1. Introduction
Matrix multiplication over various rings or semi-rings is a basic tool in science and engineering. By the definition, the matrix product of two
matrices can be easily computed using
additions and multiplications over the respective ring or semi-ring. This is optimal in the arithmetic case and the Boolean case if, respectively, only the operations of arithmetic addition and multiplication or the Boolean OR and AND are allowed [
1,
2]. Five decades ago, Strassen presented a divide-and-conquer algorithm for arithmetic matrix multiplication based on algebraic term cancellation, breaking out of the
method. It used only
multiplications, additions and subtractions [
3]. The complexity of matrix multiplication is measured in terms of
which is the smallest real number such that two
matrices can be multiplied using
operations over the field of reals, for all
(i.e., the number of operations is
[
4]. The series of improvements of the upper bounds on
starting from
culminates in the recent result of Alman and Vassilevska Williams showing
[
4]. By a straightforward reduction of the Boolean matrix product to the corresponding arithmetic one for
matrices, the same asymptotic upper bounds hold for the Boolean matrix product.
We generalize the concept of matrix product of two matrices over a ring or semi-ring to include that of a k-dimensional matrix product D of k matrices of sizes respectively, where . Note that the -dimensional product of the matrices and is equivalent to the standard matrix product of and the transpose of the matrix . For we define as the smallest real number such that the k-dimensional arithmetic product of k matrices can be computed using operations over the field of reals, for all . We show that does not exceed , where stands for the smallest real number such that an matrix can be multiplied by matrix using operations over the field of reals for all .
If A and B are two Boolean matrices and C is their Boolean matrix product, then for any entry of , a witness is an index m such that . The smallest (or, largest) possible witness is called the minimum witness (or, maximum witness, respectively).
The problems of finding “witnesses” have been studied for several decades, mostly within stringology (e.g., algorithms for symbol matches or mismatches [
5,
6]) and graph algorithms (e.g., algorithms for shortest paths [
7,
8]). More recently, the problems of finding extreme (i.e., minimum or maximum) witnesses have found numerous applications (e.g., algorithms for all-pairs lowest common ancestors [
9] or all-pairs bottleneck weight path problem [
10]). Alon and Naour showed that the witness problem for the Boolean matrix product of two Boolean matrices, i.e., the problem of reporting a witness for each non-zero entry of the product, to be solvable in time required to compute the product up to polylogarithmic multiplicative factors [
11]. (By the
time complexity of an algorithm, we mean the number of operations performed by the algorithm in the unit cost random access machine model, which is expressed as a function of an input size parameter. Note that when the inputs to the aforementioned operations are integers of size polynomial in the input size, then the number of required bit operations is larger than that of unit cost operations only by a polylogarithmic factor.) Czumaj et al. showed that the maximum witness problem, i.e., the problem of reporting the maximum witness for each non-zero entry of the Boolean matrix product of two
Boolean matrices, was solvable in
time [
9], where
satisfies the equation
.
We also generalize the concept of a witness for a non-zero entry of the Boolean matrix product of two Boolean matrices to include a witness for a non-zero entry of the k-dimensional Boolean product of k Boolean matrices. For a non-zero entry of the k-dimensional Boolean product of k Boolean matrices of sizes respectively, a witness is any index ℓ such that . The witness problem for the k-dimensional Boolean matrix product D is to report a witness for each non-zero entry of D and analogously, the maximum witness problem for D is to report the maximum witness for each non-zero entry of We show that for matrices , the witness problem for their k-dimensional Boolean product can be solved in time, while the maximum witness problem for this product admits a solution in time, where satisfies the equation and satisfies the equation . By the recent results on rectangular matrix multiplication, the latter bound for is
In the second part of our paper, we provide an alternative simple method of detection/counting copies of fixed size cliques based on the multi-dimensional matrix product. We show also an immediate reduction of the k-dominating set problem to the multi-dimensional matrix product implying the hardness of computing the product. Finally, we provide an efficient reduction of the problem of finding lowest common ancestors for all k-tuples of vertices in a directed acyclic graph to the problem of finding maximum witnesses of the Boolean variant of the multi-dimensional matrix product. These applications demonstrate the versatility of the multi-dimensional matrix product. Although the time complexities of the algorithms resulting from the aforementioned reductions solely match those of the known algorithms, the advantage of our algorithms is simplicity.
1.1. Clique Detection
Our first application of the multi-dimensional matrix product provides a simple alternative method for clique detection.
The problems of detecting, finding, counting or listing subgraphs or induced subgraphs of a host graph that are isomorphic to a pattern graph are central in graph algorithms. They are generally termed as subgraph isomorphism and induced subgraph isomorphism, respectively. Several well-known NP-hard problems such as the independent set, clique, Hamiltonian cycle or Hamiltonian path can be regarded as their special cases.
Recent examples of applications of different variants of subgraph isomorphism include among other things [
12,
13]: a comparison of bio-molecular networks by their so-called motifs [
14], an analysis of social networks by counting the number of copies of a small pattern graph [
15], graph-matching constraints in the automatic design of processor systems [
16], and the detection of communication patterns between intruders in network security [
17]. In the aforementioned applications, the pattern graphs are typically of fixed size which allows for polynomial-time solutions.
At the beginning of the 1980s, Itai and Rodeh [
18] presented the following straightforward reduction of not only triangle detection but also triangle counting to fast matrix multiplication. Let
A be the
adjacency matrix of the host graph
G on
n vertices (see Preliminaries). Consider the matrix product
Note that
is equal to the number of two-edge paths connecting the vertices
i and
Hence, if
is an edge of
G, then
is the number of triangles in
G including the edge
. Consequently, the number of triangles in an
n-vertex graph can be reported in
time.
A few years later, Necetril and Poljak [
19] showed an efficient reduction of detecting and counting copies of any pattern graph both in the standard and induced case to the aforementioned method for triangle detection and counting. The idea is to divide the pattern graph into three almost equal parts and to build an auxiliary graph on copies of subgraphs isomorphic to one of three parts. Then, the triangle detection/counting method is run on the auxiliary graph. Two decades later, Eisenbrand and Grandoni [
20] (cf. [
21]) refined this general triangle method by using fast algorithms for rectangular matrix multiplication instead of those for square matrix multiplication. For a pattern graph on
vertices and a host graph on
n vertices, the (refined) general triangle method runs in time
[
19,
20,
21].
Up to now, the general triangle method remains the fastest known universal method for the detection and counting standard and induced copies of fixed pattern graphs. In the recent two decades, there has been a real progress in the design of efficient algorithms for the detection and even counting of fixed pattern graphs both in the standard [
12,
22] and induced case [
12,
13,
23,
24,
25]. Among other things, the progress has been based on the use of equations between the numbers of copies of different fixed patterns in the host graph [
13,
21,
22,
24] and randomization [
12,
13,
24]. Unfortunately, this progress has not included complete pattern graphs, i.e.,
graphs (and their complements, i.e., edge-free pattern graphs in the induced setting). For the aforementioned pattern graphs, the generalized triangle method remains the fastest known one.
In this paper, we consider another universal and simple method that in fact can be viewed as another type of generalization of the classic algorithm for triangle detection and counting due to Itai and Rodeh. We can rephrase the description of their algorithm as follows. At the beginning, we form a list of subgraphs isomorphic to
(i.e., edges), and then for each subgraph on the list, we count the number of vertices outside it that are adjacent to both vertices of the subgraph; in other words, we count the number of extensions of the subgraph to a clique on three vertices. The latter task can be completed efficiently by squaring the adjacency matrix of the host graph. We can generalize the algorithm to include detection/counting
copies,
by replacing
with
and using the
-dimensional matrix product of
copies of the adjacency matrix instead of squaring the matrix. Listing the subgraphs of the host graph isomorphic to
can be completed by enumerating
vertex subsets and checking if they induce
For
it takes
time, so the overall time required by this simple alternative method is
where
is the smallest real number such that the
k-dimensional matrix product of
k matrices can be computed using
operations over the field of reals, for all
(see Definition 1 in
Section 3). Recall that we show in particular
. Hence, our alternative method in particular computes the number of
copies in an
n-vertex graph in
time and the number of
copies in
time. In addition, if the input graph contains a copy of
or
, respectively, then a copy of
can be found in the graph in
time while that of
can be found in the graph in
time by a slightly modified alternative method. Thus, our upper time bounds for
and
at least match those for
and
yielded by the generalized triangle method [
20]. If
for
k equal to 3 or 4, then we would achieve a breakthrough in the detection/counting of
or
respectively. For
where
the generalized triangle method asymptotically subsumes our alternative method and for
, the methods coincide.
1.2. Small Dominating Sets
Our second application of the multi-dimensional matrix product is an immediate reduction of the
k-dominating set problem to the
k-dimensional matrix product. It rephrases the known algorithm for the aforementioned problem due to Eisenbrand and Grandoni [
20] (cf. [
26]). The
k-dominating set problem for a graph
G and a fixed natural number
k is to determine if there is a set
S of at most
k vertices in
G such that each vertex in
G outside
S is adjacent to at least one vertex in
It is a basic
complete problem equivalent to the
k-set cover problem asking if there is a set cover of cardinality at most
k [
27].
1.3. Finding Lowest Common Ancestors
Our third application of the multi-dimensional matrix product provides a simple generalization of known results on finding the lowest common ancestors for all pairs of vertices to include all k-tuples of vertices for fixed
The problem of finding a
lowest common ancestor (LCA) for sets of vertices in a tree, or more generally, in a
directed acyclic graph (DAG) is a basic problem in algorithmic graph theory. It has several applications ranging from algorithm design through object-oriented programming languages [
28] to phylogenetic networks [
29]. An LCA of a set
S of vertices in a DAG is an ancestor of all vertices in
S that has no proper descendant which is an ancestor of all vertices in
S [
30]. The problem of preprocessing a DAG such that LCA queries can be answered quickly for any pair of vertices has been studied extensively in the literature [
9,
31,
32,
33]. The all-pairs LCA problem is to compute LCA for all pairs of vertices in the input tree or DAG. For trees, it can be solved in linear time [
34]. For DAGs, Bender et al. were the first to provide a substantially subcubic algorithm for this problem [
35]. Czumaj et al. improved their upper bound to
by a reduction to the problem of finding maximum witnesses for the Boolean matrix product of two
Boolean matrices [
9]. Taking into account the recent progress in fast rectangular matrix multiplication, the latter bound reduces to
Very recently, Grandoni et al. have presented an
-time algorithm for the all pairs LCA problem [
33].
The problem of finding LCAs for vertex sets of size greater than two is natural, e.g., in a genealogy search in phylogenetic networks [
29]. Yuster generalized the all-pairs LCA problem in DAGs to include finding lowest common ancestors for all
k-tuples of vertices [
36] (cf. [
37]). We term the generalized problem as the all
k-tuples LCA problem.
We provide a simple reduction of the all
k-tuples LCA problem to the maximum witness problem for the
k-dimensional Boolean matrix product of
k copies of the transitive closure matrix of the input DAG. As a result, we obtain upper time bounds for the all
k-tuples LCA problem matching those established by Yuster in [
36] and Kowaluk et al. in [
37].
1.4. Paper Organization
In the next section, the basic matrix and graph notation used in the paper is presented.
Section 3 is devoted to the
k-dimensional matrix product of
k matrices, in particular the upper time bounds on the product and the related problems of computing witnesses and maximum witnesses for the Boolean version of the product in terms of those for fast rectangular matrix multiplication. In
Section 4, the alternative method for detection/counting copies of fixed cliques in a host graph relying on the multi-dimensional matrix product is presented and analyzed. In
Section 5, the immediate reduction of the
k-dominating set problem to the
k-dimensional matrix product is given. In
Section 6, the application of the results from
Section 3 to the all
k-tuples LCA problem is presented. We conclude with final remarks.
2. Preliminaries
For a positive integer we shall denote the set of positive integers not greater than r by
For a matrix denotes its transpose. Recall that for positive real numbers denotes the smallest real number such that an matrix can be multiplied by matrix using operations over the field of reals for all For convenience, stands for
Let
stand for
The following recent lower bound on
is due to Le Gall and Urrutia [
38].
Fact 1. The inequality holds [38]. Recall also that a witness for a non-zero entry of the Boolean matrix product C of a Boolean matrix A and a Boolean matrix B is any index such that and are equal to 1. The witness problem is to report a witness for each non-zero entry of the Boolean matrix product of the two input Boolean matrices.
Alon and Naor provided a solution to the witness problem for the Boolean matrix product of two square Boolean matrices [
11] which is almost equally fast as that for square matrix multiplication [
4]. It can be easily generalized to include the Boolean product of two rectangular Boolean matrices of sizes
and
respectively. The asymptotic matrix multiplication time
is replaced by
in the generalization.
Fact 2. For positive the witness problem for the Boolean matrix product of an Boolean matrix with an Boolean matrix can be solved (deterministically) in time.
A directed acyclic graph (DAG) is a directed graph not containing directed cycles. A vertex v is an ancestor (proper ancestor) of a vertex u in a DAG if there is a directed path (directed path of non-zero length, respectively) from u to v. A vertex u is a descendant (proper descendant) of a vertex v in a DAG if v is an ancestor (proper ancestor) of u in the DAG. Recall that a lowest common ancestor (LCA) of a set of vertices in a DAG is a vertex that is an ancestor of all vertices in the set but none of its proper descendants is also an ancestor of all vertices in the set.
We shall consider also simple undirected graphs.
A subgraph of the graph is a graph such that and .
An induced subgraph of the graph is a graph such that and . A subgraph of G induced by is a graph such that and . It is denoted by
For simplicity, we shall refer to a subgraph of a graph G that is isomorphic to as a copy of in G or just a copy in
The adjacency matrix A of a graph is the matrix such that and for if and only if .
3. Multi-Dimensional Matrix Product and Its Witnesses
For the convenience of the reader, we gather all the definitions related to the multi-dimensional matrix product, repeating some of them, below.
Definition 1. For k matrices , (arithmetic or Boolean, respectively), their k-dimensional (arithmetic or Boolean, respectively) matrix product D is defined byrespectively, where for In the arithmetic case, denotes the smallest real number such that the k-dimensional arithmetic product of k matrices can be computed using operations over the field of reals, for all For convenience, stands for In the Boolean case, the corresponding numbers are denoted by and respectively. Clearly, we have and A witness for a non-zero entry of the k-dimensional Boolean matrix product is any index such that is equal to (Boolean) The witness problem for the k-dimensional Boolean matrix product is to report a witness for each non-zero entry of the product. The maximum witness problem for the k-dimensional Boolean matrix product is to report the maximum witness for each non-zero entry of the product.
Note that in particular, the -dimensional matrix product of the matrices and coincides with the standard matrix product of and which yields
The following lemma provides an upper bound on the time complexity of the multi-dimensional matrix product in terms of those for rectangular matrix multiplication.
Lemma 1. Let be three positive integers such that Both in the arithmetic and Boolean case, the k-dimensional matrix product of k matrices can be computed using arithmetic operations, consequently In addition, in the Boolean case, the witness problem for the k-dimensional matrix product can be solved in time.
Proof. To prove the first part, it is sufficient to consider the arithmetic case as the Boolean one trivially reduces to it.
Let be the input matrices. Form an matrix A whose rows are indexed by -tuples of indices in and whose columns are indexed by indices in such that Similarly, form an matrix B whose rows are indexed by -tuples of indices in and whose columns are indexed by indices in such that Compute the rectangular matrix product C of the matrix A with the matrix . By the definitions, the entry of the k-dimensional product of the input matrices is equal to the entry The matrices can be formed in time, i.e., time, while the product C can be computed in time.
To prove the second part of the lemma, it is sufficient to consider Boolean versions of the matrices and use Fact 2. □
By combining Lemma 1 with Fact 1, we obtain the following corollary.
Corollary 1. For even
Proof. We obtain the following chain of equations on the asymptotic time required by the
k-dimensional matrix product using Lemma 1 and Fact 1:
□
Consider the Boolean case. By the definition, the k-dimensional Boolean matrix product can be computed in time proportional to the size of the product multiplied by the size of witness range. By generalizing the column–row method for the Boolean matrix product of two Boolean matrices, we obtain an output-sensitive upper bound on the time required to compute the k-dimensional Boolean matrix product.
Theorem 1. Suppose and Let w be the total number of witnesses for the entries of the k-dimensional Boolean product of k Boolean matrices. The non-zero entries of the product can be listed in time. Consequently, they can be listed in time, where s is the number of non-zero entries in the product.
Proof. Let D stand for the k-dimensional Boolean matrix product. For compute the set of indices i such that Next, for compute the Cartesian product Note that coincides with the set of k-tuples such that ℓ is a witness for
Assuming we can compute the sets in time. The sets can be computed in time. On their basis, the non-negative entries of the product D can be listed in time. This proves the first part. The second part follows immediately from the fact that a non-zero entry of D can have at most n witnesses. □
The best known algorithm for the maximum witness problem for the two-dimensional Boolean matrix product from [
9] relies on the multiplication of rectangular submatrices of the input matrices. We generalize this idea to include the maximum witness problem for the
k-dimensional Boolean matrix product.
First, each of the input matrices is divided into vertical strip submatrices of an appropriate width
. Then, the multi-dimensional Boolean products of the corresponding submatrices are computed in order to detect, for each positive entry of the multi-dimensional output matrix, the interval of length
containing the maximum witness. Finally, the maximum witnesses are found separately for each of the positive entries by verifying the respective
candidates. More details can be found in the following pseudo-code (in Algorithm 1).
| Algorithm 1 Generalize the multiplication of rectangular submatrices of the input matrices to include the maximum witness problem for the k-dimensional Boolean matrix product. |
Input: Boolean matrices , and a parameter Output: maximum witnesses for all non-zero entries of the k-dimensional Boolean product of the matrices and “No” for all zero entries of the product.
For divide into vertical strip submatrices of width ℓ with the exception of the last one that can have width for compute the k-dimensional Boolean product of for all do - (a)
Find the largest p such that or set if it does not exist. - (b)
ifthen return else return “No”
|
The correctness of Algorithm 1 is obvious. By its time analysis and Lemma 1, we obtain the following theorem.
Theorem 2. Suppose and For any , the maximum witness problem for the k-dimensional Boolean product of k Boolean matrices can be solved by Algorithm 1 in time
.
Proof. Step 1 takes time. Step 2 requires time. Step 3(a) takes time totally. Finally, Step 3(b) requires time totally. □
By Theorem 2, the total time taken by Algorithm 1 for maximum witnesses is
By setting r to , our upper bound transforms to . Since a solution to the equation satisfies by , we can get rid of the additive term. In addition, it follows from that where satisfies Hence, we obtain the following result.
Theorem 3. Let λ satisfy and let satisfy respectively. Suppose The maximum witnesses for all non-zero entries of the k-dimensional Boolean product of k Boolean matrices can be computed by Algorithm 1 in time.
4. Breaking the Hegemony of the Triangle Method in Clique Detection
The following Algorithm 2 is a straightforward generalization of that due to Itai and Rodeh for triangle counting [
18] to include
counting, for
.
| Algorithm 2 A straightforward generalization of that due to Itai and Rodeh for triangle counting [18] to include counting, for . |
|
The correctness of Algorithm 2 follows from the fact that the number of copies including a given copy C of in the host graph is equal to the number of vertices outside C in the graph that are adjacent to all vertices in C and that a copy of includes exactly r distinct copies of in the graph.
The first step of Algorithm 2 can be implemented in time. We can use the -dimensional matrix product to implement the third step by using the next lemma. It immediately follows from the definition of the product.
Lemma 2. Let D be the k-dimensional matrix product of k copies of the adjacency matrix of the input graph G on n vertices. Then, for any k tuple of vertices of G, the number of vertices in G adjacent to each vertex in the k tuple is equal to
By the discussion and Lemma 2, we obtain the following theorem.
Theorem 4. The number of copies in the input graph on n vertices can be computed (by Algorithm 2) in time.
By Lemma 1, we obtain the following corollary from Theorem 4, matching the upper time bounds on the detection/counting copies of
and
established in [
20].
Corollary 2. The number of copies in an n-vertex graph can be computed (by Algorithm 2) in time while the number of copies in an n-vertex graph can be computed (by Algorithm 2) in time. In addition, if the input graph contains a copy of or , respectively, then a copy of can be found in the graph in time while that of ca n be found in the graph in time (by a modification of Algorithm 2).
5. k-Dominating Set
The problem of the
k-dominating set is to determine, for a graph
G and a fixed natural number
k, if there is a set
S of
k vertices in
G such that each vertex in
G either is adjacent to at least one vertex in
S or belongs to
It is a basic
complete problem equivalent to the
k-set cover [
27].
Eisenbrand and Grandoni improved on the straightforward enumeration algorithm by using fast rectangular matrix multiplication [
20] (cf. [
26]). Their Algorithm 3 can be simply rephrased in terms of a
k-dimensional matrix product as follows.
| Algorithm 3 Improved straightforward enumeration algorithm by using fast rectangular matrix multiplication. |
← the complement of the adjacency matrix of G D← the k dimensional matrix product of k copies of if if there is a zero entry then output “Yes” else output “No”
|
It is easy to see that for a set
of
k vertices in
G,
is just the number of vertices that are not adjacent to (dominated by) any vertex in
Thus,
S is a
k-dominating set if
. Hence, assuming that
n is the number of vertices in
we obtain the following upper bound given in [
20] by a simple application of Lemma 1.
Theorem 5. Algorithm 3 solves the k-dominating set problem in time.
The reduction of the
k-dominating set problem to the
k-dimensional matrix product given in Algorithm 3 implies the
hardness of the problem of computing the
k-dimensional matrix product. By Theorem 5.4 in [
39], we obtain the following corollary.
Corollary 3. The problem of computing the k-dimensional Boolean matrix product is not solvable in time, for any function unless
6. All k-Tuples LCA
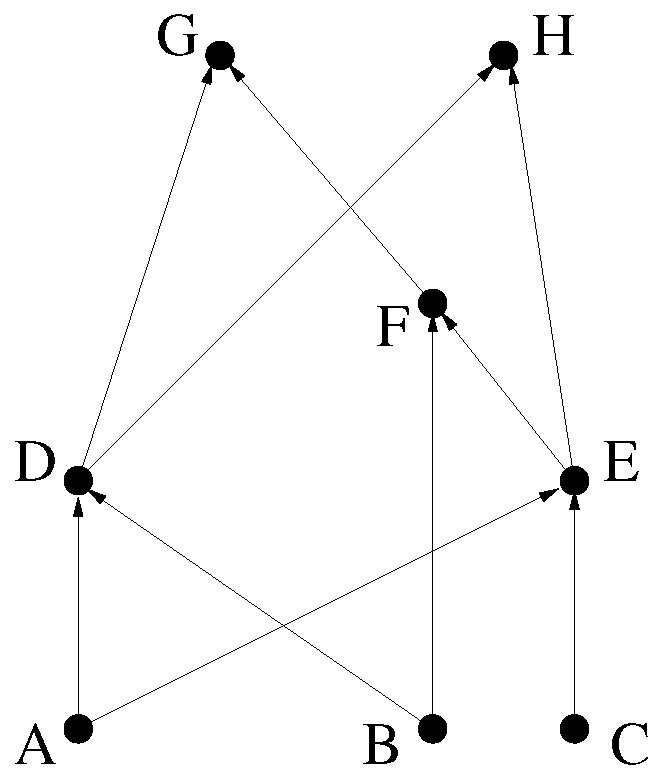
In this section, we consider the lowest common ancestors of
vertices [
30]. For an example, see
Figure 1.
Recall that an LCA of vertices is an ancestor v of each vertex , such that v has no proper descendant that is also an ancestor of each vertex , .
We can generalize the method of solving the all pairs LCA problem in DAGs based on maximum witnesses of Boolean matrix products from [
9] to include the all
k-tuples LCA problem, i.e., reporting for each
k-tuple of vertices in the input DAG an LCA, as follows (in Algorithm 4).
| Algorithm 4 Reporting for each k-tuple of vertices in the input DAG an LCA. |
Topologically sort vertices of the input DAG G and number them in the sorted order starting from the source vertices. Compute the transitive closure matrix A of G such that if and only if the vertex j is an ancestor of the vertex Compute maximum witnesses for non-zero entries of the k-dimensional Boolean matrix product D of k copies of the Boolean version of the matrix For each k-tuple of vertices, output the maximum witness of (if any) as the LCA of the k-tuple.
|
The correctness of this generalized method follows from the fact that by the definition of the matrix A and the k-dimensional Boolean matrix product D, the set of witnesses of coincides with the set of common ancestors of , and that the maximum witness of of cannot have any descendant in the aforementioned set by the vertex numbering.
The topological sort requires
time while computing the transitive closure takes
time. Hence, by Theorem 3, we obtain upper bounds basically matching those derived by Yuster in [
36] and Kowaluk et al. in [
37].
Theorem 6. Let λ satisfy and let satisfy respectively. Suppose The all k-tuples LCA problem can be solved by Algorithm 4 in time.
Corollary 4. Let and satisfy , , and , respectively. The all 3-tuples LCA problem can be solved in
time.
Proof. By dividing an matrix into n matrices, we obtain the inequality . The inequality follows from similarly as follows from in the proof of Theorem 3. By the recent results on fast rectangular multiplication, holds. □
7. Final Remarks
We have applied our results on the multi-dimensional matrix product to provide a simple alternative method for clique detection and to rephrase known algorithms for k-dominating set problem and the all k-tuples LCA problem in DAGs. Our direct reduction of the k-dominating set problem to the k-dimensional matrix product yields the hardness of the latter problem. In the context of the reduction, note that the problem of computing the k-dimensional (even Boolean) matrix product is more general than the k-dominating set problem, since the input matrices do not have to be identical as in the reduction.
It is an intriguing open problem if the upper bounds in terms of rectangular matrix multiplication on the k-dimensional matrix product of k square matrices given in Lemma 1 are asymptotically tight. In other words, the question is if holds or more specifically if ? If this was not the case for k equal to 3 or 4, then we would achieve a breakthrough in detection/counting of or respectively.
An argument for the inequality , for positive integers satisfying is that in the context of the efficient reduction in the proof of Lemma 1, the rectangular matrix product seems more general than the k-dimensional one. A reverse efficient reduction seems to be possible only under very special assumptions. However, proving such an inequality would be extremely hard as it would imply and in consequence by the straightforward reduction of the rectangular matrix product to the square one. On the other hand, this does not exclude the possibility of establishing better upper bounds on than those known on .
A related question is whether or not satisfying the equation is equal or less than satisfying the equation ? An inequality for would yield the improvement of the longstanding upper time bound for the maximum witness problem of the Boolean product of two Boolean matrices from to
These two open problems and the quest for finding further applications of the multi-dimensional matrix product form the future directions of our research.


{kind=link}
