
A Federated Generalized Linear Model for Privacy-Preserving Analysis


Abstract
:1. Introduction
1.1. Federated Learning
1.2. Generalized Linear Models
1.2.1. Estimation of a Centralized GLM
| Algorithm 1 Fisher Scoring-based Centralized GLM |
|
2. Materials and Methods
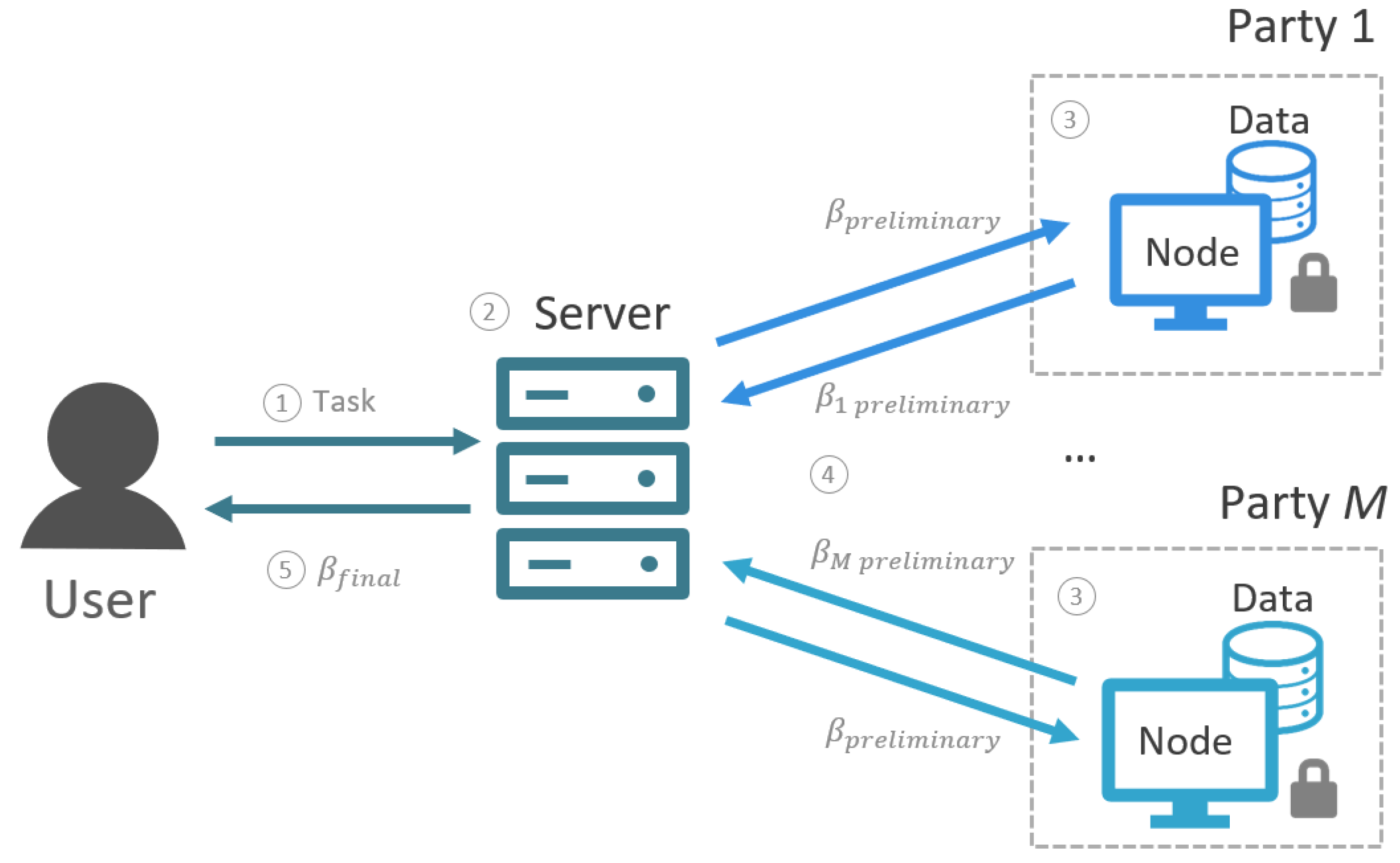
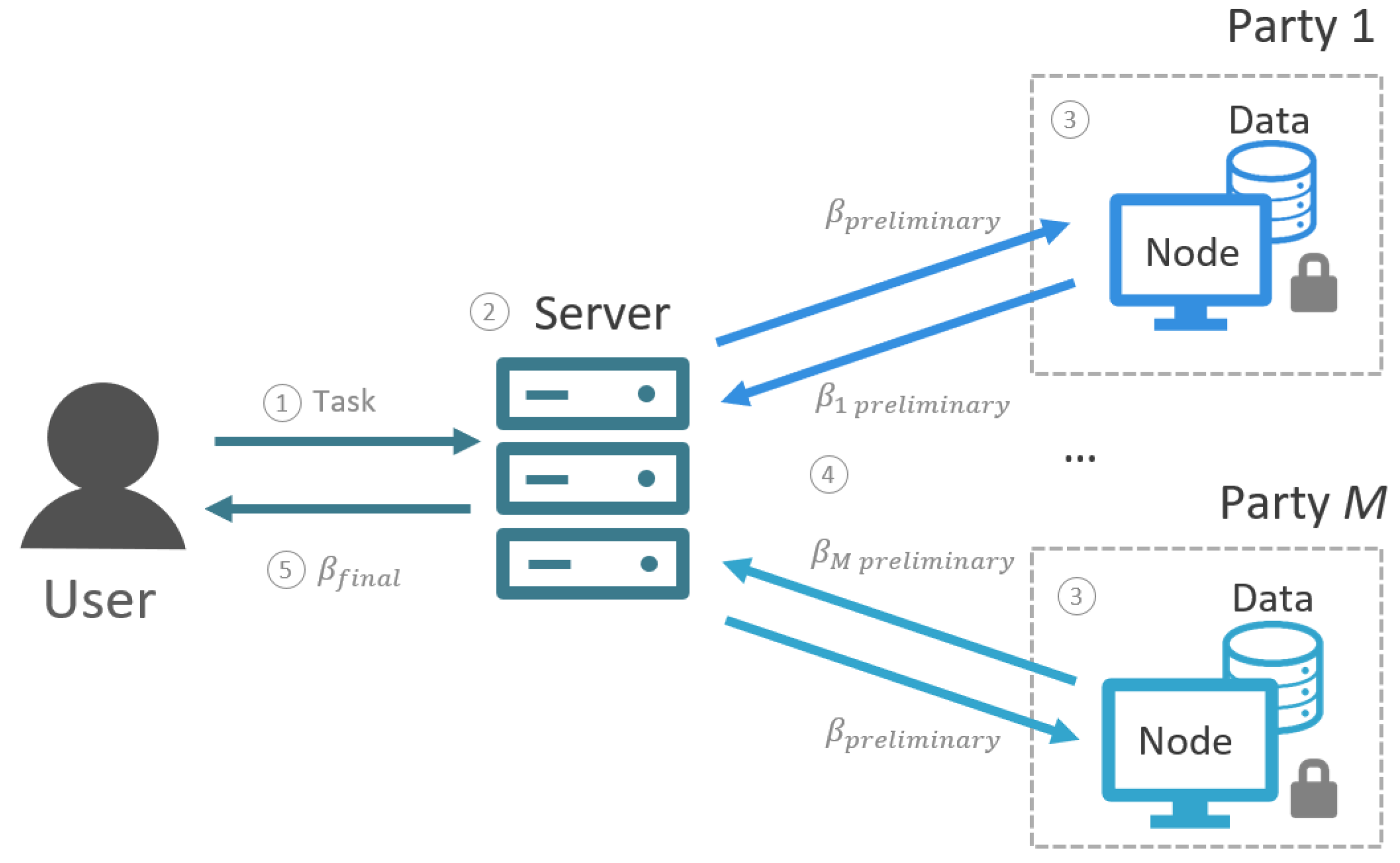
2.1. Setup
2.2. Algorithm for a Federated GLM
2.3. Validation
2.3.1. Accuracy
| Algorithm 2 Federated GLM |
Initialization Server
Initialization Node m
|
Linear Regression
Poisson Regression
Logistic Regression
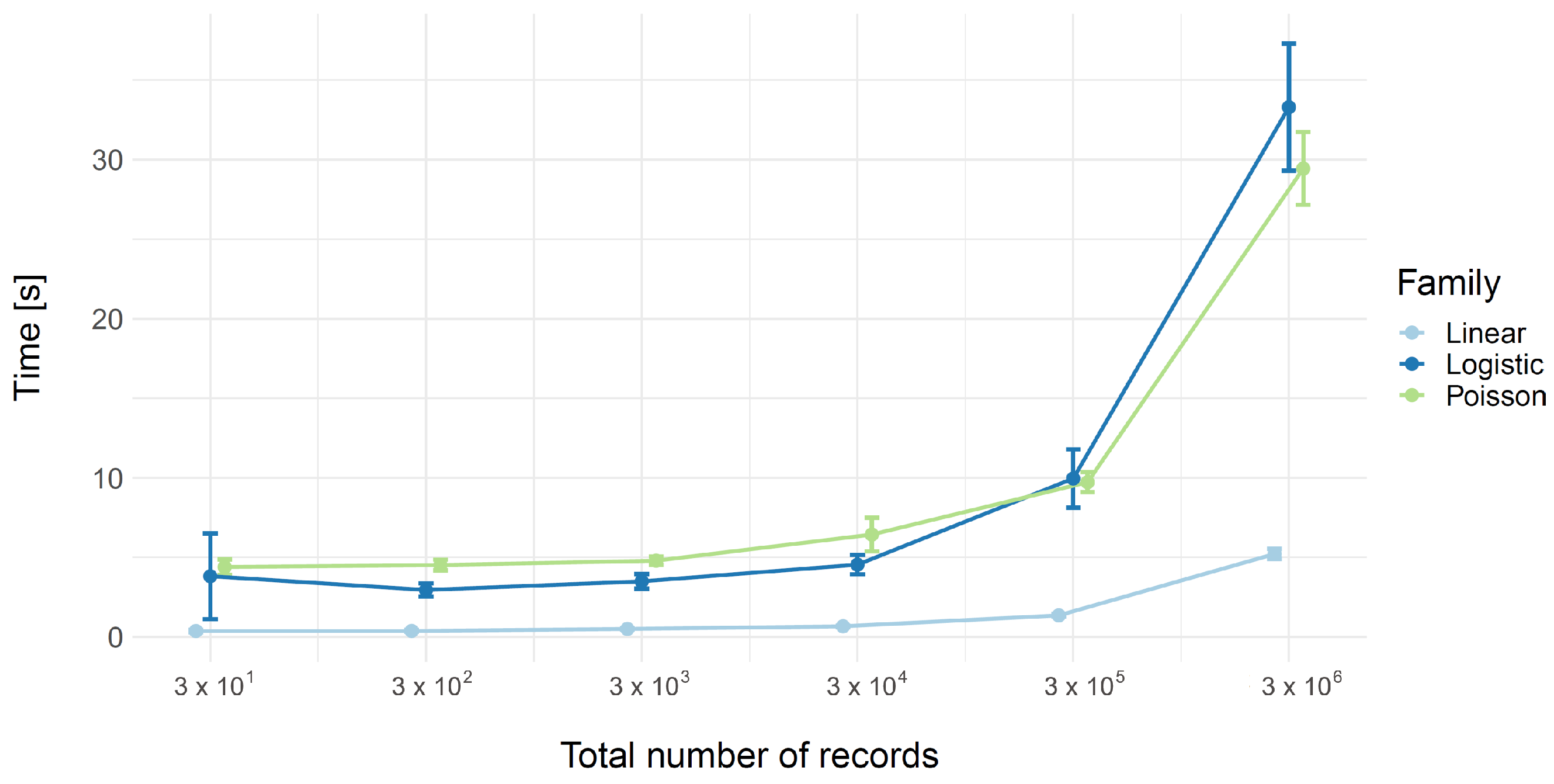
2.3.2. Execution Time
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| FL | Federated learning |
| GLM | Generalized linear model |
| ML | Machine learning |
| MLE | Maximum likelihood estimation |
References
- Sagiroglu, S.; Sinanc, D. Big data: A review. In Proceedings of the 2013 International Conference on Collaboration Technologies and Systems (CTS), San Diego, CA, USA, 20–24 May 2013; pp. 42–47. [Google Scholar]
- Hatcher, W.G.; Yu, W. A survey of deep learning: Platforms, applications and emerging research trends. IEEE Access 2018, 6, 24411–24432. [Google Scholar] [CrossRef]
- Hassani, H.; Huang, X.; Silva, E. Digitalisation and big data mining in banking. Big Data Cogn. Comput. 2018, 2, 18. [Google Scholar] [CrossRef] [Green Version]
- Wuest, T.; Weimer, D.; Irgens, C.; Thoben, K.D. Machine learning in manufacturing: Advantages, challenges, and applications. Prod. Manuf. Res. 2016, 4, 23–45. [Google Scholar] [CrossRef] [Green Version]
- Fildes, R.; Ma, S.; Kolassa, S. Retail forecasting: Research and practice. Int. J. Forecast. 2019, 35, 1–34. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Fan, Y.; Tse, M.; Lin, K.Y. A review of applications in federated learning. Comput. Ind. Eng. 2020, 149, 106854. [Google Scholar] [CrossRef]
- Group, W.A. Federated Learning White Paper; Technical Report; WeBank AI Group: Beijing, China, 2018. [Google Scholar]
- Politou, E.; Alepis, E.; Patsakis, C. Forgetting personal data and revoking consent under the GDPR: Challenges and proposed solutions. J. Cybersecur. 2018, 4, tyy001. [Google Scholar] [CrossRef]
- van Veen, E.B. Observational health research in Europe: Understanding the General Data Protection Regulation and underlying debate. Eur. J. Cancer 2018, 104, 70–80. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Piper, D. Data Protection Laws of the World; Technical Report; DLA Piper: MD, USA, 2020. [Google Scholar]
- Bukaty, P. The California Consumer Privacy Act (CCPA): An Implementation Guide; IT Governance Ltd.: Ely, UK, 2019. [Google Scholar]
- Dai, W.; Wang, S.; Xiong, H.; Jiang, X. Privacy preserving federated big data analysis. In Guide to Big Data Applications; Springer: Berlin/Heidelberg, Germany, 2018; pp. 49–82. [Google Scholar]
- Xu, J.; Wang, F. Federated Learning for Healthcare Informatics. arXiv 2019, arXiv:1911.06270. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A survey on federated learning. Knowl.-Based Syst. 2021, 216, 106775. [Google Scholar] [CrossRef]
- Lindell, Y.; Pinkas, B. Privacy preserving data mining. J. Cryptol. 2002, 15, 36–54. [Google Scholar] [CrossRef]
- Wild, E.; Mangasarian, O. Privacy-Preserving Classification of Horizontally Partitioned Data via Random Kernels; Technical Report; University of Wisconsin: Madison, WI, USA, 2007. [Google Scholar]
- Gao, D.; Ju, C.; Wei, X.; Liu, Y.; Chen, T.; Yang, Q. Hhhfl: Hierarchical heterogeneous horizontal federated learning for electroencephalography. arXiv 2019, arXiv:1909.05784. [Google Scholar]
- Tian, Z.; Zhang, R.; Hou, X.; Liu, J.; Ren, K. Federboost: Private federated learning for gbdt. arXiv 2020, arXiv:2011.02796. [Google Scholar]
- Zhao, L.; Ni, L.; Hu, S.; Chen, Y.; Zhou, P.; Xiao, F.; Wu, L. Inprivate digging: Enabling tree-based distributed data mining with differential privacy. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 15–19 April 2018; pp. 2087–2095. [Google Scholar]
- Slavkovic, A.B.; Nardi, Y.; Tibbits, M.M. “Secure” Logistic Regression of Horizontally and Vertically Partitioned Distributed Databases. In Proceedings of the Seventh IEEE International Conference on Data Mining Workshops (ICDMW 2007), Omaha, NE, USA, 28–31 October 2007; pp. 723–728. [Google Scholar]
- Lu, C.L.; Wang, S.; Ji, Z.; Wu, Y.; Xiong, L.; Jiang, X.; Ohno-Machado, L. WebDISCO: A web service for distributed cox model learning without patient-level data sharing. J. Am. Med. Inform. Assoc. 2015, 22, 1212–1219. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bonawitz, K.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Kiddon, C.; Konecny, J.; Mazzocchi, S.; McMahan, H.B.; et al. Towards Federated Learning at Scale: System Design. In Proceedings of the 2nd Conference on Systems and Machine Learning (SysML), Standford, CA, USA, 31 March–2 April 2019. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- McCullagh, P.; Nelder, J.A. Generalized Linear Models; Routledge: London, UK, 2019. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2022. [Google Scholar]
- Van Rossum, G.; Drake, F.L. Python 3 Reference Manual; Python Software Foundation: DE, USA, 2009. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Guyon, I.; Gunn, S.; Ben-Hur, A.; Dror, G. Result analysis of the NIPS 2003 feature selection challenge. Adv. Neural Inf. Process. Syst. 2004, 17, 1–8. [Google Scholar]
- Moncada-Torres, A.; Martin, F.; Sieswerda, M.; van Soest, J.; Geleijnse, G. VANTAGE6: An open source priVAcy preserviNg federaTed leArninG infrastructurE for Secure Insight eXchange. In Proceedings of the AMIA Annual Symposium Proceedings, Online, 14–18 November 2020; pp. 870–877. [Google Scholar]
- Hlavac, M. stargazer: Well-Formatted Regression and Summary Statistics Tables; R Package Version 5.2.3; Social Policy Institute: Bratislava, Slovakia, 2022. [Google Scholar]
- Hartmann, F. Federated Learning. Master’s Thesis, Frei Universität Berlin, Berlin, Germany, 2018. [Google Scholar]
- Smits, D.; van Beusekom, B.; Martin, F.; Veen, L.; Geleijnse, G.; Moncada-Torres, A. An Improved Infrastructure for Privacy-Preserving Analysis of Patient Data. In Proceedings of the International Conference of Informatics, Management, and Technology in Healthcare (ICIMTH), Athens, Greece, 1 July–3 July 2022; Volume 295, pp. 144–147. [Google Scholar]
- Wenzel, H.H.; Norberg Hardie, A.; Bekkers, R.L.; Falconer, H.; Hogdall, C.K.; Jensen, P.T.; Lemmens, V.E.; Martin, F.; van Gestel, A.J.; Moncada-Torres, A.; et al. Using Federated Learning to Identify Women with Early Stage Cervical Cancer at Low Risk For Lymph Node Metastases. 2022; under review. [Google Scholar]
- Wenzel, H. Improving Quality of Cervical Cancer Care with (Inter)National Cancer Registry Data. Ph.D. Thesis, University of Groningen, Groningen, The Netherlands, 2022. [Google Scholar]
- Rosenbaum, P.R.; Rubin, D.B. The central role of the propensity score in observational studies for causal effects. Biometrika 1983, 70, 41–55. [Google Scholar] [CrossRef]
- Hamersma, D.T. A Comparison of the Quality of Breast Cancer Care in Norway and The Netherlands. Master’s Thesis, University of Twente, Enschede, The Netherlands, 2020. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 12. [Google Scholar] [CrossRef]
- Nishio, T.; Yonetani, R. Client selection for federated learning with heterogeneous resources in mobile edge. In Proceedings of the ICC 2019–2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–7. [Google Scholar]
- Konečnỳ, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]

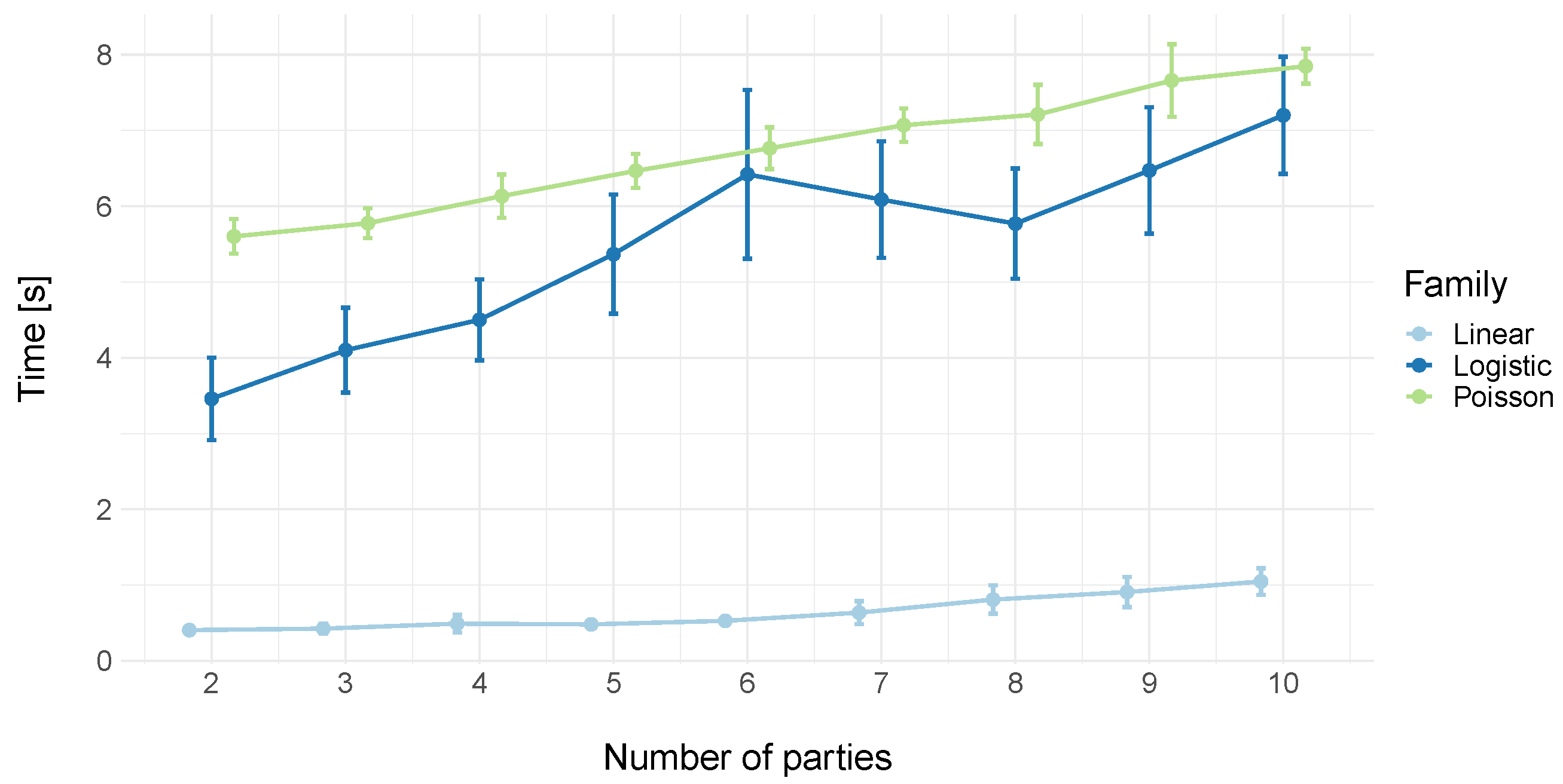

{kind=link}
{kind=link}
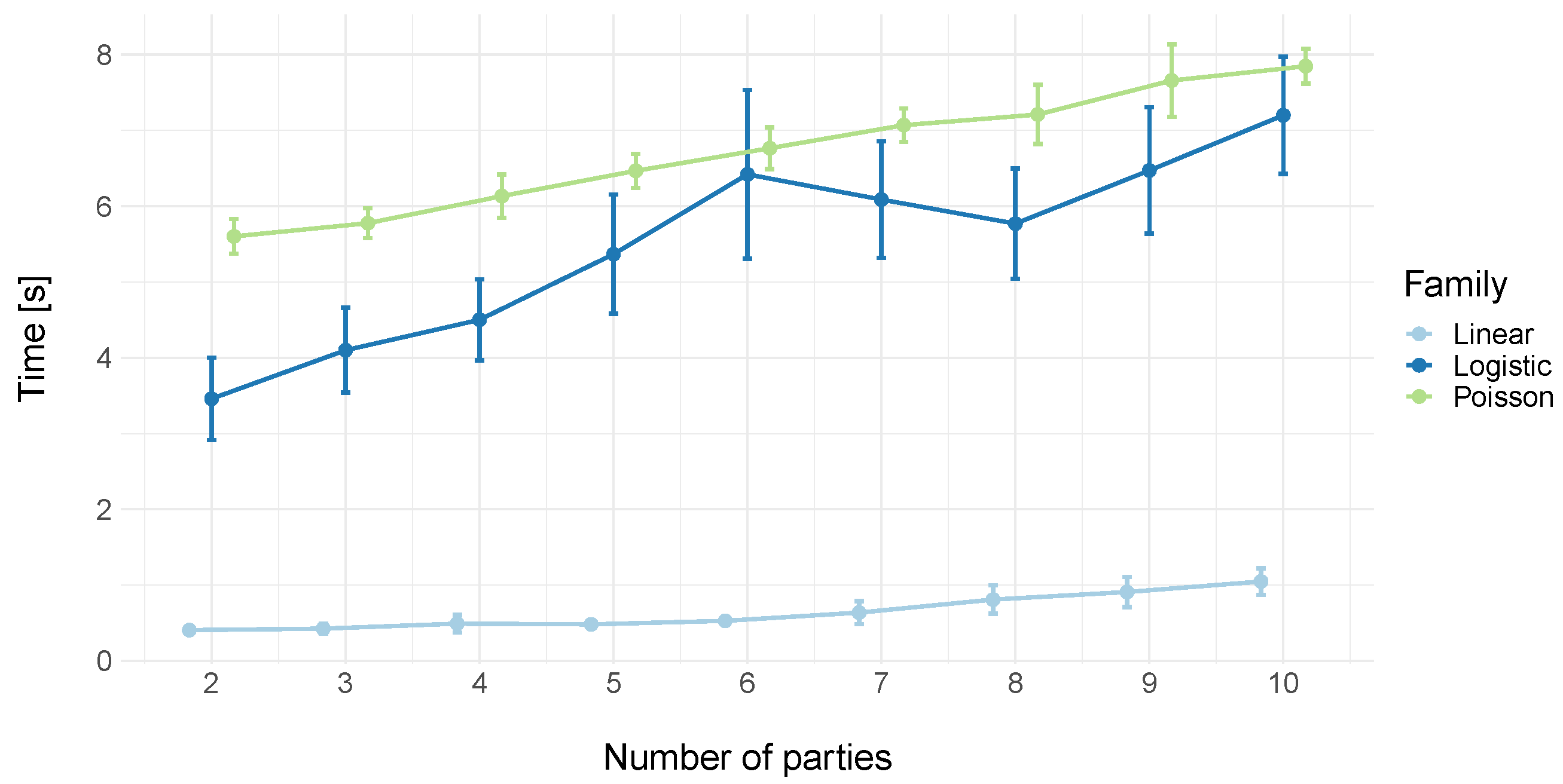{kind=link}
| Family | Parameter | Coefficients | Std. Error | p-Values | z-Values | ||||
|---|---|---|---|---|---|---|---|---|---|
| C | F | C | F | C | F | C | F | ||
| Linear | (Intercept) | ||||||||
| 0 | 0 | ||||||||
| 0 | 0 | ||||||||
| Poisson | (Intercept) | 0 | 0 | ||||||
| 0 | 0 | ||||||||
| 0 | 0 | ||||||||
| Logistic | (Intercept) | ||||||||
| 0 | 0 | ||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cellamare, M.; van Gestel, A.J.; Alradhi, H.; Martin, F.; Moncada-Torres, A. A Federated Generalized Linear Model for Privacy-Preserving Analysis. Algorithms 2022, 15, 243. https://doi.org/10.3390/a15070243
Cellamare M, van Gestel AJ, Alradhi H, Martin F, Moncada-Torres A. A Federated Generalized Linear Model for Privacy-Preserving Analysis. Algorithms. 2022; 15(7):243. https://doi.org/10.3390/a15070243
Chicago/Turabian StyleCellamare, Matteo, Anna J. van Gestel, Hasan Alradhi, Frank Martin, and Arturo Moncada-Torres. 2022. "A Federated Generalized Linear Model for Privacy-Preserving Analysis" Algorithms 15, no. 7: 243. https://doi.org/10.3390/a15070243
APA StyleCellamare, M., van Gestel, A. J., Alradhi, H., Martin, F., & Moncada-Torres, A. (2022). A Federated Generalized Linear Model for Privacy-Preserving Analysis. Algorithms, 15(7), 243. https://doi.org/10.3390/a15070243