
Optimal Algorithms for Sorting Permutations with Brooms


Abstract
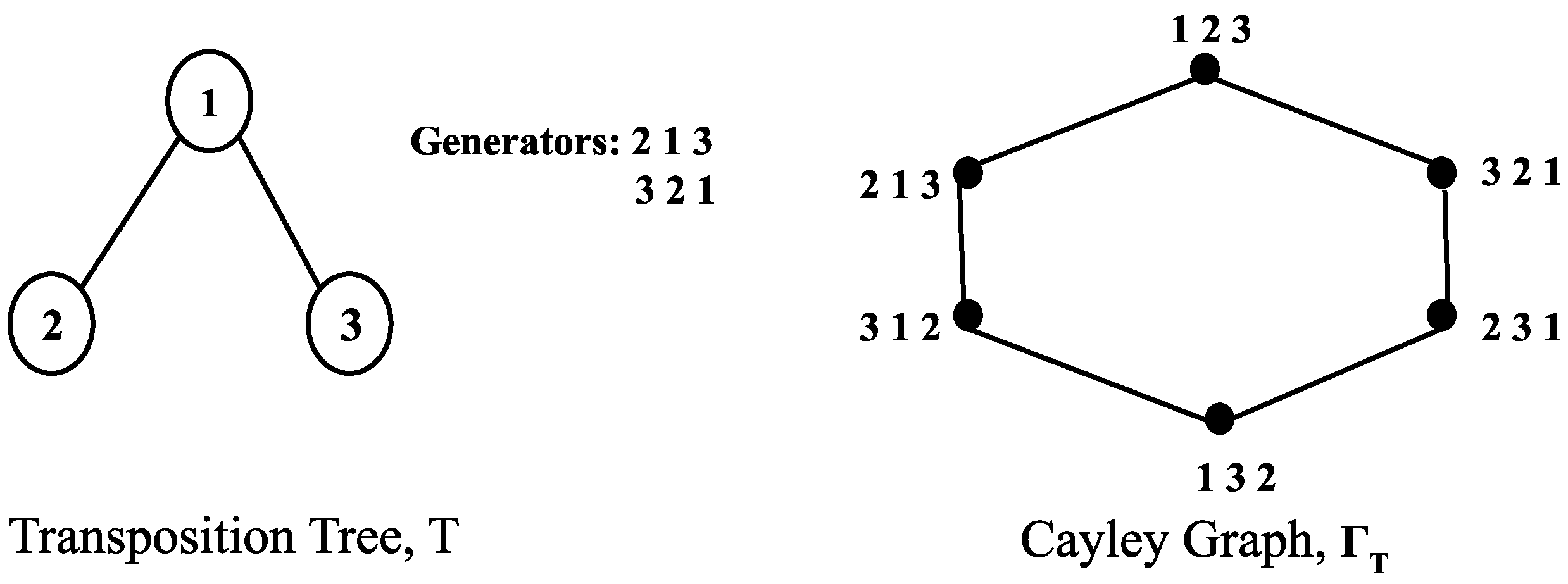
1. Introduction
2. Preliminaries and Background
3. Sorting Permutations with a Single Broom
3.1. Algorithm
- While (∃ a ), efficiently home ;
- While (∃ a ), efficiently home ;
- Efficiently home the markers in the star that need to be homed.
- Star markers residing on the path always move to the left in the increasing order of their distances from their respective homes;
- A path marker moves right to its home; thereby moving the smaller path markers towards the center;
- Swap involving two star markers will not take place on a path edge.
3.2. Analysis of
3.3. Correctness of
- A pair of markers swap at most once.Proof.We prove it using contradiction. Suppose the swap sequence , contains the swap of twice at and . Modify S by deleting and . Then, for each swap where , replace x with y and vice-versa. Resulting swap sequence is shorter and achieves the same results. □
- Star markers that enter the star from path do so in the increasing order of their distance from center.Proof.Consider two star markers x and y residing on the path. Assume x and y are at a distance d and respectively from their home. Let S be the swap sequence containing the swap which swaps y and x on the path. Marker y will be homed after a swap with the marker residing on its home , call this swap where . Similarly x will be homed after a final swap with where . Call this intermediate configuration of markers as . We show how S can be modified in order to obtain an optimal sequence. To modify S, omit and carry out further swaps with x & y and & exchanged, until the swap . Observe that we have obtained the same marker configuration as in but with fewer swaps. □
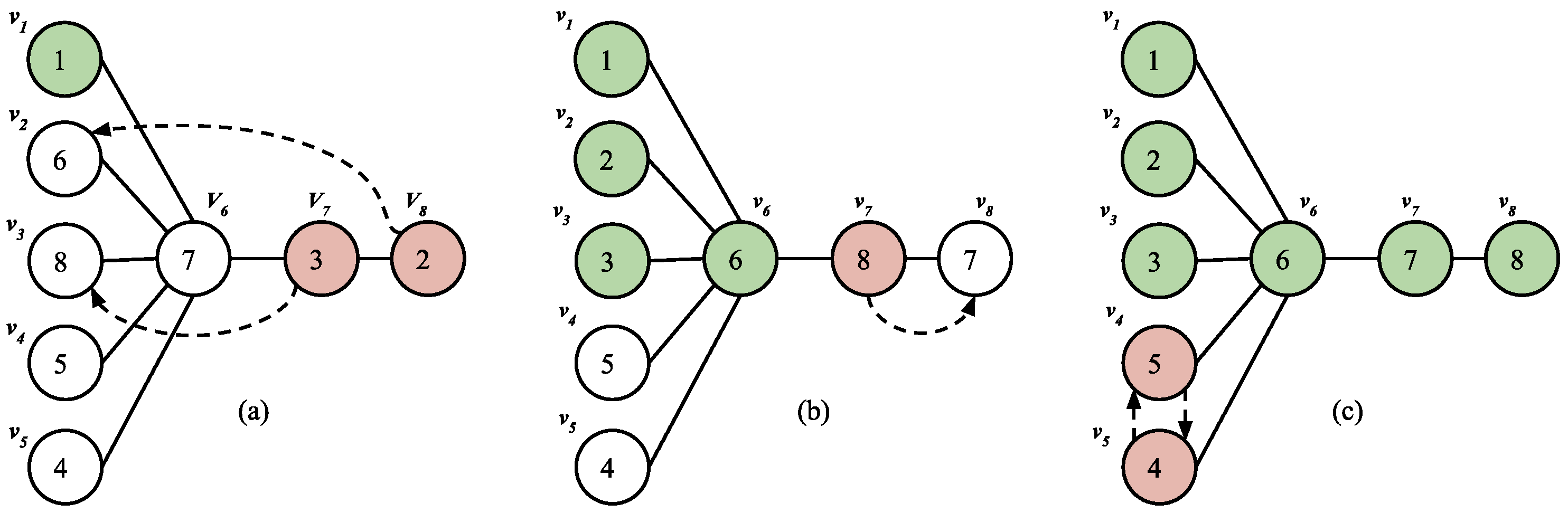
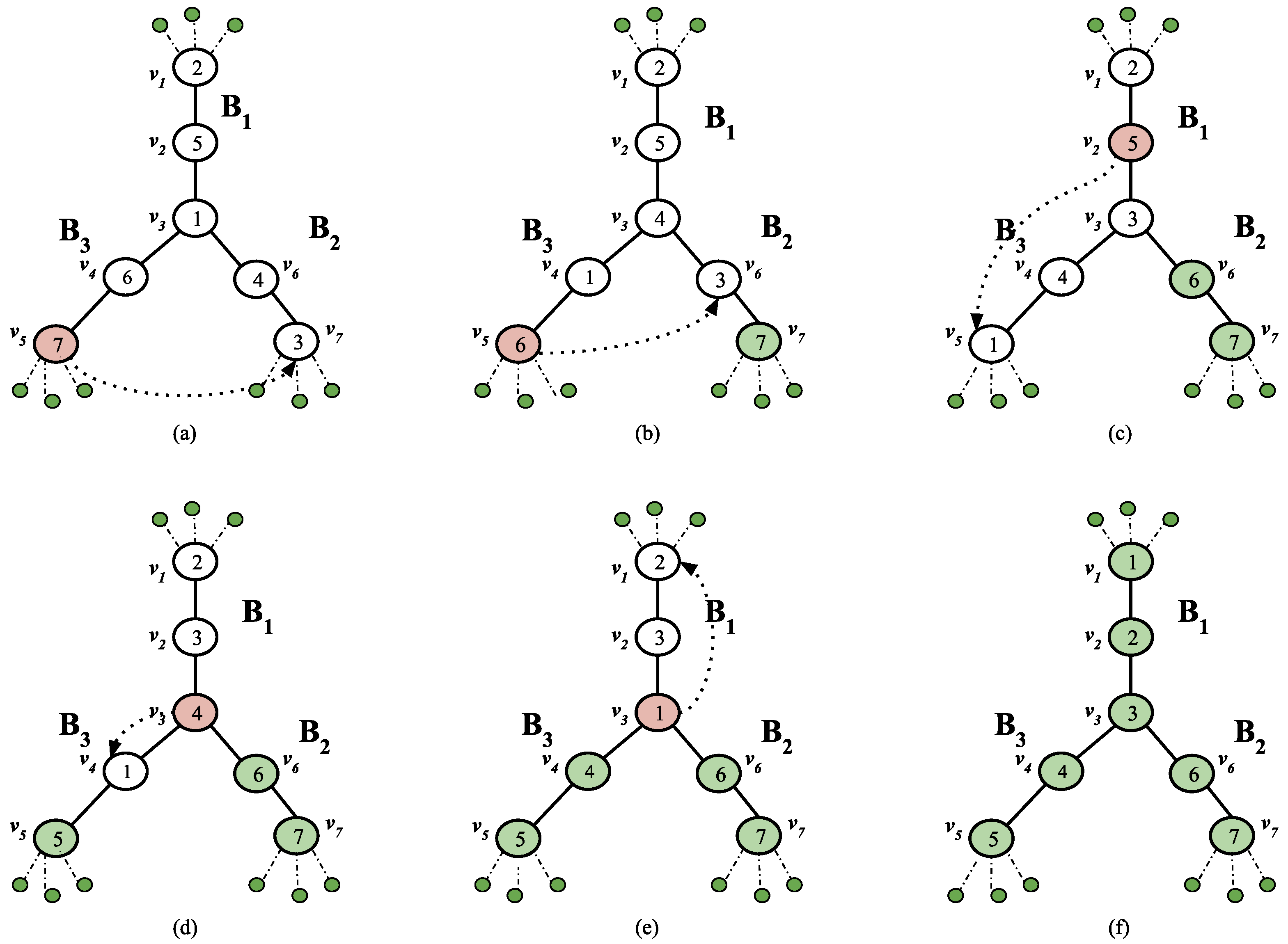
- Two star markers will never swap on a path edge.Proof.Let us take x and y to be the star markers that swap on the path edge in S. We show how S can be modified to obtain a swap sequence with a lesser number of swaps on the path. After the swap of x and y in S, at some point of time, both x and y will get into the star. Let be a sub sequence of S, where y resides on a star leaf and x on the center node. To modify S, remove the swap of x and y and replace x with y and vice versa for the following swaps. Iterate this till the point is reached in S and add a swap of x and y. We have achieved the same target state, but a swap carried out on the path is removed and compensated by adding an additional swap in the star. □To illustrate the same, consider the swap sequence . Note that , where we have 2 at star leaf (say x) and 1 at the center (say y).If we omit the swap move (1, 2) and exchange , we get the modified swap sequence as (refer Figure 4). Followed by a swap move of x and y we achieve the same configuration as but the swap of x and y on path edge is replaced by a swap on star edge, resulting in lesser swaps on path edges.
- In every swap on the path edge involving at least one path marker, the larger of the markers will move to the right.Proof.Considering the contradiction of the stated property, a bad swap involves moving a smaller valued path marker to the right and larger valued path marker to the left. Suppose S contains a bad swap. We show how S can be modified to obtain a new swap sequence which contains fewer swaps on the path. Assume smaller marker s is swapped to the right and larger marker l to the left. Property 1 restricts us from directly swapping them again. Therefore, marker l will move to the star leaf, then marker s to another star leaf and then l goes to the center of the star. Let us call this intermediate placement as . Now, to modify S, remove the swap of s and l, and continue with the preceding swaps with s and l exchanged until the state is reached. We have achieved the same target state, but a swap carried out on the path is removed and compensated for by adding an additional swap in the star; hence, reducing the swap count on the path edge. □
- No star marker moves past the first path edge from left to right.Proof.Let S include a swap in which a maker x moves past the first path edge to the right using a swap with a marker p. Let, is a swap belonging to S where which results in x reentering the star with the help of a swap with q. Taking the least possible j into account, we first establish that the marker q was residing on the star leaf during . Suppose q was on path node during , then q will lie on the right to x. Swaps involving x between and will only keep it on path nodes and not move it past the first path edge as per our assumption. Marker q is restricted to swap twice with x on the path edge as per Property 1, which proves that q lies on the right of x during , which is contradictory. We show how S can be modified to obtain a swap sequence with a lesser number of swaps on the path. Before , carry out a swap of x and q and continue with the following swaps till with x replaced with y and vice-versa. We have achieved the same target state but the swap on a path edge is removed and replaced by a swap on a star edge, hence reducing the number of swaps on the path edge. □
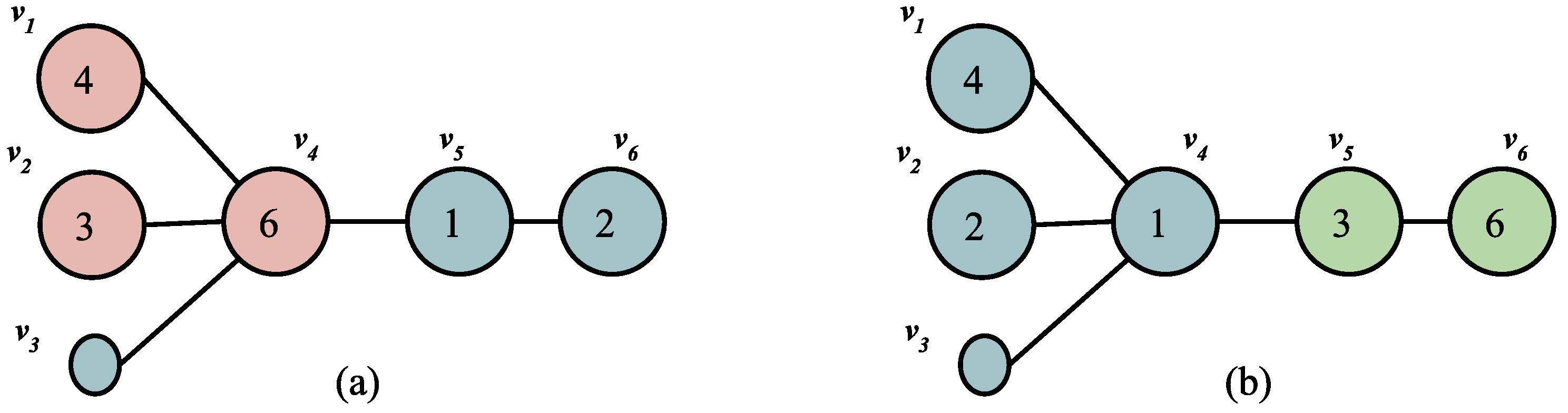
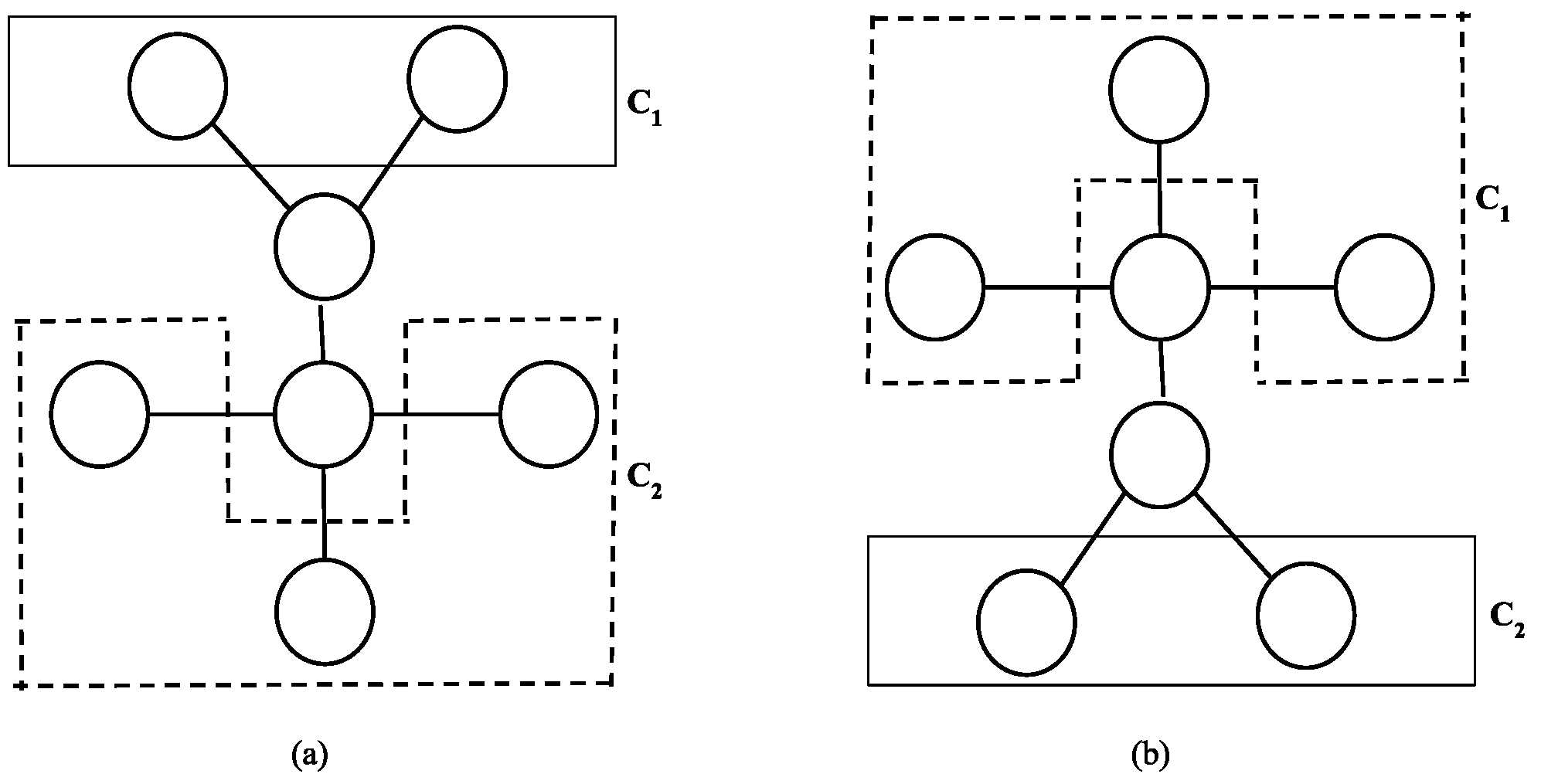
4. Sorting Permutations with a Double Broom
- While ∃ a marker, efficiently home ;
- While ∃ a marker, efficiently home ;
- (At this point, only the stem is left) While ∃ a marker, efficiently home ;
- Efficiently home the markers of and .
- Swap of two star markers belonging to a same star will never take place on a path edge;
- Stem marker moves right to its home, swapping smaller markers to the left.
4.1. Analysis of
4.2. Correctness of
- Two same markers will not swap more than once;
- Star markers belonging to the respective star enter into the star in the increasing order of their distances from that star;
- Star markers belonging to the respective star never swap with each other on the path edges. Note that the star marker belonging to treats the edges of the as path edges and vice-versa;
- Swaps on the stem involving at least one stem marker—the larger of the markers will move to the right’
- No star marker residing on one if its star vertices moves past the first path edge;
- In a swap s = () where and , l always moves to the left and r to the right.
- While ∃ a marker, home .
- Run
- Solve
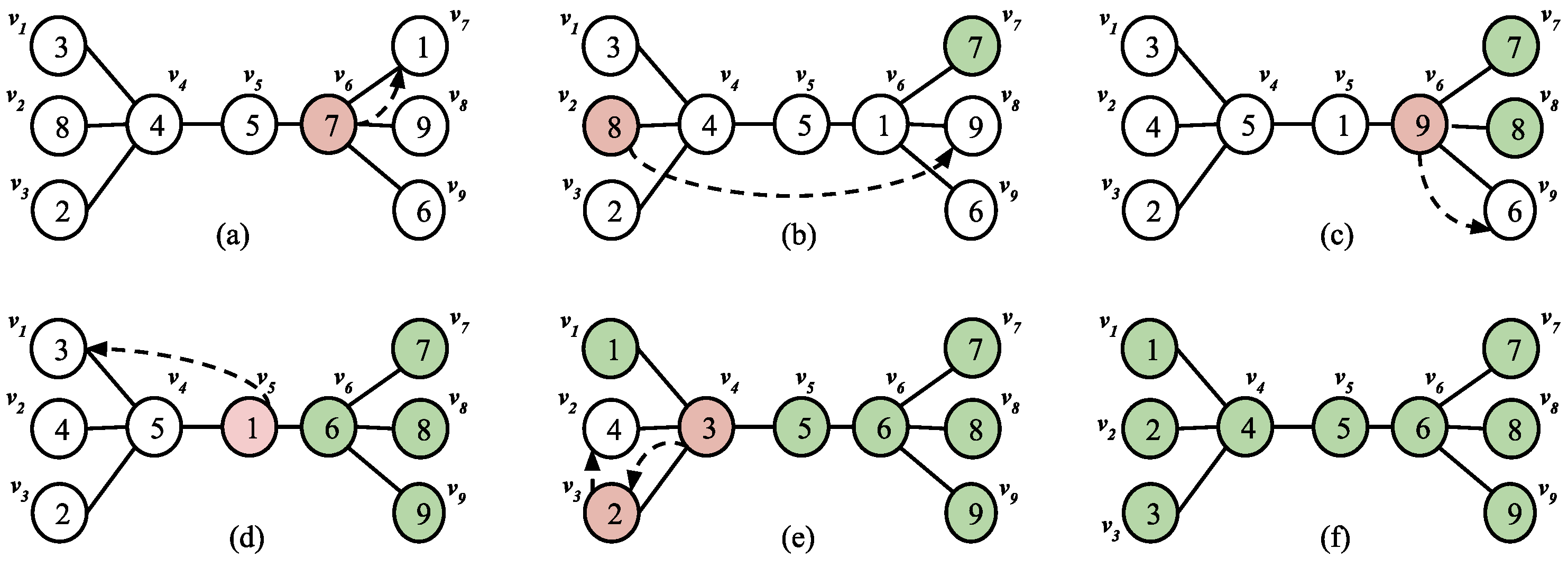
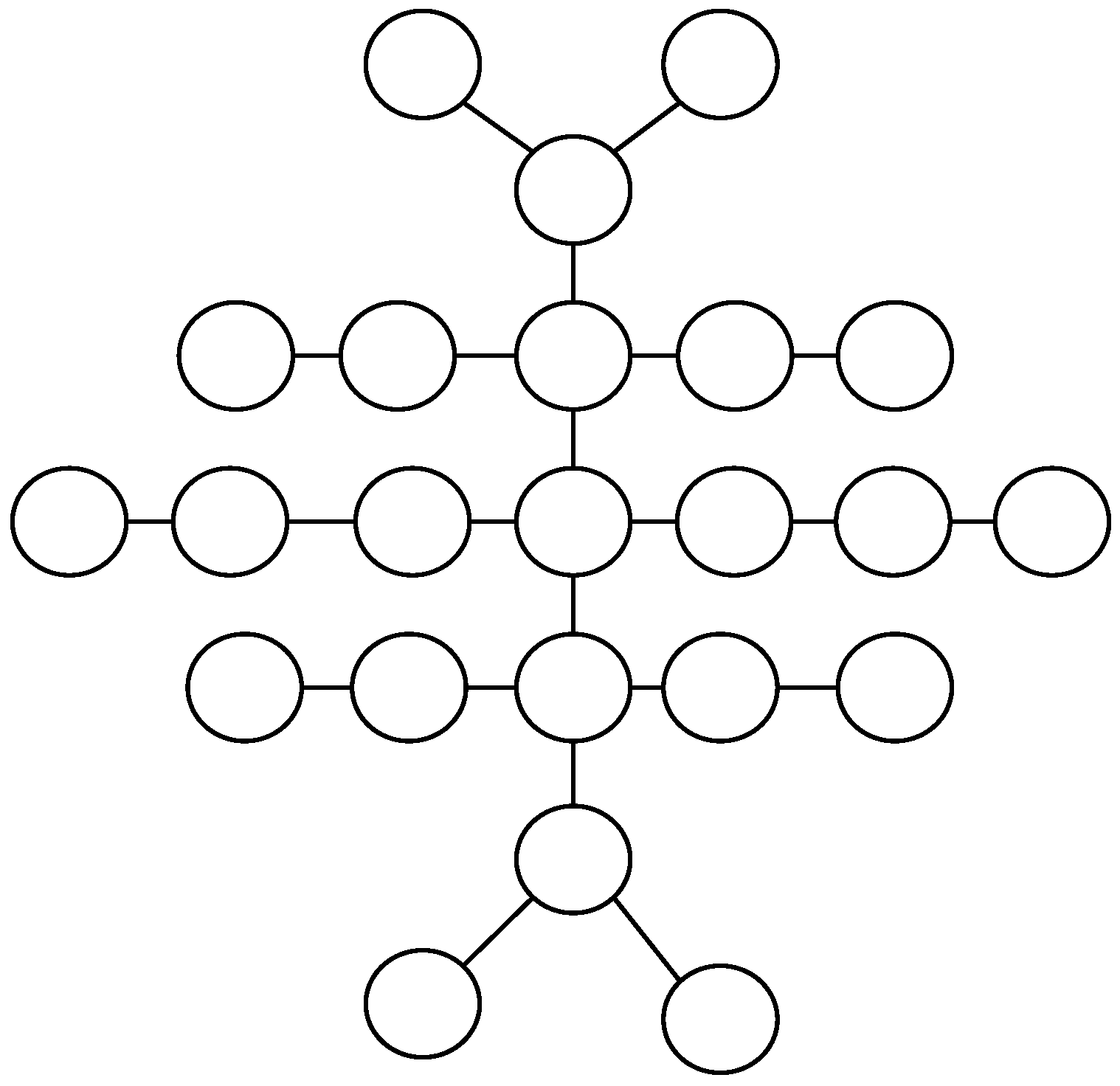
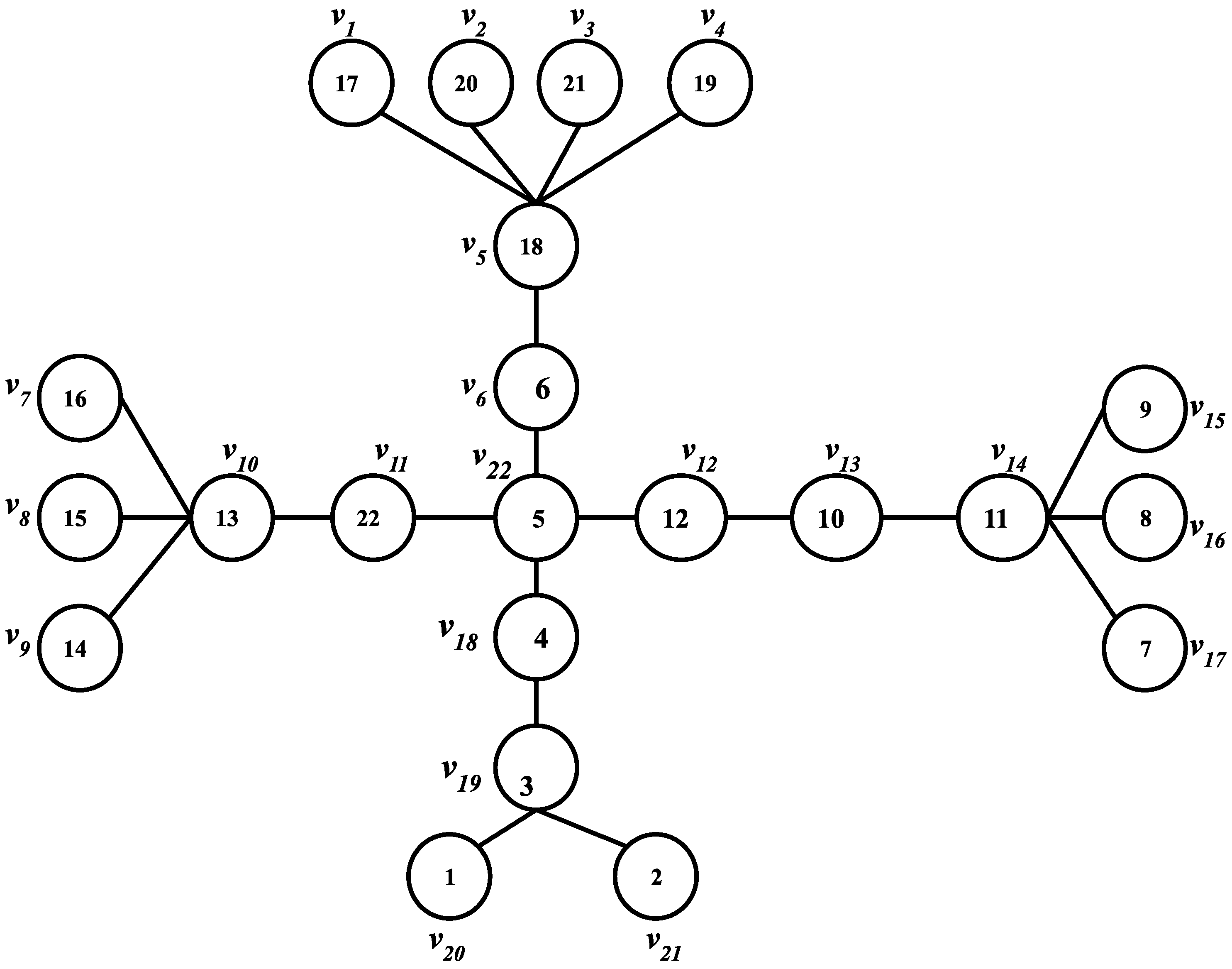
5. Analysis of Algorithm D* on Millipede Tree
5.1. Algorithm
5.2. Analysis and Results
| Algorithm 1 Algorithm [29] |
|
6. Scope for Future Research
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Akers, S.B.; Krishnamurthy, B. A group-theoretic model for symmetric interconnection networks. IEEE Trans. Comput. 1989, 38, 555–566. [Google Scholar] [CrossRef]
- Chitturi, B. On Transforming Sequences. University of Texas at Dallas. 2007. Available online: https://www.researchgate.net/profile/Bhadrachalam-Chitturi/publication/308524758_ON_TRANSFORMING_SEQUENCES/links/57e64be408aed7fe4667bb11/ON-TRANSFORMING-SEQUENCES.pdf (accessed on 1 June 2017).
- Heydemann, M.-C. Cayley graphs and interconnection networks. In Graph Symmetry; Springer: Dordrecht, The Netherlands, 1997; pp. 167–224. [Google Scholar]
- Lakshmivarahan, S.; Jwo, J.-S.; Dhall, S.K. Symmetry in interconnection networks based on Cayley graphs of permutation groups: A survey. Parallel Comput. 1993, 19, 361–407. [Google Scholar] [CrossRef]
- Jain, B.A.; Lubiw, K.; Masárová, A.; Miltzow, Z.; Mondal, T.; Naredl, D.; Murty, A.; Josef, T.; Alexi, T. Token Swapping on Trees. arXiv 2019, arXiv:1903.06981. [Google Scholar]
- Yamanaka, K.; Demaine, E.D.; Ito, T.; Kawahara, J.; Kiyomi, M.; Okamoto, Y.; Saitoh, T.; Suzuki, A.; Uchizawa, K.; Uno, T. Swapping labeled tokens on graphs. Theor. Comput. Sci. 2015, 586, 81–94. [Google Scholar] [CrossRef]
- Cooperman, G.; Finkelstein, L. New methods for using Cayley graphs in interconnection networks. Discret. Appl. Math. 1992, 37–38, 95–118. [Google Scholar] [CrossRef]
- Xu, J. Topological Structure and Analysis of Interconnection Networks; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013; Volume 7. [Google Scholar]
- Knuth, D.E. The Art of Computer Programming: Sorting and Searching, 2nd ed.; Pearson Education: London, UK, 1997; pp. 426–458. [Google Scholar]
- Vaughan, T.P. Factoring a permutation on a broom. J. Comb. Math. Comb. Comput. 1999, 30, 129–148. [Google Scholar]
- Kawahara, J.; Saitoh, T.; Yoshinaka, R. The Time Complexity of the Token Swapping Problem and Its Parallel Variants. Walcom Algorithms Comput. 2017, 448–459. [Google Scholar]
- Jerrum, M.R. The complexity of finding minimum-length generator sequences. Theor. Comput. Sci. 1985, 36, 265–289. [Google Scholar] [CrossRef]
- Christie, D.A. Genome Rearrangement Problems; The University of Glasgow: Glasgow, UK, 1998. [Google Scholar]
- Chitturi, B.; Das, P. Sorting permutations with transpositions in O(n3) amortized time. Theor. Comput. Sci. 2019, 766, 30–37. [Google Scholar] [CrossRef]
- Chitturi, B. Computing cardinalities of subsets of Sn with k adjacencies. JCMCC 2020, 113, 183–195. [Google Scholar]
- Malavika, J.; Scaria, S.; Indulekha, T.S. On Token Swapping in Labeled Tree. In Proceedings of the 2021 Third International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 2–4 September 2021; pp. 940–945. [Google Scholar]
- Bonnet, É.; Miltzow, T.; Rzazewski, P. Complexity of Token Swapping and Its Variants. Algorithmica 2017, 80, 2656–2682. [Google Scholar] [CrossRef]
- Kawahara, J.; Saitoh, T.; Yoshinaka, R. The Time Complexity of Permutation Routing via Matching, Token Swapping and a Variant. JGAA 2019, 23, 29–70. [Google Scholar] [CrossRef]
- Miltzow, T.; Narins, L.; Okamoto, Y.; Rote, G.; Thomas, A.; Uno, T. Approximation and hardness of token swapping. In Proceedings of the 24th Annual European Symposium on Algorithms (ESA 2016), Aarhus, Denmark, 22–24 August 2016; Volume 57. [Google Scholar]
- Cayley, A. LXXVII. Note on the theory of permutations. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1849, 34, 527–529. [Google Scholar] [CrossRef]
- Pak, I. Reduced decompositions of permutations in terms of star transpositions, generalized catalan numbers and k-ARY trees. Discrete Math. 1999, 204, 329–335. [Google Scholar] [CrossRef]
- Portier, F.J.; Vaughan, T.P. Whitney Numbers of the Second Kind for the Star Poset. Eur. J. Comb. 1990, 11, 277–288. [Google Scholar] [CrossRef]
- Ganesan, A. An efficient algorithm for the diameter of cayley graphs generated by transposition trees. Aeng Int. J. Appl. Math. 2012, 42, 214–223. [Google Scholar]
- Chitturi, B. Upper Bounds For Sorting Permutations With A Transposition Tree. Discret. Math. Algorithm. Appl. 2013, 5, 1350003. [Google Scholar] [CrossRef]
- Kraft, B. Diameters of Cayley graphs generated by transposition trees. Discret. Appl. Math. 2015, 184, 178–188. [Google Scholar] [CrossRef]
- Uthan, S.; Chitturi, B. Bounding the diameter of Cayley graphs generated by specific transposition trees. In Proceedings of the International Conference on Advances in Computing, Communications and Informatics (ICACCI), Udupi, India, 13–16 September 2017; pp. 1242–1248. [Google Scholar]
- Balcza, L. On inversions and cycles in permutations. Period. Polytech. Civ. Eng. 1992, 36, 369–374. [Google Scholar]
- Edelman, P.H. On Inversions and Cycles in Permutations. Eur. J. Comb. 1987, 8, 269–279. [Google Scholar] [CrossRef][Green Version]
- Chitturi, B.; Indulekha, T.S. Sorting permutations with a transposition tree. In Proceedings of the 8th International Conference on Modeling Simulation and Applied Optimization (ICMSAO), Manama, Bahrain, 15–17 April 2019. [Google Scholar]
- Das, D.K.; Chitturi, B.; Kuppili, S.S. An Upper Bound For Sorting Permutations With A Transposition Tree. Procedia Comput. Sci. 2020, 171, 72–80. [Google Scholar] [CrossRef]
- Indulekha, T.S.; Chitturi, B. Analysis of Algorithm δ* on full binary trees. In Proceedings of the 2019 Second International Conference on Advanced Computational and Communication Paradigms (ICACCP), Gangtok, India, 25–28 February 2019; pp. 1–5. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Iteration | ||||||
|---|---|---|---|---|---|---|
| 1 | (k − 1) | 2 | d | d | d | (d − 1/2) |
| 2 | k | 1 | (d − 1) | (d − 1) | (d − 1) | - |
| 3 | (k − 2) | 2 | (d − 2) | (d − 2) | (d − 2) | (d − 2 − 1/2) |
| 4 | (k − 2) | 0 | (d − 3) | - | (d − 3) | - |
| 5 | (k − 4) | 2 | (d − 4) | (d − 4) | (d − 4) | (d − 4 − 1/2) |
| 6 | (k − 4) | 0 | (d − 5) | - | (d − 5) | - |
| 7 | (k − 6) | 2 | (d − 6) | (d − 6) | (d − 6) | (d − 6 − 1/2) |
| 8 | (k − 6) | 0 | (d − 7) | - | (d − 7) | - |
| … | … | … | … | … | … | … |
| (k − 1) | 3 | 0 | 3 | - | 3 | - |
| Tree | Diameter | No:of Nodes | ||||
|---|---|---|---|---|---|---|
| 4 | 11 | 28 | 28 | 27 | 1 | |
| 6 | 23 | 92 | 92 | 90 | 2 | |
| 8 | 39 | 209 | 209 | 206 | 3 | |
| 10 | 59 | 396 | 396 | 392 | 4 | |
| 12 | 83 | 669 | 669 | 664 | 5 | |
| 14 | 111 | 1044 | 1044 | 1038 | 6 | |
| 16 | 143 | 1537 | 1537 | 1530 | 7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sadanandan, I.T.; Chitturi, B. Optimal Algorithms for Sorting Permutations with Brooms. Algorithms 2022, 15, 220. https://doi.org/10.3390/a15070220
Sadanandan IT, Chitturi B. Optimal Algorithms for Sorting Permutations with Brooms. Algorithms. 2022; 15(7):220. https://doi.org/10.3390/a15070220
Chicago/Turabian StyleSadanandan, Indulekha Thekkethuruthel, and Bhadrachalam Chitturi. 2022. "Optimal Algorithms for Sorting Permutations with Brooms" Algorithms 15, no. 7: 220. https://doi.org/10.3390/a15070220
APA StyleSadanandan, I. T., & Chitturi, B. (2022). Optimal Algorithms for Sorting Permutations with Brooms. Algorithms, 15(7), 220. https://doi.org/10.3390/a15070220