2.1. Vertical Federated Learning
Vertical federated learning (VFL) is the collaborative training of a model on a dataset in which the features of the dataset are distributed across multiple organizations, but the label information is owned by a single organization. Here, the organization which has the label information is referred to as the guest client and those without label as host client [
4]. A collaboration between general and specialized hospitals is an example of VFL. They may have the same patient’s data, but the general hospital owns the patient’s generic information (i.e., features), whereas the specialized hospital owns the patient’s specific testing results (i.e., labels/ground truth). As a result, they can use VFL to jointly train a model that predicts a specific disease examined by the specialized hospital based on the general hospital’s features [
5]. For vertically partitioned data, privacy-preserving machine-learning algorithms have been proposed, such as the secure linear regression algorithm on vertically distributed data [
6], privacy-preserving logistic regression [
7] and verifiable privacy-preserving scheme (VPRF) based on vertical federated random forest [
8].
Figure 1 [
4] illustrates the basic protocol of the vertical federated learning approach, which involves the following major steps: (1) exchanging intermediate results, (2) computing gradients or loss, and (3) updating models on each of the clients. When naively following the protocol, every participating client has to communicate the intermediate results or updated gradients during every training iteration. The total communication for each client can easily grow significantly over the course of hundreds of thousands of training iterations on large data sets. As a result, if communication bandwidth is limited or communication is expensive, FL can become ineffective [
9].
2.2. Communication-Efficient Federated Learning
In general distributed learning environments, communication costs have always been a constraint. Since federated learning is a form of distributed machine learning that deals with data privacy issues, this field has attracted a lot of interest in terms of improving communication efficiency. The studies that have been conducted related to communication-efficient FL have focused on the issue of huge communication rounds or bandwidth specifically in the HFL environment. The strategies that have been explored so far that could make communication in FL more efficient include choosing selective clients, reducing the number of model updates, and applying compression schemes to models. Client selection is a strategy for improving communication efficiency, while lowering costs by limiting the number of participants. As a result, just a portion of the parameters are updated over the communication round. Chen et al. [
10] proposed a communication-efficient FL framework using a probabilistic device selection scheme such that only those clients are selected for model transmission that have higher probabilities to improve the convergence speed and training loss. Guha et al. [
11] proposed a similar approach in which restrictions were imposed on the number of local models sent to the server for aggregation using various protocols (e.g., by random sampling, or by applying thresholds based on the amount of local data or local validation error).
As the number of communication rounds between the devices and the central server can be costly, reducing model updates is also a possible solution. Guha et al. [
11] also suggested training local models on devices to completion instead of computing increments and then applying ensemble methods to effectively capture information regarding client-specific models, reducing communication rounds to one in the best case. Bui et al. [
12] introduced a Partitioned Variational Inference (PVI) for probabilistic models, in which they train a Bayesian Neural Network (BNN) over an FL environment that allows for both synchronous and asynchronous model updates across many machines. Their proposed approach, combined with the integration of other methods, allows for more communication-efficient training of BNN on non-iid federated data. Some other studies that focus on reducing communication overhead in FL settings include a study by Li et al. [
13], in which they designed a one-shot federated learning algorithm FedKT, which uses a knowledge transfer technique that outperforms the other state-of-the-art federated learning algorithms with a single communication round. Furthermore, Kasturi et al. [
14] presented a federated fusion learning approach that allows distribution parameters of local data to be sent to the central server rather than model parameters. Synthetic data are generated at the central server using those distribution parameters, which are then merged to train a global machine learning model. Hence, the communication between the client and server occurs in a single round.
The application of compression schemes to models is a widely used strategy to mitigate the communication cost problem in large-scale machine learning. Gradient quantization is a technique of quantizing the gradients into lower precision values to reduce the number of gradients transmitted. For instance, 1-bit SGD [
15] and QSGD [
16] can reduce the gradient to
of the uncompressed data. SignSGD [
17] considers the case, wherein gradients are quantized using only
and
, and shows its convergence by the aid of a majority vote of the clients. Some studies propose that applying quantization to the local or global model can help to improve communication efficiency in FL as well. Bui et al. [
12] applied quantization to each local model before sending it to the server, reducing overall communication overhead. Similarly, quantization can be performed on the global model before broadcasting it to the clients for local updates. The Lossy FL algorithm (LFL) introduced in [
18] quantizes the global model before it broadcasts and shares it across all the devices. Ref. [
19] proposes an improved sign gradient descent [
17] to replace conventional gradient descent in FL, which maintains the privacy of model parameters, while significantly decreasing the communication resource consumption. Gradient sparsification [
20] is another compression technique that enforces transmitting
n out of
d elements at iteration
k, where
d is the total number of elements in the gradient vector and
n is the number of the most important elements to send at iteration
k. The work in [
21] proposes the sending of only gradients larger than a pre-defined constant threshold. However, determining this threshold is a challenging task for gradient sparsification. The techniques Top-k AllReduce [
22] and Deep Gradient Compression [
20] were proposed to further improve compression efficiency. Gradient sparsification has also been proven to reduce the overall training time in FL [
23] by adaptive selecting of the number of gradients or model parameters. Sattler et al. [
9] proposed a sparse ternary compression (STC), an extension of the existing compression technique of top-k gradient sparsification [
22] which was proven to outperform traditional federated averaging approach in case of bandwidth-constrained learning environments. However, experimental results demonstrating the effectiveness of most of these approaches in VFL setting were not observed.
Liu et al. [
24] proposed a Federated Stochastic Block Coordinate Descent (FedBCD) algorithm for vertically partitioned data, in which each party conducts multiple local updates before each communication to effectively reduce the number of communication rounds among clients. Furthermore, Zhang et al. [
25] developed an asynchronous stochastic quasi-Newton (AsySQN) framework for VFL, which performs descent steps scaled by approximate Hessian information, which converges much faster than Stochastic Gradient Descent (SGD)-based methods in practice, allowing for a significant reduction in the number of communication rounds. In [
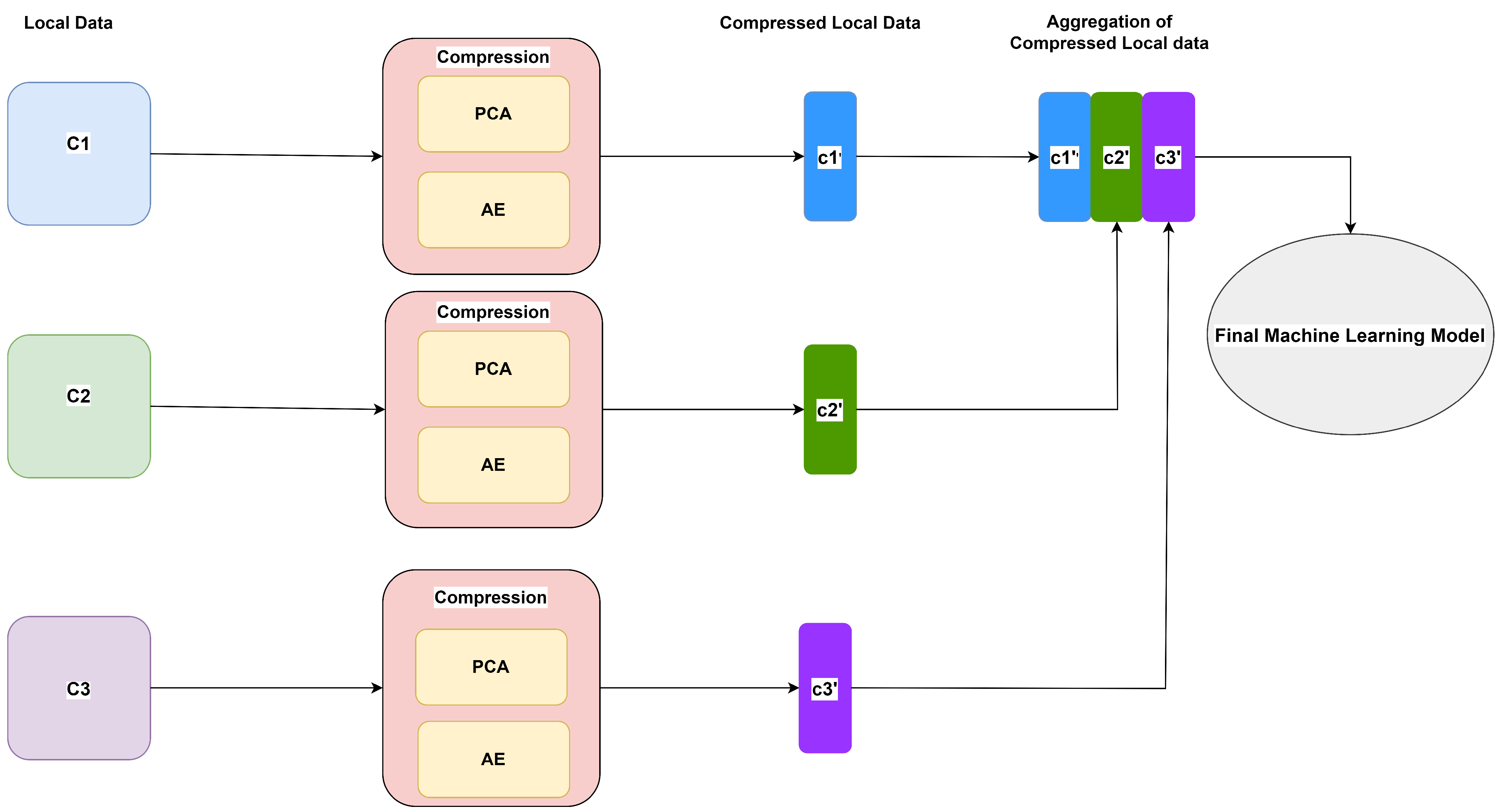
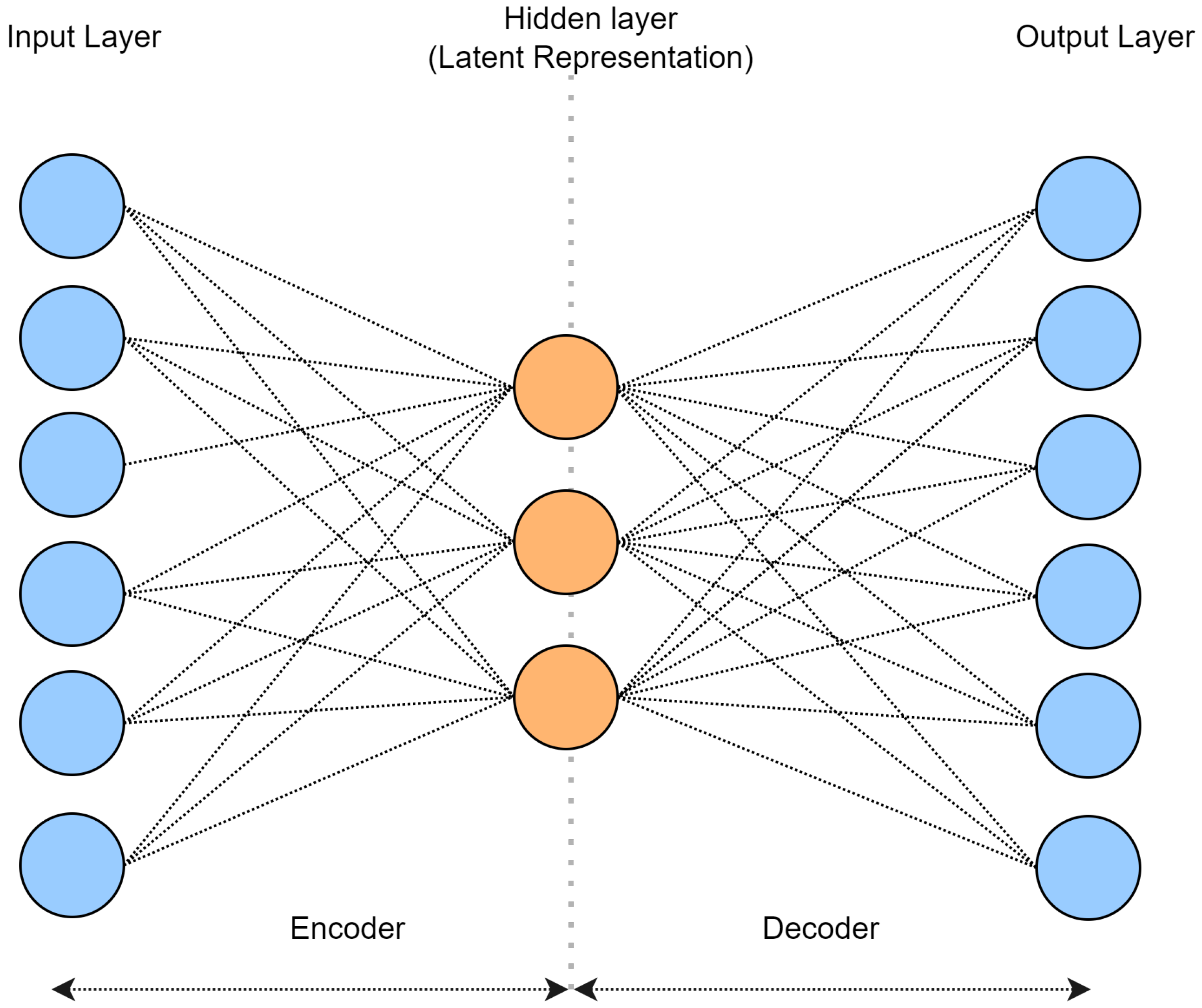
26], an asynchronous vertical federated learning framework with gradient prediction and double-end sparse compression is proposed, where the compression occurs at the local models to reduce training time as well as transmission cost. The existing compression techniques in FL are focused on gradient compression, which reduces training time and transmission costs, but still requires a sufficient number of communication rounds. On the other hand, in this paper, we propose a method based on the data compression technique that compresses local data of clients before aggregating it for final model training. Since no local data are exposed, privacy is protected, and the entire process is limited to a single communication round.






{kind=link}
{kind=link}
{kind=link}


