

A Hybrid Direct Search and Model-Based Derivative-Free Optimization Method with Dynamic Decision Processing and Application in Solid-Tank Design

 ,
,
Abstract
1. Introduction
1.1. Overview of DQL and Smart DQL Method
1.2. Definitions
2. DQL Method
2.1. Solution Acceptance Rule
| Algorithm 1 Improvement_Check (Candidate_Set, , ) |
|
2.2. Direct Step
2.2.1. Framework of the Direct Step
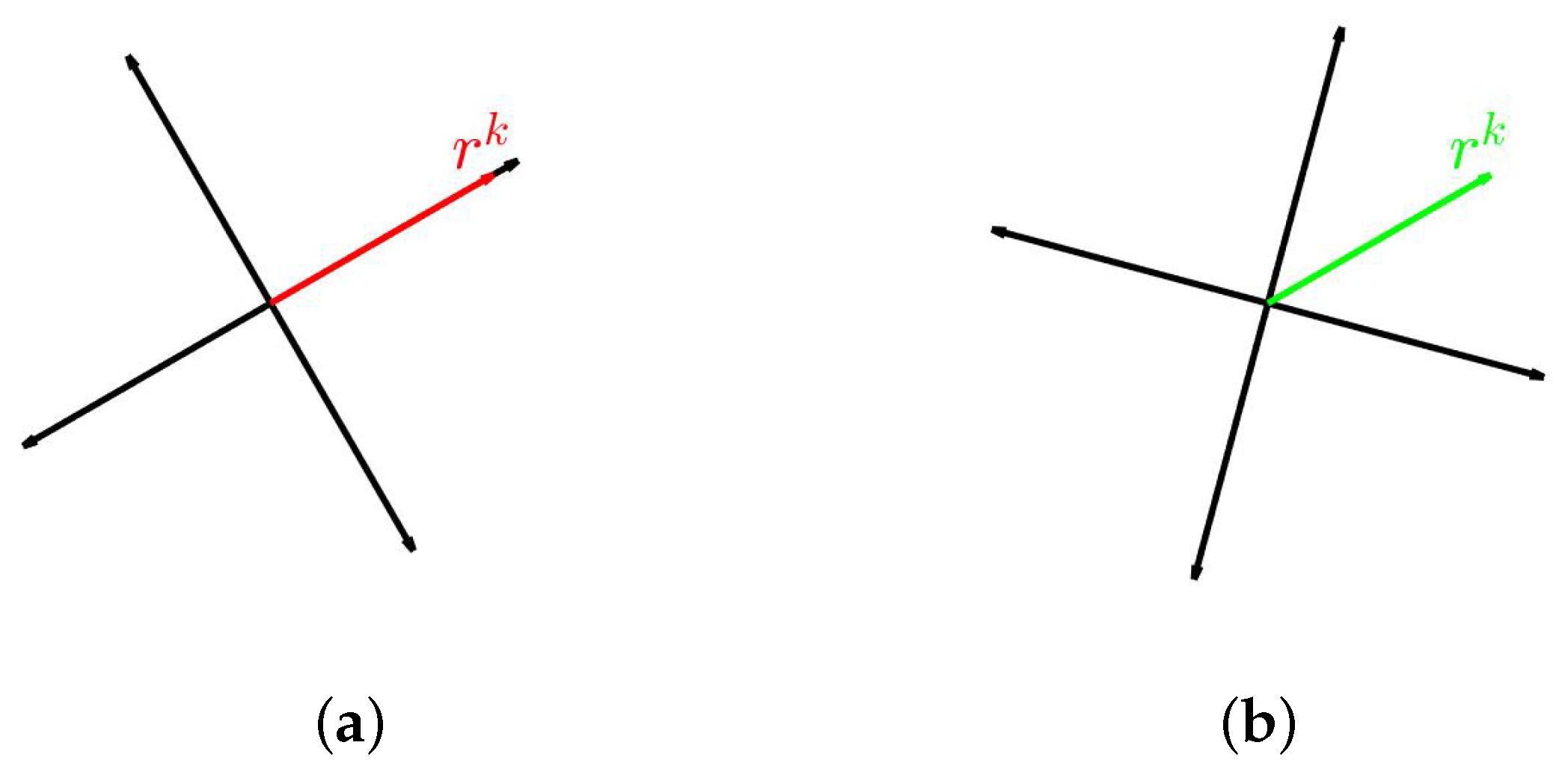
- If is a desired direction, then we construct such that it rotates one of the search directions to align with .
- If is an undesired direction, then we construct such that it rotates the vector to align with . In this way, the coordinate directions are rotated to point away from as much as possible.
Improvement_Check(, , ).
| Algorithm 2Direct_Step (, ) |
|
Direct Step Strategy
- A coordinate direction being the desired direction;
- A random direction being the desired direction.
2.3. Quadratic Step
2.3.1. Framework of Quadratic Step
| Algorithm 3 Quadratic_Step (, , , ) |
|
Quadratic Step Strategies
Discussion on Quadratic Step Strategies
- The points chosen to construct the model are different. In the quadratic step strategy 1, any evaluated points that are within the trust region are chosen. In the quadratic step strategy 2, the chosen points have an additional requirement that they should also have a gradient approximation.
- In the quadratic step strategy 1, lies within the trust region. In the quadratic step strategy 2, if the approximated Hessian is positive definite, then may lie outside of the trust region.
2.4. Linear Step
2.4.1. Framework of Linear Step
| Algorithm 4 Linear_Step (, ) |
|
Linear Step Strategies
2.5. Update Step
2.6. Pseudocode for DQL Method
| Algorithm 5 Parameter_Update (, , Direct_Flag, Quadratic_Flag, Linear_Flag) |
|
| Algorithm 6 DQL (f, , , , , max_search) |
|
3. Analysis of the DQL Method
3.1. Convergence Analysis
3.1.1. Directional Direct Search Method
3.1.2. Convergence of the Directional Direct Search Method
3.1.3. Convergence of the DQL Method
3.2. Benchmark for Step Strategies
3.2.1. Stopping Conditions
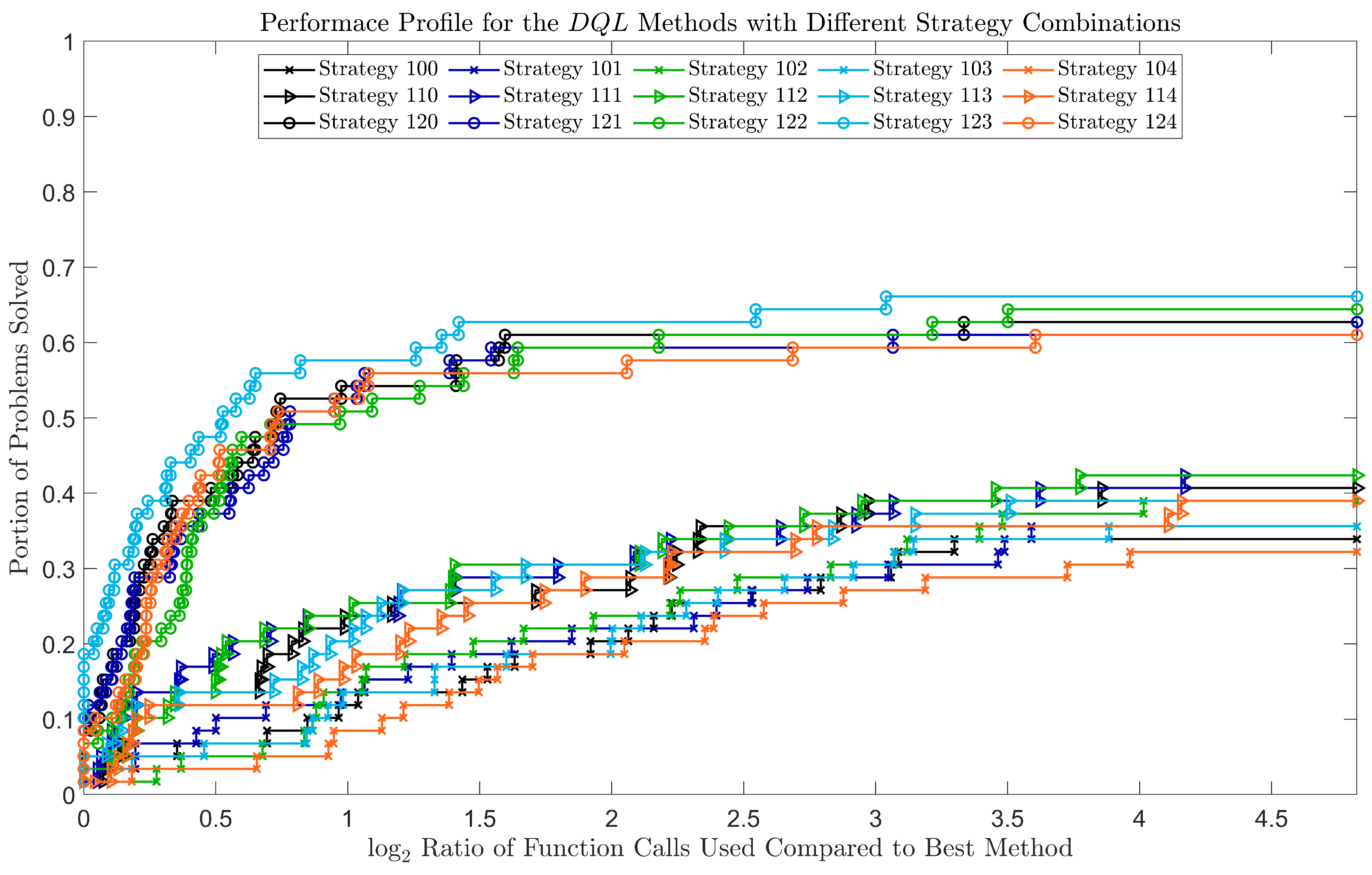
3.2.2. Performance Benchmark
3.2.3. Discussion on the Experiment Results
- Quadratic step strategy 2 outperformed quadratic step strategy 1, which outperformed disabling the quadratic step. This showed that the quadratic step led to a performance improvement.
- Linear step strategy 4 was the worst strategy in every cluster. This strategy slowed down the performance. In addition, linear step strategies 1, 2, and 3 and disabling the linear step showed a mixed performance. Their performance differences were too small to find a clear winner.
4. SMART DQL Method
4.1. Frameworks of Smart Steps
4.1.1. Smart Quadratic Step
| Algorithm 7 smart_Quadratic_Step (, ) |
|
4.1.2. Smart Linear Step
| Algorithm 8 smart_linear_step (, , ) |
|
4.1.3. Smart Direct Step
4.2. Benchmark for Smart DQL Method
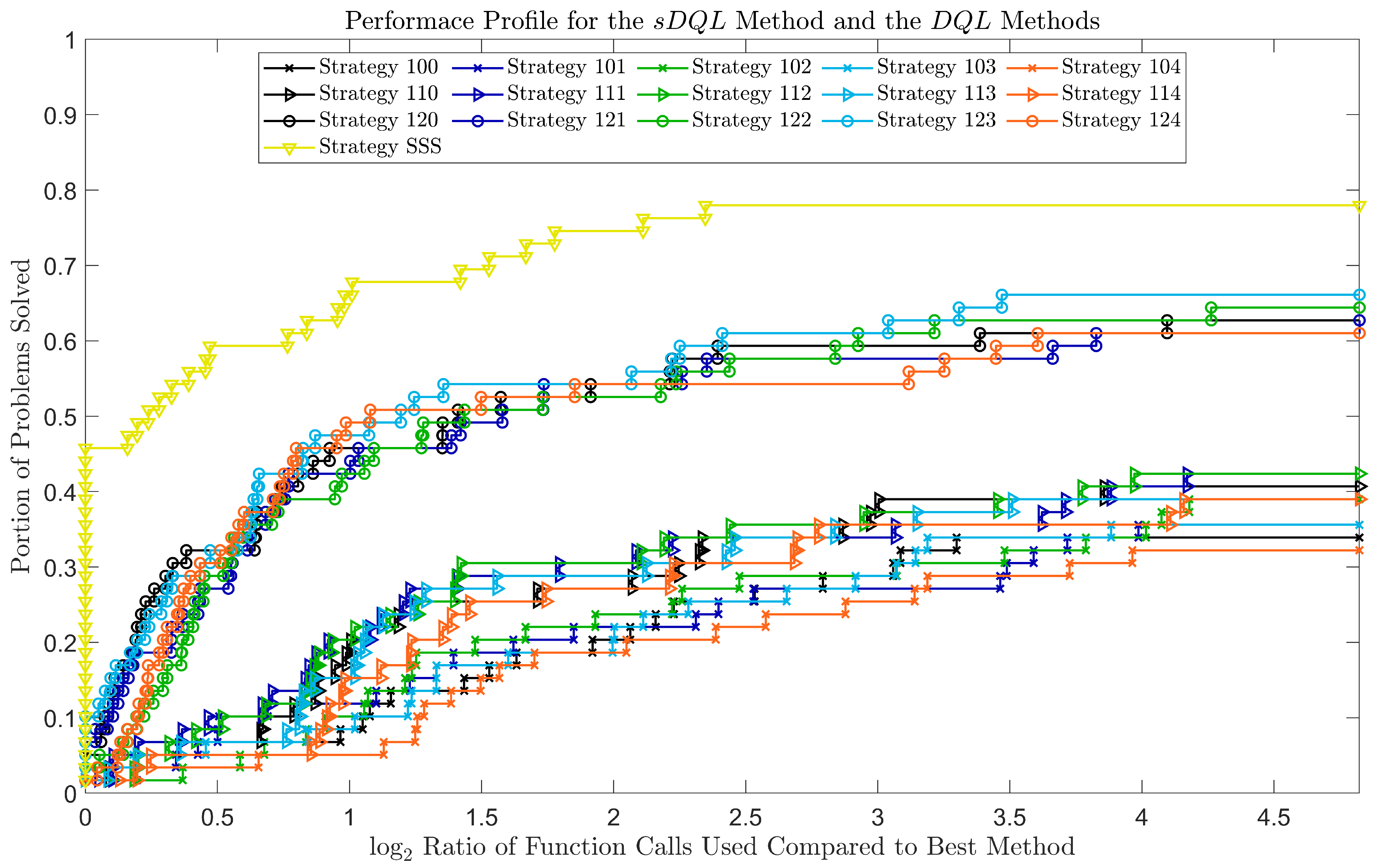
4.2.1. Experiment Result
| Algorithm 9 Determine_Rotation_Direction ( , , ) |
|
4.2.2. Discussion
5. Solid-Tank Design Problem
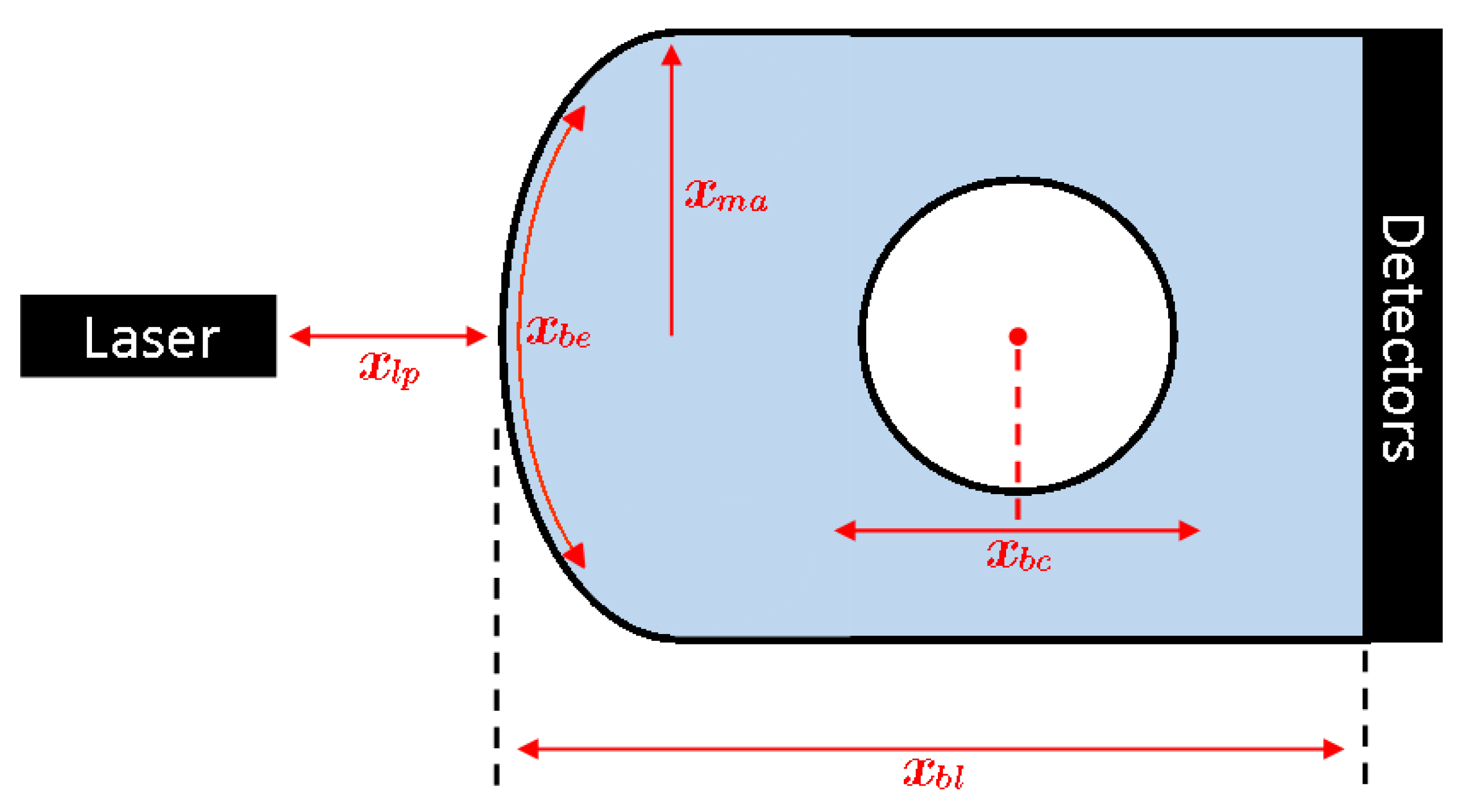
5.1. Background
5.2. Transforming the Optimization Problem
5.3. Experiment Result and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations and Nomenclature
| DFO | Derivative-free optimization | |
| BBO | Black-box optimization | |
| MBTR | Model-based trust region | |
| MBD | Model-based descent | |
| Moore–Penrose pseudoinverse | Definition 1 | |
| Generalized centred simplex gradient | Definition 2 | |
| Generalized simplex Hessian | Definition 3 | |
| Cosine measure | Definition 4 | |
| Search step length | Section 2 | |
| Initial search point | Section 2 | |
| Current best solution | Section 2 | |
| Direct step search directions | Section 2.2 | |
| Quadratic step search candidates | Section 2.3 | |
| Linear step search candidates | Section 2.4 |
References
- Ali, E.; Abd Elazim, S.; Balobaid, A. Implementation of coyote optimization algorithm for solving unit commitment problem in power systems. Energy 2023, 263, 125697. [Google Scholar] [CrossRef]
- Abd Elazim, S.; Ali, E. Optimal network restructure via improved whale optimization approach. Int. J. Commun. Syst. 2021, 34, e4617. [Google Scholar]
- Ali, E.; Abd Elazim, S. Mine blast algorithm for environmental economic load dispatch with valve loading effect. Neural Comput. Appl. 2018, 30, 261–270. [Google Scholar] [CrossRef]
- Alarie, S.; Audet, C.; Garnier, V.; Le Digabel, S.; Leclaire, L.A. Snow water equivalent estimation using blackbox optimization. Pac. J. Optim. 2013, 9, 1–21. [Google Scholar]
- Gheribi, A.; Audet, C.; Le Digabel, S.; Bélisle, E.; Bale, C.; Pelton, A. Calculating optimal conditions for alloy and process design using thermodynamic and property databases, the FactSage software and the Mesh Adaptive Direct Search algorithm. Calphad 2012, 36, 135–143. [Google Scholar] [CrossRef]
- Gheribi, A.; Pelton, A.; Bélisle, E.; Le Digabel, S.; Harvey, J.P. On the prediction of low-cost high entropy alloys using new thermodynamic multi-objective criteria. Acta Mater. 2018, 161, 73–82. [Google Scholar] [CrossRef]
- Marwaha, G.; Kokkolaras, M. System-of-systems approach to air transportation design using nested optimization and direct search. Struct. Multidiscip. Optim. 2015, 51, 885–901. [Google Scholar] [CrossRef]
- Chamseddine, I.M.; Frieboes, H.B.; Kokkolaras, M. Multi-objective optimization of tumor response to drug release from vasculature-bound nanoparticles. Sci. Rep. 2020, 10, 1–11. [Google Scholar] [CrossRef]
- Conn, A.; Scheinberg, K.; Vicente, L. Introduction to Derivative-Free Optimization; SIAM: Philadelphia, PA, USA, 2009. [Google Scholar]
- Audet, C.; Hare, W. Derivative-Free and Blackbox Optimization; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Audet, C. A survey on direct search methods for blackbox optimization and their applications. In Mathematics without Boundaries; Springer: Berlin/Heidelberg, Germany, 2014; pp. 31–56. [Google Scholar]
- Hare, W.; Nutini, J.; Tesfamariam, S. A survey of non-gradient optimization methods in structural engineering. Adv. Eng. Softw. 2013, 59, 19–28. [Google Scholar] [CrossRef]
- Custodio, A.L.; Vicente, L.N. SID-PSM: A Pattern Search Method Guided by Simplex Derivatives for Use in Derivative-Free Optimization; Departamento de Matemática, Universidade de Coimbra: Coimbra, Portugal, 2008. [Google Scholar]
- Custódio, A.L.; Rocha, H.; Vicente, L.N. Incorporating minimum Frobenius norm models in direct search. Comput. Optim. Appl. 2010, 46, 265–278. [Google Scholar] [CrossRef]
- Manno, A.; Amaldi, E.; Casella, F.; Martelli, E. A local search method for costly black-box problems and its application to CSP plant start-up optimization refinement. Optim. Eng. 2020, 21, 1563–1598. [Google Scholar] [CrossRef]
- Ogilvy, A.; Collins, S.; Tuokko, T.; Hilts, M.; Deardon, R.; Hare, W.; Jirasek, A. Optimization of solid tank design for fan-beam optical CT based 3D radiation dosimetry. Phys. Med. Biol. 2020, 65, 245012. [Google Scholar] [CrossRef] [PubMed]
- Hare, W.; Jarry–Bolduc, G.; Planiden, C. Error bounds for overdetermined and underdetermined generalized centred simplex gradients. arXiv 2020, arXiv:2006.00742. [Google Scholar] [CrossRef]
- Hare, W.; Jarry-Bolduc, G.; Planiden, C. A matrix algebra approach to approximate Hessians. Preprint 2022. Available online: https://www.researchgate.net/publication/365367734_A_matrix_algebra_approach_to_approximate_Hessians (accessed on 7 November 2021).
- Masson, P. Rotations in Higher Dimensions. 2017. Available online: https://analyticphysics.com/Higher%20Dimensions/Rotations%20in%20Higher%20Dimensions.htm (accessed on 7 November 2021).
- MathWorks. MATLAB Version 2020a. Available online: https://www.mathworks.com/products/matlab.html (accessed on 15 November 2021).
- Mifflin, R.; Strodiot, J.J. A bracketing technique to ensure desirable convergence in univariate minimization. Math. Program. 1989, 43, 117–130. [Google Scholar] [CrossRef]
- Lukšan, L.; Vlcek, J. Test problems for nonsmooth unconstrained and linearly constrained optimization. Tech. Zpráva 2000, 798, 5–23. [Google Scholar]
- Moré, J.; Garbow, B.; Hillstrom, K. Testing unconstrained optimization software. ACM Trans. Math. Softw. (TOMS) 1981, 7, 17–41. [Google Scholar] [CrossRef]
- Beiranvand, V.; Hare, W.; Lucet, Y. Best practices for comparing optimization algorithms. Optim. Eng. 2017, 18, 815–848. [Google Scholar] [CrossRef]
- Dolan, E.; Moré, J. Benchmarking optimization software with performance profiles. Math. Program. 2002, 91, 201–213. [Google Scholar] [CrossRef]
- Gould, N.; Scott, J. A note on performance profiles for benchmarking software. ACM Trans. Math. Softw. (TOMS) 2016, 43, 1–5. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Search Direction d | Search Step |
|---|---|---|
| Strategy 1 | ||
| Strategy 2 | ||
| Strategy 3 | ||
| Strategy 4 |
| Parameter | Value |
|---|---|
| max_search | |
| 10 | |
| 0.3 | |
| 3 |
| Parameter | Value |
|---|---|
| max_search () | 5000 |
| max_search () | 8000 |
| Dimension | Method | Water | FlexyDos3D | ClearViewTM |
|---|---|---|---|---|
| DQL | 0.801 | 0.979 | 0.952 | |
| Smart DQL | 0.829 | 0.981 | 0.956 | |
| DQL | 0.767 | 0.977 | 0.686 | |
| Smart DQL | 0.857 | 0.974 | 0.831 |
| Profile | (mm) | (mm) | (mm) | (mm) | |
|---|---|---|---|---|---|
| Water | 252.4 | 19.2 | 71.8 | 70.1 | 0 |
| FlexyDos3D | 282.0 | 5.8 | 51.8 | 67.0 | 0 |
| ClearViewTM | 225.1 | 21.2 | 63.1 | 69.0 | 0 |
| Profile | (mm) | (mm) | (mm) | (mm) | (mm) | (mm) | ||
|---|---|---|---|---|---|---|---|---|
| Water | 122.6 | −4.3 | 94.0 | 79.8 | 0.8 | 70.0 | 0 | 23.4 |
| FlexyDos3D | 114.0 | 0 | 100.0 | 68.3 | 0.1 | 70.0 | 0 | 0.5 |
| ClearViewTM | 114.0 | 0 | 100.0 | 93.3 | 1.0 | 70.8 | 0.3 | 46.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Z.; Ogilvy, A.; Collins, S.; Hare, W.; Hilts, M.; Jirasek, A. A Hybrid Direct Search and Model-Based Derivative-Free Optimization Method with Dynamic Decision Processing and Application in Solid-Tank Design. Algorithms 2023, 16, 92. https://doi.org/10.3390/a16020092
Huang Z, Ogilvy A, Collins S, Hare W, Hilts M, Jirasek A. A Hybrid Direct Search and Model-Based Derivative-Free Optimization Method with Dynamic Decision Processing and Application in Solid-Tank Design. Algorithms. 2023; 16(2):92. https://doi.org/10.3390/a16020092
Chicago/Turabian StyleHuang, Zhongda, Andy Ogilvy, Steve Collins, Warren Hare, Michelle Hilts, and Andrew Jirasek. 2023. "A Hybrid Direct Search and Model-Based Derivative-Free Optimization Method with Dynamic Decision Processing and Application in Solid-Tank Design" Algorithms 16, no. 2: 92. https://doi.org/10.3390/a16020092
APA StyleHuang, Z., Ogilvy, A., Collins, S., Hare, W., Hilts, M., & Jirasek, A. (2023). A Hybrid Direct Search and Model-Based Derivative-Free Optimization Method with Dynamic Decision Processing and Application in Solid-Tank Design. Algorithms, 16(2), 92. https://doi.org/10.3390/a16020092