

On the Influence of Data Imbalance on Supervised Gaussian Mixture Models

Abstract
:1. Introduction
1.1. Motivation
1.2. Aim and Organization of the Paper
2. Materials and Methods
2.1. Probabilistic Generative Models for Supervised Learning
2.2. Gaussian Mixtures for Classification
2.3. Model Selection
2.4. Classification Rule
3. Performance Measures for Imbalanced Data
4. Addressing Imbalanced Data
4.1. Cost-Sensitive Learning
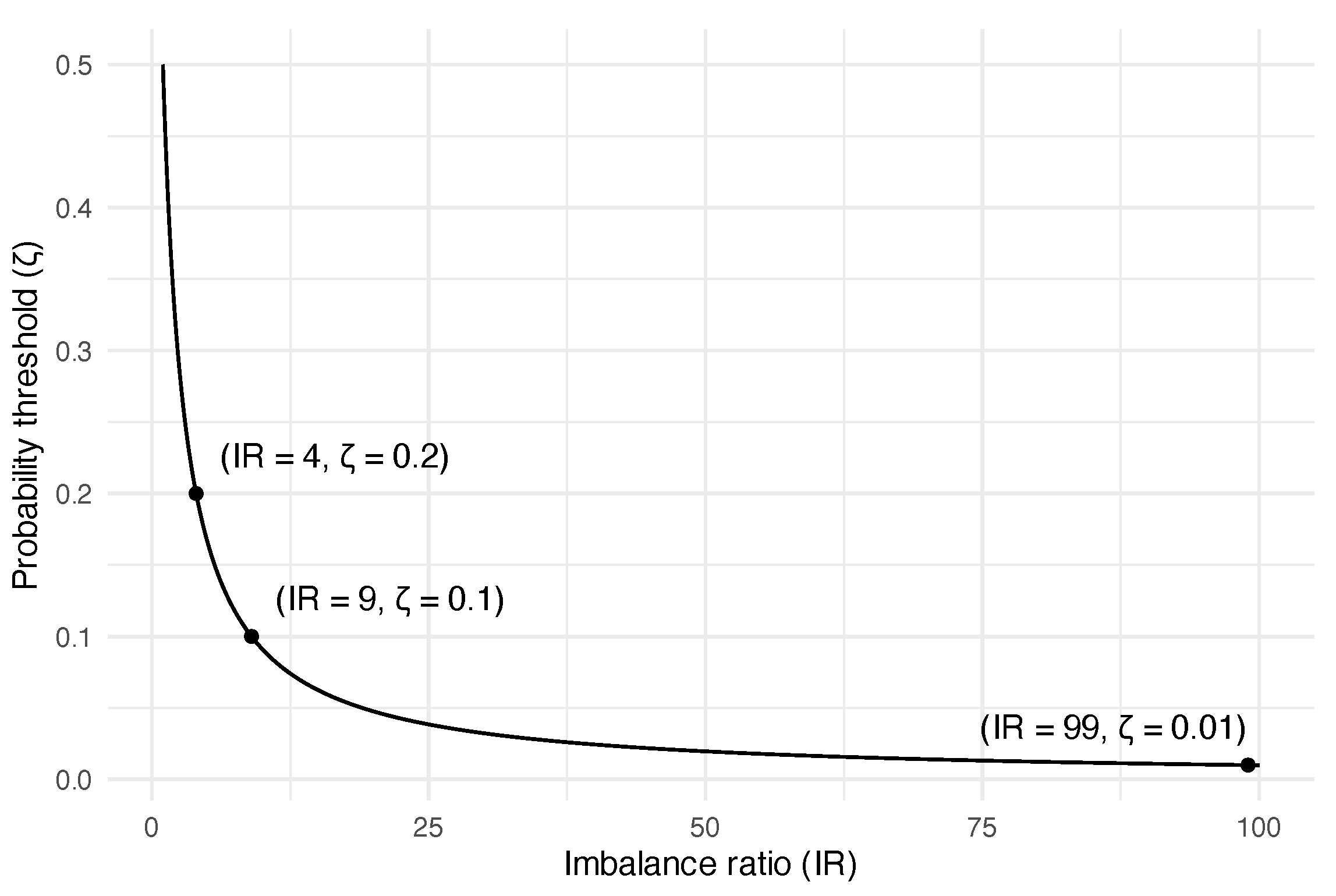
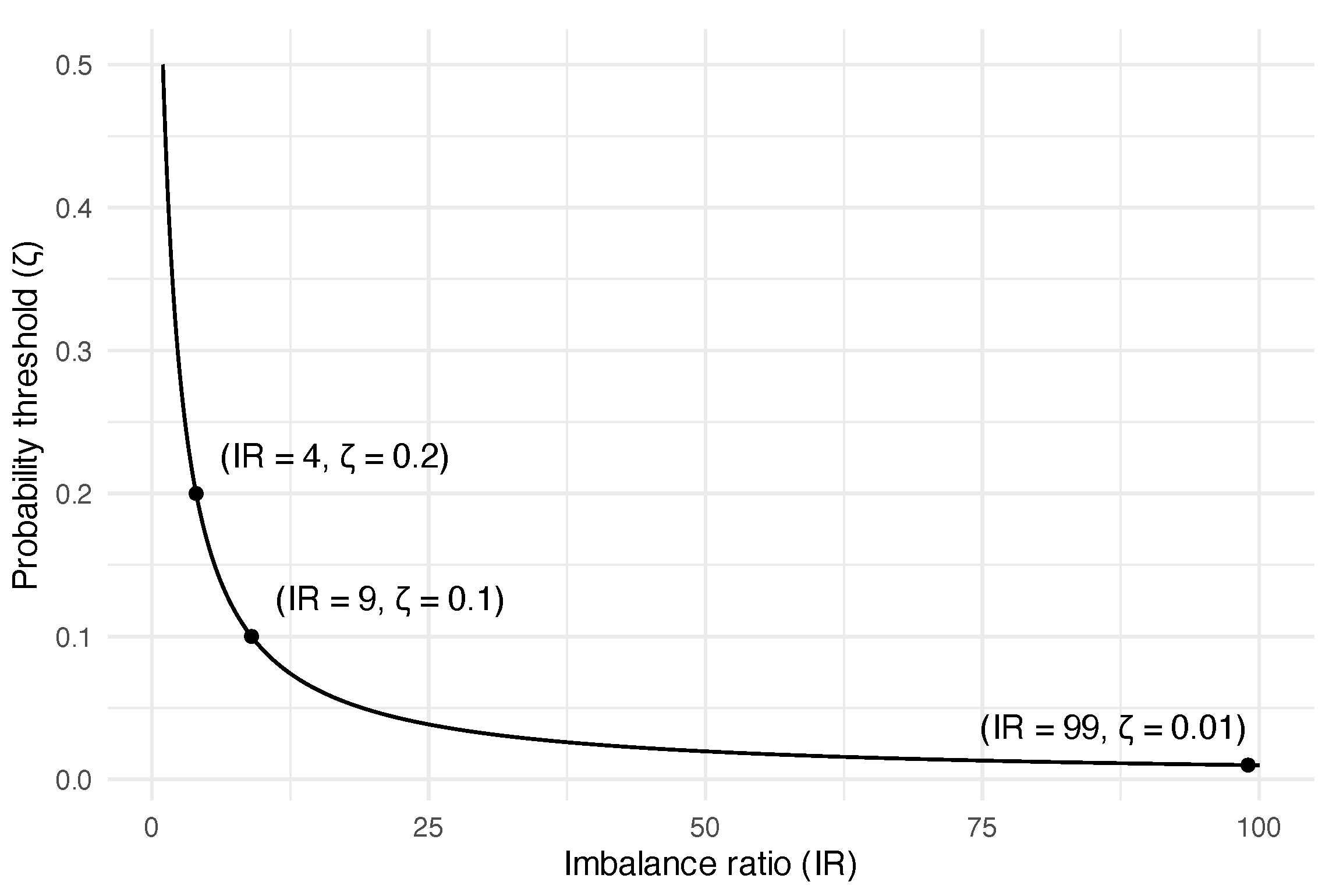
4.2. Probability Threshold Tuning
4.3. Sampling Methods
5. Results
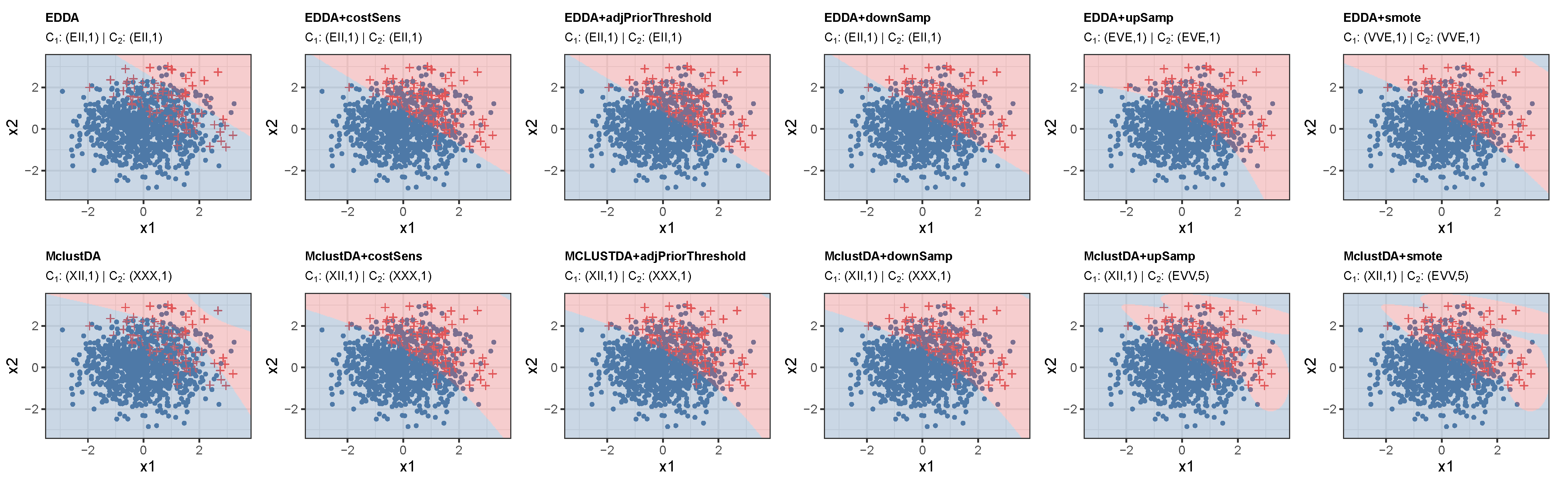
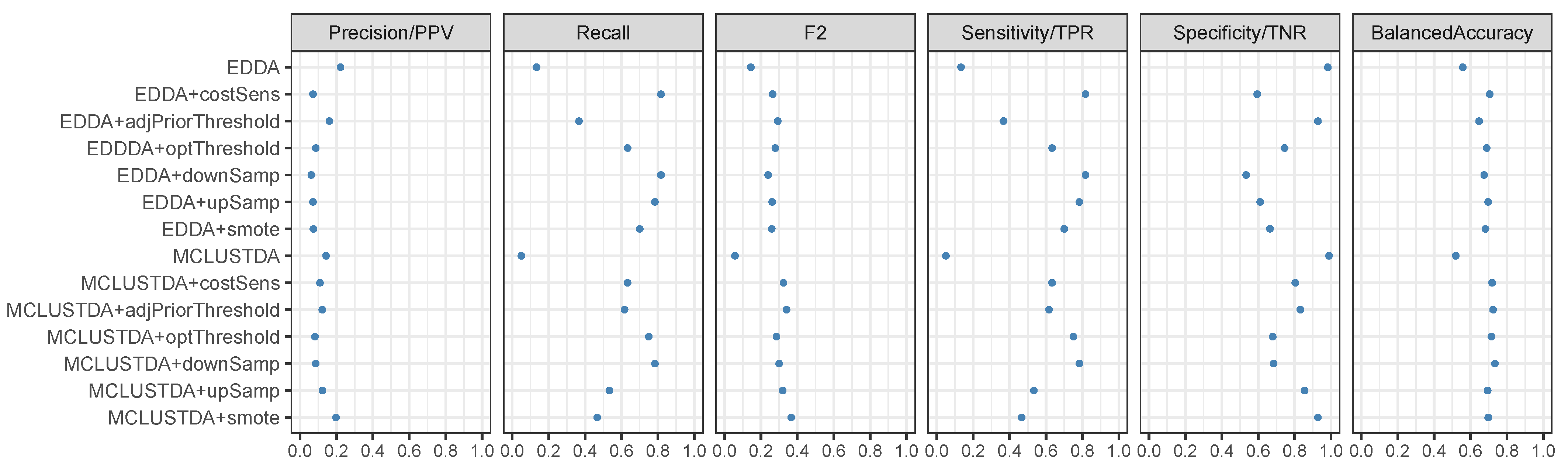
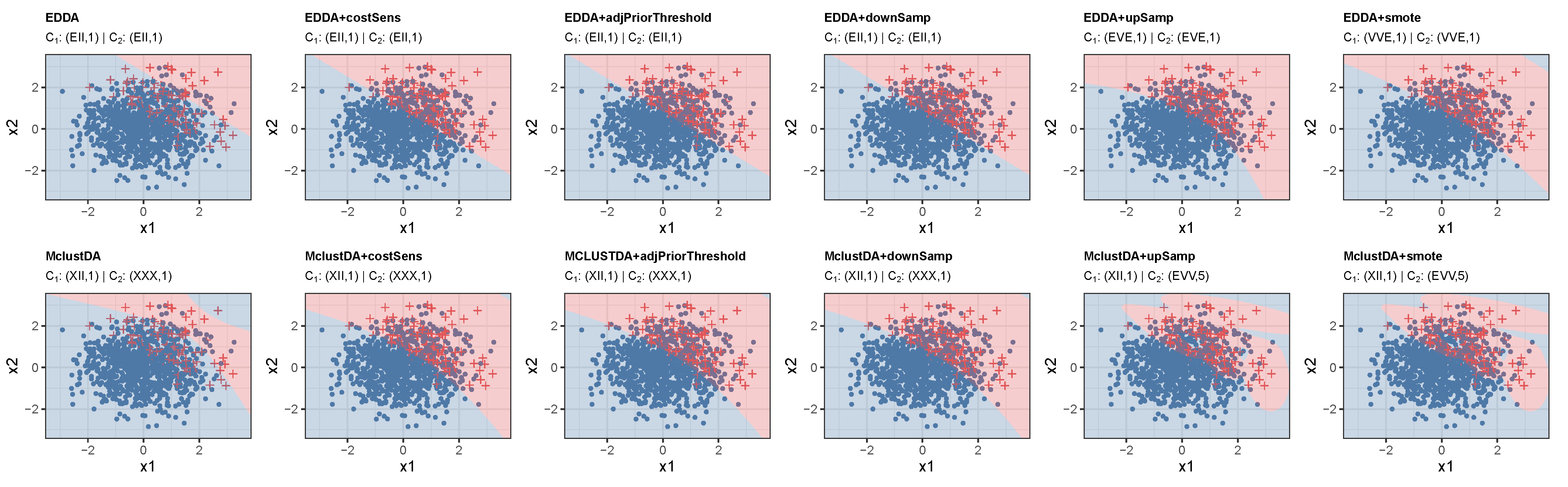
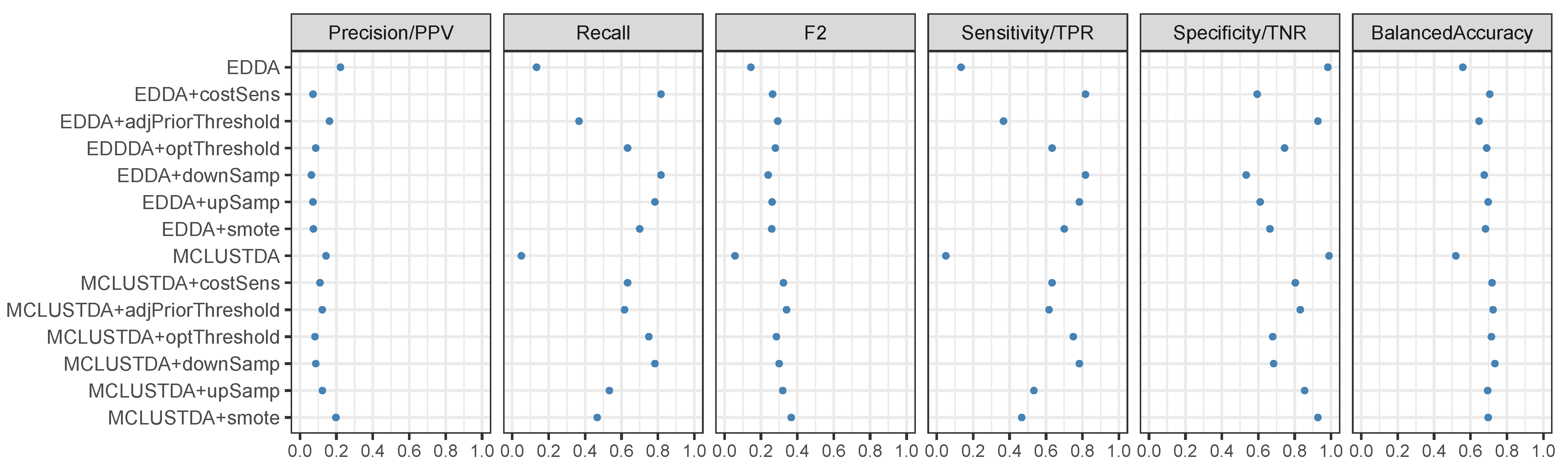
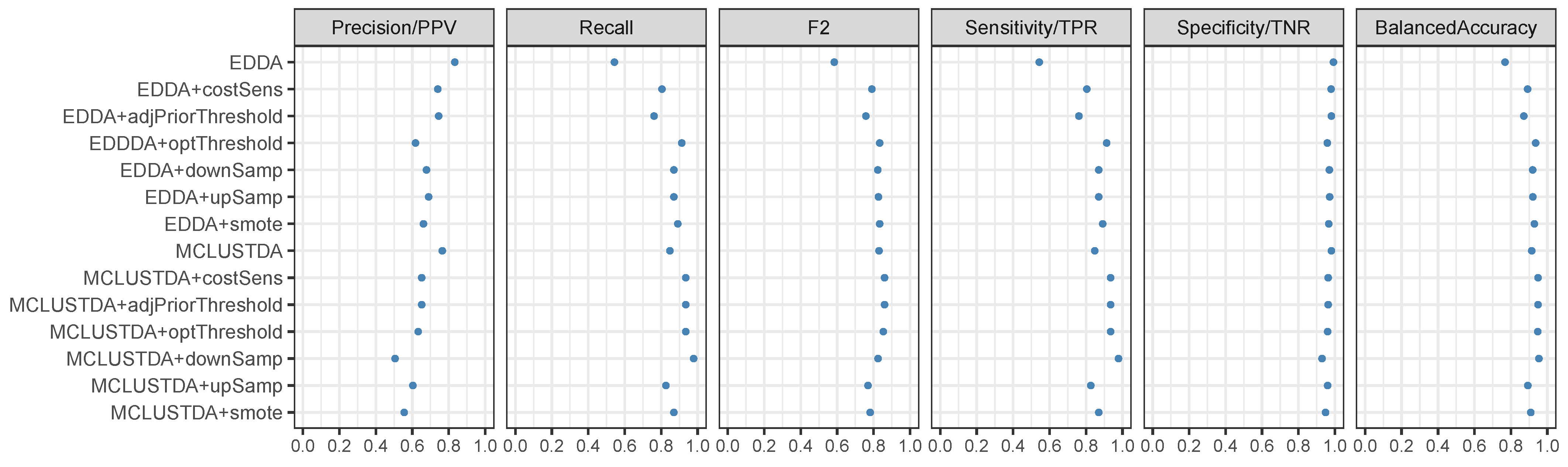
5.1. Simulation Studies
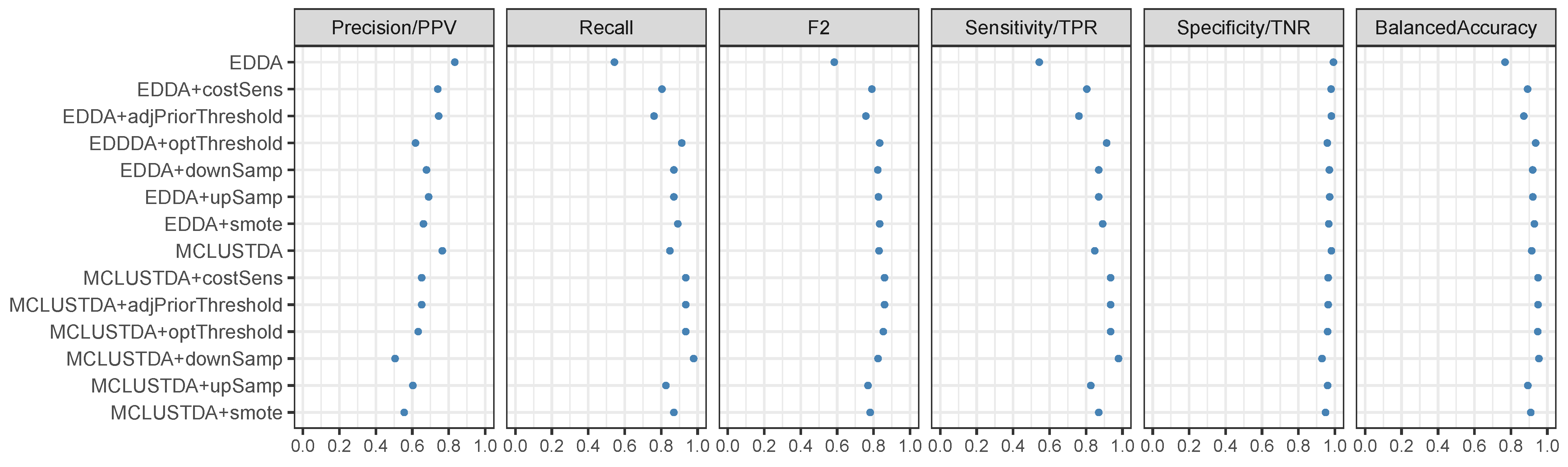
5.2. Wine Quality Data
5.3. Hypothyroid Data
6. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- McLachlan, G.J.; Peel, D. Finite Mixture Models; Wiley: New York, NY, USA, 2000. [Google Scholar]
- Fraley, C.; Raftery, A.E. Model-based Clustering, Discriminant Analysis, and Density Estimation. J. Am. Stat. Assoc. 2002, 97, 611–631. [Google Scholar] [CrossRef]
- McLachlan, G.J.; Lee, S.X.; Rathnayake, S.I. Finite Mixture Models. Annu. Rev. Stat. Appl. 2019, 6, 355–378. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm (with discussion). J. R. Stat. Soc. Ser. B Stat. Methodol. 1977, 39, 1–38. [Google Scholar] [CrossRef]
- McLachlan, G.; Krishnan, T. The EM Algorithm and Extensions, 2nd ed.; Wiley-Interscience: Hoboken, NJ, USA, 2008. [Google Scholar]
- Sun, Y.; Wong, A.K.C.; Kamel, M.S. Classification of Imbalanced Data: A Review. Int. J. Pattern Recognit. Artif. Intell. 2009, 23, 687–719. [Google Scholar] [CrossRef]
- Fernández, A.; García, S.; Galar, M.; Prati, R.C.; Krawczyk, B.; Herrera, F. Learning from Imbalanced Data Sets; Springer: Berlin, Germany, 2018. [Google Scholar] [CrossRef]
- Pal, B.; Paul, M.K. A Gaussian mixture based boosted classification scheme for imbalanced and oversampled data. In Proceedings of the 2017 International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’s Bazar, Bangladesh, 6–18 February 2017; pp. 401–405. [Google Scholar] [CrossRef]
- Han, X.; Cui, R.; Lan, Y.; Kang, Y.; Deng, J.; Jia, N. A Gaussian mixture model based combined resampling algorithm for classification of imbalanced credit data sets. Int. J. Mach. Learn. Cybern. 2019, 10, 3687–3699. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R. Discriminant analysis by Gaussian mixtures. J. R. Stat. Soc. Ser. B Stat. Methodol. 1996, 58, 155–176. [Google Scholar] [CrossRef]
- Bensmail, H.; Celeux, G. Regularized Gaussian Discriminant Analysis through Eigenvalue Decomposition. J. Am. Stat. Assoc. 1996, 91, 1743–1748. [Google Scholar] [CrossRef]
- Scrucca, L.; Fraley, C.; Murphy, T.B.; Raftery, A.E. Model-Based Clustering, Classification, and Density Estimation Using mclust in R; Chapman & Hall/CRC: New York, NY, USA, 2023. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Scrucca, L.; Fop, M.; Murphy, T.B.; Raftery, A.E. mclust 5: Clustering, Classification and Density Estimation Using Gaussian Finite Mixture Models. R J. 2016, 8, 205–233. [Google Scholar] [CrossRef]
- Fraley, C.; Raftery, A.E.; Scrucca, L. mclust: Gaussian Mixture Modelling for Model-Based Clustering, Classification, and Density Estimation; R Package Version 6.0.0; R Foundation: Vienna, Austria, 2023. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation: Vienna, Austria, 2022. [Google Scholar]
- Provost, F. Machine learning from imbalanced data sets 101. In Proceedings of the AAAI Workshop on Imbalanced Data Sets, Austin, TX, USA, 31 July 2000. [Google Scholar]
- Saerens, M.; Latinne, P.; Decaestecker, C. Adjusting the outputs of a classifier to new a priori probabilities: A simple procedure. Neural Comput. 2002, 14, 21–41. [Google Scholar] [CrossRef] [PubMed]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Menardi, G.; Torelli, N. Training and assessing classification rules with imbalanced data. Data Min. Knowl. Discov. 2012, 28, 92–122. [Google Scholar] [CrossRef]
- Murphy, K.P. Probabilistic Machine Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2022. [Google Scholar]
- Cortez, P.; Cerdeira, A.; Almeida, F.; Matos, T.; Reis, J. Wine Quality Data; UCI Machine Learning Repository; UC Irvine: Irvine, CA, USA, 2009. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2019. Available online: http://archive.ics.uci.edu/ml (accessed on 14 September 2023).
- Quinlan, R. Thyroid Disease; UCI Machine Learning Repository; UC Irvine: Irvine, CA, USA, 1987. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Actual/Observed | ||
|---|---|---|
| Negative | Positive | |
| Predicted | ||
| Negative | True Negative (TN) | False Negative (FN) |
| Positive | False Positive (FP) | True Positive (TP) |
| (a) Generic case | ||
| Actual/Observed | ||
| Negative | Positive | |
| Predicted | ||
| Negative | ||
| Positive | ||
| (b) Imbalance ratio (IR) case | ||
| Actual/Observed | ||
| Negative | Positive | |
| Predicted | ||
| Negative | 0 | 1 |
| Positive | IR | 0 |
| Method | Precision/ PPV | Recall/ TPR | F2 | Sensitivity/ TPR | Specificity/ TNR | Balanced Accuracy |
|---|---|---|---|---|---|---|
| EDDA | 0.0289 (0.0094) | 0.0002 (0.0001) | 0.0003 (0.0001) | 0.0002 (0.0001) | 0.9999 (0.0000) | 0.5001 (0.0000) |
| EDDA+costSens | 0.0339 (0.0002) | 0.8347 (0.0025) | 0.1457 (0.0009) | 0.8347 (0.0025) | 0.7612 (0.0017) | 0.7979 (0.0010) |
| EDDA+adjPriorThreshold | 0.0254 (0.0011) | 0.9030 (0.0097) | 0.1113 (0.0041) | 0.9030 (0.0097) | 0.5488 (0.0273) | 0.7259 (0.0103) |
| EDDDA+optThreshold | 0.0350 (0.0005) | 0.8221 (0.0056) | 0.1489 (0.0015) | 0.8221 (0.0056) | 0.7685 (0.0040) | 0.7953 (0.0013) |
| EDDA+downSamp | 0.0330 (0.0004) | 0.8391 (0.0037) | 0.1421 (0.0014) | 0.8391 (0.0037) | 0.7503 (0.0034) | 0.7947 (0.0015) |
| EDDA+upSamp | 0.0335 (0.0003) | 0.8491 (0.0027) | 0.1446 (0.0011) | 0.8491 (0.0027) | 0.7535 (0.0023) | 0.8013 (0.0010) |
| EDDA+smote | 0.0335 (0.0003) | 0.8408 (0.0032) | 0.1442 (0.0012) | 0.8408 (0.0032) | 0.7551 (0.0027) | 0.7980 (0.0012) |
| MCLUSTDA | 0.1190 (0.0251) | 0.0009 (0.0002) | 0.0011 (0.0002) | 0.0009 (0.0002) | 1.0000 (0.0000) | 0.5004 (0.0001) |
| MCLUSTDA+costSens | 0.0335 (0.0003) | 0.8416 (0.0032) | 0.1443 (0.0011) | 0.8416 (0.0032) | 0.7553 (0.0025) | 0.7985 (0.0012) |
| MCLUSTDA+adjPriorThreshold | 0.0295 (0.0010) | 0.8685 (0.0094) | 0.1272 (0.0039) | 0.8685 (0.0094) | 0.6388 (0.0239) | 0.7537 (0.0087) |
| MCLUSTDA+optThreshold | 0.0359 (0.0006) | 0.8144 (0.0068) | 0.1514 (0.0017) | 0.8144 (0.0068) | 0.7745 (0.0045) | 0.7944 (0.0017) |
| MCLUSTDA+downSamp | 0.0326 (0.0004) | 0.8472 (0.0039) | 0.1409 (0.0014) | 0.8472 (0.0039) | 0.7446 (0.0037) | 0.7959 (0.0016) |
| MCLUSTDA+upSamp | 0.0332 (0.0005) | 0.7019 (0.0072) | 0.1390 (0.0018) | 0.7019 (0.0072) | 0.7919 (0.0032) | 0.7469 (0.0033) |
| MCLUSTDA+smote | 0.0333 (0.0005) | 0.6867 (0.0071) | 0.1390 (0.0019) | 0.6867 (0.0071) | 0.7970 (0.0032) | 0.7419 (0.0032) |
| Method | Precision/ PPV | Recall/ TPR | F2 | Sensitivity/ TPR | Specificity/ TNR | Balanced Accuracy |
|---|---|---|---|---|---|---|
| EDDA | 0.5539 (0.0024) | 0.1478 (0.0030) | 0.1726 (0.0033) | 0.1478 (0.0030) | 0.9866 (0.0003) | 0.5672 (0.0013) |
| EDDA+costSens | 0.2782 (0.0006) | 0.8508 (0.0009) | 0.6026 (0.0005) | 0.8508 (0.0009) | 0.7551 (0.0008) | 0.8029 (0.0003) |
| EDDA+adjPriorThreshold | 0.2748 (0.0009) | 0.8566 (0.0014) | 0.6015 (0.0005) | 0.8566 (0.0014) | 0.7488 (0.0014) | 0.8027 (0.0003) |
| EDDDA+optThreshold | 0.2781 (0.0018) | 0.8498 (0.0030) | 0.6008 (0.0007) | 0.8498 (0.0030) | 0.7534 (0.0029) | 0.8016 (0.0003) |
| EDDA+downSamp | 0.2773 (0.0006) | 0.8523 (0.0010) | 0.6023 (0.0005) | 0.8523 (0.0010) | 0.7535 (0.0009) | 0.8029 (0.0003) |
| EDDA+upSamp | 0.2768 (0.0006) | 0.8542 (0.0009) | 0.6027 (0.0005) | 0.8542 (0.0009) | 0.7524 (0.0008) | 0.8033 (0.0003) |
| EDDA+smote | 0.2763 (0.0006) | 0.8547 (0.0009) | 0.6024 (0.0005) | 0.8547 (0.0009) | 0.7516 (0.0008) | 0.8032 (0.0003) |
| MCLUSTDA | 0.5753 (0.0030) | 0.1211 (0.0037) | 0.1430 (0.0041) | 0.1211 (0.0037) | 0.9897 (0.0004) | 0.5554 (0.0017) |
| MCLUSTDA+costSens | 0.2764 (0.0006) | 0.8551 (0.0009) | 0.6026 (0.0005) | 0.8551 (0.0009) | 0.7515 (0.0008) | 0.8033 (0.0003) |
| MCLUSTDA+adjPriorThreshold | 0.2740 (0.0008) | 0.8588 (0.0013) | 0.6017 (0.0005) | 0.8588 (0.0013) | 0.7473 (0.0013) | 0.8031 (0.0003) |
| MCLUSTDA+optThreshold | 0.2782 (0.0017) | 0.8506 (0.0029) | 0.6013 (0.0006) | 0.8506 (0.0029) | 0.7534 (0.0028) | 0.8020 (0.0003) |
| MCLUSTDA+downSamp | 0.2762 (0.0006) | 0.8550 (0.0010) | 0.6023 (0.0005) | 0.8550 (0.0010) | 0.7513 (0.0009) | 0.8031 (0.0003) |
| MCLUSTDA+upSamp | 0.2763 (0.0010) | 0.8497 (0.0016) | 0.6001 (0.0006) | 0.8497 (0.0016) | 0.7526 (0.0016) | 0.8011 (0.0004) |
| MCLUSTDA+smote | 0.2752 (0.0010) | 0.8490 (0.0017) | 0.5987 (0.0006) | 0.8490 (0.0017) | 0.7514 (0.0016) | 0.8002 (0.0004) |
| Method | Precision/ PPV | Recall/ TPR | F2 | Sensitivity/ TPR | Specificity/ TNR | Balanced Accuracy |
|---|---|---|---|---|---|---|
| EDDA | 0.8096 (0.0040) | 0.3336 (0.0042) | 0.3774 (0.0044) | 0.3336 (0.0042) | 0.9992 (0.0000) | 0.6664 (0.0021) |
| EDDA+costSens | 0.0912 (0.0014) | 0.9103 (0.0054) | 0.3242 (0.0040) | 0.9103 (0.0054) | 0.9050 (0.0022) | 0.9077 (0.0033) |
| EDDA+adjPriorThreshold | 0.0856 (0.0013) | 0.9192 (0.0072) | 0.3105 (0.0035) | 0.9192 (0.0072) | 0.8988 (0.0015) | 0.9090 (0.0034) |
| EDDDA+optThreshold | 0.0968 (0.0021) | 0.8988 (0.0071) | 0.3340 (0.0048) | 0.8988 (0.0071) | 0.9101 (0.0025) | 0.9045 (0.0035) |
| EDDA+downSamp | 0.0617 (0.0020) | 0.8914 (0.0122) | 0.2386 (0.0066) | 0.8914 (0.0122) | 0.8488 (0.0046) | 0.8701 (0.0075) |
| EDDA+upSamp | 0.0835 (0.0008) | 0.8007 (0.0045) | 0.2940 (0.0020) | 0.8007 (0.0045) | 0.9102 (0.0010) | 0.8555 (0.0021) |
| EDDA+smote | 0.0653 (0.0013) | 0.6305 (0.0094) | 0.2297 (0.0040) | 0.6305 (0.0094) | 0.9062 (0.0017) | 0.7684 (0.0048) |
| MCLUSTDA | 0.8470 (0.0038) | 0.3046 (0.0027) | 0.3491 (0.0028) | 0.3046 (0.0027) | 0.9994 (0.0000) | 0.6520 (0.0013) |
| MCLUSTDA+costSens | 0.0861 (0.0006) | 0.9055 (0.0023) | 0.3116 (0.0015) | 0.9055 (0.0023) | 0.9022 (0.0008) | 0.9038 (0.0010) |
| MCLUSTDA+adjPriorThreshold | 0.0717 (0.0012) | 0.9374 (0.0035) | 0.2725 (0.0034) | 0.9374 (0.0035) | 0.8727 (0.0026) | 0.9051 (0.0010) |
| MCLUSTDA+optThreshold | 0.0925 (0.0021) | 0.8923 (0.0053) | 0.3220 (0.0039) | 0.8923 (0.0053) | 0.9067 (0.0021) | 0.8995 (0.0017) |
| MCLUSTDA+downSamp | 0.0557 (0.0011) | 0.9292 (0.0047) | 0.2231 (0.0033) | 0.9292 (0.0047) | 0.8343 (0.0034) | 0.8817 (0.0022) |
| MCLUSTDA+upSamp | 0.0451 (0.0017) | 0.1121 (0.0081) | 0.0815 (0.0049) | 0.1121 (0.0081) | 0.9783 (0.0012) | 0.5452 (0.0036) |
| MCLUSTDA+smote | 0.0471 (0.0017) | 0.0845 (0.0047) | 0.0703 (0.0033) | 0.0845 (0.0047) | 0.9828 (0.0007) | 0.5337 (0.0021) |
| Method | Precision/ PPV | Recall/ TPR | F2 | Sensitivity/ TPR | Specificity/ TNR | Balanced Accuracy |
|---|---|---|---|---|---|---|
| EDDA | 0.8554 (0.0009) | 0.6067 (0.0013) | 0.6441 (0.0011) | 0.6067 (0.0013) | 0.9886 (0.0001) | 0.7976 (0.0006) |
| EDDA+costSens | 0.5292 (0.0009) | 0.9469 (0.0009) | 0.8177 (0.0005) | 0.9469 (0.0009) | 0.9064 (0.0003) | 0.9266 (0.0004) |
| EDDA+adjPriorThreshold | 0.5230 (0.0012) | 0.9511 (0.0008) | 0.8172 (0.0005) | 0.9511 (0.0008) | 0.9036 (0.0004) | 0.9274 (0.0003) |
| EDDDA+optThreshold | 0.4904 (0.0024) | 0.9701 (0.0013) | 0.8107 (0.0008) | 0.9701 (0.0013) | 0.8874 (0.0012) | 0.9288 (0.0003) |
| EDDA+downSamp | 0.5255 (0.0013) | 0.9609 (0.0012) | 0.8241 (0.0006) | 0.9609 (0.0012) | 0.9035 (0.0006) | 0.9322 (0.0005) |
| EDDA+upSamp | 0.5221 (0.0009) | 0.9498 (0.0009) | 0.8160 (0.0005) | 0.9498 (0.0009) | 0.9034 (0.0004) | 0.9266 (0.0003) |
| EDDA+smote | 0.5039 (0.0009) | 0.9231 (0.0015) | 0.7913 (0.0009) | 0.9231 (0.0015) | 0.8990 (0.0004) | 0.9110 (0.0006) |
| MCLUSTDA | 0.8550 (0.0009) | 0.6119 (0.0022) | 0.6487 (0.0019) | 0.6119 (0.0022) | 0.9885 (0.0001) | 0.8002 (0.0011) |
| MCLUSTDA+costSens | 0.5110 (0.0016) | 0.9596 (0.0014) | 0.8159 (0.0005) | 0.9596 (0.0014) | 0.8978 (0.0008) | 0.9287 (0.0004) |
| MCLUSTDA+adjPriorThreshold | 0.5134 (0.0015) | 0.9589 (0.0012) | 0.8168 (0.0006) | 0.9589 (0.0012) | 0.8989 (0.0006) | 0.9289 (0.0004) |
| MCLUSTDA+optThreshold | 0.4979 (0.0036) | 0.9679 (0.0017) | 0.8129 (0.0013) | 0.9679 (0.0017) | 0.8903 (0.0017) | 0.9291 (0.0004) |
| MCLUSTDA+downSamp | 0.5043 (0.0016) | 0.9576 (0.0016) | 0.8113 (0.0007) | 0.9576 (0.0016) | 0.8952 (0.0008) | 0.9264 (0.0005) |
| MCLUSTDA+upSamp | 0.5136 (0.0015) | 0.8717 (0.0028) | 0.7648 (0.0019) | 0.8717 (0.0028) | 0.9082 (0.0005) | 0.8900 (0.0013) |
| MCLUSTDA+smote | 0.4946 (0.0013) | 0.8108 (0.0027) | 0.7187 (0.0019) | 0.8108 (0.0027) | 0.9079 (0.0005) | 0.8593 (0.0013) |
| Techniques | Accuracy | Computational Speed | Ease of Implementation | Hyperparameter Tuning | Scalability | Parallelization |
|---|---|---|---|---|---|---|
| costSens | — | |||||
| adjPriorThreshold | ||||||
| optThreshold | ||||||
| downSamp | — | — | ||||
| upSamp | — | — | ||||
| smote | — |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Scrucca, L. On the Influence of Data Imbalance on Supervised Gaussian Mixture Models. Algorithms 2023, 16, 563. https://doi.org/10.3390/a16120563
Scrucca L. On the Influence of Data Imbalance on Supervised Gaussian Mixture Models. Algorithms. 2023; 16(12):563. https://doi.org/10.3390/a16120563
Chicago/Turabian StyleScrucca, Luca. 2023. "On the Influence of Data Imbalance on Supervised Gaussian Mixture Models" Algorithms 16, no. 12: 563. https://doi.org/10.3390/a16120563
APA StyleScrucca, L. (2023). On the Influence of Data Imbalance on Supervised Gaussian Mixture Models. Algorithms, 16(12), 563. https://doi.org/10.3390/a16120563