
Scale-Free Random SAT Instances


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Generation of Scale-Free Graphs
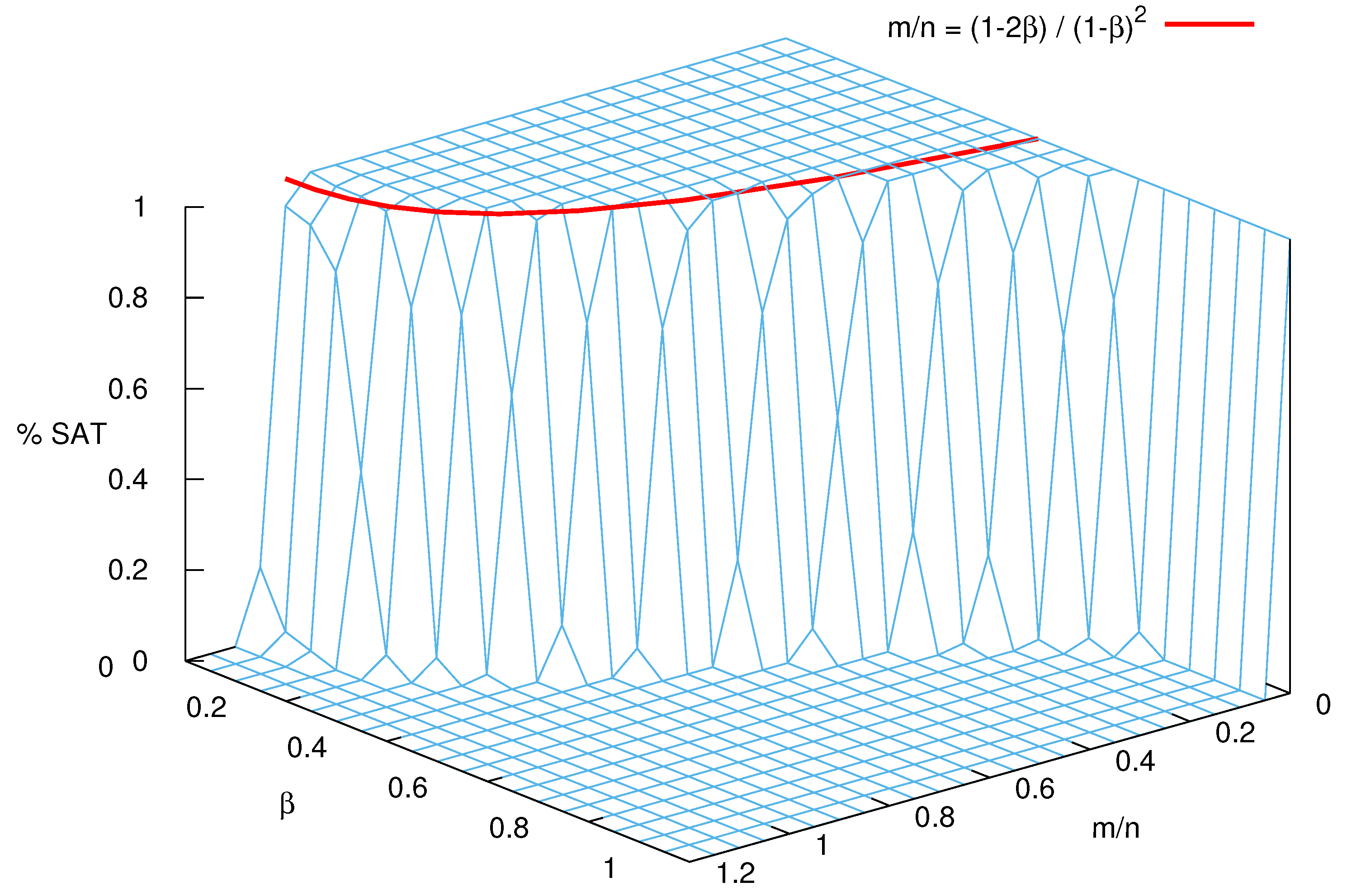
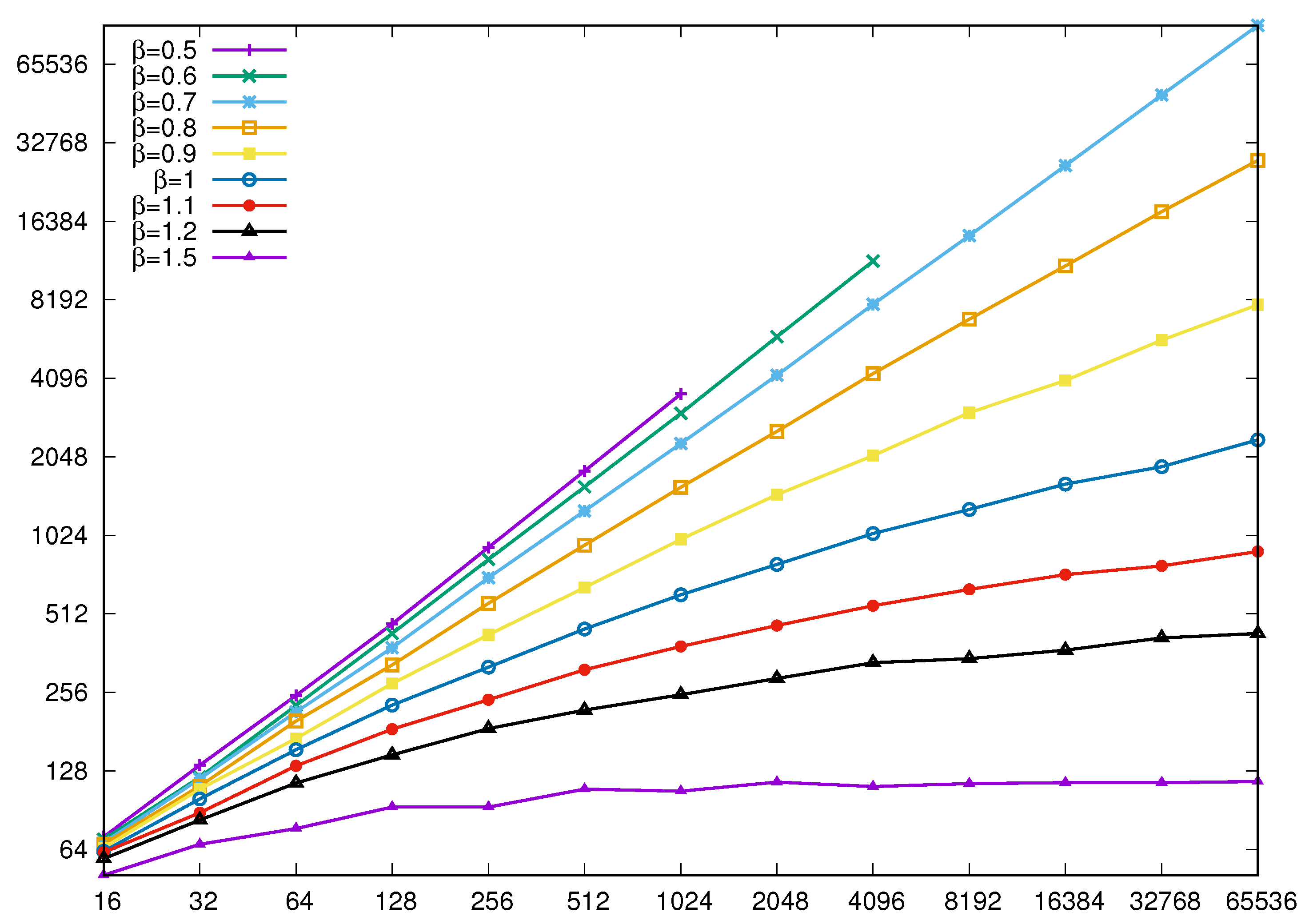
3. Scale-Free Random Formulas
3.1. Some Properties of the Model
3.2. Implementation of the Generator
| Algorithm 1: Scale-free random k-SAT formula generator. |
 |
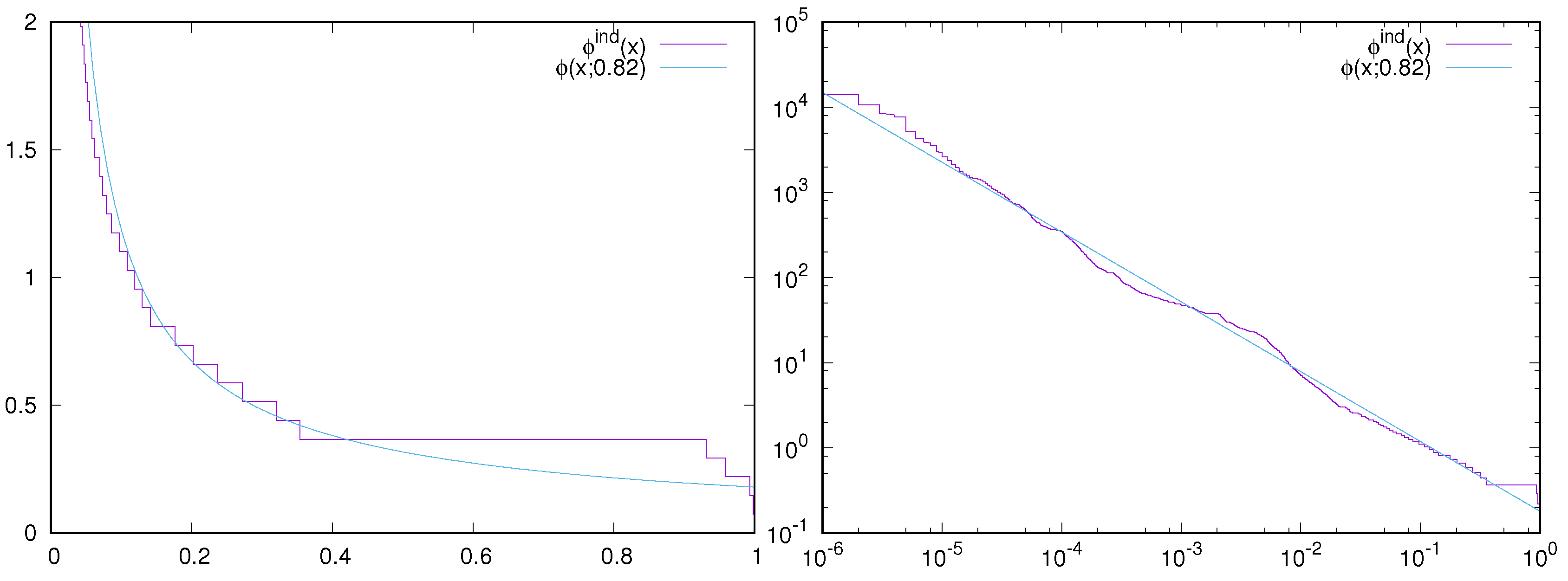
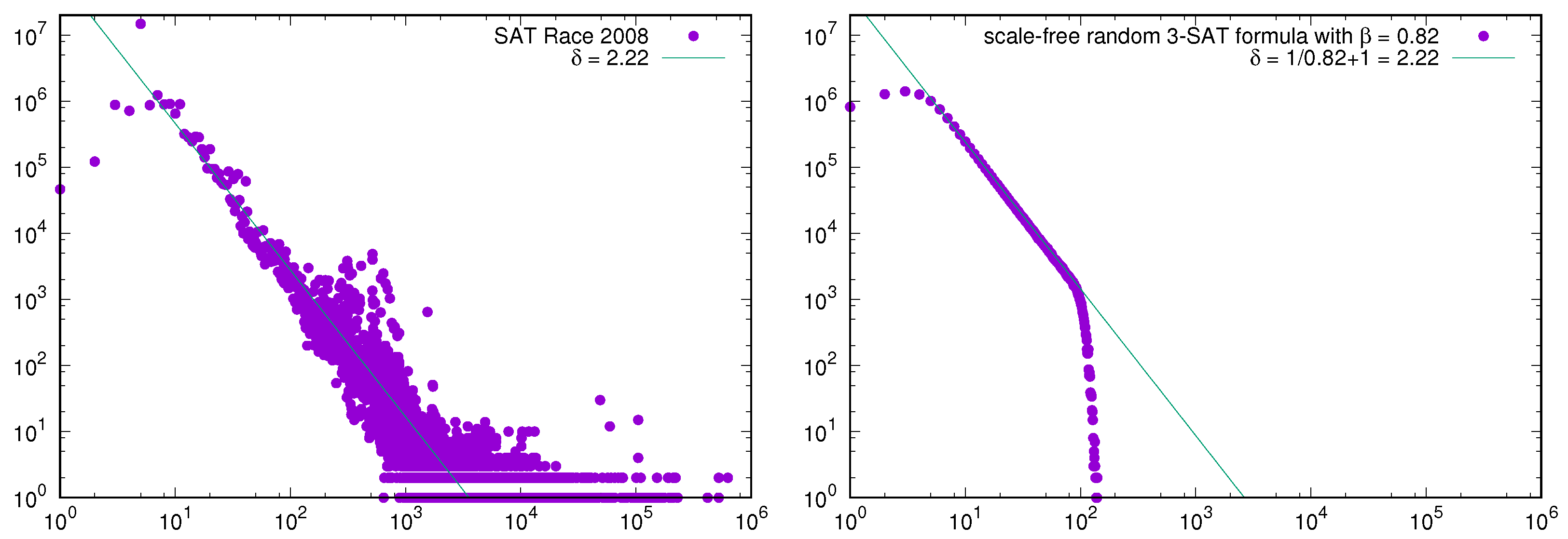
4. Industrial SAT Instances
5. Phase Transition in Scale-Free Random 2-SAT Formulas
- when , i.e., , a random graph almost surely has no connected component larger than ;
- when , i.e., a largest component of size almost surely emerges;
- when , i.e., , the graph almost surely contains a unique giant component with a fraction of the nodes and no other component contains more than nodes.
5.1. A Criterion for Phase Transition in 2-SAT
| Algorithm 2: Algorithm for finding literals implied by x. |
 |
- (case A), if and ;
- (case B), if ;
- (case C), if and .
5.2. Classical 2-SAT Formulas
5.3. Scale-Free 2-SAT Formulas
6. Unsatisfiability by Small Cores
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Selman, B.; Kautz, H.A.; McAllester, D.A. Ten Challenges in Propositional Reasoning and Search. In Proceedings of the 15th International Joint Conference on Artificial Intelligence (IJCAI 1997), Nagoya, Japan, 23–29 August 1997; pp. 50–54. [Google Scholar]
- Selman, B. Satisfiability Testing: Recent Developments and Challenge Problems. In Proceedings of the 15th Annual IEEE Symposium on Logic in Computer Science (LICS 2000), Santa Barbara, CA, USA, 26–29 June 2000; p. 178. [Google Scholar]
- Kautz, H.A.; Selman, B. Ten Challenges Redux: Recent Progress in Propositional Reasoning and Search. In Proceedings of the 9th International Conference on Principles and Practice of Constraint Programming (CP 2003), Kinsale, Ireland, 29 September–3 October 2003; pp. 1–18. [Google Scholar]
- Kautz, H.A.; Selman, B. The state of SAT. Discret. Appl. Math. 2007, 155, 1514–1524. [Google Scholar] [CrossRef]
- Ansótegui, C.; Bonet, M.L.; Levy, J. On the Structure of Industrial SAT Instances. In Proceedings of the 15th International Conference on Principles and Practice of Constraint Programming, CP 2009, Lisbon, Portugal, 20–24 September 2009; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2009; Volume 5732, pp. 127–141. [Google Scholar] [CrossRef]
- Ansótegui, C.; Bonet, M.L.; Giráldez-Cru, J.; Levy, J.; Simon, L. Community Structure in Industrial SAT Instances. J. Artif. Intell. Res. 2019, 66, 443–472. [Google Scholar] [CrossRef]
- Newsham, Z.; Ganesh, V.; Fischmeister, S.; Audemard, G.; Simon, L. Impact of Community Structure on SAT Solver Performance. In Proceedings of the 17th International Conference on Theory and Applications of Satisfiability Testing (SAT 2014), Vienna, Austria, 14–17 July 2014; pp. 252–268. [Google Scholar]
- Sonobe, T.; Kondoh, S.; Inaba, M. Community Branching for Parallel Portfolio SAT Solvers. In Proceedings of the 17th International Conference on Theory and Applications of Satisfiability Testing (SAT 2014), Vienna, Austria, 14–17 July 2014; pp. 188–196. [Google Scholar]
- Martins, R.; Manquinho, V.M.; Lynce, I. Community-Based Partitioning for MaxSAT Solving. In Proceedings of the 16th International Conference on Theory and Applications of Satisfiability Testing (SAT 2013), Helsinki, Finland, 8–12 July 2013; pp. 182–191. [Google Scholar]
- Katsirelos, G.; Simon, L. Eigenvector Centrality in Industrial SAT Instances. In Proceedings of the 18th International Conference on Principles and Practice of Constraint Programming (CP 2012), Quebec, QC, Canada, 8–12 October 2012; pp. 348–356. [Google Scholar]
- Ansótegui, C.; Bonet, M.L.; Levy, J. Towards Industrial-Like Random SAT Instances. In Proceedings of the 21st International Joint Conference on Artificial Intelligence, IJCAI 2009, Newark, NJ, USA, 2–5 November 2009; pp. 387–392. [Google Scholar]
- Friedrich, T.; Krohmer, A.; Rothenberger, R.; Sutton, A.M. Phase Transitions for Scale-Free SAT Formulas. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, AAAI 2017, San Francisco, CA, USA, 4–9 February 2017; AAAI Press: Palo Alto, CA, USA, 2017; pp. 3893–3899. [Google Scholar]
- Friedrich, T.; Krohmer, A.; Rothenberger, R.; Sauerwald, T.; Sutton, A.M. Bounds on the Satisfiability Threshold for Power Law Distributed Random SAT. In Proceedings of the 25th Annual European Symposium on Algorithms, ESA 2017, Vienna, Austria, 4–6 September 2017; LIPIcs. Schloss Dagstuhl—Leibniz-Zentrum für Informatik: Wadern, Germany, 2017; Volume 87, pp. 37:1–37:15. [Google Scholar] [CrossRef]
- Friedgut, E. Sharp Thresholds of Graph properties, and the k-SAT Problem. J. Am. Math. Soc. 1998, 12, 1017–1054. [Google Scholar] [CrossRef]
- Friedrich, T.; Rothenberger, R. Sharpness of the Satisfiability Threshold for Non-uniform Random k-SAT. In Proceedings of the 21st International Conference Theory and Applications of Satisfiability Testing, SAT 2018, Oxford, UK, 9–12 July 2018; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2018; Volume 10929, pp. 273–291. [Google Scholar] [CrossRef]
- Friedrich, T.; Rothenberger, R. The Satisfiability Threshold for Non-Uniform Random 2-SAT. In Proceedings of the 46th International Colloquium on Automata, Languages, and Programming, ICALP 2019, Patras, Greece, 8–12 July 2019; LIPIcs. Schloss Dagstuhl—Leibniz-Zentrum für Informatik: Wadern, Germany, 2019; Volume 132, pp. 61:1–61:14. [Google Scholar] [CrossRef]
- Cooper, C.; Frieze, A.; Sorkin, G.B. Random 2-SAT with Prescribed Literal Degrees. Algorithmica 2007, 48, 249–265. [Google Scholar] [CrossRef]
- Omelchenko, O.; Bulatov, A.A. Satisfiability Threshold for Power Law Random 2-SAT in Configuration Model. In Proceedings of the 22nd International Conference on Theory and Applications of Satisfiability Testing, SAT 2019, Lisbon, Portugal, 9–12 July 2019; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2019; Volume 11628, pp. 53–70. [Google Scholar] [CrossRef]
- Omelchenko, O.; Bulatov, A. Satisfiability and Algorithms for Non-uniform Random k-SAT. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Vancouver, BC, Canada, 2–9 February 2021; AAAI Press: Palo Alto, CA, USA, 2021; pp. 3886–3894. [Google Scholar]
- Omelchenko, O.; Bulatov, A.A. Satisfiability threshold for power law random 2-SAT in configuration model. Theor. Comput. Sci. 2021, 888, 70–94. [Google Scholar] [CrossRef]
- Giráldez-Cru, J.; Levy, J. Locality in Random SAT Instances. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI 2017. ijcai.org, Melbourne, Australia, 19–25 August 2017; pp. 638–644. [Google Scholar] [CrossRef]
- Giráldez-Cru, J.; Levy, J. Popularity-similarity random SAT formulas. Artif. Intell. 2021, 299, 103537. [Google Scholar] [CrossRef]
- Achlioptas, D.; Coja-Oghlan, A.; Hahn-Klimroth, M.; Lee, J.; Müller, N.; Penschuck, M.; Zhou, G. The number of satisfying assignments of random 2-SAT formulas. Random Struct. Algorithms 2021, 58, 609–647. [Google Scholar] [CrossRef]
- Bläsius, T.; Friedrich, T.; Göbel, A.; Levy, J.; Rothenberger, R. The Impact of Heterogeneity and Geometry on the Proof Complexity of Random Satisfiability. In Proceedings of the 2021 ACM-SIAM Symposium on Discrete Algorithms, SODA 2021, SIAM 2021, Virtual Conference, 10–13 January 2021; pp. 42–53. [Google Scholar] [CrossRef]
- Barabási, A.L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef]
- Dorogovtsev, S.N.; Mendes, J.F.F. Evolution of Networks: From Biological Nets to the Internet and WWW (Physics); Oxford University Press, Inc.: New York, NY, USA, 2003. [Google Scholar]
- Dorogovtsev, S.N.; Mendes, J.F.F. Evolution of networks with aging of sites. Phys. Rev. E 2000, 62, 1842–1845. [Google Scholar] [CrossRef]
- Bender, E.A.; Canfield, E. The asymptotic number of labeled graphs with given degree sequences. J. Comb. Theory Ser. A 1978, 24, 296–307. [Google Scholar] [CrossRef]
- Bollobás, B. Random Graphs; Cambridge Studies in Advanced Mathematics, Cambridge University Press: Cambridge, UK, 2001. [Google Scholar]
- Aiello, W.; Chung, F.; Lu, L. A Random Graph Model for Massive Graphs. In Proceedings of the Thirty-Second Annual ACM Symposium on Theory of Computing, Portland, OR, USA, 21–23 May 2000; pp. 171–180. [Google Scholar]
- Chung, F.; Lu, L. Connected Components in Random Graphs with Given Expected Degree Sequences. Ann. Comb. 2002, 6, 125–145. [Google Scholar] [CrossRef]
- Goh, K.I.; Kahng, B.; Kim, D. Universal behavior of load distribution in scale-free networks. Phys. Rev. Lett. 2001, 87, 278701. [Google Scholar] [CrossRef] [PubMed]
- Mase, S. Approximations to the birthday problem with unequal occurrence probabilities and their application to the surname problem in Japan. Ann. Inst. Stat. Math. 1992, 44, 479–499. [Google Scholar]
- Boufkhad, Y.; Dubois, O.; Interian, Y.; Selman, B. Regular Random k-SAT: Properties of Balanced Formulas. J. Autom. Reason. 2005, 35, 181–200. [Google Scholar] [CrossRef]
- Chvátal, V.; Reed, B.A. Mick Gets Some (the Odds Are on His Side). In Proceedings of the 33rd Annual Symposium on Foundations of Computer Science, FOCS 1992, Pittsburgh, PA, USA, 244–27 October 1992; pp. 620–627. [Google Scholar]
- Erdös, P.; Rényi, A. On Random Graphs I. Publ. Math. 1959, 6, 290–297. [Google Scholar]
- Gilbert, E.N. Random Graphs. Ann. Math. Stat. 1959, 30, 1141–1144. [Google Scholar] [CrossRef]
- Erdös, P.; Rényi, A. On the evolution of random graphs. Publ. Math. Inst. Hungary. Acad. Sci. 1960, 5, 17–61. [Google Scholar]
- Mitchell, D.G.; Selman, B.; Levesque, H.J. Hard and Easy Distributions of SAT Problems. In Proceedings of the 10th National Conference on Artificial Intelligence (AAAI 1992), San Jose, CA, USA, 12–16 July 1992; pp. 459–465. [Google Scholar]
- Gent, I.P.; Walsh, T. The SAT Phase Transition. In Proceedings of the 11th European Conference on Artificial Intelligenc (ECAI 1994), Amsterdam, The Netherlands, 8–12 August 1994; pp. 105–109. [Google Scholar]
- Achlioptas, D.; Chtcherba, A.D.; Istrate, G.; Moore, C. The phase transition in 1-in-k SAT and NAE 3-SAT. In Proceedings of the 20th Annual Symposium on Discrete Algorithms, SODA 2001, Washington, DC, USA, 7–9 January 2001; pp. 721–722. [Google Scholar]
- Sinclair, A.; Vilenchik, D. Delaying satisfiability for random 2SAT. Random Struct. Algorithms 2013, 43, 251–263. [Google Scholar] [CrossRef]
- Bollobás, B.; Borgs, C.; Chayes, J.T.; Kim, J.H.; Wilson, D.B. The Scaling Window of the 2-SAT Transition. Random Struct. Algorithms 2001, 18, 201–256. [Google Scholar] [CrossRef]
- Bollobás, B. The evolution of random graphs. Trans. Am. Math. Soc. 1984, 286, 257–274. [Google Scholar] [CrossRef]
- Monasson, R.; Zecchina, R.; Kirkpatrick, S.; Selman, B.; Troyansky, L. 2+p-SAT: Relation of typical-case complexity to the nature of the phase transition. Random Struct. Algorithms 1999, 15, 414–435. [Google Scholar] [CrossRef][Green Version]
- Aspvall, B.; Plass, M.F.; Tarjan, R.E. A Linear-Time Algorithm for Testing the Truth of Certain Quantified Boolean Formulas. Inf. Process. Lett. 1979, 8, 121–123. [Google Scholar] [CrossRef]
- Molloy, M.; Reed, B. A critical point for random graphs with a given degree sequence. Random Struct. Algorithms 1995, 6, 161–180. [Google Scholar] [CrossRef]
- Newman, M.E.J. Networks: An Introduction; Oxford University Press: Oxford; NY, USA, 2010. [Google Scholar]
- Cohen, R.; Erez, K.; ben Avraham, D.; Havlin, S. Resilience of the Internet to Random Breakdowns. Phys. Rev. Lett. 2000, 85, 4626–4628. [Google Scholar] [CrossRef] [PubMed]
- Cohen, R.; Havlin, S.; ben Avraham, D. Structural properties of scale-free networks. In Handbook of Graphs and Networks; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2002; Chapter 4; pp. 85–110. [Google Scholar] [CrossRef]
- Boufkhad, Y.; Dubois, O.; Interian, Y.; Selman, B. Regular Random k-SAT: Properties of Balanced Formulas. In Proceedings of the 8th International Conference on Theory and Applications of Satisfiability Testing (SAT 2005), St Andrews, UK, 19–23 June 2005; pp. 181–200. [Google Scholar]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ansótegui , C.; Bonet, M.L.; Levy, J. Scale-Free Random SAT Instances. Algorithms 2022, 15, 219. https://doi.org/10.3390/a15060219
Ansótegui C, Bonet ML, Levy J. Scale-Free Random SAT Instances. Algorithms. 2022; 15(6):219. https://doi.org/10.3390/a15060219
Chicago/Turabian StyleAnsótegui , Carlos, Maria Luisa Bonet, and Jordi Levy. 2022. "Scale-Free Random SAT Instances" Algorithms 15, no. 6: 219. https://doi.org/10.3390/a15060219
APA StyleAnsótegui , C., Bonet, M. L., & Levy, J. (2022). Scale-Free Random SAT Instances. Algorithms, 15(6), 219. https://doi.org/10.3390/a15060219