

A Momentum-Based Local Face Adversarial Example Generation Algorithm


Abstract
1. Introduction
1.1. Introductions
1.2. Motivations
1.3. Contributions
- We proposed a white-box adversarial example generation algorithm (AdvLocFace) based on the local face. We circled an area with intensive features on the face to construct an patch-like adversarial example within this range.
- A momentum optimization module with a dynamic learning rate was proposed. By adopting a dynamic piecewise learning rate, the optimization algorithm can accelerate convergence; the momentum parameter was introduced to avoid the algorithm oscillating near the best point, which improved the attack efficiency.
- By dynamically calculating the attack threshold, the optimal attack effect parameters were estimated, which reduced the number of modifications to the pixels in the clean images and effectively improved the transferability of the adversarial examples.
- We compared the algorithm with several traditional algorithms. The experiments showed that the algorithm had a high success rate in the white-box setting, and to also obtain an ideal transferability.
2. Preliminaries
2.1. Deep Model of Face Recognition
2.2. Classic Adversarial Attacks Algorithms
2.3. Adversarial Attacks on Face Recognition
3. Methodology and Evaluations
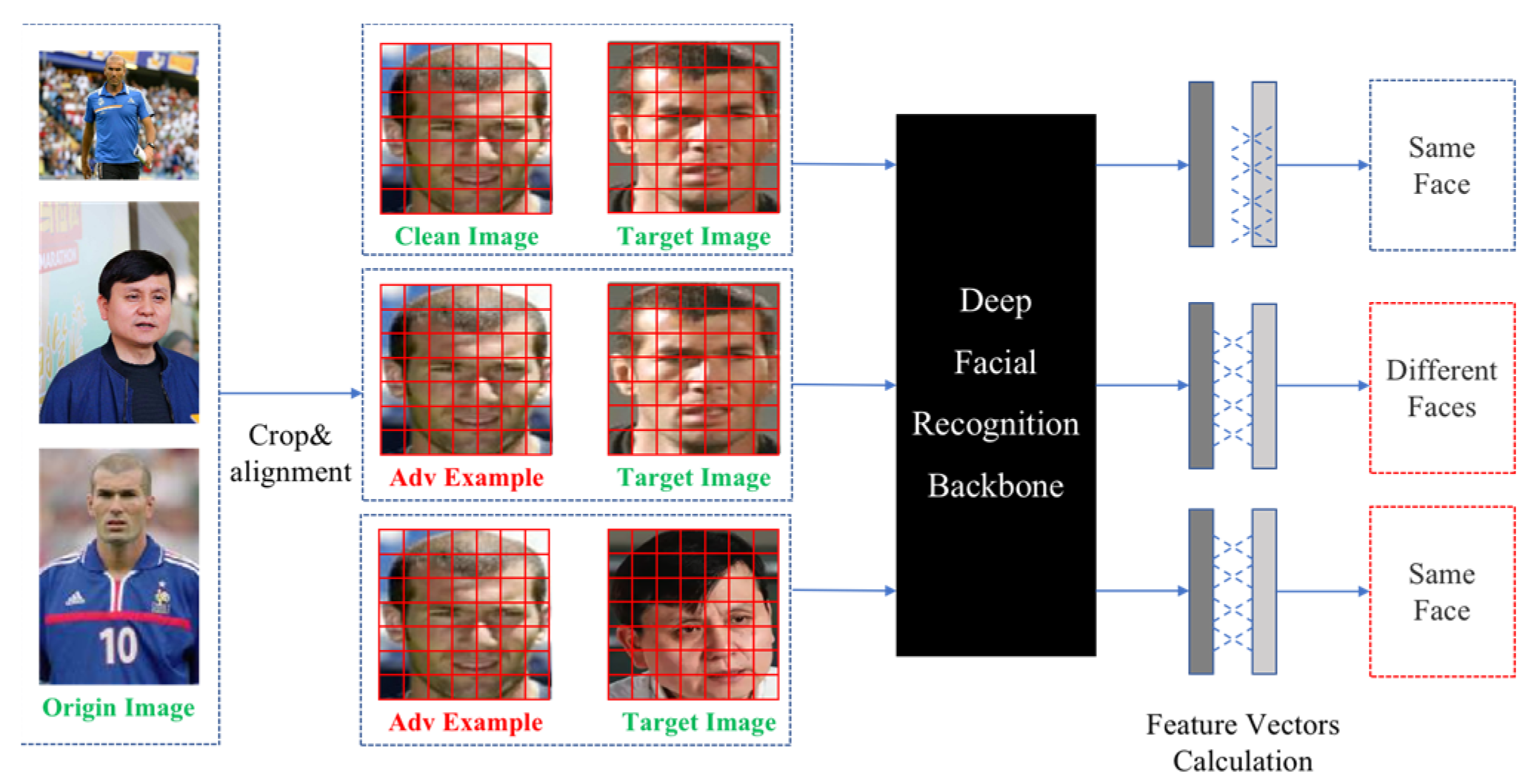
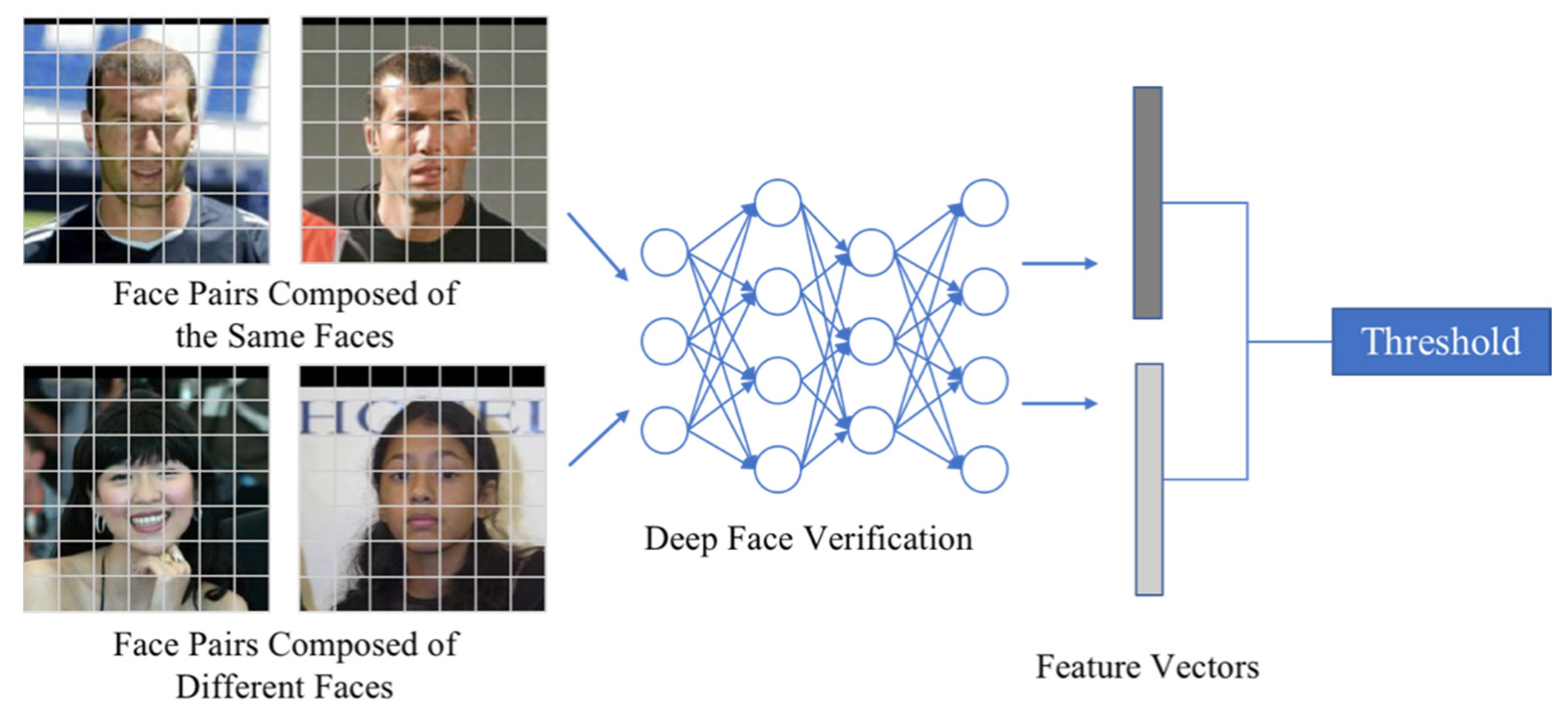
3.1. Face Recognition and Evaluation Matrix
3.2. Adversarial Attacks against Faces
3.3. Evaluation Indices of Attack
- Cosine Similarity is calculated by the cosine of the angle between two vectors, given as vector and vector , and their cosine similarity is calculated as follows.where and are the individual elements of vector and vector , respectively. The cosine similarity takes values in the range [–1, 1], and the closer the value is to 1, the closer the orientation of these two vectors (i.e., the more similar the face feature vectors). Cosine similarity can visually measure the similarity between the adversarial example and the clean image.
- Total variation (TV) [19], as a regular term loss function, reduces the variability of neighboring pixels and makes the perturbation smoother. Additionally, since perturbation smoothness is a prerequisite property for physical realizability against attacks, this lays some groundwork for future physical realizability [18]. Given a perturbation noise , is the pixel where the perturbation is located at coordinate . The value is smaller when the neighboring pixels are closer (i.e., the smoother the perturbation, and vice versa). The TV is calculated as follows:
- We used the constraints to measure the difference between the original image and the adversarial example. is used as a loss function to control the range of perturbed noise. In the application scenario of attacking, it can be intuitively interpreted as whether the modified pixels will attract human attention.
4. Our Method
4.1. Configurations for Face Adversarial Attack
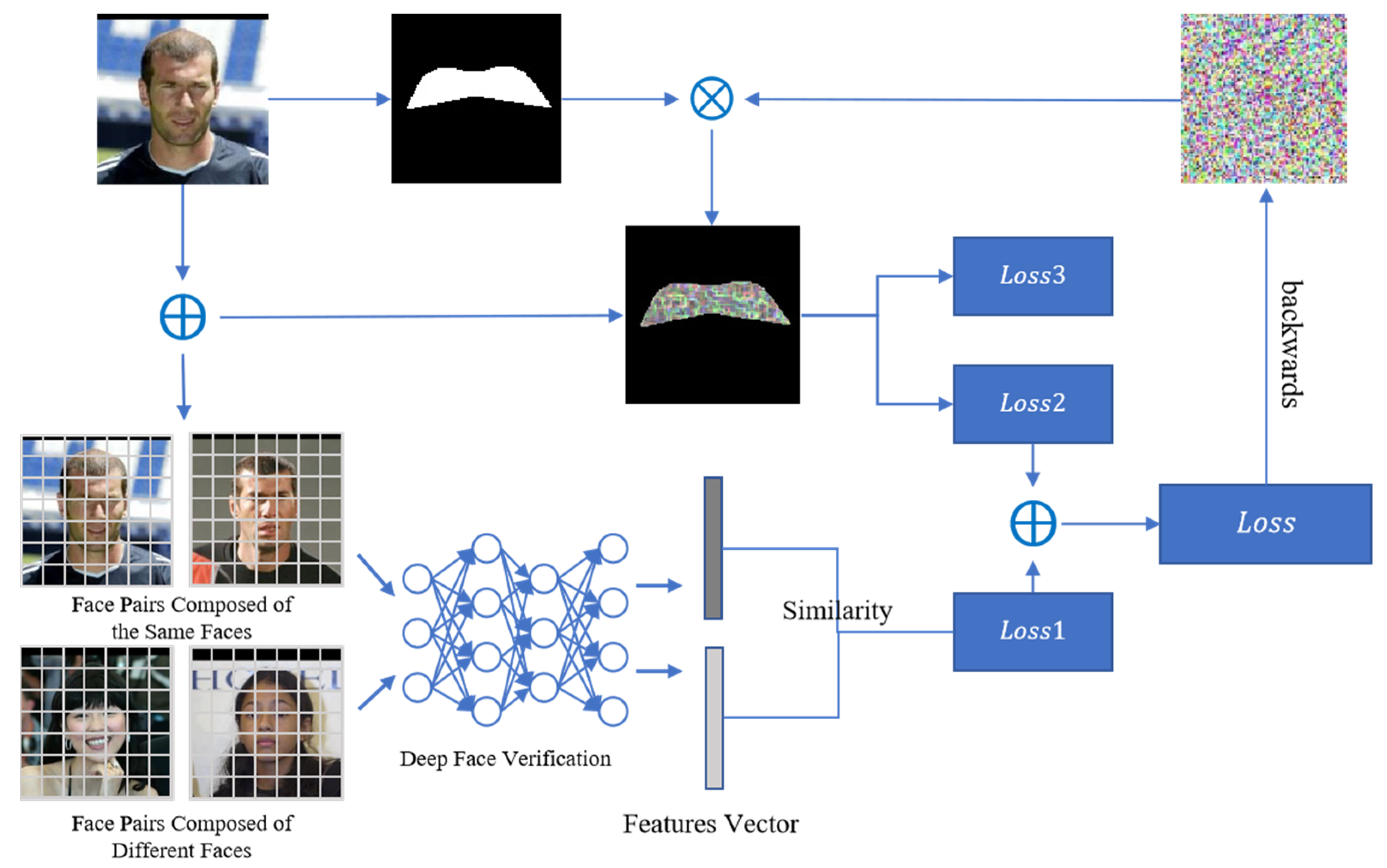
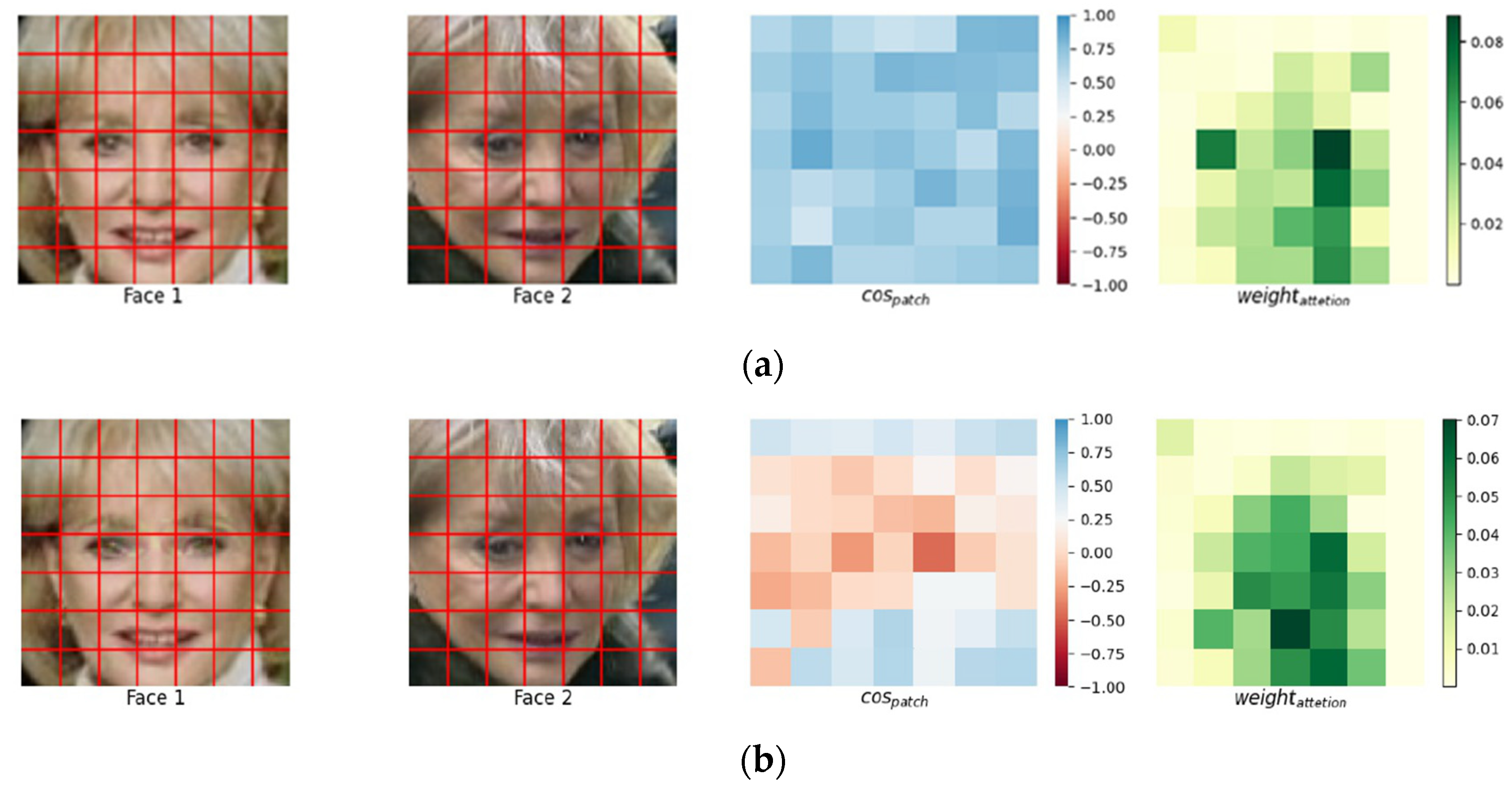
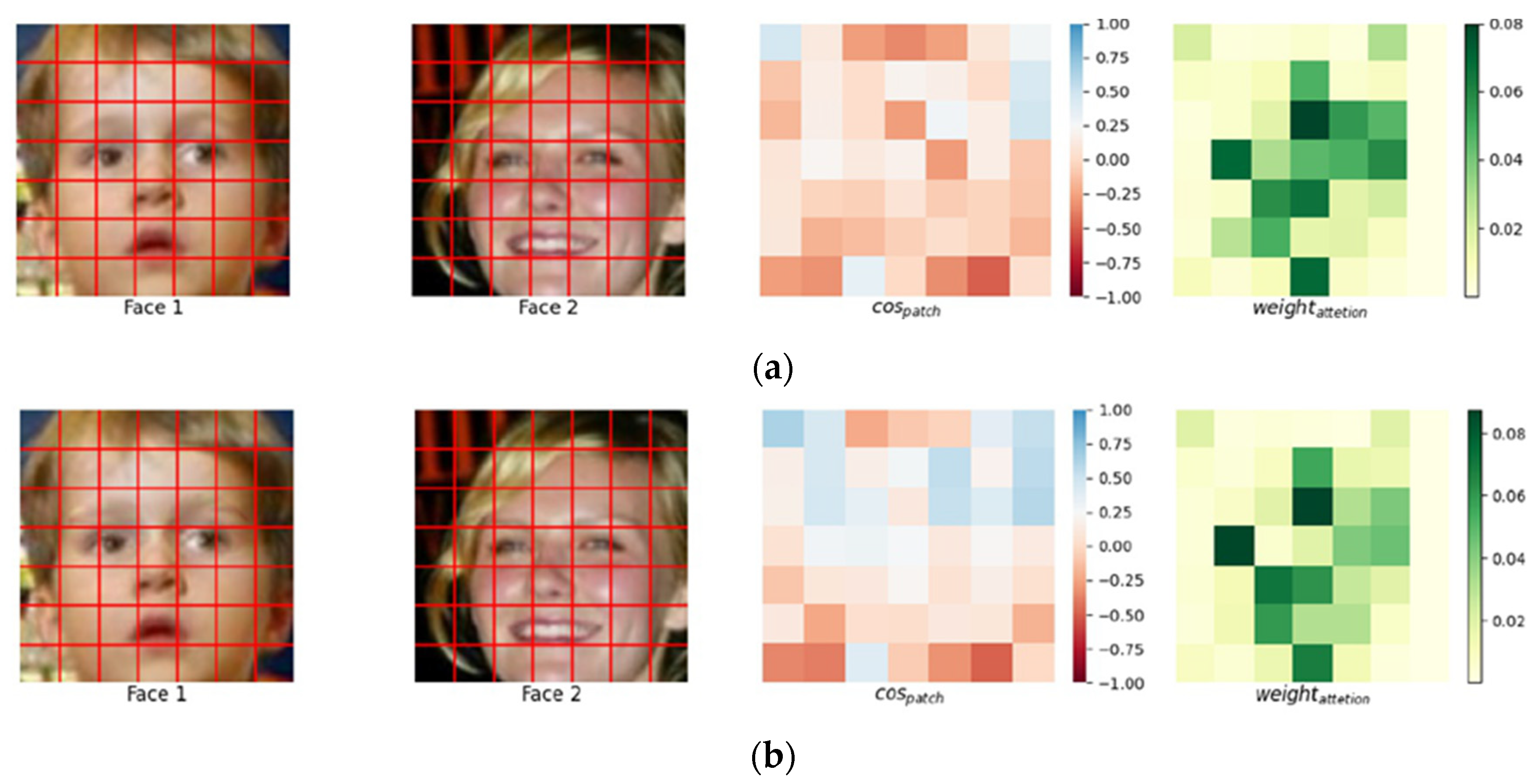
4.2. Local Area Mask Generation
4.3. Loss Functions
- (1)
- For the non-targeted attack, an adversarial example was generated for the input image so that the difference between them was as large as possible. When the difference was larger than the threshold value calculated by the deep detection model, the attack was successful; on the other hand, for the targeted attack, the generated adversarial example needed to be as similar as possible to the target image . The loss function is shown as Equation (12).where is the cosine similarity of the feature vector calculated by Equation (10); takes the value of 0 or 1, representing the non-targeted attack and targeted attack, respectively.
- (2)
- The perturbation size is constrained by the norm, thus ensuring that the visibility of the perturbation is kept within a certain range when an effective attack is implemented. The loss function in this section constrains the perturbation after the restriction as follows.where is the perturbation. The mask is that generated from the first face image of the face pair to restrict the perturbation region. It is a [0, 1] matrix scaled to the same size as the image. The ⨀ symbol indicates the dot product operation between the elements.
- (3)
- The TV is used to improve the smoothness of the perturbation through Equation (14), and the loss function of this part also deals with the perturbation after restriction, as follows.
4.4. Momentum-Based Optimization Algorithms
5. Experiments
5.1. Datasets
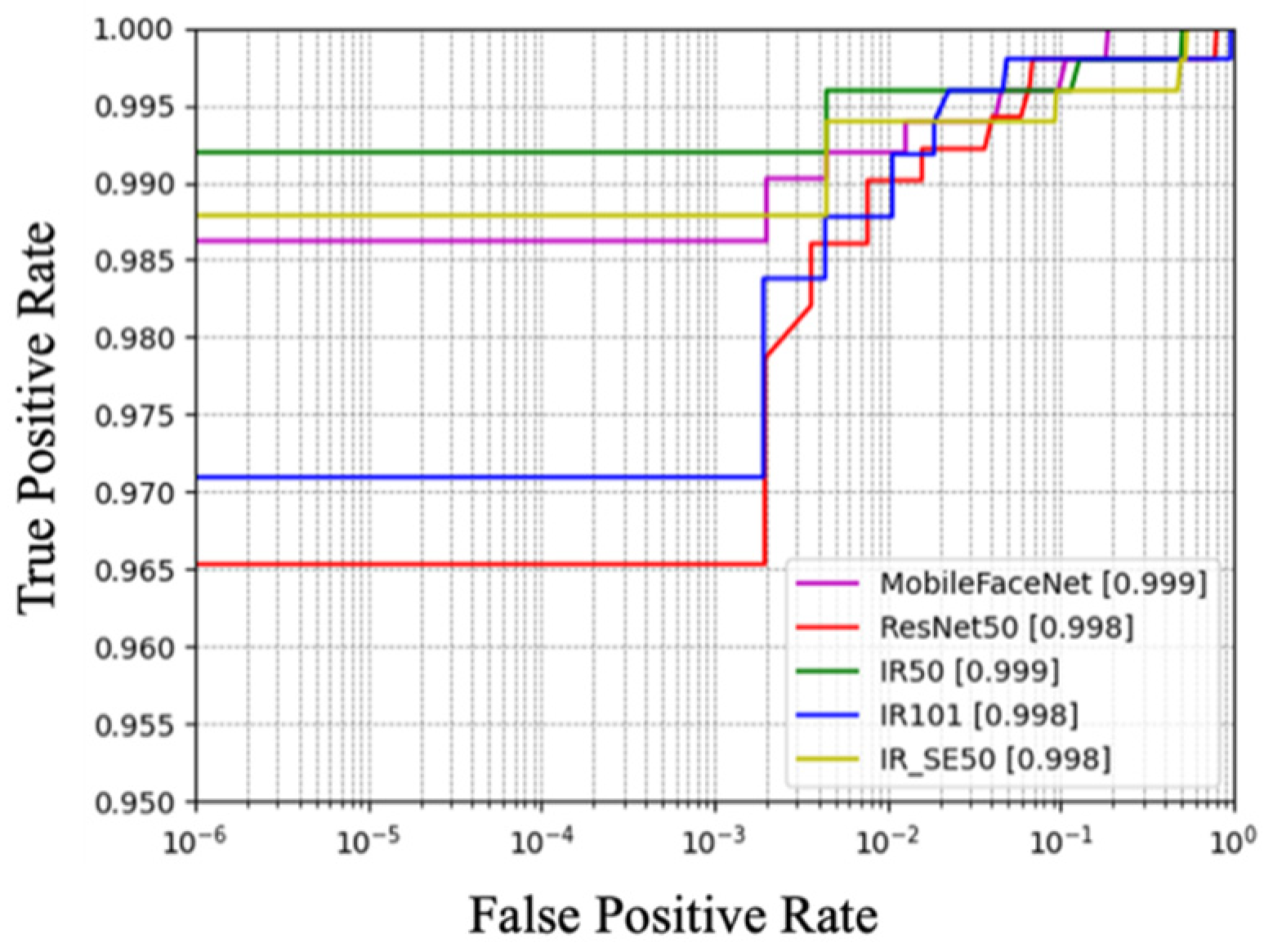
5.2. Performance Evaluation for Face Recognition Models
5.3. Attack Method Evaluation Indicators
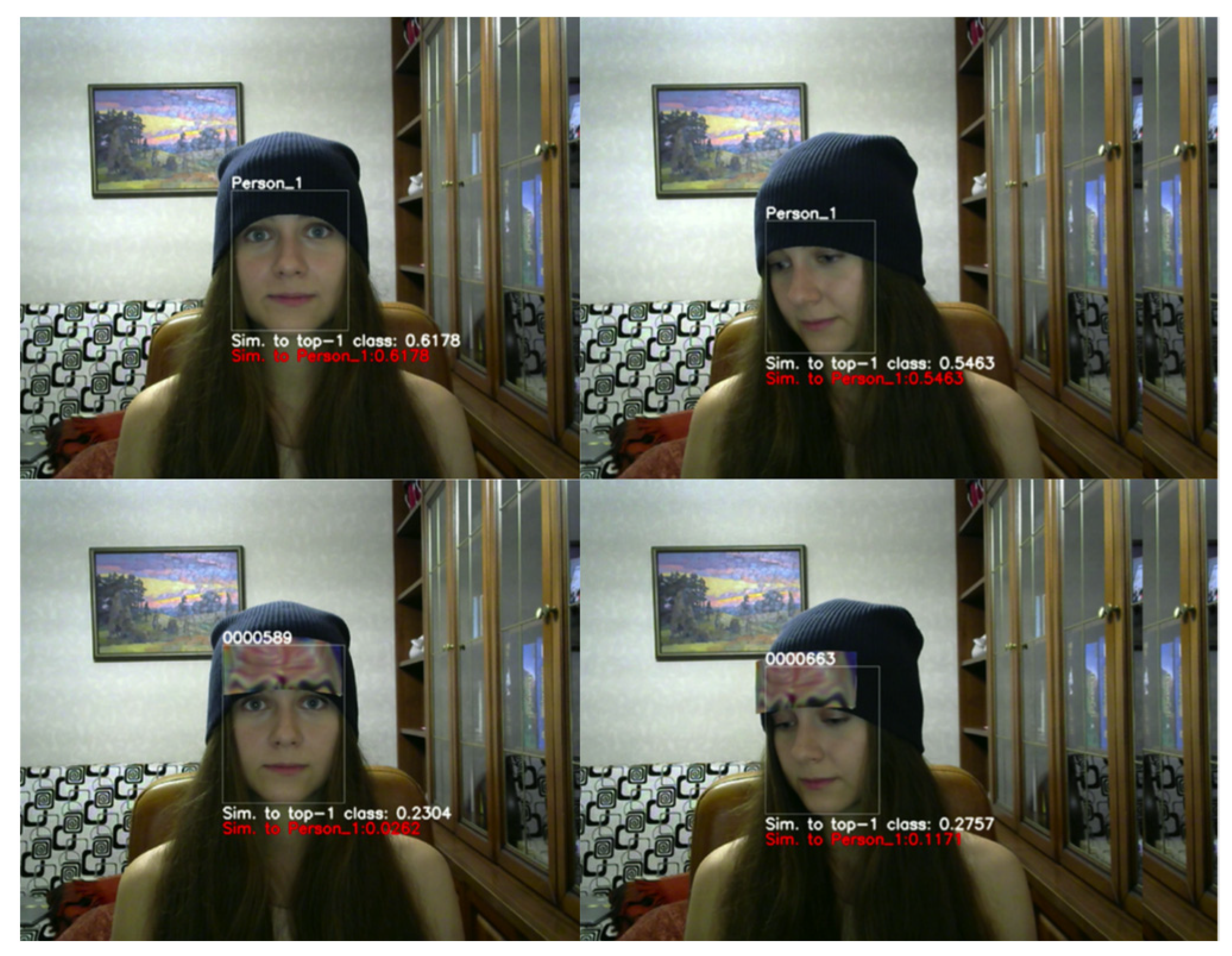
5.4. Adversarial Attack within Human Eye Area
5.4.1. Non-Targeted Attacks based on Eye Area
5.4.2. Targeted Attacks Based on Eye Area
5.4.3. Quantitative Comparison of Different Attack Models
5.4.4. Comparison of Adversarial Example Algorithms
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Taigman, Y.; Yang, M.; Ranzato, M.A.; Wolf, L. DeepFace: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.A.; Wolf, L. Web-scale training for face identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4690–4699. [Google Scholar]
- Wang, H.; Wang, Y.; Zhou, Z.; Ji, X.; Gong, D.; Zhou, J.; Li, Z.; Liu, W. Cosface: Large margin cosine loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Florian, S.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Tianyue, Z.; Deng, W.; Hu, J. Cross-age lfw: A database for studying cross-age face recognition in unconstrained environments. arXiv 2017, arXiv:1708.08197. [Google Scholar]
- Yi, D.; Lei, Z.; Liao, S.; Li, S.Z. Learning Face Representation from Scratch. arXiv 2014, arXiv:1411.7923. [Google Scholar]
- Chen, S.; Liu, Y.; Gao, X.; Han, Z. MobileFaceNets: Efficient CNNs for Accurate Real-time Face Verification on Mobile Devices. In Proceedings of the Chinese Conference on Biometric Recognition, Beijing, China, 3–4 December 2018; pp. 428–438. [Google Scholar]
- Thys, S.; Van Ranst, W.; Goedeme, T. Fooling automated surveillance cameras: Adversarial patches to attack person detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 49–55. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2014, arXiv:1312.6199. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. Available online: https://arxiv.org/abs/1412.6572 (accessed on 23 October 2022).
- Dong, Y.; Liao, F.; Pang, T.; Su, H.; Zhu, J.; Hu, X.; Li, J. Boosting Adversarial Attacks with Momentum. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9185–9193. [Google Scholar]
- Carlini, N.; Wagner, D.A. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar]
- Liu, X.; Yang, H.; Liu, Z.; Song, L.; Chen, Y.; Li, H. DPATCH: An Adversarial Patch Attack on Object Detectors. arXiv 2019, arXiv:1806.02299. [Google Scholar]
- Kevin, E.; Ivan, E.; Earlence, F.; Bo, L.; Amir, R.; Florian, T.; Atul, P.; Tadayoshi, K.; Dawn, S. Physical Adversarial Examples for Object Detectors. arXiv 2018, arXiv:1807.07769. [Google Scholar]
- Wu, Z.; Lim, S.; Davis, L.; Goldstein, T. Making an Invisibility Cloak: Real World Adversarial Attacks on Object Detectors. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Xu, K.; Zhang, G.; Liu, S.; Fan, Q.; Sun, M.; Chen, H.; Chen, P.; Wang, Y.; Lin, X. Evading Real-Time Person Detectors by Adversarial T-shirt. arXiv 2019, arXiv:1910.11099v1. [Google Scholar]
- Sharif, M.; Bhagavatula, S.; Bauer, L.; Reiter, M.K. Accessorize to a Crime: Real and Stealthy Attacks on State-of-the-Art Face Recognition. In Proceedings of the CCS’16: 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016. [Google Scholar]
- Komkov, S.; Petiushko, A. AdvHat: Real-world adversarial attack on ArcFace Face ID system. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021. [Google Scholar]
- Huang, G.B.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled faces in the wild: A database for studying face recognition in unconstrained environments. In Proceedings of the Workshop on Faces in ‘Real-Life’ Images: Detection, Alignment, and Recognition, Marseille, France, 17 October 2008; pp. 1–11. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. Sphereface: Deep hypersphere embedding for face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 212–220. [Google Scholar]
- Lang, D.; Chen, D.; Shi, R.; He, Y. Attention-Guided Digital Adversarial Patches On Visual Detection. Secur. Commun. Netw. 2021, 2021, 6637936:1–6637936:11. [Google Scholar] [CrossRef]
- Nguyen, D.; Arora, S.S.; Wu, Y.; Yang, H. Adversarial Light Projection Attacks on Face Recognition Systems: A Feasibility Study. Available online: https://arxiv.org/abs/2003.11145 (accessed on 23 October 2022).
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Zolfi, A.; Avidan, S.; Elovici, Y.; Shabtai, A. Adversarial Mask: Real-World Adversarial Attack Against Face Recognition Models. arXiv 2021, arXiv:2111.10759. [Google Scholar]
- Yin, B.; Wang, W.; Yao, T.; Guo, J.; Kong, Z.; Ding, S.; Li, J.; Liu, C. Adv-Makeup—A New Imperceptible and Transferable Attack on Face Recognition. In Proceedings of the International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–27 August 2021; pp. 1252–1258. [Google Scholar]
- Xiao, Z.; Gao, X.; Fu, C.; Dong, Y.; Gao, W.; Zhang, X.; Zhou, J.; Zhu, J. Improving transferability of adversarial patches on face recognition with generative models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 11845–11854. [Google Scholar]
- Parmar, R.; Kuribayashi, M.; Takiwaki, H.; Raval, M.S. On Fooling Facial Recognition Systems using Adversarial Patches. In Proceedings of the 2022 International Joint Conference on Neural Networks, Padova, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar]
- Jia, S.; Yin, B.; Yao, T.; Ding, S.; Shen, C.; Yang, X.; Ma, C. Adv-Attribute: Inconspicuous and Transferable Adversarial Attack on Face Recognition. arXiv 2022, arXiv:2210.06871. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Farfade, S.S.; Saberian, M.J.; Li, L.J. Multi-view Face Detection Using Deep Convolutional Neural Networks. In Proceedings of the 5th ACM on International Conference on Multimedia Retrieval, Shanghai, China, 23–26 June 2015; pp. 643–650. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Huynh-Thu, Q.; Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]
- Lin, Y.S.; Liu, Z.Y.; Chen, Y.A.; Wang, Y.S.; Chang, Y.L.; Hsu, W.H. xCos: An Explainable Cosine Metric for Face Verification Task. ACM Trans. Multimed. Comput. Commun. Appl. 2021, 17, 1–16. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | TAR (%) | FAR | Threshold | Sim-Threshold |
|---|---|---|---|---|
| IR50 | 99.596 | 0.00995 | 0.43326 | 0.20814 |
| IR101 | 98.984 | 0.01259 | 0.41311 | 0.26960 |
| IR-SE50 | 99.396 | 0.01025 | 0.42920 | 0.22060 |
| ResNet50 | 99.596 | 0.00836 | 0.45207 | 0.15001 |
| MobileFaceNet | 99.196 | 0.01076 | 0.43763 | 0.19469 |
| Models | ACC (%) | Targeted-ASR (%) | Non-Targeted-ASR (%) | Threshold |
|---|---|---|---|---|
| IR50 | 98.2 | 90.4 | 99.2 | 0.43326 |
| IR101 | 94.7 | 96.2 | 98.6 | 0.41311 |
| IR-SE50 | 92.6 | 92.2 | 98.8 | 0.42920 |
| ResNet50 | 94.5 | 93.8 | 99.4 | 0.45207 |
| MobileFaceNet | 96.6 | 91.4 | 99.2 | 0.43763 |
| Models | Targeted-PSNR | Targeted-SSIM | Targeted-L2 | Non-Targeted-PSNR | Non-Targeted-SSIM | Non-Targeted-L2 |
|---|---|---|---|---|---|---|
| IR50 | 43.69864 | 0.99358 | 0.71112 | 39.19224 | 0.98557 | 1.29420 |
| IR101 | 43.68891 | 0.99379 | 0.71556 | 42.37390 | 0.99232 | 0.84162 |
| IR-SE50 | 43.46344 | 0.99345 | 0.76280 | 39.95576 | 0.98470 | 1.22338 |
| ResNet50 | 45.51955 | 0.99531 | 0.58352 | 40.89765 | 0.98938 | 1.09996 |
| MobileFaceNet | 43.82034 | 0.99395 | 0.72392 | 41.36429 | 0.98954 | 1.04512 |
| Models | Attack Method | ResNet50 | MobileFaceNet | SphereFace | ArcFace |
|---|---|---|---|---|---|
| ResNet50 | FGSM | 77.00% | 34.81% | 31.88% | 30.26% |
| I-FGSM | 100.00% | 24.41% | 21.76% | 18.82% | |
| AdvGlasses | 100.00% | 51.05% | 48.02% | 40.58% | |
| AdvHat | 97.80% | 52.92% | 44.87% | 44.24% | |
| AdvLocFace | 99.10% | 57.15% | 51.35% | 59.00% | |
| MobileFaceNet | FGSM | 39.99% | 67.67% | 27.83% | 29.04% |
| I-FGSM | 38.86% | 100.00% | 24.59% | 20.75% | |
| AdvGlasses | 69.39% | 100.00% | 46.06% | 45.64% | |
| AdvHat | 77.61% | 97.90% | 46.29% | 37.38% | |
| AdvLocFace | 61.62% | 99.20% | 52.76% | 40.92% | |
| SphereFace | FGSM | 38.55% | 32.34% | 59.20% | 28.74% |
| I-FGSM | 41.94% | 33.37% | 99.88% | 25.91% | |
| AdvGlasses | 76.59% | 65.61% | 99.58% | 53.53% | |
| AdvHat | 68.03% | 54.06% | 93.91% | 64.16% | |
| AdvLocFace | 62.96% | 58.90% | 96.65% | 67.91% | |
| ArcFace | FGSM | 37.01% | 33.58% | 30.76% | 75.19% |
| I-FGSM | 31.56% | 25.65% | 21.96% | 98.67% | |
| AdvGlasses | 57.88% | 52.43% | 50.20% | 97.35% | |
| AdvHat | 68.61% | 65.90% | 63.19% | 100.00% | |
| AdvLocFace | 73.24% | 70.64% | 70.57% | 100.00% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lang, D.; Chen, D.; Huang, J.; Li, S. A Momentum-Based Local Face Adversarial Example Generation Algorithm. Algorithms 2022, 15, 465. https://doi.org/10.3390/a15120465
Lang D, Chen D, Huang J, Li S. A Momentum-Based Local Face Adversarial Example Generation Algorithm. Algorithms. 2022; 15(12):465. https://doi.org/10.3390/a15120465
Chicago/Turabian StyleLang, Dapeng, Deyun Chen, Jinjie Huang, and Sizhao Li. 2022. "A Momentum-Based Local Face Adversarial Example Generation Algorithm" Algorithms 15, no. 12: 465. https://doi.org/10.3390/a15120465
APA StyleLang, D., Chen, D., Huang, J., & Li, S. (2022). A Momentum-Based Local Face Adversarial Example Generation Algorithm. Algorithms, 15(12), 465. https://doi.org/10.3390/a15120465