

Detection of Cyberattacks and Anomalies in Cyber-Physical Systems: Approaches, Data Sources, Evaluation

 , , , , and
, , , , and 
Abstract
1. Introduction
- analysis of the approaches to anomaly detection for the cyber-physical systems;
- overview of the metrics used to evaluate the anomaly and attack detection models.
2. Approaches to the Anomaly and Attack Detection for the Cyber-Physical Systems
3. Datasets for the Attack and Anomaly Detection
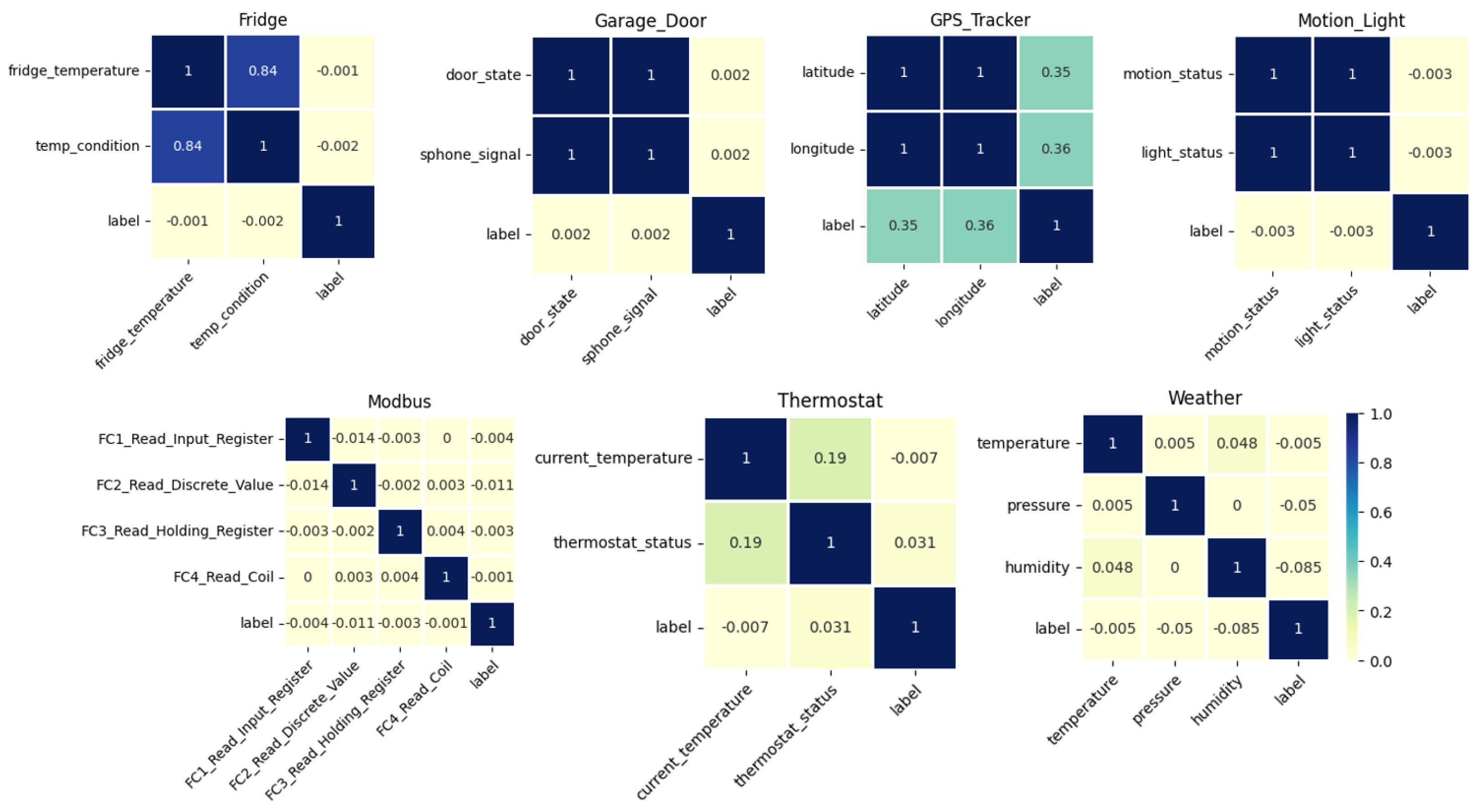
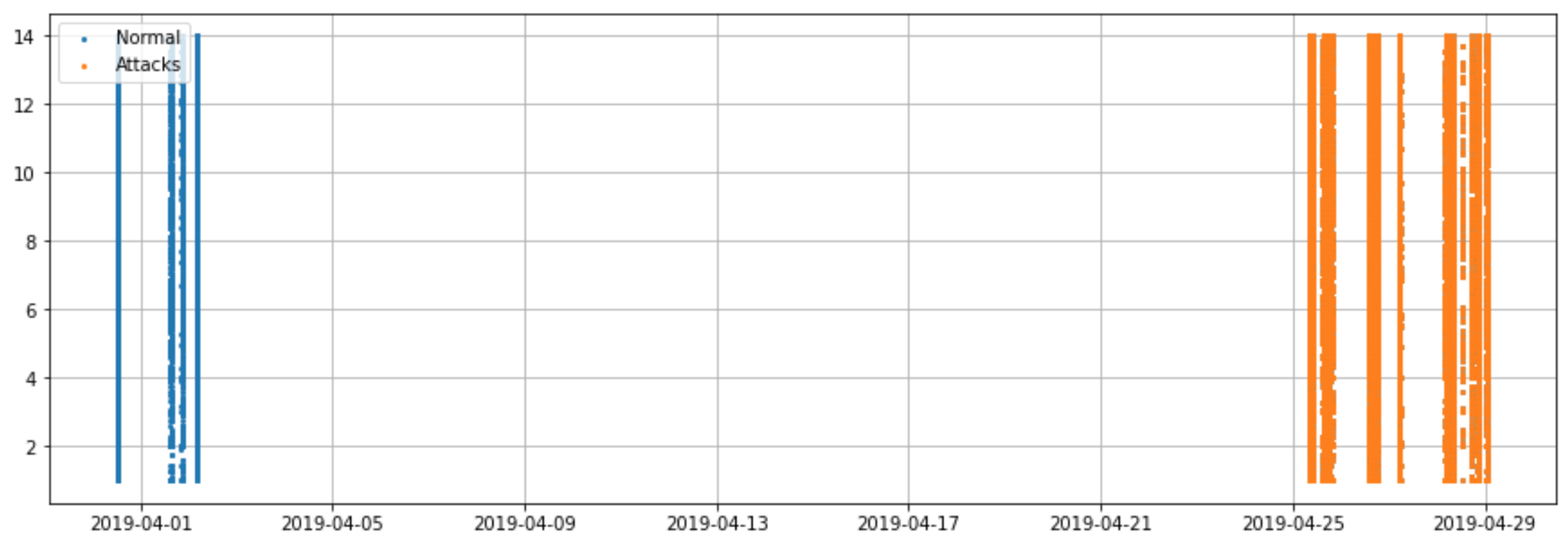
3.1. TON_IoT Dataset Analysis
3.2. SWaT Dataset Analysis
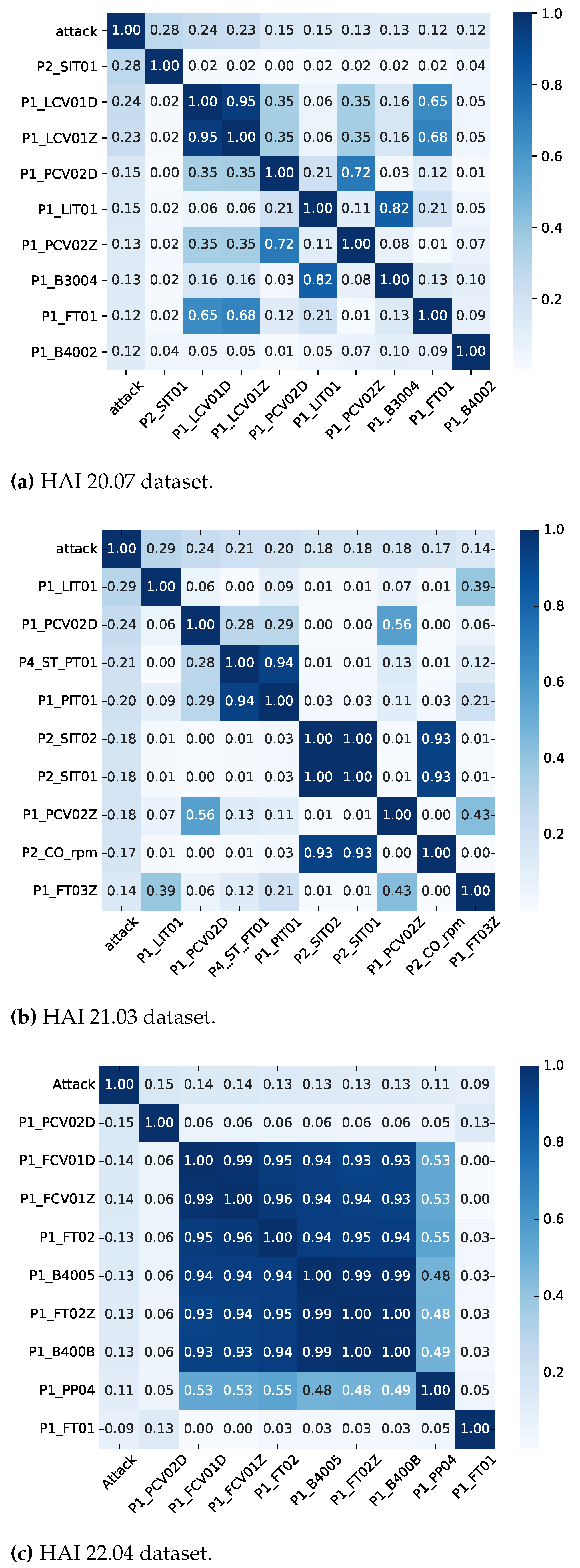
3.3. HAI Dataset Analysis
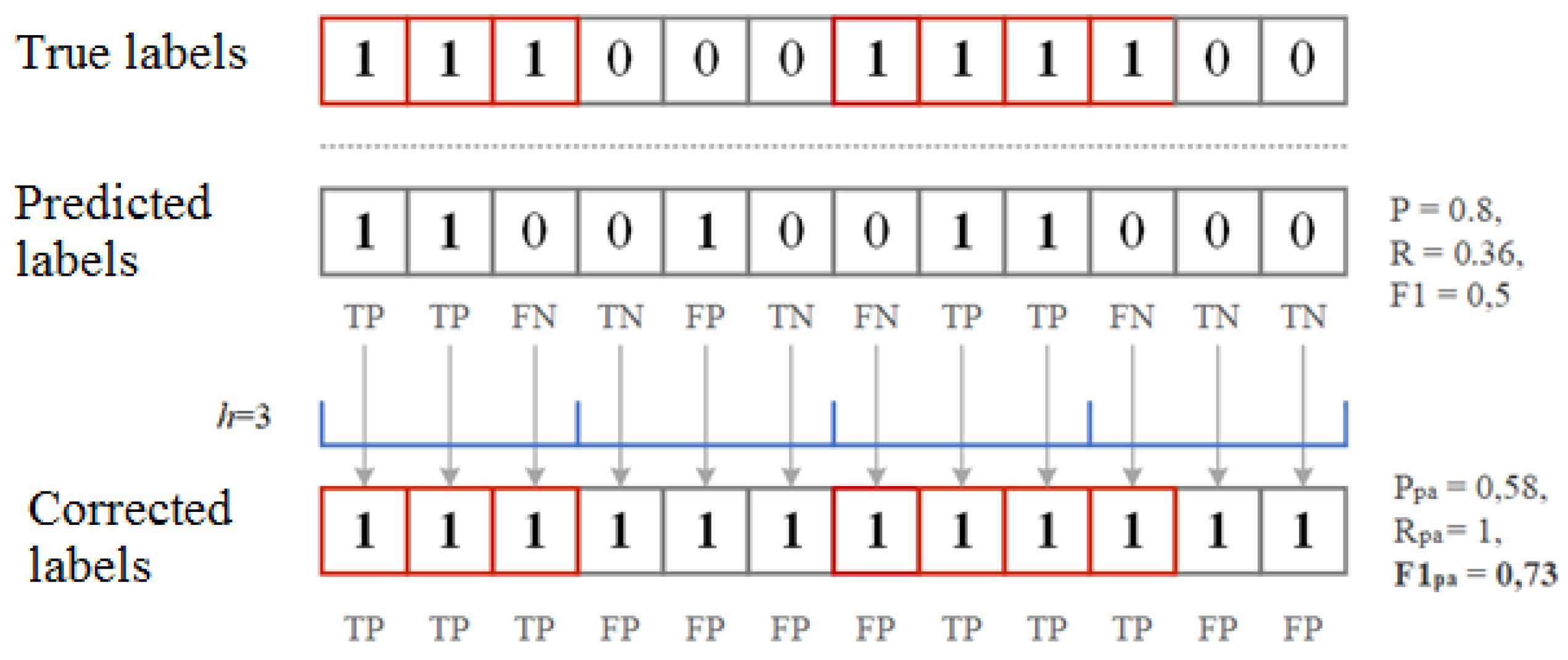
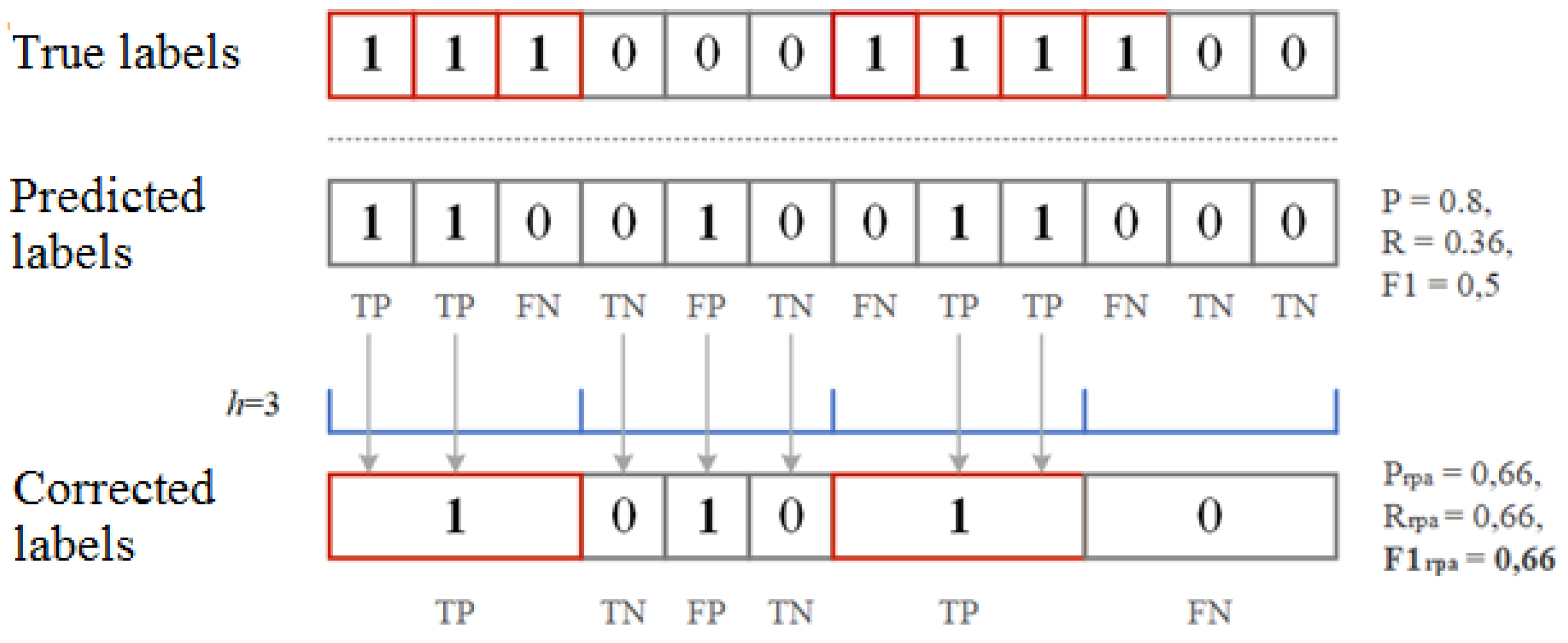
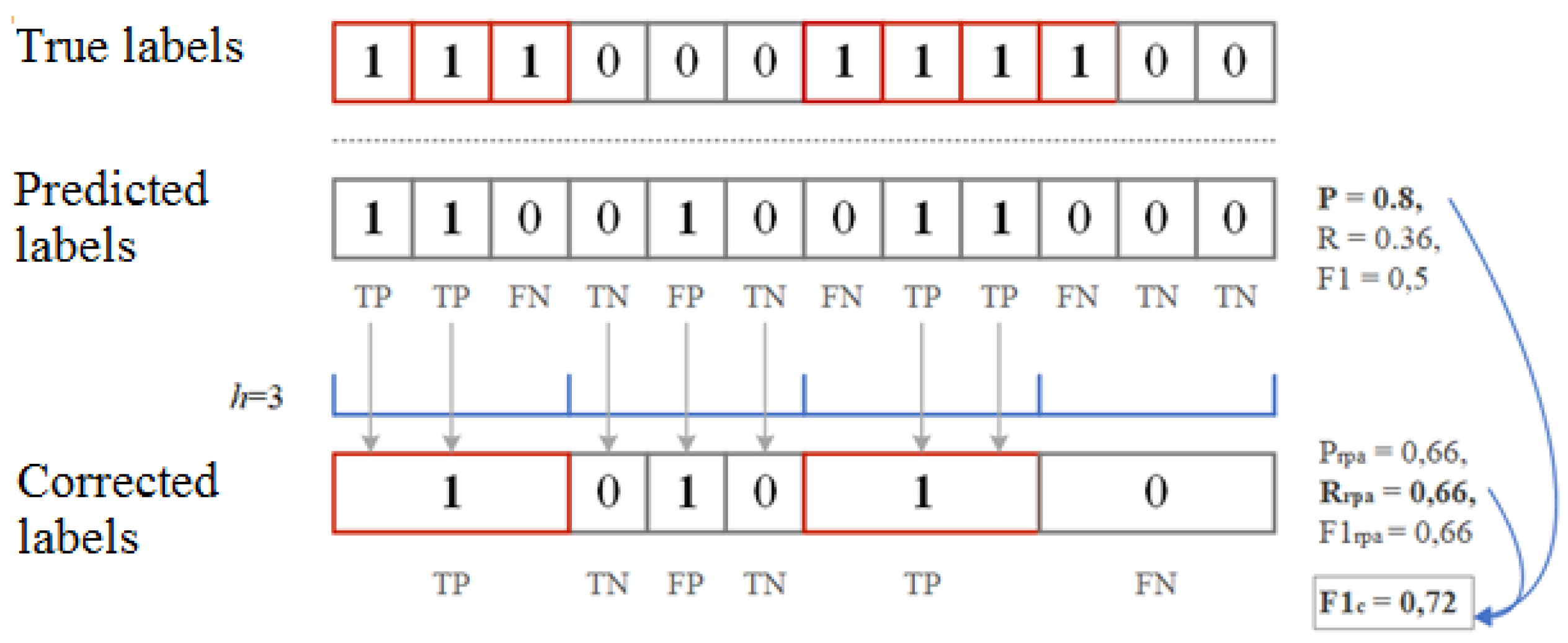
4. Performance Metrics for Anomaly and Attack Detection
- —correctly detected anomaly ();
- —false detected anomaly ();
- —correctly assigned norm ();
- —false assigned norm ().
- —any part of the predicted anomaly sequence intersects with a sequence that actually has an anomaly;
- —if no sequence that is predicted to be anomalous intersects with a real anomalous sequence;
- —all predicted anomalous sequences that do not intersect with any really anomalous sequence.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Levshun, D.; Chechulin, A.; Kotenko, I. Design of Secure Microcontroller-Based Systems: Application to Mobile Robots for Perimeter Monitoring. Sensors 2021, 21, 8451. [Google Scholar] [CrossRef]
- Turton, W.; Mehrotra, K. Hackers Breached Colonial Pipeline Using Compromised Password. 4 June 2021. Available online: https://www.bloomberg.com/news/articles/2021-06-04/hackers-breached-colonial-pipeline-using-compromised-password (accessed on 20 December 2022).
- Jones, S. Venezuela Blackout: What Caused It and What Happens Next. The Guardian 13 March 2019. Available online: https://www.theguardian.com/world/2019/mar/13/venezuela-blackout-what-caused-it-and-what-happens-next (accessed on 20 December 2022).
- Graham, R. Cyberattack Hits Germany’s Domestic Fuel Distribution System. 1 February, 2022. Available online: https://www.bloomberg.com/news/articles/2022-02-01/mabanaft-hit-by-cyberattack-that-disrupts-german-fuel-deliveries (accessed on 20 December 2022).
- Kim, S.; Jo, W.; Shon, T. APAD: Autoencoder-based payload anomaly detection for industrial IoE. Appl. Soft Comput. 2020, 88, 106017. [Google Scholar] [CrossRef]
- Wang, C.; Wang, B.; Liu, H.; Qu, H. Anomaly Detection for Industrial Control System Based on Autoencoder Neural Network. Wirel. Commun. Mob. Comput. 2020, 2020, 8897926:1–8897926:10. [Google Scholar] [CrossRef]
- Kotenko, I.; Gaifulina, D.; Zelichenok, I. Systematic Literature Review of Security Event Correlation Methods. IEEE Access 2022, 10, 43387–43420. [Google Scholar] [CrossRef]
- Alsaedi, A.; Moustafa, N.; Tari, Z.; Mahmood, A.; Anwar, A. TON_IoT telemetry dataset: A new generation dataset of IoT and IIoT for data-driven intrusion detection systems. IEEE Access 2020, 8, 165130–165150. [Google Scholar] [CrossRef]
- Goh, J.; Adepu, S.; Junejo, K.N.; Mathur, A. A dataset to support research in the design of secure water treatment systems. In Proceedings of the Critical Information Infrastructures Security: 11th International Conference, CRITIS 2016, Paris, France, 10–12 October 2016; Revised Selected Papers 11. Springer: New York, NY, USA, 2017; pp. 88–99. [Google Scholar]
- Shin, H.K.; Lee, W.; Yun, J.H.; Kim, H. HAI 1.0: HIL-based augmented ICS security dataset. In Proceedings of the 13th USENIX Conference on Cyber Security Experimentation and Test, Boston, MA, USA, 10 August 2020; p. 1. [Google Scholar]
- Meleshko, A.; Shulepov, A.; Desnitsky, V.; Novikova, E.; Kotenko, I. Visualization Assisted Approach to Anomaly and Attack Detection in Water Treatment Systems. Water 2022, 14, 2342. [Google Scholar] [CrossRef]
- Shulepov, A.; Novikova, E.; Murenin, I. Approach to Anomaly Detection in Cyber-Physical Object Behavior. In Intelligent Distributed Computing XIV; Camacho, D., Rosaci, D., Sarné, G.M.L., Versaci, M., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 417–426. [Google Scholar]
- Khan, A.A.; Beg, O.A.; Alamaniotis, M.; Ahmed, S. Intelligent anomaly identification in cyber-physical inverter-based systems. Electr. Power Syst. Res. 2021, 193, 107024. [Google Scholar] [CrossRef]
- Parto, M.; Saldana, C.; Kurfess, T. Real-time outlier detection and Bayesian classification using incremental computations for efficient and scalable stream analytics for IoT for manufacturing. Procedia Manuf. 2020, 48, 968–979. [Google Scholar] [CrossRef]
- Mohammadi Rouzbahani, H.; Karimipour, H.; Rahimnejad, A.; Dehghantanha, A.; Srivastava, G. Anomaly detection in cyber-physical systems using machine learning. In Handbook of Big Data Privacy; Springer: New York, NY, USA, 2020; pp. 219–235. [Google Scholar]
- Mokhtari, S.; Abbaspour, A.; Yen, K.K.; Sargolzaei, A. A machine learning approach for anomaly detection in industrial control systems based on measurement data. Electronics 2021, 10, 407. [Google Scholar] [CrossRef]
- Park, S.; Lee, K. Improved Mitigation of Cyber Threats in IIoT for Smart Cities: A New-Era Approach and Scheme. Sensors 2021, 21, 1976. [Google Scholar] [CrossRef] [PubMed]
- Elnour, M.; Meskin, N.; Khan, K.; Jain, R. A Dual-Isolation-Forests-Based Attack Detection Framework for Industrial Control Systems. IEEE Access 2020, 8, 36639–36651. [Google Scholar] [CrossRef]
- Gad, A.R.; Haggag, M.; Nashat, A.A.; Barakat, T.M. A Distributed Intrusion Detection System using Machine Learning for IoT based on ToN-IoT Dataset. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 548–563. [Google Scholar] [CrossRef]
- Kumar, P.; Tripathi, R.; Gupta, G.P. P2IDF: A privacy-preserving based intrusion detection framework for software defined Internet of Things-fog (SDIoT-Fog). In Proceedings of the Adjunct 2021 International Conference on Distributed Computing and Networking, Nara, Japan, 5–8 January 2021; pp. 37–42. [Google Scholar]
- Huč, A.; Šalej, J.; Trebar, M. Analysis of machine learning algorithms for anomaly detection on edge devices. Sensors 2021, 21, 4946. [Google Scholar] [CrossRef] [PubMed]
- Inoue, J.; Yamagata, Y.; Chen, Y.; Poskitt, C.M.; Sun, J. Anomaly Detection for a Water Treatment System Using Unsupervised Machine Learning. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), Orleans, LA, USA, 18–21 November 2017; pp. 1058–1065. [Google Scholar] [CrossRef]
- Gaifulina, D.; Kotenko, I. Selection of deep neural network models for IoT anomaly detection experiments. In Proceedings of the 2021 29th Euromicro International Conference on Parallel, Distributed and Network-Based Processing (PDP), Valladolid, Spain, 10–21 March 2021; IEEE: Hoboken, NJ, USA, 2021; pp. 260–265. [Google Scholar]
- Shalyga, D.; Filonov, P.; Lavrentyev, A. Anomaly Detection for Water Treatment System based on Neural Network with Automatic Architecture Optimization. arXiv 2018, arXiv:1807.07282. [Google Scholar]
- Xie, X.; Wang, B.; Wan, T.; Tang, W. Multivariate abnormal detection for industrial control systems using 1D CNN and GRU. IEEE Access 2020, 8, 88348–88359. [Google Scholar] [CrossRef]
- Nagarajan, S.M.; Deverajan, G.G.; Bashir, A.K.; Mahapatra, R.P.; Al-Numay, M.S. IADF-CPS: Intelligent Anomaly Detection Framework towards Cyber Physical Systems. Comput. Commun. 2022, 188, 81–89. [Google Scholar] [CrossRef]
- Fan, Y.; Li, Y.; Zhan, M.; Cui, H.; Zhang, Y. IoTDefender: A Federated Transfer Learning Intrusion Detection Framework for 5G IoT. In Proceedings of the 2020 IEEE 14th International Conference on Big Data Science and Engineering (BigDataSE), Guangzhou, China, 29 December 2020–1 January 2021; pp. 88–95. [Google Scholar] [CrossRef]
- Audibert, J.; Michiardi, P.; Guyard, F.; Marti, S.; Zuluaga, M.A. USAD: UnSupervised Anomaly Detection on Multivariate Time Series. In Proceedings of the KDD’20, 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 6–10 July 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 3395–3404. [Google Scholar] [CrossRef]
- Li, D.; Chen, D.; Shi, L.; Jin, B.; Goh, J.; Ng, S.K. MAD-GAN: Multivariate Anomaly Detection for Time Series Data with Generative Adversarial Networks. In Proceedings of the International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September 2019. [Google Scholar]
- Neshenko, N.; Bou-Harb, E.; Furht, B. A behavioral-based forensic investigation approach for analyzing attacks on water plants using GANs. Forensic Sci. Int. Digit. Investig. 2021, 37, 301198. [Google Scholar] [CrossRef]
- Wu, P.; Moustafa, N.; Yang, S.; Guo, H. Densely connected residual network for attack recognition. In Proceedings of the 2020 IEEE 19th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Guangzhou, China, 29 December 2020–1 January 2021; IEEE: Hoboken, NJ, USA, 2020; pp. 233–242. [Google Scholar]
- Bian, X. Detecting Anomalies in Time-Series Data using Unsupervised Learning and Analysis on Infrequent Signatures. J. IKEEE 2020, 24, 1011–1016. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the NIPS’17, 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 4768–4777. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the KDD’16, 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Lin, Q.; Adepu, S.; Verwer, S.; Mathur, A. TABOR: A Graphical Model-Based Approach for Anomaly Detection in Industrial Control Systems. In Proceedings of the ASIACCS’18, 2018 on ACM Asia Conference on Computer and Communications Security, Incheon, Republic of Korea, 4–8 June 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 525–536. [Google Scholar] [CrossRef]
- Sukhostat, L. Anomaly Detection in Industrial Control System Based on the Hierarchical Hidden Markov Model. In Cybersecurity for Critical Infrastructure Protection via Reflection of Industrial Control Systems; IOS Press: Amsterdam, The Netherlands, 2022; pp. 48–55. [Google Scholar]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Sharafaldin, I.; Habibi Lashkari, A.; Ghorbani, A. Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy (ICISSP 2018), Funchal, Portugal, 22–24 January 2018; pp. 108–116. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 10–12 November 2015; IEEE: Hoboken, NJ, USA, 2015; pp. 1–6. [Google Scholar]
- Qin, Y.; Kondo, M. Federated Learning-Based Network Intrusion Detection with a Feature Selection Approach. In Proceedings of the 2021 International Conference on Electrical, Communication, and Computer Engineering (ICECCE), Kuala Lumpur, Malaysia, 12–13 June 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Murenin, I.; Doynikova, E.; Kotenko, I. Towards Security Decision Support for large-scale Heterogeneous Distributed Information Systems. In Proceedings of the 2021 14th International Conference on Security of Information and Networks (SIN), Edinburgh, UK, 15–17 December 2021; Volume 1, pp. 1–8. [Google Scholar] [CrossRef]
- Choi, S.; Yun, J.H.; Kim, S.K. A Comparison of ICS Datasets for Security Research Based on Attack Paths. In Proceedings of the CRITIS, Kaunas, Lithuania, 24–26 September 2018. [Google Scholar]
- Lemay, A.; Fernandez, J.M. Providing SCADA Network Data Sets for Intrusion Detection Research. In Proceedings of the 9th Workshop on Cyber Security Experimentation and Test (CSET 16), Austin, TX, USA, 8 August 2016; USENIX Association: Austin, TX, USA, 2016. [Google Scholar]
- Rodofile, N.R.; Schmidt, T.; Sherry, S.T.; Djamaludin, C.; Radke, K.; Foo, E. Process Control Cyber-Attacks and Labelled Datasets on S7Comm Critical Infrastructure. In Information Security and Privacy; Pieprzyk, J., Suriadi, S., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 452–459. [Google Scholar]
- Suthaharan, S.; Alzahrani, M.; Rajasegarar, S.; Leckie, C.; Palaniswami, M. Labelled data collection for anomaly detection in wireless sensor networks. In Proceedings of the 2010 Sixth International Conference on Intelligent Sensors, Sensor Networks and Information Processing, Brisbane, Australia, 7–10 December 2010; pp. 269–274. [Google Scholar] [CrossRef]
- Sivanathan, A.; Gharakheili, H.H.; Loi, F.; Radford, A.; Wijenayake, C.; Vishwanath, A.; Sivaraman, V. Classifying IoT Devices in Smart Environments Using Network Traffic Characteristics. IEEE Trans. Mob. Comput. 2019, 18, 1745–1759. [Google Scholar] [CrossRef]
- Koroniotis, N.; Moustafa, N.; Sitnikova, E.; Turnbull, B.P. Towards the Development of Realistic Botnet Dataset in the Internet of Things for Network Forensic Analytics: Bot-IoT Dataset. Future Gener. Comput. Syst. 2019, 100, 779–796. [Google Scholar] [CrossRef]
- Hamza, A.; Gharakheili, H.H.; Benson, T.A.; Sivaraman, V. Detecting Volumetric Attacks on loT Devices via SDN-Based Monitoring of MUD Activity. In Proceedings of the 2019 ACM Symposium on SDN Research, San Jose, CA, USA, 3–4 April 2019. [Google Scholar]
- Xu, H.; Chen, W.; Zhao, N.; Li, Z.; Bu, J.; Li, Z.; Liu, Y.; Zhao, Y.; Pei, D.; Feng, Y.; et al. Unsupervised Anomaly Detection via Variational Auto-Encoder for Seasonal KPIs in Web Applications. In Proceedings of the WWW’18, 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; International World Wide Web Conferences Steering Committee: Geneva, Switzerland, 2018; pp. 187–196. [Google Scholar] [CrossRef]
- Hundman, K.; Constantinou, V.; Laporte, C.; Colwell, I.; Soderstrom, T. Detecting Spacecraft Anomalies Using LSTMs and Nonparametric Dynamic Thresholding. In Proceedings of the KDD’18, 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 387–395. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IoT Device | Normal | Attack | Total | Class Balance, % |
|---|---|---|---|---|
| Fridge | 35,000 | 24,944 | 59,944 | 58/42 |
| Garage Door | 35,000 | 24,587 | 59,587 | 59/41 |
| GPS Tracker | 35,000 | 23,960 | 58,960 | 59/41 |
| Modbus | 35,000 | 16,106 | 51,106 | 68/32 |
| Motion Light | 35,000 | 24,488 | 59,488 | 59/41 |
| Thermostat | 35,000 | 17,774 | 52,774 | 66/34 |
| Weather | 35,000 | 24,260 | 59,260 | 59/41 |
| IoT Device | LR | LDA | kNN | RF | CART | NB | SVM | LSTM |
|---|---|---|---|---|---|---|---|---|
| Fridge | 0 | 0 | 0.37 | 0.02 | 0 | 0 | 0 | 0 |
| Garage Door | 0.58 | 0 | 0.56 | 0 | 0 | 0 | 0 | 0 |
| GPS Tracker | 0.51 | 0.43 | 0.95 | 0.95 | 0.93 | 0.43 | 0.81 | 0.85 |
| Modbus | 0 | 0 | 0.87 | 0.97 | 0.97 | 0 | 0 | 0 |
| Motion Light | 0 | 0 | 0.50 | 0 | 0 | 0 | 0 | 0 |
| Thermostat | 0 | 0 | 0.26 | 0.31 | 0.33 | 0 | 0 | 0 |
| Weather | 0.10 | 0.10 | 0.95 | 0.98 | 0.97 | 0.53 | 0.58 | 0.61 |
| Record Type | Number of Impacted Processes | Impacted Processes | Number of Samples |
|---|---|---|---|
| Normal | 0 | 0 | 399,157 |
| Attack | 1 | P1 | 4053 |
| 1 | P2 | 1809 | |
| 1 | P3 | 37,860 | |
| 1 | P4 | 1700 | |
| 1 | P5 | 1044 | |
| 2 | P3, P4 | 1691 | |
| 2 | P1, P3 | 1445 | |
| 2 | P3, P6 | 697 | |
| 2 | P4, P5 | 463 |
| Optimal Threshold | Train Data | Test Data | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | FPR | F1 | AUC- ROC | AUC- PRC | P | R | FPR | F1 | AUC- ROC | AUC- PRC | |
| Sklearn | ||||||||||||
| ocSVM | 0.300 | 0.795 | 0.205 | 0.436 | 0.723 | 0.087 | 0.355 | 0.193 | 0.807 | 0.250 | 0.654 | 0.051 |
| isoF | 0.045 | 0.240 | 0.760 | 0.076 | 0.868 | 0.072 | 0.065 | 0.839 | 0.161 | 0.120 | 0.567 | 0.051 |
| PYOD | ||||||||||||
| ECOD | 0.806 | 0.668 | 0.331 | 0.731 | 0.879 | 0.772 | 0.310 | 0.270 | 0.730 | 0.289 | 0.791 | 0.240 |
| COPOD | 0.879 | 0.662 | 0.338 | 0.755 | 0.878 | 0.791 | 0.497 | 0.268 | 0.732 | 0.348 | 0.796 | 0.236 |
| KNN | 0.252 | 0.008 | 0.993 | 0.015 | 0.204 | 0.087 | 0.819 | 0.752 | 0.248 | 0.784 | 0.935 | 0.739 |
| Deep-SVDD | 0.803 | 0.011 | 0.989 | 0.022 | 0.633 | 0.187 | 0.965 | 0.079 | 0.921 | 0.147 | 0.566 | 0.143 |
| VAE | 0.729 | 0.745 | 0.255 | 0.737 | 0.892 | 0.666 | 0.364 | 0.493 | 0.507 | 0.419 | 0.785 | 0.201 |
| AutoEnc | 0.721 | 0.753 | 0.247 | 0.737 | 0.894 | 0.672 | 0.305 | 0.460 | 0.540 | 0.367 | 0.793 | 0.205 |
| AnoGAN | 0.896 | 0.653 | 0.347 | 0.756 | 0.875 | 0.777 | 0.422 | 0.212 | 0.788 | 0.282 | 0.695 | 0.182 |
| Optimal Threshold | Train Data | Test Data | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | FPR | F1 | AUC- ROC | AUC- PRC | P | R | FPR | F1 | AUC- ROC | AUC- PRC | |
| Sklearn | ||||||||||||
| ocSVM | 0.211 | 0.017 | 0.983 | 0.031 | 0.813 | 0.072 | 0.237 | 0.019 | 0.981 | 0.036 | 0.811 | 0.073 |
| isoF | 0.209 | 0.861 | 0.139 | 0.336 | 0.859 | 0.07 | 0.210 | 0.862 | 0.138 | 0.338 | 0.86 | 0.069 |
| PYOD | ||||||||||||
| ECOD | 0.928 | 0.615 | 0.385 | 0.740 | 0.876 | 0.757 | 0.934 | 0.617 | 0.383 | 0.743 | 0.878 | 0.758 |
| COPOD | 0.942 | 0.610 | 0.390 | 0.741 | 0.873 | 0.769 | 0.946 | 0.613 | 0.387 | 0.744 | 0.874 | 0.768 |
| KNN | 0.121 | 1.000 | 0.000 | 0.217 | 0.227 | 0.085 | 0.121 | 0.999 | 0.000 | 0.217 | 0.232 | 0.085 |
| Deep-SVDD | 0.191 | 0.675 | 0.325 | 0.298 | 0.583 | 0.150 | 0.191 | 0.672 | 0.329 | 0.297 | 0.585 | 0.153 |
| VAE | 0.853 | 0.689 | 0.311 | 0.763 | 0.89 | 0.653 | 0.861 | 0.690 | 0.310 | 0.766 | 0.892 | 0.661 |
| AutoEnc | 0.853 | 0.690 | 0.310 | 0.763 | 0.89 | 0.652 | 0.860 | 0.691 | 0.309 | 0.767 | 0.892 | 0.660 |
| AnoGAN | 0.989 | 0.604 | 0.396 | 0.750 | 0.862 | 0.750 | 0.989 | 0.605 | 0.395 | 0.750 | 0.864 | 0.753 |
| Optimal Threshold | Train data | Test data | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | FPR | F1 | AUC- ROC | AUC- PRC | P | R | FPR | F1 | AUC- ROC | AUC- PRC | |
| Sklearn | ||||||||||||
| ocSVM | 0.00 | 0.00 | 0.00 | 0.0 | 0.00 | 0.00 | 0.891 | 0.617 | 0.383 | 0.729 | 0.211 | 0.180 |
| isoF | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.805 | 0.623 | 0.377 | 0.702 | 0.862 | 0.032 |
| PYOD | ||||||||||||
| ECOD | 0.862 | 0.623 | 0.377 | 0.724 | 0.865 | 0.540 | 0.856 | 0.619 | 0.381 | 0.718 | 0.864 | 0.530 |
| COPOD | 0.897 | 0.621 | 0.379 | 0.734 | 0.868 | 0.575 | 0.890 | 0.617 | 0.383 | 0.729 | 0.867 | 0.563 |
| KNN | 0.058 | 1.000 | 0.000 | 0.109 | 0.209 | 0.040 | 0.058 | 0.999 | 0.000 | 0.109 | 0.213 | 0.041 |
| DeepSVDD | 0.067 | 0.832 | 0.168 | 0.124 | 0.490 | 0.054 | 0.067 | 0.826 | 0.174 | 0.124 | 0.489 | 0.055 |
| VAE | 0.772 | 0.696 | 0.304 | 0.732 | 0.896 | 0.509 | 0.770 | 0.696 | 0.304 | 0.732 | 0.896 | 0.505 |
| AutoEnc | 0.772 | 0.696 | 0.304 | 0.732 | 0.896 | 0.509 | 0.770 | 0.696 | 0.304 | 0.732 | 0.896 | 0.505 |
| AnoGAN | 0.899 | 0.644 | 0.356 | 0.751 | 0.854 | 0.568 | 0.893 | 0.641 | 0.359 | 0.746 | 0.851 | 0.555 |
| Validation Data | |||||
|---|---|---|---|---|---|
| ACC | P | R | FPR | F1 | |
| Sklearn | |||||
| ocSVM | 0.942 | 0.000 | 0.000 | 1.000 | 0.000 |
| isoF | 0.935 | 0.022 | 0.003 | 0.997 | 0.005 |
| PYOD | |||||
| ECOD | 0.942 | 0.466 | 0.011 | 0.989 | 0.021 |
| COPOD | 0.942 | 0.000 | 0.000 | 1.000 | 0.000 |
| kNN | 0.058 | 0.058 | 1.000 | 0.000 | 0.110 |
| DeepSVDD | 0.601 | 0.045 | 0.293 | 0.707 | 0.079 |
| VAE | 0.933 | 0.000 | 0.000 | 1.000 | 0.000 |
| AutoEncoder | 0.933 | 0.000 | 0.000 | 1.000 | 0.000 |
| AnoGan | 0.943 | 0.672 | 0.043 | 0.957 | 0.081 |
| Optimal Threshold | Train Data | Test Data | ||||||
|---|---|---|---|---|---|---|---|---|
| ACC | ACC | P | R | FPR | F1 | AUC- ROC | AUC- ROC | |
| Sklearn | ||||||||
| ocSVM | 0.990 | 0.936 | 0.998 | 0.585 | 0.415 | 0.738 | 0.808 | 0.082 |
| isoF | 0.960 | 0.777 | 0.124 | 0.932 | 0.068 | 0.219 | 0.833 | 0.072 |
| PYOD | ||||||||
| ECOD | 0.900 | 0.833 | 0.981 | 0.598 | 0.402 | 0.743 | 0.858 | 0.758 |
| COPOD | 0.960 | 0.919 | 0.948 | 0.619 | 0.381 | 0.749 | 0.855 | 0.756 |
| KNN | 0.960 | 0.127 | 0.987 | 0.636 | 0.364 | 0.774 | 0.816 | 0.727 |
| DeepSVDD | 0.960 | 0.766 | 0.991 | 0.646 | 0.354 | 0.783 | 0.838 | 0.732 |
| VAE | 0.960 | 0.410 | 0.991 | 0.633 | 0.368 | 0.772 | 0.820 | 0.732 |
| AutoEnc | 0.960 | 0.410 | 0.991 | 0.633 | 0.368 | 0.772 | 0.820 | 0.732 |
| File | Normal | Attack | Total | Class Balance, % | Features |
|---|---|---|---|---|---|
| hai-20.07/train1.csv.gz | 309,600 | 0 | 309,600 | 100/0 | 59 |
| hai-20.07/train2.csv.gz | 240,424 | 776 | 241,200 | 99.7/0.3 | 59 |
| hai-20.07/test1.csv.gz | 280,062 | 11,538 | 291,600 | 96/4 | 59 |
| hai-20.07/test2.csv.gz | 147,011 | 5989 | 51,106 | 96.1/3.9 | 59 |
| hai-21.03/train1.csv.gz | 216,001 | 0 | 216,001 | 100/0 | 79 |
| hai-21.03/train2.csv.gz | 226,801 | 0 | 226,801 | 100/0 | 79 |
| hai-21.03/train3.csv.gz | 478,801 | 0 | 478,801 | 100/0 | 79 |
| hai-21.03/test1.csv.gz | 42,572 | 629 | 43,201 | 98.5/1.5 | 79 |
| hai-21.03/test2.csv.gz | 115,352 | 3449 | 118,801 | 97.1/2.9 | 79 |
| hai-21.03/test3.csv.gz | 106,466 | 1535 | 108,001 | 98.6/1.4 | 79 |
| hai-21.03/test4.csv.gz | 38,444 | 1157 | 39,601 | 97.1/2.9 | 79 |
| hai-21.03/test5.csv.gz | 90,224 | 2177 | 92,401 | 97.6/2.4 | 79 |
| hai-22.04/train1.csv | 93,601 | 0 | 93,601 | 100/0 | 86 |
| hai-22.04/train2.csv | 201,600 | 0 | 201,600 | 100/0 | 86 |
| hai-22.04/train3.csv | 126,000 | 0 | 126,000 | 100/0 | 86 |
| hai-22.04/train4.csv | 86,401 | 0 | 86,401 | 100/0 | 86 |
| hai-22.04/train5.csv | 237,600 | 0 | 237,600 | 100/0 | 86 |
| hai-22.04/train6.csv | 259,200 | 0 | 259,200 | 100/0 | 86 |
| hai-22.04/test1.csv | 85,515 | 885 | 86,400 | 99/1 | 86 |
| hai-22.04/test2.csv | 79,919 | 2881 | 82,800 | 96.5/3.5 | 86 |
| hai-22.04/test3.csv | 58,559 | 3841 | 62,400 | 93.8/6.2 | 86 |
| hai-22.04/test4.csv | 125,177 | 4423 | 129,600 | 96.6/3.4 | 86 |
| File | DT | KNN | RF | LR | NN | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| F1, % | ACC, % | F1, % | ACC, % | F1, % | ACC, % | F1, % | ACC, % | F1, % | ACC, % | |
| hai-20.07/test1.csv.gz | 99.00 | 99.85 | 86.42 | 98.28 | 99.67 | 99.95 | 80.88 | 97.73 | 96.70 | 99.50 |
| hai-20.07/test2.csv.gz | 99.48 | 99.92 | 94.93 | 99.30 | 99.76 | 99.96 | 97.29 | 99.60 | 99.30 | 99.90 |
| hai-21.03/test1.csv.gz | 98.61 | 99.91 | 93.39 | 99.59 | 99.31 | 99.95 | 90.10 | 99.43 | 49.57 | 98.29 |
| hai-21.03/test2.csv.gz | 97.60 | 99.73 | 89.89 | 98.99 | 99.52 | 99.95 | 74.99 | 98.03 | 88.52 | 98.81 |
| hai-21.03/test3.csv.gz | 99.38 | 99.96 | 99.61 | 99.61 | 99.38 | 99.96 | 90.96 | 99.53 | 72.23 | 98.76 |
| hai-21.03/test4.csv.gz | 99.45 | 99.94 | 95.65 | 99.52 | 99.67 | 99.96 | 99.22 | 99.91 | 49.25 | 97.05 |
| hai-21.03/test5.csv.gz | 98.26 | 99.84 | 92.72 | 99.38 | 99.30 | 99.94 | 81.30 | 98.63 | 49.39 | 97.59 |
| hai-22.04/test1.csv | 98.66 | 99.95 | 90.87 | 99.67 | 99.11 | 99.97 | 78.76 | 99.39 | 49.75 | 98.99 |
| hai-22.04/test2.csv | 97.85 | 99.70 | 89.80 | 98.73 | 99.39 | 99.92 | 72.80 | 97.46 | 49.07 | 96.34 |
| hai-22.04/test3.csv | 98.79 | 99.73 | 94.45 | 98.83 | 99.64 | 99.92 | 90.00 | 98.03 | 94.30 | 98.65 |
| hai-22.04/test4.csv | 98.38 | 99.78 | 88.26 | 98.65 | 99.45 | 99.93 | 62.88 | 97.02 | 49.12 | 96.53 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tushkanova, O.; Levshun, D.; Branitskiy, A.; Fedorchenko, E.; Novikova, E.; Kotenko, I. Detection of Cyberattacks and Anomalies in Cyber-Physical Systems: Approaches, Data Sources, Evaluation. Algorithms 2023, 16, 85. https://doi.org/10.3390/a16020085
Tushkanova O, Levshun D, Branitskiy A, Fedorchenko E, Novikova E, Kotenko I. Detection of Cyberattacks and Anomalies in Cyber-Physical Systems: Approaches, Data Sources, Evaluation. Algorithms. 2023; 16(2):85. https://doi.org/10.3390/a16020085
Chicago/Turabian StyleTushkanova, Olga, Diana Levshun, Alexander Branitskiy, Elena Fedorchenko, Evgenia Novikova, and Igor Kotenko. 2023. "Detection of Cyberattacks and Anomalies in Cyber-Physical Systems: Approaches, Data Sources, Evaluation" Algorithms 16, no. 2: 85. https://doi.org/10.3390/a16020085
APA StyleTushkanova, O., Levshun, D., Branitskiy, A., Fedorchenko, E., Novikova, E., & Kotenko, I. (2023). Detection of Cyberattacks and Anomalies in Cyber-Physical Systems: Approaches, Data Sources, Evaluation. Algorithms, 16(2), 85. https://doi.org/10.3390/a16020085