
Learning-Based Online QoE Optimization in Multi-Agent Video Streaming


Abstract
:1. Introduction
- We model the bandwidth assignment problem for optimizing QoE and fairness objectives in multi-user online video streaming. The stall time is quantified for general cases under system dynamics.
- Due to the nature of the inter-agent fairness problem, we propose a multi-agent learning algorithm that is proven to converge and leverages two reinforcement learning modules running in parallel to effectively reduce the action space size.
- The proposed algorithm is implemented and evaluated on our testbed, which is able to simulate various configurations, including different reward functions, network conditions, and user behavior settings.
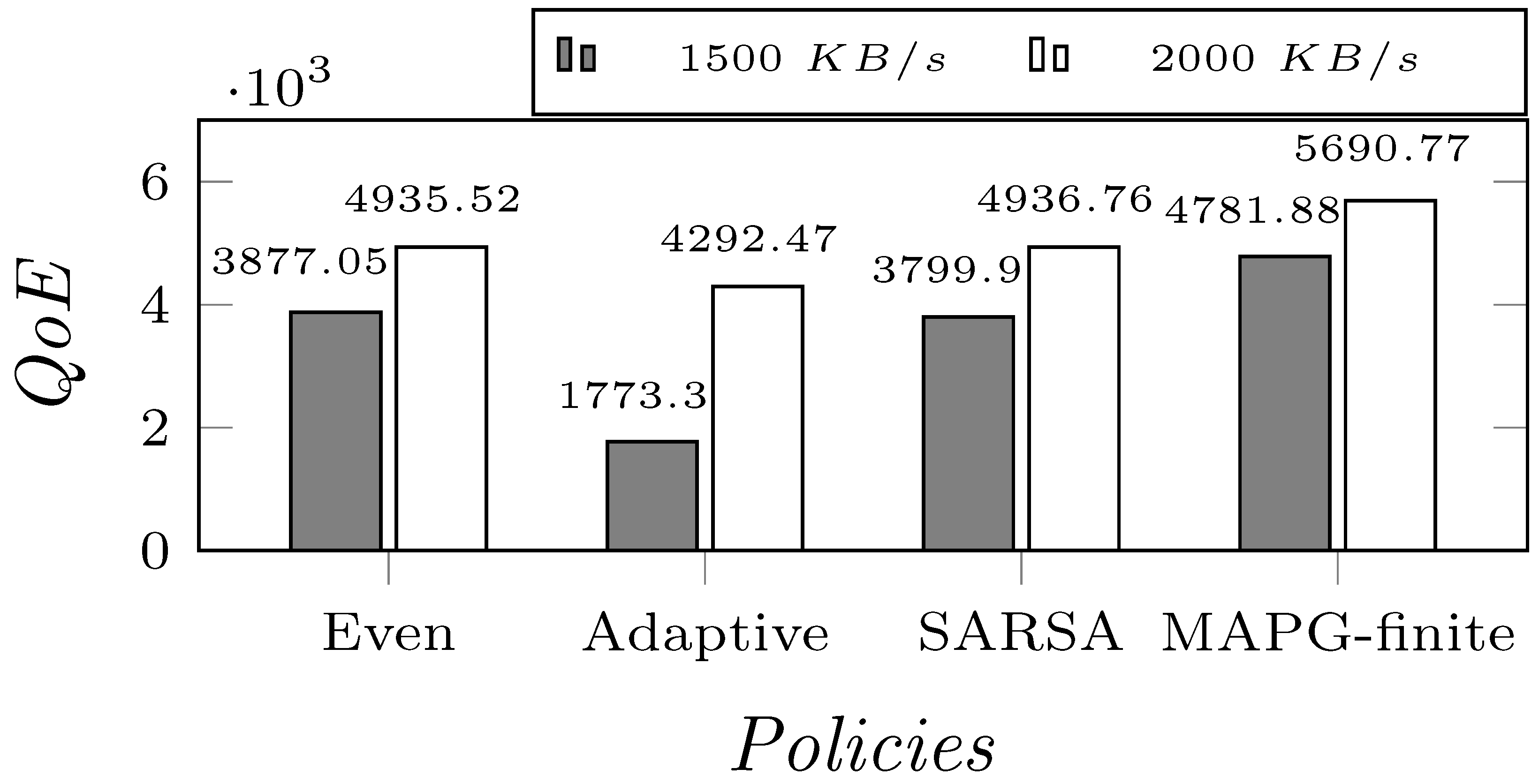
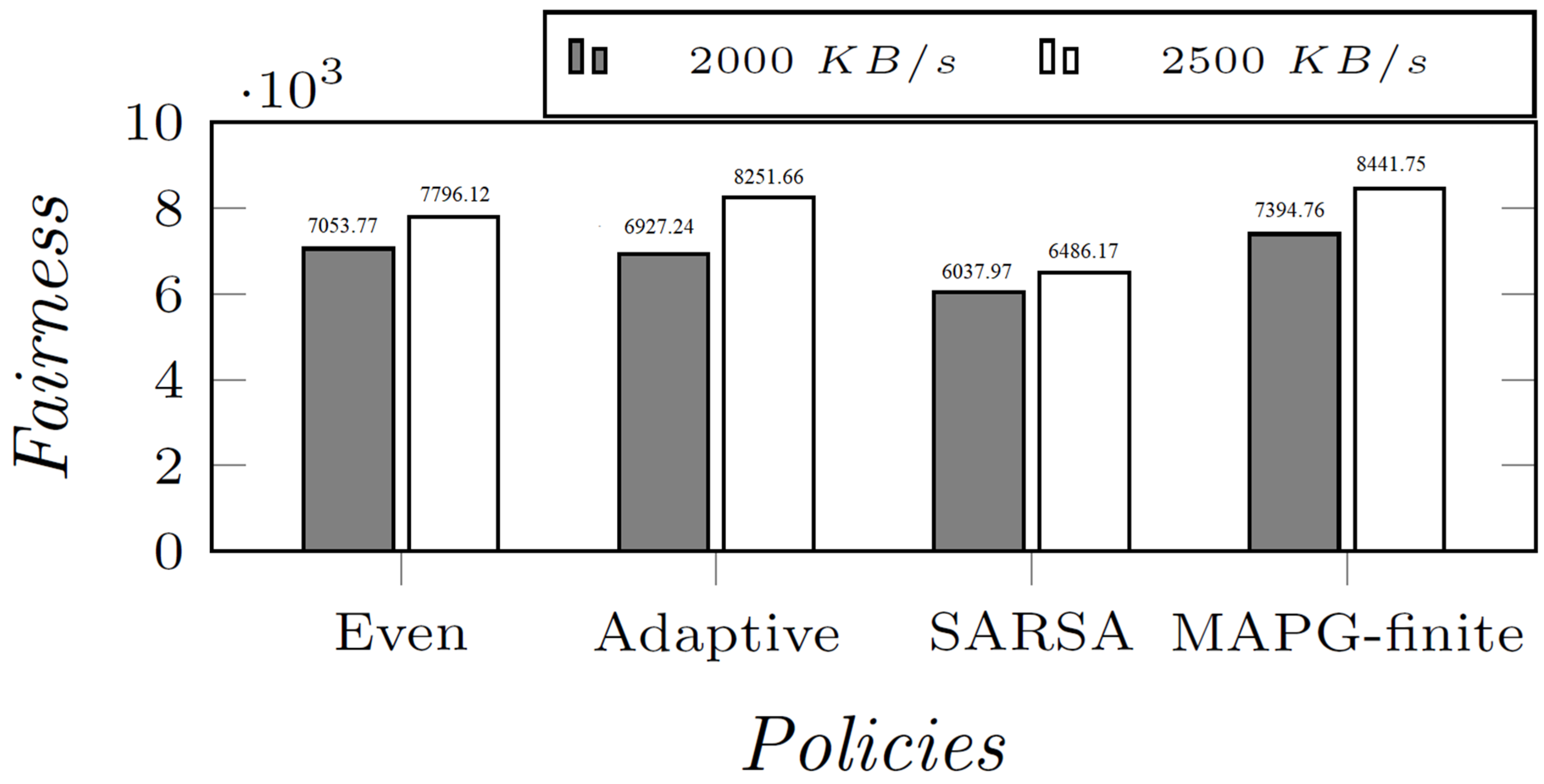
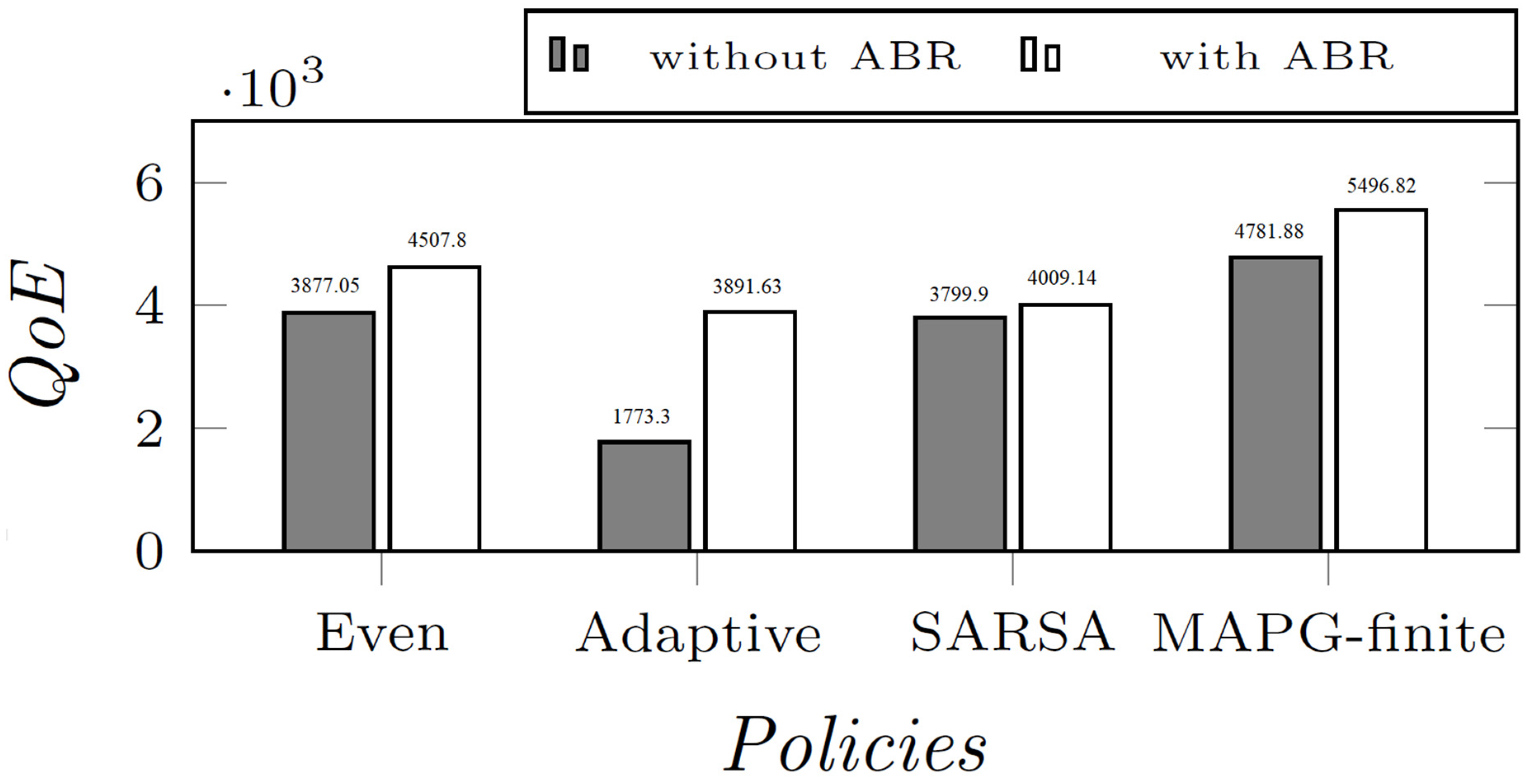
- The numerical results show that MAPG-finite outperforms a number of baselines, including “Even”, “Adaptive”, and single-agent learning policies. With CBR, MAPG-finite achieves up to a improvement in the achieved QoE, and a improvement in the logarithmic fairness; with ABR, MAPG-finite achieves up to a WoE improvement.
2. Related Work
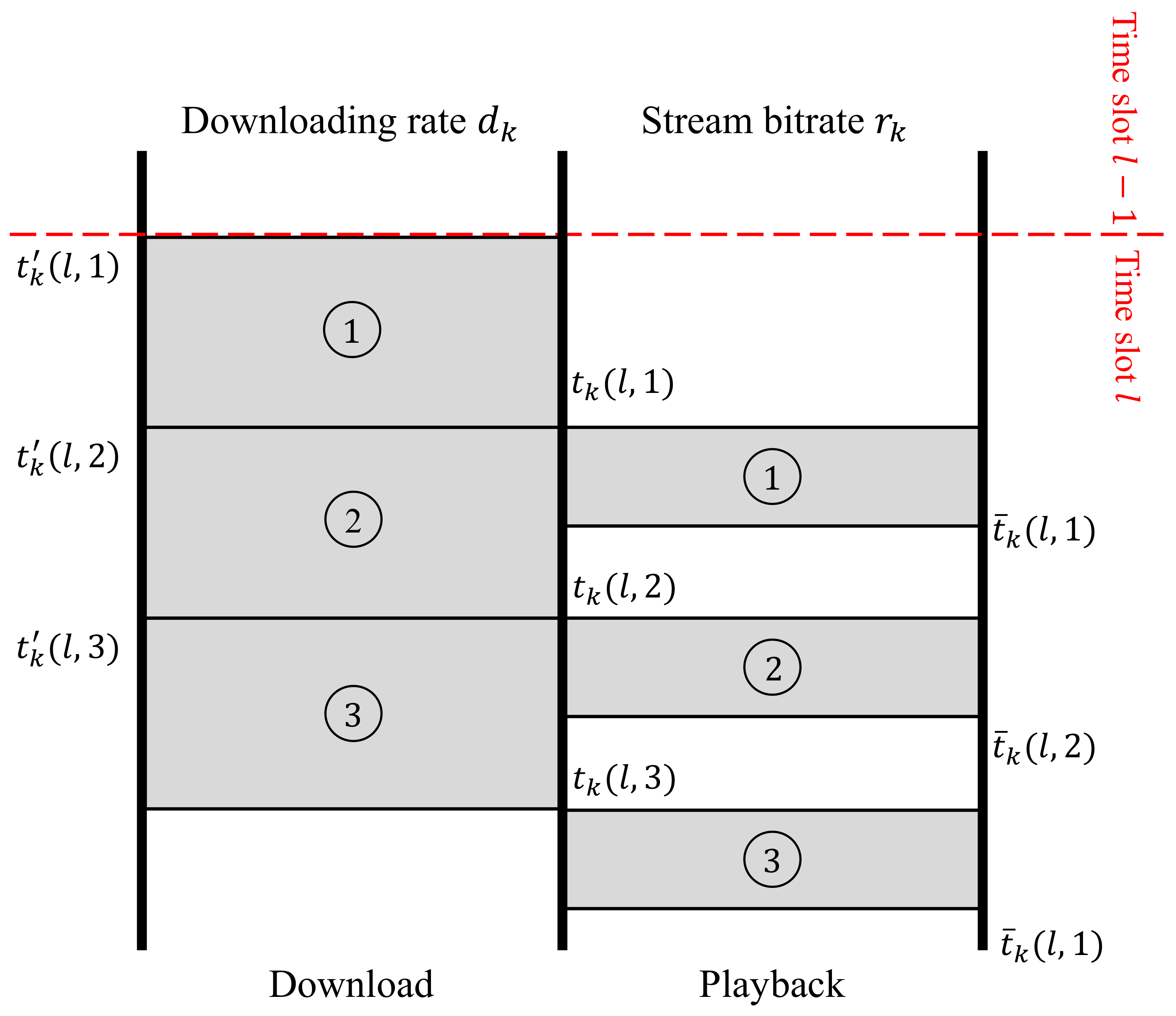
3. System Model
3.1. Class 1: User Requests a New Video
3.2. Class 2: Users Continuing with the Old Video
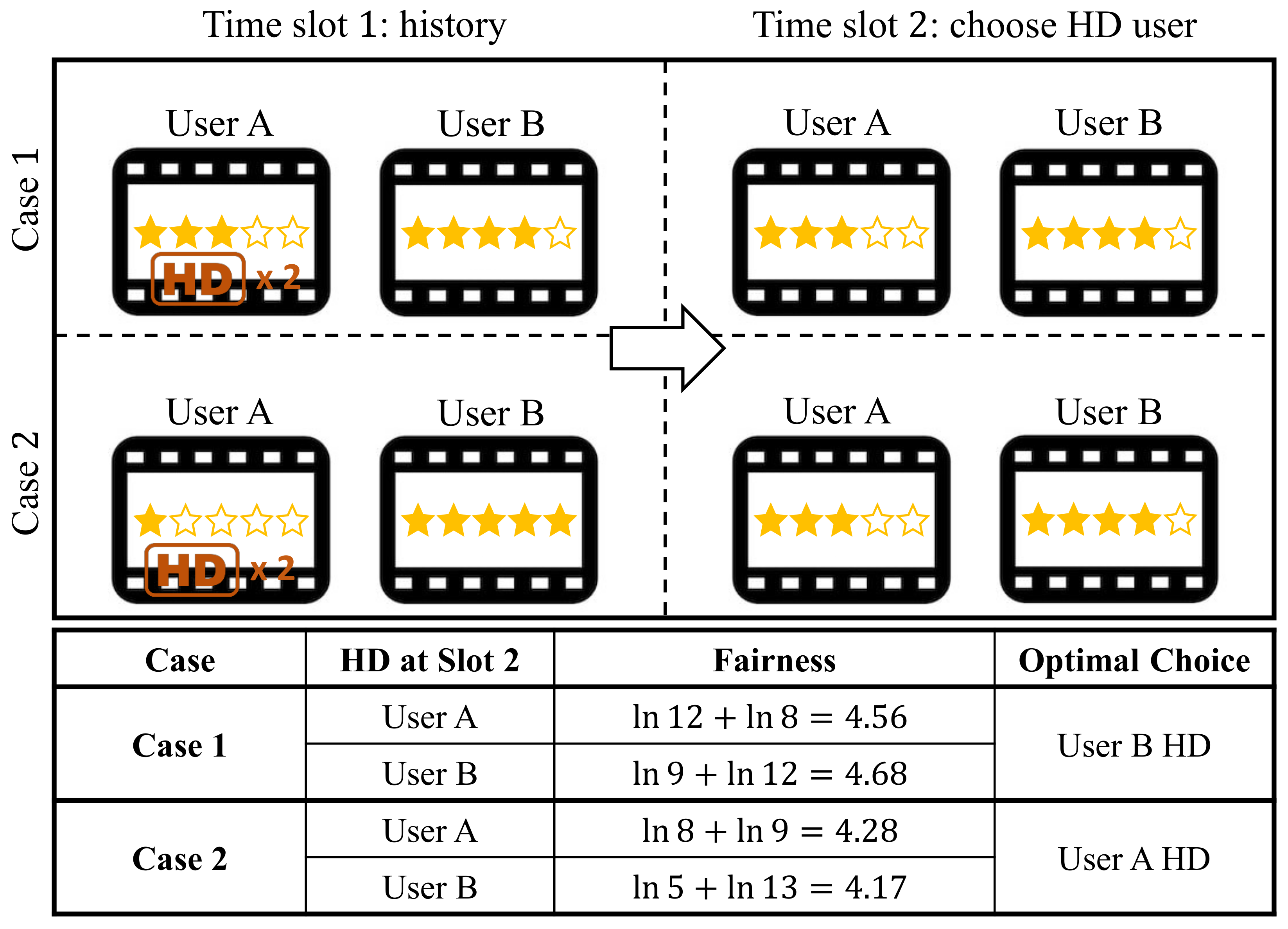
3.3. Quality of Experience
4. Problem Formulation
4.1. State
4.2. Action and State Transition
4.3. Feedback
| Algorithm 1 Proposed MA-Stream Algorithm |
| 1: Input: Set of users , maximum bandwidth B |
| 2: for slot do |
| 3: Observe state as described in Section 4.1 |
| 4: Compute bandwidth allocations for all using RL engine |
| 5: while No user switches video do |
| 6: Continue streaming with for all |
| 7: Store Stall duration, for slot l for all |
| 8: end while |
| 9: end for |
5. Policy Gradient for MA-Stream
5.1. Standard RL Algorithms
5.2. Model-Free Multi-Agent Policy Gradient Algorithm
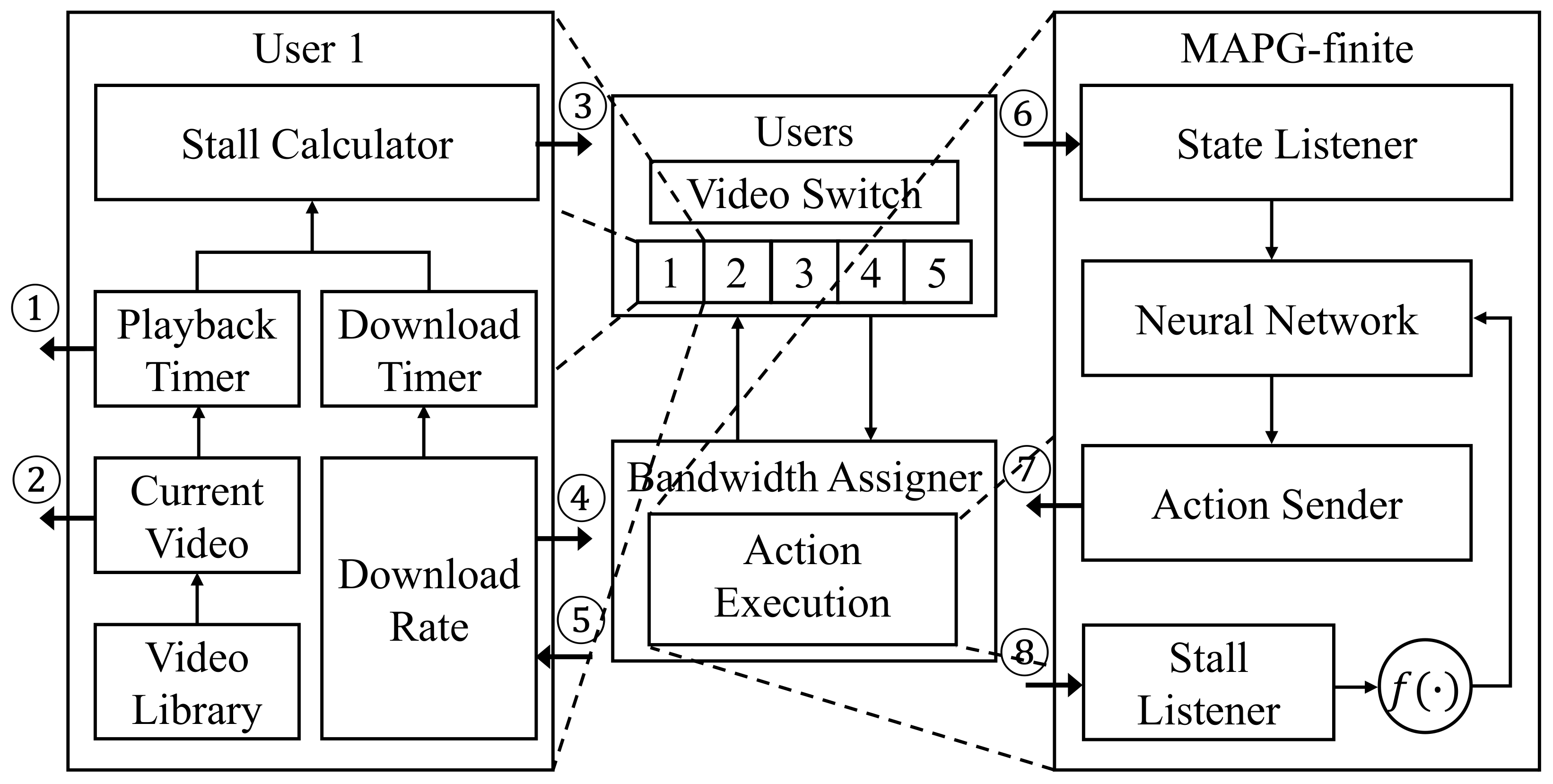
6. Evaluation
6.1. Evaluation Setup
6.1.1. Evaluated Policies
6.1.2. Reward Functions
6.1.3. Users and Videos
6.1.4. Implementation
6.2. Evaluation Results
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cisco Systems Inc. Cisco Visual Networking Index: Forecast and Methodology, 2015–2020. In CISCO White Paper; Cisco Systems Inc.: San Jose, CA, USA, 2016. [Google Scholar]
- Avcibas, I.; Sankur, B.; Sayood, K. Statistical evaluation of image quality measures. J. Electron. Imaging 2002, 11, 206–223. [Google Scholar]
- Wang, Z.; Lu, L.; Bovik, A.C. Video quality assessment based on structural distortion measurement. Signal Process. Image Commun. 2004, 19, 121–132. [Google Scholar] [CrossRef] [Green Version]
- Kaul, S.; Gruteser, M.; Rai, V.; Kenney, J. Minimizing age of information in vehicular networks. In Proceedings of the 2011 8th Annual IEEE Communications Society Conference on Sensor, Mesh and Ad Hoc Communications and Networks, Salt Lake City, UT, USA, 27–30 June 2011; pp. 350–358. [Google Scholar]
- Ruan, J.; Xie, D. A survey on QoE-oriented VR video streaming: Some research issues and challenges. Electronics 2021, 10, 2155. [Google Scholar] [CrossRef]
- Al-Abbasi, A.O.; Aggarwal, V.; Lan, T.; Xiang, Y.; Ra, M.R.; Chen, Y.F. Fasttrack: Minimizing stalls for cdn-based over-the-top video streaming systems. IEEE Trans. Cloud Comput. 2019, 9, 1453–1466. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Li, Y.; Lan, T.; Aggarwal, V. Deepchunk: Deep q-learning for chunk-based caching in wireless data processing networks. IEEE Trans. Cogn. Commun. Netw. 2019, 5, 1034–1045. [Google Scholar] [CrossRef]
- Georgopoulos, P.; Elkhatib, Y.; Broadbent, M.; Mu, M.; Race, N. Towards network-wide QoE fairness using openflow-assisted adaptive video streaming. In Proceedings of the 2013 ACM SIGCOMM workshop on Future Human-Centric Multimedia Networking, Hong Kong, China, 16 August 2013; pp. 15–20. [Google Scholar]
- Cherif, W.; Ksentini, A.; Négru, D.; Sidibé, M. A_PSQA: Efficient real-time video streaming QoE tool in a future media internet context. In Proceedings of the 2011 IEEE International Conference on Multimedia and Expo, Barcelona, Spain, 11–15 July 2011; pp. 1–6. [Google Scholar]
- Ye, D.; Zhang, M.; Yang, Y. A multi-agent framework for packet routing in wireless sensor networks. Sensors 2015, 15, 10026–10047. [Google Scholar] [CrossRef] [Green Version]
- Liang, L.; Ye, H.; Li, G.Y. Spectrum sharing in vehicular networks based on multi-agent reinforcement learning. IEEE J. Sel. Areas Commun. 2019, 37, 2282–2292. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Li, Y.; Lan, T.; Choi, N. A reinforcement learning approach for online service tree placement in edge computing. In Proceedings of the 2019 IEEE 27th International Conference on Network Protocols (ICNP), Chicago, IL, USA, 8–10 October 2019; pp. 1–6. [Google Scholar]
- Lan, T.; Kao, D.T.H.; Chiang, M.; Sabharwal, A. An Axiomatic Theory of Fairness in Network Resource Allocation. In Proceedings of the IEEE INFOCOM, San Diego, CA, USA, 14–19 March 2010. [Google Scholar]
- Zhang, X.; Sen, S.; Kurniawan, D.; Gunawi, H.; Jiang, J. E2E: Embracing user heterogeneity to improve quality of experience on the web. In Proceedings of the ACM Special Interest Group on Data Communication, Beijing, China, 19–23 August 2019; pp. 289–302. [Google Scholar]
- Agarwal, M.; Aggarwal, V.; Lan, T. Multi-Objective Reinforcement Learning with Non-Linear Scalarization. In Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems, Virtual Event, New Zealand, 9–13 May 2022; pp. 9–17. [Google Scholar]
- Margolies, R.; Sridharan, A.; Aggarwal, V.; Jana, R.; Shankaranarayanan, N.; Vaishampayan, V.A.; Zussman, G. Exploiting mobility in proportional fair cellular scheduling: Measurements and algorithms. IEEE/ACM Trans. Netw. 2014, 24, 355–367. [Google Scholar] [CrossRef]
- Bu, L.; Babu, R.; De Schutter, B. A comprehensive survey of multiagent reinforcement learning. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2008, 38, 156–172. [Google Scholar]
- Guestrin, C.; Lagoudakis, M.; Parr, R. Coordinated reinforcement learning. In Proceedings of the ICML-2002 The Nineteenth International Conference on Machine Learning, Sydney, Australia, 8–12 July 2002; Volume 2, pp. 227–234. [Google Scholar]
- Kok, J.R.; Vlassis, N. Sparse cooperative Q-learning. In Proceedings of the 21st International Conference On Machine Learning, Banff, AB, Canada, 4–8 July 2004; p. 61. [Google Scholar]
- Kok, J.R.; Vlassis, N. Using the max-plus algorithm for multiagent decision making in coordination graphs. In Proceedings of the Robot Soccer World Cup; Springer: Berlin/Heidelberg, Germany, 2005; pp. 1–12. [Google Scholar]
- Fitch, R.; Hengst, B.; Šuc, D.; Calbert, G.; Scholz, J. Structural abstraction experiments in reinforcement learning. In Proceedings of the Australasian Joint Conference on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2005; pp. 164–175. [Google Scholar]
- Busoniu, L.; De Schutter, B.; Babuska, R. Multiagent Reinforcement Learning with Adaptive State Focus. In Proceedings of the BNAIC, Brussels, Belgium, 17–18 October 2005; pp. 35–42. [Google Scholar]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Sutton, R.S.; McAllester, D.A.; Singh, S.P.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 29 November–4 December 1999; pp. 1057–1063. [Google Scholar]
- Iima, H.; Kuroe, Y.; Matsuda, S. Swarm reinforcement learning method based on ant colony optimization. In Proceedings of the 2010 IEEE International Conference on Systems, Man and Cybernetics, Istanbul, Turkey, 10–13 October 2010; pp. 1726–1733. [Google Scholar]
- Sehgal, A.; La, H.; Louis, S.; Nguyen, H. Deep reinforcement learning using genetic algorithm for parameter optimization. In Proceedings of the 2019 3rd IEEE International Conference on Robotic Computing (IRC), Naples, Italy, 25–27 February 2019; pp. 596–601. [Google Scholar]
- Liu, Y.; Cao, B.; Li, H. Improving ant colony optimization algorithm with epsilon greedy and Levy flight. Complex Intell. Syst. 2021, 7, 1711–1722. [Google Scholar] [CrossRef] [Green Version]
- D’andreagiovanni, F.; Krolikowski, J.; Pulaj, J. A fast hybrid primal heuristic for multiband robust capacitated network design with multiple time periods. Appl. Soft Comput. 2015, 26, 497–507. [Google Scholar] [CrossRef] [Green Version]
- Foerster, J.; Assael, I.A.; De Freitas, N.; Whiteson, S. Learning to communicate with deep multi-agent reinforcement learning. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2137–2145. [Google Scholar]
- Castellini, J.; Oliehoek, F.A.; Savani, R.; Whiteson, S. The representational capacity of action-value networks for multi-agent reinforcement learning. In Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, Montreal, QC, Canada, 13–17 May 2019; pp. 1862–1864. [Google Scholar]
- Fu, H.; Tang, H.; Hao, J.; Lei, Z.; Chen, Y.; Fan, C. Deep multi-agent reinforcement learning with discrete-continuous hybrid action spaces. arXiv 2019, arXiv:1903.04959. [Google Scholar]
- Wang, Y.; Zhang, Z. Experience Selection in Multi-agent Deep Reinforcement Learning. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; pp. 864–870. [Google Scholar]
- Al-Abbasi, A.O.; Ghosh, A.; Aggarwal, V. Deeppool: Distributed model-free algorithm for ride-sharing using deep reinforcement learning. IEEE Trans. Intell. Transp. Syst. 2019, 20, 4714–4727. [Google Scholar] [CrossRef] [Green Version]
- Haliem, M.; Mani, G.; Aggarwal, V.; Bhargava, B. A distributed model-free ride-sharing approach for joint matching, pricing, and dispatching using deep reinforcement learning. IEEE Trans. Intell. Transp. Syst. 2021, 22, 7931–7942. [Google Scholar] [CrossRef]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef]
- Elgabli, A.; Aggarwal, V. FastScan: Robust Low-Complexity Rate Adaptation Algorithm for Video Streaming Over HTTP. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 2240–2249. [Google Scholar] [CrossRef] [Green Version]
- Huang, T.Y.; Johari, R.; McKeown, N.; Trunnell, M.; Watson, M. A buffer-based approach to rate adaptation: Evidence from a large video streaming service. In Proceedings of the 2014 ACM Conference on SIGCOMM, Chicago, IL, USA, 17–22 August 2014; pp. 187–198. [Google Scholar]
- Spiteri, K.; Urgaonkar, R.; Sitaraman, R.K. BOLA: Near-optimal bitrate adaptation for online videos. IEEE/ACM Trans. Netw. 2020, 28, 1698–1711. [Google Scholar] [CrossRef]
- Yin, X.; Jindal, A.; Sekar, V.; Sinopoli, B. A control-theoretic approach for dynamic adaptive video streaming over HTTP. In Proceedings of the 2015 ACM Conference on Special Interest Group on Data Communication, London, UK, 17–21 August 2015; pp. 325–338. [Google Scholar]
- Elgabli, A.; Aggarwal, V.; Hao, S.; Qian, F.; Sen, S. LBP: Robust rate adaptation algorithm for SVC video streaming. IEEE/ACM Trans. Netw. 2018, 26, 1633–1645. [Google Scholar] [CrossRef] [Green Version]
- Mao, H.; Netravali, R.; Alizadeh, M. Neural adaptive video streaming with pensieve. In Proceedings of the ACM Special Interest Group on Data Communication, Los Angeles, CA, USA, 21–25 August 2017; pp. 197–210. [Google Scholar]
- Friedlander, E.; Aggarwal, V. Generalization of LRU cache replacement policy with applications to video streaming. ACM Trans. Model. Perform. Eval. Comput. Syst. (TOMPECS) 2019, 4, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Kimura, T.; Yokota, M.; Matsumoto, A.; Takeshita, K.; Kawano, T.; Sato, K.; Yamamoto, H.; Hayashi, T.; Shiomoto, K.; Miyazaki, K. QUVE: QoE maximizing framework for video-streaming. IEEE J. Sel. Top. Signal Process. 2016, 11, 138–153. [Google Scholar] [CrossRef]
- Li, C.; Toni, L.; Zou, J.; Xiong, H.; Frossard, P. QoE-driven mobile edge caching placement for adaptive video streaming. IEEE Trans. Multimed. 2017, 20, 965–984. [Google Scholar] [CrossRef] [Green Version]
- Bentaleb, A.; Begen, A.C.; Zimmermann, R. SDNDASH: Improving QoE of HTTP adaptive streaming using software defined networking. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 1296–1305. [Google Scholar]
- Qian, L.; Cheng, Z.; Fang, Z.; Ding, L.; Yang, F.; Huang, W. A QoE-driven encoder adaptation scheme for multi-user video streaming in wireless networks. IEEE Trans. Broadcast. 2016, 63, 20–31. [Google Scholar] [CrossRef]
- Miller, K.; Al-Tamimi, A.K.; Wolisz, A. QoE-based low-delay live streaming using throughput predictions. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2016, 13, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Bhattacharyya, R.; Bura, A.; Rengarajan, D.; Rumuly, M.; Shakkottai, S.; Kalathil, D.; Mok, R.K.; Dhamdhere, A. QFlow: A reinforcement learning approach to high QoE video streaming over wireless networks. In Proceedings of the 20th ACM International Symposium on Mobile Ad Hoc Networking And Computing, Catania, Italy, 2–5 July 2019; pp. 251–260. [Google Scholar]
- Zinner, T.; Hohlfeld, O.; Abboud, O.; Hoßfeld, T. Impact of frame rate and resolution on objective QoE metrics. In Proceedings of the 2010 2nd International Workshop on Quality of Multimedia Experience (QoMEX), Trondheim, Norway, 21–23 June 2010; pp. 29–34. [Google Scholar]
- Balachandran, A.; Aggarwal, V.; Halepovic, E.; Pang, J.; Seshan, S.; Venkataraman, S.; Yan, H. Modeling web quality-of-experience on cellular networks. In Proceedings of the 20th Annual International Conference on Mobile Computing and Networking, Maui, HI, USA, 7–11 September 2014; pp. 213–224. [Google Scholar]
- Alreshoodi, M.; Woods, J. Survey on QoE\QoS correlation models for multimedia services. arXiv 2013, arXiv:1306.0221. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Rummery, G.A.; Niranjan, M. On-Line Q-Learning Using Connectionist Systems; Department of Engineering, University of Cambridge: Cambridge, UK, 1994; Volume 37. [Google Scholar]
- Sutton, R.S. Generalization in reinforcement learning: Successful examples using sparse coarse coding. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 2–5 December 1996; pp. 1038–1044. [Google Scholar]
- Van Seijen, H.; Van Hasselt, H.; Whiteson, S.; Wiering, M. A theoretical and empirical analysis of Expected Sarsa. In Proceedings of the 2009 IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning, Nashville, TN, USA, 30 March–2 April 2009; pp. 177–184. [Google Scholar]
- Wang, W.; Li, B.; Liang, B. Dominant resource fairness in cloud computing systems with heterogeneous servers. In Proceedings of the IEEE INFOCOM 2014-IEEE Conference on Computer Communications, Toronto, ON, Canada, 27 April–2 May 2014; pp. 583–591. [Google Scholar]
- Bertsekas, D.P.; Tsitsiklis, J.N. Neuro-Dynamic Programming; Athena Scientific: Nashua, NH, USA, 1996. [Google Scholar]
- YouTube Help—Recommended Upload Encoding Settings. Available online: https://support.google.com/youtube/answer/1722171 (accessed on 1 May 2022).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description |
|---|---|
| K | number of clients in the system |
| k | index for agents, runs from 1 to K |
| B | total bandwidth of the system |
| l | slot index |
| L | total slots considered |
| download rate for user k in slot l | |
| bitrate of chunk sent to user k in slot l | |
| index of video streamed by user k in slot l | |
| m | chunk index of the video |
| time at which user k starts playing chunk m for video | |
| time at which server starts sending chunk m for video | |
| time at which user k finishes playing chunk m for video |
| User | Resolutions | Bitrates | Probabilities |
|---|---|---|---|
| 1 | 1080p 720p | 8 Mbps 5 Mbps | 0.5 0.5 |
| 2 | 1080p 720p | 8 Mbps 5 Mbps | 0.5 0.5 |
| 3 | 1080p 720p | 8 Mbps 5 Mbps | 0.5 0.5 |
| 4 | 480p 360p | 2.5 Mbps 1 Mbps | 0.5 0.5 |
| 5 | 480p 360p | 2.5 Mbps 1 Mbps | 0.5 0.5 |
| Policy | Total Reward | User Average | ||
|---|---|---|---|---|
| User | Stall Ratio | Reward | ||
| “Even” | 3877.05 | 1, 2, 3 (HD) 4, 5 (LD) | 0.64 0.13 | 0.07 0.86 |
| “Adaptive” | 1773.30 | 1, 2, 3 (HD) 4, 5 (LD) | 0.51 0.59 | 0.20 0.14 |
| MAPG-finite | 4781.88 | 1 2 3 4 5 | 0.34 0.50 0.39 0.07 0.08 | 0.52 0.27 0.44 0.91 0.91 |
| Policy | Total Reward | User Average | ||
|---|---|---|---|---|
| Users | Stall Ratio | Reward | ||
| “Even” | 7796.12 | 1, 2, 3 (HD) 4, 5 (LD) | 0.39 0.08 | 0.67 0.93 |
| “Adaptive” | 8251.66 | 1, 2, 3 (HD) 4, 5 (LD) | 0.18 0.28 | 0.86 0.77 |
| MAPG-finite | 8441.75 | 1, 2, 3 (HD) 4, 5 (LD) | 0.24 0.11 | 0.80 0.91 |
| “Low Dev” | 8263.49 | 1, 2, 3 (HD) 4, 5 (LD) | 0.22 0.20 | 0.82 0.84 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Agarwal, M.; Lan, T.; Aggarwal, V. Learning-Based Online QoE Optimization in Multi-Agent Video Streaming. Algorithms 2022, 15, 227. https://doi.org/10.3390/a15070227
Wang Y, Agarwal M, Lan T, Aggarwal V. Learning-Based Online QoE Optimization in Multi-Agent Video Streaming. Algorithms. 2022; 15(7):227. https://doi.org/10.3390/a15070227
Chicago/Turabian StyleWang, Yimeng, Mridul Agarwal, Tian Lan, and Vaneet Aggarwal. 2022. "Learning-Based Online QoE Optimization in Multi-Agent Video Streaming" Algorithms 15, no. 7: 227. https://doi.org/10.3390/a15070227
APA StyleWang, Y., Agarwal, M., Lan, T., & Aggarwal, V. (2022). Learning-Based Online QoE Optimization in Multi-Agent Video Streaming. Algorithms, 15(7), 227. https://doi.org/10.3390/a15070227