In this section, we present the details of the main techniques used in our paper, and how they apply to the problem at hand. We first introduce logistic regression and then discuss how it can be generalized to feed-forward neural networks.
2.1. Logistic Regression
In logistic regression, the response
is a Bernoulli
variable with a probability mass function (pmf) given by
where
if the
i-th claim is observed with probability
and
with probability
otherwise, for
.
Furthermore, we assume that the i-th claim will be observed or not using covariate information X, with corresponding to the intercept component.
As is well known,
has an exponential dispersion family (EDF) representation with canonical link function given by
where
and where the design matrix
is of full rank
. The use of the canonical link function implies that we receive unbiased estimates on a portfolio level, as can be seen in [
46].
Additionally, from Equation (
2), we obtain the sigmoid, or the inverse of the logit, function
of the prediction
The sigmoid function has the advantage that the predicted values are probabilities which yield more easily interpretable results. Furthermore, the individual coefficients in the vector can be treated as feature importance weights which result in explainable models.
Finally, it is worth noting that in addition to the logistic sigmoid function, which is given by Equation (
3), there are several other sigmoid functions, such as the hyperbolic tangent and the arctangent which are also monotonic and have a bell-shaped first derivative. Sigmoid functions were inspired by the activation potential in biological neural networks and have been widely used when designing ML algorithms, particularly as activation functions in artificial neural networks.
2.2. Training a Logistic Regression Model
Let be a set of examples where is the binary response and are explanatory variables, or input examples, such that each example is represented by d real valued features and augmented with the constant 1 that represents the intercept component. Let be the parameters that define the model and be a loss function that evaluates how well the model fits the response Y for input X. We want to optimize the loss with respect to the parameters , and thus, in the following, for brevity, we will denote by . We will present later appropriate choices for the loss function. Let us for now only assume that the first and second derivatives and with respect to the parameters are well defined and nonzero.
Unfortunately, the logistic regression model does not admit a closed form of the optimal solution (for a reasonable choice of the loss function) and we cannot directly compute an optimal solution. Instead, the solution has to be numerically estimated using an iterative process. Below we present two widely used approaches to finding an approximation of the optimal solution: namely the Newton–Raphson algorithm for the logistic regression model, which is outlined in Algorithm 1, and the gradient descent approach, which is presented in Algorithm 2.
| Algorithm 1 Newton–Raphson algorithm |
- 1
Input: A design matrix , a response vector . - 2
Set an initial value for and name it , set . - 3
Define the maximum permitted number of steps, and threshold .
|
![Algorithms 16 00099 i001]() |
| Algorithm 2 Gradient descent algorithm |
- 1
Input: A design matrix , a response vector . - 2
Set an initial value for and name it . - 3
Set a learning rate , and . - 4
Define the maximum permitted number of steps, and threshold .
|
![Algorithms 16 00099 i002]() |
Both algorithms use the gradient descent approach that iteratively approximates a local optimum by a starting at a randomly selected point and moving in the opposite direction to the gradient. For a convex loss function, this is also the global optimum. The difference between the approaches is that, if we use a small predefined constant learning rate that moves in the direction of the (local) optimum, we use the second derivative of the loss function that guarantees the convergence with a smaller number of steps. The reduced number of iterations of the Newton–Raphson algorithm comes at the price that we need the second derivative of the loss function. We will later discuss why computing the second derivative can be a computational bottleneck for neural network optimization.
2.4. Maximum Likelihood Estimation
Assume that we have a set of data points
and we want to calculate the ML estimate of the
-dimensional parameter
of the logistic regression model in Equations (
1) and (
2).
The log-likelihood function of the model is given by
for
.
Thus, by substituting
from Equation (
3) into Equation (
6), we have
where
is the sigmoid function.
To find MLE of
, one has to solve the score equation
The negative likelihood thus defines the
cross-entropy loss:
However, since there is no analytic solution for Equation (
8), the solution has to be numerically estimated using an iterative process as the one described in the previous section. Next, we show how to employ the Newton–Raphson method which is the most popular method for solving systems of nonlinear equations (note that the MLE of the logistic regression model can be obtained by calling the glm() function in programming language
whilst setting the family argument to “binomial”).
The Newton–Raphson algorithm for the logistic regression model can be described in matrix form as follows:
Let
be the estimate of
obtained after the
r-th iteration. The matrix representations of the first and the second derivative of the log-likelihood in (
6)–(
9) are given by
and
where
is the design matrix and where
, with
, where
is the pointwise product
. Furthermore, let
be an
diagonal matrix where the
i-th diagonal entry is given by
.
Then, the
r-th update is given by
The description of a gradient descent algorithm is straightforward from the above discussion, the difference being that we need to replace the second derivative with a constant learning rate . In order to obtain good quality, we will need to set a sufficiently small , and thus the gradient descent will converge in more iterations than the Newton–Raphson method. However, we avoid the computation of the second derivatives in the Hessian matrix which has a computational complexity of , whereas computing the first derivative can be performed in steps The big O notation denotes asymptotic growth. Formally, it holds iff for all for some constants and .
2.6. Model Evaluation
We split the available dataset into a learning set and a test set . We train the models only on and report results for the performance of the models on both and . We would like the quality of prediction on both datasets to be comparable, since in this case, the model’s performance is likely to be representative for new unseen datasets. This will be particularly important when training neural network models which have higher capacity, i.e., they can represent more complex functions than GLMs. In fact, one of the main results on neural networks is that they can represent arbitrary continuous functions. On the other hand, for this reason, such models are prone to overfitting the training data. Thus, it is of crucial importance to show results of comparable quality on a dataset that was not used for training.
More precisely, we perform the parameter estimation on the learning set
to achieve a minimal deviance loss as follows:
This enables the calculation of the in-sample deviance loss
and the out-of-sample deviance loss
This out-of-sample loss is then our main measure of interest when comparing the prediction performance between models. Note that the model is fit only on the learning data and thus we optimize the in-sample loss but evaluate the quality of the model on the out-of-sample loss. The expressions for in-sample and out-of-sample cross-entropy loss can be derived in a straightforward way from the above and Equation (
6).
2.7. Neural Networks
In this section, we give an overview of neural networks and we discuss how they can be used in our setting for the prediction of insurance claims in the French MTPL data we consider for our numerical illustration in
Section 4.
The design of advanced neural network architectures is a very active research area, with applications ranging from speech recognition to drug design. We refer the reader to [
47] for an overview of different neural architectures.
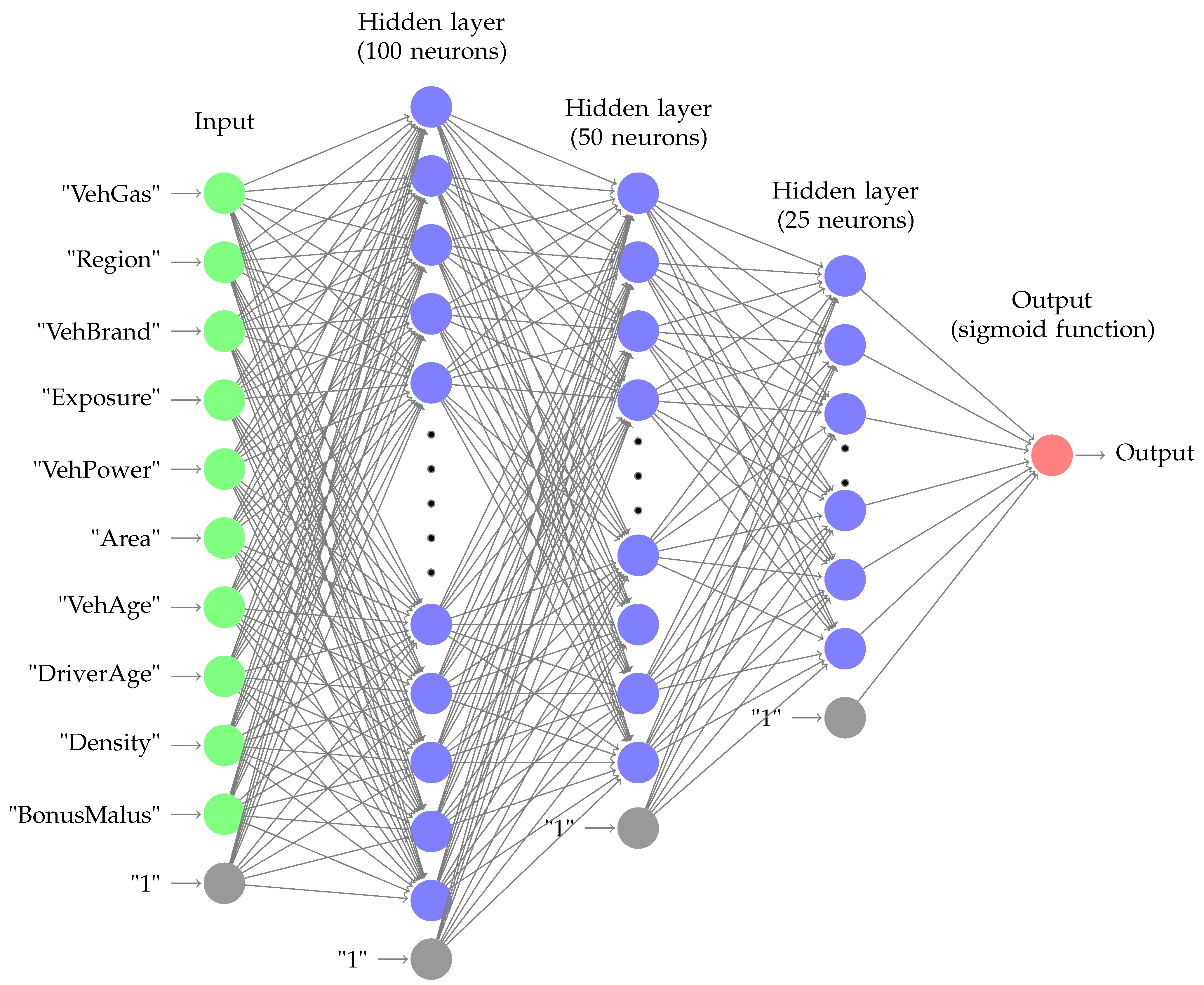
A feed-forward neural network consists of several layers such that each layer consists of a number of neurons. The first layer is the input layer and the last layer computes the output of the function. The layers between the input and the output layers are called
hidden layers. In
Figure 1, we show a neural network with three hidden layers. This is the network that we are using for our model, as more details are provided in the following sections. Each neuron computes a linear combination of all inputs from the previous layer. We can think of the output of a layer as a matrix multiplication with the input from the previous layer where the entries in the matrix should be learned by training the model. A neuron corresponds to a row in this matrix. In order to represent nonlinear functions, we apply a nonlinear activation function to the output of each layer.
More precisely, a neural network computes a function
f mapping the features
to the response
:
As the neural network consists of several hidden layers, and each layer can be expressed as a mapping, we see that
f is composed of several functions. In particular, let
be the input to the
k-th hidden layer with
neurons. Then, the function in the
k-the layer is given by
where
for a matrix
and a nonlinear activation function
that is applied entry-wise to the vector
. Thus, the
i-th neuron is represented by the
i-th row in the matrix
W. Summarizing the above, the
k-th layer computes the function
The hidden neurons are given by
with
. For
, the input
is simply the design matrix
x and
is equal to the dimension of the feature space
.
The last layer computes a predicted value for the problem at hand. In our setting, we consider a binary classification problem. Thus, to take into account the exposure of every insurance policy, just as in logistic regression, the output layer is given by
where
is the sigmoid function which computes the probability that a given example will be an insurance claim. That is equivalent to adding a layer with
and a sigmoid activation function. This basic architecture of the neural network then has a depth of
K with
parameters to be learned.
As a concrete example, we consider the neural network shown in
Figure 1. The input comprises 11 variables provided in the insurance claim dataset. There are
hidden layers with
,
,
and
neurons. Thus, there are 5100 parameters for
.
2.7.1. Logistic Regression as a Single Layer Neural Network
We can view logistic regression as a single layer network. In particular, for , and , the network implements the logistic regression model.
2.7.2. Neural Network Training
Given a dataset with examples and a target variable (where for regression problems, and for classification), we want to learn the parameters or the weights of the layers of a neural network that computes a function . This is usually achieved by choosing a particular neural network architecture and a loss function that helps us achieve a given objective, e.g., high accuracy for classification or a small absolute error for regression. In our setting, the desired objective is to reflect the probability for an insurance claim.
The loss function should be well defined and differentiable such that an optimal solution can be found. As neural networks represent complex functions, an optimal solution will not exhibit a closed form in the general case. Instead, a local optimum is found using numerical optimization methods. It is standard to use the gradient descent method. The approach starts with randomly assigned values for the weights for all neurons. The values are random but sampled from some distribution. Empirically, it was observed that sampling from a 0-mean normal distribution where the variance is a function of the number of input and output neurons at the layer guarantees the fast convergence of training.
The examples are processed in batches. For example, let be the output of a neural network for a given regression problem. For a batch with n examples , the loss is defined as where is the response we want to learn. For regression problems, a commonly used loss function is the mean squared error, thus we have to optimize the parameters of F, i.e., the weights of the layers in the neural network, such that is minimized. In the binary classification setting, appropriate choices for the loss function are cross-entropy and deviance, as discussed in the previous section.
The method of choice for neural networks is
gradient descent, as described in Algorithm 2. Weights are updated such that the weight values
move in the negative direction of the gradient of
:
where
denotes neural network evaluated at
x with weights
and
is the
learning rate. For sufficiently small
, gradient descent is guaranteed to converge to a local optimum. Thus, for a convex function, it will probably find an optimal solution.
As discussed, a neural network implements a composition of functions. Thus, the loss function can be written as
Using the chain rule for computing the derivative of a composite function, gradient descent is applied to a neural network using back propagation. Remember that
and
. In order to compute the derivative of the loss function with respect to the weight of the neurons in the
t-th layer, for
, we apply the chain rule as
In each layer, we compute the derivative at each layer with respect to the output of the previous layer. In the above, it holds that
Note that, in the above, the design matrix values, i.e., the feature values in the training dataset, are considered to be constants.
Of course, neural networks are not supposed to only model convex functions but even the local optima of non-convex loss functions yield good enough solutions in practice.
2.7.3. More on Gradient Descent Optimization
Gradient descent has become the ubiquitous approach to training neural networks, and is the method of choice in literally all platforms for neural network training. As discussed in
Section 2.1, we can apply the Newton–Raphson algorithm which converges in fewer iterations. However, this would require the computation of the second derivative with respect to the parameters at each layer, i.e., we need the Jacobian matrix of the layer parameters
. For larger networks with many parameters, this is unfeasible as the Jacobian will have
parameters, where
and
is the number of input and output neurons at the
k-th layer. Even for our relatively small neural network from
Figure 1, this would mean a Jacobian matrix with 25 million entries.
However, gradient descent comes with many challenges that need consideration:
We can get stuck in a local optimum which might result in a solution which is not good enough. Furthermore, for a non-convex function there might exist a saddle point where, in one dimension, the function has a positive slope, and a negative slope in other dimension. The derivative of a function at a saddle point is 0 but the saddle point is not a local optimum.
A small learning rate would lead to very slow convergence, and a large learning rate might lead to oscillation around the optimum.
Computing the gradient with respect to the whole training dataset might result in very slow updates.
For certain loss functions, we might encounter the problem of vanishing gradients. Consider the sigmoid function , for large or small values of z the gradient will be close to 0, and thus we will need many iterations until we reach an optimum.
The learning rate needs to be adapted in order to address changes in the curvature for complex functions. In particular, the gradients in different directions might be of largely different magnitudes, and thus using a constant learning rate might lead to oscillations.
Researchers have approached the above issues using various techniques such as
In particular, the choice of activation function is of critical importance. We discuss different activation functions and how we use them in our architecture in greater detail in the next subsection.
Mini-batch training. Compute the gradients not for the whole dataset but for a batch of examples.
Adaptive learning rate. The idea is that the learning rate is not a constant but a function of the gradients of the past iterations of the optimization process. A popular choice in practice is the Adam approach (adaptive moment estimation) where the learning rate is adjusted after each iteration by using an exponentially decreasing average of past gradients. We refer to [
48] for more details on the approach.
Parameter initialization. We start to train the neural network model by initializing the parameters with random values. However, the magnitude of these random values has to be carefully selected as it might lead to slower training or even vanishing or exploding gradients.
Note that the above list is not exhaustive since, unfortunately, neural network optimization relies on heuristic techniques and trial-and-error-based hyperparameter tuning, and is thus often characterized as being more of an art than science. Regarding the classification problem we consider herein, we provide more details in the next section wherein we discuss the results of our models.
2.7.4. Activation Functions
When the activation function is nonlinear, a deep neural network computes complex nonlinear functions. In fact, the universal approximation theorem states that any continuous function can be approximated with an arbitrarily small error by a neural network with a single hidden layer and a nonlinear activation. However, such functions are unlikely to generalize well as the hidden layer might need to be very large, and thus they will not be useful for learning a model that generalizes well to new data. Instead, one prefers multilayer networks where each layer computes certain patterns which are then combined by the next layer in order to form more complex patterns. In the context of computer vision, one can think of the first layers of a neural network of detectors of basic image features such as edges and contours, while the latter layers combine these basic shapes into more complex patterns that represent object parts.
Below, we list the most widely used activation functions.
The sigmoid function is widely used for binary classification as it returns a value in which can be treated as the probability that a given example belongs to one of two classes. For multi-classification problems, the function is generalized to the softmax function which returns the probability for each of k classes. However, the derivative of the sigmoid function is . Therefore, the maximum possible value of the derivative is 0.25. It is not advisable to use the sigmoid as the activation function for several layers as it is likely to encounter the problem of vanishing gradients: by the chain rule, we multiply the derivatives at each layer and thus the gradient will converge to 0 and updating the weights by gradient descent will converge very slowly towards an optimal solution. For this reason, the sigmoid is usually used as an activation function only for the output layer.
This is an alternative to the sigmoid function where the range of values is between −1 and 1 which might yield more insights, especially regarding the impact that certain features have on the output. Observe that , and thus the derivative is at most 1 and is close to 1 only for . Thus, stacking several layers with a hyperbolic activation function might again lead to the vanishing gradient problem, and thus it is recommended to use it only for layers close to the output layer.
This is a nonlinear function that can be used to obtain a piecewise linear approximation of arbitrary functions. As long as the weights are positive, gradient descent quickly converges towards the optimal solution. However, an obvious problem of the ReLu activation function is that if the input to a neuron is negative, then the derivative will always be 0, which is the so-called “dying” ReLUs problem. Alternatives have been proposed, such as the LeakyReLU with , where is a small constant, or the eLU for some .
In our setting, we found that the eLU activation function yields the best results, slightly outperforming the ReLU. We will comment more on this in the next section.
2.7.5. Embedding Layer
A common technique for the preprocessing of categorical features is to convert them into numeric vectors. The standard choice is to represent a feature x, with values over c possible categories , by a binary c-dimensional vector x with a single nonzero coordinate such that iff . This is the so-called “one-hot encoding”.
Neural networks offer an important alternative, namely that categorical features are represented by numerical vectors and these vectors are learnt just like we learn the weights of the individual layers. This is achieved by the so-called embedding layer that maps each feature value to its corresponding embedding, i.e., its vector representation. This is implemented by a simple hash table that keeps the corresponding representation for each feature value and loads it when required. All modern neural network frameworks such as Keras, PyTorch, etc., offer embedding layers.
One major advantage is that the learnt feature representations capture the intrinsic characteristics of the features. For example, embeddings are very popular in natural language processing where the semantic similarity between words is reflected in the embeddings. A notorious example is that .















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}