
Inference Acceleration with Adaptive Distributed DNN Partition over Dynamic Video Stream


Abstract
:1. Introduction
- We propose a distributed DNN inference framework (ADDP), which can dynamically and unevenly divide the computational tasks of DNN models according to the end-device computational capacity and network communication conditions, achieve parallel inference on multiple ends, and ensure the consistency of inference time across IoT devices as much as possible, in order to maximize the inference acceleration for DNNs and computational resource utilization for devices.
- We consider the continuous arrival of smart application data on the device and take the total inference time of the task as the optimization target. Instead of optimizing only the single DNN inference process, which is more in line with the actual application scenario, we share the edge’s computation task with the end device’s computation, effectively reducing the computation burden of the edge.
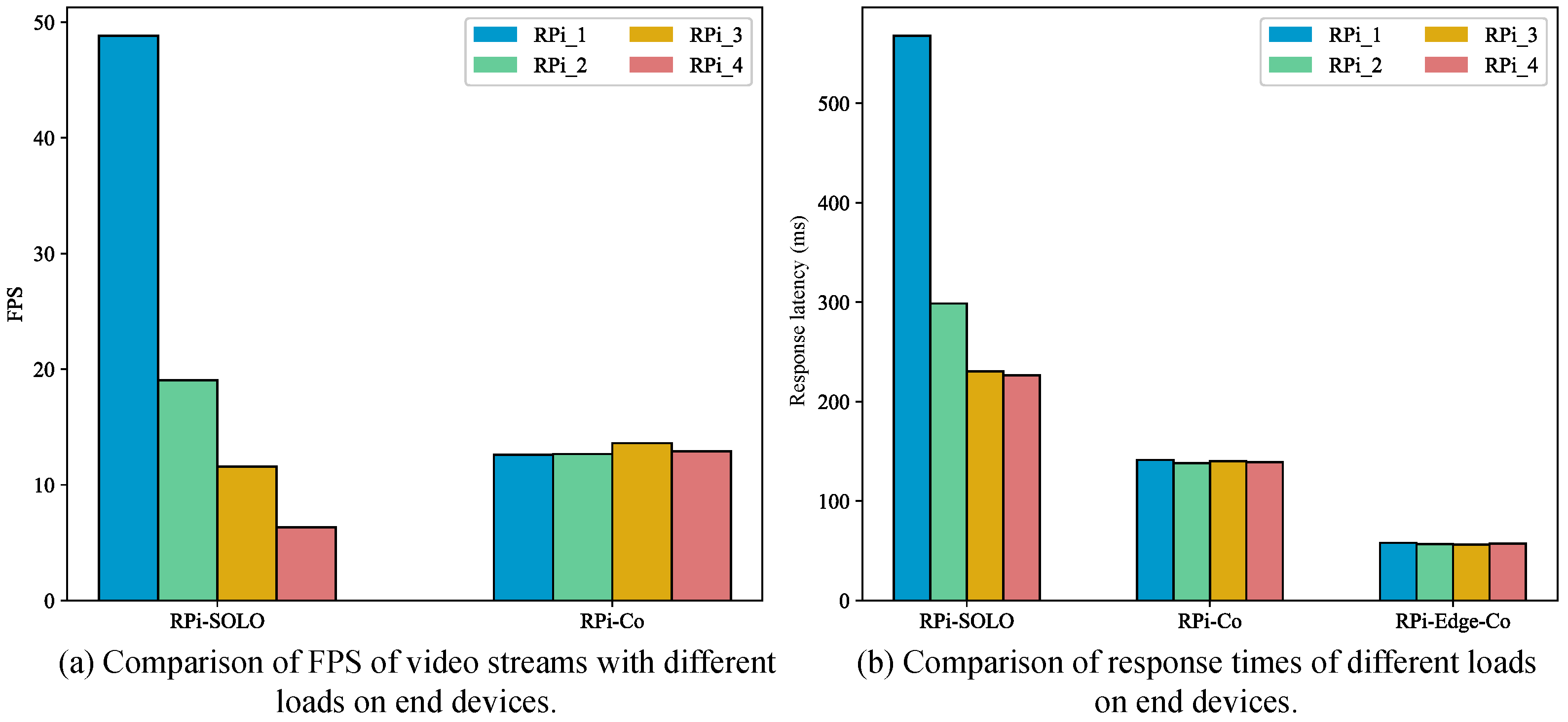
- We evaluate the ADDP to confirm its superiority by collaboratively reasoning for widely adopted DNN models on multiple devices in a real network. ADDP reduces single-frame response latency by 10–25% compared to the pure on-device processing.
2. Related Works
2.1. D2D Inference
2.2. D2C Inference
3. Preliminary
3.1. Hierarchical Prediction Model
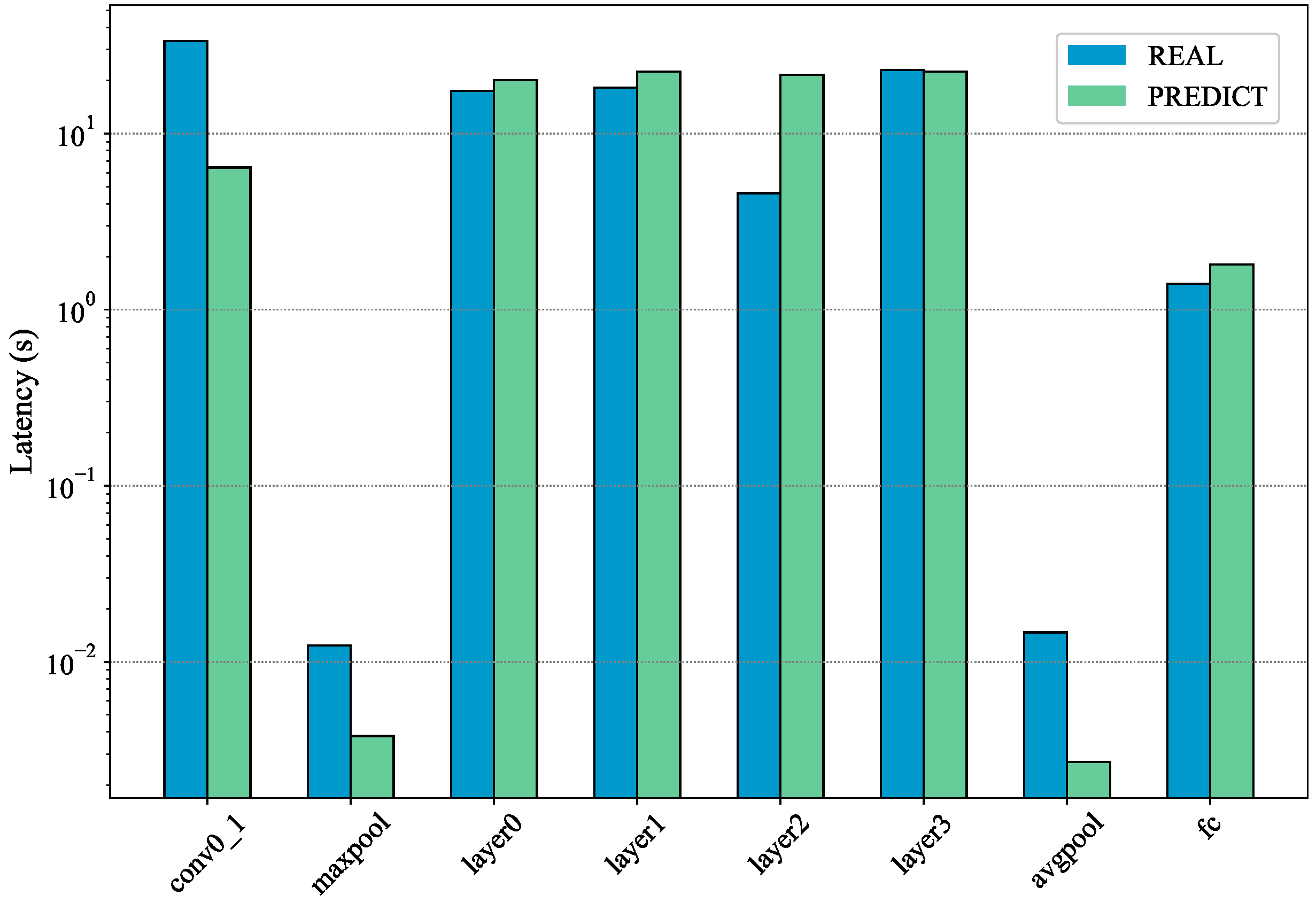
3.1.1. Estimation on Inference Delay
3.1.2. Estimation on Communication
3.2. Optimization Model
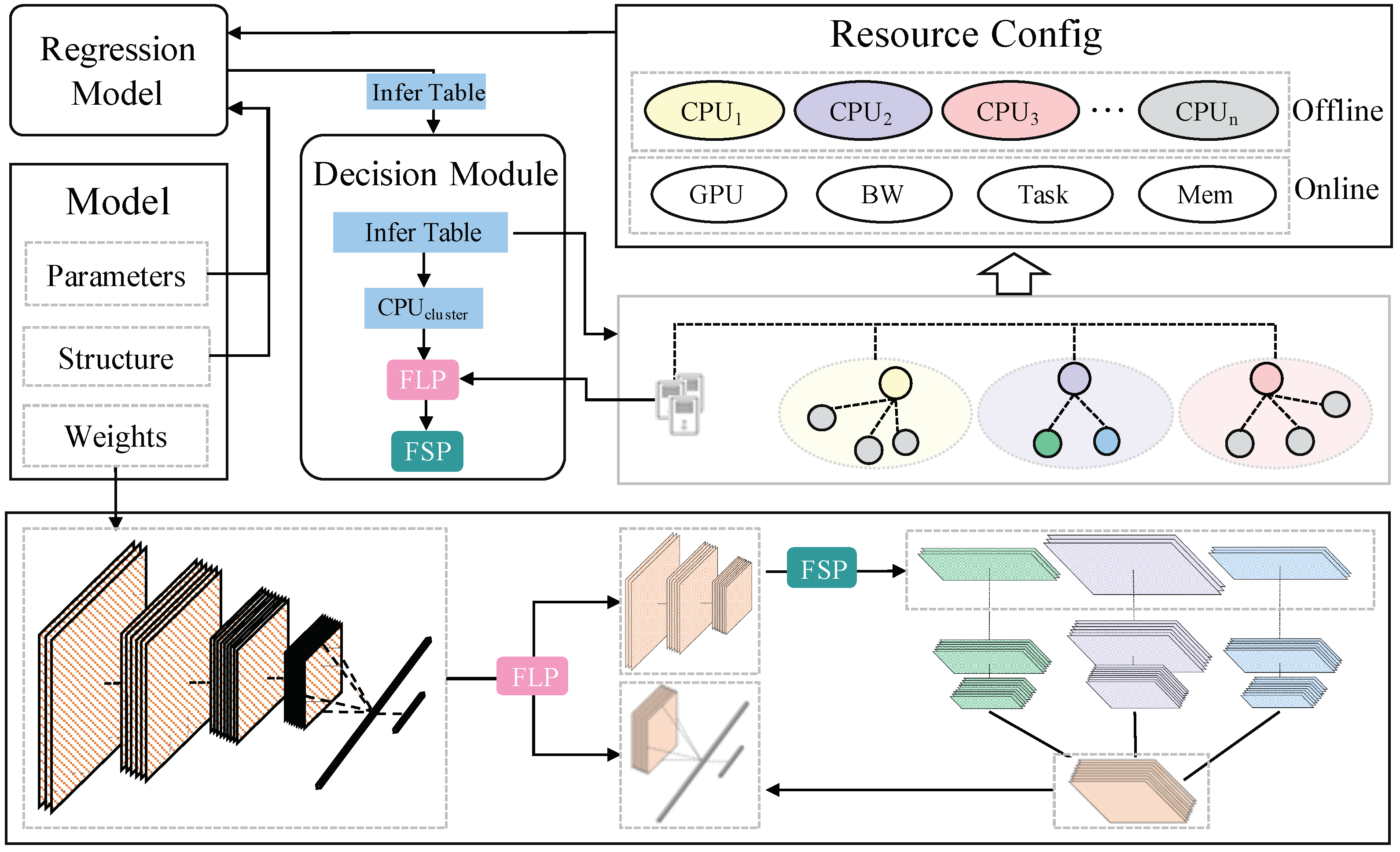
4. The Proposed ADDP Framework
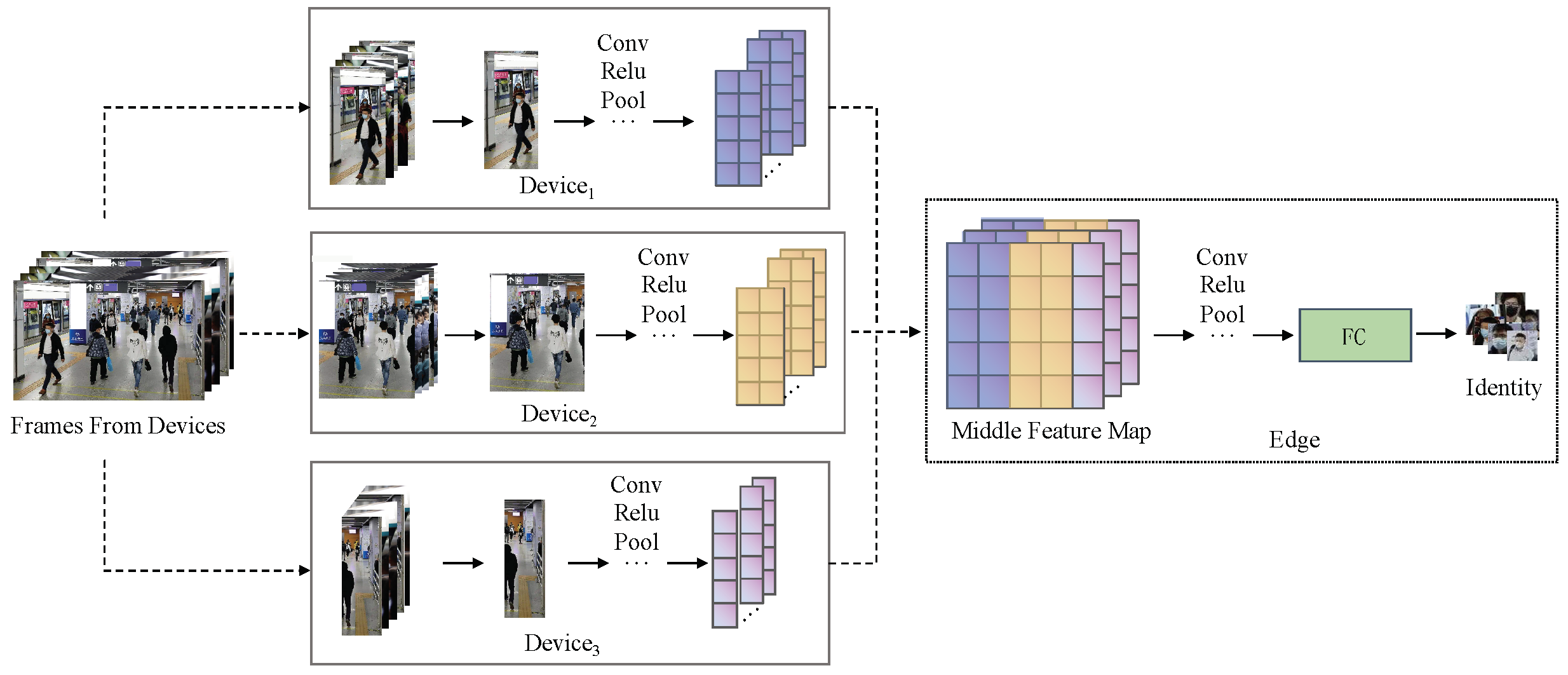
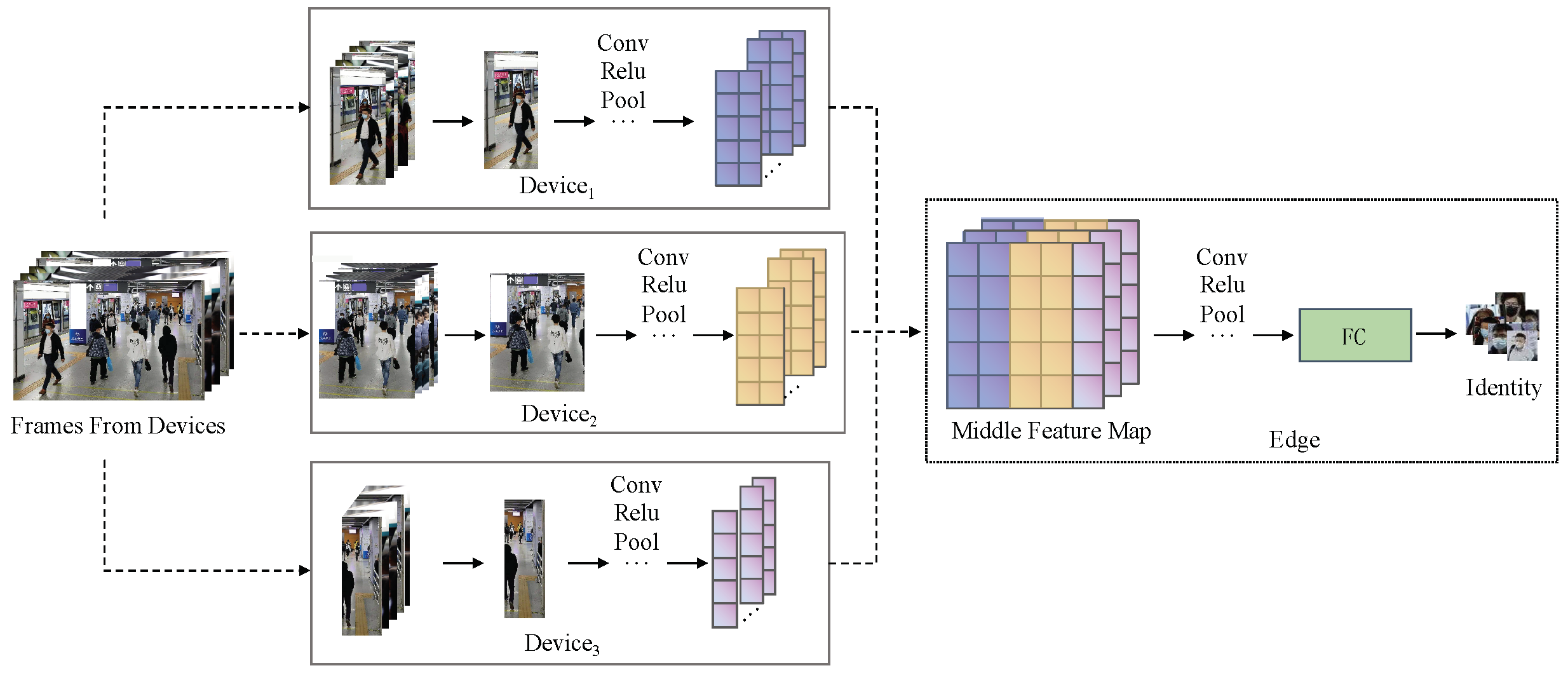
4.1. Framework Overview
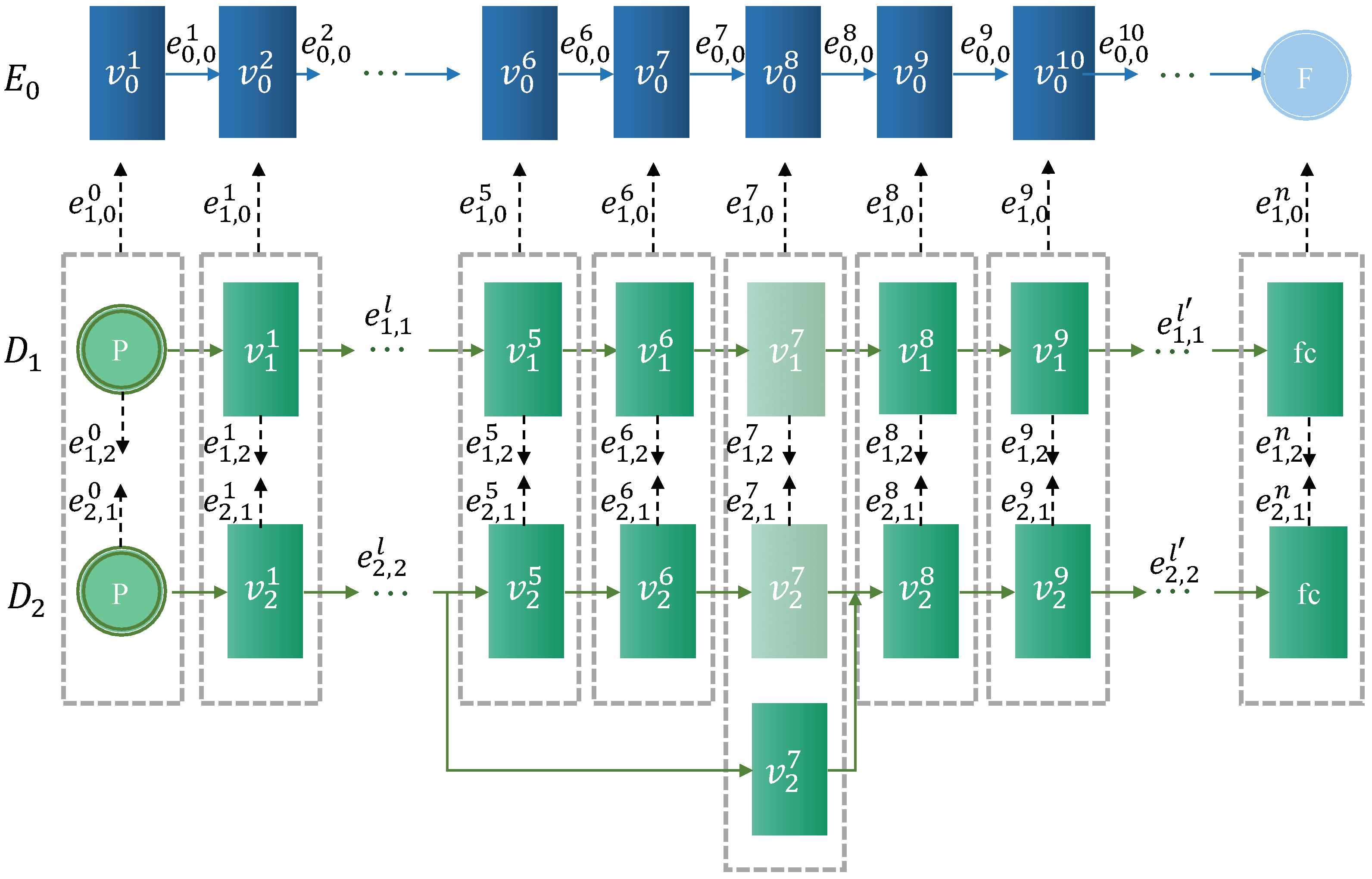
4.2. The Horizontal Partition between the Devices Cluster and the Edge
4.2.1. DNN Model Cut-Point Setting
4.2.2. Multidevice Single-Edge Cut-Point Solution
| Algorithm 1 Distributed partition decision algorithm |
initialization: each device cluster chooses the partition decision end initialization:
|
4.3. Device Intracluster Feature Map Division
4.3.1. Overlap Area Calculation
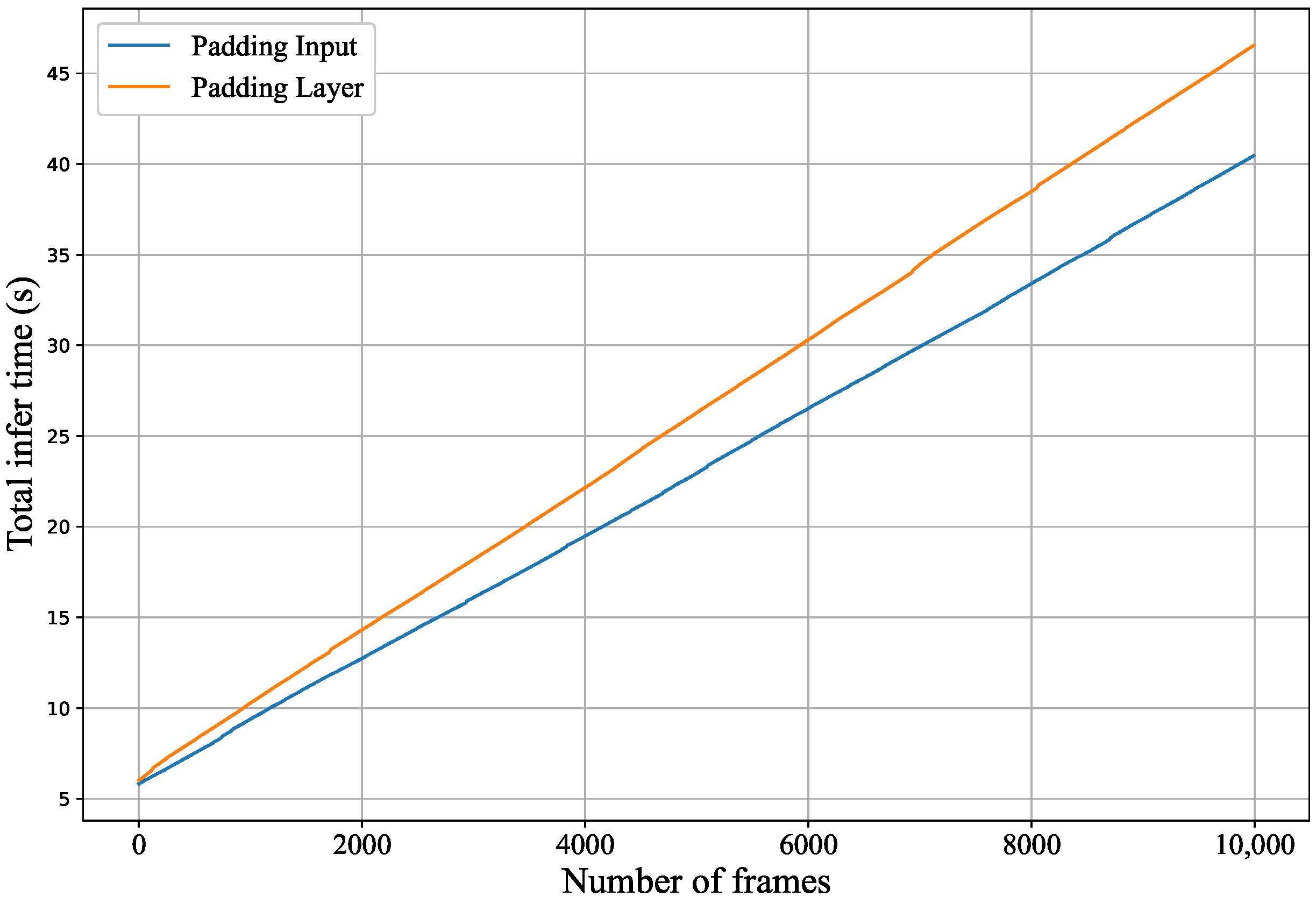
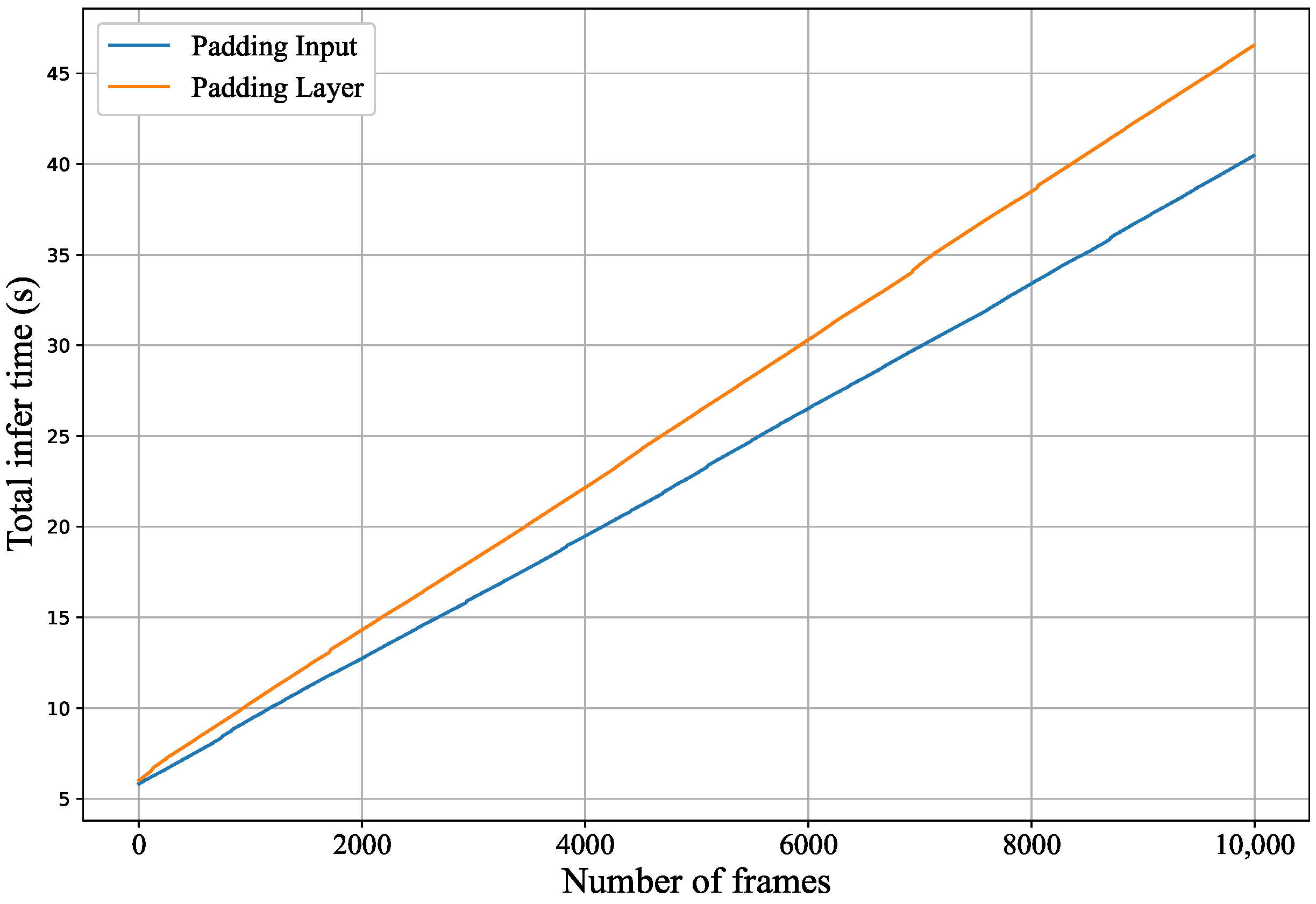
4.3.2. Tensor Padding Optimization
4.3.3. Data Segmentation
5. Performance Evaluation
5.1. Experiment Settings
- Devices: all layers of the DNN model were executed on the terminal cluster, i.e., the cut point was set to the maximum value of the corresponding model.
- Edge: DNN models of all access devices were executed on the edge server, i.e., the cut point was set to 0.
- ANS [21]: a built-in online learning module was used to search for the best cut point based on a novel contextual slot machine algorithm to generate partitioning decisions dynamically.
- MoDNN [27]: based on the characteristics of convolutional layers with computational consumption and fully connected layers with storage consumption, a differential intralayer partitioning approach was performed for different types of DNN layers, the sliced feature map was assigned to multiple devices for collaborative computation, and finally the output on each computational node was collected by the master node for the next layer of inference; the process introduced a significant communication overhead.
- DeepThings [25]: end-to-end slicing of the chain structure of the model, using layer fusion, divided the feature map process into multiple independent parallelizable computational tasks, reducing the quantity of data that needed to be communicated, and avoiding overlapping computation between adjacent task partitions by fusion slicing (FTP) method and task assignment strategy.
- DeepSlicing [26]: for the shortage of MoDNN and Deepthings, the single feature map was sliced according to bars to reduce the part of repeated computations, balanced single-layer slicing and multilayer vertical slicing, and the number of compromises was used to reduce the duplicated region of feature map and not to divide the parallel computation tasks too much.
5.2. Results
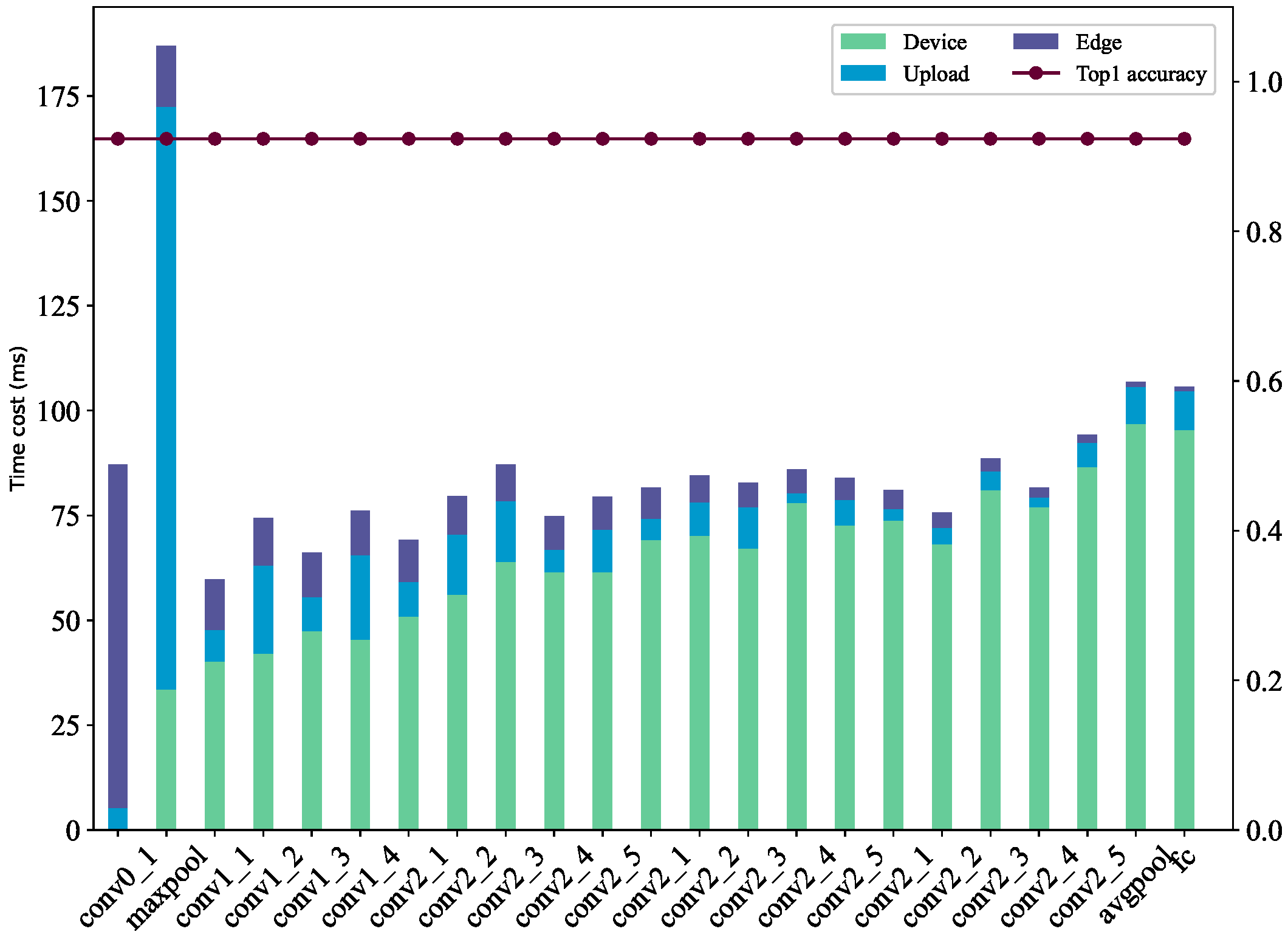
5.2.1. End-to-End Inference Delay
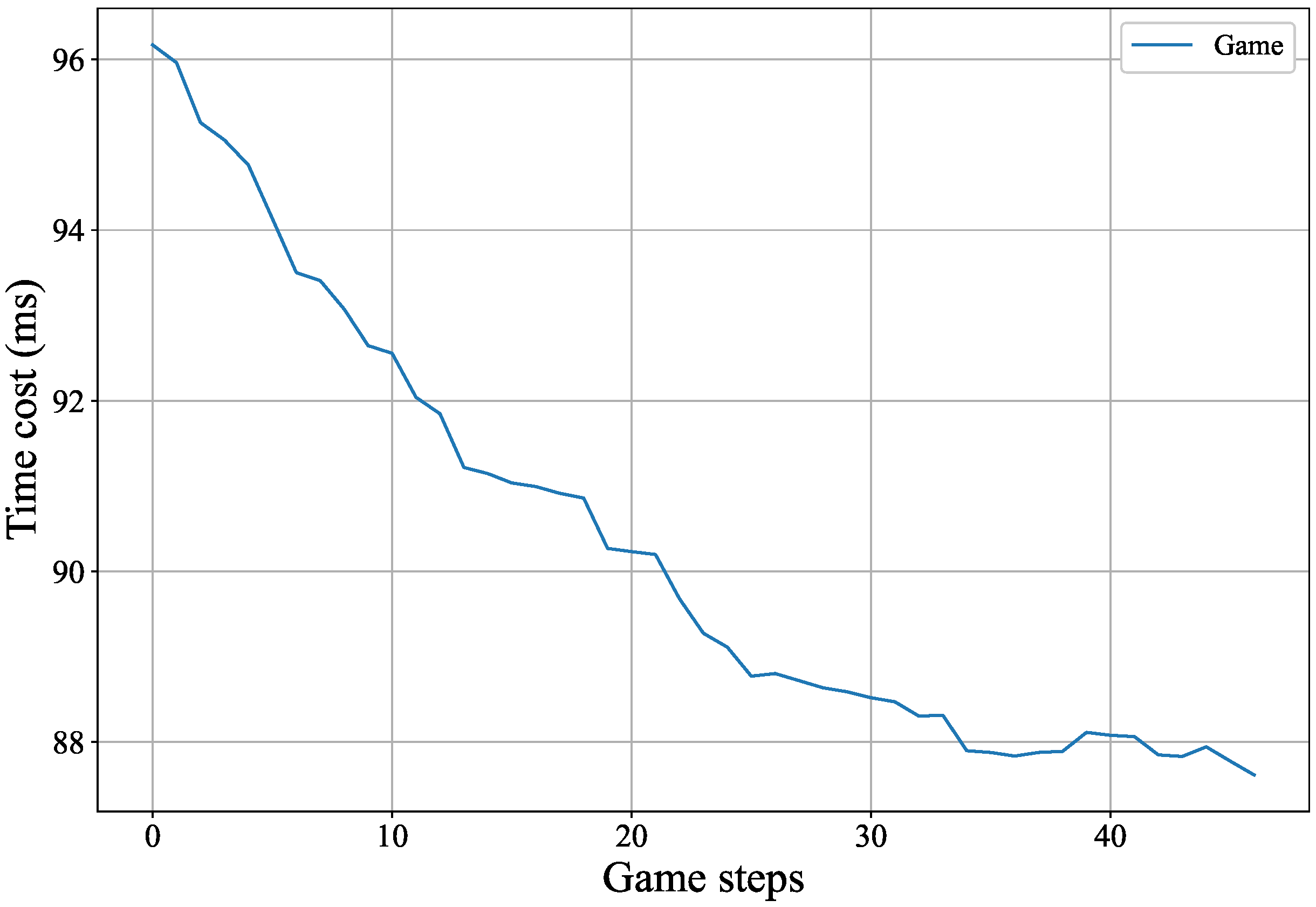
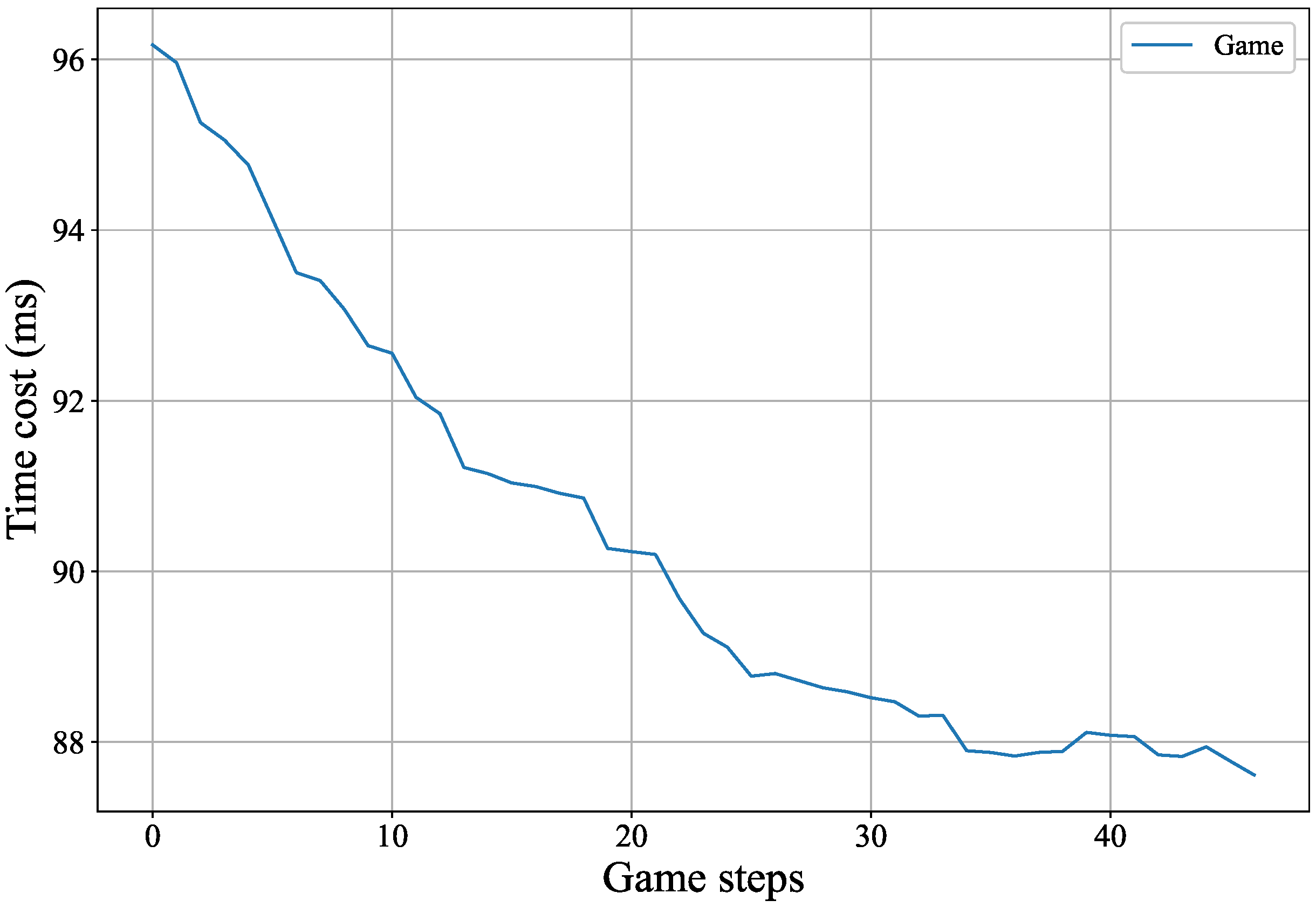
5.2.2. Delayed Changes in the Gaming Process
5.2.3. Comparison of Feature Map Segmentation Methods
5.2.4. Tensor Padding Time Cost
5.2.5. ADDP on Video Streaming
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Maiano, L.; Amerini, I.; Ricciardi Celsi, L.; Anagnostopoulos, A. Identification of social-media platform of videos through the use of shared features. J. Imaging 2021, 7, 140. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Tan, B. Electrocardiogram soft computing using hybrid deep learning CNN-ELM. Appl. Soft Comput. 2020, 86, 105778. [Google Scholar] [CrossRef]
- Cicceri, G.; De Vita, F.; Bruneo, D.; Merlino, G.; Puliafito, A. A deep learning approach for pressure ulcer prevention using wearable computing. Hum.-Centric Comput. Inf. Sci. 2020, 10, 1–21. [Google Scholar] [CrossRef]
- Zhou, Z.; Chen, X.; Li, E.; Zeng, L.; Luo, K.; Zhang, J. Edge intelligence: Paving the last mile of artificial intelligence with edge computing. Proc. IEEE 2019, 107, 1738–1762. [Google Scholar] [CrossRef] [Green Version]
- Ouyang, T.; Zhou, Z.; Chen, X. Follow me at the edge: Mobility-aware dynamic service placement for mobile edge computing. IEEE J. Sel. Areas Commun. 2018, 36, 2333–2345. [Google Scholar] [CrossRef] [Green Version]
- Cevallos Moreno, J.F.; Sattler, R.; Caulier Cisterna, R.P.; Ricciardi Celsi, L.; Sánchez Rodríguez, A.; Mecella, M. Online Service Function Chain Deployment for Live-Streaming in Virtualized Content Delivery Networks: A Deep Reinforcement Learning Approach. Future Internet 2021, 13, 278. [Google Scholar] [CrossRef]
- Zhou, J.; Wang, Y.; Ota, K.; Dong, M. AAIoT: Accelerating artificial intelligence in IoT systems. IEEE Wirel. Commun. Lett. 2019, 8, 825–828. [Google Scholar] [CrossRef]
- Hadidi, R.; Cao, J.; Woodward, M.; Ryoo, M.S.; Kim, H. Distributed perception by collaborative robots. IEEE Robot. Autom. Lett. 2018, 3, 3709–3716. [Google Scholar] [CrossRef]
- Zhou, L.; Samavatian, M.H.; Bacha, A.; Majumdar, S.; Teodorescu, R. Adaptive parallel execution of deep neural networks on heterogeneous edge devices. In Proceedings of the 4th ACM/IEEE Symposium on Edge Computing, Arlington, Virginia, 7–9 November 2019; pp. 195–208. [Google Scholar]
- He, W.; Guo, S.; Guo, S.; Qiu, X.; Qi, F. Joint DNN partition deployment and resource allocation for delay-sensitive deep learning inference in IoT. IEEE Internet Things J. 2020, 7, 9241–9254. [Google Scholar] [CrossRef]
- Zeng, L.; Chen, X.; Zhou, Z.; Yang, L.; Zhang, J. Coedge: Cooperative dnn inference with adaptive workload partitioning over heterogeneous edge devices. IEEE/ACM Trans. Netw. 2020, 29, 595–608. [Google Scholar] [CrossRef]
- Ren, P.; Qiao, X.; Huang, Y.; Liu, L.; Pu, C.; Dustdar, S. Fine-grained Elastic Partitioning for Distributed DNN towards Mobile Web AR Services in the 5G Era. IEEE Trans. Serv. Comput. 2021. [Google Scholar] [CrossRef]
- Gao, Z.; Sun, S.; Zhang, Y.; Mo, Z.; Zhao, C. EdgeSP: Scalable Multi-Device Parallel DNN Inference on Heterogeneous Edge Clusters. In Proceedings of the International Conference on Algorithms and Architectures for Parallel Processing, Virtual, 3–5 December 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 317–333. [Google Scholar]
- Jouhari, M.; Al-Ali, A.; Baccour, E.; Mohamed, A.; Erbad, A.; Guizani, M.; Hamdi, M. Distributed CNN Inference on Resource-Constrained UAVs for Surveillance Systems: Design and Optimization. IEEE Internet Things J. 2021, 9, 1227–1242. [Google Scholar] [CrossRef]
- Parthasarathy, A.; Krishnamachari, B. DEFER: Distributed Edge Inference for Deep Neural Networks. In Proceedings of the 2022 14th International Conference on COMmunication Systems & NETworkS (COMSNETS), Bangalore, India, 4–8 January 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 749–753. [Google Scholar]
- Kang, Y.; Hauswald, J.; Gao, C.; Rovinski, A.; Mudge, T.; Mars, J.; Tang, L. Neurosurgeon: Collaborative intelligence between the cloud and mobile edge. ACM SIGARCH Comput. Archit. News 2017, 45, 615–629. [Google Scholar] [CrossRef] [Green Version]
- Tu, C.H.; Sun, Q.; Cheng, M.H. On designing the adaptive computation framework of distributed deep learning models for Internet-of-Things applications. J. Supercomput. 2021, 77, 13191–13223. [Google Scholar] [CrossRef]
- Jeong, H.J.; Lee, H.J.; Shin, C.H.; Moon, S.M. IONN: Incremental offloading of neural network computations from mobile devices to edge servers. In Proceedings of the ACM Symposium on Cloud Computing, Carlsbad, CA, USA, 11–13 October 2018; pp. 401–411. [Google Scholar]
- Eshratifar, A.E.; Abrishami, M.S.; Pedram, M. JointDNN: An efficient training and inference engine for intelligent mobile cloud computing services. IEEE Trans. Mob. Comput. 2019, 20, 565–576. [Google Scholar] [CrossRef] [Green Version]
- Li, E.; Zhou, Z.; Chen, X. Edge intelligence: On-demand deep learning model co-inference with device-edge synergy. In Proceedings of the 2018 Workshop on Mobile Edge Communications, Budapest, Hungary, 20 August 2018; pp. 31–36. [Google Scholar]
- Zhang, L.; Chen, L.; Xu, J. Autodidactic neurosurgeon: Collaborative deep inference for mobile edge intelligence via online learning. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 3111–3123. [Google Scholar]
- Almeida, M.; Laskaridis, S.; Venieris, S.I.; Leontiadis, I.; Lane, N.D. DynO: Dynamic Onloading of Deep Neural Networks from Cloud to Device. ACM Trans. Embed. Comput. Syst. (TECS) 2021. [Google Scholar] [CrossRef]
- Zhang, B.; Xiang, T.; Zhang, H.; Li, T.; Zhu, S.; Gu, J. Dynamic DNN Decomposition for Lossless Synergistic Inference. In Proceedings of the 2021 IEEE 41st International Conference on Distributed Computing Systems Workshops (ICDCSW), Washington, DC, USA, 7–10 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 13–20. [Google Scholar]
- Williams, S.; Waterman, A.; Patterson, D. Roofline: An insightful visual performance model for multicore architectures. Commun. ACM 2009, 52, 65–76. [Google Scholar] [CrossRef]
- Zhao, Z.; Barijough, K.M.; Gerstlauer, A. Deepthings: Distributed adaptive deep learning inference on resource-constrained iot edge clusters. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2018, 37, 2348–2359. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, S.; Qian, Z.; Wu, J.; Jin, Y.; Lu, S. Deepslicing: Collaborative and adaptive cnn inference with low latency. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 2175–2187. [Google Scholar] [CrossRef]
- Mao, J.; Chen, X.; Nixon, K.W.; Krieger, C.; Chen, Y. Modnn: Local distributed mobile computing system for deep neural network. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Lausanne, Switzerland, 27–31 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1396–1401. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
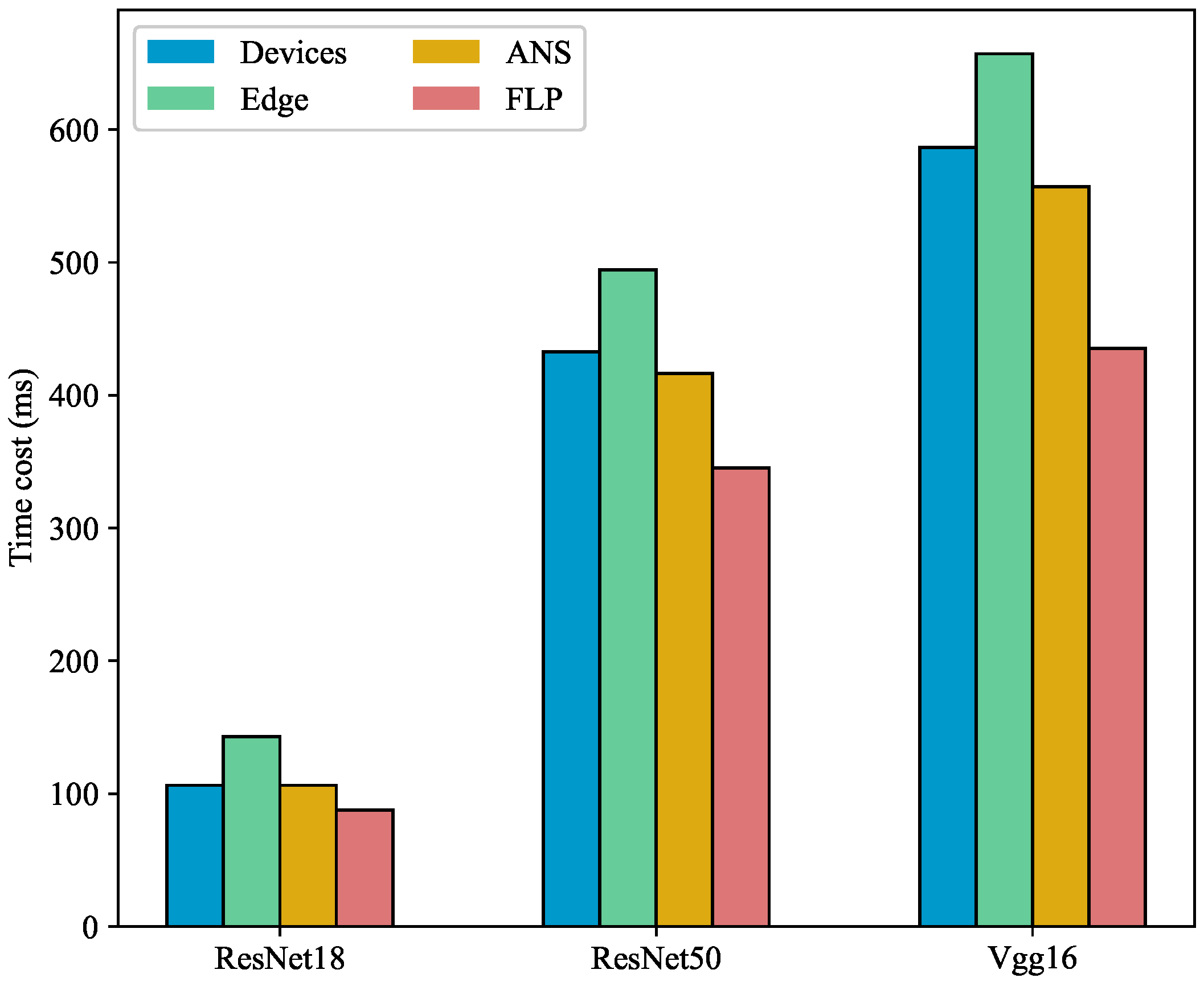{kind=link}
{kind=link}
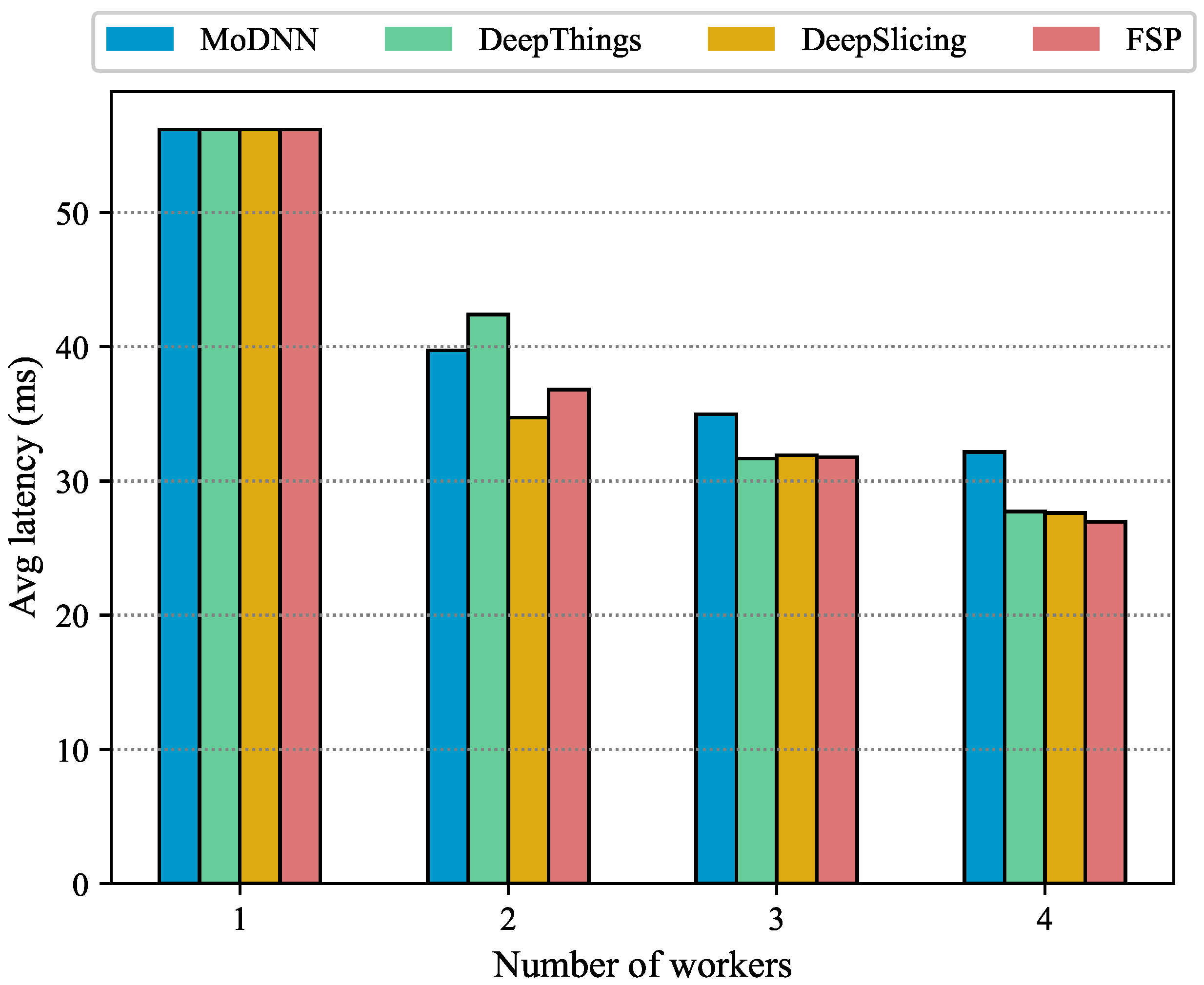{kind=link}
{kind=link}
{kind=link}
| - | |||
|---|---|---|---|
| Conv | 1 | 1 | 1 |
| FC | 1 | 1 | 1 |
| Norm | 1 | 1 | 0 |
| Pool | 1 | 1 | 0 |
| ReLU | 1 | 1 | 0 |
| Concat | 2 | 1 | 0 |
| EltWise Add | 2 | 1 | 0 |
| - | Sampling Rate | FPS (ResNet18) | FPS (ResNet50) | FPS (Vgg16) |
|---|---|---|---|---|
| Video1 | 9.04% | 48.81 | 32.86 | 10.77 |
| Video2 | 23.18% | 19.05 | 14.60 | 4.28 |
| Video3 | 38.10% | 11.58 | 8.27 | 2.79 |
| Video4 | 69.87% | 6.32 | 4.51 | 1.29 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, J.; Li, B.; Fan, M.; Liu, H. Inference Acceleration with Adaptive Distributed DNN Partition over Dynamic Video Stream. Algorithms 2022, 15, 244. https://doi.org/10.3390/a15070244
Cao J, Li B, Fan M, Liu H. Inference Acceleration with Adaptive Distributed DNN Partition over Dynamic Video Stream. Algorithms. 2022; 15(7):244. https://doi.org/10.3390/a15070244
Chicago/Turabian StyleCao, Jin, Bo Li, Mengni Fan, and Huiyu Liu. 2022. "Inference Acceleration with Adaptive Distributed DNN Partition over Dynamic Video Stream" Algorithms 15, no. 7: 244. https://doi.org/10.3390/a15070244
APA StyleCao, J., Li, B., Fan, M., & Liu, H. (2022). Inference Acceleration with Adaptive Distributed DNN Partition over Dynamic Video Stream. Algorithms, 15(7), 244. https://doi.org/10.3390/a15070244