
Detecting and Responding to Concept Drift in Business Processes


Abstract
:1. Introduction
2. Related Work
2.1. Process Mining
2.2. Markov Models
3. Preliminaries
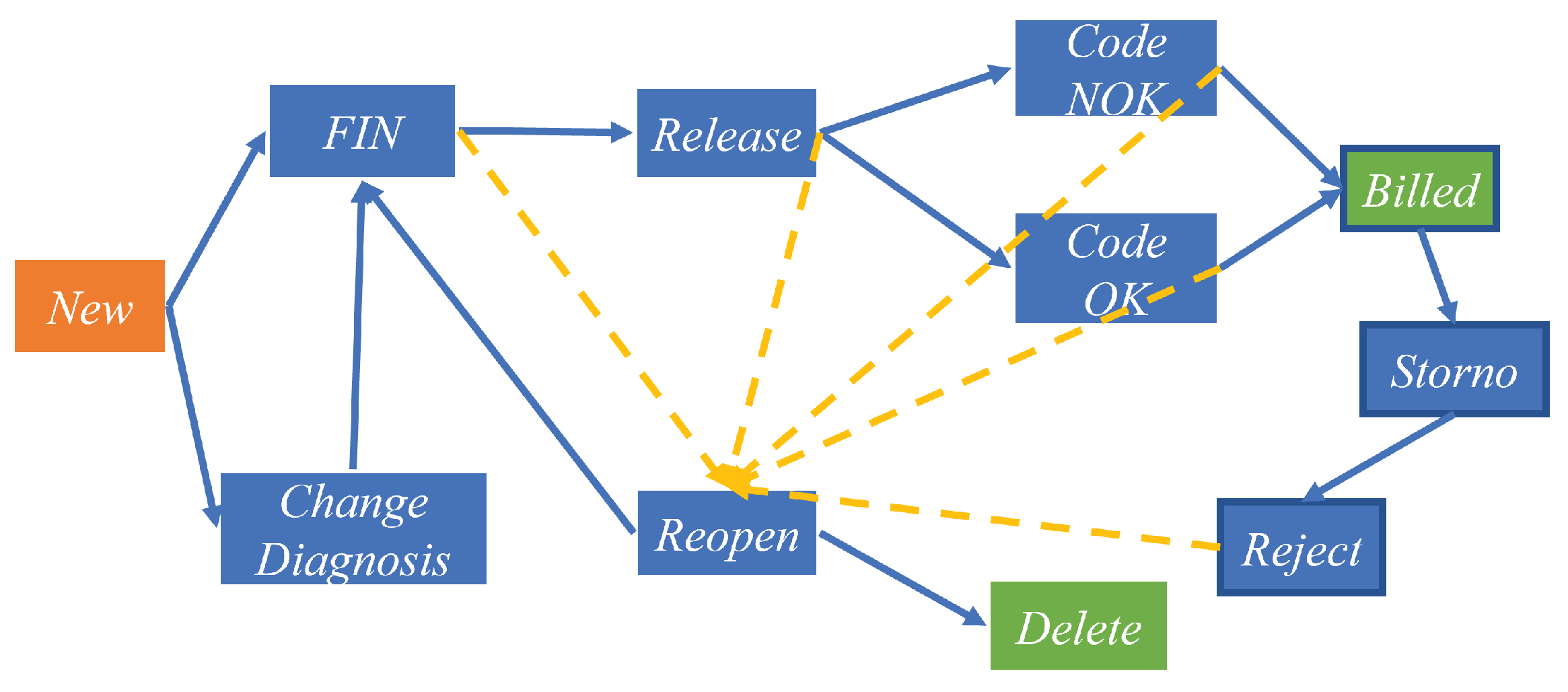
3.1. Business Process Event Log
3.2. Semi-Markov Process (SMP)
3.3. Markov Decision Process (MDP)
3.4. Gamma Mixture Model
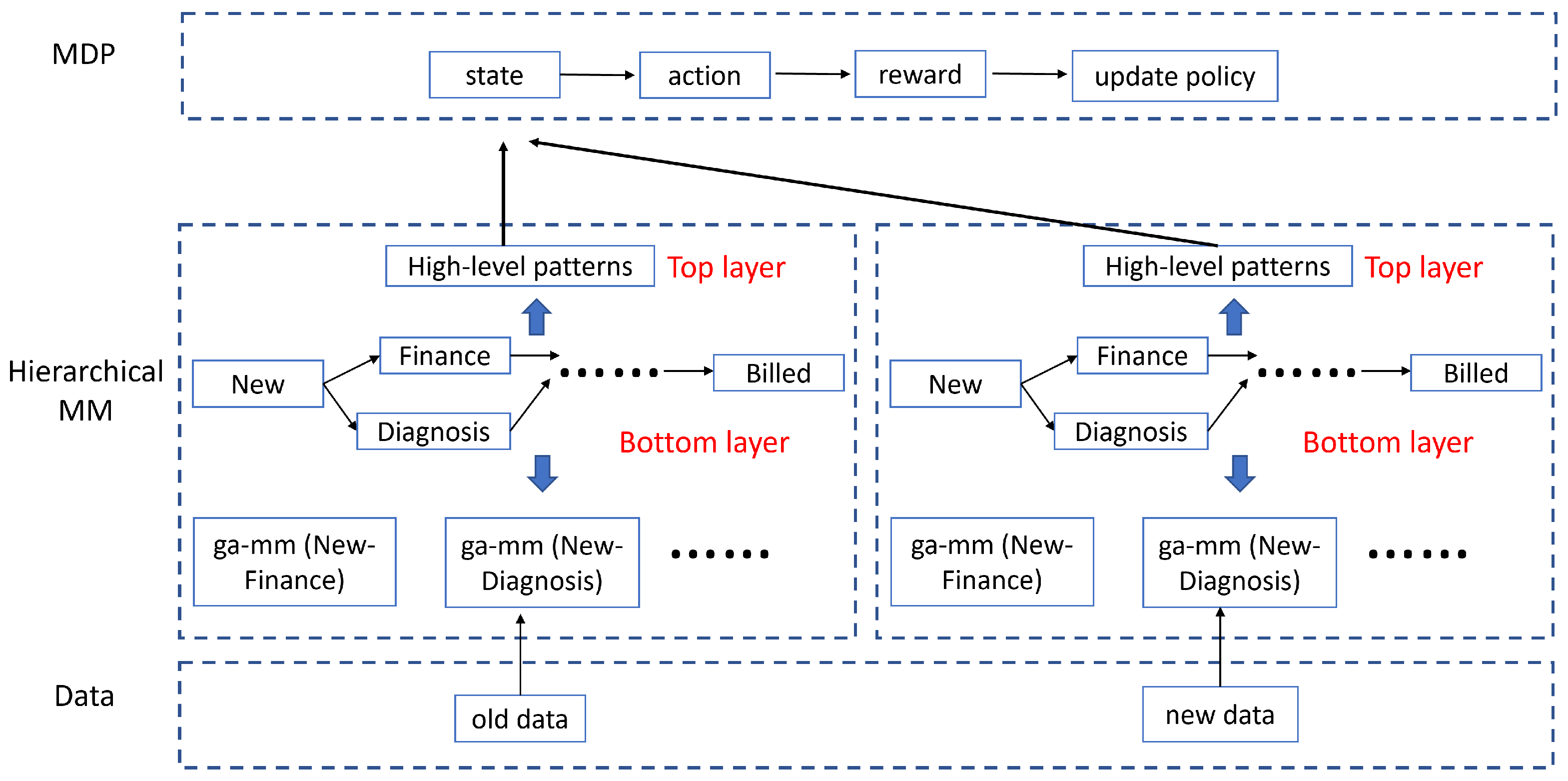
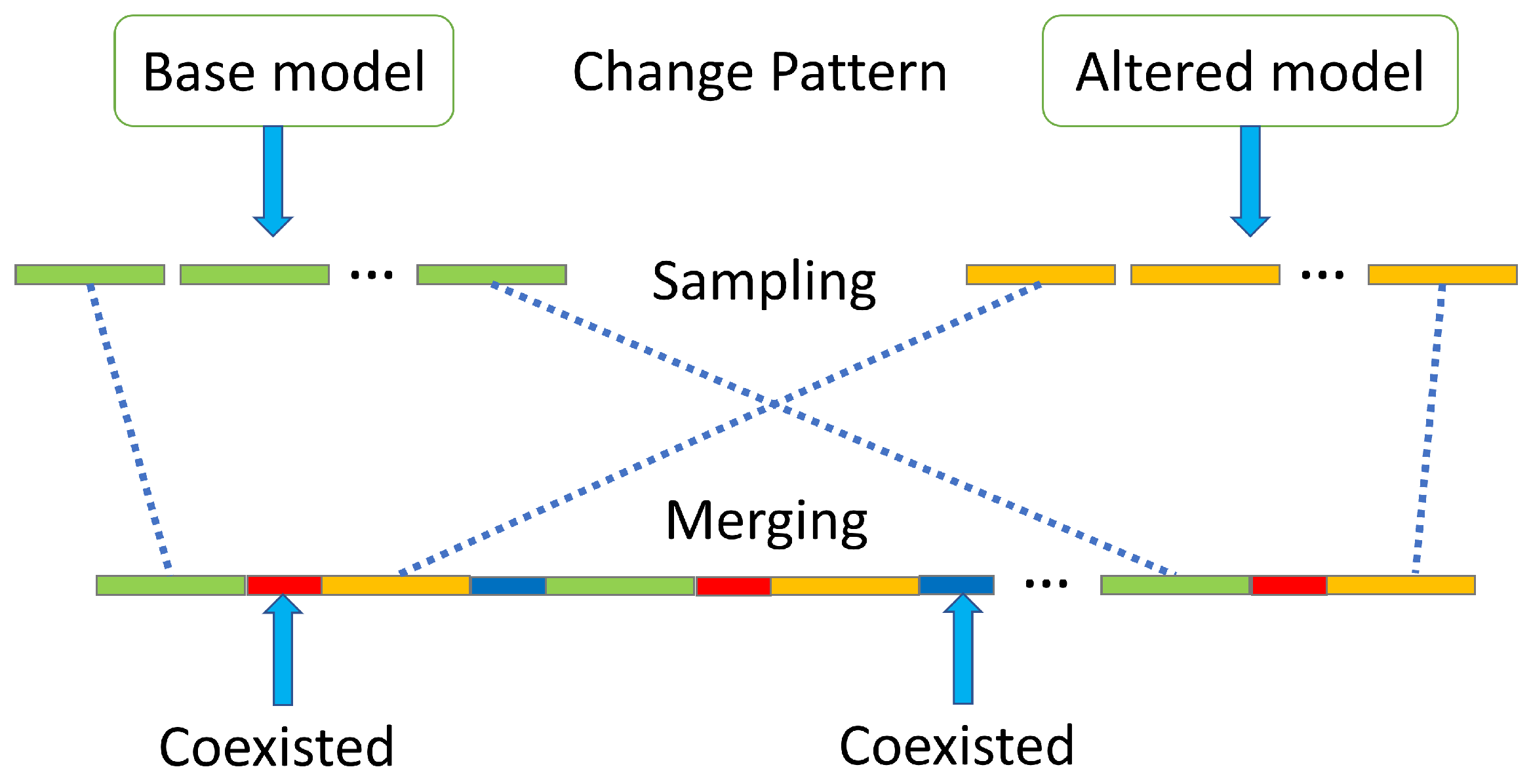
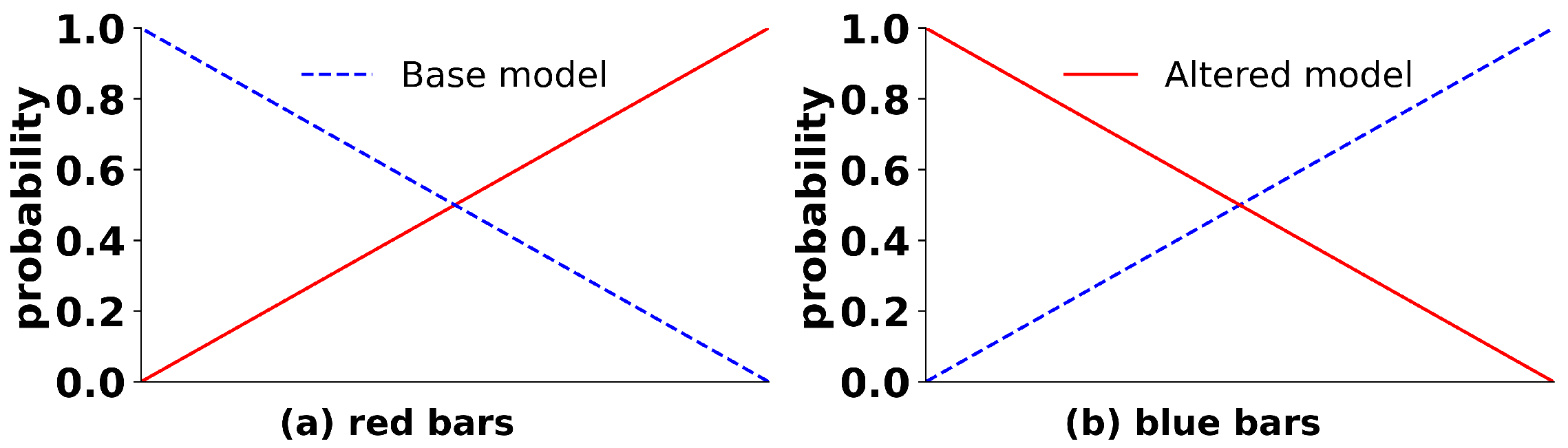
4. Methodology
4.1. Bottom Layer of the Hierarchical MM
4.2. Top Layer of the Hierarchical MM
4.3. Model Management Using MDP
| Algorithm 1: MDP policy iteration |
| Input: : the state space, |
| : the action space, |
| : the transition probability matrix, |
| : the learning rate. |
| Output: : the policy. |
| 1: for: |
| 2: for : |
| 3: Initialize |
| 4: Initialize |
| 5: end for |
| 6: end for |
| 7: Obtain , -, from the old data. |
| 8: Pass and into K-means to obtain . |
| 9: Let = [ ], . |
| 10: while A new data batch: |
| 11: Obtain , -, . |
| 12: Using K-means to obtain . |
| 13: Obtain MDP state . |
| 14: Put s into for updating . |
| 15: if has three elements: |
| 16: Update using Equation (2). |
| 17: Remove the first two elements. |
| 18: Obtain action . |
| 19: Put a into . |
| 20: Update SMP, obtain , , . |
| 21: Calculate reward using Equation (6). |
| 22: Update the Q-factor using Equation (7). |
| 23: Update using Equation (8). |
| 24: Update using and . |
| 25: . |
5. Evaluation on Artificial Data
5.1. Datasets
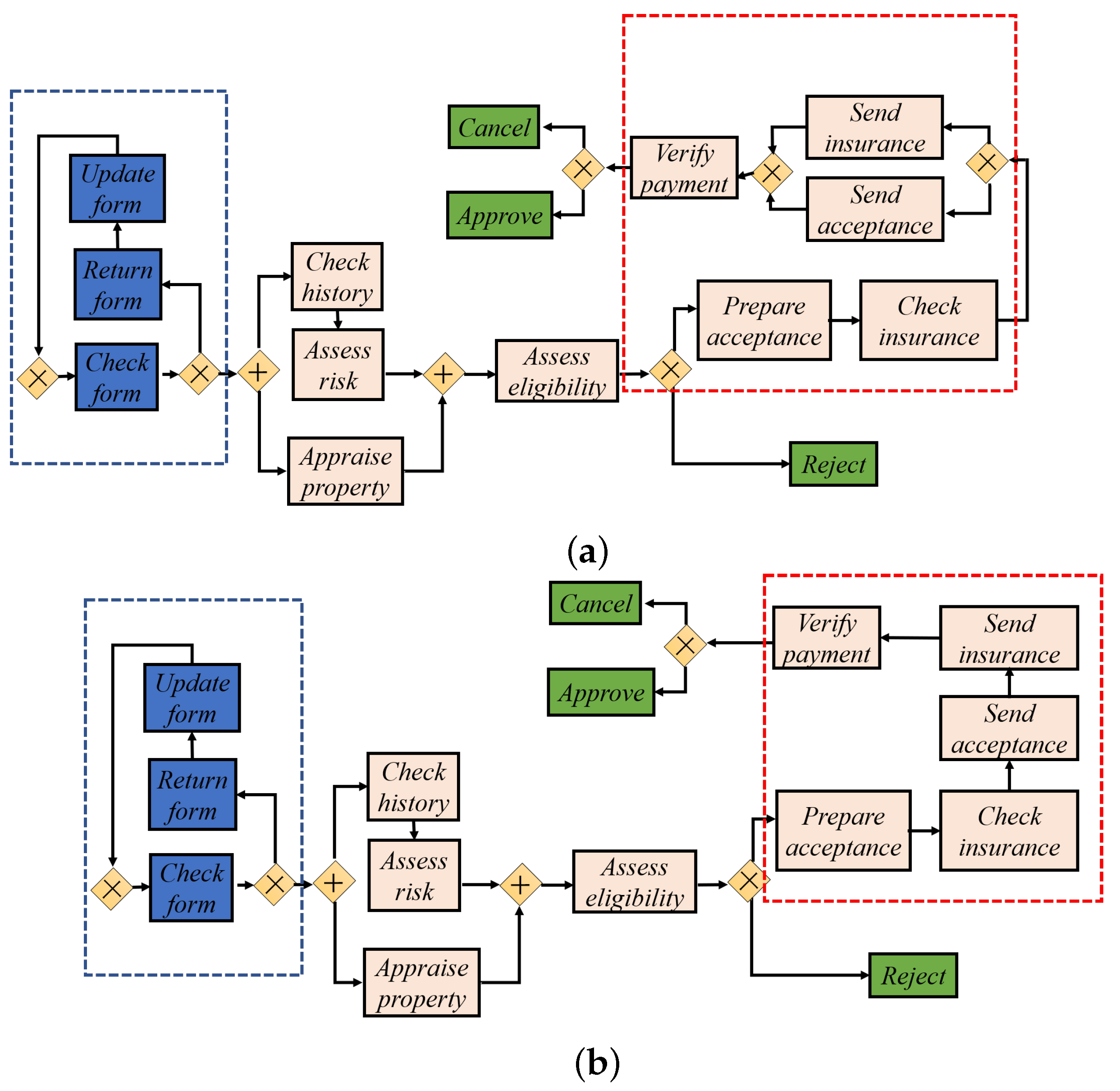
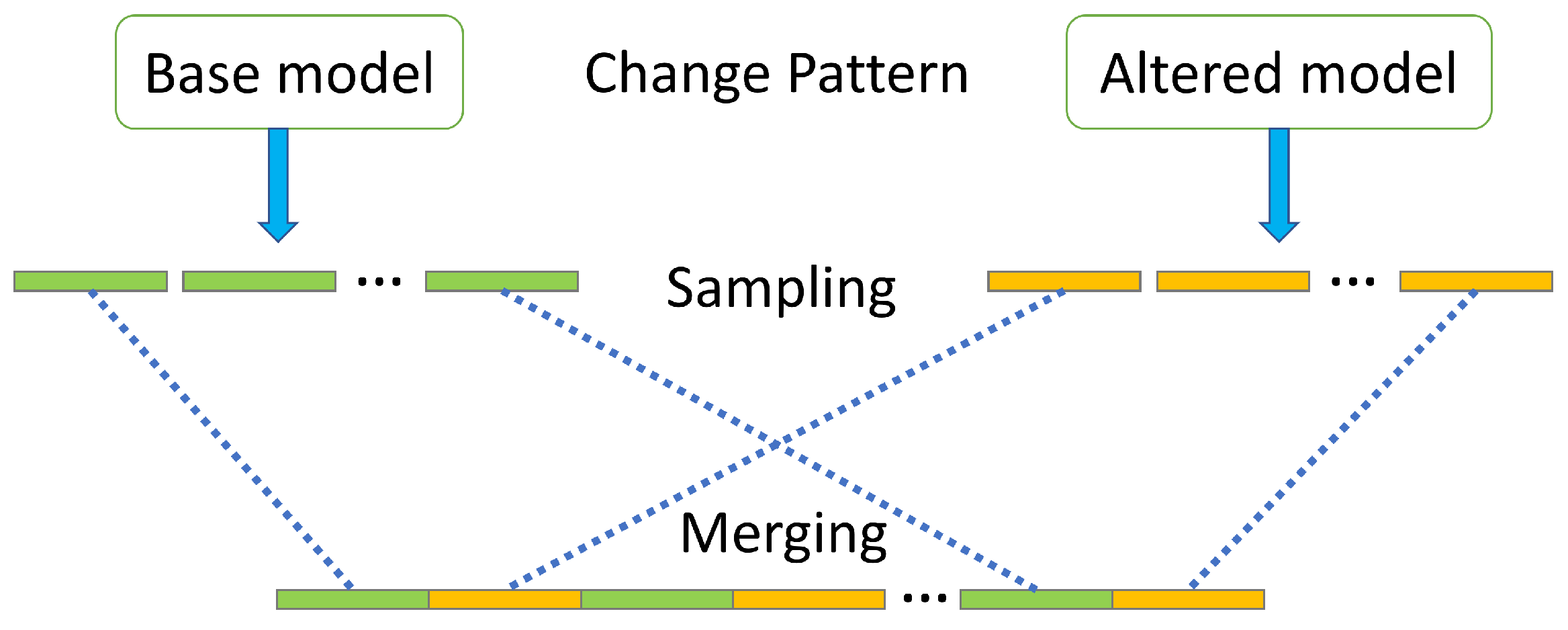
5.1.1. Sudden and Gradual Control-Flow Drift Data
5.1.2. Sudden and Gradual Duration Drift Data
5.2. Experimental Setup
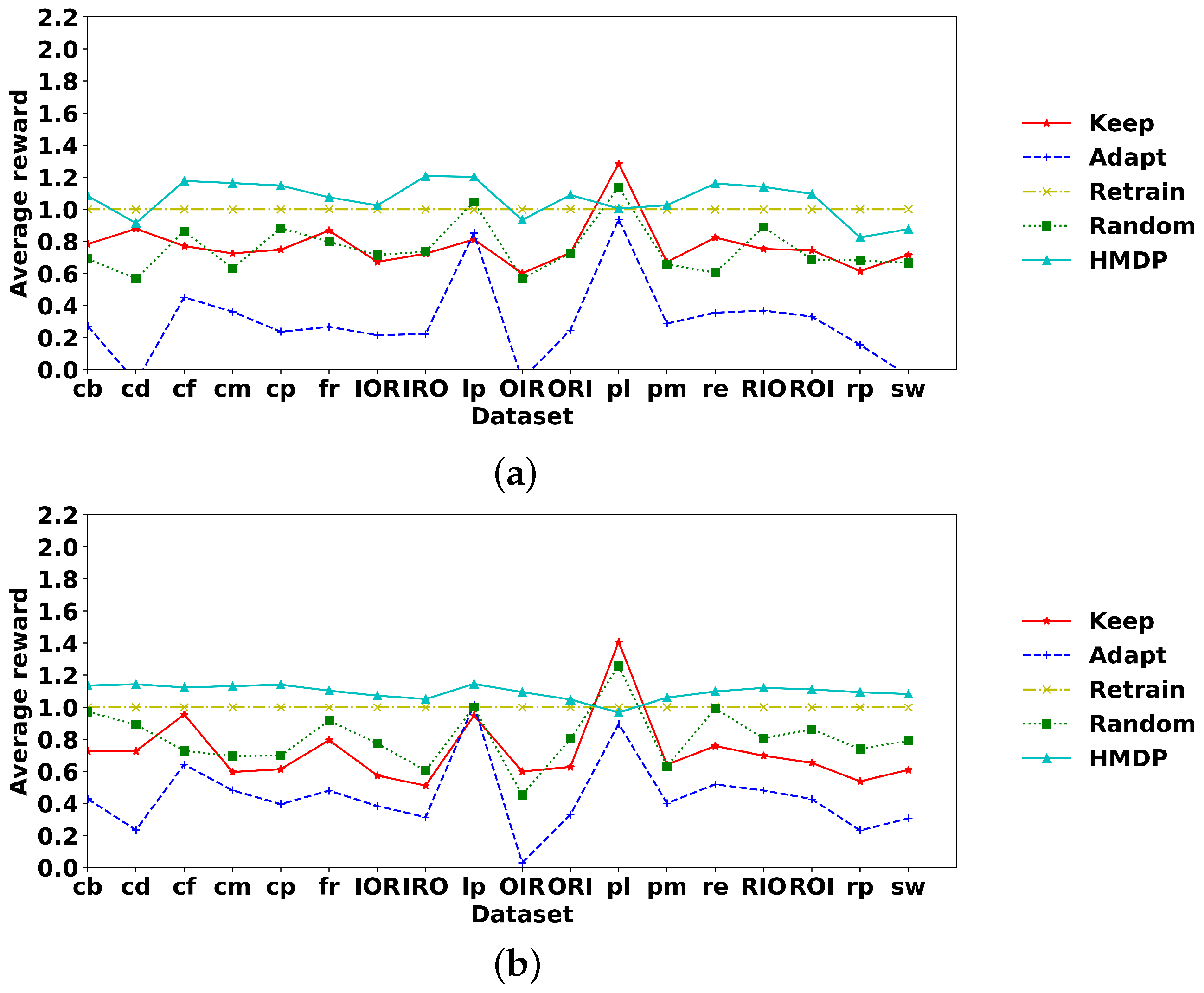
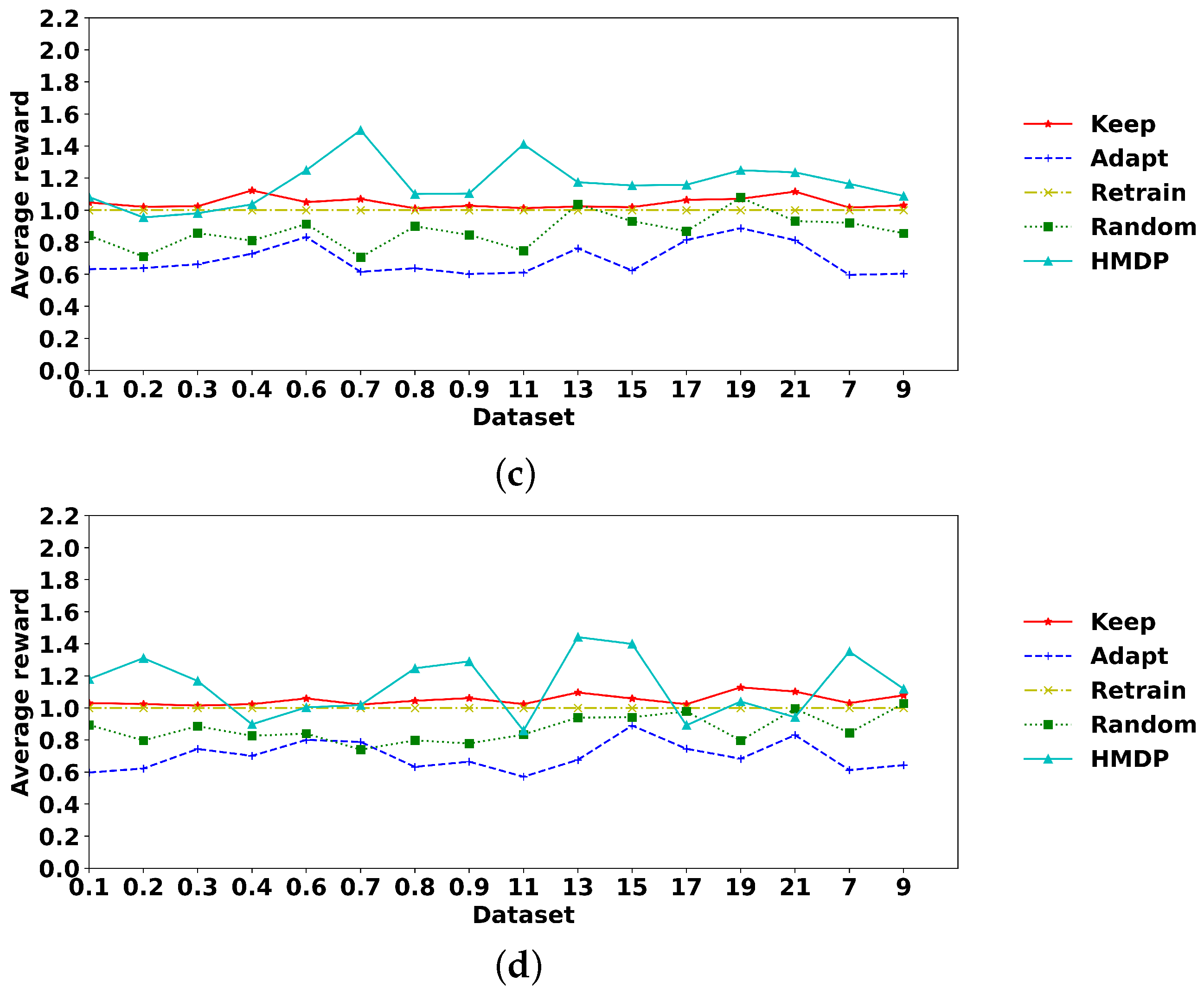
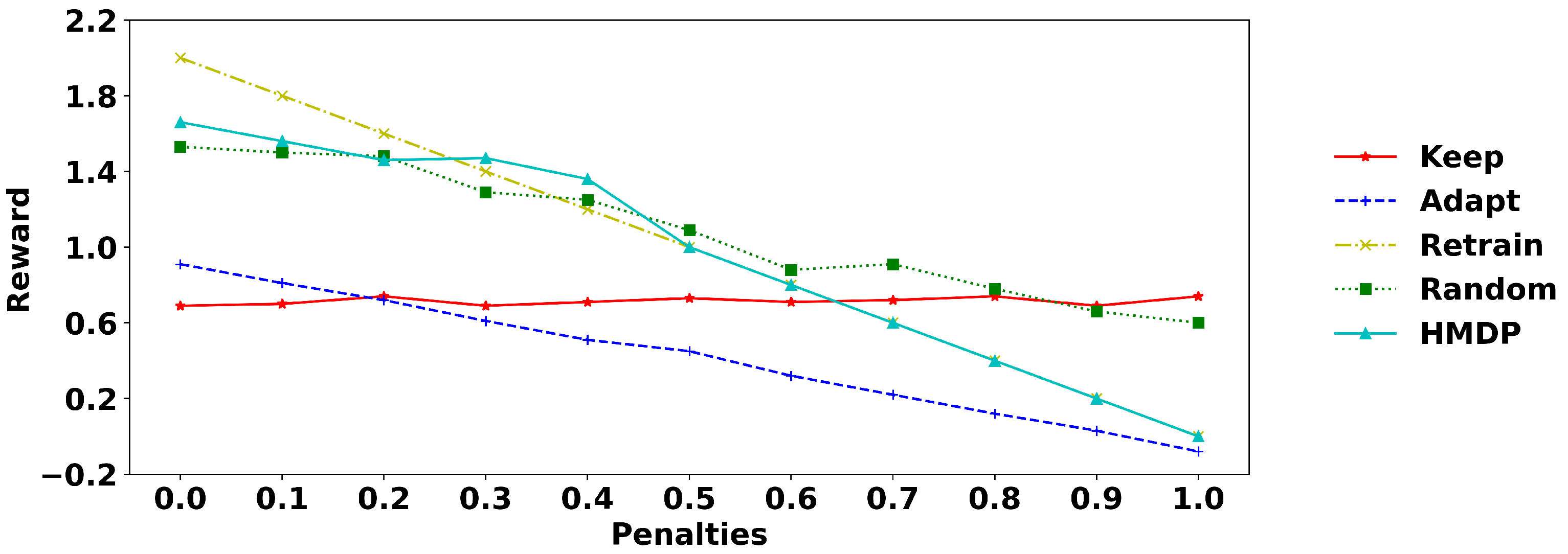
5.3. Experimental Results
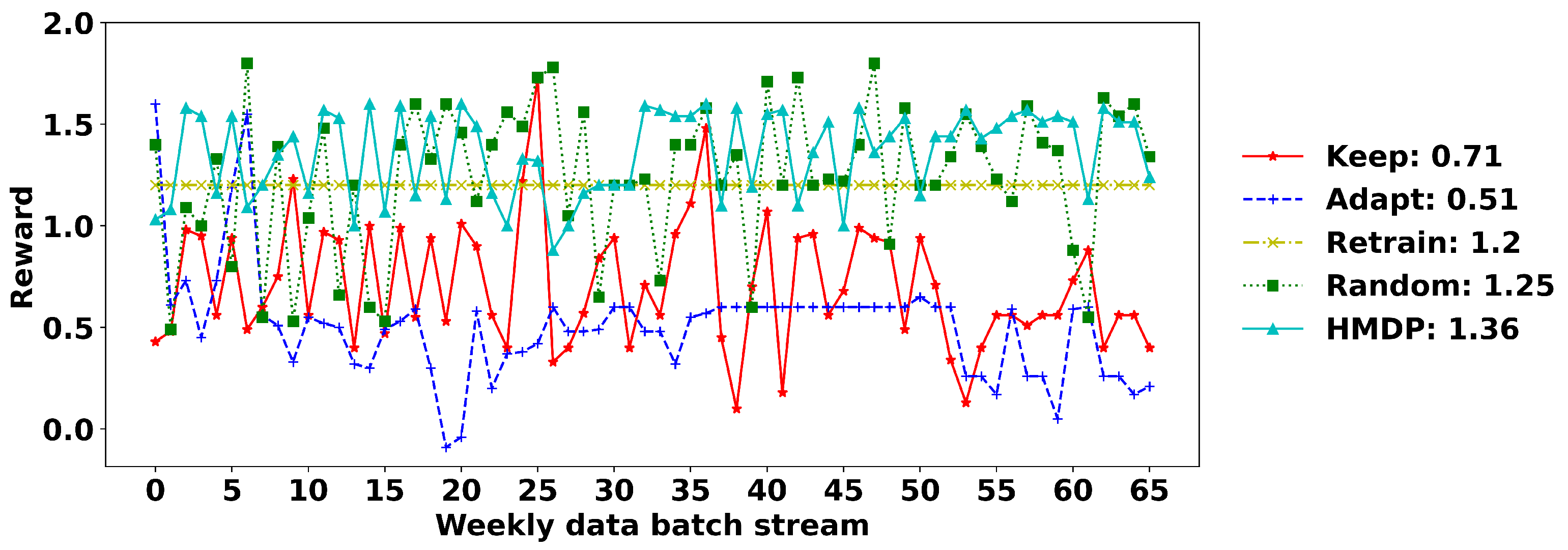
6. Evaluation of the Real-World Hospital Billing Data
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bose, R.J.C.; Van Der Aalst, W.M.; Žliobaitė, I.; Pechenizkiy, M. Dealing with concept drifts in process mining. IEEE Trans. Neural Netw. Learn. Syst. 2013, 25, 154–171. [Google Scholar] [CrossRef] [PubMed]
- Van Der Aalst, W.; Adriansyah, A.; De Medeiros, A.K.A.; Arcieri, F.; Baier, T.; Blickle, T.; Bose, J.C.; Van Den Brand, P.; Brandtjen, R.; Buijs, J.; et al. Process mining manifesto. In Proceedings of the International Conference on Business Process Management, Clermont-Ferrand, France, 28 August–2 September 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 169–194. [Google Scholar]
- R’bigui, H.; Cho, C. The state-of-the-art of business process mining challenges. Int. J. Bus. Process Integr. Manag. 2017, 8, 285–303. [Google Scholar] [CrossRef]
- Premchaiswadi, W.; Porouhan, P. Process modeling and bottleneck mining in online peer-review systems. SpringerPlus 2015, 4, 441. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Martjushev, J.; Bose, R.J.C.; van der Aalst, W.M. Change point detection and dealing with gradual and multi-order dynamics in process mining. In Proceedings of the International Conference on Business Informatics Research, Tartu, Estonia, 26–28 August 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 161–178. [Google Scholar]
- Seeliger, A.; Nolle, T.; Mühlhäuser, M. Detecting concept drift in processes using graph metrics on process graphs. In Proceedings of the 9th Conference on Subject-Oriented Business Process Management, Darmstadt, Germany, 30–31 March 2017; pp. 1–10. [Google Scholar]
- Stertz, F.; Rinderle-Ma, S. Detecting and Identifying Data Drifts in Process Event Streams Based on Process Histories. In Proceedings of the International Conference on Advanced Information Systems Engineering, Rome, Italy, 3–7 June 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 240–252. [Google Scholar]
- Nguyen, H.; Dumas, M.; La Rosa, M.; ter Hofstede, A.H. Multi-perspective comparison of business process variants based on event logs. In Proceedings of the International Conference on Conceptual Modeling, Xi’an, China, 22–25 October 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 449–459. [Google Scholar]
- Hompes, B.; Buijs, J.C.; van der Aalst, W.M.; Dixit, P.M.; Buurman, J. Detecting changes in process behavior using comparative case clustering. In Proceedings of the International Symposium on Data-Driven Process Discovery and Analysis, Vienna, Austria, 9–11 December 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 54–75. [Google Scholar]
- Hompes, B.; Buijs, J.; Van der Aalst, W.; Dixit, P.; Buurman, J. Discovering deviating cases and process variants using trace clustering. In Proceedings of the 27th Benelux Conference on Artificial Intelligence (BNAIC), Hasselt, Belgium, 5–6 November 2015; pp. 5–6. [Google Scholar]
- Huang, Z.; van der Aalst, W.M.; Lu, X.; Duan, H. Reinforcement learning based resource allocation in business process management. Data Knowl. Eng. 2011, 70, 127–145. [Google Scholar] [CrossRef]
- Elkhawaga, G.; Abuelkheir, M.; Barakat, S.I.; Riad, A.M.; Reichert, M. CONDA-PM—A Systematic Review and Framework for Concept Drift Analysis in Process Mining. Algorithms 2020, 13, 161. [Google Scholar] [CrossRef]
- Ter Hofstede, A.H.; Van der Aalst, W.M.; Adams, M.; Russell, N. Modern Business Process Automation: YAWL and Its Support Environment; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Test-Driven Data Analysis (Python TDDA library). Available online: https://github.com/tdda/tdda (accessed on 14 March 2022).
- Barile, N.; Sugiyama, S. The automation of taste: A theoretical exploration of mobile ICTs and social robots in the context of music consumption. Int. J. Soc. Robot. 2015, 7, 407–416. [Google Scholar] [CrossRef]
- Liebman, E.; Zavesky, E.; Stone, P. A stitch in time-autonomous model management via reinforcement learning. In Proceedings of the 17th International Conference on Autonomous Agents and Multiagent Systems, Stockholm, Sweden, 10–15 July 2018; pp. 990–998. [Google Scholar]
- Yang, L.; McClean, S.; Donnelly, M.; Burke, K.; Khan, K. Process Duration Modelling and Concept Drift Detection for Business Process Mining. In Proceedings of the 2021 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/IOP/SCI), Atlanta, GA, USA, 18–21 October 2021; pp. 653–658. [Google Scholar]
- Das, T.K.; Gosavi, A.; Mahadevan, S.; Marchalleck, N. Solving semi-Markov decision problems using average reward reinforcement learning. Manag. Sci. 1999, 45, 560–574. [Google Scholar] [CrossRef] [Green Version]
- Tijms, H.C.; Tijms, H.C. Stochastic Models: An Algorithmic Approach; Wiley: New York, NY, USA, 1994; Volume 303. [Google Scholar]
- Gama, J.; Žliobaitė, I.; Bifet, A.; Pechenizkiy, M.; Bouchachia, A. A survey on concept drift adaptation. ACM Comput. Surv. (CSUR) 2014, 46, 1–37. [Google Scholar] [CrossRef]
- Maisenbacher, M.; Weidlich, M. Handling Concept Drift in Predictive Process Monitoring. In Proceedings of the IEEE International Conference on Services Computing (SCC), Honolulu, HI, USA, 25–30 June 2017; Volume 17, pp. 1–8. [Google Scholar]
- Ostovar, A.; Leemans, S.J.; Rosa, M.L. Robust drift characterization from event streams of business processes. ACM Trans. Knowl. Discov. Data (TKDD) 2020, 14, 1–57. [Google Scholar] [CrossRef] [Green Version]
- Ostovar, A.; Maaradji, A.; La Rosa, M.; ter Hofstede, A.H. Characterizing drift from event streams of business processes. In Proceedings of the International Conference on Advanced Information Systems Engineering, Melbourne, VIC, Australia, 28 June–2 July 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 210–228. [Google Scholar]
- Yeshchenko, A.; Di Ciccio, C.; Mendling, J.; Polyvyanyy, A. Comprehensive process drift detection with visual analytics. In Proceedings of the International Conference on Conceptual Modeling, Salvador, Brazil, 4–7 November 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 119–135. [Google Scholar]
- Adams, J.N.; van Zelst, S.J.; Quack, L.; Hausmann, K.; van der Aalst, W.M.; Rose, T. A Framework for Explainable Concept Drift Detection in Process Mining. arXiv 2021, arXiv:2105.13155. [Google Scholar]
- Maaradji, A.; Dumas, M.; La Rosa, M.; Ostovar, A. Detecting sudden and gradual drifts in business processes from execution traces. IEEE Trans. Knowl. Data Eng. 2017, 29, 2140–2154. [Google Scholar] [CrossRef]
- Bose, R.J.C.; van der Aalst, W.M. Trace clustering based on conserved patterns: Towards achieving better process models. In Proceedings of the International Conference on Business Process Management, Ulm, Germany, 7–10 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 170–181. [Google Scholar]
- Hompes, B.; Buijs, J.C.; van der Aalst, W.M.; Dixit, P.M.; Buurman, H. Detecting Change in Processes Using Comparative Trace Clustering. In Proceedings of the 5th International Symposium on Data-driven Process Discovery and Analysis (SIMPDA 2015), Vienna, Austria, 9–11 December 2015; pp. 95–108. [Google Scholar]
- Zheng, C.; Wen, L.; Wang, J. Detecting process concept drifts from event logs. In Proceedings of the OTM Confederated International Conferences “On the Move to Meaningful Internet Systems”, Rhodes, Greece, 23–28 October 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 524–542. [Google Scholar]
- Barbon Junior, S.; Tavares, G.M.; da Costa, V.G.T.; Ceravolo, P.; Damiani, E. A framework for human-in-the-loop monitoring of concept-drift detection in event log stream. In Proceedings of the Companion Proceedings of the the Web Conference 2018, Lyon, France, 23–27 April 2018; pp. 319–326. [Google Scholar]
- Tavares, G.M.; Ceravolo, P.; Da Costa, V.G.T.; Damiani, E.; Junior, S.B. Overlapping analytic stages in online process mining. In Proceedings of the 2019 IEEE International Conference on Services Computing (SCC), Milan, Italy, 8–13 July 2019; pp. 167–175. [Google Scholar]
- Spenrath, Y.; Hassani, M. Ensemble-Based Prediction of Business Processes Bottlenecks With Recurrent Concept Drifts. In Proceedings of the EDBT/ICDT Workshops, Lisbon, Portugal, 26–29 March 2019. [Google Scholar]
- Grabski, F. Semi-Markov Processes: Applications in System Reliability and Maintenance; Elsevier: Amsterdam, The Netherlands, 2015; Volume 599. [Google Scholar]
- Wu, D.; Yuan, C.; Kumfer, W.; Liu, H. A life-cycle optimization model using semi-markov process for highway bridge maintenance. Appl. Math. Model. 2017, 43, 45–60. [Google Scholar] [CrossRef]
- Papadopoulou, A.; McClean, S.; Garg, L. Discrete semi Markov patient pathways through hospital care via Markov modelling. In Stochastic Modeling, Data Analysis and Statistical Applications; ISAST: Oakland, CA, USA, 2015; pp. 65–72. [Google Scholar]
- Qi, W.; Zong, G.; Karimi, H.R. Sliding mode control for nonlinear stochastic singular semi-Markov jump systems. IEEE Trans. Autom. Control 2019, 65, 361–368. [Google Scholar] [CrossRef]
- Ferreira, D.R.; Szimanski, F.; Ralha, C.G. A hierarchical Markov model to understand the behaviour of agents in business processes. In Proceedings of the International Conference on Business Process Management, Tallinn, Estonia, 3–6 September 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 150–161. [Google Scholar]
- Mitchell, H.J.; Marshall, A.H.; Zenga, M. A joint likelihood approach to the analysis of length of stay data utilising the continuous-time hidden Markov model and Coxian phase-type distribution. J. Oper. Res. Soc. 2021, 72, 2529–2541. [Google Scholar] [CrossRef]
- Gosavi, A. A Tutorial for Reinforcement Learning; The State University of New York at Buffalo: Buffalo, NY, USA, 2017. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Żbikowski, K.; Ostapowicz, M.; Gawrysiak, P. Deep Reinforcement Learning for Resource Allocation in Business Processes. arXiv 2021, arXiv:2104.00541. [Google Scholar]
- Kober, J.; Bagnell, J.A.; Peters, J. Reinforcement learning in robotics: A survey. Int. J. Robot. Res. 2013, 32, 1238–1274. [Google Scholar] [CrossRef] [Green Version]
- Ye, D.; Chen, G.; Zhang, W.; Chen, S.; Yuan, B.; Liu, B.; Chen, J.; Liu, Z.; Qiu, F.; Yu, H.; et al. Towards playing full moba games with deep reinforcement learning. arXiv 2020, arXiv:2011.12692. [Google Scholar]
- Deng, Y.; Bao, F.; Kong, Y.; Ren, Z.; Dai, Q. Deep direct reinforcement learning for financial signal representation and trading. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 653–664. [Google Scholar] [CrossRef]
- Gosavi, A. Relative value iteration for average reward semi-Markov control via simulation. In Proceedings of the 2013 Winter Simulations Conference (WSC), Washington, DC, USA, 8–11 December 2013; pp. 623–630. [Google Scholar]
- Likas, A.; Vlassis, N.; Verbeek, J.J. The global k-means clustering algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef] [Green Version]
- Burnham, K.P.; Anderson, D.R. Multimodel inference: Understanding AIC and BIC in model selection. Sociol. Methods Res. 2004, 33, 261–304. [Google Scholar] [CrossRef]
- Singer, S.; Singer, S. Efficient implementation of the Nelder–Mead search algorithm. Appl. Numer. Anal. Comput. Math. 2004, 1, 524–534. [Google Scholar] [CrossRef]
- Engels, B. XNomial: Exact Goodness-of-Fit Test for Multinomial Data with Fixed Probabilities. R Package Version. 2015. Available online: https://cran.r-project.org/web/packages/XNomial/index.html (accessed on 14 March 2022).
- Rosenthal, R. Combining results of independent studies. Psychol. Bull. 1978, 85, 185. [Google Scholar] [CrossRef]
- Dumas, M.; La Rosa, M.; Mendling, J.; Reijers, H.A. Fundamentals of Business Process Management; Springer: Berlin/Heidelberg, Germany, 2013; Volume 1. [Google Scholar]
- Mannhardt, F. Multi-perspective Process Mining. In Proceedings of the BPM (Dissertation/Demos/Industry), Sydney, Australia, 9–14 September 2018; pp. 41–45. [Google Scholar]
- Mannhardt, F.; de Leoni, M.; Reijers, H.A.; van der Aalst, W.M. Data-driven process discovery-revealing conditional infrequent behavior from event logs. In Proceedings of the International Conference on Advanced Information Systems Engineering, Essen, Germany, 12–16 June 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 545–560. [Google Scholar]
- Klein, J.P.; Moeschberger, M.L. Survival Analysis: Techniques for Censored and Truncated Data; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case ID | Activity | Timestamp |
|---|---|---|
| case0 | New | 11 February 2015 16:30:00 |
| case0 | FIN | 11 February 2015 16:30:00 |
| case0 | Release | 11 February 2015 09:59:02 |
| case0 | Code OK | 12 February 2015 09:59:02 |
| case0 | Billed | 12 February 2015 10:21:01 |
| case1 | New | 11 May 2015 12:07:00 |
| case1 | Change Diagnosis | 12 May 2015 12:30:40 |
| case1 | Release | 17 May 2015 12:54:09 |
| case1 | Code OK | 21 May 2015 15:22:14 |
| case1 | Billed | 12 June 2015 09:21:29 |
| ⋯ | ⋯ | ⋯ |
| Penalty | Sudden Drifts | Gradual Drifts | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Keep | Adapt | Retrain | Random | HMDP | Keep | Adapt | Retrain | Random | HMDP | |
| 0 | 1.160 | 0.884 | 2.000 | 1.377 | 1.967 | 0.726 | 0.954 | 2.000 | 1.321 | 1.495 |
| 0.1 | 0.783 | 0.692 | 1.800 | 1.155 | 1.697 | 0.714 | 0.847 | 1.800 | 1.200 | 1.787 |
| 0.2 | 0.770 | 0.619 | 1.600 | 1.044 | 1.529 | 0.739 | 0.747 | 1.600 | 1.117 | 1.620 |
| 0.3 | 0.793 | 0.507 | 1.400 | 0.916 | 1.373 | 0.731 | 0.664 | 1.400 | 1.004 | 1.439 |
| 0.4 | 0.780 | 0.391 | 1.200 | 0.828 | 1.221 | 0.712 | 0.544 | 1.200 | 0.881 | 1.262 |
| 0.5 | 0.773 | 0.299 | 1.000 | 0.753 | 1.064 | 0.721 | 0.444 | 1.000 | 0.812 | 1.096 |
| 0.6 | 0.786 | 0.205 | 0.800 | 0.632 | 0.888 | 0.727 | 0.347 | 0.800 | 0.728 | 0.928 |
| 0.7 | 0.786 | 0.095 | 0.600 | 0.529 | 0.740 | 0.734 | 0.261 | 0.600 | 0.619 | 0.750 |
| 0.8 | 0.788 | 0.005 | 0.400 | 0.476 | 0.595 | 0.740 | 0.156 | 0.400 | 0.497 | 0.573 |
| 0.9 | 0.796 | −0.099 | 0.200 | 0.347 | 0.431 | 0.724 | 0.038 | 0.200 | 0.397 | 0.405 |
| 1.0 | 0.778 | −0.204 | 0.000 | 0.260 | 0.276 | 0.739 | −0.049 | 0.000 | 0.313 | 0.229 |
| Penalty | Sudden Drifts | Gradual Drifts | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Keep | Adapt | Retrain | Random | HMDP | Keep | Adapt | Retrain | Random | HMDP | |
| 0 | 1.042 | 1.196 | 2.000 | 1.339 | 1.741 | 1.051 | 1.244 | 2.000 | 1.384 | 1.873 |
| 0.1 | 1.041 | 1.097 | 1.800 | 1.279 | 1.650 | 1.056 | 1.114 | 1.800 | 1.246 | 1.725 |
| 0.2 | 1.036 | 0.988 | 1.600 | 1.158 | 1.538 | 1.049 | 0.993 | 1.600 | 1.172 | 1.564 |
| 0.3 | 1.058 | 0.886 | 1.400 | 1.052 | 1.398 | 1.043 | 0.901 | 1.400 | 1.062 | 1.402 |
| 0.4 | 1.051 | 0.795 | 1.200 | 0.961 | 1.269 | 1.061 | 0.792 | 1.200 | 0.972 | 1.285 |
| 0.5 | 1.045 | 0.691 | 1.000 | 0.872 | 1.165 | 1.051 | 0.700 | 1.000 | 0.870 | 1.135 |
| 0.6 | 1.046 | 0.610 | 0.800 | 0.745 | 1.058 | 1.040 | 0.625 | 0.800 | 0.751 | 0.965 |
| 0.7 | 1.039 | 0.494 | 0.600 | 0.666 | 0.934 | 1.057 | 0.499 | 0.600 | 0.655 | 0.767 |
| 0.8 | 1.045 | 0.400 | 0.400 | 0.604 | 0.748 | 1.052 | 0.414 | 0.400 | 0.558 | 0.659 |
| 0.9 | 1.043 | 0.286 | 0.200 | 0.469 | 0.599 | 1.047 | 0.310 | 0.200 | 0.480 | 0.497 |
| 1.0 | 1.047 | 0.216 | 0.000 | 0.349 | 0.306 | 1.058 | 0.199 | 0.000 | 0.375 | 0.327 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, L.; McClean, S.; Donnelly, M.; Burke, K.; Khan, K. Detecting and Responding to Concept Drift in Business Processes. Algorithms 2022, 15, 174. https://doi.org/10.3390/a15050174
Yang L, McClean S, Donnelly M, Burke K, Khan K. Detecting and Responding to Concept Drift in Business Processes. Algorithms. 2022; 15(5):174. https://doi.org/10.3390/a15050174
Chicago/Turabian StyleYang, Lingkai, Sally McClean, Mark Donnelly, Kevin Burke, and Kashaf Khan. 2022. "Detecting and Responding to Concept Drift in Business Processes" Algorithms 15, no. 5: 174. https://doi.org/10.3390/a15050174
APA StyleYang, L., McClean, S., Donnelly, M., Burke, K., & Khan, K. (2022). Detecting and Responding to Concept Drift in Business Processes. Algorithms, 15(5), 174. https://doi.org/10.3390/a15050174