1. Introduction
Carbonate rock reservoirs are believed to contain nearly 50% of the world’s hydrocarbons. The carbonate rocks are dominated by a few carbonate minerals (mainly calcite and dolomite) and contain additional traces of minerals such as silica, detrital grains, phosphate and glauconite. On the other hand, carbonate rocks may contain organic residues and some cementing material. Petrography helps identify grains, leading to the detailed classification of rocks, the determination of the types of deposition and the indicators of historical post-depositional alteration (diagenesis). It also helps determine the timing of porosity development. Comparing these grains with photographs allows us to readily identify the essential properties/features that can potentially predict the amount of petroleum under adequate trap conditions in the oil and gas industry. In this study, the pore/fracture space component using multi-objective classification is based on microscopic studies, particularly of Malaysian carbonate rocks. Here we focus on the image analysis of rock image samples to automatically reach a conclusion on pores or fractures contained in the image sample instead of illustrating the quantitative petrophysical method. Hence, we will not work on overall petrography analysis but only its segment related to image analysis.
Porosity is widely considered a fundamental parameter for reservoir characterisation and is used in many hydrogeological and geophysical calculations. For crystalline rock, it can be calculated as the sum of micro-fractures, irregular micro-pores and fluid inclusions [
1]. Porosity also determines the storage capacity of a specific reservoir. To our knowledge, most hydrocarbon reservoirs belong to sedimentary rock formations in which porosity values vary between 10% and 40% for sandstones and 5% and 25% for carbonates [
2]. The micro-pores are spherical or nearly spherical [
3]. In contrast, fractures are assumed to maintain near linearity (i.e. their length is longer than their width). Total porosity can be divided into two types: connected (characterised using flow and diffusion) and unconnected (because of the presence of isolated pores) [
1]. Unconnected spherical or near-spherical pores along with micro-porosity can effectively change the elastic properties of the rock frame, making porosity an important parameter for reservoir characterisation in terms of estimating elastic moduli [
3].
The current study aims to propose a novel meta-heuristic image analysis approach using the multi-objective algorithm approach to alleviate the previous difficulty in identifying pores and fractures (natural and induced, even at the micro-level) in the wells of a hydrocarbon reservoir. Furthermore, we present better identification accuracy in the grayscale sample rock images in this work.
The high-level idea of the proposed methodology is multi-objective, i.e. the primary objective is to find the neighbouring dark pixels of every discovered dark pixel within a specific region and create a bag of contiguous pixels. A secondary objective is to classify the shapes obtained from the pixel bag into pores or fractures based on a certain chosen hyper-parameter. This methodology was compared with the CNN (convolution neural network)-based [
4,
5] approach, which is considered a state-of-the-art framework for image classification. CNNs comprise pixel-to-pixel and end-to-end architectures, which use a large image dataset with features and tuneable neural network parameters. Our proposed method can obtain more accurate results than a deep learning CNN, which thus far has been considered the most efficient method for identifying pores and fractures in hydrocarbon reservoirs.
1.1. History of Existing Research Work
Researchers have undertaken these challenges and have tried to deploy various intelligent techniques, such as deep learning approaches. In an early study, Lucia et al. [
6] developed a carbonate rock porosity detection method that uses the visual inspection of a sample rock as an input. This method [
6] relies on the expertise of a scientist for porosity detection. In a ground-breaking work, Ehrlich et al. [
7] also developed an image analysis technique that considers colour images (RGB) to detect micro-pores and fractures, although we are unconvinced of its efficacy in the presence of grayscale images. Similarly, the work of Funk et al. [
8] describes sample rock pore size distributions by analysing the petrophysical properties derived from a rock’s colour images. Van den Berg et al. [
9] showcased an image-processing method for porosity detection that uses high-quality image inputs. The pore and fracture sizes are quite large and visually identifiable [
9]. In another study of semi-automated rock texture identification image-processing techniques, Perring et al. [
10] considered high-resolution images as input samples. We believe that this method might not be able to replicate its performance in the presence of low-quality grayscale images. Additionally, several contemporary studies [
11,
12,
13,
14] on pore/fracture detection used simple image analysis techniques. In another study, Chen, J., et al. [
15] developed an automated image processing-based method to identify rock fracture segmentation and its trace quantification using a CNN-based model to extract the skeleton of the cracks and a chain code-based method to quantify the fracture traces. They extended this research [
16] into rock trace identification using a hybrid of the synthetic minority oversampling technique, random search hyper-parameter optimization and gradient boosting trees. Chen, J., et al. [
16] proceeded to propose a novel CNN-based water inflow evaluation method that emulates a typical field engineer’s inspection process. This method classifies the undamaged and damaged regions and segments the detailed water inflow damage to the rock tunnel faces. Most of the abovementioned studies used higher-resolution images; however, we suspect that the above proposed methods may not be able to replicate their performances in the presence of lower-quality grayscale images.
In the contemporary literature, a few studies employing machine learning, such as the support vector machine (SVM) classifier and deep learning, achieved the pore/fracture detection of various reservoir rocks, and the noteworthy works are illustrated below. Leal et al. [
17] used the fractal dimensions of images, gamma rays and resistivity logs as the input dataset to an SVM classifier to detect micro-fractures. However, the detection accuracy was not the best in class, and we suspect that it might suffer from poor image quality with grayscale. Abedini et al. [
18] employed deep learning and autoencoder techniques to identify the pores/fractures from rock images. Although they used visually discriminating images [
18], their detection does not require advanced techniques such as deep learning. This strategy may fail in the presence of a tiny training image sample set with high similarities among images (low divergence). From the above study, it is evident that the existing contemporary detection and classification methods need further advancements to improve their accuracy, particularly in the presence of a tiny training set. A tiny training set is a real problem challenging the accuracy of deep learning strategies for low-quality image samples. Hence, in the current work, we tried to devise a method that works well with a small number of low-quality grayscale image samples.
The current work addresses the identification of pores and fractures that do not have a fixed geometric shape; hence, before discussing the principal findings of the present work, a brief discussion of the recent noteworthy findings of machine learning regarding the identification of irregularly shaped objects would be useful. In an early work, Viola and Jones [
19] presented a face detection framework capable of detecting faces from an image and hence, suitable for detecting objects with near-fixed geometric structures. This framework mainly focuses on collecting Haar-like features along with the histograms of oriented gradients (HOGs) of the objects with fixed geometric shapes for their possible detection. However, these Haar and HOG features were found to be relatively inefficient in detecting irregularly shaped objects, which is highly required in the current context as the shapes of pores and fractures are highly irregular. Lienhart and Mayst [
20] introduced limited and arbitrary rotations for object identification, which are relatively inefficient in identifying objects of irregular shapes. David Gerónimo et al. [
21] proposed a pedestrian classifier based on Haar wavelets () and edge orientation histograms (EOHs) with AdaBoost; which is compared to SVMs using HOGs. The results show that the HW + EOH classifier achieves comparable accuracy but at a much lower processing time than the HOG. In another contemporary work, Smith et al. [
22] introduced a ray feature set that considers image characteristics at distant contour points to gather information about an object’s shape. However, this strategy is often computationally expensive and may often be challenging for identifying the necessary context-specific ray features [
22].
Modern deep learning and other machine learning classifiers require many training samples to correctly extract shape-related information necessary for identifying a specific object. However, the scenario becomes more complex in the presence of a low-quality, tiny training image set of extremely deformable objects (such as pores and fractures in the current case) since identifying the shape-related features necessary for their unique identification often becomes extremely difficult. Hence, a low-level pixel intensity-based image analysis approach could be more computationally efficient and accurate if used to identify irregular objects instead of the deep learning and machine learning counterparts.
1.2. Contribution of the Current Work
Visual quality evaluation has traditionally focused on the perception of quality from a human subjects’ viewpoint, which motivates us to characterise the effect of image quality on current computer vision systems. However, these notions of image quality may not be directly comparable, as a computer can often be fooled by images that are perceived by humans to be identical [
23], or in some cases, the computer can recognise images that are indistinguishable from noise by a human observer [
24]. Hence, how image quality often affects the accuracy of a computer vision technique must be separately considered. In this study, we found that the accuracy of the existing methodologies [
18,
25] substantially deteriorates with grayscale images. Hence, an approach that can work successfully given a tiny set of low-quality image samples as input is urgently needed. Here, we propose an approach that delivers robust results even if the quality of the input image is severely deteriorated (low quality and distorted). We addressed this approach in the following sections of the current article.
To address this issue, we analyzed the brightness of every pixel and classified it as bright or dark based on some preconceived notions, which are flexible depending on the respective problem definitions, image sample quality, and necessary geophysical properties of the rock sample used. Next, the pores and fractures are identified from the input grayscale images based on some shape-related preconceived logic (pores spherical or near-spherical, while the fractures are more linear in shapes, in general, as per the contemporary literature) and the pixel classification results.
The proposed approach has been tested with CT-scan images of carbonate rocks, and results are found more accurate than those of the deep-CNN and other contemporary approaches, as is shown later in the present work.
1.3. Paper Structure
The rest of the paper is arranged as follows:
Section 2 describes the methodology for micro-pore and fracture identification from the input grayscale CT-scan image samples;
Section 3 shows the implementation of the proposed method and presents detailed comparisons with the noteworthy contemporary approaches from the accuracy point of view. The main points of the present study are articulated in
Section 4.
2. Materials and Methods—Porosity Classification and Fracture Identification
This section elaborates on the developed image analysis methodology for porosity classification and fracture identification of rock. To make our proposition more robust, we assume the input images are of low quality, primarily grayscale, and less statistically divergent. Here, less statistical divergence in the dataset () points to the high similarity among its various image samples, which subsequently might make the mini-batch samples very similar and might lead to the mode collapse for the deep learning models.
The basic idea of the proposed methodology is multi-objective—to find the k-immediate neighboring dark pixels of every discovered dark pixel within a specific region in an input grayscale image Gn ∈ M and then to classify it as a pore or a fracture. This is because, from the image processing point of view, we consider a pore or a fracture as a region within an image that contains a large number of contiguous dark pixels, even if not all of them are dark. Hence, we name the developed algorithm as “Pixel-wise k-Immediate Neighbors” (Pixel-wise k-IN) approach, where the set of k-immediate neighboring pixels (k-IN) of any specific pixel located at (x, y) in , n = 0, 1 · · · are listed as k-IN(x, y) = {(x − 1, y − 1), (x, y − 1), (x + 1, y − 1), (x −1, y), (x + 1, y), (x − 1, y + 1), (x, y + 1), (x + 1, y + 1)}, where x, y, x − 1, x + 1, y − 1, y + 1∈. In short, the k-IN of (x, y) can be defined as k-IN(x, y) = {(x ± i, y ± j); ∀x, y∈; i, j = 0, 1; i, j ≠ 0 simultaneously}.
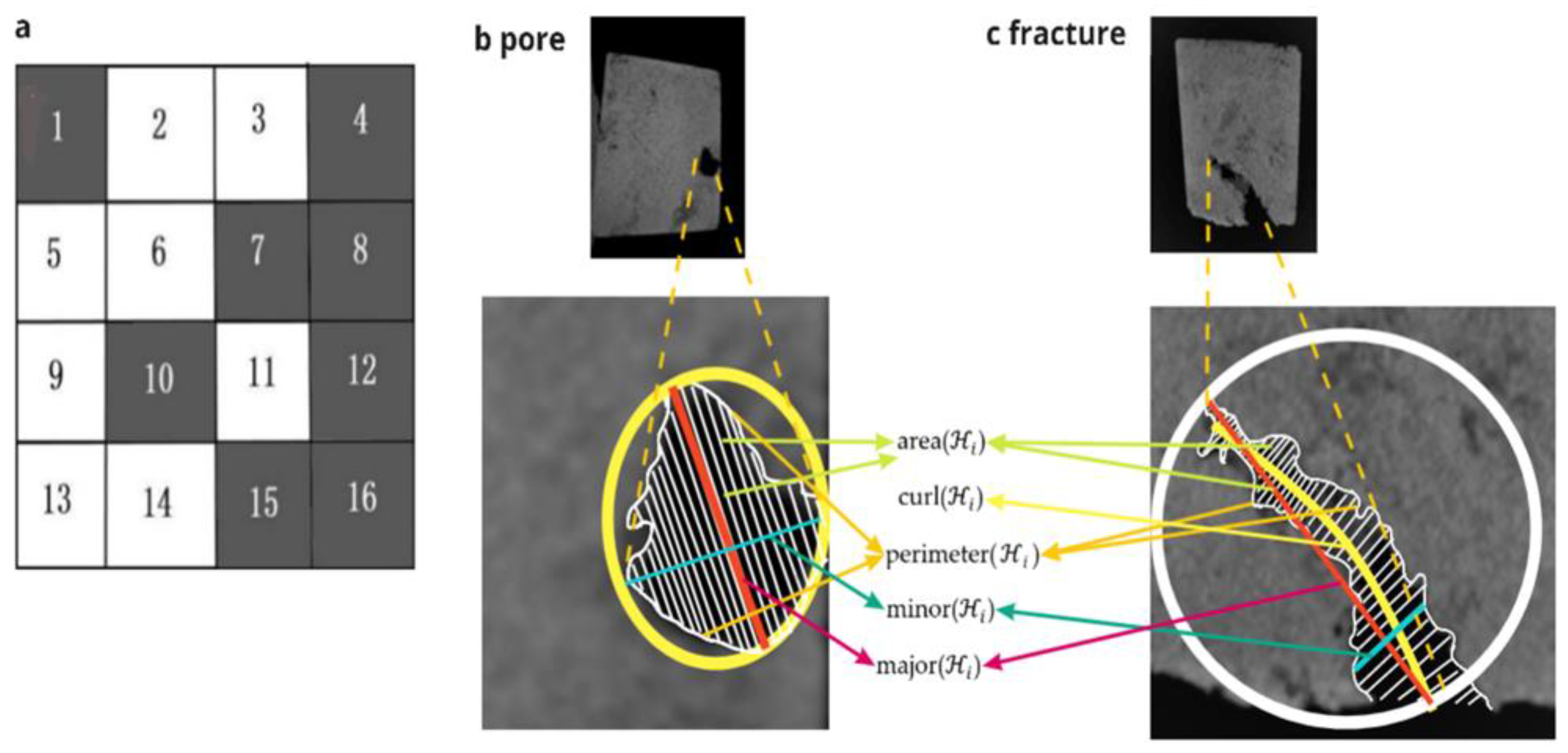
For more clarity, in
Figure 1a, the set of
k-INs computed for pixel 6 is {1, 2, 3, 5, 7, 9, 10, 11}, where that for the pixel 1 is {2, 5, 6}. The procedure to classify every individual pixel in an input grayscale image as dark or bright is shown in
Section 2.1. Later, we articulate the procedure to identify the
k-immediate neighboring dark pixels of any specific pixel and classify a region containing a large number of contiguous dark pixels as pore or fracture, as is shown in
Section 2.4. and Algorithm 2.
2.1. Classifying Bright and Dark Pixels
All the images are in grayscale with an average pixel intensity of 101/image. Each pixel in a grayscale image represents only the amount of light or the intensity information. Grayscale images are a black-and-white or gray monochrome that is composed exclusively of shades of gray. We measured the intensity (
), the measure of brightness /darkness) of any pixel
. We classify a pixel as dark or bright if
∈ [0,
I] and
∈(
I, 255] respectively, where
I will be the threshold with range 0
< I < 255 (see Algorithm 1). Here,
= 0 means fully dark, whereas
= 255 classifies as fully bright.
I mostly depends on the resolution of the available image dataset, and we humbly encourage the readers to choose suitable
I values based on their expert judgments. In easy words, we classify pixels (as bright or dark) based on their computed
values. The proposed image processing technique will be applied only in the effective region of every individual image, which we will term as the red boundary. The proposed image processing technique understands the red boundary by analyzing the brightness of the bordering pixels based on their
values.
| Algorithm 1 Pixel Classification Procedure |
| Input: Grayscale image of rock contain l × s pixels. |
| Variables & Parameters: , ∀ i ≤ l, j ≤ s; |
| Outputs: Classification of every pixel as dark and bright. |
| 1: procedure PIXEL_CLASSIFICATION() |
| 2: for (i = 0; i < l; i++) do { |
| 3: for (j = 0; j < s; j++) do { ▷ starting pixel at i,j-=0, 0 (top left) |
| 4: if (∈ [0, I ]) then is dark |
| 5: else if (∈(I, 255]) then is bright |
| } |
| } |
| 6: End. |
2.2. Calculating Similarity among the Images
More often than not, it is quintessential to measure the similarity/dissimilarity between different image samples within the dataset under consideration to scrutinize and understand the reasons behind every specific unusual or unsatisfactory outcome. The resulting accuracy of various image analysis methods (including deep learning) is often found relying on their adopted learning techniques and might suffer because of the similarity/dissimilarity between the individual image samples in the training and testing sets. For example, a machine vision system fails to recognize a set of cars if it is trained to identify a set of a few specific animals. Apart from that, a reasonable similarity measure between image samples is often considered as one of the essential parts of most of the image classification systems [
26], and since, in the current work, our prime objective is to identify the pores and fractures within the grayscale rock images, we have presented our similarity measure as below.
The present subsection describes the adopted similarity evaluation technique in detail. We assume
= {
}; 1 ≤
i ≤
N is the image dataset, and each image contains
m ×
n pixels. Each image of
is represented by the pixel intensity vector
= {
} ⊂
; 1 ≤
p ≤
m; 1 ≤
q ≤
n, where
is the intensity value (scalar) of the pixel (
p, q) of an image
, which is evaluated as in
Section 2.1, Algorithm 1.
Next, our job is to find the
k most similar images to a given image
based on some defined similarity criterion. We further assume that all images have equal prior probability, and the query image (
) is represented by the pixel intensity vector
. From the probabilistic point of view, each pixel intensity vector contains
m ×
n realizations of
i.i.d (independent and identically distributed) random variables
; …;
, which follow a parametric distribution with probability density function
p(
);
. Given that
is a consistent estimator of the parameter vector
, it is quite evident that for an image
to be the most similar to
, whose parameter vector
leads to the maximization of the following log-likelihood function, then:
By applying the weak law of large numbers to the Equation (1) with
m, n → ∞, we obtain the following:
where
(·) is the expectation with respect to
(
) and
L is the domain of
p(L|·). By observing
(L|
) as an independent term for the maximization, Equation (3) can be rewritten as follows:
In Equation (5) is between (|) and (|) or DKL((|)||(|)). Hence, in the asymptotic case, maximum likelihood selection is equivalent to the minimization of the and subsequently, the image similarity can be calculated using DKL((|)||(|.
2.3. Dataset Specification and Pre-Processing
In this study, we focus on image analysis of the rock images samples to automatically arrive at a conclusion on the type of pores or fractures instead of the quantitative petrophysical method. Thus, we will not work on overall petrography analysis but only its segment related to image analysis.
The pore/fracture space component classification is based on a microscopic study from peninsular Malaysia in Kinta Valley, Perak. The pore types include mouldic, intraparticle, interparticle, fractured and vuggy porosity. The initial observation indicated that the pore system is isolated in nature. From the perspective of visual image analysis, in most cases, the shape and size of the micro-pores and fractures were highly irregular in shape. In contrast, our techniques showed fractures to be near linear (i.e., length is bigger than width). They were also found to be well cemented. Fractures were found to be enlarged by solution activity or can be healed by secondary calcite or sparite. Based on the previous experience, in general, we found the lengths of the fractures are much greater than their widths. The shape variations of a fracture from that of the circles and ellipses of same perimeter are found much greater than that of the pores. On the contrary, as expected the shapes of the pores were found to be spherical or near-spherical, and in general, their sizes are relatively smaller than those of the fractures but still irregular in shape from the computer vision context. Further, the image data generated in the current work shows limited divergence among most of the samples, i.e., the visual quality of most of the samples is found to be very similar. Low divergence samples have been identified as a major problem for the existing deep learning methodologies in the presence of a small number of grayscale image samples with low divergence, especially in the case of the current image samples.
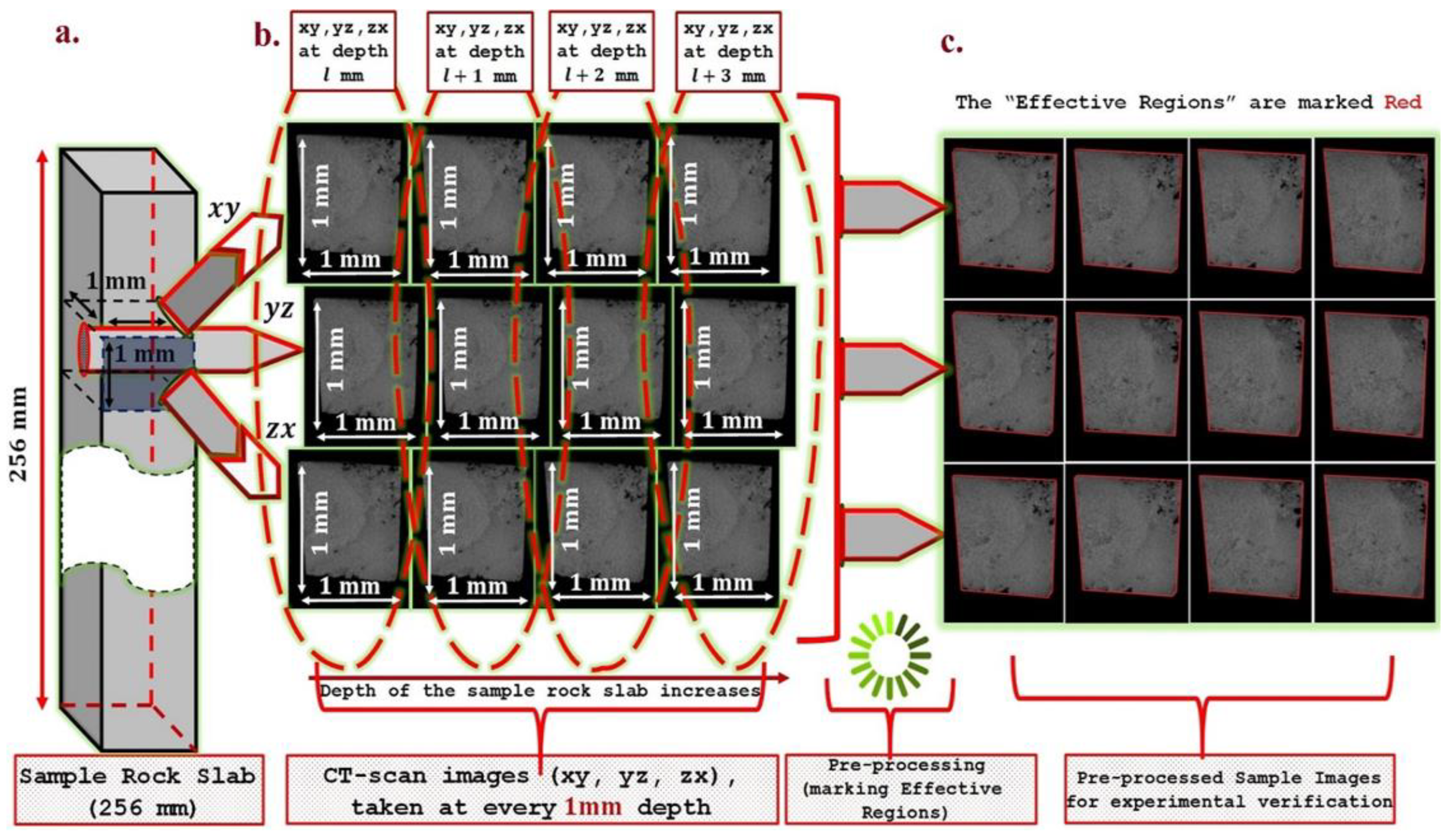
Optical thin section and Scanning Electron Microscopy (SEM) images were used to characterize and describe the different components and structures within the carbonate rock. Before diving into details of the proposed algorithm, we would like to discuss the specification of the rock image samples used in the current study to understand its utility more clearly. We used the CT-scan images of a carbonate rock slab of length 256 mm, breadth 1 mm, and width 1 mm taken at every 1 mm height in all
xy,
yz and
zx planes (see
Figure 2). We call every image a micro-image. Hence, the image data set contains a total of 256 × 3 number of micro-images of varying numbers of pixels, which are then resized to fixed 1280 × 1064 square pixels, where each pixel area is approximately limited to 4.4 µm
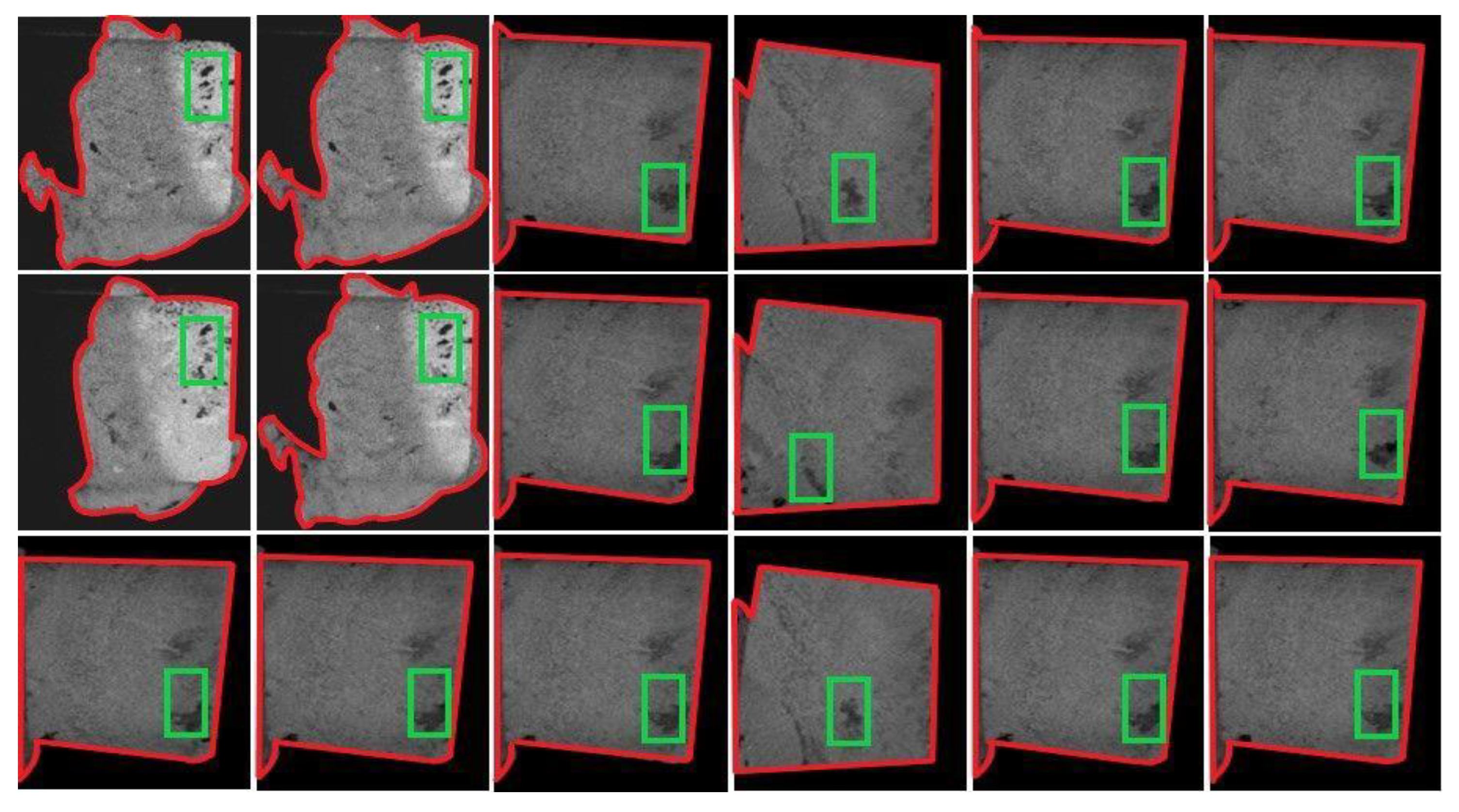
2, and one micro-image creates a field view of 1 × 1 mm. The spectral noise of the collected CT-scan image samples was reduced using a median filter, and the contrast between features was enhanced with a linear contrast stretch. Most of the individual sample micro-images look very similar (see
Figure 2). This observed high visual similarity among various sample micro-images is due to the small size of the sample carbonate rock slab (256 mm) considered during CT-scan imaging. High visual variations among the sample micro-images can be experienced if the chosen size of the rock sample is larger (at least around a couple of meters). Further qualitative analysis of each 3 arbitrary planes (
xy,
yz and
zx ) shows that some of the individual pores are large and isolated.
All the images are in grayscale with an average pixel intensity of 101/image. Each pixel in a grayscale image represents only the amount of light or the intensity information. Grayscale images are a kind of black-and-white or gray monochrome that is composed exclusively of shades of gray. The subsequent values are respectively calculated as 50, 120 and 255 (see
Section 2.1). Based on the computed values, we classify every individual pixel using Algorithm 1.
Each image has contiguous dark regions lying on its borders, which are neither pores nor fractures (see
Figure 2), and we must exclude them before beginning the computations. Hence, to eliminate these dark regions during computation, we manually marked their borders with red (
= 255,
= 0,
= 0) (see
Figure 2) during data pre-processing, and we call the regions enclosed within the red boundaries as the “effective regions.” The proposed image processing technique understands the red boundary by analyzing the brightness of the bordering pixels based on their
-values (see
Section 2.1). We have kept data distribution (size of training, validation, test splits) as 60:20:20 for deep-CNN. For our proposed method we did not follow any data distribution since the method does not call for any training. Hence, to compare both we have to translate all deep-CNN metrics into Accuracy (Accuracy =
) so as to match it to results captured from our proposed methods which are displayed in the
Table 1.
2.4. Pixel-Wise k-IN Approach to Determine Rock Fractures and Pores
As we discussed earlier, our primary objective is to find the regions (
;
i) (with irregular shapes) within a given grayscale image (
) that contains all contiguous dark pixels. Our secondary objective it is to later classify the region as a pore or a fracture. In the current work, we identify a region as
containing a contiguous collection of 100 or more dark pixels (at least of area 100 × 4.4 µm
2, see
Figure 1a,c). However, readers are encouraged to modify this convention based on the quality of available rock image samples, problem definitions, and necessary geophysical properties of the respective rock sample (such as porosity, etc.).
Information about the shape geometry of is extracted from the significant shape descriptors such as the shape boundary (sensing the abrupt change in the intensity level using intensity gradients), perimeter(), major(), minor(), shape variations of with respect to circle ()) and ellipse ()) of the same perimeters, etc. The induced logic to classify any as a pore or a fracture is discussed later in the current subsection.
2.4.1. Fracture Shape Geometry in a CT-Scan Image Sample
A fracture is defined as any separation in a geological formation that divides the rock into two or more pieces [
27], which in the subsequent grayscale image can be seen as a region with its length much larger than its width and containing a large number of contiguous dark pixels. From a reservoir point of view, fractures are planar discontinuities or deep fissures in rocks due to mechanical deformations or physical diagenesis [
17,
28]. Fractures are often found enlarged by the solution activity or can be healed by secondary calcite or sparite. Based on the previous experience, in general, we found the lengths of the fractures are much larger than their widths, and hence, in the current study, we assume that, to be a fracture,
should follow
(=1.3 in the current study) and in general, their shapes are much deviated from a circle or ellipse of the same perimeter as
. In the current work, we measure the length of
as major(
), whereas the width of
is measured as minor(
) (defined later). The shape variations of a fracture from that of the circles and ellipses of same perimeter are found much larger than for pores. In the current work, we encourage the readers to decide the
value based on the porosity and other necessary geophysical properties of the sample rock used for their experiments.
2.4.2. Pore Shape Geometry in a CT-Scan Image Sample
On the contrary, the shapes of the pores are considered to be spherical or near-spherical, and in general, their sizes are relatively smaller than those of the fractures (though not necessarily, which can be argued in various scenarios). To be a pore, in the present work, needs to roughly satisfy . In the current context, we kept value around 0.8. The ranges are flexible, and the authors encourage the readers to modify them based on their problem definition of porosity and other necessary geophysical properties of the sample rock.
We presented the variation of the accuracy of the proposed algorithm based on the varying
+ in
Table 1. The following subsections show the procedure to calculate the shape variations of any
with respect to the circle (circle variation or
)) and ellipse (ellipse variation or
)) of the same perimeter. The current work classifies any region
in an input image as a pore or a fracture based on the shape variances discussed in
Section 2.4.4,
Section 2.4.5 and
Section 2.4.6. However, before the decision, it is inevitable to identify
s, and for this we have devised an exhaustive and recursive search technique to loop over all the dark pixels and their immediate neighbors, as shown in Algorithm 2.
| Algorithm 2 Pixel-Wise k- IN and Classification (Pores or Fracture) |
| Input: Grayscale images (CT-scan) of rocks contain l × s pixels within the red boundary. |
| Variables & Parameters:k∈; ; 0 < I < 255; (for the current work). |
| Objective: Compute s and then classify them to pores and fractures. |
| Output: Pores and fractures are identified in the input grayscale images. |
| 1: for (i = 0; i < l; i++) do { |
| 2: for (j = 0; j < s; j+ +) do { |
| 3: if ( ≤ I) then ← location() } ▷ starting pixel at i,j = 0, 0 (top left) |
| 4: } |
| 5: function 1 PIXEL-WISE_k-IN() //Primary Objective: identify |
| 6: for (i = 0; i < area(); i++) do { |
| 7: ← k-IN dark pixels of each |
| 8: return PIXEL-WISE_k-IN() |
| 9: function 2 classify Pore or Fracture //Secondary Objective: Classification of pores and fractures using the bags of pixels |
| 10: for (i = 0; i <Size(); i++) do { |
| 11: if(area( ≠ 0) then |
| 12: for (j = 0; j < area(); j++) do { |
| 13: for (r = 0; r < area(); r++) do {←[r] } } |
| ▷ is the bag of pixels for [r] and [r] is the rth element of the ith bag of pixels, called . |
| 14: compute the major axis length of or major() |
| 15: compute the major_angle() |
| 16: compute the minor axis length of or minor() |
| 17: compute area() = Total number of pixels in |
| 18: compute the perimeter of or perimeter() |
| 19: compute ) and ) |
| 20. compactness() = ≥ 1 |
| 21. curl() = |
| 22: width() = |
| 23: if ((lp ≤ area() && ( ≤ ||0 ≤||0 ≤ )) then is a pore |
| 24: else if ((lf ≤ area() && (||||)) then is identified as a fracture |
| } |
| 25: End |
2.4.3. Finding the Contiguous Dark Pixels Using k-IN
Initially, we determine the
values of all the pixels in a given input image sample and classify each of them based on their respective
values (see Algorithm 1). Next, we locate all the dark pixels in the input image and store their relevant information (mainly location) in a separate bag of pixels, i.e.,
. Quite expectedly, the size of
should be any positive integer greater than 0. Next, we recursively identify all
k-immediate dark neighboring pixels (0 ≤
k ≤ 8, see
Figure 1a and
Figure 3) for every dark pixel in
, which covers most of the dark regions in an image sample; this, in turn, points to the identification of the majority of the rock pores and fractures.
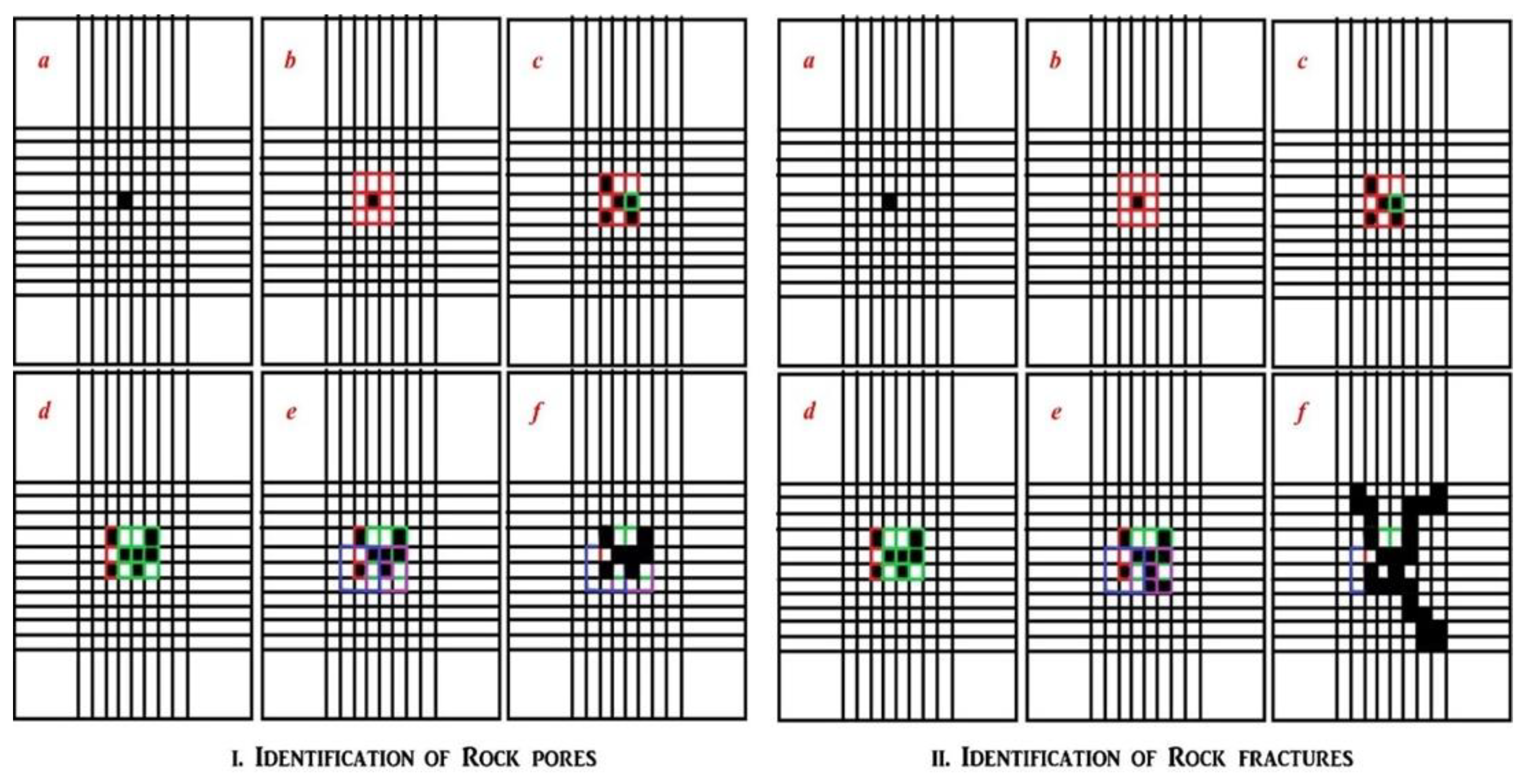
For better and clearer understanding, we present an over-simplified toy example of one 4 × 4 image (see
Figure 1). Of 16 pixels, eight among them are classified dark (classifications are done using Algorithm 1), whose locations are 1, 4, 7, 8, 10, 12, 15 and 16. We have to classify these pixels as a pore (if any), given that the collection of two or more contiguous dark pixels is considered as a pore. Initially, we kept all eight dark pixels in the bag of pixels
= {1,4,7,8,10,12,15,16} and the subsequent bags of pixels for each element of
are
(no adjacent dark pixel);
= {7,8};
= {4,8,10,12};
= {4,7,12};
= {7,15};
= {7,8,15,16};
= {10,12,16} and
= {12,15}. This has been done using the recursive function PIXEL-WISE_
k-IN(
) (see Algorithm 2).
Next, from the other bags of pixels,
is a null set, and hence pixel
cannot either be a pore or a fracture. Then for the next bag of pixel
we found 7 and 8 are the dark neighbors of pixel 4 and again from
and
, it can be confirmed that
= {4,7,8,10,12}. After analyzing
and
(since occurring in
and
),
can be extended to
= {4,7,8,10,12,15,16}. Later analyzing
and
since occurrence in
and
) we finalized
as
= {4,7,8,10,12,15,16}. Since
contains more than two pixels, hence it is considered a pore (see
Figure 1a). After all the analyses, it can be confirmed that this toy example has only one identifiable pore. As mentioned earlier, it is an over-simplified case presented for a better understanding of the proposition, for which the detailed implementation of the proposed technique in the presence of a complex data set has been given in the later part to show its wide applicability range. A pictorial representation of the step-wise execution of the proposed algorithm is shown in
Figure 3.
2.4.4. Shape Variance of with Respect to the Circle
In the current work, we have compared the shape of
with that of a circle, where the circle has the same perimeter. Perimeter (
) is the number of pixels lying on its boundary. We assume there are
n pixels {
,
, ⋯,
} lying on the boundary of
and the perimeter is computed as
. We define the shape similarity of
with that of a circle as
) =
, where
(
) is the mean of radial distances from the centroid (
,
) of
to its boundary points and
(
) is the standard deviation of radial distances from the centroid of
to the boundary points [
29,
30]. Now,
(
) and
(
) can be calculated as
(
) =
, and
(
) =
, respectively, where
=
. Now,
) = 0 shows the shape of
) is a perfect circle, however, with bigger
) values its shape diverges from that of a circle. Hence, for a pore, we restrict
) between [0,
], i.e., 0 ≤
) ≤
+, whereas
is classified as a fracture if
)
> in the present work.
In the current work, we primarily varied
-value between (0, 1), and subsequent accuracy variations of the current algorithm are listed in
Table 1. The present data samples are the CT-scan micro images of carbonate rock that contain a large number of micro-pores and fractures of shapes similar to the circle (our presumption for the present case). We encourage the readers to make realistic presumptions considering the geological properties of the physical rock sample and image quality. Hence, for the best accuracy of the proposed algorithm, we decided
-value range between (0, 0.45].
2.4.5. Shape Variance of with Respect to the Ellipse
Next, we calculate the shape variance of
with respect to the ellipse, where the ellipse has the same perimeter (perimeter(
)). We calculate the shape variance
=
, where
is defined as the mean of radial distances from the centroid (
,
) of
to its boundary points and
(
) is the mean standard deviation of the radial distances from the centroid of
to its boundary points. Here,
=
and
(
) =
where
=
information about the variance of
and the ellipse based on the radial distance,
and
is the covariance matrix between the shape
and the ellipse.
= 0, classifies the shape of
as a perfect ellipse. Now, for
to be classified as a pore, we decided the range of
as [0,
], where 0 <
≤ 1. Quite similar to the case described in
Section 2.4.4, the authors encourage the readers to modify the range of
depending on their problem definitions, sample rock porosity, and other necessary geophysical properties. For the best identification accuracy in the current sample images, we keep
values low, and hence, we decided
-value as 0 <
≤ 0.45.
2.4.6. Shape Variance Using Length and Width of
Apart from the above two measures, we also computed the ratio between the length and width of . Here, the length is assumed to be the major axis of . The major axis of is the longest straight line drawn through joining the endpoints (, ) and (, ) and its length can be computed as major() = . The angle between the major axis of and the x-axis (also known as the orientation of has been computed as major_angle() = ). Similarly, the width of has been assumed to be its minor axis, which is the longest line drawn through joining its two endpoints (, ) and (, ) and perpendicular to the major axis. Its length is computed as minor() = . The major and minor axes endpoints are found by computing the pixel distance between every combination of border pixels in the object boundary and finding the pair with the maximum length, where the two straight lines are perpendicular to each other. Since the shapes of the pores are assumed to be spherical or near-spherical, we restrict the range of between [1, 1.3] (), whereas for fractures, the ratio has been kept within (1.3, ꝏ) in the current context. To reiterate, the authors encourage the readers to modify the regions based on their problem statements, the porosity of the rock sample, and its other necessary geophysical properties.
2.4.7. Classification Logic
The present algorithm classifies one
as a micro-pore or a fracture based on its size and shape. In general, the size of a fracture is often found to be larger than that of a pore (although this proposition remains arguable in several situations). Hence, the adopted logic [
31,
32,
33,
34] to classify a pore initially checks the number of dark pixels in
(or area(
)) and if the area(
) lies within a specific range
lp ≤ area(
(decided by the model developers) and at least one among the three
, 0 ≤
and 0 ≤
is satisfied then we can classify
as a pore (see line no. 23 in Algorithm 2). Here,
lp are the lower and upper-bounds of area (
) respectively, values of which should be decided based on the historical information about the sizes of the pores and fractures and porosity of the original rock sample.
Again, a region containing a large number of dark pixels or should be classified as a fracture if lf ≤ area() ≤ and at least one among the three conditions , and is satisfied (see line no. 24 in Algorithm 2). Quite similarly, lf are, respectively, the lower and upper-bounds of the area() for fracture. We may again repeated that the model parameters are flexible and depend on the problem definitions, sample rock porosity, and other geophysical properties.
We have also computed some other measures for a specific
such as compactness(
), curl(
) and width(
). Here, compactness(
) is an intrinsic property of
and defined as the ratio of the area of
to the area of a circle with the same perimeter (perimeter(
)). Mathematically, compactness(
) =
, where perimeter(
) is the total number of pixels residing on the perimeter of
and area(
) is the total number of pixels in
; curl(
) of
is the degree to which an object is curled up. Lastly, the width(
) is the average width of any
. These shape-specific measures can be used as features in deep-CNN, which will be considered in our upcoming research work. Visual representations of these measures are shown in
Figure 1b,c.
2.4.8. Overall High-Level Architecture and Computational Complexity of the Proposed Pixel-Wise k-IN Algorithm
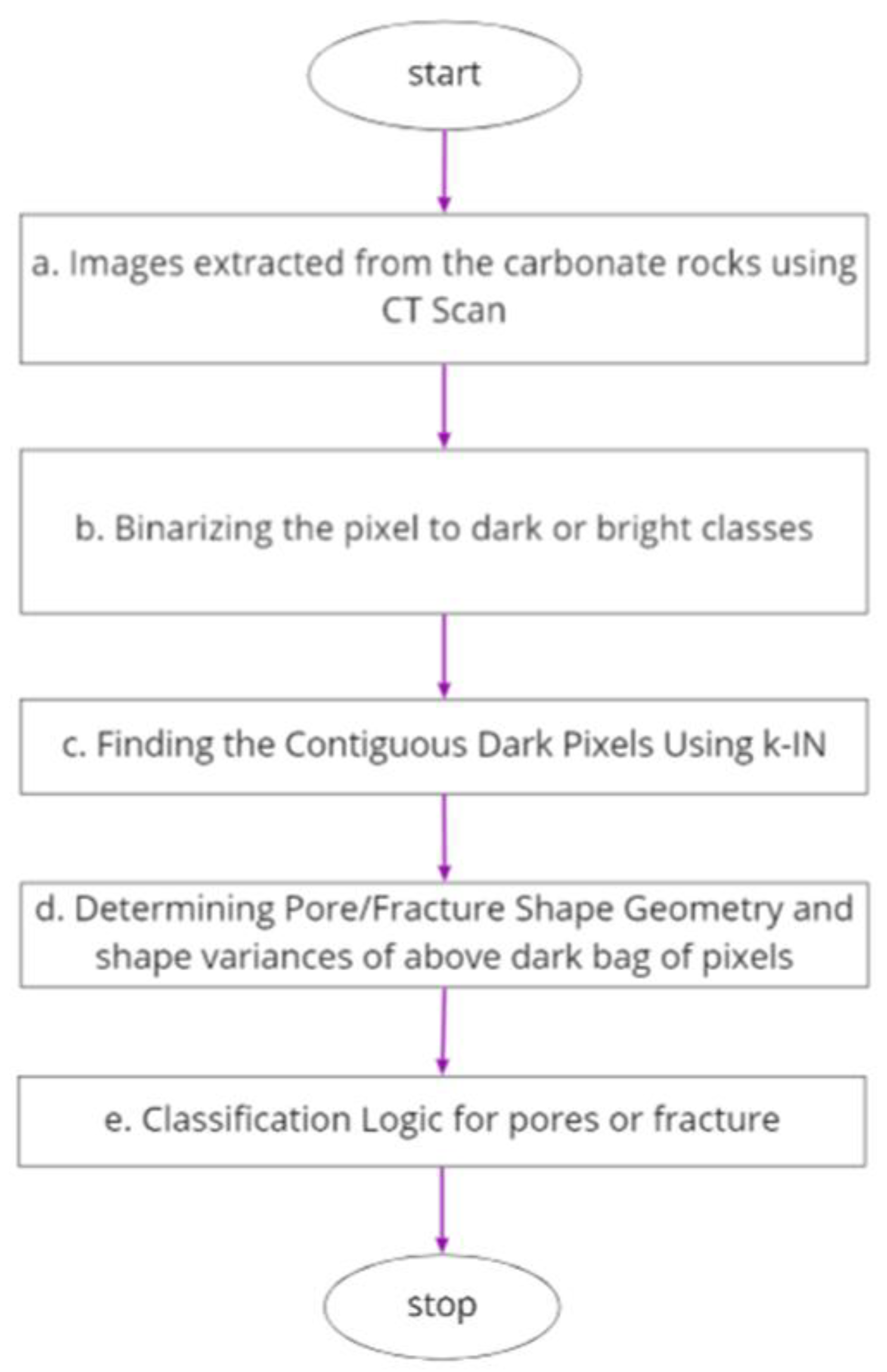
We felt that the overall architecture/logical flow of our proposed approach would help us explain it comprehensively. Below, we present an overall flowchart (
Figure 4) combining the above steps to provide a snapshot view of our proposed algorithm: (a) images extracted from the carbonate rocks using CT Scan, (b) binarizing the pixel to dark or bright classes (c) procedure to find
k-INs of any pixels as per Algorithm 1 (d) calculation of shape geometry KPI’s such as area(
), major(
), minor(
), perimeter(
) and curl(
) of pore and fracture also with shape variances, (e) Classification as per the logic into pore or fracture.
Further to the overview above, we would like to deliberate on the computational complexity of Algorithm 2. Assuming that for each operation the computer takes the same time, and is the size of the input. Where image length = and breadth = assuming a square image for the convenience of calculating computational complexity, and the size of (bag of pixels) ∀ <; . As we can see, we have mainly a few blocks of code as follows:
(a) Computing computational complexity of our proposed approach:
Ingest pixels for process # runs times
2 nested loop #runs ()—(line 5)
Outer for loop to iterate on the length of the image (starting LoC 1), runs times
Inner for loop to iterate on the height of the image (starting LoC 2), runs times
Similarly, additional loop starting, runs times—(line 6)
Similarly, next 3 nested loops, runs times—(line 10)
Next steps are the calculation and if statements, runs times each
compute the major axis length of or major()—(line 14)
compute the major_angle()—(line 15)
compute the minor()—(line 16)
compute area()—(line 17)
compute the perimeter()—(line 18)
compute ) and ); 2 time—(line 19)
compactness()—(line 20)
curl()—(line 21)
width()—(line 22)
check for Pore or Fracture—(line 23)
Thus, the combined execution time is ++ ++ 11. Now we can ignore the lower order terms since the lower order terms are relatively insignificant for large inputs compared to the highest order term. Therefore only the highest order term is taken (without constant). So, the calculation complexity Big(0) will be O().
(b). Computing the computational complexity of YOLO and RCNN approaches:
In general, an MLP with
inputs and
hidden layers, where the
-th hidden layer contains
hidden neurons and
output neurons, will perform the following multiplications (excluding activation functions):
which in a big-O notation can be written as
where
is the lower bound and big-O is the upper bound.
Add the convolution layer: Inputs: Image () and convolution mask ( ). The convolution computation complexity is O(). For simplicity, we assume = . The equation translates to O(). Dropping the constant and considering only highest-order terms again will result in O().
By putting them together, we have
By generalising the above steps for the RCNN and YOLO, the computation complexity for both will be ().
The comparison of both shows that the RCNN and YOLO approaches tend to be more complex than the proposed approach.
3. Results and Discussion
This section briefly articulates the results of the proposed method in the presence of the pre-processed dataset shown in
Section 2.3. A few output samples are shown in the image below (see
Figure 5). We encircled each
considering the distance between the two farthest dark pixels of
(say,
= (
,
) and
= (
,
), and
(
,
) is the distance between them) or major(
) as the diameter of the circle (see
Figure 4b). We chose a yellow circle if
is classified as a pore and a white circle for a fracture (see
Figure 5). Here,
(
,
) =
is the Euclidean distance between
and
(see
Figure 5b).
To test the effectiveness and applicability of the proposed identification strategy (see
Section 2.4), we used the pre-processed data elaborated on in
Section 2.3 and confined its execution within the effective region of each image. The subsequently detected pores (encircled yellow) and fractures (encircled white) are shown in
Figure 5. Here, the pores and fractures are classified based on the shape and size of
(see Algorithm 2).
3.1. Performance Comparison
We compared the performance of the proposed approach with that of supervised deep CNNs [
18,
31,
35,
36,
37]. This is because we found use of the latter in recent geology literature focusing on rock porosity classification. In addition, we also compared them with industry-standard object detection models such as YOLO5 [
34,
38] and Faster RCNN [
37]. All experimental verifications were performed using an HP-Blade server with 64-bit Ubuntu 16:04, kernel 4.4, Intel Xeon(R) CPU E5-2690 2.6 GHz (64 cores), RAM 128GB, 5.4TB SSD [
32,
33,
37,
39]. Detailed comparative criticisms are presented in the following subsections.
3.1.1. Comparison with Abedini et al.
We compared our proposed study with [
18], which employs deep learning involving back-propagation (network containing three layers and 30 neurons) and stacked autoencoder networks. The network structure was not clearly articulated in their study [
18], i.e. without any pixel, resolution and dimension-specific information about the used image samples. Moreover, the visual evidence of detecting pores and fractures using this strategy [
18] was not presented to corroborate their claim of accuracy, which certainly reduces its acceptability to the larger image-processing community. The induced strategy of [
18] was to extract the shapes of pores and fractures from the image samples using ‘Image Pro Plus’ software and then use these extracted shapes as a training set to identify the same in the testing of high-resolution (with good chrominance) image samples containing a single large pore or a single large fracture. The used images have good chrominance values, as the pores and fractures are marked in blue in their study. Additionally, the pores and fractures in training and testing data used in [
18] are visually large and clearly recognisable to the human eye, which makes the detection mechanism relatively simple. Hence, we suspect that the identification mechanism of [
18] will fail in the presence of the few low-quality grayscale images containing micro-pores and fractures in our dataset. Several reasons for this failure are possible: (i) an inadequate number of training samples for learning the necessary features to understand the shapes of pores and fractures using deep learning and (ii) extracting shape-related information from micro-pores and fractures is a tough challenge for the strategy [
18].
In contrast, our proposed pixel-wise
k-IN does not require a large image set for accurate identification. The strategy presented in [
18] is mostly not applicable in the current dataset (see
Section 2.3) because of its adopted learning style that requires a single pore or a fracture for training and a single pore or a fracture for testing.
3.1.2. Comparison with Supervised Deep CNN
Comparison with Custom Object CNN model (
Figure 5):
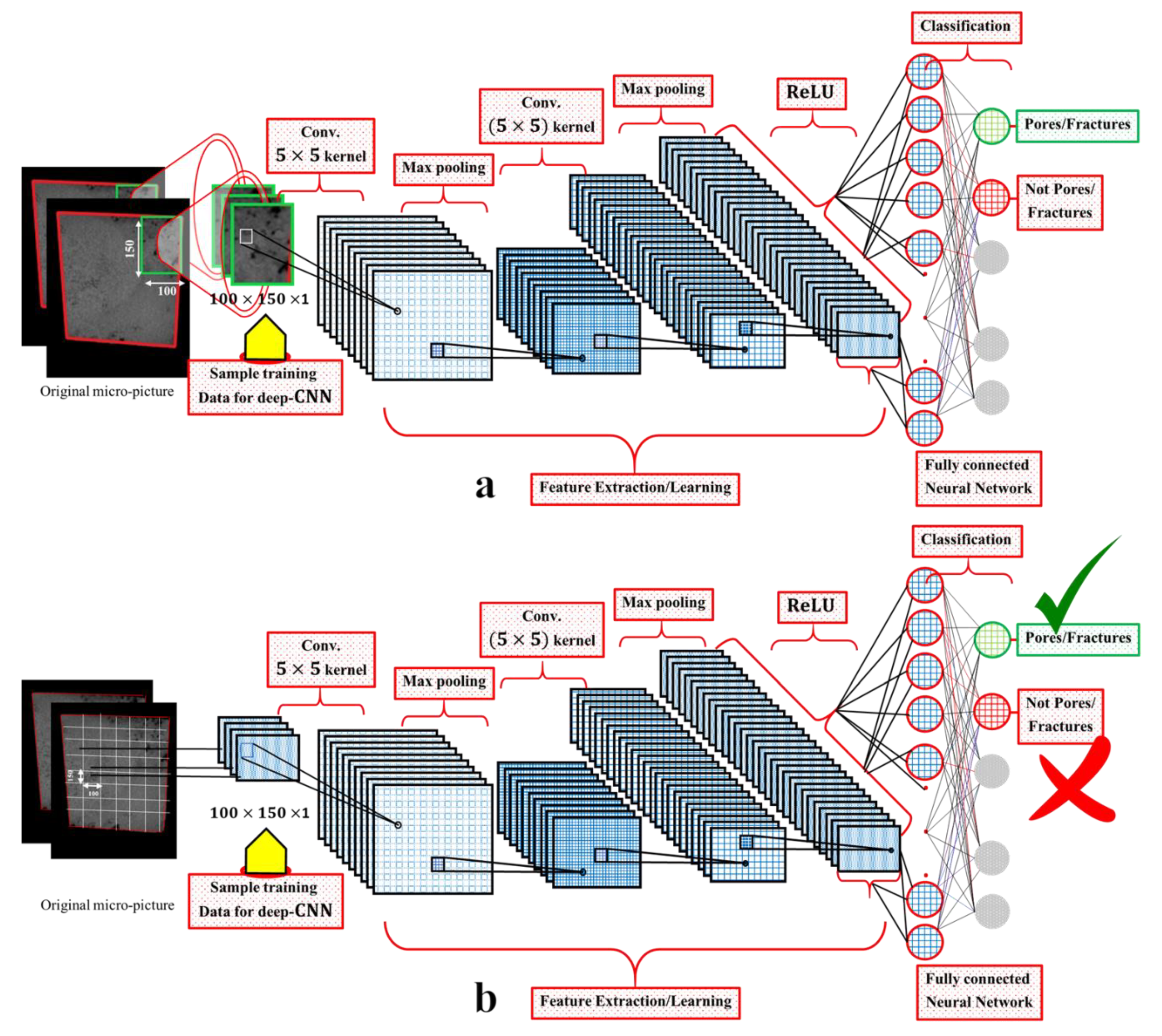
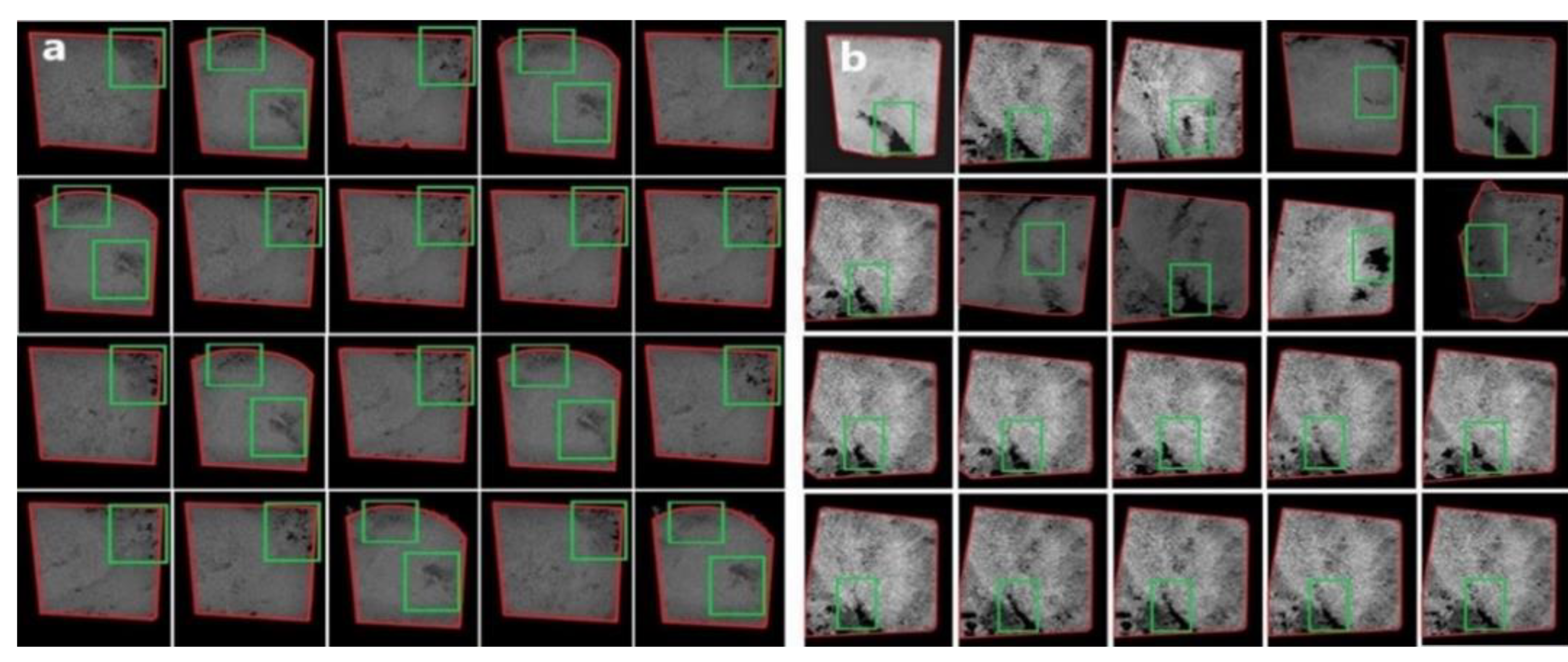
We prepared the data in a slightly different manner. Here, we manually segmented each micro-image sample based on the many contiguous dark pixels within them. The segment size was kept fixed to 100 × 150 pixels, and each segment is enclosed in a green rectangle (see
Figure 6a). Next, we used these segments as the training set for the Custom Object CNN. Here, we relied on the human eye to prepare the training set, whereas for testing, we use the pre-processed full micro-images shown in
Section 2.3. A sample visualisation of the construction of the segments is shown in
Figure 6a. Our goal is to locate the region from each micro-image from the testing set containing the most dark pixels and subsequently classify it as a pore or a fracture. Our code reads every consecutive region containing 100 × 150 pixels from each testing image sample and subsequently classifies it as a pore or a fracture. The resulting images from this strategy locate the regions by enclosing them with green rectangles of 100 × 150 pixels (see
Figure 7).
To our knowledge, deep CNN models [
31] have never been tested with grayscale CT scan images to identify rock pores and fractures, particularly at the micro-level. We found that the identification accuracy of the Custom Object CNN model is poorer than that of the proposed method. For Custom Object CNN models, we considered two 5 × 5 convolution (non-strided), max-pooling layers and fully connected layers with ReLU activation (see
Figure 6). Max pool was used as a noise suppressant. It discards the noisy activation altogether and performs denoising along with dimensionality reduction and thus can be considered better than average pooling.
Comparison with the YOLO and RCNN models:
We further trained and tested industry-standard CNN networks, such as YOLO5 [
34] and Faster RCNN [
37,
39] (see
Figure 8 and
Figure 9), for object detection. These object detection models combine bounding box prediction and object classification into a single end-to-end differentiable network.
Faster RCNN, on the other hand, is the fastest member of the RCNN family. RCNN extracts a bunch of regions from a given image using a selective search and then checks if any of these boxes contains an object. We first extract these regions, and for each region, CNN is used to extract specific features. Finally, these features are then used to detect objects. Unfortunately, RCNN becomes rather slow because of these multiple steps in the process. RCNN uses selective search to generate regions. Faster RCNN replaces the selective search method with a region proposal network, from which the algorithm gets its speed much faster.
YOLO was written and is maintained in a framework called Darknet. YOLOv5 is the first YOLO model to be written in the PyTorch framework, and it is much more lightweight and easier to use. YOLO stands for ‘You Only Look Once’. YOLO5 is a novel CNN that detects objects in real time (fastest) with great accuracy. This approach uses a single neural network to process the entire picture, then separates it into parts and predicts bounding boxes and probabilities for each component. These bounding boxes are weighted by the expected probability. Comparing Faster RCNN with YOLO5, we found that YOLO5 is better in accuracy for real time prediction whereas RCNN delivers better accuracy for static predictions such as video post processing as seen in
Figure 8 and
Figure 9 and
Table 1.
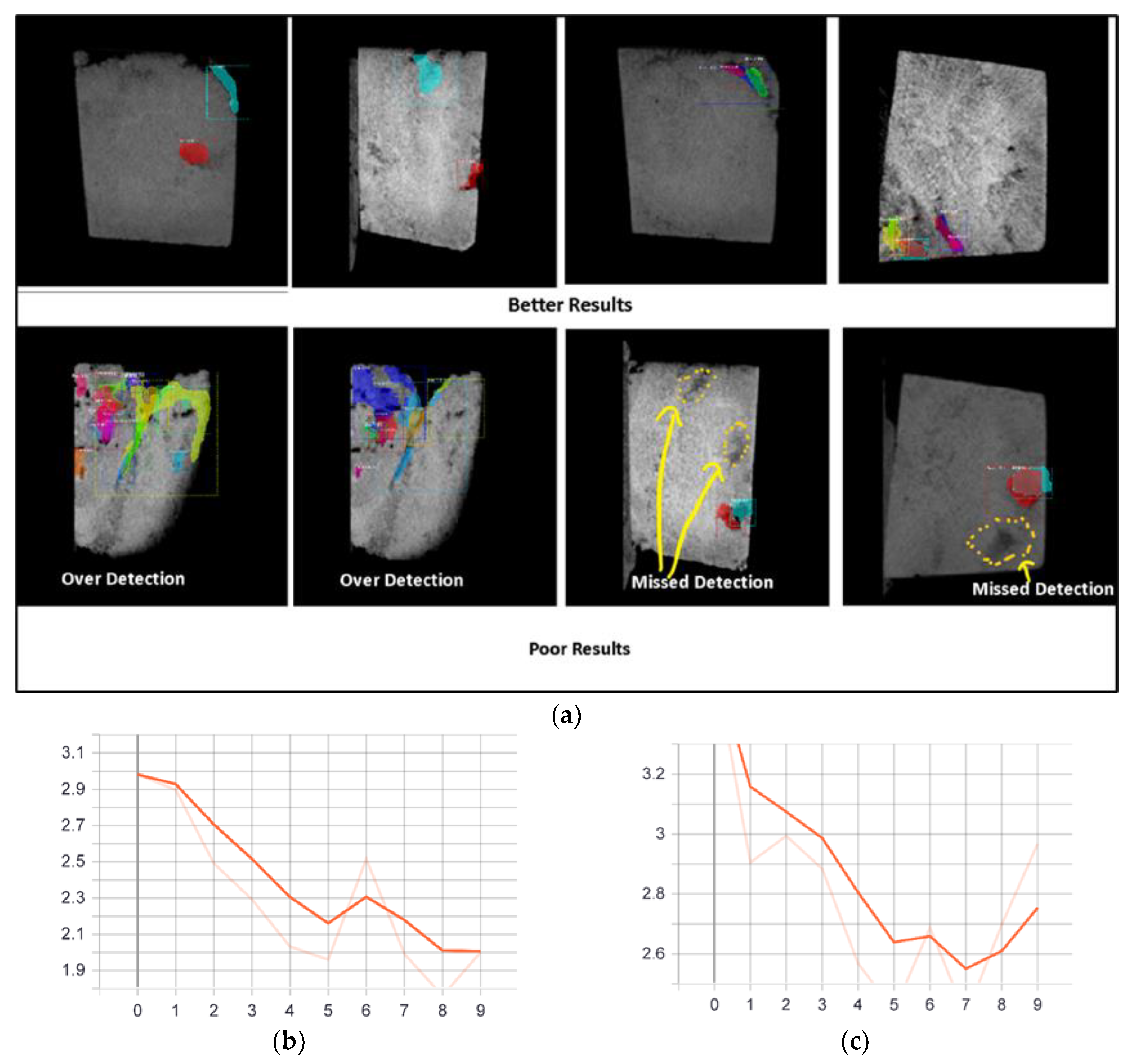
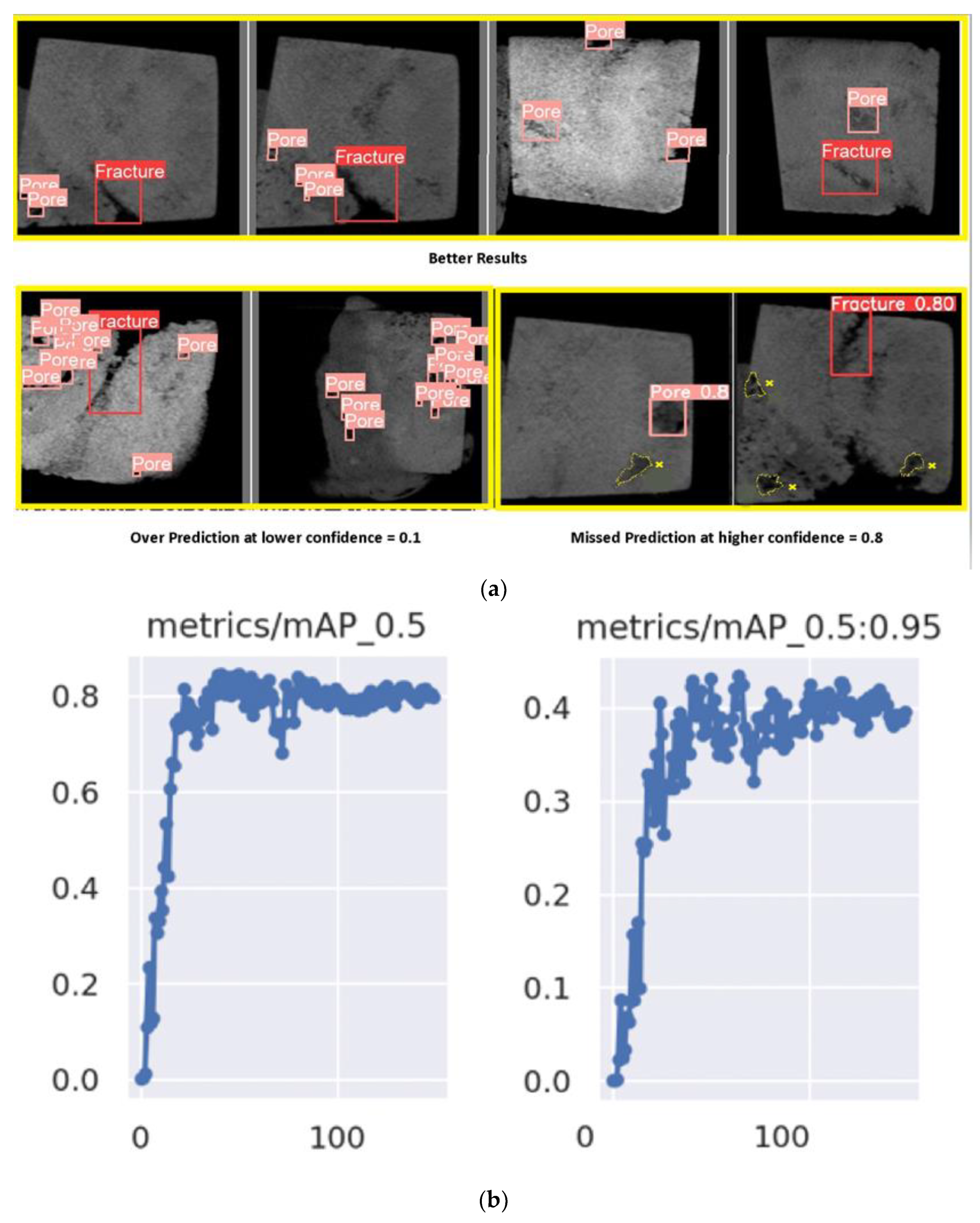
The accuracy of the abovementioned deep CNN models was quite unsatisfactory compared to that of the proposed method. This deficiency was often due to the black-box nature of deep CNN architectures, which sometimes makes them difficult to trace, verify and debug. Additionally, while handling the image samples, we often noticed very thin (mostly vague) boundaries of the pores and fractures (
). This characteristic is mainly due to negligible intensity differences between the bordering pixels and the pixels residing just outside
. Moreover, in many cases, we often observed negligible intensity differences among most pixels residing in a specific
and the other pixels residing in several other parts of the same image sample, which makes it very difficult for deep CNN to extract pore- and fracture-specific shape information, possibly increasing the chance of misclassification [
34,
37]. In contrast, models such as YOLO5 [
34] and Faster RCNN [
37,
39] seem to underperform because of the low quality of images and the irregular shape of pores and fractures, as detailed in the forthcoming sections.
However, we also suspect the implementation strategy of CUSTOM Object CNN which was included in the current work for comparison with the performance of the proposed approach might be the other reason behind its poor performance. This can be rectified in future work, which will be a novel contribution in the field of identifying pores and fractures of the rock from the CT-scan images.
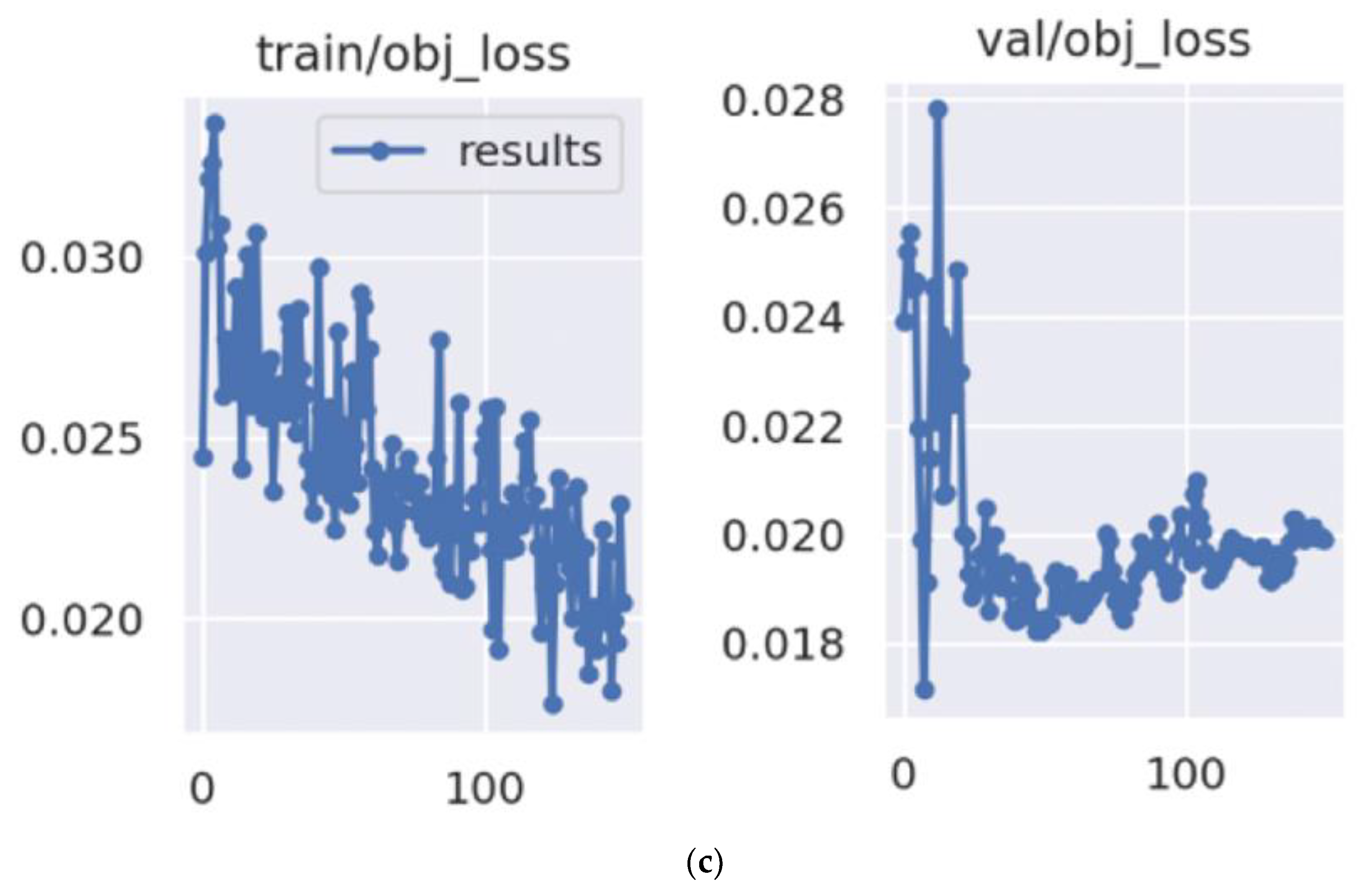
3.1.3. Accuracy/Result: Process and Comparison
To compare the accuracy of the proposed method with Custom Object CNN, we manually classified each
in every image sample as a pore or a fracture after analysing its visual properties (area and shape). This classification was further supported by its geophysical properties from its mother carbonate sample rock. This dataset will be our reference for further comparison. Next, we automatically classify every individual
using the proposed pixel-wise
k-IN and the deep CNN models and compare their results with the above reference dataset. The results, listed in
Table 1, demonstrate that the accuracy of the proposed method pixel-wise
k-IN (
Figure 5) evidences better performance than the three deep CNN models (
Figure 7,
Figure 8 and
Figure 9). From
Table 1, the accuracy of the proposed method is 85.9%. The error rate shown is due to the few observed variations in the geometric shapes of pores and fractures from the identification logic used in Algorithm 2 (see line nos. 23–24). For example, we manually identified a few micro-pores (
s) after carefully analysing their visual and geophysical properties, classified incorrectly by Algorithm 2. Similarly, we manually identified a few fractures that do not satisfy the criteria shown in line no. 24 of Algorithm 2. Additionally, we showed the variation in the accuracy of the proposed algorithm by varying the model parameters
in
Table 1. This action also shows that the correct combination of parameters for the current dataset is
.
In contrast, the error rate of the industry-leading deep CNN models (YOLO and RCNN) was due to the poor learning of different shape-related features and the fewness of training samples. The YOLO model provides accuracy that is based on the intersection of actual bounding boxes and predicted by the feedforward network. Since the predicted bounding box will not match the ground truth (see
Figure 7 and
Figure 9a), we obtain a ratio by dividing the area of intersection between the two boxes by the area of their union, which is called the intersection of unit. The higher this ratio is, the better the prediction. By equating this prediction with the ground truth, we obtain the accuracy of the model.
The possible reasons for the better performance of the proposed approach in the presence of the current image samples are elaborated on in the subsequent subsections.
3.2. Reasons behind the Failures of the Contemporary Approaches
This section briefly discusses the possible reasons behind the failures of the modern contemporary approaches (deep CNN models) and the several advantages of the proposed algorithm in detecting rock pores and fractures by analysing their CT scan images. One of the most important advantages of the proposed technique is its simplicity of implementation and easy understanding. The remaining advantages are based on structural/conceptual comparisons with the existing techniques in a similar domain.
3.2.1. Unavailability of High-Quality Data
Image quality is often considered an important, frequently faced challenge in machine vision systems. Image quality refers to the high resolution and chrominance of the image. Commonly, machine vision systems are trained and tested on a high-quality image dataset, yet the high quality of the dataset cannot always be assumed [
40]. For this reason, several contemporary machine vision algorithms underperform in the real world. Quite expectedly, we also found that the detection quality of a deep CNN model’s performance strongly depends on the quality of the samples.
However, as discussed earlier, the proposed pixel-wise k-IN is robust in this situation because of its exhaustive search mechanisms to locate the dark pixels and their k-immediate dark neighbours deterministically. This approach helps pixel-wise k-IN identify the rock pores and fractures in each image sample. Other model parameters, such as , are responsible for classifying as a pore or a fracture. The values of the model parameters depend on the problem statement, sample rock porosity and its other necessary geophysical properties.
3.2.2. Samples with Less Divergence
Low divergence samples accompanied by a small number of grayscale image samples constitute another issue we encounter in achieving accuracy using conventional methods. The dataset used in the current work has considerably less divergence, i.e., the visual quality (the location and shape of
) of most images in the sample is very similar. The reason behind the visual similarity is given in
Section 2.3, and a method for measuring the similarity between the image samples is provided in
Section 2.2. Even in the presence of a formidably large number of grayscale image samples, we found deep-CNN models (including ours) were failing to identify the regions containing the pores and fractures with an accuracy as high as in
Figure 10 [
18,
25]. This failure could be due to the poorly crafted training samples (having fewer unique images) leading to a mode-collapse problem, i.e., being stuck in local minima because of poor learning.
To combat this problem, we conducted experiments using the Custom Object CNN model in two ways: (i) Learning manually identified regions containing the maximum numbers of micro-pores and fractures as training samples. We maintained higher visual dissimilarity while preparing the training samples. A comparative study considering the training sample divergence is shown in
Figure 11. (ii) Learning the geometric shapes of individual micro-pores and fractures to identify them correctly in the test samples. The manually identified regions of several images containing the most pores and fractures are chosen as training samples in case (i), whereas the normal shapes of the pores and fractures are taken as training samples for the latter case (ii). Each experiment strategy is described below.
Manually identify the regions containing the most possible pores and fractures: For this task, initially, we manually encircled (in green boxes) the regions containing the most possible pores and fractures to create a training set containing 300 images (see
Figure 10a). We then used this training set to train the Custom Object CNN model in
Section 3.1.2 and used the remaining images as a test dataset. High visual similarity can be observed among different grayscale images of the current sample, triggering a mode-collapse problem that forces the Custom Object CNN model to stick to a suboptimal solution due to the high degree of similarity among the extracted features.
Figure 10b shows the evidence of mode collapse.
Learning the shapes of an individual pore and a fracture [
18]: For this task, we extracted the images of the
from 400 micro-image samples as described in the work of [
18] and created a training set of five shapes (such as intra-particle, vuggy, moldic, biomoldic and fracture [
18]) with 50 examples of each category for the deep learning models for feature extraction and found considerably low detection accuracy because of the high geometric and visual similarity (insignificant dissimilarity) in the shapes of different types of pores and fractures in the used micro-image samples. The extracted micro-pores and fractures have inferior quality and remarkably similar shapes because of their tiny sizes. Moreover, the quality of the used grayscale image samples prevents the ‘Image Pro Plus’ software from extracting the high-resolution images of pores and fractures that could further be used as training samples for the Custom Object CNN. Consequently, the Custom Object CNN model fails to extract the above features that help perform the porosity classifications and fracture identifications uniquely.
We found that the training grayscale image samples of micro-pores and fracture images (extracted using the ‘Image Pro Plus’) are highly distorted (irregularly shaped geometry) in most cases and subsequently, extracting their shape geometry-related features became extremely difficult in reality for CNN-based object detection systems, which are square bounding-based detection, whereas pores are generally irregularly shaped. These pores can sometimes be much smaller than the size of the convolution filters chosen, which leads to false positives. Hence, the identification accuracy of this strategy, only approximately 10%, is very inferior to that of case (i). In contrast, the proposed approach shows better accuracy than the above deep learning approaches because of the benefit of its pixel-level in-depth analysis and the adoption of an exhaustive search approach to identify new neighbouring dark pixels of a detected dark pixel.
3.2.3. Sample with an Extremely Small Training Set
The unavailability of large and diverse set of training samples is widely considered a major practical problem behind the unsuccessful implementation of the Custom Object CNN [
33,
41,
42]. In addition, we could not find any public dataset similar to our study to enhance the sample set size. Large datasets are often needed to ensure that the deep CNN delivers the desired results. The success of deep learning methods [
18,
25] is often found to entirely depend on the availability of a large and diverse set of training samples. Particularly in the present scenario, the size of the dataset is unsatisfactory; hence, the accuracy of the current Custom Object CNN, including the YOLO and RCNN models, was inferior to the proposed approach. We firmly believe that the accuracy can barely be improved in the absence of a large set of training samples. Similarly, the other deep learning implementation [
18] will not be successful without a large set of training samples.
This problem has been successfully countered using the proposed approach of analysing individual images based on pixel intensity. The proposed approach does not require a learning phase and hence can successfully and accurately be applied in the presence of a tiny number of grayscale image samples.
3.2.4. Detecting Objects of Irregular Shape
This problem could be a major difficulty for the deep CNN approaches and [
18] the tiny size of inferior quality (grayscale, resolution) images containing micro-pores and micro-fractures (visually small, in the current case). As discussed above, thin boundaries of pores and fractures are frequently observed along with a negligible level of intensity differences among the pixels lying inside or out of any tiny (small)
,
i ∈
in any image sample in the present dataset (see
Section 2.3).
As a result, the pores and fractures are objects of extremely unusual shapes, and accurately retrieving their shape-related relevant information (for their future identification) using the present deep CNN implementation becomes quite imperfect, thus increasing misclassification. This result could be due to the layers of deep CNN extract better and specific features related to identifying pores and fractures. Hence, to identify unusual-shaped objects such as pores and fractures (in the current situation), even at the micro-level, their features must be firmly defined before classification. This task is quite difficult in the current case because of the unusual shapes of the pores and fractures, thus the number of misclassification events increases. When using deep CNN and [
15], the number of misclassifications increases even more if the training samples are few. In contrast, the proposed approach can detect unusually shaped pores and fractures with higher accuracy. This ability is a benefit of the pixel-wise exhaustive search (by analysing the intensity) approach in every image sample and the flexible choosing of the I -value (depending on the image quality and problem requirements) adopted by the proposed procedure, which is documented in
Table 1. In contrast, as mentioned before, the proposed method does not require training and hence can work well with a few datasets.
3.3. Advantages of the Proposed Algorithm
From the above sections, the advantages of the proposed algorithm are quite evident and listed as follows:
The proposed technique is relatively easy to understand and implement. In addition, its identification accuracy meets our expectations for the present dataset.
It can be successfully applied to a few grayscale image samples, whereas deep learning approaches such as Custom Object CNN, YOLO and RCNN suffer from poor accuracy in the presence of a small image dataset. These famous image classification models are trained on massive datasets. Among these datasets, the top three used for training are as follows:
- ○
ImageNet—1.5 million images with 1000 object categories/classes,
- ○
Microsoft Common Objects in Context (COCO)—2.5 million images, 91 object categories,
- ○
PASCAL VOC Dataset—500K images, 20 object categories.
The proposed algorithm can be successfully applied to a small image dataset, such as 300 images, because it does not require training for object identification.
Further referring to our limitations of the size of the dataset and quality of the images, this technique can use samples with a low divergence and lower rank hardware resource for computing on the edge. As we know, deep CNN models depend on hyper-parameter choices such as the filter size, regularisation chosen and quantisation levels [
38,
42,
43]. Some of the hyper-parameters we finetune in deep learning methods that can impact the accuracy gain and robustness of the models are epochs (min 1), batch size (min 1), loss function (cross entropy, L1 loss, mean square loss, negative likelihood), optimiser algorithm. learning rate, weight decay, rho, lambda, alpha, epsilon, momentum and learning rate decay. These parameter (more than 15) settings may have an infinite combination and may lead to another combinatorial optimization problem in this case [
43], 320 random hyper-parameter settings (in this case) and hence it can swing an average random accuracy by as much as 41.8 ± 24.3 [
43]. This result shows the amount of variation parametric choices can have over the results. Such high-dimension problems are then reduced in trials with extensive domain expertise, which again becomes very close to an empirical approach such as ours. In comparison, the proposed model has less than five parameters (
) to optimise in our proposed approach. Hence, it is a much simpler and straightforward comparison.
We have tried deep learning in our separate experiments on the Advance Drive Assistance System (ADAS) and for various COVID-19 related apps that run deep learning on-the edge computing. We found that the accuracy levels have drastically reduced the inference of the full Resnet and YOLO-based object detection model after model quantisation. There is a limit on the capacity of deep learning models, whereas our proposed model can easily make inferences on edge (IoT) hardware such as Jetson Nano and even Raspberry Pi.
Our proposed model can be used to identify objects without fixed geometric shapes and sizes (such as pores and fractures). In contrast, deep CNN models are inefficient in this scenario because of an insufficient understanding of the necessary shape-related features required to classify any correctly.
Furthermore, though being scientifically regressive, back-propagation (BP) with the gradient descent (GD) has the inherent issue that it frequently gets stuck in local optima [
44]. This result was further supported by Gori et al. [
45], who found that BP with GD can be guaranteed to find global minima only if the problem is linearly classified. As a learning algorithm, BP, unless supported by empirical techniques such as adaptive learning rate, momentum, noise randomisation and weight spawning, cannot find guaranteed global minima using current deep learning techniques, as discussed above. Furthermore, it is necessary to investigate the hyper-parameters of shallow layer perceptron to show the existence of several local minima and saddle points [
46]. Again, this problem can be resolved with the help of choosing the right kind of hyper-parameter settings or some heuristics. To summarise, the issue with BP and GD is that they are slowly converging and may get stuck in local minima and saddle points indefinitely. Furthermore, it is computationally very expensive (calculate derivatives) being its inherent disadvantages, which tie back to its above-discussed limitation to deploying on-the-edge equipment. Therefore, we have proposed a lightweight method with a minimum adjustments of parameters, and we can obtain better results given the above-specified limitations.
In addition, the computing resource requirement for the proposed approach is relatively less stringent as for manual involvement during the feature extraction process; only CPUs are sufficient to do the inferencing. In contrast, higher computing resources are needed in terms of training and inferring from deep learning experiments [
47,
48,
49]. Training a deep neural network is very time-consuming. We need dedicated hardware (high-powered GPUs, high RAM, SSD, etc.) [
50] to train the latest state-of-the-art image classification models in a day and on top of it in case undesirable results imagine retaining the model Imagine this issue with our attempt to create a robotic instrument using computing on the edge which can make real-time inference for pores and fractures with some empirical methods specific accuracy to the domain. We found that the accuracy levels drastically reduced the inference of the full RCNN and YOLO-based object detection model after we quantised [
49] the model. Therefore, there is a limit on productionising deep learning models, whereas we found that our proposed model can easily make inferences on edge (IoT) hardware such as Jetson Nano and even Raspberry Pi.
3.4. Restrictions of the Proposed Algorithm
Despite having several advantages, the proposed algorithm has a few noteworthy restrictions that are listed below:
The proposed method should be chosen only in the absence of a large and high-quality training set with considerable similarities and dissimilarities among the sample images. This restriction is given not because of its accuracy but because of its high computational time and adopted pixel-wise exhaustive image analysis mechanism. The proposed approach processes each image, and hence, its computation time might substantially increase in the presence of a large and high-resolution image dataset, although the identification error should remain the lowest [
35,
36,
37]. However, in the presence of a large training set, deep CNNs might also suffer from high computational costs.
Sometimes, in the presence of CT scan images containing micro-pores and fractures, it can be difficult to choose suitable I, values, where we must rely on expert judgement. However, the same problem remains in deep CNN, where we often need to decide on several model hyper-parameter values.
Multi-objective algorithms pose higher complexity and computation in comparison to their single-objective counterparts.
4. Conclusions
The imaging, accurate identification and modelling of pores and fractures have become flagship programmes in the leading oil and gas industries because of their immense applications in contaminant transport and CO2 storage, and often, porosity is considered a basic parameter for reservoir characterisation. However, quite frequently, the identification procedure of pores and fractures from the image samples is manual or inaccurate if automated. Above all, micro-pores and fractures in a grayscale rock image (CT scan samples) are mostly unidentifiable or indistinguishable using the contemporary techniques of automatic identification.
Prompted by this fact, in the current work, we developed a novel pixel-wise multi-objective image analysis strategy to automatically identify the pores and fractures from the input CT scan images of rocks. We have tested the applicability and efficiency of the proposed technique using CT scan images of carbonate rocks, and we firmly believe that the proposed methodology will retain its success in the presence of the CT scan images of various other types of rock samples. This belief is held because of its adopted pixel-wise intensity analysis mechanism, which enables the algorithm to understand the largest intensity variations among different pixels along with its neighbouring pixels and accordingly, classify them as bright or dark, thus helping to identify pores and fractures in the CT scan images. However, an accurate understanding of the intensity variation among the pixels in an input image sample depends on a perfect selection of α, β, γ, δ and I ∈ R+, which requires expert judgement ability of the model developer. Next, to juxtapose the accuracy of the proposed methodology, we compared its performance with that of deep CNN and the method developed by [
15] using the same image samples. The results clearly show a better identification accuracy of pores and fractures by the proposed approach using the input CT scan images.
We identified a possible reason for the poor identification accuracy of supervised deep CNNs as the unidentified necessary shape-related features of any , which are highly required during the training of supervised deep CNNs to accurately classify any specific as a pore or fracture. Particularly, the irregular shapes of all make it difficult for model developers to identify the suitable supervised deep CNN features for their accurate classifications.
However, this problem might be handled well using capable unsupervised deep CNN counterparts, which can automatically and intelligently identify the features required to recognise irregular objects with higher accuracy. This possibility will be investigated in our subsequent research works. The poor identification accuracy of deep CNN might be due to its present implementation, although we firmly believe that the accuracy can barely be improved in the absence of large and high-quality training samples.
Possible Implementation of the Proposed System: The proposed system can be prepared as a module, attached to the imaging device and linked with its guiding software to simultaneously identify the pores and fractures (even at the micro-level) during the imaging of rock samples. Gathering many meaningful real data samples has always been a major problem in any real-world rock imaging scenario, which often has a major negative impact on the identification accuracy of deep learning contemporaries. Therefore, a deep CNN module, if attached to a subsequent imaging device and its guiding software as an add-on, should be pre-trained because of the lack of relevant training samples. However, the biggest challenge for the pre-trained models for understanding objects without fixed geometric shapes (such as pores and fractures) is perfectly defining and learning the necessary shape-related features that distinguish the pores from the fractures. This approach might increase the number of misclassifications for a deep CNN model. In contrast, the proposed method only requires an accurate range of its parameters such as α, β, γ and I to uniquely identify pores and fractures. The accuracy of the proposed method was corroborated by various experiments presented in the current work.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}