Author Contributions
Conceptualization, M.N., D.W.; methodology, M.N., D.W.; software, M.N., D.W.; validation, M.N., D.W. and A.R.; investigation, M.N., D.W.; resources, A.R.; data curation, M.N.; writing—original draft preparation, M.N., D.W.; writing—review and editing, M.N., D.W. and A.R.; visualization, M.N., D.W.; supervision, A.R.; project administration, M.N., A.R.; funding acquisition, A.R. All authors have read and agreed to the published version of the manuscript.
Figure 1.
Comparison of RandAugment and SmartAugment.
Figure 1.
Comparison of RandAugment and SmartAugment.
Figure 2.
Comparison of TrivialAugment and SmartSamplingAugment.
Figure 2.
Comparison of TrivialAugment and SmartSamplingAugment.
Figure 3.
Performance (mean IoU) analysis for different numbers of operations for RandAugment++ on EM. These results indicate that the number of applied operations should optimally not be limited to three, as in classical RandAugment.
Figure 3.
Performance (mean IoU) analysis for different numbers of operations for RandAugment++ on EM. These results indicate that the number of applied operations should optimally not be limited to three, as in classical RandAugment.
Figure 4.
Infrastructure mapping datasets.
Figure 4.
Infrastructure mapping datasets.
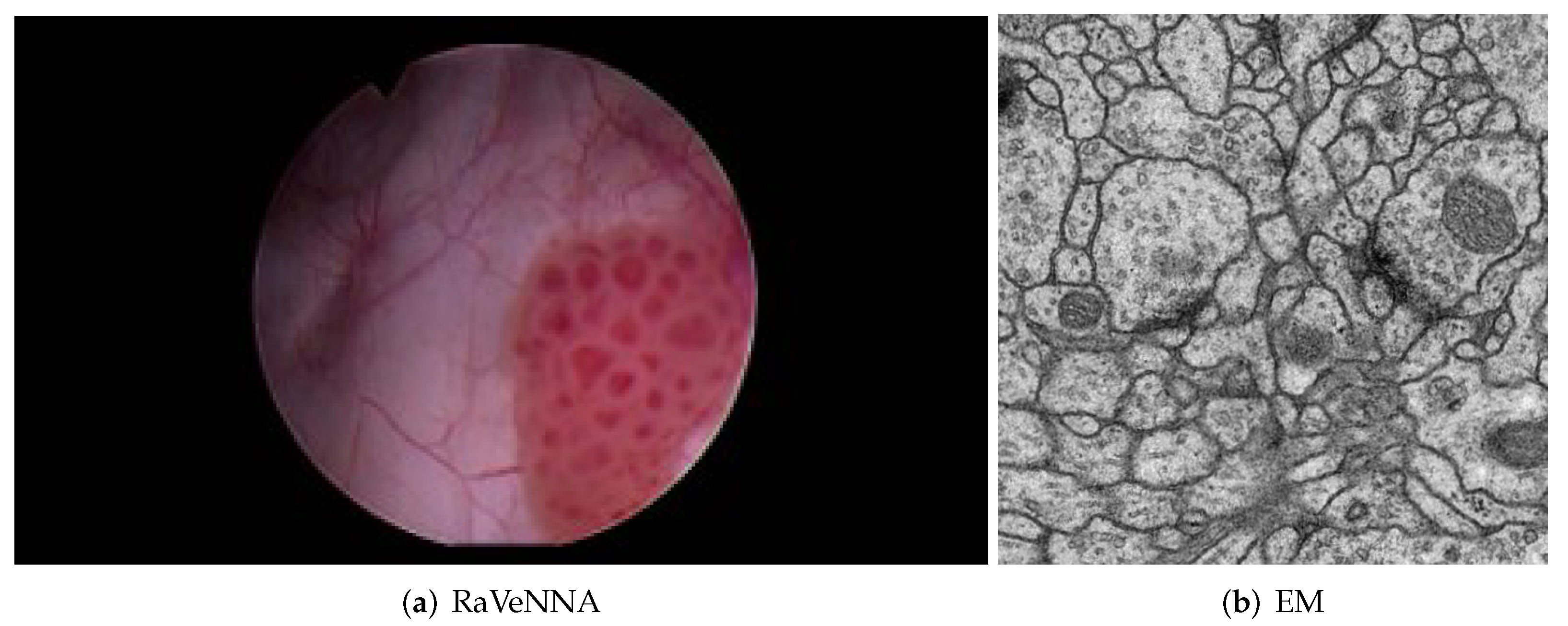
Figure 5.
Biomedical datasets.
Figure 5.
Biomedical datasets.
Figure 6.
The impact of hyperparameters on different datasets based on performance metric mean IoU. This figure shows that the good values for each hyperparameter depend on the dataset. In this example, higher number of color ops and color magnitude is optimal for EM dataset but detrimental for KITTI dataset.
Figure 6.
The impact of hyperparameters on different datasets based on performance metric mean IoU. This figure shows that the good values for each hyperparameter depend on the dataset. In this example, higher number of color ops and color magnitude is optimal for EM dataset but detrimental for KITTI dataset.
Figure 7.
Comparison of the probability hyperparameter of applying data augmentations. These results indicate that the EM dataset needs much more data augmentation than the RaVeNNa dataset. MeanIoU is used as performance metric.
Figure 7.
Comparison of the probability hyperparameter of applying data augmentations. These results indicate that the EM dataset needs much more data augmentation than the RaVeNNa dataset. MeanIoU is used as performance metric.
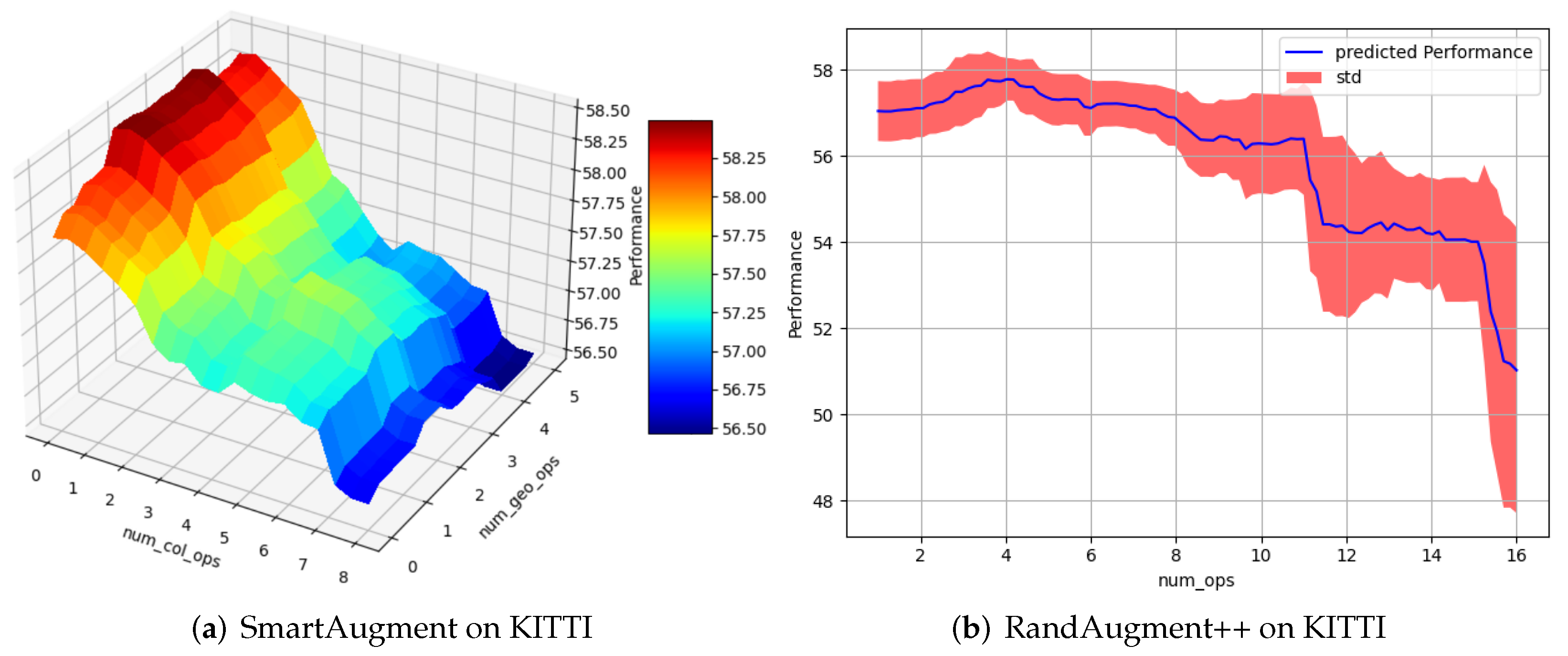
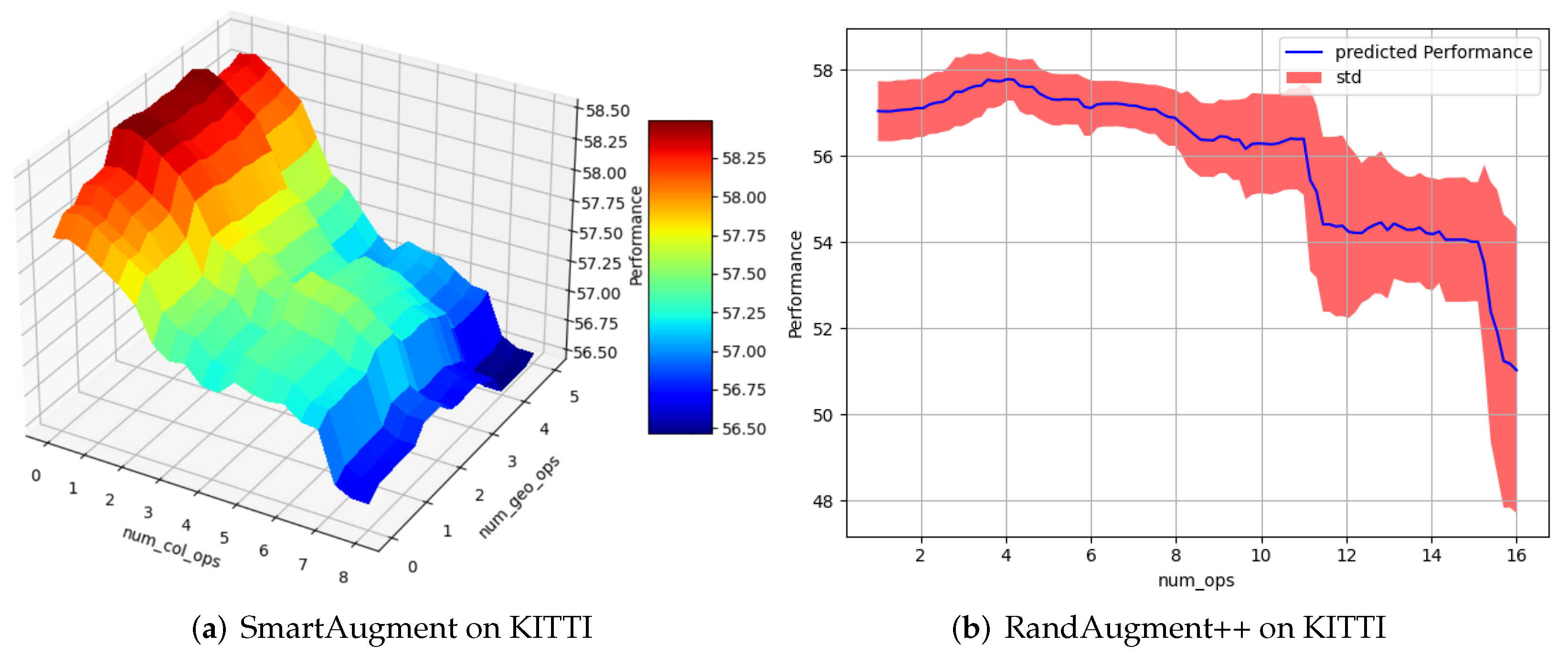
Figure 8.
Comparison considering the number of applied augmentations: RandAugment++ optimizes the total number of augmentations, whereas SmartAugment differs between the number of color augmentations and geometric augmentations. This figure shows that the performance of a total number of augmentations depends on the types of augmentations. Please note that mean IoU is used as a performance metric.
Figure 8.
Comparison considering the number of applied augmentations: RandAugment++ optimizes the total number of augmentations, whereas SmartAugment differs between the number of color augmentations and geometric augmentations. This figure shows that the performance of a total number of augmentations depends on the types of augmentations. Please note that mean IoU is used as a performance metric.
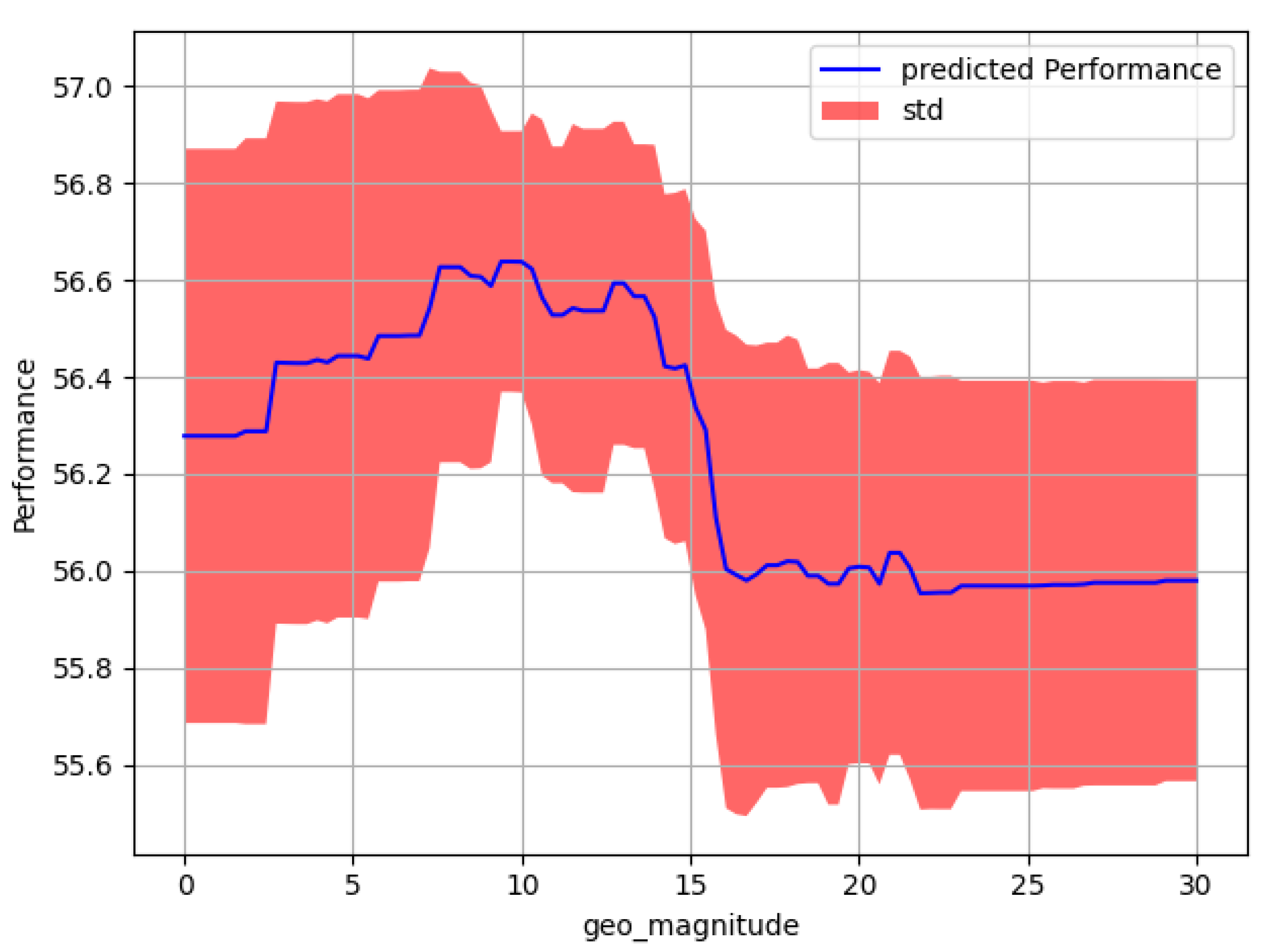
Figure 9.
Results from SmartAugment on the KITTI dataset indicate that the geometric magnitude, which is the most important hyperparameter for this particular dataset, should be low. Taking this into account gives a possible explanation for why weighting the data augmentation with weights that focus on geometric augmentations might hurt performance (mean IoU) for the KITTI dataset.
Figure 9.
Results from SmartAugment on the KITTI dataset indicate that the geometric magnitude, which is the most important hyperparameter for this particular dataset, should be low. Taking this into account gives a possible explanation for why weighting the data augmentation with weights that focus on geometric augmentations might hurt performance (mean IoU) for the KITTI dataset.
Figure 10.
Visualization of three images from the KITTI (left) and EM (right) datasets, each rotated with a different magnitude.
Figure 10.
Visualization of three images from the KITTI (left) and EM (right) datasets, each rotated with a different magnitude.
Table 1.
Test mean Intersection over Union (IoU) in percentage for different algorithms on semantic segmentation datasets. SmartAugment outperforms all other data augmentation strategies across all datasets. SmartSamplingAugment competes with the previous state-of-the-art approaches and outperforms TrivialAugment, a comparably cheap method. For DefaultAugment, TrivialAugment, and SmartSamplingAugment, we evaluated each experiment three times using different seeds to obtain the mean performance. For RandAugment++ (an extended version of RandAugment) and SmartAugment, we took the mean test IoU over the three best performing validation configurations. Please note that DefaultAugment represents the baseline, and the higher the value, the better the performance. # iterations refers to the number of BO iterations completed to find best configuration.
Table 1.
Test mean Intersection over Union (IoU) in percentage for different algorithms on semantic segmentation datasets. SmartAugment outperforms all other data augmentation strategies across all datasets. SmartSamplingAugment competes with the previous state-of-the-art approaches and outperforms TrivialAugment, a comparably cheap method. For DefaultAugment, TrivialAugment, and SmartSamplingAugment, we evaluated each experiment three times using different seeds to obtain the mean performance. For RandAugment++ (an extended version of RandAugment) and SmartAugment, we took the mean test IoU over the three best performing validation configurations. Please note that DefaultAugment represents the baseline, and the higher the value, the better the performance. # iterations refers to the number of BO iterations completed to find best configuration.
| Dataset | Default | Rand++ | Trivial | Smart | SmartSampling |
|---|
| KITTI | 65.07 | 67.19 | 64.82 | 68.84 | 66.53 |
| RaVeNNa | 88.37 | 90.71 | 90.53 | 91.00 | 90.72 |
| EM | 77.25 | 78.83 | 78.15 | 79.04 | 78.42 |
| ErfASst | 67.01 | 68.75 | 66.79 | 73.72 | 70.24 |
| # Iterations | 1 | 50 | 1 | 50 | 1 |
Table 2.
Detailed overview of data augmentation operations and their magnitude ranges. We use the same augmentations as in RandAugment paper [
12]. * The Identity operation only belongs to this list for the RandAugment and TrivialAugment approaches.
Table 2.
Detailed overview of data augmentation operations and their magnitude ranges. We use the same augmentations as in RandAugment paper [
12]. * The Identity operation only belongs to this list for the RandAugment and TrivialAugment approaches.
| Color Ops | Range | Geometric Ops | Range |
|---|
| Sharpness | (0.1, 1.9) | Rotate | (0, 30) |
| AutoContrast | (0, 1) | ShearX | (0.0, 0.3) |
| Equalize | (0, 1) | ShearY | (0.0, 0.3) |
| Solarize | (0, 256) | TranslateX | (0.0, 0.33) |
| Color | (0.1, 1.9) | TranslateY | (0.0, 0.33) |
| Contrast | (0.1, 1.9) | Identity * | |
| Brightness | (0.1, 1.9) | | |
Table 3.
Training parameters for each dataset. Train, val, test denote the data split used during training.
Table 3.
Training parameters for each dataset. Train, val, test denote the data split used during training.
| Dataset | Resolution | Batch Size | Learning Rate | Epochs | #Data | #Train | #Val | #Test |
|---|
| KITTI | | 4 | 0.001 | 4000 | 200 | 140 | 30 | 30 |
| RaVeNNa | | 3 | 0.001 | 2000 | 1684 | 1107 | 216 | 361 |
| EM | | 2 | 0.01 | 500 | 30 | 20 | 5 | 5 |
| ErfASst | | 2 | 0.05 | 5000 | 50 | 30 | 10 | 10 |
Table 4.
Approximate estimate of computing costs (in hours) for each dataset and augmentation approach. The costs are the time required until the maximum number of epochs is reached. Due to computational resource constraints, we run Smart, Rand++, with four GPUs in parallel. is RandAugment that uses GridSearch for optimization.
Table 4.
Approximate estimate of computing costs (in hours) for each dataset and augmentation approach. The costs are the time required until the maximum number of epochs is reached. Due to computational resource constraints, we run Smart, Rand++, with four GPUs in parallel. is RandAugment that uses GridSearch for optimization.
| Dataset | Default | Rand++ | Trivial | Smart | Smart Sampling | Rand |
|---|
| KITTI | 12 h | 150 h | 12 h | 150 h | 12 h | 276 h |
| RaVeNNa | 13 h | 163 h | 13 h | 13 h | 163 h | 302 h |
| EM | 0.5 h | 6 h | 0.5 h | 6 h | 0.5 h | 11.6 h |
| ErfASst | 23 h | 287 h | 23 h | 287 h | 23 h | 537 h |
| # Iterations | 1 | 50 | 1 | 50 | 1 | 93 |
Table 5.
Hyperparameter importance study for different hyperparameters across different datasets on SmartAugment experiments. For instance, for the RaVeNNa dataset, the probability of applying a data augmentation strategy is responsible for 46% of mean IoU’s variability across the configuration space. The higher the importance value, the more potential it has to improve the performance for a given dataset.
Table 5.
Hyperparameter importance study for different hyperparameters across different datasets on SmartAugment experiments. For instance, for the RaVeNNa dataset, the probability of applying a data augmentation strategy is responsible for 46% of mean IoU’s variability across the configuration space. The higher the importance value, the more potential it has to improve the performance for a given dataset.
| Dataset | p(aug) | col_mag | geo_mag | #col_ops | #geo_ops |
|---|
| KITTI | 0.13 | 0.12 | 0.24 | 0.14 | 0.03 |
| RaVeNNa | 0.46 | 0.04 | 0.06 | 0.06 | 0.05 |
| EM | 0.25 | 0.14 | 0.09 | 0.04 | 0.03 |
| ErFASst | 0.1 | 0.12 | 0.04 | 0.22 | 0.04 |
Table 6.
Comparison of RandAugment variants with SmartAugment on the EM dataset. For each of the results, we took the test mean IoU of the best three performing configurations evaluated on the validation set. The results show that SmartAugment outperforms RandAugment(++), independent of the hyperparameter optimization algorithm.
Table 6.
Comparison of RandAugment variants with SmartAugment on the EM dataset. For each of the results, we took the test mean IoU of the best three performing configurations evaluated on the validation set. The results show that SmartAugment outperforms RandAugment(++), independent of the hyperparameter optimization algorithm.
| Method | HPO Algorithm | EM Dataset | # Iterations |
|---|
| Rand | Grid Search (classic approach) | 78.54 | 93 |
| Rand++ | Random Search | 78.83 | 50 |
| Rand++ | Bayesian Optimization | 78.84 | 50 |
| Smart | Bayesian Optimization | 79.04 | 50 |
Table 7.
SmartSamplingAugment ablation study analyzing the impact of weighting the augmentations and annealing the probability hyperparameter over the whole epochs for different datasets. We evaluated each experiment three times using different seeds to obtain the mean IoU. For the experiments without annealing, we set the probability P of applying augmentations to 1.
Table 7.
SmartSamplingAugment ablation study analyzing the impact of weighting the augmentations and annealing the probability hyperparameter over the whole epochs for different datasets. We evaluated each experiment three times using different seeds to obtain the mean IoU. For the experiments without annealing, we set the probability P of applying augmentations to 1.
| Dataset | Weighting | Without Weighting |
|---|
| Annealing | No-Annealing | Annealing | No-Annealing |
|---|
| KITTI | 66.53 | 67.15 | 67.49 | 67.13 |
| RaVeNNa | 90.72 | 87.07 | 85.65 | 85.68 |
| EM | 78.52 | 79.26 | 77.94 | 78.47 |
| ErFASst | 70.24 | 68.27 | 64.99 | 64.51 |














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}