zero expectation, i.e., . The responses are generated as follows:Values of parameters a, b, s, and t for performing numerical experiments with power functions are as follows:
- The control group: parameters a and b are uniformly generated from intervals and , respectively; parameter s is .
- The treatment group: parameters a and b are uniformly generated from intervals and , respectively; parameter s is .
- Values of t are uniformly generated in interval .
- Indicator functions [25]: The functions are expressed through the indicator function I taking value 1 if its argument is true.
- The function for controls is represented as
- The function for treatments is represented as
- Vector is uniformly distributed in interval ; values of features , are uniformly generated from interval .
5.2. Study of the TNW-CATE Properties
5.2.1. Experiments with Numbers of Training Data
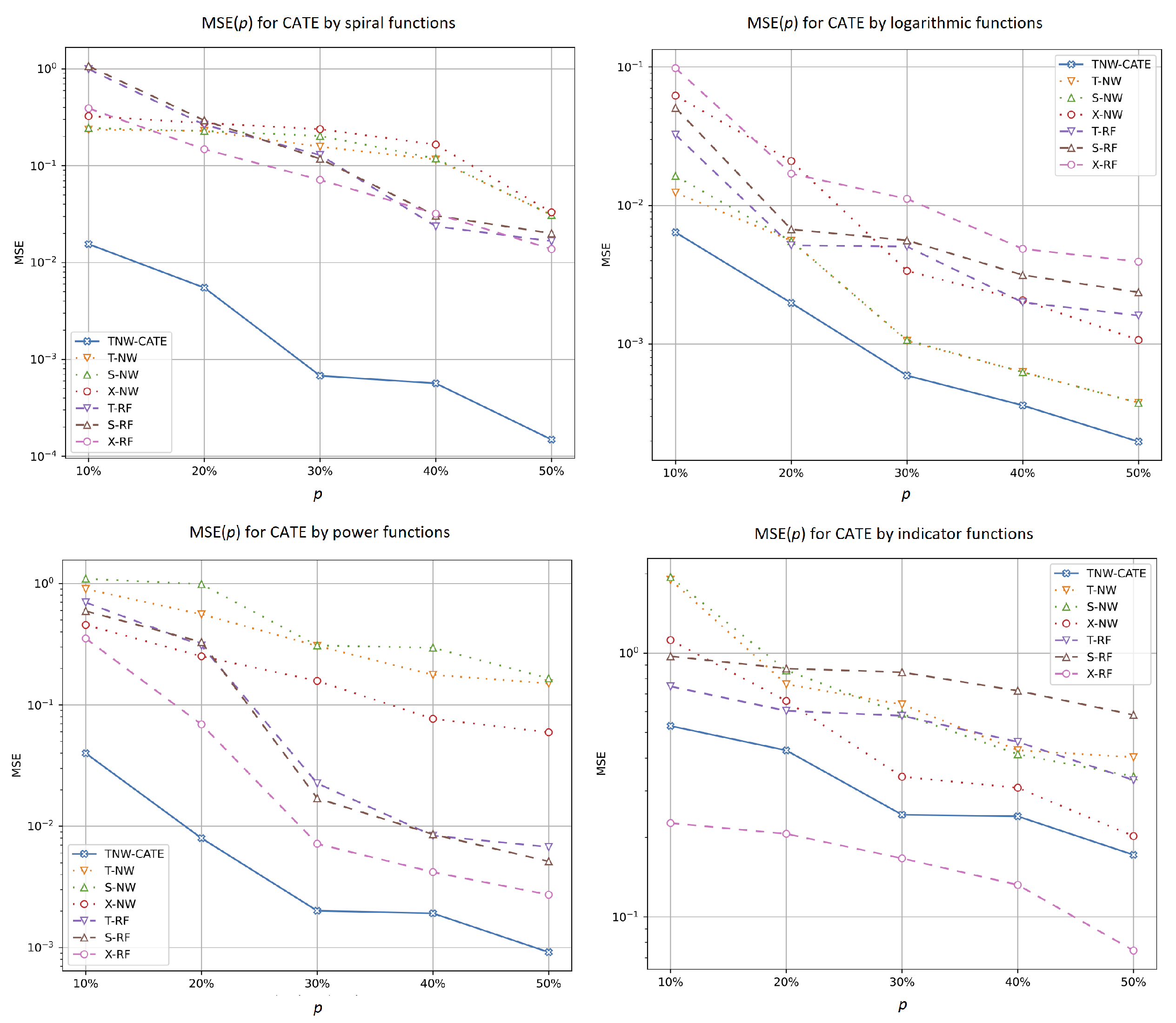
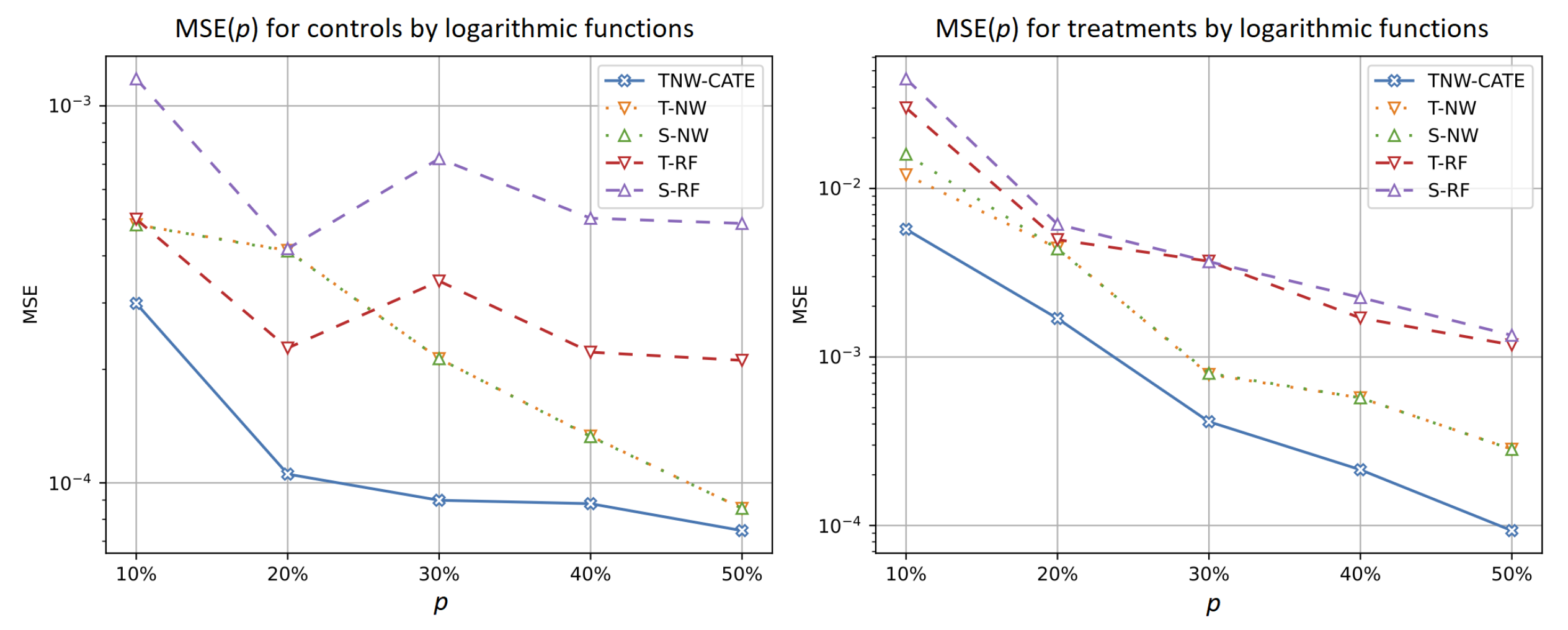
5.2.2. Experiments with Different Values of the Treatment Ratio
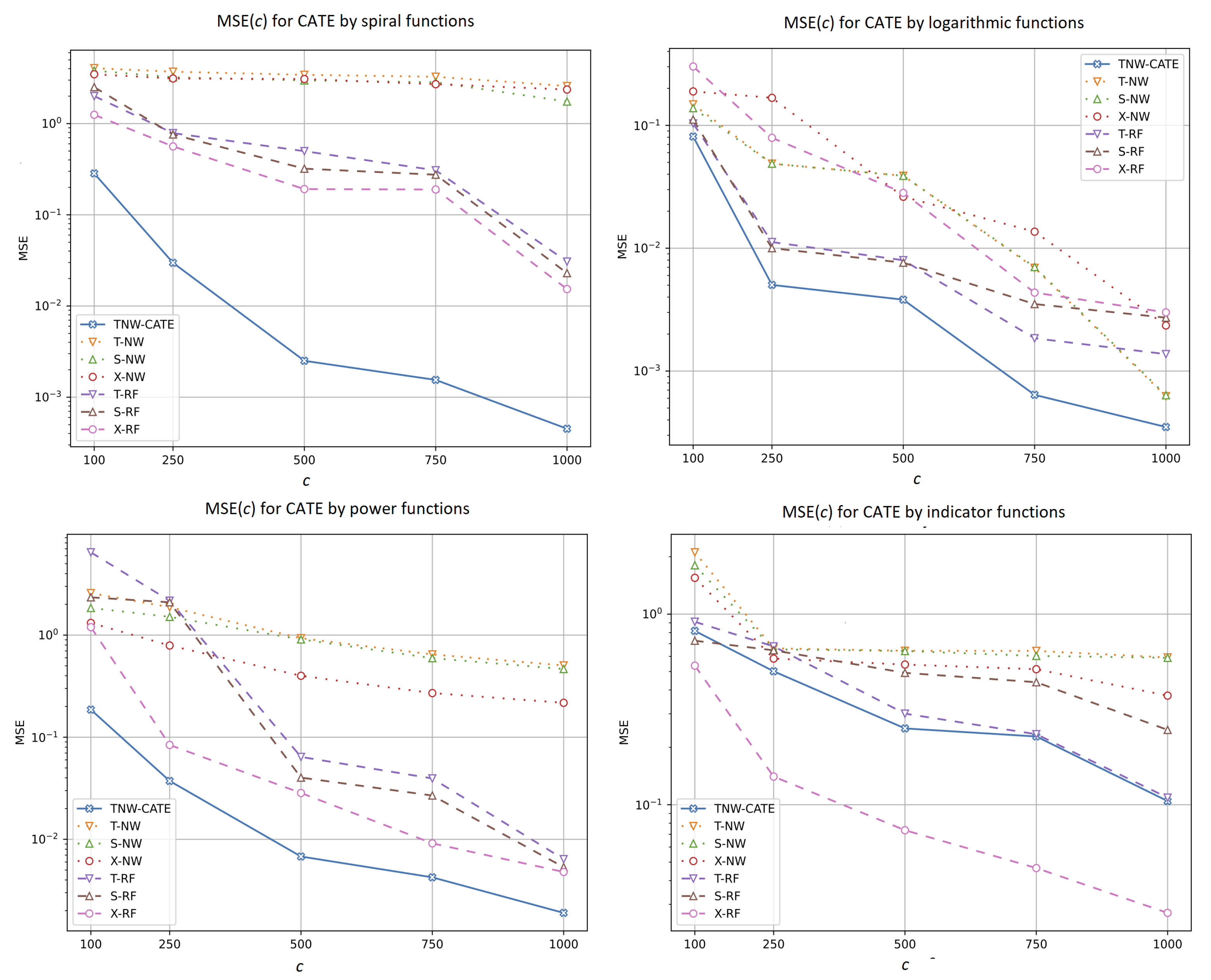
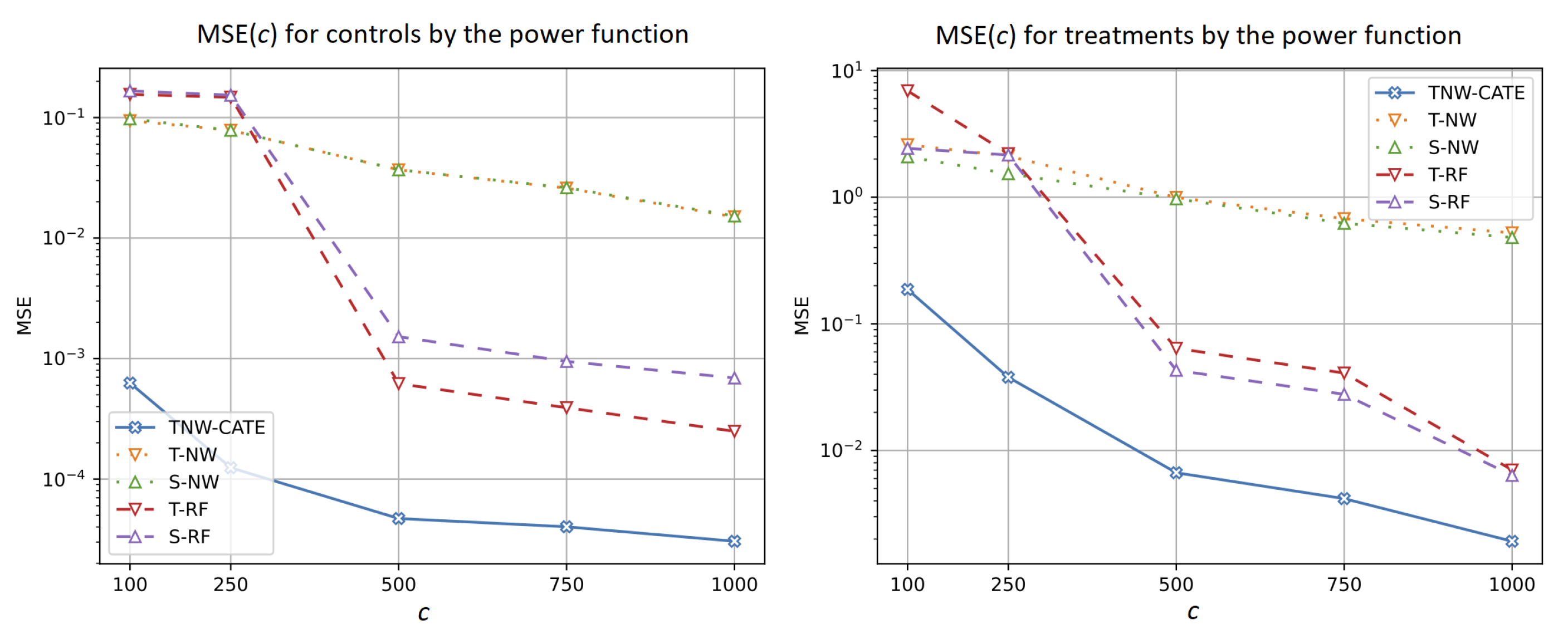
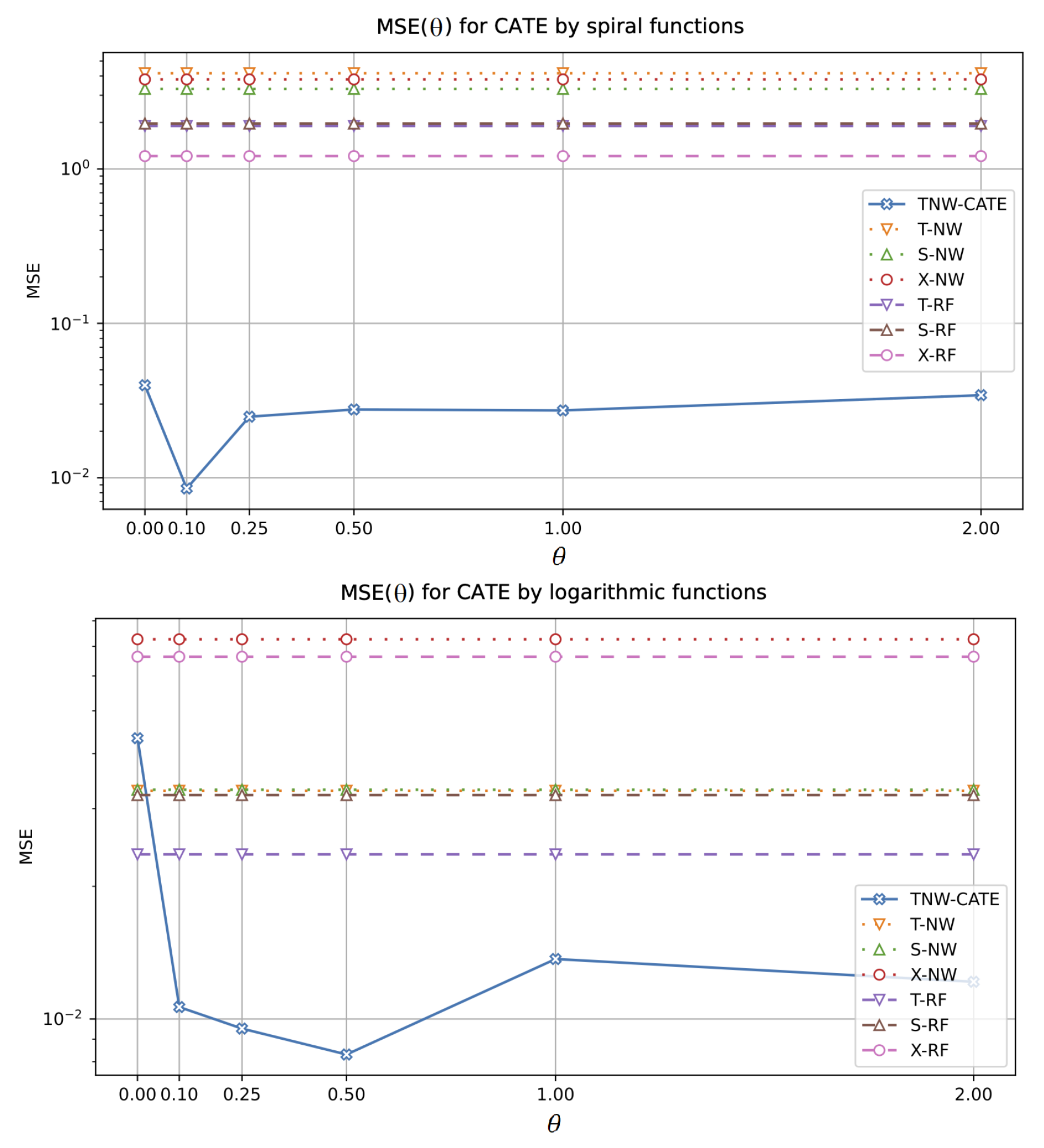
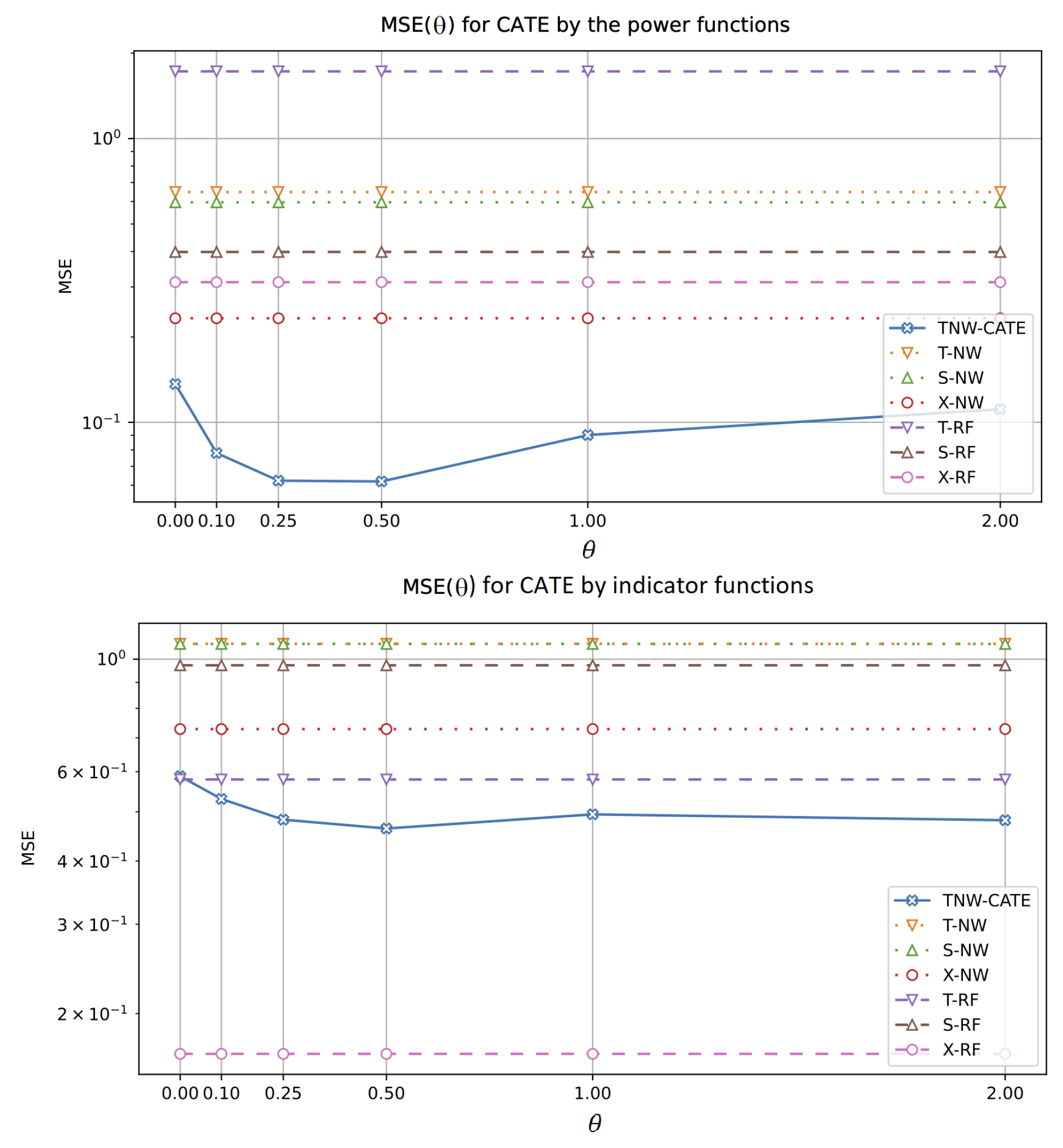
5.2.3. Experiments with Different Values of
5.3. Real Dataset
- The results significantly depend on the structure of the control and treatment data. The most complex structure among the considered ones is produced by the spiral function, and we observe that TNW-CATE outperforms the results in comparison with other models, especially when the number of controls is rather large. The large number of controls prevents the neural network from overfitting. The worst results provided by TNW-CATE and models based on the Gaussian kernels (T-NW, S-NW, and X-NW) for the indicator function are caused by the fact that the random forest can be regarded as one of the best models for the functions such as the indicator. The neural network cannot cope with this structure due to the properties of its training.
- It can be seen from the experiments that the difference between TNW-CATE and other models increases as the number of treatments decreases. It does not mean that the MSE of TNW-CATE is increased. The MSE is decreased. However, this decrease is not as significant as in other models. This is caused by joint use of controls and treatments in training the neural network. It follows from the above that the co-training of the neural network on treatments corrects the network weights when the domain of the treatment group is shifted relative to the control domain.
- The main conclusion from the experiments using the dataset IHDP is that the neural network is perfectly adapted to the data structure which is totally unknown. In other words, the neural network tries to implement is own distance function and a form of the kernel to fit the data structure. This is an important distinction of TNW-CATE from other approaches.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lu, M.; Sadiq, S.; Feaster, D.; Ishwaran, H. Estimating Individual Treatment Effect in Observational Data Using Random Forest Methods. arXiv 2017, arXiv:1701.05306v2. [Google Scholar] [CrossRef] [PubMed]
- Shalit, U.; Johansson, F.; Sontag, D. Estimating individual treatment effect: Generalization bounds and algorithms. In Proceedings of the 34th International Conference on Machine Learning (ICML 2017), Sydney, Australia, 6–11 August 2017; Volume PMLR 70, pp. 3076–3085. [Google Scholar]
- Xie, Y.; Brand, J.; Jann, B. Estimating Heterogeneous Treatment Effects with Observational Data. Sociol. Methodol. 2012, 42, 314–347. [Google Scholar] [CrossRef] [PubMed]
- Caron, A.; Baio, G.; Manolopoulou, I. Estimating Individual Treatment Effects using Non-Parametric Regression Models: A Review. J. R. Stat. Soc. Ser. A Stat. Soc. 2022, 185, 1115–1149. [Google Scholar] [CrossRef]
- Zhou, X.; Xie, Y. Heterogeneous Treatment Effects in the Presence of Self-Selection: A Propensity Score Perspective. Sociol. Methodol. 2020, 50, 350–385. [Google Scholar] [CrossRef] [PubMed]
- Fan, Y.; Lv, J.; Wang, J. DNN: A Two-Scale Distributional Tale of Heterogeneous Treatment Effect Inference. arXiv 2018, arXiv:1808.08469v1. [Google Scholar] [CrossRef]
- Green, D.; Kern, H. Modeling heterogeneous treatment effects in survey experiments with Bayesian additive regression trees. Public Opin. Q. 2012, 76, 491–511. [Google Scholar] [CrossRef]
- Hill, J. Bayesian nonparametric modeling for causal inference. J. Comput. Graph. Stat. 2011, 20, 217–240. [Google Scholar] [CrossRef]
- Kallus, N. Learning to personalize from observational data. arXiv 2016, arXiv:1608.08925. [Google Scholar]
- Wager, S.; Athey, S. Estimation and inference of heterogeneous treatment effects using random forests. arXiv 2017, arXiv:1510.0434. [Google Scholar] [CrossRef]
- Aoki, R.; Ester, M. Causal Inference from Small High-dimensional Datasets. arXiv 2022, arXiv:2205.09281. [Google Scholar]
- Alaa, A.; van der Schaar, M. Limits of Estimating Heterogeneous Treatment Effects: Guidelines for Practical Algorithm Design. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 129–138. [Google Scholar]
- Kunzel, S.; Stadie, B.; Vemuri, N.; Ramakrishnan, V.; Sekhon, J.; Abbeel, P. Transfer Learning for Estimating Causal Effects using Neural Networks. arXiv 2018, arXiv:1808.07804v1. [Google Scholar]
- Shi, C.; Blei, D.; Veitch, V. Adapting Neural Networks for the Estimation of Treatment Effects. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32, pp. 1–11. [Google Scholar]
- Wendling, T.; Jung, K.; Callahan, A.; Schuler, A.; Shah, N.; Gallego, B. Comparing methods for estimation of heterogeneous treatment effects using observational data from health care databases. Stat. Med. 2018, 37, 3309–3324. [Google Scholar] [CrossRef]
- Dorie, V.; Perrett, G.; Hill, J.; Goodrich, B. Stan and BART for Causal Inference: Estimating Heterogeneous Treatment Effects Using the Power of Stan and the Flexibility of Machine Learning. Entropy 2022, 24, 1782. [Google Scholar] [CrossRef] [PubMed]
- Acharki, N.; Garnier, J.; Bertoncello, A.; Lugo, R. Heterogeneous Treatment Effects Estimation: When Machine Learning meets multiple treatment regime. arXiv 2022, arXiv:2205.14714. [Google Scholar]
- Athey, S.; Imbens, G. Recursive partitioning for heterogeneous causal effects. Proc. Natl. Acad. Sci. USA 2016, 113, 7353–7360. [Google Scholar] [CrossRef]
- Deng, A.; Zhang, P.; Chen, S.; Kim, D.; Lu, J. Concise Summarization of Heterogeneous Treatment Effect Using Total Variation Regularized Regression. arXiv 2016, arXiv:1610.03917. [Google Scholar]
- Fernandez-Loria, C.; Provost, F. Causal Classification: Treatment Effect Estimation vs. Outcome Prediction. J. Mach. Learn. Res. 2022, 23, 1–35. [Google Scholar]
- Fernandez-Loria, C.; Provost, F. Causal Decision Making and Causal Effect Estimation Are Not the Same…and Why It Matters. INFORMS J. Data Sci. 2022, 1, 4–16. [Google Scholar] [CrossRef]
- Gong, X.; Hu, M.; Basu, M.; Zhao, L. Heterogeneous treatment effect analysis based on machine-learning methodology. CPT Pharmacomet. Syst. Pharmacol. 2021, 10, 1433–1443. [Google Scholar] [CrossRef]
- Hatt, T.; Berrevoets, J.; Curth, A.; Feuerriegel, S.; van der Schaar, M. Combining Observational and Randomized Data for Estimating Heterogeneous Treatment Effects. arXiv 2016, arXiv:2202.12891. [Google Scholar]
- Jiang, H.; Qi, P.; Zhou, J.; Zhou, J.; Rao, S. A Short Survey on Forest Based Heterogeneous Treatment Effect Estimation Methods: Meta-learners and Specific Models. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 3006–3012. [Google Scholar]
- Kunzel, S.; Sekhona, J.; Bickel, P.; Yu, B. Meta-learners for Estimating Heterogeneous Treatment Effects using Machine Learning. Proc. Natl. Acad. Sci. USA 2019, 116, 4156–4165. [Google Scholar] [CrossRef] [PubMed]
- Utkin, L.; Kots, M.; Chukanov, V.; Konstantinov, A.; Meldo, A. Estimation of Personalized Heterogeneous Treatment Effects Using Concatenation and Augmentation of Feature Vectors. Int. J. Artif. Intell. Tools 2020, 29, 2050005. [Google Scholar] [CrossRef]
- Wu, L.; Yang, S. Integrative learner of heterogeneous treatment effects combining experimental and observational studies. In Proceedings of the First Conference on Causal Learning and Reasoning (CLeaR 2022), Eureka, CA, USA, 11–13 April 2022; pp. 1–23. [Google Scholar]
- Yadlowsky, S.; Fleming, S.; Shah, N.; Brunskill, E.; Wager, S. Evaluating Treatment Prioritization Rules via Rank-Weighted Average Treatment Effects. arXiv 2021, arXiv:2111.07966. [Google Scholar]
- Zhang, W.; Li, J.; Liu, L. A Unified Survey of Treatment Effect Heterogeneity Modelling and Uplift Modelling. ACM Comput. Surv. 2022, 54, 1–36. [Google Scholar] [CrossRef]
- Zhao, Y.; Zeng, D.; Rush, A.; Kosorok, M. Estimating Individualized Treatment Rules Using Outcome Weighted Learning. J. Am. Stat. Assoc. 2012, 107, 1106–1118. [Google Scholar] [CrossRef]
- Bica, I.; Jordon, J.; van der Schaar, M. Estimating the effects of continuous-valued interventions using generative adversarial networks. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Virtual, 6–12 December 2020; Volume 33, pp. 16434–16445. [Google Scholar]
- Curth, A.; van der Schaar, M. Nonparametric Estimation of Heterogeneous Treatment Effects: From Theory to Learning Algorithms. In Proceedings of the International Conference on Artificial Intelligence and Statistics, PMLR, Virtual, 13–15 April 2021; pp. 1810–1818. [Google Scholar]
- Guo, Z.; Zheng, S.; Liu, Z.; Yan, K.; Zhu, Z. CETransformer: Casual Effect Estimation via Transformer Based Representation Learning. In Proceedings of the Pattern Recognition and Computer Vision, PRCV, Beijing, China, 29 October–1 November 2021; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2021; Volume 13022, pp. 524–535. [Google Scholar]
- Melnychuk, V.; Frauen, D.; Feuerriegel, S. Causal Transformer for Estimating Counterfactual Outcomes. arXiv 2022, arXiv:2204.07258. [Google Scholar]
- Zhang, Y.F.; Zhang, H.; Lipton, Z.; Li, L.E.; Xing, E.P. Can Transformers be Strong Treatment Effect Estimators? arXiv 2022, arXiv:2202.01336. [Google Scholar]
- Zhang, Y.F.; Zhang, H.; Lipton, Z.; Li, L.E.; Xing, E.P. Exploring Transformer Backbones for Heterogeneous Treatment Effect Estimation. Available online: https://openreview.net/forum?id=NkJ60ZZkcrW (accessed on 19 April 2023).
- Nadaraya, E. On estimating regression. Theory Probab. Its Appl. 1964, 9, 141–142. [Google Scholar] [CrossRef]
- Watson, G. Smooth regression analysis. Sankhya Indian J. Stat. Ser. A 1964, 359–372. [Google Scholar]
- Bartlett, P.; Montanari, A.; Rakhlin, A. Deep learning: A statistical viewpoint. Acta Numer. 2021, 30, 87–201. [Google Scholar] [CrossRef]
- Gao, Z.; Han, Y. Minimax optimal nonparametric estimation of heterogeneous treatment effects. Proc. Adv. Neural Inf. Process. Syst. 2020, 33, 21751–21762. [Google Scholar]
- Hsu, Y.C.; Lai, T.C.; Lieli, R. Counterfactual treatment effects: Estimation and inference. J. Bus. Econ. Stat. 2022, 40, 240–255. [Google Scholar] [CrossRef]
- Padilla, O.; Yu, Y. Dynamic and heterogeneous treatment effects with abrupt changes. arXiv 2022, arXiv:2206.09092. [Google Scholar]
- Sun, X. Estimation of Heterogeneous Treatment Effects Using a Conditional Moment Based Approach. arXiv 2022, arXiv:2210.15829. [Google Scholar]
- Lu, J.; Behbood, V.; Hao, P.; Zuo, H.; Xue, S.; Zhang, G. Transfer learning using computational intelligence: A survey. Knowl.-Based Syst. 2015, 80, 14–23. [Google Scholar] [CrossRef]
- Pan, S.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 1–40. [Google Scholar] [CrossRef]
- Powers, S.; Qian, J.; Jung, K.; Schuler, A.; Shah, N.; Hastie, T.; Tibshirani, R. Some methods for heterogeneous treatment effect estimation in high-dimensions Some methods for heterogeneous treatment effect estimation in high-dimensions. arXiv 2017, arXiv:1707.00102v1. [Google Scholar] [CrossRef]
- Jeng, X.; Lu, W.; Peng, H. High-dimensional inference for personalized treatment decision. Electron. J. Stat. 2018, 12, 2074–2089. [Google Scholar] [CrossRef]
- Zhou, X.; Mayer-Hamblett, N.; Khan, U.; Kosorok, M. Residual Weighted Learning for Estimating Individualized Treatment Rules. J. Am. Stat. Assoc. 2017, 112, 169–187. [Google Scholar] [CrossRef]
- Athey, S.; Tibshirani, J.; Wager, S. Solving heterogeneous estimating equations with gradient forests. arXiv 2017, arXiv:1610.01271. [Google Scholar]
- Athey, S.; Tibshirani, J.; Wager, S. Generalized random forests. arXiv 2019, arXiv:1610.0171v4. [Google Scholar] [CrossRef]
- Zhang, W.; Le, T.; Liu, L.; Zhou, Z.H.; Li, J. Mining heterogeneous causal effects for personalized cancer treatment. Bioinformatics 2017, 33, 2372–2378. [Google Scholar] [CrossRef]
- Xie, Y.; Chen, N.; Shi, X. False Discovery Rate Controlled Heterogeneous Treatment Effect Detection for Online Controlled Experiments. arXiv 2018, arXiv:1808.04904v1. [Google Scholar]
- Oprescu, M.; Syrgkanis, V.; Wu, Z. Orthogonal Random Forest for Heterogeneous Treatment Effect Estimation. arXiv 2019, arXiv:1806.03467v2. [Google Scholar]
- III, E.M.; Somanchi, S.; Neill, D. Efficient Discovery of Heterogeneous Treatment Effects in Randomized Experiments via Anomalous Pattern Detection. arXiv 2018, arXiv:1803.09159v2. [Google Scholar]
- Chen, R.; Liu, H. Heterogeneous Treatment Effect Estimation through Deep Learning. arXiv 2018, arXiv:1810.11010v1. [Google Scholar]
- Grimmer, J.; Messing, S.; Westwood, S. Estimating Heterogeneous Treatment Effects and the Effects of Heterogeneous Treatments with Ensemble Methods. Polit. Anal. 2017, 25, 413–434. [Google Scholar] [CrossRef]
- Kallus, N.; Puli, A.; Shalit, U. Removing Hidden Confounding by Experimental Grounding. arXiv 2018, arXiv:1810.11646v1. [Google Scholar]
- Kallus, N.; Zhou, A. Confounding-Robust Policy Improvement. arXiv 2018, arXiv:1805.08593v2. [Google Scholar]
- Knaus, M.; Lechner, M.; Strittmatter, A. Machine Learning Estimation of Heterogeneous Causal Effects: Empirical Monte Carlo Evidence. arXiv 2018, arXiv:1810.13237v1. [Google Scholar]
- Kunzel, S.; Walter, S.; Sekhon, J. Causaltoolbox—Estimator Stability for Heterogeneous Treatment Effects. arXiv 2019, arXiv:1811.02833v1. [Google Scholar] [CrossRef]
- Levy, J.; van der Laan, M.; Hubbard, A.; Pirracchio, R. A Fundamental Measure of Treatment Effect Heterogeneity. arXiv 2018, arXiv:1811.03745v1. [Google Scholar] [CrossRef]
- Rhodes, W. Heterogeneous Treatment Effects: What Does a Regression Estimate? Eval. Rev. 2010, 34, 334–361. [Google Scholar] [CrossRef]
- Yao, L.; Lo, C.; Nir, I.; Tan, S.; Evnine, A.; Lerer, A.; Peysakhovich, A. Efficient Heterogeneous Treatment Effect Estimation with Multiple Experiments and Multiple Outcomes. arXiv 2022, arXiv:2206.04907. [Google Scholar]
- Wang, Y.; Wu, P.; Liu, Y.; Weng, C.; Zeng, D. Learning Optimal Individualized Treatment Rules from Electronic Health Record Data. In Proceedings of the IEEE International Conference on Healthcare Informatics (ICHI), Chicago, IL, USA, 4–7 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 65–71. [Google Scholar]
- Curth, A.; van der Schaar, M. On Inductive Biases for Heterogeneous Treatment Effect Estimation. In Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021), Virtual, 6–14 December 2021; pp. 1–12. [Google Scholar]
- Du, X.; Fan, Y.; Lv, J.; Sun, T.; Vossler, P. Dimension-Free Average Treatment Effect Inference with Deep Neural Networks. arXiv 2021, arXiv:2112.01574. [Google Scholar]
- Nair, N.; Gurumoorthy, K.; Mandalapu, D. Individual Treatment Effect Estimation Through Controlled Neural Network Training in Two Stages. arXiv 2022, arXiv:2201.08559. [Google Scholar]
- Nie, L.; Ye, M.; Liu, Q.; Nicolae, D. Vcnet and functional targeted regularization for learning causal effects of continuous treatments. In Proceedings of the International Conference on Learning Representations (ICLR 2021), Virtual, 3–7 May 2021; pp. 1–24. [Google Scholar]
- Parbhoo, S.; Bauer, S.; Schwab, P. Ncore: Neural counterfactual representation learning for combinations of treatments. arXiv 2021, arXiv:2103.11175. [Google Scholar]
- Qin, T.; Wang, T.Z.; Zhou, Z.H. Budgeted Heterogeneous Treatment Effect Estimation. In Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; Volume 139, pp. 8693–8702. [Google Scholar]
- Schwab, P.; Linhardt, L.; Bauer, S.; Buhmann, J.; Karlen, W. Learning counterfactual representations for estimating individual dose-response curves. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5612–5619. [Google Scholar]
- Veitch, V.; Wang, Y.; Blei, D. Using Embeddings to Correct for Unobserved Confounding in Networks. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; pp. 1–11. [Google Scholar]
- Chaudhari, S.; Mithal, V.; Polatkan, G.; Ramanath, R. An attentive survey of attention models. arXiv 2021, arXiv:1904.02874. [Google Scholar] [CrossRef]
- Guo, W.; Wang, S.; Ding, P.; Wang, Y.; Jordan, M. Multi-Source Causal Inference Using Control Variates. arXiv 2021, arXiv:2103.16689. [Google Scholar]
- Imbens, G. Nonparametric estimation of average treatment effects under exogeneity: A review. Rev. Econ. Stat. 2004, 86, 4–29. [Google Scholar] [CrossRef]
- Park, J.; Shalit, U.; Scholkopf, B.; Muandet, K. Conditional Distributional Treatment Effect with Kernel Conditional Mean Embeddings and U-Statistic Regression. In Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; Volume 139, pp. 8401–8412. [Google Scholar]
- Ghassabeh, Y.; Rudzicz, F. The mean shift algorithm and its relation to kernel regression. Inf. Sci. 2016, 348, 198–208. [Google Scholar] [CrossRef]
- Hanafusa, R.; Okadome, T. Bayesian kernel regression for noisy inputs based on Nadaraya–Watson estimator constructed from noiseless training data. Adv. Data Sci. Adapt. Anal. 2020, 12, 2050004-1–2050004-17. [Google Scholar] [CrossRef]
- Konstantinov, A.; Utkin, L.; Kirpichenko, S. AGBoost: Attention-based Modification of Gradient Boosting Machine. In Proceedings of the 31st Conference of Open Innovations Association (FRUCT), Helsinki, Finland, 27–29 April 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 96–101. [Google Scholar]
- Liu, F.; Huang, X.; Gong, C.; Yang, J.; Li, L. Learning Data-adaptive Non-parametric Kernels. J. Mach. Learn. Res. 2020, 21, 1–39. [Google Scholar]
- Shapiai, M.; Ibrahim, Z.; Khalid, M.; Jau, L.W.; Pavlovich, V. A Non-linear Function Approximation from Small Samples Based on Nadaraya-Watson Kernel Regression. In Proceedings of the 2010 2nd International Conference on Computational Intelligence, Communication Systems and Networks, Liverpool, UK, 28–30 July 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 28–32. [Google Scholar]
- Xiao, J.; Xiang, Z.; Wang, D.; Xiao, Z. Nonparametric kernel smoother on topology learning neural networks for incremental and ensemble regression. Neural Comput. Appl. 2019, 31, 2621–2633. [Google Scholar] [CrossRef]
- Zhang, Y. Bandwidth Selection for Nadaraya-Watson Kernel Estimator Using Cross-Validation Based on Different Penalty Functions. In Proceedings of the International Conference on Machine Learning and Cybernetics (ICMLC 2014), Lanzhou, China, 13–16 July 2014; Communications in Computer and Information Science. Springer: Berlin/Heidelberg, Germany, 2014; Volume 481, pp. 88–96. [Google Scholar]
- Park, B.; Lee, Y.; Ha, S. L2 boosting in kernel regression. Bernoulli 2009, 15, 599–613. [Google Scholar] [CrossRef]
- Noh, Y.K.; Sugiyama, M.; Kim, K.E.; Park, F.; Lee, D. Generative Local Metric Learning for Kernel Regression. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 1–11. [Google Scholar]
- Conn, D.; Li, G. An oracle property of the Nadaraya-Watson kernel estimator for high-dimensional nonparametric regression. Scand. J. Stat. 2019, 46, 735–764. [Google Scholar] [CrossRef]
- De Brabanter, K.; De Brabanter, J.; Suykens, J.A.K.; De Moor, B. Kernel Regression in the Presence of Correlated Errors. J. Mach. Learn. Res. 2011, 12, 1955–1976. [Google Scholar]
- Szczotka, A.; Shakir, D.; Ravi, D.; Clarkson, M.; Pereira, S.; Vercauteren, T. Learning from irregularly sampled data for endomicroscopy super-resolution: A comparative study of sparse and dense approaches. Int. J. Comput. Assist. Radiol. Surg. 2020, 15, 1167–1175. [Google Scholar] [CrossRef]
- Liu, X.; Min, Y.; Chen, L.; Zhang, X.; Feng, C. Data-driven Transient Stability Assessment Based on Kernel Regression and Distance Metric Learning. J. Mod. Power Syst. Clean Energy 2021, 9, 27–36. [Google Scholar] [CrossRef]
- Ito, T.; Hamada, N.; Ohori, K.; Higuchi, H. A Fast Approximation of the Nadaraya-Watson Regression with the k-Nearest Neighbor Crossover Kernel. In Proceedings of the 2020 7th International Conference on Soft Computing & Machine Intelligence (ISCMI), Stockholm, Sweden, 14–15 November 2020; pp. 39–44. [Google Scholar]
- Ghalebikesabi, S.; Ter-Minassian, L.; Diaz-Ordaz, K.; Holmes, C. On Locality of Local Explanation Models. In Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021), Virtual, 6–14 December 2021; pp. 1–13. [Google Scholar]
- Zhang, A.; Lipton, Z.; Li, M.; Smola, A. Dive into Deep Learning. arXiv 2021, arXiv:2106.11342. [Google Scholar]
- Rubin, D. Causal inference using potential outcomes: Design, modeling, decisions. J. Am. Stat. Assoc. 2005, 100, 322–331. [Google Scholar] [CrossRef]
- Rosenbaum, P.; Rubin, D. The central role of the propensity score in observational studies for causal effects. Biometrika 1983, 70, 41–55. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Kha, Q.H.; Ho, Q.T.; Le, N.Q.K. Identifying SNARE Proteins Using an Alignment-Free Method Based on Multiscan Convolutional Neural Network and PSSM Profiles. J. Chem. Inf. Model. 2022, 62, 4820–4826. [Google Scholar] [CrossRef] [PubMed]
- Le, N.Q.K.; Ho, Q.T.; Ou, Y.Y. Using two-dimensional convolutional neural networks for identifying GTP binding sites in Rab proteins. J. Bioinform. Comput. Biol. 2019, 17, 1950005. [Google Scholar] [CrossRef] [PubMed]
- Friedman, J. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Functions | ||||
|---|---|---|---|---|
| Model | Spiral | Logarithmic | Power | Indicator |
| T-NW | ||||
| S-NW | ||||
| X-NW | ||||
| T-RF | ||||
| S-RF | ||||
| X-RF | ||||
| TNW-CATE | ||||
| Number of Treatments | |||
|---|---|---|---|
| Model | 139 | 70 | 35 |
| T-NW | |||
| S-NW | |||
| X-NW | |||
| T-RF | |||
| S-RF | |||
| X-RF | |||
| TNW-CATE | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Konstantinov, A.; Kirpichenko, S.; Utkin, L. Heterogeneous Treatment Effect with Trained Kernels of the Nadaraya–Watson Regression. Algorithms 2023, 16, 226. https://doi.org/10.3390/a16050226
Konstantinov A, Kirpichenko S, Utkin L. Heterogeneous Treatment Effect with Trained Kernels of the Nadaraya–Watson Regression. Algorithms. 2023; 16(5):226. https://doi.org/10.3390/a16050226
Chicago/Turabian StyleKonstantinov, Andrei, Stanislav Kirpichenko, and Lev Utkin. 2023. "Heterogeneous Treatment Effect with Trained Kernels of the Nadaraya–Watson Regression" Algorithms 16, no. 5: 226. https://doi.org/10.3390/a16050226
APA StyleKonstantinov, A., Kirpichenko, S., & Utkin, L. (2023). Heterogeneous Treatment Effect with Trained Kernels of the Nadaraya–Watson Regression. Algorithms, 16(5), 226. https://doi.org/10.3390/a16050226