
Intuitionistic and Interval-Valued Fuzzy Set Representations for Data Mining


{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Background
2.1. Uncertainty Representations
2.1.1. Fuzzy Set Theory
2.1.2. Interval-Valued Fuzzy Sets
2.1.3. Intuitionistic Fuzzy Sets
2.1.4. Type-2 Fuzzy Sets
2.1.5. Rough Set Theory
- The lower approximation of N is the set RlX = {ai ∈ D/[ai]R ⊆ N}.
- The upper approximation of N is the set RuX = {ai ∈ D/[ai]R ∩ N ≠ ∅}.
2.1.6. Dempster–Shafer Uncertainty Theory
3. Attribute Generalization and Concept Hierarchies
3.1. Attribute Generalization
3.2. Concept Hierarchies
3.3. Generalization with Respect to Partitions
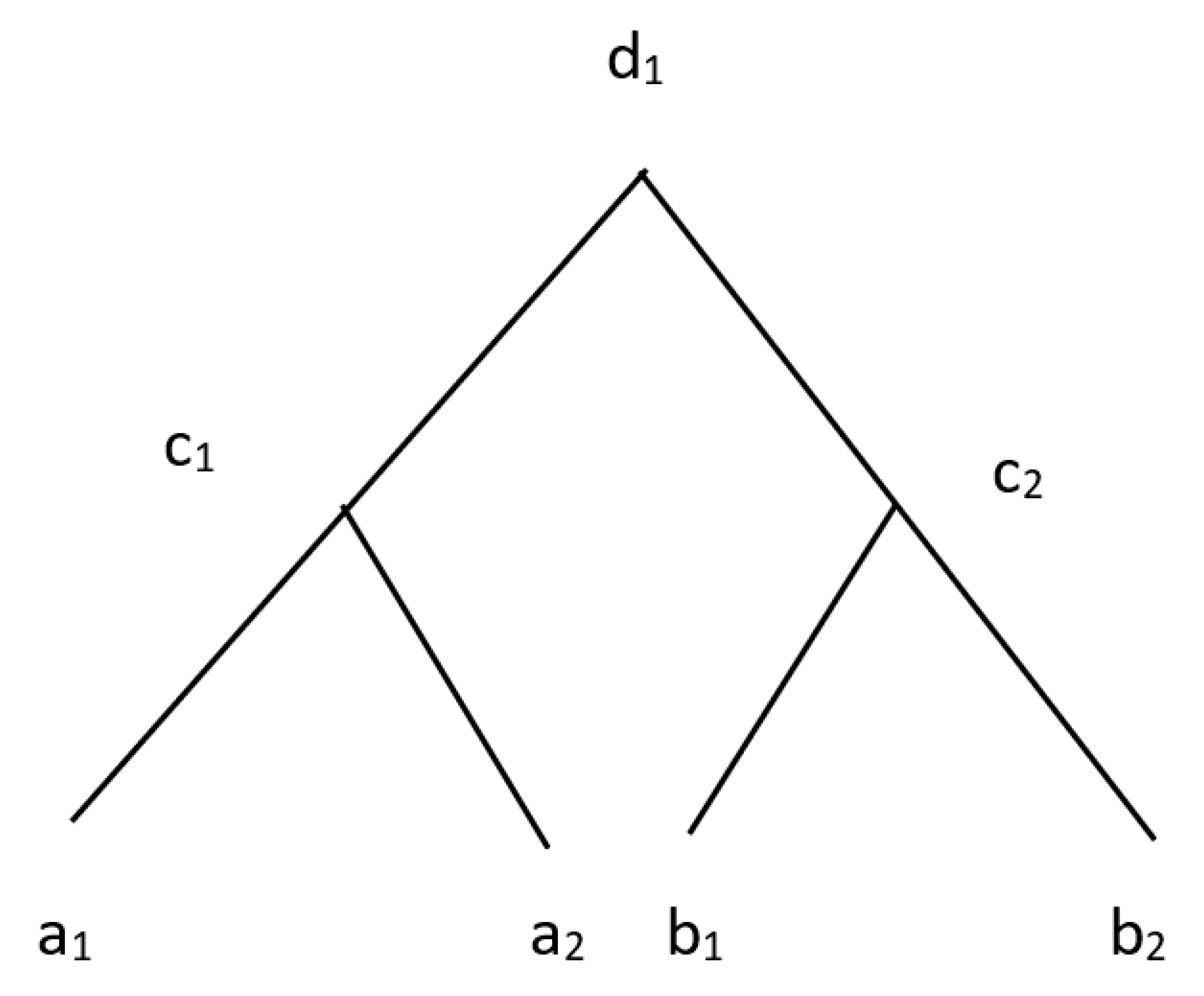
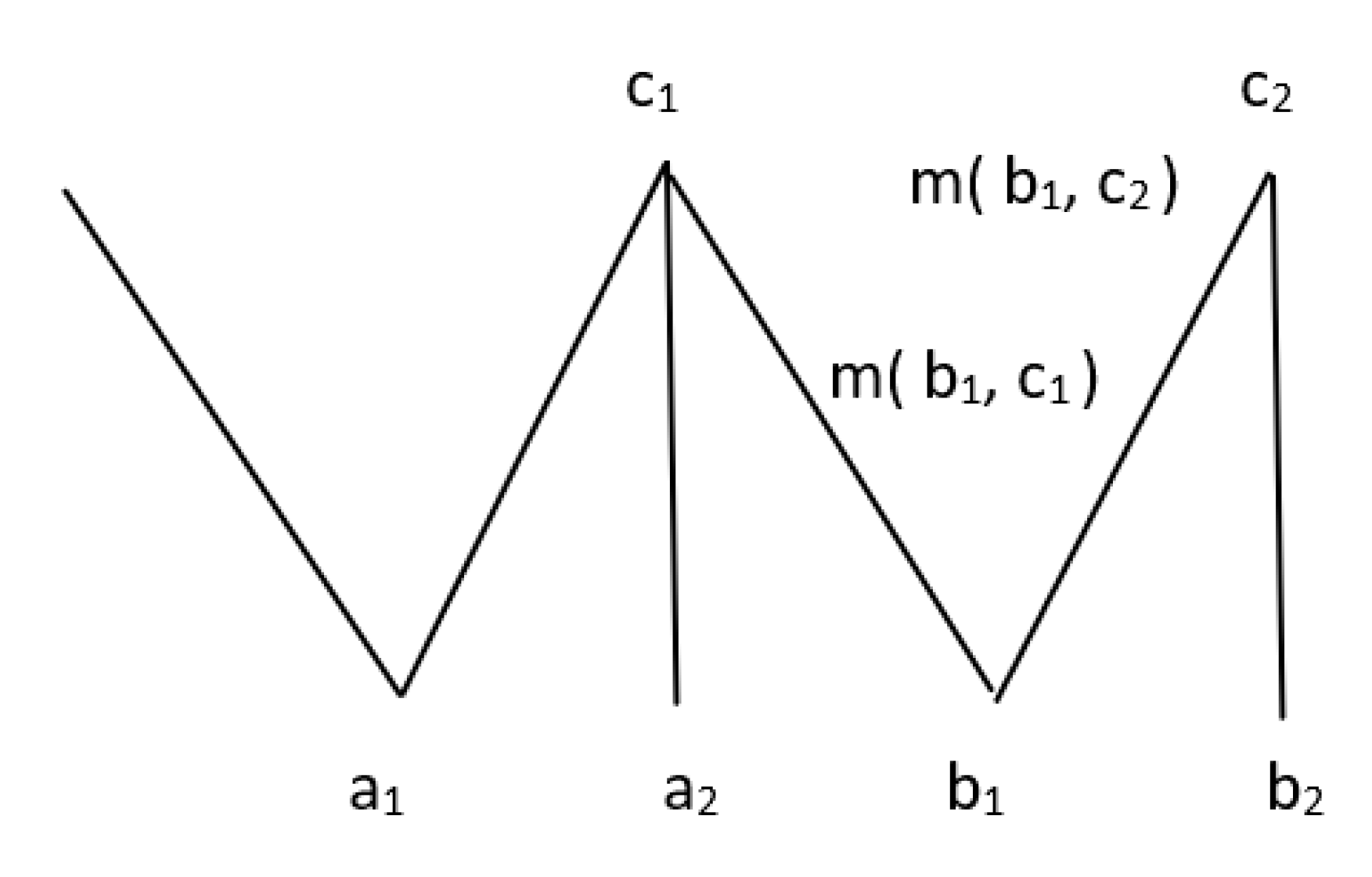
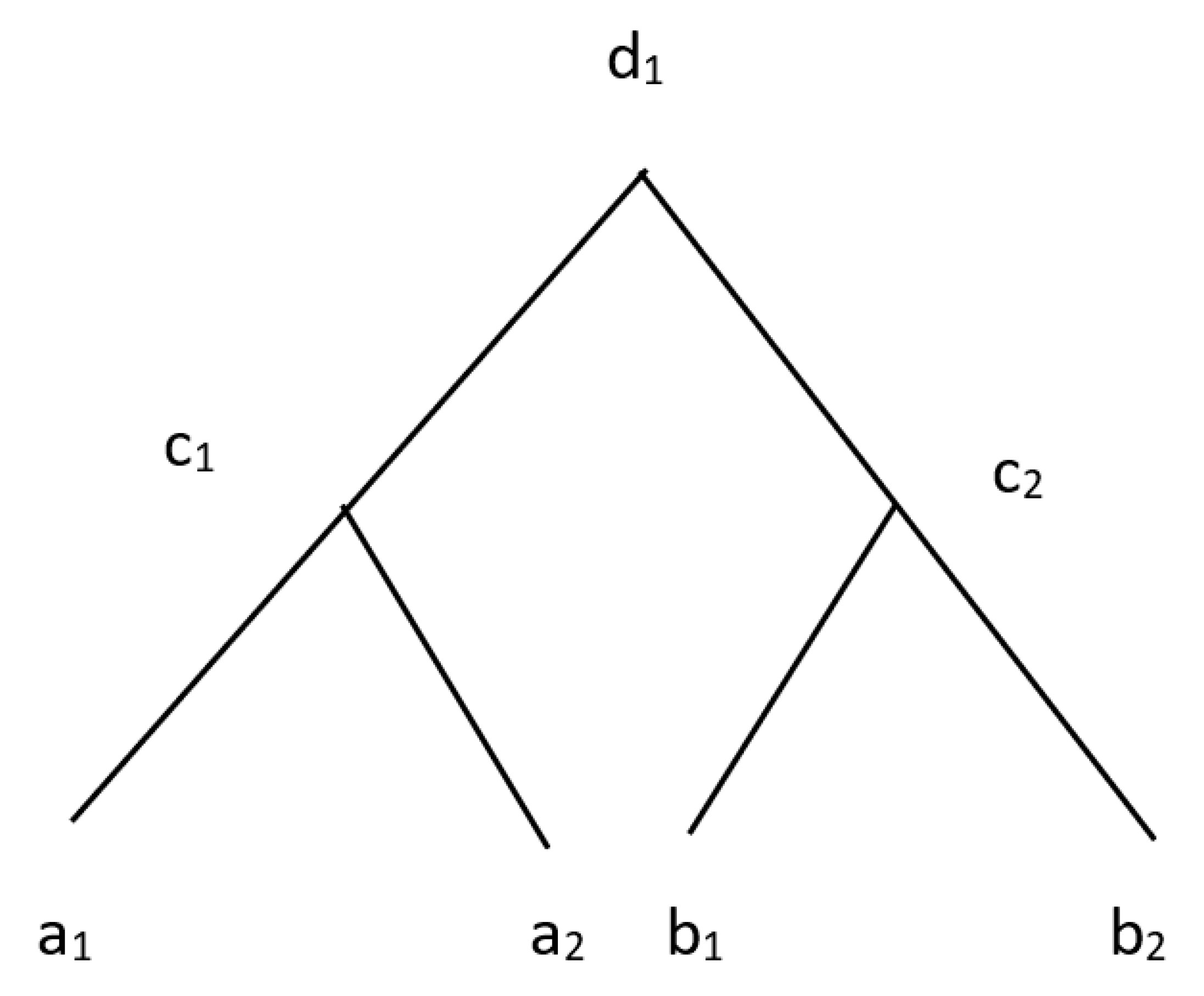
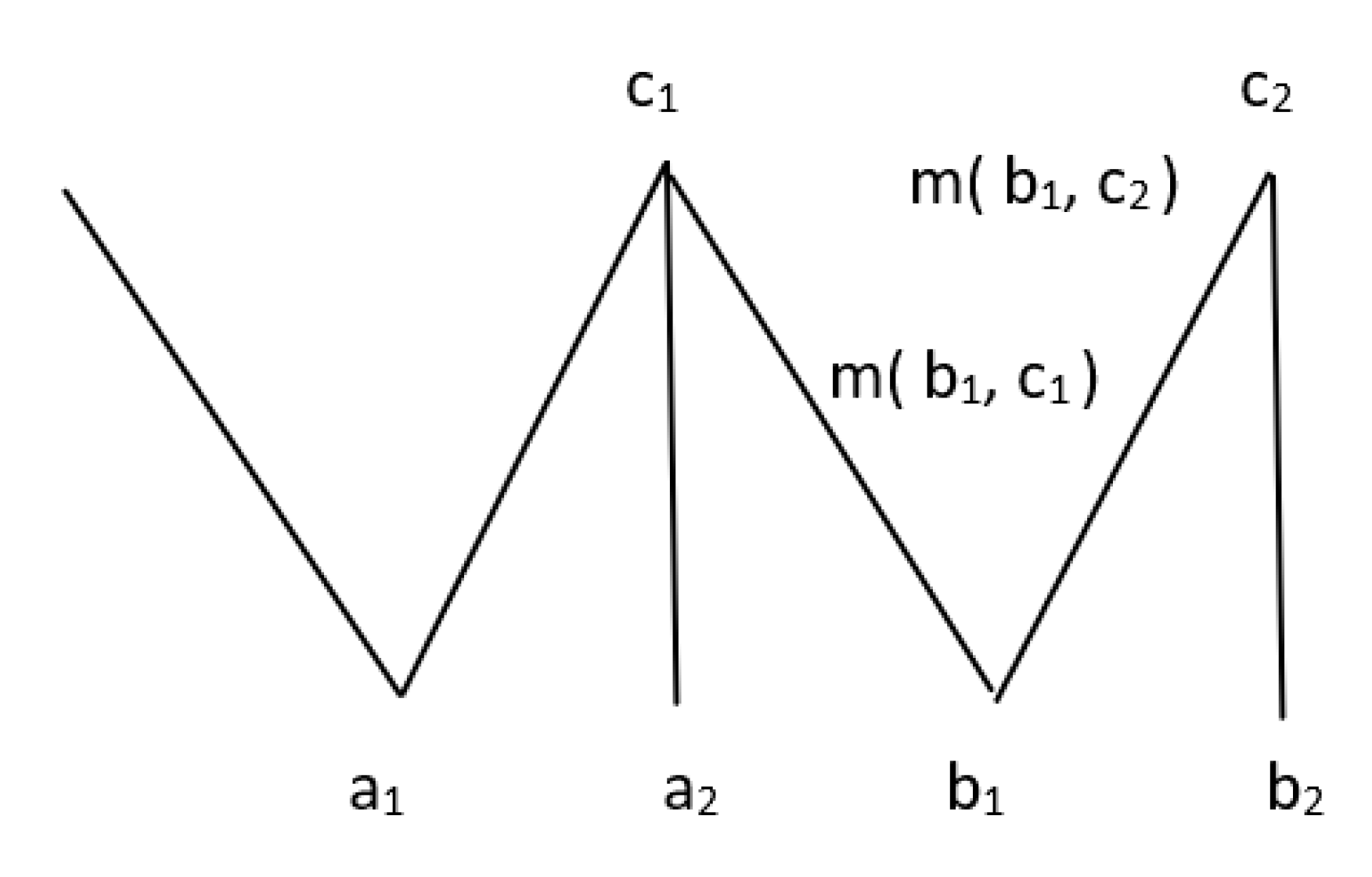
4. Generalization Involving Interval-Valued and Intuitionistic Fuzzy Information
4.1. Generalization with Ordinary Hierarchies
4.1.1. IVF Data
4.1.2. IVF Concepts in Hierarchies
4.1.3. Evaluation of Generalization
4.1.4. IFS Data
P12j = {a′|(mj(a′) > 0 ∧ mj(a′) ≥ m*j(a′) ∧ mj(a′) < T)}
N11j = {a′|(mj(a′) > 0 ∧ mj(a′) ≤ m*j(a′) ∧ m*j(a′) ≥ T)}
N12j = {a′|(mj(a′) > 0 ∧ mj(a′) ≤ m*j(a′)) ∧ m*j(a′) < T}
4.2. Generalization with Complex Hierarchies
Fuzzy Hierarchies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yager, R. On linguistic summaries of data. In Knowledge Discovery in Databases; Piatesky-Shapiro, G., Frawley, W., Eds.; MIT Press: Cambridge, MA, USA, 1991; pp. 347–363. [Google Scholar]
- Kacprzyk, J. Fuzzy logic for linguistic summarization of databases. In Proceedings of the FUZZ-IEEE’99, 1999 IEEE International Fuzzy Systems, Seoul, Korea, 22–25 August 1999; pp. 813–818. [Google Scholar]
- Dubois, D.; Prade, H. Fuzzy sets in data summaries-outline of a new approach. In Proceedings of the 8th International Conference on Information Processing and Management of Uncertainty in Knowledge-based Systems (IPMU 2000), Madrid, Spain, 3 July 2000; pp. 1035–1040. [Google Scholar]
- Miller, M.; Miller, K. Big data: New opportunities and new challenges. IEEE Comput. 2013, 46, 22–25. [Google Scholar]
- Richards, D.; Rowe, W. Decision-making with heterogeneous sources of information. Risk Anal. 1999, 19, 69–81. [Google Scholar] [CrossRef]
- Belcastro, L.; Cantini, R.; Marozzo, F.; Orsino, A.; Talia, D.; Trunfio, P. Programming big data analysis: Principles and solutions. J. Big Data 2022, 9, 1–50. [Google Scholar] [CrossRef]
- Vranopoulos, G.; Clarke, N.; Atkinson, S. Addressing big data variety using an automated approach for data characterization. J. Big Data 2022, 9, 1–28. [Google Scholar] [CrossRef]
- Hirota, K.; Pedrycz, W. Fuzzy computing for data mining. Proc. IEEE 1999, 87, 1575–1599. [Google Scholar] [CrossRef]
- Laurent, A. A new approach for the generation of fuzzy summaries based on fuzzy multidimensional databases. Intell. Data Anal. 2003, 7, 155–177. [Google Scholar] [CrossRef]
- Raschia, G.; Mouaddib, N. Mouaddib. SAINTETIQ: A fuzzy set-based approach to database summarization. Fuzzy Sets Syst. 2002, 129, 137–162. [Google Scholar] [CrossRef]
- Yager, R.; Petry, F. A multi-criteria approach to data summarization using concept ontologies. IEEE Trans. Fuzzy Syst. 2006, 14, 767–780. [Google Scholar] [CrossRef]
- Petry, F.; Yager, R. Fuzzy concept hierarchies and evidence resolution. IEEE Trans. Fuzzy Syst. 2014, 22, 1151–1161. [Google Scholar] [CrossRef]
- Kruse, R.; Mostaghim, S.; Borgelt, C.; Braune, C.; Steinbrecher, M. Computational Intelligence: A Methodological Introduction, 3rd ed.; Springer Nature: Cham, Switzerland, 2022. [Google Scholar]
- Zadeh, L. Fuzzy sets. Inf. Control. 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- Klir, G.; St. Clair, U.; Yuan, B. Fuzzy Set Theory: Foundations and Applications; Prentice Hall: Hoboken, NJ, USA, 1997. [Google Scholar]
- Moore, R. Interval Analysis; Prentice Hall: Englewood Cliffs, NJ, USA, 1966. [Google Scholar]
- Moore, R.; Kearfott, B.; Cloud, M. Introduction to Interval Analysis; SIAM: Philadelphia, PA, USA, 2009. [Google Scholar]
- Deschrijver, G. Arithmetic operators in interval-valued fuzzy set theory. Inf. Sci. 2007, 177, 2906–2924. [Google Scholar] [CrossRef]
- Reza, F. An Introduction to Information Theory; McGraw Hill: New York, NY, USA, 1961. [Google Scholar]
- Burillo, P.; Bustince, H. Entropy on intuitionistic fuzzy sets and on interval-valued fuzzy sets. Fuzzy Sets Syst. 1996, 78, 305–316. [Google Scholar] [CrossRef]
- Atanassov, K. Intuitionistic fuzzy sets. Fuzzy Sets Syst. 1986, 20, 87–96. [Google Scholar] [CrossRef]
- Mendel, J. Type-2 fuzzy sets and systems: An overview. IEEE Comput. Intell. Mag. 2007, 2, 20–29. [Google Scholar] [CrossRef]
- Bustince, H.; Fernandez, J.; Hagras, H.; Herrera, F.; Pagola, M.; Barrenechea, E. Interval type-2 fuzzy sets are generalization of interval-valued fuzzy sets: Toward a wider view on their relationship. IEEE Trans. Fuzzy Syst. 2015, 23, 1876–1882. [Google Scholar]
- Pawlak, Z. Rough sets and fuzzy sets. Fuzzy Sets Syst. 1985, 17, 99–102. [Google Scholar] [CrossRef]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976. [Google Scholar]
- Carter, C.L.; Hamilton, H.J. Efficient attribute-oriented generalization for knowledge discovery from large databases. IEEE Trans. Knowl. Data Eng. 1998, 10, 193–208. [Google Scholar] [CrossRef]
- Hilderman, R.J.; Hamilton, H.J.; Cercone, N. Data mining in large databases using domain generalization graphs. J. Intell. Inf. Syst. 1999, 13, 195–234. [Google Scholar] [CrossRef]
- Han, J.; Kamber, M. Data Mining: Concepts and Techniques, 4th ed.; Morgan Kaufmann: San Francisco, CA, USA, 2022. [Google Scholar]
- Buckles, B.; Petry, F. A fuzzy representation for relational data bases. Int. J. Fuzzy Sets Syst. 1982, 7, 213–226. [Google Scholar] [CrossRef]
- Angryk, R.; Petry, F. Attribute-oriented Generalization in proximity and similarity-based relational database systems. Int. J. Intell. Syst. 2007, 22, 763–779. [Google Scholar] [CrossRef]
- Beaubouef, T.; Buckles, B.; Petry, F. An attribute-oriented approach for knowledge discovery in rough relational databases. In Proceedings of the Twentieth International Florida Artificial Intelligence Research Society Conference, Key West, FL, USA, 7–9 May 2007; pp. 507–509. [Google Scholar]
- Bachman, R. What IS-A is and isn’t: An analysis of the taxonomic links in semantic networks. IEEE Comput. 1983, 16, 30–36. [Google Scholar] [CrossRef]
- Petry, F.; Zhao, L. Data mining by ttribute generalization with fuzzy hierarchies in fuzzy databases. Fuzzy Sets Syst. 2009, 160, 2206–2223. [Google Scholar] [CrossRef]
- Ćirić, M.; Ignjatović, J.; Bogdanović, S. Fuzzy equivalence relations and their equivalence classes. Int. J. Fuzzy Sets Syst. 2007, 158, 1295–1313. [Google Scholar] [CrossRef]
- Lee, D.H.; Kim, M.H. Database summarization using fuzzy ISA hierarchies. IEEE Trans. Syst. Man Cybern. Part B Cybern. 1997, 27, 68–78. [Google Scholar]
- Yager, R. Pythagorean membership grades in multicriteria decision making. IEEE Trans. Fuzzy Syst. 2014, 22, 958–966. [Google Scholar] [CrossRef]
- Li, H.; Cao, Y.; Su, L. Pythagorean fuzzy multi-criteria decision-making approach based on Spearman rank correlation coefficient. Soft Comput. 2022, 26, 3001–3012. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Petry, F.; Yager, R. Intuitionistic and Interval-Valued Fuzzy Set Representations for Data Mining. Algorithms 2022, 15, 249. https://doi.org/10.3390/a15070249
Petry F, Yager R. Intuitionistic and Interval-Valued Fuzzy Set Representations for Data Mining. Algorithms. 2022; 15(7):249. https://doi.org/10.3390/a15070249
Chicago/Turabian StylePetry, Fred, and Ronald Yager. 2022. "Intuitionistic and Interval-Valued Fuzzy Set Representations for Data Mining" Algorithms 15, no. 7: 249. https://doi.org/10.3390/a15070249
APA StylePetry, F., & Yager, R. (2022). Intuitionistic and Interval-Valued Fuzzy Set Representations for Data Mining. Algorithms, 15(7), 249. https://doi.org/10.3390/a15070249