
Topic Scaling: A Joint Document Scaling–Topic Model Approach to Learn Time-Specific Topics


Abstract
1. Introduction
1.1. Document Scaling
1.2. Topic Models
1.3. State Of The Union Addresses
2. Method
| Algorithm 1 Topic Scaling |
|
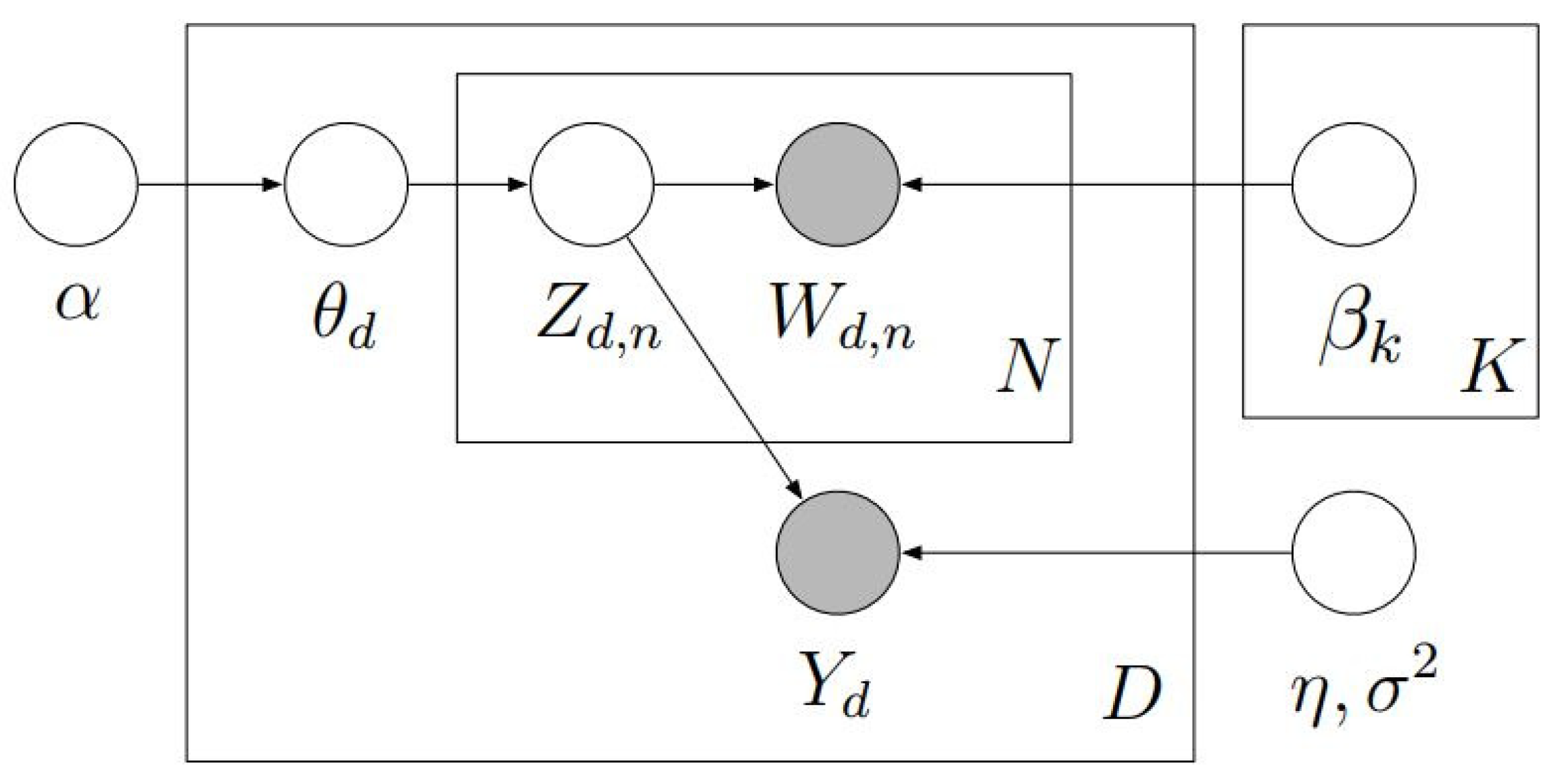
2.1. Measurement Model
2.2. Supervised LDA
3. Data and Results
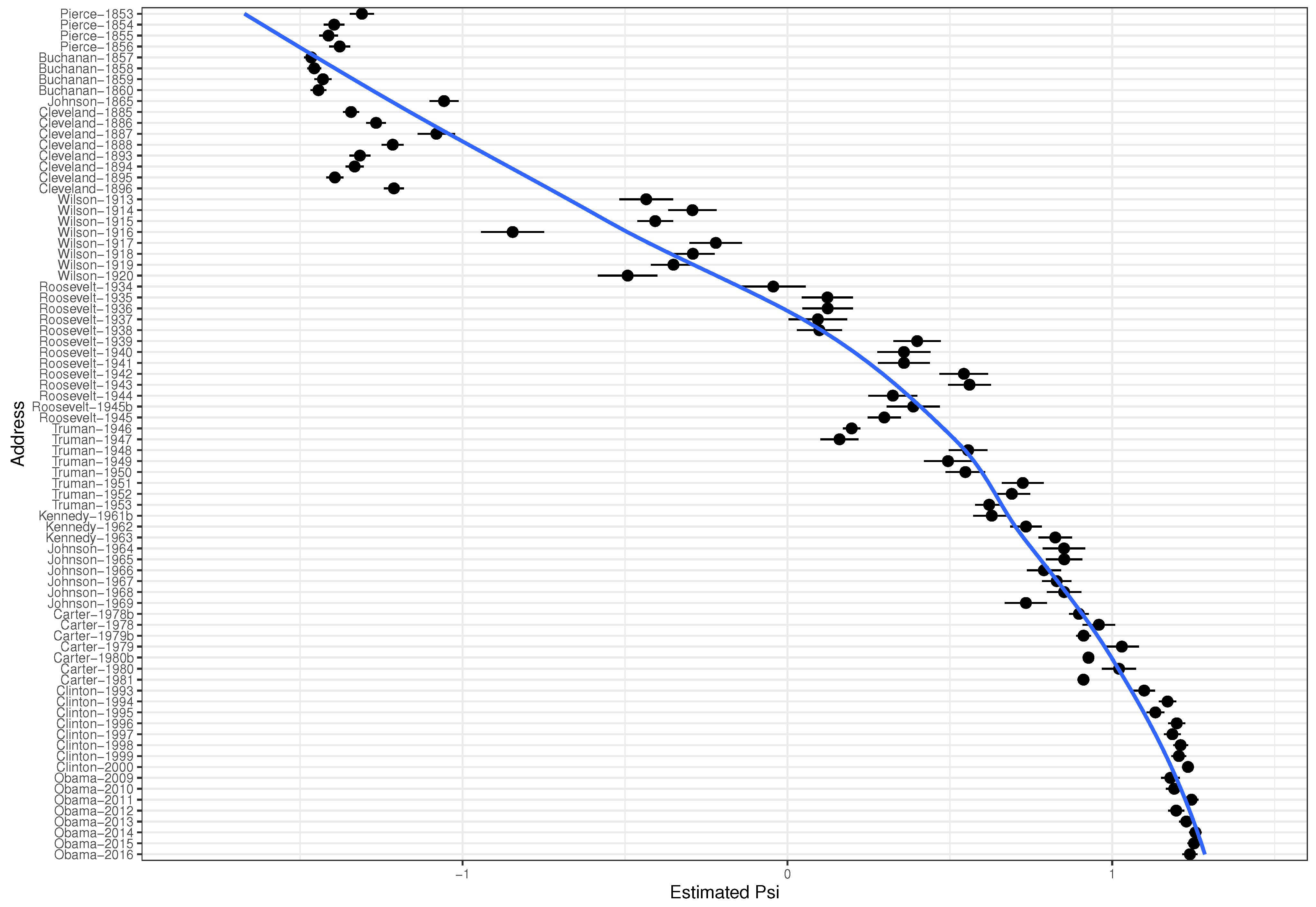
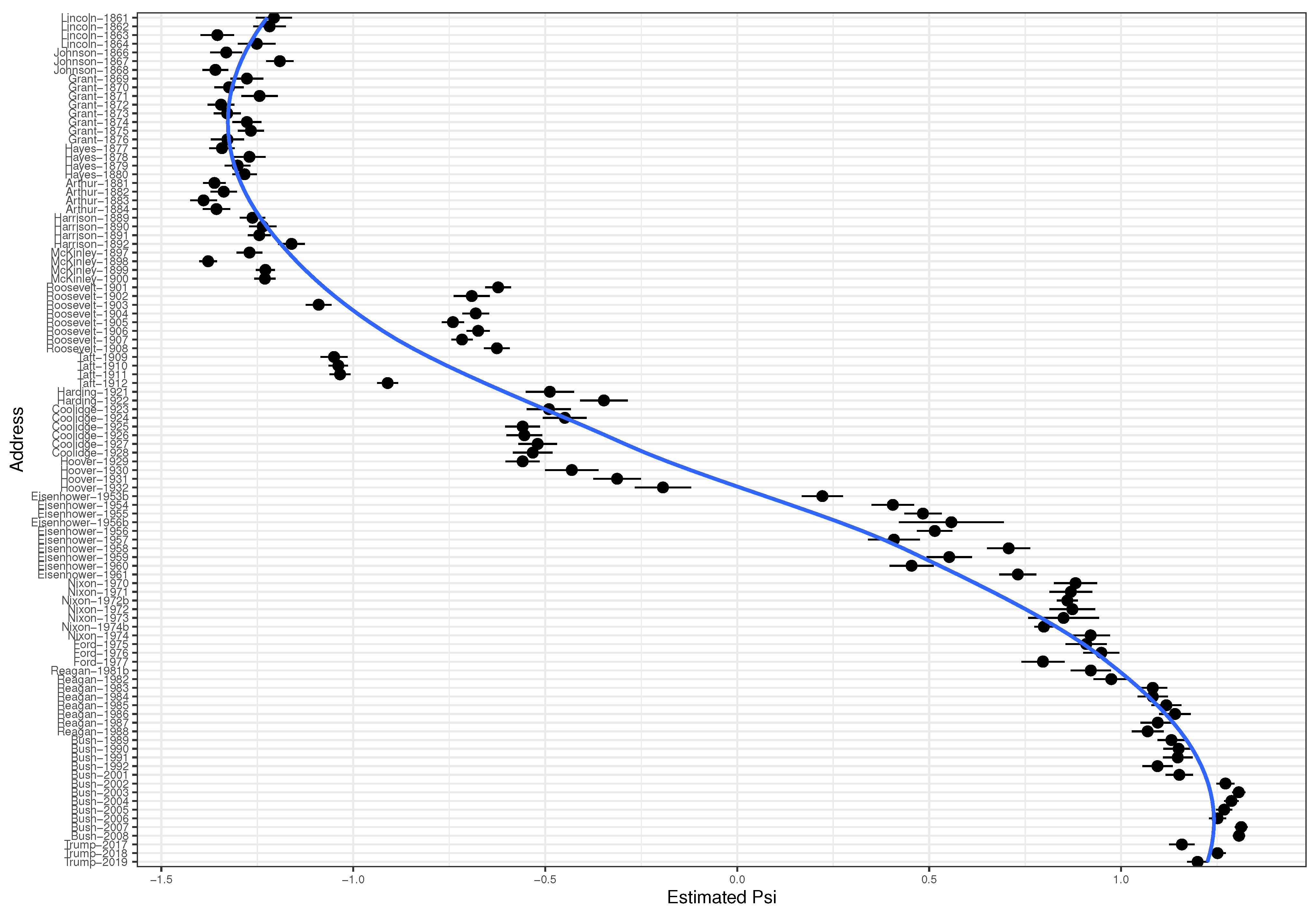
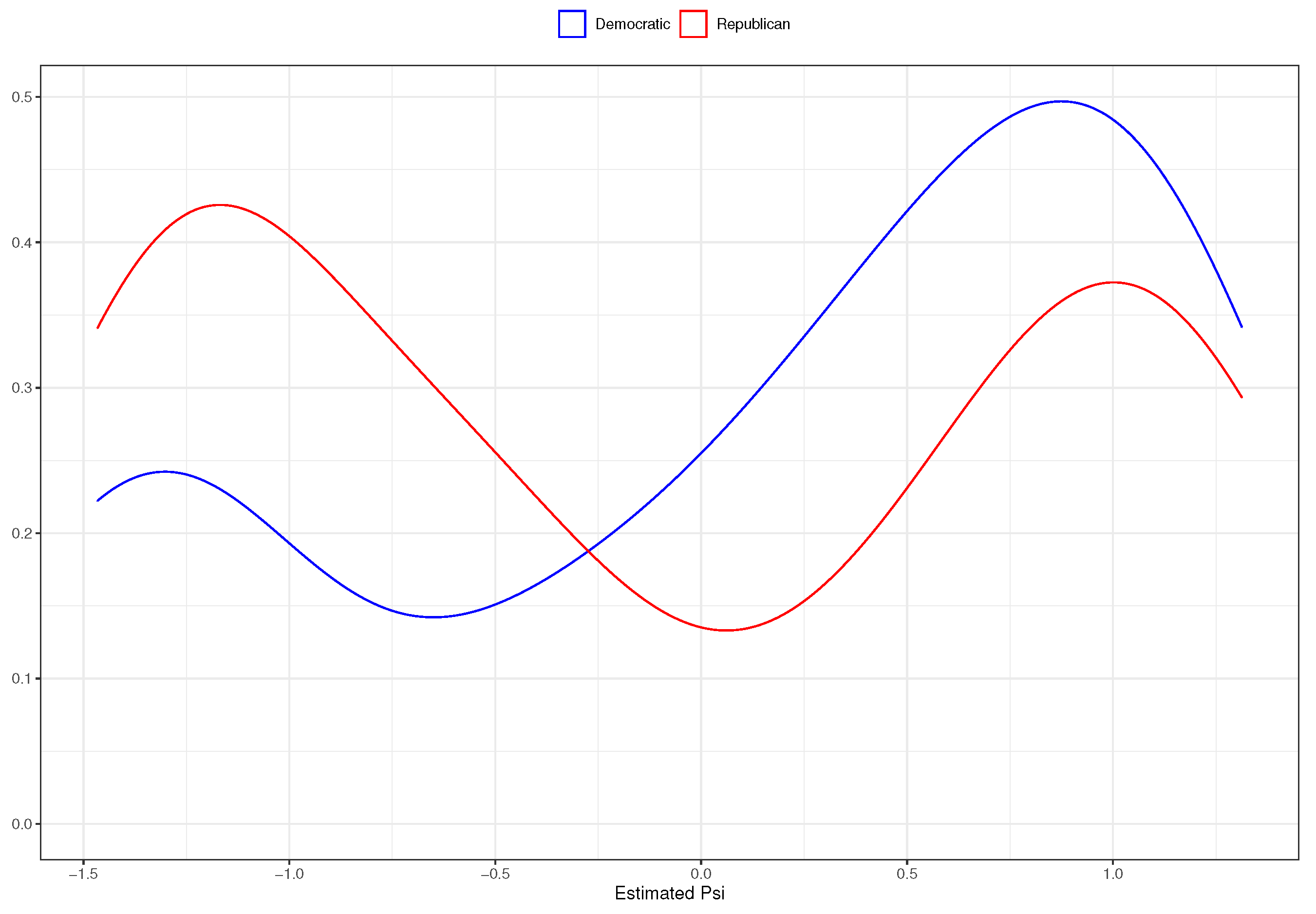
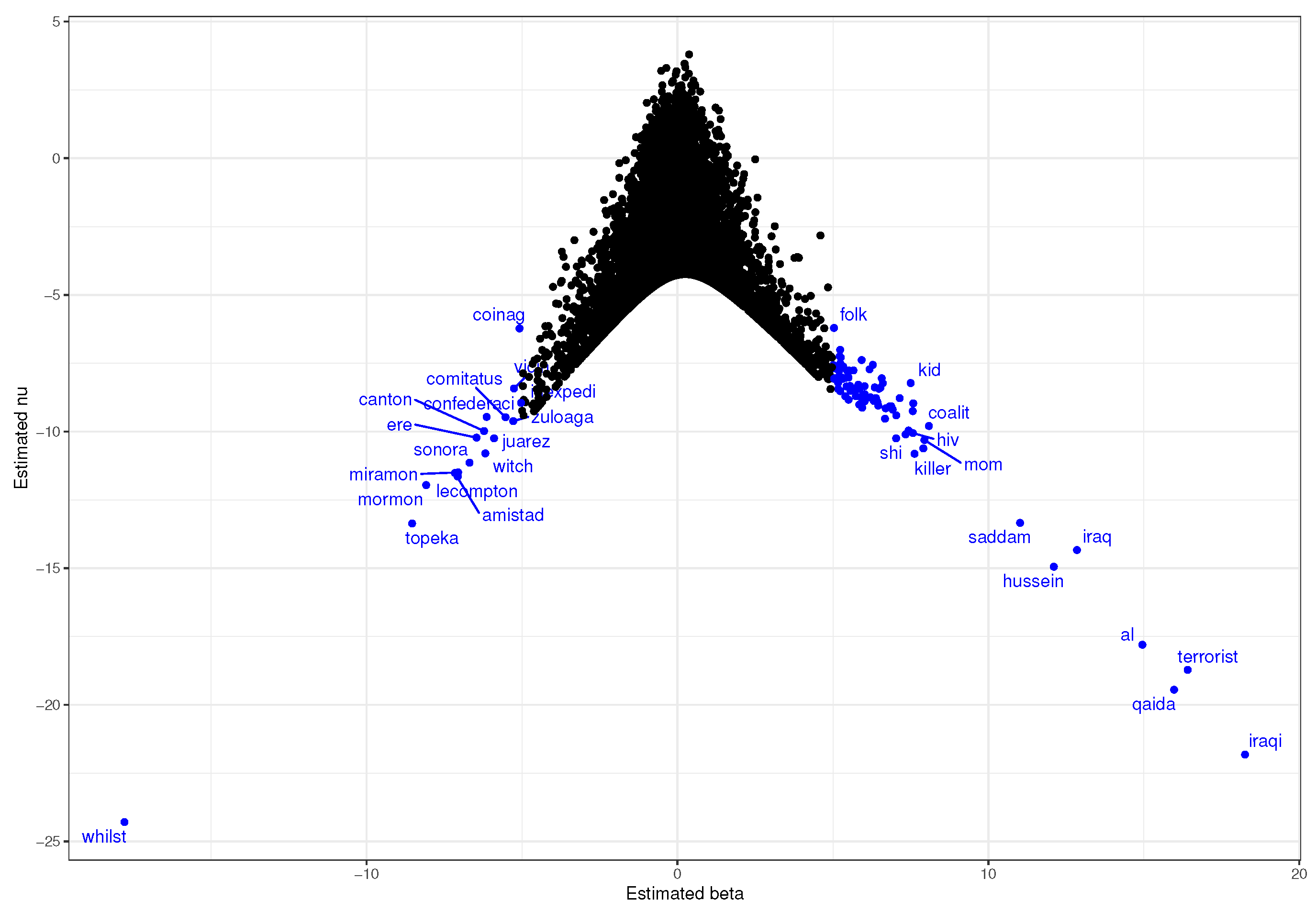
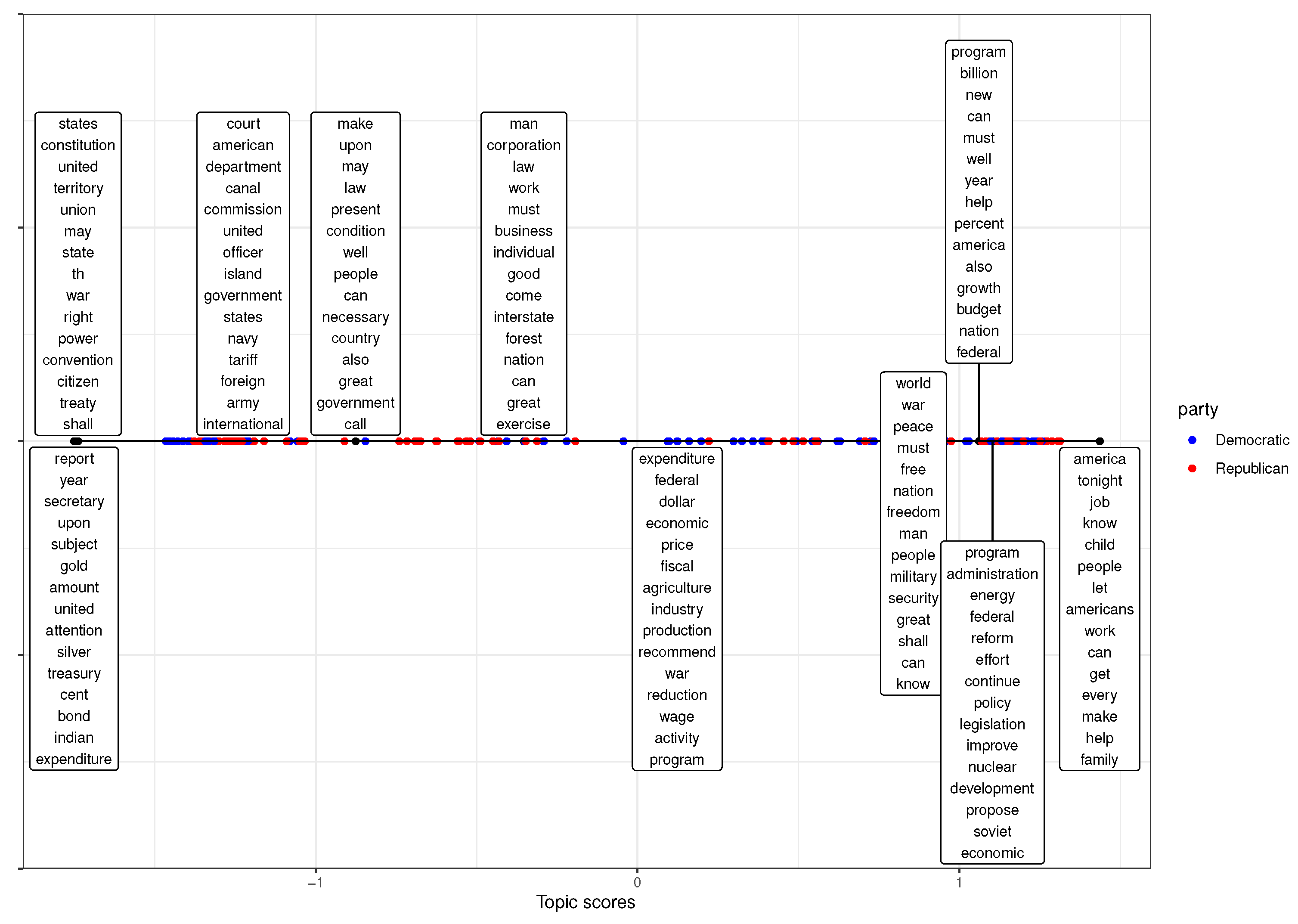
3.1. State of the Union Corpus
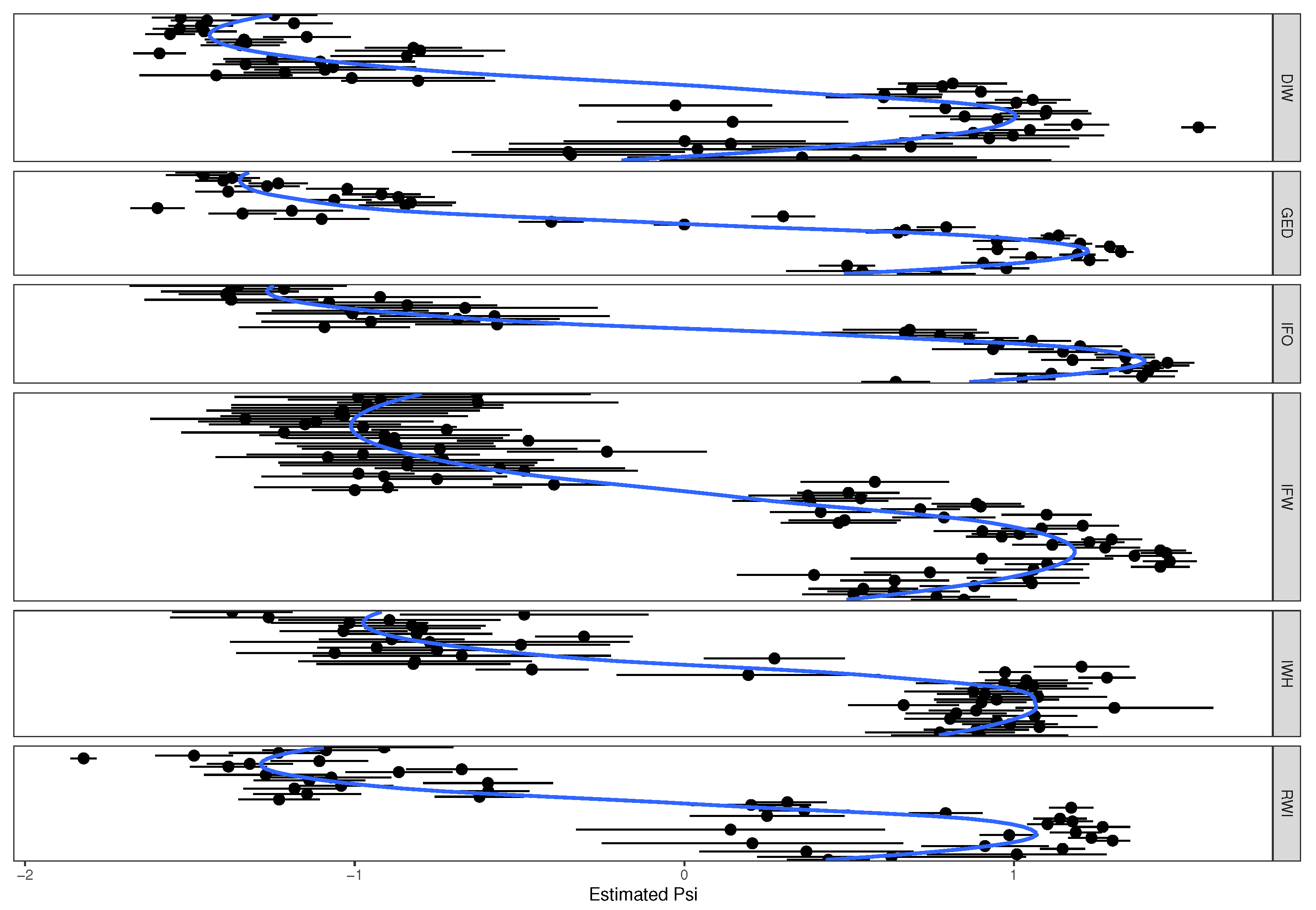
3.2. German Macroeconomic Forecasting Reports
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- McCallum, A.; Nigam, K. A comparison of event models for Naive Bayes text classification. In Proceedings of the IN AAAI-98 Workshop on Learning for Text Categorization; AAAI Press: Palo Alto, CA, USA, 1998; pp. 41–48. [Google Scholar]
- Laver, M.; Benoit, K.; Garry, J. Extracting policy positions from political texts using words as data. Am. Political Sci. Rev. 2003, 97, 311–331. [Google Scholar] [CrossRef]
- Slapin, J.B.; Proksch, S.O. A Scaling Model for Estimating Time-Series Party Positions from Texts. Am. J. Political Sci. 2008, 52, 705–722. [Google Scholar] [CrossRef]
- Lauderdale, B.E.; Herzog, A. Measuring Political Positions from Legislative Speech. Political Anal. 2016, 24, 374–394. [Google Scholar] [CrossRef]
- Grimmer, J.; Stewart, B.M. Text as Data: The Promise and Pitfalls of Automatic Content Analysis Methods for Political Texts. Political Anal. 2013, 21, 267–297. [Google Scholar] [CrossRef]
- Goet, N.D. Measuring Polarization with Text Analysis: Evidence from the UK House of Commons, 1811–2015. Political Anal. 2019, 27, 518–539. [Google Scholar] [CrossRef]
- Denny, M.J.; Spirling, A. Text Preprocessing For Unsupervised Learning: Why It Matters, When It Misleads, And What To Do About It. Political Anal. 2018, 26, 168–189. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Boyd-Graber, J.; Mimno, D.; Newman, D. Care and Feeding of Topic Models: Problems, Diagnostics, and Improvements. In Handbook of Mixed Membership Models and Their Applications; CRC Handbooks of Modern Statistical Methods; Chapman and Hall/CRC: Boca Raton, FL, USA, 2014. [Google Scholar]
- Blei, D.M.; Lafferty, J.D. Dynamic Topic Models. In Proceedings of the 23rd International Conference on Machine Learning, ICML ’06, Pittsburgh, PA, USA, 25–29 June 2006; Association for Computing Machinery: New York, NY, USA, 2006; pp. 113–120. [Google Scholar]
- McAuliffe, J.D.; Blei, D.M. Supervised Topic Models. In Advances in Neural Information Processing Systems 20; Platt, J.C., Koller, D., Singer, Y., Roweis, S.T., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2008; pp. 121–128. [Google Scholar]
- Boyd-Graber, J.; Resnik, P. Holistic Sentiment Analysis across Languages: Multilingual Supervised Latent Dirichlet Allocation. In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, EMNLP ’10, Cambridge, MA, USA, 9–11 October 2010; Association for Computational Linguistics: Chicago, IL, USA, 2010; pp. 45–55. [Google Scholar]
- Blei, D.M.; Jordan, M.I.; Griffiths, T.L.; Tenenbaum, J.B. Hierarchical Topic Models and the Nested Chinese Restaurant Process. In Proceedings of the 16th International Conference on Neural Information Processing Systems, NIPS’03, Online, 16–20 November 2003; MIT Press: Cambridge, MA, USA, 2003; pp. 17–24. [Google Scholar]
- Li, W.; McCallum, A. Pachinko Allocation: DAG-Structured Mixture Models of Topic Correlations. In Proceedings of the 23rd International Conference on Machine Learning, ICML ’06, Pittsburgh, PA, USA, 25–29 June 2006; Association for Computing Machinery: New York, NY, USA, 2006; pp. 577–584. [Google Scholar]
- Lu, B.; Ott, M.; Cardie, C.; Tsou, B.K. Multi-Aspect Sentiment Analysis with Topic Models. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining Workshops, ICDMW ’11, Vancouver, BC, Canada, 11 December 2011; IEEE Computer Society: Washington, DC, USA, 2011; pp. 81–88. [Google Scholar]
- Wang, C.; Paisley, J.; Blei, D. Online Variational Inference for the Hierarchical Dirichlet Process. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2021; Gordon, G., Dunson, D., Dudík, M., Eds.; Proceedings of Machine Learning Research. JMLR Workshop and Conference Proceedings: Fort Lauderdale, FL, USA, 2011; Volume 15, pp. 752–760. [Google Scholar]
- Greene, D.; Cross, J.P. Exploring the Political Agenda of the European Parliament Using a Dynamic Topic Modeling Approach. Political Anal. 2017, 25, 77–94. [Google Scholar] [CrossRef]
- Roberts, M.E.; Stewart, B.M.; Tingley, D.; Lucas, C.; Leder-Luis, J.; Gadarian, S.K.; Albertson, B.; Rand, D.G. Structural Topic Models for Open-Ended Survey Responses. Am. J. Political Sci. 2014, 58, 1064–1082. [Google Scholar] [CrossRef]
- Roberts, M.E.; Stewart, B.M.; Airoldi, E.M. A Model of Text for Experimentation in the Social Sciences. J. Am. Stat. Assoc. 2016, 111, 988–1003. [Google Scholar] [CrossRef]
- Diaf, S.; Döpke, J.; Fritsche, U.; Rockenbach, I. Sharks and minnows in a shoal of words: Measuring latent ideological positions based on text mining techniques. Eur. J. Political Econ. 2022, 102179. [Google Scholar] [CrossRef]
- Shogan, C. The President’s State of the Union Address: Tradition, Function, and Policy Implications. Congr. Res. Serv. Rep. 2016, R40132. Available online: https://crsreports.congress.gov/product/pdf/R/R40132 (accessed on 12 September 2022).
- Savoy, J. Text clustering: An application with the State of the Union addresses. J. Assoc. Inf. Sci. Technol. 2015, 66, 1645–1654. [Google Scholar] [CrossRef]
- Petrocik, J.R.; Benoit, W.L.; Hansen, G.J. Issue Ownership and Presidential Campaigning, 1952–2000. Political Sci. Q. 2003, 118, 599–626. [Google Scholar] [CrossRef]
- Savoy, J. Vocabulary Growth Study: An Example with the State of the Union Addresses. J. Quant. Linguist. 2015, 22, 289–310. [Google Scholar] [CrossRef]
- Savoy, J. Text representation strategies: An example with the State of the union addresses. J. Assoc. Inf. Sci. Technol. 2016, 67, 1858–1870. [Google Scholar] [CrossRef]
- Lei, L.; Wen, J. Is dependency distance experiencing a process of minimization? A diachronic study based on the State of the Union addresses. Lingua 2020, 239, 102762. [Google Scholar] [CrossRef]
- Teten, R.L. Evolution of the Modern Rhetorical Presidency: Presidential Presentation and Development of the State of the Union Address. Pres. Stud. Q. 2003, 33, 333–346. [Google Scholar] [CrossRef]
- Cummins, J. State of the Union addresses and presidential position taking: Do presidents back their rhetoric in the legislative arena? Soc. Sci. J. 2008, 45, 365–381. [Google Scholar] [CrossRef]
- Lo, J.; Proksch, S.O.; Slapin, J.B. Ideological Clarity in Multiparty Competition: A New Measure and Test Using Election Manifestos. Br. J. Political Sci. 2016, 46, 591–610. [Google Scholar] [CrossRef]
- Koltcov, S.; Ignatenko, V.; Boukhers, Z.; Staab, S. Analyzing the Influence of Hyper-parameters and Regularizers of Topic Modeling in Terms of Renyi Entropy. Entropy 2020, 22, 394. [Google Scholar] [CrossRef] [PubMed]
- Benoit, K.; Watanabe, K.; Wang, H.; Nulty, P.; Obeng, A.; Müller, S.; Matsuo, A. quanteda: An R package for the quantitative analysis of textual data. J. Open Source Softw. 2018, 3, 774. [Google Scholar] [CrossRef]
- Honnibal, M.; Montani, I.; Landeghem, S.V.; Boyd, A. spaCy: Industrial-Strength Natural Language Processing in Python. 2020. Available online: https://doi.org/10.5281/zenodo.3358113 (accessed on 12 September 2022).
- Cleveland, W.S.; Loader, C. Smoothing by Local Regression: Principles and Methods. In Proceedings of the Statistical Theory and Computational Aspects of Smoothing; Härdle, W., Schimek, M.G., Eds.; Physica-Verlag HD: Heidelberg, Germany, 1996; pp. 10–49. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Topics | Log-Likelihood | Rényi Entropy | Number of Topics | Log-Likelihood | Rényi Entropy | ||
|---|---|---|---|---|---|---|---|
| 4 | 0.9963 | 236.5854 | −3.7986 | 15 | 0.9976 | 287.9229 | −3.3353 |
| 5 | 0.9946 | 207.1414 | −3.6783 | 16 | 0.9975 | 276.7568 | −3.4440 |
| 6 | 0.9964 | 246.9864 | −3.6557 | 17 | 0.9969 | 261.3767 | −3.3559 |
| 7 | 0.9962 | 240.2083 | −3.6772 | 18 | 0.9978 | 281.0514 | −3.3979 |
| 8 | 0.9957 | 228.3746 | −3.5676 | 19 | 0.9980 | 293.1175 | −3.4628 |
| 9 | 0.9963 | 235.5375 | −3.5626 | 20 | 0.9981 | 298.9496 | −3.5025 |
| 10 | 0.9963 | 245.5822 | −3.3909 | 21 | 0.9978 | 295.9086 | −3.5367 |
| 11 | 0.9977 | 273.5398 | −3.4583 | 22 | 0.9976 | 272.1873 | −3.5247 |
| 12 | 0.9968 | 255.8592 | −3.4838 | 23 | 0.9980 | 285.0266 | −3.6266 |
| 13 | 0.9976 | 279.4950 | −3.3901 | 24 | 0.9981 | 301.2945 | −3.5919 |
| 14 | 0.9967 | 245.8567 | −3.4175 | 25 | 0.9977 | 293.4041 | −3.6431 |
| Topic | Top 10 Words |
|---|---|
| 1 | energy, will, program, administration, year, reform, continue, nuclear, oil, work |
| 2 | united, island, cuba, government, spain, states, treaty, international, spanish, authority |
| 3 | program, will, federal, year, billion, dollar, million, budget, increase, new |
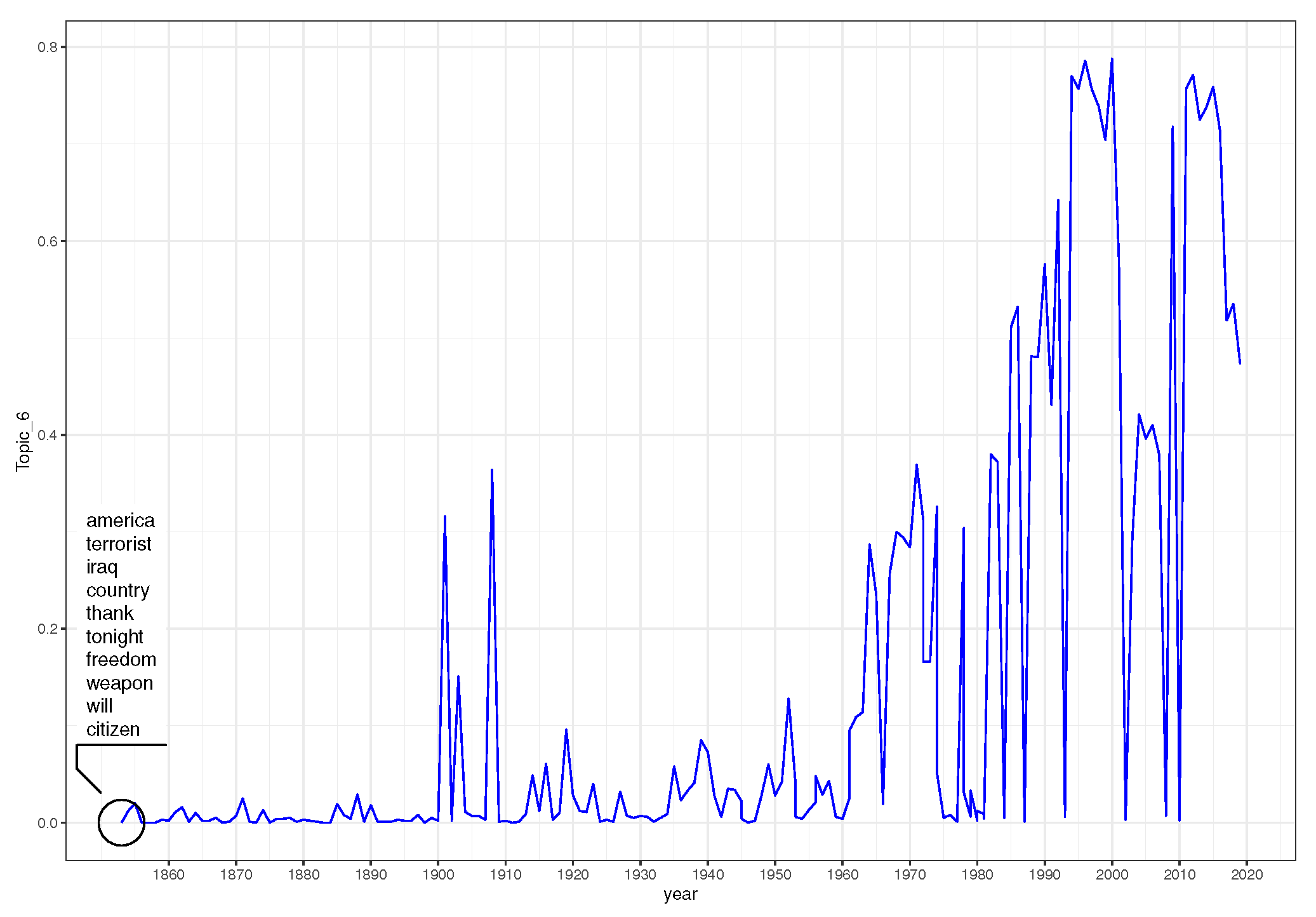
| 4 | america, terrorist, iraq, country, thank, tonight, freedom, weapon, will, citizen |
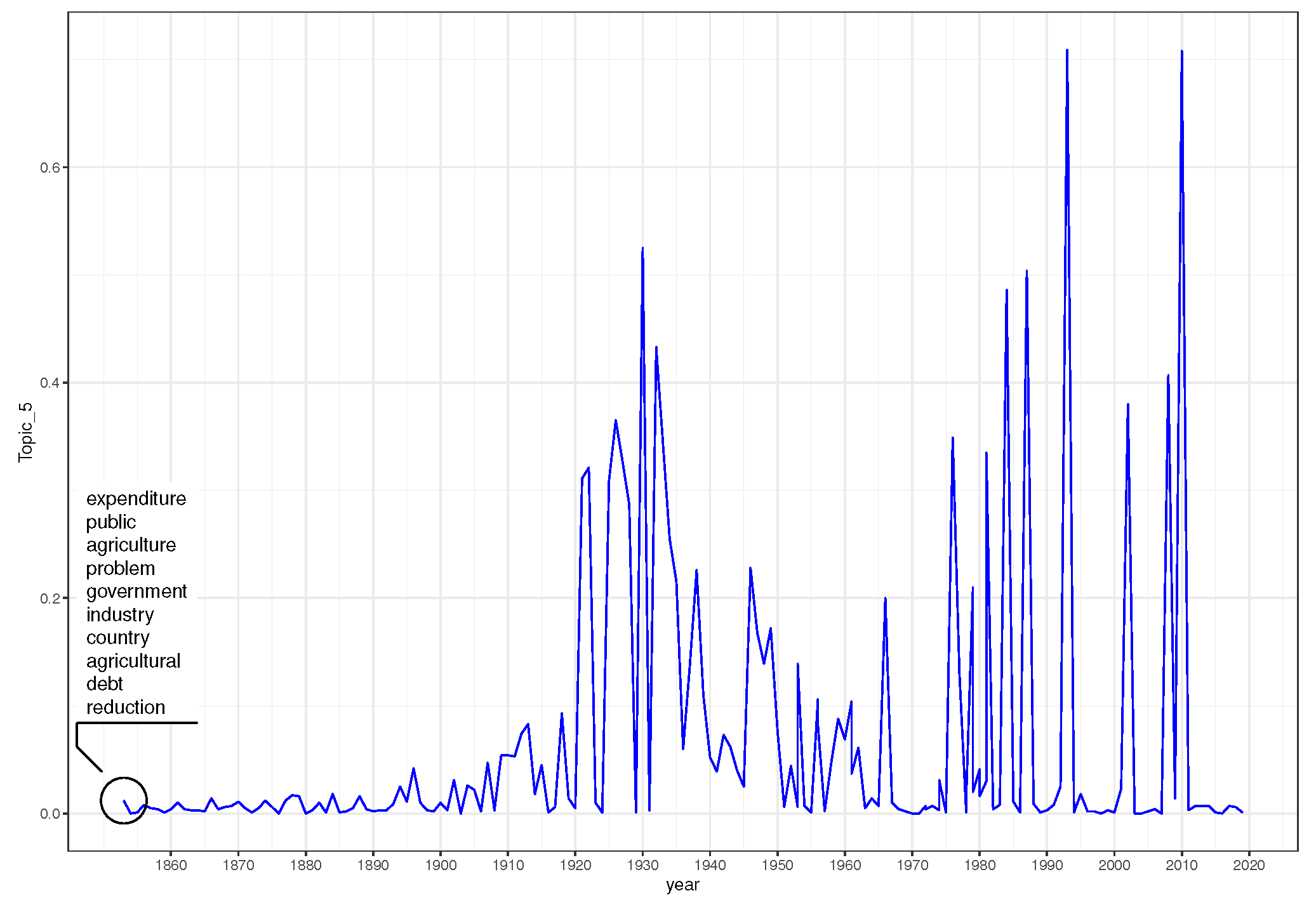
| 5 | expenditure, public, agriculture, problem, government, industry, country, agricultural, debt, reduction |
| 6 | will, america, job, can, year, americans, help, know, tonight, let |
| 7 | man, public, work, corporation, law, business, interstate, labor, forest, industrial |
| 8 | department, court, government, make, commission, american, foreign, canal, army, commerce |
| 9 | war, fight, will, nations, production, man, enemy, peace, victory, must |
| 10 | states, subject, united, year, country, congress, public, consideration, service, may |
| 11 | constitution, state, states, union, government, may, duty, power, right, republic |
| 12 | can, will, people, great, make, nation, every, well, one, country |
| 13 | world, nation, must, peace, free, freedom, economic, today, defense, strength |
| 14 | year, upon, cent, pension, revenue, per, total, reservation, fiscal, report |
| 15 | gold, treasury, note, silver, currency, bond, government, upon, amount, duty |
| Topic | Top 10 Words |
|---|---|
| 1 | will, america, must, world, nation, can, year, people, help, freedom |
| 2 | will, war, world, nation, can, must, people, great, man, peace |
| 3 | will, program, year, must, government, can, nation, congress, federal, new |
| 4 | government, will, year, make, war, congress, country, can, federal, public |
| 5 | man, law, will, government, make, can, great, nation, people, work |
| 6 | will, year, program, congress, federal, administration, new, increase, continue, energy |
| 7 | states, united, government, congress, year, may, will, country, upon, make |
| 8 | will, upon, make, year, law, people, government, country, public, great |
| 9 | government, states, united, year, will, make, upon, congress, american, may |
| 10 | states, government, united, state, may, congress, will, power, constitution, upon |
| 11 | will, year, must, work, people, can, child, america, new, make |
| 12 | will, year, can, america, people, new, american, great, congress, nation |
| 13 | government, make, will, states, united, congress, department, american, year, law |
| 14 | government, upon, condition, may, present, year, law, make, gold, time |
| 15 | will, year, can, job, make, work, america, people, new, american |
| Decade | 1853–1859 | 1860–1869 | 1870–1879 | 1880–1889 | 1890–1899 | ||||||||||
| Topics | 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 |
| states | constitution | people | states | constitution | people | states | government | people | states | government | people | government | government | people | |
| government | would | great | government | would | great | government | would | great | government | would | great | states | would | great | |
| united | government | nation | united | government | nation | united | people | nation | united | people | nation | united | people | nation | |
| congress | states | would | congress | states | would | congress | constitution | peace | congress | states | world | congress | public | world | |
| would | people | peace | would | people | peace | would | states | world | would | public | peace | would | states | peace | |
| country | country | world | country | country | world | country | country | would | country | country | every | great | country | every | |
| public | congress | every | public | congress | every | public | public | every | public | congress | would | country | congress | would | |
| great | public | power | great | public | power | great | congress | government | great | constitution | government | general | present | government | |
| people | power | government | people | power | government | people | power | nations | people | present | nations | service | national | nations | |
| citizens | state | nations | citizens | state | nations | general | present | power | general | power | power | people | business | national | |
| Decade | 1900–1909 | 1910–1919 | 1920–1929 | 1930–1939 | 1940–1949 | ||||||||||
| Topics | 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 |
| government | government | people | government | government | people | government | government | world | government | government | world | government | government | world | |
| states | would | great | states | would | world | states | congress | people | states | congress | people | congress | federal | people | |
| united | public | nation | united | public | nation | congress | would | nation | congress | federal | nation | states | congress | nation | |
| congress | congress | world | congress | congress | great | united | public | great | united | public | peace | united | program | peace | |
| would | people | peace | would | country | peace | would | federal | peace | would | would | nations | would | public | nations | |
| great | country | every | american | states | every | american | national | nations | country | national | great | country | legislation | government | |
| american | states | would | great | people | government | great | country | government | american | legislation | government | great | national | congress | |
| service | national | government | country | national | would | country | states | would | great | states | congress | service | would | great | |
| country | business | nations | service | business | nations | service | people | every | service | country | national | american | states | national | |
| general | present | national | department | federal | national | department | legislation | national | department | program | would | department | administration | economic | |
| Decade | 1950–1959 | 1960–1969 | 1970–1979 | 1980–1989 | |||||||||||
| Topics | 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 | |||
| government | federal | world | government | federal | world | congress | federal | world | congress | administration | world | ||||
| congress | government | people | congress | program | people | government | administration | people | government | federal | people | ||||
| states | congress | nation | states | government | congress | states | program | congress | states | program | congress | ||||
| united | program | nations | united | congress | nation | united | congress | years | energy | congress | years | ||||
| would | legislation | peace | would | administration | years | energy | legislation | nation | united | legislation | america | ||||
| country | administration | congress | energy | legislation | government | administration | government | government | administration | development | american | ||||
| service | public | government | administration | development | peace | would | development | america | would | government | government | ||||
| great | national | years | country | national | nations | legislation | policy | american | legislation | policy | nation | ||||
| american | development | economic | legislation | policy | economic | foreign | national | peace | foreign | national | programs | ||||
| department | would | great | service | public | american | country | states | economic | country | assistance | economic | ||||
| Decade | 1990–1999 | 2000–2009 | 2010–2019 | ||||||||||||
| Topics | 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 | ||||||
| congress | administration | people | congress | administration | america | congress | administration | america | |||||||
| government | federal | america | government | federal | people | government | federal | people | |||||||
| states | program | world | states | program | american | states | program | american | |||||||
| energy | congress | years | energy | congress | years | energy | legislation | years | |||||||
| united | legislation | congress | united | legislation | world | united | congress | world | |||||||
| administration | development | american | administration | development | congress | administration | development | americans | |||||||
| would | government | government | would | government | americans | would | government | congress | |||||||
| legislation | policy | nation | legislation | policy | every | american | policy | every | |||||||
| american | national | americans | american | national | government | legislation | national | country | |||||||
| country | assistance | every | country | states | nation | country | states | tonight | |||||||
| Topic | Top 10 Words |
|---|---|
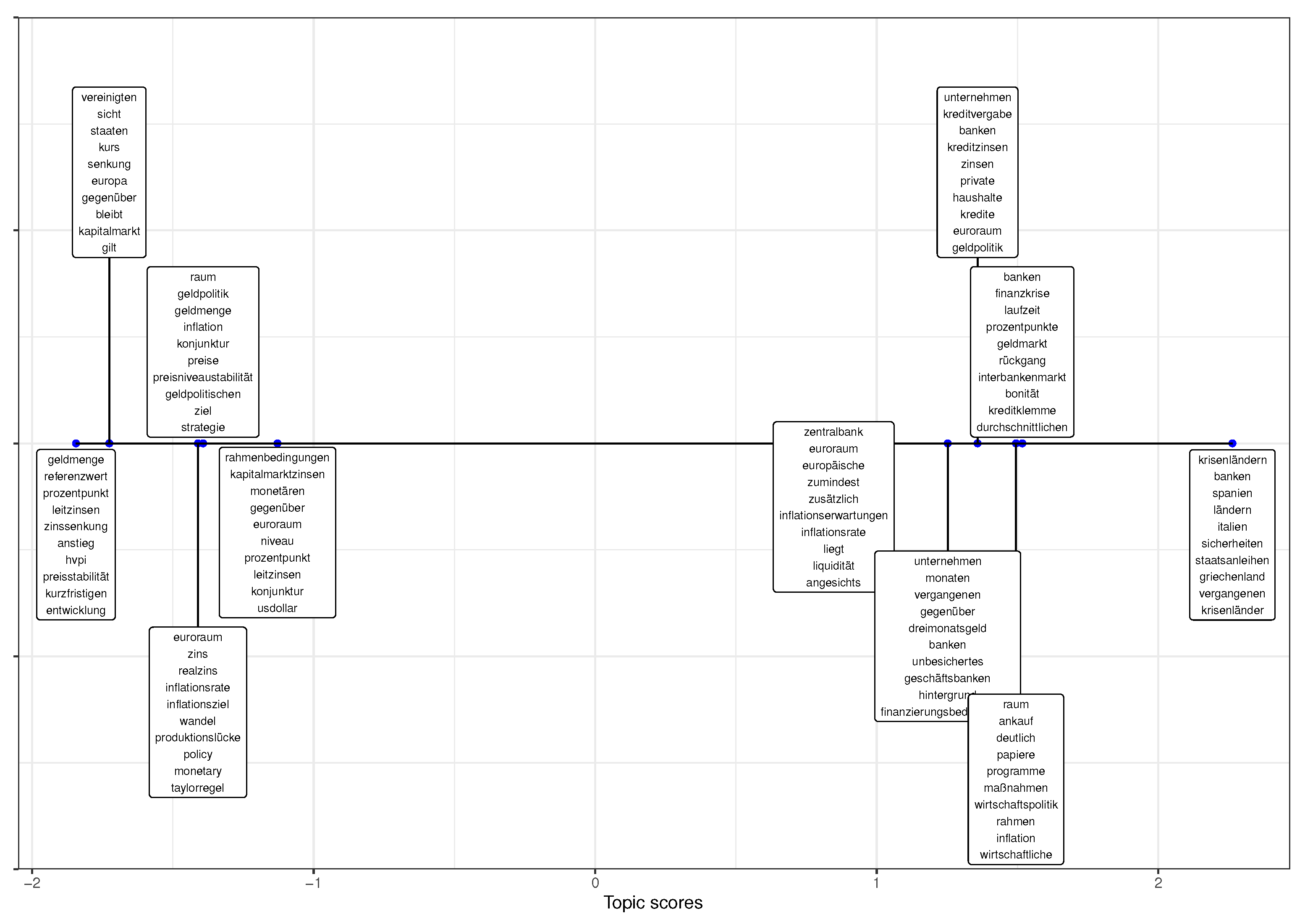
| 1 | unternehmen, kreditvergabe, banken, kreditzinsen, zinsen, private, haushalte, kredite, euroraum, geldpolitik |
| 2 | vereinigten, sicht, staaten, kurs, senkung, europa, gegenüber, bleibt, kapitalmarkt, gilt |
| 3 | zentralbank, euroraum, europäische, zumindest, zusätzlich, inflationserwartungen, inflationsrate, liegt, liquidität, angesichts |
| 4 | raum, ankauf, deutlich, papiere, programme, maßnahmen, wirtschaftspolitik, rahmen, inflation, wirtschaftliche |
| 5 | unternehmen, monaten, vergangenen, gegenüber, dreimonatsgeld, banken, unbesichertes, geschäftsbanken, |
| hintergrund, finanzierungsbedingungen | |
| 6 | euroraum, zins, realzins, inflationsrate, inflationsziel, wandel, produktionslücke, policy, monetary, taylorregel |
| 7 | banken, finanzkrise, laufzeit, prozentpunkte, geldmarkt, rückgang, interbankenmarkt, bonität, kreditklemme, durchschnittlichen |
| 8 | geldmenge, referenzwert, prozentpunkt, leitzinsen, zinssenkung, anstieg, hvpi, preisstabilität, kurzfristigen, entwicklung |
| 9 | krisenländern, banken, spanien, ländern, italien, sicherheiten, staatsanleihen, griechenland, vergangenen, krisenländer |
| 10 | rahmenbedingungen, kapitalmarktzinsen, monetären, gegenüber, euroraum, niveau, prozentpunkt, leitzinsen, konjunktur, usdollar |
| 11 | raum, geldpolitik, geldmenge, inflation, konjunktur, preise, preisniveaustabilität, geldpolitischen, ziel, strategie |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Diaf, S.; Fritsche, U. Topic Scaling: A Joint Document Scaling–Topic Model Approach to Learn Time-Specific Topics. Algorithms 2022, 15, 430. https://doi.org/10.3390/a15110430
Diaf S, Fritsche U. Topic Scaling: A Joint Document Scaling–Topic Model Approach to Learn Time-Specific Topics. Algorithms. 2022; 15(11):430. https://doi.org/10.3390/a15110430
Chicago/Turabian StyleDiaf, Sami, and Ulrich Fritsche. 2022. "Topic Scaling: A Joint Document Scaling–Topic Model Approach to Learn Time-Specific Topics" Algorithms 15, no. 11: 430. https://doi.org/10.3390/a15110430
APA StyleDiaf, S., & Fritsche, U. (2022). Topic Scaling: A Joint Document Scaling–Topic Model Approach to Learn Time-Specific Topics. Algorithms, 15(11), 430. https://doi.org/10.3390/a15110430