2.3. Traditional Machine Learning
2.3.1. Relationship Analysis of the Features
The examination data in this paper are too large and complicated. After removing redundant data, we used the random forest [
18] method to analyze relationships among the features.
The random forest (RF) model, developed on the basis of the decision regression tree model, builds multiple classification trees by the bootstrap method. Then, it selects data randomly to carry out training on each classification tree. Features selected for different classification trees are also chosen at random. Finally, we compared the importance of different features based on the training effect of each classification tree.
Table 2 and
Table 3 show the top 10 and bottom 10 in terms of importance. It is easy to find that information related to pregnogram data is much more important than information related to biochemical D data, which lays the foundation of our later strategy to fill in missing values and work to reduce the dimension of the data.
2.3.2. Outlier Detection
Outliers are abnormal data that fall outside the cluster. Many fields in medical datasets are manually input, so input errors occur easily. For example, some decimals may be ignored, causing the value to increase 100 times, which obviously leads to abnormal data and results in difficulty in data analysis. This kind of abnormal data will affect the performance of our algorithm if we do not handle it. The concrete method to detect outliers is described as follows.
Detection based on distance measurement [
19]: First, we define the distance between samples and then set a threshold distance. Outliers are defined as data points that are far from the others. This method has the advantage of simplicity, which requires low computation and storage costs, but the threshold value is hard to set, and its computation complexity is too big, which is unacceptable for big datasets.
Detection based on clustering algorithms [
20]: A clustering model is built, and outliers are defined as data points that are far from all clusters or do not belong to any cluster significantly. This method has an advantage in that there are clustering algorithms that have been developed already, but the method is too sensitive to the selection of the number of clusters.
Detection based on density [
21]: The local density of outliers is significantly lower than for neighboring points. The score of an outlier of a sample is the inverse of the density of the area the sample is in. Different definitions of density correspond to different detection methods.
Detection based on statistical methods: A statistical distribution method is built, and outliers are defined as data points with low possibilities. This method has the advantage of the solid foundation of statistics, but it is necessary to obtain the type of distribution of the dataset first; otherwise, it may cause a heavy-tailed distribution.
As this dataset consists of examination indicators, which have relatively fixed ranges, we selected methods based on statistics. For each indicator, we used Matlab to generate a scatter diagram. As the number of outliers was too small, we detected them with a priori knowledge and manually selected them to fix or propose.
2.3.3. Data Filtering
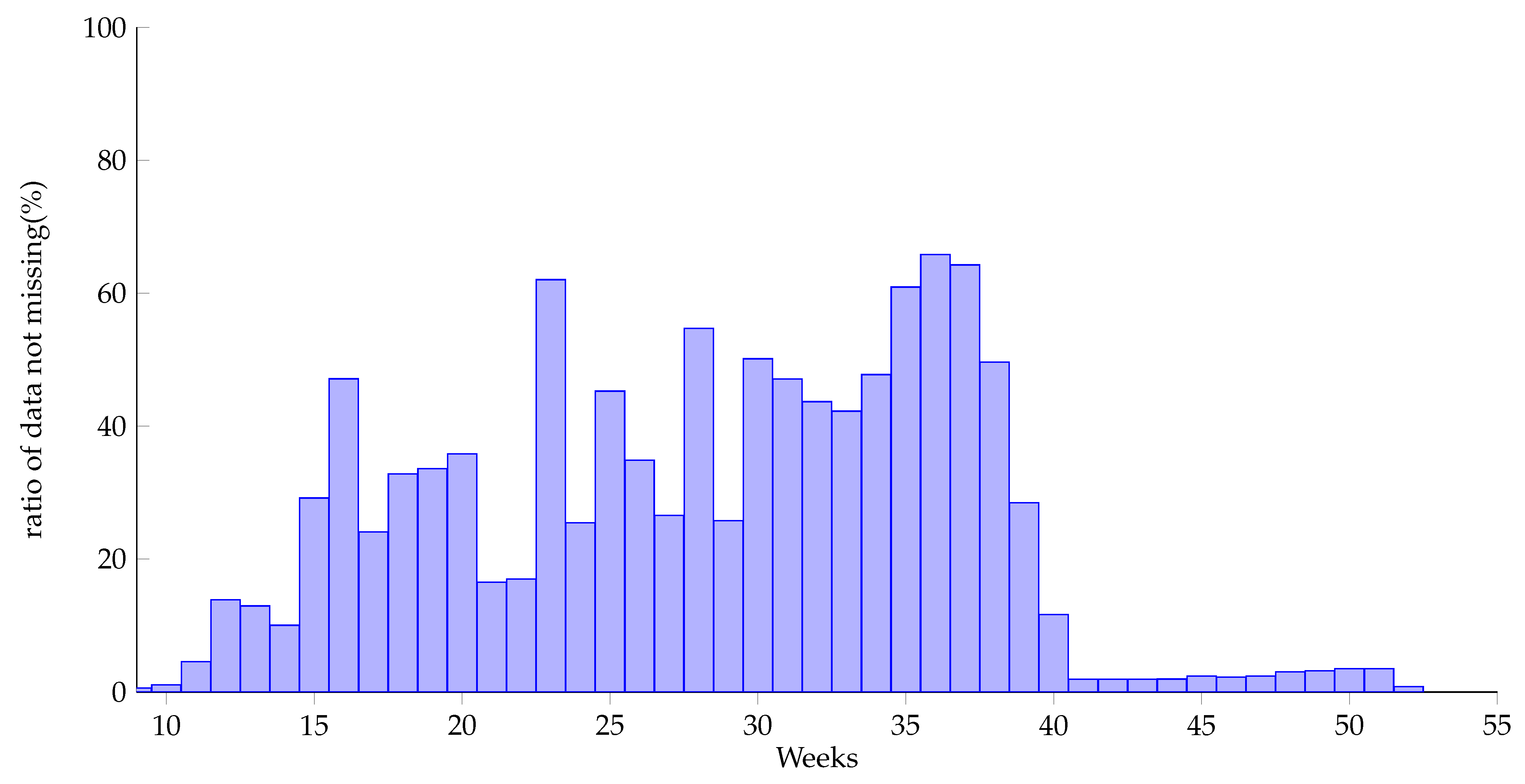
According to the missing mechanism, Rubin [
22] divided missing data into 3 categories: completely random missing, random missing and incompletely random missing data. This dataset is of the category of incompletely random missing data. The missing nature of the data depends on the pregnancy week. After analysis, the missing data rate of each pregnancy week is shown in
Figure 3. It can be found that data are mainly in the range from week 11 to week 40 (with the ratio of data not missing over 5%), and the later the weeks are, the more pregnancy examination records there are. Therefore, this paper selects data from week 11 to week 40 to be processed and analyzed.
As some pregnant women have relatively few examinations, in the 30 weeks from week 11 to week 40, about 10% of the samples have less than 5 examinations. To improve the quality of the dataset, these data should be removed. However, to utilize the dataset as much as possible, this paper uses the selection method described as follows. We consider the degree of the concentration of the pregnancy weeks of the sample with low examination times. If the pregnancy weeks of the examinations are concentrated in the early or late weeks, the sample is considered to be worthless and removable, but if the weeks are scattered, the sample is considered to have the effect of “supporting” and should be kept. Therefore, this paper calculates the ratio of the range between the pregnancy weeks of each sample and the selected pregnancy week range and selects samples with a ratio greater than 0.8.
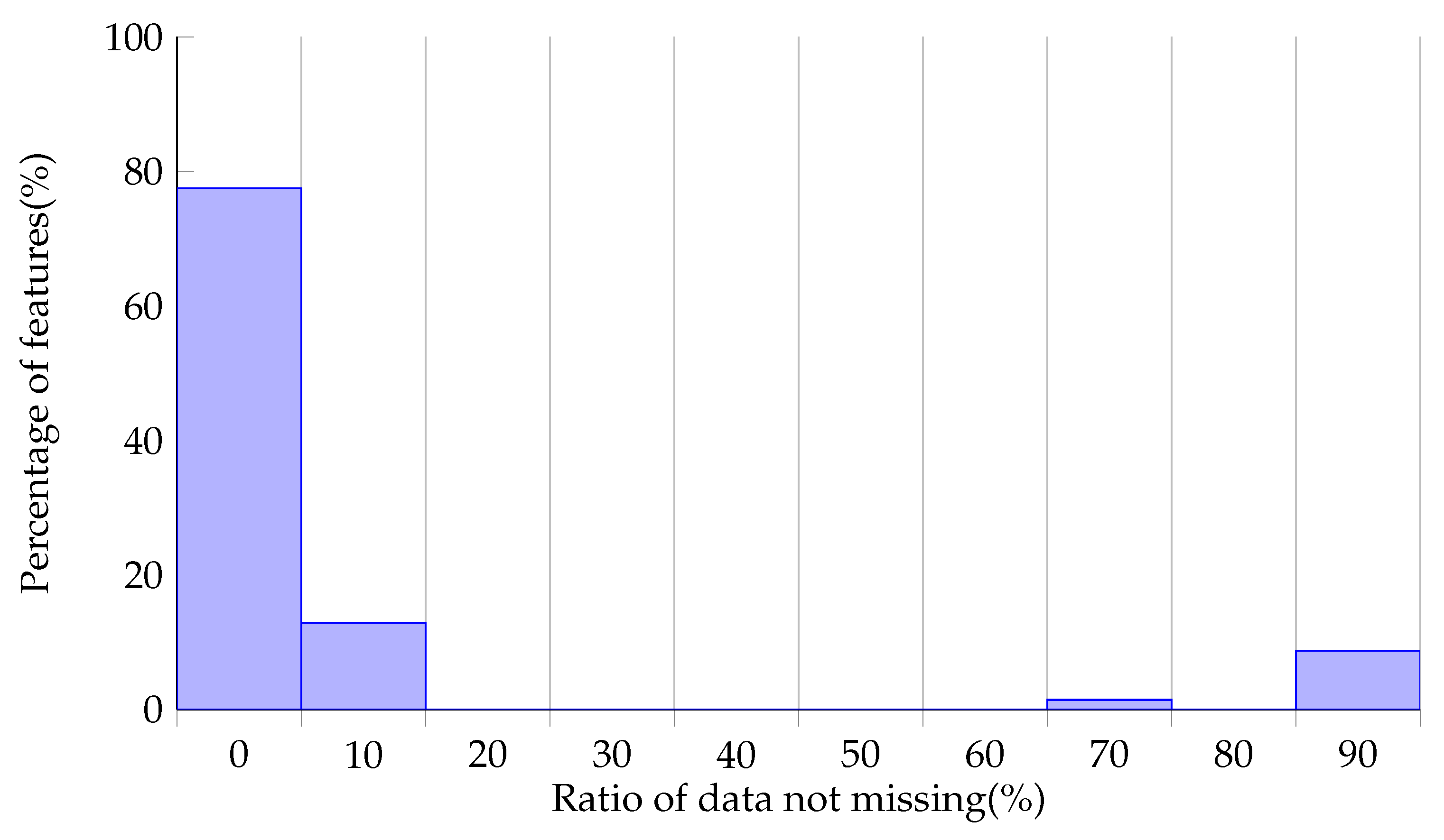
This dataset has a large number of complicated indicators, the total number of which is 200. The missing status on each feature is shown in
Figure 4. It is shown that that data of most features are severely missing, with only about 10% left. The data of a small number of features are in a good state. Considering the model’s performance and the difficulty of training, we selected features with a missing rate lower than 30% to build the dataset.
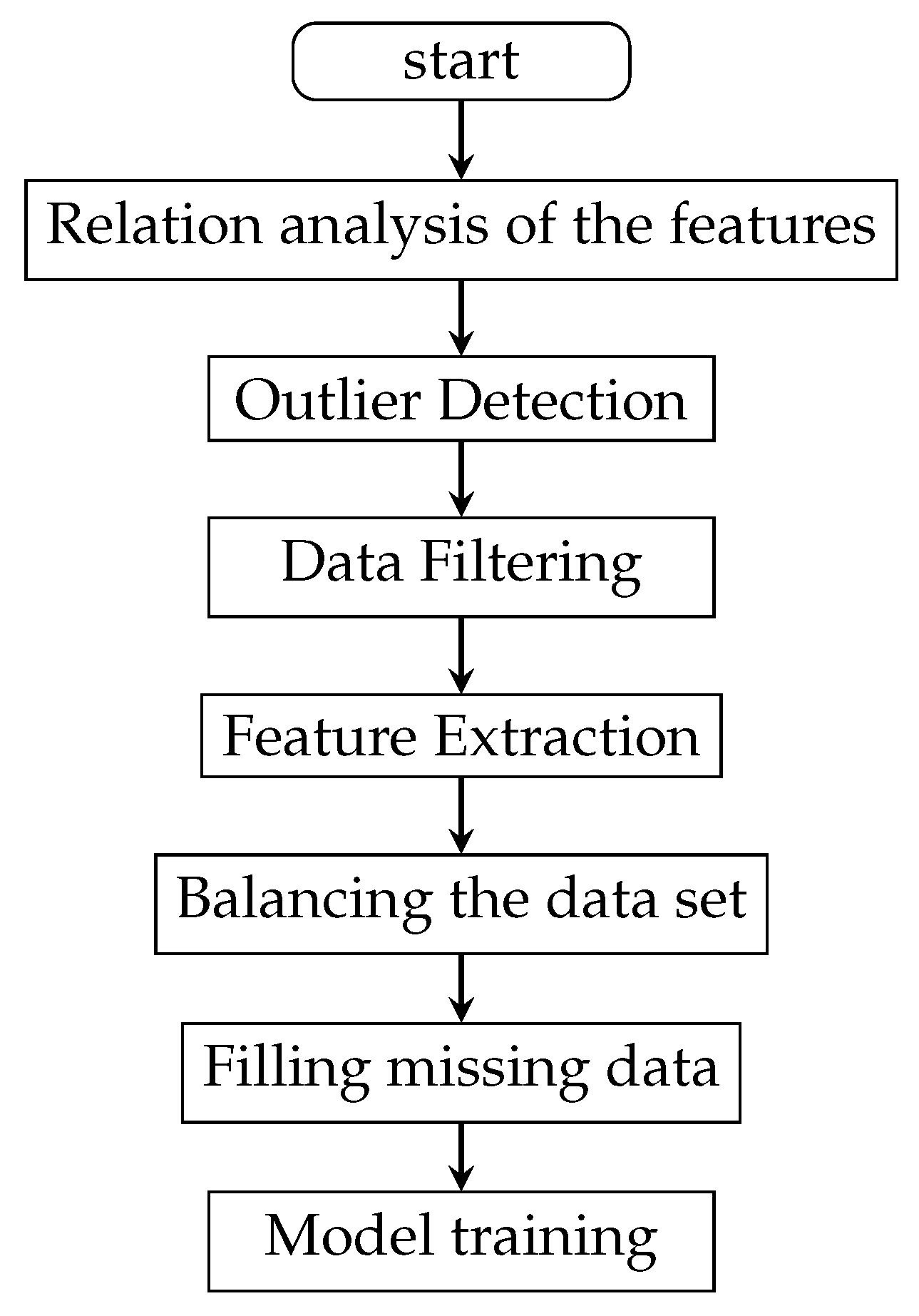
2.3.4. Feature Extraction
In the previous relationship analysis of features, except for a few kinds of information of pregnograms that are highly related with the disease state of pregnant women, the relationship of a large amount of information of biochemical D, routine blood, and routine urine data is relatively scattered, but they contain a lot of health information regarding the pregnant women. Therefore, methods such as the missing rate ratio, low variance filtering, high relation filtering, and even random forest are not suitable for feature extraction in this paper. The reason is that these methods directly remove a large number of irrelevant features in the dimension reduction process, which greatly damages the richness of the dataset of HDP.
On the other hand, the dataset of HDP is large, containing nearly one million data records. Therefore, the efficiency of feature extraction is also an important factor affecting our decision.
Table 4 is a comparison of common feature extraction methods. Reverse feature removal and forward feature construction both need to pre-train the model to select features. The size of the dataset of HDP greatly limits the speed of the model’s training, causing the feature extraction work to consume too much, so they are also not feasible.
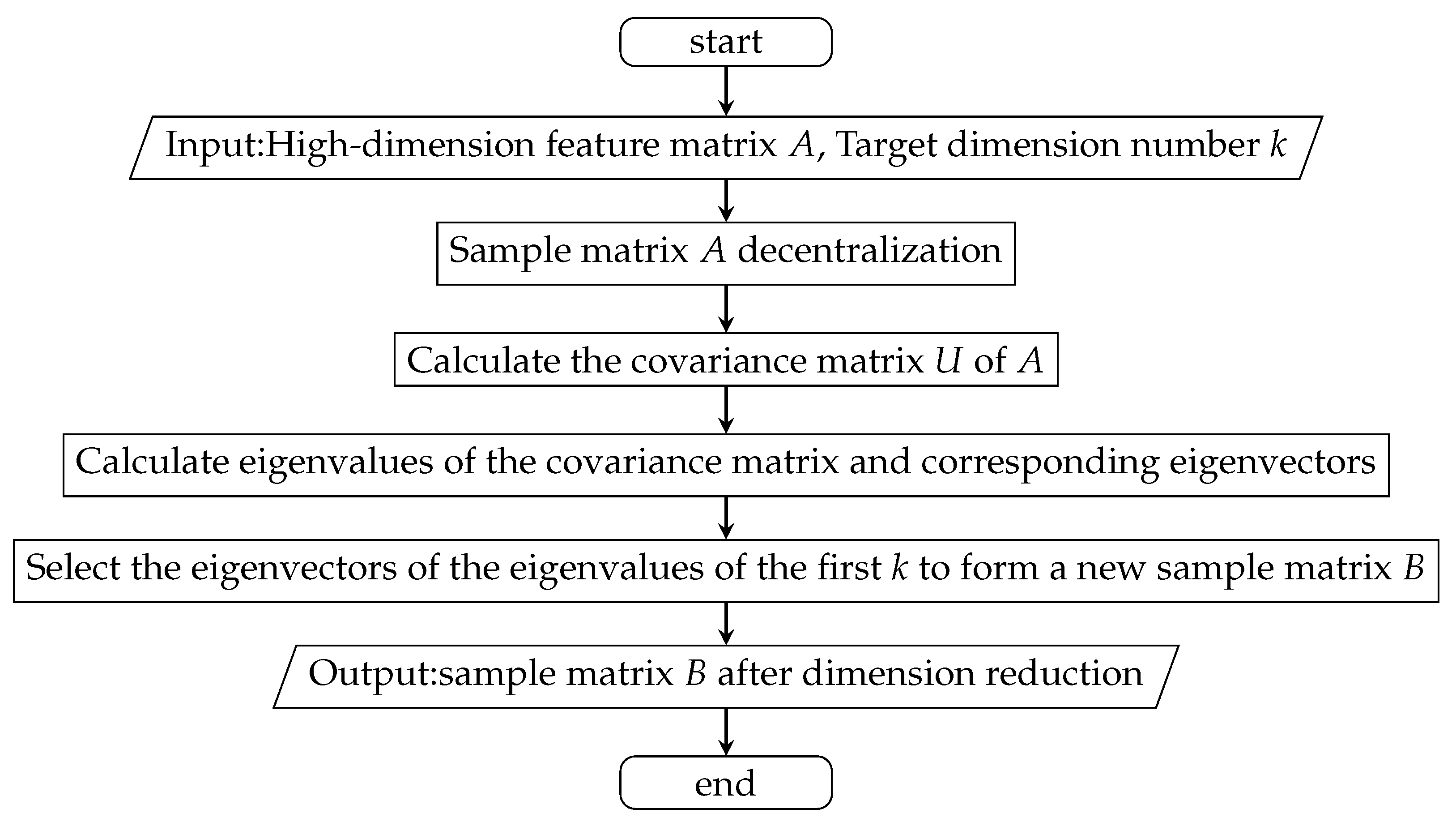
After comprehensive consideration, this paper selected principal component analysis (PCA) for the reduction of the dimensions of the data of the HDP dataset [
23,
24]. Considering the characteristics of the prediction model of HDP, the dataset of HDP after dimension reduction has 32 feature items.
Figure 5 shows the process of feature extraction.
2.3.5. Balancing the Dataset
The positive and negative samples are extremely imbalanced in the original dataset, the proportion of which is about 1:10. If original data are used for training directly, the model will not be able to learn the characteristics of positive samples effectively. There are two common methods to balance a dataset: using an oversampling method, such as SMOTE [
25], and undersampling. Oversampling will copy or approximate the samples with a small number to supplement the samples so as to balance the number of positive and negative samples. However, such a method to copy or approximate samples will increase the risk of over-fitting, especially in this case of an extreme imbalance of positive and negative samples. Therefore, this paper used the method of random undersampling of negative samples. Negative samples with a number equal to the positive samples were randomly selected to construct the dataset. This method also reduces the difficulty and cost of training effectively.
2.3.6. Processed Data
Table 5 shows the changes before and after data preprocessing. After traditional machine learning processing, redundant and useless data were eliminated. We only retained feature data that were highly relevant to the HDP. The following experiments are based on the processed data.
2.4. Strategy to Fill Missing Values—Bi-LSTM
This dataset has severe missing data in the dimensions of time and features, so it is of great significance to discuss the influence of missing data processing on the model’s effect. There are three ways to analyze data with missing values: (1) analyze the data with missing values directly; (2) select methods that are insensitive to missing data for analysis; (3) analyze the missing data after interpolation and filling. Filling missing data has always been a hot topic in various fields. Currently, several effective missing data filling methods have been proposed by experts and scholars. For example, the commonly used mean value interpolation method uses the mean value of sample variables to replace the missing value [
26]. Random interpolation, on the basis of the sample distribution, extracts a substitution of missing values with a specific possibility from the population. Regression interpolation uses the linear relationship between auxiliary variables and target variables to predict missing values. Dempster proposed the EM (expectation maximization) algorithm [
27] in 1977, which is used to estimate unknown parameters under known variables and can effectively carry out the task of the interpolation of missing data. These methods have high accuracy when filling a small amount of missing data in a static situation but are not satisfactory when processing missing data with a nonlinear relationship, time series characteristics and multiple variables. Recently, with the rapid development of the field of neural networks and the improvement of computing capabilities, neural networks have been widely used in the processing and analysis of missing data, recurrent neural networks (RNN) [
28] especially. They are capable of finding long-term time dependences and analyzing time series of variable length, thus playing a very important role in time series analysis.
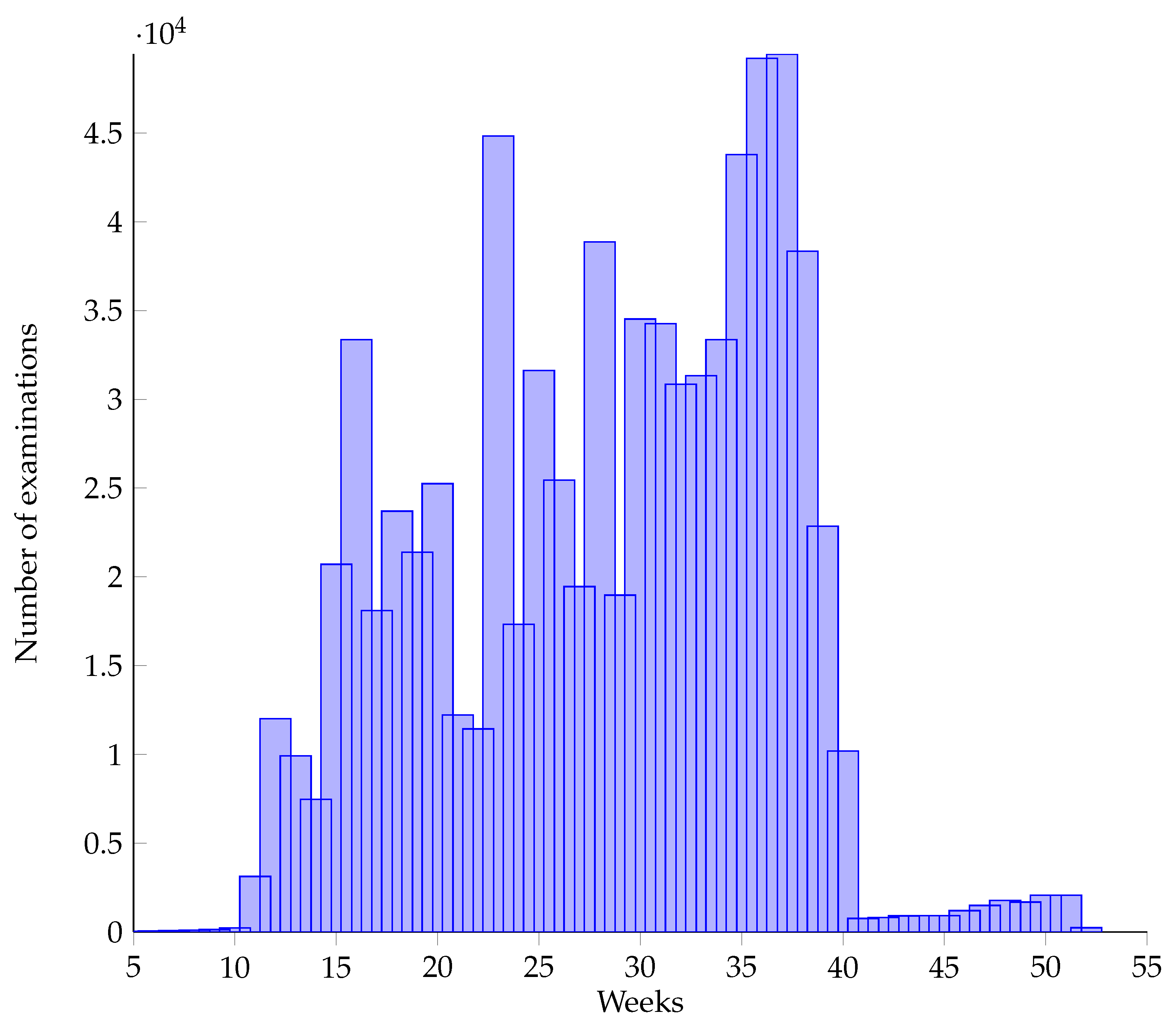
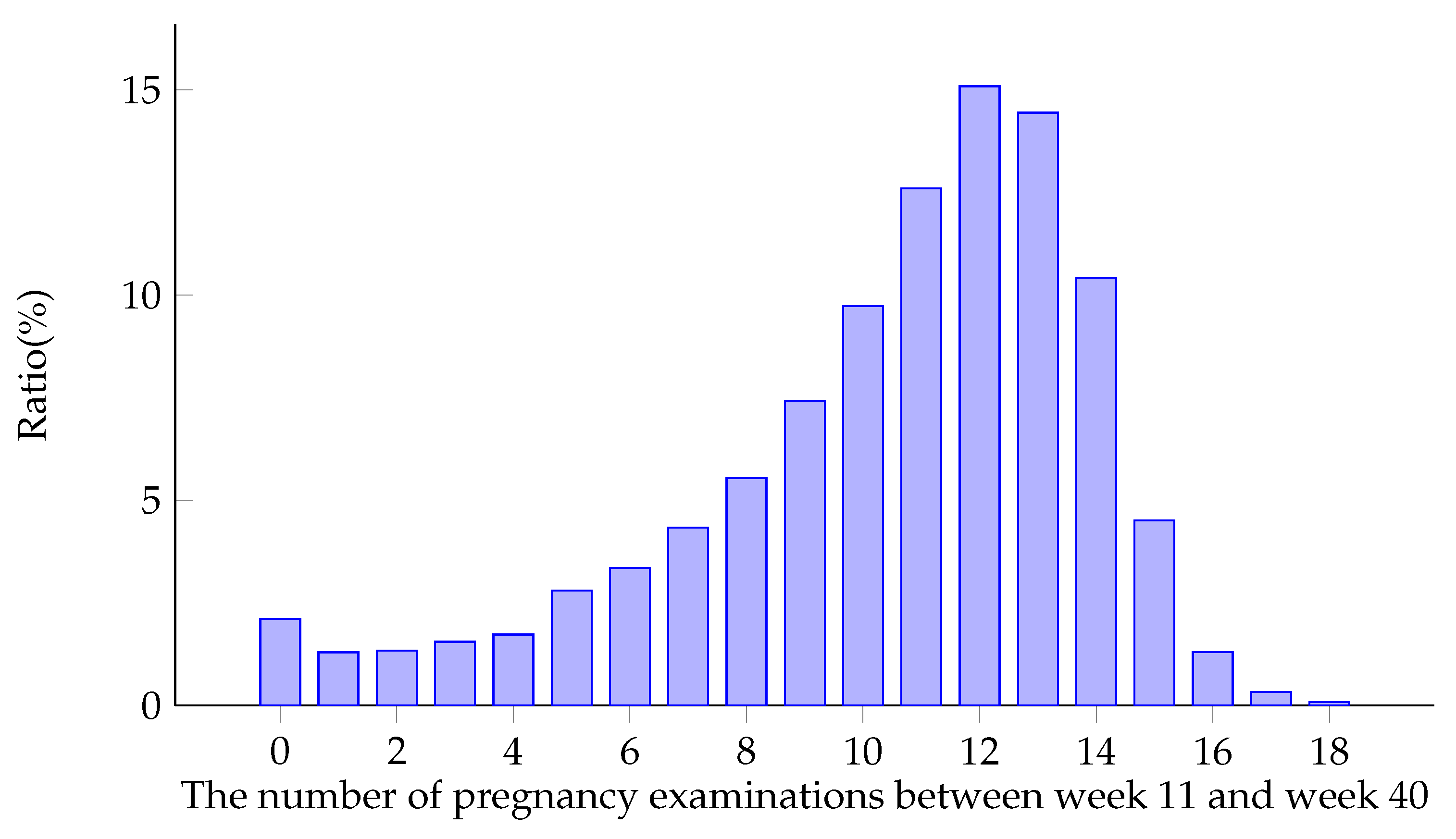
Figure 6 shows the distribution of the number of pregnancy examinations (i.e., the length of time series) between week 11 and week 40. It can be seen from the figure that the length of the series of most samples is about 11 times. In
Figure 1, it can be seen that the data are not uniformly distributed at different time points, and most of the data are concentrated in the later weeks.
This paper selected data of a part of time as markers and selected other data as training data. The filling effect was evaluated by the prediction results and symmetric mean absolute percentage error (SMAPE) of markers. Considering the distribution of data at each time point, markers should not be selected randomly in order to prevent losing the data of important time points and severely affecting the results. This paper proposes a method described as follows: let
represent the missing state of a series of data:
For
,
represents the “ignorability” of the data of the time point in the series. The less missing data near this value, the more “unimportant” the time point is, and it can be selected from the training set as a marker, where
is the decay rate.
Table 6 is the result of calculating the missing data state when the sequence length is 10 and the decay rate is 0.5.
For
,
represents the data storage rate of time point
i in the whole data set. The higher it is, the lower the missing data rate of the time point is, and the lower the possibility it needs to be filled is. Thus, for each series, the possibility that each time point is selected to be a marker
, where
and
are the parameters that adds up to 1, which are used to adjust the influence of the two parts of the possibility. We select data of a certain number of time points in each series as markers to construct the data and markers of the training set. According to distribution of the data, the final parameters used in this paper are
, and the data at four time points are selected as markers.
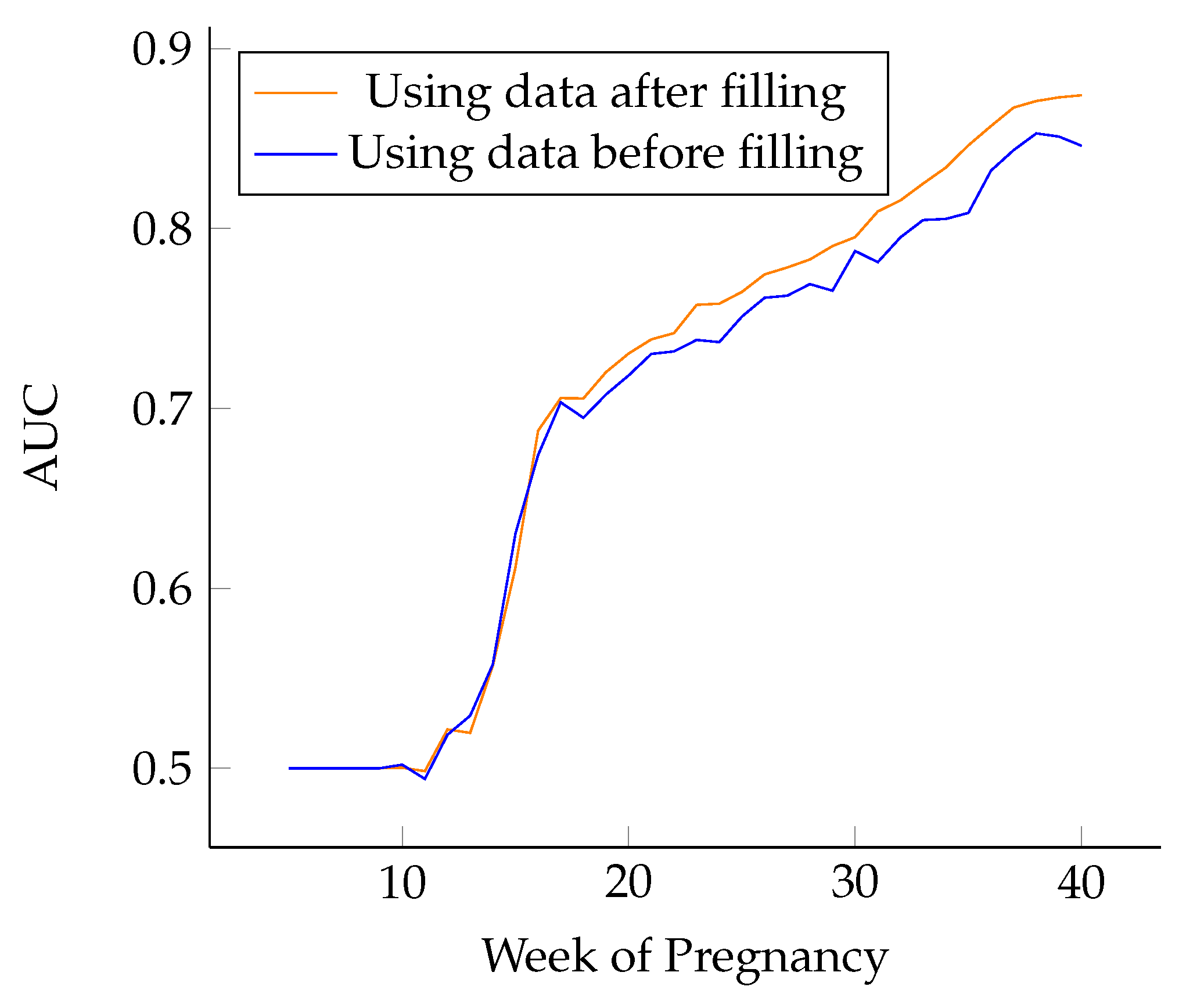
In this paper, we compare several methods of filling missing values, including traditional machine learning methods, such as cubic spline interpolation and KNN filling, and deep learning methods, such as the LSTM model and bidirectional LSTM model.
- 1
Cubic spline interpolation
Cubic spline interpolation (spline interpolation) [
29] is a process of obtaining the curve function group by solving the three-moment equations through a series of value points on the curve. First, we select an interval containing missing values of the dataset, construct a cubic interpolation equation to represent the interval, and then conduct interpolation for the missing values according to the equation.
- 2
KNN filling
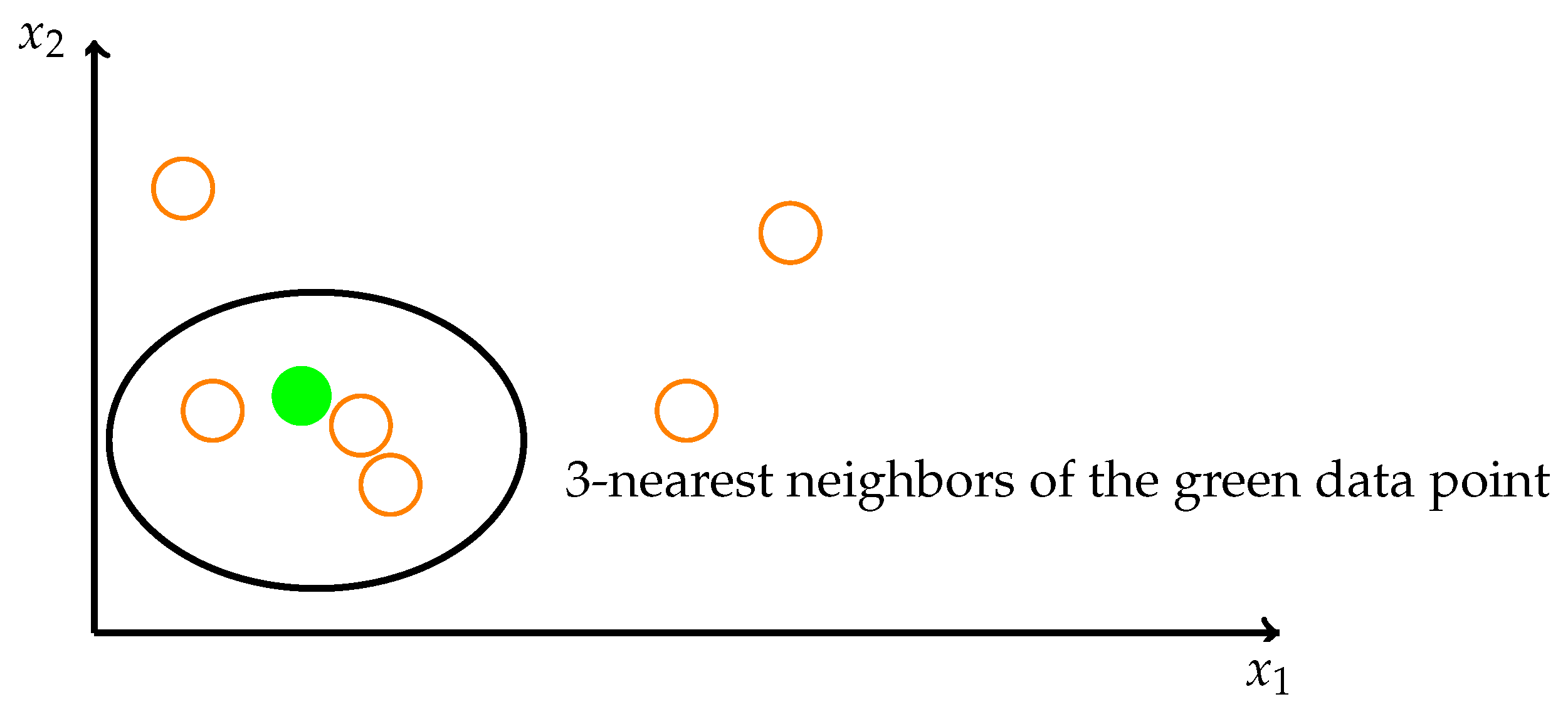
The idea of the KNN method is to identify k spatially similar samples in the dataset. We then use these “k” samples to estimate the value of the missing data points. The missing value of each sample is interpolated using the mean value of the “k” neighborhood found in the data set. In this case, as
Figure 7 shows, the missing value is determined by its neighbors. The green point’s neighbors are the orange points in the ellipse. Each pregnant woman’s data are mapped to a vector in a high-dimensional space. To be spatially close means to be physically similar.
- 3
ST-MVL
ST-MVL is a spatio-temporal multiview-based learning (ST-MVL) method [
30] to collectively fill missing readings in a collection of geosensory time series data considering (1) the temporal correlation between readings at different timestamps in the same series and (2) the spatial correlation between different time series. The method combines empirical statistic models, consisting of inverse distance weighting and simple exponential smoothing, with data-driven algorithms, comprised of user-based and item-based collaborative filtering.
- 4
LSTM Model
The LSTM model is a special kind of recurrent neural network (RNN), which was first proposed by Hochreiter and Schmidhuber [
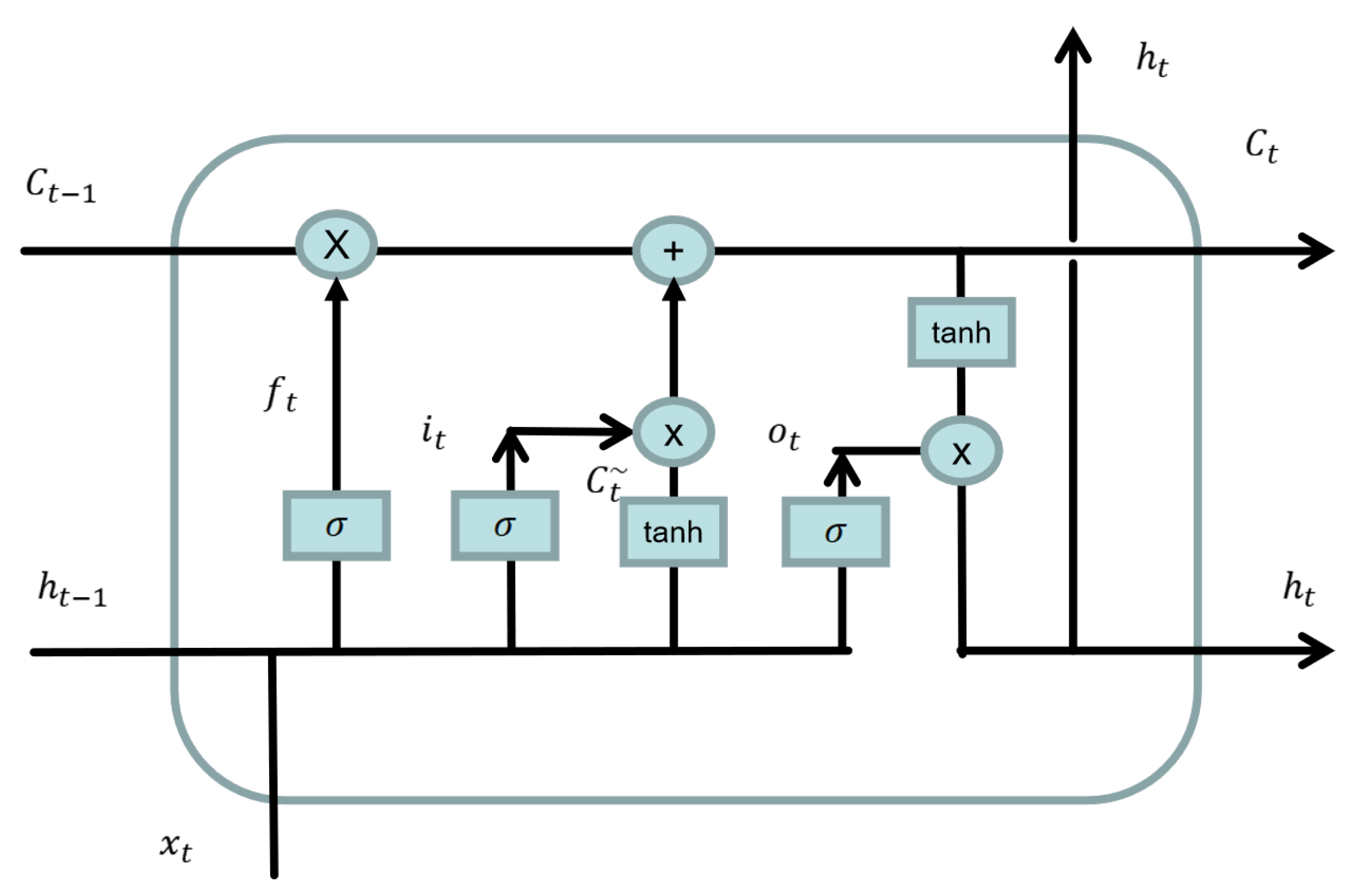
31] in 1997 and solved the problem of the vanishing gradient and long-term dependence (i.e., the inability to integrate dependencies of a series that are too long) of RNNs. As shown in
Figure 8, an LSTM consists of a memory unit
c and three gates (an input gate
i, output gate
o, and forgetting gate
f).
The first step of the LSTM is to determine how much of the state of the previous time point
will be retained to the current moment
. This decision is made by the “forgetting gate”. The forgetting gate uses the output
of the previous neural cell and the input
of the current cell to calculate a number between 0 and 1, representing how much data from the previous cell was recorded. Here, 1 indicates complete recording, and 0 indicates complete forgetting. The equation is shown as follows, where
is the weight matrix of the forgetting gate,
is the bias term of the forgetting gate, and
is the sigmoid activation function:
The second step of LSTM is to determine what information is to be stored in the current unit state, which is divided into two parts. First, an input gate determines which values to update, and then a new candidate vector
is created through the tanh layer and added to the state. The current state of the unit is calculated as follows. First, we forget the data that need to be forgotten by multiplying the state of the last time point by
. Then, we add
to obtain the value of the current unit:
The third step of the LSTM is to determine the output of the unit. The output is based on the state of previous calculating unit, first through the sigmoid layer to determine which parts of the unit to output, then through tanh to reset the system state (setting the value to between −1 and 1). Then, we multiply it by a sigmoid gate to determine the final output:
- 5
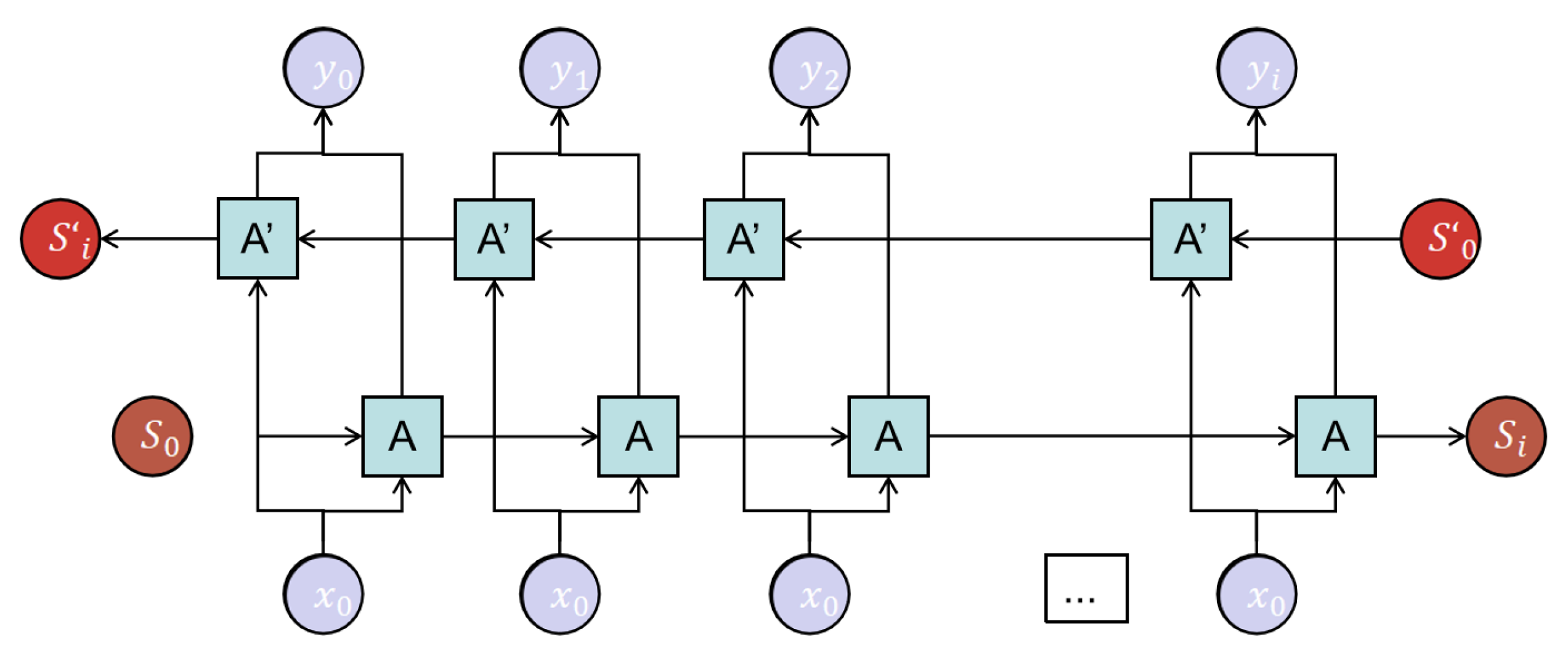
Bidirectional LSTM Model
The bidirectional LSTM model consists of a forward LSTM structure and a reverse LSTM structure, as is shown in
Figure 9. They have the same structure and are independent of each other and only accept input of different word orders. The bidirectional LSTM deep learning network has great advantages, a clear structure, a clear output meaning of the middle layer, and it is easier to find optimization methods for it. The bidirectional LSTM model takes the influence of forward and reverse word order of sentences into account, which can better extract the semantic information of sentence structures. In this task, compared with unidirectional LSTM, the effect of filling missing data with bidirectional LSTM is better.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









